
1. Przegląd
W tym ćwiczeniu pokażemy prostą i łatwą metodę konfigurowania AlloyDB.

Co utworzysz
W ramach tego procesu utworzysz instancję i klaster AlloyDB za pomocą instalacji jednym kliknięciem. Dowiesz się też, jak szybko skonfigurować je w przyszłych projektach.
Wymagania
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie włączone są płatności.
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API: kliknij link i włącz interfejsy API.
Możesz też użyć polecenia gcloud. Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
3. Dlaczego warto używać AlloyDB do przechowywania firmowych baz danych i AI?
AlloyDB for PostgreSQL to nie tylko kolejna zarządzana usługa Postgres. To fundamentalna modernizacja silnika zaprojektowana z myślą o erze AI. Oto dlaczego wyróżnia się na tle standardowych baz danych:
- Hybrydowe przetwarzanie transakcyjne i analityczne (HTAP)
Większość baz danych wymusza przenoszenie danych do hurtowni danych na potrzeby analiz. AlloyDB ma wbudowany silnik kolumnowy, który automatycznie przechowuje odpowiednie dane w pamięci w postaci kolumn. Dzięki temu zapytania analityczne są nawet 100 razy szybsze niż w standardowej wersji PostgreSQL, co umożliwia uruchamianie analizy biznesowej w czasie rzeczywistym na danych operacyjnych bez złożonych potoków ETL.
- Natywna integracja AI:
AlloyDB wypełnia lukę między danymi a generatywną AI. Dzięki rozszerzeniu google_ml_integration możesz wywoływać modele Vertex AI (np. Gemini) bezpośrednio w zapytaniach SQL. Oznacza to, że możesz przeprowadzać analizę nastawienia, tłumaczenie lub wyodrębnianie jednostek jako standardową transakcję w bazie danych, zapewniając bezpieczeństwo danych i minimalizując czas oczekiwania.
- Zaawansowane wyszukiwanie wektorowe:
Standardowa baza danych PostgreSQL używa pgvector, ale AlloyDB wzbogaca ją o indeks ScaNN (Scalable Nearest Neighbors) opracowany przez zespół ds. badań Google. Zapewnia to znacznie szybsze wyszukiwanie podobieństw wektorowych i większe przywoływanie na dużą skalę w porównaniu ze standardowymi indeksami HNSW dostępnymi w innych ofertach Postgres. Umożliwia natywne tworzenie aplikacji RAG (Retrieval Augmented Generation) o wysokiej wydajności.
- Skuteczność na dużą skalę:
AlloyDB oferuje nawet 4-krotnie większą wydajność transakcyjną niż standardowa wersja PostgreSQL. Oddziela ona zasoby obliczeniowe od pamięci masowej, co umożliwia ich niezależne skalowanie. Warstwa pamięci jest inteligentna i obsługuje przetwarzanie zapisywania logów z wyprzedzeniem (WAL), aby odciążyć instancję główną.
- Dostępność dla firm:
Usługa ta oferuje gwarancję jakości usług (SLA) na poziomie 99,99%, która obejmuje konserwację. Ten poziom niezawodności bazy danych zgodnej z PostgreSQL jest osiągany dzięki architekturze natywnej dla chmury, która zapewnia szybkie przywracanie po awarii i trwałość pamięci masowej.
4. Konfiguracja AlloyDB
W tym module użyjemy AlloyDB jako bazy danych do przechowywania danych testowych. Używa klastrów do przechowywania wszystkich zasobów, takich jak bazy danych i logi. Każdy klaster ma instancję główną, która zapewnia punkt dostępu do danych. Tabele będą zawierać rzeczywiste dane.
Utwórzmy klaster, instancję i tabelę AlloyDB, do których zostanie załadowany testowy zbiór danych.
