
1. ภาพรวม
ใน Codelab นี้ คุณจะได้สร้างเอเจนต์ Supply Chain Orchestrator แอปพลิเคชันนี้ช่วยให้ผู้ใช้สามารถวิเคราะห์สินค้าคงคลัง ติดตามโลจิสติกส์ และจัดการความเสี่ยงในซัพพลายเชนโดยใช้ภาษาที่เป็นธรรมชาติ
เราจะใช้ประโยชน์จาก Agent Development Kit (ADK) ของ Google เพื่อสร้างสถาปัตยกรรมแบบหลาย Agent ที่รักษาบริบท จดจำค่ากำหนดของผู้ใช้ผ่าน Vertex AI Memory Bank และโต้ตอบกับชุดข้อมูลขนาดใหญ่ที่จัดเก็บไว้ใน AlloyDB ผ่าน MCP Toolbox
สิ่งที่คุณจะสร้าง
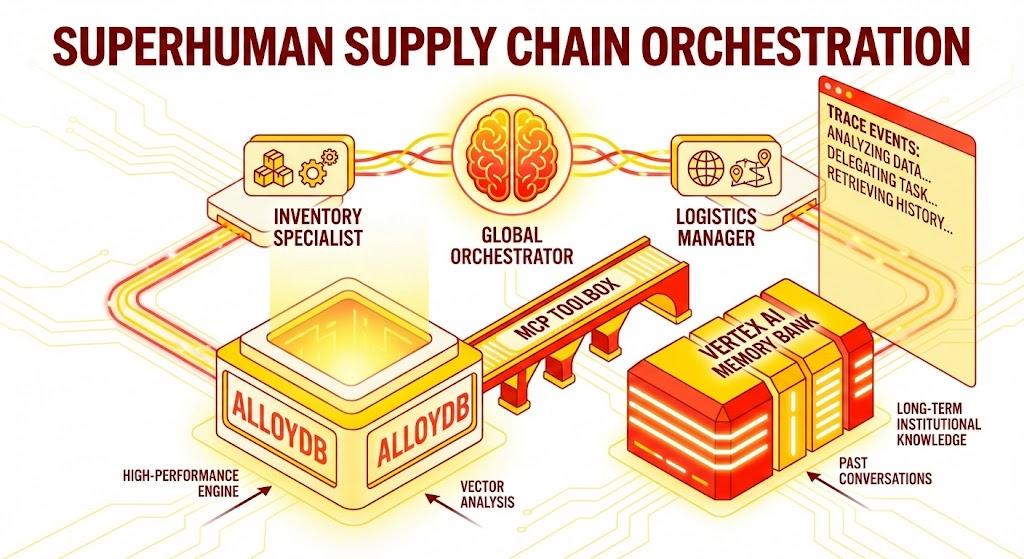
แอปพลิเคชัน Python Flask ซึ่งประกอบด้วย
Global Orchestrator Agent: เอเจนต์รูทที่จัดการโฟลว์การสนทนาและการมอบหมาย
ตัวแทนผู้เชี่ยวชาญ: "InventorySpecialist" และ "LogisticsManager" สำหรับงานที่เจาะจงโดเมน
การผสานรวมหน่วยความจำ: หน่วยความจำเซสชันระยะสั้นและหน่วยความจำระยะยาวโดยใช้ Vertex AI Memory Bank
UI แบบบรรยาย: อินเทอร์เฟซเว็บที่แสดงกระบวนการให้เหตุผลของ Agent (บริบทการติดตาม)
สิ่งที่คุณจะได้เรียนรู้
- วิธีใช้ Google ADK เพื่อสร้างเอเจนต์และเอเจนต์ย่อยเฉพาะทาง
- วิธีผสานรวม Vertex AI Memory Bank สำหรับหน่วยความจำของเอเจนต์ในระยะยาว
- วิธีใช้ MCP Toolbox เพื่อเชื่อมต่อ Agent กับเครื่องมือข้อมูล AlloyDB
- วิธีใช้การเรียกกลับของ ADK เพื่อติดตามและแสดงภาพการให้เหตุผลของเอเจนต์
- วิธีการทำให้โซลูชันใช้งานได้โดยใช้ Cloud Run หรือดำเนินการในเครื่อง
สถาปัตยกรรม
The Tech Stack
- AlloyDB สำหรับ PostgreSQL: ทำหน้าที่เป็นฐานข้อมูลด้านการดำเนินงานที่มีประสิทธิภาพสูงซึ่งมีบันทึกซัพพลายเชนกว่า 50,000 รายการ ซึ่งขับเคลื่อนการค้นหาและการดึงข้อมูลเวกเตอร์
- MCP Toolbox สำหรับฐานข้อมูล: ทำหน้าที่เป็น "Orchestration Maestro" โดยแสดงข้อมูล AlloyDB เป็นเครื่องมือที่เรียกใช้งานได้ซึ่ง Agent สามารถเรียกใช้ได้
- Agent Development Kit (ADK): เฟรมเวิร์กที่ใช้กำหนดเอเจนต์ คำสั่ง และเครื่องมือ
- คลังความทรงจำของ Vertex AI: ให้ความทรงจำระยะยาว ซึ่งช่วยให้เอเจนต์จดจำค่ากำหนดของผู้ใช้และการโต้ตอบที่ผ่านมาในเซสชันต่างๆ ได้
- บริการเซสชัน Vertex AI: จัดการบริบทการสนทนาระยะสั้น
The Flow
- คำค้นหาของผู้ใช้: ผู้ใช้ถามคำถาม (เช่น "ตรวจสอบสต็อกไอศกรีมพรีเมียม")
- การตรวจสอบหน่วยความจำ: Orchestrator จะตรวจสอบคลังหน่วยความจำเพื่อหาข้อมูลที่เกี่ยวข้องในอดีต (เช่น "ผู้ใช้เป็นผู้จัดการระดับภูมิภาคของ EMEA")
- การมอบหมาย: Orchestrator มอบหมายงานให้ InventorySpecialist
- การดำเนินการเครื่องมือ: ผู้เชี่ยวชาญใช้เครื่องมือที่ MCP Toolbox จัดเตรียมไว้เพื่อค้นหา AlloyDB
- คำตอบ: เอเจนต์จะประมวลผลข้อมูลและแสดงผลตารางที่จัดรูปแบบ Markdown
- ที่เก็บความทรงจำ: ระบบจะบันทึกการโต้ตอบที่สำคัญกลับไปที่ธนาคารความทรงจำ
ข้อกำหนด
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธีตรวจสอบว่าโปรเจ็กต์เปิดใช้การเรียกเก็บเงินหรือไม่
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์โดยใช้คำสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คำสั่งต่อไปนี้เพื่อตั้งค่า
gcloud config set project <YOUR_PROJECT_ID>
- เปิดใช้ API ที่จำเป็น: ทำตามลิงก์และเปิดใช้ API
หรือจะใช้คำสั่ง gcloud สำหรับการดำเนินการนี้ก็ได้ โปรดดูคำสั่งและการใช้งาน gcloud ในเอกสารประกอบ
ข้อควรระวังและการแก้ปัญหา
กลุ่มอาการ"โปรเจ็กต์ผี" | คุณเรียกใช้ |
แผงกั้น การเรียกเก็บเงิน | คุณเปิดใช้โปรเจ็กต์แล้ว แต่ลืมบัญชีสำหรับการเรียกเก็บเงิน AlloyDB เป็นเครื่องมือที่มีประสิทธิภาพสูง จึงจะไม่เริ่มทำงานหาก "ถังน้ำมัน" (การเรียกเก็บเงิน) ว่างเปล่า |
ความล่าช้าการเผยแพร่ API | คุณคลิก "เปิดใช้ API" แต่บรรทัดคำสั่งยังคงแสดง |
คำถามที่พบบ่อยเกี่ยวกับโควต้า | หากใช้บัญชีทดลองใช้ใหม่ คุณอาจพบโควต้าระดับภูมิภาคสำหรับอินสแตนซ์ AlloyDB หาก |
ตัวแทนบริการ"ซ่อน" | บางครั้งระบบไม่ได้มอบบทบาท |
3. การตั้งค่าฐานข้อมูล
หัวใจสำคัญของแอปพลิเคชันของเราคือ AlloyDB สำหรับ PostgreSQL เราใช้ประโยชน์จากความสามารถด้านเวกเตอร์ที่มีประสิทธิภาพและผสานรวมเครื่องมือแบบคอลัมน์เพื่อสร้างการฝังสำหรับบันทึก SCM กว่า 50,000 รายการ ซึ่งช่วยให้วิเคราะห์เวกเตอร์แบบเกือบเรียลไทม์ได้ ทำให้ตัวแทนของเราสามารถระบุความผิดปกติของสินค้าคงคลังหรือความเสี่ยงด้านลอจิสติกส์ในชุดข้อมูลขนาดใหญ่ได้ในเวลาไม่กี่มิลลิวินาที
