
1. Descripción general
En este codelab, compilarás un agente de Supply Chain Orchestrator. Esta aplicación permite a los usuarios analizar el inventario, hacer un seguimiento de la logística y administrar los riesgos de la cadena de suministro con lenguaje natural.
Aprovecharemos el Kit de desarrollo de agentes (ADK) de Google para crear una arquitectura multiagente que mantenga el contexto, recuerde las preferencias del usuario a través de Memory Bank de Vertex AI y que interactúe con un conjunto de datos masivo almacenado en AlloyDB a través de la Caja de herramientas del MCP.
Qué compilarás
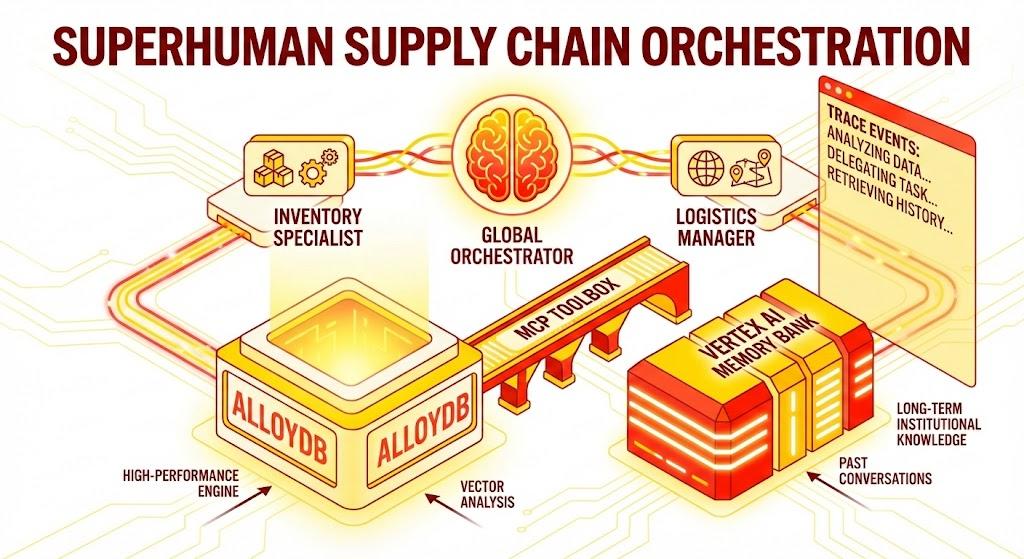
Una aplicación de Flask en Python que consta de lo siguiente:
Agente organizador global: Es el agente raíz que administra el flujo de conversación y la delegación.
Agentes especialistas: Un "InventorySpecialist" y un "LogisticsManager" para tareas específicas del dominio.
Integración de memoria: Memoria de sesión a corto plazo y memoria a largo plazo con Vertex AI Memory Bank
IU narrativa: Una interfaz web que visualiza el proceso de razonamiento del agente (contexto de seguimiento).
Qué aprenderás
- Cómo usar el ADK de Google para crear agentes y subagentes especializados
- Cómo integrar Vertex AI Memory Bank para la memoria a largo plazo del agente
- Cómo usar MCP Toolbox para conectar agentes a herramientas de datos de AlloyDB
- Cómo implementar devoluciones de llamada del ADK para rastrear y visualizar el razonamiento del agente
- Cómo implementar la solución con Cloud Run o ejecutarla de forma local
La arquitectura
El tech stack
- AlloyDB para PostgreSQL: Sirve como la base de datos operativa de alto rendimiento que contiene más de 50,000 registros de la cadena de suministro. Potencia la búsqueda y recuperación de vectores.
- MCP Toolbox para bases de datos: Actúa como el "director de orquesta" y expone los datos de AlloyDB como herramientas ejecutables a las que pueden llamar los agentes.
- Kit de desarrollo de agentes (ADK): Es el framework que se usa para definir los agentes, las instrucciones y las herramientas.
- Vertex AI Memory Bank: Proporciona memoria a largo plazo, lo que permite que el agente recuerde las preferencias del usuario y las interacciones anteriores en todas las sesiones.
- Servicio de sesiones de Vertex AI: Administra el contexto de conversación a corto plazo.
