
1. Ringkasan
Dalam codelab ini, Anda akan membuat agen Supply Chain Orchestrator. Aplikasi ini memungkinkan pengguna menganalisis inventaris, melacak logistik, dan mengelola risiko rantai pasokan menggunakan bahasa alami.
Kita akan memanfaatkan Agent Development Kit (ADK) Google untuk membangun arsitektur multi-agen yang mempertahankan konteks, mengingat preferensi pengguna melalui Vertex AI Memory Bank, dan berinteraksi dengan set data besar yang disimpan di AlloyDB melalui MCP Toolbox.
Yang akan Anda build
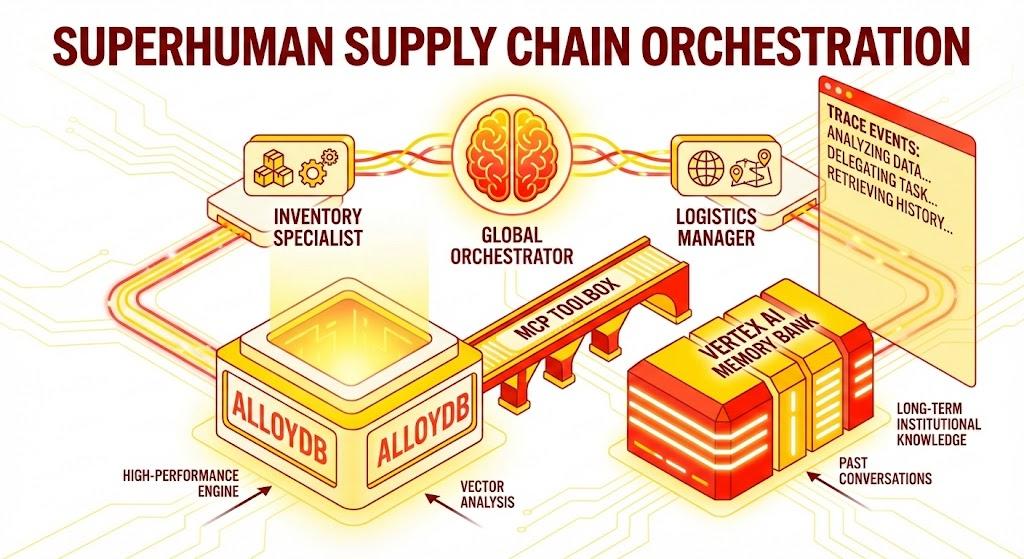
Aplikasi Python Flask yang terdiri dari:
Agen Pengelola Global: Agen root yang mengelola alur percakapan dan pendelegasian.
Agen Khusus: "InventorySpecialist" dan "LogisticsManager" untuk tugas khusus domain.
Integrasi Memori: Memori sesi jangka pendek dan memori jangka panjang menggunakan Vertex AI Memory Bank.
UI Naratif: Antarmuka web yang memvisualisasikan proses penalaran agen (Konteks Pelacakan).
Yang akan Anda pelajari
- Cara menggunakan Google ADK untuk membuat agen dan sub-agen khusus.
- Cara mengintegrasikan Vertex AI Memory Bank untuk memori agen jangka panjang.
- Cara menggunakan MCP Toolbox untuk menghubungkan agen ke alat data AlloyDB.
- Cara menerapkan Callback ADK untuk melacak dan memvisualisasikan penalaran agen.
- Cara men-deploy solusi menggunakan Cloud Run atau menjalankannya secara lokal.
Arsitektur
The Tech Stack
- AlloyDB untuk PostgreSQL: Berfungsi sebagai database operasional berperforma tinggi yang menyimpan lebih dari 50.000 catatan rantai pasokan. Fitur ini mendukung penelusuran dan pengambilan vektor.
- MCP Toolbox for Databases: Bertindak sebagai "Orchestration Maestro", yang mengekspos data AlloyDB sebagai alat yang dapat dieksekusi yang dapat dipanggil oleh agen.
- Agent Development Kit (ADK): Framework yang digunakan untuk menentukan agen, petunjuk, dan alat.
- Vertex AI Memory Bank: Menyediakan memori jangka panjang, sehingga agen dapat mengingat preferensi pengguna dan interaksi sebelumnya di seluruh sesi.
- Vertex AI Session Service: Mengelola konteks percakapan jangka pendek.
Alur
- Kueri Pengguna: Pengguna mengajukan pertanyaan (misalnya, "Cek stok Es Krim Premium").
- Pemeriksaan Memori: Pengelola memeriksa Bank Memori untuk mendapatkan informasi masa lalu yang relevan (misalnya, "Pengguna adalah manajer regional untuk EMEA").
- Delegasi: Orchestrator mendelegasikan tugas ke InventorySpecialist.
- Eksekusi Alat: Specialist menggunakan alat yang disediakan oleh MCP Toolbox untuk mengkueri AlloyDB.
- Respons: Agen memproses data dan menampilkan tabel berformat Markdown.
- Penyimpanan Memori: Interaksi penting disimpan kembali ke Bank Memori.
Persyaratan
2. Sebelum memulai
Membuat project
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project.
- Anda akan menggunakan Cloud Shell, lingkungan command line yang berjalan di Google Cloud. Klik Activate Cloud Shell di bagian atas konsol Google Cloud.