ในแล็บนี้ เราจะใช้ AlloyDB เป็นฐานข้อมูลสำหรับข้อมูลทดสอบ โดยจะใช้คลัสเตอร์เพื่อจัดเก็บทรัพยากรทั้งหมด เช่น ฐานข้อมูลและบันทึก แต่ละคลัสเตอร์มีอินสแตนซ์หลักที่ให้จุดเข้าใช้งานข้อมูล ตารางจะเก็บข้อมูลจริง
มาสร้างคลัสเตอร์ อินสแตนซ์ และตาราง AlloyDB ที่จะโหลดชุดข้อมูลทดสอบกัน
- คลิกปุ่มหรือคัดลอกลิงก์ด้านล่างไปยังเบราว์เซอร์ที่คุณเข้าสู่ระบบผู้ใช้คอนโซล Google Cloud
หรือคุณสามารถไปที่เทอร์มินัล Cloud Shell จากโปรเจ็กต์ที่คุณแลกรับบัญชีสำหรับการเรียกเก็บเงิน และโคลนที่เก็บ GitHub แล้วไปยังโปรเจ็กต์โดยใช้คำสั่งด้านล่าง
git clone https://github.com/AbiramiSukumaran/easy-alloydb-setup
cd easy-alloydb-setup
- เมื่อทำขั้นตอนนี้เสร็จแล้ว ระบบจะโคลนที่เก็บไปยังโปรแกรมแก้ไข Cloud Shell ในเครื่อง และคุณจะเรียกใช้คำสั่งด้านล่างจากโฟลเดอร์โปรเจ็กต์ได้ (โปรดตรวจสอบว่าคุณอยู่ในไดเรกทอรีโปรเจ็กต์)
sh run.sh
- ตอนนี้ให้ใช้ UI (คลิกลิงก์ในเทอร์มินัลหรือคลิกลิงก์ "แสดงตัวอย่างบนเว็บ" ในเทอร์มินัล
- ป้อนรายละเอียดสำหรับรหัสโปรเจ็กต์ ชื่อคลัสเตอร์ และชื่ออินสแตนซ์เพื่อเริ่มต้นใช้งาน
- ไปหาเครื่องดื่มมาจิบระหว่างที่บันทึกเลื่อนไปเรื่อยๆ และคุณสามารถอ่านเกี่ยวกับวิธีที่ระบบดำเนินการนี้เบื้องหลังได้ที่นี่
ข้อควรระวังและการแก้ปัญหา
ปัญหาเรื่อง "ความอดทน" | คลัสเตอร์ฐานข้อมูลเป็นโครงสร้างพื้นฐานที่มีขนาดใหญ่ หากรีเฟรชหน้าเว็บหรือปิดเซสชัน Cloud Shell เนื่องจาก "ดูเหมือนว่าค้างอยู่" คุณอาจมีอินสแตนซ์ "ผี" ที่มีการจัดสรรบางส่วนและลบไม่ได้หากไม่ดำเนินการด้วยตนเอง |
ภูมิภาคไม่ตรงกัน | หากเปิดใช้ API ใน |
คลัสเตอร์ซอมบี้ | หากก่อนหน้านี้คุณใช้ชื่อเดียวกันสำหรับคลัสเตอร์และไม่ได้ลบคลัสเตอร์ออก สคริปต์อาจแจ้งว่ามีชื่อคลัสเตอร์อยู่แล้ว ชื่อคลัสเตอร์ต้องไม่ซ้ำกันภายในโปรเจ็กต์ |
การหมดเวลาของ Cloud Shell | หากคุณพักดื่มกาแฟเป็นเวลา 30 นาที Cloud Shell อาจเข้าสู่โหมดสลีปและยกเลิกการเชื่อมต่อกระบวนการ |
4. การจัดสรรสคีมา
เมื่อคลัสเตอร์และอินสแตนซ์ AlloyDB ทำงานแล้ว ให้ไปที่เครื่องมือแก้ไข SQL ของ AlloyDB Studio เพื่อเปิดใช้ส่วนขยาย AI และจัดสรรสคีมา
คุณอาจต้องรอให้อินสแตนซ์สร้างเสร็จ เมื่อพร้อมแล้ว ให้ลงชื่อเข้าใช้ AlloyDB โดยใช้ข้อมูลเข้าสู่ระบบที่คุณสร้างขึ้นเมื่อสร้างคลัสเตอร์ ใช้ข้อมูลต่อไปนี้เพื่อตรวจสอบสิทธิ์ใน PostgreSQL
- ชื่อผู้ใช้ : "
postgres" - ฐานข้อมูล : "
postgres" - รหัสผ่าน : "
alloydb" (หรือรหัสผ่านที่คุณตั้งค่าไว้ตอนสร้าง)
เมื่อตรวจสอบสิทธิ์เข้าสู่ AlloyDB Studio สำเร็จแล้ว ให้ป้อนคำสั่ง SQL ในเอดิเตอร์ คุณเพิ่มหน้าต่างเอดิเตอร์หลายหน้าต่างได้โดยใช้เครื่องหมายบวกทางด้านขวาของหน้าต่างสุดท้าย
คุณจะป้อนคำสั่งสำหรับ AlloyDB ในหน้าต่างเอดิเตอร์ โดยใช้ตัวเลือกเรียกใช้ จัดรูปแบบ และล้างตามที่จำเป็น
เปิดใช้ส่วนขยาย
ในการสร้างแอปนี้ เราจะใช้ส่วนขยาย pgvector และ google_ml_integration ส่วนขยาย pgvector ช่วยให้คุณจัดเก็บและค้นหาการฝังเวกเตอร์ได้ ส่วนขยาย google_ml_integration มีฟังก์ชันที่คุณใช้เพื่อเข้าถึงปลายทางการคาดการณ์ของ Vertex AI เพื่อรับการคาดการณ์ใน SQL เปิดใช้ส่วนขยายเหล่านี้โดยเรียกใช้ DDL ต่อไปนี้
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
สร้างตาราง
คุณสร้างตารางได้โดยใช้คำสั่ง DDL ด้านล่างใน AlloyDB Studio
DROP TABLE IF EXISTS shipments;
DROP TABLE IF EXISTS products;
-- 1. Product Inventory Table
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
category VARCHAR(100),
stock_level INTEGER,
distribution_center VARCHAR(100),
region VARCHAR(50),
embedding vector(768),
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. Logistics & Shipments
CREATE TABLE shipments (
shipment_id SERIAL PRIMARY KEY,
product_id INTEGER REFERENCES products(id),
status VARCHAR(50), -- 'In Transit', 'Delayed', 'Delivered', 'Pending'
estimated_arrival TIMESTAMP,
route_efficiency_score DECIMAL(3, 2)
);