The Flow
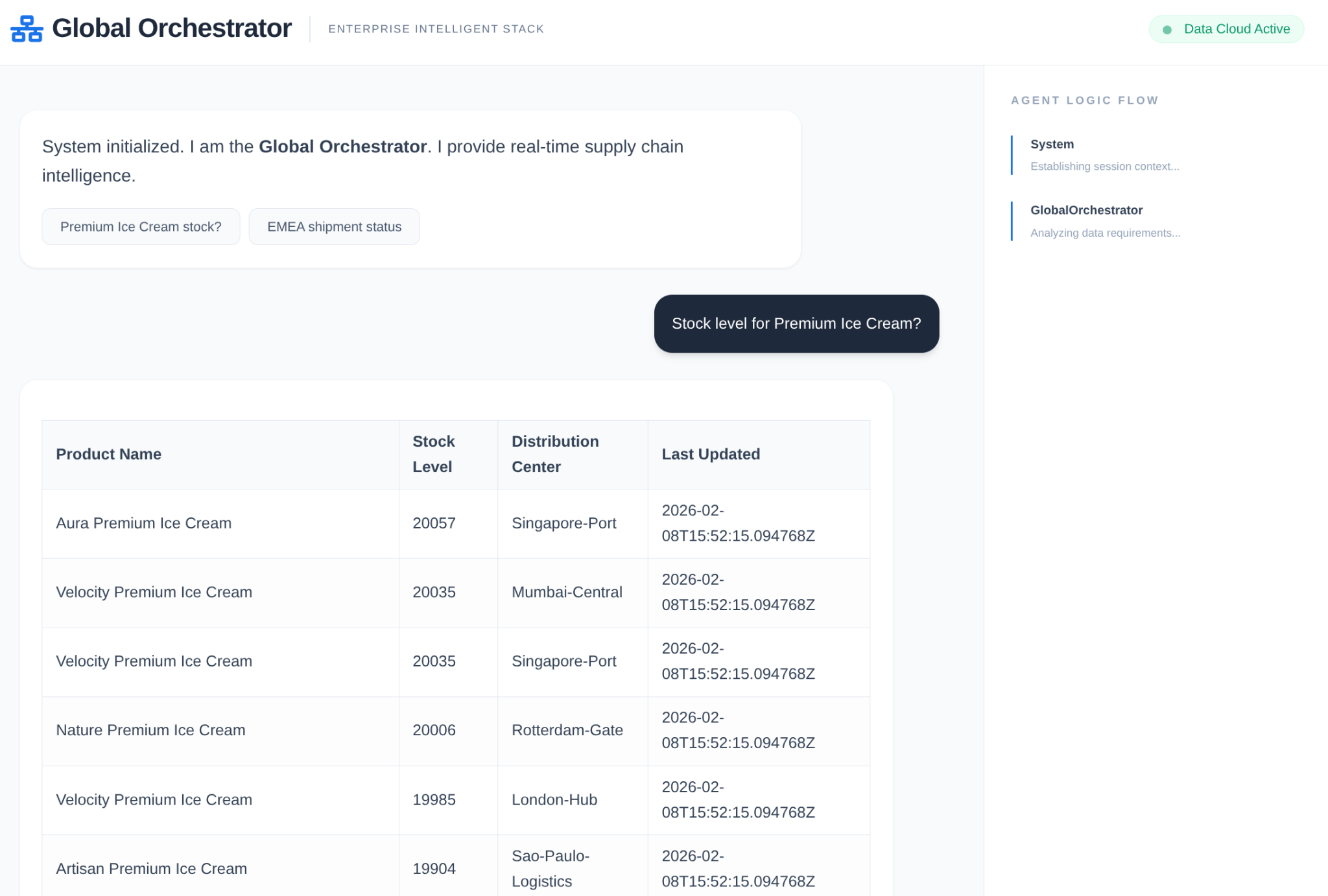
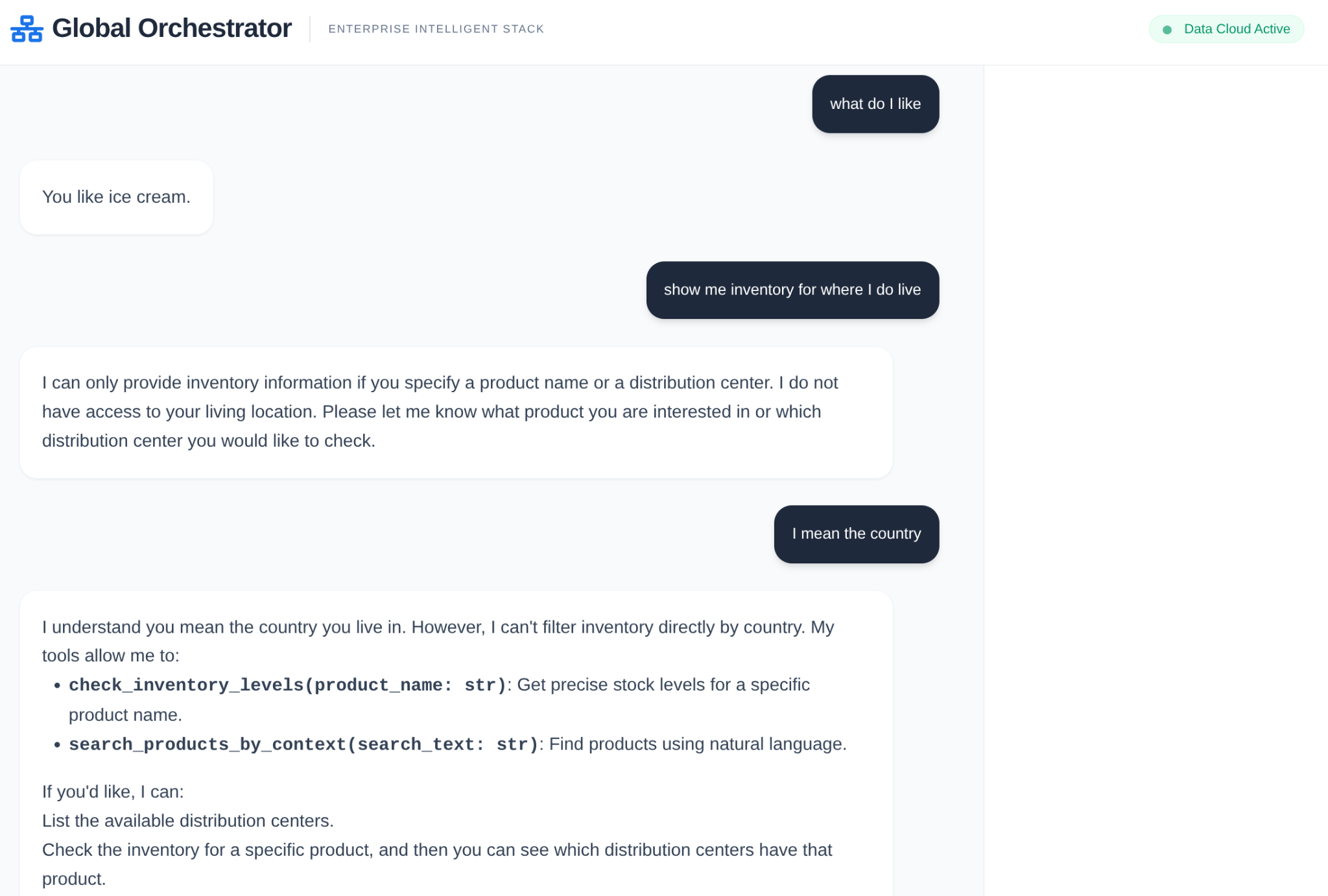
- Búsqueda del usuario: El usuario hace una pregunta (p.ej., "Verifica el stock de helado Premium").
