
1. 简介
使用生成式 AI 创建测试方案的潜力源于其能够解决现代质量保证中的两大挑战:速度和全面性。在当今快速的敏捷和 DevOps 周期中,手动撰写详细的测试计划是一个严重的瓶颈,会延迟整个测试流程。借助生成式 AI 赋能的智能体,您可以在几分钟内(而不是几天内)提取用户故事和技术要求,生成全面的测试计划,确保 QA 流程与开发保持同步。此外,AI 擅长识别人类可能会忽略的复杂场景、极端情况和负面路径,从而大幅提高测试覆盖率,并显著减少逃逸到生产环境中的 bug。
在此 Codelab 中,我们将探讨如何构建这样一种代理:它可以从 Confluence 中检索产品需求文档,能够提供建设性反馈,还可以生成可导出到 CSV 文件中的全面测试计划。
在此 Codelab 中,您将采用以下分步方法:
- 准备好您的 Google Cloud 云项目,并在其中启用所有必需的 API
- 为编码环境设置工作区
- 为 Confluence 准备本地 mcp-server
- 构建 ADK 代理源代码、提示和工具以连接到 MCP 服务器
- 了解制品服务和工具上下文的利用率
- 使用 ADK 本地 Web 开发界面测试智能体
- 管理环境变量并设置将应用部署到 Cloud Run 所需的文件
- 将应用部署到 Cloud Run
架构概览
前提条件
- 能够熟练使用 Python
- 了解使用 HTTP 服务的全栈基本架构
学习内容
- 在利用 ADK 的多种功能的同时设计 ADK 代理
- 将工具与自定义工具和 MCP 搭配使用
- 使用 Artifact Service 管理功能设置代理的文件输出
- 利用 BuiltInPlanner 通过 Gemini 2.5 Flash 的思考功能进行规划,从而提高任务执行效率
- 通过 ADK 网页界面进行互动和调试
- 使用 Dockerfile 将应用部署到 Cloud Run 并提供环境变量
所需条件
- Chrome 网络浏览器
- Gmail 账号
- 启用了结算功能的 Cloud 项目
- (可选)包含产品要求文档页面的 Confluence 空间
此 Codelab 专为各种水平的开发者(包括新手)设计,并在示例应用中使用 Python。不过,您无需了解 Python 即可理解所介绍的概念。如果您没有 Confluence 空间,也不用担心,我们会提供凭据供您试用此 Codelab
2. 准备工作
在 Cloud 控制台中选择有效项目
此 Codelab 假定您已拥有一个启用了结算功能的 Google Cloud 项目。如果您还没有,可以按照以下说明开始使用。
- 在 Google Cloud Console 的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
在 Cloud Shell 终端中设置 Cloud 项目
- 您将使用 Cloud Shell,它是在 Google Cloud 中运行的命令行环境。点击 Google Cloud 控制台顶部的“激活 Cloud Shell”。
- 连接到 Cloud Shell 后,您可以使用以下命令检查自己是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目。
gcloud config list project
- 如果项目未设置,请使用以下命令进行设置:
gcloud config set project <YOUR_PROJECT_ID>
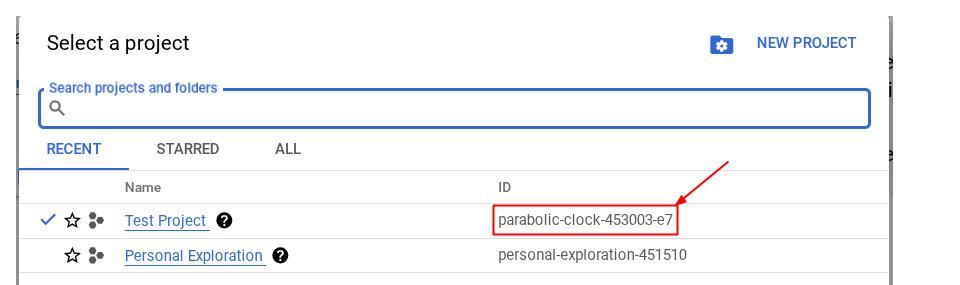
或者,您也可以在控制台中看到 PROJECT_ID ID
点击该项目,您将看到所有项目,以及右侧的项目 ID
- 通过以下命令启用所需的 API。这可能需要几分钟的时间,请耐心等待。
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
成功执行该命令后,您应该会看到类似如下所示的消息:
Operation "operations/..." finished successfully.
除了使用 gcloud 命令,您还可以通过控制台搜索每个产品或使用此链接。
如果遗漏了任何 API,您始终可以在实施过程中启用它。
如需了解 gcloud 命令和用法,请参阅文档。
前往 Cloud Shell 编辑器并设置应用工作目录
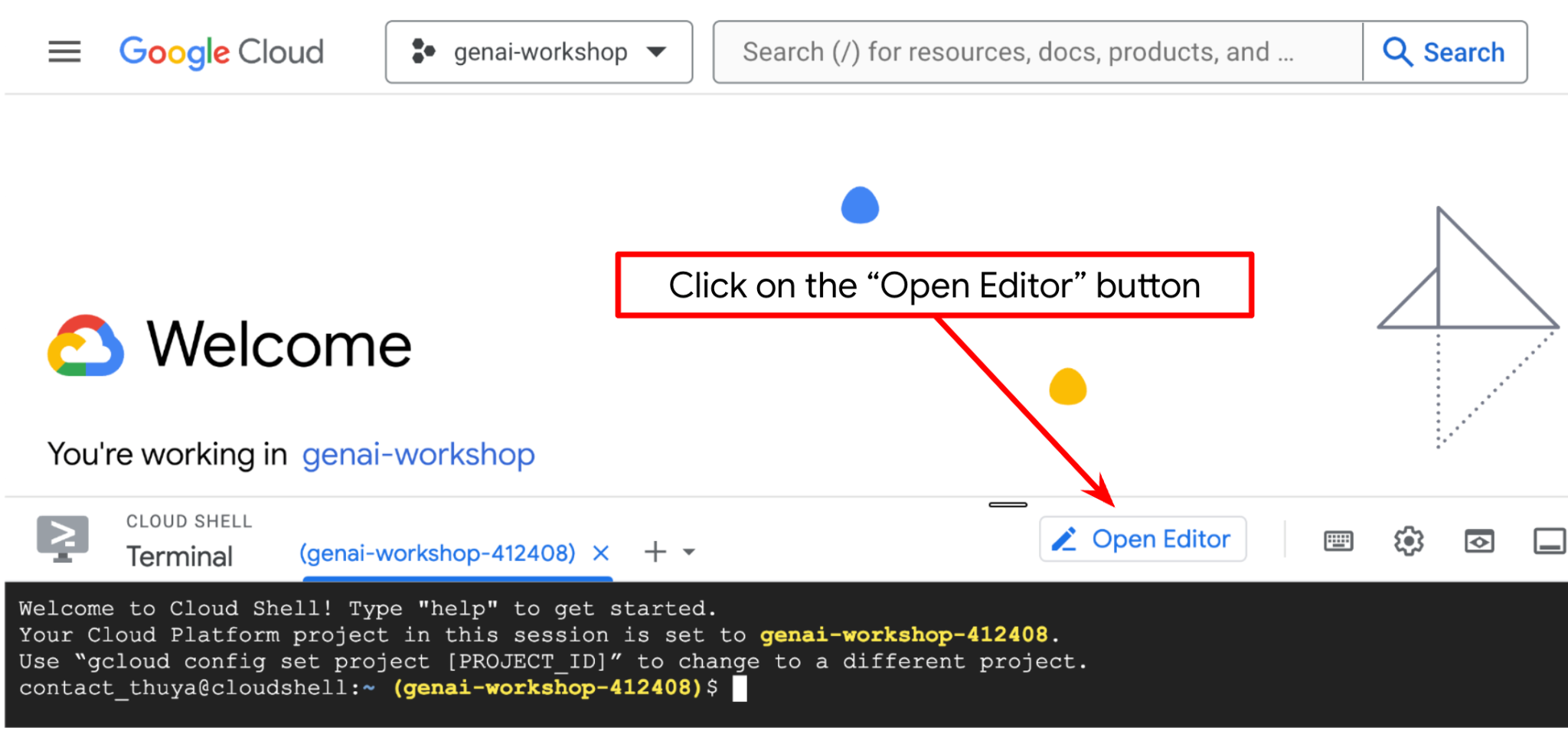
现在,我们可以设置代码编辑器来执行一些编码操作。我们将使用 Cloud Shell 编辑器来完成此
- 点击“打开编辑器”按钮,系统会打开 Cloud Shell 编辑器,我们可以在这里编写代码
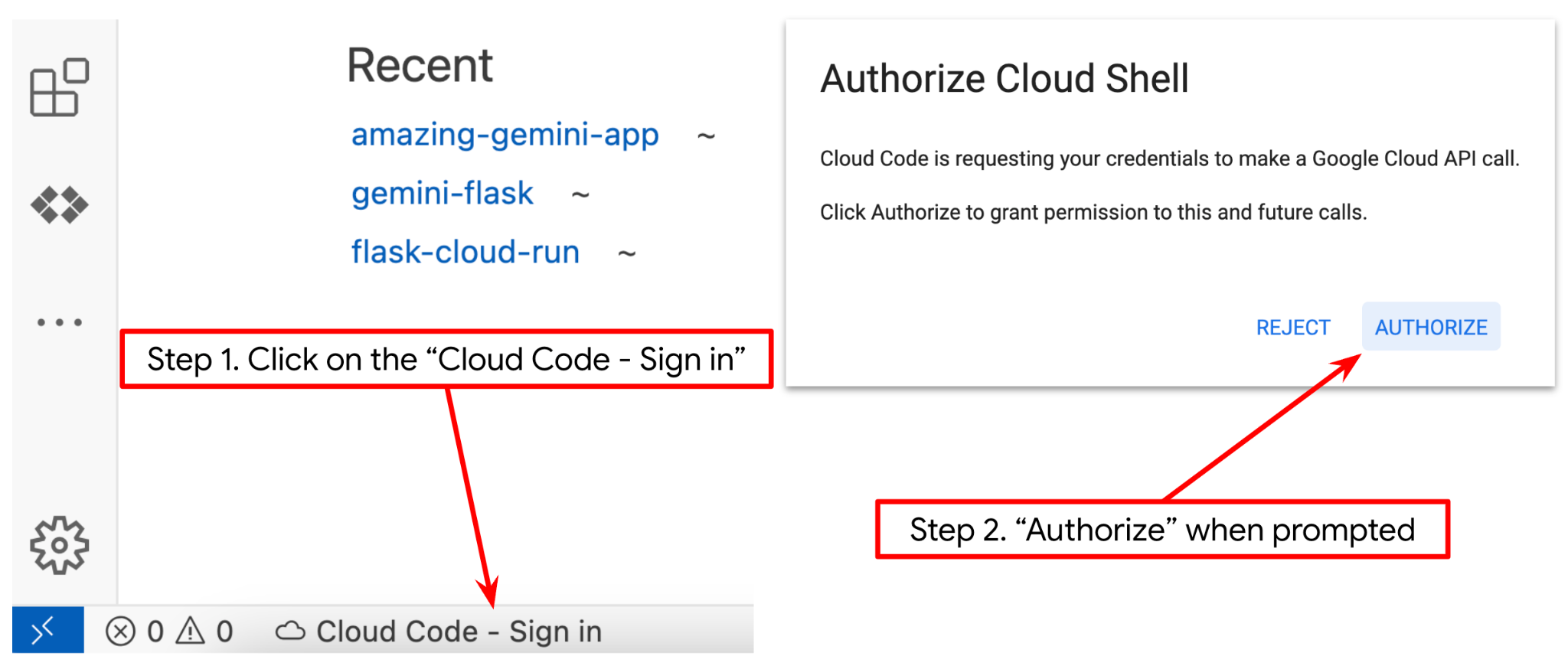
- 确保 Cloud Code 项目已在 Cloud Shell 编辑器的左下角(状态栏)中设置,如下图中突出显示的那样,并且已设置为已启用结算的有效 Google Cloud 项目。如果系统提示,请点击授权。如果您已按照之前的命令操作,该按钮可能还会直接指向您已启用的项目,而不是登录按钮
- 接下来,我们从 GitHub 克隆此 Codelab 的模板工作目录,运行以下命令。它将在 qa-test-planner-agent 目录中创建工作目录
git clone https://github.com/alphinside/qa-test-planner-agent.git qa-test-planner-agent
- 之后,前往 Cloud Shell 编辑器的顶部部分,依次点击文件->打开文件夹,找到您的用户名目录,然后找到 qa-test-planner-agent 目录,再点击“确定”按钮。这样一来,所选目录就会成为主工作目录。在此示例中,用户名为 alvinprayuda,因此目录路径如下所示
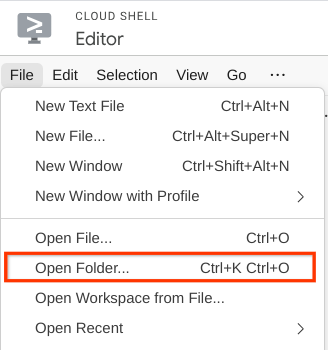
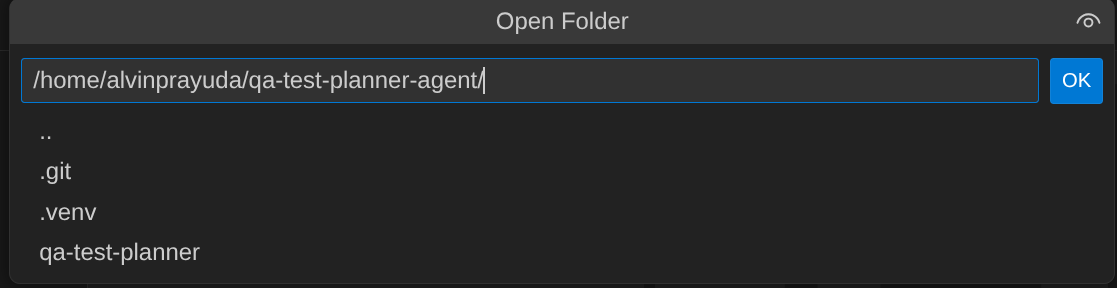
现在,您的 Cloud Shell 编辑器应如下所示
环境设置
准备 Python 虚拟环境
下一步是准备开发环境。当前活跃的终端应位于 qa-test-planner-agent 工作目录中。在本 Codelab 中,我们将使用 Python 3.12,并使用 uv Python 项目管理器来简化创建和管理 Python 版本和虚拟环境的需求
- 如果您尚未打开终端,请依次点击终端 -> 新建终端,或使用 Ctrl + Shift + C,这将在浏览器底部打开一个终端窗口

- 下载
uv并使用以下命令安装 Python 3.12
curl -LsSf https://astral.sh/uv/0.7.19/install.sh | sh && \
source $HOME/.local/bin/env && \
uv python install 3.12
- 现在,我们使用
uv初始化虚拟环境,运行以下命令
uv sync --frozen
这会创建 .venv 目录并安装依赖项。快速浏览一下 pyproject.toml,您会看到如下所示的依赖项信息
dependencies = [
"google-adk>=1.5.0",
"mcp-atlassian>=0.11.9",
"pandas>=2.3.0",
"python-dotenv>=1.1.1",
]
- 如需测试虚拟环境,请创建新文件 main.py 并复制以下代码
def main():
print("Hello from qa-test-planner-agent")
if __name__ == "__main__":
main()
- 然后,运行以下命令
uv run main.py
您将获得如下所示的输出
Using CPython 3.12 Creating virtual environment at: .venv Hello from qa-test-planner-agent!