- Setelah terhubung ke Cloud Shell, Anda dapat memeriksa bahwa Anda sudah diautentikasi dan project sudah ditetapkan ke project ID Anda menggunakan perintah berikut:
gcloud auth list
- Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa perintah gcloud mengetahui project Anda.
gcloud config list project
- Jika project Anda belum ditetapkan, gunakan perintah berikut untuk menetapkannya:
gcloud config set project <YOUR_PROJECT_ID>
- Aktifkan API yang diperlukan: Ikuti link dan aktifkan API.
Atau, Anda dapat menggunakan perintah gcloud untuk melakukannya. Baca dokumentasi untuk mempelajari perintah gcloud dan penggunaannya.
Gotcha & Pemecahan Masalah
Sindrom "Project Hantu" | Anda menjalankan |
Penghalang Penagihan | Anda mengaktifkan project, tetapi lupa akun penagihan. AlloyDB adalah mesin berperforma tinggi; mesin ini tidak akan dimulai jika "tangki bahan bakar" (penagihan) kosong. |
Keterlambatan Penyebaran API | Anda mengklik "Aktifkan API", tetapi command line masih menampilkan |
Quags Kuota | Jika menggunakan akun uji coba yang baru, Anda mungkin mencapai kuota regional untuk instance AlloyDB. Jika |
Agen Layanan"Tersembunyi" | Terkadang, Agen Layanan AlloyDB tidak otomatis diberi peran |
3. Penyiapan database
Di inti aplikasi kami terdapat AlloyDB untuk PostgreSQL. Kami memanfaatkan kemampuan vektornya yang canggih dan mesin columnar terintegrasi untuk membuat penyematan bagi lebih dari 50.000 catatan SCM. Hal ini memungkinkan analisis vektor hampir real-time, sehingga agen kami dapat mengidentifikasi anomali inventaris atau risiko logistik di seluruh set data besar dalam milidetik.
Di lab ini, kita akan menggunakan AlloyDB sebagai database untuk data pengujian. Cloud SQL menggunakan cluster untuk menyimpan semua resource, seperti database dan log. Setiap cluster memiliki instance utama yang menyediakan titik akses ke data. Tabel akan menyimpan data sebenarnya.
Mari kita buat cluster, instance, dan tabel AlloyDB tempat set data pengujian akan dimuat.
- Klik tombol atau Salin link di bawah ke browser tempat Anda login sebagai pengguna Konsol Google Cloud.
Atau, Anda dapat membuka Terminal Cloud Shell dari project tempat Anda menukarkan akun penagihan, lalu meng-clone repo github dan membuka project menggunakan perintah di bawah:
git clone https://github.com/AbiramiSukumaran/easy-alloydb-setup
cd easy-alloydb-setup
- Setelah langkah ini selesai, repo akan di-clone ke editor Cloud Shell lokal Anda dan Anda akan dapat menjalankan perintah di bawah dari folder project (penting untuk memastikan Anda berada di direktori project):
sh run.sh
- Sekarang gunakan UI (dengan mengklik link di terminal atau mengklik link "preview on web" di terminal.
- Masukkan detail Anda untuk project id, nama cluster, dan nama instance untuk memulai.
- Pergilah minum kopi sambil melihat log yang terus bergulir dan Anda dapat membaca tentang cara kerjanya di balik layar di sini.
Gotcha & Pemecahan Masalah
Masalah "Kesabaran" | Cluster database adalah infrastruktur yang berat. Jika Anda memuat ulang halaman atau menghentikan sesi Cloud Shell karena "tampaknya macet", Anda mungkin akan mendapatkan instance "hantu" yang disediakan sebagian dan tidak dapat dihapus tanpa intervensi manual. |
Ketidakcocokan Region | Jika Anda mengaktifkan API di |
Cluster Zombie | Jika sebelumnya Anda menggunakan nama yang sama untuk cluster dan tidak menghapusnya, skrip mungkin akan menyatakan bahwa nama cluster sudah ada. Nama cluster harus unik dalam project. |
Waktu Tunggu Cloud Shell | Jika istirahat kopi Anda berlangsung selama 30 menit, Cloud Shell mungkin akan memasuki mode tidur dan menghentikan proses |
4. Penyediaan Skema
Setelah cluster dan instance AlloyDB Anda berjalan, buka editor SQL AlloyDB Studio untuk mengaktifkan ekstensi AI dan menyediakan skema.
Anda mungkin perlu menunggu hingga instance selesai dibuat. Setelah selesai, login ke AlloyDB menggunakan kredensial yang Anda buat saat membuat cluster. Gunakan data berikut untuk melakukan autentikasi ke PostgreSQL:
- Nama pengguna : "
postgres" - Database : "
postgres" - Sandi : "
alloydb" (atau apa pun yang Anda tetapkan pada saat pembuatan)
Setelah Anda berhasil diautentikasi ke AlloyDB Studio, perintah SQL dimasukkan di Editor. Anda dapat menambahkan beberapa jendela Editor menggunakan tanda plus di sebelah kanan jendela terakhir.
Anda akan memasukkan perintah untuk AlloyDB di jendela editor, menggunakan opsi Jalankan, Format, dan Hapus sesuai kebutuhan.
