
1. Przegląd
W tym ćwiczeniu utworzysz agenta aranżera łańcucha dostaw. Ta aplikacja umożliwia użytkownikom analizowanie zapasów, śledzenie logistyki i zarządzanie ryzykiem w łańcuchu dostaw za pomocą języka naturalnego.
Do utworzenia architektury opartej na wielu agentach, która zachowuje kontekst, zapamiętuje preferencje użytkownika za pomocą Vertex AI Bank zapamiętanych informacji i wchodzi w interakcje z ogromnym zbiorem danych przechowywanym w AlloyDB za pomocą MCP Toolbox, użyjemy pakietu Agent Development Kit (ADK) od Google.
Co utworzysz
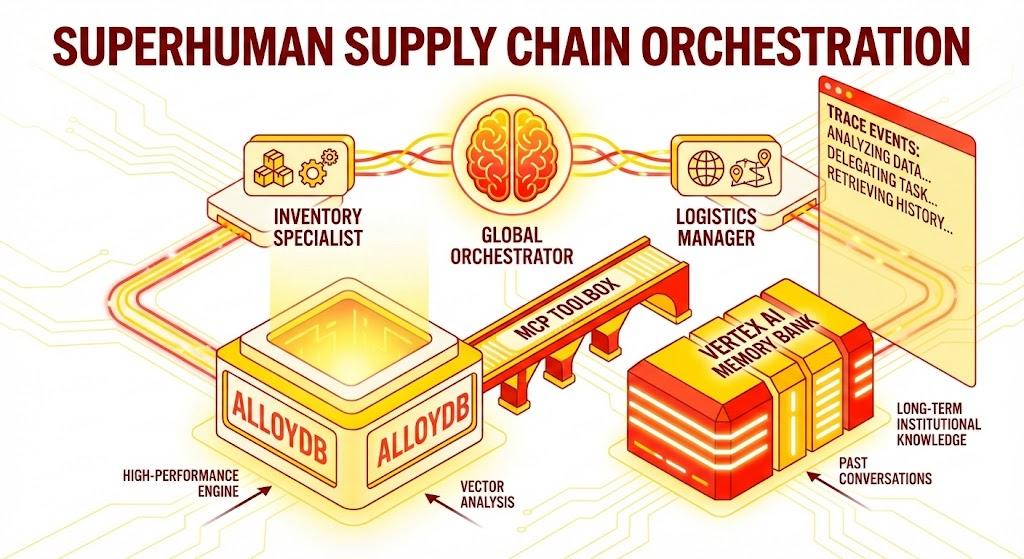
Aplikacja Flask w języku Python, która zawiera:
Globalny agent orkiestracji: agent główny, który zarządza przepływem konwersacji i delegowaniem.
Specjaliści: „InventorySpecialist” i „LogisticsManager” do wykonywania zadań specyficznych dla domeny.
Integracja pamięci: pamięć krótkotrwała sesji i pamięć długotrwała za pomocą Banku zapamiętanych informacji Vertex AI.
Interfejs narracyjny: interfejs internetowy, który wizualizuje proces rozumowania agenta (kontekst śledzenia).
Czego się nauczysz
- Jak używać Google ADK do tworzenia wyspecjalizowanych agentów i podagentów.
- Jak zintegrować Bank zapamiętanych informacji Vertex AI w celu długoterminowego przechowywania informacji o agencie.
- Jak używać zestawu narzędzi MCP do łączenia agentów z narzędziami do obsługi danych AlloyDB.
- Jak wdrożyć wywołania zwrotne ADK, aby śledzić i wizualizować rozumowanie agenta.
- Jak wdrożyć rozwiązanie za pomocą Cloud Run lub uruchomić je lokalnie.
Architektura
Stos technologiczny
- AlloyDB for PostgreSQL: wydajna operacyjna baza danych zawierająca ponad 50 tys. rekordów łańcucha dostaw. Umożliwia wyszukiwanie i pobieranie wektorowe.
- MCP Toolbox for Databases: działa jako „mistrz orkiestracji”, udostępniając dane AlloyDB jako narzędzia wykonywalne, które mogą wywoływać agenci.
- Pakiet Agent Development Kit (ADK): platforma używana do definiowania agentów, instrukcji i narzędzi.
- Bank zapamiętanych informacji Vertex AI: zapewnia pamięć długotrwałą, dzięki czemu agent może zapamiętywać preferencje użytkownika i wcześniejsze interakcje w różnych sesjach.
- Usługa sesji Vertex AI: zarządza krótkoterminowym kontekstem rozmowy.
