
1. Introdução
Última atualização:15/09/2021
Os dados necessários para gerar insights sobre preços e otimização são diferentes por natureza (diferentes sistemas, diferentes realidades locais etc.), por isso, é crucial desenvolver uma tabela de CDM bem estruturada, padronizada e limpa. Isso inclui atributos importantes para a otimização de preços, como transações, produtos, preços e clientes. Neste documento, explicamos as etapas descritas abaixo, fornecendo um início rápido para análises de preços que você pode estender e personalizar de acordo com suas próprias necessidades. O diagrama a seguir descreve as etapas abordadas neste documento.
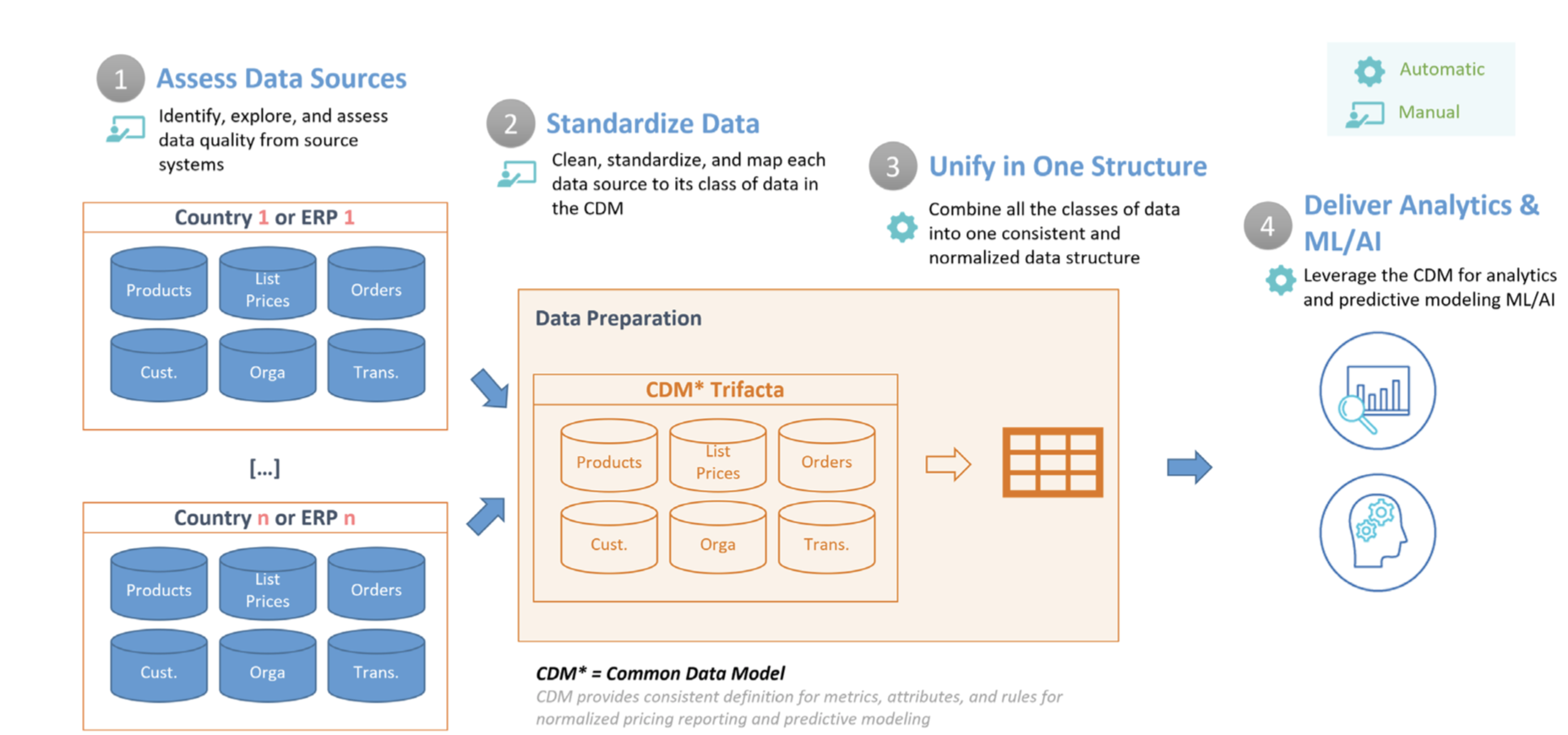
- Avaliar as fontes de dados: primeiro, é preciso ter um inventário das fontes de dados que serão usadas para criar o CDM. Nesta etapa, o Dataprep também é usado para explorar e identificar problemas dos dados de entrada. Por exemplo, valores ausentes e incompatíveis, convenções de nomenclatura inconsistentes, cópias, problemas de integridade dos dados, outliers etc.
- Padronização de dados:em seguida, os problemas já identificados são corrigidos para garantir precisão, integridade, consistência e integridade dos dados. Esse processo pode envolver várias transformações no Dataprep, como formatação de datas, padronização de valores, conversão de unidades, filtragem de campos e valores desnecessários e divisão, mesclagem ou eliminação de duplicação dos dados de origem.
- Unificar em uma estrutura:a próxima etapa do pipeline une cada fonte de dados em uma única tabela ampla no BigQuery que contém todos os atributos no melhor nível granular. Essa estrutura desnormalizada permite consultas analíticas eficientes que não exigem junções.
- Forneça análises e ML/IA: depois que os dados são limpos e formatados para análise, os analistas podem explorar os dados históricos para entender o impacto de alterações anteriores de preços. Além disso, o BigQuery ML pode ser usado para criar modelos preditivos que estimam vendas futuras. O resultado desses modelos pode ser incorporado em painéis no Looker para criar "cenários hipotéticos" em que os usuários comerciais podem analisar como serão as vendas com determinadas alterações de preço.
O diagrama a seguir mostra os componentes do Google Cloud usados para criar o pipeline de análise de otimização de preços.
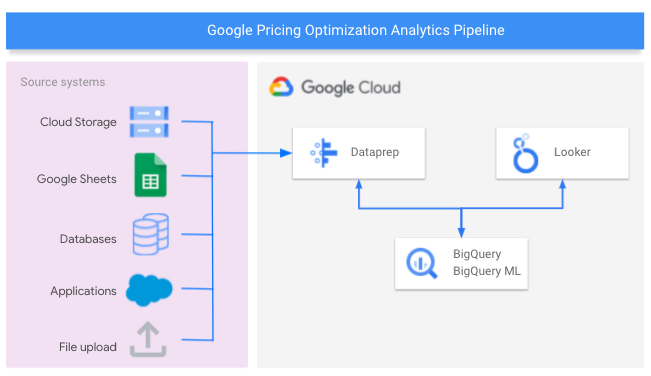
O que você vai criar
Aqui, vamos mostrar como projetar um data warehouse para otimização de preços, automatizar a preparação de dados ao longo do tempo, usar machine learning para prever o impacto de mudanças nos preços de produtos e desenvolver relatórios para fornecer insights úteis à sua equipe.
O que você vai aprender
- Como conectar o Dataprep a fontes de dados para análise de preços, que podem ser armazenadas em bancos de dados relacionais, arquivos simples, Planilhas Google e outros aplicativos compatíveis.
- Como criar um fluxo do Dataprep para gerar uma tabela do CDM no data warehouse do BigQuery.
- Como usar o BigQuery ML para prever receitas futuras.
- Como criar relatórios no Looker para analisar tendências históricas de preços e vendas e entender o impacto de futuras mudanças de preços.
O que é necessário
- Ter um projeto do Google Cloud com o faturamento ativado. Saiba como confirmar se o faturamento está ativado para o projeto.
- O BigQuery precisa estar ativado no projeto. Ele é ativado automaticamente em novos projetos. Caso contrário, ative-a em um projeto existente. Saiba mais sobre como começar a usar o BigQuery no console do Cloud aqui.
- O Dataprep também precisa estar ativado no seu projeto. O Dataprep está ativado no Console do Google, no menu de navegação à esquerda na seção "Big Data". Siga as etapas de inscrição para ativá-lo.
- Para configurar seus próprios painéis do Looker, você precisa ter acesso de desenvolvedor em uma instância do Looker. Para solicitar um teste, entre em contato com nossa equipe ou use nosso painel público para analisar os resultados do pipeline de dados nos nossos dados de amostra.
- Ter experiência com linguagem de consulta estruturada (SQL) e conhecimentos básicos sobre os seguintes assuntos: Dataprep by Trifacta, BigQuery e Looker
2. Crie o CDM no BigQuery
Nesta seção, você vai criar o modelo de dados comuns (CDM, na sigla em inglês), que oferece uma visão consolidada das informações necessárias para analisar e sugerir mudanças nos preços.
- Abra o console do BigQuery.
- Selecione o projeto que você quer usar para testar esse padrão de referência.
- Use um conjunto de dados atual ou crie um conjunto de dados do BigQuery. Dê o nome
Pricing_CDMao conjunto de dados. - Crie a tabela:
create table `CDM_Pricing`
(
Fiscal_Date DATETIME,
Product_ID STRING,
Client_ID INT64,
Customer_Hierarchy STRING,
Division STRING,
Market STRING,
Channel STRING,
Customer_code INT64,
Customer_Long_Description STRING,
Key_Account_Manager INT64,
Key_Account_Manager_Description STRING,
Structure STRING,
Invoiced_quantity_in_Pieces FLOAT64,
Gross_Sales FLOAT64,
Trade_Budget_Costs FLOAT64,
Cash_Discounts_and_other_Sales_Deductions INT64,
Net_Sales FLOAT64,
Variable_Production_Costs_STD FLOAT64,
Fixed_Production_Costs_STD FLOAT64,
Other_Cost_of_Sales INT64,
Standard_Gross_Margin FLOAT64,
Transportation_STD FLOAT64,
Warehouse_STD FLOAT64,
Gross_Margin_After_Logistics FLOAT64,
List_Price_Converged FLOAT64
);
3. Avaliar as fontes de dados
Neste tutorial, você vai usar fontes de dados de amostra armazenadas nas Planilhas Google e no BigQuery.
