
1. Visão geral
Neste codelab, você vai criar um agente do orquestrador da cadeia de suprimentos. Com ele, os usuários podem analisar o inventário, rastrear a logística e gerenciar os riscos da cadeia de suprimentos usando linguagem natural.
Vamos usar o Kit de Desenvolvimento de Agente (ADK) do Google para criar uma arquitetura multiagente que mantém o contexto, lembra as preferências do usuário com o Vertex AI Memory Bank e interage com um conjunto de dados enorme armazenado no AlloyDB usando a MCP Toolbox.
O que você vai criar
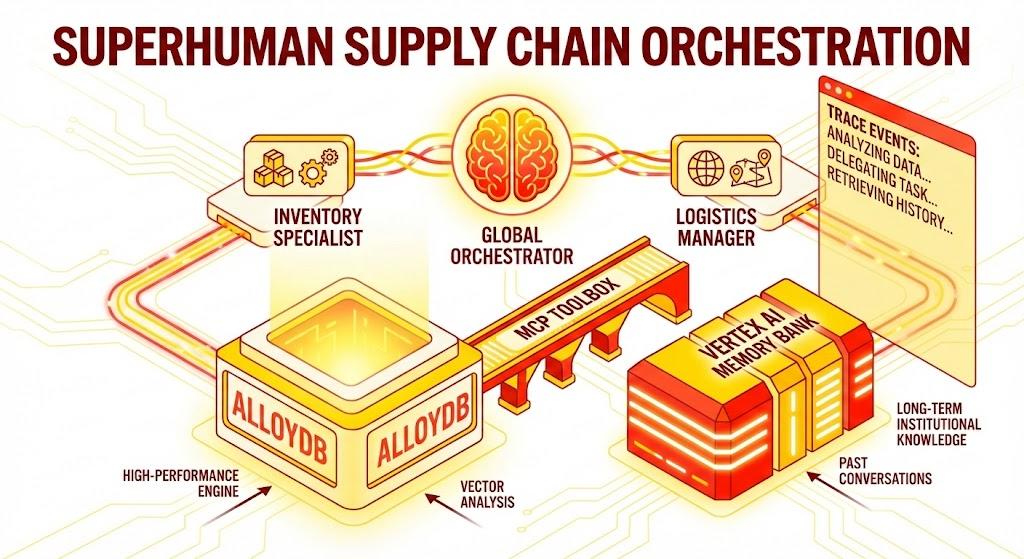
Um aplicativo Python Flask que consiste em:
Agente orquestrador global:o agente raiz que gerencia o fluxo e a delegação de conversas.
Agentes especializados:um "InventorySpecialist" e um "LogisticsManager" para tarefas específicas do domínio.
Integração de memória:memória de sessão de curto prazo e memória de longo prazo usando o Vertex AI Memory Bank.
Interface narrativa:uma interface da Web que mostra o processo de raciocínio do agente (contexto de rastreamento).
O que você vai aprender
- Como usar o ADK do Google para criar agentes e subagentes especializados.
- Como integrar o Vertex AI Memory Bank para a memória de longo prazo do agente.
- Como usar a MCP Toolbox para conectar agentes às ferramentas de dados do AlloyDB.
- Como implementar callbacks do ADK para rastrear e visualizar o raciocínio do agente.
- Como implantar a solução usando o Cloud Run ou executá-la localmente.
A arquitetura
The Tech Stack (em inglês)
- AlloyDB para PostgreSQL:serve como o banco de dados operacional de alto desempenho que contém mais de 50.000 registros da cadeia de suprimentos. Ele alimenta a pesquisa e a recuperação de vetores.
- MCP Toolbox for Databases:atua como o "maestro de orquestração", expondo dados do AlloyDB como ferramentas executáveis que os agentes podem chamar.
- Kit de Desenvolvimento de Agente (ADK): o framework usado para definir os agentes, as instruções e as ferramentas.
- Memory Bank da Vertex AI:oferece memória de longo prazo, permitindo que o agente se lembre das preferências do usuário e das interações anteriores em todas as sessões.
- Serviço de sessão da Vertex AI:gerencia o contexto de conversas de curto prazo.
