
1. Обзор
В этом практическом занятии мы продемонстрируем простой и легкий в выполнении метод настройки AlloyDB.

Что вы построите
В рамках этого курса вы создадите экземпляр AlloyDB и кластер с установкой в один клик, а также научитесь быстро настраивать их в своих будущих проектах.
Требования
2. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.

- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его установки:
gcloud config set project <YOUR_PROJECT_ID>
- Включите необходимые API: перейдите по ссылке и включите API.
В качестве альтернативы можно использовать команду gcloud. Для получения информации о командах gcloud и их использовании обратитесь к документации .
3. Почему AlloyDB лучше всего подходит для ваших бизнес-данных и ИИ?
AlloyDB for PostgreSQL — это не просто ещё один управляемый сервис PostgreSQL. Это фундаментальная модернизация движка, разработанного для эпохи искусственного интеллекта. Вот почему он выделяется на фоне стандартных баз данных:
- Гибридная транзакционная и аналитическая обработка (HTAP)
Большинство баз данных заставляют перемещать данные в хранилище данных для аналитики. AlloyDB имеет встроенный столбцовый механизм , который автоматически хранит необходимые данные в столбцовом хранилище в оперативной памяти. Это делает аналитические запросы до 100 раз быстрее, чем в стандартной PostgreSQL, позволяя вам проводить бизнес-аналитику в режиме реального времени на основе ваших оперативных данных без сложных конвейеров ETL.
- Встроенная интеграция ИИ:
AlloyDB устраняет разрыв между вашими данными и генеративным ИИ. Благодаря расширению google_ml_integration вы можете вызывать модели Vertex AI (например, Gemini) непосредственно в своих SQL-запросах. Это означает, что вы можете выполнять анализ настроения, перевод или извлечение сущностей как стандартную транзакцию базы данных, обеспечивая безопасность данных и минимизируя задержки.
- Превосходный векторный поиск:
В то время как стандартный PostgreSQL использует pgvector , AlloyDB значительно расширяет его возможности за счет индекса ScaNN (Scalable Nearest Neighbors), разработанного Google Research. Это обеспечивает значительно более быстрый поиск векторного сходства и более высокую полноту в масштабе по сравнению со стандартными индексами HNSW, используемыми в других решениях Postgres. Это позволяет создавать высокопроизводительные приложения RAG (Retrieval Augmented Generation) непосредственно в PostgreSQL.
- Масштабируемая производительность:
AlloyDB обеспечивает до 4 раз более высокую скорость транзакций, чем стандартный PostgreSQL. Она разделяет вычислительные ресурсы и хранилище, позволяя им масштабироваться независимо друг от друга. Уровень хранения данных является интеллектуальным и обрабатывает протокол предварительной записи (WAL), разгружая основной экземпляр от основной работы.
- Доступность для корпоративных пользователей:
Она предлагает соглашение об уровне обслуживания (SLA) с гарантированным временем безотказной работы 99,99% , включая техническое обслуживание. Такой уровень надежности для базы данных, совместимой с PostgreSQL, достигается за счет облачной архитектуры, которая обеспечивает быстрое восстановление после сбоев и надежность хранения данных.
4. Настройка AlloyDB
В этой лабораторной работе мы будем использовать AlloyDB в качестве базы данных для тестовых данных. Она использует кластеры для хранения всех ресурсов, таких как базы данных и журналы. Каждый кластер имеет основной экземпляр , который обеспечивает точку доступа к данным. Таблицы будут содержать сами данные.