- A planilha Google transactions, que contém uma linha para cada transação. Ele contém detalhes como a quantidade de cada produto vendido, o total de vendas brutas e os custos associados.
- O arquivo das Planilhas Google com preços dos produtos, que contém o preço mensal de cada produto para determinado cliente.
- A tabela company_descriptions do BigQuery que contém informações de clientes individuais.
Essa tabela do BigQuery "company_descriptions" pode ser criada usando a seguinte instrução:
create table `Company_Descriptions`
(
Customer_ID INT64,
Customer_Long_Description STRING
);
insert into `Company_Descriptions` values (15458, 'ENELTEN');
insert into `Company_Descriptions` values (16080, 'NEW DEVICES CORP.');
insert into `Company_Descriptions` values (19913, 'ENELTENGAS');
insert into `Company_Descriptions` values (30108, 'CARTOON NT');
insert into `Company_Descriptions` values (32492, 'Thomas Ed Automobiles');
4. Criar o fluxo
Nesta etapa, você vai importar um fluxo de amostra do Dataprep, que será usado para transformar e unificar os conjuntos de dados de exemplo listados na seção anterior. Um fluxo representa um pipeline, ou um objeto que reúne conjuntos de dados e roteiros, que são usados para transformar e mesclar.
- Faça o download do pacote de fluxo Pricing Optimization Pattern no GitHup, mas não descompacte-o. Esse arquivo contém o fluxo do padrão de design de otimização de preços usado para transformar os dados de amostra.
- No Dataprep, clique no ícone "Flows" na barra de navegação à esquerda. Em seguida, na visualização "Flows", selecione Import no menu de contexto. Depois de importar o fluxo, você pode selecioná-lo para visualizá-lo e editá-lo.
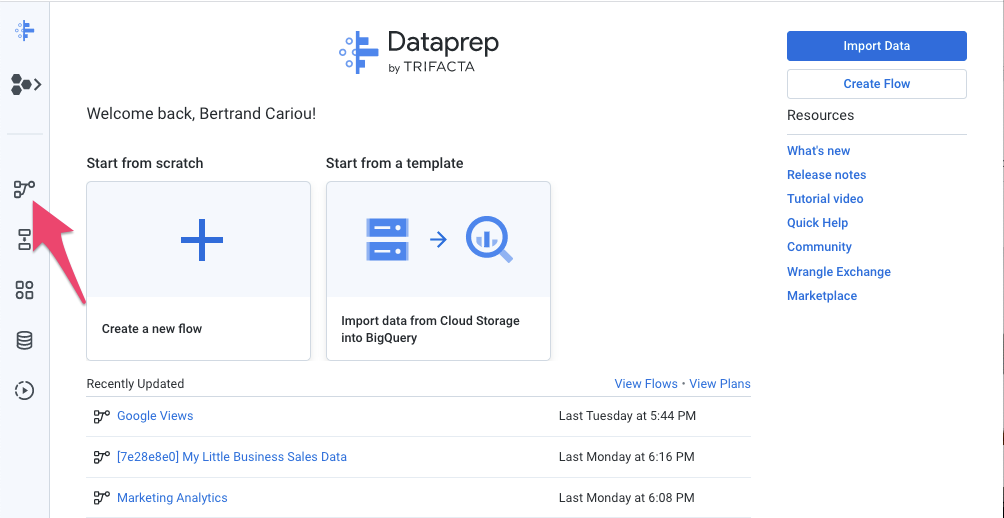
- No lado esquerdo do fluxo, os preços do produto e cada uma das três transações do Planilhas Google precisam estar conectados como conjuntos de dados. Para fazer isso, clique com o botão direito do mouse nos objetos do conjunto de dados do Planilhas Google e selecione Substituir. Em seguida, clique no link Import Datasets. Clique no botão "Editar caminho" um lápis, como mostrado no diagrama a seguir.
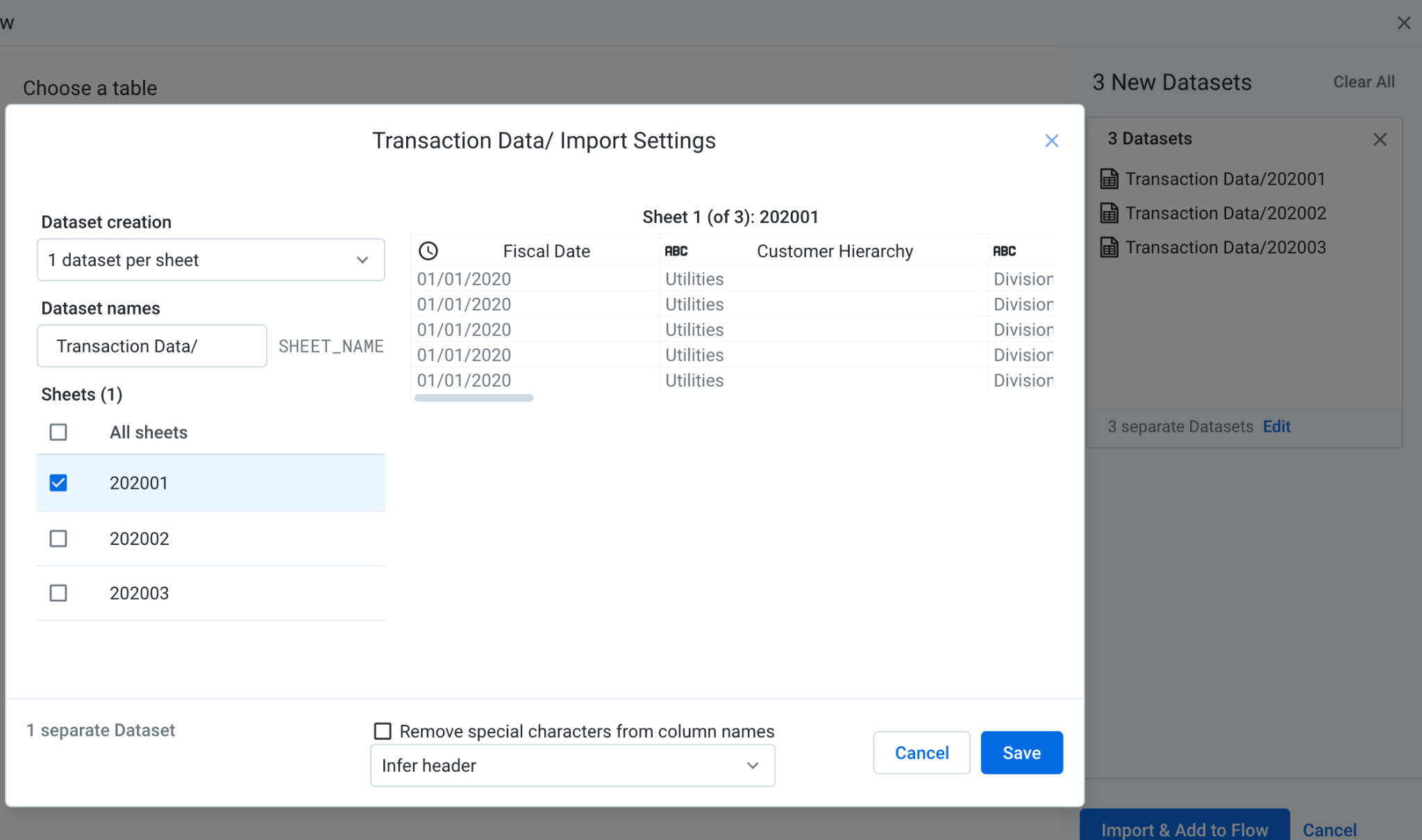
Substitua o valor atual pelo link que aponta para transações e preços dos produtos das Planilhas Google .
Quando o Planilhas Google tiver várias guias, você poderá selecionar a que deseja usar no menu. Clique em Editar e selecione as guias que você quer usar como fonte de dados. Depois, clique em Salvar e em Importar e Adicionar ao fluxo. Quando voltar ao modal, clique em Substituir. Nesse fluxo, cada planilha é representada como seu próprio conjunto de dados para demonstrar a união de fontes diferentes posteriormente em um roteiro posterior.
- Definir tabelas de saída do BigQuery:
Nesta etapa, você vai associar o local da tabela de saída CDM_Pricing do BigQuery que será carregada sempre que executar o job do Dataoprep.
Em "Flow View", clique no ícone "Schema Mapping Output" no painel "Detalhes", depois na guia "Destinos". A partir daí, edite os resultados dos destinos manuais usados para teste e dos destinos programados usados quando você quiser automatizar todo o fluxo. Para isso, siga estas instruções:
- Edite os "Destinos manuais" no painel "Detalhes", na seção "Destinos manuais", clique no botão "Editar". Na página Configurações de publicação, em "Ações de publicação", se uma ação de publicação já existir, edite-a. Caso contrário, clique no botão "Adicionar ação". Em seguida, navegue pelos conjuntos de dados do BigQuery para o conjunto de dados
Pricing_CDMque você criou em uma etapa anterior e selecione a tabelaCDM_Pricing. Confirme se a opção Append to this table every run está marcada e clique em Add. Clique em Save Settings. - Edite os "Destinos programados"
No painel "Detalhes", na seção "Destinos programados", clique em Editar.
As configurações são herdadas dos destinos manuais e você não precisa fazer nenhuma alteração. Clique em "Salvar configurações".