- Verificación de la memoria: El orquestador verifica el Memory Bank para obtener información pasada pertinente (p.ej., "El usuario es gerente regional para EMEA").
- Delegación: El organizador delega la tarea al InventorySpecialist.
- Ejecución de herramientas: El especialista usa las herramientas que proporciona MCP Toolbox para consultar AlloyDB.
- Respuesta: El agente procesa los datos y devuelve una tabla con formato de Markdown.
- Almacenamiento de la memoria: Las interacciones significativas se guardan en el Memory Bank.
Requisitos
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las APIs necesarias: Sigue el vínculo y habilita las APIs.
Como alternativa, puedes usar el comando de gcloud para esto. Consulta la documentación para ver los comandos y el uso de gcloud.
Problemas potenciales y solución de problemas
El "Proyecto Fantasma" : Síndrome | Ejecutaste |
La barricada de facturación | Habilitaste el proyecto, pero olvidaste la cuenta de facturación. AlloyDB es un motor de alto rendimiento que no se iniciará si el "tanque de combustible" (facturación) está vacío. |
Retraso de la propagación de la API | Hiciste clic en "Habilitar APIs", pero la línea de comandos aún dice |
Cuota de Quags | Si usas una cuenta de prueba nueva, es posible que alcances una cuota regional para las instancias de AlloyDB. Si falla |
Agente de servicio"oculto" | A veces, al agente de servicio de AlloyDB no se le otorga automáticamente el rol de |
3. Configuración de la base de datos
AlloyDB para PostgreSQL es el núcleo de nuestra aplicación. Aprovechamos sus potentes capacidades de vectores y su motor de columnas integrado para generar incorporaciones para más de 50,000 registros de la SCM. Esto permite realizar análisis de vectores casi en tiempo real, lo que permite a nuestros agentes identificar anomalías en el inventario o riesgos logísticos en conjuntos de datos masivos en milisegundos.
En este lab, usaremos AlloyDB como la base de datos para los datos de prueba. Utiliza clústeres para contener todos los recursos, como bases de datos y registros. Cada clúster tiene una instancia principal que proporciona un punto de acceso a los datos. Las tablas contendrán los datos reales.
Creemos un clúster, una instancia y una tabla de AlloyDB en los que se cargará el conjunto de datos de prueba.
- Haz clic en el botón o copia el siguiente vínculo en el navegador en el que accediste como usuario a la consola de Google Cloud.
Como alternativa, puedes ir a la terminal de Cloud Shell desde tu proyecto en el que canjeaste la cuenta de facturación, clonar el repositorio de GitHub y navegar al proyecto con los siguientes comandos:
git clone https://github.com/AbiramiSukumaran/easy-alloydb-setup
cd easy-alloydb-setup
- Una vez que se complete este paso, el repo se clonará en tu editor local de Cloud Shell y podrás ejecutar el siguiente comando desde la carpeta del proyecto (es importante que te asegures de estar en el directorio del proyecto):
sh run.sh
- Ahora usa la IU (haz clic en el vínculo de la terminal o en el vínculo "preview on web" de la terminal).
- Ingresa los detalles del ID del proyecto, el clúster y los nombres de las instancias para comenzar.
- Ve a tomar un café mientras se desplazan los registros y puedes leer cómo se hace esto tras bambalinas aquí.
Problemas potenciales y solución de problemas
El problema de la "paciencia" | Los clústeres de bases de datos son una infraestructura pesada. Si actualizas la página o finalizas la sesión de Cloud Shell porque "parece que se detuvo", es posible que termines con una instancia "fantasma" que se aprovisionó parcialmente y que es imposible borrar sin intervención manual. |
Región no coincidente | Si habilitaste tus APIs en |
Clústeres de zombis | Si antes usaste el mismo nombre para un clúster y no lo borraste, es posible que la secuencia de comandos indique que el nombre del clúster ya existe. Los nombres de los clústeres deben ser únicos dentro de un proyecto. |
Tiempo de espera de Cloud Shell | Si tu descanso para tomar café dura 30 minutos, es posible que Cloud Shell entre en modo de suspensión y desconecte el proceso |
4. Aprovisionamiento de esquemas
Una vez que tengas en funcionamiento tu clúster y tu instancia de AlloyDB, dirígete al editor de SQL de AlloyDB Studio para habilitar las extensiones de IA y aprovisionar el esquema.