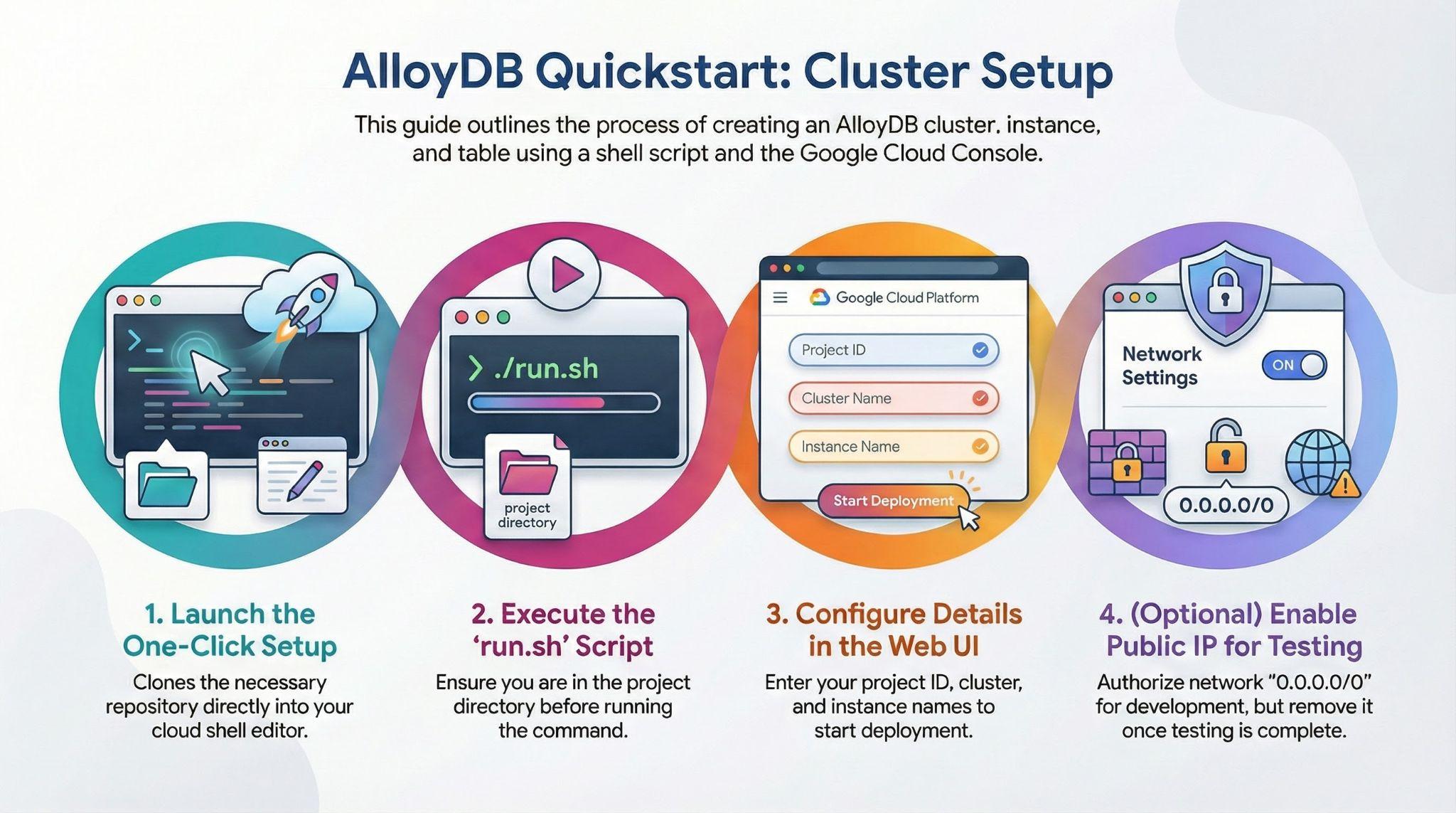
Давайте создадим кластер AlloyDB, экземпляр и таблицу, куда будет загружен тестовый набор данных.
- Нажмите на кнопку или скопируйте ссылку ниже в браузер, где вы авторизованы в Google Cloud Console.
Альтернативный способ нажатия на кнопку выше (рекомендуемый):
# 1. Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# 2. Navigate to the project directory
cd devrel-demos/infrastructure/easy-alloydb-setup
- После завершения этого шага репозиторий будет клонирован в ваш локальный редактор CloudShell, и вы сможете выполнить приведенную ниже команду из папки проекта (важно убедиться, что вы находитесь в каталоге проекта):
sh run.sh
- Теперь воспользуйтесь пользовательским интерфейсом (щелкните ссылку в терминале или щелкните ссылку «предварительный просмотр в веб-браузере» в терминале).
- Введите данные для идентификатора проекта, названия кластера и экземпляра, чтобы начать работу.
- Пока прокручиваются логи, выпейте кофе, а подробнее о том, как это всё происходит за кулисами, вы можете прочитать здесь.
5. Иллюстрация процесса настройки
6. Уборка
После завершения этой тестовой среды не забудьте удалить кластер и экземпляр AlloyDB.
Это должно привести к очистке кластера вместе с его экземплярами.
7. Поздравляем!
Всё в порядке!!!
Начните быстро и легко настраивать свои данные в AlloyDB!!!