O fluxo
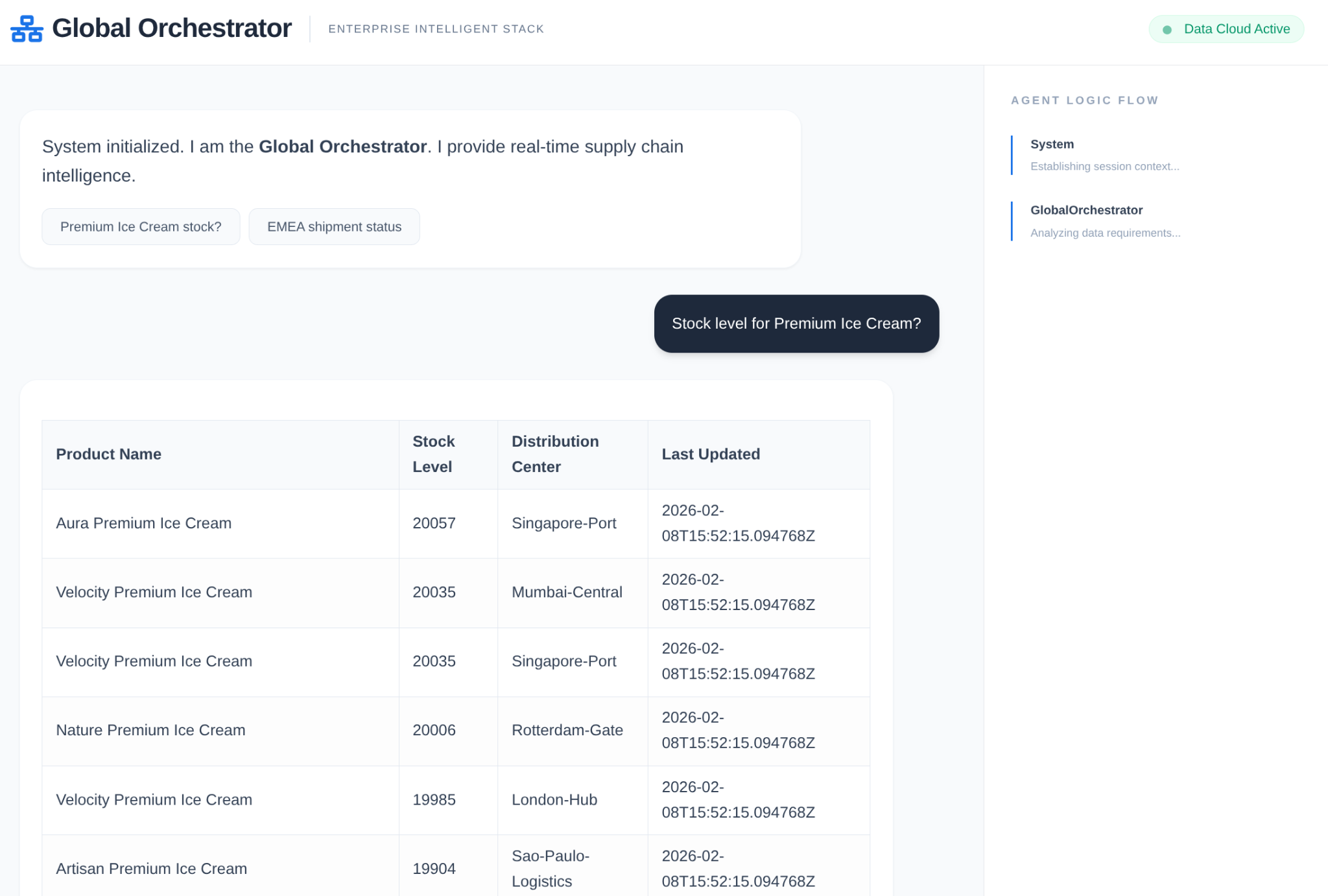
- Consulta do usuário:o usuário faz uma pergunta (por exemplo, "Verifique o estoque de sorvete premium").
- Verificação de memória:o Orchestrator verifica o Memory Bank para encontrar informações relevantes do passado (por exemplo, "O usuário é um gerente regional da EMEA").
- Delegação:o orquestrador delega a tarefa ao InventorySpecialist.
- Execução de ferramentas:o especialista usa ferramentas fornecidas pela MCP Toolbox para consultar o AlloyDB.
- Resposta:o agente processa os dados e retorna uma tabela formatada em Markdown.
- Armazenamento de memória:as interações significativas são salvas no Memory Bank.
Requisitos
2. Antes de começar
Criar um projeto
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Confira se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud. Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud.

- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com seu ID do projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se o projeto não estiver definido, use este comando:
gcloud config set project <YOUR_PROJECT_ID>
- Ative as APIs necessárias: siga o link e ative as APIs.
Como alternativa, use o comando gcloud. Consulte a documentação para ver o uso e os comandos gcloud.
Problemas e solução de problemas
A síndrome do projeto fantasma | Você executou |
A barricada de faturamento | Você ativou o projeto, mas esqueceu a conta de faturamento. O AlloyDB é um mecanismo de alto desempenho. Ele não vai iniciar se o "tanque de combustível" (faturamento) estiver vazio. |
Atraso na propagação da API | Você clicou em "Ativar APIs", mas a linha de comando ainda mostra |
Quags de cota | Se você estiver usando uma conta de teste nova, poderá atingir uma cota regional para instâncias do AlloyDB. Se |
Agente de serviço"oculto" | Às vezes, o agente de serviço do AlloyDB não recebe automaticamente o papel |
3. Configuração do banco de dados
O AlloyDB para PostgreSQL é o coração do nosso aplicativo. Aproveitamos os recursos avançados de vetor e o mecanismo colunar integrado para gerar incorporações de mais de 50.000 registros de SCM. Isso permite uma análise de vetores quase em tempo real, permitindo que nossos agentes identifiquem anomalias de inventário ou riscos de logística em grandes conjuntos de dados em milissegundos.
Neste laboratório, vamos usar o AlloyDB como banco de dados para os dados de teste. Ele usa clusters para armazenar todos os recursos, como bancos de dados e registros. Cada cluster tem uma instância principal que fornece um ponto de acesso aos dados. As tabelas vão conter os dados reais.
Vamos criar um cluster, uma instância e uma tabela do AlloyDB em que o conjunto de dados de teste será carregado.
- Clique no botão ou copie o link abaixo para o navegador em que o usuário do console do Google Cloud está conectado.
