
1. סקירה כללית
ב-Codelab הזה תלמדו איך ליצור סוכן לתזמור שרשרת אספקה. האפליקציה הזו מאפשרת למשתמשים לנתח את המלאי, לעקוב אחרי לוגיסטיקה ולנהל סיכונים בשרשרת האספקה באמצעות שפה טבעית.
נשתמש בערכה לפיתוח סוכנים (ADK) של Google כדי ליצור ארכיטקטורה מרובת סוכנים ששומרת על ההקשר, זוכרת את העדפות המשתמש באמצעות Vertex AI Memory Bank ומתקשרת עם מערך נתונים עצום שמאוחסן ב-AlloyDB באמצעות MCP Toolbox.
מה תפַתחו
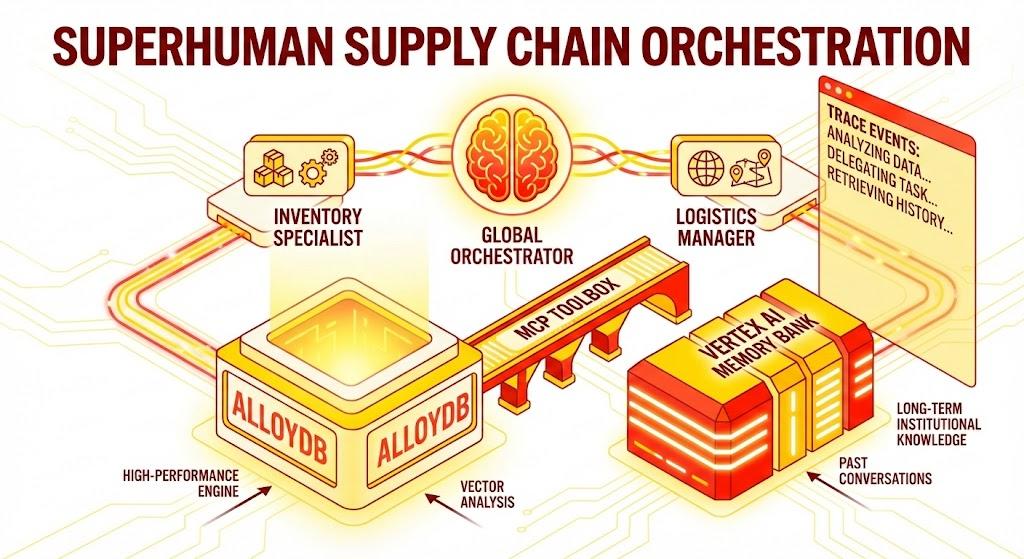
אפליקציית Python Flask שמורכבת מ:
סוכן גלובלי לניהול תהליכים: סוכן הבסיס שמנהל את זרימת השיחה ואת ההקצאה.
סוכנים מומחים: סוכנים כמו InventorySpecialist ו-LogisticsManager למשימות ספציפיות לדומיין.
שילוב זיכרון: זיכרון לטווח קצר של סשן וזיכרון לטווח ארוך באמצעות Vertex AI Memory Bank.
ממשק משתמש נרטיבי: ממשק אינטרנט שמציג באופן חזותי את תהליך החשיבה של הסוכן (הקשר של מעקב).
מה תלמדו
- איך משתמשים ב-Google ADK כדי ליצור סוכנים ותת-סוכנים ייעודיים.
- איך משלבים את Vertex AI Memory Bank לזיכרון ארוך טווח של סוכנים.
- איך משתמשים ב-MCP Toolbox כדי לקשר סוכנים לכלי נתונים של AlloyDB.
- איך מטמיעים קריאות חוזרות (callback) של ADK כדי לעקוב אחרי הנימוקים של הסוכן ולהציג אותם באופן חזותי.
- איך פורסים את הפתרון באמצעות Cloud Run או מפעילים אותו באופן מקומי.
הארכיטקטורה
הסטאק הטכנולוגי
- AlloyDB ל-PostgreSQL: משמש כמסד נתונים תפעולי עם ביצועים גבוהים שמכיל יותר מ-50,000 רשומות של שרשרת אספקה. הוא מפעיל את החיפוש והאחזור של וקטורים.
- MCP Toolbox for Databases: פועל כ "מנהל התזמור", ומציג נתונים של AlloyDB ככלים שניתנים להפעלה והסוכנים יכולים להפעיל.
- ערכה לפיתוח סוכנים (ADK): המסגרת שמשמשת להגדרת הסוכנים, ההוראות והכלים.
- Vertex AI Memory Bank: מאפשר לבוט לזכור את ההעדפות של המשתמשים ואת האינטראקציות הקודמות שלהם בסשנים שונים.
- Vertex AI Session Service: מנהל את ההקשר של שיחות לטווח קצר.
