
1. Introducción
Última actualización: 15/09/2021
Los datos necesarios para generar estadísticas y optimizar los precios son dispares por naturaleza (diferentes sistemas, diferentes realidades locales, etcétera), por lo que es fundamental desarrollar una tabla del CDM bien estructurada, estandarizada y limpia. Esto incluye atributos clave para la optimización de precios, como transacciones, productos, precios y clientes. En este documento, te explicamos los pasos que se describen a continuación y te proporcionamos una guía de inicio rápido para el análisis de precios que puedes extender y personalizar según tus necesidades. En el siguiente diagrama, se describen los pasos que se explican en este documento.

- Evalúa las fuentes de datos: Primero, debes obtener un inventario de las fuentes de datos que se usarán para crear el CDM. En este paso, también se usa Dataprep para explorar e identificar problemas en los datos de entrada. Por ejemplo, valores faltantes o que no coinciden, convenciones de nomenclatura incoherentes, duplicados, problemas de integridad de los datos, valores atípicos, etcétera
- Estandarizar los datos: A continuación, se corrigen los problemas identificados anteriormente para garantizar la exactitud, la integridad, la coherencia y la integridad de los datos. Este proceso puede incluir varias transformaciones en Dataprep, como el formato de fechas, la estandarización de valores, la conversión de unidades, el filtrado de campos y valores innecesarios, y la división, la unión o la eliminación de duplicados de los datos de origen.
- Unificación en una sola estructura: La siguiente etapa de la canalización une cada fuente de datos en una sola tabla amplia en BigQuery que contiene todos los atributos en el nivel de granularidad más detallado. Esta estructura desnormalizada permite realizar consultas analíticas eficientes que no requieren uniones.
- Proporcionar estadísticas y AA/IA: Una vez que los datos están limpios y formateados para el análisis, los analistas pueden explorar los datos históricos para comprender el impacto de los cambios de precios anteriores. Además, se puede usar BigQuery ML para crear modelos predictivos que estimen las ventas futuras. El resultado de estos modelos se puede incorporar a los paneles de Looker para crear "situaciones hipotéticas" en las que los usuarios empresariales pueden analizar cómo podrían ser las ventas con ciertos cambios de precios.
En el siguiente diagrama, se muestran los componentes de Google Cloud que se usan para compilar la canalización de análisis de optimización de precios.
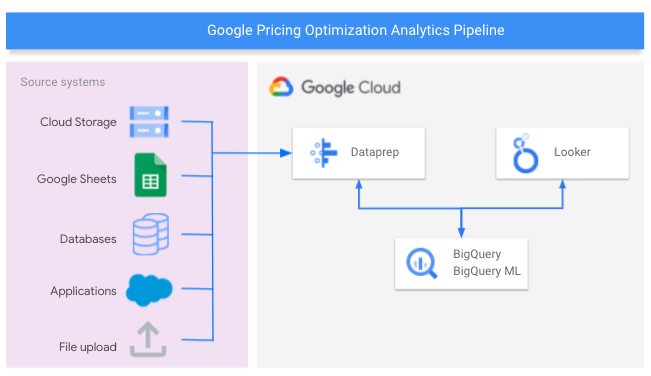
Qué compilarás
Aquí te mostraremos cómo diseñar un almacén de datos de optimización de precios, automatizar la preparación de datos con el tiempo, usar el aprendizaje automático para predecir el impacto de los cambios en los precios de los productos y desarrollar informes para proporcionar estadísticas prácticas a tu equipo.
Qué aprenderás
- Cómo conectar Dataprep a fuentes de datos para el análisis de precios, que se pueden almacenar en bases de datos relacionales, archivos planos, Hojas de cálculo de Google y otras aplicaciones compatibles
- Cómo crear un flujo de Dataprep para crear una tabla del CDM en tu almacén de datos de BigQuery
- Cómo usar BigQuery ML para predecir ingresos futuros
- Cómo generar informes en Looker para analizar las tendencias históricas de precios y ventas, y comprender el impacto de los cambios futuros en los precios
Requisitos
- Un proyecto de Google Cloud con facturación habilitada. Descubre cómo confirmar que tienes habilitada la facturación en un proyecto.
- BigQuery debe estar habilitado en tu proyecto. Se habilita automáticamente en proyectos nuevos. De lo contrario, habilítalo en un proyecto existente. También puedes obtener más información para comenzar a usar BigQuery desde la consola de Cloud aquí.
- Dataprep también debe estar habilitado en tu proyecto. Dataprep está habilitado en la consola de Google, en el menú de navegación de la izquierda, en la sección Big Data. Sigue los pasos de registro para activarla.
- Para configurar tus propios paneles de Looker, debes tener acceso de desarrollador en una instancia de Looker. Para solicitar una prueba, comunícate con nuestro equipo aquí o usa nuestro panel público para explorar los resultados de la canalización de datos en nuestros datos de muestra.