Mengaktifkan Ekstensi
Untuk membangun aplikasi ini, kita akan menggunakan ekstensi pgvector dan google_ml_integration. Ekstensi pgvector memungkinkan Anda menyimpan dan menelusuri embedding vektor. Ekstensi google_ml_integration menyediakan fungsi yang Anda gunakan untuk mengakses endpoint prediksi Vertex AI guna mendapatkan prediksi di SQL. Aktifkan ekstensi ini dengan menjalankan DDL berikut:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Membuat tabel
Anda dapat membuat tabel menggunakan pernyataan DDL di bawah di AlloyDB Studio:
DROP TABLE IF EXISTS shipments;
DROP TABLE IF EXISTS products;
-- 1. Product Inventory Table
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
category VARCHAR(100),
stock_level INTEGER,
distribution_center VARCHAR(100),
region VARCHAR(50),
embedding vector(768),
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. Logistics & Shipments
CREATE TABLE shipments (
shipment_id SERIAL PRIMARY KEY,
product_id INTEGER REFERENCES products(id),
status VARCHAR(50), -- 'In Transit', 'Delayed', 'Delivered', 'Pending'
estimated_arrival TIMESTAMP,
route_efficiency_score DECIMAL(3, 2)
);
Kolom embedding akan memungkinkan penyimpanan untuk nilai vektor beberapa kolom teks.
Penyerapan Data
Jalankan kumpulan pernyataan SQL di bawah untuk menyisipkan 50.000 data secara massal dalam tabel produk:
-- We use a CROSS JOIN pattern with realistic naming segments to create meaningful variety
DO $$
DECLARE
brand_names TEXT[] := ARRAY['Artisan', 'Nature', 'Elite', 'Pure', 'Global', 'Eco', 'Velocity', 'Heritage', 'Aura', 'Summit'];
product_types TEXT[] := ARRAY['Ice Cream', 'Body Wash', 'Laundry Detergent', 'Shampoo', 'Mayonnaise', 'Deodorant', 'Tea', 'Soup', 'Face Cream', 'Soap'];
variants TEXT[] := ARRAY['Classic', 'Gold', 'Premium', 'Eco-Friendly', 'Organic', 'Night-Repair', 'Extra-Fresh', 'Zero-Sugar', 'Sensitive', 'Maximum-Strength'];
regions TEXT[] := ARRAY['EMEA', 'APAC', 'LATAM', 'NAMER'];
dcs TEXT[] := ARRAY['London-Hub', 'Mumbai-Central', 'Sao-Paulo-Logistics', 'Singapore-Port', 'Rotterdam-Gate', 'New-York-DC'];
BEGIN
INSERT INTO products (name, category, stock_level, distribution_center, region)
SELECT
b || ' ' || v || ' ' || t as name,
CASE
WHEN t IN ('Ice Cream', 'Mayonnaise', 'Tea', 'Soup') THEN 'Food & Refreshment'
WHEN t IN ('Body Wash', 'Shampoo', 'Deodorant', 'Face Cream', 'Soap') THEN 'Personal Care'
ELSE 'Home Care'
END as category,
floor(random() * 20000 + 100)::int as stock_level,
dcs[floor(random() * 6 + 1)] as distribution_center,
regions[floor(random() * 4 + 1)] as region
FROM
unnest(brand_names) b,
unnest(variants) v,
unnest(product_types) t,
generate_series(1, 50); -- 10 * 10 * 10 * 50 = 50,000 records
END $$;
Mari kita masukkan rekaman khusus demo untuk memastikan jawaban yang dapat diprediksi untuk pertanyaan gaya eksekutif
-- These ensure you have predictable answers for specific "Executive" questions
INSERT INTO products (name, category, stock_level, distribution_center, region) VALUES
('Magnum Ultra Gold Limited Edition', 'Food & Refreshment', 45, 'Rotterdam-Gate', 'EMEA'),
('Dove Pro-Health Deep Moisture', 'Personal Care', 12000, 'Mumbai-Central', 'APAC'),
('Hellmanns Real Organic Mayonnaise', 'Food & Refreshment', 8000, 'London-Hub', 'EMEA');
Memasukkan data pengiriman
-- Shipments Generation (More shipments than products)
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT
id,
CASE
WHEN random() > 0.8 THEN 'Delayed'
WHEN random() > 0.4 THEN 'In Transit'
ELSE 'Delivered'
END,
NOW() + (random() * 10 || ' days')::interval,
(random() * 0.5 + 0.5)::decimal(3,2)
FROM products
WHERE random() > 0.3; -- Create shipments for ~70% of products
-- Add duplicate shipments for some products to show complex logistics
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT id, 'In Transit', NOW() + INTERVAL '12 days', 0.88
FROM products
LIMIT 5000;
Berikan Izin
Jalankan pernyataan di bawah untuk memberikan izin eksekusi pada fungsi "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Memberikan PERAN Vertex AI User ke akun layanan AlloyDB
Dari konsol IAM Google Cloud, berikan akses akun layanan AlloyDB (yang terlihat seperti ini: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) ke peran "Pengguna Vertex AI". PROJECT_NUMBER akan memiliki nomor project Anda.