הזרימה
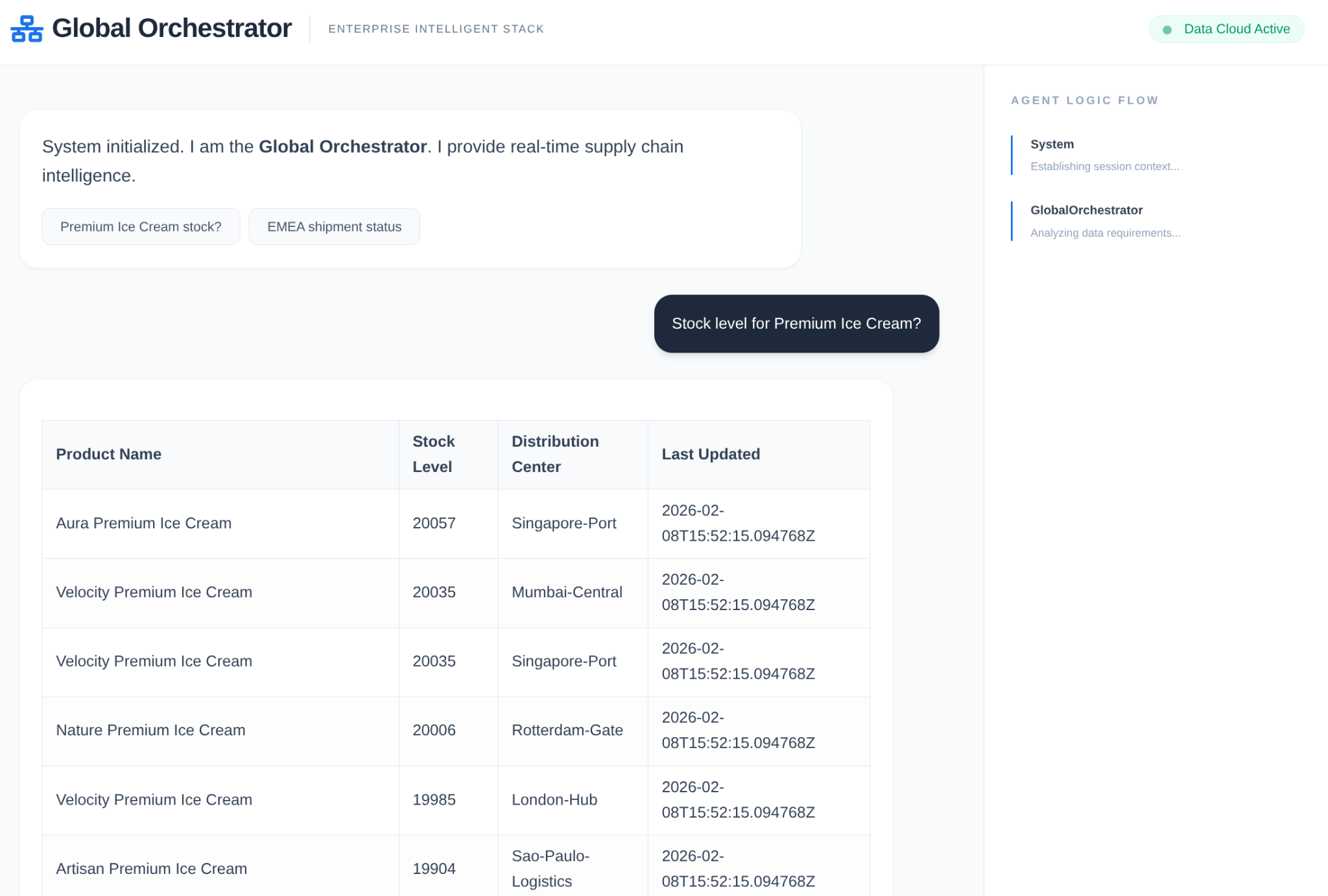
- שאילתת משתמש: המשתמש שואל שאלה (לדוגמה, "תבדוק אם יש במלאי גלידה פרימיום").
- בדיקת הזיכרון: המארגן בודק את מאגר הזיכרון כדי למצוא מידע רלוונטי מהעבר (לדוגמה, "המשתמש הוא מנהל אזורי באזור EMEA").
- העברת משימה: ה-Orchestrator מעביר את המשימה אל InventorySpecialist.
- הפעלת כלי: המומחה משתמש בכלים שסופקו על ידי MCP Toolbox כדי לשלוח שאילתות ל-AlloyDB.
- תשובה: הסוכן מעבד את הנתונים ומחזיר טבלה בפורמט Markdown.
- אחסון הזיכרון: אינטראקציות משמעותיות נשמרות ב-Memory Bank.
דרישות
2. לפני שמתחילים
יצירת פרויקט
- ב-מסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- מוודאים שהחיוב מופעל בפרויקט ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט.
- תשתמשו ב-Cloud Shell, סביבת שורת פקודה שפועלת ב-Google Cloud. לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud.

- אחרי שמתחברים ל-Cloud Shell, אפשר לבדוק שכבר בוצע אימות ושהפרויקט מוגדר לפי מזהה הפרויקט באמצעות הפקודה הבאה:
gcloud auth list
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט.
gcloud config list project
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו:
gcloud config set project <YOUR_PROJECT_ID>
- מפעילים את ממשקי ה-API הנדרשים: לוחצים על הקישור ומפעילים את ממשקי ה-API.
אפשר גם להשתמש בפקודת gcloud. אפשר לעיין במאמרי העזרה בנושא פקודות gcloud ושימוש בהן.
נקודות חשובות ופתרון בעיות
תסמונת 'פרויקט הרפאים' | הפעלת את הפקודה |
מחסום בחיוב | הפעלתם את הפרויקט, אבל שכחתם להוסיף חשבון לחיוב. AlloyDB הוא מנוע עם ביצועים גבוהים, והוא לא יופעל אם 'מיכל הדלק' (החיוב) ריק. |
השהיה בהפצת API | לחצתם על 'הפעלת ממשקי API', אבל בשורת הפקודה עדיין מופיעה ההודעה |
מכסה Quags | אם אתם משתמשים בחשבון ניסיון חדש לגמרי, יכול להיות שתגיעו למכסה אזורית של מופעי AlloyDB. אם הפעולה |
סוכן שירות 'מוסתר' | לפעמים סוכן השירות של AlloyDB לא מקבל אוטומטית את התפקיד |
3. הגדרת מסד נתונים
בבסיס האפליקציה שלנו נמצא AlloyDB ל-PostgreSQL. השתמשנו ביכולות הווקטוריות המתקדמות שלו ובמנוע העמודות המשולב כדי ליצור הטמעות עבור 50,000 רשומות SCM ומעלה. הניתוח הווקטורי מתבצע כמעט בזמן אמת, וכך הסוכנים שלנו יכולים לזהות חריגות במלאי או סיכונים לוגיסטיים במערכי נתונים עצומים בתוך אלפיות השנייה.
בשיעור ה-Lab הזה נשתמש ב-AlloyDB כבסיס הנתונים של נתוני הבדיקה. הוא משתמש באשכולות כדי להכיל את כל המשאבים, כמו מסדי נתונים ויומנים. לכל אשכול יש מופע ראשי שמספק נקודת גישה לנתונים. הטבלאות יכילו את הנתונים בפועל.
