
이 Codelab 정보
1. 소개
최종 업데이트: 2021년 9월 15일
가격 책정 정보 및 최적화를 제공하는 데 필요한 데이터는 본질적으로 상이하기 때문에 (다양한 시스템, 다양한 현지 현실 등) 잘 구조화되고 표준화되며 정리된 CDM 테이블을 개발하는 것이 중요합니다. 여기에는 거래, 제품, 가격, 고객 등 가격 최적화를 위한 주요 속성이 포함됩니다. 이 문서에서는 아래에 설명된 단계를 안내하며, 자체 니즈에 맞게 확장하고 맞춤설정할 수 있는 가격 분석을 빠르게 시작할 수 있습니다. 다음 다이어그램은 이 문서에서 다루는 단계를 간략히 보여줍니다.
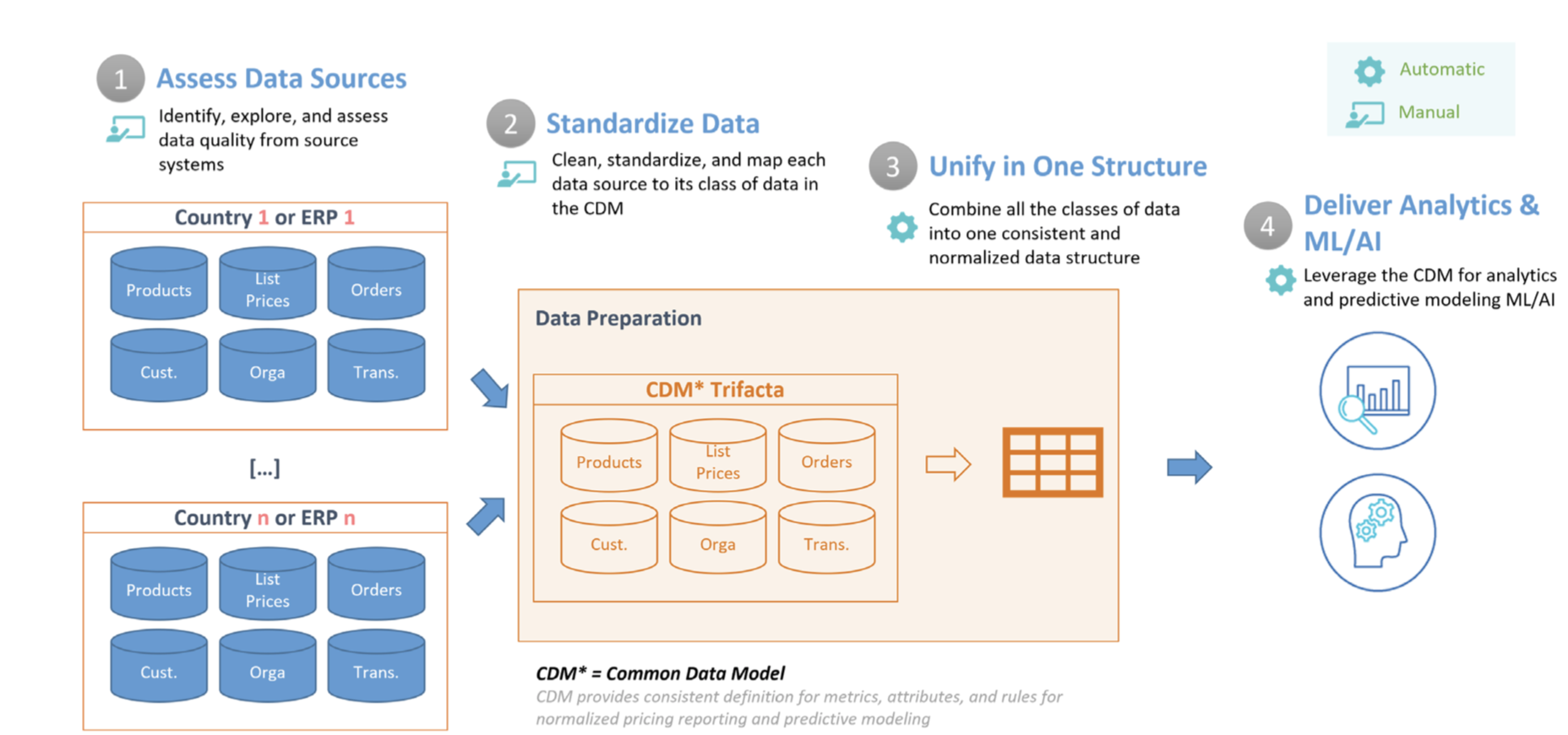
- 데이터 소스 평가: 먼저 CDM을 만드는 데 사용할 데이터 소스 인벤토리를 확보해야 합니다. 이 단계에서 Dataprep은 입력 데이터에서 문제를 탐색하고 식별하는 데도 사용됩니다. 예: 누락된 값과 일치하지 않는 값, 일관되지 않은 이름 지정 규칙, 중복, 데이터 무결성 문제, 이상점 등
- 데이터 표준화: 다음으로, 데이터 정확성, 무결성, 일관성, 완전성을 보장하기 위해 이전에 식별된 문제를 수정합니다. 이 프로세스에는 날짜 형식 지정, 값 표준화, 단위 변환, 불필요한 필드 및 값 필터링, 소스 데이터의 분할, 조인 또는 중복 삭제와 같은 다양한 Dataprep에서의 변환이 포함될 수 있습니다.
- 하나의 구조로 통합: 파이프라인의 다음 단계에서는 각 데이터 소스를 가장 세부적인 수준의 모든 속성을 포함하는 BigQuery의 넓은 단일 테이블로 조인합니다. 이러한 비정규화된 구조는 조인이 필요 없는 효율적인 분석 쿼리를 가능하게 합니다.
- 분석 및 ML/AI: 분석을 위해 데이터를 정리하고 형식을 지정하면 분석가는 이전 데이터를 탐색하여 이전 가격 변경의 영향을 파악할 수 있습니다. 또한 BigQuery ML 을 사용하여 향후 판매를 예측하는 예측 모델을 만들 수 있습니다. 이러한 모델의 출력을 Looker 내 대시보드에 통합하여 'What-if 시나리오'를 만들 수 있습니다. 여기에서 비즈니스 사용자가 특정 가격 변경에 따른 판매 상황을 분석할 수 있습니다.
다음 다이어그램은 가격 최적화 분석 파이프라인을 빌드하는 데 사용되는 Google Cloud 구성요소를 보여줍니다.
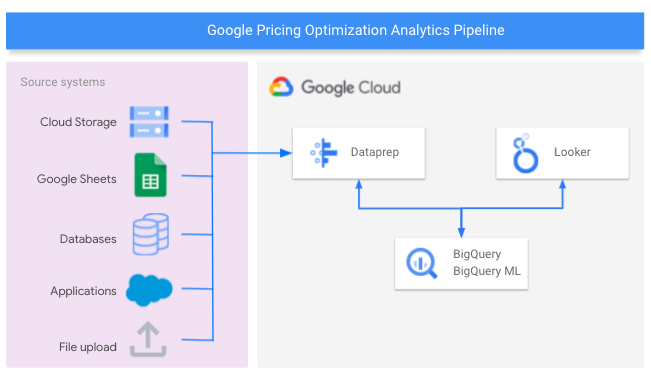
빌드할 항목
여기서는 가격 최적화 데이터 웨어하우스를 설계하고, 시간 경과에 따른 데이터 준비를 자동화하고, 머신러닝을 사용하여 제품 가격 변동의 영향을 예측하고, 팀에 활용 가능한 분석 정보를 제공하는 보고서를 개발하는 방법을 알아봅니다.
학습할 내용
- 가격 분석을 위해 관계형 데이터베이스, 플랫 파일, Google Sheets, 기타 지원되는 애플리케이션에 저장할 수 있는 데이터 소스에 Dataprep을 연결하는 방법
- Dataprep 흐름을 빌드하여 BigQuery 데이터 웨어하우스에서 CDM 테이블을 만드는 방법
- BigQuery ML을 사용하여 향후 수익을 예측하는 방법
- Looker에서 보고서를 작성하여 이전 가격 및 판매 트렌드를 분석하고 향후 가격 변동의 영향을 이해하는 방법
필요한 항목
- 결제가 사용 설정된 Google Cloud 프로젝트. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
- 프로젝트에서 BigQuery를 사용 설정해야 합니다. 새 프로젝트에 자동으로 사용 설정됩니다. 기존 프로젝트가 없으면 기존 프로젝트에서 사용 설정하세요. 여기에서 Cloud 콘솔에서 BigQuery를 시작하는 방법을 자세히 알아볼 수도 있습니다.
- 프로젝트에서 Dataprep도 사용 설정해야 합니다. Google 콘솔의 빅데이터 섹션의 왼쪽 탐색 메뉴에서 Dataprep이 사용 설정되어 있습니다. 가입 단계에 따라 활성화합니다.
- 자체 Looker 대시보드를 설정하려면 Looker 인스턴스에 대한 개발자 액세스 권한이 있어야 합니다. 무료 체험을 요청하려면 여기에서 Google팀에 문의하거나 공개 대시보드를 사용하여 샘플 데이터의 데이터 파이프라인 결과를 살펴보세요.
- 구조화된 쿼리 언어 (SQL)를 사용해 본 경험과 Trifacta의 Dataprep, BigQuery, Looker에 대한 기본 지식이 도움이 됩니다.
2. BigQuery에서 CDM 만들기
이 섹션에서는 분석하고 가격 변경을 제안해야 하는 정보를 종합적으로 보여주는 공통 데이터 모델 (CDM)을 만듭니다.
- BigQuery 콘솔을 엽니다.
- 이 참조 패턴을 테스트하는 데 사용할 프로젝트를 선택합니다.
- 기존 데이터 세트를 사용하거나 BigQuery 데이터 세트를 생성합니다. 데이터 세트 이름을
Pricing_CDM로 지정합니다. - 테이블을 만듭니다.
create table `CDM_Pricing`
(
Fiscal_Date DATETIME,
Product_ID STRING,
Client_ID INT64,
Customer_Hierarchy STRING,
Division STRING,
Market STRING,
Channel STRING,
Customer_code INT64,
Customer_Long_Description STRING,
Key_Account_Manager INT64,
Key_Account_Manager_Description STRING,
Structure STRING,
Invoiced_quantity_in_Pieces FLOAT64,
Gross_Sales FLOAT64,
Trade_Budget_Costs FLOAT64,
Cash_Discounts_and_other_Sales_Deductions INT64,
Net_Sales FLOAT64,
Variable_Production_Costs_STD FLOAT64,
Fixed_Production_Costs_STD FLOAT64,
Other_Cost_of_Sales INT64,
Standard_Gross_Margin FLOAT64,
Transportation_STD FLOAT64,
Warehouse_STD FLOAT64,
Gross_Margin_After_Logistics FLOAT64,
List_Price_Converged FLOAT64
);
3. 데이터 소스 평가
이 튜토리얼에서는 Google Sheets와 BigQuery에 저장된 샘플 데이터 소스를 사용합니다.
