
1. 개요
이 Codelab에서는 AlloyDB를 설정하는 간단하고 쉬운 방법을 보여줍니다.

빌드할 항목
이 과정에서 원클릭 설치로 AlloyDB 인스턴스와 클러스터를 만들고 향후 프로젝트에서도 빠르게 설정하는 방법을 알아봅니다.
요구사항
2. 시작하기 전에
프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있어야 하므로 프로젝트에서 결제가 사용 설정되어 있는지 확인하는 방법을 알아봅니다.
- Google Cloud에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다. Google Cloud 콘솔 상단에서 Cloud Shell 활성화 를 클릭합니다.

- Cloud Shell에 연결되면 다음 명령어를 사용하여 이미 인증되었고 프로젝트가 프로젝트 ID로 설정되어 있는지 확인합니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
gcloud config set project <YOUR_PROJECT_ID>
- 필요한 API를 사용 설정합니다. 링크를 따라 API를 사용 설정합니다.
또는 gcloud 명령어를 사용할 수 있습니다. gcloud 명령어 및 사용법은 문서를 참조하세요.
3. 비즈니스 데이터 및 AI에 AlloyDB를 사용하는 이유
PostgreSQL용 AlloyDB는 또 다른 관리형 Postgres 서비스가 아닙니다. AI 시대를 위해 설계된 엔진의 근본적인 현대화입니다. 표준 데이터베이스와 비교하여 AlloyDB가 독보적인 이유는 다음과 같습니다.
- 하이브리드 트랜잭션 및 분석 처리 (HTAP)
대부분의 데이터베이스에서는 분석을 위해 데이터를 데이터 웨어하우스로 이동해야 합니다. AlloyDB에는 관련 데이터를 인메모리 열 스토어에 자동으로 보관하는 기본 열 기반 엔진 이 있습니다. 이를 통해 분석 쿼리가 표준 PostgreSQL보다 최대 100배 빨라지므로 복잡한 ETL 파이프라인 없이 운영 데이터에 대한 실시간 비즈니스 인텔리전스를 실행할 수 있습니다.
- 기본 AI 통합:
AlloyDB는 데이터와 생성형 AI 간의 격차를 해소합니다. google_ml_integration 확장 프로그램을 사용하면 SQL 쿼리 내에서 직접 Vertex AI 모델 (예: Gemini)을 호출할 수 있습니다. 즉, 데이터 보안을 보장하고 지연 시간을 최소화하면서 감정 분석, 번역 또는 항목 추출을 표준 데이터베이스 트랜잭션으로 수행할 수 있습니다.
- 우수한 벡터 검색:
표준 PostgreSQL은 pgvector를 사용하는 반면 AlloyDB는 Google Research에서 개발한 ScaNN 색인 (확장 가능한 최근접 이웃)으로 이를 강화합니다. 이를 통해 다른 Postgres 제품에서 제공되는 표준 HNSW 색인에 비해 벡터 유사성 검색이 훨씬 빨라지고 대규모로 더 높은 재현율을 제공합니다. 이를 통해 고성능 RAG (검색 증강 생성) 애플리케이션을 기본적으로 빌드할 수 있습니다.
- 규모에 따른 성능:
AlloyDB는 표준 PostgreSQL보다 최대 4배 더 빠른 트랜잭션 성능을 제공합니다. 컴퓨팅과 스토리지를 분리하여 독립적으로 확장할 수 있습니다. 스토리지 레이어는 지능형으로, WAL (Write-Ahead Logging) 처리를 처리하여 기본 인스턴스에서 작업을 오프로드합니다.
- 엔터프라이즈 가용성:
유지보수를 포함하여 99.99% 업타임 SLA를 제공합니다. PostgreSQL 호환 데이터베이스의 이러한 수준의 안정성은 빠른 장애 복구와 스토리지 내구성을 보장하는 클라우드 네이티브 아키텍처를 통해 달성됩니다.
4. AlloyDB 설정
이 실습에서는 AlloyDB를 테스트 데이터의 데이터베이스로 사용합니다. 데이터베이스 및 로그와 같은 모든 리소스를 보관하는 데 클러스터 를 사용합니다. 각 클러스터에는 데이터에 대한 액세스 지점을 제공하는 기본 인스턴스 가 있습니다. 테이블에는 실제 데이터가 보관됩니다.