ניצור אשכול, מכונה וטבלה של AlloyDB שבהם ייטען מערך הנתונים של הבדיקה.
- לוחצים על הלחצן או מעתיקים את הקישור שלמטה לדפדפן שבו המשתמש מחובר למסוף Google Cloud.
לחלופין, אפשר לעבור אל Cloud Shell Terminal מהפרויקט שבו מימשתם את החשבון לחיוב, לשכפל את מאגר GitHub ולעבור אל הפרויקט באמצעות הפקודות הבאות:
git clone https://github.com/AbiramiSukumaran/easy-alloydb-setup
cd easy-alloydb-setup
- אחרי שהשלב הזה יסתיים, המאגר ישוכפל לעורך המקומי של Cloud Shell ותוכלו להריץ את הפקודה שלמטה מתוך תיקיית הפרויקט (חשוב לוודא שאתם בספריית הפרויקט):
sh run.sh
- עכשיו משתמשים בממשק המשתמש (לוחצים על הקישור במסוף או על הקישור 'תצוגה מקדימה באינטרנט' במסוף).
- כדי להתחיל, מזינים את הפרטים של מזהה הפרויקט, האשכול ושמות המופעים.
- אפשר ללכת לשתות קפה בזמן שהיומנים מתגללים, וכאן אפשר לקרוא איך זה קורה מאחורי הקלעים.
נקודות חשובות ופתרון בעיות
הבעיה של 'סבלנות' | אשכולות של מסדי נתונים הם תשתית כבדה. אם תרעננו את הדף או תסיימו את הסשן ב-Cloud Shell כי נראה שהוא נתקע, יכול להיות שתקבלו מופע 'רפאים' שהוקצה באופן חלקי ואי אפשר למחוק אותו בלי התערבות ידנית. |
חוסר התאמה באזור | אם הפעלתם את ממשקי ה-API ב- |
Zombie Clusters | אם השתמשתם בעבר באותו שם לאשכול ולא מחקתם אותו, יכול להיות שהסקריפט יציין שהשם של האשכול כבר קיים. שמות האשכולות צריכים להיות ייחודיים בתוך פרויקט. |
פסק זמן ב-Cloud Shell | אם הפסקת הקפה נמשכת 30 דקות, יכול להיות ש-Cloud Shell יעבור למצב שינה וינתק את התהליך |
4. הקצאת הרשאות לסכימה
אחרי שמפעילים את האשכול ואת המכונה של AlloyDB, עוברים אל עורך ה-SQL ב-AlloyDB Studio כדי להפעיל את תוספי ה-AI ולספק את הסכימה.
יכול להיות שתצטרכו לחכות עד שהמופע שלכם יסיים את תהליך היצירה. אחרי שזה קורה, נכנסים ל-AlloyDB באמצעות פרטי הכניסה שיצרתם כשנוצר האשכול. משתמשים בנתונים הבאים כדי לבצע אימות ב-PostgreSQL:
- שם משתמש : "
postgres" - מסד נתונים : "
postgres" - סיסמה:
alloydb(או כל סיסמה אחרת שהגדרתם בזמן היצירה)
אחרי שתעברו בהצלחה את תהליך האימות ב-AlloyDB Studio, תוכלו להזין פקודות SQL בכלי העריכה. אפשר להוסיף כמה חלונות של Editor באמצעות סימן הפלוס שמימין לחלון האחרון.
מזינים פקודות ל-AlloyDB בחלונות העריכה, ומשתמשים באפשרויות Run (הפעלה), Format (עיצוב) ו-Clear (ניקוי) לפי הצורך.
הפעלת תוספים
כדי ליצור את האפליקציה הזו, נשתמש בתוספים pgvector ו-google_ml_integration. התוסף pgvector מאפשר לכם לאחסן ולחפש הטמעות של וקטורים. התוסף google_ml_integration מספק פונקציות שמשמשות לגישה לנקודות קצה (endpoints) של חיזוי ב-Vertex AI כדי לקבל חיזויים ב-SQL. מפעילים את התוספים האלה על ידי הפעלת פקודות ה-DDL הבאות:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
צור טבלה
אתם יכולים ליצור טבלה באמצעות הצהרת ה-DDL שבהמשך ב-AlloyDB Studio:
DROP TABLE IF EXISTS shipments;
DROP TABLE IF EXISTS products;
-- 1. Product Inventory Table
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
category VARCHAR(100),
stock_level INTEGER,
distribution_center VARCHAR(100),
region VARCHAR(50),
embedding vector(768),
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. Logistics & Shipments
CREATE TABLE shipments (
shipment_id SERIAL PRIMARY KEY,
product_id INTEGER REFERENCES products(id),
status VARCHAR(50), -- 'In Transit', 'Delayed', 'Delivered', 'Pending'
estimated_arrival TIMESTAMP,
route_efficiency_score DECIMAL(3, 2)
);
בעמודה embedding אפשר לאחסן את ערכי הווקטור של חלק משדות הטקסט.
