
1. Einführung
Letzte Aktualisierung:15.09.2021
Die Daten, die für Preisanalysen und ‑optimierungen erforderlich sind, sind von Natur aus unterschiedlich (verschiedene Systeme, unterschiedliche lokale Gegebenheiten usw.). Daher ist es wichtig, eine gut strukturierte, standardisierte und bereinigte CDM-Tabelle zu erstellen. Dazu gehören wichtige Attribute für die Preisoptimierung wie Transaktionen, Produkte, Preise und Kunden. In diesem Dokument werden die unten beschriebenen Schritte erläutert. So erhalten Sie einen schnellen Einstieg in die Preisanalyse, die Sie nach Bedarf erweitern und anpassen können. Das folgende Diagramm zeigt die Schritte, die in diesem Dokument behandelt werden.

- Datenquellen bewerten:Zuerst müssen Sie eine Liste der Datenquellen erstellen, die zum Erstellen des CDM verwendet werden. In diesem Schritt wird auch Dataprep verwendet, um Probleme in den Eingabedaten zu untersuchen und zu identifizieren. Dazu gehören beispielsweise fehlende und nicht übereinstimmende Werte, inkonsistente Namenskonventionen, Duplikate, Probleme mit der Datenintegrität und Ausreißer.
- Daten standardisieren:Als Nächstes werden die zuvor ermittelten Probleme behoben, um die Genauigkeit, Integrität, Konsistenz und Vollständigkeit der Daten zu gewährleisten. Dieser Prozess kann verschiedene Transformationen in Dataprep umfassen, z. B. die Formatierung von Datumsangaben, die Standardisierung von Werten, die Umrechnung von Einheiten, das Herausfiltern unnötiger Felder und Werte sowie das Aufteilen, Zusammenführen oder Deduplizieren der Quelldaten.
- In einer Struktur zusammenführen:In der nächsten Phase der Pipeline werden die einzelnen Datenquellen in einer einzigen breiten Tabelle in BigQuery zusammengeführt, die alle Attribute auf der feinsten Granularitätsebene enthält. Diese denormalisierte Struktur ermöglicht effiziente analytische Abfragen, für die keine Joins erforderlich sind.
- Analysen und ML/KI bereitstellen:Sobald die Daten bereinigt und für die Analyse formatiert sind, können Analysten Verlaufsdaten untersuchen, um die Auswirkungen früherer Preisänderungen zu verstehen. Außerdem können mit BigQuery ML Vorhersagemodelle erstellt werden, mit denen sich zukünftige Umsätze schätzen lassen. Die Ausgabe dieser Modelle kann in Dashboards in Looker eingebunden werden, um „Was-wäre-wenn-Szenarien“ zu erstellen. So können Nutzer analysieren, wie sich der Umsatz bei bestimmten Preisänderungen entwickeln könnte.
Das folgende Diagramm zeigt die Google Cloud-Komponenten, die zum Erstellen der Analytics-Pipeline zur Preisoptimierung verwendet werden.

Umfang
Hier erfahren Sie, wie Sie ein Data Warehouse zur Preisoptimierung entwerfen, die Datenvorbereitung im Laufe der Zeit automatisieren, maschinelles Lernen verwenden, um die Auswirkungen von Änderungen an der Produktpreisgestaltung vorherzusagen, und Berichte erstellen, um Ihrem Team umsetzbare Statistiken zu liefern.
Lerninhalte
- Dataprep mit Datenquellen für die Preisanalyse verbinden, die in relationalen Datenbanken, flachen Dateien, Google Sheets und anderen unterstützten Anwendungen gespeichert sein können
- So erstellen Sie einen Dataprep-Ablauf, um eine CDM-Tabelle in Ihrem BigQuery-Data Warehouse zu erstellen.
- BigQuery ML zur Vorhersage des zukünftigen Umsatzes verwenden
- So erstellen Sie Berichte in Looker, um vergangene Preis- und Verkaufstrends zu analysieren und die Auswirkungen zukünftiger Preisänderungen zu verstehen.
Voraussetzungen
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion. So prüfen Sie, ob die Abrechnung für Ihr Projekt aktiviert ist.
- BigQuery muss für Ihr Projekt aktiviert sein. Sie ist in neuen Projekten automatisch aktiviert. Andernfalls aktivieren Sie sie in einem vorhandenen Projekt. Weitere Informationen zum Einstieg in BigQuery über die Cloud Console
- Dataprep muss für Ihr Projekt aktiviert sein. Dataprep wird in der Google Console im linken Navigationsmenü im Bereich „Big Data“ aktiviert. Folgen Sie der Anleitung, um es zu aktivieren.
- Wenn Sie eigene Looker-Dashboards einrichten möchten, benötigen Sie Entwicklerzugriff auf eine Looker-Instanz. Wenn Sie eine Testversion anfordern möchten, wenden Sie sich bitte hier an unser Team. Alternativ können Sie unser öffentliches Dashboard verwenden, um die Ergebnisse der Datenpipeline anhand unserer Beispieldaten zu analysieren.
- Erfahrung mit Structured Query Language (SQL) und grundlegende Kenntnisse der folgenden Produkte sind hilfreich: Dataprep by Trifacta, BigQuery, Looker
2. CDM in BigQuery erstellen
In diesem Abschnitt erstellen Sie das Common Data Model (CDM), das eine konsolidierte Ansicht der Informationen bietet, die Sie zum Analysieren und Vorschlagen von Preisänderungen benötigen.
- Öffnen Sie die BigQuery Console.
- Wählen Sie das Projekt aus, das Sie zum Testen dieses Referenzmusters verwenden möchten.
- Verwenden Sie ein vorhandenes Dataset oder erstellen Sie ein BigQuery-Dataset. Benennen Sie das Dataset
Pricing_CDM. - Tabelle erstellen:
create table `CDM_Pricing`
(
Fiscal_Date DATETIME,
Product_ID STRING,
Client_ID INT64,
Customer_Hierarchy STRING,
Division STRING,
Market STRING,
Channel STRING,
Customer_code INT64,
Customer_Long_Description STRING,
Key_Account_Manager INT64,
Key_Account_Manager_Description STRING,
Structure STRING,
Invoiced_quantity_in_Pieces FLOAT64,
Gross_Sales FLOAT64,
Trade_Budget_Costs FLOAT64,
Cash_Discounts_and_other_Sales_Deductions INT64,
Net_Sales FLOAT64,
Variable_Production_Costs_STD FLOAT64,
Fixed_Production_Costs_STD FLOAT64,
Other_Cost_of_Sales INT64,
Standard_Gross_Margin FLOAT64,
Transportation_STD FLOAT64,
Warehouse_STD FLOAT64,
Gross_Margin_After_Logistics FLOAT64,
List_Price_Converged FLOAT64
);
3. Datenquellen bewerten
In dieser Anleitung verwenden Sie Beispieldatenquellen, die in Google Sheets und BigQuery gespeichert sind.