Es posible que debas esperar a que termine de crearse la instancia. Una vez que lo hagas, accede a AlloyDB con las credenciales que creaste cuando creaste el clúster. Usa los siguientes datos para autenticarte en PostgreSQL:
- Nombre de usuario : "
postgres" - Base de datos : "
postgres" - Contraseña : "
alloydb" (o la que hayas configurado en el momento de la creación)
Una vez que te autentiques correctamente en AlloyDB Studio, ingresa los comandos SQL en el editor. Puedes agregar varias ventanas del editor con el signo más que se encuentra a la derecha de la última ventana.
Ingresarás comandos para AlloyDB en ventanas del editor, y usarás las opciones Ejecutar, Formatear y Borrar según sea necesario.
Habilitar extensiones
Para compilar esta app, usaremos las extensiones pgvector y google_ml_integration. La extensión pgvector te permite almacenar y buscar embeddings de vectores. La extensión google_ml_integration proporciona funciones que usas para acceder a los extremos de predicción de Vertex AI y obtener predicciones en SQL. Habilita estas extensiones ejecutando los siguientes DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Crea una tabla
Puedes crear una tabla con la siguiente instrucción DDL en AlloyDB Studio:
DROP TABLE IF EXISTS shipments;
DROP TABLE IF EXISTS products;
-- 1. Product Inventory Table
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
category VARCHAR(100),
stock_level INTEGER,
distribution_center VARCHAR(100),
region VARCHAR(50),
embedding vector(768),
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. Logistics & Shipments
CREATE TABLE shipments (
shipment_id SERIAL PRIMARY KEY,
product_id INTEGER REFERENCES products(id),
status VARCHAR(50), -- 'In Transit', 'Delayed', 'Delivered', 'Pending'
estimated_arrival TIMESTAMP,
route_efficiency_score DECIMAL(3, 2)
);
La columna embedding permitirá el almacenamiento de los valores de vectores de algunos de los campos de texto.
Transferencia de datos
Ejecuta el siguiente conjunto de instrucciones de SQL para insertar de forma masiva 50,000 registros en la tabla de productos:
-- We use a CROSS JOIN pattern with realistic naming segments to create meaningful variety
DO $$
DECLARE
brand_names TEXT[] := ARRAY['Artisan', 'Nature', 'Elite', 'Pure', 'Global', 'Eco', 'Velocity', 'Heritage', 'Aura', 'Summit'];
product_types TEXT[] := ARRAY['Ice Cream', 'Body Wash', 'Laundry Detergent', 'Shampoo', 'Mayonnaise', 'Deodorant', 'Tea', 'Soup', 'Face Cream', 'Soap'];
variants TEXT[] := ARRAY['Classic', 'Gold', 'Premium', 'Eco-Friendly', 'Organic', 'Night-Repair', 'Extra-Fresh', 'Zero-Sugar', 'Sensitive', 'Maximum-Strength'];
regions TEXT[] := ARRAY['EMEA', 'APAC', 'LATAM', 'NAMER'];
dcs TEXT[] := ARRAY['London-Hub', 'Mumbai-Central', 'Sao-Paulo-Logistics', 'Singapore-Port', 'Rotterdam-Gate', 'New-York-DC'];
BEGIN
INSERT INTO products (name, category, stock_level, distribution_center, region)
SELECT
b || ' ' || v || ' ' || t as name,
CASE
WHEN t IN ('Ice Cream', 'Mayonnaise', 'Tea', 'Soup') THEN 'Food & Refreshment'
WHEN t IN ('Body Wash', 'Shampoo', 'Deodorant', 'Face Cream', 'Soap') THEN 'Personal Care'
ELSE 'Home Care'
END as category,
floor(random() * 20000 + 100)::int as stock_level,
dcs[floor(random() * 6 + 1)] as distribution_center,
regions[floor(random() * 4 + 1)] as region
FROM
unnest(brand_names) b,
unnest(variants) v,
unnest(product_types) t,
generate_series(1, 50); -- 10 * 10 * 10 * 50 = 50,000 records
END $$;
Insertemos registros específicos de la demostración para garantizar respuestas predecibles a las preguntas de estilo ejecutivo
-- These ensure you have predictable answers for specific "Executive" questions
INSERT INTO products (name, category, stock_level, distribution_center, region) VALUES
('Magnum Ultra Gold Limited Edition', 'Food & Refreshment', 45, 'Rotterdam-Gate', 'EMEA'),
('Dove Pro-Health Deep Moisture', 'Personal Care', 12000, 'Mumbai-Central', 'APAC'),
('Hellmanns Real Organic Mayonnaise', 'Food & Refreshment', 8000, 'London-Hub', 'EMEA');
Cómo insertar datos de envíos
-- Shipments Generation (More shipments than products)
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT
id,
CASE
WHEN random() > 0.8 THEN 'Delayed'
WHEN random() > 0.4 THEN 'In Transit'
ELSE 'Delivered'
END,
NOW() + (random() * 10 || ' days')::interval,
(random() * 0.5 + 0.5)::decimal(3,2)
FROM products
WHERE random() > 0.3; -- Create shipments for ~70% of products
-- Add duplicate shipments for some products to show complex logistics
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT id, 'In Transit', NOW() + INTERVAL '12 days', 0.88
FROM products
LIMIT 5000;
Otorgar permiso
Ejecuta la siguiente sentencia para otorgar permiso de ejecución en la función "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Otorga el rol de usuario de Vertex AI a la cuenta de servicio de AlloyDB
En la consola de IAM de Google Cloud, otorga a la cuenta de servicio de AlloyDB (que se ve así: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) acceso al rol "Usuario de Vertex AI". PROJECT_NUMBER tendrá tu número de proyecto.