这表明 Python 项目正在正确设置。
现在,我们可以进入下一步,构建代理,然后构建服务
3. 使用 Google ADK 和 Gemini 2.5 构建智能体
ADK 目录结构简介
我们先来了解一下 ADK 的功能以及如何构建代理。您可以通过此网址访问 ADK 的完整文档。ADK 在其 CLI 命令执行中提供了许多实用程序。其中一些如下所示:
- 设置代理目录结构
- 通过 CLI 输入/输出快速尝试互动
- 快速设置本地开发界面网页界面
现在,我们使用 CLI 命令创建代理目录结构。运行以下命令
uv run adk create qa_test_planner \
--model gemini-2.5-flash \
--project {your-project-id} \
--region global
它将在当前工作目录中创建以下代理目录结构
qa_test_planner/ ├── __init__.py ├── .env ├── agent.py
如果您检查 init.py 和 agent.py,您会看到以下代码
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
构建质量保证测试规划器代理
让我们来构建质量检查测试规划器智能体!打开 qa_test_planner/agent.py 文件,然后复制以下包含 root_agent 的代码。
# qa_test_planner/agent.py
from google.adk.agents import Agent
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
from google.adk.planners import BuiltInPlanner
from google.genai import types
from dotenv import load_dotenv
import os
from pathlib import Path
from pydantic import BaseModel
from typing import Literal
import tempfile
import pandas as pd
from google.adk.tools import ToolContext
load_dotenv(dotenv_path=Path(__file__).parent / ".env")
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
class TestPlan(BaseModel):
test_case_key: str
test_type: Literal["manual", "automatic"]
summary: str
preconditions: str
test_steps: str
expected_result: str
associated_requirements: str
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
description="You are an expert QA Test Planner and Product Manager assistant",
instruction=f"""
Help user search any product requirement documents on Confluence. Furthermore you also can provide the following capabilities when asked:
- evaluate product requirement documents and assess it, then give expert input on what can be improved
- create a comprehensive test plan following Jira Xray mandatory field formatting, result showed as markdown table. Each test plan must also have explicit mapping on
which user stories or requirements identifier it's associated to
Here is the Confluence space ID with it's respective document grouping:
- "{os.getenv("CONFLUENCE_PRD_SPACE_ID")}" : space to store Product Requirements Documents
Do not making things up, Always stick to the fact based on data you retrieve via tools.
""",
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
)
设置配置文件
现在,我们需要为此项目添加额外的配置设置,因为此代理需要访问 Confluence
打开 qa_test_planner/.env 并向其中添加以下环境变量值,确保生成的 .env 文件如下所示
GOOGLE_GENAI_USE_VERTEXAI=1
GOOGLE_CLOUD_PROJECT={YOUR-CLOUD-PROJECT-ID}
GOOGLE_CLOUD_LOCATION=global
CONFLUENCE_URL={YOUR-CONFLUENCE-DOMAIN}
CONFLUENCE_USERNAME={YOUR-CONFLUENCE-USERNAME}
CONFLUENCE_TOKEN={YOUR-CONFLUENCE-API-TOKEN}
CONFLUENCE_PRD_SPACE_ID={YOUR-CONFLUENCE-SPACE-ID}
很遗憾,此 Confluence 空间无法公开,因此您可以检查这些文件,以读取可用的产品需求文档,这些文档将使用上述凭据提供。
代码说明
此脚本包含我们的代理启动,我们在其中初始化了以下内容:
- 将要使用的模型设置为
gemini-2.5-flash - 设置将通过 Stdio 进行通信的 Confluence MCP 工具
- 设置
write_test_tool自定义工具以编写测试计划并将 CSV 转储到制品 - 设置代理说明和指令
- 在生成最终回答或执行操作之前,使用 Gemini 2.5 Flash 的思考能力启用规划
当智能体由具有内置思考功能的 Gemini 模型提供支持,并配置了 planner 实参时,它本身可以展示其思考能力,并显示在 Web 界面上。用于配置此功能的代码如下所示
# qa-test-planner/agent.py
from google.adk.planners import BuiltInPlanner
from google.genai import types
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
...
在采取行动之前,我们可以看到它的思考过程
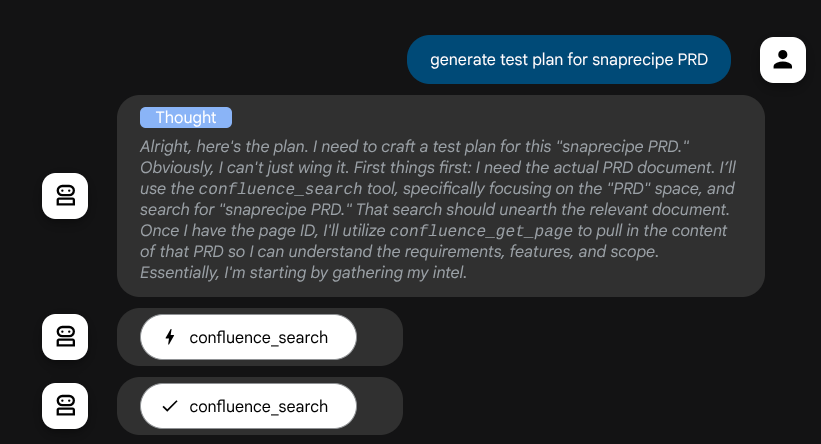
Confluence MCP 工具
如需从 ADK 连接到 MCP 服务器,我们需要使用可从 google.adk.tools.mcp_tool.mcp_toolset 模块导入的 MCPToolSet。此处显示的初始化代码如下(为提高效率而截断):
# qa-test-planner/agent.py
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
...