- Die Google-Tabelle Transaktionen, die eine Zeile für jede Transaktion enthält. Sie enthält Details wie die Menge der einzelnen verkauften Produkte, den gesamten Bruttoumsatz und die zugehörigen Kosten.
- Die Google-Tabelle Produktpreise, die den Preis jedes Produkts für einen bestimmten Kunden für jeden Monat enthält.
- Die BigQuery-Tabelle „company_descriptions“, die Informationen zu einzelnen Kunden enthält.
Diese BigQuery-Tabelle „company_descriptions“ kann mit der folgenden Anweisung erstellt werden:
create table `Company_Descriptions`
(
Customer_ID INT64,
Customer_Long_Description STRING
);
insert into `Company_Descriptions` values (15458, 'ENELTEN');
insert into `Company_Descriptions` values (16080, 'NEW DEVICES CORP.');
insert into `Company_Descriptions` values (19913, 'ENELTENGAS');
insert into `Company_Descriptions` values (30108, 'CARTOON NT');
insert into `Company_Descriptions` values (32492, 'Thomas Ed Automobiles');
4. Ablauf erstellen
In diesem Schritt importieren Sie einen Dataprep-Beispielflow, mit dem Sie die im vorherigen Abschnitt aufgeführten Beispieldatasets transformieren und vereinheitlichen. Ein Ablauf stellt eine Pipeline oder ein Objekt dar, in dem Datasets und Schemas zusammengeführt werden, die zum Transformieren und Verknüpfen der Datasets verwendet werden.
- Laden Sie das Flow-Paket Pricing Optimization Pattern von GitHub herunter, entpacken Sie es aber nicht. Diese Datei enthält den Ablauf des Designmusters zur Preisoptimierung, mit dem die Beispieldaten transformiert werden.
- Klicken Sie in Dataprep in der linken Navigationsleiste auf das Symbol für Abläufe. Wählen Sie dann in der Ansicht „Flows“ (Abläufe) im Kontextmenü die Option Import (Importieren) aus. Nachdem Sie den Flow importiert haben, können Sie ihn auswählen, um ihn anzusehen und zu bearbeiten.

- Auf der linken Seite des Ablaufs müssen die Google-Tabellen „Produktpreise“ und die drei Google-Tabellen „Transaktionen“ als Datasets verbunden sein. Klicken Sie dazu mit der rechten Maustaste auf die Google-Tabellen-Dataset-Objekte und wählen Sie Ersetzen aus. Klicken Sie dann auf den Link Datasets importieren. Klicken Sie auf das Stiftsymbol „Pfad bearbeiten“, wie im folgenden Diagramm dargestellt.

Ersetzen Sie den aktuellen Wert durch den Link zu den Google-Tabellen Transaktionen und Produktpreise .
Wenn Google-Tabellen mehrere Tabs enthalten, können Sie den gewünschten Tab im Menü auswählen. Klicken Sie auf Bearbeiten, wählen Sie die Tabs aus, die Sie als Datenquelle verwenden möchten, klicken Sie auf Speichern und dann auf Importieren und dem Ablauf hinzufügen. Klicken Sie im Modal wieder auf Ersetzen. In diesem Ablauf wird jedes Tabellenblatt als eigenes Dataset dargestellt, um das Zusammenführen unterschiedlicher Quellen in einem späteren Rezept zu demonstrieren.

- BigQuery-Ausgabetabellen definieren:
In diesem Schritt verknüpfen Sie den Speicherort für die BigQuery-Ausgabetabelle „CDM_Pricing“, die jedes Mal geladen werden soll, wenn Sie den Dataoprep-Job ausführen.
Klicken Sie in der Ablaufansicht auf das Symbol für die Schemazuordnungsausgabe und dann im Detailbereich auf den Tab „Ziele“. Bearbeiten Sie dort sowohl die Ausgabe für manuelle Ziele, die für Tests verwendet wird, als auch die Ausgabe für geplante Ziele, die verwendet wird, wenn Sie den gesamten Ablauf automatisieren möchten. Gehen Sie dazu so vor:
- Manuelle Ziele bearbeiten: Klicken Sie im Detailbereich unter „Manuelle Ziele“ auf die Schaltfläche „Bearbeiten“. Klicken Sie auf der Seite Veröffentlichungseinstellungen unter „Veröffentlichungsaktionen“ auf „Bearbeiten“, wenn bereits eine Veröffentlichungsaktion vorhanden ist. Klicken Sie andernfalls auf die Schaltfläche „Aktion hinzufügen“. Rufen Sie dort die BigQuery-Datasets auf, um das Dataset
Pricing_CDMauszuwählen, das Sie in einem vorherigen Schritt erstellt haben, und wählen Sie die TabelleCDM_Pricingaus. Prüfen Sie, ob Append to this table every run (Bei jedem Lauf an diese Tabelle anhängen) ausgewählt ist, und klicken Sie dann auf Add (Hinzufügen) und Save Settings (Einstellungen speichern). - Geplante Ziele bearbeiten
Klicken Sie im Bereich „Details“ unter „Geplante Ziele“ auf Bearbeiten.
Die Einstellungen werden von den manuellen Zielvorhaben übernommen und Sie müssen keine Änderungen vornehmen. Klicken Sie auf „Save Settings“ (Einstellungen speichern).
5. Daten standardisieren
Mit den bereitgestellten Flow-Unions werden die Transaktionsdaten formatiert und bereinigt. Das Ergebnis wird dann für die Berichterstellung mit den Unternehmensbeschreibungen und aggregierten Preisdaten zusammengeführt. Hier werden die Komponenten des Ablaufs beschrieben, die im Bild unten zu sehen sind.

6. Rezept für Transaktionsdaten
Zuerst sehen Sie sich an, was im Rezept für Transaktionsdaten passiert, das zum Vorbereiten von Transaktionsdaten verwendet wird. Klicken Sie in der Flussansicht auf das Objekt „Transaktionsdaten“ und dann im Detailbereich auf die Schaltfläche „Schema bearbeiten“.
Die Seite „Transformer“ wird geöffnet und das Schema wird im Detailbereich angezeigt. Das Schema enthält alle Transformationsschritte, die auf die Daten angewendet werden. Sie können im Rezept navigieren, indem Sie zwischen die einzelnen Schritte klicken, um den Status der Daten an dieser bestimmten Stelle im Rezept zu sehen.