5. Padronizar dados
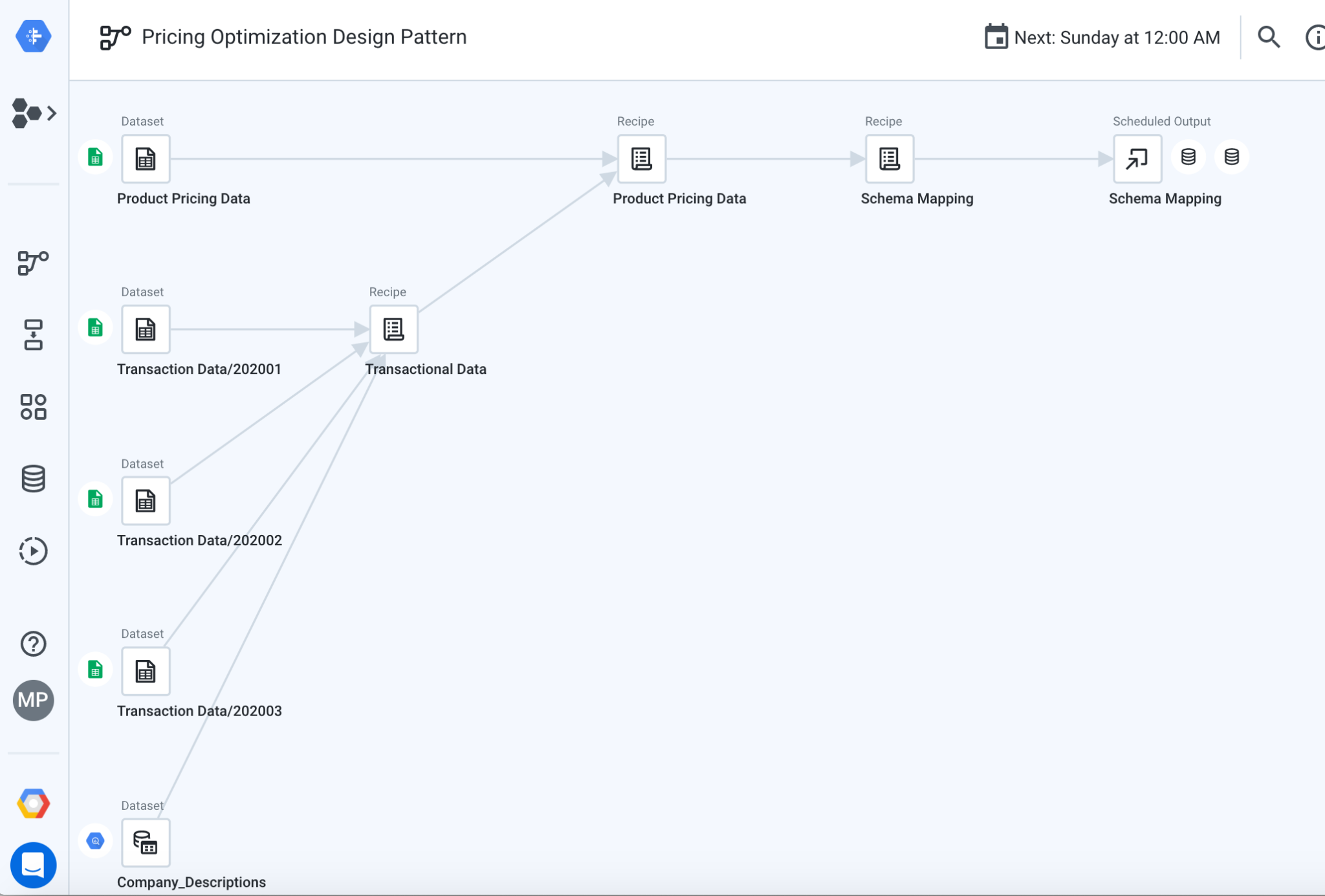
As uniões de fluxo fornecidas, formatam e limpam os dados das transações e, em seguida, mescla o resultado com as descrições da empresa e os dados de preços agregados para gerar relatórios. Aqui, você percorrerá os componentes do fluxo, que podem ser vistos na imagem abaixo.
6. Explore o roteiro dos dados transacionais
Primeiro você vai descobrir o que acontece no roteiro de dados transacionais, usado para preparar dados de transações. Clique no objeto "Dados da transação" na Visualização de fluxo, no painel "Detalhes", e no botão "Editar roteiro".
A página "Transformer" é aberta com o roteiro apresentado no painel "Detalhes". O roteiro contém todas as etapas de transformação que são aplicadas aos dados. Para navegar no roteiro, clique entre cada uma das etapas para ver o estado dos dados nessa posição específica.
Também é possível clicar no menu "Mais" para cada etapa do roteiro e selecionar "Selecionar" ou "Editar" para explorar como a transformação funciona.
- Transações de união:a primeira etapa das transações de uniões da receita de dados transacionais armazenadas em planilhas diferentes, representando cada mês.
- Padronizar descrições de clientes:a próxima etapa da receita padroniza as descrições dos clientes. Isso significa que os nomes dos clientes podem ser semelhantes com pequenas alterações e queremos normalizar como no nome. O roteiro demonstra duas abordagens possíveis. Primeiro, ele usa o Algoritmo de padronização, que pode ser configurado com diferentes opções de padronização, como "Strings semelhantes". em que valores com caracteres em comum são agrupados, ou "Pronúncia" em que valores que soam parecidos são agrupados. Você também pode consultar a descrição da empresa na tabela do BigQuery mencionada acima usando o ID da empresa.
Você pode navegar mais pelo roteiro para descobrir as várias outras técnicas que são aplicadas para limpar e formatar os dados: excluir linhas, formatar com base em padrões, enriquecer dados com pesquisas, lidar com valores ausentes ou substituir caracteres indesejados.
7. Explore o roteiro dos dados de preços dos produtos
Em seguida, você pode explorar o que acontece no roteiro dos dados de preços do produto, que mescla os dados de transações preparados com os dados de preços agregados.
Clique em "PADRÃO DE DESIGN DE OTIMIZAÇÃO DE PREÇOS" na parte superior da página para fechar a página "Transformer" e voltar para a "Visualização de fluxo". Depois, clique no objeto "Dados de preços do produto" e em "Editar o roteiro".
- Colunas de preço mensal não pivot: clique no roteiro entre as duas e três etapas para ver como os dados ficam antes da etapa de Unpivot. Você vai notar que os dados contêm o valor da transação em uma coluna distinta para cada mês: Jan Fev Mar. Esse não é um formato conveniente para aplicar o cálculo de agregação (ou seja, soma, transação média) no SQL. Os dados não estão dinamizados para que cada coluna se torne uma linha na tabela do BigQuery. O roteiro aproveita a função unpivot para transformar as três colunas em uma linha para cada mês, facilitando ainda mais a aplicação de cálculos de grupo.
- Calcular o valor médio da transação por cliente, produto e data: queremos determinar o valor médio da transação para cada cliente, produto e dados. Podemos usar a função Aggregate e gerar uma nova tabela (opção "Agrupar por como uma nova tabela"). Nesse caso, os dados são agregados no nível do grupo, e perdemos os detalhes de cada transação individual. Ou podemos decidir manter os detalhes e os valores agregados no mesmo conjunto de dados (opção "Agrupar por como uma nova coluna"), o que é muito conveniente aplicar uma proporção (ou seja, porcentagem de contribuição da categoria do produto para a receita geral). Você pode testar esse comportamento editando a etapa 7 da receita e selecionando a opção "Agrupar por como uma nova tabela" ou "Agrupar por como uma nova coluna" para entender as diferenças.
- Data de preço da mesclagem:por fim, uma mesclagem é usada para combinar vários conjuntos de dados em um maior, adicionando colunas ao conjunto inicial. Nesta etapa, os dados de preços são unidos à saída do roteiro de dados transacionais com base em "Dados de preços.Código do produto" = Dados da transação.SKU' e "Pricing Data.Price Date" = "Dados da transação.Data fiscal"
Para saber mais sobre as transformações que podem ser aplicadas com o Dataprep, confira a Folha de referências sobre disponibilização de dados Trifacta.
8. Explore o roteiro do mapeamento de esquemas
O último roteiro, "Mapeamento de esquema", garante que a tabela de CDM resultante corresponda ao esquema da tabela de saída do BigQuery. Aqui, a funcionalidade Meta rápida é usada na reformatação da estrutura de dados para corresponder à tabela do BigQuery usando a correspondência difusa para comparar os dois esquemas e aplicar alterações automáticas.
9. Unifique em uma estrutura
Agora que as origens e os destinos foram configurados e as etapas dos fluxos foram exploradas, é possível executar o fluxo para transformar e carregar a tabela do CDM no BigQuery.
- Saída de mapeamento de esquema:na visualização de fluxo, selecione o objeto de saída de mapeamento de esquema e clique em "Executar". no painel "Detalhes". Selecione "Trifacta Photon". em execução e desmarque "Ignorar erros de roteiro". Em seguida, clique no botão Executar. Se a tabela especificada do BigQuery existir, o Dataprep anexará novas linhas. Caso contrário, uma nova tabela será criada.
- Visualizar o status do job: o Dataprep abre automaticamente a página "Executar job" para que você possa monitorar a execução do job. O processo levará alguns minutos para continuar e carregar a tabela do BigQuery. Quando o job for concluído, a saída do CDM de preços será carregada no BigQuery em um formato limpo, estruturado e normalizado, pronto para análise.
10. Forneça análises e ML/IA
Pré-requisitos do Google Analytics
Para executar algumas análises e um modelo preditivo com resultados interessantes, criamos um conjunto de dados maior e relevante para descobrir insights específicos. Você precisa fazer o upload desses dados para o conjunto de dados do BigQuery antes de prosseguir com este guia.
- Faça o download do grande conjunto de dados deste repositório do GitHub.
- No Console do Google para BigQuery, navegue até o projeto e o conjunto de dados CDM_Pricing.
- Clique no menu e abra o conjunto de dados. Vamos criar a tabela carregando os dados de um arquivo local.