Como alternativa, acesse o terminal do Cloud Shell no projeto em que você resgatou a conta de faturamento, clone o repositório do GitHub e navegue até o projeto usando os comandos abaixo:
git clone https://github.com/AbiramiSukumaran/easy-alloydb-setup
cd easy-alloydb-setup
- Depois que essa etapa for concluída, o repositório será clonado no editor local do Cloud Shell, e você poderá executar o comando abaixo na pasta do projeto. É importante verificar se você está no diretório do projeto:
sh run.sh
- Agora use a interface (clique no link no terminal ou no link "visualizar na Web" no terminal).
- Insira os detalhes do ID do projeto, do cluster e dos nomes das instâncias para começar.
- Tome um café enquanto os registros rolam e leia aqui como isso é feito nos bastidores.
Problemas e solução de problemas
O problema da "paciência" | Os clusters de banco de dados são uma infraestrutura pesada. Se você atualizar a página ou encerrar a sessão do Cloud Shell porque ela "parece travada", poderá acabar com uma instância "fantasma" parcialmente provisionada e impossível de excluir sem intervenção manual. |
Incompatibilidade de região | Se você ativou as APIs em |
Clusters zumbis | Se você usou o mesmo nome para um cluster e não o excluiu, o script pode informar que o nome do cluster já existe. Os nomes de cluster precisam ser exclusivos em um projeto. |
Tempo limite do Cloud Shell | Se o intervalo para o café durar 30 minutos, o Cloud Shell poderá entrar em modo de espera e desconectar o processo |
4. Provisionamento de esquema
Depois que o cluster e a instância do AlloyDB estiverem em execução, acesse o editor de SQL do AlloyDB Studio para ativar as extensões de IA e provisionar o esquema.
Talvez seja necessário aguardar a conclusão da criação da instância. Depois disso, faça login no AlloyDB usando as credenciais criadas ao criar o cluster. Use os seguintes dados para autenticar no PostgreSQL:
- Nome de usuário : "
postgres" - Banco de dados : "
postgres" - Senha : "
alloydb" (ou o que você definiu no momento da criação)
Depois de se autenticar no AlloyDB Studio, os comandos SQL são inseridos no editor. É possível adicionar várias janelas do Editor usando o sinal de mais à direita da última janela.
Você vai inserir comandos para o AlloyDB nas janelas do editor, usando as opções "Executar", "Formatar" e "Limpar" conforme necessário.
Ativar extensões
Para criar esse app, vamos usar as extensões pgvector e google_ml_integration. A extensão pgvector permite armazenar e pesquisar embeddings de vetores. A extensão google_ml_integration oferece funções que você usa para acessar endpoints de previsão da Vertex AI e receber previsões em SQL. Ative essas extensões executando os seguintes DDLs:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Criar uma tabela
É possível criar uma tabela usando a instrução DDL abaixo no AlloyDB Studio:
DROP TABLE IF EXISTS shipments;
DROP TABLE IF EXISTS products;
-- 1. Product Inventory Table
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
category VARCHAR(100),
stock_level INTEGER,
distribution_center VARCHAR(100),
region VARCHAR(50),
embedding vector(768),
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. Logistics & Shipments
CREATE TABLE shipments (
shipment_id SERIAL PRIMARY KEY,
product_id INTEGER REFERENCES products(id),
status VARCHAR(50), -- 'In Transit', 'Delayed', 'Delivered', 'Pending'
estimated_arrival TIMESTAMP,
route_efficiency_score DECIMAL(3, 2)
);
A coluna embedding permite o armazenamento dos valores vetoriais de alguns campos de texto.
Ingestão de dados
Execute o conjunto de instruções SQL abaixo para inserir em massa 50.000 registros na tabela de produtos:
-- We use a CROSS JOIN pattern with realistic naming segments to create meaningful variety
DO $$
DECLARE
brand_names TEXT[] := ARRAY['Artisan', 'Nature', 'Elite', 'Pure', 'Global', 'Eco', 'Velocity', 'Heritage', 'Aura', 'Summit'];
product_types TEXT[] := ARRAY['Ice Cream', 'Body Wash', 'Laundry Detergent', 'Shampoo', 'Mayonnaise', 'Deodorant', 'Tea', 'Soup', 'Face Cream', 'Soap'];
variants TEXT[] := ARRAY['Classic', 'Gold', 'Premium', 'Eco-Friendly', 'Organic', 'Night-Repair', 'Extra-Fresh', 'Zero-Sugar', 'Sensitive', 'Maximum-Strength'];
regions TEXT[] := ARRAY['EMEA', 'APAC', 'LATAM', 'NAMER'];
dcs TEXT[] := ARRAY['London-Hub', 'Mumbai-Central', 'Sao-Paulo-Logistics', 'Singapore-Port', 'Rotterdam-Gate', 'New-York-DC'];
BEGIN
INSERT INTO products (name, category, stock_level, distribution_center, region)
SELECT
b || ' ' || v || ' ' || t as name,
CASE
WHEN t IN ('Ice Cream', 'Mayonnaise', 'Tea', 'Soup') THEN 'Food & Refreshment'
WHEN t IN ('Body Wash', 'Shampoo', 'Deodorant', 'Face Cream', 'Soap') THEN 'Personal Care'
ELSE 'Home Care'
END as category,
floor(random() * 20000 + 100)::int as stock_level,
dcs[floor(random() * 6 + 1)] as distribution_center,
regions[floor(random() * 4 + 1)] as region
FROM
unnest(brand_names) b,
unnest(variants) v,
unnest(product_types) t,
generate_series(1, 50); -- 10 * 10 * 10 * 50 = 50,000 records
END $$;
Vamos inserir registros específicos da demonstração para garantir respostas previsíveis a perguntas no estilo executivo
-- These ensure you have predictable answers for specific "Executive" questions
INSERT INTO products (name, category, stock_level, distribution_center, region) VALUES
('Magnum Ultra Gold Limited Edition', 'Food & Refreshment', 45, 'Rotterdam-Gate', 'EMEA'),
('Dove Pro-Health Deep Moisture', 'Personal Care', 12000, 'Mumbai-Central', 'APAC'),
('Hellmanns Real Organic Mayonnaise', 'Food & Refreshment', 8000, 'London-Hub', 'EMEA');
Inserir dados de remessas
-- Shipments Generation (More shipments than products)
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT
id,
CASE
WHEN random() > 0.8 THEN 'Delayed'
WHEN random() > 0.4 THEN 'In Transit'
ELSE 'Delivered'
END,
NOW() + (random() * 10 || ' days')::interval,
(random() * 0.5 + 0.5)::decimal(3,2)
FROM products
WHERE random() > 0.3; -- Create shipments for ~70% of products
-- Add duplicate shipments for some products to show complex logistics
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT id, 'In Transit', NOW() + INTERVAL '12 days', 0.88
FROM products
LIMIT 5000;
Conceder permissão
Execute a instrução abaixo para conceder a execução da função "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Conceder o papel de usuário da Vertex AI à conta de serviço do AlloyDB
No console do Google Cloud IAM, conceda à conta de serviço do AlloyDB (que tem esta aparência: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) acesso à função "Usuário da Vertex AI". PROJECT_NUMBER vai ter o número do seu projeto.