- Es útil tener experiencia con el lenguaje de consulta estructurado (SQL) y conocimientos básicos de lo siguiente: Dataprep by Trifacta, BigQuery y Looker.
2. Crea el CDM en BigQuery
En esta sección, crearás el modelo de datos común (CDM), que proporciona una vista consolidada de la información que necesitas para analizar y sugerir cambios en los precios.
- Abre la consola de BigQuery.
- Selecciona el proyecto que deseas usar para probar este patrón de referencia.
- Usa un conjunto de datos existente o crea un conjunto de datos de BigQuery. Asigna el nombre
Pricing_CDMal conjunto de datos. - Crea la tabla:
create table `CDM_Pricing`
(
Fiscal_Date DATETIME,
Product_ID STRING,
Client_ID INT64,
Customer_Hierarchy STRING,
Division STRING,
Market STRING,
Channel STRING,
Customer_code INT64,
Customer_Long_Description STRING,
Key_Account_Manager INT64,
Key_Account_Manager_Description STRING,
Structure STRING,
Invoiced_quantity_in_Pieces FLOAT64,
Gross_Sales FLOAT64,
Trade_Budget_Costs FLOAT64,
Cash_Discounts_and_other_Sales_Deductions INT64,
Net_Sales FLOAT64,
Variable_Production_Costs_STD FLOAT64,
Fixed_Production_Costs_STD FLOAT64,
Other_Cost_of_Sales INT64,
Standard_Gross_Margin FLOAT64,
Transportation_STD FLOAT64,
Warehouse_STD FLOAT64,
Gross_Margin_After_Logistics FLOAT64,
List_Price_Converged FLOAT64
);
3. Evalúa las fuentes de datos
En este instructivo, usarás fuentes de datos de muestra que se almacenan en Hojas de cálculo de Google y BigQuery.
- La hoja de cálculo de Google transactions, que contiene una fila para cada transacción. Contiene detalles como la cantidad de cada producto vendido, las ventas brutas totales y los costos asociados.
- La hoja de cálculo de Google de precios de productos que contiene el precio de cada producto para un cliente determinado cada mes.
- Tabla company_descriptions de BigQuery que contiene información de clientes individuales.
Esta tabla company_descriptions de BigQuery se puede crear con la siguiente instrucción:
create table `Company_Descriptions`
(
Customer_ID INT64,
Customer_Long_Description STRING
);
insert into `Company_Descriptions` values (15458, 'ENELTEN');
insert into `Company_Descriptions` values (16080, 'NEW DEVICES CORP.');
insert into `Company_Descriptions` values (19913, 'ENELTENGAS');
insert into `Company_Descriptions` values (30108, 'CARTOON NT');
insert into `Company_Descriptions` values (32492, 'Thomas Ed Automobiles');
4. Crea el flujo
En este paso, importarás un flujo de Dataprep de muestra que usarás para transformar y unificar los conjuntos de datos de ejemplo mencionados en la sección anterior. Un flujo representa una canalización o un objeto que reúne conjuntos de datos y recetas, que se usan para transformarlos y unirlos.
- Descarga el paquete de flujo del patrón de optimización de precios desde GitHub, pero no lo descomprimas. Este archivo contiene el flujo del patrón de diseño de optimización de precios que se usa para transformar los datos de muestra.
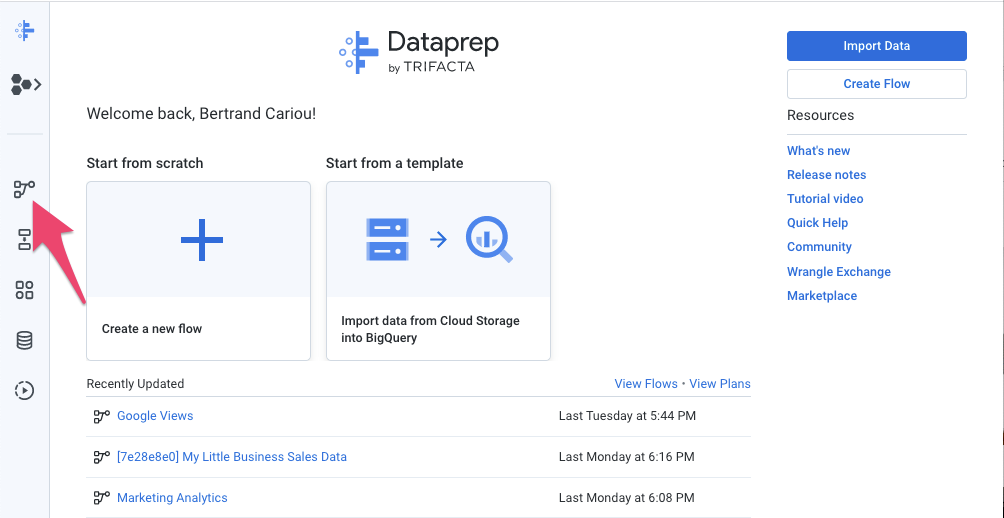
- En Dataprep, haz clic en el ícono de flujos en la barra de navegación izquierda. Luego, en la vista Flujos, selecciona Importar en el menú contextual. Después de importar el flujo, puedes seleccionarlo para verlo y editarlo.