Clique no botão + Criar tabela e defina estes parâmetros:
- Crie a tabela com base no upload e selecione o arquivo CDM_Pricing_Large_Table.csv
- Detecção automática de esquema, verificação de parâmetros de esquema e entrada
- Opções avançadas, Preferência de gravação, Substituir tabela
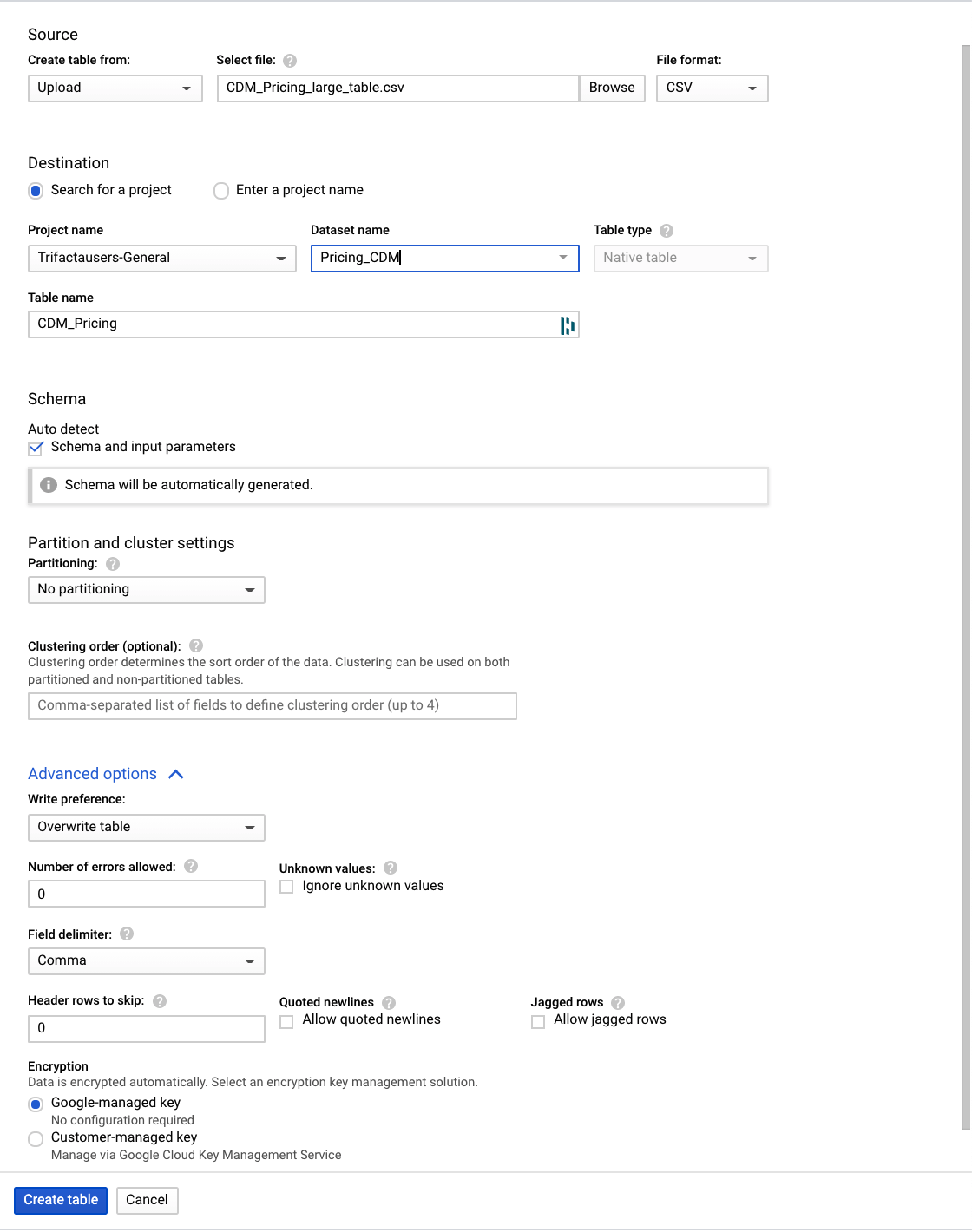
- Clique em Criar tabela
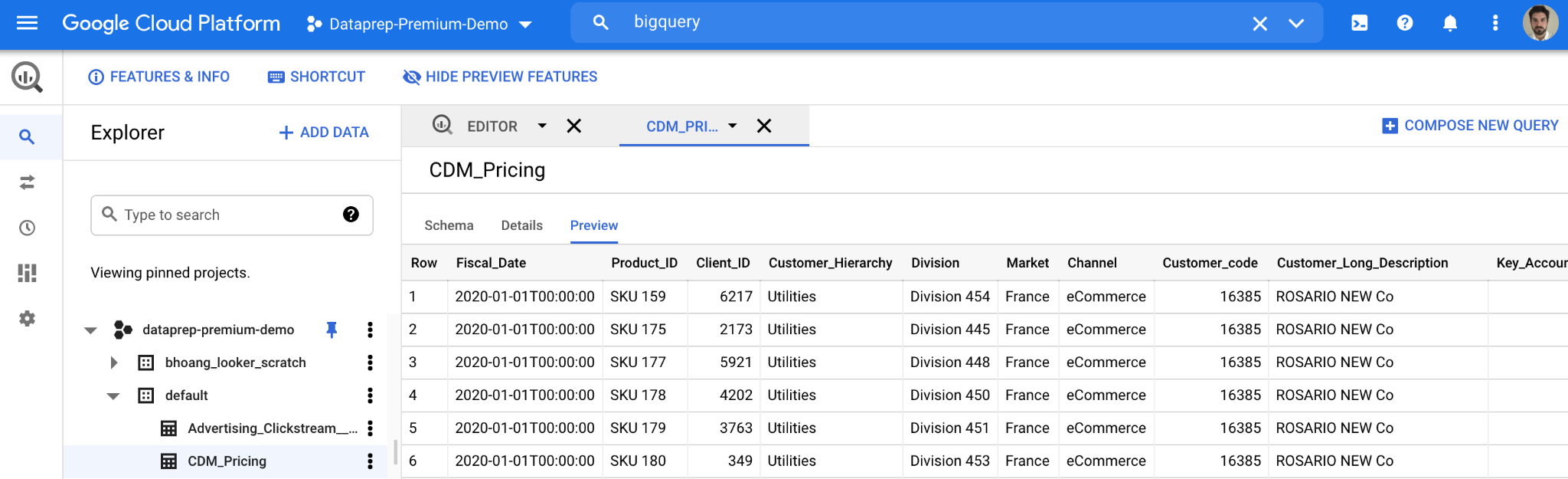
Depois que a tabela for criada e os dados forem enviados, no Google Console para BigQuery, você verá os detalhes da nova tabela, conforme mostrado abaixo. Com os dados de preços no BigQuery, podemos fazer perguntas mais abrangentes para analisar seus dados de preços em um nível mais profundo.
11. Conferir o efeito das mudanças nos preços
Um exemplo de algo que você pode querer analisar é uma mudança no comportamento do pedido quando você alterou anteriormente o preço de um item.
- Primeiro, você cria uma tabela temporária que tem uma linha sempre que o preço de um produto muda, com informações sobre o preço desse produto específico, como quantos itens foram pedidos com cada preço e o total de vendas líquidas associadas a esse preço.
create temp table price_changes as (
select
product_id,
list_price_converged,
total_ordered_pieces,
total_net_sales,
first_price_date,
lag(list_price_converged) over(partition by product_id order by first_price_date asc) as previous_list,
lag(total_ordered_pieces) over(partition by product_id order by first_price_date asc) as previous_total_ordered_pieces,
lag(total_net_sales) over(partition by product_id order by first_price_date asc) as previous_total_net_sales,
lag(first_price_date) over(partition by product_id order by first_price_date asc) as previous_first_price_date
from (
select
product_id,list_price_converged,sum(invoiced_quantity_in_pieces) as total_ordered_pieces, sum(net_sales) as total_net_sales, min(fiscal_date) as first_price_date
from `{{my_project}}.{{my_dataset}}.CDM_Pricing` AS cdm_pricing
group by 1,2
order by 1, 2 asc
)
);
select * from price_changes where previous_list is not null order by product_id, first_price_date desc

- Em seguida, com a tabela temporária em vigor, você pode calcular a mudança média de preço entre SKUs:
select avg((previous_list-list_price_converged)/nullif(previous_list,0))*100 as average_price_change from price_changes;
- Por fim, você pode analisar o que acontece depois que um preço é alterado analisando a relação entre cada mudança de preço e a quantidade total de itens pedidos:
select
(total_ordered_pieces-previous_total_ordered_pieces)/nullif(previous_total_ordered_pieces,0)
as
price_changes_percent_ordered_change,
(list_price_converged-previous_list)/nullif(previous_list,0)
as
price_changes_percent_price_change
from price_changes
12. Criar um modelo de previsão de série temporal
Em seguida, com os recursos de machine learning integrados do BigQuery, é possível criar um modelo de previsão de série temporal ARIMA para prever a quantidade de cada item que será vendido.
- Primeiro, você cria um modelo ARIMA_PLUS
create or replace `{{my_project}}.{{my_dataset}}.bqml_arima`
options
(model_type = 'ARIMA_PLUS',
time_series_timestamp_col = 'fiscal_date',
time_series_data_col = 'total_quantity',
time_series_id_col = 'product_id',
auto_arima = TRUE,
data_frequency = 'AUTO_FREQUENCY',
decompose_time_series = TRUE
) as
select
fiscal_date,
product_id,
sum(invoiced_quantity_in_pieces) as total_quantity
from
`{{my_project}}.{{my_dataset}}.CDM_Pricing`
group by 1,2;
- Em seguida, você usa a função ML.FORECAST para prever vendas futuras em cada produto:
select
*
from
ML.FORECAST(model testing.bqml_arima,
struct(30 as horizon, 0.8 as confidence_level));
- Com essas previsões disponíveis, é possível tentar entender o que pode acontecer se você aumentar os preços. Por exemplo, se você aumentar o preço de cada produto em 15%, poderá calcular a receita total estimada para o próximo mês com uma consulta como esta:
select
sum(forecast_value * list_price) as total_revenue
from ml.forecast(mode testing.bqml_arima,
struct(30 as horizon, 0.8 as confidence_level)) forecasts
left join (select product_id,
array_agg(list_price_converged
order by fiscal_date desc limit 1)[offset(0)] as list_price
from `leigha-bq-dev.retail.cdm_pricing` group by 1) recent_prices
using (product_id);
13. Criar um relatório
Agora que os dados de preços desnormalizados estão centralizados no BigQuery e você sabe como executar consultas significativas nesses dados, é hora de criar um relatório para permitir que usuários comerciais explorem e realizem ações com base nessas informações.