- 각 거래당 하나의 행이 포함된 transactions Google 시트입니다. 여기에는 제품별 판매량, 총매출, 관련 비용 등의 세부정보가 포함됩니다.
- 특정 고객의 월별 제품 가격이 포함된 제품 가격 책정 Google 시트입니다.
- 개별 고객 정보가 포함된 company_descriptions BigQuery 테이블입니다.
이 company_descriptions BigQuery 테이블은 다음 문을 사용하여 만들 수 있습니다.
create table `Company_Descriptions`
(
Customer_ID INT64,
Customer_Long_Description STRING
);
insert into `Company_Descriptions` values (15458, 'ENELTEN');
insert into `Company_Descriptions` values (16080, 'NEW DEVICES CORP.');
insert into `Company_Descriptions` values (19913, 'ENELTENGAS');
insert into `Company_Descriptions` values (30108, 'CARTOON NT');
insert into `Company_Descriptions` values (32492, 'Thomas Ed Automobiles');
4. 흐름 만들기
이 단계에서는 이전 섹션에 나열된 데이터 세트를 변환하고 통합하는 데 사용하는 샘플 Dataprep 흐름을 가져옵니다. 흐름은 데이터 세트와 레시피를 변환하고 조인하는 데 사용되는 데이터 세트와 레시피를 결합하는 파이프라인 또는 객체를 나타냅니다.
- GitHup에서 가격 최적화 패턴 흐름 패키지를 다운로드하되 압축을 풀지 마세요. 이 파일에는 샘플 데이터를 변환하는 데 사용되는 가격 최적화 설계 패턴 흐름이 포함되어 있습니다.
- Dataprep의 왼쪽 탐색 메뉴에서 Flow(흐름) 아이콘을 클릭합니다. 그런 다음 Flows(흐름) 뷰의 컨텍스트 메뉴에서 Import(가져오기)를 선택합니다. 흐름을 가져온 후에는 이를 선택하여 확인하고 수정할 수 있습니다.
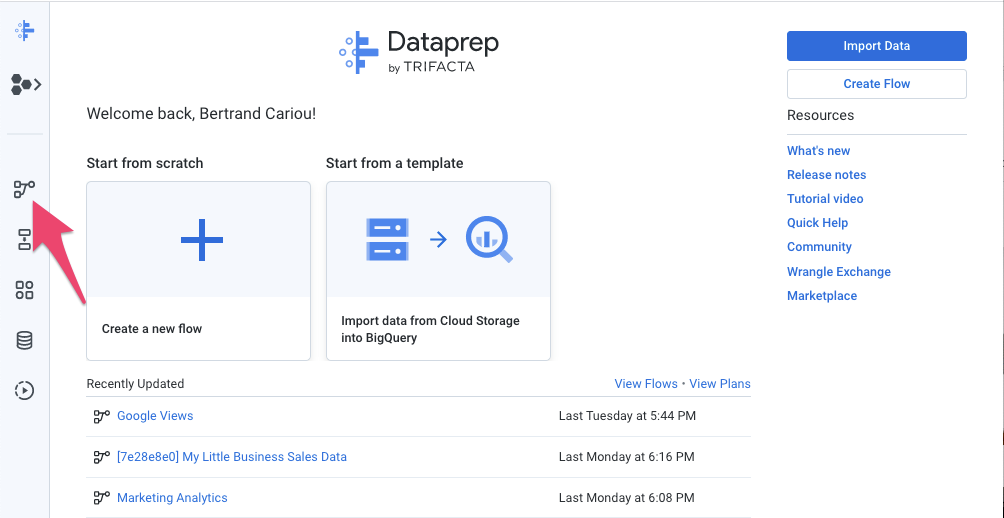
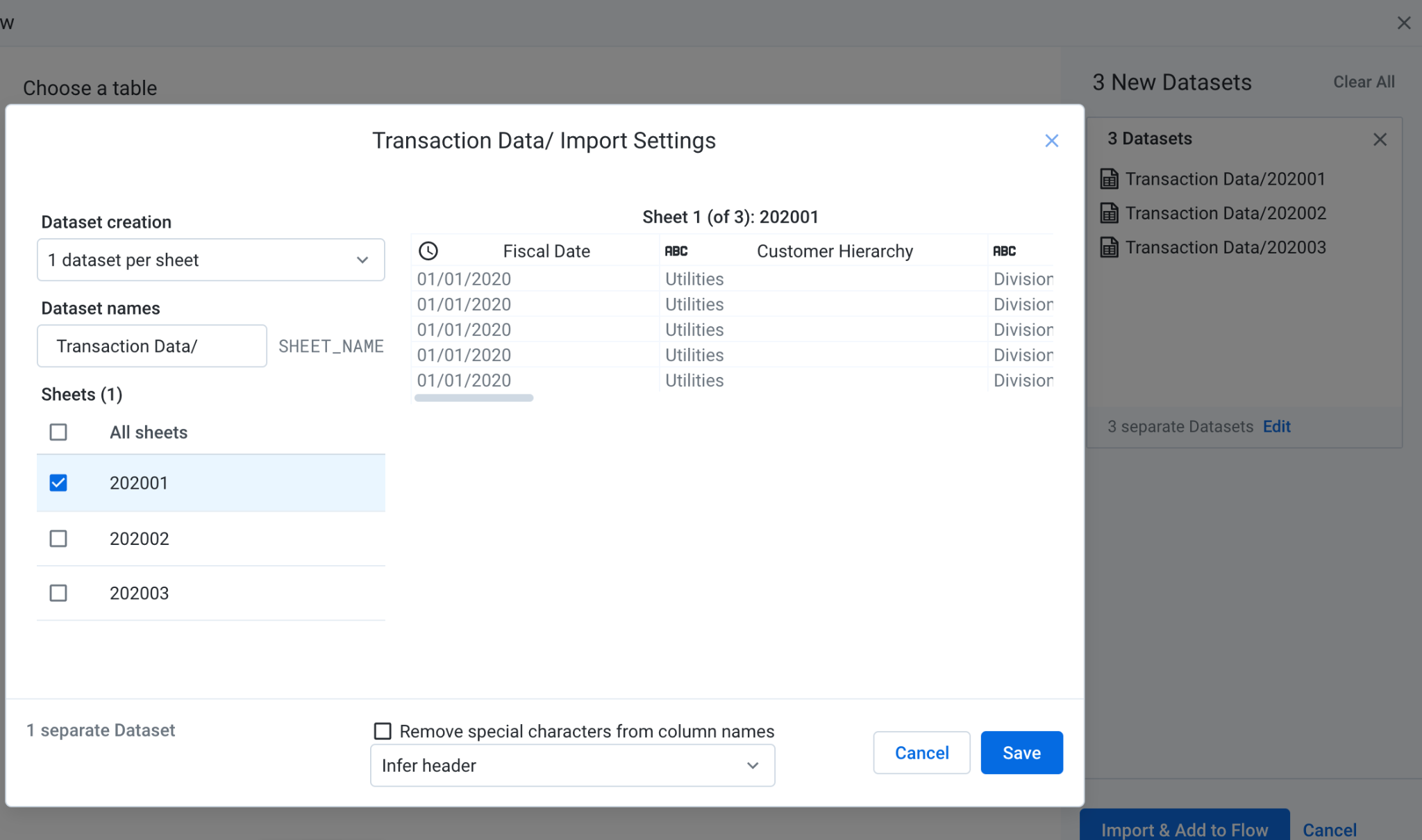
- 절차의 왼쪽에서 제품 가격 및 Google Sheets의 각 세 가지 거래를 데이터 세트로 연결해야 합니다. 이렇게 하려면 Google Sheets 데이터 세트 객체를 마우스 오른쪽 버튼으로 클릭하고 Replace를 선택합니다. 그런 다음 Import Datasets(데이터 세트 가져오기) 링크를 클릭합니다. '경로 수정'을 클릭합니다. 색깔이 연필 모양으로 그려집니다.
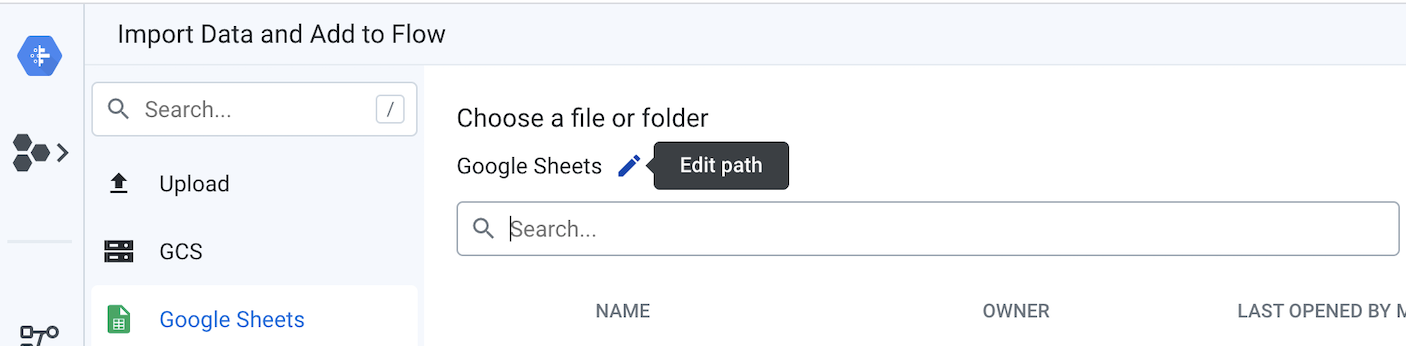
현재 값을 거래 및 제품 가격 Google Sheets 로 연결되는 링크로 바꿉니다.
Google 시트에 여러 개의 탭이 있는 경우 메뉴에서 사용할 탭을 선택할 수 있습니다. 수정을 클릭하고 데이터 소스로 사용할 탭을 선택한 다음 저장을 클릭하고 가져오기 및 Add to Flow(흐름에 추가)를 클릭합니다. 모달로 돌아오면 바꾸기를 클릭합니다. 이 흐름에서는 나중에 레시피에서 서로 다른 소스의 결합을 보여주기 위해 각 시트가 자체 데이터 세트로 표시됩니다.
- BigQuery 출력 테이블 정의:
이 단계에서는 Dataoprep 작업을 실행할 때마다 로드할 BigQuery CDM_Pricing 출력 테이블의 위치를 연결합니다.
