
1. Übersicht
In diesem Codelab erstellen Sie einen Supply Chain Orchestrator-Agenten. Mit dieser Anwendung können Nutzer Inventar analysieren, Logistik verfolgen und Lieferkettenrisiken in natürlicher Sprache verwalten.
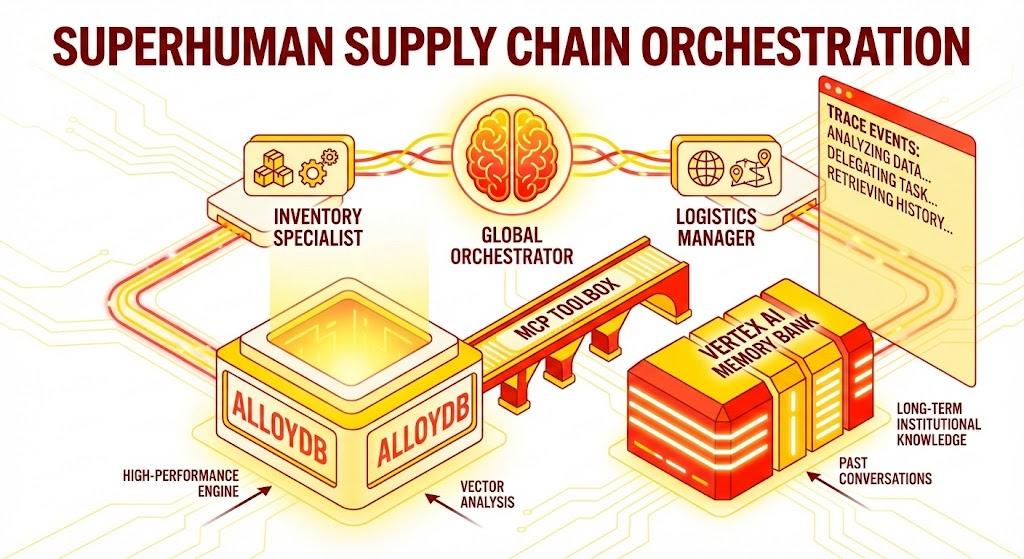
Wir nutzen das Agent Development Kit (ADK) von Google, um eine Architektur mit mehreren Agenten zu erstellen, die den Kontext beibehält, sich über die Vertex AI Memory Bank die Nutzereinstellungen merkt und über die MCP Toolbox mit einem in AlloyDB gespeicherten umfangreichen Datensatz interagiert.
Aufgaben
Eine Python Flask-Anwendung, die Folgendes umfasst:
Global Orchestrator Agent:Der Stamm-Agent, der den Unterhaltungsverlauf und die Delegierung verwaltet.
Spezialisten-Agents: „InventorySpecialist“ und „LogisticsManager“ für domainspezifische Aufgaben.
Speicherintegration:Kurzzeitspeicher für Sitzungen und Langzeitspeicher mit Vertex AI Memory Bank.
Narrative UI:Eine Weboberfläche, auf der der Denkprozess des Agents (Trace Context) visualisiert wird.
Lerninhalte
- So erstellen Sie mit dem Google ADK spezialisierte Agents und Sub-Agents.
- So integrieren Sie die Vertex AI Memory Bank für das Langzeitgedächtnis von Agents.
- So verwenden Sie die MCP Toolbox, um Agenten mit AlloyDB-Datentools zu verbinden.
- ADK-Callbacks implementieren, um die Argumentation des Agenten nachzuvollziehen und zu visualisieren
- So stellen Sie die Lösung mit Cloud Run bereit oder führen sie lokal aus.
Die Architektur
Der Tech-Stack
- AlloyDB for PostgreSQL:Dient als leistungsstarke operative Datenbank mit über 50.000 Datensätzen zur Lieferkette. Sie ist die Grundlage für die Vektorsuche und das Abrufen von Informationen.
- MCP Toolbox for Databases:Fungiert als „Orchestration Maestro“ und stellt AlloyDB-Daten als ausführbare Tools bereit, die von den Agenten aufgerufen werden können.
- Agent Development Kit (ADK): Das Framework, mit dem die Agenten, Anweisungen und Tools definiert werden.
- Vertex AI Memory Bank:Bietet langfristigen Speicher, sodass sich der Agent sitzungsübergreifend an Nutzerpräferenzen und frühere Interaktionen erinnern kann.
- Vertex AI Session Service:Verwaltet den kurzfristigen Konversationskontext.
Der Flow
- Nutzeranfrage:Der Nutzer stellt eine Frage (z.B. „Check stock for Premium Ice Cream“).
- Speicherprüfung:Der Orchestrator prüft die Memory Bank auf relevante vergangene Informationen (z.B. „Der Nutzer ist Regional Manager für EMEA“).
- Delegierung:Der Orchestrator delegiert die Aufgabe an den InventorySpecialist.
- Tool-Ausführung:Der Spezialist verwendet Tools, die von der MCP Toolbox bereitgestellt werden, um AlloyDB abzufragen.
- Antwort:Der KI-Agent verarbeitet die Daten und gibt eine Markdown-formatierte Tabelle zurück.
- Speicher:Wichtige Interaktionen werden in der Memory Bank gespeichert.
Voraussetzungen
2. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.

- Sobald die Verbindung mit der Cloud Shell hergestellt ist, prüfen Sie mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
- Aktivieren Sie die erforderlichen APIs: Folgen Sie dem Link und aktivieren Sie die APIs.