Como alternativa, puedes ejecutar el siguiente comando desde la terminal de Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Genera embeddings
A continuación, generemos embeddings de vectores para campos de texto significativos específicos:
WITH
rows_to_update AS (
SELECT
id
FROM
products
WHERE
embedding IS NULL
LIMIT
5000 )
UPDATE
products
SET
embedding = ai.embedding('text-embedding-005', name || ' ' || category || ' ' || distribution_center || ' ' || region)::vector
FROM
rows_to_update
WHERE
products.id = rows_to_update.id
AND embedding IS null;
En la instrucción anterior, establecimos el límite en 5,000, así que asegúrate de ejecutarla varias veces hasta que no haya ninguna fila en la tabla con la columna de incorporación como NULL.
Problemas potenciales y solución de problemas
El bucle de "amnesia de contraseña" | Si usaste la configuración "Con un clic" y no recuerdas tu contraseña, ve a la página de información básica de la instancia en la consola y haz clic en "Editar" para restablecer la contraseña de |
El error "No se encontró la extensión" | Si |
La brecha de propagación de IAM | Ejecutaste el comando de IAM |
Vector Dimension Mismatch | La tabla |
Error de escritura en el ID del proyecto | En la llamada |
5. Configuración de Tools & Toolbox
MCP Toolbox for Databases es un servidor de MCP de código abierto para bases de datos. Te permite desarrollar herramientas de forma más fácil, rápida y segura, ya que se encarga de las complejidades, como la agrupación de conexiones, la autenticación y mucho más. Toolbox te ayuda a crear herramientas de IA generativa que permiten que tus agentes accedan a los datos de tu base de datos.
Usamos la caja de herramientas del Protocolo de contexto del modelo (MCP) para bases de datos como el "director". Actúa como middleware estandarizado entre nuestros agentes y AlloyDB. Si defines una configuración de tools.yaml, la caja de herramientas expone automáticamente operaciones complejas de la base de datos como herramientas limpias y ejecutables, como search_products_by_context o check_inventory_levels. Esto elimina la necesidad de agrupar conexiones manualmente o de usar código SQL estándar dentro de la lógica del agente.
Instala el servidor de Toolbox
En la terminal de Cloud Shell, crea una carpeta para guardar el nuevo archivo YAML de herramientas y el archivo binario de la caja de herramientas:
mkdir scm-agent-toolbox
cd scm-agent-toolbox
Desde esa carpeta nueva, ejecuta el siguiente conjunto de comandos:
# see releases page for other versions
export VERSION=0.27.0
curl -L -o toolbox https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
A continuación, crea el archivo tools.yaml dentro de esa nueva carpeta. Para ello, navega al editor de Cloud Shell y copia el contenido de este archivo del repo en el archivo tools.yaml.
sources:
supply_chain_db:
kind: "alloydb-postgres"
project: "YOUR_PROJECT_ID"
region: "us-central1"
cluster: "YOUR_CLUSTER"
instance: "YOUR_INSTANCE"
database: "postgres"
user: "postgres"
password: "YOUR_PASSWORD"
tools:
search_products_by_context:
kind: postgres-sql
source: supply_chain_db
description: Find products in the inventory using natural language search and vector embeddings.
parameters:
- name: search_text
type: string
description: Description of the product or category the user is looking for.
statement: |
SELECT name, category, stock_level, distribution_center, region
FROM products
ORDER BY embedding <=> ai.embedding('text-embedding-005', $1)::vector
LIMIT 5;
check_inventory_levels:
kind: postgres-sql
source: supply_chain_db
description: Get precise stock levels for a specific product name.
parameters:
- name: product_name
type: string
description: The exact or partial name of the product.
statement: |
SELECT name, stock_level, distribution_center, last_updated
FROM products
WHERE name ILIKE '%' || $1 || '%'
ORDER BY stock_level DESC;
track_shipment_status:
kind: postgres-sql
source: supply_chain_db
description: Retrieve real-time logistics and shipping status for a specific region or product.
parameters:
- name: region
type: string
description: The geographical region to filter shipments (e.g., EMEA, APAC).
statement: |
SELECT p.name, s.status, s.estimated_arrival, s.route_efficiency_score
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE p.region = $1
ORDER BY s.estimated_arrival ASC;
analyze_supply_chain_risk:
kind: postgres-sql
source: supply_chain_db
description: Rerank and filter shipments based on risk profiles and efficiency scores using Google ML reranker.
parameters:
- name: risk_context
type: string
description: The business context for risk analysis (e.g., 'heatwave impact' or 'port strike').
statement: |
WITH initial_ranking AS (
SELECT s.shipment_id, p.name, s.status, p.distribution_center,
ROW_NUMBER() OVER () AS ref_number
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE s.status != 'Delivered'
LIMIT 10
),
reranked_results AS (
SELECT index, score FROM
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => $1,
documents => (SELECT ARRAY_AGG(name || ' at ' || distribution_center ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT i.name, i.status, i.distribution_center, r.score
FROM initial_ranking i, reranked_results r
WHERE i.ref_number = r.index
ORDER BY r.score DESC;
toolsets:
supply_chain_toolset:
- search_products_by_context
- check_inventory_levels
- track_shipment_status
- analyze_supply_chain_risk
Ahora, prueba el archivo tools.yaml en el servidor local:
./toolbox --tools-file "tools.yaml"
También puedes probarlo en la IU.