Se você já tem uma instância do Looker, use o LookML neste repositório do GitHub para começar a analisar os dados de preços desse padrão. Basta criar um novo projeto do Looker, adicionar o LookML e substituir a conexão e os nomes da tabela em cada um dos arquivos de visualização para corresponder à configuração do BigQuery.
Neste modelo, você vai encontrar a tabela derivada ( neste arquivo de visualização) que mostramos anteriormente para examinar mudanças de preço:
view: price_changes {
derived_table: {
sql: select
product_id,
list_price_converged,
total_ordered_pieces,
total_net_sales,
first_price_date,
lag(list_price_converged) over(partition by product_id order by first_price_date asc) as previous_list,
lag(total_ordered_pieces) over(partition by product_id order by first_price_date asc) as previous_total_ordered_pieces,
lag(total_net_sales) over(partition by product_id order by first_price_date asc) as previous_total_net_sales,
lag(first_price_date) over(partition by product_id order by first_price_date asc) as previous_first_price_date
from (
select
product_id,list_price_converged,sum(invoiced_quantity_in_pieces) as total_ordered_pieces, sum(net_sales) as total_net_sales, min(fiscal_date) as first_price_date
from ${cdm_pricing.SQL_TABLE_NAME} AS cdm_pricing
group by 1,2
order by 1, 2 asc
)
;;
}
...
}
Assim como o modelo ARIMA do BigQuery ML que mostramos anteriormente, para prever vendas futuras ( neste arquivo de visualização)
