
1. はじめに
最終更新日: 2021 年 9 月 15 日
価格設定の分析情報と最適化に必要なデータは、性質上、異種(異なるシステム、異なる地域の現実など)であるため、構造化され、標準化され、クリーンな CDM テーブルを開発することが重要です。これには、トランザクション、商品、価格、顧客など、価格の最適化に重要な属性が含まれます。このドキュメントでは、以下の手順について説明します。この手順に沿って、独自のニーズに合わせて拡張およびカスタマイズできる価格分析のクイック スタートをすばやく開始できます。次の図は、このドキュメントで説明する手順の概要を示しています。

- データソースを評価する: まず、CDM の作成に使用するデータソースのインベントリを取得する必要があります。このステップでは、Dataprep を使用して、入力データから問題を探索して特定します。たとえば、欠損値や不一致の値、命名規則の不整合、重複、データの完全性の問題、外れ値などです。
- データを標準化する: 次に、以前に特定された問題を修正して、データの精度、完全性、整合性、完全性を確保します。このプロセスには、日付形式の設定、値の標準化、単位の変換、不要なフィールドと値のフィルタリング、ソースデータの分割、結合、重複除去など、Dataprep のさまざまな変換が含まれる場合があります。
- 1 つの構造に統合する: パイプラインの次のステージでは、各データソースが BigQuery の単一のワイド テーブルに結合されます。このテーブルには、最も細かい粒度ですべての属性が含まれています。この非正規化構造により、結合を必要としない効率的な分析クエリが可能になります。
- アナリティクスと ML/AI の提供: データがクリーンアップされ、分析用にフォーマットされたら、アナリストは過去のデータを調べて、過去の価格変更の影響を把握できます。また、BigQuery ML を利用して、将来の売上を推定する予測モデルを作成できます。これらのモデルの出力は Looker のダッシュボードに組み込まれ、ビジネス ユーザーが特定の価格変更によって売上がどのようになるかを分析できる「what-if シナリオ」を作成できます。
次の図は、価格最適化分析パイプラインの構築に使用される Google Cloud コンポーネントを示しています。

作成するアプリの概要
ここでは、価格最適化データ ウェアハウスを設計し、データ準備を自動化し、機械学習を使用して商品価格の変更の影響を予測し、チームに実用的な分析情報を提供するレポートを作成する方法について説明します。
学習内容
- Dataprep を価格分析用のデータソースに接続する方法。データソースは、リレーショナル データベース、フラット ファイル、Google スプレッドシート、その他のサポートされているアプリケーションに保存できます。
- Dataprep フローを構築して、BigQuery データ ウェアハウスに CDM テーブルを作成する方法。
- BigQuery ML を使用して将来の収益を予測する方法。
- Looker でレポートを作成して、過去の価格と販売の傾向を分析し、将来の価格変更の影響を把握する方法。
必要なもの
- 課金が有効になっている Google Cloud プロジェクト。プロジェクトに対して課金が有効になっていることを確認する方法を確認する。
- プロジェクトで BigQuery が有効になっている必要があります。新しいプロジェクトでは自動的に有効になります。それ以外の場合は、既存のプロジェクトで有効にします。Cloud コンソールから BigQuery を始める方法もご覧ください。
- プロジェクトで Dataprep も有効にする必要があります。Dataprep は、Google Console の左側のナビゲーション メニューにある [ビッグデータ] セクションで有効にします。登録の手順に沿って有効にします。
- 独自の Looker ダッシュボードを設定するには、Looker インスタンスに対するデベロッパー アクセス権が必要です。トライアルをリクエストするには、こちらからチームにお問い合わせください。または、一般公開ダッシュボードを使用して、サンプルデータに対するデータ パイプラインの結果を確認してください。
- 構造化クエリ言語(SQL)の経験と、次の基本的な知識があると役立ちます。Dataprep by Trifacta、BigQuery、Looker
2. BigQuery で CDM を作成する
このセクションでは、価格変更の分析と提案に必要な情報を統合的に表示する Common Data Model(CDM)を作成します。
- BigQuery コンソールを開きます。
- このリファレンス パターンのテストに使用するプロジェクトを選択します。
- 既存のデータセットを使用するか、BigQuery データセットを作成します。データセットに
Pricing_CDMという名前を付けます。 - テーブルを作成する:
create table `CDM_Pricing`
(
Fiscal_Date DATETIME,
Product_ID STRING,
Client_ID INT64,
Customer_Hierarchy STRING,
Division STRING,
Market STRING,
Channel STRING,
Customer_code INT64,
Customer_Long_Description STRING,
Key_Account_Manager INT64,
Key_Account_Manager_Description STRING,
Structure STRING,
Invoiced_quantity_in_Pieces FLOAT64,
Gross_Sales FLOAT64,
Trade_Budget_Costs FLOAT64,
Cash_Discounts_and_other_Sales_Deductions INT64,
Net_Sales FLOAT64,
Variable_Production_Costs_STD FLOAT64,
Fixed_Production_Costs_STD FLOAT64,
Other_Cost_of_Sales INT64,
Standard_Gross_Margin FLOAT64,
Transportation_STD FLOAT64,
Warehouse_STD FLOAT64,
Gross_Margin_After_Logistics FLOAT64,
List_Price_Converged FLOAT64
);
3. データソースを評価する
このチュートリアルでは、Google スプレッドシートと BigQuery に保存されているサンプル データソースを使用します。
- 取引 Google スプレッドシート。取引ごとに 1 行が含まれています。販売された各商品の数量、総売上高、関連費用などの詳細情報が表示されます。
- 特定の顧客の各商品の価格を月ごとに含む 商品価格の Google スプレッドシート。
- 個々の顧客情報を含む company_descriptions BigQuery テーブル。