./toolbox --ui
¡Perfecto! Una vez que te asegures de que todo funciona, implementa el servicio en Cloud Run de la siguiente manera.
Implementación de Cloud Run
- Configura la variable de entorno PROJECT_ID:
export PROJECT_ID="my-project-id"
- Inicializa la CLI de gcloud:
gcloud init
gcloud config set project $PROJECT_ID
- Debes tener habilitadas las siguientes APIs:
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Crea una cuenta de servicio de backend si aún no tienes una:
gcloud iam service-accounts create toolbox-identity
- Otorga permisos para usar Secret Manager:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
- Otorga permisos adicionales a la cuenta de servicio que son específicos de nuestra fuente de AlloyDB (roles/alloydb.client y roles/serviceusage.serviceUsageConsumer).
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role serviceusage.serviceUsageConsumer
- Sube tools.yaml como un secreto:
gcloud secrets create tools-scm-agent --data-file=tools.yaml
- Si ya tienes un secreto y quieres actualizar su versión, ejecuta el siguiente comando:
gcloud secrets versions add tools-scm-agent --data-file=tools.yaml
- Establece una variable de entorno en la imagen de contenedor que deseas usar para Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Implementa Toolbox en Cloud Run con el siguiente comando:
Si habilitaste el acceso público en tu instancia de AlloyDB (no recomendado), sigue el siguiente comando para la implementación en Cloud Run:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
Si usas una red de VPC, usa el siguiente comando:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
# TODO(dev): update the following to match your VPC details
--network <<YOUR_NETWORK_NAME>> \
--subnet <<YOUR_SUBNET_NAME>> \
--allow-unauthenticated
6. Configuración del agente
Con el Kit de desarrollo de agentes (ADK), pasamos de las instrucciones monolíticas a una arquitectura especializada de varios agentes:
- InventorySpecialist: Se enfoca en las métricas de stock de productos y almacenes.
- LogisticsManager: Es experto en rutas de envío globales y análisis de riesgos.
- GlobalOrchestrator: Es el "cerebro" que usa el razonamiento para delegar tareas y sintetizar hallazgos.
Clona este repo en tu proyecto y analicémoslo.
Para clonar este proyecto, ejecuta el siguiente comando desde la terminal de Cloud Shell (en el directorio raíz o desde donde quieras crear este proyecto):
git clone https://github.com/AbiramiSukumaran/scm-memory-agent
- Esto debería crear el proyecto, y puedes verificarlo en el editor de Cloud Shell.

- Asegúrate de actualizar el archivo .env con los valores de tu proyecto y tu instancia.
Explicación del código
Un vistazo rápido al agente de Orchestrator
Go to app.py and you should be able to see the following snippet:
orchestrator = adk.Agent(
name="GlobalOrchestrator",
model="gemini-2.5-flash",
description="Global Supply Chain Orchestrator root agent.",
instruction="""
You are the Global Supply Chain Brain. You are responsible for products, inventory and logistics.
You also have access to the memory tool, remember to include all the information that the tool can provide you with about the user before you respond.
1. Understand intent and delegate to specialists. As the Global Orchestrator, you have access to the full conversation history with the user.
When you transfer a query to a specialist agent, sub agent or tool, share the important facts and information from your memory to them so they can operate with the full context.
2. Ensure the final response is professional and uses Markdown tables for data.
3. If a specialist provides a long list, ensure only the top 10 items are shown initially.
4. Conclude with a brief, high-level executive summary of what the data implies.
""",
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
sub_agents=[inventory_agent, logistics_agent],
#after_agent_callback=auto_save_session_to_memory_callback,
)
Este fragmento es la definición de la raíz, que es el agente orquestador que recibe la conversación o la solicitud del usuario y enruta al subagente o usuario correspondiente las herramientas correspondientes según la tarea.
- Veamos el agente de inventario
inventory_agent = adk.Agent(
name="InventorySpecialist",
model="gemini-2.5-flash",
description="Specialist in product stock and warehouse data.",
instruction="""
Analyze inventory levels.
1. Use 'search_products_by_context' or 'check_inventory_levels'.
2. ALWAYS format results as a clean Markdown table.
3. If there are many results, display only the TOP 10 most relevant ones.
4. At the end, state: 'There are additional records available. Would you like to see more?'
""",
tools=tools
)
Este subagente en particular se especializa en actividades de inventario, como la búsqueda contextual de productos y la verificación de los niveles de inventario.
- Luego, está el subagente de logística:
logistics_agent = adk.Agent(
name="LogisticsManager",
model="gemini-2.5-flash",
description="Expert in global shipping routes and logistics tracking.",
instruction="""
Check shipment statuses.