흐름 보기에서 스키마 매핑 출력 아이콘을 클릭하고 세부정보 패널에서 대상 탭을 클릭합니다. 여기에서 테스트에 사용되는 수동 대상 출력과 전체 흐름을 자동화하려는 경우 사용되는 예약된 대상 출력을 모두 수정합니다. 방법은 다음과 같습니다.
- '수동 대상' 수정 세부정보 패널의 수동 대상 섹션에서 수정 버튼을 클릭합니다. 게시 설정 페이지의 게시 작업 아래에 게시 작업이 이미 있으면 수정하고, 작업 추가 버튼을 클릭합니다. 여기에서 BigQuery 데이터 세트를 이전 단계에서 만든
Pricing_CDM데이터 세트로 이동하고CDM_Pricing테이블을 선택합니다. 실행마다 이 테이블에 추가가 선택되어 있는지 확인한 후 추가를 클릭하고 설정 저장을 클릭합니다. - '예약된 대상' 수정
세부정보 패널의 예약된 대상 섹션에서 수정을 클릭합니다.
설정은 수동 도착 페이지에서 상속되므로 변경할 필요가 없습니다. 설정 저장을 클릭합니다.
5. 데이터 표준화
제공된 흐름은 트랜잭션 데이터를 통합하고 형식을 지정하며 정리한 다음 결과를 회사 설명 및 집계된 가격 데이터와 조인하여 보고합니다. 이 흐름의 구성요소를 살펴보겠습니다. 이 흐름은 아래 이미지와 같습니다.
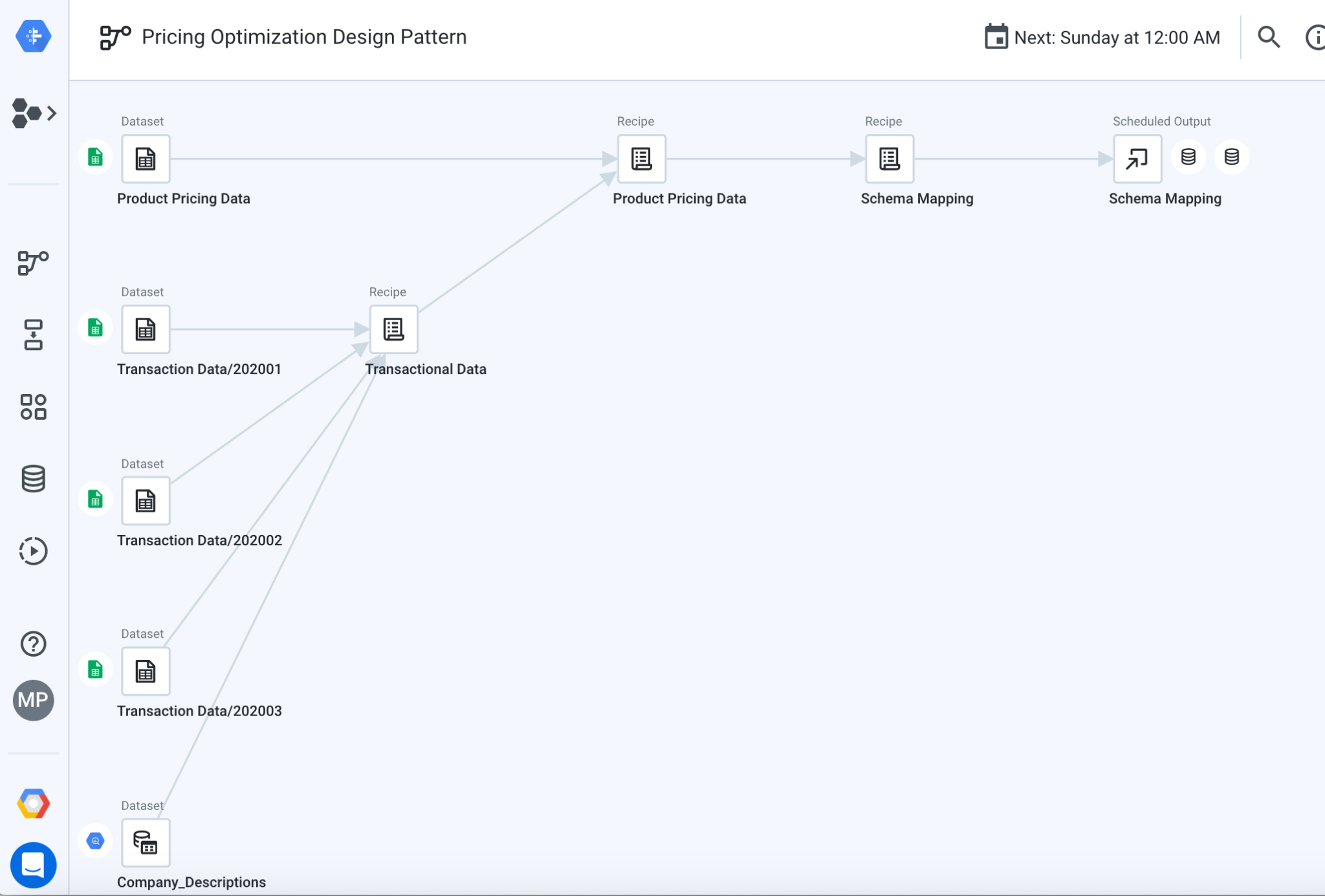
6. 트랜잭션 데이터 레시피 살펴보기
먼저 트랜잭션 데이터를 준비하는 데 사용되는 트랜잭션 데이터 레시피 내에서 어떤 일이 일어나는지 살펴보겠습니다. Flow View(흐름 뷰)에서 Transaction Data(트랜잭션 데이터) 객체를 클릭하고 Details(세부정보) 패널에서 Edit Recipe(레시피 수정) 버튼을 클릭합니다.
세부정보 패널에 표시된 레시피와 함께 변환기 페이지가 열립니다. 레시피에는 데이터에 적용되는 모든 변환 단계가 포함됩니다. 각 단계 사이를 클릭하여 레시피를 탐색하면 레시피의 특정 위치에 있는 데이터 상태를 볼 수 있습니다.
또한 각 레시피 단계의 더보기 메뉴를 클릭하고 선택됨으로 이동 또는 편집을 선택하여 변환이 작동하는 방식을 살펴볼 수도 있습니다.
- 통합 트랜잭션: 트랜잭션 데이터 레시피의 첫 번째 단계는 각 월을 나타내는 여러 시트에 저장된 트랜잭션을 통합합니다.
- Standardize Customer Descriptions(고객 설명 표준화): 레시피의 다음 단계는 고객 설명을 표준화합니다. 즉, 고객 이름이 약간 변경되어도 유사할 수 있으므로 이름으로 정규화하고자 합니다. 이 레시피는 두 가지 가능한 접근 방식을 보여줍니다. 첫째, '유사한 문자열'과 같은 다양한 표준화 옵션으로 구성할 수 있는 표준화 알고리즘을 활용합니다. 공통된 문자가 있는 값이 함께 클러스터링되거나 '발음' 여기서 비슷하게 들리는 값이 함께 클러스터링됩니다. 또는 위에 언급된 BigQuery 테이블에서 회사 ID를 사용하여 회사 설명을 조회할 수 있습니다.
레시피를 더 탐색하여 행 삭제, 패턴 기반 형식 지정, 조회를 통한 데이터 보강, 누락된 값 처리, 원치 않는 문자 교체 등 데이터 정리 및 형식 지정에 적용되는 다양한 기술을 확인할 수 있습니다.
7. 제품 가격 데이터 레시피 살펴보기
다음으로 준비된 거래 데이터를 집계된 가격 데이터에 조인하는 제품 가격 데이터 레시피에서 어떤 일이 일어나는지 살펴볼 수 있습니다.
페이지 상단에서 가격 최적화 설계 패턴을 클릭하여 변환기 페이지를 닫고 흐름 뷰로 돌아갑니다. 여기에서 제품 가격 데이터 객체를 클릭하고 레시피를 수정합니다.
- 월간 가격 열 피벗 해제: 2단계와 3단계 사이의 레시피를 클릭하여 피벗 해제 단계 전에 데이터가 어떻게 표시되는지 확인합니다. 데이터의 개별 열(1월 2월 3월)에 트랜잭션 값이 포함되어 있음을 알 수 있습니다. 이 형식은 SQL에서 집계(즉, 합계, 평균 트랜잭션) 계산을 적용하는 데 편리한 형식이 아닙니다. 각 열이 BigQuery 테이블의 행이 되도록 데이터를 피봇팅해야 합니다. 이 레시피는 unpivot 함수를 사용하여 매월 3개의 열을 하나의 행으로 변환하므로 그룹 계산을 더욱 쉽게 적용할 수 있습니다.
- 고객, 제품, 날짜별 평균 거래 가치 계산: 각 고객, 제품, 데이터의 평균 거래 가치를 계산하려고 합니다. Aggregate 함수를 사용하여 새 테이블을 생성할 수 있습니다('새 테이블로 그룹화' 옵션). 이 경우 데이터는 그룹 수준에서 집계되며 각 개별 거래의 세부정보는 손실됩니다. 또는 세부정보와 집계된 값을 모두 동일한 데이터 세트에 유지('새 열로 그룹화 기준' 옵션)하도록 결정할 수 있습니다. 이렇게 하면 비율(즉, 전체 수익에 대한 제품 카테고리의 기여도)을 적용하는 것이 매우 편리해집니다. 레시피 7단계를 수정하고 '새 테이블로 그룹화' 옵션을 선택하여 이 동작을 시도해 볼 수 있습니다. 또는 '새 열로 그룹화 기준' 차이점을 확인할 수 있습니다
- 조인 가격 책정 날짜: 마지막으로 조인은 여러 데이터 세트를 더 큰 데이터 세트로 결합하여 초기 데이터 세트에 열을 추가하는 데 사용됩니다. 이 단계에서는 가격 데이터를 ‘Pricing Data.Product Code'에 따라 거래 데이터 레시피의 출력과 조인합니다. = 거래 데이터.SKU 및 ‘Pricing Data.Price Date’ = ‘거래 데이터.회계 날짜’
Dataprep에 적용할 수 있는 변환에 대한 자세한 내용은 Trifacta 데이터 랭글링 요약본을 참조하세요.
8. 스키마 매핑 레시피 살펴보기
마지막 레시피인 스키마 매핑은 결과 CDM 테이블이 기존 BigQuery 출력 테이블의 스키마와 일치하도록 합니다. 여기서 빠른 대상 기능은 퍼지 일치를 사용하여 BigQuery 테이블과 일치하도록 데이터 구조의 형식을 다시 지정하여 두 스키마를 비교하고 자동 변경사항을 적용하는 데 사용됩니다.
9. 하나의 구조로 통합
소스와 대상이 구성되었고 흐름의 단계를 살펴보았으므로 이제 흐름을 실행하여 CDM 테이블을 변환하고 BigQuery에 로드할 수 있습니다.