The Flow
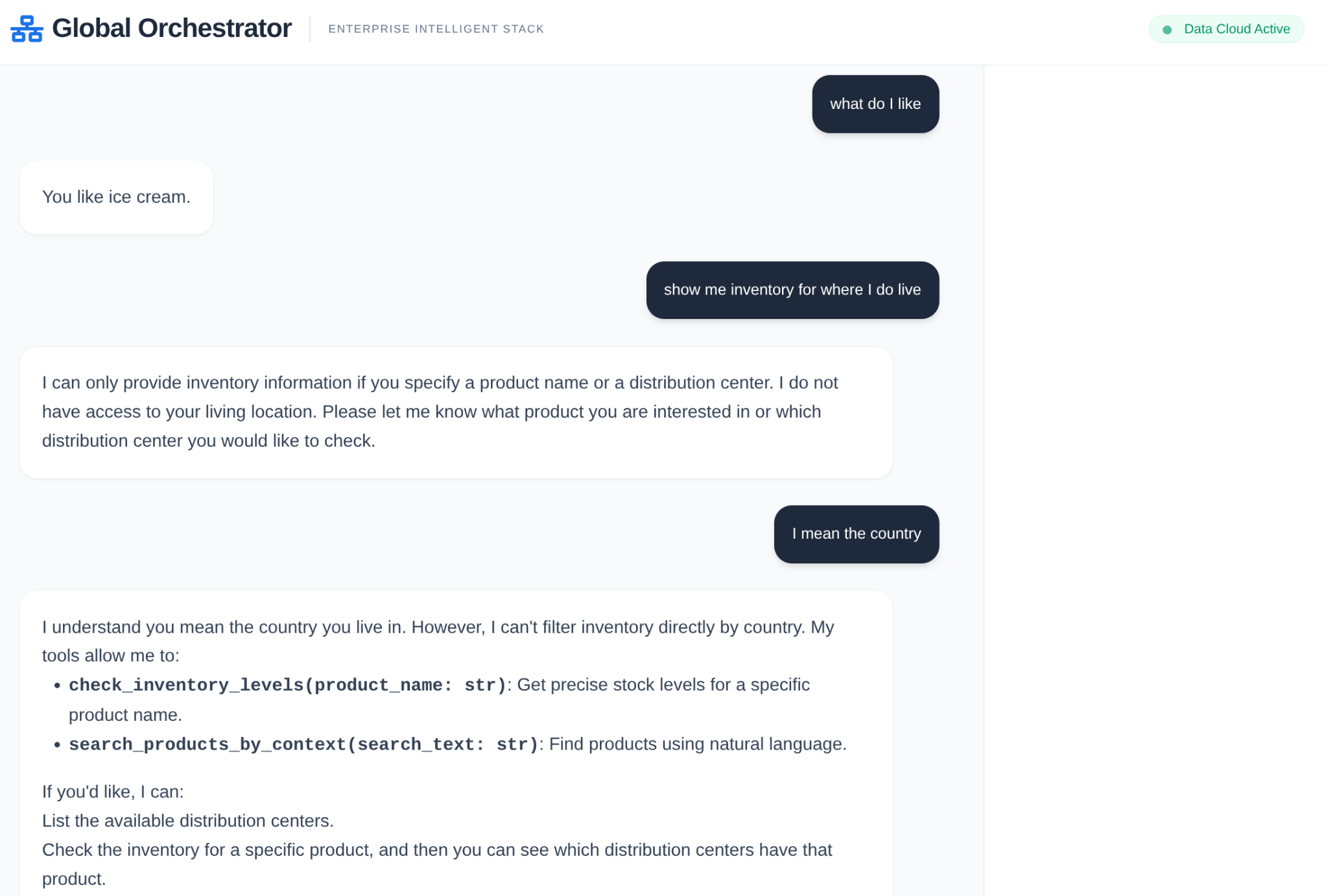
- Zapytanie użytkownika: użytkownik zadaje pytanie (np. „Sprawdź dostępność lodów Premium”).
- Sprawdzanie pamięci: orkiestrator sprawdza bank pamięci pod kątem odpowiednich informacji z przeszłości (np. „Użytkownik jest menedżerem regionalnym na region EMEA”).
- Przekazywanie: aranżer przekazuje zadanie do InventorySpecialist.
- Wykonywanie narzędzi: specjalista używa narzędzi udostępnianych przez zestaw narzędzi MCP do wykonywania zapytań w AlloyDB.
- Odpowiedź: agent przetwarza dane i zwraca tabelę sformatowaną w Markdownie.
- Pamięć: Ważne interakcje są zapisywane w Banku zapamiętanych informacji.
Wymagania
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie włączone są płatności.
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API: kliknij link i włącz interfejsy API.
Możesz też użyć polecenia gcloud. Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
Pułapki i rozwiązywanie problemów
Syndrom „projektu widma” | Uruchomiono polecenie |
Bariera rozliczeniowa | Projekt został włączony, ale zapomniano o koncie rozliczeniowym. AlloyDB to silnik o wysokiej wydajności, który nie uruchomi się, jeśli „zbiornik paliwa” (płatności) jest pusty. |
Opóźnienie propagacji interfejsu API | Kliknięto „Włącz interfejsy API”, ale w wierszu poleceń nadal widnieje znak |
Limit Quags | Jeśli korzystasz z nowego konta próbnego, możesz osiągnąć regionalny limit instancji AlloyDB. Jeśli |
„Ukryty” agent usługi | Czasami agent usługi AlloyDB nie otrzymuje automatycznie roli |
3. Konfiguracja bazy danych
W centrum naszej aplikacji znajduje się AlloyDB for PostgreSQL. Wykorzystaliśmy jego zaawansowane funkcje wektorowe i zintegrowany silnik kolumnowy do wygenerowania osadzeń dla ponad 50 tys. rekordów SCM. Umożliwia to analizę wektorową w czasie zbliżonym do rzeczywistego, dzięki czemu nasi agenci mogą w milisekundach wykrywać anomalie w asortymencie lub zagrożenia logistyczne w ogromnych zbiorach danych.
W tym module użyjemy AlloyDB jako bazy danych do przechowywania danych testowych. Używa klastrów do przechowywania wszystkich zasobów, takich jak bazy danych i logi. Każdy klaster ma instancję główną, która zapewnia punkt dostępu do danych. Tabele będą zawierać rzeczywiste dane.
Utwórzmy klaster, instancję i tabelę AlloyDB, do których zostanie załadowany testowy zbiór danych.
- Kliknij przycisk lub skopiuj poniższy link do przeglądarki, w której zalogowany jest użytkownik konsoli Google Cloud.
Możesz też otworzyć terminal Cloud Shell w projekcie, w którym zostało wykorzystane konto rozliczeniowe, sklonować repozytorium GitHub i przejść do projektu, używając tych poleceń:
git clone https://github.com/AbiramiSukumaran/easy-alloydb-setup
cd easy-alloydb-setup
- Po wykonaniu tego kroku repozytorium zostanie sklonowane do lokalnego edytora Cloud Shell i będziesz mieć możliwość uruchomienia poniższego polecenia z folderu projektu (ważne jest, aby upewnić się, że jesteś w katalogu projektu):
sh run.sh
- Teraz użyj interfejsu (kliknij link w terminalu lub link „Podgląd w internecie” w terminalu).
