
1. Descripción general
Con este codelab, demostraremos un método simple y fácil de realizar para configurar AlloyDB.

Qué compilarás
Como parte de esto, crearás una instancia y un clúster de AlloyDB con un solo clic y aprenderás a configurarlos rápidamente en tus proyectos futuros.
Requisitos
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto esté configurado con tu ID del proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las APIs necesarias: Sigue el vínculo y habilita las APIs.
Como alternativa, puedes usar el comando gcloud para esto. Consulta la documentación para ver los comandos y el uso de gcloud.
3. ¿Por qué AlloyDB para tus datos empresariales y la IA?
AlloyDB para PostgreSQL no es solo otro servicio de Postgres administrado. Es una modernización fundamental del motor diseñado para la era de la IA. Este es el motivo por el que se destaca en comparación con las bases de datos estándar:
- Procesamiento híbrido transaccional y analítico (HTAP)
La mayoría de las bases de datos te obligan a trasladar datos a un almacén de datos para realizar análisis. AlloyDB tiene un motor columnar integrado que mantiene automáticamente los datos relevantes en un almacén de columnas en la memoria. Esto hace que las consultas analíticas sean hasta 100 veces más rápidas que PostgreSQL estándar, lo que te permite ejecutar inteligencia empresarial en tiempo real en tus datos operativos sin canalizaciones de ETL complejas.
- Integración de IA nativa:
AlloyDB une la brecha entre tus datos y la IA generativa. Con la extensión google_ml_integration, puedes llamar a los modelos de Vertex AI (como Gemini) directamente dentro de tus consultas de SQL. Esto significa que puedes realizar análisis de opiniones, traducción o extracción de entidades como una transacción de base de datos estándar, lo que garantiza la seguridad de los datos y minimiza la latencia.
- Búsqueda de vectores superior:
Si bien PostgreSQL estándar usa pgvector, AlloyDB lo potencia con el índice ScaNN (vecinos más cercanos escalables), desarrollado por Google Research. Esto proporciona una búsqueda de similitud de vectores significativamente más rápida y una recuperación más alta a gran escala en comparación con los índices HNSW estándar que se encuentran en otras ofertas de Postgres. Te permite compilar aplicaciones de RAG (generación mejorada por recuperación) de alto rendimiento de forma nativa.
- Rendimiento a gran escala:
AlloyDB ofrece un rendimiento transaccional hasta 4 veces más rápido que PostgreSQL estándar. Separa el procesamiento del almacenamiento, lo que permite que se escale de forma independiente. La capa de almacenamiento es inteligente y controla el procesamiento de registros de escritura anticipada (WAL) para descargar el trabajo de la instancia principal.
- Disponibilidad empresarial:
Ofrece un ANS de tiempo de actividad del 99.99%, que incluye el mantenimiento. Este nivel de confiabilidad para una base de datos compatible con PostgreSQL se logra a través de una arquitectura nativa de la nube que garantiza una recuperación rápida ante fallas y durabilidad del almacenamiento.
4. Configuración de AlloyDB
En este lab, usaremos AlloyDB como la base de datos para los datos de prueba. Usa clústeres para contener todos los recursos, como bases de datos y registros. Cada clúster tiene una instancia principal que proporciona un punto de acceso a los datos. Las tablas contendrán los datos reales.
Creemos un clúster, una instancia y una tabla de AlloyDB en los que se cargará el conjunto de datos de prueba.