- En el lado izquierdo del flujo, el precio del producto y cada una de las tres hojas de cálculo de Google de transacciones deben estar conectados como conjuntos de datos. Para ello, haz clic con el botón derecho en los objetos del conjunto de datos de Hojas de cálculo de Google y selecciona Reemplazar. Luego, haz clic en el vínculo Import Datasets. Haz clic en el lápiz "Editar ruta", como se muestra en el siguiente diagrama.
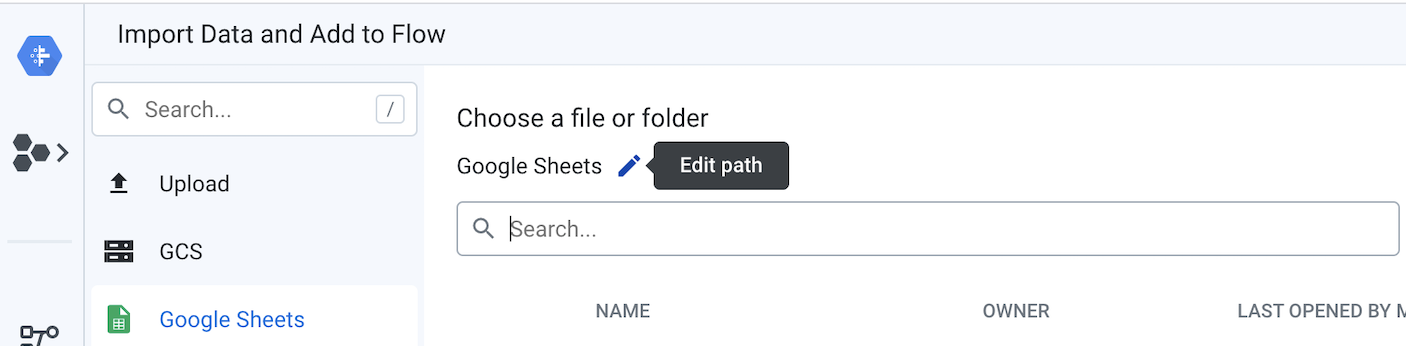
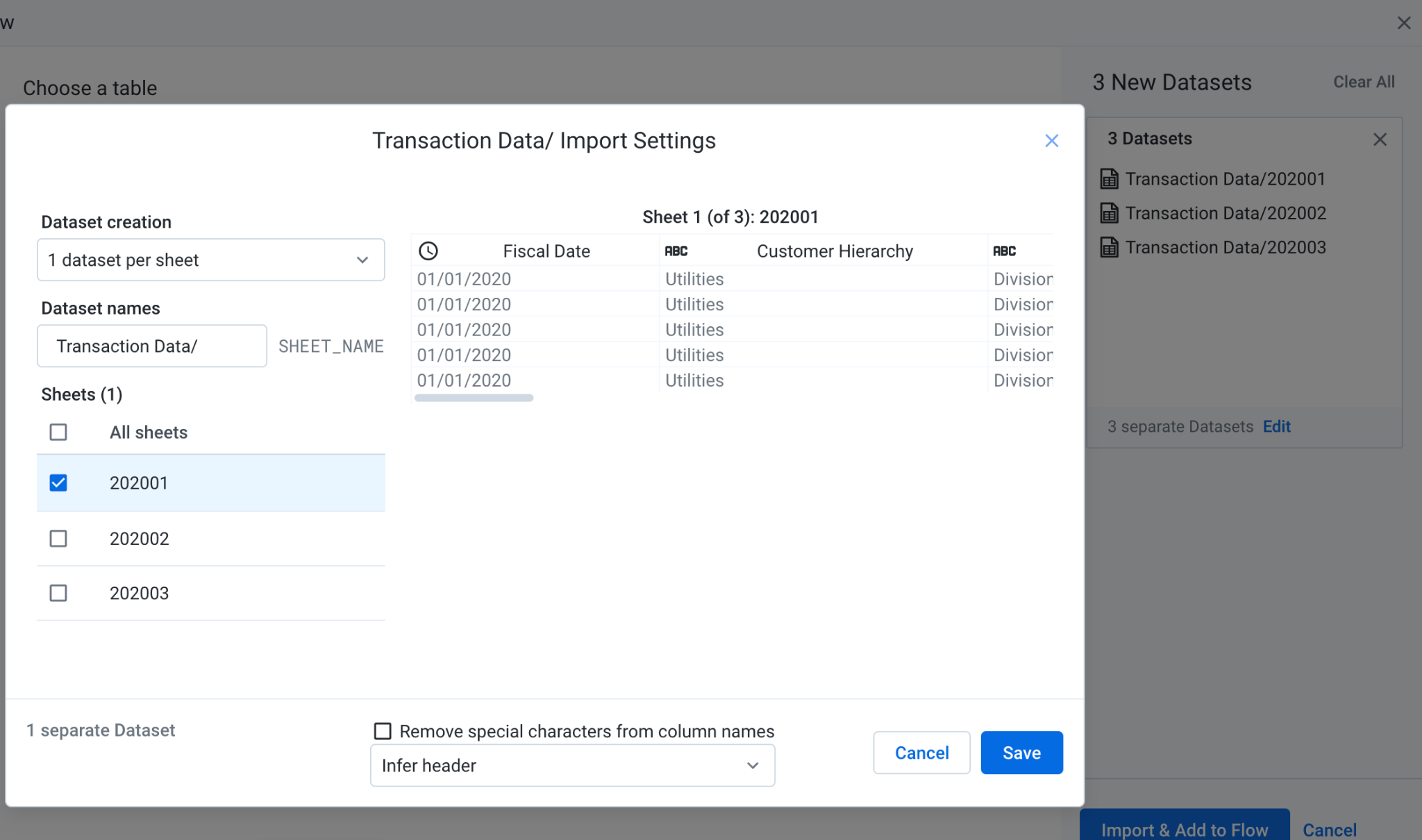
Reemplaza el valor actual por el vínculo que apunta a las hojas de cálculo de transacciones y precios de productos de Google .