- Aby rozpocząć, wpisz szczegóły identyfikatora projektu, klastra i nazw instancji.
- Idź po kawę, podczas gdy dzienniki będą się przewijać. Tutaj możesz przeczytać, jak to działa za kulisami.
Pułapki i rozwiązywanie problemów
Problem z „cierpliwością” | Klastry baz danych to rozbudowana infrastruktura. Jeśli odświeżysz stronę lub zakończysz sesję Cloud Shell, ponieważ „utknęła”, możesz skończyć z „duchem” instancji, która jest częściowo udostępniona i niemożliwa do usunięcia bez ręcznej interwencji. |
Niezgodny region | Jeśli interfejsy API zostały włączone w regionie |
Zombie Clusters | Jeśli nazwa klastra była już wcześniej używana i nie została usunięta, skrypt może wyświetlić komunikat, że nazwa klastra już istnieje. Nazwy klastrów muszą być unikalne w projekcie. |
Limit czasu Cloud Shell | Jeśli przerwa na kawę trwa 30 minut, Cloud Shell może przejść w stan uśpienia i odłączyć proces |
4. Obsługa administracyjna schematu
Gdy klaster i instancja AlloyDB będą działać, przejdź do edytora SQL w AlloyDB Studio, aby włączyć rozszerzenia AI i udostępnić schemat.
Może być konieczne poczekanie na zakończenie tworzenia instancji. Gdy to zrobisz, zaloguj się w AlloyDB przy użyciu danych logowania utworzonych podczas tworzenia klastra. Do uwierzytelniania w PostgreSQL użyj tych danych:
- Nazwa użytkownika: „
postgres” - Baza danych: „
postgres” - Hasło: „
alloydb” (lub inne hasło ustawione podczas tworzenia)
Po pomyślnym uwierzytelnieniu w AlloyDB Studio polecenia SQL są wprowadzane w Edytorze. Możesz dodać wiele okien Edytora, klikając znak plusa po prawej stronie ostatniego okna.
Polecenia dla AlloyDB będziesz wpisywać w oknach edytora, używając w razie potrzeby opcji Uruchom, Formatuj i Wyczyść.
Włącz rozszerzenia
Do utworzenia tej aplikacji użyjemy rozszerzeń pgvector i google_ml_integration. Rozszerzenie pgvector umożliwia przechowywanie wektorów dystrybucyjnych i wyszukiwanie ich. Rozszerzenie google_ml_integration udostępnia funkcje, których możesz używać do uzyskiwania dostępu do punktów końcowych prognozowania Vertex AI w celu uzyskiwania prognoz w SQL. Włącz te rozszerzenia, uruchamiając te DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Tworzenie tabeli
Tabelę możesz utworzyć za pomocą instrukcji DDL poniżej w AlloyDB Studio:
DROP TABLE IF EXISTS shipments;
DROP TABLE IF EXISTS products;
-- 1. Product Inventory Table
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
category VARCHAR(100),
stock_level INTEGER,
distribution_center VARCHAR(100),
region VARCHAR(50),
embedding vector(768),
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. Logistics & Shipments
CREATE TABLE shipments (
shipment_id SERIAL PRIMARY KEY,
product_id INTEGER REFERENCES products(id),
status VARCHAR(50), -- 'In Transit', 'Delayed', 'Delivered', 'Pending'
estimated_arrival TIMESTAMP,
route_efficiency_score DECIMAL(3, 2)
);
Kolumna embedding będzie umożliwiać przechowywanie wartości wektorowych niektórych pól tekstowych.
Pozyskiwanie danych
Uruchom podany niżej zestaw instrukcji SQL, aby zbiorczo wstawić 50 000 rekordów do tabeli produktów:
-- We use a CROSS JOIN pattern with realistic naming segments to create meaningful variety
DO $$
DECLARE
brand_names TEXT[] := ARRAY['Artisan', 'Nature', 'Elite', 'Pure', 'Global', 'Eco', 'Velocity', 'Heritage', 'Aura', 'Summit'];
product_types TEXT[] := ARRAY['Ice Cream', 'Body Wash', 'Laundry Detergent', 'Shampoo', 'Mayonnaise', 'Deodorant', 'Tea', 'Soup', 'Face Cream', 'Soap'];
variants TEXT[] := ARRAY['Classic', 'Gold', 'Premium', 'Eco-Friendly', 'Organic', 'Night-Repair', 'Extra-Fresh', 'Zero-Sugar', 'Sensitive', 'Maximum-Strength'];
regions TEXT[] := ARRAY['EMEA', 'APAC', 'LATAM', 'NAMER'];
dcs TEXT[] := ARRAY['London-Hub', 'Mumbai-Central', 'Sao-Paulo-Logistics', 'Singapore-Port', 'Rotterdam-Gate', 'New-York-DC'];
BEGIN
INSERT INTO products (name, category, stock_level, distribution_center, region)
SELECT
b || ' ' || v || ' ' || t as name,
CASE
WHEN t IN ('Ice Cream', 'Mayonnaise', 'Tea', 'Soup') THEN 'Food & Refreshment'
WHEN t IN ('Body Wash', 'Shampoo', 'Deodorant', 'Face Cream', 'Soap') THEN 'Personal Care'
ELSE 'Home Care'
END as category,
floor(random() * 20000 + 100)::int as stock_level,
dcs[floor(random() * 6 + 1)] as distribution_center,
regions[floor(random() * 4 + 1)] as region
FROM
unnest(brand_names) b,
unnest(variants) v,
unnest(product_types) t,
generate_series(1, 50); -- 10 * 10 * 10 * 50 = 50,000 records
END $$;
Wstawmy rekordy specyficzne dla wersji demonstracyjnej, aby zapewnić przewidywalne odpowiedzi na pytania w stylu kierowniczym
-- These ensure you have predictable answers for specific "Executive" questions
INSERT INTO products (name, category, stock_level, distribution_center, region) VALUES
('Magnum Ultra Gold Limited Edition', 'Food & Refreshment', 45, 'Rotterdam-Gate', 'EMEA'),
('Dove Pro-Health Deep Moisture', 'Personal Care', 12000, 'Mumbai-Central', 'APAC'),
('Hellmanns Real Organic Mayonnaise', 'Food & Refreshment', 8000, 'London-Hub', 'EMEA');
Wstawianie danych o przesyłkach
-- Shipments Generation (More shipments than products)
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT
id,
CASE
WHEN random() > 0.8 THEN 'Delayed'
WHEN random() > 0.4 THEN 'In Transit'
ELSE 'Delivered'
END,
NOW() + (random() * 10 || ' days')::interval,
(random() * 0.5 + 0.5)::decimal(3,2)
FROM products
WHERE random() > 0.3; -- Create shipments for ~70% of products
-- Add duplicate shipments for some products to show complex logistics
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT id, 'In Transit', NOW() + INTERVAL '12 days', 0.88
FROM products
LIMIT 5000;
Przyznaj uprawnienia
Aby przyznać uprawnienia do wykonywania funkcji „embedding”, uruchom to polecenie:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Przyznawanie roli Użytkownik Vertex AI kontu usługi AlloyDB
W konsoli IAM Google Cloud przyznaj kontu usługi AlloyDB (które wygląda tak: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) dostęp do roli „Użytkownik Vertex AI”. Zmienna PROJECT_NUMBER będzie zawierać numer Twojego projektu.