Como alternativa, execute o comando abaixo no terminal do Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Gerar embeddings
Em seguida, vamos gerar embeddings de vetor para campos de texto significativos específicos:
WITH
rows_to_update AS (
SELECT
id
FROM
products
WHERE
embedding IS NULL
LIMIT
5000 )
UPDATE
products
SET
embedding = ai.embedding('text-embedding-005', name || ' ' || category || ' ' || distribution_center || ' ' || region)::vector
FROM
rows_to_update
WHERE
products.id = rows_to_update.id
AND embedding IS null;
Na instrução acima, definimos o limite como 5.000. Portanto, execute-a repetidamente até que não haja nenhuma linha na tabela com a incorporação de coluna como NULL.
Problemas e solução de problemas
O loop de "amnésia de senha" | Se você usou a configuração "Um clique" e não se lembra da senha, acesse a página de informações básicas da instância no console e clique em "Editar" para redefinir a senha |
O erro "Extensão não encontrada" | Se |
A lacuna de propagação do IAM | Você executou o comando do IAM |
Incompatibilidade de dimensão do vetor | A tabela |
Erro de digitação no ID do projeto | Na chamada |
5. Configuração de ferramentas e da caixa de ferramentas
A MCP Toolbox for Databases é um servidor MCP de código aberto para bancos de dados. Ele permite desenvolver ferramentas com mais facilidade, rapidez e segurança, lidando com complexidades como pool de conexões, autenticação e muito mais. A caixa de ferramentas ajuda você a criar ferramentas de IA generativa que permitem que seus agentes acessem dados no seu banco de dados.
Usamos a caixa de ferramentas do Protocolo de Contexto de Modelo (MCP) para bancos de dados como o "condutor". Ele atua como um middleware padronizado entre nossos agentes e o AlloyDB. Ao definir uma configuração tools.yaml, a caixa de ferramentas expõe automaticamente operações complexas do banco de dados como ferramentas limpas e executáveis, como search_products_by_context ou check_inventory_levels. Isso elimina a necessidade de agrupamento de conexões manual ou SQL boilerplate na lógica do agente.
Como instalar o servidor da caixa de ferramentas
No terminal do Cloud Shell, crie uma pasta para salvar o novo arquivo YAML de ferramentas e o binário da caixa de ferramentas:
mkdir scm-agent-toolbox
cd scm-agent-toolbox
Na nova pasta, execute o seguinte conjunto de comandos:
# see releases page for other versions
export VERSION=0.27.0
curl -L -o toolbox https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Em seguida, crie o arquivo tools.yaml dentro dessa nova pasta navegando até o editor do Cloud Shell e copie o conteúdo deste arquivo do repositório para o arquivo tools.yaml.
sources:
supply_chain_db:
kind: "alloydb-postgres"
project: "YOUR_PROJECT_ID"
region: "us-central1"
cluster: "YOUR_CLUSTER"
instance: "YOUR_INSTANCE"
database: "postgres"
user: "postgres"
password: "YOUR_PASSWORD"
tools:
search_products_by_context:
kind: postgres-sql
source: supply_chain_db
description: Find products in the inventory using natural language search and vector embeddings.
parameters:
- name: search_text
type: string
description: Description of the product or category the user is looking for.
statement: |
SELECT name, category, stock_level, distribution_center, region
FROM products
ORDER BY embedding <=> ai.embedding('text-embedding-005', $1)::vector
LIMIT 5;
check_inventory_levels:
kind: postgres-sql
source: supply_chain_db
description: Get precise stock levels for a specific product name.
parameters:
- name: product_name
type: string
description: The exact or partial name of the product.
statement: |
SELECT name, stock_level, distribution_center, last_updated
FROM products
WHERE name ILIKE '%' || $1 || '%'
ORDER BY stock_level DESC;
track_shipment_status:
kind: postgres-sql
source: supply_chain_db
description: Retrieve real-time logistics and shipping status for a specific region or product.