Sie können auch für jeden Rezeptschritt auf das Dreipunkt-Menü klicken und „Zu Auswahl gehen“ oder „Bearbeiten“ auswählen, um zu sehen, wie die Transformation funktioniert.
- Transaktionen zusammenführen:Im ersten Schritt des Schemas für Transaktionsdaten werden Transaktionen, die in verschiedenen Tabellenblättern für die einzelnen Monate gespeichert sind, zusammengeführt.
- Kundenbeschreibungen standardisieren:Im nächsten Schritt des Rezepts werden Kundenbeschreibungen standardisiert. Das bedeutet, dass Kundennamen ähnlich sein können, sich aber leicht unterscheiden. Wir möchten sie normalisieren, sodass sie als ein Name behandelt werden. Im Rezept werden zwei mögliche Ansätze vorgestellt. Zuerst wird der Standardisierungsalgorithmus verwendet, der mit verschiedenen Standardisierungsoptionen konfiguriert werden kann, z. B. „Ähnliche Strings“, bei denen Werte mit gemeinsamen Zeichen zusammengefasst werden, oder „Aussprache“, bei denen Werte, die gleich klingen, zusammengefasst werden. Alternativ können Sie die Unternehmensbeschreibung anhand der Unternehmens-ID in der oben genannten BigQuery-Tabelle nachschlagen.
Im Rezept finden Sie weitere Techniken zum Bereinigen und Formatieren der Daten: Zeilen löschen, anhand von Mustern formatieren, Daten mit Lookups anreichern, mit fehlenden Werten umgehen oder unerwünschte Zeichen ersetzen.
7. Rezept für Produktdaten zur Preisgestaltung ansehen
Als Nächstes können Sie sich ansehen, was im Rezept für Produktpreisdaten passiert. Dort werden die vorbereiteten Transaktionsdaten mit den aggregierten Preisdaten zusammengeführt.
Klicken Sie oben auf der Seite auf das DESIGNMUSTER FÜR DIE PREISOPTIMIERUNG, um die Seite „Transformer“ zu schließen und zur Ablaufansicht zurückzukehren. Klicken Sie dort auf das Objekt „Product Pricing Data“ (Produktpreisdaten) und bearbeiten Sie das Schema.
- Monatliche Preisspalten entpivotieren:Klicken Sie auf das Rezept zwischen Schritt 2 und Schritt 3, um zu sehen, wie die Daten vor dem Schritt „Entpivotieren“ aussehen. Die Daten enthalten den Transaktionswert in einer separaten Spalte für jeden Monat: Jan, Feb, Mar. Dieses Format ist nicht geeignet, um Aggregationsberechnungen (z. B. Summe, durchschnittliche Transaktion) in SQL anzuwenden. Die Daten müssen entpivotisiert werden, damit jede Spalte zu einer Zeile in der BigQuery-Tabelle wird. Im Rezept wird die Funktion unpivot verwendet, um die drei Spalten in eine Zeile für jeden Monat zu transformieren. So lassen sich leichter weitere Gruppenberechnungen anwenden.
- Durchschnittlichen Transaktionswert nach Kunde, Produkt und Datum berechnen: Wir möchten den durchschnittlichen Transaktionswert für jeden Kunden, jedes Produkt und jedes Datum berechnen. Wir können die Aggregatfunktion verwenden und eine neue Tabelle generieren (Option „Gruppieren nach als neue Tabelle“). In diesem Fall werden die Daten auf Gruppenebene aggregiert und die Details der einzelnen Transaktionen gehen verloren. Alternativ können wir sowohl die Details als auch die aggregierten Werte im selben Dataset beibehalten (Option „Group by as a new column(s)“). Das ist sehr praktisch, wenn wir ein Verhältnis anwenden möchten, z. B. den prozentualen Beitrag der Produktkategorie zum Gesamtumsatz. Sie können dieses Verhalten ausprobieren, indem Sie den siebten Rezeptschritt bearbeiten und die Option „Gruppieren nach als neue Tabelle“ oder „Gruppieren nach als neue Spalte(n)“ auswählen, um die Unterschiede zu sehen.
- Zusammenführen von Preisdaten:Schließlich werden mehrere Datasets mit einem Join zu einem größeren Dataset zusammengeführt, indem dem ursprünglichen Dataset Spalten hinzugefügt werden. In diesem Schritt werden die Preisdaten mit der Ausgabe des Schemas für Transaktionsdaten zusammengeführt. Die entsprechenden Bedingungen sind „Pricing Data.Product Code“ = „Transaction Data.SKU“ und „Pricing Data.Price Date“ = „Transaction Data.Fiscal Date“.
Weitere Informationen zu den Transformationen, die Sie mit Dataprep anwenden können, finden Sie im Trifacta Data Wrangling Cheat Sheet.
8. Rezept für die Schemazuordnung ansehen
Im letzten Rezept, „Schema Mapping“, wird dafür gesorgt, dass die resultierende CDM-Tabelle mit dem Schema der vorhandenen BigQuery-Ausgabetabelle übereinstimmt. Hier wird die Funktion Rapid Target verwendet, um die Datenstruktur so zu formatieren, dass sie der BigQuery-Tabelle entspricht. Dazu wird ein unscharfer Abgleich verwendet, um beide Schemas zu vergleichen und automatische Änderungen anzuwenden.
9. In einer Struktur zusammenführen
Nachdem Sie nun Quellen und Ziele konfiguriert und die Schritte der Flows untersucht haben, können Sie den Flow ausführen, um die CDM-Tabelle zu transformieren und in BigQuery zu laden.
- Schema Mapping-Ausgabe ausführen:Wählen Sie in der Ablaufansicht das Schema Mapping-Ausgabeobjekt aus und klicken Sie im Detailbereich auf die Schaltfläche „Ausführen“. Wählen Sie die Ausführungsumgebung „Trifacta Photon“ aus und deaktivieren Sie „Rezeptfehler ignorieren“. Klicken Sie dann auf die Schaltfläche „Ausführen“. Wenn die angegebene BigQuery-Tabelle vorhanden ist, werden neue Zeilen angehängt. Andernfalls wird eine neue Tabelle erstellt.
- Jobstatus ansehen:Dataprep öffnet automatisch die Seite „Job ausführen“, damit Sie die Jobausführung überwachen können. Es sollte einige Minuten dauern, bis die BigQuery-Tabelle geladen wird. Nach Abschluss des Jobs wird die CDM-Ausgabe für die Preisgestaltung in einem bereinigten, strukturierten und normalisierten Format in BigQuery geladen, das sich für die Analyse eignet.