คอลัมน์ embedding จะอนุญาตให้จัดเก็บค่าเวกเตอร์ของช่องข้อความบางช่อง
การนำเข้าข้อมูล
เรียกใช้ชุดคำสั่ง SQL ด้านล่างเพื่อแทรกระเบียน 50000 รายการในตารางผลิตภัณฑ์พร้อมกัน
-- We use a CROSS JOIN pattern with realistic naming segments to create meaningful variety
DO $$
DECLARE
brand_names TEXT[] := ARRAY['Artisan', 'Nature', 'Elite', 'Pure', 'Global', 'Eco', 'Velocity', 'Heritage', 'Aura', 'Summit'];
product_types TEXT[] := ARRAY['Ice Cream', 'Body Wash', 'Laundry Detergent', 'Shampoo', 'Mayonnaise', 'Deodorant', 'Tea', 'Soup', 'Face Cream', 'Soap'];
variants TEXT[] := ARRAY['Classic', 'Gold', 'Premium', 'Eco-Friendly', 'Organic', 'Night-Repair', 'Extra-Fresh', 'Zero-Sugar', 'Sensitive', 'Maximum-Strength'];
regions TEXT[] := ARRAY['EMEA', 'APAC', 'LATAM', 'NAMER'];
dcs TEXT[] := ARRAY['London-Hub', 'Mumbai-Central', 'Sao-Paulo-Logistics', 'Singapore-Port', 'Rotterdam-Gate', 'New-York-DC'];
BEGIN
INSERT INTO products (name, category, stock_level, distribution_center, region)
SELECT
b || ' ' || v || ' ' || t as name,
CASE
WHEN t IN ('Ice Cream', 'Mayonnaise', 'Tea', 'Soup') THEN 'Food & Refreshment'
WHEN t IN ('Body Wash', 'Shampoo', 'Deodorant', 'Face Cream', 'Soap') THEN 'Personal Care'
ELSE 'Home Care'
END as category,
floor(random() * 20000 + 100)::int as stock_level,
dcs[floor(random() * 6 + 1)] as distribution_center,
regions[floor(random() * 4 + 1)] as region
FROM
unnest(brand_names) b,
unnest(variants) v,
unnest(product_types) t,
generate_series(1, 50); -- 10 * 10 * 10 * 50 = 50,000 records
END $$;
มาแทรกเรคคอร์ดเฉพาะการสาธิตเพื่อให้มั่นใจว่าคำตอบสำหรับคำถามสไตล์ผู้บริหารจะคาดการณ์ได้
-- These ensure you have predictable answers for specific "Executive" questions
INSERT INTO products (name, category, stock_level, distribution_center, region) VALUES
('Magnum Ultra Gold Limited Edition', 'Food & Refreshment', 45, 'Rotterdam-Gate', 'EMEA'),
('Dove Pro-Health Deep Moisture', 'Personal Care', 12000, 'Mumbai-Central', 'APAC'),
('Hellmanns Real Organic Mayonnaise', 'Food & Refreshment', 8000, 'London-Hub', 'EMEA');
การแทรกข้อมูลการจัดส่ง
-- Shipments Generation (More shipments than products)
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT
id,
CASE
WHEN random() > 0.8 THEN 'Delayed'
WHEN random() > 0.4 THEN 'In Transit'
ELSE 'Delivered'
END,
NOW() + (random() * 10 || ' days')::interval,
(random() * 0.5 + 0.5)::decimal(3,2)
FROM products
WHERE random() > 0.3; -- Create shipments for ~70% of products
-- Add duplicate shipments for some products to show complex logistics
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT id, 'In Transit', NOW() + INTERVAL '12 days', 0.88
FROM products
LIMIT 5000;
ให้สิทธิ์
เรียกใช้คำสั่งด้านล่างเพื่อให้สิทธิ์ดำเนินการในฟังก์ชัน "ฝัง"
GRANT EXECUTE ON FUNCTION embedding TO postgres;
มอบบทบาทผู้ใช้ Vertex AI ให้กับบัญชีบริการ AlloyDB
จากคอนโซล Google Cloud IAM ให้สิทธิ์เข้าถึงบทบาท "ผู้ใช้ Vertex AI" แก่บัญชีบริการ AlloyDB (ซึ่งมีลักษณะดังนี้ service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com) PROJECT_NUMBER จะมีหมายเลขโปรเจ็กต์ของคุณ
หรือคุณอาจเรียกใช้คำสั่งด้านล่างจากเทอร์มินัล Cloud Shell ก็ได้
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
สร้างการฝัง
จากนั้นมาสร้างการฝังเวกเตอร์สำหรับฟิลด์ข้อความที่มีความหมายเฉพาะกัน
WITH
rows_to_update AS (
SELECT
id
FROM
products
WHERE
embedding IS NULL
LIMIT
5000 )
UPDATE
products
SET
embedding = ai.embedding('text-embedding-005', name || ' ' || category || ' ' || distribution_center || ' ' || region)::vector
FROM
rows_to_update
WHERE
products.id = rows_to_update.id
AND embedding IS null;