parameters:
- name: region
type: string
description: The geographical region to filter shipments (e.g., EMEA, APAC).
statement: |
SELECT p.name, s.status, s.estimated_arrival, s.route_efficiency_score
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE p.region = $1
ORDER BY s.estimated_arrival ASC;
analyze_supply_chain_risk:
kind: postgres-sql
source: supply_chain_db
description: Rerank and filter shipments based on risk profiles and efficiency scores using Google ML reranker.
parameters:
- name: risk_context
type: string
description: The business context for risk analysis (e.g., 'heatwave impact' or 'port strike').
statement: |
WITH initial_ranking AS (
SELECT s.shipment_id, p.name, s.status, p.distribution_center,
ROW_NUMBER() OVER () AS ref_number
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE s.status != 'Delivered'
LIMIT 10
),
reranked_results AS (
SELECT index, score FROM
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => $1,
documents => (SELECT ARRAY_AGG(name || ' at ' || distribution_center ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT i.name, i.status, i.distribution_center, r.score
FROM initial_ranking i, reranked_results r
WHERE i.ref_number = r.index
ORDER BY r.score DESC;
toolsets:
supply_chain_toolset:
- search_products_by_context
- check_inventory_levels
- track_shipment_status
- analyze_supply_chain_risk
Agora teste o arquivo tools.yaml no servidor local:
./toolbox --tools-file "tools.yaml"
Você também pode testar na interface
./toolbox --ui
Perfeito!! Depois de confirmar que tudo funciona, implante no Cloud Run da seguinte maneira.
Implantação do Cloud Run
- Defina a variável de ambiente PROJECT_ID:
export PROJECT_ID="my-project-id"
- Inicialize a CLI gcloud:
gcloud init
gcloud config set project $PROJECT_ID
- Você precisa ter as seguintes APIs ativadas:
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Crie uma conta de serviço de back-end se ainda não tiver uma:
gcloud iam service-accounts create toolbox-identity
- Conceda permissões para usar o Secret Manager:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
- Conceda permissões adicionais à conta de serviço específicas da nossa origem do AlloyDB (roles/alloydb.client e roles/serviceusage.serviceUsageConsumer).
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role serviceusage.serviceUsageConsumer
- Faça upload de tools.yaml como um secret:
gcloud secrets create tools-scm-agent --data-file=tools.yaml
- Se você já tiver um secret e quiser atualizar a versão dele, execute o seguinte:
gcloud secrets versions add tools-scm-agent --data-file=tools.yaml
- Defina uma variável de ambiente para a imagem do contêiner que você quer usar no Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Implante a caixa de ferramentas no Cloud Run usando o seguinte comando:
Se você tiver ativado o acesso público na instância do AlloyDB (não recomendado), siga o comando abaixo para implantação no Cloud Run:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
Se você estiver usando uma rede VPC, use o comando abaixo:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
# TODO(dev): update the following to match your VPC details
--network <<YOUR_NETWORK_NAME>> \
--subnet <<YOUR_SUBNET_NAME>> \
--allow-unauthenticated
6. Configuração do agente
Usando o Kit de Desenvolvimento de Agente (ADK), passamos de comandos monolíticos para uma arquitetura multiagente especializada:
- InventorySpecialist: focado em métricas de estoque de produtos e armazém.
- LogisticsManager: especialista em rotas de frete globais e análise de risco.
- GlobalOrchestrator: o "cérebro" que usa o raciocínio para delegar tarefas e sintetizar descobertas.
Clone este repositório no seu projeto e vamos analisar.
Para clonar, no terminal do Cloud Shell (no diretório raiz ou em qualquer lugar em que você queira criar o projeto), execute o seguinte comando:
git clone https://github.com/AbiramiSukumaran/scm-memory-agent
- Isso vai criar o projeto, e você pode verificar no editor do Cloud Shell.

- Atualize o arquivo .env com os valores do projeto e da instância.
Instruções sobre o código
Uma visão geral rápida do agente do Orchestrator
Go to app.py and you should be able to see the following snippet:
orchestrator = adk.Agent(
name="GlobalOrchestrator",
model="gemini-2.5-flash",
description="Global Supply Chain Orchestrator root agent.",
instruction="""
You are the Global Supply Chain Brain. You are responsible for products, inventory and logistics.
You also have access to the memory tool, remember to include all the information that the tool can provide you with about the user before you respond.
1. Understand intent and delegate to specialists. As the Global Orchestrator, you have access to the full conversation history with the user.
When you transfer a query to a specialist agent, sub agent or tool, share the important facts and information from your memory to them so they can operate with the full context.
2. Ensure the final response is professional and uses Markdown tables for data.
3. If a specialist provides a long list, ensure only the top 10 items are shown initially.
4. Conclude with a brief, high-level executive summary of what the data implies.
""",
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
sub_agents=[inventory_agent, logistics_agent],
#after_agent_callback=auto_save_session_to_memory_callback,
)
Este trecho é a definição da raiz, que é o agente orquestrador que recebe a conversa ou a solicitação do usuário e encaminha para o subagente ou usuário correspondente as ferramentas adequadas com base na tarefa.
- Vamos analisar o agente de inventário
inventory_agent = adk.Agent(
name="InventorySpecialist",
model="gemini-2.5-flash",
description="Specialist in product stock and warehouse data.",
instruction="""
Analyze inventory levels.