10. Analysen und ML/KI bereitstellen
Voraussetzungen für Analytics
Um einige Analysen und ein Vorhersagemodell mit interessanten Ergebnissen auszuführen, haben wir ein Dataset erstellt, das größer ist und relevante Informationen enthält. Sie müssen diese Daten in Ihr BigQuery-Dataset hochladen, bevor Sie mit dieser Anleitung fortfahren.
- Laden Sie den großen Datensatz aus diesem GitHub-Repository herunter.
- Rufen Sie in der Google Console für BigQuery Ihr Projekt und das Dataset „CDM_Pricing“ auf.
- Klicken Sie auf das Menü und öffnen Sie das Dataset. Wir erstellen die Tabelle, indem wir Daten aus einer lokalen Datei laden.
Klicken Sie auf die Schaltfläche „+ Tabelle erstellen“ und definieren Sie die folgenden Parameter:
- Wählen Sie „Create table from upload“ (Tabelle aus hochgeladenen Daten erstellen) und die Datei „CDM_Pricing_Large_Table.csv“ aus.
- Klicken Sie bei „Schema automatisch erkennen“ auf das Kästchen neben „Schema und Eingabeparameter“.
- Erweiterte Optionen, Schreibeinstellung, Tabelle überschreiben

- Klicken Sie auf „Tabelle erstellen“.
Nachdem die Tabelle erstellt und die Daten hochgeladen wurden, sollten Sie in der Google Console für BigQuery die Details der neuen Tabelle sehen, wie unten dargestellt. Mit den Preisdaten in BigQuery können wir ganz einfach umfassendere Fragen stellen, um Ihre Preisdaten genauer zu analysieren.

11. Auswirkungen von Preisänderungen ansehen
Ein Beispiel für etwas, das Sie analysieren möchten, ist eine Änderung des Bestellverhaltens, nachdem Sie den Preis eines Artikels geändert haben.
- Zuerst erstellen Sie eine temporäre Tabelle mit einer Zeile für jede Preisänderung eines Produkts. Sie enthält Informationen zur Preisgestaltung des jeweiligen Produkts, z. B. wie viele Artikel zu jedem Preis bestellt wurden und wie hoch der Gesamtnettoumsatz für diesen Preis ist.
create temp table price_changes as (
select
product_id,
list_price_converged,
total_ordered_pieces,
total_net_sales,
first_price_date,
lag(list_price_converged) over(partition by product_id order by first_price_date asc) as previous_list,
lag(total_ordered_pieces) over(partition by product_id order by first_price_date asc) as previous_total_ordered_pieces,
lag(total_net_sales) over(partition by product_id order by first_price_date asc) as previous_total_net_sales,
lag(first_price_date) over(partition by product_id order by first_price_date asc) as previous_first_price_date
from (
select
product_id,list_price_converged,sum(invoiced_quantity_in_pieces) as total_ordered_pieces, sum(net_sales) as total_net_sales, min(fiscal_date) as first_price_date
from `{{my_project}}.{{my_dataset}}.CDM_Pricing` AS cdm_pricing
group by 1,2
order by 1, 2 asc
)
);
select * from price_changes where previous_list is not null order by product_id, first_price_date desc

- Als Nächstes können Sie mit der temporären Tabelle die durchschnittliche Preisänderung für alle SKUs berechnen:
select avg((previous_list-list_price_converged)/nullif(previous_list,0))*100 as average_price_change from price_changes;
- Schließlich können Sie analysieren, was nach einer Preisänderung passiert, indem Sie sich die Beziehung zwischen jeder Preisänderung und der Gesamtzahl der bestellten Artikel ansehen:
select
(total_ordered_pieces-previous_total_ordered_pieces)/nullif(previous_total_ordered_pieces,0)
wie
price_changes_percent_ordered_change,
(list_price_converged-previous_list)/nullif(previous_list,0)
wie
price_changes_percent_price_change
from price_changes
12. Zeitreihen-Prognosemodell erstellen
Als Nächstes können Sie mit den integrierten Machine-Learning-Funktionen von BigQuery ein ARIMA-Zeitreihenprognosemodell erstellen, um die Menge der einzelnen Artikel vorherzusagen, die verkauft werden.
- Zuerst erstellen Sie ein ARIMA_PLUS-Modell.
create or replace `{{my_project}}.{{my_dataset}}.bqml_arima`
options
(model_type = 'ARIMA_PLUS',
time_series_timestamp_col = 'fiscal_date',
time_series_data_col = 'total_quantity',
time_series_id_col = 'product_id',
auto_arima = TRUE,
data_frequency = 'AUTO_FREQUENCY',
decompose_time_series = TRUE
) as
select
fiscal_date,
product_id,
sum(invoiced_quantity_in_pieces) as total_quantity
from
`{{my_project}}.{{my_dataset}}.CDM_Pricing`
group by 1,2;
- Als Nächstes verwenden Sie die Funktion ML.FORECAST, um zukünftige Umsätze für jedes Produkt vorherzusagen:
select
*
from
ML.FORECAST(model testing.bqml_arima,
struct(30 as horizon, 0.8 as confidence_level));
- Anhand dieser Vorhersagen können Sie nachvollziehen, was passieren könnte, wenn Sie die Preise erhöhen. Wenn Sie beispielsweise den Preis jedes Produkts um 15% erhöhen, können Sie den geschätzten Gesamtumsatz für den nächsten Monat mit einer Abfrage wie dieser berechnen:
select
sum(forecast_value * list_price) as total_revenue
from ml.forecast(mode testing.bqml_arima,
struct(30 as horizon, 0.8 as confidence_level)) forecasts
left join (select product_id,
array_agg(list_price_converged
order by fiscal_date desc limit 1)[offset(0)] as list_price
from `leigha-bq-dev.retail.cdm_pricing` group by 1) recent_prices
using (product_id);
13. Bericht erstellen
Nachdem Ihre denormalisierten Preisdaten nun in BigQuery zentralisiert sind und Sie wissen, wie Sie aussagekräftige Abfragen für diese Daten ausführen, ist es an der Zeit, einen Bericht zu erstellen, damit Geschäftsnutzer diese Informationen analysieren und darauf reagieren können.
Wenn Sie bereits eine Looker-Instanz haben, können Sie mit dem LookML in diesem GitHub-Repository mit der Analyse der Preisdaten für dieses Muster beginnen. Erstellen Sie einfach ein neues Looker-Projekt, fügen Sie das LookML hinzu und ersetzen Sie die Verbindung und die Tabellennamen in jeder der Ansichtsdateien, damit sie Ihrer BigQuery-Konfiguration entsprechen.