הטמעת נתונים
מריצים את קבוצת הצהרות ה-SQL הבאה כדי להוסיף 50,000 רשומות לטבלת המוצרים:
-- We use a CROSS JOIN pattern with realistic naming segments to create meaningful variety
DO $$
DECLARE
brand_names TEXT[] := ARRAY['Artisan', 'Nature', 'Elite', 'Pure', 'Global', 'Eco', 'Velocity', 'Heritage', 'Aura', 'Summit'];
product_types TEXT[] := ARRAY['Ice Cream', 'Body Wash', 'Laundry Detergent', 'Shampoo', 'Mayonnaise', 'Deodorant', 'Tea', 'Soup', 'Face Cream', 'Soap'];
variants TEXT[] := ARRAY['Classic', 'Gold', 'Premium', 'Eco-Friendly', 'Organic', 'Night-Repair', 'Extra-Fresh', 'Zero-Sugar', 'Sensitive', 'Maximum-Strength'];
regions TEXT[] := ARRAY['EMEA', 'APAC', 'LATAM', 'NAMER'];
dcs TEXT[] := ARRAY['London-Hub', 'Mumbai-Central', 'Sao-Paulo-Logistics', 'Singapore-Port', 'Rotterdam-Gate', 'New-York-DC'];
BEGIN
INSERT INTO products (name, category, stock_level, distribution_center, region)
SELECT
b || ' ' || v || ' ' || t as name,
CASE
WHEN t IN ('Ice Cream', 'Mayonnaise', 'Tea', 'Soup') THEN 'Food & Refreshment'
WHEN t IN ('Body Wash', 'Shampoo', 'Deodorant', 'Face Cream', 'Soap') THEN 'Personal Care'
ELSE 'Home Care'
END as category,
floor(random() * 20000 + 100)::int as stock_level,
dcs[floor(random() * 6 + 1)] as distribution_center,
regions[floor(random() * 4 + 1)] as region
FROM
unnest(brand_names) b,
unnest(variants) v,
unnest(product_types) t,
generate_series(1, 50); -- 10 * 10 * 10 * 50 = 50,000 records
END $$;
אפשר להוסיף רשומות ספציפיות להדגמה כדי להבטיח תשובות צפויות לשאלות בסגנון מנהלים
-- These ensure you have predictable answers for specific "Executive" questions
INSERT INTO products (name, category, stock_level, distribution_center, region) VALUES
('Magnum Ultra Gold Limited Edition', 'Food & Refreshment', 45, 'Rotterdam-Gate', 'EMEA'),
('Dove Pro-Health Deep Moisture', 'Personal Care', 12000, 'Mumbai-Central', 'APAC'),
('Hellmanns Real Organic Mayonnaise', 'Food & Refreshment', 8000, 'London-Hub', 'EMEA');
הוספת נתוני משלוחים
-- Shipments Generation (More shipments than products)
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT
id,
CASE
WHEN random() > 0.8 THEN 'Delayed'
WHEN random() > 0.4 THEN 'In Transit'
ELSE 'Delivered'
END,
NOW() + (random() * 10 || ' days')::interval,
(random() * 0.5 + 0.5)::decimal(3,2)
FROM products
WHERE random() > 0.3; -- Create shipments for ~70% of products
-- Add duplicate shipments for some products to show complex logistics
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT id, 'In Transit', NOW() + INTERVAL '12 days', 0.88
FROM products
LIMIT 5000;
מתן הרשאה
מריצים את ההצהרה הבאה כדי להעניק הרשאת הפעלה לפונקציה embedding:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
נותנים לחשבון השירות של AlloyDB את התפקיד Vertex AI User
במסוף IAM של Google Cloud, מעניקים לחשבון השירות של AlloyDB (שנראה כך: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) גישה לתפקיד Vertex AI User. PROJECT_NUMBER יכיל את מספר הפרויקט.
לחלופין, אפשר להריץ את הפקודה הבאה מ-Cloud Shell Terminal:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
יצירת הטמעות
בשלב הבא, ניצור הטמעות וקטוריות לשדות טקסט ספציפיים עם משמעות:
WITH
rows_to_update AS (
SELECT
id
FROM
products
WHERE
embedding IS NULL
LIMIT
5000 )
UPDATE
products
SET
embedding = ai.embedding('text-embedding-005', name || ' ' || category || ' ' || distribution_center || ' ' || region)::vector
FROM
rows_to_update
WHERE
products.id = rows_to_update.id
AND embedding IS null;
בהצהרה שלמעלה הגדרנו את המגבלה כ-5,000, לכן חשוב להריץ אותה שוב ושוב עד שלא תהיה שורה בטבלה עם ההטמעה של העמודה כ-NULL.
נקודות חשובות ופתרון בעיות
הלולאה של 'שכחתי את הסיסמה' | אם השתמשתם בהגדרה 'קליק אחד' ואתם לא זוכרים את הסיסמה, עוברים לדף 'פרטים בסיסיים של מופע' במסוף ולוחצים על 'עריכה' כדי לאפס את הסיסמה של |
השגיאה 'התוסף לא נמצא' | אם הפעולה |
הפער בהפצת IAM | הפעלתם את פקודת IAM |
חוסר התאמה במאפיין וקטור | הטבלה |
שגיאת הקלדה במזהה הפרויקט | בשיחה |
5. כלים והגדרת ארגז הכלים
MCP Toolbox for Databases הוא שרת MCP בקוד פתוח למסדי נתונים. היא מאפשרת לכם לפתח כלים בקלות, במהירות ובאופן מאובטח יותר, כי היא מטפלת במורכבויות כמו איגום חיבורים, אימות ועוד. ה-Toolbox עוזר לכם ליצור כלי AI גנרטיבי שמאפשרים לסוכנים שלכם לגשת לנתונים במסד הנתונים.
אנחנו משתמשים ב-Model Context Protocol (MCP) Toolbox for Databases בתור "מנצח". הוא משמש כתוכנת ביניים סטנדרטית בין הסוכנים שלנו לבין AlloyDB. הגדרת tools.yaml מאפשרת ל-toolbox לחשוף באופן אוטומטי פעולות מורכבות במסד הנתונים ככלים נקיים וניתנים להרצה, כמו search_products_by_context או check_inventory_levels. כך אין צורך בניהול ידני של מאגר חיבורים או ב-SQL סטנדרטי בתוך הלוגיקה של הסוכן.