1. Use 'search_products_by_context' or 'check_inventory_levels'.
2. ALWAYS format results as a clean Markdown table.
3. If there are many results, display only the TOP 10 most relevant ones.
4. At the end, state: 'There are additional records available. Would you like to see more?'
""",
tools=tools
)
Esse subagente é especializado em atividades de inventário, como pesquisar produtos contextualmente e verificar os níveis de inventário.
- Depois, há o subagente de logística:
logistics_agent = adk.Agent(
name="LogisticsManager",
model="gemini-2.5-flash",
description="Expert in global shipping routes and logistics tracking.",
instruction="""
Check shipment statuses.
1. Use 'track_shipment_status' or 'analyze_supply_chain_risk'.
2. ALWAYS format results as a clean Markdown table.
3. Limit initial output to the top 10 shipments.
4. Ask if the user needs the full manifest if more results exist.
""",
tools=tools
)
Esse subagente específico é especializado em atividades de logística, como rastreamento de remessas e análise de riscos na cadeia de suprimentos.
- Todos os três agentes que discutimos até agora usam ferramentas, e elas são referenciadas pelo nosso servidor da caixa de ferramentas, que já foi implantado na seção anterior. Consulte o snippet abaixo:
from toolbox_core import ToolboxSyncClient
TOOLBOX_SERVER = os.environ["TOOLBOX_SERVER"]
TOOLBOX_TOOLSET = os.environ["TOOLBOX_TOOLSET"]
# --- ADK TOOLBOX CONFIGURATION ---
toolbox = ToolboxSyncClient(TOOLBOX_SERVER)
tools = toolbox.load_toolset(TOOLBOX_TOOLSET)
Esse subagente específico é especializado em atividades de logística, como rastreamento de remessas e análise de riscos na cadeia de suprimentos.
7. Mecanismo do agente
Na execução inicial, crie o Agent Engine.
import vertexai
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
client = vertexai.Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_LOCATION
)
agent_engine = client.agent_engines.create()
- Para a próxima execução, atualize o Agent Engine com a configuração do Memory Bank:
agent_engine = client.agent_engines.update(
name=APP_NAME,
config={
"context_spec": {
"memory_bank_config": {
"generation_config": {
"model": f"projects/{PROJECT_ID}/locations/{GOOGLE_CLOUD_LOCATION}/publishers/google/models/gemini-2.5-flash"
}
}
}
})
8. Contexto, execução e memória
O gerenciamento de contexto é dividido em duas camadas distintas para garantir que o agente pareça um parceiro contínuo em vez de um bot sem estado:
Memória de curto prazo (sessões): gerenciada via VertexAiSessionService, ela rastreia o histórico de eventos imediatos (mensagens do usuário, respostas da ferramenta) em uma única interação.
Memória de longo prazo (Memory Bank): tecnologia do Memory Bank do Vertex AI via adk.memorybankservice. Essa camada extrai informações "significativas", como a preferência de um usuário por transportadoras específicas ou atrasos recorrentes no armazém, e as mantém em todas as sessões.
Inicializar a sessão para a memória de sessão no escopo da conversa
Essa é a parte do snippet que cria a sessão para o app atual do usuário atual.
from google.adk.sessions import VertexAiSessionService
...
session_service = VertexAiSessionService(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
...
# Initialize the session *outside* of the route handler to avoid repeated creation
session = None
session_lock = threading.Lock()
async def initialize_session():
global session
try:
session = await session_service.create_session(app_name=APP_NAME, user_id=USER_ID)
print(f"Session {session.id} created successfully.") # Add a log
except Exception as e:
print(f"Error creating session: {e}")
session = None # Ensure session is None in case of error
# Create the session on app startup
asyncio.run(initialize_session())
Inicializar o Vertex AI Memory Bank para memória de longo prazo
Esta é a parte do snippet que cria uma instância do objeto de serviço do Vertex AI Memory Bank para o Agent Engine.
from google.adk.memory import InMemoryMemoryService
from google.adk.memory import VertexAiMemoryBankService
...
try:
memory_bank_service = adk.memory.VertexAiMemoryBankService(
agent_engine_id=AGENT_ENGINE_ID,
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
#in_memory_service = InMemoryMemoryService()
print("Memory Bank Service initialized successfully.")
except Exception as e:
print(f"Error initializing Memory Bank Service: {e}")
memory_bank_service = None
runner = adk.Runner(
agent=orchestrator,
app_name=APP_NAME,
session_service=session_service,
memory_service=memory_bank_service,
)
...
O que é configurado?
Nesta parte do snippet, estamos configurando o serviço do Vertex AI Memory Bank para memória de longo prazo. Ele armazena contextualmente a sessão do app específico para o usuário específico como uma memória no Vertex AI Memory Bank.
O que é executado como parte da execução do agente?
async def run_and_collect():
final_text = ""
try:
async for event in runner.run_async(
new_message=content,
user_id=user_id,
session_id=session_id
):
if hasattr(event, 'author') and event.author:
if not any(log['agent'] == event.author for log in execution_logs):
execution_logs.append({
"agent": event.author,
"action": "Analyzing data requirements...",
"type": "orchestration_event"
})
if hasattr(event, 'text') and event.text:
final_text = event.text
elif hasattr(event, 'content') and hasattr(event.content, 'parts'):
for part in event.content.parts:
if hasattr(part, 'text') and part.text:
final_text = part.text
except Exception as e:
print(f"Error during runner.run_async: {e}")
raise # Re-raise the exception to signal failure
finally:
gc.collect()
return final_text
Ele processa o conteúdo de entrada do usuário no objeto new_message com o ID do usuário e o ID da sessão no escopo. Em seguida, o agente assume o controle, e a resposta dele é processada e retornada.