view: arima_model {
derived_table: {
persist_for: "24 hours"
sql_create:
create or replace model ${sql_table_name}
options
(model_type = 'arima_plus',
time_series_timestamp_col = 'fiscal_date',
time_series_data_col = 'total_quantity',
time_series_id_col = 'product_id',
auto_arima = true,
data_frequency = 'auto_frequency',
decompose_time_series = true
) as
select
fiscal_date,
product_id,
sum(invoiced_quantity_in_pieces) as total_quantity
from
${cdm_pricing.sql_table_name}
group by 1,2 ;;
}
}
...
}
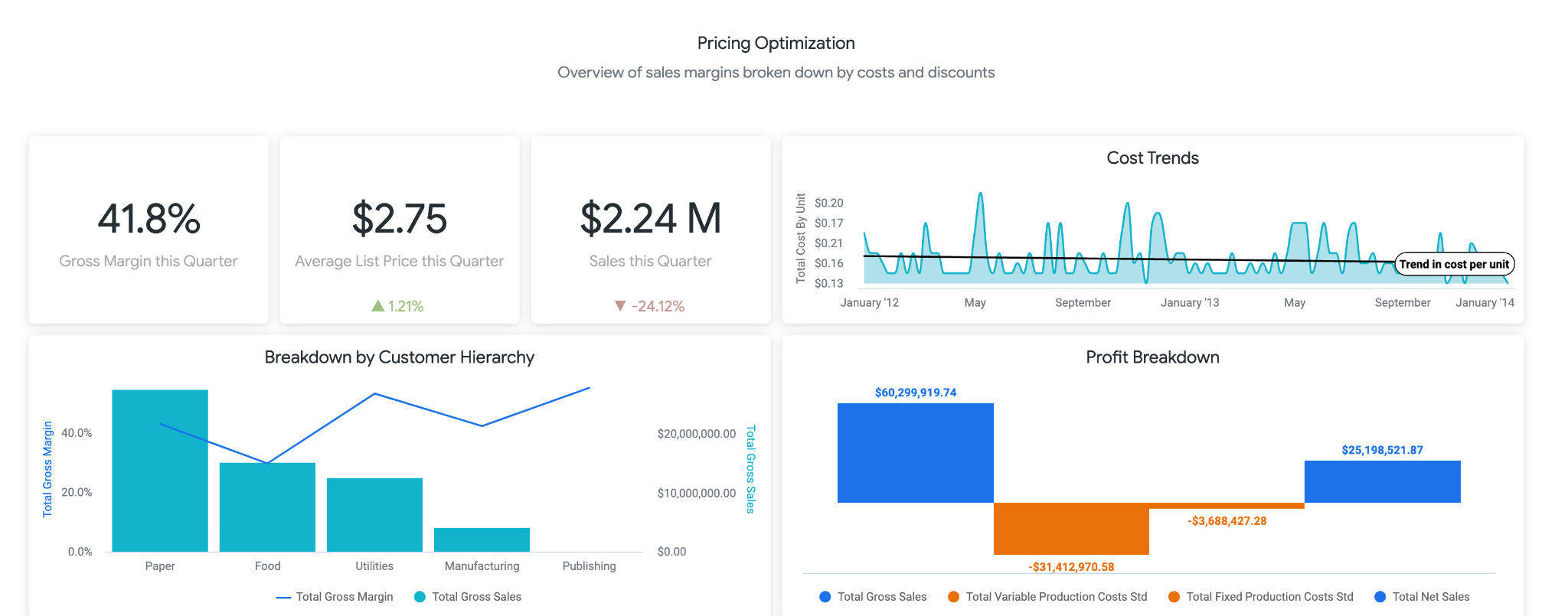
O LookML também contém um painel de amostra. Acesse uma versão de demonstração do painel aqui. A primeira parte do painel fornece aos usuários informações de alto nível sobre mudanças em vendas, custos, preços e margens. Como usuário comercial, convém criar um alerta para saber se as vendas caíram abaixo de X%, porque isso pode significar que você deve reduzir os preços.
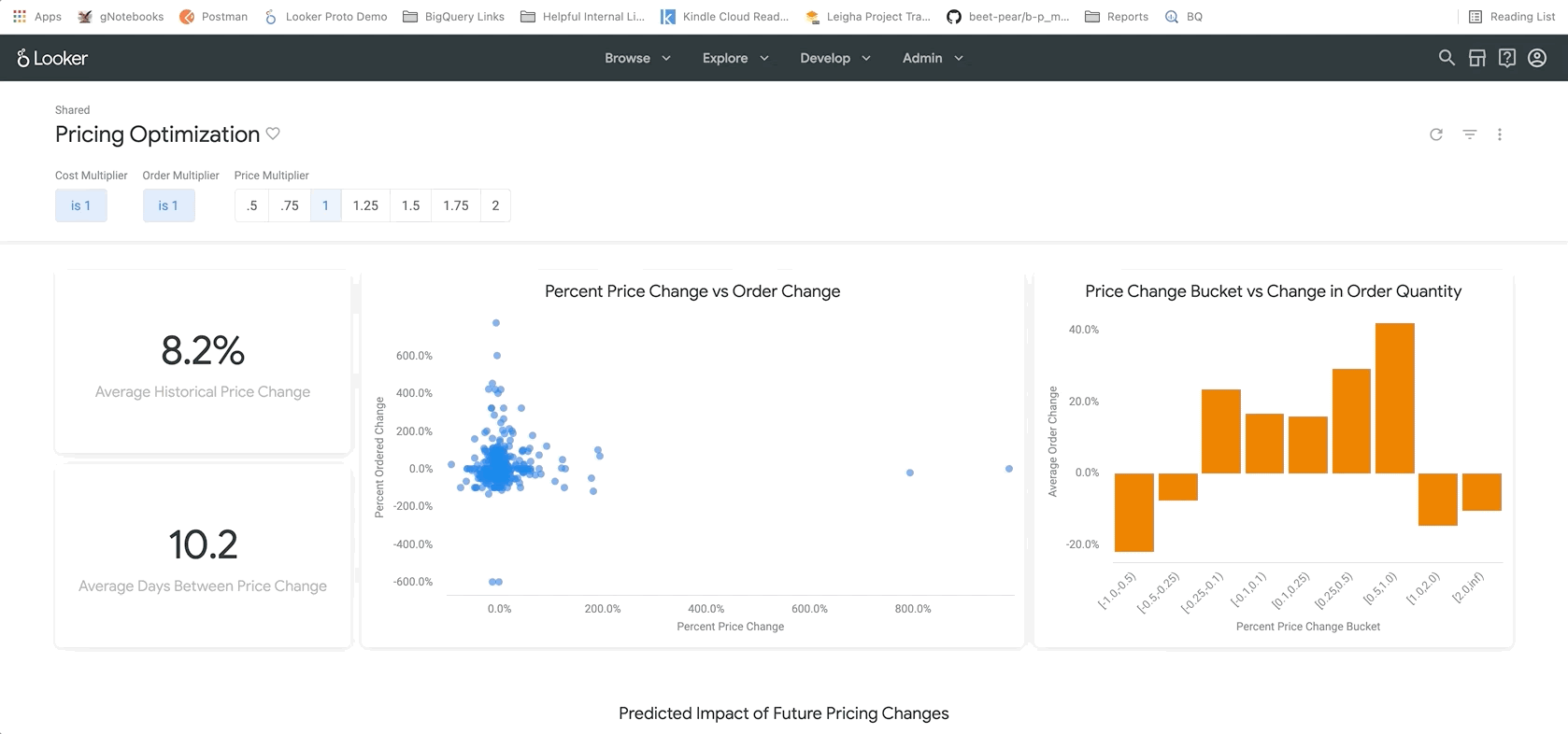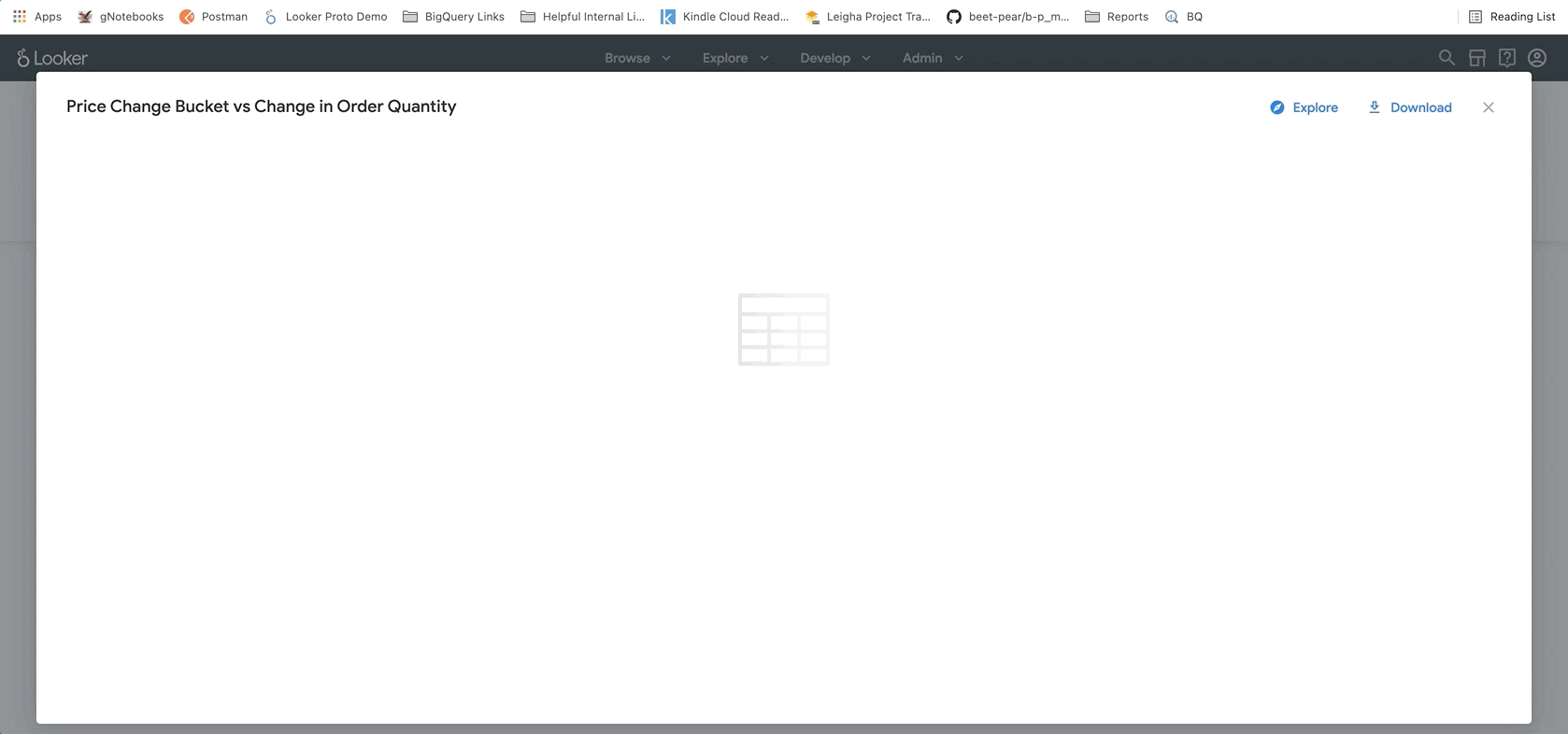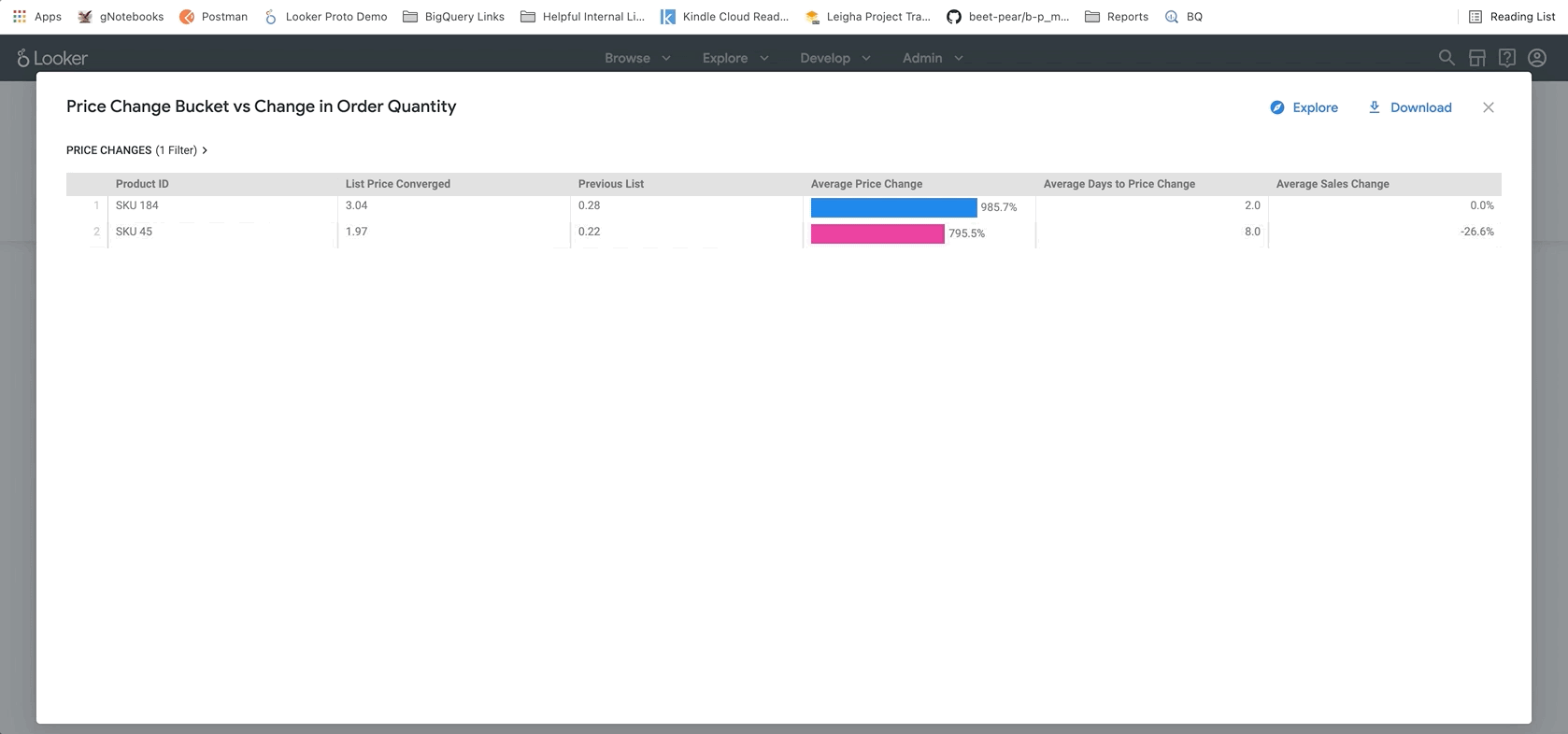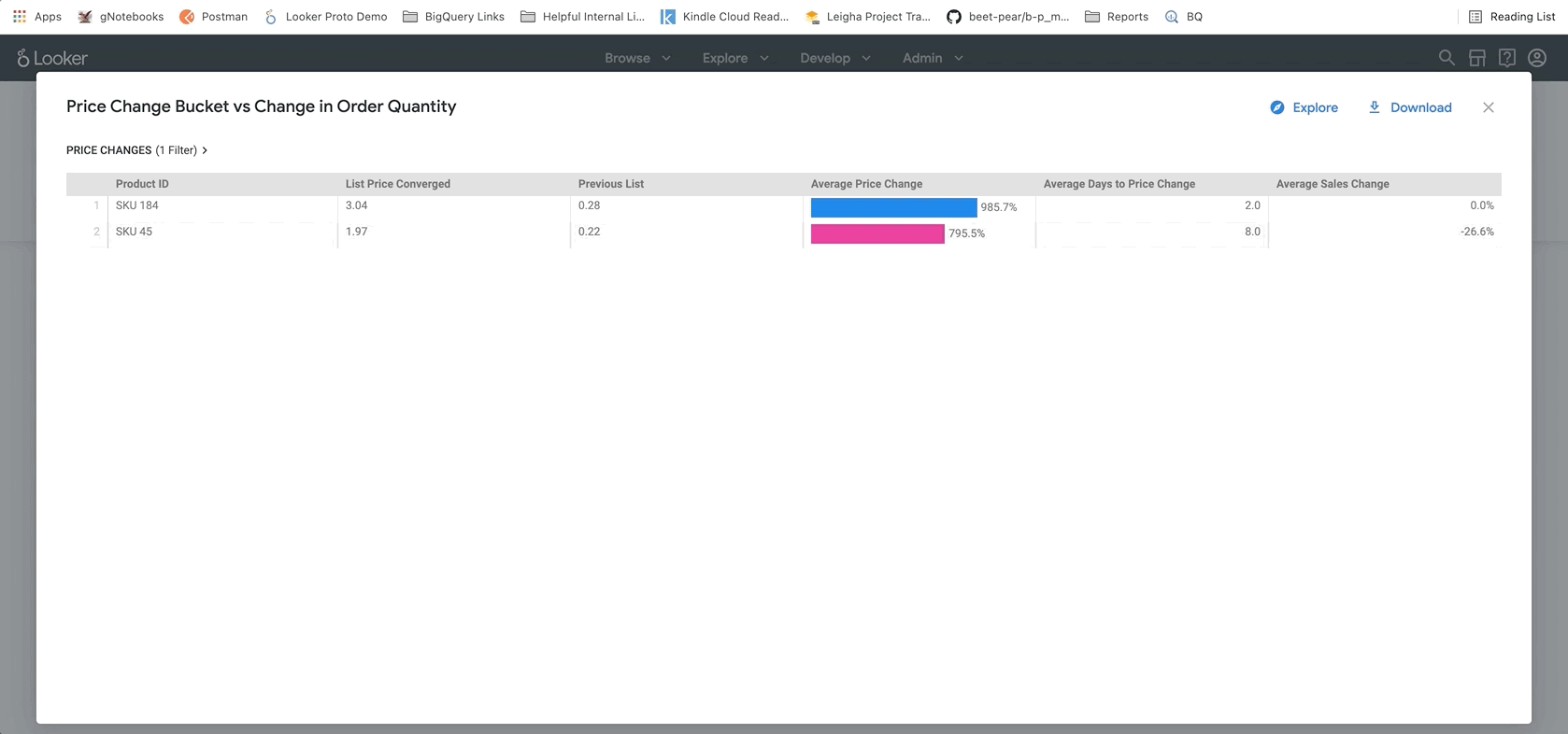
A próxima seção, mostrada abaixo, permite que os usuários se aprofundem nas tendências em torno das mudanças nos preços. Aqui, você pode detalhar produtos específicos para ver o preço de tabela exato e para que preços foram alterados, o que pode ser útil para identificar produtos específicos para fazer mais pesquisas.