התקנת שרת Toolbox
במסוף Cloud Shell, יוצרים תיקייה לשמירת קובץ ה-YAML של כלי חדש וקובץ הבינארי של ארגז הכלים:
mkdir scm-agent-toolbox
cd scm-agent-toolbox
מתוך התיקייה החדשה, מריצים את קבוצת הפקודות הבאה:
# see releases page for other versions
export VERSION=0.27.0
curl -L -o toolbox https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
לאחר מכן יוצרים את הקובץ tools.yaml בתוך התיקייה החדשה. כדי לעשות זאת, עוברים אל Cloud Shell Editor ומעתיקים את התוכן של קובץ המאגר הזה אל הקובץ tools.yaml.
sources:
supply_chain_db:
kind: "alloydb-postgres"
project: "YOUR_PROJECT_ID"
region: "us-central1"
cluster: "YOUR_CLUSTER"
instance: "YOUR_INSTANCE"
database: "postgres"
user: "postgres"
password: "YOUR_PASSWORD"
tools:
search_products_by_context:
kind: postgres-sql
source: supply_chain_db
description: Find products in the inventory using natural language search and vector embeddings.
parameters:
- name: search_text
type: string
description: Description of the product or category the user is looking for.
statement: |
SELECT name, category, stock_level, distribution_center, region
FROM products
ORDER BY embedding <=> ai.embedding('text-embedding-005', $1)::vector
LIMIT 5;
check_inventory_levels:
kind: postgres-sql
source: supply_chain_db
description: Get precise stock levels for a specific product name.
parameters:
- name: product_name
type: string
description: The exact or partial name of the product.
statement: |
SELECT name, stock_level, distribution_center, last_updated
FROM products
WHERE name ILIKE '%' || $1 || '%'
ORDER BY stock_level DESC;
track_shipment_status:
kind: postgres-sql
source: supply_chain_db
description: Retrieve real-time logistics and shipping status for a specific region or product.
parameters:
- name: region
type: string
description: The geographical region to filter shipments (e.g., EMEA, APAC).
statement: |
SELECT p.name, s.status, s.estimated_arrival, s.route_efficiency_score
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE p.region = $1
ORDER BY s.estimated_arrival ASC;
analyze_supply_chain_risk:
kind: postgres-sql
source: supply_chain_db
description: Rerank and filter shipments based on risk profiles and efficiency scores using Google ML reranker.
parameters:
- name: risk_context
type: string
description: The business context for risk analysis (e.g., 'heatwave impact' or 'port strike').
statement: |
WITH initial_ranking AS (
SELECT s.shipment_id, p.name, s.status, p.distribution_center,
ROW_NUMBER() OVER () AS ref_number
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE s.status != 'Delivered'
LIMIT 10
),
reranked_results AS (
SELECT index, score FROM
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => $1,
documents => (SELECT ARRAY_AGG(name || ' at ' || distribution_center ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT i.name, i.status, i.distribution_center, r.score
FROM initial_ranking i, reranked_results r
WHERE i.ref_number = r.index
ORDER BY r.score DESC;
toolsets:
supply_chain_toolset:
- search_products_by_context
- check_inventory_levels
- track_shipment_status
- analyze_supply_chain_risk
עכשיו בודקים את הקובץ tools.yaml בשרת המקומי:
./toolbox --tools-file "tools.yaml"
אפשר גם לבדוק אותו בממשק המשתמש
./toolbox --ui
מושלם!! אחרי שמוודאים שהכל עובד, אפשר לפרוס את האפליקציה ב-Cloud Run באופן הבא.
פריסה ב-Cloud Run
- מגדירים את משתנה הסביבה PROJECT_ID:
export PROJECT_ID="my-project-id"
- מאתחלים את ה-CLI של gcloud:
gcloud init
gcloud config set project $PROJECT_ID
- צריך להפעיל את ממשקי ה-API הבאים:
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- אם עדיין אין לכם חשבון שירות לקצה העורפי, יוצרים חשבון שירות לקצה העורפי:
gcloud iam service-accounts create toolbox-identity
- נותנים הרשאות לשימוש במנהל הסודות:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
- נותנים לחשבון השירות הרשאות נוספות שספציפיות למקור AlloyDB שלנו (roles/alloydb.client ו-roles/serviceusage.serviceUsageConsumer)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role serviceusage.serviceUsageConsumer
- מעלים את הקובץ tools.yaml כסוד:
gcloud secrets create tools-scm-agent --data-file=tools.yaml
- אם כבר יש לכם סוד ואתם רוצים לעדכן את גרסת הסוד, מריצים את הפקודה הבאה:
gcloud secrets versions add tools-scm-agent --data-file=tools.yaml
- מגדירים משתנה סביבה לקובץ אימג' של קונטיינר שרוצים להשתמש בו ב-Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- מפעילים את Toolbox ב-Cloud Run באמצעות הפקודה הבאה:
אם הפעלתם גישה ציבורית במופע AlloyDB (לא מומלץ), אתם יכולים להשתמש בפקודה הבאה כדי לבצע פריסה ב-Cloud Run:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
אם אתם משתמשים ברשת VPC, משתמשים בפקודה הבאה:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
# TODO(dev): update the following to match your VPC details
--network <<YOUR_NETWORK_NAME>> \
--subnet <<YOUR_SUBNET_NAME>> \
--allow-unauthenticated
6. הגדרת הסוכן
באמצעות הערכה לפיתוח סוכנים (ADK), עברנו מהנחיות מונוליטיות לארכיטקטורה מיוחדת מרובת סוכנים:
- InventorySpecialist: מתמקד במלאי המוצרים ובמדדים של מחסנים.
- LogisticsManager: מומחה בנתיבי משלוח גלובליים ובניתוח סיכונים.
- GlobalOrchestrator: ה "מוח" שמשתמש בחשיבה רציונלית כדי להקצות משימות ולזקק ממצאים.
שכפלו את המאגר הזה לפרויקט שלכם, ונסביר לכם איך הוא פועל.
כדי לשכפל את הפרויקט, מריצים את הפקודה הבאה בטרמינל של Cloud Shell (בספריית הבסיס או בכל מקום שבו רוצים ליצור את הפרויקט):
git clone https://github.com/AbiramiSukumaran/scm-memory-agent
- הפעולה הזו אמורה ליצור את הפרויקט, ואפשר לוודא זאת בעורך Cloud Shell.

- חשוב לעדכן את קובץ .env בערכים של הפרויקט והמופע.
הסבר מפורט על הקוד
סקירה מהירה של סוכן Orchestrator
Go to app.py and you should be able to see the following snippet:
orchestrator = adk.Agent(
name="GlobalOrchestrator",
model="gemini-2.5-flash",
description="Global Supply Chain Orchestrator root agent.",
instruction="""
You are the Global Supply Chain Brain. You are responsible for products, inventory and logistics.