- Run Schema Mapping 출력: 흐름 보기에서 스키마 매핑 출력 객체를 선택하고 '실행'을 클릭합니다. 버튼을 클릭합니다. 'Trifacta Photon'을 선택합니다. 실행 중인 환경과 레시피 오류 무시를 선택 해제하세요. 그런 다음 실행 버튼을 클릭합니다. 지정된 BigQuery 테이블이 있으면 Dataprep은 새 행을 추가하고, 그렇지 않으면 새 테이블을 만듭니다.
- 작업 상태 보기: 작업 실행을 모니터링할 수 있도록 Dataprep이 작업 실행 페이지를 자동으로 엽니다. 계속 진행하여 BigQuery 테이블을 로드하는 데는 몇 분 정도 걸립니다. 작업이 완료되면 가격 책정 CDM 출력이 분석 가능한 깔끔하고 구조화된 정규화된 형식으로 BigQuery에 로드됩니다.
10. 분석 및 ML/AI
애널리틱스 기본 요건
흥미로운 결과로 일부 분석 및 예측 모델을 실행하기 위해 특정 인사이트를 발견할 수 있을 만큼 더 크고 관련성 있는 데이터 세트를 만들었습니다. 이 가이드를 계속하기 전에 이 데이터를 BigQuery 데이터 세트에 업로드해야 합니다.
- 이 GitHub 저장소에서 대규모 데이터 세트 다운로드
- BigQuery용 Google 콘솔에서 프로젝트 및 CDM_Pricing 데이터 세트로 이동합니다.
- 메뉴를 클릭하고 데이터 세트를 엽니다. 로컬 파일에서 데이터를 로드하여 테이블을 만듭니다.
+ 테이블 만들기 버튼을 클릭하고 다음 매개변수를 정의합니다.
- 업로드를 통해 테이블을 만들고 CDM_Pricing_Large_Table.csv 파일을 선택합니다.
- 스키마 자동 감지, 스키마 및 입력 매개변수 확인
- 고급 옵션, 쓰기 환경설정, 테이블 덮어쓰기
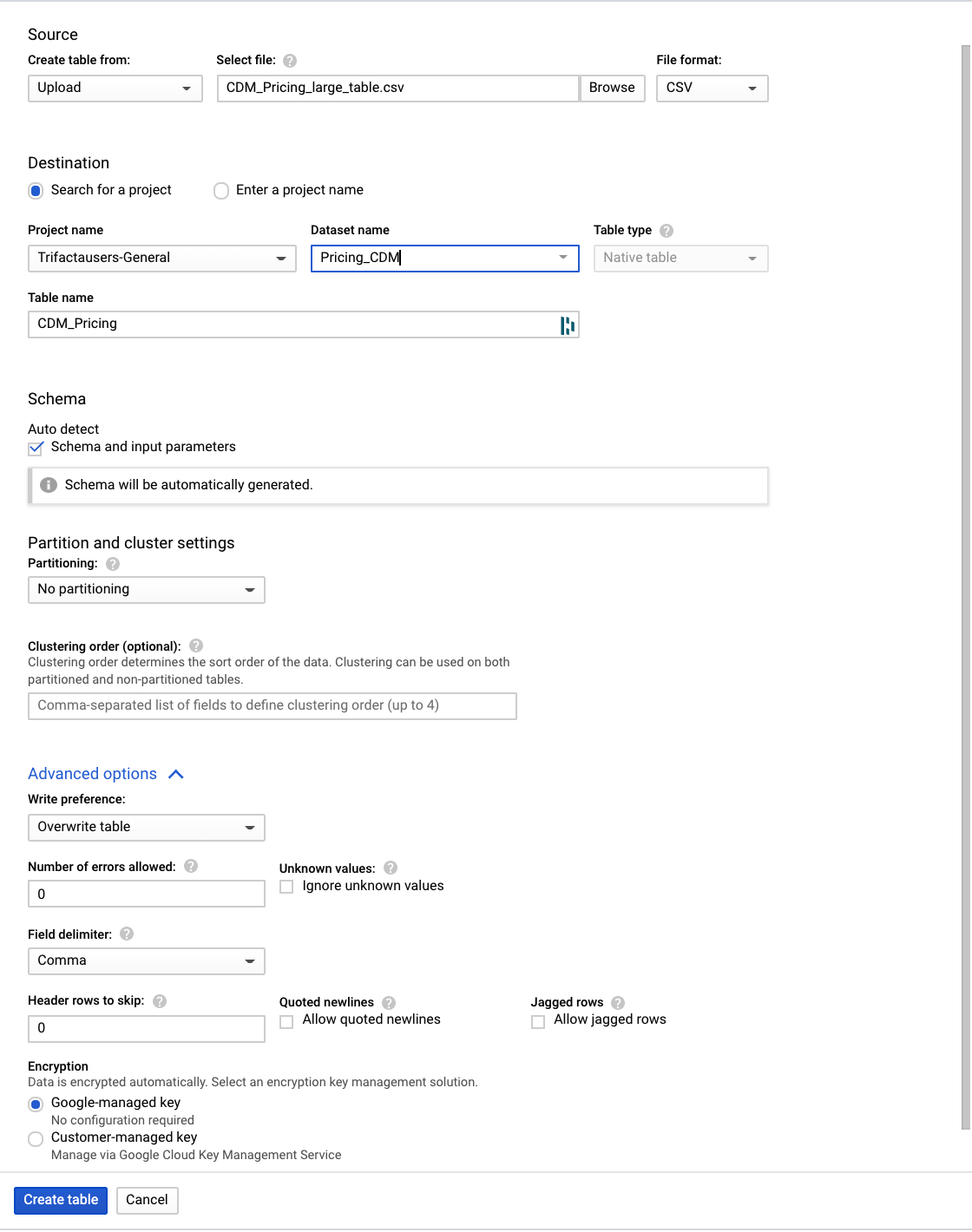
- 테이블 만들기를 클릭합니다.
테이블을 만들고 데이터를 업로드하면 BigQuery용 Google 콘솔에 아래와 같이 새 테이블의 세부정보가 표시됩니다. BigQuery의 가격 데이터로 보다 포괄적인 질문을 쉽게 던져 가격 데이터를 보다 심층적으로 분석할 수 있습니다.
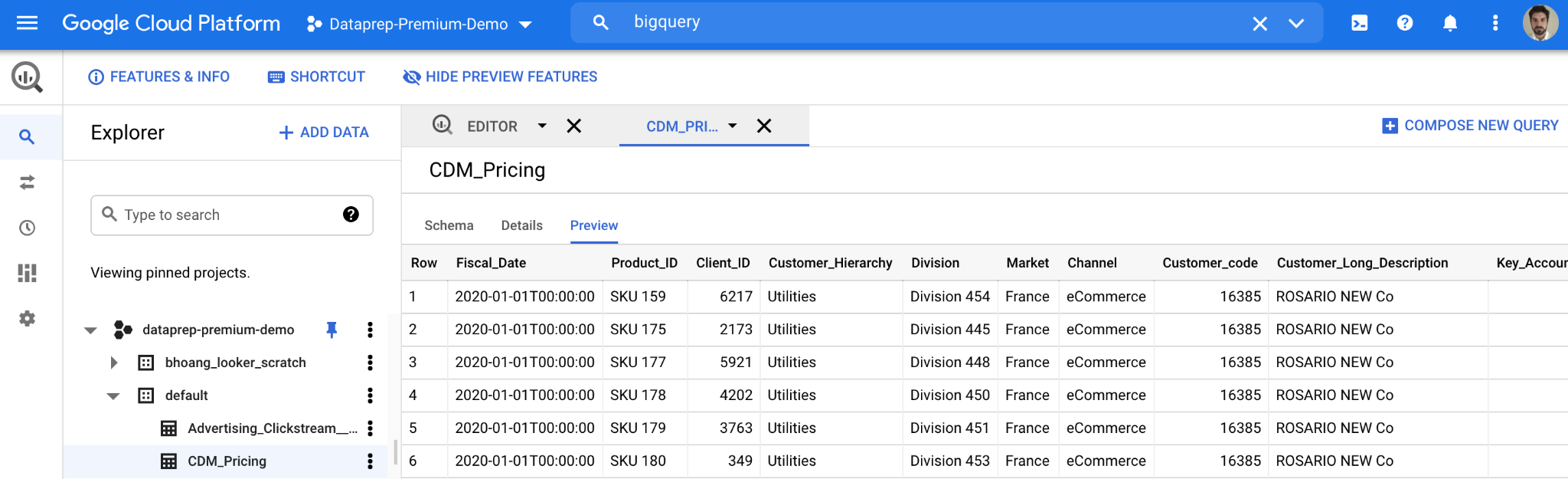
11. 가격 변경의 영향 보기
분석해야 할 사항의 한 가지 예는 이전에 품목 가격을 변경했을 때 주문 행동 변경을 들 수 있습니다.
- 먼저 제품 가격이 변경될 때마다 한 줄이 포함된 임시 표를 만듭니다. 여기에는 각 가격으로 주문된 상품 수, 해당 가격과 관련된 순매출 합계와 같은 특정 제품 가격에 대한 정보가 포함되어 있습니다.
create temp table price_changes as (
select
product_id,
list_price_converged,
total_ordered_pieces,
total_net_sales,
first_price_date,
lag(list_price_converged) over(partition by product_id order by first_price_date asc) as previous_list,
lag(total_ordered_pieces) over(partition by product_id order by first_price_date asc) as previous_total_ordered_pieces,
lag(total_net_sales) over(partition by product_id order by first_price_date asc) as previous_total_net_sales,
lag(first_price_date) over(partition by product_id order by first_price_date asc) as previous_first_price_date
from (
select
product_id,list_price_converged,sum(invoiced_quantity_in_pieces) as total_ordered_pieces, sum(net_sales) as total_net_sales, min(fiscal_date) as first_price_date
from `{{my_project}}.{{my_dataset}}.CDM_Pricing` AS cdm_pricing
group by 1,2
order by 1, 2 asc
)
);
select * from price_changes where previous_list is not null order by product_id, first_price_date desc

- 그런 다음 임시 테이블을 사용하여 SKU 간 평균 가격 변동을 계산할 수 있습니다.
select avg((previous_list-list_price_converged)/nullif(previous_list,0))*100 as average_price_change from price_changes;
- 마지막으로 각 가격 변경과 주문된 총 항목 수 간의 관계를 살펴보면 가격이 변경된 후 어떤 일이 일어나는지 분석할 수 있습니다.
select
(total_ordered_pieces-previous_total_ordered_pieces)/nullif(previous_total_ordered_pieces,0)
as
price_changes_percent_ordered_change,
(list_price_converged-previous_list)/nullif(previous_list,0)
as
price_changes_percent_price_change
from price_changes
12. 시계열 예측 모델 빌드
다음으로 BigQuery의 기본 제공 머신러닝 기능을 사용하여 ARIMA 시계열 예측 모델을 빌드하여 판매될 각 상품의 수량을 예측할 수 있습니다.