Możesz też uruchomić to polecenie w terminalu Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Generowanie wektorów dystrybucyjnych
Następnie wygenerujmy wektory dystrybucyjne dla określonych pól tekstowych o znaczeniu:
WITH
rows_to_update AS (
SELECT
id
FROM
products
WHERE
embedding IS NULL
LIMIT
5000 )
UPDATE
products
SET
embedding = ai.embedding('text-embedding-005', name || ' ' || category || ' ' || distribution_center || ' ' || region)::vector
FROM
rows_to_update
WHERE
products.id = rows_to_update.id
AND embedding IS null;
W powyższej instrukcji ustawiliśmy limit na 5000, więc stosuj je wielokrotnie, dopóki w tabeli nie będzie wiersza z kolumną wektora dystrybucyjnego o wartości null.
Pułapki i rozwiązywanie problemów
Pętla „amnezji hasła” | Jeśli używasz konfiguracji „Jedno kliknięcie” i nie pamiętasz hasła, otwórz stronę podstawowych informacji o instancji w konsoli i kliknij „Edytuj”, aby zresetować hasło |
Błąd „Nie znaleziono rozszerzenia” | Jeśli |
Opóźnienie propagacji uprawnień | Uruchomiono polecenie |
Niezgodność wymiarów wektora | Tabela |
Błąd w identyfikatorze projektu | Jeśli w wywołaniu |
5. Narzędzia i konfiguracja zestawu narzędzi
Narzędzia MCP dla baz danych to serwer MCP typu open source przeznaczony dla baz danych. Umożliwia łatwiejsze, szybsze i bezpieczniejsze tworzenie narzędzi dzięki obsłudze złożonych procesów, takich jak pulowanie połączeń, uwierzytelnianie i inne. Zestaw narzędzi pomaga tworzyć narzędzia generatywnej AI, które umożliwiają agentom dostęp do danych w bazie danych.
Jako „dyrygenta” wykorzystujemy zestaw narzędzi Model Context Protocol (MCP) Toolbox for Databases. Działa jako standardowe oprogramowanie pośredniczące między naszymi agentami a AlloyDB. Dzięki zdefiniowaniu tools.yaml konfiguracji zestaw narzędzi automatycznie udostępnia złożone operacje na bazie danych jako proste, wykonywalne narzędzia, takie jak search_products_by_context czy check_inventory_levels. Eliminuje to konieczność ręcznego tworzenia puli połączeń lub standardowego kodu SQL w logice agenta.
Instalowanie serwera Toolbox
W terminalu Cloud Shell utwórz folder, w którym zapiszesz nowy plik YAML narzędzi i binarny plik przybornika:
mkdir scm-agent-toolbox
cd scm-agent-toolbox
W tym nowym folderze uruchom te polecenia:
# see releases page for other versions
export VERSION=0.27.0
curl -L -o toolbox https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Następnie utwórz w tym nowym folderze plik tools.yaml. W tym celu przejdź do edytora Cloud Shell i skopiuj zawartość tego pliku repozytorium do pliku tools.yaml.
sources:
supply_chain_db:
kind: "alloydb-postgres"
project: "YOUR_PROJECT_ID"
region: "us-central1"
cluster: "YOUR_CLUSTER"
instance: "YOUR_INSTANCE"
database: "postgres"
user: "postgres"
password: "YOUR_PASSWORD"
tools:
search_products_by_context:
kind: postgres-sql
source: supply_chain_db
description: Find products in the inventory using natural language search and vector embeddings.
parameters:
- name: search_text
type: string
description: Description of the product or category the user is looking for.
statement: |
SELECT name, category, stock_level, distribution_center, region
FROM products
ORDER BY embedding <=> ai.embedding('text-embedding-005', $1)::vector
LIMIT 5;
check_inventory_levels:
kind: postgres-sql
source: supply_chain_db
description: Get precise stock levels for a specific product name.
parameters:
- name: product_name
type: string
description: The exact or partial name of the product.
statement: |
SELECT name, stock_level, distribution_center, last_updated
FROM products
WHERE name ILIKE '%' || $1 || '%'
ORDER BY stock_level DESC;
track_shipment_status:
kind: postgres-sql
source: supply_chain_db
description: Retrieve real-time logistics and shipping status for a specific region or product.
