
1. Tổng quan
Trong lớp học lập trình này, bạn sẽ tạo một tác nhân Điều phối chuỗi cung ứng. Ứng dụng này cho phép người dùng phân tích kho hàng, theo dõi hoạt động hậu cần và quản lý rủi ro trong chuỗi cung ứng bằng ngôn ngữ tự nhiên.
Chúng ta sẽ tận dụng Agent Development Kit (ADK) của Google để xây dựng một kiến trúc nhiều tác nhân duy trì ngữ cảnh, ghi nhớ các lựa chọn ưu tiên của người dùng thông qua Vertex AI Memory Bank và tương tác với một tập dữ liệu khổng lồ được lưu trữ trong AlloyDB thông qua Bộ công cụ MCP.
Sản phẩm bạn sẽ tạo ra
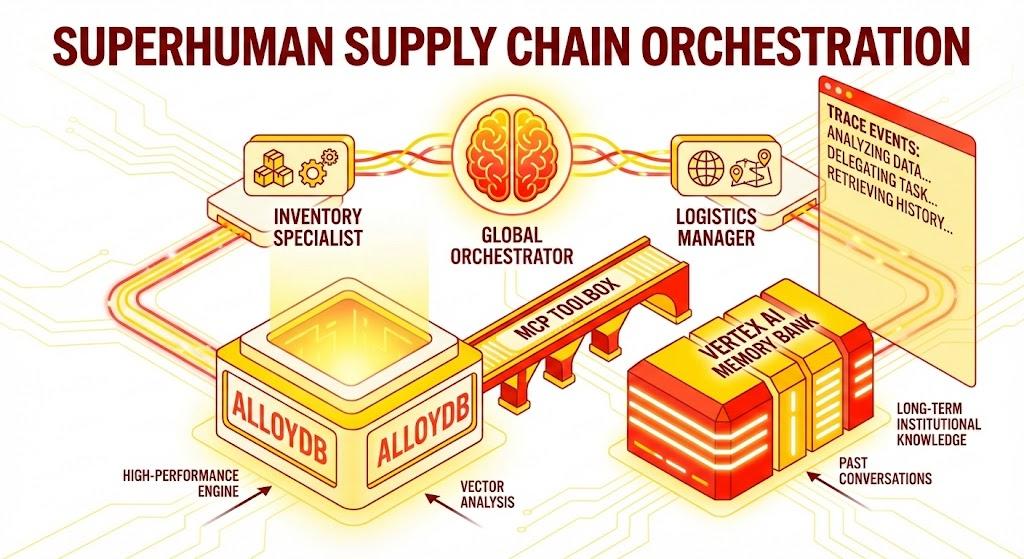
Một ứng dụng Python Flask bao gồm:
Tác nhân điều phối toàn cầu: Tác nhân gốc quản lý quy trình trò chuyện và việc uỷ quyền.
Đặc vụ chuyên trách: "InventorySpecialist" và "LogisticsManager" cho các nhiệm vụ cụ thể theo miền.
Tích hợp bộ nhớ: Bộ nhớ phiên ngắn hạn và bộ nhớ dài hạn bằng Vertex AI Memory Bank.
Giao diện người dùng tường thuật: Giao diện web trực quan hoá quy trình suy luận của tác nhân (Ngữ cảnh dấu vết).
Kiến thức bạn sẽ học được
- Cách sử dụng ADK của Google để tạo các tác nhân và tác nhân phụ chuyên biệt.
- Cách tích hợp Vertex AI Memory Bank để lưu trữ bộ nhớ dài hạn của tác nhân.
- Cách sử dụng Bộ công cụ MCP để kết nối các tác nhân với các công cụ dữ liệu AlloyDB.
- Cách triển khai ADK Callbacks để theo dõi và trực quan hoá quá trình suy luận của tác nhân.
- Cách triển khai giải pháp bằng Cloud Run hoặc chạy giải pháp cục bộ.
Kiến trúc
The Tech Stack
- AlloyDB cho PostgreSQL: Đóng vai trò là cơ sở dữ liệu vận hành hiệu suất cao,lưu trữ hơn 50.000 bản ghi chuỗi cung ứng. Công cụ này hỗ trợ tính năng tìm kiếm và truy xuất vectơ.
- Bộ công cụ MCP cho cơ sở dữ liệu: Đóng vai trò là "Nhạc trưởng điều phối", cung cấp dữ liệu AlloyDB dưới dạng các công cụ có thể thực thi mà các tác nhân có thể gọi.
- Bộ công cụ phát triển tác nhân (ADK): Khung được dùng để xác định các tác nhân, hướng dẫn và công cụ.