In diesem Modell finden Sie die abgeleitete Tabelle ( in dieser Ansichtsdatei), die wir zuvor gezeigt haben, um Preisänderungen zu untersuchen:
view: price_changes {
derived_table: {
sql: select
product_id,
list_price_converged,
total_ordered_pieces,
total_net_sales,
first_price_date,
lag(list_price_converged) over(partition by product_id order by first_price_date asc) as previous_list,
lag(total_ordered_pieces) over(partition by product_id order by first_price_date asc) as previous_total_ordered_pieces,
lag(total_net_sales) over(partition by product_id order by first_price_date asc) as previous_total_net_sales,
lag(first_price_date) over(partition by product_id order by first_price_date asc) as previous_first_price_date
from (
select
product_id,list_price_converged,sum(invoiced_quantity_in_pieces) as total_ordered_pieces, sum(net_sales) as total_net_sales, min(fiscal_date) as first_price_date
from ${cdm_pricing.SQL_TABLE_NAME} AS cdm_pricing
group by 1,2
order by 1, 2 asc
)
;;
}
...
}
Neben dem BigQuery ML ARIMA-Modell, das wir bereits vorgestellt haben, um zukünftige Umsätze vorherzusagen ( in dieser Ansichtsdatei)
view: arima_model {
derived_table: {
persist_for: "24 hours"
sql_create:
create or replace model ${sql_table_name}
options
(model_type = 'arima_plus',
time_series_timestamp_col = 'fiscal_date',
time_series_data_col = 'total_quantity',
time_series_id_col = 'product_id',
auto_arima = true,
data_frequency = 'auto_frequency',
decompose_time_series = true
) as
select
fiscal_date,
product_id,
sum(invoiced_quantity_in_pieces) as total_quantity
from
${cdm_pricing.sql_table_name}
group by 1,2 ;;
}
}
...
}
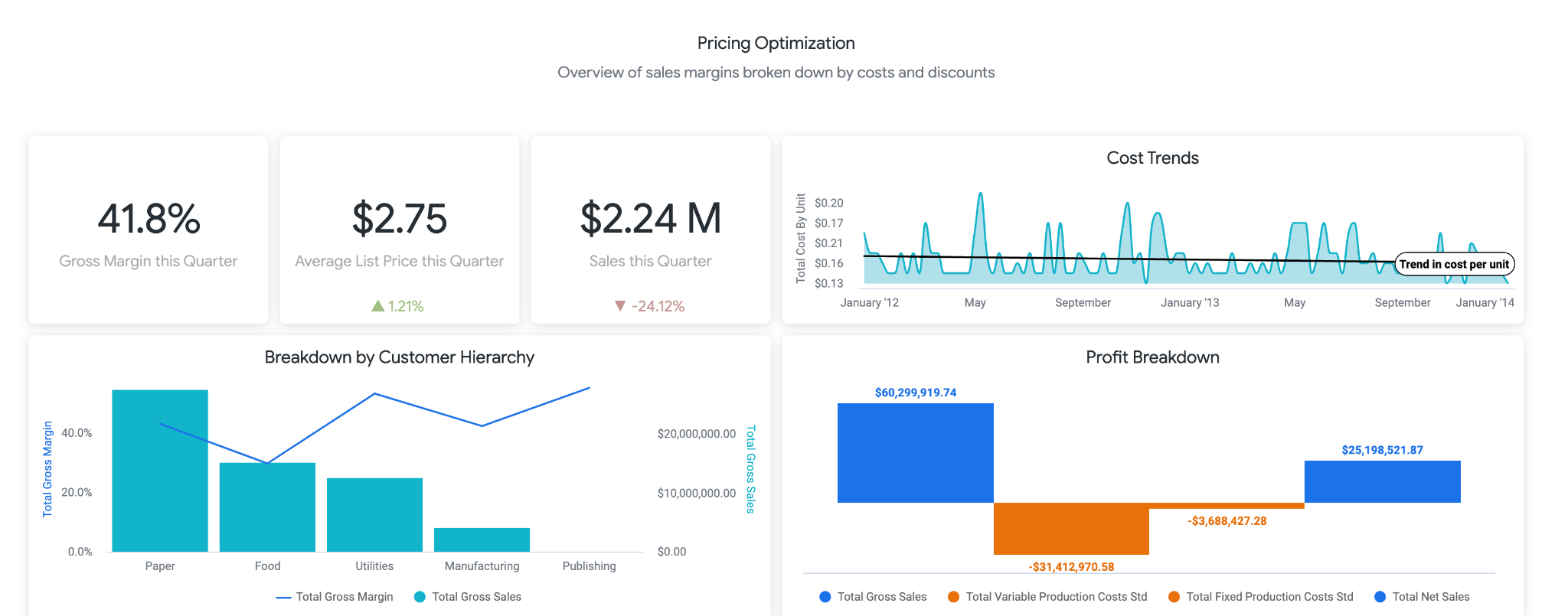
Die LookML enthält auch ein Beispieldashboard. Hier können Sie auf eine Demoversion des Dashboards zugreifen. Im ersten Teil des Dashboards finden Nutzer allgemeine Informationen zu Änderungen bei Umsatz, Kosten, Preisen und Margen. Als Unternehmensnutzer sollten Sie möglicherweise einen Benachrichtigung einrichten, um zu erfahren, ob der Umsatz unter X% gesunken ist. Das könnte bedeuten, dass Sie die Preise senken sollten.
Im nächsten Abschnitt, der unten zu sehen ist, können Nutzer Trends im Zusammenhang mit Preisänderungen genauer untersuchen. Hier können Sie sich die genauen Listenpreise und die neuen Preise für bestimmte Produkte ansehen. Das kann hilfreich sein, um bestimmte Produkte zu identifizieren, zu denen Sie weitere Informationen benötigen.