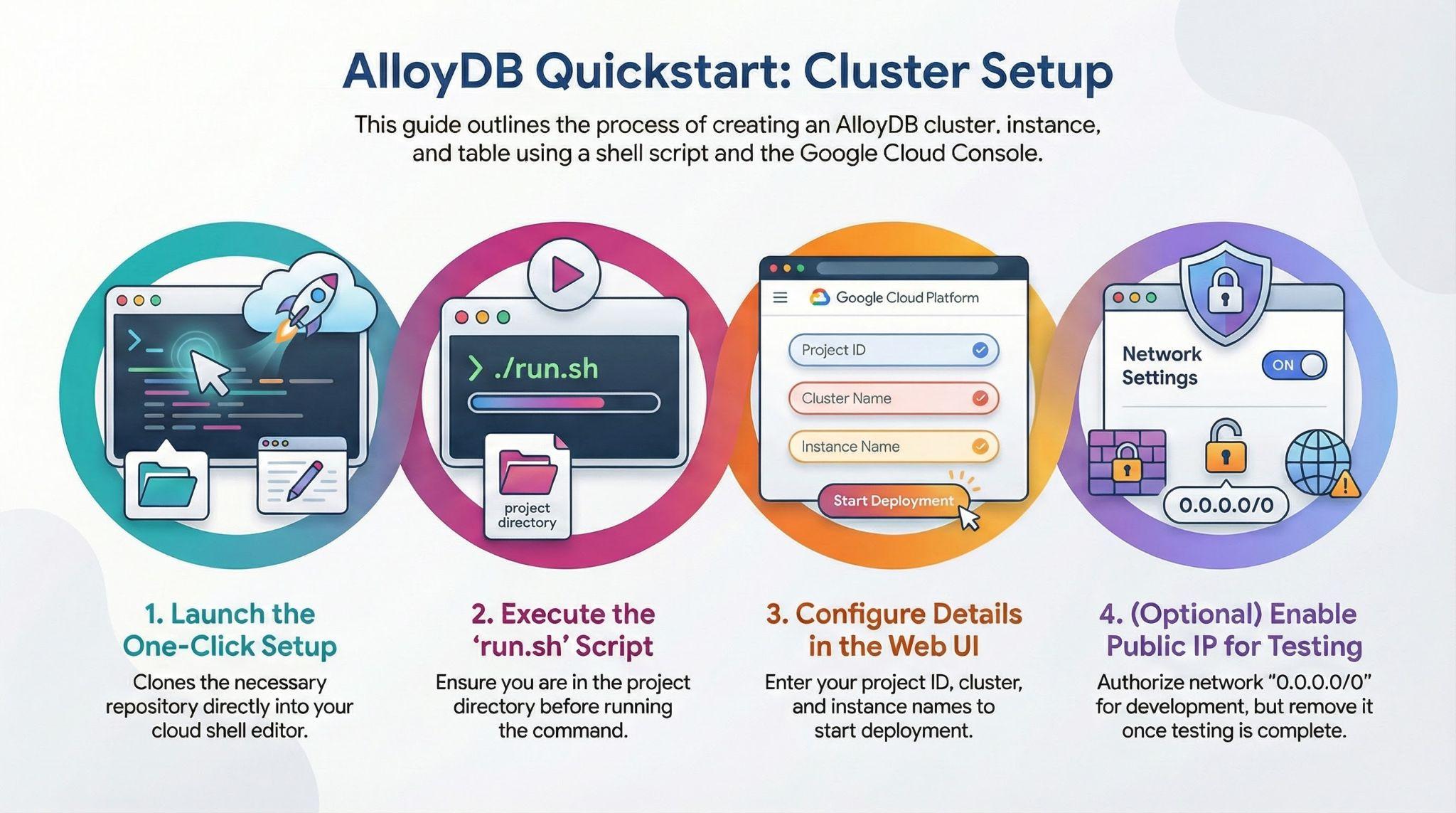
- Kliknij przycisk lub skopiuj poniższy link do przeglądarki, w której zalogowany jest użytkownik konsoli Google Cloud.
Alternatywny sposób kliknięcia powyższego przycisku (zalecany):
# 1. Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# 2. Navigate to the project directory
cd devrel-demos/infrastructure/easy-alloydb-setup
- Po wykonaniu tego kroku repozytorium zostanie sklonowane do lokalnego edytora Cloud Shell i będziesz mieć możliwość uruchomienia poniższego polecenia w folderze projektu (ważne, aby upewnić się, że jesteś w katalogu projektu):
sh run.sh
- Teraz użyj interfejsu (kliknij link w terminalu lub link „Podgląd w internecie” w terminalu).
- Aby rozpocząć, wpisz szczegóły identyfikatora projektu, klastra i nazw instancji.
- Idź po kawę, podczas gdy dzienniki będą się przewijać. Tutaj możesz przeczytać, jak to działa za kulisami.
5. Konfiguracja z ilustracjami
6. Czyszczenie
Po ukończeniu tego modułu próbnego nie zapomnij usunąć klastra i instancji AlloyDB.
Powinien on zwalniać miejsce w klastrze wraz z jego instancjami.
7. Gratulacje
Wszystko gotowe!!!
Zacznij konfigurować dane w AlloyDB szybko i łatwo.