# Initialize the Confluence MCP Tool via Stdio Output
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
...
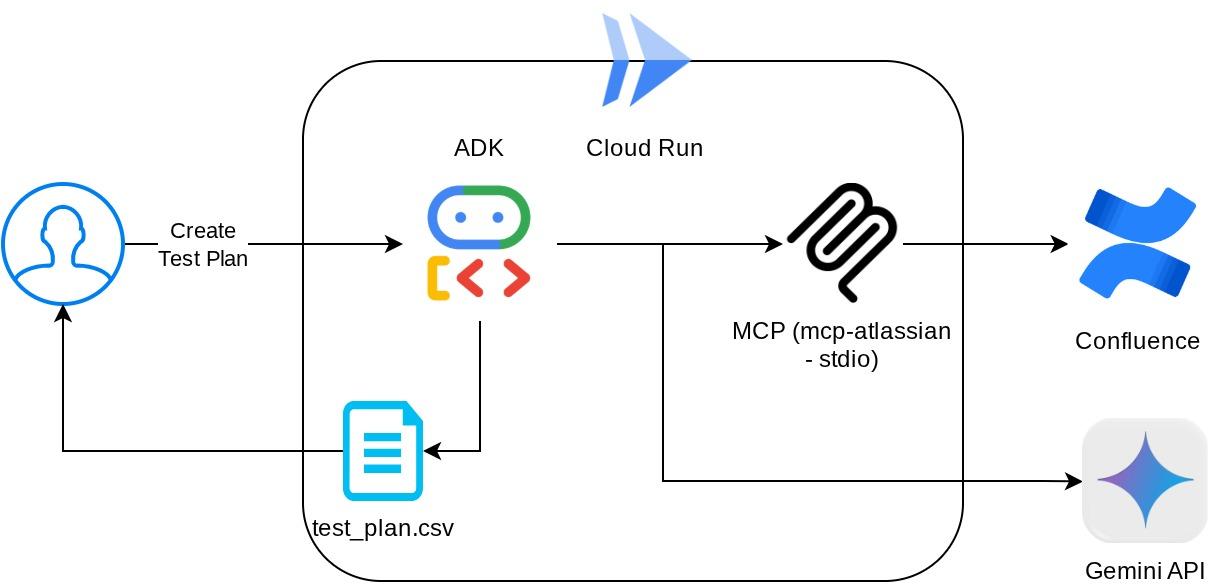
通过此配置,代理将初始化 Confluence MCP 服务器作为单独的进程,并通过 Studio I/O 处理与这些进程的通信。此流程如下图所示的 MCP 架构图(红色框内)所示。
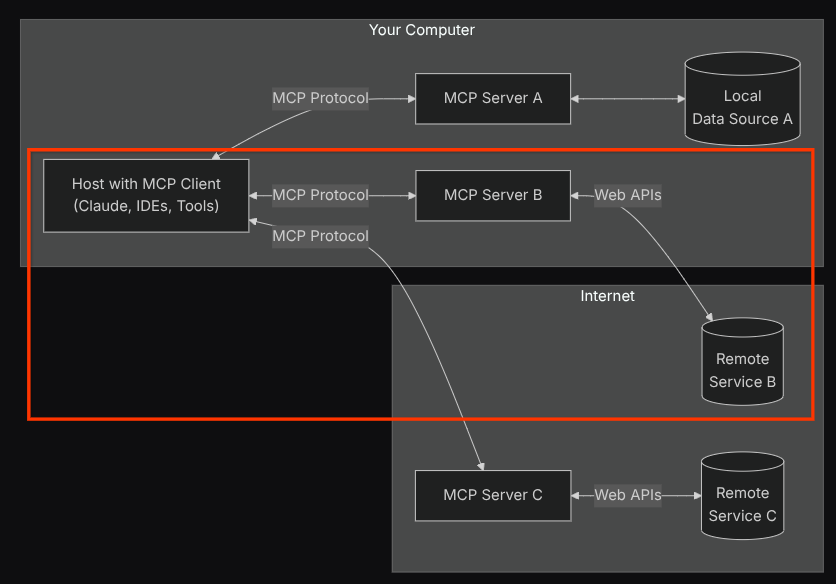
此外,在 MCP 初始化的命令实参中,我们还将可使用的工具限制为仅限以下工具:confluence_search、confluence_get_page 和 confluence_get_page_children,这些工具支持我们的 QA 测试代理使用情形。在此 Codelab 教程中,我们使用了社区贡献的 Atlassian MCP 服务器(如需了解详情,请参阅完整文档)。
“写测试”工具
在代理从 Confluence MCP 工具接收到上下文后,它可以为用户构建必要的测试计划。不过,我们希望生成一个包含此测试计划的文件,以便保存并与他人分享。为了支持这一点,我们提供了以下自定义工具 write_test_tool
# qa-test-planner/agent.py
...
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
...