You also have access to the memory tool, remember to include all the information that the tool can provide you with about the user before you respond.
1. Understand intent and delegate to specialists. As the Global Orchestrator, you have access to the full conversation history with the user.
When you transfer a query to a specialist agent, sub agent or tool, share the important facts and information from your memory to them so they can operate with the full context.
2. Ensure the final response is professional and uses Markdown tables for data.
3. If a specialist provides a long list, ensure only the top 10 items are shown initially.
4. Conclude with a brief, high-level executive summary of what the data implies.
""",
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
sub_agents=[inventory_agent, logistics_agent],
#after_agent_callback=auto_save_session_to_memory_callback,
)
הקטע הזה הוא ההגדרה של הרכיב הבסיסי, שהוא סוכן התזמור שמקבל את השיחה או הבקשה מהמשתמש ומנתב לסוכן המשנה המתאים או למשתמש את הכלים המתאימים על סמך המשימה.
- בואו נסתכל על סוכן המלאי
inventory_agent = adk.Agent(
name="InventorySpecialist",
model="gemini-2.5-flash",
description="Specialist in product stock and warehouse data.",
instruction="""
Analyze inventory levels.
1. Use 'search_products_by_context' or 'check_inventory_levels'.
2. ALWAYS format results as a clean Markdown table.
3. If there are many results, display only the TOP 10 most relevant ones.
4. At the end, state: 'There are additional records available. Would you like to see more?'
""",
tools=tools
)
הסוכן המשנה הזה מתמחה בפעילויות שקשורות למלאי, כמו חיפוש מוצרים בהקשר מסוים וגם בדיקת רמות המלאי.
- לאחר מכן יש את סוכן המשנה ללוגיסטיקה:
logistics_agent = adk.Agent(
name="LogisticsManager",
model="gemini-2.5-flash",
description="Expert in global shipping routes and logistics tracking.",
instruction="""
Check shipment statuses.
1. Use 'track_shipment_status' or 'analyze_supply_chain_risk'.
2. ALWAYS format results as a clean Markdown table.
3. Limit initial output to the top 10 shipments.
4. Ask if the user needs the full manifest if more results exist.
""",
tools=tools
)
סוכן המשנה הזה מתמחה בפעילויות לוגיסטיות כמו מעקב אחר משלוחים וניתוח סיכונים בשרשרת האספקה.
- כל שלושת הסוכנים שדיברנו עליהם עד עכשיו משתמשים בכלים, והכלים מפנים לשרת Toolbox שכבר פרסנו בקטע הקודם. אפשר לעיין בקטע הקוד לדוגמה שבהמשך:
from toolbox_core import ToolboxSyncClient
TOOLBOX_SERVER = os.environ["TOOLBOX_SERVER"]
TOOLBOX_TOOLSET = os.environ["TOOLBOX_TOOLSET"]
# --- ADK TOOLBOX CONFIGURATION ---
toolbox = ToolboxSyncClient(TOOLBOX_SERVER)
tools = toolbox.load_toolset(TOOLBOX_TOOLSET)
סוכן המשנה הזה מתמחה בפעילויות לוגיסטיות כמו מעקב אחר משלוחים וניתוח סיכונים בשרשרת האספקה.
7. Agent Engine
יצירת מנוע הסוכן בהרצה הראשונית
import vertexai
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
client = vertexai.Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_LOCATION
)
agent_engine = client.agent_engines.create()
- לריצה הבאה, מעדכנים את Agent Engine עם ההגדרה Memory Bank:
agent_engine = client.agent_engines.update(
name=APP_NAME,
config={
"context_spec": {
"memory_bank_config": {
"generation_config": {
"model": f"projects/{PROJECT_ID}/locations/{GOOGLE_CLOUD_LOCATION}/publishers/google/models/gemini-2.5-flash"
}
}
}
})
8. הקשר, הפעלה וזיכרון
ניהול ההקשרים מחולק לשתי שכבות נפרדות כדי שהסוכן ירגיש כמו שותף רציף ולא כמו בוט חסר מצב:
זיכרון לטווח קצר (סשנים): מנוהל באמצעות VertexAiSessionService, ועוקב אחרי היסטוריית האירועים המיידית (הודעות משתמשים, תשובות של כלי) במסגרת אינטראקציה אחת.
זיכרון לטווח ארוך (מאגר זיכרון): מבוסס על מאגר הזיכרון של Vertex AI באמצעות adk.memorybankservice. השכבה הזו מחלצת מידע 'משמעותי' – כמו העדפה של משתמש לחברות משלוחים ספציפיות או עיכובים חוזרים ונשנים במחסן – ושומרת אותו בין סשנים.
אתחול של סשן לזיכרון של הסשן בהיקף השיחה
זהו החלק בקטע הקוד שיוצר את הסשן עבור האפליקציה הנוכחית של המשתמש הנוכחי.
from google.adk.sessions import VertexAiSessionService
...
session_service = VertexAiSessionService(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
...
# Initialize the session *outside* of the route handler to avoid repeated creation
session = None
session_lock = threading.Lock()
async def initialize_session():
global session
try:
session = await session_service.create_session(app_name=APP_NAME, user_id=USER_ID)
print(f"Session {session.id} created successfully.") # Add a log
except Exception as e:
print(f"Error creating session: {e}")
session = None # Ensure session is None in case of error
# Create the session on app startup
asyncio.run(initialize_session())
איך מאתחלים את Vertex AI Memory Bank לזיכרון לטווח ארוך
זהו החלק בקטע הקוד שיוצר מופע של אובייקט השירות Vertex AI Memory Bank עבור מנוע הסוכן.
from google.adk.memory import InMemoryMemoryService
from google.adk.memory import VertexAiMemoryBankService
...
try:
memory_bank_service = adk.memory.VertexAiMemoryBankService(
agent_engine_id=AGENT_ENGINE_ID,
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
#in_memory_service = InMemoryMemoryService()
print("Memory Bank Service initialized successfully.")
except Exception as e:
print(f"Error initializing Memory Bank Service: {e}")
memory_bank_service = None
runner = adk.Runner(
agent=orchestrator,
app_name=APP_NAME,
session_service=session_service,
memory_service=memory_bank_service,
)
...