1. Use 'track_shipment_status' or 'analyze_supply_chain_risk'.
2. ALWAYS format results as a clean Markdown table.
3. Limit initial output to the top 10 shipments.
4. Ask if the user needs the full manifest if more results exist.
""",
tools=tools
)
Este agente secundario en particular se especializa en actividades logísticas, como el seguimiento de envíos y el análisis de riesgos en la cadena de suministro.
- Todos los 3 agentes que analizamos hasta ahora usan herramientas, y estas se referencian a través de nuestro servidor de Toolbox que ya implementamos en la sección anterior. Consulta el siguiente fragmento:
from toolbox_core import ToolboxSyncClient
TOOLBOX_SERVER = os.environ["TOOLBOX_SERVER"]
TOOLBOX_TOOLSET = os.environ["TOOLBOX_TOOLSET"]
# --- ADK TOOLBOX CONFIGURATION ---
toolbox = ToolboxSyncClient(TOOLBOX_SERVER)
tools = toolbox.load_toolset(TOOLBOX_TOOLSET)
Este agente secundario en particular se especializa en actividades logísticas, como el seguimiento de envíos y el análisis de riesgos en la cadena de suministro.
7. Motor del agente
En la ejecución inicial, crea Agent Engine
import vertexai
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
client = vertexai.Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_LOCATION
)
agent_engine = client.agent_engines.create()
- Para la próxima ejecución, actualiza la configuración de Agent Engine con la configuración de Memory Bank:
agent_engine = client.agent_engines.update(
name=APP_NAME,
config={
"context_spec": {
"memory_bank_config": {
"generation_config": {
"model": f"projects/{PROJECT_ID}/locations/{GOOGLE_CLOUD_LOCATION}/publishers/google/models/gemini-2.5-flash"
}
}
}
})
8. Contexto, ejecución y memoria
La administración del contexto se divide en dos capas distintas para garantizar que el agente se sienta como un socio continuo en lugar de un bot sin estado:
Memoria a corto plazo (sesiones): Se administra a través de VertexAiSessionService y hace un seguimiento del historial de eventos inmediato (mensajes del usuario, respuestas de herramientas) dentro de una sola interacción.
Memoria a largo plazo (Memory Bank): Con tecnología del Memory Bank de Vertex AI a través de adk.memorybankservice. Esta capa extrae información "significativa", como la preferencia de un usuario por empresas de transporte específicas o las demoras recurrentes en el almacén, y la conserva en todas las sesiones.
Inicializa la sesión para la memoria de sesión dentro del alcance de la conversación.
Esta es la parte del fragmento que crea la sesión para la app actual del usuario actual.
from google.adk.sessions import VertexAiSessionService
...
session_service = VertexAiSessionService(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
...
# Initialize the session *outside* of the route handler to avoid repeated creation
session = None
session_lock = threading.Lock()
async def initialize_session():
global session
try:
session = await session_service.create_session(app_name=APP_NAME, user_id=USER_ID)
print(f"Session {session.id} created successfully.") # Add a log
except Exception as e:
print(f"Error creating session: {e}")
session = None # Ensure session is None in case of error
# Create the session on app startup
asyncio.run(initialize_session())
Inicializa Vertex AI Memory Bank para la memoria a largo plazo
Esta es la parte del fragmento que crea una instancia del objeto de servicio de Vertex AI Memory Bank para el motor de agentes.
from google.adk.memory import InMemoryMemoryService
from google.adk.memory import VertexAiMemoryBankService
...
try:
memory_bank_service = adk.memory.VertexAiMemoryBankService(
agent_engine_id=AGENT_ENGINE_ID,
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
#in_memory_service = InMemoryMemoryService()
print("Memory Bank Service initialized successfully.")
except Exception as e:
print(f"Error initializing Memory Bank Service: {e}")
memory_bank_service = None
runner = adk.Runner(
agent=orchestrator,
app_name=APP_NAME,
session_service=session_service,
memory_service=memory_bank_service,
)
...
¿Qué se configura?
En esta parte del fragmento, configuramos el servicio de Vertex AI Memory Bank para la memoria a largo plazo. Almacena de forma contextual la sesión de la app específica para el usuario específico como una memoria dentro de Vertex AI Memory Bank.
¿Qué se ejecuta como parte de la ejecución del agente?
async def run_and_collect():
final_text = ""
try:
async for event in runner.run_async(
new_message=content,
user_id=user_id,
session_id=session_id
):
if hasattr(event, 'author') and event.author:
if not any(log['agent'] == event.author for log in execution_logs):
execution_logs.append({
"agent": event.author,
"action": "Analyzing data requirements...",
"type": "orchestration_event"
})
if hasattr(event, 'text') and event.text:
final_text = event.text
elif hasattr(event, 'content') and hasattr(event.content, 'parts'):
for part in event.content.parts:
if hasattr(part, 'text') and part.text:
final_text = part.text
except Exception as e:
print(f"Error during runner.run_async: {e}")
raise # Re-raise the exception to signal failure
finally:
gc.collect()
return final_text
Procesa el contenido de entrada del usuario en el objeto new_message con el ID del usuario y el ID de la sesión en el alcance. Luego, el agente toma el control, se procesa la respuesta del agente y se devuelve.
¿Qué se almacena en la memoria a largo plazo?
El detalle de la sesión en el alcance de la app y el usuario se extrae en la variable de sesión.