この company_descriptions BigQuery テーブルは、次のステートメントを使用して作成できます。
create table `Company_Descriptions`
(
Customer_ID INT64,
Customer_Long_Description STRING
);
insert into `Company_Descriptions` values (15458, 'ENELTEN');
insert into `Company_Descriptions` values (16080, 'NEW DEVICES CORP.');
insert into `Company_Descriptions` values (19913, 'ENELTENGAS');
insert into `Company_Descriptions` values (30108, 'CARTOON NT');
insert into `Company_Descriptions` values (32492, 'Thomas Ed Automobiles');
4. フローを構築する
このステップでは、サンプル Dataprep フローをインポートします。このフローを使用して、前のセクションに記載されている サンプル データセットを変換して統合します。フローは、パイプライン、またはデータセットとレシピをまとめるオブジェクトを表します。これらのオブジェクトは、データセットとレシピの変換と結合に使用されます。
- GitHub から Pricing Optimization Pattern フロー パッケージをダウンロードします。ただし、解凍はしないでください。このファイルには、サンプルデータの変換に使用される料金最適化設計パターンのフローが含まれています。
- Dataprep で、左側のナビゲーション バーにあるフローアイコンをクリックします。次に、フロービューで、コンテキスト メニューから [インポート] を選択します。フローをインポートしたら、そのフローを選択して表示および編集できます。

- フローの左側では、商品価格と 3 つのトランザクションの各 Google スプレッドシートをデータセットとして接続する必要があります。これを行うには、Google スプレッドシートのデータセット オブジェクトを右クリックして、[置換] を選択します。[Import Datasets] リンクをクリックします。次の図に示すように、[パスを編集] の鉛筆アイコンをクリックします。

現在の値を、取引と商品価格の Google スプレッドシート へのリンクに置き換えます。
Google スプレッドシートに複数のタブが含まれている場合は、メニューで使用するタブを選択できます。[Edit] をクリックし、データソースとして使用するタブを選択して、[Save] をクリックし、[Import & Add to Flow] をクリックします。モーダルに戻ったら、[置換] をクリックします。このフローでは、各シートが独自のデータセットとして表されます。これは、後でレシピで異なるソースを統合する方法を示すためです。

- BigQuery 出力テーブルを定義する:
このステップでは、Dataoprep ジョブを実行するたびに読み込まれる BigQuery CDM_Pricing 出力テーブルのロケーションを関連付けます。
フロービューでスキーマ マッピング出力アイコンをクリックし、詳細パネルで [宛先] タブをクリックします。そこから、テストに使用する手動デスティネーションの出力と、フロー全体を自動化する場合に使用するスケジュール設定済みデスティネーションの出力を編集します。手順は次のとおりです。
- [手動設定の宛先] を編集する: [詳細] パネルの [手動設定の宛先] セクションで、[編集] ボタンをクリックします。[公開設定] ページの [公開操作] で、公開操作がすでに存在する場合は編集し、存在しない場合は [操作を追加] ボタンをクリックします。そこから、BigQuery データセットを前の手順で作成した
Pricing_CDMデータセットに移動し、CDM_Pricingテーブルを選択します。[Append to this table every run](実行ごとにこのテーブルに追加)がオンになっていることを確認し、[Add](追加)をクリックします。[Save Settings](設定を保存)をクリックします。 - 「スケジュールされた目的地」を編集する
[詳細] パネルの [スケジュールされた宛先] セクションで、[編集] をクリックします。
設定は手動のリンク先から継承されるため、変更する必要はありません。[Save Settings] をクリックします。
5. データを標準化する
提供されたフローは、トランザクション データを統合、フォーマット、クリーンアップし、レポート用に結果を会社の説明と集計された価格データに結合します。ここでは、下の図に示すフローのコンポーネントについて説明します。

6. トランザクション データ レシピを調べる
まず、トランザクション データの準備に使用されるトランザクション データ レシピ内で何が起こるかを確認します。フロービューで Transaction Data オブジェクトをクリックし、詳細パネルで [レシピを編集] ボタンをクリックします。
Transformer ページが開き、レシピが詳細パネルに表示されます。レシピには、データに適用されるすべての変換ステップが含まれています。レシピ内のステップ間をクリックすると、レシピのその位置にあるデータの状態を確認できます。
各レシピステップの [その他] メニューをクリックし、[選択したステップに移動] または [編集] を選択して、変換の仕組みを確認することもできます。
- トランザクションを統合: トランザクション データ レシピの最初のステップでは、各月を表す異なるシートに保存されているトランザクションを統合します。
- 顧客の説明を標準化する: レシピの次のステップでは、顧客の説明を標準化します。お客様の名前がわずかに異なるだけで、同じ名前として正規化したい場合に使用します。このレシピでは、2 つのアプローチを紹介します。まず、標準化アルゴリズムを活用します。このアルゴリズムは、共通の文字を含む値をクラスタリングする「類似文字列」や、発音が似ている値をクラスタリングする「発音」など、さまざまな標準化オプションで構成できます。または、会社 ID を使用して、上記の BigQuery テーブルで会社の説明を検索することもできます。
レシピをさらにナビゲートして、データのクリーンアップと形式設定に適用されるさまざまな手法(行の削除、パターンに基づく形式設定、ルックアップによるデータの拡充、欠損値の処理、不要な文字の置換など)を確認できます。
7. 商品価格データのレシピを確認する
次に、準備したトランザクション データを集計された価格データに結合する商品価格データ レシピで何が起こるかを確認します。