上述声明的函数用于支持以下功能:
- 检查生成的测试计划,确保其符合强制性字段规范;我们使用 Pydantic 模型进行检查,如果发生错误,我们会将错误消息返回给代理
- 使用 Pandas 功能将结果转储到 CSV 文件
- 然后,使用 Artifact Service 功能将生成的文件另存为制品,该功能可通过可在每次工具调用中访问的 ToolContext 对象进行访问
如果我们保存生成的文件作为制品,它将在 ADK 运行时中标记为事件,并且稍后会在 Web 界面上的代理互动中显示
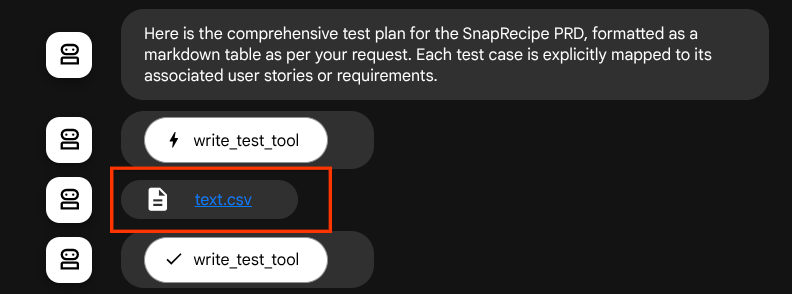
这样一来,我们就可以动态设置代理的文件响应,以便提供给用户。
4. 测试代理
现在,我们尝试通过 CLI 与代理进行通信,运行以下命令
uv run adk run qa_test_planner
系统会显示如下输出,您可以在其中与代理轮流聊天,但只能通过此界面发送文本
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent qa_test_planner_agent, type exit to exit. user: hello [qa_test_planner_agent]: Hello there! How can I help you today? user:
很高兴能通过 CLI 与智能体聊天。不过,如果我们能与它进行愉快的网络聊天,那就更好了,而我们也可以做到这一点!ADK 还允许我们使用开发界面来互动和检查互动期间发生的情况。运行以下命令以启动本地开发界面服务器
uv run adk web --port 8080
它将生成类似于以下示例的输出,这意味着我们已经可以访问 Web 界面了
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
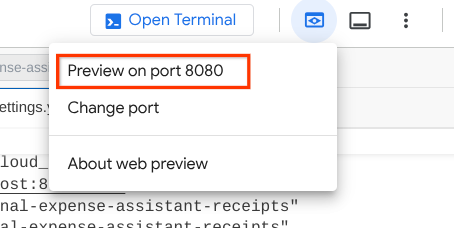
现在,如需检查,请点击 Cloud Shell 编辑器顶部区域的网页预览按钮,然后选择在端口 8080 上预览
您将看到以下网页,您可以在左上角的下拉按钮中选择可用的代理(在本例中应为 qa_test_planner),并与该机器人互动。您将在左侧窗口中看到有关代理运行时日志详情的许多信息
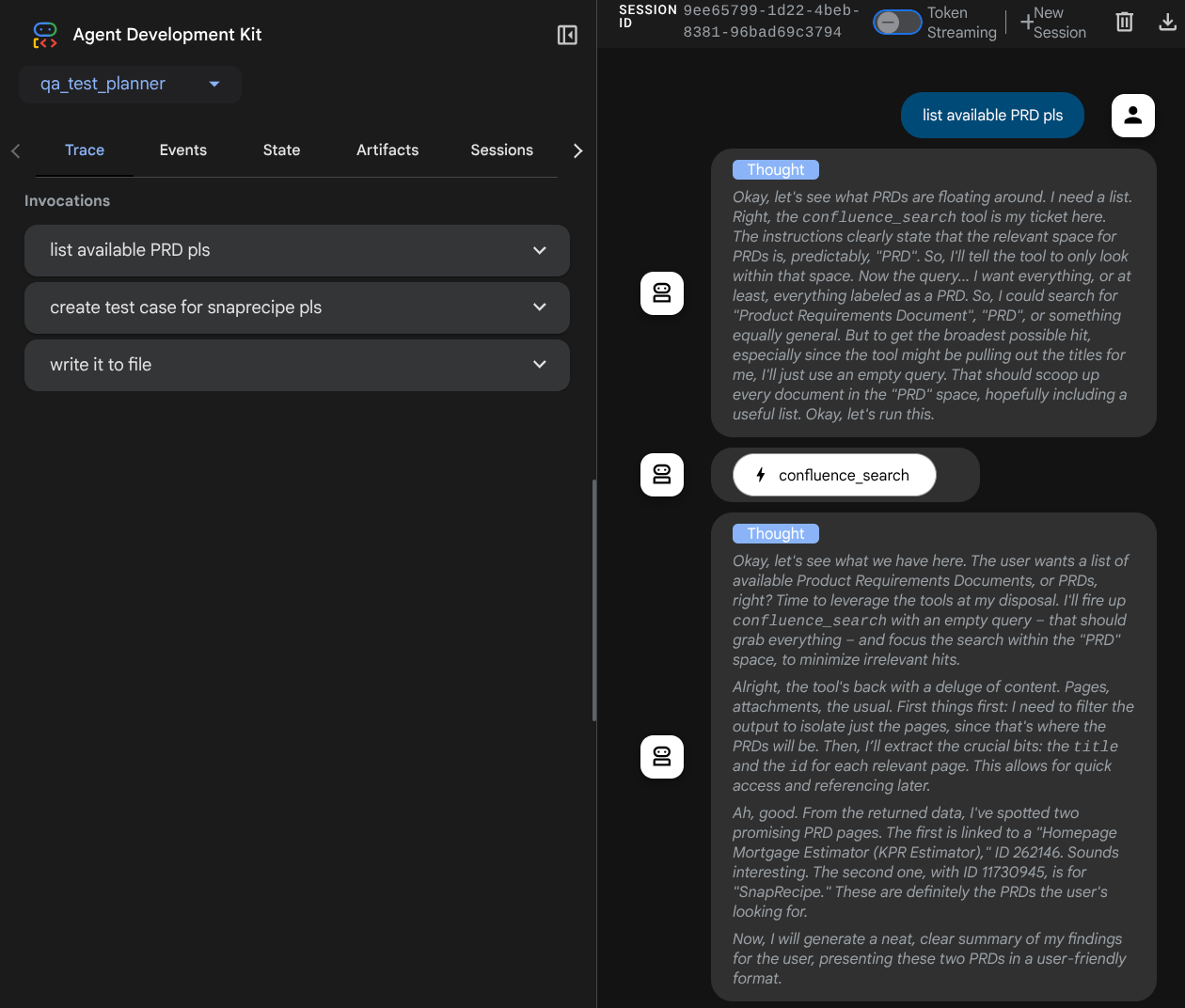