Atau, Anda dapat menjalankan perintah di bawah dari Terminal Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Membuat Embedding
Selanjutnya, mari kita buat embedding vektor untuk kolom teks bermakna tertentu:
WITH
rows_to_update AS (
SELECT
id
FROM
products
WHERE
embedding IS NULL
LIMIT
5000 )
UPDATE
products
SET
embedding = ai.embedding('text-embedding-005', name || ' ' || category || ' ' || distribution_center || ' ' || region)::vector
FROM
rows_to_update
WHERE
products.id = rows_to_update.id
AND embedding IS null;
Dalam pernyataan di atas, kita telah menetapkan batasnya sebagai 5.000, jadi pastikan untuk menjalankannya berulang kali hingga tidak ada baris dalam tabel dengan sematan kolom sebagai NULL.
Gotcha & Pemecahan Masalah
Loop "Lupa Sandi" | Jika Anda menggunakan penyiapan "Satu Klik" dan tidak dapat mengingat sandi, buka halaman Informasi dasar instance di konsol dan klik "Edit" untuk mereset sandi |
Error "Ekstensi Tidak Ditemukan" | Jika |
IAM Propagation Gap | Anda menjalankan perintah IAM |
Ketidakcocokan Dimensi Vektor | Tabel |
Kesalahan Pengetikan Project ID | Dalam panggilan |
5. Penyiapan Alat & Toolbox
MCP Toolbox for Databases adalah server MCP open source untuk database. Hal ini memungkinkan Anda mengembangkan alat dengan lebih mudah, cepat, dan aman dengan menangani kompleksitas seperti penggabungan koneksi, autentikasi, dan lainnya. Toolbox membantu Anda membangun alat AI Generatif yang memungkinkan agen Anda mengakses data di database Anda.
Kita menggunakan Model Context Protocol (MCP) Toolbox for Databases sebagai "konduktor". Aplikasi ini berfungsi sebagai middleware standar antara agen kami dan AlloyDB. Dengan menentukan konfigurasi tools.yaml, toolbox akan otomatis mengekspos operasi database yang kompleks sebagai alat yang bersih dan dapat dieksekusi seperti search_products_by_context atau check_inventory_levels. Hal ini menghilangkan kebutuhan akan penggabungan koneksi manual atau SQL boilerplate dalam logika agen.
Menginstal server Toolbox
Dari Terminal Cloud Shell, buat folder untuk menyimpan file yaml alat baru dan biner toolbox:
mkdir scm-agent-toolbox
cd scm-agent-toolbox
Dari dalam folder baru tersebut, jalankan serangkaian perintah berikut:
# see releases page for other versions
export VERSION=0.27.0
curl -L -o toolbox https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Selanjutnya, buat file tools.yaml di dalam folder baru tersebut dengan membuka Cloud Shell Editor dan menyalin konten file repo ini ke dalam file tools.yaml.
sources:
supply_chain_db:
kind: "alloydb-postgres"
project: "YOUR_PROJECT_ID"
region: "us-central1"
cluster: "YOUR_CLUSTER"
instance: "YOUR_INSTANCE"
database: "postgres"
user: "postgres"
password: "YOUR_PASSWORD"
tools:
search_products_by_context:
kind: postgres-sql
source: supply_chain_db
description: Find products in the inventory using natural language search and vector embeddings.
parameters:
- name: search_text
type: string
description: Description of the product or category the user is looking for.
statement: |
SELECT name, category, stock_level, distribution_center, region
FROM products
ORDER BY embedding <=> ai.embedding('text-embedding-005', $1)::vector
LIMIT 5;
check_inventory_levels:
kind: postgres-sql
source: supply_chain_db
description: Get precise stock levels for a specific product name.
parameters:
- name: product_name
type: string
description: The exact or partial name of the product.
statement: |
SELECT name, stock_level, distribution_center, last_updated
FROM products
WHERE name ILIKE '%' || $1 || '%'
ORDER BY stock_level DESC;
track_shipment_status:
kind: postgres-sql
source: supply_chain_db
description: Retrieve real-time logistics and shipping status for a specific region or product.
parameters:
- name: region
type: string
description: The geographical region to filter shipments (e.g., EMEA, APAC).
statement: |
SELECT p.name, s.status, s.estimated_arrival, s.route_efficiency_score
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE p.region = $1
ORDER BY s.estimated_arrival ASC;
analyze_supply_chain_risk:
kind: postgres-sql
source: supply_chain_db
description: Rerank and filter shipments based on risk profiles and efficiency scores using Google ML reranker.
parameters:
- name: risk_context
type: string
description: The business context for risk analysis (e.g., 'heatwave impact' or 'port strike').
statement: |
WITH initial_ranking AS (
SELECT s.shipment_id, p.name, s.status, p.distribution_center,
ROW_NUMBER() OVER () AS ref_number
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE s.status != 'Delivered'
LIMIT 10
),
reranked_results AS (
SELECT index, score FROM
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => $1,
documents => (SELECT ARRAY_AGG(name || ' at ' || distribution_center ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT i.name, i.status, i.distribution_center, r.score
FROM initial_ranking i, reranked_results r
WHERE i.ref_number = r.index
ORDER BY r.score DESC;
toolsets:
supply_chain_toolset:
- search_products_by_context
- check_inventory_levels
- track_shipment_status
- analyze_supply_chain_risk
Sekarang, uji file tools.yaml di server lokal:
./toolbox --tools-file "tools.yaml"
Atau, Anda dapat mengujinya di UI
./toolbox --ui
Sempurna!! Setelah Anda yakin bahwa semuanya berfungsi, lanjutkan dan deploy di Cloud Run sebagai berikut.