- 먼저 ARIMA_PLUS 모델을 만듭니다.
create or replace `{{my_project}}.{{my_dataset}}.bqml_arima`
options
(model_type = 'ARIMA_PLUS',
time_series_timestamp_col = 'fiscal_date',
time_series_data_col = 'total_quantity',
time_series_id_col = 'product_id',
auto_arima = TRUE,
data_frequency = 'AUTO_FREQUENCY',
decompose_time_series = TRUE
) as
select
fiscal_date,
product_id,
sum(invoiced_quantity_in_pieces) as total_quantity
from
`{{my_project}}.{{my_dataset}}.CDM_Pricing`
group by 1,2;
- 다음으로, ML.FORECAST 함수를 사용하여 각 제품의 향후 판매를 예측합니다.
select
*
from
ML.FORECAST(model testing.bqml_arima,
struct(30 as horizon, 0.8 as confidence_level));
- 이러한 예측을 사용하면 가격을 인상할 경우 어떤 일이 일어날지 미리 파악할 수 있습니다. 예를 들어 모든 제품의 가격을 15% 올리는 경우 다음과 같은 쿼리를 통해 다음 달 예상 총수익을 계산할 수 있습니다.
select
sum(forecast_value * list_price) as total_revenue
from ml.forecast(mode testing.bqml_arima,
struct(30 as horizon, 0.8 as confidence_level)) forecasts
left join (select product_id,
array_agg(list_price_converged
order by fiscal_date desc limit 1)[offset(0)] as list_price
from `leigha-bq-dev.retail.cdm_pricing` group by 1) recent_prices
using (product_id);
13. 보고서 작성
이제 비정규화된 가격 책정 데이터가 BigQuery에 중앙 집중화되었고 이 데이터에 대해 의미 있는 쿼리를 실행하는 방법을 이해했으므로 비즈니스 사용자가 이 정보를 탐색하고 조치를 취할 수 있도록 보고서를 작성해 보겠습니다.
이미 Looker 인스턴스가 있다면 이 GitHub 저장소의 LookML을 사용하여 이 패턴의 가격 책정 데이터 분석을 시작할 수 있습니다. 새 Looker 프로젝트를 만들고 LookML을 추가한 후 각 뷰 파일의 연결 및 테이블 이름을 BigQuery 구성과 일치하도록 바꾸기만 하면 됩니다.
이 모델에서는 앞서 보여준 가격 변경사항을 검토하기 위해 파생된 테이블 ( 이 뷰 파일)을 확인할 수 있습니다.
view: price_changes {
derived_table: {
sql: select
product_id,
list_price_converged,
total_ordered_pieces,
total_net_sales,
first_price_date,
lag(list_price_converged) over(partition by product_id order by first_price_date asc) as previous_list,
lag(total_ordered_pieces) over(partition by product_id order by first_price_date asc) as previous_total_ordered_pieces,
lag(total_net_sales) over(partition by product_id order by first_price_date asc) as previous_total_net_sales,
lag(first_price_date) over(partition by product_id order by first_price_date asc) as previous_first_price_date
from (
select
product_id,list_price_converged,sum(invoiced_quantity_in_pieces) as total_ordered_pieces, sum(net_sales) as total_net_sales, min(fiscal_date) as first_price_date
from ${cdm_pricing.SQL_TABLE_NAME} AS cdm_pricing
group by 1,2
order by 1, 2 asc
)
;;
}
...
}
앞서 보여준 BigQuery ML ARIMA 모델뿐만 아니라 향후 판매 예측을 위해 ( 이 뷰 파일)
view: arima_model {
derived_table: {
persist_for: "24 hours"
sql_create:
create or replace model ${sql_table_name}
options
(model_type = 'arima_plus',
time_series_timestamp_col = 'fiscal_date',
time_series_data_col = 'total_quantity',
time_series_id_col = 'product_id',
auto_arima = true,
data_frequency = 'auto_frequency',
decompose_time_series = true
) as
select
fiscal_date,
product_id,
sum(invoiced_quantity_in_pieces) as total_quantity
from
${cdm_pricing.sql_table_name}
group by 1,2 ;;
}
}
...
}
LookML에는 샘플 대시보드도 포함되어 있습니다. 여기에서 대시보드의 데모 버전에 액세스할 수 있습니다. 대시보드의 첫 번째 부분에서는 사용자에게 판매, 비용, 가격 및 마진의 변동에 대한 고급 정보를 제공합니다. 비즈니스 사용자는 가격을 낮춰야 함을 의미할 수 있으므로 판매량이 X% 아래로 떨어지면 이를 알 수 있도록 알림을 생성하는 것이 좋습니다.
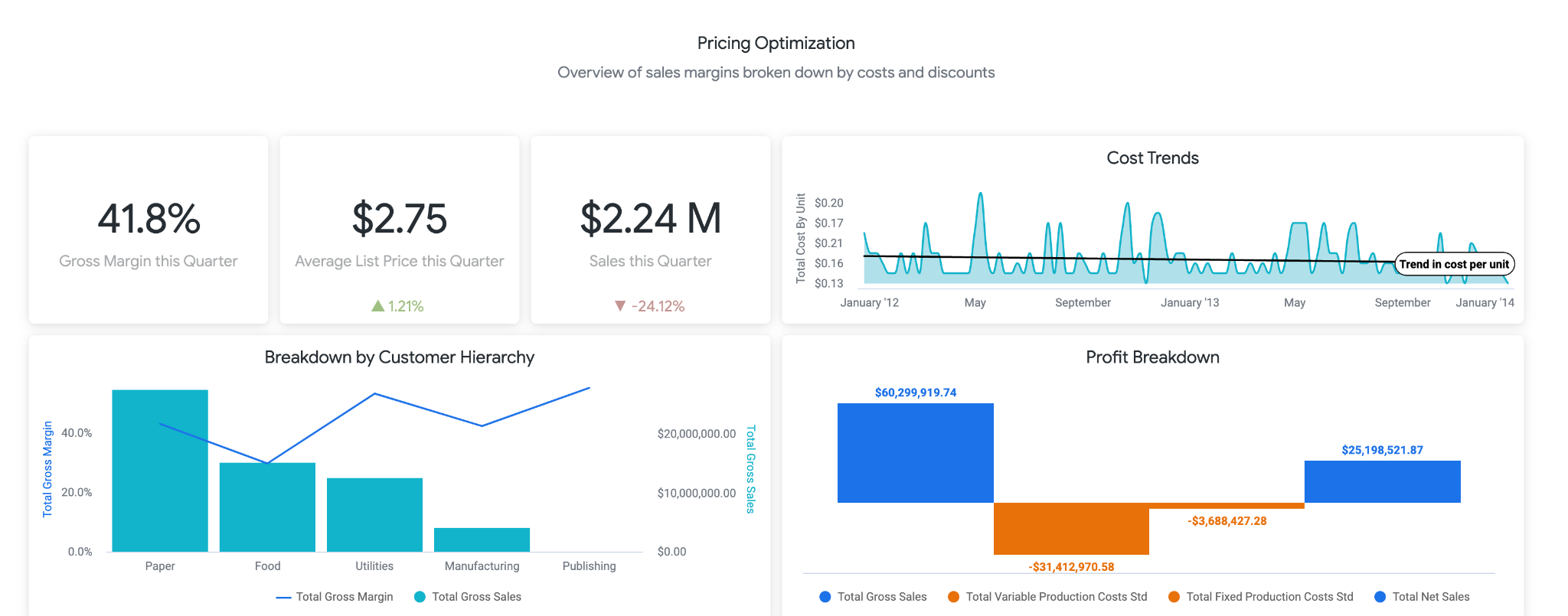
아래 표시된 다음 섹션에서 사용자는 가격 변경과 관련한 동향을 자세히 살펴볼 수 있습니다. 여기에서 특정 제품을 상세히 살펴보고 정확한 정가와 변경된 가격을 확인할 수 있습니다. 이렇게 하면 더 자세히 조사해야 할 특정 제품을 정확히 파악하는 데 도움이 될 수 있습니다.