parameters:
- name: region
type: string
description: The geographical region to filter shipments (e.g., EMEA, APAC).
statement: |
SELECT p.name, s.status, s.estimated_arrival, s.route_efficiency_score
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE p.region = $1
ORDER BY s.estimated_arrival ASC;
analyze_supply_chain_risk:
kind: postgres-sql
source: supply_chain_db
description: Rerank and filter shipments based on risk profiles and efficiency scores using Google ML reranker.
parameters:
- name: risk_context
type: string
description: The business context for risk analysis (e.g., 'heatwave impact' or 'port strike').
statement: |
WITH initial_ranking AS (
SELECT s.shipment_id, p.name, s.status, p.distribution_center,
ROW_NUMBER() OVER () AS ref_number
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE s.status != 'Delivered'
LIMIT 10
),
reranked_results AS (
SELECT index, score FROM
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => $1,
documents => (SELECT ARRAY_AGG(name || ' at ' || distribution_center ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT i.name, i.status, i.distribution_center, r.score
FROM initial_ranking i, reranked_results r
WHERE i.ref_number = r.index
ORDER BY r.score DESC;
toolsets:
supply_chain_toolset:
- search_products_by_context
- check_inventory_levels
- track_shipment_status
- analyze_supply_chain_risk
Teraz przetestuj plik tools.yaml na serwerze lokalnym:
./toolbox --tools-file "tools.yaml"
Możesz też przetestować ją w interfejsie
./toolbox --ui
Świetnie! Gdy upewnisz się, że wszystko działa, wdróż aplikację w Cloud Run w ten sposób:
Wdrożenie Cloud Run
- Ustaw zmienną środowiskową PROJECT_ID:
export PROJECT_ID="my-project-id"
- Zainicjuj gcloud CLI:
gcloud init
gcloud config set project $PROJECT_ID
- Musisz mieć włączone te interfejsy API:
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Jeśli nie masz jeszcze konta usługi backendu:
gcloud iam service-accounts create toolbox-identity
- Przyznaj uprawnienia do korzystania z usługi Secret Manager:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
- Przyznaj kontu usługi dodatkowe uprawnienia specyficzne dla naszego źródła AlloyDB (role/alloydb.client i roles/serviceusage.serviceUsageConsumer).
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role serviceusage.serviceUsageConsumer
- Prześlij plik tools.yaml jako tajny token:
gcloud secrets create tools-scm-agent --data-file=tools.yaml
- Jeśli masz już obiekt tajny i chcesz zaktualizować jego wersję, wykonaj te czynności:
gcloud secrets versions add tools-scm-agent --data-file=tools.yaml
- Ustaw zmienną środowiskową na obraz kontenera, którego chcesz użyć w Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Wdróż Toolbox w Cloud Run za pomocą tego polecenia:
Jeśli w instancji AlloyDB masz włączony dostęp publiczny (nie jest to zalecane), wykonaj to polecenie, aby wdrożyć ją w Cloud Run:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
Jeśli używasz sieci VPC, użyj tego polecenia:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
# TODO(dev): update the following to match your VPC details
--network <<YOUR_NETWORK_NAME>> \
--subnet <<YOUR_SUBNET_NAME>> \
--allow-unauthenticated
6. Konfiguracja agenta
Korzystając z pakietu Agent Development Kit (ADK), odeszliśmy od monolitycznych promptów na rzecz specjalistycznej architektury opartej na wielu agentach:
- InventorySpecialist: skupia się na danych dotyczących zapasów produktów i magazynów.
- LogisticsManager: ekspert w zakresie globalnych tras transportowych i analizy ryzyka.
- GlobalOrchestrator: „mózg”, który wykorzystuje rozumowanie do delegowania zadań i syntetyzowania wyników.
Sklonuj to repozytorium do swojego projektu i przejdźmy przez nie.
Aby sklonować ten projekt, w terminalu Cloud Shell (w katalogu głównym lub w dowolnym miejscu, w którym chcesz utworzyć ten projekt) uruchom to polecenie:
git clone https://github.com/AbiramiSukumaran/scm-memory-agent
- Powinno to spowodować utworzenie projektu. Możesz to sprawdzić w edytorze Cloud Shell.

- Zaktualizuj plik .env, podając wartości dla projektu i instancji.
Instrukcja dotycząca kodu
Krótkie omówienie agenta aranżera
Go to app.py and you should be able to see the following snippet:
orchestrator = adk.Agent(
name="GlobalOrchestrator",
model="gemini-2.5-flash",
description="Global Supply Chain Orchestrator root agent.",
instruction="""
You are the Global Supply Chain Brain. You are responsible for products, inventory and logistics.
You also have access to the memory tool, remember to include all the information that the tool can provide you with about the user before you respond.
1. Understand intent and delegate to specialists. As the Global Orchestrator, you have access to the full conversation history with the user.
When you transfer a query to a specialist agent, sub agent or tool, share the important facts and information from your memory to them so they can operate with the full context.
2. Ensure the final response is professional and uses Markdown tables for data.
3. If a specialist provides a long list, ensure only the top 10 items are shown initially.
4. Conclude with a brief, high-level executive summary of what the data implies.
""",
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
sub_agents=[inventory_agent, logistics_agent],
#after_agent_callback=auto_save_session_to_memory_callback,
)
Ten fragment kodu to definicja głównego agenta, który jest agentem orkiestrującym. Otrzymuje on rozmowę lub prośbę od użytkownika i kieruje ją do odpowiedniego podrzędnego agenta lub użytkownika, a także do odpowiednich narzędzi na podstawie zadania.
- Przyjrzyjmy się agentowi asortymentu
inventory_agent = adk.Agent(
name="InventorySpecialist",
model="gemini-2.5-flash",
description="Specialist in product stock and warehouse data.",
instruction="""
Analyze inventory levels.