Cuando las Hojas de cálculo de Google contienen varias pestañas, puedes seleccionar la que quieras usar en el menú. Haz clic en Editar, selecciona las pestañas que deseas usar como fuente de datos, haz clic en Guardar y, luego, en Import & Add to Flow. Cuando vuelvas al modal, haz clic en Reemplazar. En este flujo, cada hoja se representa como su propio conjunto de datos para demostrar la unión de fuentes dispares en una receta posterior.
- Define las tablas de salida de BigQuery:
En este paso, asociarás la ubicación de la tabla de salida CDM_Pricing de BigQuery para que se cargue cada vez que ejecutes el trabajo de Dataprep.
En la vista de flujos, haz clic en el ícono de salida de la asignación de esquema y, en el panel de detalles, haz clic en la pestaña Destinos. Desde allí, edita el resultado de Manual Destinations que se usa para las pruebas y el resultado de Scheduled Destinations que se usa cuando deseas automatizar todo tu flujo. Sigue estas instrucciones para hacerlo:
- Edita los "Destinos manuales". En el panel Detalles, en la sección Destinos manuales, haz clic en el botón Editar. En la página Configuración de publicación, en Acciones de publicación, si ya existe una acción de publicación, edítala. De lo contrario, haz clic en el botón Agregar acción. Desde allí, navega por los conjuntos de datos de BigQuery hasta el conjunto de datos
Pricing_CDMque creaste en un paso anterior y selecciona la tablaCDM_Pricing. Confirma que la opción Agregar a esta tabla en cada ejecución esté marcada y, luego, haz clic en Agregar y en Guardar configuración. - Cómo editar los "Destinos programados"
En el panel Detalles, en la sección Destinos programados, haz clic en Editar.
La configuración se hereda de los destinos manuales, por lo que no es necesario que realices ningún cambio. Haz clic en Save Settings.
5. Estandariza los datos
El flujo proporcionado une, da formato y limpia los datos de las transacciones, y, luego, une el resultado con las descripciones de la empresa y los datos de precios agregados para generar informes. Aquí, verás los componentes del flujo, que se pueden observar en la siguiente imagen.

6. Explora la receta de datos transaccionales
Primero, explorarás lo que sucede dentro de la receta de datos transaccionales, que se usa para preparar los datos de transacciones. Haz clic en el objeto Transaction Data en la vista de flujo y, en el panel Details, haz clic en el botón Edit Recipe.
Se abrirá la página de transformaciones con la receta presentada en el panel de detalles. La receta contiene todos los pasos de transformación que se aplican a los datos. Puedes navegar dentro de la receta haciendo clic entre cada uno de los pasos para ver el estado de los datos en esa posición particular de la receta.
También puedes hacer clic en el menú Más de cada paso de la receta y seleccionar Ir al paso seleccionado o Editarlo para explorar cómo funciona la transformación.
- Unión de transacciones: El primer paso en la receta de datos transaccionales es unir las transacciones almacenadas en diferentes hojas que representan cada mes.
- Estandariza las descripciones de los clientes: El siguiente paso de la receta estandariza las descripciones de los clientes. Esto significa que los nombres de los clientes pueden ser similares con pequeños cambios, y queremos normalizarlos como un solo nombre. La receta muestra dos enfoques posibles. Primero, aprovecha el algoritmo de estandarización, que se puede configurar con diferentes opciones de estandarización, como "Cadenas similares", en la que los valores con caracteres en común se agrupan, o "Pronunciación", en la que los valores que suenan igual se agrupan. Como alternativa, puedes buscar la descripción de la empresa en la tabla de BigQuery a la que se hace referencia más arriba con el ID de la empresa.