מה מוגדר?
בחלק הזה של קטע הקוד אנחנו מגדירים את שירות Vertex AI Memory Bank לזיכרון לטווח ארוך. השירות הזה מאחסן את ההקשר של הסשן עבור האפליקציה הספציפית של המשתמש הספציפי כזיכרון ב-Vertex AI Memory Bank.
מה מופעל כחלק מההרצה של הסוכן?
async def run_and_collect():
final_text = ""
try:
async for event in runner.run_async(
new_message=content,
user_id=user_id,
session_id=session_id
):
if hasattr(event, 'author') and event.author:
if not any(log['agent'] == event.author for log in execution_logs):
execution_logs.append({
"agent": event.author,
"action": "Analyzing data requirements...",
"type": "orchestration_event"
})
if hasattr(event, 'text') and event.text:
final_text = event.text
elif hasattr(event, 'content') and hasattr(event.content, 'parts'):
for part in event.content.parts:
if hasattr(part, 'text') and part.text:
final_text = part.text
except Exception as e:
print(f"Error during runner.run_async: {e}")
raise # Re-raise the exception to signal failure
finally:
gc.collect()
return final_text
הוא מעבד את תוכן הקלט של המשתמש לאובייקט new_message עם מזהה המשתמש ומזהה הסשן בהיקף. הסוכן משתלט על השיחה, והתשובה שלו מעובדת ומוחזרת.
מה מאוחסן בזיכרון לטווח ארוך?
פרטי הסשן בהיקף האפליקציה והמשתמש מחולצים במשתנה הסשן.
הסשן הזה מתווסף לזיכרון של המשתמש הנוכחי באפליקציה הנוכחית של אובייקט Vertex AI Memory Bank באמצעות השיטה add_session_to_memory.
session = asyncio.run(session_service.get_session(app_name=APP_NAME, user_id=USER_ID, session_id=session.id))
if memory_bank_service and session: # Check memory service AND session
try:
#asyncio.run(in_memory_service.add_session_to_memory(session))
asyncio.run(memory_bank_service.add_session_to_memory(session))
'''
client.agent_engines.memories.generate(
scope={"app_name": APP_NAME, "user_id": USER_ID},
name=APP_NAME,
direct_contents_source={
"events": [
{"content": content}
]
},
config={"wait_for_completion": True},
)
'''
print("Successfully added session to memory.******")
print(session.id)
except Exception as e:
print(f"Error adding session to memory: {e}")
שליפת זיכרון
כדי להעביר את הזיכרון כחלק מההקשר למנהל ולסוכנים אחרים, לפי הצורך, אנחנו צריכים לאחזר את הזיכרון לטווח ארוך ששמור באמצעות שם האפליקציה ושם המשתמש כהיקף (כי זה ההיקף שבו שמרנו את הזיכרונות).
results = client.agent_engines.memories.retrieve(
name=APP_NAME,
scope={"app_name": APP_NAME, "user_id": USER_ID}
)
# RetrieveMemories returns a pager. You can use `list` to retrieve all pages' memories.
list(results)
print(list(results))
איך הזיכרון שאוחזר נטען כחלק מההקשר?
אנחנו משתמשים במאפיין הבא בהגדרת סוכן Orchestrator, שמאפשר לסוכן הבסיס לטעון מראש את ההקשר ממאגר הזיכרון. בנוסף לכלים שאנחנו מקבלים גישה אליהם משרת ארגז הכלים עבור סוכני המשנה.
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
הקשר של השיחה החוזרת
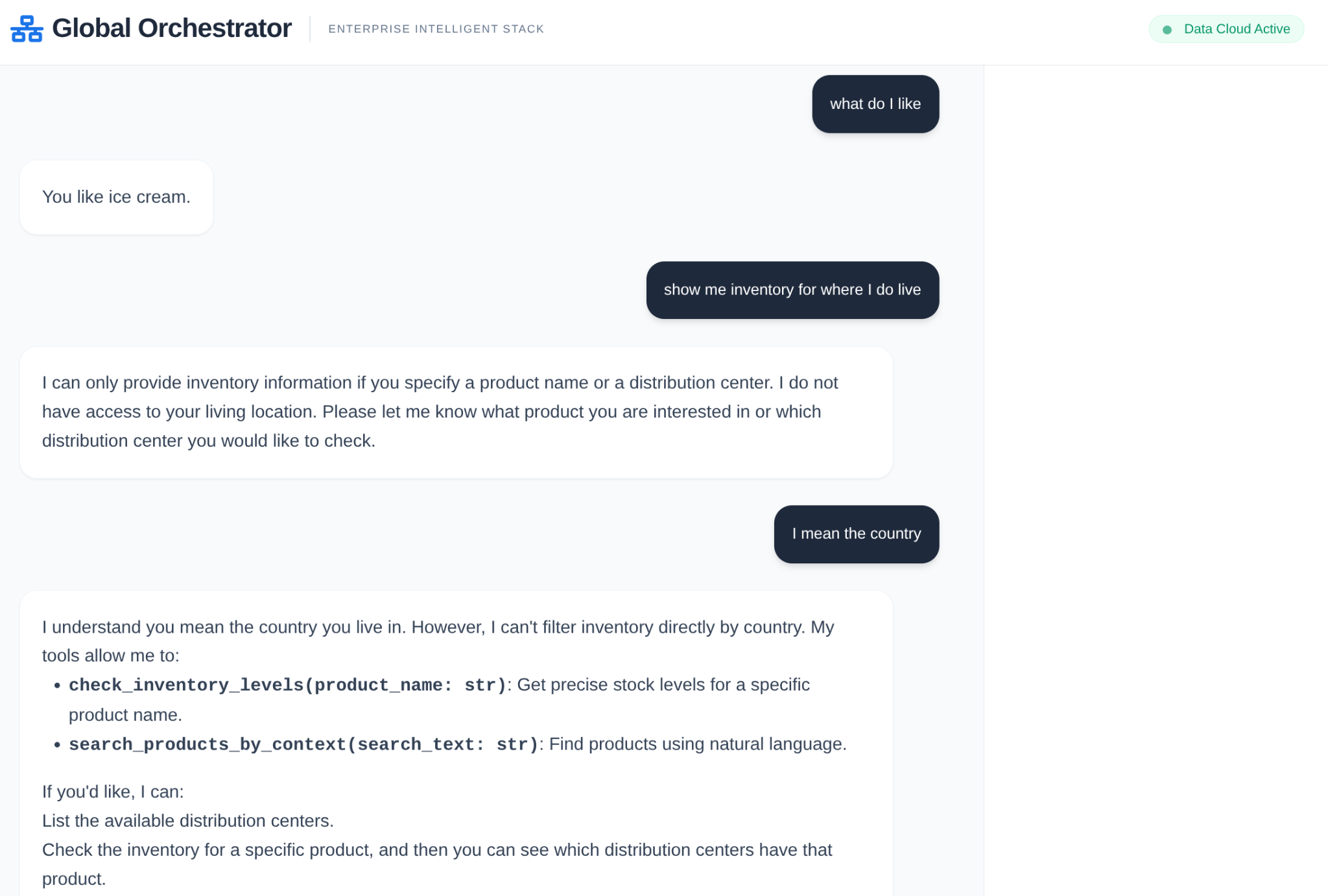