1. Use 'search_products_by_context' or 'check_inventory_levels'.
2. ALWAYS format results as a clean Markdown table.
3. If there are many results, display only the TOP 10 most relevant ones.
4. At the end, state: 'There are additional records available. Would you like to see more?'
""",
tools=tools
)
Ten konkretny podagent specjalizuje się w działaniach związanych z asortymentem, takich jak wyszukiwanie produktów w kontekście i sprawdzanie poziomu zapasów.
- Następnie jest podagent logistyczny:
logistics_agent = adk.Agent(
name="LogisticsManager",
model="gemini-2.5-flash",
description="Expert in global shipping routes and logistics tracking.",
instruction="""
Check shipment statuses.
1. Use 'track_shipment_status' or 'analyze_supply_chain_risk'.
2. ALWAYS format results as a clean Markdown table.
3. Limit initial output to the top 10 shipments.
4. Ask if the user needs the full manifest if more results exist.
""",
tools=tools
)
Ten konkretny sub-agent specjalizuje się w działaniach logistycznych, takich jak śledzenie przesyłek i analizowanie ryzyka w łańcuchu dostaw.
- Wszyscy 3 agenci, o których mówiliśmy do tej pory, korzystają z narzędzi, do których odwołują się za pomocą serwera Toolbox, który został już wdrożony w poprzedniej sekcji. Zobacz fragment kodu poniżej:
from toolbox_core import ToolboxSyncClient
TOOLBOX_SERVER = os.environ["TOOLBOX_SERVER"]
TOOLBOX_TOOLSET = os.environ["TOOLBOX_TOOLSET"]
# --- ADK TOOLBOX CONFIGURATION ---
toolbox = ToolboxSyncClient(TOOLBOX_SERVER)
tools = toolbox.load_toolset(TOOLBOX_TOOLSET)
Ten konkretny sub-agent specjalizuje się w działaniach logistycznych, takich jak śledzenie przesyłek i analizowanie ryzyka w łańcuchu dostaw.
7. Silnik agenta
W pierwszym uruchomieniu utwórz Agent Engine.
import vertexai
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
client = vertexai.Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_LOCATION
)
agent_engine = client.agent_engines.create()
- Przy następnym uruchomieniu zaktualizuj Agent Engine za pomocą konfiguracji Banku zapamiętanych informacji:
agent_engine = client.agent_engines.update(
name=APP_NAME,
config={
"context_spec": {
"memory_bank_config": {
"generation_config": {
"model": f"projects/{PROJECT_ID}/locations/{GOOGLE_CLOUD_LOCATION}/publishers/google/models/gemini-2.5-flash"
}
}
}
})
8. Kontekst, uruchamianie i pamięć
Zarządzanie kontekstem jest podzielone na 2 odrębne warstwy, aby agent sprawiał wrażenie stałego partnera, a nie bezstanowego bota:
Pamięć krótkotrwała (sesje): zarządzana za pomocą VertexAiSessionService, śledzi historię zdarzeń (wiadomości użytkownika, odpowiedzi narzędzia) w ramach jednej interakcji.
Pamięć długotrwała (Bank zapamiętanych informacji): oparta na Vertex AI Memory Bank za pomocą adk.memorybankservice. Ta warstwa wyodrębnia „istotne” informacje, takie jak preferencje użytkownika dotyczące konkretnych przewoźników lub powtarzające się opóźnienia w magazynie, i przechowuje je w różnych sesjach.
Inicjowanie sesji na potrzeby pamięci sesji w zakresie rozmowy
Jest to fragment kodu, który tworzy sesję bieżącej aplikacji dla bieżącego użytkownika.
from google.adk.sessions import VertexAiSessionService
...
session_service = VertexAiSessionService(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
...
# Initialize the session *outside* of the route handler to avoid repeated creation
session = None
session_lock = threading.Lock()
async def initialize_session():
global session
try:
session = await session_service.create_session(app_name=APP_NAME, user_id=USER_ID)
print(f"Session {session.id} created successfully.") # Add a log
except Exception as e:
print(f"Error creating session: {e}")
session = None # Ensure session is None in case of error
# Create the session on app startup
asyncio.run(initialize_session())
Inicjowanie banku zapamiętanych informacji Vertex AI na potrzeby pamięci długotrwałej
Jest to fragment kodu, który tworzy instancję obiektu usługi Vertex AI Bank zapamiętanych informacji dla silnika agenta.
from google.adk.memory import InMemoryMemoryService
from google.adk.memory import VertexAiMemoryBankService
...
try:
memory_bank_service = adk.memory.VertexAiMemoryBankService(
agent_engine_id=AGENT_ENGINE_ID,
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
#in_memory_service = InMemoryMemoryService()
print("Memory Bank Service initialized successfully.")
except Exception as e:
print(f"Error initializing Memory Bank Service: {e}")
memory_bank_service = None
runner = adk.Runner(
agent=orchestrator,
app_name=APP_NAME,
session_service=session_service,
memory_service=memory_bank_service,
)
...
Co jest skonfigurowane?
W tej części fragmentu kodu konfigurujemy usługę Vertex AI Bank zapamiętanych informacji na potrzeby pamięci długotrwałej. Kontekstowo przechowuje ona sesję konkretnej aplikacji dla konkretnego użytkownika jako pamięć w banku zapamiętanych informacji Vertex AI.