Alternativ können Sie dazu den gcloud-Befehl verwenden. Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
Wichtige Hinweise und Fehlerbehebung
Das „Geisterprojekt“-Syndrom | Sie haben |
Die Abrechnungsbarrikade | Sie haben das Projekt aktiviert, aber das Rechnungskonto vergessen. AlloyDB ist eine leistungsstarke Engine, die nicht startet, wenn der „Benzintank“ (Abrechnung) leer ist. |
Verzögerung bei der API-Weitergabe | Sie haben auf „APIs aktivieren“ geklickt, aber in der Befehlszeile wird weiterhin |
Kontingent – Häufig gestellte Fragen | Wenn Sie ein brandneues Testkonto verwenden, erreichen Sie möglicherweise ein regionales Kontingent für AlloyDB-Instanzen. Wenn |
Verborgener Kundenservicemitarbeiter | Manchmal wird dem AlloyDB-Dienst-Agenten die Rolle |
3. Datenbank einrichten
Das Herzstück unserer Anwendung ist AlloyDB for PostgreSQL. Wir haben die leistungsstarken Vektorfähigkeiten und die integrierte spaltenbasierte Engine genutzt,um Einbettungen für über 50.000 SCM-Datensätze zu generieren. Dies ermöglicht eine Vektoranalyse in nahezu Echtzeit, sodass unsere Agenten Inventaranomalien oder Logistikrisiken in riesigen Datasets in Millisekunden erkennen können.
In diesem Lab verwenden wir AlloyDB als Datenbank für die Testdaten. Darin werden Cluster verwendet, um alle Ressourcen wie Datenbanken und Logs zu speichern. Jeder Cluster hat eine primäre Instanz, die einen Zugriffspunkt auf die Daten bietet. Tabellen enthalten die tatsächlichen Daten.
Erstellen wir einen AlloyDB-Cluster, eine AlloyDB-Instanz und eine AlloyDB-Tabelle, in die das Test-Dataset geladen wird.
- Klicken Sie auf den Button oder kopieren Sie den Link unten in den Browser, in dem der Google Cloud Console-Nutzer angemeldet ist.
Alternativ können Sie in Ihrem Projekt, in dem Sie das Abrechnungskonto eingelöst haben, zum Cloud Shell-Terminal wechseln, das GitHub-Repository klonen und mit den folgenden Befehlen zum Projekt navigieren:
git clone https://github.com/AbiramiSukumaran/easy-alloydb-setup
cd easy-alloydb-setup
- Sobald dieser Schritt abgeschlossen ist, wird das Repository in Ihren lokalen Cloud Shell-Editor geklont und Sie können den folgenden Befehl über den Projektordner ausführen. Achten Sie darauf, dass Sie sich im Projektverzeichnis befinden:
sh run.sh
- Verwenden Sie jetzt die Benutzeroberfläche (klicken Sie auf den Link im Terminal oder auf den Link „Vorschau im Web“ im Terminal).
- Geben Sie die Details für Projekt-ID, Cluster- und Instanznamen ein, um zu beginnen.
- Holen Sie sich einen Kaffee, während die Logs durchlaufen. Hier können Sie nachlesen, wie das im Hintergrund funktioniert.
Wichtige Hinweise und Fehlerbehebung
Das Problem mit der Geduld | Datenbankcluster sind eine schwere Infrastruktur. Wenn Sie die Seite aktualisieren oder die Cloud Shell-Sitzung beenden, weil sie „hängt“, kann es passieren, dass eine „Geisterinstanz“ entsteht, die teilweise bereitgestellt wurde und ohne manuellen Eingriff nicht gelöscht werden kann. |
Region stimmt nicht überein | Wenn Sie Ihre APIs in |
Zombie-Cluster | Wenn Sie zuvor denselben Namen für einen Cluster verwendet und ihn nicht gelöscht haben, wird im Skript möglicherweise angezeigt, dass der Clustername bereits vorhanden ist. Cluster-Namen müssen innerhalb eines Projekts eindeutig sein. |
Cloud Shell-Zeitüberschreitung | Wenn Ihre Kaffeepause 30 Minuten dauert, wird Cloud Shell möglicherweise inaktiv und die Verbindung zum |
4. Schemabereitstellung
Sobald Ihr AlloyDB-Cluster und Ihre Instanz ausgeführt werden, können Sie im SQL-Editor von AlloyDB Studio die KI-Erweiterungen aktivieren und das Schema bereitstellen.
Möglicherweise müssen Sie warten, bis die Instanz erstellt wurde. Melden Sie sich dann mit den Anmeldedaten in AlloyDB an, die Sie beim Erstellen des Clusters erstellt haben. Verwenden Sie die folgenden Daten für die Authentifizierung bei PostgreSQL:
- Nutzername: „
postgres“ - Datenbank: „
postgres“ - Passwort: „
alloydb“ (oder das Passwort, das Sie bei der Erstellung festgelegt haben)
Nachdem Sie sich erfolgreich in AlloyDB Studio authentifiziert haben, werden SQL-Befehle im Editor eingegeben. Sie können mehrere Editorfenster hinzufügen, indem Sie auf das Pluszeichen rechts neben dem letzten Fenster klicken.
Sie geben Befehle für AlloyDB in Editorfenstern ein und verwenden bei Bedarf die Optionen „Ausführen“, „Formatieren“ und „Löschen“.
Erweiterungen aktivieren
Für die Entwicklung dieser App verwenden wir die Erweiterungen pgvector und google_ml_integration. Mit der pgvector-Erweiterung können Sie Vektoreinbettungen speichern und durchsuchen. Die Erweiterung google_ml_integration bietet Funktionen, mit denen Sie auf Vertex AI-Vorhersageendpunkte zugreifen können, um Vorhersagen in SQL zu erhalten. Aktivieren Sie diese Erweiterungen, indem Sie die folgenden DDLs ausführen:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Tabelle erstellen
Sie können eine Tabelle mit der folgenden DDL-Anweisung in AlloyDB Studio erstellen:
DROP TABLE IF EXISTS shipments;
DROP TABLE IF EXISTS products;
-- 1. Product Inventory Table
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
category VARCHAR(100),
stock_level INTEGER,
distribution_center VARCHAR(100),
region VARCHAR(50),
embedding vector(768),
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. Logistics & Shipments
CREATE TABLE shipments (
shipment_id SERIAL PRIMARY KEY,
product_id INTEGER REFERENCES products(id),
status VARCHAR(50), -- 'In Transit', 'Delayed', 'Delivered', 'Pending'
estimated_arrival TIMESTAMP,
route_efficiency_score DECIMAL(3, 2)
);
In der Spalte embedding können die Vektorwerte einiger Textfelder gespeichert werden.