Puedes navegar más por la receta para descubrir las otras técnicas que se aplican para limpiar y formatear los datos: borrar filas, formatear según patrones, enriquecer los datos con búsquedas, controlar los valores faltantes o reemplazar caracteres no deseados.
7. Explora la receta de datos de precios de productos
A continuación, puedes explorar lo que sucede en la receta de datos de precios de productos, que une los datos de transacciones preparados con los datos de precios agregados.
Haz clic en el PATRÓN DE DISEÑO DE OPTIMIZACIÓN DE PRECIOS en la parte superior de la página para cerrar la página de Transformer y volver a la vista de flujo. Desde allí, haz clic en el objeto Product Pricing Data y edita la receta.
- Desapilar las columnas de precios mensuales: Haz clic en la receta entre los pasos 2 y 3 para ver cómo se ven los datos antes del paso Unpivot. Notarás que los datos contienen el valor de la transacción en una columna distinta para cada mes: Ene Feb Mar. Este no es un formato conveniente para aplicar el cálculo de agregación (es decir, la suma o el promedio de la transacción) en SQL. Los datos deben despivotarse para que cada columna se convierta en una fila en la tabla de BigQuery. La receta aprovecha la función unpivot para transformar las 3 columnas en una fila para cada mes, de modo que sea más fácil aplicar cálculos de grupo más adelante.
- Calcula el valor promedio de la transacción por cliente, producto y fecha: Queremos calcular el valor promedio de la transacción para cada cliente, producto y fecha. Podemos usar la función Aggregate y generar una tabla nueva (opción "Group by as a new table"). En ese caso, los datos se agregan a nivel del grupo y perdemos los detalles de cada transacción individual. También podemos decidir conservar los detalles y los valores agregados en el mismo conjunto de datos (opción "Agrupar por como columnas nuevas"), lo que resulta muy conveniente para aplicar una proporción (es decir, el porcentaje de contribución de la categoría de producto a los ingresos generales). Para probar este comportamiento, edita el paso 7 de la receta y selecciona la opción "Agrupar por como una tabla nueva" o "Agrupar por como columnas nuevas" para ver las diferencias.
- Fecha de unión de precios: Por último, se usa una unión para combinar varios conjuntos de datos en uno más grande, lo que agrega columnas al conjunto de datos inicial. En este paso, los datos de precios se unen con el resultado de la receta de datos transaccionales según "Datos de precios.Código de producto" = "Datos de transacción.SKU" y "Datos de precios.Fecha de precio" = "Datos de transacción.Fecha fiscal".
Si deseas obtener más información sobre las transformaciones que puedes aplicar con Dataprep, consulta la hoja de referencia de Trifacta sobre la manipulación de datos.
8. Explora la receta de asignación de esquemas
La última receta, Schema Mapping, garantiza que la tabla del CDM resultante coincida con el esquema de la tabla de salida de BigQuery existente. Aquí, la función Rapid Target se usa para reformatear la estructura de datos de modo que coincida con la tabla de BigQuery a través de la correlación aproximada para comparar ambos esquemas y aplicar cambios automáticos.
9. Unifica en una sola estructura
Ahora que se configuraron las fuentes y los destinos, y se exploraron los pasos de los flujos, puedes ejecutar el flujo para transformar y cargar la tabla del CDM en BigQuery.
- Ejecuta la salida de Schema Mapping: En la vista de flujo, selecciona el objeto de salida de Schema Mapping y haz clic en el botón "Ejecutar" en el panel Detalles. Selecciona el entorno de ejecución "Trifacta Photon" y desmarca la opción Ignore Recipe Errors. Luego, haz clic en el botón Ejecutar. Si existe la tabla de BigQuery especificada, Dataprep agregará filas nuevas. De lo contrario, creará una tabla nueva.
- Consulta el estado del trabajo: Dataprep abre automáticamente la página Ejecutar trabajo para que puedas supervisar la ejecución del trabajo. El proceso de carga de la tabla de BigQuery debería tardar unos minutos. Cuando se complete el trabajo, el resultado del CDM de precios se cargará en BigQuery en un formato limpio, estructurado y normalizado listo para el análisis.
10. Proporciona análisis y AA/IA
Requisitos previos de Analytics
Para ejecutar algunas estadísticas y un modelo predictivo con resultados interesantes, creamos un conjunto de datos más grande y pertinente para descubrir estadísticas específicas. Debes subir estos datos a tu conjunto de datos de BigQuery antes de continuar con esta guía.
- Descarga el conjunto de datos grande de este repositorio de GitHub.
- En la consola de Google para BigQuery, navega a tu proyecto y al conjunto de datos CDM_Pricing.
- Haz clic en el menú y abre el conjunto de datos. Crearemos la tabla cargando los datos desde un archivo local.
Haz clic en el botón + Crear tabla y define estos parámetros:
- Crea una tabla desde la carga y selecciona el archivo CDM_Pricing_Large_Table.csv.
- Detección automática de esquema, marca Esquema y parámetros de entrada
- Opciones avanzadas, Preferencia de escritura, Reemplazar tabla

- Haz clic en Crear tabla.