Co jest uruchamiane w ramach wykonania agenta?
async def run_and_collect():
final_text = ""
try:
async for event in runner.run_async(
new_message=content,
user_id=user_id,
session_id=session_id
):
if hasattr(event, 'author') and event.author:
if not any(log['agent'] == event.author for log in execution_logs):
execution_logs.append({
"agent": event.author,
"action": "Analyzing data requirements...",
"type": "orchestration_event"
})
if hasattr(event, 'text') and event.text:
final_text = event.text
elif hasattr(event, 'content') and hasattr(event.content, 'parts'):
for part in event.content.parts:
if hasattr(part, 'text') and part.text:
final_text = part.text
except Exception as e:
print(f"Error during runner.run_async: {e}")
raise # Re-raise the exception to signal failure
finally:
gc.collect()
return final_text
Przetwarza ona dane wejściowe użytkownika na obiekt new_message z identyfikatorem użytkownika i identyfikatorem sesji w zakresie. Następnie agent przejmuje kontrolę, a jego odpowiedź jest przetwarzana i zwracana.
Co jest przechowywane w pamięci długotrwałej?
Szczegóły sesji w zakresie aplikacji i użytkownika są wyodrębniane w zmiennej sesji.
Sesja jest następnie dodawana jako pamięć bieżącego użytkownika w bieżącej aplikacji obiektu Vertex AI Bank zapamiętanych informacji za pomocą metody „add_session_to_memory”.
session = asyncio.run(session_service.get_session(app_name=APP_NAME, user_id=USER_ID, session_id=session.id))
if memory_bank_service and session: # Check memory service AND session
try:
#asyncio.run(in_memory_service.add_session_to_memory(session))
asyncio.run(memory_bank_service.add_session_to_memory(session))
'''
client.agent_engines.memories.generate(
scope={"app_name": APP_NAME, "user_id": USER_ID},
name=APP_NAME,
direct_contents_source={
"events": [
{"content": content}
]
},
config={"wait_for_completion": True},
)
'''
print("Successfully added session to memory.******")
print(session.id)
except Exception as e:
print(f"Error adding session to memory: {e}")
Przywoływanie wspomnień
Aby przekazać zapisaną pamięć długotrwałą w ramach kontekstu do koordynatora i innych agentów, musimy ją pobrać, używając nazwy aplikacji i nazwy użytkownika jako zakresu (ponieważ w tym zakresie zapisaliśmy pamięć).
results = client.agent_engines.memories.retrieve(
name=APP_NAME,
scope={"app_name": APP_NAME, "user_id": USER_ID}
)
# RetrieveMemories returns a pager. You can use `list` to retrieve all pages' memories.
list(results)
print(list(results))
Jak odzyskane wspomnienie jest wczytywane jako część kontekstu?
W definicji agenta Orchestrator używamy tego atrybutu, który umożliwia agentowi głównemu wstępne wczytywanie kontekstu z pamięci. Oprócz tego subagenci mają dostęp do narzędzi z serwera skrzynki narzędziowej.
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
Kontekst wywołania zwrotnego
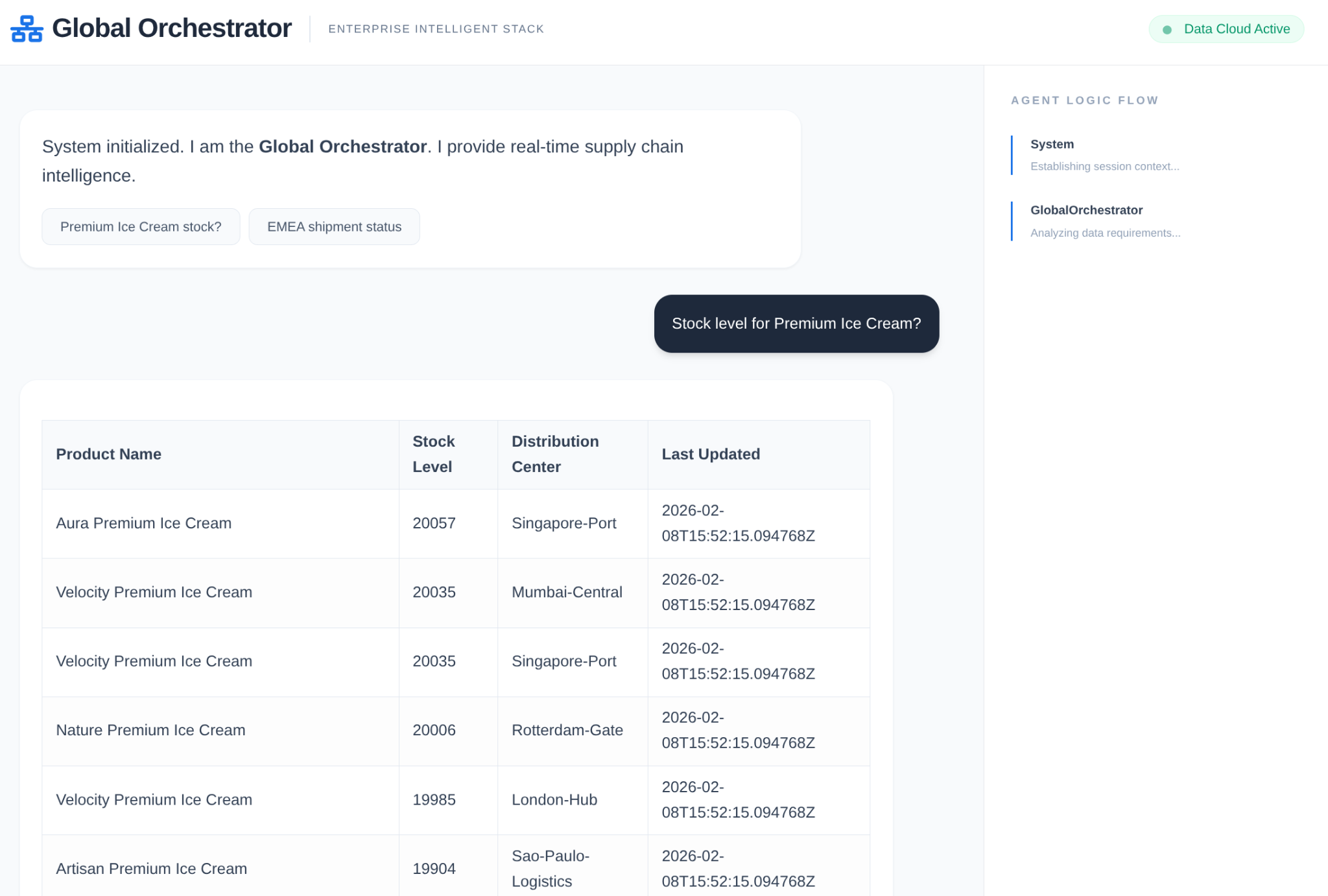
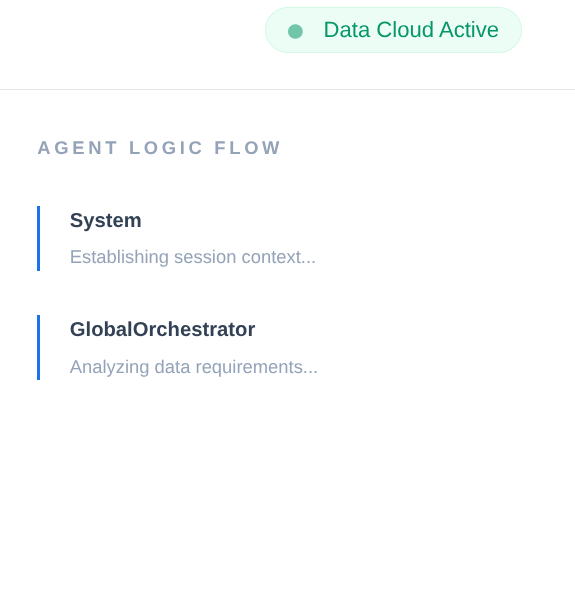
W łańcuchu dostaw przedsiębiorstwa nie może być „czarnej skrzynki”. Do utworzenia Narrative Engine używamy elementu CallbackContext z ADK. Dzięki podłączeniu się do działania agenta rejestrujemy każdy proces myślowy i wywołanie narzędzia, przesyłając je do paska bocznego interfejsu.
