
1. نظرة عامة
في هذا الدرس التطبيقي حول الترميز، ستنشئ وكيل Supply Chain Orchestrator. يتيح هذا التطبيق للمستخدمين تحليل المستودع وتتبُّع الخدمات اللوجستية وإدارة مخاطر سلسلة التوريد باستخدام اللغة الطبيعية.
سنستفيد من "حزمة تطوير الوكلاء" (ADK) من Google لإنشاء بنية متعددة الوكلاء تحافظ على السياق، وتتذكّر إعدادات المستخدم المفضّلة من خلال Vertex AI Memory Bank، وتتفاعل مع مجموعة بيانات ضخمة مخزّنة في AlloyDB من خلال MCP Toolbox.
ما ستنشئه
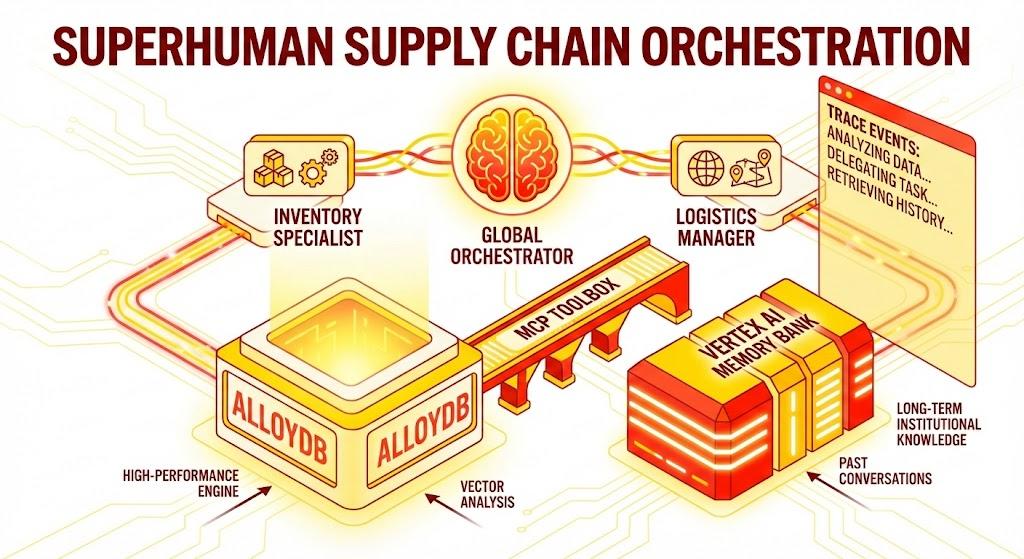
تطبيق Python Flask يتضمّن ما يلي:
الوكيل المنسّق العام: هو الوكيل الأساسي الذي يدير مسار المحادثة وتفويض المهام.
الوكلاء المتخصّصون: "InventorySpecialist" و "LogisticsManager" لإنجاز مهام خاصة بالنطاق.
دمج الذاكرة: ذاكرة الجلسة القصيرة المدى والذاكرة الطويلة المدى باستخدام Vertex AI Memory Bank
واجهة المستخدم السردية: هي واجهة ويب تعرض عملية الاستدلال التي يجريها الوكيل (سياق التتبُّع).
أهداف الدورة التعليمية
- كيفية استخدام Google ADK لإنشاء وكلاء متخصصين ووكلاء فرعيين
- كيفية دمج Vertex AI Memory Bank لتوفير ذاكرة طويلة المدى للوكيل
- كيفية استخدام MCP Toolbox لربط الوكلاء بأدوات بيانات AlloyDB
- كيفية تنفيذ عمليات ردّ الاتصال في حزمة تطوير الوكيل (ADK) لتتبُّع عملية الاستدلال التي يجريها الوكيل وعرضها بشكل مرئي
- كيفية نشر الحل باستخدام Cloud Run أو تشغيله محليًا
البنية
حزمة التكنولوجيا
- AlloyDB for PostgreSQL: تعمل كقاعدة بيانات تشغيلية عالية الأداء تحتوي على أكثر من 50,000 سجلّ لسلسلة التوريد. وهي تتيح البحث عن المتّجهات واسترجاعها.
- MCP Toolbox for Databases: يعمل كـ "قائد الأوركسترا"، حيث يعرض بيانات AlloyDB كأدوات قابلة للتنفيذ يمكن للوكلاء استدعاؤها.
- حزمة تطوير الوكلاء (ADK): هي إطار العمل المستخدَم لتحديد الوكلاء والتعليمات والأدوات.
- Vertex AI Memory Bank: توفّر ذاكرة طويلة الأمد، ما يسمح للوكيل بتذكُّر الإعدادات المفضّلة للمستخدم والتفاعلات السابقة في الجلسات المختلفة.
- خدمة الجلسات في Vertex AI: تدير سياق المحادثات القصيرة الأمد.
The Flow
- طلب بحث المستخدم: يطرح المستخدم سؤالاً (مثلاً، "التحقّق من توفّر آيس كريم فاخر").
- التحقّق من الذاكرة: يتحقّق Orchestrator من بنك الذاكرة بحثًا عن معلومات سابقة ذات صلة (مثل "المستخدم هو مدير إقليمي لمنطقة أوروبا والشرق الأوسط وأفريقيا").
- التفويض: يفوّض Orchestrator المهمة إلى InventorySpecialist.
- تنفيذ الأداة: يستخدم "المتخصّص" أدوات مقدَّمة من MCP Toolbox لإجراء طلب بحث في AlloyDB.
- الردّ: يعالج البرنامج البيانات ويعرض جدولاً بتنسيق Markdown.
- مساحة تخزين الذاكرة: يتم حفظ التفاعلات المهمة في "بنك الذاكرة".
المتطلبات
2. قبل البدء
إنشاء مشروع
- في Google Cloud Console، ضمن صفحة اختيار المشروع، اختَر أو أنشِئ مشروعًا على Google Cloud.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. كيفية التحقّق من تفعيل الفوترة في مشروع
- ستستخدم Cloud Shell، وهي بيئة سطر أوامر تعمل في Google Cloud. انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud".

- بعد الاتصال بـ Cloud Shell، يمكنك التأكّد من أنّك قد أثبتّ هويتك وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك.
gcloud config list project
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه:
gcloud config set project <YOUR_PROJECT_ID>
- فعِّل واجهات برمجة التطبيقات المطلوبة: اتّبِع الرابط وفعِّل واجهات برمجة التطبيقات.
يمكنك بدلاً من ذلك استخدام أمر gcloud لهذا الغرض. راجِع المستندات لمعرفة أوامر gcloud وطريقة استخدامها.
المشاكل المحتملة وتحديد المشاكل وحلّها
متلازمة "المشروع الوهمي" | نفّذت الأمر |
حاجز الفوترة | لقد فعّلت المشروع، ولكن نسيت حساب الفوترة. AlloyDB هو محرّك عالي الأداء، ولن يبدأ إذا كان "خزان الوقود" (الفوترة) فارغًا. |
تأخّر في نشر واجهة برمجة التطبيقات | نقرت على "تفعيل واجهات برمجة التطبيقات"، ولكن سطر الأوامر لا يزال يعرض |
Quota Quags | إذا كنت تستخدم حسابًا تجريبيًا جديدًا تمامًا، قد تبلغ حصة إقليمية لمثيلات AlloyDB. إذا تعذّر تنفيذ |
وكيل الخدمة"مخفي" | في بعض الأحيان، لا يتم منح دور |
3- إعداد قاعدة البيانات
يستند تطبيقنا بشكل أساسي إلى AlloyDB for PostgreSQL. استفدنا من إمكانات المتجهات الفعّالة والمحرّك العمودي المدمج لإنشاء تضمينات لأكثر من 50,000 سجلّ من "إدارة سلسلة الإمداد". يتيح ذلك إجراء تحليل متّجه في الوقت الفعلي تقريبًا، ما يسمح لبرامجنا بتحديد أيّ قيم شاذة في المستودع أو مخاطر لوجستية في مجموعات البيانات الضخمة في غضون أجزاء من الثانية.
في هذا التمرين العملي، سنستخدم AlloyDB كقاعدة بيانات لبيانات الاختبار. يستخدم المجموعات للاحتفاظ بجميع الموارد، مثل قواعد البيانات والسجلات. تحتوي كل مجموعة على مثيل أساسي يوفّر نقطة وصول إلى البيانات. ستحتوي الجداول على البيانات الفعلية.
لننشئ مجموعة ومثيل وجدول AlloyDB سيتم تحميل مجموعة البيانات الاختبارية فيها.
- انقر على الزر أو انسخ الرابط أدناه إلى المتصفّح الذي سجّلت فيه الدخول إلى حساب مستخدم Google Cloud Console.
بدلاً من ذلك، يمكنك الانتقال إلى "وحدة Cloud Shell" من مشروعك الذي استرددت فيه حساب الفوترة، واستنساخ مستودع github والانتقال إلى المشروع باستخدام الأوامر أدناه:
git clone https://github.com/AbiramiSukumaran/easy-alloydb-setup
cd easy-alloydb-setup
- بعد إكمال هذه الخطوة، سيتم استنساخ المستودع إلى محرّر Cloud Shell المحلي، وستتمكّن من تنفيذ الأمر أدناه من مجلد المشروع (من المهم التأكّد من أنّك في دليل المشروع):
sh run.sh
- استخدِم الآن واجهة المستخدم (من خلال النقر على الرابط في الوحدة الطرفية أو على الرابط "معاينة على الويب" في الوحدة الطرفية).
- أدخِل تفاصيل معرّف المشروع واسمَي المجموعة والآلة الافتراضية للبدء.
- يمكنك تناول القهوة أثناء تصفّح السجلات، ويمكنك الاطّلاع على كيفية تنفيذ ذلك في الخلفية هنا.
المشاكل المحتملة وتحديد المشاكل وحلّها
مشكلة "الصبر" | مجموعات قواعد البيانات هي بنية أساسية ثقيلة. إذا أعَدت تحميل الصفحة أو أغلقت جلسة Cloud Shell لأنّها "تبدو عالقة"، قد ينتهي بك الأمر إلى إنشاء آلة افتراضية "وهمية" تم توفيرها جزئيًا ولا يمكن حذفها بدون تدخّل يدوي. |
عدم تطابق المنطقة | إذا فعّلت واجهات برمجة التطبيقات في |
مجموعات الأجهزة غير النشطة | إذا سبق لك استخدام الاسم نفسه لمجموعة ولم تحذفها، قد تشير البرمجة النصية إلى أنّ اسم المجموعة مستخدَم من قبل. يجب أن تكون أسماء المجموعات فريدة ضمن المشروع. |
مهلة Cloud Shell | إذا استغرقت استراحة القهوة 30 دقيقة، قد ينتقل Cloud Shell إلى وضع السكون ويقطع عملية |
4. توفير المخطط
بعد تشغيل مجموعة AlloyDB ومثيلها، انتقِل إلى أداة تعديل لغة الاستعلامات البنيوية (SQL) في AlloyDB Studio لتفعيل إضافات الذكاء الاصطناعي وتوفير المخطط.
قد تحتاج إلى الانتظار إلى أن يكتمل إنشاء الجهاز الظاهري. بعد ذلك، سجِّل الدخول إلى AlloyDB باستخدام بيانات الاعتماد التي أنشأتها عند إنشاء المجموعة. استخدِم البيانات التالية للمصادقة على PostgreSQL:
- اسم المستخدم : "
postgres" - قاعدة البيانات : "
postgres" - كلمة المرور : "
alloydb" (أو أي كلمة مرور تم ضبطها عند إنشاء الحساب)
بعد إكمال عملية المصادقة بنجاح في AlloyDB Studio، يتم إدخال أوامر SQL في "المحرّر". يمكنك إضافة نوافذ "المحرّر" متعددة باستخدام علامة الجمع على يسار النافذة الأخيرة.
ستُدخل أوامر AlloyDB في نوافذ المحرّر، باستخدام الخيارات "تشغيل" و"تنسيق" و"محو" حسب الحاجة.
تفعيل الإضافات
لإنشاء هذا التطبيق، سنستخدم الإضافتين pgvector وgoogle_ml_integration. تتيح لك إضافة pgvector تخزين عمليات التضمين المتجهة والبحث عنها. توفّر إضافة google_ml_integration دوال يمكنك استخدامها للوصول إلى نقاط نهاية التوقّع في Vertex AI من أجل الحصول على توقّعات في SQL. فعِّل هذه الإضافات من خلال تنفيذ تعريفات البيانات التالية:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
إنشاء جدول
يمكنك إنشاء جدول باستخدام عبارة DDL أدناه في AlloyDB Studio:
DROP TABLE IF EXISTS shipments;
DROP TABLE IF EXISTS products;
-- 1. Product Inventory Table
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
category VARCHAR(100),
stock_level INTEGER,
distribution_center VARCHAR(100),
region VARCHAR(50),
embedding vector(768),
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. Logistics & Shipments
CREATE TABLE shipments (
shipment_id SERIAL PRIMARY KEY,
product_id INTEGER REFERENCES products(id),
status VARCHAR(50), -- 'In Transit', 'Delayed', 'Delivered', 'Pending'
estimated_arrival TIMESTAMP,
route_efficiency_score DECIMAL(3, 2)
);
سيسمح عمود embedding بتخزين قيم المتجهات لبعض الحقول النصية.
نقل البيانات
نفِّذ مجموعة عبارات SQL أدناه لإدراج 50,000 سجلّ بشكل مجمّع في جدول المنتجات:
-- We use a CROSS JOIN pattern with realistic naming segments to create meaningful variety
DO $$
DECLARE
brand_names TEXT[] := ARRAY['Artisan', 'Nature', 'Elite', 'Pure', 'Global', 'Eco', 'Velocity', 'Heritage', 'Aura', 'Summit'];
product_types TEXT[] := ARRAY['Ice Cream', 'Body Wash', 'Laundry Detergent', 'Shampoo', 'Mayonnaise', 'Deodorant', 'Tea', 'Soup', 'Face Cream', 'Soap'];
variants TEXT[] := ARRAY['Classic', 'Gold', 'Premium', 'Eco-Friendly', 'Organic', 'Night-Repair', 'Extra-Fresh', 'Zero-Sugar', 'Sensitive', 'Maximum-Strength'];
regions TEXT[] := ARRAY['EMEA', 'APAC', 'LATAM', 'NAMER'];
dcs TEXT[] := ARRAY['London-Hub', 'Mumbai-Central', 'Sao-Paulo-Logistics', 'Singapore-Port', 'Rotterdam-Gate', 'New-York-DC'];
BEGIN
INSERT INTO products (name, category, stock_level, distribution_center, region)
SELECT
b || ' ' || v || ' ' || t as name,
CASE
WHEN t IN ('Ice Cream', 'Mayonnaise', 'Tea', 'Soup') THEN 'Food & Refreshment'
WHEN t IN ('Body Wash', 'Shampoo', 'Deodorant', 'Face Cream', 'Soap') THEN 'Personal Care'
ELSE 'Home Care'
END as category,
floor(random() * 20000 + 100)::int as stock_level,
dcs[floor(random() * 6 + 1)] as distribution_center,
regions[floor(random() * 4 + 1)] as region
FROM
unnest(brand_names) b,
unnest(variants) v,
unnest(product_types) t,
generate_series(1, 50); -- 10 * 10 * 10 * 50 = 50,000 records
END $$;
لنُدرج سجلّات خاصة بالعرض التوضيحي لضمان الحصول على إجابات متوقّعة للأسئلة التي تتضمّن أسلوبًا تنفيذيًا
-- These ensure you have predictable answers for specific "Executive" questions
INSERT INTO products (name, category, stock_level, distribution_center, region) VALUES
('Magnum Ultra Gold Limited Edition', 'Food & Refreshment', 45, 'Rotterdam-Gate', 'EMEA'),
('Dove Pro-Health Deep Moisture', 'Personal Care', 12000, 'Mumbai-Central', 'APAC'),
('Hellmanns Real Organic Mayonnaise', 'Food & Refreshment', 8000, 'London-Hub', 'EMEA');
إدراج بيانات الشحنات
-- Shipments Generation (More shipments than products)
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT
id,
CASE
WHEN random() > 0.8 THEN 'Delayed'
WHEN random() > 0.4 THEN 'In Transit'
ELSE 'Delivered'
END,
NOW() + (random() * 10 || ' days')::interval,
(random() * 0.5 + 0.5)::decimal(3,2)
FROM products
WHERE random() > 0.3; -- Create shipments for ~70% of products
-- Add duplicate shipments for some products to show complex logistics
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT id, 'In Transit', NOW() + INTERVAL '12 days', 0.88
FROM products
LIMIT 5000;
منح الإذن
نفِّذ العبارة أدناه لمنح إذن التنفيذ على الدالة "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
منح دور "مستخدم Vertex AI" لحساب خدمة AlloyDB
من وحدة تحكّم Google Cloud IAM، امنح حساب خدمة AlloyDB (الذي يبدو على النحو التالي: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) إذن الوصول إلى الدور "مستخدم Vertex AI". سيحتوي PROJECT_NUMBER على رقم مشروعك.
بدلاً من ذلك، يمكنك تنفيذ الأمر أدناه من "وحدة Cloud Shell الطرفية":
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
إنشاء تضمينات
بعد ذلك، لننشئ تضمينات متّجهات لحقول نصية محددة ذات معنى:
WITH
rows_to_update AS (
SELECT
id
FROM
products
WHERE
embedding IS NULL
LIMIT
5000 )
UPDATE
products
SET
embedding = ai.embedding('text-embedding-005', name || ' ' || category || ' ' || distribution_center || ' ' || region)::vector
FROM
rows_to_update
WHERE
products.id = rows_to_update.id
AND embedding IS null;
في العبارة أعلاه، ضبطنا الحد الأقصى على 5000، لذا احرص على تشغيلها بشكل متكرر إلى أن لا يظهر أي صف في الجدول مع تضمين العمود كقيمة NULL.
المشاكل المحتملة وتحديد المشاكل وحلّها
حلقة "فقدان الذاكرة" بشأن كلمات المرور | إذا كنت قد استخدمت عملية الإعداد "بنقرة واحدة" ولم تتمكّن من تذكُّر كلمة المرور، انتقِل إلى صفحة "المعلومات الأساسية للمثيل" في وحدة التحكّم وانقر على "تعديل" لإعادة ضبط كلمة مرور |
رسالة الخطأ "لم يتم العثور على الإضافة" | إذا تعذّر تنفيذ |
فجوة نشر إدارة الهوية وإمكانية الوصول | لقد نفّذت أمر |
عدم تطابق سمة المتّجه | تم ضبط الجدول |
خطأ إملائي في رقم تعريف المشروع | في استدعاء |
5- الأدوات وإعداد صندوق الأدوات
MCP Toolbox for Databases هو خادم MCP مفتوح المصدر لقواعد البيانات. تتيح لك هذه الخدمة تطوير الأدوات بسهولة أكبر وبسرعة أكبر وبشكل أكثر أمانًا من خلال التعامل مع التعقيدات، مثل تجميع الاتصالات والمصادقة والمزيد. تساعدك Toolbox في إنشاء أدوات الذكاء الاصطناعي التوليدي التي تتيح للوكلاء الوصول إلى البيانات في قاعدة البيانات.
نستخدم أداة Model Context Protocol (MCP) Toolbox for Databases كـ "قائد". تعمل هذه الأداة كبرنامج وسيط موحَّد بين الوكلاء وAlloyDB. من خلال تحديد tools.yaml، تعرض مجموعة الأدوات تلقائيًا عمليات قواعد البيانات المعقّدة كأدوات قابلة للتنفيذ وواضحة، مثل search_products_by_context أو check_inventory_levels. يُغنيك ذلك عن تجميع الاتصالات يدويًا أو استخدام SQL النموذجي ضمن منطق الوكيل.
تثبيت خادم "أدوات المطوّرين"
من "وحدة طرفية Cloud Shell"، أنشئ مجلدًا لحفظ ملف yaml الخاص بالأدوات الجديدة وثنائي صندوق الأدوات:
mkdir scm-agent-toolbox
cd scm-agent-toolbox
من داخل هذا المجلد الجديد، شغِّل مجموعة الأوامر التالية:
# see releases page for other versions
export VERSION=0.27.0
curl -L -o toolbox https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
بعد ذلك، أنشئ الملف tools.yaml داخل هذا المجلد الجديد من خلال الانتقال إلى "محرّر Cloud Shell" ونسخ محتوى ملف مستودع الرموز هذا إلى ملف tools.yaml.
sources:
supply_chain_db:
kind: "alloydb-postgres"
project: "YOUR_PROJECT_ID"
region: "us-central1"
cluster: "YOUR_CLUSTER"
instance: "YOUR_INSTANCE"
database: "postgres"
user: "postgres"
password: "YOUR_PASSWORD"
tools:
search_products_by_context:
kind: postgres-sql
source: supply_chain_db
description: Find products in the inventory using natural language search and vector embeddings.
parameters:
- name: search_text
type: string
description: Description of the product or category the user is looking for.
statement: |
SELECT name, category, stock_level, distribution_center, region
FROM products
ORDER BY embedding <=> ai.embedding('text-embedding-005', $1)::vector
LIMIT 5;
check_inventory_levels:
kind: postgres-sql
source: supply_chain_db
description: Get precise stock levels for a specific product name.
parameters:
- name: product_name
type: string
description: The exact or partial name of the product.
statement: |
SELECT name, stock_level, distribution_center, last_updated
FROM products
WHERE name ILIKE '%' || $1 || '%'
ORDER BY stock_level DESC;
track_shipment_status:
kind: postgres-sql
source: supply_chain_db
description: Retrieve real-time logistics and shipping status for a specific region or product.
parameters:
- name: region
type: string
description: The geographical region to filter shipments (e.g., EMEA, APAC).
statement: |
SELECT p.name, s.status, s.estimated_arrival, s.route_efficiency_score
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE p.region = $1
ORDER BY s.estimated_arrival ASC;
analyze_supply_chain_risk:
kind: postgres-sql
source: supply_chain_db
description: Rerank and filter shipments based on risk profiles and efficiency scores using Google ML reranker.
parameters:
- name: risk_context
type: string
description: The business context for risk analysis (e.g., 'heatwave impact' or 'port strike').
statement: |
WITH initial_ranking AS (
SELECT s.shipment_id, p.name, s.status, p.distribution_center,
ROW_NUMBER() OVER () AS ref_number
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE s.status != 'Delivered'
LIMIT 10
),
reranked_results AS (
SELECT index, score FROM
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => $1,
documents => (SELECT ARRAY_AGG(name || ' at ' || distribution_center ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT i.name, i.status, i.distribution_center, r.score
FROM initial_ranking i, reranked_results r
WHERE i.ref_number = r.index
ORDER BY r.score DESC;
toolsets:
supply_chain_toolset:
- search_products_by_context
- check_inventory_levels
- track_shipment_status
- analyze_supply_chain_risk
اختبِر الآن ملف tools.yaml في الخادم المحلي:
./toolbox --tools-file "tools.yaml"
يمكنك بدلاً من ذلك اختباره في واجهة المستخدم
./toolbox --ui
ممتاز!! بعد التأكّد من أنّ كل ذلك يعمل، يمكنك المتابعة ونشره في Cloud Run على النحو التالي.
نشر Cloud Run
- اضبط متغيّر البيئة PROJECT_ID:
export PROJECT_ID="my-project-id"
- افتح gcloud CLI:
gcloud init
gcloud config set project $PROJECT_ID
- يجب تفعيل واجهات برمجة التطبيقات التالية:
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- أنشئ حساب خدمة للخادم الخلفي إذا لم يكن لديك حساب:
gcloud iam service-accounts create toolbox-identity
- امنح الأذونات لاستخدام Secret Manager:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
- امنح حساب الخدمة أذونات إضافية خاصة بمصدر AlloyDB (الأدوار roles/alloydb.client وroles/serviceusage.serviceUsageConsumer).
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role serviceusage.serviceUsageConsumer
- حمِّل ملف tools.yaml كمفتاح سرّي:
gcloud secrets create tools-scm-agent --data-file=tools.yaml
- إذا كان لديك رمز سري حالي وأردت تعديل إصدار الرمز السري، نفِّذ ما يلي:
gcloud secrets versions add tools-scm-agent --data-file=tools.yaml
- اضبط متغيّر بيئة على صورة الحاوية التي تريد استخدامها في Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- يمكنك نشر Toolbox على Cloud Run باستخدام الأمر التالي:
إذا فعّلت الوصول العام في مثيل AlloyDB (لا يُنصح بذلك)، اتّبِع الأمر أدناه للنشر على Cloud Run:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
إذا كنت تستخدم شبكة VPC، استخدِم الأمر أدناه:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
# TODO(dev): update the following to match your VPC details
--network <<YOUR_NETWORK_NAME>> \
--subnet <<YOUR_SUBNET_NAME>> \
--allow-unauthenticated
6. إعداد الوكيل
باستخدام حزمة تطوير الوكلاء (ADK)، ابتعدنا عن الطلبات الموحّدة واتّجهنا نحو بنية متخصّصة ومتعددة الوكلاء:
- InventorySpecialist: يركّز على مقاييس مستودع المنتجات.
- LogisticsManager: خبير في طرق الشحن العالمية وتحليل المخاطر
- GlobalOrchestrator: هو "العقل" الذي يستخدم التحليل المنطقي لتفويض المهام وتجميع النتائج.
استنسِخ هذا المستودع في مشروعك وسنستعرضه معًا.
لاستنساخ هذا المستودع، نفِّذ الأمر التالي من "وحدة Cloud Shell الطرفية" (في الدليل الجذر أو من أي مكان تريد إنشاء هذا المشروع فيه):
git clone https://github.com/AbiramiSukumaran/scm-memory-agent
- من المفترض أن يؤدي ذلك إلى إنشاء المشروع، ويمكنك التأكّد من ذلك في "محرِّر Cloud Shell".

- احرص على تعديل ملف .env بالقيم الخاصة بمشروعك ومثيلك.
جولة تفصيلية حول الرموز البرمجية
نظرة سريعة على Orchestrator Agent
Go to app.py and you should be able to see the following snippet:
orchestrator = adk.Agent(
name="GlobalOrchestrator",
model="gemini-2.5-flash",
description="Global Supply Chain Orchestrator root agent.",
instruction="""
You are the Global Supply Chain Brain. You are responsible for products, inventory and logistics.
You also have access to the memory tool, remember to include all the information that the tool can provide you with about the user before you respond.
1. Understand intent and delegate to specialists. As the Global Orchestrator, you have access to the full conversation history with the user.
When you transfer a query to a specialist agent, sub agent or tool, share the important facts and information from your memory to them so they can operate with the full context.
2. Ensure the final response is professional and uses Markdown tables for data.
3. If a specialist provides a long list, ensure only the top 10 items are shown initially.
4. Conclude with a brief, high-level executive summary of what the data implies.
""",
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
sub_agents=[inventory_agent, logistics_agent],
#after_agent_callback=auto_save_session_to_memory_callback,
)
هذه المقتطفة هي تعريف للعنصر الأساسي الذي يمثّل الوكيل المنسّق الذي يتلقّى المحادثة أو الطلب من المستخدم ويوجهه إلى الوكيل الفرعي أو المستخدم المناسب أو الأدوات المناسبة استنادًا إلى المهمة.
- لنلقِ نظرة على وكيل المستودع
inventory_agent = adk.Agent(
name="InventorySpecialist",
model="gemini-2.5-flash",
description="Specialist in product stock and warehouse data.",
instruction="""
Analyze inventory levels.
1. Use 'search_products_by_context' or 'check_inventory_levels'.
2. ALWAYS format results as a clean Markdown table.
3. If there are many results, display only the TOP 10 most relevant ones.
4. At the end, state: 'There are additional records available. Would you like to see more?'
""",
tools=tools
)
هذا الوكيل الفرعي تحديدًا متخصص في أنشطة المستودع، مثل البحث عن المنتجات حسب السياق والتحقّق من مستويات المخزون.
- ثم هناك الوكيل الفرعي للخدمات اللوجستية:
logistics_agent = adk.Agent(
name="LogisticsManager",
model="gemini-2.5-flash",
description="Expert in global shipping routes and logistics tracking.",
instruction="""
Check shipment statuses.
1. Use 'track_shipment_status' or 'analyze_supply_chain_risk'.
2. ALWAYS format results as a clean Markdown table.
3. Limit initial output to the top 10 shipments.
4. Ask if the user needs the full manifest if more results exist.
""",
tools=tools
)
هذا الوكيل الفرعي تحديدًا متخصص في الأنشطة اللوجستية، مثل تتبُّع الشحنات وتحليل المخاطر في سلسلة التوريد.
- تستخدم جميع البرامج الثلاثة التي ناقشناها حتى الآن أدوات، ويتم الرجوع إلى الأدوات من خلال خادم "صندوق الأدوات" الذي سبق أن نشرناه في القسم السابق. راجِع المقتطف أدناه:
from toolbox_core import ToolboxSyncClient
TOOLBOX_SERVER = os.environ["TOOLBOX_SERVER"]
TOOLBOX_TOOLSET = os.environ["TOOLBOX_TOOLSET"]
# --- ADK TOOLBOX CONFIGURATION ---
toolbox = ToolboxSyncClient(TOOLBOX_SERVER)
tools = toolbox.load_toolset(TOOLBOX_TOOLSET)
هذا الوكيل الفرعي تحديدًا متخصص في الأنشطة اللوجستية، مثل تتبُّع الشحنات وتحليل المخاطر في سلسلة التوريد.
7. Agent Engine
في عملية التشغيل الأولية، أنشئ Agent Engine
import vertexai
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
client = vertexai.Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_LOCATION
)
agent_engine = client.agent_engines.create()
- في عملية التشغيل التالية، عدِّل "محرك الوكيل" باستخدام إعدادات "بنك الذاكرة":
agent_engine = client.agent_engines.update(
name=APP_NAME,
config={
"context_spec": {
"memory_bank_config": {
"generation_config": {
"model": f"projects/{PROJECT_ID}/locations/{GOOGLE_CLOUD_LOCATION}/publishers/google/models/gemini-2.5-flash"
}
}
}
})
8. السياق والتشغيل والذاكرة
تنقسم إدارة السياق إلى طبقتَين مختلفتَين لضمان أن يبدو الوكيل كشريك مستمر بدلاً من أن يكون برنامجًا آليًا بلا حالة:
الذاكرة القصيرة الأمد (الجلسات): تتم إدارتها من خلال VertexAiSessionService، وتتتبّع سجلّ الأحداث المباشر (رسائل المستخدمين، وردود الأدوات) ضمن تفاعل واحد.
الذاكرة الطويلة الأمد (مستودع الذاكرة): يتم تشغيلها من خلال مستودع الذاكرة في Vertex AI عبر adk.memorybankservice. تستخرج هذه الطبقة معلومات "مفيدة"، مثل تفضيل المستخدم لشركات شحن معيّنة أو حالات التأخير المتكرّرة في المستودع، وتحتفظ بها في جميع الجلسات.
تهيئة الجلسة لذاكرة الجلسة ضمن نطاق المحادثة
هذا هو الجزء من المقتطف الذي ينشئ الجلسة للتطبيق الحالي للمستخدم الحالي.
from google.adk.sessions import VertexAiSessionService
...
session_service = VertexAiSessionService(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
...
# Initialize the session *outside* of the route handler to avoid repeated creation
session = None
session_lock = threading.Lock()
async def initialize_session():
global session
try:
session = await session_service.create_session(app_name=APP_NAME, user_id=USER_ID)
print(f"Session {session.id} created successfully.") # Add a log
except Exception as e:
print(f"Error creating session: {e}")
session = None # Ensure session is None in case of error
# Create the session on app startup
asyncio.run(initialize_session())
تهيئة Vertex AI Memory Bank للذاكرة الطويلة الأمد
هذا هو الجزء من المقتطف الذي ينشئ عنصر خدمة Vertex AI Memory Bank لمحرك الوكيل.
from google.adk.memory import InMemoryMemoryService
from google.adk.memory import VertexAiMemoryBankService
...
try:
memory_bank_service = adk.memory.VertexAiMemoryBankService(
agent_engine_id=AGENT_ENGINE_ID,
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
#in_memory_service = InMemoryMemoryService()
print("Memory Bank Service initialized successfully.")
except Exception as e:
print(f"Error initializing Memory Bank Service: {e}")
memory_bank_service = None
runner = adk.Runner(
agent=orchestrator,
app_name=APP_NAME,
session_service=session_service,
memory_service=memory_bank_service,
)
...
ما هي الإعدادات التي تم ضبطها؟
في هذا الجزء من المقتطف، نعمل على إعداد خدمة "بنك الذاكرة" في Vertex AI للذاكرة الطويلة الأمد، وهي تخزّن الجلسة بشكل سياقي للتطبيق المحدّد والمستخدم المحدّد كذاكرة داخل "بنك الذاكرة" في Vertex AI.
ما هي العمليات التي يتم تنفيذها كجزء من تنفيذ الوكيل؟
async def run_and_collect():
final_text = ""
try:
async for event in runner.run_async(
new_message=content,
user_id=user_id,
session_id=session_id
):
if hasattr(event, 'author') and event.author:
if not any(log['agent'] == event.author for log in execution_logs):
execution_logs.append({
"agent": event.author,
"action": "Analyzing data requirements...",
"type": "orchestration_event"
})
if hasattr(event, 'text') and event.text:
final_text = event.text
elif hasattr(event, 'content') and hasattr(event.content, 'parts'):
for part in event.content.parts:
if hasattr(part, 'text') and part.text:
final_text = part.text
except Exception as e:
print(f"Error during runner.run_async: {e}")
raise # Re-raise the exception to signal failure
finally:
gc.collect()
return final_text
تعالج هذه الدالة المحتوى الذي أدخله المستخدم في الكائن new_message مع معرّف المستخدم ومعرّف الجلسة في النطاق. بعد ذلك، يتولّى الوكيل الأمر ويتمّ معالجة ردّه وإرجاعه.
ما هي المعلومات التي يتم تخزينها في الذاكرة الطويلة الأمد؟
يتم استخراج تفاصيل الجلسة في نطاق التطبيق والمستخدم في متغيّر الجلسة.
تتم إضافة هذه الجلسة بعد ذلك كذاكرة للمستخدم الحالي للتطبيق الحالي لكائن "بنك الذاكرة" في Vertex AI باستخدام الطريقة "add_session_to_memory".
session = asyncio.run(session_service.get_session(app_name=APP_NAME, user_id=USER_ID, session_id=session.id))
if memory_bank_service and session: # Check memory service AND session
try:
#asyncio.run(in_memory_service.add_session_to_memory(session))
asyncio.run(memory_bank_service.add_session_to_memory(session))
'''
client.agent_engines.memories.generate(
scope={"app_name": APP_NAME, "user_id": USER_ID},
name=APP_NAME,
direct_contents_source={
"events": [
{"content": content}
]
},
config={"wait_for_completion": True},
)
'''
print("Successfully added session to memory.******")
print(session.id)
except Exception as e:
print(f"Error adding session to memory: {e}")
استرجاع الذاكرة
نحتاج إلى استرداد الذاكرة الطويلة الأمد المخزّنة باستخدام اسم التطبيق واسم المستخدم كنطاق (لأنّ هذا هو النطاق الذي خزّنّا الذكريات فيه) لنتمكّن من تمريرها كجزء من السياق إلى أداة التنسيق والوكلاء الآخرين حسب الاقتضاء.
results = client.agent_engines.memories.retrieve(
name=APP_NAME,
scope={"app_name": APP_NAME, "user_id": USER_ID}
)
# RetrieveMemories returns a pager. You can use `list` to retrieve all pages' memories.
list(results)
print(list(results))
كيف يتم تحميل الذكرى المسترجَعة كجزء من السياق؟
نستخدم السمة التالية في تعريف وكيل Orchestrator الذي يسمح للوكيل الرئيسي بالتحميل المُسبَق للسياق من مستودع الذاكرة. يضاف ذلك إلى الأدوات التي يمكننا الوصول إليها من خادم صندوق الأدوات للوكلاء الفرعيين.
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
سياق معاودة الاتصال
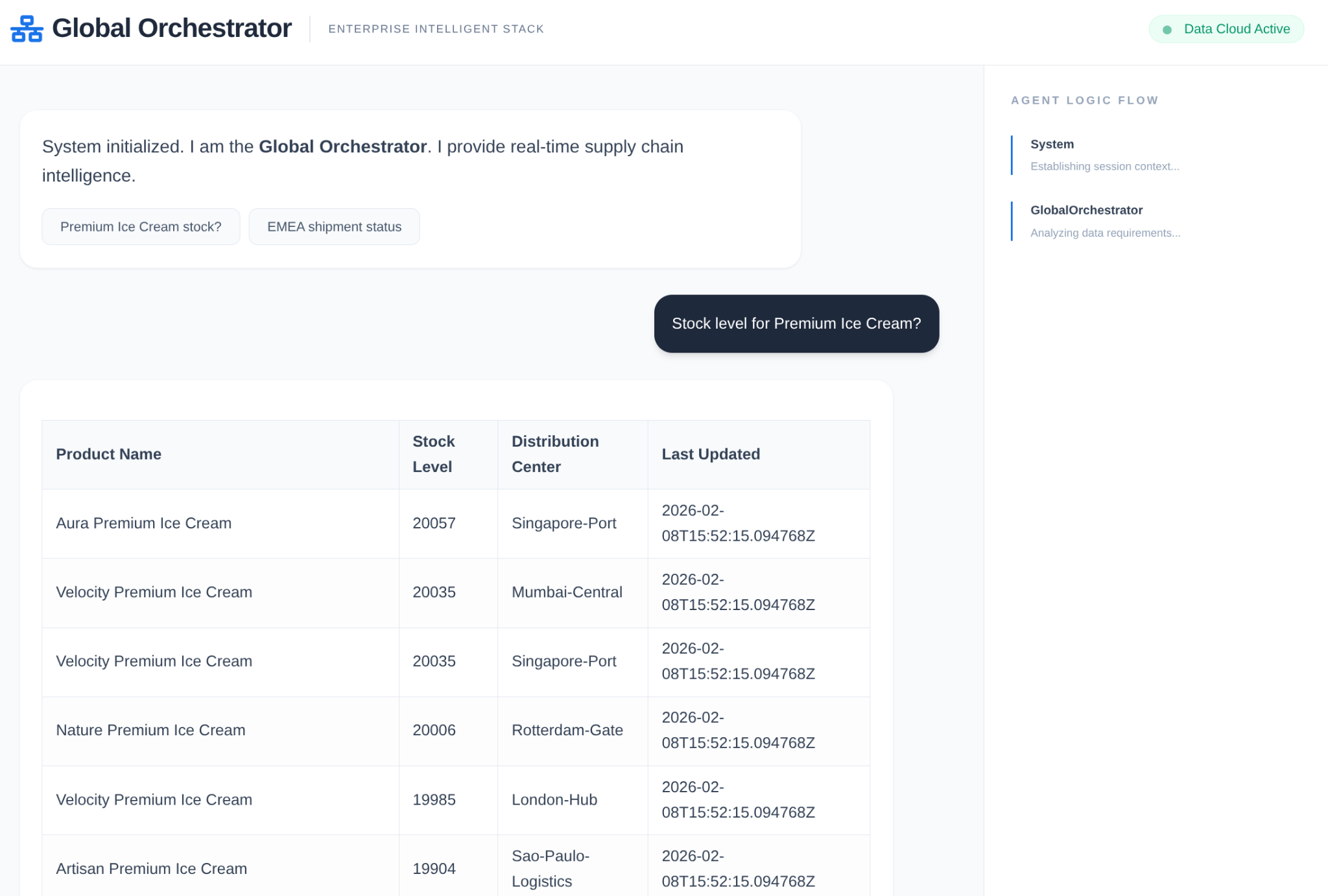
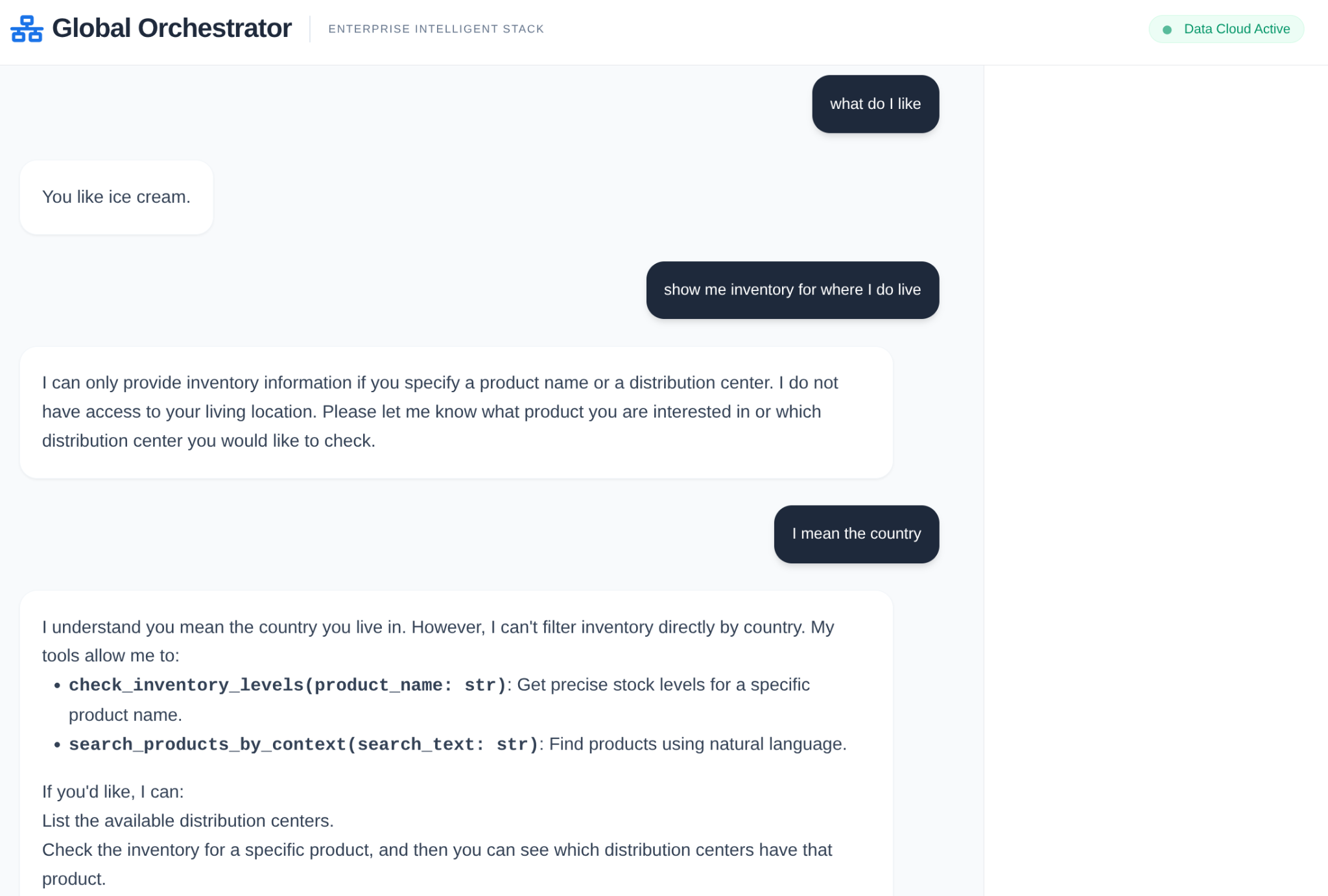
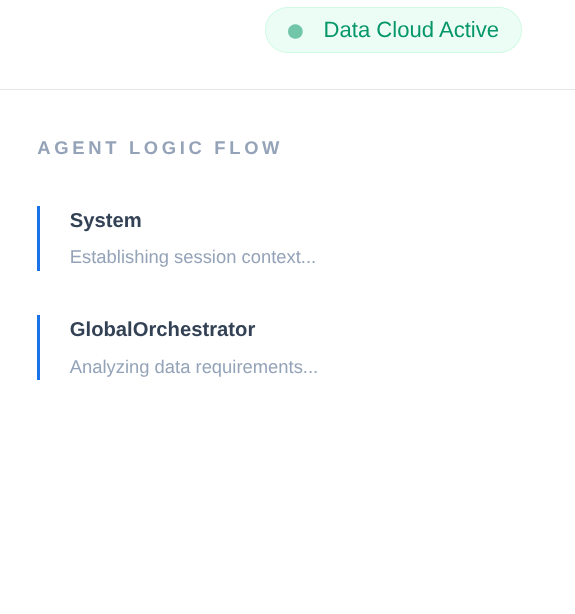
في سلسلة إمداد المؤسسات، لا يمكن أن يكون هناك "صندوق أسود". نستخدم CallbackContext في حزمة تطوير التطبيقات (ADK) لإنشاء Narrative Engine. من خلال ربط عملية التنفيذ الخاصة بالوكيل، يمكننا تسجيل كل عملية تفكير واستدعاء أداة، وبثها إلى الشريط الجانبي لواجهة المستخدم.
- حدث التتبُّع: "يحلّل GlobalOrchestrator متطلبات البيانات..."
- تتبُّع الحدث: "تفويض إلى InventorySpecialist بشأن مستويات المخزون..."
- حدث التتبُّع: "جارٍ استرداد أنماط التأخير السابقة للمورّد من Memory Bank..."
يُعدّ سجلّ التدقيق هذا قيّمًا لتحديد الأخطاء ويضمن قدرة المشغّلين البشريين على الوثوق بالقرارات المستقلة التي يتخذها الوكيل.
from google.adk.agents.callback_context import CallbackContext
...
# --- ADK CALLBACKS (Narrative Engine) ---
execution_logs = []
async def trace_callback(context: CallbackContext):
"""
Captures agent and tool invocation flow for the UI narrative.
"""
agent_name = context.agent.name
event = {
"agent": agent_name,
"action": "Processing request steps...",
"type": "orchestration_event"
}
execution_logs.append(event)
return None
...
هذا كل ما في الأمر!!! لقد استنسخنا المشروع بنجاح وتعرّفنا على تفاصيل الوكيل والذاكرة والسياق.
يمكنك اختبار ذلك من خلال الانتقال إلى مجلد المشروع الخاص بالمستودع الذي تم استنساخه وتنفيذ الأوامر التالية:
>> pip install -r requirements.txt
>> python app.py
من المفترض أن يؤدي ذلك إلى بدء تشغيل الوكيل على جهازك محليًا وأن تتمكّن من اختباره.
9- لننشره على Cloud Run
- يمكنك نشرها على Cloud Run من خلال تنفيذ الأمر التالي من "وحدة Cloud Shell الطرفية" حيث يتم استنساخ المشروع والتأكّد من أنّك داخل المجلد الجذر للمشروع.
نفِّذ ما يلي في وحدة Cloud Shell الطرفية:
gcloud run deploy supply-chain-agent --source . --platform managed --region us-central1 --allow-unauthenticated --set-env-vars GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT>>,GOOGLE_CLOUD_LOCATION=us-central1,GOOGLE_GENAI_USE_VERTEXAI=TRUE,REASONING_ENGINE_APP_NAME=<<YOUR_APP_ENGINE_URL>>,TOOLBOX_SERVER=<<YOUR_TOOLBOX_SERVER>>,TOOLBOX_TOOLSET=supply_chain_toolset,AGENT_ENGINE_ID=<<YOUR_AGENT_ENGINE_ID>>
استبدِل قيم العناصر النائبة <<YOUR_PROJECT>>, <<YOUR_APP_ENGINE_URL>>, <<YOUR_TOOLBOX_SERVER>> و<<YOUR_AGENT_ENGINE_ID>>
بعد انتهاء الأمر، سيتم عرض عنوان URL للخدمة. انسخها.
- امنح دور عميل AlloyDB لحساب خدمة Cloud Run.يتيح ذلك لتطبيقك الذي لا يحتاج إلى خادم إنشاء نفق آمن إلى قاعدة البيانات.
نفِّذ ما يلي في وحدة Cloud Shell الطرفية:
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
استخدِم الآن عنوان URL للخدمة (نقطة نهاية Cloud Run التي نسختها سابقًا) واختبِر التطبيق.
ملاحظة: إذا واجهت مشكلة في الخدمة، وتم ذكر الذاكرة كسبب، جرِّب زيادة الحدّ الأقصى المخصّص للذاكرة إلى 1 غيغابايت لاختبارها.
10. تَنظيم
بعد الانتهاء من هذا المختبر، لا تنسَ حذف مجموعة AlloyDB ونسختها.
يجب أن يؤدي ذلك إلى تنظيف المجموعة مع مثيلاتها.
11. تهانينا
من خلال الجمع بين سرعة AlloyDB وكفاءة التنسيق في MCP Toolbox و"الذاكرة المؤسسية" في Vertex AI Memory Bank، أنشأنا نظامًا لسلسلة الإمداد يتطوّر باستمرار. لا يقتصر دوره على الإجابة عن الأسئلة، بل يتذكّر أنّ مستودعك في سنغافورة يعاني دائمًا من التأخيرات المرتبطة بالرياح الموسمية، ويقترح بشكل استباقي إعادة توجيه الشحنات قبل أن تطلب ذلك.