Datenaufnahme
Führen Sie die folgenden SQL-Anweisungen aus, um 50.000 Datensätze in die Tabelle „products“ einzufügen:
-- We use a CROSS JOIN pattern with realistic naming segments to create meaningful variety
DO $$
DECLARE
brand_names TEXT[] := ARRAY['Artisan', 'Nature', 'Elite', 'Pure', 'Global', 'Eco', 'Velocity', 'Heritage', 'Aura', 'Summit'];
product_types TEXT[] := ARRAY['Ice Cream', 'Body Wash', 'Laundry Detergent', 'Shampoo', 'Mayonnaise', 'Deodorant', 'Tea', 'Soup', 'Face Cream', 'Soap'];
variants TEXT[] := ARRAY['Classic', 'Gold', 'Premium', 'Eco-Friendly', 'Organic', 'Night-Repair', 'Extra-Fresh', 'Zero-Sugar', 'Sensitive', 'Maximum-Strength'];
regions TEXT[] := ARRAY['EMEA', 'APAC', 'LATAM', 'NAMER'];
dcs TEXT[] := ARRAY['London-Hub', 'Mumbai-Central', 'Sao-Paulo-Logistics', 'Singapore-Port', 'Rotterdam-Gate', 'New-York-DC'];
BEGIN
INSERT INTO products (name, category, stock_level, distribution_center, region)
SELECT
b || ' ' || v || ' ' || t as name,
CASE
WHEN t IN ('Ice Cream', 'Mayonnaise', 'Tea', 'Soup') THEN 'Food & Refreshment'
WHEN t IN ('Body Wash', 'Shampoo', 'Deodorant', 'Face Cream', 'Soap') THEN 'Personal Care'
ELSE 'Home Care'
END as category,
floor(random() * 20000 + 100)::int as stock_level,
dcs[floor(random() * 6 + 1)] as distribution_center,
regions[floor(random() * 4 + 1)] as region
FROM
unnest(brand_names) b,
unnest(variants) v,
unnest(product_types) t,
generate_series(1, 50); -- 10 * 10 * 10 * 50 = 50,000 records
END $$;
Wir fügen demospezifische Datensätze ein, um vorhersehbare Antworten auf Fragen im Executive-Stil zu erhalten.
-- These ensure you have predictable answers for specific "Executive" questions
INSERT INTO products (name, category, stock_level, distribution_center, region) VALUES
('Magnum Ultra Gold Limited Edition', 'Food & Refreshment', 45, 'Rotterdam-Gate', 'EMEA'),
('Dove Pro-Health Deep Moisture', 'Personal Care', 12000, 'Mumbai-Central', 'APAC'),
('Hellmanns Real Organic Mayonnaise', 'Food & Refreshment', 8000, 'London-Hub', 'EMEA');
Versanddaten einfügen
-- Shipments Generation (More shipments than products)
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT
id,
CASE
WHEN random() > 0.8 THEN 'Delayed'
WHEN random() > 0.4 THEN 'In Transit'
ELSE 'Delivered'
END,
NOW() + (random() * 10 || ' days')::interval,
(random() * 0.5 + 0.5)::decimal(3,2)
FROM products
WHERE random() > 0.3; -- Create shipments for ~70% of products
-- Add duplicate shipments for some products to show complex logistics
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT id, 'In Transit', NOW() + INTERVAL '12 days', 0.88
FROM products
LIMIT 5000;
Berechtigung gewähren
Führen Sie die folgende Anweisung aus, um die Ausführung der Funktion „embedding“ zu gewähren:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB-Dienstkonto die Rolle „Vertex AI User“ gewähren
Gewähren Sie in der Google Cloud IAM-Konsole dem AlloyDB-Dienstkonto (das so aussieht: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) Zugriff auf die Rolle „Vertex AI-Nutzer“. PROJECT_NUMBER enthält Ihre Projektnummer.
Alternativ können Sie den folgenden Befehl im Cloud Shell-Terminal ausführen:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Einbettungen generieren
Als Nächstes generieren wir Vektoreinbettungen für bestimmte aussagekräftige Textfelder:
WITH
rows_to_update AS (
SELECT
id
FROM
products
WHERE
embedding IS NULL
LIMIT
5000 )
UPDATE
products
SET
embedding = ai.embedding('text-embedding-005', name || ' ' || category || ' ' || distribution_center || ' ' || region)::vector
FROM
rows_to_update
WHERE
products.id = rows_to_update.id
AND embedding IS null;
In der obigen Anweisung haben wir das Limit auf 5.000 festgelegt. Führen Sie die Anweisung also wiederholt aus, bis in der Tabelle keine Zeile mehr vorhanden ist, in der die Spalte „embedding“ den Wert NULL hat.
Wichtige Hinweise und Fehlerbehebung
Die „Passwort vergessen“-Schleife | Wenn Sie die Einrichtung mit nur einem Klick verwendet haben und sich nicht mehr an Ihr Passwort erinnern, rufen Sie in der Konsole die Seite „Instance basic information“ (Allgemeine Informationen zur Instanz) auf und klicken Sie auf „Edit“ (Bearbeiten), um das |
Fehler „Erweiterung nicht gefunden“ | Wenn |
IAM-Weitergabeverzögerung | Sie haben den IAM-Befehl |
Falsche Vektordimension | Die Tabelle |
Tippfehler bei der Projekt-ID | Wenn Sie im |
5. Tools und Toolbox einrichten
Die MCP Toolbox for Databases ist ein Open-Source-MCP-Server für Datenbanken. Damit können Sie Tools einfacher, schneller und sicherer entwickeln, da Komplexitäten wie Connection Pooling, Authentifizierung und mehr abgedeckt werden. Mit der Toolbox können Sie GenAI-Tools erstellen, mit denen Ihre Agenten auf Daten in Ihrer Datenbank zugreifen können.