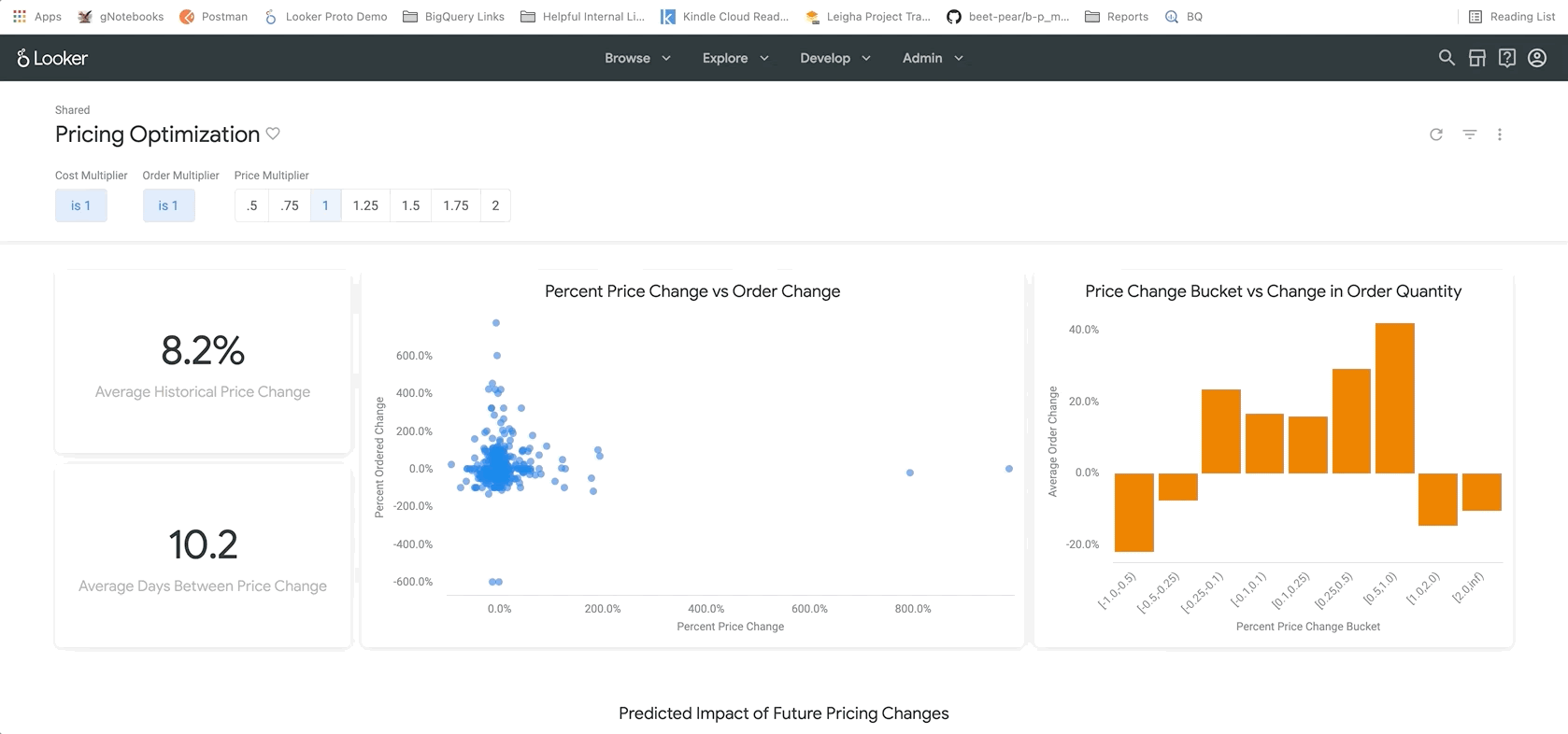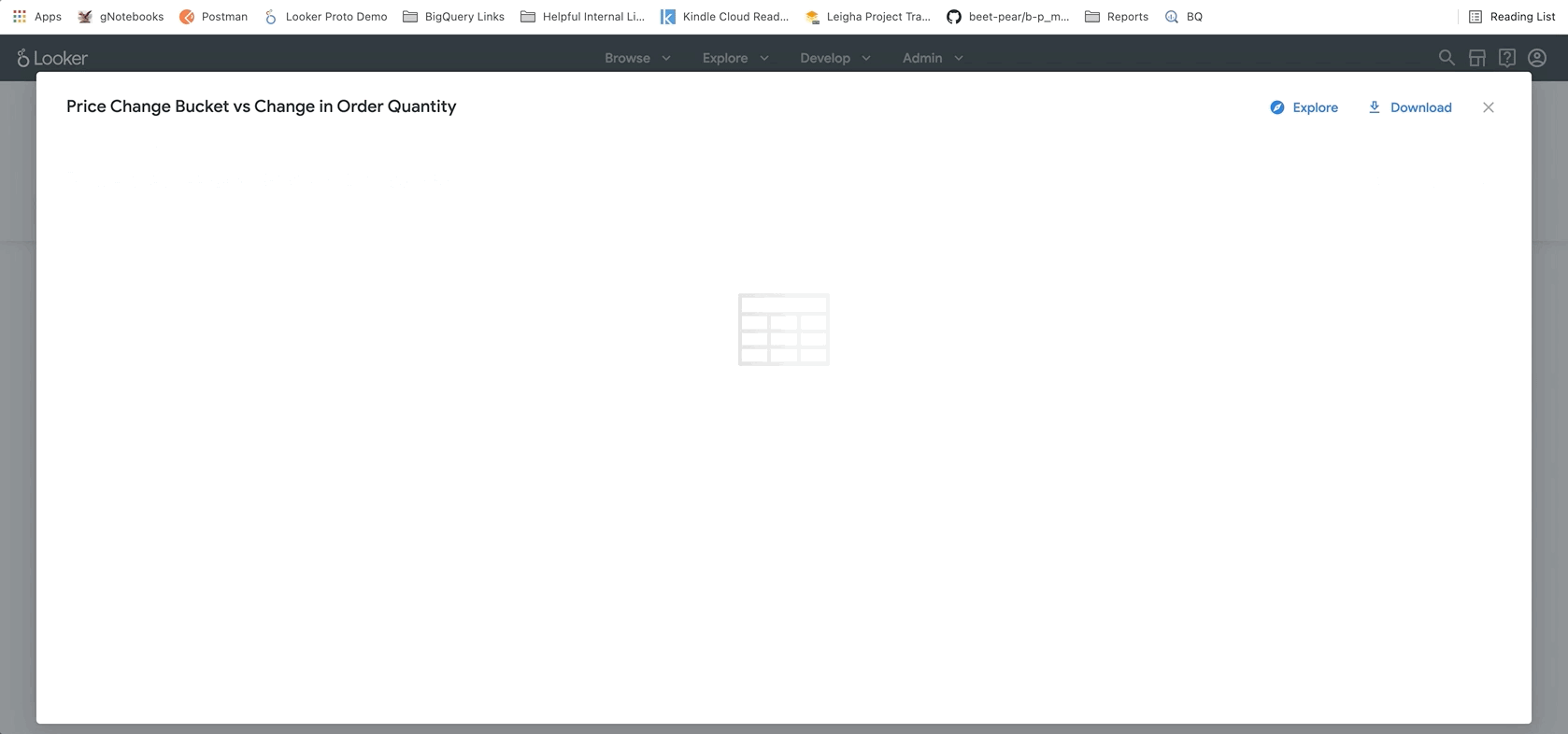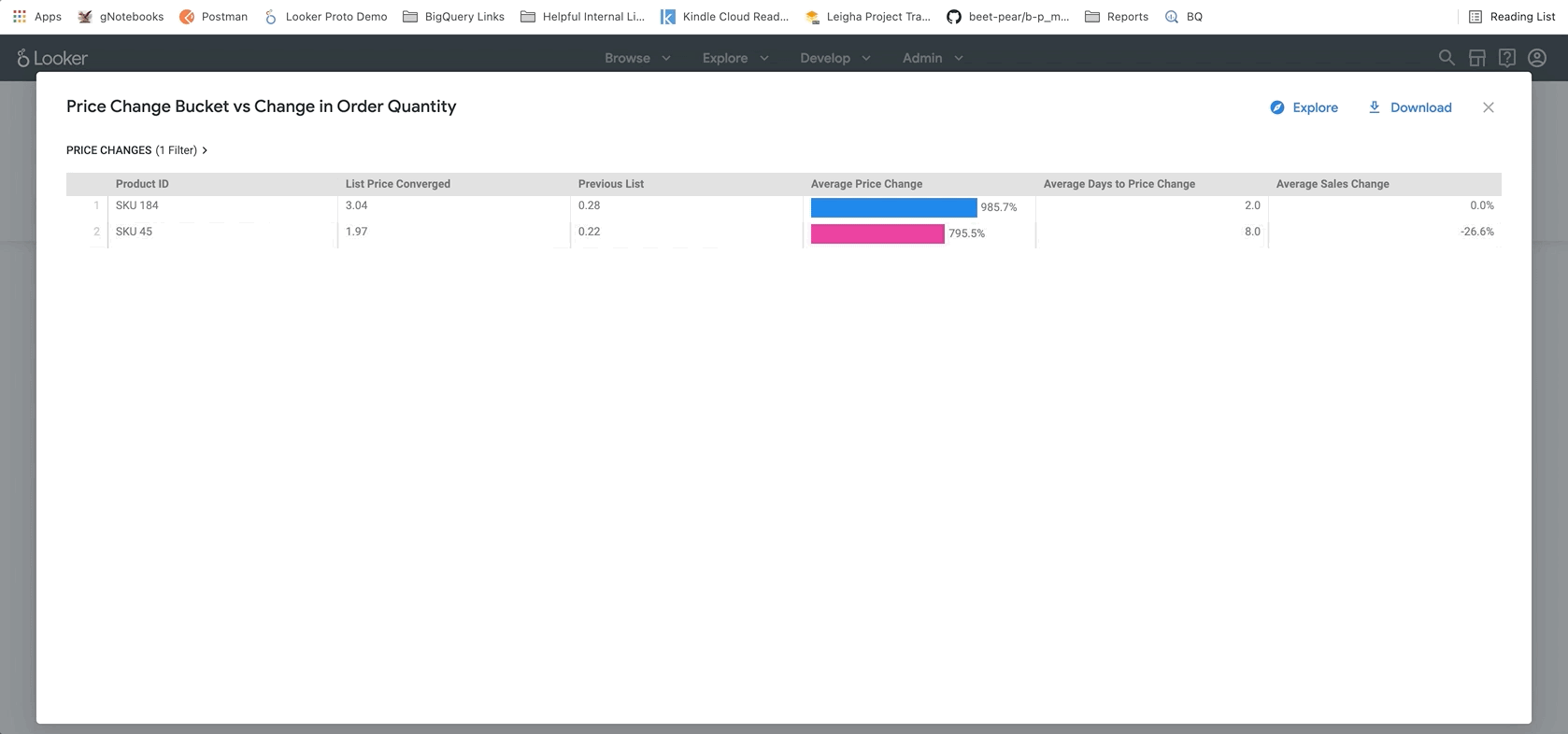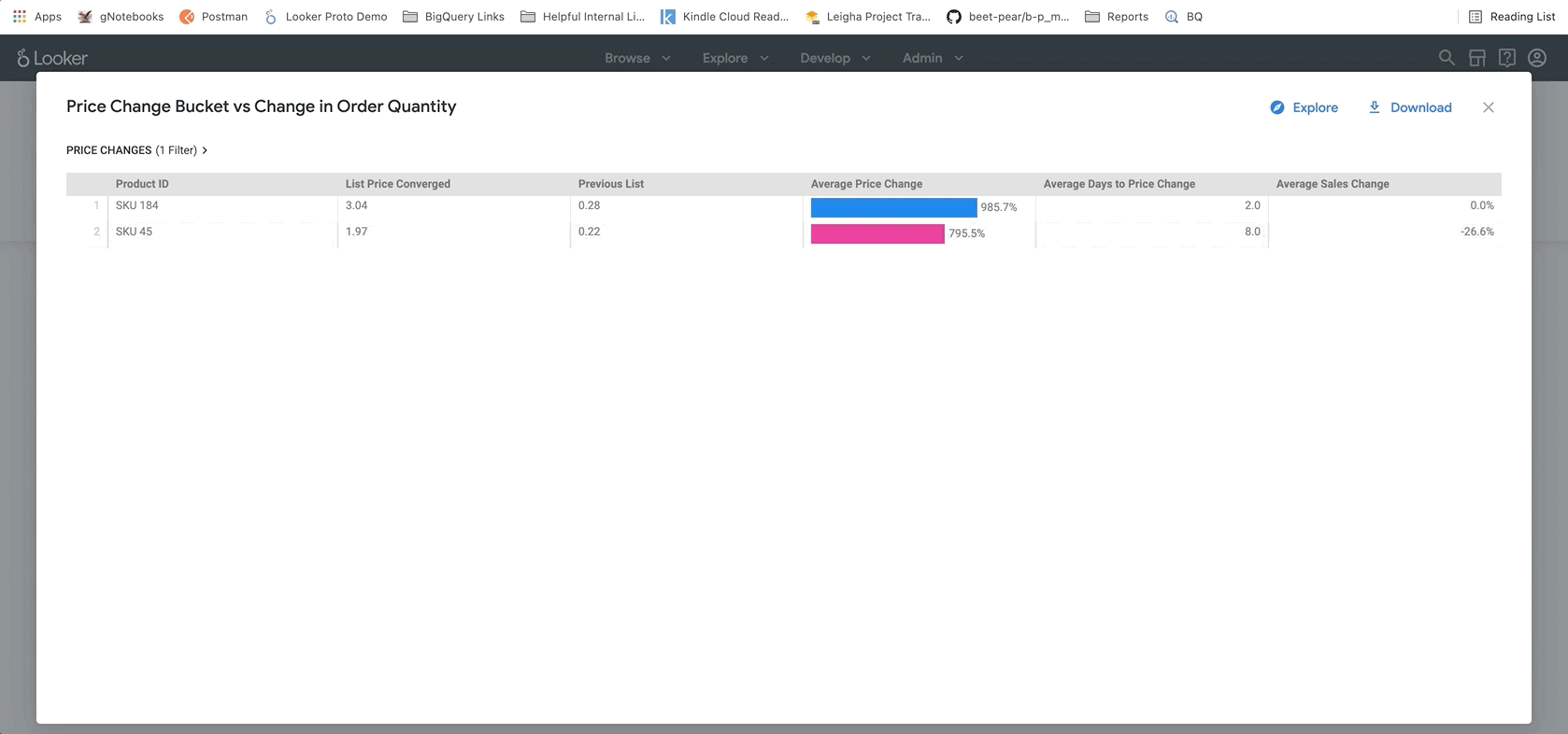
Ganz unten im Bericht finden Sie die Ergebnisse unseres BigQueryML-Modells. Mit den Filtern oben im Looker-Dashboard können Sie ganz einfach Parameter eingeben, um verschiedene Szenarien zu simulieren, wie oben beschrieben. Sie können beispielsweise sehen, was passieren würde, wenn das Bestellvolumen auf 75% des prognostizierten Werts sinkt und die Preise für alle Produkte um 25 % steigen, wie unten dargestellt.