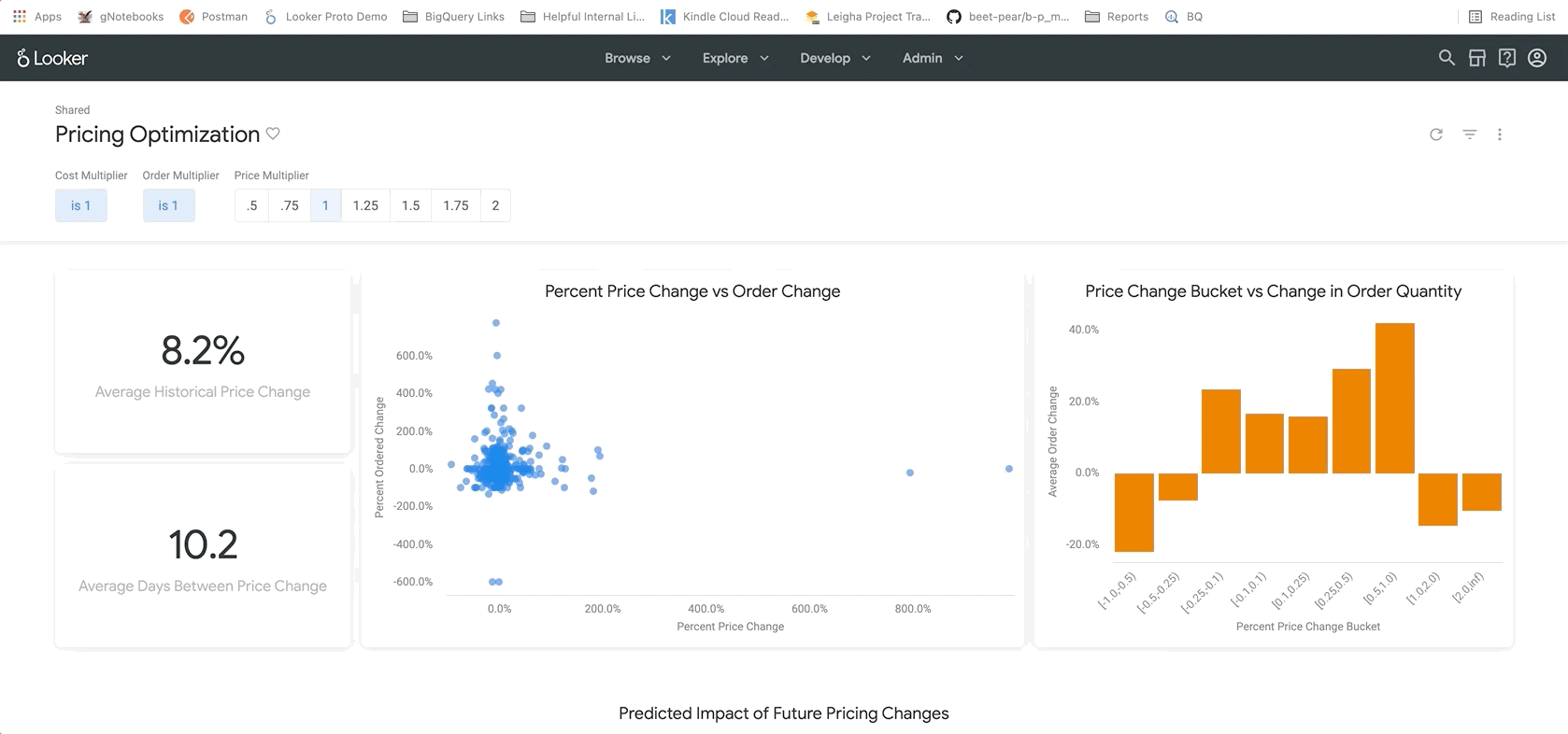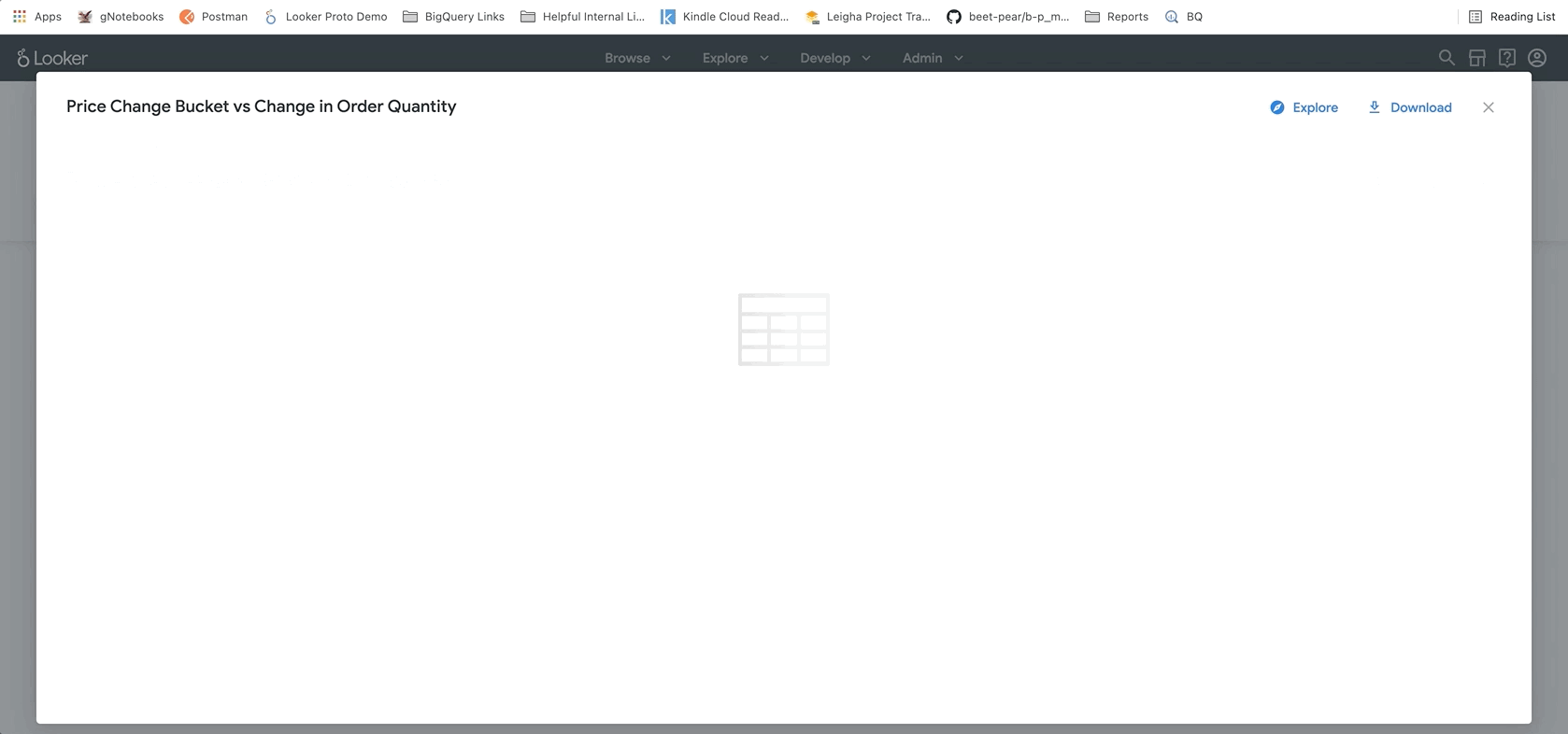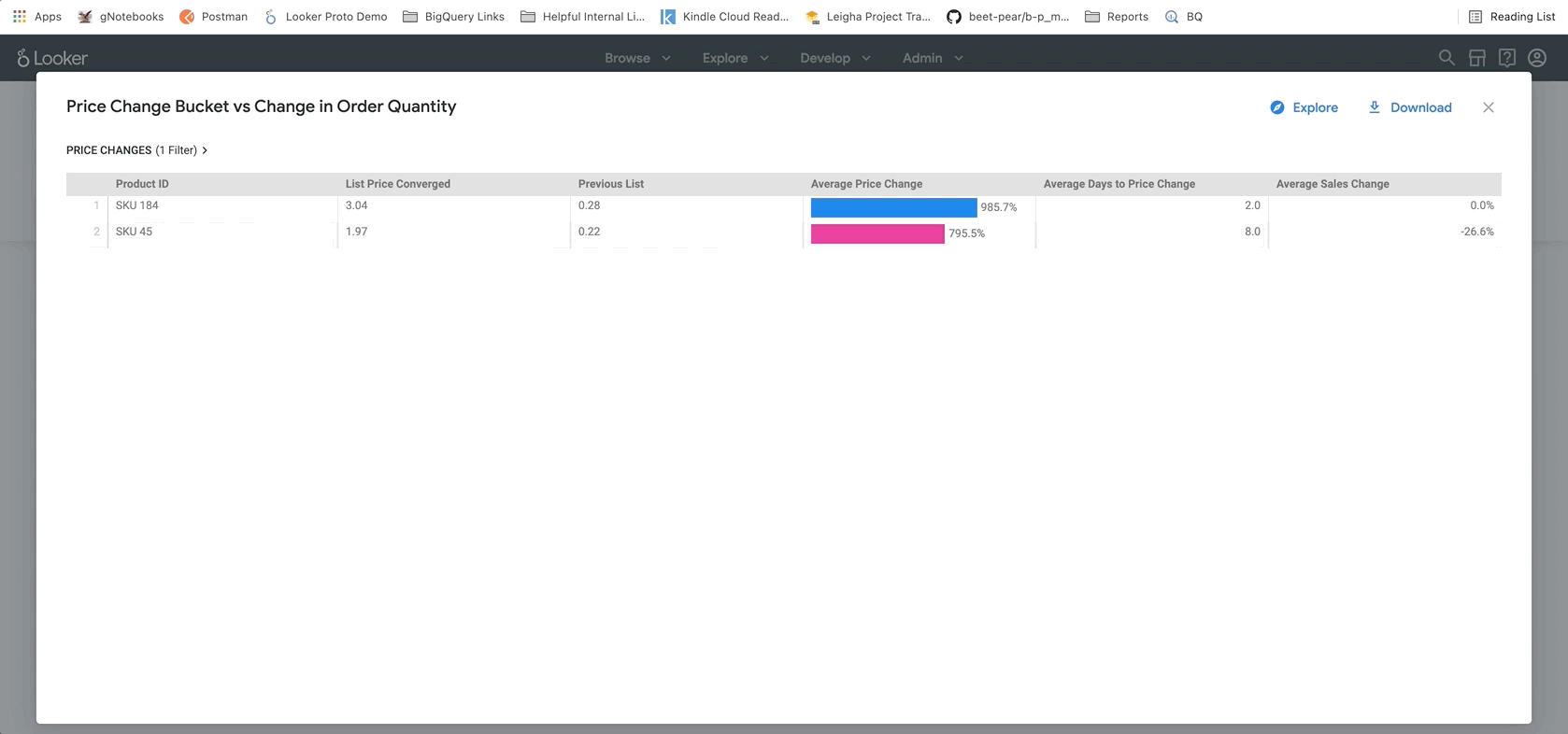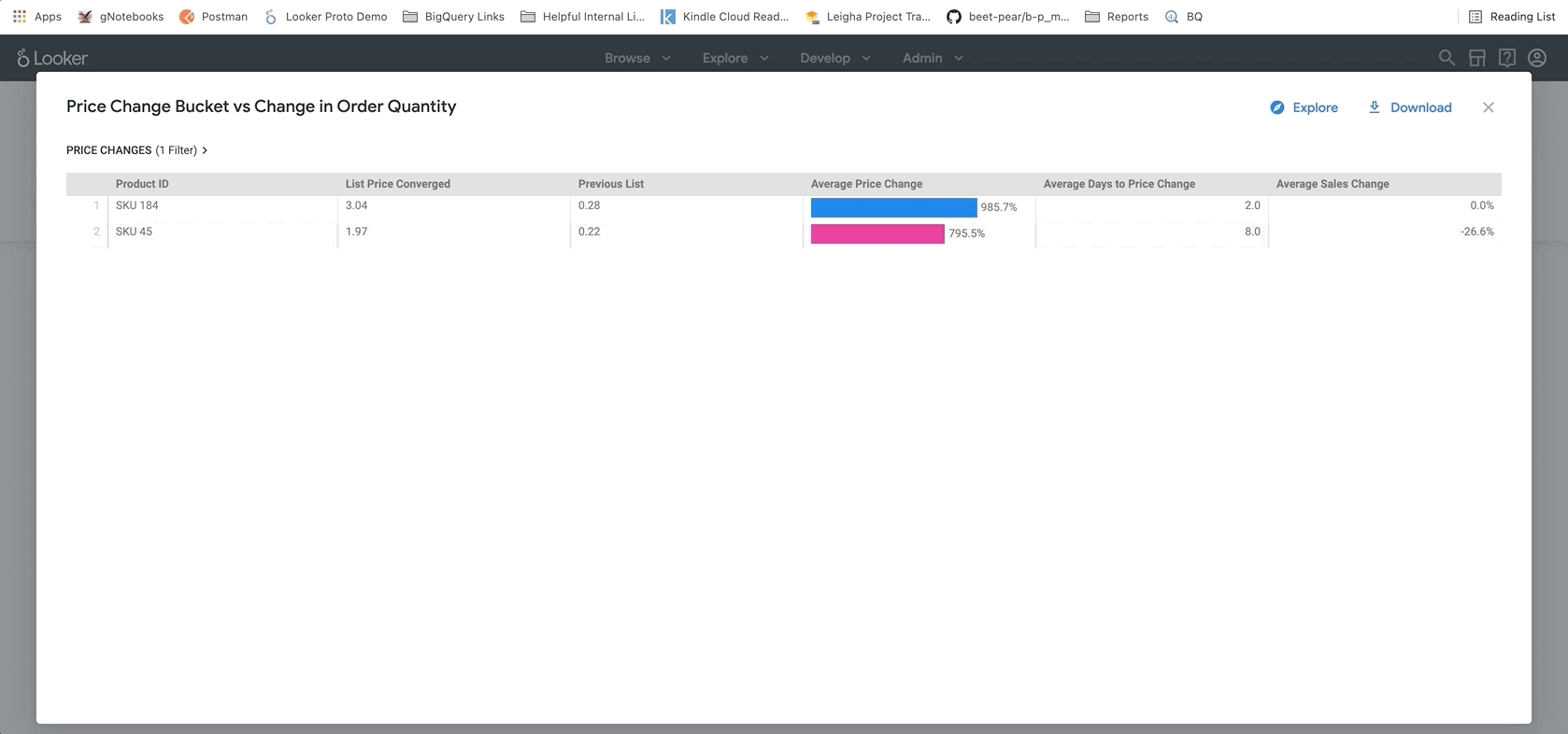
마지막으로 보고서 하단에는 BigQueryML 모델의 결과가 나와 있습니다. Looker 대시보드 상단의 필터를 사용하면 매개변수를 쉽게 입력하여 위에서 설명한 것과 유사한 다양한 시나리오를 시뮬레이션할 수 있습니다. 아래 그림과 같이 주문량이 예상 금액의 75% 까지 감소하고 모든 제품의 가격을 25% 인상할 경우 어떤 일이 발생할지 확인하는 예를 들면 다음과 같습니다.