Por fim, na parte inferior do relatório, estão os resultados do nosso modelo BigQueryML. Usando os filtros na parte de cima do painel do Looker, é possível inserir parâmetros com facilidade para simular diferentes cenários semelhantes aos descritos acima. Por exemplo, ver o que aconteceria se o volume de pedidos caísse para 75% do valor previsto e o preço em todos os produtos aumentasse em 25%, conforme mostrado abaixo
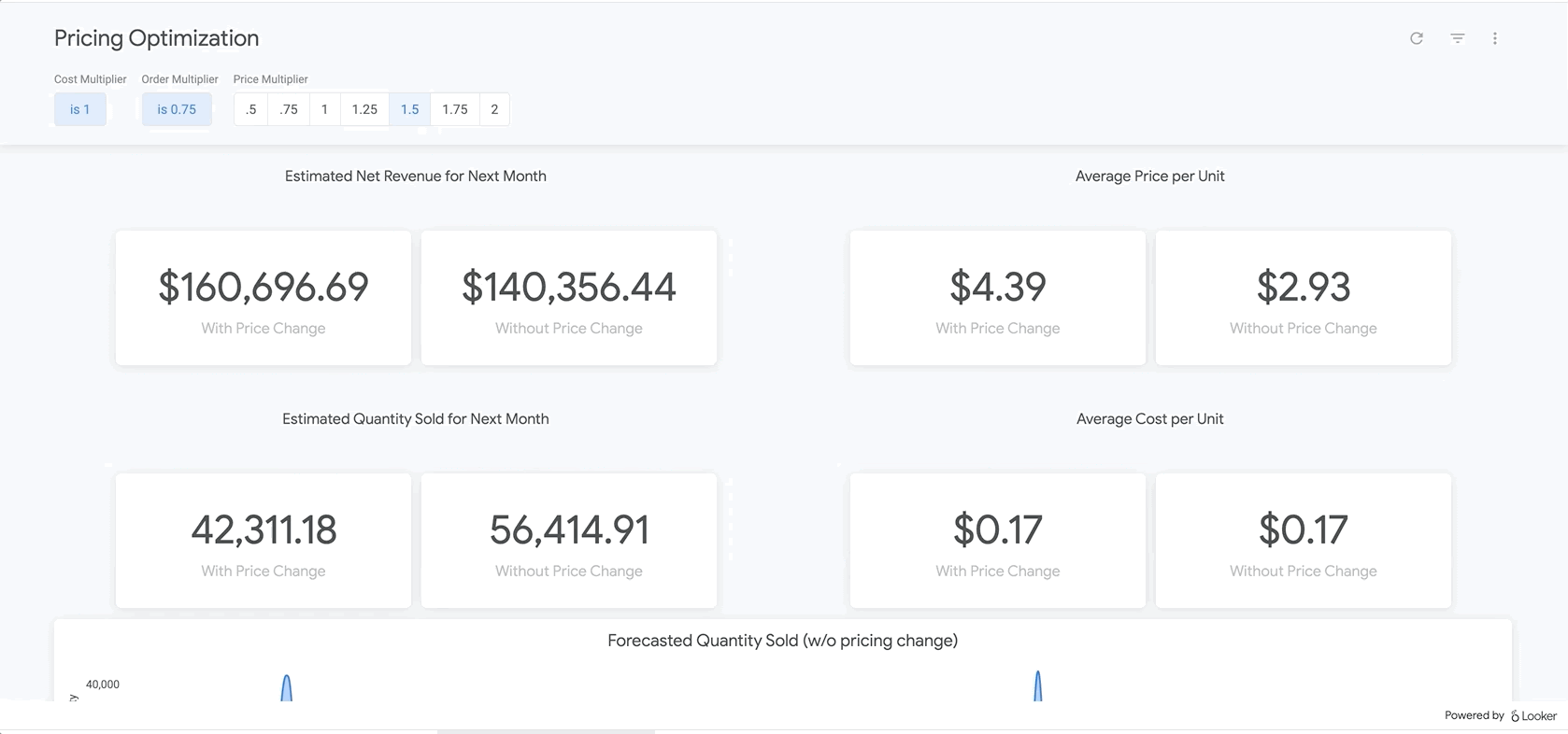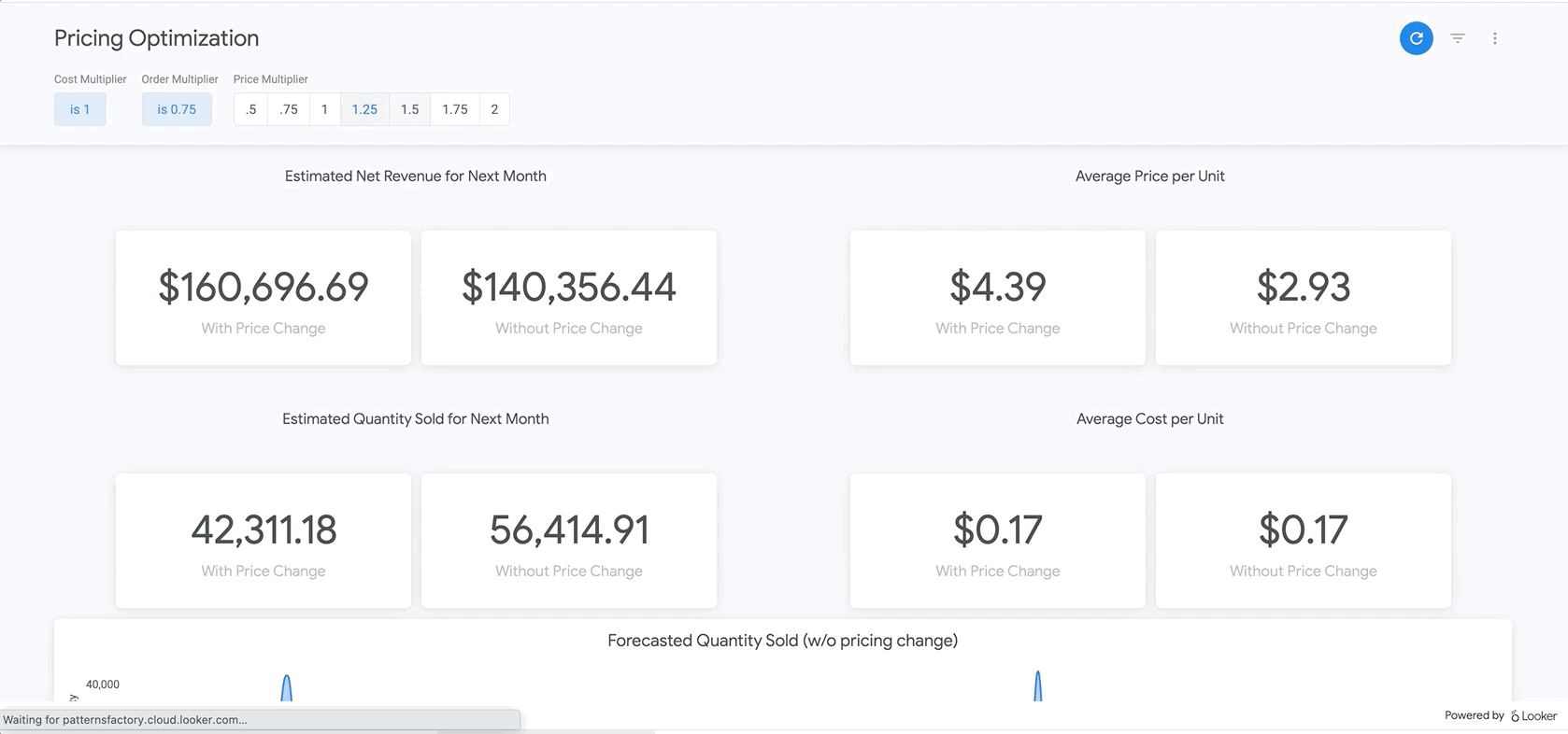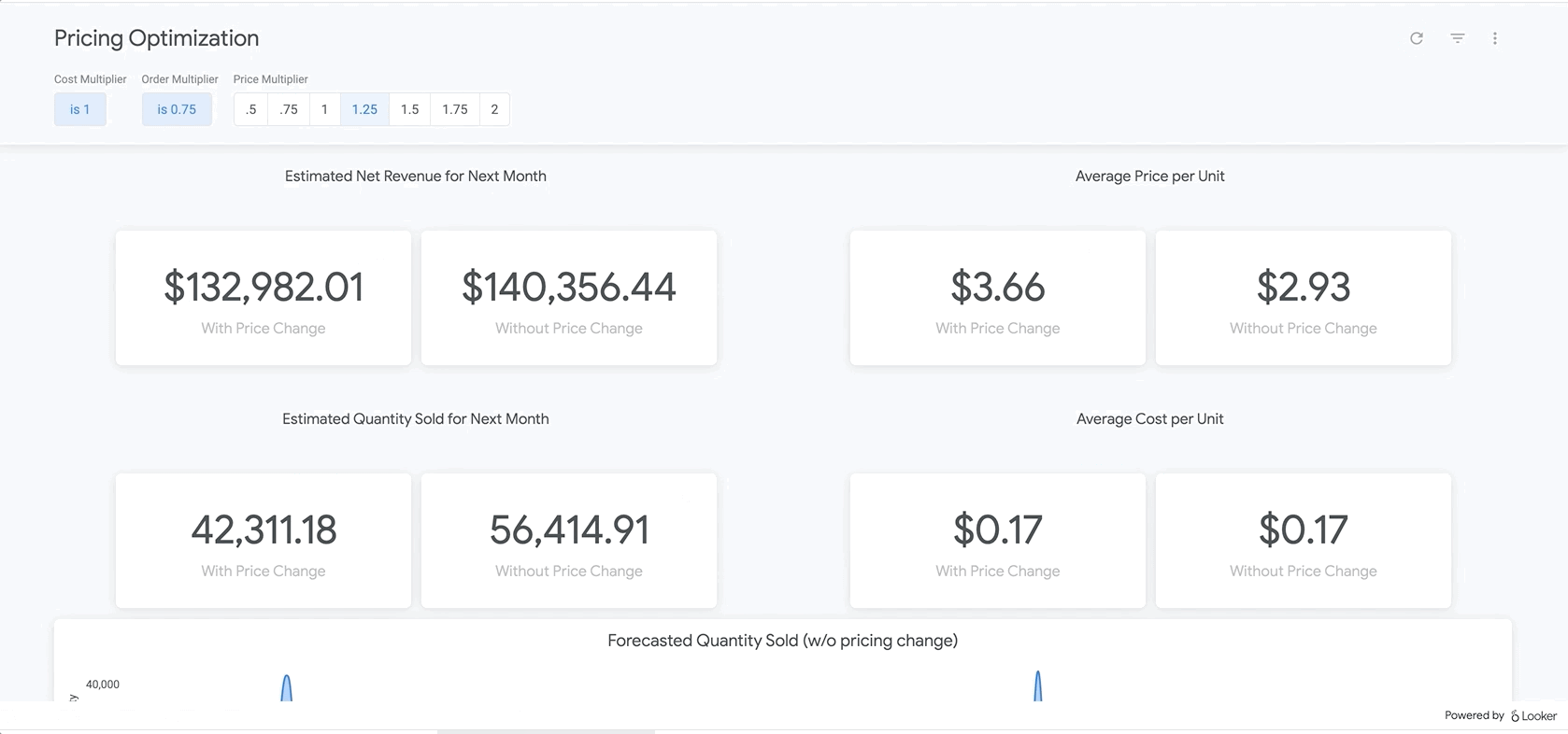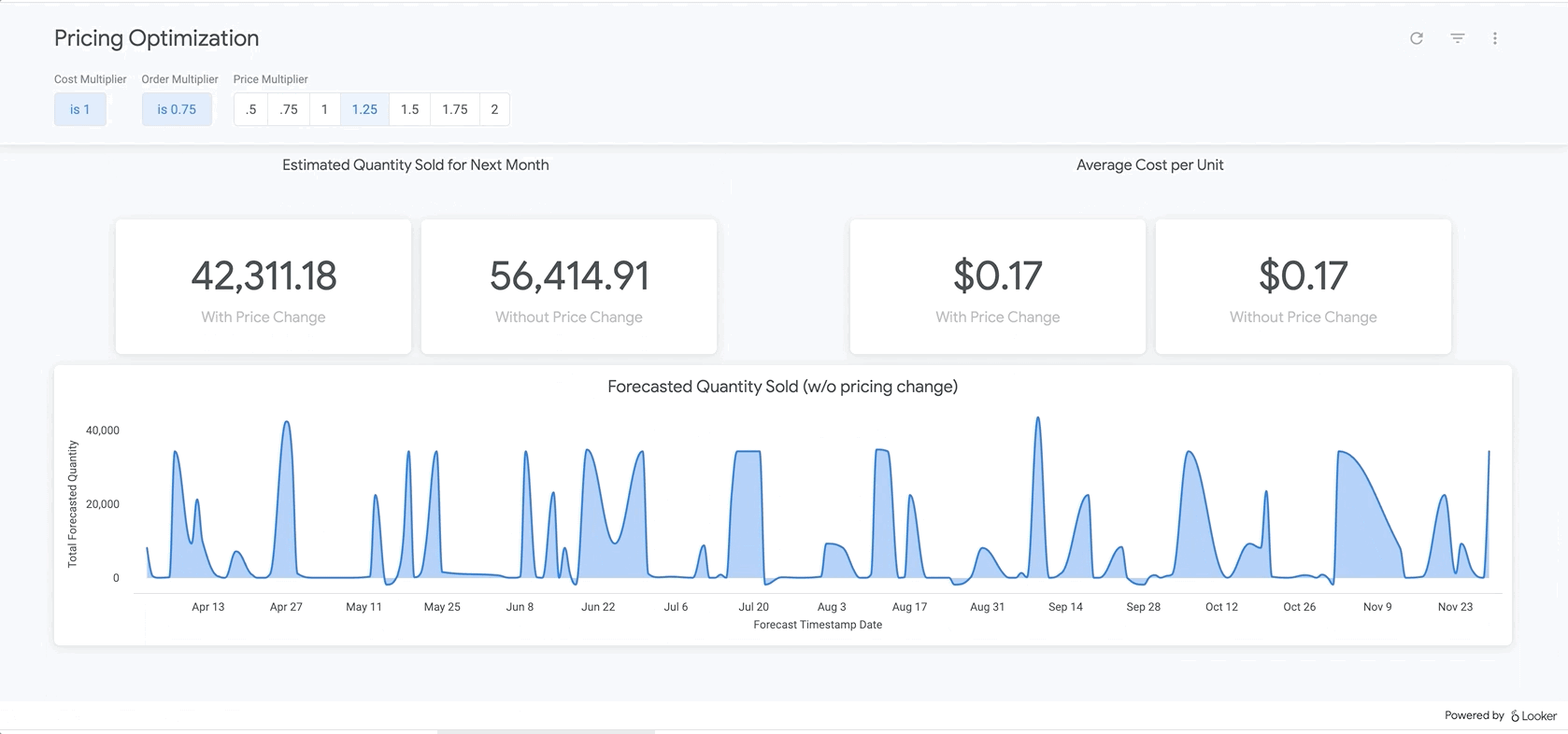
Ela usa parâmetros no LookML, que são incorporados diretamente nos cálculos de medidas encontrados aqui. Com esse tipo de relatório, você pode encontrar o preço ideal para todos os produtos ou analisar produtos específicos para determinar onde aumentar ou reduzir os preços e qual seria o resultado nas receitas bruta e líquida.
14. Adapte os seus sistemas de preços
Embora este tutorial transforme fontes de dados de amostra, você enfrentará desafios de dados muito semelhantes para os recursos de preço presentes em suas várias plataformas. Os recursos de preços têm diferentes formatos de exportação (geralmente xls, planilhas, csv, txt, bancos de dados relacionais, aplicativos comerciais) para gerar resultados resumidos e detalhados. Cada um deles pode ser conectado ao Dataprep. Recomendamos que você comece descrevendo seus requisitos de transformação de maneira semelhante aos exemplos fornecidos acima. Depois de esclarecer as especificações e identificar os tipos de transformações necessários, você poderá projetá-las com o Dataprep.
- Faça uma cópia do fluxo do Dataprep (clique no botão **... "**mais" à direita do fluxo e selecione a opção "Duplicar") que você personalizará ou comece do zero usando um novo fluxo do Dataprep.
- Conecte-se ao seu próprio conjunto de dados de preços. Formatos de arquivo como Excel, CSV, Planilhas Google e JSON têm suporte nativo no Dataprep. Você também pode se conectar a outros sistemas usando conectores do Dataprep.
- Envie seus ativos de dados para as várias categorias de transformação que você identificou. Para cada categoria, crie um roteiro. Inspire-se no fluxo fornecido nesse padrão de design para transformar os dados e escrever suas próprias receitas. Se você não souber o que fazer, não se preocupe, peça ajuda na caixa de diálogo de chat no canto inferior esquerdo da tela do Dataprep.