בשרשרת אספקה ארגונית, לא יכול להיות 'קופסה שחורה'. אנחנו משתמשים ב-CallbackContext של ADK כדי ליצור מנוע נרטיבי. אנחנו מתחברים להרצת הסוכן כדי לתעד כל תהליך חשיבה וכל קריאה לכלי, ומשדרים אותם לסרגל צד בממשק המשתמש.
- אירוע מעקב: GlobalOrchestrator מנתח את דרישות הנתונים...
- אירוע מעקב: "העברה למומחה מלאי לבדיקת רמות המלאי..."
- אירוע מעקב: 'שליפת דפוסי עיכוב היסטוריים של ספקים מ-Memory Bank...'
נתיב הביקורת הזה חשוב מאוד לניפוי באגים, והוא מבטיח שאנשי תפעול יוכלו לסמוך על ההחלטות האוטונומיות של הסוכן.
from google.adk.agents.callback_context import CallbackContext
...
# --- ADK CALLBACKS (Narrative Engine) ---
execution_logs = []
async def trace_callback(context: CallbackContext):
"""
Captures agent and tool invocation flow for the UI narrative.
"""
agent_name = context.agent.name
event = {
"agent": agent_name,
"action": "Processing request steps...",
"type": "orchestration_event"
}
execution_logs.append(event)
return None
...
זהו!!! הצלחנו לשכפל את הפרויקט והסברנו את הפרטים של הסוכן, הזיכרון וההקשר.
כדי לבדוק את זה, עוברים לתיקיית הפרויקט של המאגר המשוכפל ומריצים את הפקודות הבאות:
>> pip install -r requirements.txt
>> python app.py
הפעולה הזו אמורה להפעיל את הסוכן באופן מקומי, ותהיה לכם אפשרות לבדוק אותו.
9. בואו נפרוס אותו ב-Cloud Run
- פורסים אותו ב-Cloud Run על ידי הפעלת הפקודה הבאה מ-Cloud Shell Terminal שבו הפרויקט משוכפל, מוודאים שאתם בתוך תיקיית הבסיס של הפרויקט.
מריצים את הפקודה הבאה בטרמינל Cloud Shell:
gcloud run deploy supply-chain-agent --source . --platform managed --region us-central1 --allow-unauthenticated --set-env-vars GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT>>,GOOGLE_CLOUD_LOCATION=us-central1,GOOGLE_GENAI_USE_VERTEXAI=TRUE,REASONING_ENGINE_APP_NAME=<<YOUR_APP_ENGINE_URL>>,TOOLBOX_SERVER=<<YOUR_TOOLBOX_SERVER>>,TOOLBOX_TOOLSET=supply_chain_toolset,AGENT_ENGINE_ID=<<YOUR_AGENT_ENGINE_ID>>
מחליפים את הערכים של placeholders <<YOUR_PROJECT>>, <<YOUR_APP_ENGINE_URL>>, <<YOUR_TOOLBOX_SERVER>> ו- <<YOUR_AGENT_ENGINE_ID>>
אחרי שהפקודה מסתיימת, היא מחזירה כתובת URL של שירות. מעתיקים אותו.
- מקצים לחשבון השירות של Cloud Run את התפקיד AlloyDB Client.כך האפליקציה בלי שרת (serverless) יכולה ליצור מנהרה מאובטחת אל מסד הנתונים.
מריצים את הפקודה הבאה בטרמינל Cloud Shell:
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
עכשיו משתמשים בכתובת ה-URL של השירות (נקודת הקצה של Cloud Run שהעתקתם קודם) ובודקים את האפליקציה.
הערה: אם נתקלתם בבעיה בשירות, והזיכרון מצוין כסיבה, נסו להגדיל את מגבלת הזיכרון שהוקצה ל-1 גיגה-בייט כדי לבדוק את זה.
10. הסרת המשאבים
אחרי שמסיימים את ה-Lab הזה, חשוב למחוק את אשכול AlloyDB ואת המכונה.
הוא צריך לנקות את האשכול יחד עם המכונות שלו.
11. מזל טוב
שילבנו בין המהירות של AlloyDB, היעילות של MCP Toolbox בניהול תהליכים והזיכרון המוסדי של Vertex AI Memory Bank, ויצרנו מערכת לניהול שרשרת אספקה שמתפתחת כל הזמן. הוא לא רק עונה על שאלות, אלא גם זוכר שהמחסן שלכם בסינגפור תמיד מתמודד עם עיכובים שקשורים למונסון, ומציע באופן יזום לשנות את מסלול המשלוחים עוד לפני שאתם שואלים.