Después de crear la tabla y subir los datos, en la consola de Google para BigQuery, deberías ver los detalles de la tabla nueva, como se muestra a continuación. Con los datos de precios en BigQuery, podemos hacer preguntas más completas para analizar tus datos de precios con mayor profundidad.

11. Consulta el efecto de los cambios de precios
Un ejemplo de algo que tal vez quieras analizar es un cambio en el comportamiento de los pedidos después de haber cambiado el precio de un artículo.
- Primero, crearás una tabla temporal que tenga una línea cada vez que cambie el precio de un producto, con información sobre el precio de ese producto en particular, como la cantidad de artículos que se pidieron con cada precio y las ventas netas totales asociadas a ese precio.
create temp table price_changes as (
select
product_id,
list_price_converged,
total_ordered_pieces,
total_net_sales,
first_price_date,
lag(list_price_converged) over(partition by product_id order by first_price_date asc) as previous_list,
lag(total_ordered_pieces) over(partition by product_id order by first_price_date asc) as previous_total_ordered_pieces,
lag(total_net_sales) over(partition by product_id order by first_price_date asc) as previous_total_net_sales,
lag(first_price_date) over(partition by product_id order by first_price_date asc) as previous_first_price_date
from (
select
product_id,list_price_converged,sum(invoiced_quantity_in_pieces) as total_ordered_pieces, sum(net_sales) as total_net_sales, min(fiscal_date) as first_price_date
from `{{my_project}}.{{my_dataset}}.CDM_Pricing` AS cdm_pricing
group by 1,2
order by 1, 2 asc
)
);
select * from price_changes where previous_list is not null order by product_id, first_price_date desc

- A continuación, con la tabla temporal ya creada, puedes calcular el cambio de precio promedio en todos los SKU:
select avg((previous_list-list_price_converged)/nullif(previous_list,0))*100 as average_price_change from price_changes;
- Por último, puedes analizar lo que sucede después de que se cambia un precio observando la relación entre cada cambio de precio y la cantidad total de artículos que se pidieron:
select
(total_ordered_pieces-previous_total_ordered_pieces)/nullif(previous_total_ordered_pieces,0)
as
price_changes_percent_ordered_change,
(list_price_converged-previous_list)/nullif(previous_list,0)
as
price_changes_percent_price_change
from price_changes
12. Crea un modelo de previsión de series temporales
Luego, con las capacidades integradas de aprendizaje automático de BigQuery, puedes compilar un modelo de previsión de series temporales ARIMA para predecir la cantidad de cada artículo que se venderá.
- Primero, crea un modelo ARIMA_PLUS.
create or replace `{{my_project}}.{{my_dataset}}.bqml_arima`
options
(model_type = 'ARIMA_PLUS',
time_series_timestamp_col = 'fiscal_date',
time_series_data_col = 'total_quantity',
time_series_id_col = 'product_id',
auto_arima = TRUE,
data_frequency = 'AUTO_FREQUENCY',
decompose_time_series = TRUE
) as
select
fiscal_date,
product_id,
sum(invoiced_quantity_in_pieces) as total_quantity
from
`{{my_project}}.{{my_dataset}}.CDM_Pricing`
group by 1,2;
- A continuación, usa la función ML.FORECAST para predecir las ventas futuras de cada producto:
select
*
from
ML.FORECAST(model testing.bqml_arima,
struct(30 as horizon, 0.8 as confidence_level));
- Con estas predicciones disponibles, puedes intentar comprender qué podría suceder si aumentas los precios. Por ejemplo, si aumentas el precio de todos los productos en un 15%, podrías calcular los ingresos totales estimados para el próximo mes con una consulta como esta:
select
sum(forecast_value * list_price) as total_revenue
from ml.forecast(mode testing.bqml_arima,
struct(30 as horizon, 0.8 as confidence_level)) forecasts
left join (select product_id,
array_agg(list_price_converged
order by fiscal_date desc limit 1)[offset(0)] as list_price
from `leigha-bq-dev.retail.cdm_pricing` group by 1) recent_prices
using (product_id);
13. Crea un informe
Ahora que tus datos de precios desnormalizados están centralizados en BigQuery y sabes cómo ejecutar consultas significativas en estos datos, es momento de crear un informe para permitir que los usuarios empresariales exploren esta información y actúen en función de ella.
Si ya tienes una instancia de Looker, puedes usar el LookML en este repositorio de GitHub para comenzar a analizar los datos de precios de este patrón. Simplemente crea un proyecto nuevo de Looker, agrega el LookML y reemplaza los nombres de la conexión y la tabla en cada uno de los archivos de vista para que coincidan con tu configuración de BigQuery.