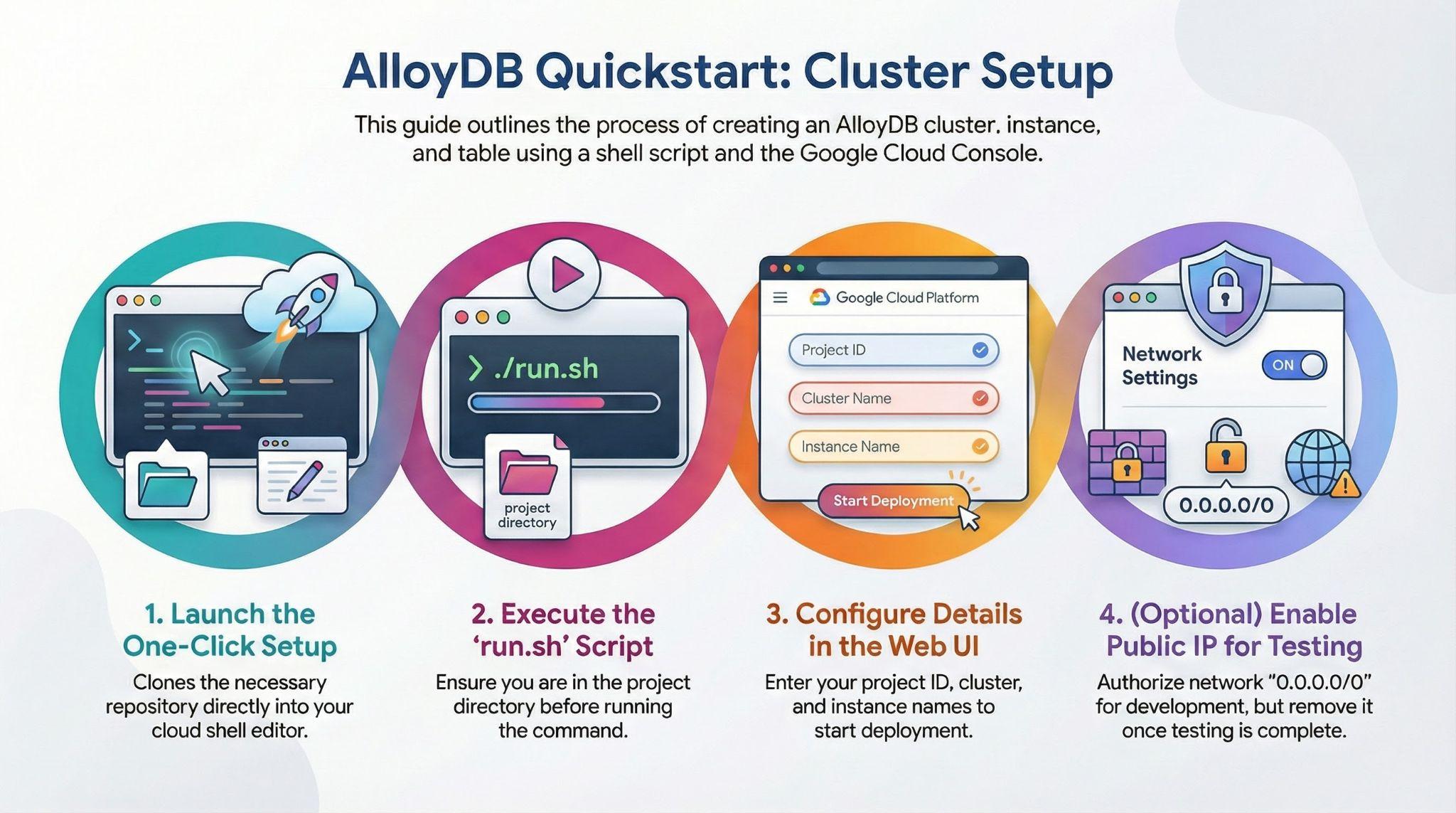
- Haz clic en el botón o copia el vínculo que aparece a continuación en el navegador en el que tienes registrado el usuario de la consola de Google Cloud.
Enfoque alternativo para hacer clic en el botón anterior (recomendado):
# 1. Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# 2. Navigate to the project directory
cd devrel-demos/infrastructure/easy-alloydb-setup
- Una vez que se complete este paso, el repositorio se clonará en tu editor de Cloud Shell local y podrás ejecutar el siguiente comando desde la carpeta del proyecto (es importante asegurarte de estar en el directorio del proyecto):
sh run.sh
- Ahora usa la IU (haz clic en el vínculo de la terminal o en el vínculo "vista previa en la Web" en la terminal).
- Ingresa los detalles del ID del proyecto, el clúster y los nombres de las instancias para comenzar.
- Ve a tomar un café mientras se desplazan los registros y puedes leer cómo lo hace en segundo plano aquí.
5. Configuración ilustrada
6. Limpieza
Una vez que finalice este lab de prueba, no olvides borrar el clúster y la instancia de AlloyDB.
Debería limpiar el clúster junto con sus instancias.
7. Felicitaciones
¡Ya está todo listo!
Comienza a configurar tus datos con AlloyDB de forma rápida y sencilla.