Deployment Cloud Run
- Tetapkan variabel lingkungan PROJECT_ID:
export PROJECT_ID="my-project-id"
- Lakukan inisialisasi gcloud CLI:
gcloud init
gcloud config set project $PROJECT_ID
- Anda harus mengaktifkan API berikut:
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Buat akun layanan backend jika Anda belum memilikinya:
gcloud iam service-accounts create toolbox-identity
- Berikan izin untuk menggunakan Secret Manager:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
- Berikan izin tambahan ke akun layanan yang khusus untuk sumber AlloyDB kami (roles/alloydb.client dan roles/serviceusage.serviceUsageConsumer)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role serviceusage.serviceUsageConsumer
- Upload tools.yaml sebagai secret:
gcloud secrets create tools-scm-agent --data-file=tools.yaml
- Jika Anda sudah memiliki secret dan ingin memperbarui versi secret, jalankan perintah berikut:
gcloud secrets versions add tools-scm-agent --data-file=tools.yaml
- Tetapkan variabel lingkungan ke image container yang ingin Anda gunakan untuk Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Deploy Toolbox ke Cloud Run menggunakan perintah berikut:
Jika Anda telah mengaktifkan akses publik di instance AlloyDB (tidak direkomendasikan), ikuti perintah di bawah untuk deployment ke Cloud Run:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
Jika Anda menggunakan jaringan VPC, gunakan perintah di bawah:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
# TODO(dev): update the following to match your VPC details
--network <<YOUR_NETWORK_NAME>> \
--subnet <<YOUR_SUBNET_NAME>> \
--allow-unauthenticated
6. Penyiapan Agen
Dengan menggunakan Agent Development Kit (ADK), kami telah beralih dari perintah monolitik ke arsitektur multi-agen yang khusus:
- InventorySpecialist: Berfokus pada metrik stok produk dan gudang.
- LogisticsManager: Pakar dalam rute pengiriman global dan analisis risiko.
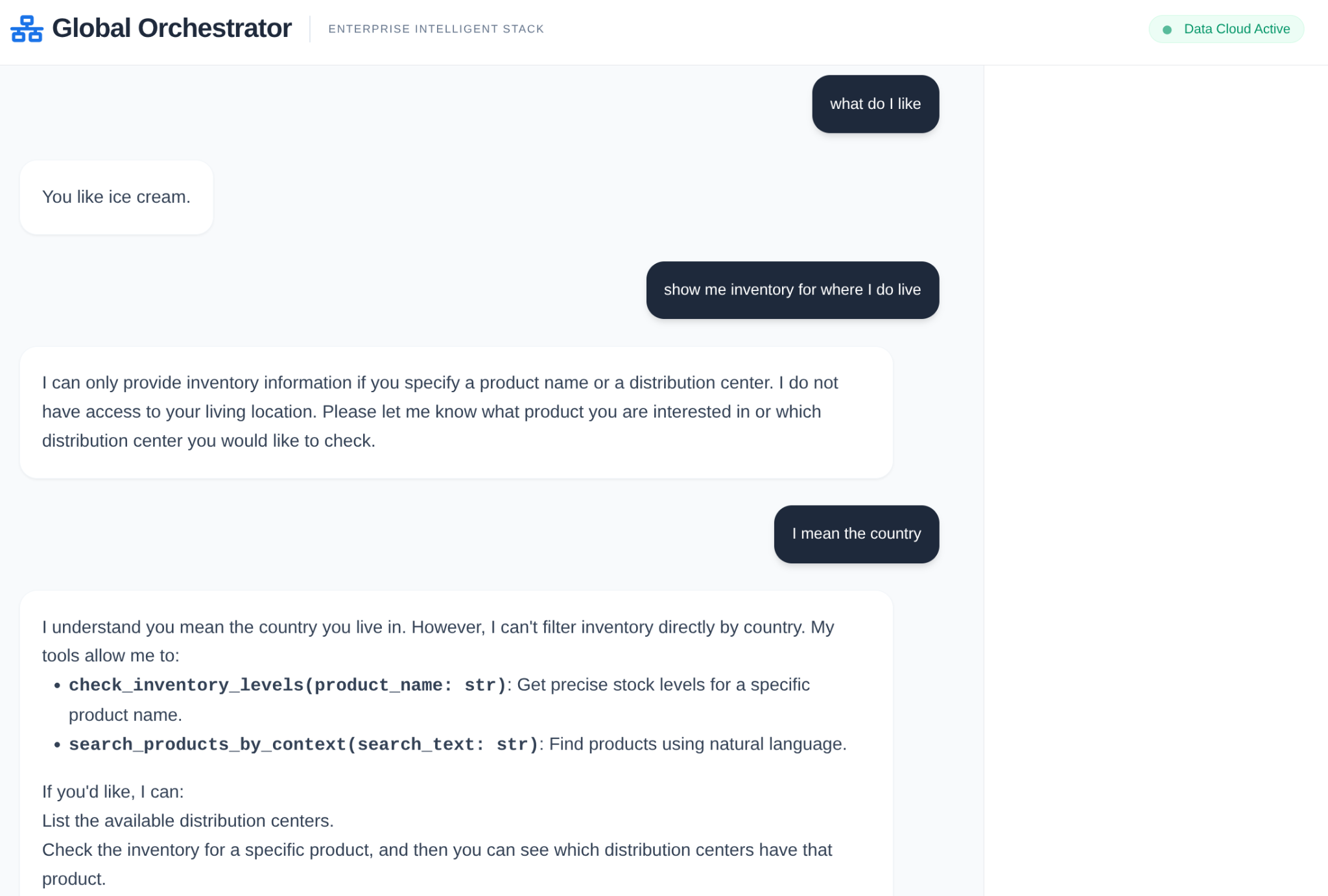
- GlobalOrchestrator: "Otak" yang menggunakan penalaran untuk mendelegasikan tugas dan menyintesis temuan.