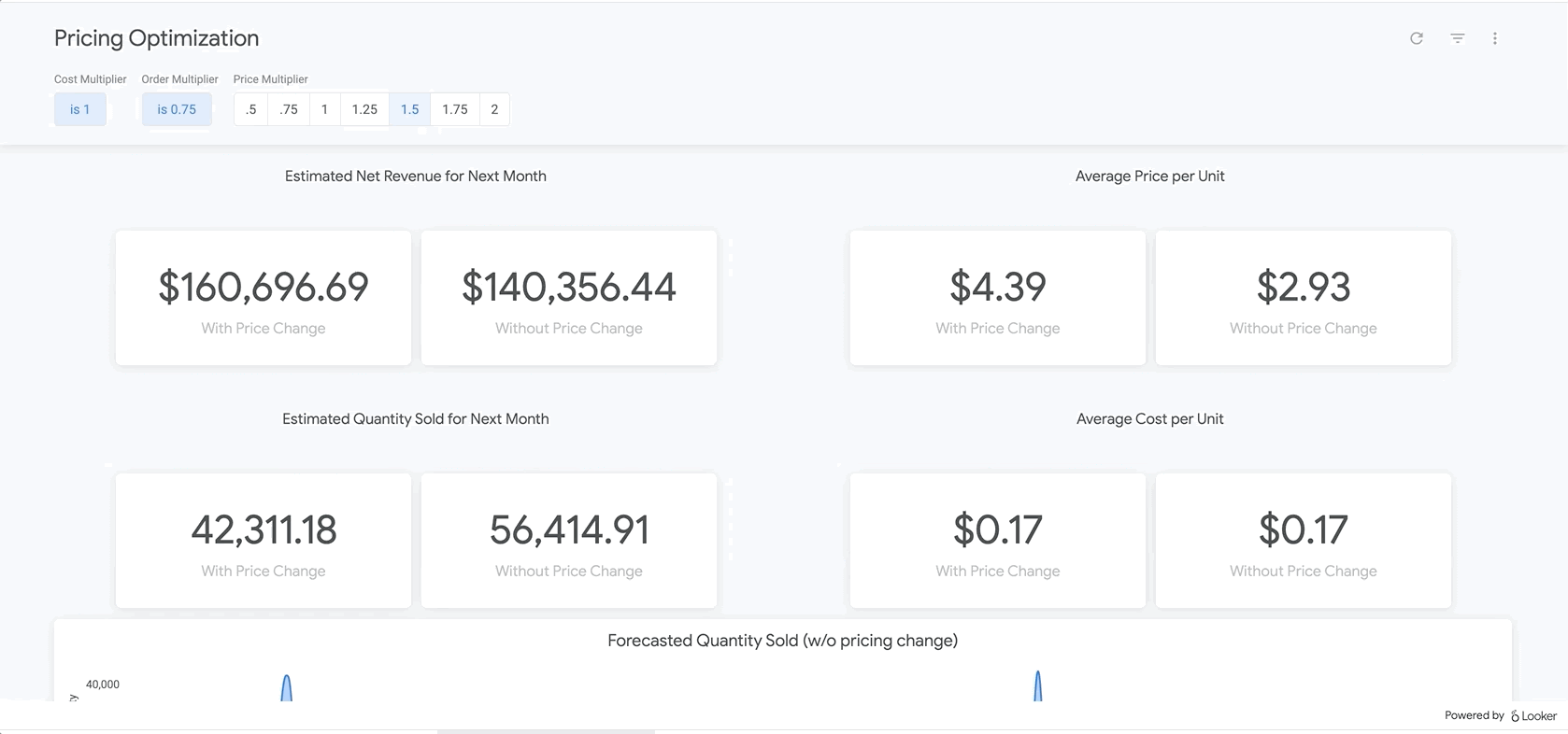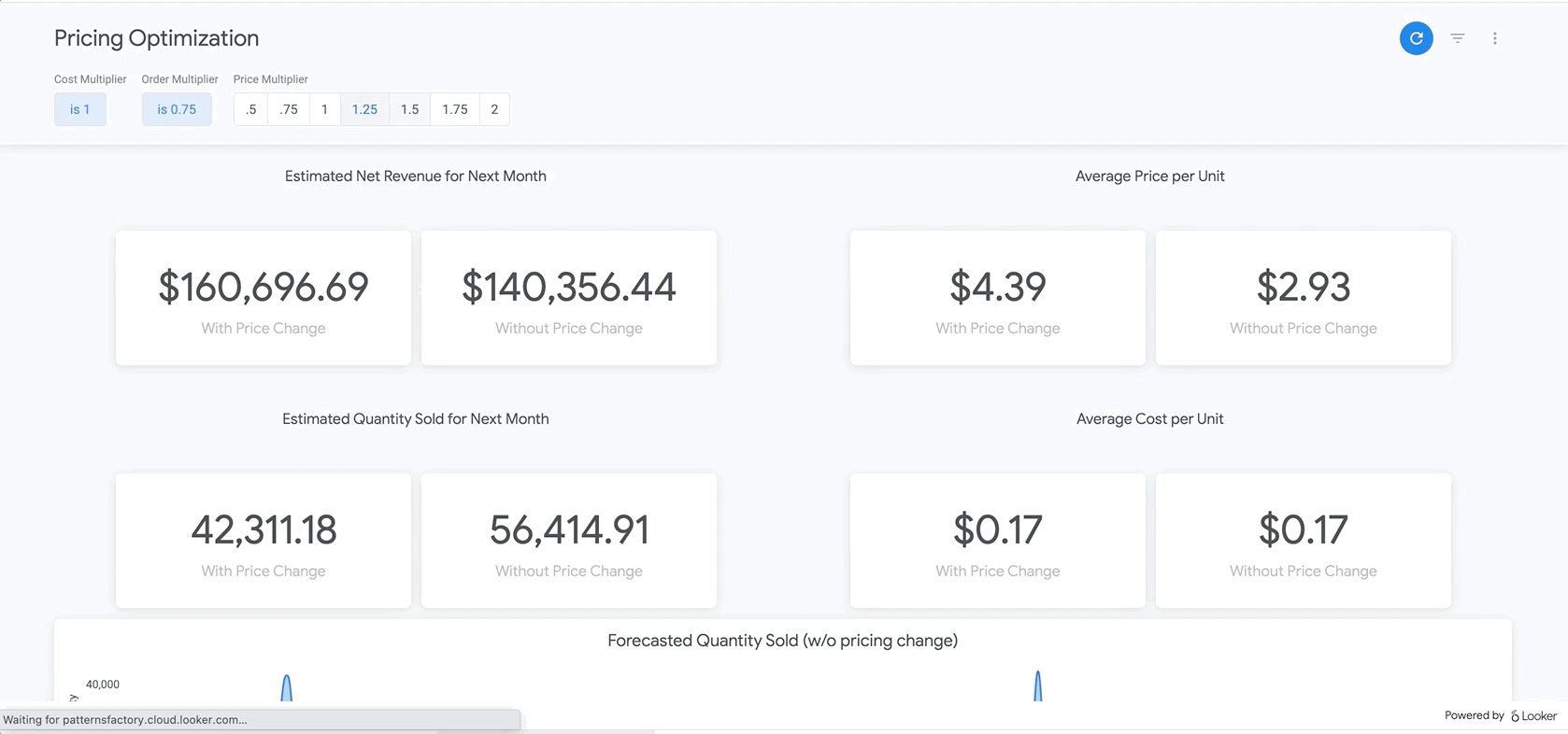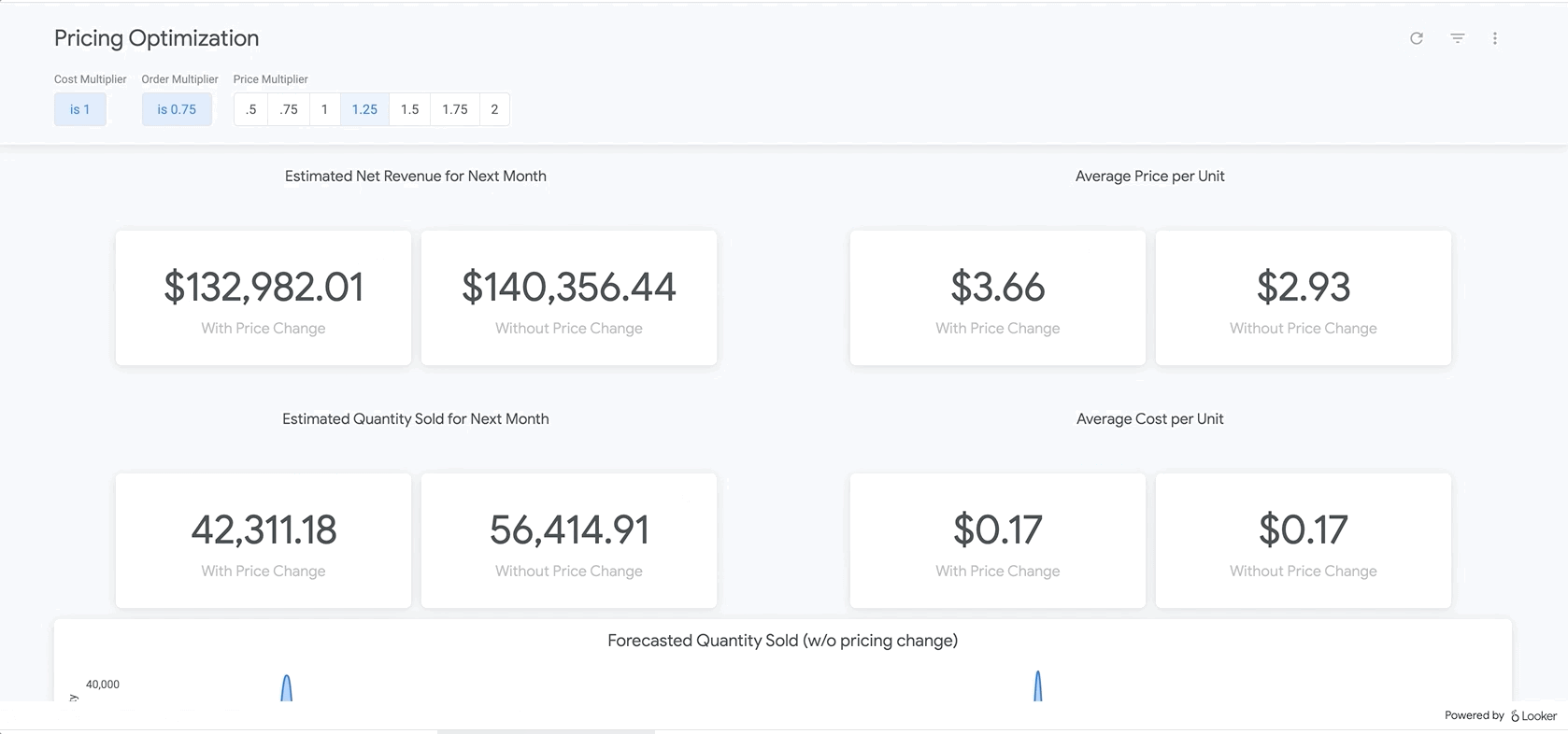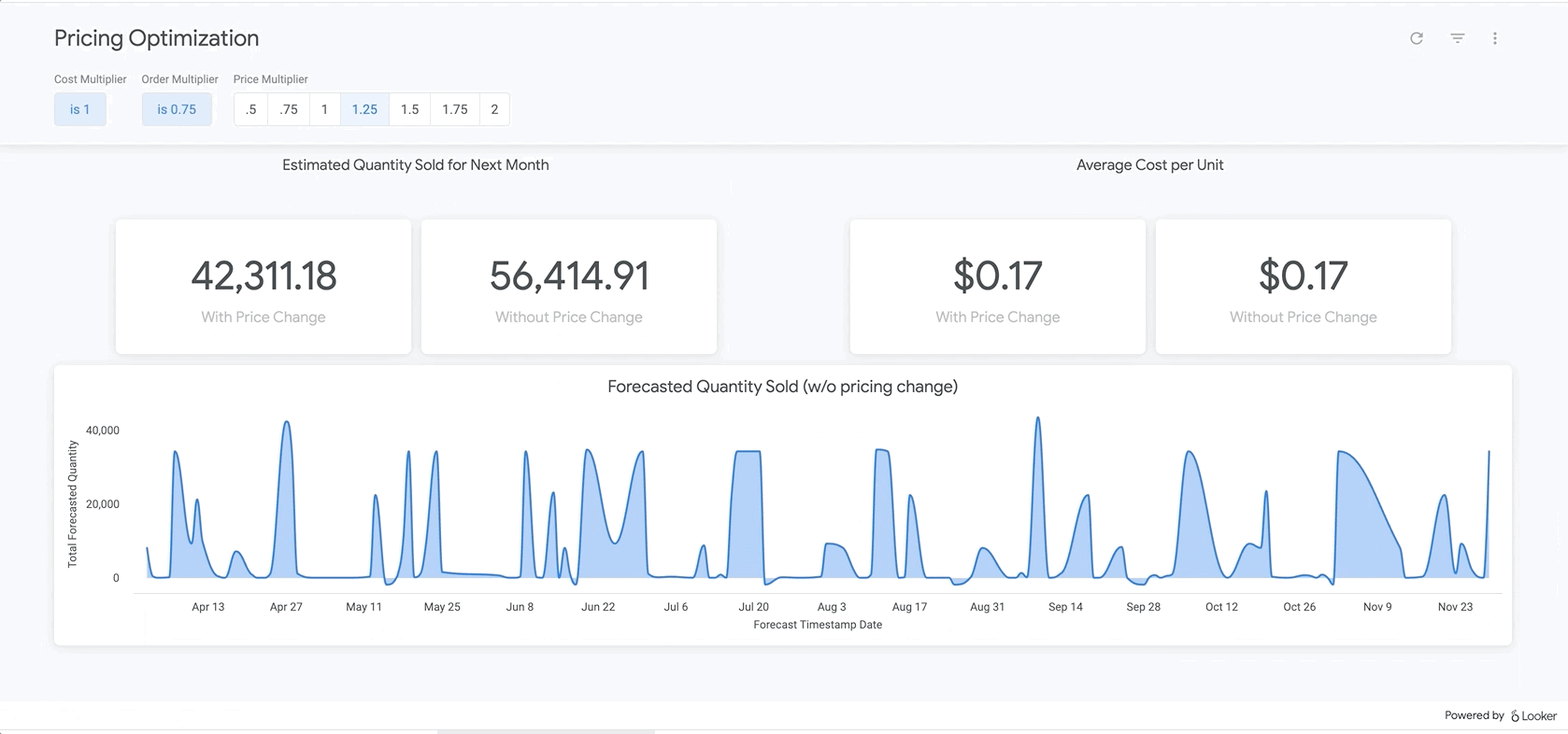
이는 LookML의 매개변수를 기반으로 하며, 이 매개변수는 여기에서 찾을 수 있는 측정 계산에 직접 통합됩니다. 이러한 유형의 보고서를 사용하면 모든 제품에 대한 최적의 가격을 찾거나 특정 제품을 상세히 분석하여 가격을 인상 또는 할인해야 하는 부분과 총수익 및 순수익에 대해 예상되는 결과를 결정할 수 있습니다.
14. 가격 책정 시스템 조정
이 튜토리얼에서 샘플 데이터 소스를 변환하는 동안 다양한 플랫폼에 존재하는 가격 책정 애셋에서도 비슷한 데이터 문제를 겪게 됩니다. 가격 애셋에는 요약 및 세부 결과에 대한 다양한 내보내기 형식 (대개 xls, Sheets, csv, txt, 관계형 데이터베이스, 비즈니스 애플리케이션)이 있으며 각 형식을 Dataprep에 연결할 수 있습니다. 먼저 위에 제공된 예제와 유사하게 변환 요구사항을 설명하는 것이 좋습니다. 사양을 명확히 하고 필요한 변환 유형을 식별한 후 Dataprep을 사용하여 설계할 수 있습니다.
- 맞춤설정할 Dataprep 흐름 사본을 만들거나 (흐름 오른쪽에 있는 **... '**더보기' 버튼을 클릭하고 복제 옵션 선택) 새 Dataprep 흐름을 사용하여 처음부터 시작합니다.
- 자체 가격 책정 데이터 세트에 연결합니다. Dataprep은 기본적으로 Excel, CSV, Google Sheets, JSON과 같은 파일 형식을 지원합니다. Dataprep 커넥터를 사용하여 다른 시스템에 연결할 수도 있습니다.
- 파악한 다양한 변환 카테고리로 데이터 애셋을 전달합니다. 카테고리별로 레시피를 하나씩 만듭니다. 이 설계 패턴에서 제공하는 흐름에서 아이디어를 얻어 데이터를 변환하고 나만의 레시피를 작성하세요. 문제가 생기면 걱정 마세요. Dataprep 화면 왼쪽 하단의 채팅 대화상자에서 도움을 요청하세요.