Wir verwenden die MCP-Toolbox (Model Context Protocol) für Datenbanken als „Dirigent“. Sie fungiert als standardisierte Middleware zwischen unseren Agents und AlloyDB. Durch die Definition einer tools.yaml-Konfiguration stellt die Toolbox komplexe Datenbankvorgänge automatisch als übersichtliche, ausführbare Tools wie search_products_by_context oder check_inventory_levels zur Verfügung. Dadurch entfällt die Notwendigkeit für manuelles Connection Pooling oder Boilerplate-SQL in der Agent-Logik.
Toolbox-Server installieren
Erstellen Sie im Cloud Shell-Terminal einen Ordner zum Speichern der neuen YAML-Datei für die Tools und der Toolbox-Binärdatei:
mkdir scm-agent-toolbox
cd scm-agent-toolbox
Führen Sie in diesem neuen Ordner die folgenden Befehle aus:
# see releases page for other versions
export VERSION=0.27.0
curl -L -o toolbox https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Erstellen Sie als Nächstes die Datei tools.yaml in diesem neuen Ordner. Rufen Sie dazu den Cloud Shell-Editor auf und kopieren Sie den Inhalt dieser Repository-Datei in die Datei „tools.yaml“.
sources:
supply_chain_db:
kind: "alloydb-postgres"
project: "YOUR_PROJECT_ID"
region: "us-central1"
cluster: "YOUR_CLUSTER"
instance: "YOUR_INSTANCE"
database: "postgres"
user: "postgres"
password: "YOUR_PASSWORD"
tools:
search_products_by_context:
kind: postgres-sql
source: supply_chain_db
description: Find products in the inventory using natural language search and vector embeddings.
parameters:
- name: search_text
type: string
description: Description of the product or category the user is looking for.
statement: |
SELECT name, category, stock_level, distribution_center, region
FROM products
ORDER BY embedding <=> ai.embedding('text-embedding-005', $1)::vector
LIMIT 5;
check_inventory_levels:
kind: postgres-sql
source: supply_chain_db
description: Get precise stock levels for a specific product name.
parameters:
- name: product_name
type: string
description: The exact or partial name of the product.
statement: |
SELECT name, stock_level, distribution_center, last_updated
FROM products
WHERE name ILIKE '%' || $1 || '%'
ORDER BY stock_level DESC;
track_shipment_status:
kind: postgres-sql
source: supply_chain_db
description: Retrieve real-time logistics and shipping status for a specific region or product.
parameters:
- name: region
type: string
description: The geographical region to filter shipments (e.g., EMEA, APAC).
statement: |
SELECT p.name, s.status, s.estimated_arrival, s.route_efficiency_score
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE p.region = $1
ORDER BY s.estimated_arrival ASC;
analyze_supply_chain_risk:
kind: postgres-sql
source: supply_chain_db
description: Rerank and filter shipments based on risk profiles and efficiency scores using Google ML reranker.
parameters:
- name: risk_context
type: string
description: The business context for risk analysis (e.g., 'heatwave impact' or 'port strike').
statement: |
WITH initial_ranking AS (
SELECT s.shipment_id, p.name, s.status, p.distribution_center,
ROW_NUMBER() OVER () AS ref_number
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE s.status != 'Delivered'
LIMIT 10
),
reranked_results AS (
SELECT index, score FROM
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => $1,
documents => (SELECT ARRAY_AGG(name || ' at ' || distribution_center ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT i.name, i.status, i.distribution_center, r.score
FROM initial_ranking i, reranked_results r
WHERE i.ref_number = r.index
ORDER BY r.score DESC;
toolsets:
supply_chain_toolset:
- search_products_by_context
- check_inventory_levels
- track_shipment_status
- analyze_supply_chain_risk
Testen Sie nun die Datei „tools.yaml“ auf dem lokalen Server:
./toolbox --tools-file "tools.yaml"
Alternativ können Sie es in der Benutzeroberfläche testen.
./toolbox --ui
Perfekt! Wenn Sie sicher sind, dass alles funktioniert, können Sie die Anwendung wie unten beschrieben in Cloud Run bereitstellen.
Cloud Run-Bereitstellung
- Legen Sie die Umgebungsvariable PROJECT_ID fest:
export PROJECT_ID="my-project-id"
- Initialisieren Sie die gcloud CLI:
gcloud init
gcloud config set project $PROJECT_ID
- Die folgenden APIs müssen aktiviert sein:
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Erstellen Sie ein Backend-Dienstkonto, falls Sie noch keines haben:
gcloud iam service-accounts create toolbox-identity
- Berechtigungen zur Verwendung von Secret Manager erteilen:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
- Gewähren Sie dem Dienstkonto zusätzliche Berechtigungen, die für unsere AlloyDB-Quelle spezifisch sind (roles/alloydb.client und roles/serviceusage.serviceUsageConsumer).
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role serviceusage.serviceUsageConsumer
- Laden Sie „tools.yaml“ als Secret hoch:
gcloud secrets create tools-scm-agent --data-file=tools.yaml
- Wenn Sie bereits ein Secret haben und die Secret-Version aktualisieren möchten, führen Sie Folgendes aus:
gcloud secrets versions add tools-scm-agent --data-file=tools.yaml
- Legen Sie eine Umgebungsvariable für das Container-Image fest, das Sie für Cloud Run verwenden möchten:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Stellen Sie die Toolbox mit dem folgenden Befehl in Cloud Run bereit:
Wenn Sie öffentlichen Zugriff in Ihrer AlloyDB-Instanz aktiviert haben (nicht empfohlen), folgen Sie dem Befehl unten für das Deployment in Cloud Run:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
Wenn Sie ein VPC-Netzwerk verwenden, verwenden Sie den folgenden Befehl:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
# TODO(dev): update the following to match your VPC details
--network <<YOUR_NETWORK_NAME>> \
--subnet <<YOUR_SUBNET_NAME>> \
--allow-unauthenticated
6. Agent-Einrichtung
Mit dem Agent Development Kit (ADK) haben wir uns von monolithischen Prompts hin zu einer spezialisierten Multi-Agent-Architektur verabschiedet:
- InventorySpecialist: Schwerpunkt auf Produktbestand und Lagerkennzahlen.