ในคำสั่งด้านบน เราได้กำหนดขีดจำกัดเป็น 5,000 ดังนั้นโปรดดำเนินการซ้ำๆ จนกว่าจะไม่มีแถวในตารางที่มีการฝังคอลัมน์เป็น NULL
ข้อควรระวังและการแก้ปัญหา
วงจร "ลืมรหัสผ่าน" | หากคุณใช้การตั้งค่า "คลิกเดียว" และจำรหัสผ่านไม่ได้ ให้ไปที่หน้าข้อมูลพื้นฐานของอินสแตนซ์ในคอนโซล แล้วคลิก "แก้ไข" เพื่อรีเซ็ตรหัสผ่าน |
ข้อผิดพลาด "ไม่พบส่วนขยาย" | หาก |
ช่องว่างในการเผยแพร่ IAM | คุณเรียกใช้ |
มิติข้อมูลเวกเตอร์ไม่ตรงกัน | ตั้งค่าตาราง |
พิมพ์รหัสโปรเจ็กต์ผิด | ใน |
5. การตั้งค่าเครื่องมือและกล่องเครื่องมือ
MCP Toolbox สำหรับฐานข้อมูลคือเซิร์ฟเวอร์ MCP แบบโอเพนซอร์สสำหรับฐานข้อมูล ซึ่งช่วยให้คุณพัฒนาเครื่องมือได้ง่ายขึ้น เร็วขึ้น และปลอดภัยยิ่งขึ้นด้วยการจัดการความซับซ้อนต่างๆ เช่น การจัดกลุ่มการเชื่อมต่อ การตรวจสอบสิทธิ์ และอื่นๆ กล่องเครื่องมือช่วยคุณสร้างเครื่องมือ Gen AI ที่ช่วยให้เอเจนต์เข้าถึงข้อมูลในฐานข้อมูลได้
เราใช้ Model Context Protocol (MCP) Toolbox สำหรับฐานข้อมูลเป็น "ตัวนำ" โดยทำหน้าที่เป็นมิดเดิลแวร์มาตรฐานระหว่างเอเจนต์กับ AlloyDB การกำหนดtools.yamlการกำหนดค่าทำให้กล่องเครื่องมือแสดงการดำเนินการฐานข้อมูลที่ซับซ้อนโดยอัตโนมัติเป็นเครื่องมือที่สะอาดและเรียกใช้งานได้ เช่น search_products_by_context หรือ check_inventory_levels ซึ่งจะช่วยให้ไม่ต้องใช้การจัดกลุ่มการเชื่อมต่อด้วยตนเองหรือ SQL แบบ Boilerplate ภายในตรรกะของเอเจนต์
การติดตั้งเซิร์ฟเวอร์กล่องเครื่องมือ
จากเทอร์มินัล Cloud Shell ให้สร้างโฟลเดอร์เพื่อบันทึกไฟล์ YAML ของเครื่องมือใหม่และไบนารีของกล่องเครื่องมือ
mkdir scm-agent-toolbox
cd scm-agent-toolbox
จากภายในโฟลเดอร์ใหม่ ให้เรียกใช้ชุดคำสั่งต่อไปนี้
# see releases page for other versions
export VERSION=0.27.0
curl -L -o toolbox https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
จากนั้นสร้างไฟล์ tools.yaml ภายในโฟลเดอร์ใหม่นั้นโดยไปที่ Cloud Shell Editor แล้วคัดลอกเนื้อหาของไฟล์ในที่เก็บนี้ลงในไฟล์ tools.yaml
sources:
supply_chain_db:
kind: "alloydb-postgres"
project: "YOUR_PROJECT_ID"
region: "us-central1"
cluster: "YOUR_CLUSTER"
instance: "YOUR_INSTANCE"
database: "postgres"
user: "postgres"
password: "YOUR_PASSWORD"
tools:
search_products_by_context:
kind: postgres-sql
source: supply_chain_db
description: Find products in the inventory using natural language search and vector embeddings.
parameters:
- name: search_text
type: string
description: Description of the product or category the user is looking for.
statement: |
SELECT name, category, stock_level, distribution_center, region
FROM products
ORDER BY embedding <=> ai.embedding('text-embedding-005', $1)::vector
LIMIT 5;
check_inventory_levels:
kind: postgres-sql
source: supply_chain_db
description: Get precise stock levels for a specific product name.
parameters:
- name: product_name
type: string
description: The exact or partial name of the product.
statement: |
SELECT name, stock_level, distribution_center, last_updated
FROM products
WHERE name ILIKE '%' || $1 || '%'
ORDER BY stock_level DESC;
track_shipment_status:
kind: postgres-sql
source: supply_chain_db
description: Retrieve real-time logistics and shipping status for a specific region or product.
parameters:
- name: region
type: string
description: The geographical region to filter shipments (e.g., EMEA, APAC).
statement: |
SELECT p.name, s.status, s.estimated_arrival, s.route_efficiency_score
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE p.region = $1
ORDER BY s.estimated_arrival ASC;
analyze_supply_chain_risk:
kind: postgres-sql
source: supply_chain_db
description: Rerank and filter shipments based on risk profiles and efficiency scores using Google ML reranker.
parameters:
- name: risk_context
type: string
description: The business context for risk analysis (e.g., 'heatwave impact' or 'port strike').