O que é armazenado na memória de longo prazo?
O detalhe da sessão no escopo do app e do usuário é extraído na variável de sessão.
Essa sessão é adicionada como a memória do usuário atual para o app atual do objeto Vertex AI Memory Bank usando o método "add_session_to_memory".
session = asyncio.run(session_service.get_session(app_name=APP_NAME, user_id=USER_ID, session_id=session.id))
if memory_bank_service and session: # Check memory service AND session
try:
#asyncio.run(in_memory_service.add_session_to_memory(session))
asyncio.run(memory_bank_service.add_session_to_memory(session))
'''
client.agent_engines.memories.generate(
scope={"app_name": APP_NAME, "user_id": USER_ID},
name=APP_NAME,
direct_contents_source={
"events": [
{"content": content}
]
},
config={"wait_for_completion": True},
)
'''
print("Successfully added session to memory.******")
print(session.id)
except Exception as e:
print(f"Error adding session to memory: {e}")
Recuperação de memória
Precisamos recuperar a memória de longo prazo armazenada usando o nome do app e o nome do usuário como escopo (já que é o escopo em que armazenamos as memórias) para transmiti-la como parte do contexto ao orquestrador e a outros agentes, conforme aplicável.
results = client.agent_engines.memories.retrieve(
name=APP_NAME,
scope={"app_name": APP_NAME, "user_id": USER_ID}
)
# RetrieveMemories returns a pager. You can use `list` to retrieve all pages' memories.
list(results)
print(list(results))
Como a recordação recuperada é carregada como parte do contexto?
Usamos o seguinte atributo na definição do agente do Orchestrator, que permite que o agente raiz pré-carregue o contexto do banco de memória. Isso além das ferramentas que acessamos no servidor da caixa de ferramentas para os subagentes.
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
Contexto de callback
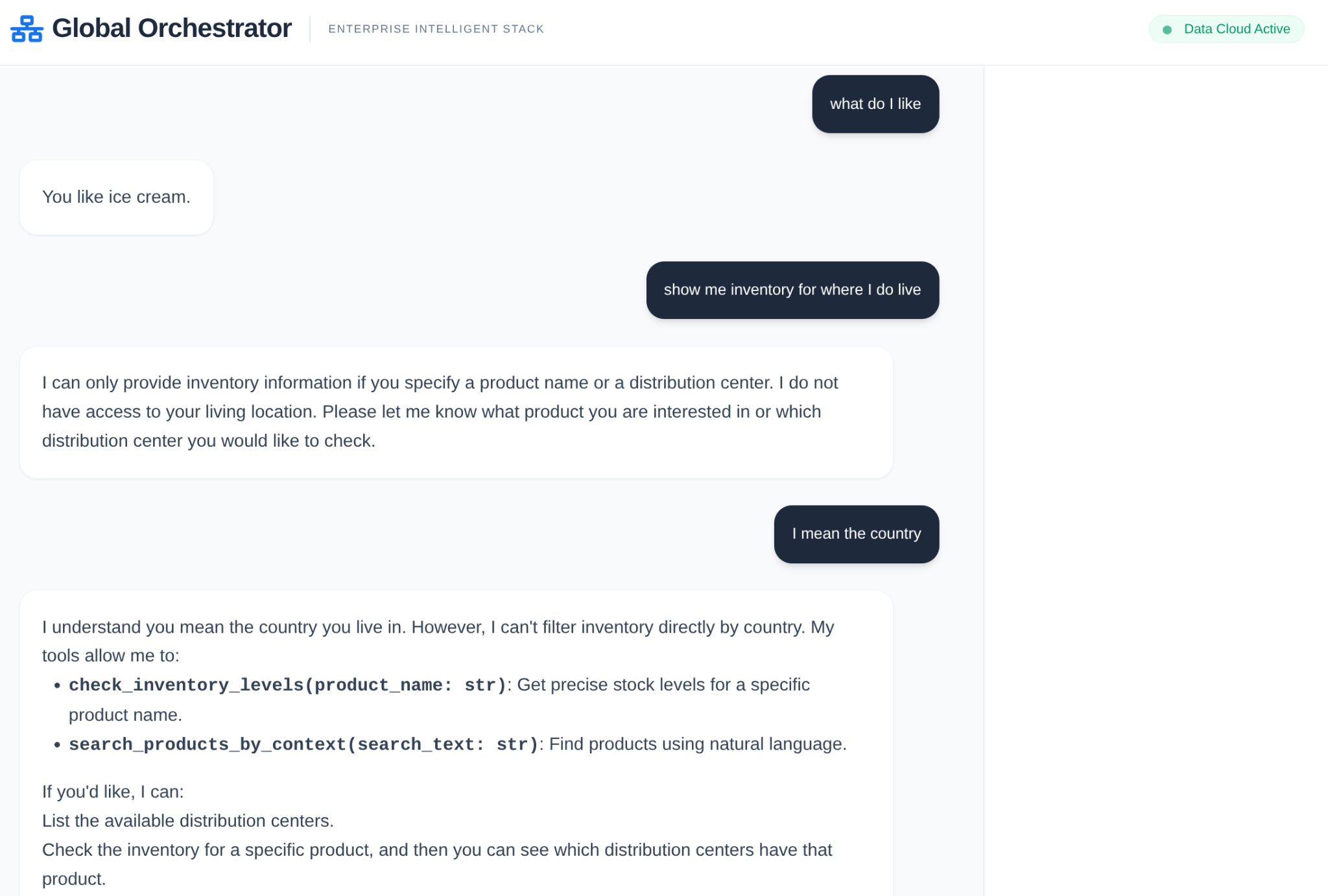
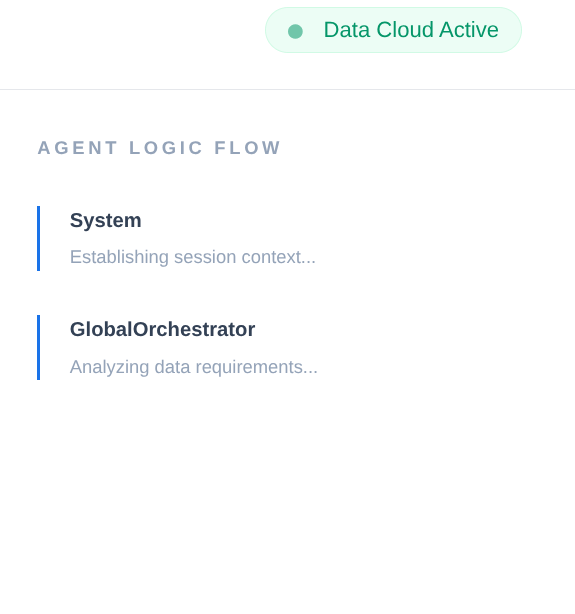
Em uma cadeia de suprimentos corporativa, não é possível ter uma "caixa preta". Usamos o CallbackContext do ADK para criar um Narrative Engine. Ao se conectar à execução do agente, capturamos todos os processos de raciocínio e chamadas de ferramentas, transmitindo-os para uma barra lateral da interface.
- Evento de rastreamento: "GlobalOrchestrator is analyzing data requirements..."
- Evento de rastreamento: "Delegating to InventorySpecialist for stock levels..."
- Evento de rastreamento: "Recuperando padrões históricos de atraso de fornecedores do Memory Bank..."
Essa trilha de auditoria é muito útil para depuração e garante que os operadores humanos possam confiar nas decisões autônomas do agente.