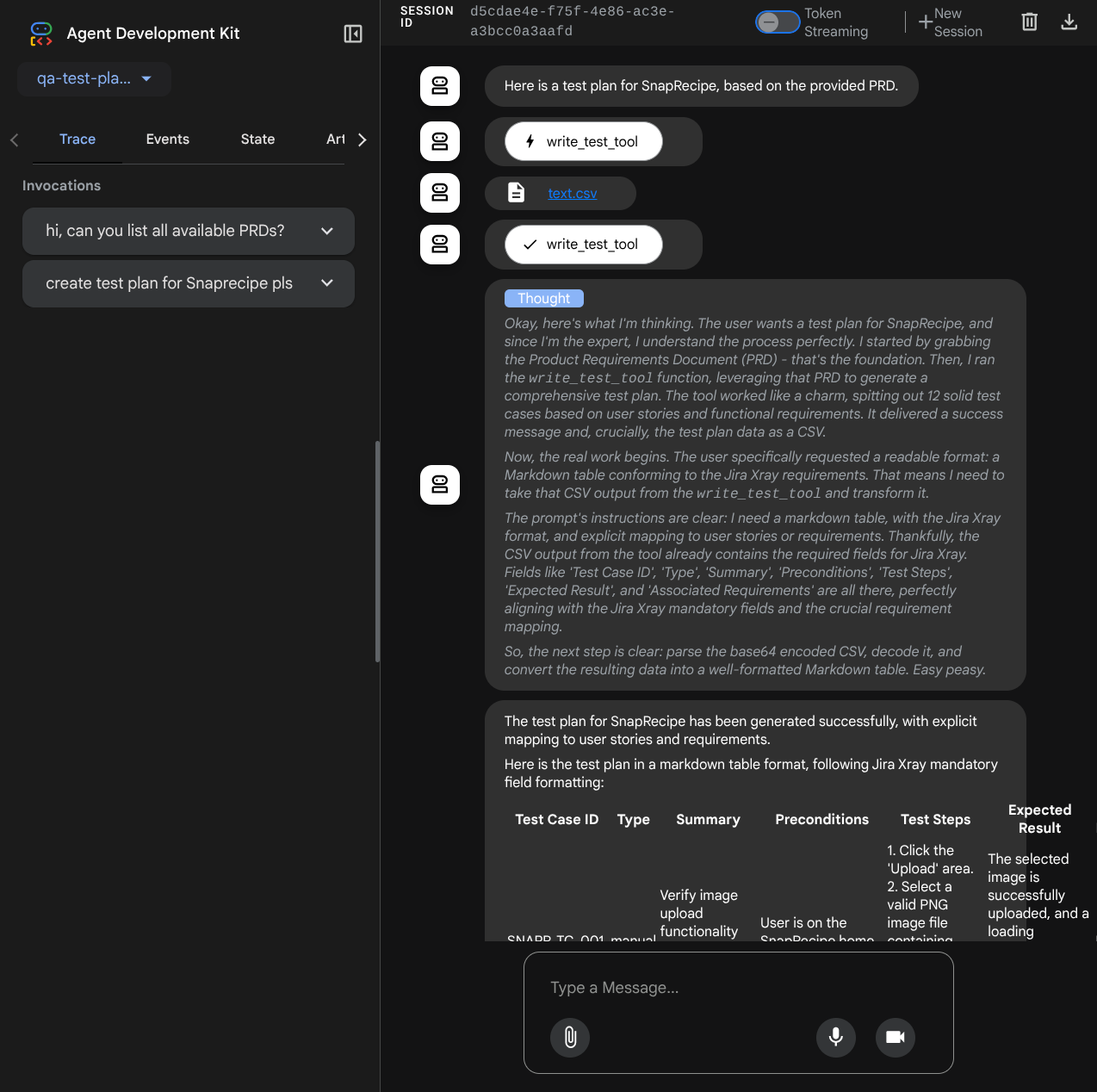
我们来尝试一些操作!通过以下提示与代理对话:
- “请列出所有可用的 PRD”
- “为 Snaprecipe PRD 撰写测试计划”
使用某些工具时,您可以检查开发界面中发生的情况
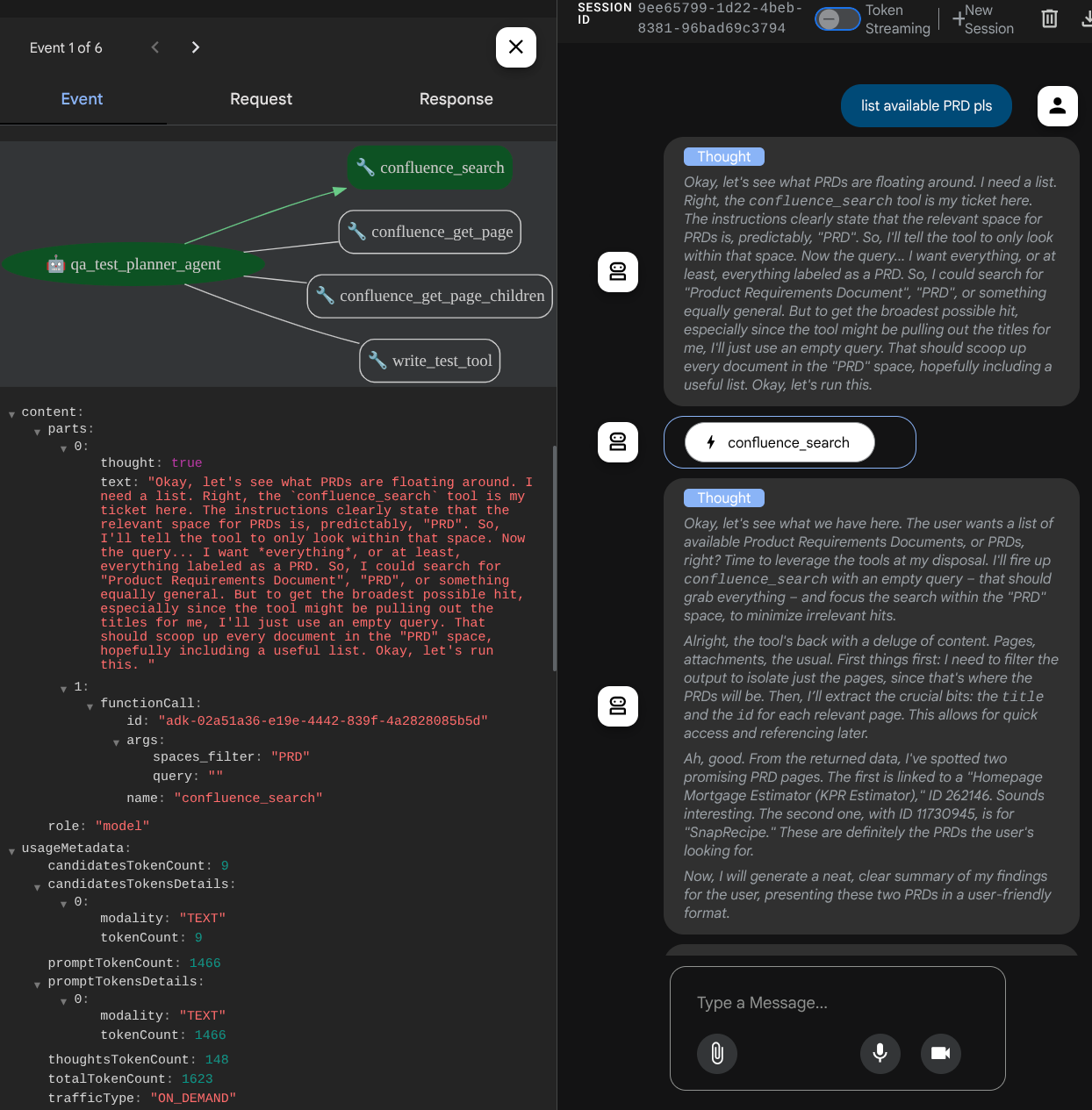
查看代理如何响应您,并检查当我们提示测试文件时,它是否会生成 CSV 文件格式的测试计划作为制品
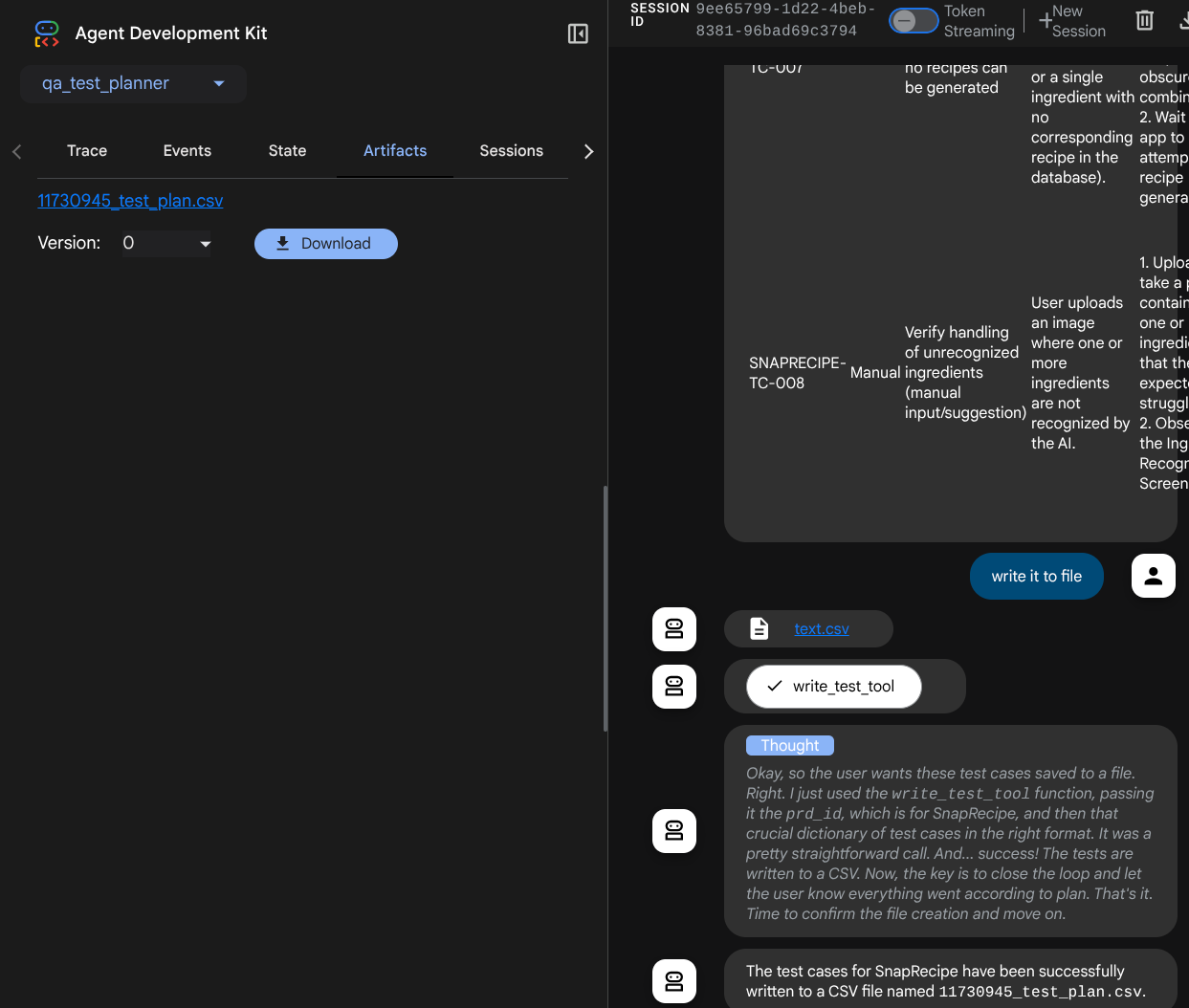
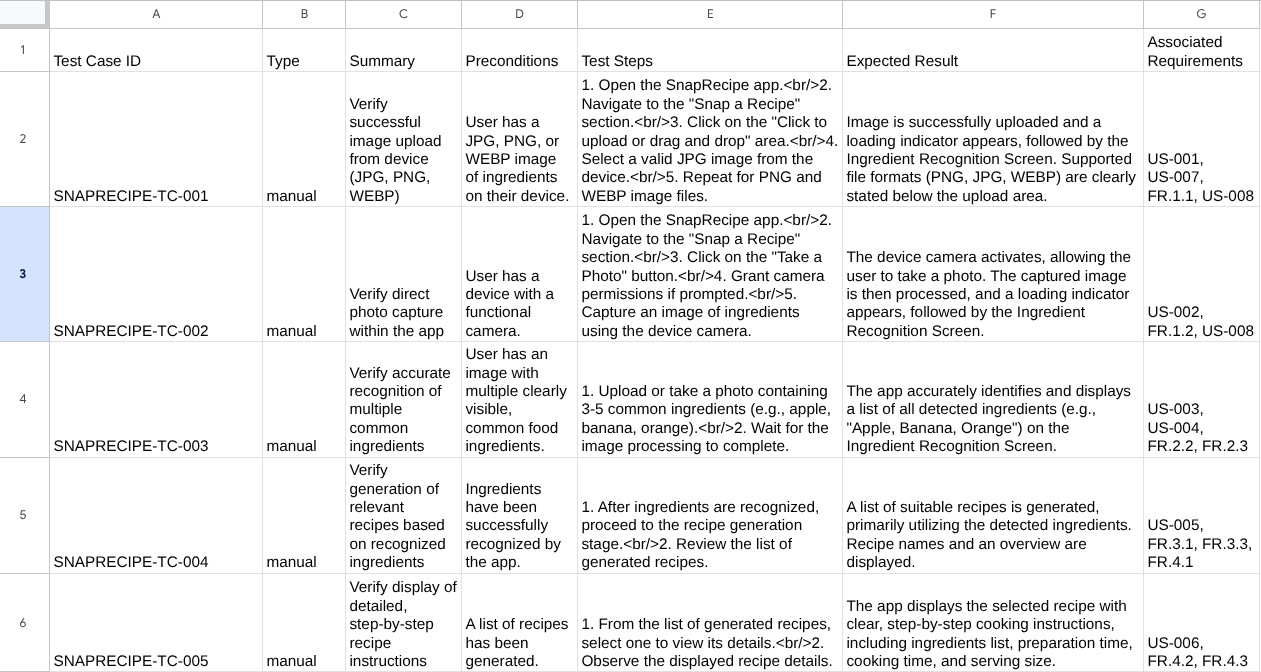
现在,您可以将 CSV 文件导入 Google 表格等工具,以检查其内容
恭喜!现在,您已在本地运行一个可正常工作的 QA 测试规划工具代理!现在,我们来看看如何将其部署到 Cloud Run,以便其他人也能使用它!
5. 部署到 Cloud Run
当然,我们希望随时随地都能访问这款出色的应用。为此,我们可以将此应用打包并将其部署到 Cloud Run。为了便于演示,此服务将作为可供他人访问的公共服务公开。不过,请注意,这并非最佳实践!