statement: |
WITH initial_ranking AS (
SELECT s.shipment_id, p.name, s.status, p.distribution_center,
ROW_NUMBER() OVER () AS ref_number
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE s.status != 'Delivered'
LIMIT 10
),
reranked_results AS (
SELECT index, score FROM
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => $1,
documents => (SELECT ARRAY_AGG(name || ' at ' || distribution_center ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT i.name, i.status, i.distribution_center, r.score
FROM initial_ranking i, reranked_results r
WHERE i.ref_number = r.index
ORDER BY r.score DESC;
toolsets:
supply_chain_toolset:
- search_products_by_context
- check_inventory_levels
- track_shipment_status
- analyze_supply_chain_risk
ตอนนี้ให้ทดสอบไฟล์ tools.yaml ในเซิร์ฟเวอร์ในเครื่องโดยทำดังนี้
./toolbox --tools-file "tools.yaml"
หรือจะทดสอบใน UI ก็ได้
./toolbox --ui
เยี่ยมเลย เมื่อแน่ใจว่าทุกอย่างทำงานได้แล้ว ให้ติดตั้งใช้งานใน Cloud Run ดังนี้
การทำให้ใช้งานได้ใน Cloud Run
- ตั้งค่าตัวแปรสภาพแวดล้อม PROJECT_ID
export PROJECT_ID="my-project-id"
- เริ่มต้น gcloud CLI
gcloud init
gcloud config set project $PROJECT_ID
- คุณต้องเปิดใช้ API ต่อไปนี้
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- สร้างบัญชีบริการแบ็กเอนด์หากยังไม่มี
gcloud iam service-accounts create toolbox-identity
- ให้สิทธิ์ในการใช้ Secret Manager โดยทำดังนี้
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
- ให้สิทธิ์เพิ่มเติมแก่บัญชีบริการที่เฉพาะเจาะจงกับแหล่งที่มาของ AlloyDB (roles/alloydb.client และ roles/serviceusage.serviceUsageConsumer)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role serviceusage.serviceUsageConsumer
- อัปโหลด tools.yaml เป็นข้อมูลลับ
gcloud secrets create tools-scm-agent --data-file=tools.yaml
- หากมีข้อมูลลับอยู่แล้วและต้องการอัปเดตเวอร์ชันของข้อมูลลับ ให้ดำเนินการดังนี้
gcloud secrets versions add tools-scm-agent --data-file=tools.yaml
- ตั้งค่าตัวแปรสภาพแวดล้อมเป็นอิมเมจคอนเทนเนอร์ที่ต้องการใช้สำหรับ Cloud Run ดังนี้
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- ทำให้ Toolbox ใช้งานได้กับ Cloud Run โดยใช้คำสั่งต่อไปนี้
หากเปิดใช้การเข้าถึงแบบสาธารณะในอินสแตนซ์ AlloyDB (ไม่แนะนำ) ให้ทำตามคำสั่งด้านล่างเพื่อติดตั้งใช้งานใน Cloud Run
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
หากคุณใช้เครือข่าย VPC ให้ใช้คำสั่งด้านล่าง
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
# TODO(dev): update the following to match your VPC details
--network <<YOUR_NETWORK_NAME>> \
--subnet <<YOUR_SUBNET_NAME>> \
--allow-unauthenticated
6. การตั้งค่า Agent
เราได้เปลี่ยนจากพรอมต์แบบ Monolithic ไปเป็นสถาปัตยกรรมแบบหลาย Agent ที่เฉพาะเจาะจงโดยใช้ Agent Development Kit (ADK)
- InventorySpecialist: มุ่งเน้นที่สต็อกผลิตภัณฑ์และเมตริกคลังสินค้า
- LogisticsManager: ผู้เชี่ยวชาญด้านเส้นทางการจัดส่งทั่วโลกและการวิเคราะห์ความเสี่ยง
- GlobalOrchestrator: "สมอง" ที่ใช้การให้เหตุผลเพื่อมอบหมายงานและสังเคราะห์ผลลัพธ์
โคลนที่เก็บนี้ลงในโปรเจ็กต์ของคุณ แล้วมาดูรายละเอียดกัน
หากต้องการโคลน ให้เรียกใช้คำสั่งต่อไปนี้จากเทอร์มินัล Cloud Shell (ในไดเรกทอรีรากหรือจากที่ใดก็ตามที่ต้องการสร้างโปรเจ็กต์นี้)
git clone https://github.com/AbiramiSukumaran/scm-memory-agent
- ซึ่งจะสร้างโปรเจ็กต์และคุณสามารถยืนยันได้ใน Cloud Shell Editor

- อย่าลืมอัปเดตไฟล์ .env ด้วยค่าสำหรับโปรเจ็กต์และอินสแตนซ์
คำแนะนำแบบทีละขั้นเกี่ยวกับโค้ด
ภาพรวมคร่าวๆ ของ Orchestrator Agent
Go to app.py and you should be able to see the following snippet:
orchestrator = adk.Agent(
name="GlobalOrchestrator",
model="gemini-2.5-flash",
description="Global Supply Chain Orchestrator root agent.",
instruction="""
You are the Global Supply Chain Brain. You are responsible for products, inventory and logistics.
You also have access to the memory tool, remember to include all the information that the tool can provide you with about the user before you respond.
1. Understand intent and delegate to specialists. As the Global Orchestrator, you have access to the full conversation history with the user.
When you transfer a query to a specialist agent, sub agent or tool, share the important facts and information from your memory to them so they can operate with the full context.
2. Ensure the final response is professional and uses Markdown tables for data.
3. If a specialist provides a long list, ensure only the top 10 items are shown initially.
4. Conclude with a brief, high-level executive summary of what the data implies.
""",
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
sub_agents=[inventory_agent, logistics_agent],
#after_agent_callback=auto_save_session_to_memory_callback,
)
ข้อมูลโค้ดนี้คือคำจำกัดความของรูทซึ่งเป็นตัวแทนผู้ประสานงานที่รับการสนทนาหรือคำขอจากผู้ใช้ และกำหนดเส้นทางไปยังตัวแทนย่อยหรือผู้ใช้ที่เกี่ยวข้อง รวมถึงเครื่องมือที่เกี่ยวข้องตามงาน
- มาดู Inventory Agent กัน
inventory_agent = adk.Agent(
name="InventorySpecialist",
model="gemini-2.5-flash",
description="Specialist in product stock and warehouse data.",
instruction="""
Analyze inventory levels.
1. Use 'search_products_by_context' or 'check_inventory_levels'.
2. ALWAYS format results as a clean Markdown table.
3. If there are many results, display only the TOP 10 most relevant ones.
4. At the end, state: 'There are additional records available. Would you like to see more?'
""",
tools=tools
)
เอเจนต์ย่อยนี้มีความเชี่ยวชาญด้านกิจกรรมในคลัง เช่น การค้นหาผลิตภัณฑ์ตามบริบทและการตรวจสอบระดับสินค้าคงคลัง
- จากนั้นก็มีตัวแทนย่อยด้านโลจิสติกส์
logistics_agent = adk.Agent(
name="LogisticsManager",
model="gemini-2.5-flash",
description="Expert in global shipping routes and logistics tracking.",
instruction="""
Check shipment statuses.
1. Use 'track_shipment_status' or 'analyze_supply_chain_risk'.
2. ALWAYS format results as a clean Markdown table.
3. Limit initial output to the top 10 shipments.
4. Ask if the user needs the full manifest if more results exist.
""",
tools=tools
)
Agent ย่อยรายนี้มีความเชี่ยวชาญด้านกิจกรรมด้านลอจิสติกส์ เช่น การติดตามการจัดส่งและการวิเคราะห์ความเสี่ยงในซัพพลายเชน
- เอเจนต์ทั้ง 3 รายที่เราพูดถึงไปแล้วใช้เครื่องมือ และมีการอ้างอิงเครื่องมือผ่านเซิร์ฟเวอร์กล่องเครื่องมือที่เราได้ติดตั้งใช้งานในส่วนก่อนหน้าแล้ว โปรดดูข้อมูลโค้ดด้านล่าง
from toolbox_core import ToolboxSyncClient
TOOLBOX_SERVER = os.environ["TOOLBOX_SERVER"]
TOOLBOX_TOOLSET = os.environ["TOOLBOX_TOOLSET"]
# --- ADK TOOLBOX CONFIGURATION ---
toolbox = ToolboxSyncClient(TOOLBOX_SERVER)
tools = toolbox.load_toolset(TOOLBOX_TOOLSET)
Agent ย่อยรายนี้มีความเชี่ยวชาญด้านกิจกรรมด้านลอจิสติกส์ เช่น การติดตามการจัดส่งและการวิเคราะห์ความเสี่ยงในซัพพลายเชน
7. Agent Engine
สร้าง Agent Engine ในการเรียกใช้ครั้งแรก
import vertexai
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
client = vertexai.Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_LOCATION
)
agent_engine = client.agent_engines.create()
- สำหรับการเรียกใช้ครั้งถัดไป ให้อัปเดต Agent Engine ด้วยการกำหนดค่า Memory Bank ดังนี้
agent_engine = client.agent_engines.update(
name=APP_NAME,
config={
"context_spec": {
"memory_bank_config": {
"generation_config": {
"model": f"projects/{PROJECT_ID}/locations/{GOOGLE_CLOUD_LOCATION}/publishers/google/models/gemini-2.5-flash"
}
}
}
})
8. บริบท การเรียกใช้ และหน่วยความจำ
การจัดการบริบทแบ่งออกเป็น 2 เลเยอร์ที่แตกต่างกันเพื่อให้มั่นใจว่า Agent จะรู้สึกเหมือนเป็นพาร์ทเนอร์ที่ทำงานร่วมกันอย่างต่อเนื่อง ไม่ใช่บ็อตที่ไม่มีสถานะ
หน่วยความจำระยะสั้น (เซสชัน): จัดการผ่าน VertexAiSessionService ซึ่งจะติดตามประวัติเหตุการณ์ล่าสุด (ข้อความของผู้ใช้ คำตอบของเครื่องมือ) ภายในปฏิสัมพันธ์เดียว
หน่วยความจำระยะยาว (ธนาคารหน่วยความจำ): ขับเคลื่อนโดยธนาคารหน่วยความจำของ Vertex AI ผ่าน adk.memorybankservice เลเยอร์นี้จะดึงข้อมูลที่ "มีความหมาย" เช่น ค่ากำหนดของผู้ใช้สำหรับผู้ให้บริการจัดส่งที่เฉพาะเจาะจงหรือความล่าช้าของคลังสินค้าที่เกิดขึ้นซ้ำ และคงข้อมูลเหล่านั้นไว้ในเซสชันต่างๆ
เริ่มต้นเซสชันสำหรับหน่วยความจำเซสชันภายในขอบเขตของการสนทนา
ส่วนนี้คือส่วนของข้อมูลโค้ดที่สร้างเซสชันสำหรับแอปปัจจุบันของผู้ใช้ปัจจุบัน
from google.adk.sessions import VertexAiSessionService
...
session_service = VertexAiSessionService(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
...
# Initialize the session *outside* of the route handler to avoid repeated creation
session = None
session_lock = threading.Lock()
async def initialize_session():
global session
try:
session = await session_service.create_session(app_name=APP_NAME, user_id=USER_ID)
print(f"Session {session.id} created successfully.") # Add a log
except Exception as e:
print(f"Error creating session: {e}")
session = None # Ensure session is None in case of error
# Create the session on app startup
asyncio.run(initialize_session())
เริ่มต้น Vertex AI Memory Bank สำหรับหน่วยความจำระยะยาว
นี่คือส่วนของข้อมูลโค้ดที่สร้างออบเจ็กต์บริการ Vertex AI Memory Bank สำหรับ Agent Engine
from google.adk.memory import InMemoryMemoryService
from google.adk.memory import VertexAiMemoryBankService
...
try:
memory_bank_service = adk.memory.VertexAiMemoryBankService(
agent_engine_id=AGENT_ENGINE_ID,
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
#in_memory_service = InMemoryMemoryService()
print("Memory Bank Service initialized successfully.")
except Exception as e:
print(f"Error initializing Memory Bank Service: {e}")
memory_bank_service = None
runner = adk.Runner(
agent=orchestrator,
app_name=APP_NAME,
session_service=session_service,
memory_service=memory_bank_service,
)
...
มีการกำหนดค่าอะไรบ้าง
ในส่วนนี้ของข้อมูลโค้ด เรากำลังกำหนดค่าบริการ Vertex AI Memory Bank สำหรับหน่วยความจำระยะยาว โดยจะจัดเก็บเซสชันตามบริบทสำหรับแอปที่เฉพาะเจาะจงสำหรับผู้ใช้ที่เฉพาะเจาะจงเป็นหน่วยความจำภายใน Vertex AI Memory Bank
อะไรที่ทำงานเป็นส่วนหนึ่งของการดำเนินการของเอเจนต์
async def run_and_collect():
final_text = ""
try:
async for event in runner.run_async(
new_message=content,
user_id=user_id,
session_id=session_id
):
if hasattr(event, 'author') and event.author:
if not any(log['agent'] == event.author for log in execution_logs):
execution_logs.append({
"agent": event.author,
"action": "Analyzing data requirements...",
"type": "orchestration_event"
})
if hasattr(event, 'text') and event.text:
final_text = event.text
elif hasattr(event, 'content') and hasattr(event.content, 'parts'):
for part in event.content.parts:
if hasattr(part, 'text') and part.text:
final_text = part.text
except Exception as e:
print(f"Error during runner.run_async: {e}")
raise # Re-raise the exception to signal failure
finally:
gc.collect()
return final_text
โดยจะประมวลผลเนื้อหาอินพุตของผู้ใช้เป็นออบเจ็กต์ new_message ที่มีรหัสผู้ใช้และรหัสเซสชันในขอบเขต จากนั้นเอเจนต์จะเข้ามาดูแลต่อ และระบบจะประมวลผลและส่งคืนคำตอบของเอเจนต์
อะไรบ้างที่จัดเก็บไว้ในหน่วยความจำระยะยาว
รายละเอียดเซสชันในขอบเขตของแอปและผู้ใช้จะได้รับการดึงข้อมูลในตัวแปรเซสชัน
จากนั้นระบบจะเพิ่มเซสชันนี้เป็นหน่วยความจำสำหรับผู้ใช้ปัจจุบันของออบเจ็กต์ Vertex AI Memory Bank สำหรับแอปปัจจุบันโดยใช้วิธี "add_session_to_memory"
session = asyncio.run(session_service.get_session(app_name=APP_NAME, user_id=USER_ID, session_id=session.id))
if memory_bank_service and session: # Check memory service AND session
try:
#asyncio.run(in_memory_service.add_session_to_memory(session))
asyncio.run(memory_bank_service.add_session_to_memory(session))
'''
client.agent_engines.memories.generate(
scope={"app_name": APP_NAME, "user_id": USER_ID},
name=APP_NAME,
direct_contents_source={
"events": [
{"content": content}
]
},
config={"wait_for_completion": True},
)
'''
print("Successfully added session to memory.******")
print(session.id)
except Exception as e:
print(f"Error adding session to memory: {e}")
การดึงข้อมูลจากหน่วยความจำ
เราต้องดึงข้อมูลหน่วยความจำระยะยาวที่จัดเก็บไว้โดยใช้ชื่อแอปและชื่อผู้ใช้เป็นขอบเขต (เนื่องจากเป็นขอบเขตที่เราจัดเก็บหน่วยความจำไว้) เพื่อให้ส่งข้อมูลดังกล่าวเป็นส่วนหนึ่งของบริบทไปยังตัวประสานงานและเอเจนต์อื่นๆ ได้ตามความเหมาะสม
results = client.agent_engines.memories.retrieve(
name=APP_NAME,
scope={"app_name": APP_NAME, "user_id": USER_ID}
)
# RetrieveMemories returns a pager. You can use `list` to retrieve all pages' memories.
list(results)
print(list(results))
ระบบโหลดความทรงจำที่ดึงมาเป็นส่วนหนึ่งของบริบทอย่างไร
เราใช้แอตทริบิวต์ต่อไปนี้ในการกำหนด Agent Orchestrator ซึ่งช่วยให้ Agent รูทโหลดบริบทล่วงหน้าจากธนาคารความจำได้ ซึ่งเป็นเครื่องมือเพิ่มเติมจากเครื่องมือที่เราเข้าถึงจากเซิร์ฟเวอร์กล่องเครื่องมือสำหรับ Agent ย่อย
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
บริบทการเรียกกลับ
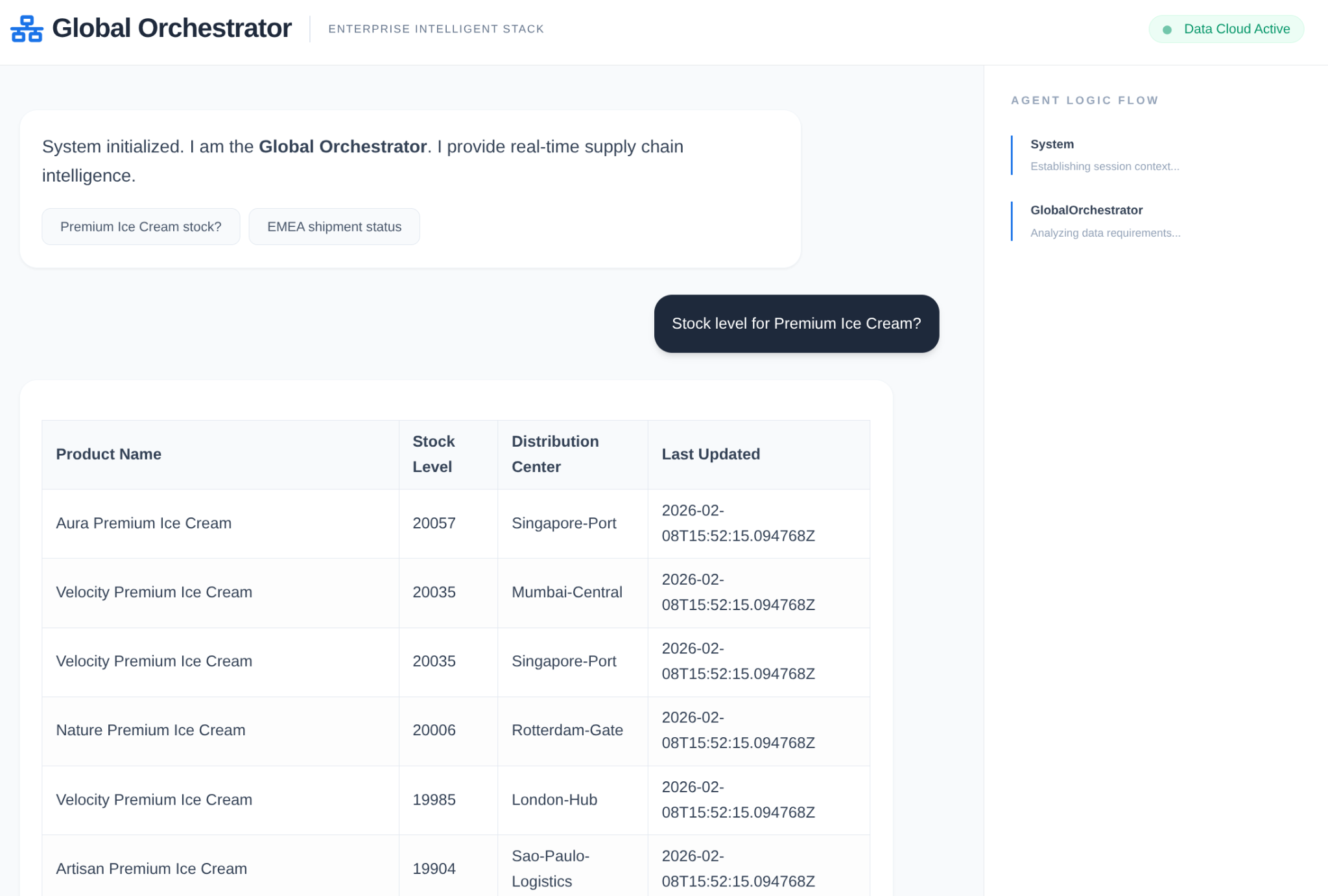
ในซัพพลายเชนขององค์กร คุณไม่สามารถมี "กล่องดำ" ได้ เราใช้ CallbackContext ของ ADK เพื่อสร้าง Narrative Engine การเชื่อมต่อกับการดำเนินการของเอเจนต์ช่วยให้เราบันทึกกระบวนการคิดและการเรียกใช้เครื่องมือทุกอย่าง แล้วสตรีมไปยังแถบด้านข้างของ UI
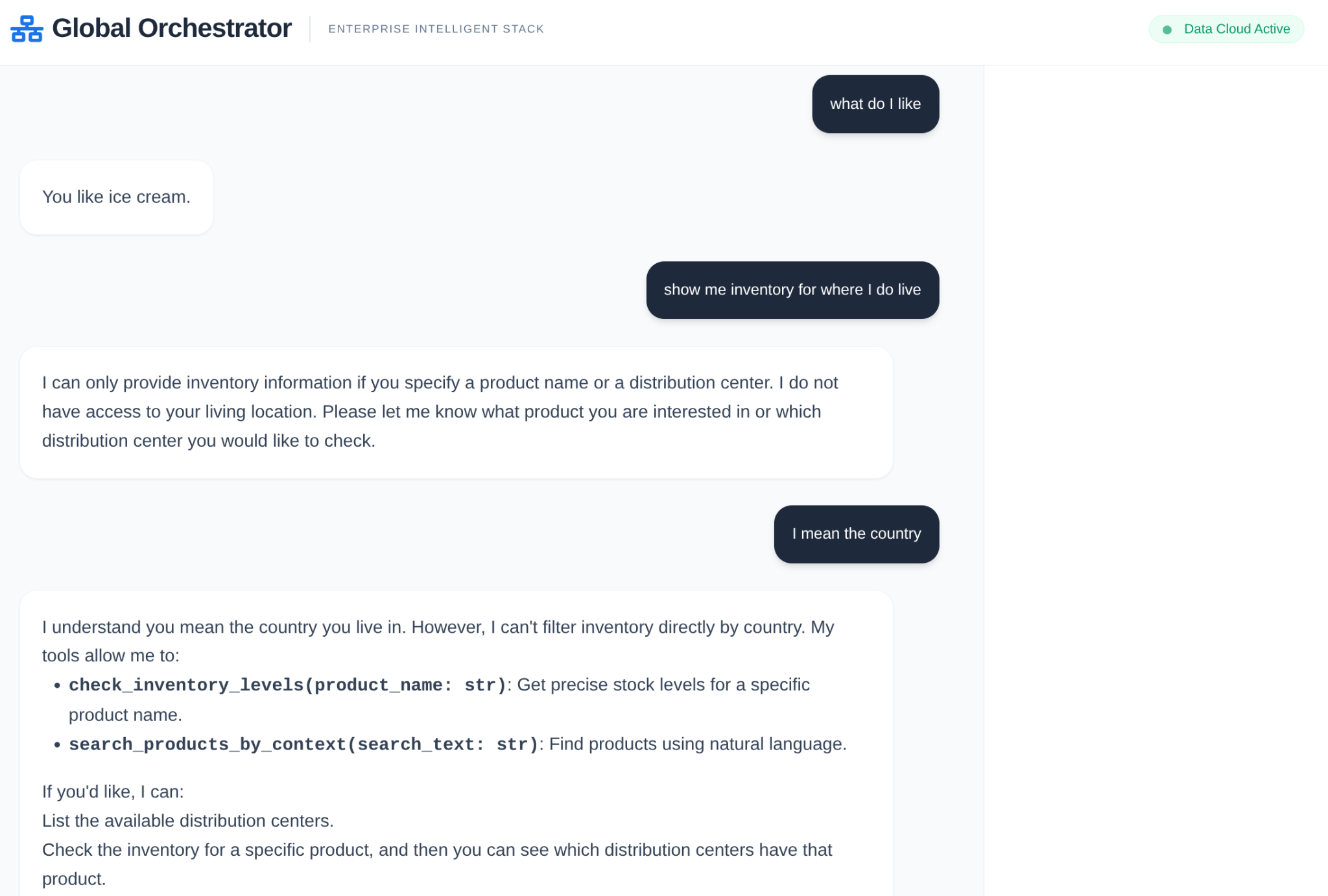
- เหตุการณ์การติดตาม: "GlobalOrchestrator กําลังวิเคราะห์ข้อกําหนดของข้อมูล..."
- เหตุการณ์การติดตาม: "มอบหมายให้ InventorySpecialist สำหรับระดับสต็อก..."
- เหตุการณ์การติดตาม: "กำลังดึงรูปแบบความล่าช้าของซัพพลายเออร์ในอดีตจาก Memory Bank..."
บันทึกการตรวจสอบนี้มีประโยชน์อย่างยิ่งสำหรับการแก้ไขข้อบกพร่อง และช่วยให้ผู้ปฏิบัติงานที่เป็นมนุษย์มั่นใจได้ว่าการตัดสินใจอัตโนมัติของเอเจนต์นั้นเชื่อถือได้
from google.adk.agents.callback_context import CallbackContext
...
# --- ADK CALLBACKS (Narrative Engine) ---
execution_logs = []
async def trace_callback(context: CallbackContext):
"""
Captures agent and tool invocation flow for the UI narrative.
"""
agent_name = context.agent.name
event = {
"agent": agent_name,
"action": "Processing request steps...",
"type": "orchestration_event"
}
execution_logs.append(event)
return None
...
เท่านี้ก็เรียบร้อย!!! เราได้โคลนโปรเจ็กต์และดูรายละเอียดของเอเจนต์ หน่วยความจำ และบริบทเรียบร้อยแล้ว
คุณทดสอบได้โดยไปที่โฟลเดอร์โปรเจ็กต์ของที่เก็บที่โคลนมา แล้วเรียกใช้คำสั่งต่อไปนี้
>> pip install -r requirements.txt
>> python app.py
ซึ่งจะเริ่มตัวแทนในเครื่องและคุณควรจะทดสอบได้
9. มาทำให้ใช้งานได้ใน Cloud Run กัน
- ทำให้ใช้งานได้ใน Cloud Run โดยเรียกใช้คำสั่งต่อไปนี้จากเทอร์มินัล Cloud Shell ที่โคลนโปรเจ็กต์และตรวจสอบว่าคุณอยู่ในโฟลเดอร์รูทของโปรเจ็กต์
เรียกใช้คำสั่งนี้ในเทอร์มินัล Cloud Shell
gcloud run deploy supply-chain-agent --source . --platform managed --region us-central1 --allow-unauthenticated --set-env-vars GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT>>,GOOGLE_CLOUD_LOCATION=us-central1,GOOGLE_GENAI_USE_VERTEXAI=TRUE,REASONING_ENGINE_APP_NAME=<<YOUR_APP_ENGINE_URL>>,TOOLBOX_SERVER=<<YOUR_TOOLBOX_SERVER>>,TOOLBOX_TOOLSET=supply_chain_toolset,AGENT_ENGINE_ID=<<YOUR_AGENT_ENGINE_ID>>
แทนที่ค่าสำหรับตัวยึดตำแหน่ง <<YOUR_PROJECT>>, <<YOUR_APP_ENGINE_URL>>, <<YOUR_TOOLBOX_SERVER>> และ <<YOUR_AGENT_ENGINE_ID>>
เมื่อคำสั่งเสร็จสิ้นแล้ว ระบบจะแสดง URL ของบริการ คัดลอก
- มอบบทบาทไคลเอ็นต์ AlloyDB ให้บัญชีบริการ Cloud Run ซึ่งจะช่วยให้แอปพลิเคชันแบบไม่มีเซิร์ฟเวอร์ของคุณสามารถสร้างอุโมงค์ไปยังฐานข้อมูลได้อย่างปลอดภัย
เรียกใช้คำสั่งนี้ในเทอร์มินัล Cloud Shell
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
ตอนนี้ให้ใช้ URL ของบริการ (ปลายทาง Cloud Run ที่คุณคัดลอกไว้ก่อนหน้านี้) และทดสอบแอป
หมายเหตุ: หากพบปัญหาเกี่ยวกับบริการและมีการระบุว่าหน่วยความจำเป็นสาเหตุ ให้ลองเพิ่มขีดจำกัดหน่วยความจำที่จัดสรรเป็น 1 GiB เพื่อทดสอบ
10. ล้างข้อมูล
เมื่อแล็บนี้เสร็จแล้ว อย่าลืมลบคลัสเตอร์และอินสแตนซ์ AlloyDB
ซึ่งควรล้างข้อมูลคลัสเตอร์พร้อมกับอินสแตนซ์
11. ขอแสดงความยินดี
การผสานความเร็วของ AlloyDB, ประสิทธิภาพการจัดการเป็นกลุ่มของ MCP Toolbox และ "หน่วยความจำขององค์กร" ของ Vertex AI Memory Bank ทำให้เราสร้างระบบซัพพลายเชนที่พัฒนาอย่างต่อเนื่องได้ โดยไม่ได้แค่ตอบคำถาม แต่ยังจดจำได้ว่าคลังสินค้าของคุณในสิงคโปร์มักประสบปัญหาความล่าช้าที่เกี่ยวข้องกับมรสุม และแนะนำการเปลี่ยนเส้นทางการจัดส่งอย่างรวดเร็วโดยที่คุณยังไม่ได้ถามด้วยซ้ำ