En este modelo, encontrarás la tabla derivada ( en este archivo de vista) que mostramos anteriormente para examinar los cambios de precios:
view: price_changes {
derived_table: {
sql: select
product_id,
list_price_converged,
total_ordered_pieces,
total_net_sales,
first_price_date,
lag(list_price_converged) over(partition by product_id order by first_price_date asc) as previous_list,
lag(total_ordered_pieces) over(partition by product_id order by first_price_date asc) as previous_total_ordered_pieces,
lag(total_net_sales) over(partition by product_id order by first_price_date asc) as previous_total_net_sales,
lag(first_price_date) over(partition by product_id order by first_price_date asc) as previous_first_price_date
from (
select
product_id,list_price_converged,sum(invoiced_quantity_in_pieces) as total_ordered_pieces, sum(net_sales) as total_net_sales, min(fiscal_date) as first_price_date
from ${cdm_pricing.SQL_TABLE_NAME} AS cdm_pricing
group by 1,2
order by 1, 2 asc
)
;;
}
...
}
Además del modelo ARIMA de BigQuery ML que mostramos anteriormente, para predecir las ventas futuras ( en este archivo de vista)
view: arima_model {
derived_table: {
persist_for: "24 hours"
sql_create:
create or replace model ${sql_table_name}
options
(model_type = 'arima_plus',
time_series_timestamp_col = 'fiscal_date',
time_series_data_col = 'total_quantity',
time_series_id_col = 'product_id',
auto_arima = true,
data_frequency = 'auto_frequency',
decompose_time_series = true
) as
select
fiscal_date,
product_id,
sum(invoiced_quantity_in_pieces) as total_quantity
from
${cdm_pricing.sql_table_name}
group by 1,2 ;;
}
}
...
}
El LookML también contiene un panel de ejemplo. Puedes acceder a una versión de demostración del panel aquí. En la primera parte del panel, se brinda a los usuarios información general sobre los cambios en las ventas, los costos, los precios y los márgenes. Como usuario empresarial, es posible que desees crear una alerta para saber si las ventas disminuyeron por debajo de un determinado porcentaje, ya que esto podría significar que debes bajar los precios.
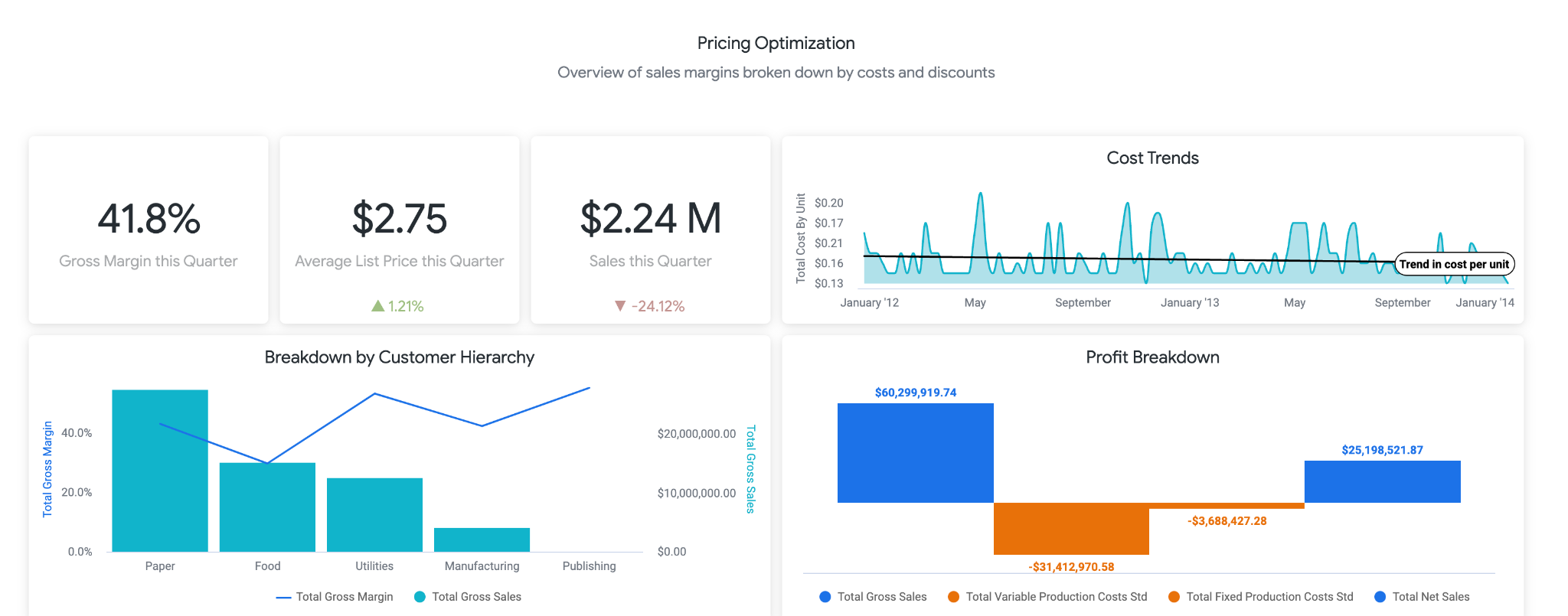
En la siguiente sección, que se muestra a continuación, los usuarios pueden analizar las tendencias relacionadas con los cambios de precios. Aquí, puedes desglosar productos específicos para ver el precio de lista exacto y los precios a los que se cambiaron, lo que puede ser útil para identificar productos específicos sobre los que deseas investigar más.