- LogisticsManager: Experte für globale Versandrouten und Risikoanalysen.
- GlobalOrchestrator: Das „Gehirn“, das Aufgaben delegiert und Ergebnisse zusammenfasst.
Klonen Sie dieses Repository in Ihr Projekt und sehen wir uns die einzelnen Schritte an.
Führen Sie zum Klonen des Repositorys im Cloud Shell-Terminal (im Stammverzeichnis oder an einem beliebigen Ort, an dem Sie das Projekt erstellen möchten) den folgenden Befehl aus:
git clone https://github.com/AbiramiSukumaran/scm-memory-agent
- Dadurch sollte das Projekt erstellt werden. Sie können dies im Cloud Shell Editor überprüfen.

- Achten Sie darauf, dass Sie die .env-Datei mit den Werten für Ihr Projekt und Ihre Instanz aktualisieren.
Schritt-für-Schritt-Anleitung zum Code
Kurzvorstellung des Orchestrator-Agents
Go to app.py and you should be able to see the following snippet:
orchestrator = adk.Agent(
name="GlobalOrchestrator",
model="gemini-2.5-flash",
description="Global Supply Chain Orchestrator root agent.",
instruction="""
You are the Global Supply Chain Brain. You are responsible for products, inventory and logistics.
You also have access to the memory tool, remember to include all the information that the tool can provide you with about the user before you respond.
1. Understand intent and delegate to specialists. As the Global Orchestrator, you have access to the full conversation history with the user.
When you transfer a query to a specialist agent, sub agent or tool, share the important facts and information from your memory to them so they can operate with the full context.
2. Ensure the final response is professional and uses Markdown tables for data.
3. If a specialist provides a long list, ensure only the top 10 items are shown initially.
4. Conclude with a brief, high-level executive summary of what the data implies.
""",
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
sub_agents=[inventory_agent, logistics_agent],
#after_agent_callback=auto_save_session_to_memory_callback,
)
Dieses Snippet ist die Definition für den Stamm, also den Orchestrator-Agent, der die Unterhaltung oder Anfrage vom Nutzer empfängt und je nach Aufgabe an den entsprechenden untergeordneten Agenten oder Nutzer weiterleitet.
- Sehen wir uns den Inventar-Agenten an.
inventory_agent = adk.Agent(
name="InventorySpecialist",
model="gemini-2.5-flash",
description="Specialist in product stock and warehouse data.",
instruction="""
Analyze inventory levels.
1. Use 'search_products_by_context' or 'check_inventory_levels'.
2. ALWAYS format results as a clean Markdown table.
3. If there are many results, display only the TOP 10 most relevant ones.
4. At the end, state: 'There are additional records available. Would you like to see more?'
""",
tools=tools
)
Dieser spezielle untergeordnete Agent ist auf Inventaraktivitäten wie die kontextbezogene Suche nach Produkten und die Überprüfung von Inventarbeständen spezialisiert.
- Dann gibt es noch den Logistik-Untervertreter:
logistics_agent = adk.Agent(
name="LogisticsManager",
model="gemini-2.5-flash",
description="Expert in global shipping routes and logistics tracking.",
instruction="""
Check shipment statuses.
1. Use 'track_shipment_status' or 'analyze_supply_chain_risk'.
2. ALWAYS format results as a clean Markdown table.
3. Limit initial output to the top 10 shipments.
4. Ask if the user needs the full manifest if more results exist.
""",
tools=tools
)
Dieser spezielle Sub-Agent ist auf Logistikaktivitäten wie das Verfolgen von Sendungen und die Analyse von Risiken in der Lieferkette spezialisiert.
- Alle drei bisher besprochenen Agents verwenden Tools, auf die über unseren Toolbox-Server verwiesen wird, den wir bereits im vorherigen Abschnitt bereitgestellt haben. Hier ein Beispiel:
from toolbox_core import ToolboxSyncClient
TOOLBOX_SERVER = os.environ["TOOLBOX_SERVER"]
TOOLBOX_TOOLSET = os.environ["TOOLBOX_TOOLSET"]
# --- ADK TOOLBOX CONFIGURATION ---
toolbox = ToolboxSyncClient(TOOLBOX_SERVER)
tools = toolbox.load_toolset(TOOLBOX_TOOLSET)
Dieser spezielle Sub-Agent ist auf Logistikaktivitäten wie das Verfolgen von Sendungen und die Analyse von Risiken in der Lieferkette spezialisiert.
7. Agent Engine
Agent Engine im ersten Lauf erstellen
import vertexai
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
client = vertexai.Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_LOCATION
)
agent_engine = client.agent_engines.create()
- Aktualisieren Sie für den nächsten Lauf die Agent Engine mit der Memory Bank-Konfiguration:
agent_engine = client.agent_engines.update(
name=APP_NAME,
config={
"context_spec": {
"memory_bank_config": {
"generation_config": {
"model": f"projects/{PROJECT_ID}/locations/{GOOGLE_CLOUD_LOCATION}/publishers/google/models/gemini-2.5-flash"
}
}
}
})
8. Kontext, Ausführung und Arbeitsspeicher
Die Kontextverwaltung ist in zwei separate Ebenen unterteilt, damit sich der Agent wie ein kontinuierlicher Partner und nicht wie ein zustandsloser Bot anfühlt:
Kurzzeitgedächtnis (Sitzungen): Das Kurzzeitgedächtnis wird über VertexAiSessionService verwaltet und zeichnet den unmittelbaren Ereignisverlauf (Nutzernachrichten, Tool-Antworten) innerhalb einer einzelnen Interaktion auf.
Langzeitspeicher (Memory Bank): Basierend auf der Vertex AI Memory Bank über adk.memorybankservice. In dieser Ebene werden „aussagekräftige“ Informationen wie die bevorzugten Versandunternehmen eines Nutzers oder wiederkehrende Lagerverzögerungen extrahiert und sitzungsübergreifend gespeichert.
Sitzung für das Sitzungsgedächtnis im Rahmen der Unterhaltung initialisieren
Dieser Teil des Snippets erstellt die Sitzung für die aktuelle App für den aktuellen Nutzer.
from google.adk.sessions import VertexAiSessionService
...
session_service = VertexAiSessionService(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
...
# Initialize the session *outside* of the route handler to avoid repeated creation
session = None
session_lock = threading.Lock()
async def initialize_session():
global session
try:
session = await session_service.create_session(app_name=APP_NAME, user_id=USER_ID)
print(f"Session {session.id} created successfully.") # Add a log
except Exception as e:
print(f"Error creating session: {e}")
session = None # Ensure session is None in case of error
# Create the session on app startup
asyncio.run(initialize_session())
Vertex AI Memory Bank für langfristigen Speicher initialisieren
In diesem Teil des Snippets wird das Vertex AI Memory Bank Service-Objekt für die Agent Engine instanziiert.
from google.adk.memory import InMemoryMemoryService
from google.adk.memory import VertexAiMemoryBankService
...
try:
memory_bank_service = adk.memory.VertexAiMemoryBankService(
agent_engine_id=AGENT_ENGINE_ID,
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
#in_memory_service = InMemoryMemoryService()
print("Memory Bank Service initialized successfully.")
except Exception as e:
print(f"Error initializing Memory Bank Service: {e}")
memory_bank_service = None
runner = adk.Runner(
agent=orchestrator,
app_name=APP_NAME,
session_service=session_service,
memory_service=memory_bank_service,
)
...
Was wird konfiguriert?
In diesem Teil des Snippets konfigurieren wir den Vertex AI Memory Bank Service für das Langzeitgedächtnis. Die Sitzung für die jeweilige App für den jeweiligen Nutzer wird kontextbezogen als Erinnerung in der Vertex AI-Speicherbank gespeichert.
Was wird im Rahmen der Agent-Ausführung ausgeführt?
async def run_and_collect():
final_text = ""
try:
async for event in runner.run_async(
new_message=content,
user_id=user_id,
session_id=session_id
):
if hasattr(event, 'author') and event.author:
if not any(log['agent'] == event.author for log in execution_logs):
execution_logs.append({
"agent": event.author,
"action": "Analyzing data requirements...",
"type": "orchestration_event"
})
if hasattr(event, 'text') and event.text:
final_text = event.text
elif hasattr(event, 'content') and hasattr(event.content, 'parts'):
for part in event.content.parts:
if hasattr(part, 'text') and part.text:
final_text = part.text
except Exception as e:
print(f"Error during runner.run_async: {e}")
raise # Re-raise the exception to signal failure
finally:
gc.collect()
return final_text
Die Eingabeinhalte des Nutzers werden in das Objekt „new_message“ mit der Nutzer-ID und der Sitzungs-ID im Bereich verarbeitet. Anschließend übernimmt der Agent und die Agent-Antwort wird verarbeitet und zurückgegeben.
Was wird im Langzeitgedächtnis gespeichert?
Die Sitzungsdetails im Bereich der App und des Nutzers werden in der Sitzungsvariable extrahiert.
Diese Sitzung wird dann als Speicher für den aktuellen Nutzer für die aktuelle App des Vertex AI Memory Bank-Objekts mit der Methode „add_session_to_memory“ hinzugefügt.
session = asyncio.run(session_service.get_session(app_name=APP_NAME, user_id=USER_ID, session_id=session.id))
if memory_bank_service and session: # Check memory service AND session
try:
#asyncio.run(in_memory_service.add_session_to_memory(session))
asyncio.run(memory_bank_service.add_session_to_memory(session))
'''
client.agent_engines.memories.generate(
scope={"app_name": APP_NAME, "user_id": USER_ID},
name=APP_NAME,
direct_contents_source={
"events": [
{"content": content}
]
},
config={"wait_for_completion": True},
)
'''
print("Successfully added session to memory.******")
print(session.id)
except Exception as e:
print(f"Error adding session to memory: {e}")
Abruf von Informationen aus dem Gedächtnis
Wir müssen den gespeicherten Langzeitspeicher mit dem App-Namen und dem Nutzernamen als Bereich abrufen, da dies der Bereich ist, für den wir die Erinnerungen gespeichert haben. So können wir ihn als Teil des Kontexts an den Orchestrator und gegebenenfalls andere Agents übergeben.
results = client.agent_engines.memories.retrieve(
name=APP_NAME,
scope={"app_name": APP_NAME, "user_id": USER_ID}
)
# RetrieveMemories returns a pager. You can use `list` to retrieve all pages' memories.
list(results)
print(list(results))
Wie wird die abgerufene Erinnerung als Teil des Kontexts geladen?
Wir verwenden das folgende Attribut in der Definition des Orchestrator-Agents, damit der Stamm-Agent den Kontext aus dem Memory Bank vorab laden kann. Dies gilt zusätzlich zu den Tools, auf die wir über den Toolbox-Server für die untergeordneten Agents zugreifen.
