
১. সংক্ষিপ্ত বিবরণ
এই কোডল্যাবে, আপনি একটি সাপ্লাই চেইন অর্কেস্ট্রেটর এজেন্ট তৈরি করবেন। এই অ্যাপ্লিকেশনটি ব্যবহারকারীদের স্বাভাবিক ভাষা ব্যবহার করে ইনভেন্টরি বিশ্লেষণ, লজিস্টিকস ট্র্যাক এবং সাপ্লাই চেইন ঝুঁকি পরিচালনা করতে সাহায্য করে।
আমরা গুগলের এজেন্ট ডেভেলপমেন্ট কিট (ADK) ব্যবহার করে একটি মাল্টি-এজেন্ট আর্কিটেকচার তৈরি করব, যা কনটেক্সট বজায় রাখবে, ভার্টেক্স এআই মেমোরি ব্যাংকের মাধ্যমে ব্যবহারকারীর পছন্দ মনে রাখবে এবং এমসিপি টুলবক্সের মাধ্যমে অ্যালয়ডিবি-তে সংরক্ষিত একটি বিশাল ডেটাসেটের সাথে ইন্টারঅ্যাক্ট করবে।
আপনি যা তৈরি করবেন
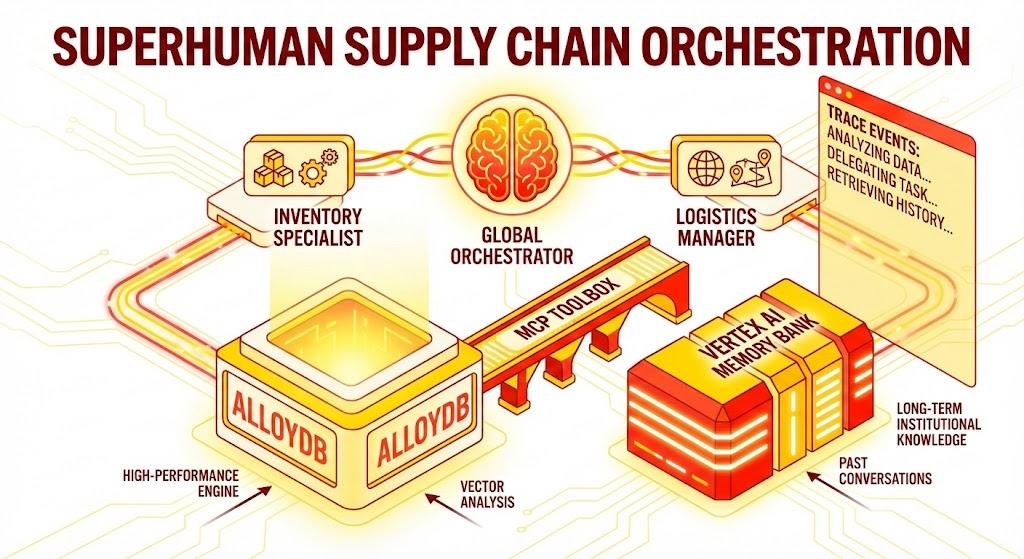
একটি পাইথন ফ্লাস্ক অ্যাপ্লিকেশন, যা নিম্নলিখিত উপাদানগুলো নিয়ে গঠিত:
গ্লোবাল অর্কেস্ট্রেটর এজেন্ট: মূল এজেন্ট যা কথোপকথনের প্রবাহ এবং দায়িত্ব অর্পণ পরিচালনা করে।
বিশেষজ্ঞ এজেন্ট: নির্দিষ্ট ক্ষেত্রের কাজের জন্য একজন "ইনভেন্টরি স্পেশালিস্ট" এবং "লজিস্টিকস ম্যানেজার"।
স্মৃতি একীকরণ: ভার্টেক্স এআই মেমোরি ব্যাংক ব্যবহার করে স্বল্পমেয়াদী সেশন স্মৃতি এবং দীর্ঘমেয়াদী স্মৃতি।
ন্যারেটিভ ইউআই: একটি ওয়েব ইন্টারফেস যা এজেন্টের যুক্তি প্রক্রিয়াকে দৃশ্যমান করে (ট্রেস কনটেক্সট)।
আপনি যা শিখবেন
- গুগল এডিকে ব্যবহার করে কীভাবে বিশেষায়িত এজেন্ট ও সাব-এজেন্ট তৈরি করা যায়।
- দীর্ঘমেয়াদী এজেন্ট মেমরির জন্য কীভাবে ভার্টেক্স এআই মেমরি ব্যাংক একীভূত করা যায়।
- MCP টুলবক্স ব্যবহার করে কীভাবে এজেন্টদের AlloyDB ডেটা টুলের সাথে সংযুক্ত করবেন।
- এজেন্টের যুক্তি পর্যবেক্ষণ ও দৃশ্যায়নের জন্য কীভাবে ADK কলব্যাক প্রয়োগ করতে হয়।
- ক্লাউড রান ব্যবহার করে কীভাবে সলিউশনটি ডেপ্লয় করবেন অথবা লোকালি চালাবেন।
স্থাপত্য
টেক স্ট্যাক
- AlloyDB for PostgreSQL: এটি একটি উচ্চ-কর্মক্ষমতাসম্পন্ন অপারেশনাল ডেটাবেস হিসেবে কাজ করে, যেখানে ৫০,০০০-এর বেশি সাপ্লাই চেইন রেকর্ড সংরক্ষিত থাকে। এটি ভেক্টর সার্চ এবং ডেটা পুনরুদ্ধারের সুবিধা প্রদান করে।
- MCP টুলবক্স ফর ডেটাবেস: এটি 'অর্কেস্ট্রেশন মায়েস্ট্রো' হিসেবে কাজ করে, AlloyDB ডেটাকে এক্সিকিউটেবল টুল হিসেবে প্রকাশ করে যা এজেন্টরা কল করতে পারে।
- এজেন্ট ডেভেলপমেন্ট কিট (ADK): এজেন্ট, নির্দেশাবলী এবং টুলসমূহ সংজ্ঞায়িত করতে ব্যবহৃত কাঠামো।
- ভার্টেক্স এআই মেমোরি ব্যাংক: এটি দীর্ঘমেয়াদী স্মৃতি সরবরাহ করে, যা এজেন্টকে বিভিন্ন সেশন জুড়ে ব্যবহারকারীর পছন্দ এবং পূর্ববর্তী কার্যকলাপ মনে রাখতে সাহায্য করে।
- ভার্টেক্স এআই সেশন সার্ভিস: স্বল্পমেয়াদী কথোপকথনের প্রেক্ষাপট পরিচালনা করে।
প্রবাহ
- ব্যবহারকারীর জিজ্ঞাসা: ব্যবহারকারী একটি প্রশ্ন জিজ্ঞাসা করেন (যেমন, "প্রিমিয়াম আইসক্রিমের স্টক আছে কিনা দেখুন")।
- মেমরি চেক: অর্কেস্ট্রেটর প্রাসঙ্গিক পূর্ববর্তী তথ্যের জন্য মেমরি ব্যাংক পরীক্ষা করে (যেমন, "ব্যবহারকারী EMEA-এর একজন আঞ্চলিক ব্যবস্থাপক")।
- দায়িত্ব অর্পণ: অর্কেস্ট্রেটর কাজটি ইনভেন্টরি স্পেশালিস্টকে অর্পণ করেন।
- টুলের প্রয়োগ: বিশেষজ্ঞ AlloyDB-তে কোয়েরি করার জন্য MCP টুলবক্স দ্বারা প্রদত্ত টুলগুলো ব্যবহার করেন।
- প্রতিক্রিয়া: এজেন্ট ডেটা প্রক্রিয়াকরণ করে একটি মার্কডাউন-ফরম্যাট করা টেবিল ফেরত দেয়।
- স্মৃতি সংরক্ষণ: গুরুত্বপূর্ণ মিথস্ক্রিয়াগুলো মেমরি ব্যাংকে সংরক্ষিত হয়।
প্রয়োজনীয়তা
- একটি ব্রাউজার, যেমন ক্রোম বা ফায়ারফক্স ।
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
- SQL এবং Python সম্পর্কে প্রাথমিক ধারণা।
২. শুরু করার আগে
একটি প্রকল্প তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন ।
- আপনি ক্লাউড শেল ব্যবহার করবেন, যা গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ। গুগল ক্লাউড কনসোলের শীর্ষে থাকা ‘Activate Cloud Shell’-এ ক্লিক করুন।

- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি নিম্নলিখিত কমান্ডটি ব্যবহার করে যাচাই করে নিন যে আপনি ইতিমধ্যেই প্রমাণীকৃত এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে:
gcloud auth list
- gcloud কমান্ডটি আপনার প্রজেক্ট সম্পর্কে অবগত আছে কিনা, তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান।
gcloud config list project
- আপনার প্রজেক্টটি সেট করা না থাকলে, এটি সেট করতে নিম্নলিখিত কমান্ডটি ব্যবহার করুন:
gcloud config set project <YOUR_PROJECT_ID>
- প্রয়োজনীয় এপিআইগুলো সক্রিয় করুন: লিঙ্কটি অনুসরণ করুন এবং এপিআইগুলো সক্রিয় করুন।
বিকল্পভাবে আপনি এর জন্য gcloud কমান্ড ব্যবহার করতে পারেন। gcloud কমান্ড এবং এর ব্যবহার সম্পর্কে জানতে ডকুমেন্টেশন দেখুন।
অপ্রত্যাশিত সমস্যা ও সমাধান
"ঘোস্ট প্রজেক্ট" সিন্ড্রোম | আপনি |
বিলিং ব্যারিকেড | আপনি প্রজেক্টটি চালু করেছেন, কিন্তু বিলিং অ্যাকাউন্টটি দিতে ভুলে গেছেন। AlloyDB একটি উচ্চ-ক্ষমতাসম্পন্ন ইঞ্জিন; এর 'গ্যাস ট্যাঙ্ক' (বিলিং) খালি থাকলে এটি চালু হবে না। |
এপিআই প্রচার বিলম্ব | আপনি "এপিআই সক্ষম করুন" এ ক্লিক করেছেন, কিন্তু কমান্ড লাইনে এখনও |
কোটা কোয়াগস | আপনি যদি একটি একেবারে নতুন ট্রায়াল অ্যাকাউন্ট ব্যবহার করেন, তাহলে AlloyDB ইনস্ট্যান্সের জন্য আপনার আঞ্চলিক কোটা শেষ হয়ে যেতে পারে। যদি |
"লুকানো" পরিষেবা এজেন্ট | কখনও কখনও AlloyDB সার্ভিস এজেন্টকে স্বয়ংক্রিয়ভাবে |
৩. ডাটাবেস সেটআপ
আমাদের অ্যাপ্লিকেশনের কেন্দ্রবিন্দুতে রয়েছে AlloyDB for PostgreSQL । আমরা এর শক্তিশালী ভেক্টর সক্ষমতা এবং সমন্বিত কলামার ইঞ্জিনকে কাজে লাগিয়ে ৫০,০০০-এরও বেশি SCM রেকর্ডের জন্য এমবেডিং তৈরি করেছি। এটি প্রায় রিয়েল-টাইম ভেক্টর বিশ্লেষণ সক্ষম করে, যার ফলে আমাদের এজেন্টরা মিলিসেকেন্ডের মধ্যে বিশাল ডেটাসেট জুড়ে ইনভেন্টরির অসঙ্গতি বা লজিস্টিকস ঝুঁকি শনাক্ত করতে পারে।
এই ল্যাবে আমরা পরীক্ষার ডেটার জন্য ডাটাবেস হিসেবে AlloyDB ব্যবহার করব। এটি ডাটাবেস এবং লগের মতো সমস্ত রিসোর্স ধারণ করার জন্য ক্লাস্টার ব্যবহার করে। প্রতিটি ক্লাস্টারে একটি প্রাইমারি ইনস্ট্যান্স থাকে যা ডেটাতে অ্যাক্সেস পয়েন্ট সরবরাহ করে। টেবিলগুলোতে আসল ডেটা থাকবে।
চলুন একটি AlloyDB ক্লাস্টার, ইনস্ট্যান্স এবং টেবিল তৈরি করি যেখানে টেস্ট ডেটাসেটটি লোড করা হবে।
- নিচের বোতামটিতে ক্লিক করুন অথবা লিঙ্কটি কপি করে আপনার ব্রাউজারে পেস্ট করুন, যেখানে গুগল ক্লাউড কনসোল ব্যবহারকারী লগ ইন করা আছেন।
বিকল্পভাবে , আপনি আপনার প্রজেক্ট থেকে ক্লাউড শেল টার্মিনালে যেতে পারেন, যেখানে আপনি বিলিং অ্যাকাউন্টটি রিডিম করেছেন, এবং নিচের কমান্ডগুলো ব্যবহার করে গিটহাব রিপোটি ক্লোন করে প্রজেক্টটিতে নেভিগেট করতে পারেন:
git clone https://github.com/AbiramiSukumaran/easy-alloydb-setup
cd easy-alloydb-setup
- এই ধাপটি সম্পন্ন হলে রিপোটি আপনার লোকাল ক্লাউড শেল এডিটরে ক্লোন করা হবে এবং আপনি প্রজেক্ট ফোল্ডার থেকে নিচের কমান্ডটি চালাতে পারবেন (আপনাকে অবশ্যই প্রজেক্ট ডিরেক্টরিতে থাকতে হবে):
sh run.sh
- এখন UI ব্যবহার করুন (টার্মিনালে থাকা লিঙ্কে ক্লিক করে অথবা টার্মিনালে থাকা 'preview on web' লিঙ্কে ক্লিক করে)।
- শুরু করার জন্য আপনার প্রজেক্ট আইডি, ক্লাস্টার এবং ইনস্ট্যান্সের নামগুলোর বিবরণ লিখুন।
- লগগুলো স্ক্রল হতে হতে আপনি এক কাপ কফি নিয়ে আসুন এবং পর্দার আড়ালে এটি কীভাবে কাজ করছে তা এখানে পড়ে নিন।
অপ্রত্যাশিত সমস্যা ও সমাধান
"ধৈর্য" সমস্যা | ডাটাবেস ক্লাস্টার একটি ভারী অবকাঠামো। যদি আপনি পৃষ্ঠাটি রিফ্রেশ করেন বা ক্লাউড শেল সেশনটি "আটকে গেছে" ভেবে বন্ধ করে দেন, তাহলে এর ফলে একটি "ঘোস্ট" ইনস্ট্যান্স তৈরি হতে পারে যা আংশিকভাবে প্রোভিশন করা এবং ম্যানুয়াল হস্তক্ষেপ ছাড়া মুছে ফেলা অসম্ভব। |
অঞ্চলের অমিল | আপনি যদি |
জম্বি ক্লাস্টার | যদি আপনি আগে কোনো ক্লাস্টারের জন্য একই নাম ব্যবহার করে থাকেন এবং সেটি মুছে না ফেলেন, তাহলে স্ক্রিপ্টটি বলতে পারে যে ক্লাস্টারের নামটি ইতিমধ্যেই বিদ্যমান। একটি প্রোজেক্টের মধ্যে ক্লাস্টারের নাম অবশ্যই অনন্য হতে হবে। |
ক্লাউড শেল টাইমআউট | আপনার কফি বিরতি যদি ৩০ মিনিটের হয়, তাহলে ক্লাউড শেল স্লিপ মোডে চলে যেতে পারে এবং |
৪. স্কিমা প্রোভিশনিং
আপনার AlloyDB ক্লাস্টার এবং ইনস্ট্যান্স চালু হয়ে গেলে, AI এক্সটেনশনগুলি সক্রিয় করতে এবং স্কিমাটি প্রোভিশন করতে AlloyDB Studio SQL এডিটরে যান।
আপনার ইনস্ট্যান্সটি তৈরি হওয়া শেষ না হওয়া পর্যন্ত আপনাকে অপেক্ষা করতে হতে পারে। এটি তৈরি হয়ে গেলে, ক্লাস্টার তৈরির সময় আপনি যে ক্রেডেনশিয়ালগুলো তৈরি করেছিলেন, সেগুলো ব্যবহার করে AlloyDB-তে সাইন ইন করুন। PostgreSQL-এ প্রমাণীকরণের জন্য নিম্নলিখিত ডেটা ব্যবহার করুন:
- ব্যবহারকারীর নাম : "
postgres" - ডাটাবেস : "
postgres" - পাসওয়ার্ড : "
alloydb" (অথবা তৈরির সময় আপনি যা সেট করেছিলেন)
AlloyDB Studio-তে সফলভাবে প্রমাণীকরণের পর, এডিটর-এ SQL কমান্ডগুলো প্রবেশ করানো হয়। শেষ উইন্ডোটির ডানদিকে থাকা প্লাস চিহ্নটি ব্যবহার করে আপনি একাধিক এডিটর উইন্ডো যোগ করতে পারেন।
আপনি এডিটর উইন্ডোতে AlloyDB-এর জন্য কমান্ড লিখবেন এবং প্রয়োজন অনুযায়ী Run, Format ও Clear অপশনগুলো ব্যবহার করবেন।
এক্সটেনশনগুলি সক্ষম করুন
এই অ্যাপটি তৈরি করার জন্য, আমরা pgvector এবং google_ml_integration এক্সটেনশনগুলো ব্যবহার করব। pgvector এক্সটেনশনটি আপনাকে ভেক্টর এমবেডিং সংরক্ষণ এবং অনুসন্ধান করার সুযোগ দেয়। google_ml_integration এক্সটেনশনটি এমন সব ফাংশন সরবরাহ করে যা ব্যবহার করে আপনি Vertex AI প্রেডিকশন এন্ডপয়েন্টগুলো অ্যাক্সেস করে SQL-এ প্রেডিকশন পেতে পারেন। নিম্নলিখিত DDL-গুলো রান করে এই এক্সটেনশনগুলো সক্রিয় করুন :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
একটি টেবিল তৈরি করুন
আপনি AlloyDB Studio-তে নিচের DDL স্টেটমেন্টটি ব্যবহার করে একটি টেবিল তৈরি করতে পারেন:
DROP TABLE IF EXISTS shipments;
DROP TABLE IF EXISTS products;
-- 1. Product Inventory Table
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
category VARCHAR(100),
stock_level INTEGER,
distribution_center VARCHAR(100),
region VARCHAR(50),
embedding vector(768),
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. Logistics & Shipments
CREATE TABLE shipments (
shipment_id SERIAL PRIMARY KEY,
product_id INTEGER REFERENCES products(id),
status VARCHAR(50), -- 'In Transit', 'Delayed', 'Delivered', 'Pending'
estimated_arrival TIMESTAMP,
route_efficiency_score DECIMAL(3, 2)
);
embedding কলামটি কিছু টেক্সট ফিল্ডের ভেক্টর মান সংরক্ষণের সুযোগ দেবে।
ডেটা ইনজেশন
products টেবিলে একসাথে ৫০,০০০ রেকর্ড ইনসার্ট করতে নিচের SQL স্টেটমেন্টগুলো চালান:
-- We use a CROSS JOIN pattern with realistic naming segments to create meaningful variety
DO $$
DECLARE
brand_names TEXT[] := ARRAY['Artisan', 'Nature', 'Elite', 'Pure', 'Global', 'Eco', 'Velocity', 'Heritage', 'Aura', 'Summit'];
product_types TEXT[] := ARRAY['Ice Cream', 'Body Wash', 'Laundry Detergent', 'Shampoo', 'Mayonnaise', 'Deodorant', 'Tea', 'Soup', 'Face Cream', 'Soap'];
variants TEXT[] := ARRAY['Classic', 'Gold', 'Premium', 'Eco-Friendly', 'Organic', 'Night-Repair', 'Extra-Fresh', 'Zero-Sugar', 'Sensitive', 'Maximum-Strength'];
regions TEXT[] := ARRAY['EMEA', 'APAC', 'LATAM', 'NAMER'];
dcs TEXT[] := ARRAY['London-Hub', 'Mumbai-Central', 'Sao-Paulo-Logistics', 'Singapore-Port', 'Rotterdam-Gate', 'New-York-DC'];
BEGIN
INSERT INTO products (name, category, stock_level, distribution_center, region)
SELECT
b || ' ' || v || ' ' || t as name,
CASE
WHEN t IN ('Ice Cream', 'Mayonnaise', 'Tea', 'Soup') THEN 'Food & Refreshment'
WHEN t IN ('Body Wash', 'Shampoo', 'Deodorant', 'Face Cream', 'Soap') THEN 'Personal Care'
ELSE 'Home Care'
END as category,
floor(random() * 20000 + 100)::int as stock_level,
dcs[floor(random() * 6 + 1)] as distribution_center,
regions[floor(random() * 4 + 1)] as region
FROM
unnest(brand_names) b,
unnest(variants) v,
unnest(product_types) t,
generate_series(1, 50); -- 10 * 10 * 10 * 50 = 50,000 records
END $$;
এক্সিকিউটিভ স্টাইলের প্রশ্নের জন্য অনুমানযোগ্য উত্তর নিশ্চিত করতে ডেমো-নির্দিষ্ট রেকর্ড সন্নিবেশ করা যাক।
-- These ensure you have predictable answers for specific "Executive" questions
INSERT INTO products (name, category, stock_level, distribution_center, region) VALUES
('Magnum Ultra Gold Limited Edition', 'Food & Refreshment', 45, 'Rotterdam-Gate', 'EMEA'),
('Dove Pro-Health Deep Moisture', 'Personal Care', 12000, 'Mumbai-Central', 'APAC'),
('Hellmanns Real Organic Mayonnaise', 'Food & Refreshment', 8000, 'London-Hub', 'EMEA');
চালানের তথ্য সন্নিবেশ করা হচ্ছে
-- Shipments Generation (More shipments than products)
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT
id,
CASE
WHEN random() > 0.8 THEN 'Delayed'
WHEN random() > 0.4 THEN 'In Transit'
ELSE 'Delivered'
END,
NOW() + (random() * 10 || ' days')::interval,
(random() * 0.5 + 0.5)::decimal(3,2)
FROM products
WHERE random() > 0.3; -- Create shipments for ~70% of products
-- Add duplicate shipments for some products to show complex logistics
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT id, 'In Transit', NOW() + INTERVAL '12 days', 0.88
FROM products
LIMIT 5000;
অনুমতি প্রদান করুন
'embedding' ফাংশনটিতে execute অনুমোদন দিতে নিচের স্টেটমেন্টটি চালান:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB পরিষেবা অ্যাকাউন্টে Vertex AI ব্যবহারকারীর ROLE প্রদান করুন।
Google Cloud IAM কনসোল থেকে, AlloyDB সার্ভিস অ্যাকাউন্টকে (যা দেখতে এইরকম: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) "Vertex AI User" রোলের অ্যাক্সেস দিন। PROJECT_NUMBER-এ আপনার প্রজেক্ট নম্বরটি থাকবে।
বিকল্পভাবে আপনি ক্লাউড শেল টার্মিনাল থেকে নিচের কমান্ডটি চালাতে পারেন:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
এমবেডিং তৈরি করুন
এরপরে, নির্দিষ্ট অর্থপূর্ণ টেক্সট ফিল্ডগুলোর জন্য ভেক্টর এমবেডিং তৈরি করা যাক:
WITH
rows_to_update AS (
SELECT
id
FROM
products
WHERE
embedding IS NULL
LIMIT
5000 )
UPDATE
products
SET
embedding = ai.embedding('text-embedding-005', name || ' ' || category || ' ' || distribution_center || ' ' || region)::vector
FROM
rows_to_update
WHERE
products.id = rows_to_update.id
AND embedding IS null;
উপরের এই স্টেটমেন্টটিতে আমরা লিমিট ৫০০০ নির্ধারণ করেছি, তাই টেবিলের এমন কোনো রো না থাকা পর্যন্ত এটি বারবার চালান, যেটির কলাম এমবেডিং NULL।
অপ্রত্যাশিত সমস্যা ও সমাধান
"পাসওয়ার্ড অ্যামনেসিয়া" লুপ | আপনি যদি "ওয়ান ক্লিক" সেটআপ ব্যবহার করে থাকেন এবং আপনার পাসওয়ার্ড মনে না থাকে, তাহলে কনসোলের ইনস্ট্যান্স বেসিক ইনফরমেশন পেজে গিয়ে |
"এক্সটেনশন খুঁজে পাওয়া যায়নি" ত্রুটি | যদি |
আইএএম প্রসারণ ব্যবধান | আপনি |
ভেক্টর মাত্রার অমিল | |
প্রজেক্ট আইডি টাইপো | |
৫. টুলস ও টুলবক্স সেটআপ
MCP টুলবক্স ফর ডেটাবেস হলো ডেটাবেসের জন্য একটি ওপেন সোর্স MCP সার্ভার। এটি কানেকশন পুলিং, অথেন্টিকেশন এবং আরও অনেক জটিল বিষয় সামলানোর মাধ্যমে আপনাকে আরও সহজে, দ্রুত এবং নিরাপদে টুল তৈরি করতে সক্ষম করে। টুলবক্স আপনাকে এমন জেন এআই (Gen AI) টুল তৈরি করতে সাহায্য করে, যা আপনার এজেন্টদেরকে আপনার ডেটাবেসের ডেটা অ্যাক্সেস করতে দেয়।
আমরা ডেটাবেসের জন্য মডেল কনটেক্সট প্রোটোকল (MCP) টুলবক্সকে 'কন্ডাক্টর' হিসেবে ব্যবহার করি। এটি আমাদের এজেন্ট এবং AlloyDB-এর মধ্যে একটি প্রমিত মিডলওয়্যার হিসেবে কাজ করে। একটি tools.yaml কনফিগারেশন সংজ্ঞায়িত করার মাধ্যমে, টুলবক্সটি স্বয়ংক্রিয়ভাবে জটিল ডেটাবেস অপারেশনগুলোকে search_products_by_context বা check_inventory_levels মতো পরিচ্ছন্ন, নির্বাহযোগ্য টুল হিসেবে প্রকাশ করে। এর ফলে এজেন্ট লজিকের মধ্যে ম্যানুয়াল কানেকশন পুলিং বা বয়লারপ্লেট SQL-এর প্রয়োজনীয়তা দূর হয়।
টুলবক্স সার্ভার ইনস্টল করা হচ্ছে
আপনার ক্লাউড শেল টার্মিনাল থেকে, আপনার নতুন টুলস yaml ফাইল এবং টুলবক্স বাইনারি সংরক্ষণের জন্য একটি ফোল্ডার তৈরি করুন:
mkdir scm-agent-toolbox
cd scm-agent-toolbox
সেই নতুন ফোল্ডারটির ভেতর থেকে, নিম্নলিখিত কমান্ডগুলো চালান:
# see releases page for other versions
export VERSION=0.27.0
curl -L -o toolbox https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
এরপর ক্লাউড শেল এডিটর-এ প্রবেশ করে এই রিপো ফাইলের বিষয়বস্তুগুলো কপি করে সেই নতুন ফোল্ডারের ভিতরে tools.yaml ফাইলটি তৈরি করুন।
sources:
supply_chain_db:
kind: "alloydb-postgres"
project: "YOUR_PROJECT_ID"
region: "us-central1"
cluster: "YOUR_CLUSTER"
instance: "YOUR_INSTANCE"
database: "postgres"
user: "postgres"
password: "YOUR_PASSWORD"
tools:
search_products_by_context:
kind: postgres-sql
source: supply_chain_db
description: Find products in the inventory using natural language search and vector embeddings.
parameters:
- name: search_text
type: string
description: Description of the product or category the user is looking for.
statement: |
SELECT name, category, stock_level, distribution_center, region
FROM products
ORDER BY embedding <=> ai.embedding('text-embedding-005', $1)::vector
LIMIT 5;
check_inventory_levels:
kind: postgres-sql
source: supply_chain_db
description: Get precise stock levels for a specific product name.
parameters:
- name: product_name
type: string
description: The exact or partial name of the product.
statement: |
SELECT name, stock_level, distribution_center, last_updated
FROM products
WHERE name ILIKE '%' || $1 || '%'
ORDER BY stock_level DESC;
track_shipment_status:
kind: postgres-sql
source: supply_chain_db
description: Retrieve real-time logistics and shipping status for a specific region or product.
parameters:
- name: region
type: string
description: The geographical region to filter shipments (e.g., EMEA, APAC).
statement: |
SELECT p.name, s.status, s.estimated_arrival, s.route_efficiency_score
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE p.region = $1
ORDER BY s.estimated_arrival ASC;
analyze_supply_chain_risk:
kind: postgres-sql
source: supply_chain_db
description: Rerank and filter shipments based on risk profiles and efficiency scores using Google ML reranker.
parameters:
- name: risk_context
type: string
description: The business context for risk analysis (e.g., 'heatwave impact' or 'port strike').
statement: |
WITH initial_ranking AS (
SELECT s.shipment_id, p.name, s.status, p.distribution_center,
ROW_NUMBER() OVER () AS ref_number
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE s.status != 'Delivered'
LIMIT 10
),
reranked_results AS (
SELECT index, score FROM
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => $1,
documents => (SELECT ARRAY_AGG(name || ' at ' || distribution_center ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT i.name, i.status, i.distribution_center, r.score
FROM initial_ranking i, reranked_results r
WHERE i.ref_number = r.index
ORDER BY r.score DESC;
toolsets:
supply_chain_toolset:
- search_products_by_context
- check_inventory_levels
- track_shipment_status
- analyze_supply_chain_risk
এখন স্থানীয় সার্ভারে tools.yaml ফাইলটি পরীক্ষা করুন:
./toolbox --tools-file "tools.yaml"
বিকল্পভাবে আপনি UI-তে এটি পরীক্ষা করতে পারেন।
./toolbox --ui
চমৎকার!! সবকিছু ঠিকঠাক কাজ করছে বলে নিশ্চিত হয়ে গেলে, নিচের নির্দেশ অনুযায়ী ক্লাউড রান-এ এটি ডেপ্লয় করুন।
ক্লাউড রান ডিপ্লয়মেন্ট
- PROJECT_ID এনভায়রনমেন্ট ভেরিয়েবল সেট করুন:
export PROJECT_ID="my-project-id"
- gcloud CLI চালু করুন:
gcloud init
gcloud config set project $PROJECT_ID
- আপনার নিম্নলিখিত API গুলি সক্রিয় থাকতে হবে:
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- আপনার যদি আগে থেকে একটি ব্যাকএন্ড সার্ভিস অ্যাকাউন্ট না থাকে, তাহলে একটি তৈরি করুন:
gcloud iam service-accounts create toolbox-identity
- সিক্রেট ম্যানেজার ব্যবহারের অনুমতি দিন:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
- সার্ভিস অ্যাকাউন্টকে আমাদের AlloyDB সোর্সের জন্য নির্দিষ্ট অতিরিক্ত অনুমতিগুলো (roles/alloydb.client এবং roles/serviceusage.serviceUsageConsumer) প্রদান করুন।
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role serviceusage.serviceUsageConsumer
- tools.yaml ফাইলটিকে সিক্রেট হিসেবে আপলোড করুন:
gcloud secrets create tools-scm-agent --data-file=tools.yaml
- আপনার যদি আগে থেকেই একটি সিক্রেট থাকে এবং আপনি সেটির ভার্সন আপডেট করতে চান, তাহলে নিম্নলিখিতটি সম্পাদন করুন:
gcloud secrets versions add tools-scm-agent --data-file=tools.yaml
- ক্লাউড রানের জন্য আপনি যে কন্টেইনার ইমেজটি ব্যবহার করতে চান, সেটির জন্য একটি এনভায়রনমেন্ট ভেরিয়েবল সেট করুন:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- নিম্নলিখিত কমান্ড ব্যবহার করে টুলবক্সকে ক্লাউড রানে স্থাপন করুন:
আপনি যদি আপনার AlloyDB ইনস্ট্যান্সে পাবলিক অ্যাক্সেস চালু করে থাকেন (যা সুপারিশ করা হয় না), তাহলে Cloud Run-এ ডেপ্লয়মেন্টের জন্য নিচের কমান্ডটি অনুসরণ করুন:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
আপনি যদি VPC নেটওয়ার্ক ব্যবহার করেন, তাহলে নিচের কমান্ডটি ব্যবহার করুন:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
# TODO(dev): update the following to match your VPC details
--network <<YOUR_NETWORK_NAME>> \
--subnet <<YOUR_SUBNET_NAME>> \
--allow-unauthenticated
৬. এজেন্ট সেটআপ
এজেন্ট ডেভেলপমেন্ট কিট (ADK) ব্যবহার করে, আমরা একক প্রম্পট ব্যবস্থা থেকে সরে এসে একটি বিশেষায়িত, বহু-এজেন্ট স্থাপত্যের দিকে অগ্রসর হয়েছি:
- ইনভেন্টরি স্পেশালিস্ট : পণ্যের স্টক এবং গুদামের মেট্রিক্সে মনোনিবেশ করেন।
- লজিস্টিকস ম্যানেজার : বৈশ্বিক শিপিং রুট এবং ঝুঁকি বিশ্লেষণে বিশেষজ্ঞ।
- গ্লোবালঅর্কেস্ট্রেটর : সেই 'মস্তিষ্ক' যা যুক্তির মাধ্যমে কাজ অর্পণ করে এবং প্রাপ্ত তথ্য সংশ্লেষণ করে।
এই রিপোটি আপনার প্রজেক্টে ক্লোন করুন এবং চলুন বিষয়টি ধাপে ধাপে দেখি।
এটি ক্লোন করতে, আপনার ক্লাউড শেল টার্মিনাল থেকে (রুট ডিরেক্টরিতে অথবা যেখান থেকে আপনি এই প্রজেক্টটি তৈরি করতে চান), নিম্নলিখিত কমান্ডটি চালান:
git clone https://github.com/AbiramiSukumaran/scm-memory-agent
- এতে প্রজেক্টটি তৈরি হয়ে যাবে এবং আপনি ক্লাউড শেল এডিটর-এ তা যাচাই করতে পারবেন।

- আপনার প্রজেক্ট এবং ইনস্ট্যান্সের মানগুলো দিয়ে .env ফাইলটি আপডেট করতে ভুলবেন না।
কোড ওয়াকথ্রু
অর্কেস্ট্রেটর এজেন্টের উপর একটি সংক্ষিপ্ত দৃষ্টিপাত
Go to app.py and you should be able to see the following snippet:
orchestrator = adk.Agent(
name="GlobalOrchestrator",
model="gemini-2.5-flash",
description="Global Supply Chain Orchestrator root agent.",
instruction="""
You are the Global Supply Chain Brain. You are responsible for products, inventory and logistics.
You also have access to the memory tool, remember to include all the information that the tool can provide you with about the user before you respond.
1. Understand intent and delegate to specialists. As the Global Orchestrator, you have access to the full conversation history with the user.
When you transfer a query to a specialist agent, sub agent or tool, share the important facts and information from your memory to them so they can operate with the full context.
2. Ensure the final response is professional and uses Markdown tables for data.
3. If a specialist provides a long list, ensure only the top 10 items are shown initially.
4. Conclude with a brief, high-level executive summary of what the data implies.
""",
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
sub_agents=[inventory_agent, logistics_agent],
#after_agent_callback=auto_save_session_to_memory_callback,
)
এই কোড স্নিপেটটি হলো রুটের সংজ্ঞা, যা হলো সেই অর্কেস্ট্রেটর এজেন্ট যেটি ব্যবহারকারীর কাছ থেকে কথোপকথন বা অনুরোধ গ্রহণ করে এবং কাজের উপর ভিত্তি করে সংশ্লিষ্ট সাব-এজেন্ট বা ব্যবহারকারীর কাছে প্রয়োজনীয় টুলগুলো পাঠিয়ে দেয়।
- চলুন ইনভেন্টরি এজেন্টকে দেখি
inventory_agent = adk.Agent(
name="InventorySpecialist",
model="gemini-2.5-flash",
description="Specialist in product stock and warehouse data.",
instruction="""
Analyze inventory levels.
1. Use 'search_products_by_context' or 'check_inventory_levels'.
2. ALWAYS format results as a clean Markdown table.
3. If there are many results, display only the TOP 10 most relevant ones.
4. At the end, state: 'There are additional records available. Would you like to see more?'
""",
tools=tools
)
এই নির্দিষ্ট সাব-এজেন্ট প্রাসঙ্গিকভাবে পণ্য অনুসন্ধান করা এবং মজুদের স্তর পরীক্ষা করার মতো মজুদ সংক্রান্ত কার্যকলাপে বিশেষায়িত।
- তারপর রয়েছে লজিস্টিকস সাব এজেন্ট:
logistics_agent = adk.Agent(
name="LogisticsManager",
model="gemini-2.5-flash",
description="Expert in global shipping routes and logistics tracking.",
instruction="""
Check shipment statuses.
1. Use 'track_shipment_status' or 'analyze_supply_chain_risk'.
2. ALWAYS format results as a clean Markdown table.
3. Limit initial output to the top 10 shipments.
4. Ask if the user needs the full manifest if more results exist.
""",
tools=tools
)
এই নির্দিষ্ট সাব-এজেন্ট চালান ট্র্যাক করা এবং সরবরাহ শৃঙ্খলের ঝুঁকি বিশ্লেষণ করার মতো লজিস্টিক কার্যকলাপে বিশেষায়িত।
- এখন পর্যন্ত আমরা যে তিনটি এজেন্ট নিয়ে আলোচনা করেছি, তারা সবাই টুল ব্যবহার করে এবং এই টুলগুলোকে আমাদের টুলবক্স সার্ভারের মাধ্যমে রেফারেন্স করা হয়, যা আমরা পূর্ববর্তী অংশে ইতিমধ্যেই ডেপ্লয় করেছি। নিচের কোড স্নিপেটটি দেখুন:
from toolbox_core import ToolboxSyncClient
TOOLBOX_SERVER = os.environ["TOOLBOX_SERVER"]
TOOLBOX_TOOLSET = os.environ["TOOLBOX_TOOLSET"]
# --- ADK TOOLBOX CONFIGURATION ---
toolbox = ToolboxSyncClient(TOOLBOX_SERVER)
tools = toolbox.load_toolset(TOOLBOX_TOOLSET)
এই নির্দিষ্ট সাব-এজেন্ট চালান ট্র্যাক করা এবং সরবরাহ শৃঙ্খলের ঝুঁকি বিশ্লেষণ করার মতো লজিস্টিক কার্যকলাপে বিশেষায়িত।
৭. এজেন্ট ইঞ্জিন
প্রাথমিক রানে, এজেন্ট ইঞ্জিন তৈরি করুন।
import vertexai
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
client = vertexai.Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_LOCATION
)
agent_engine = client.agent_engines.create()
- পরবর্তী রানের জন্য, মেমরি ব্যাংক কনফিগারেশন দিয়ে এজেন্ট ইঞ্জিন আপডেট করুন:
agent_engine = client.agent_engines.update(
name=APP_NAME,
config={
"context_spec": {
"memory_bank_config": {
"generation_config": {
"model": f"projects/{PROJECT_ID}/locations/{GOOGLE_CLOUD_LOCATION}/publishers/google/models/gemini-2.5-flash"
}
}
}
})
৮. প্রেক্ষাপট, চালনা এবং স্মৃতি
এজেন্টকে একটি অবস্থাহীন বটের পরিবর্তে একজন অবিচ্ছিন্ন অংশীদার হিসেবে অনুভব করানো নিশ্চিত করতে, প্রসঙ্গ ব্যবস্থাপনাকে দুটি স্বতন্ত্র স্তরে বিভক্ত করা হয়েছে:
স্বল্পমেয়াদী স্মৃতি (সেশন) : VertexAiSessionService মাধ্যমে পরিচালিত, এটি একটি একক ইন্টারঅ্যাকশনের মধ্যেকার তাৎক্ষণিক ঘটনার ইতিহাস (ব্যবহারকারীর বার্তা, টুলের প্রতিক্রিয়া) ট্র্যাক করে।
দীর্ঘমেয়াদী স্মৃতি (মেমরি ব্যাংক) : adk.memorybankservice এর মাধ্যমে Vertex AI মেমরি ব্যাংক দ্বারা চালিত। এই স্তরটি ব্যবহারকারীর নির্দিষ্ট শিপিং ক্যারিয়ারের প্রতি পছন্দ বা গুদামে বারবার বিলম্বের মতো "অর্থপূর্ণ" তথ্য সংগ্রহ করে এবং সেশন জুড়ে সেগুলোকে সংরক্ষণ করে।
কথোপকথনের পরিধির মধ্যে সেশন মেমরির জন্য সেশন শুরু করুন।
কোড স্নিপেটের এই অংশটি বর্তমান ব্যবহারকারীর জন্য বর্তমান অ্যাপের সেশন তৈরি করে।
from google.adk.sessions import VertexAiSessionService
...
session_service = VertexAiSessionService(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
...
# Initialize the session *outside* of the route handler to avoid repeated creation
session = None
session_lock = threading.Lock()
async def initialize_session():
global session
try:
session = await session_service.create_session(app_name=APP_NAME, user_id=USER_ID)
print(f"Session {session.id} created successfully.") # Add a log
except Exception as e:
print(f"Error creating session: {e}")
session = None # Ensure session is None in case of error
# Create the session on app startup
asyncio.run(initialize_session())
দীর্ঘমেয়াদী স্মৃতির জন্য ভার্টেক্স এআই মেমরি ব্যাংক চালু করুন
কোড স্নিপেটের এই অংশটি এজেন্ট ইঞ্জিনের জন্য Vertex AI Memory Bank Service অবজেক্টটি ইনস্ট্যানশিয়েট করে।
from google.adk.memory import InMemoryMemoryService
from google.adk.memory import VertexAiMemoryBankService
...
try:
memory_bank_service = adk.memory.VertexAiMemoryBankService(
agent_engine_id=AGENT_ENGINE_ID,
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
#in_memory_service = InMemoryMemoryService()
print("Memory Bank Service initialized successfully.")
except Exception as e:
print(f"Error initializing Memory Bank Service: {e}")
memory_bank_service = None
runner = adk.Runner(
agent=orchestrator,
app_name=APP_NAME,
session_service=session_service,
memory_service=memory_bank_service,
)
...
কী কনফিগার করা আছে?
কোড স্নিপেটের এই অংশে আমরা দীর্ঘমেয়াদী স্মৃতির জন্য ভার্টেক্স এআই মেমোরি ব্যাংক সার্ভিসটি কনফিগার করছি, যা নির্দিষ্ট ব্যবহারকারীর নির্দিষ্ট অ্যাপের সেশনটিকে ভার্টেক্স এআই মেমোরি ব্যাংকের মধ্যে একটি মেমোরি হিসেবে প্রাসঙ্গিকভাবে সংরক্ষণ করে।
এজেন্ট এক্সিকিউশনের অংশ হিসেবে কী চালানো হয়?
async def run_and_collect():
final_text = ""
try:
async for event in runner.run_async(
new_message=content,
user_id=user_id,
session_id=session_id
):
if hasattr(event, 'author') and event.author:
if not any(log['agent'] == event.author for log in execution_logs):
execution_logs.append({
"agent": event.author,
"action": "Analyzing data requirements...",
"type": "orchestration_event"
})
if hasattr(event, 'text') and event.text:
final_text = event.text
elif hasattr(event, 'content') and hasattr(event.content, 'parts'):
for part in event.content.parts:
if hasattr(part, 'text') and part.text:
final_text = part.text
except Exception as e:
print(f"Error during runner.run_async: {e}")
raise # Re-raise the exception to signal failure
finally:
gc.collect()
return final_text
এটি ব্যবহারকারীর ইনপুট করা বিষয়বস্তুকে ইউজার আইডি এবং সেশন আইডি সহ 'new_message' অবজেক্টে প্রসেস করে। এরপর এজেন্ট দায়িত্ব গ্রহণ করে এবং এজেন্টের প্রতিক্রিয়া প্রসেস করে ফেরত পাঠানো হয়।
দীর্ঘমেয়াদী স্মৃতিতে কী সংরক্ষিত থাকে?
অ্যাপ এবং ব্যবহারকারীর আওতাধীন সেশনের বিবরণ সেশন ভেরিয়েবলে সংরক্ষণ করা হয়।
এরপর " add_session_to_memory " মেথডটি ব্যবহার করে এই সেশনটিকে Vertex AI Memory Bank অবজেক্টের বর্তমান অ্যাপের জন্য বর্তমান ব্যবহারকারীর মেমরি হিসেবে যুক্ত করা হয়।
session = asyncio.run(session_service.get_session(app_name=APP_NAME, user_id=USER_ID, session_id=session.id))
if memory_bank_service and session: # Check memory service AND session
try:
#asyncio.run(in_memory_service.add_session_to_memory(session))
asyncio.run(memory_bank_service.add_session_to_memory(session))
'''
client.agent_engines.memories.generate(
scope={"app_name": APP_NAME, "user_id": USER_ID},
name=APP_NAME,
direct_contents_source={
"events": [
{"content": content}
]
},
config={"wait_for_completion": True},
)
'''
print("Successfully added session to memory.******")
print(session.id)
except Exception as e:
print(f"Error adding session to memory: {e}")
স্মৃতি পুনরুদ্ধার
আমাদের সংরক্ষিত দীর্ঘমেয়াদী স্মৃতি পুনরুদ্ধার করতে হবে অ্যাপের নাম এবং ব্যবহারকারীর নামকে স্কোপ হিসেবে ব্যবহার করে (যেহেতু আমরা এই স্কোপের জন্যই স্মৃতিগুলো সংরক্ষণ করেছিলাম), যাতে প্রযোজ্য ক্ষেত্রে অর্কেস্ট্রেটর এবং অন্যান্য এজেন্টের কাছে কনটেক্সটের অংশ হিসেবে তা প্রেরণ করা যায়।
results = client.agent_engines.memories.retrieve(
name=APP_NAME,
scope={"app_name": APP_NAME, "user_id": USER_ID}
)
# RetrieveMemories returns a pager. You can use `list` to retrieve all pages' memories.
list(results)
print(list(results))
পুনরুদ্ধার করা মেমরিকে কীভাবে কনটেক্সটের অংশ হিসেবে লোড করা হয়?
আমরা অর্কেস্ট্রেটর এজেন্টের সংজ্ঞায় নিম্নলিখিত অ্যাট্রিবিউটটি ব্যবহার করি, যা রুট এজেন্টকে মেমোরি ব্যাংক থেকে কনটেক্সট প্রি-লোড করার সুযোগ দেয়। সাব-এজেন্টদের জন্য আমরা টুলবক্স সার্ভার থেকে যে টুলগুলো অ্যাক্সেস করি, এটি তার অতিরিক্ত একটি সুবিধা।
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
কলব্যাক প্রসঙ্গ
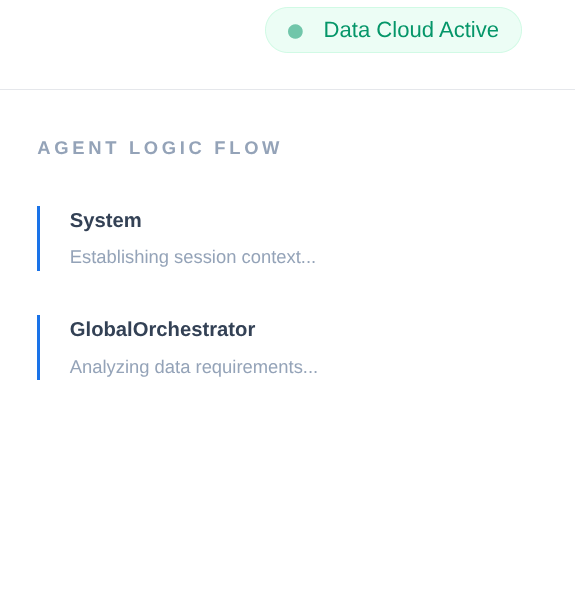
একটি এন্টারপ্রাইজ সাপ্লাই চেইনে কোনো 'ব্ল্যাক বক্স' থাকতে পারে না। আমরা একটি ন্যারেটিভ ইঞ্জিন তৈরি করতে ADK-এর CallbackContext ব্যবহার করি। এজেন্টের এক্সিকিউশনে হুক করার মাধ্যমে, আমরা প্রতিটি চিন্তার প্রক্রিয়া এবং টুল কল ক্যাপচার করে সেগুলোকে একটি UI সাইডবারে স্ট্রিম করি।
- ট্রেস ইভেন্ট : "গ্লোবালঅর্কেস্ট্রেটর ডেটার প্রয়োজনীয়তা বিশ্লেষণ করছে..."
- ট্রেস ইভেন্ট : "স্টক লেভেলের জন্য ইনভেন্টরি স্পেশালিস্টকে দায়িত্ব অর্পণ করা হচ্ছে..."
- ট্রেস ইভেন্ট : "মেমরি ব্যাংক থেকে ঐতিহাসিক সরবরাহকারীর বিলম্বের প্যাটার্ন পুনরুদ্ধার করা হচ্ছে..."
এই নিরীক্ষা বিবরণটি ডিবাগিংয়ের জন্য অমূল্য এবং এটি নিশ্চিত করে যে মানব অপারেটররা এজেন্টের স্বায়ত্তশাসিত সিদ্ধান্তের উপর আস্থা রাখতে পারে।
from google.adk.agents.callback_context import CallbackContext
...
# --- ADK CALLBACKS (Narrative Engine) ---
execution_logs = []
async def trace_callback(context: CallbackContext):
"""
Captures agent and tool invocation flow for the UI narrative.
"""
agent_name = context.agent.name
event = {
"agent": agent_name,
"action": "Processing request steps...",
"type": "orchestration_event"
}
execution_logs.append(event)
return None
...
এই তো!!! আমরা সফলভাবে প্রজেক্টটি ক্লোন করেছি এবং এজেন্ট, মেমরি ও কনটেক্সটের খুঁটিনাটি বিষয়গুলো আলোচনা করেছি।
আপনি ক্লোন করা রিপোজিটরির প্রজেক্ট ফোল্ডারে গিয়ে নিম্নলিখিত কমান্ডগুলো চালিয়ে এটি পরীক্ষা করতে পারেন:
>> pip install -r requirements.txt
>> python app.py
এটি আপনার এজেন্টকে স্থানীয়ভাবে চালু করবে এবং আপনি এটি পরীক্ষা করতে পারবেন।
৯. চলুন এটি ক্লাউড রানে ডেপ্লয় করি।
- প্রজেক্টটি যেখানে ক্লোন করা হয়েছে, সেখানকার ক্লাউড শেল টার্মিনাল থেকে নিম্নলিখিত কমান্ডটি চালিয়ে ক্লাউড রান-এ এটি ডিপ্লয় করুন এবং নিশ্চিত করুন যে আপনি প্রজেক্টটির রুট ফোল্ডারের ভিতরে আছেন ।
আপনার ক্লাউড শেল টার্মিনালে এটি চালান:
gcloud run deploy supply-chain-agent --source . --platform managed --region us-central1 --allow-unauthenticated --set-env-vars GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT>>,GOOGLE_CLOUD_LOCATION=us-central1,GOOGLE_GENAI_USE_VERTEXAI=TRUE,REASONING_ENGINE_APP_NAME=<<YOUR_APP_ENGINE_URL>>,TOOLBOX_SERVER=<<YOUR_TOOLBOX_SERVER>>,TOOLBOX_TOOLSET=supply_chain_toolset,AGENT_ENGINE_ID=<<YOUR_AGENT_ENGINE_ID>>
<<YOUR_PROJECT>>, <<YOUR_APP_ENGINE_URL>>, <<YOUR_TOOLBOX_SERVER>> এবং <<YOUR_AGENT_ENGINE_ID>> প্লেসহোল্ডারগুলির মান প্রতিস্থাপন করুন।
কমান্ডটি শেষ হলে এটি একটি সার্ভিস ইউআরএল (Service URL) দেবে। সেটি কপি করুন।
- ক্লাউড রান সার্ভিস অ্যাকাউন্টকে AlloyDB ক্লায়েন্ট রোলটি প্রদান করুন। এর ফলে আপনার সার্ভারলেস অ্যাপ্লিকেশনটি নিরাপদে ডাটাবেসে টানেল করতে পারবে।
আপনার ক্লাউড শেল টার্মিনালে এটি চালান:
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
এখন সার্ভিস ইউআরএলটি (আগে কপি করা ক্লাউড রান এন্ডপয়েন্ট) ব্যবহার করে অ্যাপটি পরীক্ষা করুন।
দ্রষ্টব্য: যদি আপনি কোনো পরিষেবা সংক্রান্ত সমস্যার সম্মুখীন হন এবং কারণ হিসেবে মেমরির কথা উল্লেখ থাকে, তবে তা পরীক্ষা করার জন্য বরাদ্দকৃত মেমরির সীমা ১ GiB পর্যন্ত বাড়িয়ে দেখতে পারেন।
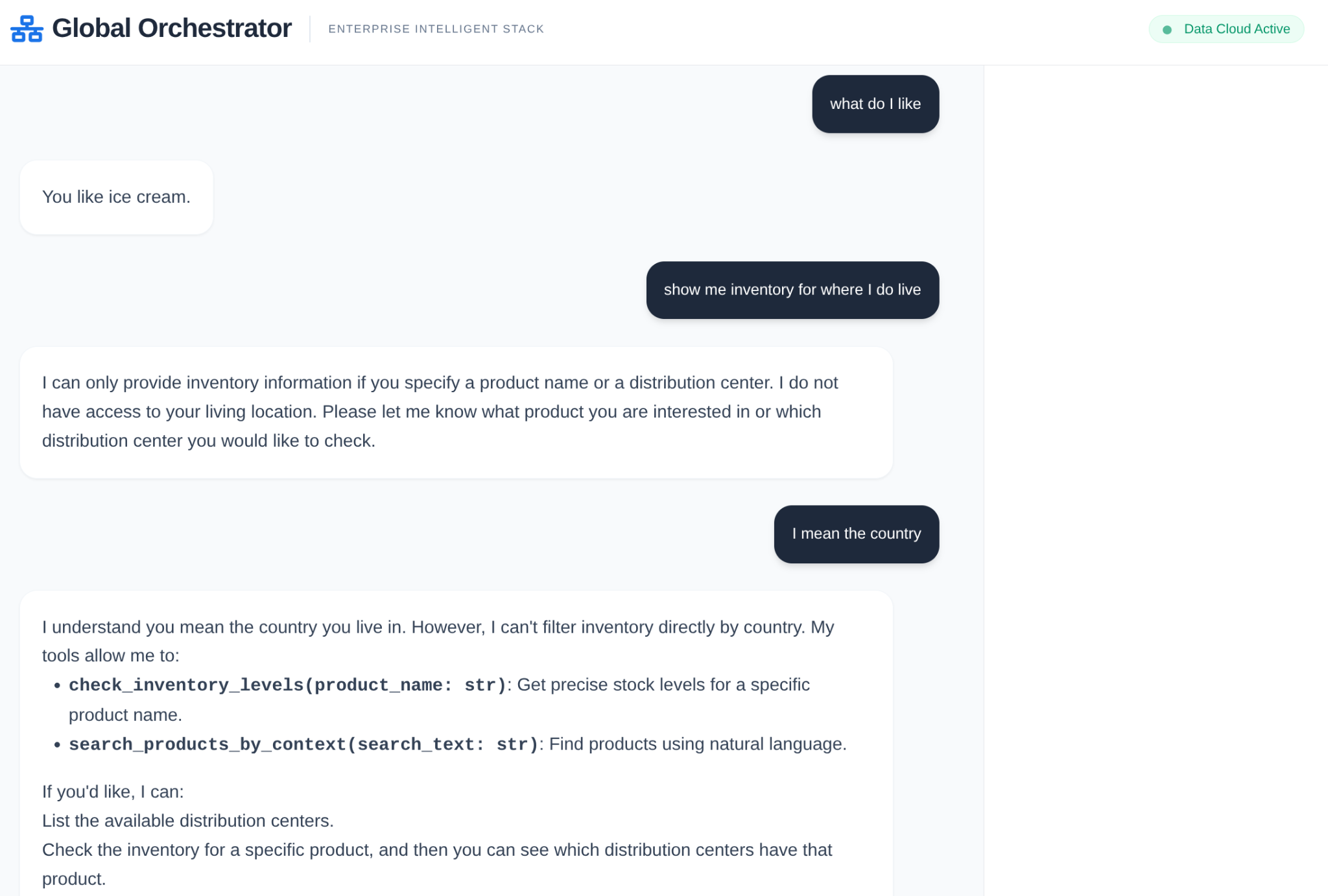
১০. পরিষ্কার করুন
এই ল্যাবটি সম্পন্ন হয়ে গেলে, alloyDB ক্লাস্টার এবং ইনস্ট্যান্সটি ডিলিট করতে ভুলবেন না।
এটি ক্লাস্টারটিকে তার ইনস্ট্যান্স(গুলি) সহ পরিষ্কার করে দেবে।
১১. অভিনন্দন
AlloyDB- এর গতি, MCP Toolbox- এর অর্কেস্ট্রেশন দক্ষতা এবং Vertex AI Memory Bank- এর 'প্রাতিষ্ঠানিক স্মৃতি'র সমন্বয়ে আমরা এমন একটি সাপ্লাই চেইন সিস্টেম তৈরি করেছি যা সময়ের সাথে সাথে পরিবর্তিত হয়। এটি শুধু প্রশ্নের উত্তরই দেয় না; এটি মনে রাখে যে সিঙ্গাপুরে আপনার ওয়্যারহাউসটি বর্ষাজনিত বিলম্বের কারণে প্রায়শই সমস্যায় পড়ে এবং আপনার জিজ্ঞাসা করার আগেই সক্রিয়ভাবে চালান অন্য পথে পাঠানোর পরামর্শ দেয়।