Luego, esta sesión se agrega como la memoria del usuario actual para la app actual del objeto Memory Bank de Vertex AI con el método "add_session_to_memory".
session = asyncio.run(session_service.get_session(app_name=APP_NAME, user_id=USER_ID, session_id=session.id))
if memory_bank_service and session: # Check memory service AND session
try:
#asyncio.run(in_memory_service.add_session_to_memory(session))
asyncio.run(memory_bank_service.add_session_to_memory(session))
'''
client.agent_engines.memories.generate(
scope={"app_name": APP_NAME, "user_id": USER_ID},
name=APP_NAME,
direct_contents_source={
"events": [
{"content": content}
]
},
config={"wait_for_completion": True},
)
'''
print("Successfully added session to memory.******")
print(session.id)
except Exception as e:
print(f"Error adding session to memory: {e}")
Recuperación de memoria
Necesitamos recuperar la memoria a largo plazo almacenada usando el nombre de la app y el nombre de usuario como alcance (ya que ese es el alcance para el que almacenamos los recuerdos) para poder pasarlo como parte del contexto al organizador y a otros agentes según corresponda.
results = client.agent_engines.memories.retrieve(
name=APP_NAME,
scope={"app_name": APP_NAME, "user_id": USER_ID}
)
# RetrieveMemories returns a pager. You can use `list` to retrieve all pages' memories.
list(results)
print(list(results))
¿Cómo se carga la memoria recuperada como parte del contexto?
Usamos el siguiente atributo en la definición del agente de Orchestrator que permite que el agente raíz precargue el contexto del banco de memoria. Esto se suma a las herramientas a las que accedemos desde el servidor de la caja de herramientas para los subagentes.
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
Contexto de devolución de llamada
En una cadena de suministro empresarial, no puede haber una "caja negra". Usamos CallbackContext del ADK para crear un Narrative Engine. Al conectarnos a la ejecución del agente, capturamos cada proceso de pensamiento y cada llamada a una herramienta, y los transmitimos a una barra lateral de la IU.
- Evento de seguimiento: "GlobalOrchestrator está analizando los requisitos de datos…"
- Trace Event: "Delegating to InventorySpecialist for stock levels…"
- Trace Event: "Retrieving historical supplier delay patterns from Memory Bank…"
Este registro de auditoría es invaluable para la depuración y garantiza que los operadores humanos puedan confiar en las decisiones autónomas del agente.
from google.adk.agents.callback_context import CallbackContext
...
# --- ADK CALLBACKS (Narrative Engine) ---
execution_logs = []
async def trace_callback(context: CallbackContext):
"""
Captures agent and tool invocation flow for the UI narrative.
"""
agent_name = context.agent.name
event = {
"agent": agent_name,
"action": "Processing request steps...",
"type": "orchestration_event"
}
execution_logs.append(event)
return None
...
¡Eso es todo! Clonamos correctamente el proyecto y analizamos los detalles del agente, la memoria y el contexto.
Para probarlo, navega a la carpeta del proyecto del repo clonado y ejecuta los siguientes comandos:
>> pip install -r requirements.txt
>> python app.py
Esto debería iniciar tu agente de forma local, y deberías poder probarlo.
9. Implementémosla en Cloud Run
- Para implementarlo en Cloud Run, ejecuta el siguiente comando desde la terminal de Cloud Shell en la que se clonó el proyecto y asegúrate de estar dentro de la carpeta raíz del proyecto.
Ejecuta este comando en tu terminal de Cloud Shell:
gcloud run deploy supply-chain-agent --source . --platform managed --region us-central1 --allow-unauthenticated --set-env-vars GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT>>,GOOGLE_CLOUD_LOCATION=us-central1,GOOGLE_GENAI_USE_VERTEXAI=TRUE,REASONING_ENGINE_APP_NAME=<<YOUR_APP_ENGINE_URL>>,TOOLBOX_SERVER=<<YOUR_TOOLBOX_SERVER>>,TOOLBOX_TOOLSET=supply_chain_toolset,AGENT_ENGINE_ID=<<YOUR_AGENT_ENGINE_ID>>
Reemplaza los valores de los marcadores de posición <<YOUR_PROJECT>>, <<YOUR_APP_ENGINE_URL>>, <<YOUR_TOOLBOX_SERVER>> y <<YOUR_AGENT_ENGINE_ID>>.
Una vez que finalice el comando, se mostrará una URL de servicio. Cópiala.
- Otorga el rol de cliente de AlloyDB a la cuenta de servicio de Cloud Run.Esto permite que tu aplicación sin servidores cree un túnel seguro hacia la base de datos.
Ejecuta este comando en tu terminal de Cloud Shell:
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
Ahora, usa la URL del servicio (el extremo de Cloud Run que copiaste antes) y prueba la app.
Nota: Si tienes un problema con el servicio y se menciona la memoria como motivo, intenta aumentar el límite de memoria asignado a 1 GiB para probarlo.
10. Limpia
Cuando termines este lab, no olvides borrar el clúster y la instancia de AlloyDB.
Debería limpiar el clúster junto con sus instancias.
11. Felicitaciones
Al combinar la velocidad de AlloyDB, la eficiencia de organización de MCP Toolbox y la "memoria institucional" de Vertex AI Memory Bank, creamos un sistema de cadena de suministro que evoluciona. No solo responde preguntas, sino que recuerda que tu almacén en Singapur siempre tiene problemas con los retrasos relacionados con los monzones y sugiere de forma proactiva desviar los envíos antes de que se lo pidas.