在当前工作目录中,我们已经拥有将应用部署到 Cloud Run 所需的所有文件 - 代理目录、Dockerfile 和 server.py(主服务脚本),接下来我们来部署它。前往 Cloud Shell 终端,确保当前项目已配置为您的有效项目。如果不是,您需要使用 gcloud configure 命令设置项目 ID:
gcloud config set project [PROJECT_ID]
然后,运行以下命令以将其部署到 Cloud Run。
gcloud run deploy qa-test-planner-agent \
--source . \
--port 8080 \
--project {YOUR_PROJECT_ID} \
--allow-unauthenticated \
--region us-central1 \
--update-env-vars GOOGLE_GENAI_USE_VERTEXAI=1 \
--update-env-vars GOOGLE_CLOUD_PROJECT={YOUR_PROJECT_ID} \
--update-env-vars GOOGLE_CLOUD_LOCATION=global \
--update-env-vars CONFLUENCE_URL={YOUR_CONFLUENCE_URL} \
--update-env-vars CONFLUENCE_USERNAME={YOUR_CONFLUENCE_USERNAME} \
--update-env-vars CONFLUENCE_TOKEN={YOUR_CONFLUENCE_TOKEN} \
--update-env-vars CONFLUENCE_PRD_SPACE_ID={YOUR_PRD_SPACE_ID} \
--memory 1G
如果系统提示您确认要为 Docker 代码库创建制品注册表,只需回答 Y 即可。请注意,我们在此处允许未经身份验证的访问,因为这是一个演示应用。建议为企业和生产应用使用适当的身份验证。
部署完成后,您应该会获得类似于以下内容的链接:
https://qa-test-planner-agent-*******.us-central1.run.app
当您访问该网址时,会进入与本地尝试时类似的 Web 开发者界面。接下来,您可以在无痕式窗口或移动设备上使用您的应用。该功能应该已经上线。
现在,我们再次尝试这些不同的提示(按顺序),看看会发生什么:
- “你能找到与抵押贷款估算器相关的 PRD 吗?”
- “请就我们可以在哪些方面改进提供反馈”
- “为其编写测试计划”
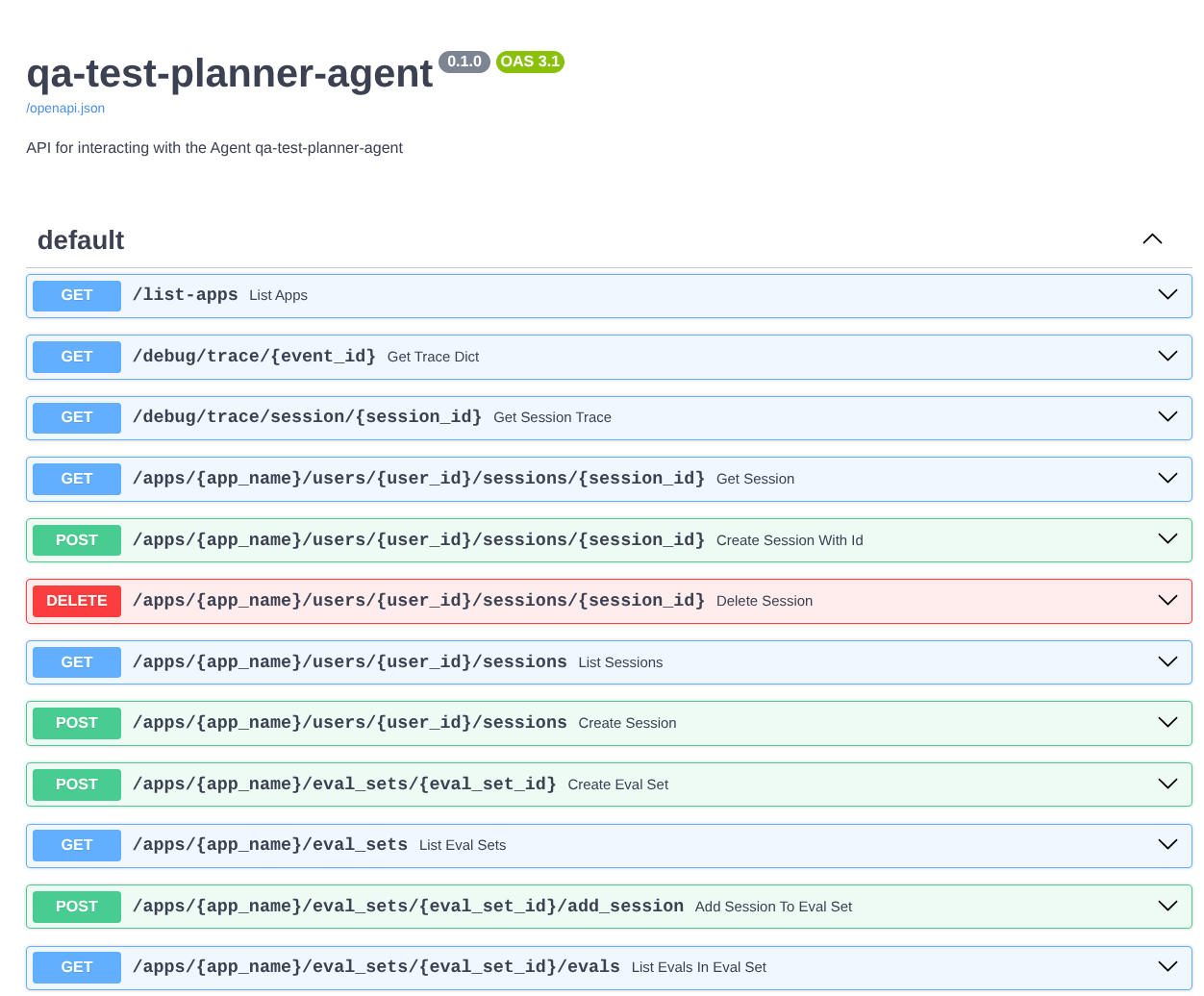
此外,由于我们将代理作为 FastAPI 应用运行,因此还可以检查 /docs 路由中的所有 API 路由。例如,如果您访问的网址如下所示:https://qa-test-planner-agent-*******.us-central1.run.app/docs,您将看到如下所示的 Swagger 文档页面
代码说明
现在,我们来检查一下部署所需的必要文件,首先是 server.py
# server.py
import os
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
app_args = {"agents_dir": AGENT_DIR, "web": True}
app: FastAPI = get_fast_api_app(**app_args)
app.title = "qa-test-planner-agent"
app.description = "API for interacting with the Agent qa-test-planner-agent"
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
我们可以使用 get_fast_api_app 函数轻松地将智能体转换为 FastAPI 应用。在此函数中,我们可以设置各种功能,例如配置会话服务、制品服务,甚至将跟踪数据发送到云端。
您还可以在此处设置应用生命周期(如果需要)。之后,我们可以使用 uvicorn 运行 Fast API 应用
之后,Dockerfile 将为我们提供运行应用所需的步骤
# Dockerfile
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
6. 挑战
现在,是时候展现您的探索技能了。您能否再创建一个工具,以便将 PRD 审核反馈也写入文件?
7. 清理
为避免系统因本 Codelab 中使用的资源向您的 Google Cloud 账号收取费用,请按照以下步骤操作: