
1. Обзор
В этом практическом задании вы создадите агента для управления цепочкой поставок. Это приложение позволяет пользователям анализировать запасы, отслеживать логистику и управлять рисками в цепочке поставок, используя естественный язык.
Мы будем использовать комплект разработки агентов Google (ADK) для создания многоагентной архитектуры, которая поддерживает контекст, запоминает пользовательские предпочтения с помощью Vertex AI Memory Bank и взаимодействует с огромным набором данных, хранящимся в AlloyDB, через MCP Toolbox.
Что вы построите
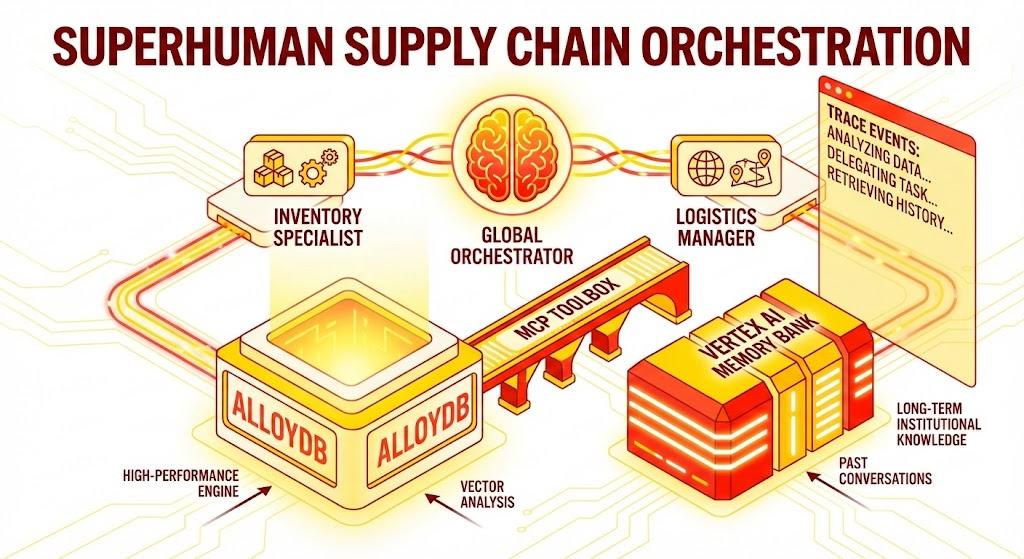
Приложение на Python Flask, состоящее из:
Агент глобального оркестратора: основной агент, управляющий потоком диалогов и делегированием полномочий.
Специалисты-агенты: «Специалист по инвентаризации» и «Менеджер по логистике» для выполнения задач, специфичных для данной области.
Интеграция памяти: кратковременная и долговременная память с использованием банка памяти Vertex AI.
Narrative UI: Веб-интерфейс, визуализирующий процесс рассуждений агента (Trace Context).
Что вы узнаете
- Как использовать Google ADK для создания специализированных агентов и субагентов.
- Как интегрировать Vertex AI Memory Bank для долговременной памяти агентов.
- Как использовать MCP Toolbox для подключения агентов к инструментам обработки данных AlloyDB.
- Как реализовать обратные вызовы ADK для отслеживания и визуализации логики работы агентов.
- Как развернуть решение с помощью Cloud Run или запустить его локально.
Архитектура
Технологический стек
- AlloyDB для PostgreSQL: служит высокопроизводительной операционной базой данных, хранящей более 50 000 записей о цепочках поставок. Она обеспечивает векторный поиск и извлечение данных.
- MCP Toolbox for Databases: выступает в роли «маэстро оркестровки», предоставляя доступ к данным AlloyDB в виде исполняемых инструментов, которые могут вызывать агенты.
- Комплект разработки агентов (ADK): структура, используемая для определения агентов, инструкций и инструментов.
- Vertex AI Memory Bank: Обеспечивает долговременную память, позволяя агенту воспроизводить пользовательские предпочтения и прошлые взаимодействия в разных сессиях.
- Сервис Vertex AI Session Service: управляет краткосрочным контекстом разговора.
Поток
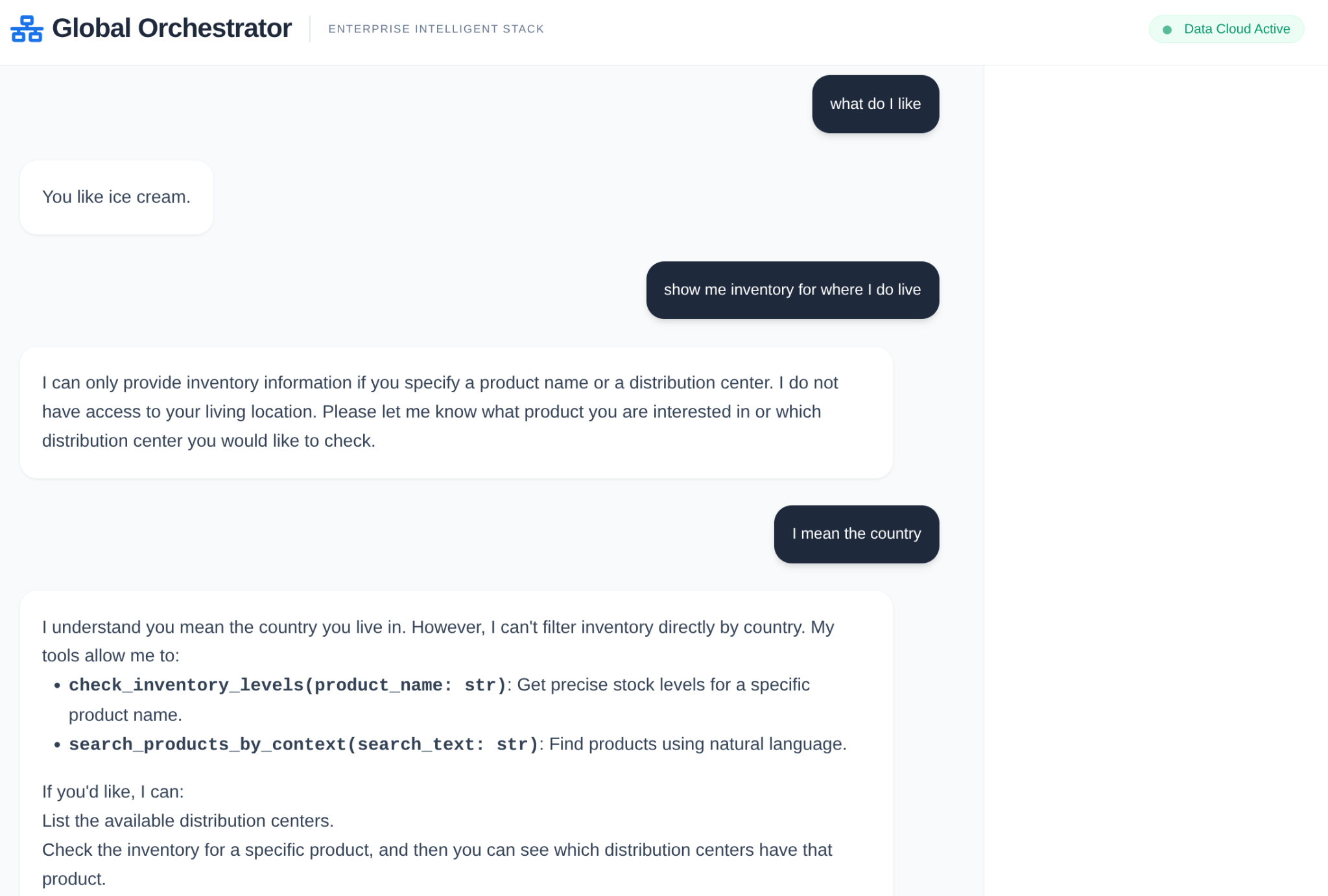
- Запрос пользователя: Пользователь задает вопрос (например, «Проверить наличие мороженого премиум-класса»).
- Проверка памяти: Оркестратор проверяет банк памяти на наличие соответствующей информации из прошлого (например, «Пользователь является региональным менеджером по региону EMEA»).
- Делегирование: Координатор делегирует задачу Специалисту по инвентаризации .
- Выполнение инструментов: Специалист использует инструменты, предоставляемые MCP Toolbox , для выполнения запросов к AlloyDB .
- Ответ: Агент обрабатывает данные и возвращает таблицу в формате Markdown.
- Хранение в памяти: Важные взаимодействия сохраняются в банке памяти.
Требования
2. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.

- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его установки:
gcloud config set project <YOUR_PROJECT_ID>
- Включите необходимые API: перейдите по ссылке и включите API.
В качестве альтернативы можно использовать команду gcloud. Для получения информации о командах gcloud и их использовании обратитесь к документации .
Подводные камни и устранение неполадок
Синдром «Проекта-призрака» | Вы выполнили команду |
Баррикада Биллинга | Вы активировали проект, но забыли указать платежный аккаунт. AlloyDB — высокопроизводительный движок; он не запустится, если «топливо» (платежный бак) пуст. |
Задержка распространения API | Вы нажали «Включить API», но в командной строке по-прежнему отображается сообщение |
Квота Квагс | Если вы используете совершенно новую пробную учетную запись, вы можете столкнуться с региональной квотой на экземпляры AlloyDB. Если |
«Скрытый» сервисный агент | Иногда агенту службы AlloyDB автоматически не предоставляется роль |
3. Настройка базы данных
В основе нашего приложения лежит AlloyDB для PostgreSQL . Мы использовали его мощные векторные возможности и встроенный столбцовый механизм для генерации векторных представлений для более чем 50 000 записей SCM . Это позволяет проводить векторный анализ практически в реальном времени, что дает нашим агентам возможность выявлять аномалии в инвентаризации или логистические риски в огромных массивах данных за миллисекунды.
В этой лабораторной работе мы будем использовать AlloyDB в качестве базы данных для тестовых данных. Она использует кластеры для хранения всех ресурсов, таких как базы данных и журналы. Каждый кластер имеет основной экземпляр , который обеспечивает точку доступа к данным. Таблицы будут содержать сами данные.
Давайте создадим кластер AlloyDB, экземпляр и таблицу, куда будет загружен тестовый набор данных.
- Нажмите на кнопку или скопируйте ссылку ниже в браузер, где вы авторизованы в Google Cloud Console.
В качестве альтернативы вы можете перейти в терминал Cloud Shell из проекта, где вы активировали платежный аккаунт, клонировать репозиторий GitHub и перейти к проекту, используя приведенные ниже команды:
git clone https://github.com/AbiramiSukumaran/easy-alloydb-setup
cd easy-alloydb-setup
- После завершения этого шага репозиторий будет клонирован в ваш локальный редактор CloudShell, и вы сможете запустить приведенную ниже команду, указав папку проекта (важно убедиться, что вы находитесь в каталоге проекта):
sh run.sh
- Теперь воспользуйтесь пользовательским интерфейсом (щелкните ссылку в терминале или щелкните ссылку «предварительный просмотр в веб-браузере» в терминале).
- Введите данные для идентификатора проекта, названия кластера и экземпляра, чтобы начать работу.
- Пока прокручиваются логи, выпейте кофе, а подробнее о том, как это всё происходит за кулисами, вы можете прочитать здесь.
Подводные камни и устранение неполадок
Проблема «терпения» | Кластеры баз данных — это ресурсоемкая инфраструктура. Если вы обновите страницу или завершите сессию Cloud Shell, потому что она «зависла», вы можете получить «фантомный» экземпляр, который будет частично выделен и его невозможно будет удалить без ручного вмешательства. |
Региональное несоответствие | Если вы включили API в регионе |
Скопления зомби | Если вы ранее использовали это же имя для кластера и не удалили его, скрипт может сообщить, что имя кластера уже существует. Имена кластеров должны быть уникальными в рамках одного проекта. |
Таймаут облачной оболочки | Если ваш перерыв на кофе длится 30 минут, Cloud Shell может перейти в спящий режим и отключить процесс |
4. Предоставление схемы
После запуска кластера и экземпляра AlloyDB перейдите в редактор SQL AlloyDB Studio, чтобы включить расширения AI и настроить схему.
Возможно, вам потребуется дождаться завершения создания экземпляра. После этого войдите в AlloyDB, используя учетные данные, которые вы создали при создании кластера. Для аутентификации в PostgreSQL используйте следующие данные:
- Имя пользователя: "
postgres" - База данных: "
postgres" - Пароль: "
alloydb" (или тот, который вы указали при создании учетной записи)
После успешной аутентификации в AlloyDB Studio команды SQL вводятся в редакторе. Вы можете добавить несколько окон редактора, используя значок плюса справа от последнего окна.
Команды для AlloyDB будут вводиться в окнах редактора, используя при необходимости параметры «Выполнить», «Форматировать» и «Очистить».
Включить расширения
Для создания этого приложения мы будем использовать расширения pgvector и google_ml_integration . Расширение pgvector позволяет хранить и искать векторные представления. Расширение google_ml_integration предоставляет функции, которые вы используете для доступа к конечным точкам прогнозирования Vertex AI и получения прогнозов в формате SQL. Включите эти расширения, выполнив следующие DDL-скрипты:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Создайте таблицу
В AlloyDB Studio можно создать таблицу, используя приведенный ниже оператор DDL:
DROP TABLE IF EXISTS shipments;
DROP TABLE IF EXISTS products;
-- 1. Product Inventory Table
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
category VARCHAR(100),
stock_level INTEGER,
distribution_center VARCHAR(100),
region VARCHAR(50),
embedding vector(768),
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. Logistics & Shipments
CREATE TABLE shipments (
shipment_id SERIAL PRIMARY KEY,
product_id INTEGER REFERENCES products(id),
status VARCHAR(50), -- 'In Transit', 'Delayed', 'Delivered', 'Pending'
estimated_arrival TIMESTAMP,
route_efficiency_score DECIMAL(3, 2)
);
Столбец embedding позволит хранить векторные значения некоторых текстовых полей.
Ввод данных
Выполните приведенный ниже набор SQL-запросов для массовой вставки 50000 записей в таблицу products:
-- We use a CROSS JOIN pattern with realistic naming segments to create meaningful variety
DO $$
DECLARE
brand_names TEXT[] := ARRAY['Artisan', 'Nature', 'Elite', 'Pure', 'Global', 'Eco', 'Velocity', 'Heritage', 'Aura', 'Summit'];
product_types TEXT[] := ARRAY['Ice Cream', 'Body Wash', 'Laundry Detergent', 'Shampoo', 'Mayonnaise', 'Deodorant', 'Tea', 'Soup', 'Face Cream', 'Soap'];
variants TEXT[] := ARRAY['Classic', 'Gold', 'Premium', 'Eco-Friendly', 'Organic', 'Night-Repair', 'Extra-Fresh', 'Zero-Sugar', 'Sensitive', 'Maximum-Strength'];
regions TEXT[] := ARRAY['EMEA', 'APAC', 'LATAM', 'NAMER'];
dcs TEXT[] := ARRAY['London-Hub', 'Mumbai-Central', 'Sao-Paulo-Logistics', 'Singapore-Port', 'Rotterdam-Gate', 'New-York-DC'];
BEGIN
INSERT INTO products (name, category, stock_level, distribution_center, region)
SELECT
b || ' ' || v || ' ' || t as name,
CASE
WHEN t IN ('Ice Cream', 'Mayonnaise', 'Tea', 'Soup') THEN 'Food & Refreshment'
WHEN t IN ('Body Wash', 'Shampoo', 'Deodorant', 'Face Cream', 'Soap') THEN 'Personal Care'
ELSE 'Home Care'
END as category,
floor(random() * 20000 + 100)::int as stock_level,
dcs[floor(random() * 6 + 1)] as distribution_center,
regions[floor(random() * 4 + 1)] as region
FROM
unnest(brand_names) b,
unnest(variants) v,
unnest(product_types) t,
generate_series(1, 50); -- 10 * 10 * 10 * 50 = 50,000 records
END $$;
Давайте добавим записи, специфичные для конкретной демонстрации, чтобы обеспечить предсказуемые ответы на вопросы в стиле "для руководителей".
-- These ensure you have predictable answers for specific "Executive" questions
INSERT INTO products (name, category, stock_level, distribution_center, region) VALUES
('Magnum Ultra Gold Limited Edition', 'Food & Refreshment', 45, 'Rotterdam-Gate', 'EMEA'),
('Dove Pro-Health Deep Moisture', 'Personal Care', 12000, 'Mumbai-Central', 'APAC'),
('Hellmanns Real Organic Mayonnaise', 'Food & Refreshment', 8000, 'London-Hub', 'EMEA');
Вставка данных о грузах
-- Shipments Generation (More shipments than products)
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT
id,
CASE
WHEN random() > 0.8 THEN 'Delayed'
WHEN random() > 0.4 THEN 'In Transit'
ELSE 'Delivered'
END,
NOW() + (random() * 10 || ' days')::interval,
(random() * 0.5 + 0.5)::decimal(3,2)
FROM products
WHERE random() > 0.3; -- Create shipments for ~70% of products
-- Add duplicate shipments for some products to show complex logistics
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT id, 'In Transit', NOW() + INTERVAL '12 days', 0.88
FROM products
LIMIT 5000;
Предоставить разрешение
Выполните указанное ниже выражение, чтобы предоставить права на выполнение функции "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Предоставьте учетной записи службы AlloyDB роль пользователя Vertex AI.
В консоли Google Cloud IAM предоставьте учетной записи службы AlloyDB (которая выглядит следующим образом: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) доступ к роли "Пользователь Vertex AI". В поле PROJECT_NUMBER будет указан номер вашего проекта.
В качестве альтернативы вы можете выполнить следующую команду в терминале Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Сгенерировать векторные представления
Далее, давайте сгенерируем векторные представления для конкретных значимых текстовых полей:
WITH
rows_to_update AS (
SELECT
id
FROM
products
WHERE
embedding IS NULL
LIMIT
5000 )
UPDATE
products
SET
embedding = ai.embedding('text-embedding-005', name || ' ' || category || ' ' || distribution_center || ' ' || region)::vector
FROM
rows_to_update
WHERE
products.id = rows_to_update.id
AND embedding IS null;
В приведенном выше запросе мы установили лимит в 5000, поэтому обязательно запускайте его многократно, пока в таблице не останется ни одной строки, в которой столбец embedding имеет значение NULL.
Подводные камни и устранение неполадок
Цикл «Забвения паролей» | Если вы использовали настройку "в один клик" и не помните свой пароль, перейдите на страницу основной информации об экземпляре в консоли и нажмите "Изменить", чтобы сбросить пароль |
Ошибка "Расширение не найдено" | Если |
Разрыв в распространении IAM | Вы выполнили команду |
Несоответствие размерности вектора | Таблица |
Опечатка в идентификаторе проекта | Если в вызове функции |
5. Подготовка инструментов и ящика для инструментов
MCP Toolbox for Databases — это сервер MCP с открытым исходным кодом для баз данных. Он позволяет разрабатывать инструменты проще, быстрее и безопаснее, обрабатывая такие сложные процессы, как пулы соединений, аутентификация и многое другое . Toolbox помогает создавать инструменты Gen AI, которые позволяют вашим агентам получать доступ к данным в вашей базе данных.
В качестве "дирижера" мы используем Model Context Protocol (MCP) Toolbox for Databases . Он выступает в роли стандартизированного промежуточного программного обеспечения между нашими агентами и AlloyDB. Определив конфигурацию tools.yaml , Toolbox автоматически предоставляет доступ к сложным операциям с базой данных в виде простых, исполняемых инструментов, таких как search_products_by_context или check_inventory_levels . Это устраняет необходимость в ручном формировании пулов соединений или шаблонном SQL-коде в логике агента.
Установка сервера Toolbox
В терминале Cloud Shell создайте папку для сохранения нового YAML-файла инструментов и исполняемого файла панели инструментов:
mkdir scm-agent-toolbox
cd scm-agent-toolbox
В новой папке выполните следующий набор команд:
# see releases page for other versions
export VERSION=0.27.0
curl -L -o toolbox https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Далее создайте файл tools.yaml внутри этой новой папки, перейдя в редактор Cloud Shell и скопировав содержимое этого файла репозитория в файл tools.yaml.
sources:
supply_chain_db:
kind: "alloydb-postgres"
project: "YOUR_PROJECT_ID"
region: "us-central1"
cluster: "YOUR_CLUSTER"
instance: "YOUR_INSTANCE"
database: "postgres"
user: "postgres"
password: "YOUR_PASSWORD"
tools:
search_products_by_context:
kind: postgres-sql
source: supply_chain_db
description: Find products in the inventory using natural language search and vector embeddings.
parameters:
- name: search_text
type: string
description: Description of the product or category the user is looking for.
statement: |
SELECT name, category, stock_level, distribution_center, region
FROM products
ORDER BY embedding <=> ai.embedding('text-embedding-005', $1)::vector
LIMIT 5;
check_inventory_levels:
kind: postgres-sql
source: supply_chain_db
description: Get precise stock levels for a specific product name.
parameters:
- name: product_name
type: string
description: The exact or partial name of the product.
statement: |
SELECT name, stock_level, distribution_center, last_updated
FROM products
WHERE name ILIKE '%' || $1 || '%'
ORDER BY stock_level DESC;
track_shipment_status:
kind: postgres-sql
source: supply_chain_db
description: Retrieve real-time logistics and shipping status for a specific region or product.
parameters:
- name: region
type: string
description: The geographical region to filter shipments (e.g., EMEA, APAC).
statement: |
SELECT p.name, s.status, s.estimated_arrival, s.route_efficiency_score
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE p.region = $1
ORDER BY s.estimated_arrival ASC;
analyze_supply_chain_risk:
kind: postgres-sql
source: supply_chain_db
description: Rerank and filter shipments based on risk profiles and efficiency scores using Google ML reranker.
parameters:
- name: risk_context
type: string
description: The business context for risk analysis (e.g., 'heatwave impact' or 'port strike').
statement: |
WITH initial_ranking AS (
SELECT s.shipment_id, p.name, s.status, p.distribution_center,
ROW_NUMBER() OVER () AS ref_number
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE s.status != 'Delivered'
LIMIT 10
),
reranked_results AS (
SELECT index, score FROM
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => $1,
documents => (SELECT ARRAY_AGG(name || ' at ' || distribution_center ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT i.name, i.status, i.distribution_center, r.score
FROM initial_ranking i, reranked_results r
WHERE i.ref_number = r.index
ORDER BY r.score DESC;
toolsets:
supply_chain_toolset:
- search_products_by_context
- check_inventory_levels
- track_shipment_status
- analyze_supply_chain_risk
Теперь протестируйте файл tools.yaml на локальном сервере:
./toolbox --tools-file "tools.yaml"
В качестве альтернативы вы можете протестировать это в пользовательском интерфейсе.
./toolbox --ui
Отлично!! Как только вы убедитесь, что всё работает, разверните приложение в Cloud Run следующим образом.
Развертывание в облаке
- Установите переменную среды PROJECT_ID:
export PROJECT_ID="my-project-id"
- Инициализация интерфейса командной строки gcloud:
gcloud init
gcloud config set project $PROJECT_ID
- Для корректной работы необходимо включить следующие API:
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Если у вас его еще нет, создайте учетную запись для бэкэнд-сервиса:
gcloud iam service-accounts create toolbox-identity
- Предоставьте разрешение на использование менеджера секретов:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
- Предоставьте учетной записи службы дополнительные разрешения, специфичные для нашего источника AlloyDB (roles/alloydb.client и roles/serviceusage.serviceUsageConsumer).
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role serviceusage.serviceUsageConsumer
- Загрузите файл tools.yaml в качестве секретного ключа:
gcloud secrets create tools-scm-agent --data-file=tools.yaml
- Если у вас уже есть секретный ключ и вы хотите обновить его версию, выполните следующие действия:
gcloud secrets versions add tools-scm-agent --data-file=tools.yaml
- Установите переменную среды, указывающую на образ контейнера, который вы хотите использовать для Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Разверните Toolbox в Cloud Run, используя следующую команду:
Если вы включили публичный доступ к своему экземпляру AlloyDB (не рекомендуется), выполните следующую команду для развертывания в Cloud Run:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
Если вы используете сеть VPC , воспользуйтесь приведенной ниже командой:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
# TODO(dev): update the following to match your VPC details
--network <<YOUR_NETWORK_NAME>> \
--subnet <<YOUR_SUBNET_NAME>> \
--allow-unauthenticated
6. Настройка агента
Используя комплект разработки агентов (ADK) , мы отошли от монолитных систем запросов к специализированной многоагентной архитектуре:
- Специалист по инвентаризации : специализируется на учете товарных запасов и складских показателях.
- Менеджер по логистике : эксперт в области глобальных морских маршрутов и анализа рисков.
- GlobalOrchestrator : «мозг», который использует логическое мышление для распределения задач и обобщения результатов.
Клонируйте этот репозиторий в свой проект, и давайте разберемся.
Чтобы клонировать этот проект, в терминале Cloud Shell (в корневом каталоге или в любом другом месте, где вы хотите его создать) выполните следующую команду:
git clone https://github.com/AbiramiSukumaran/scm-memory-agent
- Это должно создать проект, и вы можете проверить это в редакторе Cloud Shell.

- Обязательно обновите файл .env, указав значения для вашего проекта и экземпляра.
Пошаговое руководство по коду
Краткий обзор агента Orchestrator
Go to app.py and you should be able to see the following snippet:
orchestrator = adk.Agent(
name="GlobalOrchestrator",
model="gemini-2.5-flash",
description="Global Supply Chain Orchestrator root agent.",
instruction="""
You are the Global Supply Chain Brain. You are responsible for products, inventory and logistics.
You also have access to the memory tool, remember to include all the information that the tool can provide you with about the user before you respond.
1. Understand intent and delegate to specialists. As the Global Orchestrator, you have access to the full conversation history with the user.
When you transfer a query to a specialist agent, sub agent or tool, share the important facts and information from your memory to them so they can operate with the full context.
2. Ensure the final response is professional and uses Markdown tables for data.
3. If a specialist provides a long list, ensure only the top 10 items are shown initially.
4. Conclude with a brief, high-level executive summary of what the data implies.
""",
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
sub_agents=[inventory_agent, logistics_agent],
#after_agent_callback=auto_save_session_to_memory_callback,
)
Этот фрагмент кода определяет корневой объект, который является агентом-оркестратором, получающим диалог или запрос от пользователя и направляющим соответствующие инструменты подагенту или пользователю в зависимости от задачи.
- Давайте рассмотрим агента по учету запасов.
inventory_agent = adk.Agent(
name="InventorySpecialist",
model="gemini-2.5-flash",
description="Specialist in product stock and warehouse data.",
instruction="""
Analyze inventory levels.
1. Use 'search_products_by_context' or 'check_inventory_levels'.
2. ALWAYS format results as a clean Markdown table.
3. If there are many results, display only the TOP 10 most relevant ones.
4. At the end, state: 'There are additional records available. Would you like to see more?'
""",
tools=tools
)
Этот конкретный субагент специализируется на операциях с запасами, таких как контекстный поиск товаров, а также проверка уровня запасов.
- Затем есть еще суб-агент по логистике:
logistics_agent = adk.Agent(
name="LogisticsManager",
model="gemini-2.5-flash",
description="Expert in global shipping routes and logistics tracking.",
instruction="""
Check shipment statuses.
1. Use 'track_shipment_status' or 'analyze_supply_chain_risk'.
2. ALWAYS format results as a clean Markdown table.
3. Limit initial output to the top 10 shipments.
4. Ask if the user needs the full manifest if more results exist.
""",
tools=tools
)
Данный субагент специализируется на логистических операциях, таких как отслеживание грузов и анализ рисков в цепочке поставок.
- Все 3 агента, которые мы обсуждали до сих пор, используют инструменты, и эти инструменты доступны через наш сервер Toolbox, который мы уже развернули в предыдущем разделе. См. фрагмент кода ниже:
from toolbox_core import ToolboxSyncClient
TOOLBOX_SERVER = os.environ["TOOLBOX_SERVER"]
TOOLBOX_TOOLSET = os.environ["TOOLBOX_TOOLSET"]
# --- ADK TOOLBOX CONFIGURATION ---
toolbox = ToolboxSyncClient(TOOLBOX_SERVER)
tools = toolbox.load_toolset(TOOLBOX_TOOLSET)
Данный субагент специализируется на логистических операциях, таких как отслеживание грузов и анализ рисков в цепочке поставок.
7. Агентский движок
При первом запуске создайте Agent Engine.
import vertexai
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
client = vertexai.Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_LOCATION
)
agent_engine = client.agent_engines.create()
- Для следующего запуска обновите конфигурацию банка памяти в Agent Engine:
agent_engine = client.agent_engines.update(
name=APP_NAME,
config={
"context_spec": {
"memory_bank_config": {
"generation_config": {
"model": f"projects/{PROJECT_ID}/locations/{GOOGLE_CLOUD_LOCATION}/publishers/google/models/gemini-2.5-flash"
}
}
}
})
8. Контекст, выполнение и память
Управление контекстом разделено на два отдельных уровня, чтобы агент воспринимался как постоянный партнер, а не как бот без сохранения состояния:
Кратковременная память (сессии) : управляется через VertexAiSessionService и отслеживает историю событий (сообщения пользователей, ответы инструментов) в рамках одного взаимодействия.
Долговременная память (банк памяти) : работает на основе банка памяти Vertex AI через adk.memorybankservice . Этот слой извлекает «значимую» информацию — например, предпочтения пользователя в отношении конкретных транспортных компаний или повторяющиеся задержки на складе — и сохраняет ее между сессиями.
Инициализация сессии для использования памяти сессии в рамках диалога.
Это та часть фрагмента кода, которая создает сессию для текущего приложения для текущего пользователя.
from google.adk.sessions import VertexAiSessionService
...
session_service = VertexAiSessionService(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
...
# Initialize the session *outside* of the route handler to avoid repeated creation
session = None
session_lock = threading.Lock()
async def initialize_session():
global session
try:
session = await session_service.create_session(app_name=APP_NAME, user_id=USER_ID)
print(f"Session {session.id} created successfully.") # Add a log
except Exception as e:
print(f"Error creating session: {e}")
session = None # Ensure session is None in case of error
# Create the session on app startup
asyncio.run(initialize_session())
Инициализация банка памяти Vertex AI для долговременной памяти.
Это та часть фрагмента кода, которая создает экземпляр объекта Vertex AI Memory Bank Service для агентского движка.
from google.adk.memory import InMemoryMemoryService
from google.adk.memory import VertexAiMemoryBankService
...
try:
memory_bank_service = adk.memory.VertexAiMemoryBankService(
agent_engine_id=AGENT_ENGINE_ID,
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
#in_memory_service = InMemoryMemoryService()
print("Memory Bank Service initialized successfully.")
except Exception as e:
print(f"Error initializing Memory Bank Service: {e}")
memory_bank_service = None
runner = adk.Runner(
agent=orchestrator,
app_name=APP_NAME,
session_service=session_service,
memory_service=memory_bank_service,
)
...
Что настроено?
В этой части фрагмента кода мы настраиваем службу Vertex AI Memory Bank Service для долговременной памяти. Она контекстно сохраняет сессию для конкретного приложения для конкретного пользователя в виде памяти внутри банка памяти Vertex AI.
Что выполняется в рамках запуска агента?
async def run_and_collect():
final_text = ""
try:
async for event in runner.run_async(
new_message=content,
user_id=user_id,
session_id=session_id
):
if hasattr(event, 'author') and event.author:
if not any(log['agent'] == event.author for log in execution_logs):
execution_logs.append({
"agent": event.author,
"action": "Analyzing data requirements...",
"type": "orchestration_event"
})
if hasattr(event, 'text') and event.text:
final_text = event.text
elif hasattr(event, 'content') and hasattr(event.content, 'parts'):
for part in event.content.parts:
if hasattr(part, 'text') and part.text:
final_text = part.text
except Exception as e:
print(f"Error during runner.run_async: {e}")
raise # Re-raise the exception to signal failure
finally:
gc.collect()
return final_text
Он обрабатывает введенные пользователем данные и сохраняет их в объекте new_message, в область видимости которого входят идентификатор пользователя и идентификатор сессии. Затем управление переходит к агенту, который обрабатывает и возвращает ответ.
Что хранится в долговременной памяти?
Подробная информация о сессии в рамках приложения и пользователя извлекается в переменную сессии.
Затем эта сессия добавляется в память текущего пользователя для текущего приложения объекта Vertex AI Memory Bank с помощью метода " add_session_to_memory ".
session = asyncio.run(session_service.get_session(app_name=APP_NAME, user_id=USER_ID, session_id=session.id))
if memory_bank_service and session: # Check memory service AND session
try:
#asyncio.run(in_memory_service.add_session_to_memory(session))
asyncio.run(memory_bank_service.add_session_to_memory(session))
'''
client.agent_engines.memories.generate(
scope={"app_name": APP_NAME, "user_id": USER_ID},
name=APP_NAME,
direct_contents_source={
"events": [
{"content": content}
]
},
config={"wait_for_completion": True},
)
'''
print("Successfully added session to memory.******")
print(session.id)
except Exception as e:
print(f"Error adding session to memory: {e}")
Извлечение памяти
Нам необходимо получить доступ к сохраненной долговременной памяти, используя имя приложения и имя пользователя в качестве области видимости (поскольку именно в этой области видимости мы хранили воспоминания), чтобы иметь возможность передать ее в составе контекста оркестратору и другим агентам, если это необходимо.
results = client.agent_engines.memories.retrieve(
name=APP_NAME,
scope={"app_name": APP_NAME, "user_id": USER_ID}
)
# RetrieveMemories returns a pager. You can use `list` to retrieve all pages' memories.
list(results)
print(list(results))
Как извлеченная память загружается в контекст?
В определении агента Orchestrator мы используем следующий атрибут, который позволяет корневому агенту предварительно загружать контекст из банка памяти. Это в дополнение к инструментам, к которым мы получаем доступ с сервера Toolbox для дочерних агентов.
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
Контекст обратного вызова
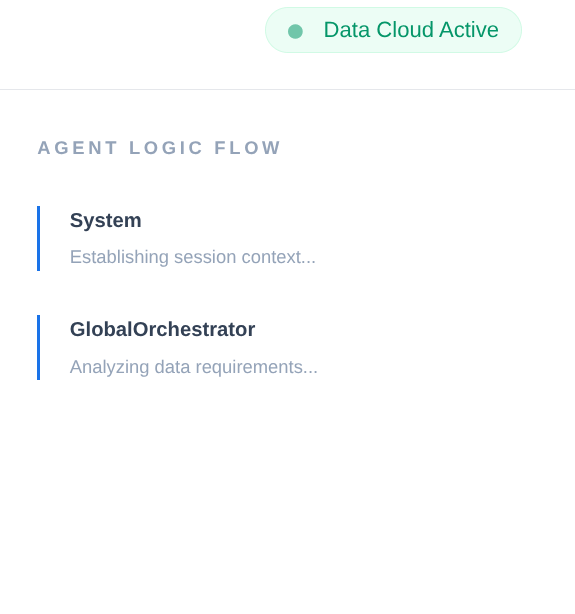
В корпоративной цепочке поставок недопустим «черный ящик». Мы используем CallbackContext из ADK для создания механизма повествования. Подключаясь к выполнению агента, мы фиксируем каждый мыслительный процесс и вызов инструмента, передавая их в боковую панель пользовательского интерфейса.
- Событие трассировки : "GlobalOrchestrator анализирует требования к данным..."
- Событие отслеживания : «Передача полномочий специалисту по инвентаризации для определения уровня запасов...»
- Событие трассировки : «Извлечение исторических данных о задержках поставщиков из базы данных памяти...»
Этот журнал аудита бесценен для отладки и гарантирует, что операторы-люди могут доверять автономным решениям агента.
from google.adk.agents.callback_context import CallbackContext
...
# --- ADK CALLBACKS (Narrative Engine) ---
execution_logs = []
async def trace_callback(context: CallbackContext):
"""
Captures agent and tool invocation flow for the UI narrative.
"""
agent_name = context.agent.name
event = {
"agent": agent_name,
"action": "Processing request steps...",
"type": "orchestration_event"
}
execution_logs.append(event)
return None
...
Вот и всё!!! Мы успешно клонировали проект и подробно рассмотрели работу агента, памяти и контекста.
Вы можете проверить это, перейдя в папку проекта клонированного репозитория и выполнив следующие команды:
>> pip install -r requirements.txt
>> python app.py
Это должно запустить ваш агент локально, и вы сможете его протестировать.
9. Давайте развернем его в Cloud Run.
- Разверните проект в Cloud Run, выполнив следующую команду в терминале Cloud Shell, куда клонирован проект, и убедитесь, что вы находитесь в корневой папке проекта .
Выполните следующую команду в терминале Cloud Shell:
gcloud run deploy supply-chain-agent --source . --platform managed --region us-central1 --allow-unauthenticated --set-env-vars GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT>>,GOOGLE_CLOUD_LOCATION=us-central1,GOOGLE_GENAI_USE_VERTEXAI=TRUE,REASONING_ENGINE_APP_NAME=<<YOUR_APP_ENGINE_URL>>,TOOLBOX_SERVER=<<YOUR_TOOLBOX_SERVER>>,TOOLBOX_TOOLSET=supply_chain_toolset,AGENT_ENGINE_ID=<<YOUR_AGENT_ENGINE_ID>>
Замените значения для заполнителей <<YOUR_PROJECT>>, <<YOUR_APP_ENGINE_URL>>, <<YOUR_TOOLBOX_SERVER>> и <<YOUR_AGENT_ENGINE_ID>>
После завершения выполнения команды она выведет URL-адрес сервиса. Скопируйте его.
- Предоставьте учетной записи службы Cloud Run роль клиента AlloyDB. Это позволит вашему бессерверному приложению безопасно подключаться к базе данных через туннель.
Выполните следующую команду в терминале Cloud Shell:
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
Теперь воспользуйтесь URL-адресом сервиса (конечной точкой Cloud Run, которую вы скопировали ранее) и протестируйте приложение.
Примечание: Если вы столкнулись с проблемой в работе сервиса, и в качестве причины указана нехватка памяти, попробуйте увеличить лимит выделенной памяти до 1 ГБ для проверки.
10. Уборка
После завершения этой лабораторной работы не забудьте удалить кластер и экземпляр AlloyDB.
Это должно привести к очистке кластера вместе с его экземплярами.
11. Поздравляем!
Объединив скорость AlloyDB , эффективность оркестрации MCP Toolbox и «институциональную память» Vertex AI Memory Bank , мы создали систему управления цепочкой поставок, которая развивается. Она не просто отвечает на вопросы; она помнит, что ваш склад в Сингапуре постоянно сталкивается с задержками, связанными с сезоном дождей, и заблаговременно предлагает перенаправить поставки еще до того, как вы об этом попросите.