Clone repo ini ke project Anda dan mari kita bahas.
Untuk meng-clone-nya, dari Terminal Cloud Shell (di direktori root atau dari tempat Anda ingin membuat project ini), jalankan perintah berikut:
git clone https://github.com/AbiramiSukumaran/scm-memory-agent
- Tindakan ini akan membuat project dan Anda dapat memverifikasinya di Cloud Shell Editor.

- Pastikan untuk memperbarui file .env dengan nilai untuk project dan instance Anda.
Panduan Kode
Melihat sekilas Agen Orchestrator
Go to app.py and you should be able to see the following snippet:
orchestrator = adk.Agent(
name="GlobalOrchestrator",
model="gemini-2.5-flash",
description="Global Supply Chain Orchestrator root agent.",
instruction="""
You are the Global Supply Chain Brain. You are responsible for products, inventory and logistics.
You also have access to the memory tool, remember to include all the information that the tool can provide you with about the user before you respond.
1. Understand intent and delegate to specialists. As the Global Orchestrator, you have access to the full conversation history with the user.
When you transfer a query to a specialist agent, sub agent or tool, share the important facts and information from your memory to them so they can operate with the full context.
2. Ensure the final response is professional and uses Markdown tables for data.
3. If a specialist provides a long list, ensure only the top 10 items are shown initially.
4. Conclude with a brief, high-level executive summary of what the data implies.
""",
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
sub_agents=[inventory_agent, logistics_agent],
#after_agent_callback=auto_save_session_to_memory_callback,
)
Cuplikan ini adalah definisi untuk root yang merupakan agen orkestrator yang menerima percakapan atau permintaan dari pengguna dan merutekan ke sub-agen atau pengguna yang sesuai dengan alat yang sesuai berdasarkan tugas.
- Mari kita lihat agen inventaris
inventory_agent = adk.Agent(
name="InventorySpecialist",
model="gemini-2.5-flash",
description="Specialist in product stock and warehouse data.",
instruction="""
Analyze inventory levels.
1. Use 'search_products_by_context' or 'check_inventory_levels'.
2. ALWAYS format results as a clean Markdown table.
3. If there are many results, display only the TOP 10 most relevant ones.
4. At the end, state: 'There are additional records available. Would you like to see more?'
""",
tools=tools
)
Sub-agen khusus ini dikhususkan untuk aktivitas inventaris seperti menelusuri produk secara kontekstual dan juga memeriksa tingkat inventaris.
- Kemudian ada sub-agen logistik:
logistics_agent = adk.Agent(
name="LogisticsManager",
model="gemini-2.5-flash",
description="Expert in global shipping routes and logistics tracking.",
instruction="""
Check shipment statuses.
1. Use 'track_shipment_status' or 'analyze_supply_chain_risk'.
2. ALWAYS format results as a clean Markdown table.
3. Limit initial output to the top 10 shipments.
4. Ask if the user needs the full manifest if more results exist.
""",
tools=tools
)
Sub-agen khusus ini mengkhususkan diri dalam aktivitas logistik seperti melacak pengiriman dan menganalisis risiko dalam rantai pasokan.
- Ketiga agen yang telah kita bahas sejauh ini menggunakan alat dan alat tersebut dirujuk melalui server Toolbox yang telah kita deploy di bagian sebelumnya. Lihat cuplikan di bawah:
from toolbox_core import ToolboxSyncClient
TOOLBOX_SERVER = os.environ["TOOLBOX_SERVER"]
TOOLBOX_TOOLSET = os.environ["TOOLBOX_TOOLSET"]
# --- ADK TOOLBOX CONFIGURATION ---
toolbox = ToolboxSyncClient(TOOLBOX_SERVER)
tools = toolbox.load_toolset(TOOLBOX_TOOLSET)
Sub-agen khusus ini mengkhususkan diri dalam aktivitas logistik seperti melacak pengiriman dan menganalisis risiko dalam rantai pasokan.
7. Agent Engine
Pada sesi awal, buat Agent Engine
import vertexai
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
client = vertexai.Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_LOCATION
)
agent_engine = client.agent_engines.create()
- Untuk menjalankan berikutnya, perbarui Agent Engine dengan konfigurasi Memory Bank:
agent_engine = client.agent_engines.update(
name=APP_NAME,
config={
"context_spec": {
"memory_bank_config": {
"generation_config": {
"model": f"projects/{PROJECT_ID}/locations/{GOOGLE_CLOUD_LOCATION}/publishers/google/models/gemini-2.5-flash"
}
}
}
})
8. Konteks, Jalankan & Memori
Pengelolaan konteks dibagi menjadi dua lapisan yang berbeda untuk memastikan agen terasa seperti partner yang berkelanjutan, bukan bot tanpa status:
Memori Jangka Pendek (Sesi): Dikelola melalui VertexAiSessionService, ini melacak histori peristiwa langsung (pesan pengguna, respons alat) dalam satu interaksi.