from google.adk.agents.callback_context import CallbackContext
...
# --- ADK CALLBACKS (Narrative Engine) ---
execution_logs = []
async def trace_callback(context: CallbackContext):
"""
Captures agent and tool invocation flow for the UI narrative.
"""
agent_name = context.agent.name
event = {
"agent": agent_name,
"action": "Processing request steps...",
"type": "orchestration_event"
}
execution_logs.append(event)
return None
...
Pronto!!! Clonamos o projeto e explicamos os detalhes do agente, da memória e do contexto.
Para testar, navegue até a pasta do projeto do repositório clonado e execute os seguintes comandos:
>> pip install -r requirements.txt
>> python app.py
Isso vai iniciar o agente localmente, e você poderá testá-lo.
9. Vamos implantar no Cloud Run
- Implante no Cloud Run executando o seguinte comando no terminal do Cloud Shell, em que o projeto é clonado. Verifique se você está na pasta raiz do projeto.
Execute o seguinte no terminal do Cloud Shell:
gcloud run deploy supply-chain-agent --source . --platform managed --region us-central1 --allow-unauthenticated --set-env-vars GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT>>,GOOGLE_CLOUD_LOCATION=us-central1,GOOGLE_GENAI_USE_VERTEXAI=TRUE,REASONING_ENGINE_APP_NAME=<<YOUR_APP_ENGINE_URL>>,TOOLBOX_SERVER=<<YOUR_TOOLBOX_SERVER>>,TOOLBOX_TOOLSET=supply_chain_toolset,AGENT_ENGINE_ID=<<YOUR_AGENT_ENGINE_ID>>
Substitua os valores dos marcadores de posição <<YOUR_PROJECT>>, <<YOUR_APP_ENGINE_URL>>, <<YOUR_TOOLBOX_SERVER>> e <<YOUR_AGENT_ENGINE_ID>>.
Quando o comando terminar, ele vai gerar um URL de serviço. Copie.
- Conceda o papel Cliente do AlloyDB à conta de serviço do Cloud Run.Isso permite que seu aplicativo sem servidor faça um túnel seguro no banco de dados.
Execute o seguinte no terminal do Cloud Shell:
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
Agora use o URL do serviço (endpoint do Cloud Run que você copiou antes) e teste o app.
Observação:se você encontrar um problema no serviço e ele citar a memória como motivo, tente aumentar o limite de memória alocado para 1 GiB para testar.
10. Limpar
Depois de concluir este laboratório, não se esqueça de excluir o cluster e a instância do AlloyDB.
Ele vai limpar o cluster e as instâncias dele.
11. Parabéns
Ao combinar a velocidade do AlloyDB, a eficiência de orquestração da MCP Toolbox e a "memória institucional" do Memory Bank da Vertex AI, criamos um sistema de cadeia de suprimentos que evolui. Ele não apenas responde a perguntas, mas também lembra que seu armazém em Singapura sempre tem problemas com atrasos relacionados às monções e sugere proativamente o redirecionamento de remessas antes mesmo de você perguntar.