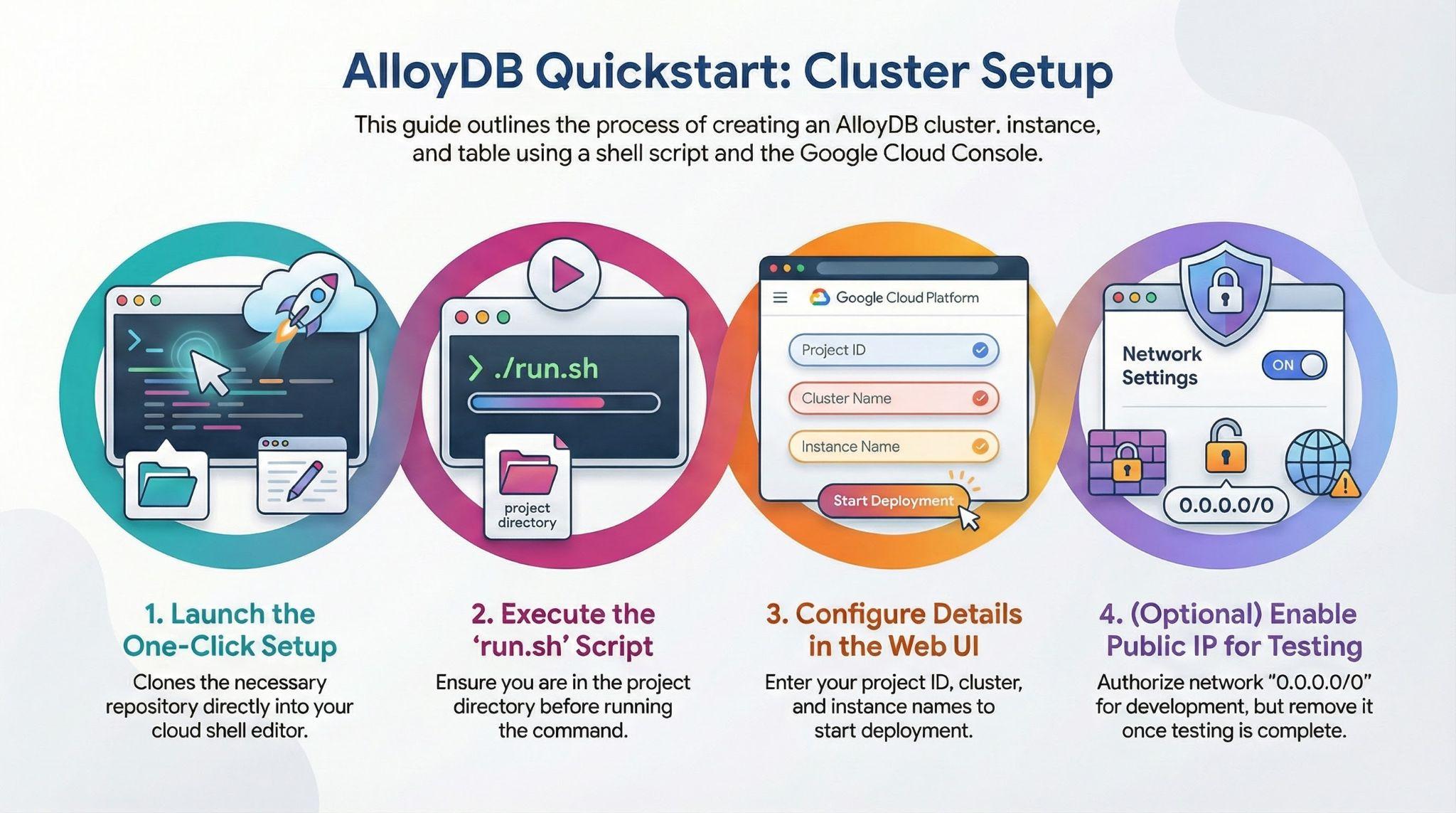
테스트 데이터 세트가 로드될 AlloyDB 클러스터, 인스턴스, 테이블을 만들어 보겠습니다.
- Google Cloud 콘솔 사용자가 로그인한 브라우저에서 아래 버튼을 클릭하거나 링크를 복사합니다.
위 버튼을 클릭하는 대체 방법 (권장):
# 1. Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# 2. Navigate to the project directory
cd devrel-demos/infrastructure/easy-alloydb-setup
- 이 단계가 완료되면 저장소가 로컬 Cloud Shell 편집기에 클론되고 프로젝트 폴더 내에서 아래 명령어를 실행할 수 있습니다 (프로젝트 디렉터리에 있는지 확인하는 것이 중요함).
sh run.sh
- 이제 UI를 사용합니다 (터미널에서 링크를 클릭하거나 터미널에서 '웹에서 미리보기' 링크를 클릭).
- 프로젝트 ID, 클러스터, 인스턴스 이름의 세부정보를 입력하여 시작합니다.
- 로그가 스크롤되는 동안 커피를 마시면서 여기에서 백그라운드에서 이 작업을 수행하는 방법을 읽어보세요.
5. 설정 설명
6. 삭제
이 체험판 실습이 완료되면 alloyDB 클러스터와 인스턴스를 삭제하는 것을 잊지 마세요.
클러스터와 인스턴스가 정리됩니다.
7. 축하합니다
이제 시작할 수 있습니다.