- 레시피를 BigQuery 인스턴스에 연결합니다. BigQuery에서 테이블을 직접 만들지 않아도 Dataprep이 자동으로 처리합니다. 흐름에 출력을 추가할 때 수동 대상을 선택하고 실행할 때마다 테이블을 삭제하는 것이 좋습니다. 예상되는 결과가 나올 때까지 각 레시피를 개별적으로 테스트합니다. 테스트가 완료되면 이전 데이터가 삭제되지 않도록 실행할 때마다 출력을 테이블에 '추가'로 변환합니다.
- 일정에 따라 실행되도록 흐름을 연결할 수도 있습니다. 이는 프로세스를 지속적으로 실행해야 할 때 유용합니다. 필요한 최신 상태에 따라 매일 또는 매시간 응답을 로드하도록 일정을 정의할 수 있습니다. 일정에 따라 흐름을 실행하려면 각 레시피의 흐름에 일정 대상 출력을 추가해야 합니다.
BigQuery 머신러닝 모델 수정하기
이 튜토리얼에서는 샘플 ARIMA 모델을 제공합니다. 하지만 모델을 개발할 때 데이터에 가장 적합하도록 제어할 수 있는 추가 매개변수가 있습니다. 자세한 내용은 이 문서의 예를 참조하세요. 또한 BigQuery ML.ARIMA_EVALUATE, ML.ARIMA_COEFFICIENTS, ML.EXPLAIN_FORECAST 함수를 사용하여 모델에 대한 자세한 정보를 얻고 최적화 결정을 내릴 수 있습니다.
Looker 보고서 수정
위에서 설명한 대로 LookML을 자체 프로젝트에 가져온 후 직접 수정하여 필드를 추가하고, 계산 또는 사용자가 입력한 매개변수를 수정하고, 대시보드의 시각화를 비즈니스 니즈에 맞게 변경할 수 있습니다. LookML에서 개발하기 및 Looker에서 데이터를 시각화하는 방법
15. 축하합니다
지금까지 소매 제품을 최적화하는 데 필요한 주요 단계를 알아봤습니다. 가격 책정에 사용됩니다.
다음 단계
다른 스마트 분석 참조 패턴 살펴보기
추가 자료
- 블로그 읽기
- 여기에서 Dataprep에 대해 자세히 알아보세요.
- 여기에서 BigQuery 머신러닝에 대해 자세히 알아보세요.
- 여기에서 Looker 자세히 알아보기