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
Callback-Kontext
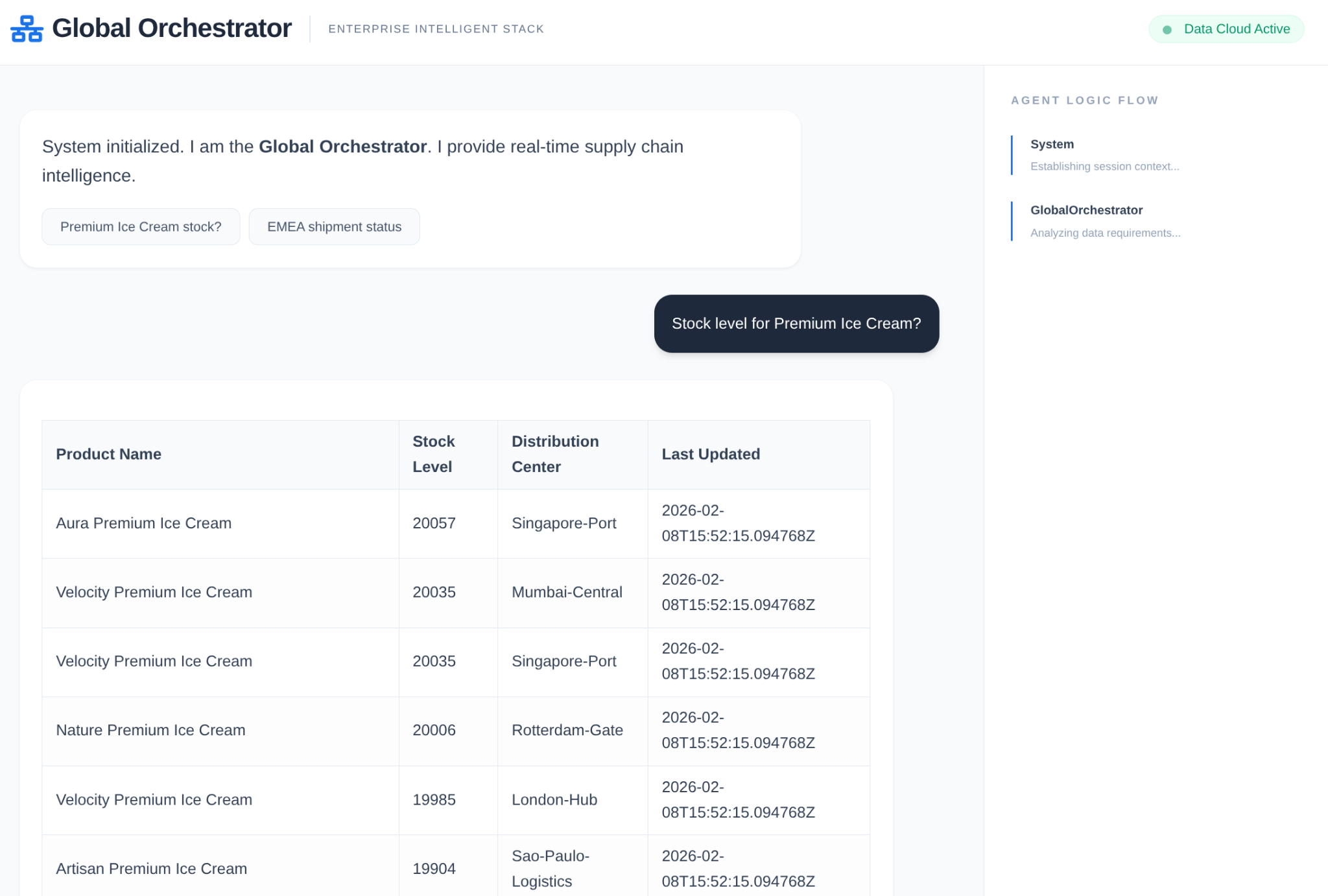
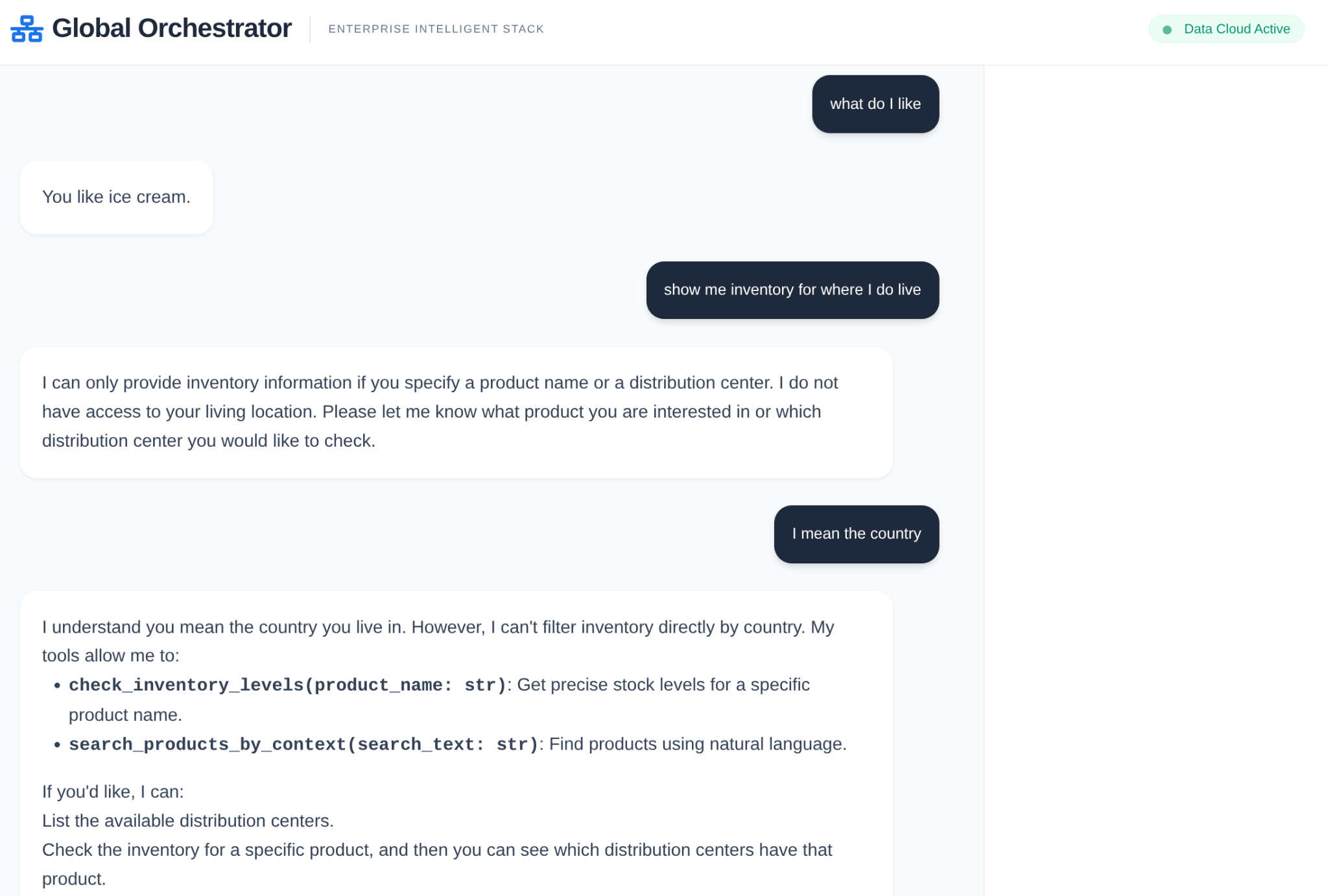
In einer Unternehmenslieferkette darf es keine „Blackbox“ geben. Wir verwenden den CallbackContext des ADK, um eine Narrative Engine zu erstellen. Durch das Einbinden in die Ausführung des Agents erfassen wir jeden Denkprozess und jeden Toolaufruf und streamen sie an eine Seitenleiste in der Benutzeroberfläche.