Long-Term Memory (Memory Bank): Didukung oleh Vertex AI Memory Bank melalui adk.memorybankservice. Lapisan ini mengekstrak informasi "bermakna"—seperti preferensi pengguna untuk ekspedisi tertentu atau keterlambatan berulang di gudang—dan mempertahankan informasi tersebut di seluruh sesi.
Menginisialisasi sesi untuk memori sesi dalam cakupan percakapan
Ini adalah bagian cuplikan yang membuat sesi untuk aplikasi saat ini bagi pengguna saat ini.
from google.adk.sessions import VertexAiSessionService
...
session_service = VertexAiSessionService(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
...
# Initialize the session *outside* of the route handler to avoid repeated creation
session = None
session_lock = threading.Lock()
async def initialize_session():
global session
try:
session = await session_service.create_session(app_name=APP_NAME, user_id=USER_ID)
print(f"Session {session.id} created successfully.") # Add a log
except Exception as e:
print(f"Error creating session: {e}")
session = None # Ensure session is None in case of error
# Create the session on app startup
asyncio.run(initialize_session())
Menginisialisasi Vertex AI Memory Bank untuk memori jangka panjang
Ini adalah bagian cuplikan yang membuat instance objek Vertex AI Memory Bank Service untuk mesin agen.
from google.adk.memory import InMemoryMemoryService
from google.adk.memory import VertexAiMemoryBankService
...
try:
memory_bank_service = adk.memory.VertexAiMemoryBankService(
agent_engine_id=AGENT_ENGINE_ID,
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
#in_memory_service = InMemoryMemoryService()
print("Memory Bank Service initialized successfully.")
except Exception as e:
print(f"Error initializing Memory Bank Service: {e}")
memory_bank_service = None
runner = adk.Runner(
agent=orchestrator,
app_name=APP_NAME,
session_service=session_service,
memory_service=memory_bank_service,
)
...
Apa yang dikonfigurasi?
Di bagian cuplikan ini, kita mengonfigurasi Vertex AI Memory Bank Service untuk memori jangka panjang. Layanan ini menyimpan sesi secara kontekstual untuk aplikasi tertentu bagi pengguna tertentu sebagai memori dalam Vertex AI Memory Bank.
Apa yang dijalankan sebagai bagian dari eksekusi agen?
async def run_and_collect():
final_text = ""
try:
async for event in runner.run_async(
new_message=content,
user_id=user_id,
session_id=session_id
):
if hasattr(event, 'author') and event.author:
if not any(log['agent'] == event.author for log in execution_logs):
execution_logs.append({
"agent": event.author,
"action": "Analyzing data requirements...",
"type": "orchestration_event"
})
if hasattr(event, 'text') and event.text:
final_text = event.text
elif hasattr(event, 'content') and hasattr(event.content, 'parts'):
for part in event.content.parts:
if hasattr(part, 'text') and part.text:
final_text = part.text
except Exception as e:
print(f"Error during runner.run_async: {e}")
raise # Re-raise the exception to signal failure
finally:
gc.collect()
return final_text
Fungsi ini memproses konten input pengguna ke dalam objek new_message dengan ID pengguna dan ID sesi dalam cakupan. Kemudian, agen mengambil alih dan respons agen diproses serta ditampilkan.
Apa yang disimpan dalam memori jangka panjang?
Detail sesi dalam cakupan aplikasi dan pengguna diekstrak dalam variabel sesi.
Sesi ini kemudian ditambahkan sebagai memori untuk pengguna saat ini untuk aplikasi saat ini dari objek Vertex AI Memory Bank menggunakan metode "add_session_to_memory".
session = asyncio.run(session_service.get_session(app_name=APP_NAME, user_id=USER_ID, session_id=session.id))
if memory_bank_service and session: # Check memory service AND session
try:
#asyncio.run(in_memory_service.add_session_to_memory(session))
asyncio.run(memory_bank_service.add_session_to_memory(session))
'''
client.agent_engines.memories.generate(
scope={"app_name": APP_NAME, "user_id": USER_ID},
name=APP_NAME,
direct_contents_source={
"events": [
{"content": content}
]
},
config={"wait_for_completion": True},
)
'''
print("Successfully added session to memory.******")
print(session.id)
except Exception as e:
print(f"Error adding session to memory: {e}")
Pengambilan Memori
Kita perlu mengambil memori jangka panjang yang disimpan menggunakan nama aplikasi dan nama pengguna sebagai cakupan (karena itulah cakupan yang kita gunakan untuk menyimpan memori) agar dapat meneruskannya sebagai bagian dari konteks ke pengelola dan agen lain sebagaimana berlaku.
results = client.agent_engines.memories.retrieve(
name=APP_NAME,
scope={"app_name": APP_NAME, "user_id": USER_ID}
)
# RetrieveMemories returns a pager. You can use `list` to retrieve all pages' memories.
list(results)
print(list(results))
Bagaimana memori yang diambil dimuat sebagai bagian dari konteks?
Kita menggunakan atribut berikut dalam definisi agen Orchestrator yang memungkinkan agen root memuat konteks dari bank memori. Hal ini merupakan tambahan untuk alat yang kita akses dari server toolbox untuk sub-agen.