Por último, en la parte inferior del informe, se encuentran los resultados de nuestro modelo de BigQueryML. Con los filtros que se encuentran en la parte superior del panel de Looker, puedes ingresar parámetros fácilmente para simular diferentes situaciones, como se describió anteriormente. Por ejemplo, ver qué sucedería si el volumen de pedidos se redujera al 75% del valor previsto y los precios de todos los productos aumentaran en un 25%, como se muestra a continuación

Esto se basa en los parámetros de LookML, que luego se incorporan directamente en los cálculos de las medidas que se encuentran aquí. Con este tipo de informes, puedes encontrar los precios óptimos para todos los productos o analizar productos específicos para determinar dónde debes aumentar o reducir los precios, y cuál sería el resultado en los ingresos brutos y netos.
14. Adaptarse a tus sistemas de precios
Si bien este instructivo transforma fuentes de datos de muestra, te enfrentarás a desafíos de datos muy similares para los recursos de precios que se encuentran en tus diversas plataformas. Los recursos de precios tienen diferentes formatos de exportación (a menudo, xls, hojas, csv, txt, bases de datos relacionales, aplicaciones comerciales) para los resultados resumidos y detallados, y cada uno de ellos se puede conectar a Dataprep. Te recomendamos que comiences por describir tus requisitos de transformación de manera similar a los ejemplos proporcionados anteriormente. Una vez que se aclaren tus especificaciones y hayas identificado los tipos de transformaciones necesarias, puedes diseñarlas con Dataprep.
- Haz una copia del flujo de Dataprep (haz clic en el botón **"…"** "más" a la derecha del flujo y selecciona la opción Duplicar) que personalizarás o, simplemente, comienza desde cero con un nuevo flujo de Dataprep.
- Conéctate a tu propio conjunto de datos de precios. Dataprep admite de forma nativa formatos de archivo como Excel, CSV, Hojas de cálculo de Google y JSON. También puedes conectarte a otros sistemas con los conectores de Dataprep.
- Envía tus activos de datos a las distintas categorías de transformación que identificaste. Crea una receta para cada categoría. Inspírate en el flujo que se proporciona en este patrón de diseño para transformar los datos y escribir tus propias recetas. Si te quedas atascado, no te preocupes, pide ayuda en el diálogo de chat que se encuentra en la parte inferior izquierda de la pantalla de Dataprep.
- Conecta tu receta a tu instancia de BigQuery. No tienes que preocuparte por crear las tablas de forma manual en BigQuery, ya que Dataprep se encargará de hacerlo automáticamente. Te sugerimos que, cuando agregues el resultado a tu flujo, selecciones un destino manual y descartes la tabla en cada ejecución. Prueba cada receta de forma individual hasta que obtengas los resultados esperados. Una vez que termines las pruebas, convertirás el resultado en Append to the table en cada ejecución para evitar borrar los datos anteriores.
- De manera opcional, puedes asociar el flujo para que se ejecute según una programación. Esto es útil si tu proceso debe ejecutarse de forma continua. Podrías definir un programa para cargar la respuesta todos los días o cada hora según la actualización que necesites. Si decides ejecutar el flujo de forma programada, deberás agregar un destino de salida de programación en el flujo para cada receta.
Modifica el modelo de aprendizaje automático de BigQuery
En este instructivo, se proporciona un ejemplo de modelo ARIMA. Sin embargo, hay parámetros adicionales que puedes controlar cuando desarrollas el modelo para asegurarte de que se ajuste mejor a tus datos. Puedes ver más detalles en el ejemplo de nuestra documentación aquí. Además, también puedes usar las funciones de BigQuery ML.ARIMA_EVALUATE, ML.ARIMA_COEFFICIENTS y ML.EXPLAIN_FORECAST para obtener más detalles sobre tu modelo y tomar decisiones de optimización.
Editar informes de Looker
Después de importar el código LookML a tu propio proyecto como se describió anteriormente, puedes realizar ediciones directas para agregar campos adicionales, modificar los cálculos o los parámetros ingresados por el usuario, y cambiar las visualizaciones en los paneles para que se adapten a las necesidades de tu empresa. Puedes encontrar detalles sobre el desarrollo en LookML aquí y sobre la visualización de datos en Looker aquí.
15. Felicitaciones
Ahora conoces los pasos clave necesarios para optimizar los precios de tus productos minoristas.
¿Qué sigue?
Explora otros patrones de referencia de estadísticas inteligentes
Lecturas adicionales
- Lee el blog aquí
- Obtén más información sobre Dataprep aquí
- Obtén más información sobre el aprendizaje automático en BigQuery aquí
- Obtén más información sobre Looker aquí.