- Conecte o roteiro à instância do BigQuery. Você não precisa se preocupar em criar as tabelas manualmente no BigQuery, o Dataprep cuidará disso para você automaticamente. Ao adicionar a saída ao fluxo, sugerimos selecionar um destino manual e descartar a tabela em cada execução. Teste cada roteiro individualmente até receber os resultados esperados. Após a conclusão do teste, você converterá a saída para Append à tabela em cada execução para evitar a exclusão dos dados anteriores.
- Também é possível associar o fluxo para que ele seja executado de acordo com a programação. Isso é algo útil se seu processo precisa ser executado continuamente. É possível definir uma programação para carregar a resposta todos os dias ou a cada hora com base na atualização necessária. Se você decidir executar o fluxo em uma programação, precisará adicionar uma saída de destino de programação no fluxo para cada roteiro.
Modificar o modelo de machine learning do BigQuery
Este tutorial fornece um exemplo de modelo ARIMA. No entanto, há parâmetros adicionais que você pode controlar ao desenvolver o modelo para garantir que ele se ajuste melhor aos seus dados. Veja mais detalhes no exemplo de em nossa documentação. Além disso, também é possível usar as funções ML.ARIMA_EVALUATE, ML.ARIMA_COEFFICIENTS e ML.EXPLAIN_FORECAST do BigQuery para conferir mais detalhes sobre seu modelo e tomar decisões de otimização.
Editar relatórios do Looker
Depois de importar o LookML para seu próprio projeto conforme descrito acima, é possível fazer edições diretas para adicionar outros campos, modificar cálculos ou parâmetros inseridos pelo usuário e alterar as visualizações nos dashboards para atender às suas necessidades de negócios. Confira detalhes sobre como desenvolver no LookML e visualizar dados no Looker aqui.
15. Parabéns
Agora você sabe as principais etapas necessárias para otimizar os produtos de varejo preços.
Qual é a próxima etapa?
Conheça outros padrões de referência de análises inteligentes
Leia mais
- Leia o blog aqui
- Saiba mais sobre o Dataprep.
- Saiba mais sobre o BigQuery Machine Learning aqui.
- Saiba mais sobre o Looker aqui