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
Konteks Callback
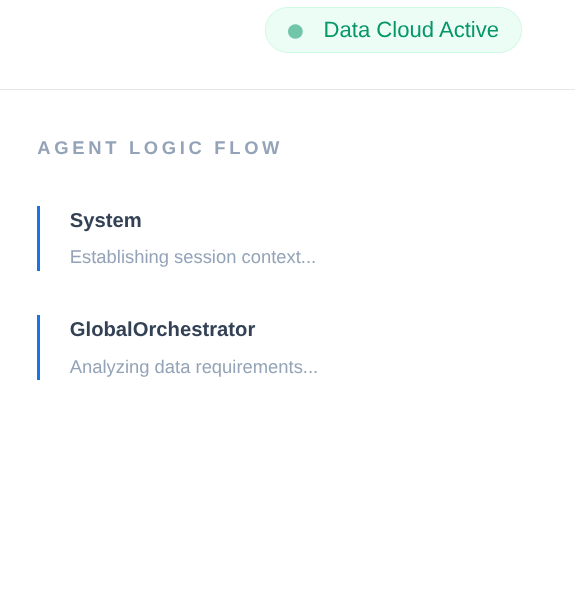
Dalam rantai pasokan perusahaan, Anda tidak boleh memiliki "kotak hitam". Kita menggunakan CallbackContext ADK untuk membuat Narrative Engine. Dengan mengaitkan diri ke eksekusi agen, kita dapat merekam setiap proses pemikiran dan panggilan alat, lalu melakukan streaming ke sidebar UI.
- Peristiwa Pelacakan: "GlobalOrchestrator sedang menganalisis persyaratan data..."
- Trace Event: "Delegating to InventorySpecialist for stock levels..." (Mendelegasikan ke InventorySpecialist untuk tingkat stok...)
- Trace Event: "Retrieving historical supplier delay patterns from Memory Bank..." (Mengambil pola keterlambatan historis pemasok dari Memory Bank...)
Log audit ini sangat berharga untuk proses penelusuran kesalahan dan memastikan bahwa operator manusia dapat memercayai keputusan otonom agen.
from google.adk.agents.callback_context import CallbackContext
...
# --- ADK CALLBACKS (Narrative Engine) ---
execution_logs = []
async def trace_callback(context: CallbackContext):
"""
Captures agent and tool invocation flow for the UI narrative.
"""
agent_name = context.agent.name
event = {
"agent": agent_name,
"action": "Processing request steps...",
"type": "orchestration_event"
}
execution_logs.append(event)
return None
...
Selesai!!! Kita telah berhasil meng-clone project dan mempelajari detail agen, memori, dan konteks.
Anda dapat mengujinya dengan membuka folder project dari repositori yang di-clone dan menjalankan perintah berikut:
>> pip install -r requirements.txt
>> python app.py
Tindakan ini akan memulai agen Anda secara lokal dan Anda akan dapat mengujinya.
9. Mari kita deploy ke Cloud Run
- Deploy di Cloud Run dengan menjalankan perintah berikut dari Terminal Cloud Shell tempat project di-clone dan pastikan Anda berada di dalam folder root project.
Jalankan perintah ini di terminal Cloud Shell Anda:
gcloud run deploy supply-chain-agent --source . --platform managed --region us-central1 --allow-unauthenticated --set-env-vars GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT>>,GOOGLE_CLOUD_LOCATION=us-central1,GOOGLE_GENAI_USE_VERTEXAI=TRUE,REASONING_ENGINE_APP_NAME=<<YOUR_APP_ENGINE_URL>>,TOOLBOX_SERVER=<<YOUR_TOOLBOX_SERVER>>,TOOLBOX_TOOLSET=supply_chain_toolset,AGENT_ENGINE_ID=<<YOUR_AGENT_ENGINE_ID>>
Ganti nilai untuk placeholder <<YOUR_PROJECT>>, <<YOUR_APP_ENGINE_URL>>, <<YOUR_TOOLBOX_SERVER>> dan <<YOUR_AGENT_ENGINE_ID>>
Setelah perintah selesai, URL Layanan akan ditampilkan. Salin.
- Berikan peran Klien AlloyDB ke akun layanan Cloud Run.Dengan demikian, aplikasi serverless Anda dapat membuat tunnel ke database dengan aman.
Jalankan perintah ini di terminal Cloud Shell Anda:
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
Sekarang gunakan URL layanan (endpoint Cloud Run yang Anda salin sebelumnya) dan uji aplikasi.
Catatan: Jika Anda mengalami masalah layanan, dan masalah tersebut menyebutkan memori sebagai penyebabnya, coba tingkatkan batas memori yang dialokasikan menjadi 1 GiB untuk mengujinya.
10. Pembersihan
Setelah lab ini selesai, jangan lupa untuk menghapus cluster dan instance AlloyDB.
Perintah ini akan membersihkan cluster beserta instance-nya.
11. Selamat
Dengan menggabungkan kecepatan AlloyDB, efisiensi orkestrasi MCP Toolbox, dan "memori institusional" Vertex AI Memory Bank, kami telah membangun sistem rantai pasokan yang terus berkembang. Gemini tidak hanya menjawab pertanyaan; Gemini mengingat bahwa gudang Anda di Singapura selalu mengalami keterlambatan terkait musim hujan dan secara proaktif menyarankan pengalihan rute pengiriman bahkan sebelum Anda bertanya.