- Zdarzenie śledzenia: „GlobalOrchestrator analizuje wymagania dotyczące danych…”.
- Trace Event: „Delegating to InventorySpecialist for stock levels..."
- Trace Event: „Retrieving historical supplier delay patterns from Bank zapamiętanych informacji..."
Ścieżka audytu jest nieoceniona w procesie debugowania i zapewnia, że operatorzy mogą ufać autonomicznym decyzjom agenta.
from google.adk.agents.callback_context import CallbackContext
...
# --- ADK CALLBACKS (Narrative Engine) ---
execution_logs = []
async def trace_callback(context: CallbackContext):
"""
Captures agent and tool invocation flow for the UI narrative.
"""
agent_name = context.agent.name
event = {
"agent": agent_name,
"action": "Processing request steps...",
"type": "orchestration_event"
}
execution_logs.append(event)
return None
...
To wszystko!!! Udało nam się sklonować projekt i zapoznać ze szczegółami dotyczącymi agenta, pamięci i kontekstu.
Możesz to sprawdzić, przechodząc do folderu projektu sklonowanego repozytorium i wykonując te polecenia:
>> pip install -r requirements.txt
>> python app.py
Spowoduje to uruchomienie agenta lokalnie i umożliwi jego przetestowanie.
9. Wdróżmy go w Cloud Run
- Wdróż go w Cloud Run, uruchamiając to polecenie w terminalu Cloud Shell, w którym sklonowano projekt. Upewnij się, że jesteś w folderze głównym projektu.
Uruchom to polecenie w terminalu Cloud Shell:
gcloud run deploy supply-chain-agent --source . --platform managed --region us-central1 --allow-unauthenticated --set-env-vars GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT>>,GOOGLE_CLOUD_LOCATION=us-central1,GOOGLE_GENAI_USE_VERTEXAI=TRUE,REASONING_ENGINE_APP_NAME=<<YOUR_APP_ENGINE_URL>>,TOOLBOX_SERVER=<<YOUR_TOOLBOX_SERVER>>,TOOLBOX_TOOLSET=supply_chain_toolset,AGENT_ENGINE_ID=<<YOUR_AGENT_ENGINE_ID>>
Zastąp wartości symboli zastępczych <<YOUR_PROJECT>>, <<YOUR_APP_ENGINE_URL>>, <<YOUR_TOOLBOX_SERVER>> i <<YOUR_AGENT_ENGINE_ID>>.
Po zakończeniu działania polecenia wyświetli się URL usługi. Skopiuj go.
- Przyznaj wykonawczemu kontu usługi Cloud Run rolę Klient AlloyDB.Umożliwi to bezserwerowej aplikacji bezpieczne tunelowanie do bazy danych.
Uruchom to polecenie w terminalu Cloud Shell:
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
Teraz użyj adresu URL usługi (skopiowanego wcześniej punktu końcowego Cloud Run) i przetestuj aplikację.
Uwaga: jeśli napotkasz problem z usługą, a jako przyczynę podano pamięć, spróbuj zwiększyć przydzielony limit pamięci do 1 GiB, aby to sprawdzić.
10. Czyszczenie danych
Po ukończeniu tego laboratorium nie zapomnij usunąć klastra i instancji AlloyDB.
Powinien on zwalniać miejsce w klastrze wraz z jego instancjami.
11. Gratulacje
Łącząc szybkość AlloyDB, wydajność orkiestracji MCP Toolbox i „pamięć instytucjonalną” Vertex AI Bank zapamiętanych informacji, stworzyliśmy system łańcucha dostaw, który się rozwija. Nie tylko odpowiada na pytania, ale też pamięta, że Twój magazyn w Singapurze zawsze ma problemy z opóźnieniami związanymi z monsunami, i proaktywnie sugeruje zmianę trasy przesyłek, zanim jeszcze o to zapytasz.