- Trace-Ereignis: „GlobalOrchestrator is analyzing data requirements...“
- Trace-Ereignis: „Delegating to InventorySpecialist for stock levels...“ (Delegiere an InventorySpecialist für Lagerbestände…)
- Trace-Ereignis: „Retrieving historical supplier delay patterns from Memory Bank...“ (Abrufen von Mustern für Lieferantenverzögerungen aus Memory Bank...)
Dieser Prüfpfad ist für das Debugging von unschätzbarem Wert und sorgt dafür, dass menschliche Bediener den autonomen Entscheidungen des Agents vertrauen können.
from google.adk.agents.callback_context import CallbackContext
...
# --- ADK CALLBACKS (Narrative Engine) ---
execution_logs = []
async def trace_callback(context: CallbackContext):
"""
Captures agent and tool invocation flow for the UI narrative.
"""
agent_name = context.agent.name
event = {
"agent": agent_name,
"action": "Processing request steps...",
"type": "orchestration_event"
}
execution_logs.append(event)
return None
...
Das war es!!! Wir haben das Projekt erfolgreich geklont und die Details des Agents, des Speichers und des Kontexts durchgegangen.
Sie können dies testen, indem Sie zum Projektordner des geklonten Repositorys wechseln und die folgenden Befehle ausführen:
>> pip install -r requirements.txt
>> python app.py
Dadurch sollte Ihr Agent lokal gestartet werden und Sie sollten ihn testen können.
9. In Cloud Run bereitstellen
- Stellen Sie die App in Cloud Run bereit, indem Sie den folgenden Befehl im Cloud Shell-Terminal ausführen, in dem das Projekt geklont wurde. Achten Sie darauf, dass Sie sich im Stammordner des Projekts befinden.
Führen Sie diesen Befehl in Ihrem Cloud Shell-Terminal aus:
gcloud run deploy supply-chain-agent --source . --platform managed --region us-central1 --allow-unauthenticated --set-env-vars GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT>>,GOOGLE_CLOUD_LOCATION=us-central1,GOOGLE_GENAI_USE_VERTEXAI=TRUE,REASONING_ENGINE_APP_NAME=<<YOUR_APP_ENGINE_URL>>,TOOLBOX_SERVER=<<YOUR_TOOLBOX_SERVER>>,TOOLBOX_TOOLSET=supply_chain_toolset,AGENT_ENGINE_ID=<<YOUR_AGENT_ENGINE_ID>>
Ersetzen Sie die Werte für die Platzhalter <<YOUR_PROJECT>>, <<YOUR_APP_ENGINE_URL>>, <<YOUR_TOOLBOX_SERVER>> und <<YOUR_AGENT_ENGINE_ID>>.
Nach Abschluss des Befehls wird eine Dienst-URL ausgegeben. Kopieren.
- Weisen Sie dem Cloud Run-Dienstkonto die Rolle AlloyDB-Client zu.So kann Ihre serverlose Anwendung einen sicheren Tunnel zur Datenbank herstellen.
Führen Sie diesen Befehl in Ihrem Cloud Shell-Terminal aus:
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
Verwenden Sie nun die Dienst-URL (den zuvor kopierten Cloud Run-Endpunkt), um die App zu testen.
Hinweis:Wenn ein Dienstproblem auftritt und als Grund der Arbeitsspeicher angegeben wird, versuchen Sie, das zugewiesene Arbeitsspeicherlimit auf 1 GiB zu erhöhen, um das Problem zu testen.
10. Bereinigen
Vergessen Sie nicht, den AlloyDB-Cluster und die AlloyDB-Instanz zu löschen, wenn Sie dieses Lab abgeschlossen haben.
Dadurch sollte der Cluster zusammen mit seinen Instanzen bereinigt werden.
11. Glückwunsch
Durch die Kombination der Geschwindigkeit von AlloyDB, der Orchestrierungseffizienz der MCP Toolbox und des „institutionellen Gedächtnisses“ von Vertex AI Memory Bank haben wir ein Lieferkettensystem entwickelt, das sich weiterentwickelt. Gemini beantwortet nicht nur Fragen, sondern erinnert sich auch daran, dass Ihr Lager in Singapur immer mit monsunbedingten Verzögerungen zu kämpfen hat, und schlägt proaktiv vor, Sendungen umzuleiten, bevor Sie überhaupt fragen.