Dies wird durch Parameter in LookML ermöglicht, die dann direkt in die hier aufgeführten Messwertberechnungen einbezogen werden. Mit dieser Art von Berichterstellung können Sie den optimalen Preis für alle Produkte ermitteln oder sich bestimmte Produkte genauer ansehen, um herauszufinden, wo Sie die Preise erhöhen oder senken sollten und wie sich das auf den Brutto- und Nettoumsatz auswirken würde.
14. An Ihre Preissysteme anpassen
In diesem Tutorial werden Beispieldatenquellen transformiert. Sie werden jedoch mit sehr ähnlichen Datenproblemen für die Preis-Assets konfrontiert sein, die auf Ihren verschiedenen Plattformen vorhanden sind. Für Preisgestaltungs-Assets sind unterschiedliche Exportformate (häufig XLS, Sheets, CSV, TXT, relationale Datenbanken, Geschäftsanwendungen) für Zusammenfassungs- und detaillierte Ergebnisse verfügbar, die jeweils mit Dataprep verbunden werden können. Wir empfehlen, dass Sie Ihre Anforderungen an die Transformation ähnlich wie in den obigen Beispielen beschreiben. Nachdem Ihre Spezifikationen geklärt sind und Sie die erforderlichen Transformationstypen ermittelt haben, können Sie sie mit Dataprep entwerfen.
- Erstellen Sie eine Kopie des Dataprep-Flows, den Sie anpassen möchten. Klicken Sie dazu rechts neben dem Flow auf das Dreipunkt-Menü und wählen Sie die Option „Duplizieren“ aus. Alternativ können Sie auch einen neuen Dataprep-Flow erstellen.
- Verbindung zu Ihrem eigenen Preis-Dataset herstellen Dateiformate wie Excel, CSV, Google Sheets und JSON werden von Dataprep nativ unterstützt. Mit Dataprep-Connectors können Sie auch eine Verbindung zu anderen Systemen herstellen.
- Ordnen Sie Ihre Daten-Assets den verschiedenen Transformationskategorien zu, die Sie identifiziert haben. Erstellen Sie für jede Kategorie ein Rezept. Lassen Sie sich von dem in diesem Designmuster bereitgestellten Ablauf inspirieren, um die Daten zu transformieren und eigene Rezepte zu schreiben. Wenn Sie nicht weiterkommen, können Sie im Chatdialog unten links auf dem Dataprep-Bildschirm um Hilfe bitten.
- Verbinden Sie das Rezept mit Ihrer BigQuery-Instanz. Sie müssen die Tabellen nicht manuell in BigQuery erstellen. Dataprep erledigt das automatisch für Sie. Wenn Sie die Ausgabe in Ihren Ablauf einfügen, empfehlen wir, ein manuelles Ziel auszuwählen und die Tabelle bei jeder Ausführung zu löschen. Testen Sie jedes Rezept einzeln, bis Sie die erwarteten Ergebnisse erzielen. Nach Abschluss der Tests wandeln Sie die Ausgabe in „An die Tabelle anhängen“ um, um zu vermeiden, dass die vorherigen Daten gelöscht werden.
- Optional können Sie den Ablauf so verknüpfen, dass er nach einem Zeitplan ausgeführt wird. Das ist nützlich, wenn Ihr Prozess kontinuierlich ausgeführt werden muss. Sie können einen Zeitplan definieren, um die Antwort je nach Bedarf täglich oder stündlich zu laden. Wenn Sie den Ablauf nach einem Zeitplan ausführen möchten, müssen Sie für jedes Schema eine Ausgabe für das Ziel „Zeitplan“ hinzufügen.
BigQuery ML-Modell ändern
In diesem Tutorial wird ein Beispiel für ein ARIMA-Modell bereitgestellt. Es gibt jedoch zusätzliche Parameter, die Sie bei der Entwicklung des Modells steuern können, um sicherzustellen, dass es am besten zu Ihren Daten passt. Weitere Informationen finden Sie in diesem Beispiel in unserer Dokumentation. Außerdem können Sie die BigQuery-Funktionen ML.ARIMA_EVALUATE, ML.ARIMA_COEFFICIENTS und ML.EXPLAIN_FORECAST verwenden, um weitere Details zu Ihrem Modell zu erhalten und Optimierungsentscheidungen zu treffen.
Looker-Berichte bearbeiten
Nachdem Sie den LookML-Code wie oben beschrieben in Ihr eigenes Projekt importiert haben, können Sie ihn direkt bearbeiten, um zusätzliche Felder hinzuzufügen, Berechnungen oder von Nutzern eingegebene Parameter zu ändern und die Visualisierungen in den Dashboards an Ihre geschäftlichen Anforderungen anzupassen. Weitere Informationen zur Entwicklung in LookML und zur Visualisierung von Daten in Looker
15. Glückwunsch
Sie kennen jetzt die wichtigsten Schritte zur Optimierung der Preise Ihrer Einzelhandelsprodukte.
Nächste Schritte
Weitere Referenzmuster für intelligente Analysen