ページ上部の [PRICING OPTIMIZATION DESIGN PATTERN] をクリックして、Transformer ページを閉じ、フロービューに戻ります。[Product Pricing Data] オブジェクトをクリックして、レシピを編集します。
- 月ごとの価格列のピボット解除: ステップ 2 とステップ 3 の間のレシピをクリックして、ピボット解除ステップの前のデータの状態を確認します。データには、各月の取引額が個別の列(Jan、Fev、Mar)に含まれています。この形式は、SQL で集計(合計、平均取引など)計算を適用するのに適していません。各列が BigQuery テーブルの行になるように、データをピボット解除する必要があります。このレシピでは、unpivot 関数を使用して 3 つの列を月ごとに 1 つの行に変換し、グループ計算をさらに簡単に適用できるようにします。
- クライアント、商品、日付ごとの平均取引額を計算する: 各クライアント、商品、日付の平均取引額を計算します。集計関数を使用して、新しいテーブルを生成できます([グループ化を新しいテーブルとして] オプション)。この場合、データはグループ単位で集計されるため、個々のトランザクションの詳細は失われます。また、詳細と集計値の両方を同じデータセットに保持することもできます([Group by as a new column(s)] オプション)。このオプションは、比率(商品カテゴリの総収益に対する貢献度など)を適用する場合に非常に便利です。この動作を試すには、レシピのステップ 7 を編集し、[新しいテーブルとしてグループ化] または [新しい列としてグループ化] オプションを選択して、違いを確認します。
- 価格設定日を結合する: 最後に、結合を使用して、複数のデータセットを 1 つの大きなデータセットに結合し、初期データセットに列を追加します。このステップでは、「Pricing Data.Product Code」=「Transaction Data.SKU」および「Pricing Data.Price Date」=「Transaction Data.Fiscal Date」に基づいて、価格データがトランザクション データ レシピの出力と結合されます。
Dataprep で適用できる変換の詳細については、Trifacta データ ラングリング チートシートをご覧ください。
8. スキーマ マッピングのレシピを確認する
最後のレシピであるスキーマ マッピングでは、結果の CDM テーブルが既存の BigQuery 出力テーブルのスキーマと一致するようにします。ここでは、Rapid Target 機能を使用して、ファジー マッチングで両方のスキーマを比較し、自動変更を適用して、BigQuery テーブルと一致するようにデータ構造を再フォーマットします。
9. 1 つの構造に統合する
ソースと宛先が構成され、フローの手順が確認されたので、フローを実行して CDM テーブルを変換し、BigQuery に読み込むことができます。
- スキーマ マッピングの出力を実行する: フロービューで、スキーマ マッピングの出力オブジェクトを選択し、[詳細] パネルの [実行] ボタンをクリックします。[Trifacta Photon] 実行環境を選択し、[レシピエラーを無視] のチェックを外します。[実行] ボタンをクリックします。指定された BigQuery テーブルが存在する場合は、新しい行が追加されます。存在しない場合は、新しいテーブルが作成されます。
- ジョブのステータスを表示する: Dataprep は [ジョブの実行] ページを自動的に開くため、ジョブの実行をモニタリングできます。BigQuery テーブルの処理と読み込みには数分かかります。ジョブが完了すると、価格設定 CDM 出力が BigQuery に読み込まれます。出力は、分析の準備が整った、クリーンで構造化された正規化形式になります。
10. 分析と ML/AI を提供する
アナリティクスの前提条件
興味深い結果が得られる分析と予測モデルを実行するために、特定の分析情報を発見するのに適した、より大規模なデータセットを作成しました。このガイドを続行する前に、このデータを BigQuery データセットにアップロードする必要があります。
- この GitHub リポジトリから大規模なデータセットをダウンロードします。
- BigQuery の Google コンソールで、プロジェクトと CDM_Pricing データセットに移動します。
- メニューをクリックして、データセットを開きます。テーブルは、ローカル ファイルからデータを読み込んで作成します。
[+ テーブルを作成] ボタンをクリックし、次のパラメータを定義します。
- アップロードからテーブルを作成し、CDM_Pricing_Large_Table.csv ファイルを選択します。
- スキーマの自動検出: スキーマと入力パラメータをオンにする
- 詳細オプション、書き込み設定、テーブルを上書きする

- [テーブルを作成] をクリックします
テーブルが作成され、データがアップロードされると、BigQuery の Google コンソールに、次のように新しいテーブルの詳細が表示されます。BigQuery に料金データがあるため、より包括的な質問を簡単に実行して、料金データをより詳細に分析できます。

11. 価格変更の効果を確認する
分析の対象となるものとしては、たとえば、以前にアイテムの価格を変更したときの注文行動の変化などがあります。
- まず、商品の価格が変更されるたびに 1 行が追加される一時テーブルを作成します。このテーブルには、各価格で注文されたアイテムの数や、その価格に関連付けられた純売上高の合計など、その商品の価格設定に関する情報が格納されます。
create temp table price_changes as (
select
product_id,
list_price_converged,
total_ordered_pieces,
total_net_sales,
first_price_date,
lag(list_price_converged) over(partition by product_id order by first_price_date asc) as previous_list,
lag(total_ordered_pieces) over(partition by product_id order by first_price_date asc) as previous_total_ordered_pieces,
lag(total_net_sales) over(partition by product_id order by first_price_date asc) as previous_total_net_sales,
lag(first_price_date) over(partition by product_id order by first_price_date asc) as previous_first_price_date
from (
select
product_id,list_price_converged,sum(invoiced_quantity_in_pieces) as total_ordered_pieces, sum(net_sales) as total_net_sales, min(fiscal_date) as first_price_date
from `{{my_project}}.{{my_dataset}}.CDM_Pricing` AS cdm_pricing
group by 1,2
order by 1, 2 asc
)
);
select * from price_changes where previous_list is not null order by product_id, first_price_date desc

- 次に、一時テーブルを使用して、SKU 全体の平均価格変動を計算します。
select avg((previous_list-list_price_converged)/nullif(previous_list,0))*100 as average_price_change from price_changes;
- 最後に、価格変更後の状況を分析するには、各価格変更と注文されたアイテムの合計額の関係を確認します。
select
(total_ordered_pieces-previous_total_ordered_pieces)/nullif(previous_total_ordered_pieces,0)
as
price_changes_percent_ordered_change,
(list_price_converged-previous_list)/nullif(previous_list,0)
as
price_changes_percent_price_change
from price_changes
12. 時系列予測モデルを構築する
次に、BigQuery の組み込みの ML 機能を使用して、ARIMA 時系列予測モデルを構築し、販売される各アイテムの数量を予測します。
- まず、ARIMA_PLUS モデルを作成します。
create or replace `{{my_project}}.{{my_dataset}}.bqml_arima`
options
(model_type = 'ARIMA_PLUS',
time_series_timestamp_col = 'fiscal_date',
time_series_data_col = 'total_quantity',
time_series_id_col = 'product_id',
auto_arima = TRUE,
data_frequency = 'AUTO_FREQUENCY',
decompose_time_series = TRUE
) as
select
fiscal_date,
product_id,
sum(invoiced_quantity_in_pieces) as total_quantity
from
`{{my_project}}.{{my_dataset}}.CDM_Pricing`
group by 1,2;
- 次に、ML.FORECAST 関数を使用して、各商品の将来の売上を予測します。
select
*
from
ML.FORECAST(model testing.bqml_arima,
struct(30 as horizon, 0.8 as confidence_level));
- これらの予測を利用して、価格を引き上げた場合に何が起こるかを把握できます。たとえば、すべての商品の価格を 15% 引き上げた場合、次のクエリを使用して、翌月の推定総収益を計算できます。
select
sum(forecast_value * list_price) as total_revenue
from ml.forecast(mode testing.bqml_arima,
struct(30 as horizon, 0.8 as confidence_level)) forecasts
left join (select product_id,
array_agg(list_price_converged
order by fiscal_date desc limit 1)[offset(0)] as list_price
from `leigha-bq-dev.retail.cdm_pricing` group by 1) recent_prices
using (product_id);
13. レポートを作成する
非正規化された料金データが BigQuery で一元管理され、このデータに対して有意義なクエリを実行する方法を理解できたので、ビジネス ユーザーがこの情報を探索して活用できるようにレポートを作成します。
Looker インスタンスがすでにある場合は、この GitHub リポジトリの LookML を使用して、このパターンの料金データの分析を開始できます。新しい Looker プロジェクトを作成し、LookML を追加して、各ビュー ファイルの接続とテーブル名を BigQuery の構成に合わせて置き換えます。
このモデルには、価格の変動を調べるために先ほど示した派生テーブル(このビューファイル内)があります。
view: price_changes {
derived_table: {
sql: select
product_id,
list_price_converged,
total_ordered_pieces,
total_net_sales,
first_price_date,
lag(list_price_converged) over(partition by product_id order by first_price_date asc) as previous_list,
lag(total_ordered_pieces) over(partition by product_id order by first_price_date asc) as previous_total_ordered_pieces,
lag(total_net_sales) over(partition by product_id order by first_price_date asc) as previous_total_net_sales,
lag(first_price_date) over(partition by product_id order by first_price_date asc) as previous_first_price_date
from (
select
product_id,list_price_converged,sum(invoiced_quantity_in_pieces) as total_ordered_pieces, sum(net_sales) as total_net_sales, min(fiscal_date) as first_price_date
from ${cdm_pricing.SQL_TABLE_NAME} AS cdm_pricing
group by 1,2
order by 1, 2 asc
)
;;
}
...
}
BigQuery ML ARIMA モデル(前述)と同様に、将来の売上を予測します(このビューファイル)。
view: arima_model {
derived_table: {
persist_for: "24 hours"
sql_create:
create or replace model ${sql_table_name}
options
(model_type = 'arima_plus',
time_series_timestamp_col = 'fiscal_date',
time_series_data_col = 'total_quantity',
time_series_id_col = 'product_id',
auto_arima = true,
data_frequency = 'auto_frequency',
decompose_time_series = true
) as
select
fiscal_date,
product_id,
sum(invoiced_quantity_in_pieces) as total_quantity
from
${cdm_pricing.sql_table_name}
group by 1,2 ;;
}
}
...
}
LookML にはサンプル ダッシュボードも含まれています。ダッシュボードのデモ版はこちらからアクセスできます。ダッシュボードの最初の部分には、売上、費用、価格設定、利益率の変化に関する概要情報が表示されます。ビジネス ユーザーは、売上が X% を下回った場合にアラートを作成して、価格を下げる必要があるかどうかを確認できます。

次のセクション(以下を参照)では、料金変更に関する傾向を詳しく調べることができます。ここでは、特定の商品にドリルダウンして、正確な正規価格と変更後の価格を確認できます。これは、特定の商品を特定してさらに調査するのに役立ちます。
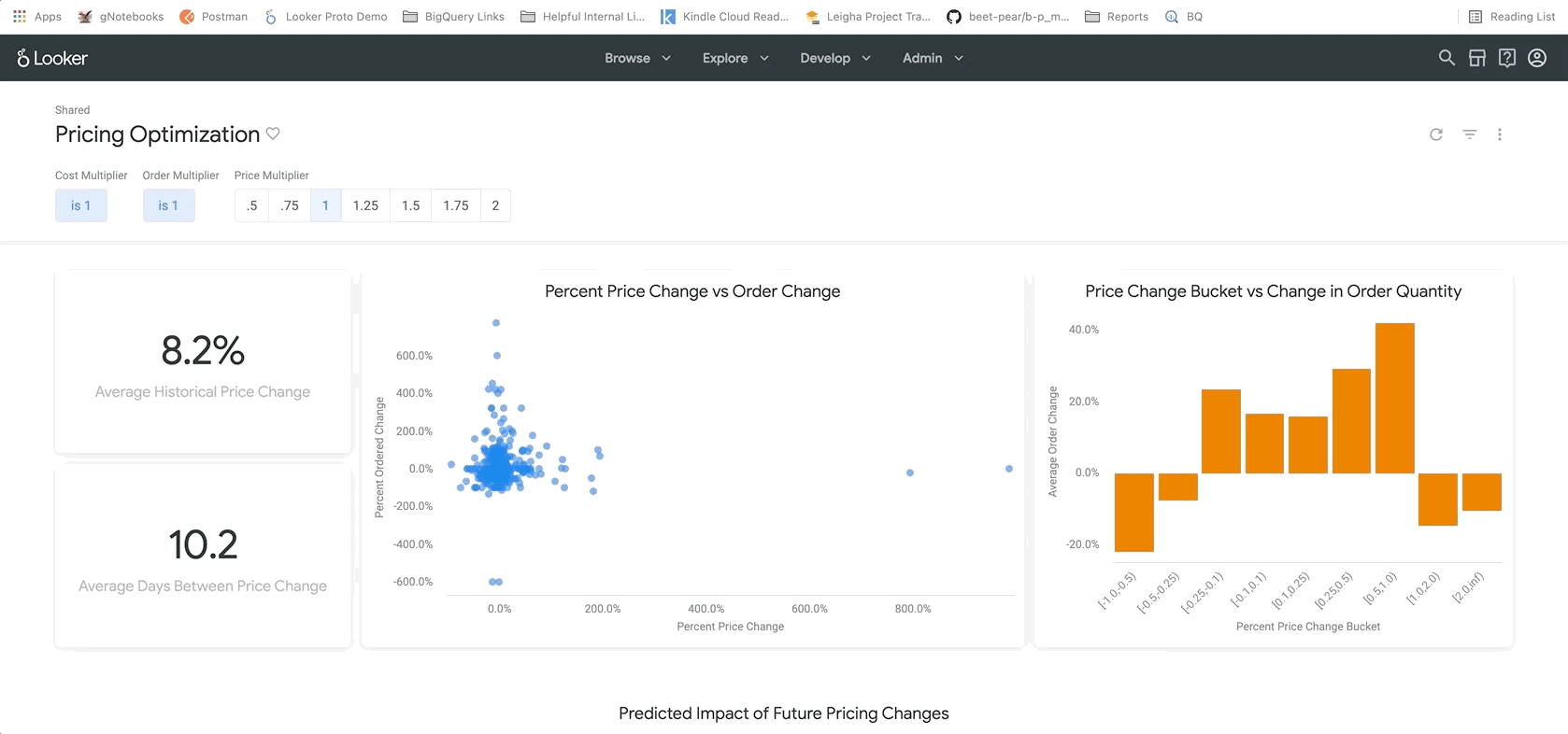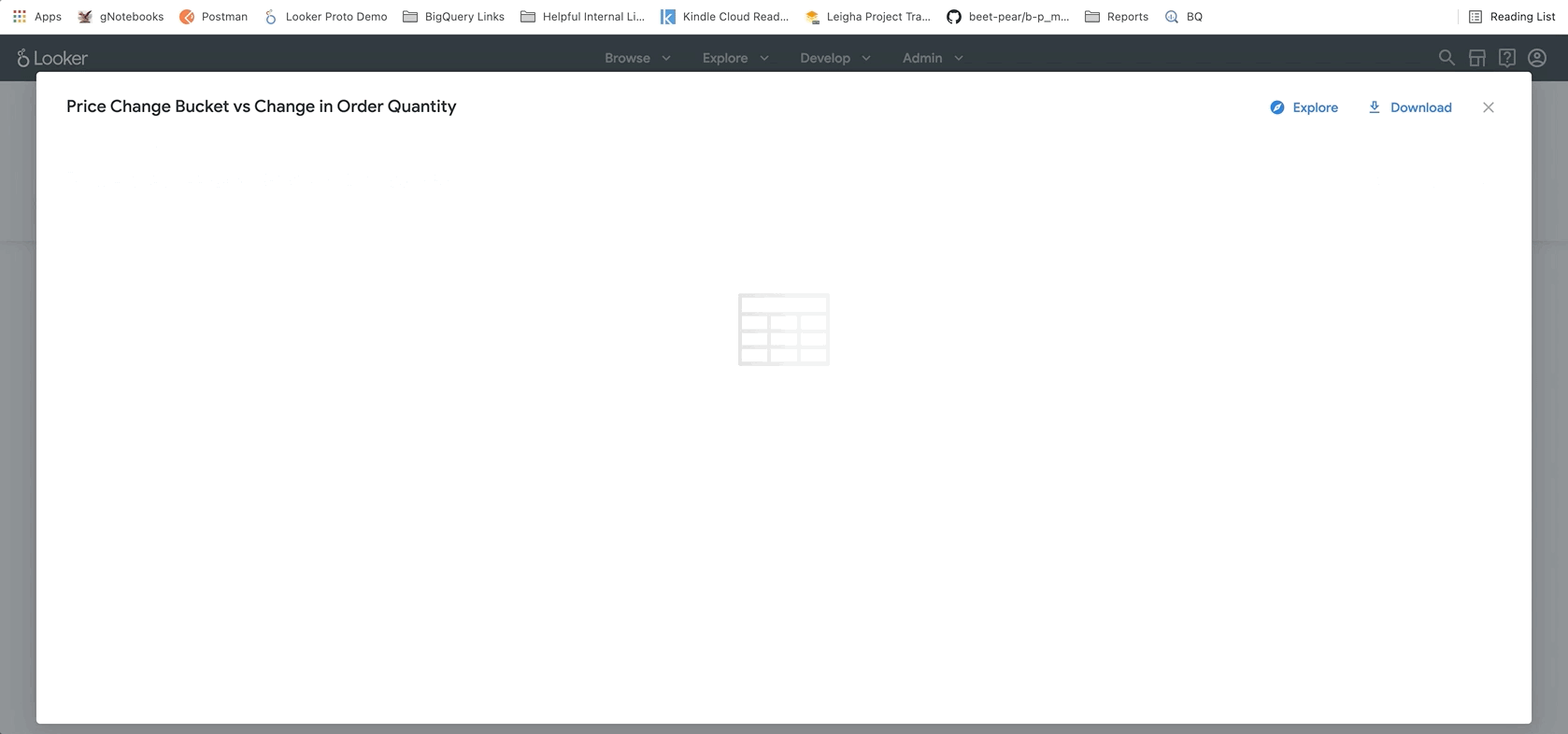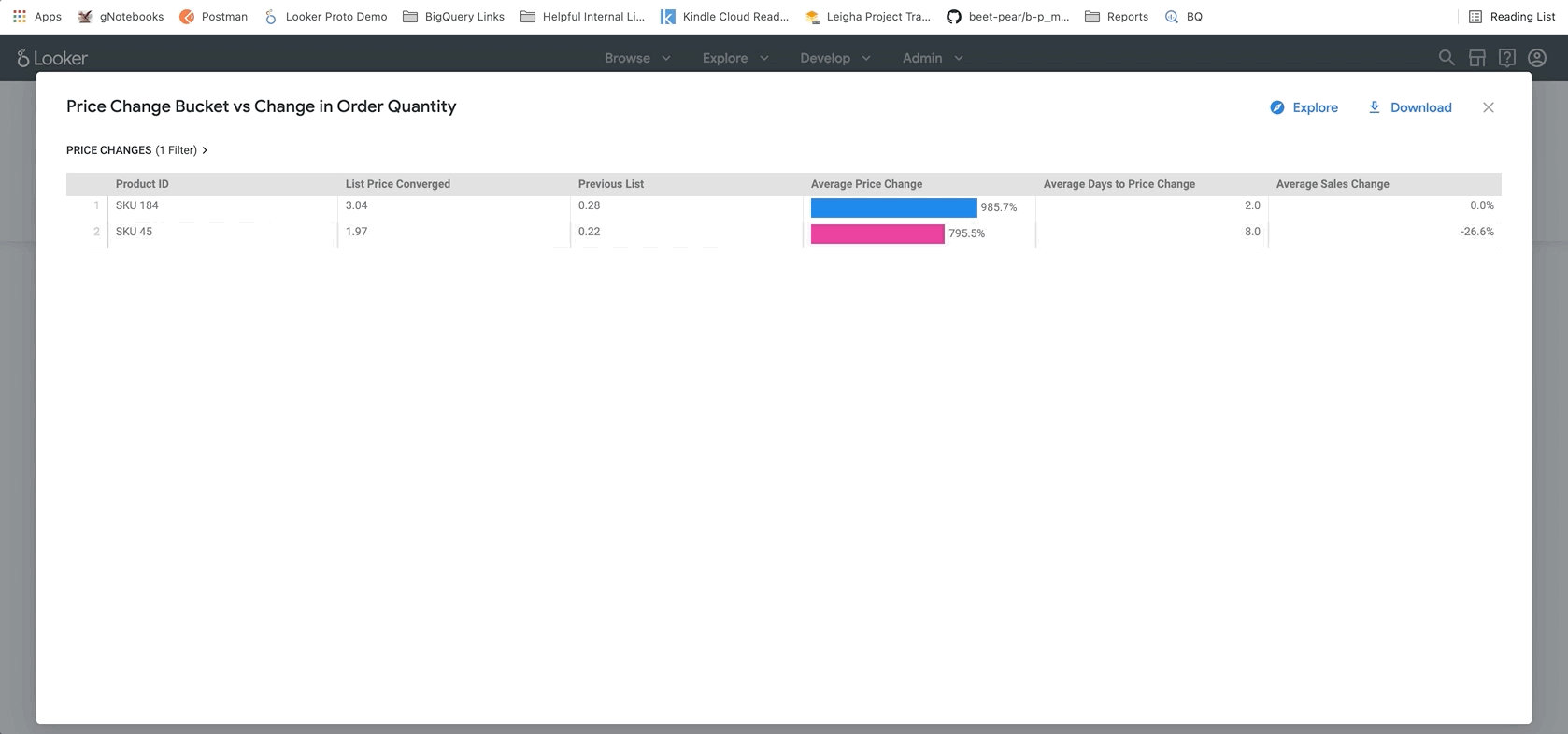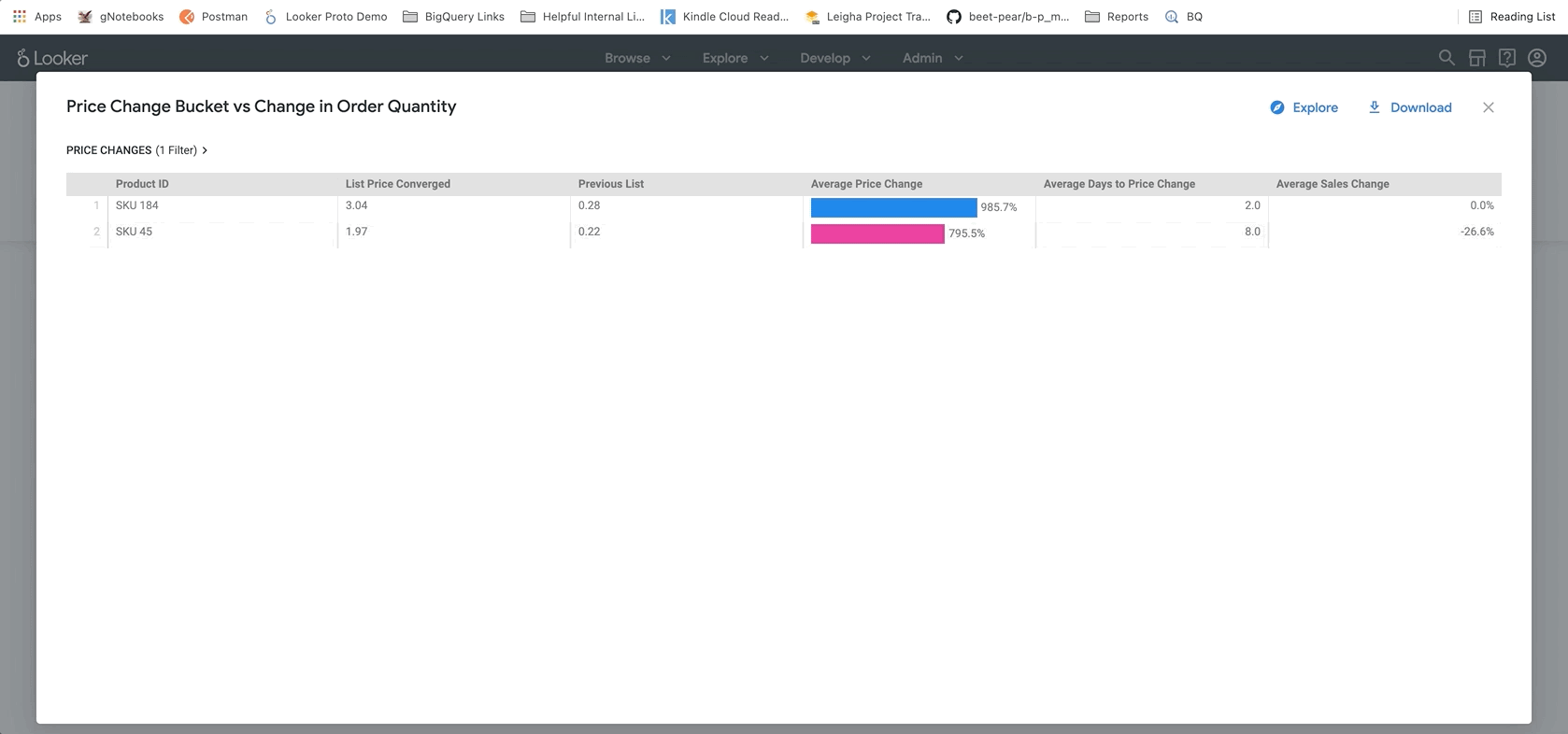
最後に、レポートの下部に BigQueryML モデルの結果が表示されます。Looker ダッシュボードの上部にあるフィルタを使用すると、上記の例と同様に、さまざまなシナリオをシミュレートするためのパラメータを簡単に入力できます。たとえば、注文量が予測値の 75% に減少し、すべての商品の価格が 25% 上昇した場合に何が起こるかを確認します。

これは LookML のパラメータによって実現されており、そのパラメータは、ここに記載されている指標の計算に直接組み込まれています。 このタイプのレポートでは、すべての商品の最適な価格を見つけたり、特定の商品を詳しく分析して、価格を引き上げるべきか引き下げるべきか、また、総収益と純収益にどのような影響があるかを判断したりできます。
14. 価格設定システムに適合させる
このチュートリアルではサンプル データソースを変換しますが、さまざまなプラットフォームに存在する料金アセットについても、同様のデータに関する課題に直面することになります。価格設定アセットには、概要と詳細な結果についてさまざまなエクスポート形式(xls、シート、csv、txt、リレーショナル データベース、ビジネス アプリケーションなど)があり、それぞれを Dataprep に接続できます。まず、上記の例と同様に、変換の要件を記述することをおすすめします。仕様が明確になり、必要な変換の種類が特定されたら、Dataprep で変換を設計できます。
- カスタマイズする Dataprep フローのコピーを作成するか(フローの右側にある [**...**](その他)ボタンをクリックして [複製] オプションを選択)、新しい Dataprep フローを使用して最初から作成します。
- 独自の価格設定データセットに接続します。Dataprep は、Excel、CSV、Google スプレッドシート、JSON などのファイル形式をネイティブにサポートしています。Dataprep コネクタを使用して他のシステムに接続することもできます。
- データアセットを特定したさまざまな変換カテゴリにディスパッチします。カテゴリごとに 1 つのレシピを作成します。このデザイン パターンで提供されているフローを参考に、データを変換して独自のレシピを作成してください。行き詰まった場合は、Dataprep 画面の左下にあるチャット ダイアログでサポートをリクエストしてください。
- レシピを BigQuery インスタンスに接続します。BigQuery でテーブルを手動で作成する必要はありません。Dataprep が自動的に処理します。フローに出力を追加する際は、[Manual Destination] を選択し、[Drop the table at each run] を選択することをおすすめします。期待する結果が得られるまで、各レシピを個別にテストします。テストが完了したら、以前のデータを削除しないように、実行ごとにテーブルへの追加に変換します。
- 必要に応じて、スケジュールに従って実行するフローを関連付けることができます。これは、プロセスを継続的に実行する必要がある場合に便利です。必要な鮮度に基づいて、毎日または毎時間レスポンスを読み込むスケジュールを定義できます。フローをスケジュールに従って実行する場合は、レシピごとにフローにスケジュール宛先出力を追加する必要があります。
BigQuery Machine Learning モデルを変更する
このチュートリアルでは、ARIMA モデルのサンプルを示します。ただし、モデルを開発する際に制御できる追加のパラメータがあり、データに最適なモデルを作成できます。詳細については、 こちらのドキュメントの例をご覧ください。また、BigQuery の ML.ARIMA_EVALUATE、ML.ARIMA_COEFFICIENTS、ML.EXPLAIN_FORECAST 関数を使用して、モデルの詳細を取得し、最適化の決定を行うこともできます。
Looker レポートを編集する
上記の説明に沿って LookML を独自のプロジェクトにインポートしたら、直接編集してフィールドを追加したり、計算やユーザー入力パラメータを変更したり、ビジネスニーズに合わせてダッシュボードの可視化を変更したりできます。LookML での開発の詳細についてはこちら、Looker でのデータの可視化の詳細についてはこちら をご覧ください。
15. 完了
これで、小売商品の価格を最適化するために必要な主な手順について確認しました。
次のステップ
他のスマート アナリティクスのリファレンス パターンを確認する