- Vertex AI Memory Bank: Cung cấp bộ nhớ dài hạn, cho phép tác nhân nhớ lại các lựa chọn ưu tiên của người dùng và các hoạt động tương tác trước đây trong các phiên.
- Vertex AI Session Service: Quản lý ngữ cảnh trò chuyện ngắn hạn.
The Flow
- Câu hỏi của người dùng: Người dùng đặt câu hỏi (ví dụ: "Kiểm tra kho hàng của Kem cao cấp").
- Kiểm tra bộ nhớ: Orchestrator kiểm tra Ngân hàng bộ nhớ để tìm thông tin liên quan trong quá khứ (ví dụ: "Người dùng là nhà quản lý khu vực của EMEA").
- Uỷ quyền: Orchestrator uỷ quyền nhiệm vụ cho InventorySpecialist.
- Thực thi công cụ: Chuyên gia sử dụng các công cụ do Bộ công cụ MCP cung cấp để truy vấn AlloyDB.
- Phản hồi: Trợ lý xử lý dữ liệu và trả về một bảng được định dạng bằng Markdown.
- Lưu trữ kỷ niệm: Những hoạt động tương tác quan trọng sẽ được lưu vào Ngân hàng kỷ niệm.
Yêu cầu
2. Trước khi bắt đầu
Tạo dự án
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo rằng bạn đã bật tính năng thanh toán cho dự án trên Cloud. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên một dự án hay không.
- Bạn sẽ sử dụng Cloud Shell, một môi trường dòng lệnh chạy trong Google Cloud. Nhấp vào Kích hoạt Cloud Shell ở đầu bảng điều khiển Cloud.

- Sau khi kết nối với Cloud Shell, hãy kiểm tra để đảm bảo bạn đã được xác thực và dự án được đặt thành mã dự án của bạn bằng lệnh sau:
gcloud auth list
- Chạy lệnh sau trong Cloud Shell để xác nhận rằng lệnh gcloud biết về dự án của bạn.
gcloud config list project
- Nếu bạn chưa đặt dự án, hãy dùng lệnh sau để đặt:
gcloud config set project <YOUR_PROJECT_ID>
- Bật các API bắt buộc: Truy cập vào đường liên kết rồi bật các API.
Ngoài ra, bạn có thể dùng lệnh gcloud cho việc này. Tham khảo tài liệu để biết các lệnh và cách sử dụng gcloud.
Các lỗi thường gặp và cách khắc phục sự cố
Hội chứng "Dự án ma" | Bạn đã chạy |
Rào chắn thanh toán | Bạn đã bật dự án nhưng quên tài khoản thanh toán. AlloyDB là một công cụ hiệu suất cao; công cụ này sẽ không khởi động nếu "bình xăng" (thanh toán) trống. |
Độ trễ API Propagation | Bạn đã nhấp vào "Bật API", nhưng dòng lệnh vẫn hiển thị |
Hạn mức Quags | Nếu đang sử dụng tài khoản dùng thử hoàn toàn mới, bạn có thể đạt đến hạn mức theo vùng cho các thực thể AlloyDB. Nếu |
Nhân viên hỗ trợ dịch vụ"bị ẩn" | Đôi khi, AlloyDB Service Agent không được tự động cấp vai trò |
3. Thiết lập cơ sở dữ liệu
Ứng dụng của chúng tôi dựa trên AlloyDB cho PostgreSQL. Chúng tôi đã tận dụng các chức năng vectơ mạnh mẽ và tích hợp công cụ theo cột để tạo các mục nhúng cho hơn 50.000 bản ghi SCM. Điều này giúp phân tích vectơ gần với thời gian thực, cho phép các nhân viên của chúng tôi xác định điểm bất thường về kho hàng hoặc rủi ro về hậu cần trên các tập dữ liệu khổng lồ trong vài mili giây.
Trong phòng thí nghiệm này, chúng ta sẽ sử dụng AlloyDB làm cơ sở dữ liệu cho dữ liệu kiểm thử. Nó sử dụng cụm để lưu giữ tất cả các tài nguyên, chẳng hạn như cơ sở dữ liệu và nhật ký. Mỗi cụm có một phiên bản chính cung cấp một điểm truy cập vào dữ liệu. Các bảng sẽ chứa dữ liệu thực tế.
Hãy tạo một cụm, thực thể và bảng AlloyDB để tải tập dữ liệu kiểm thử.
- Nhấp vào nút hoặc Sao chép đường liên kết bên dưới vào trình duyệt mà bạn đã đăng nhập người dùng Google Cloud Console.
Ngoài ra, bạn có thể chuyển đến Cloud Shell Terminal trong dự án mà bạn đã đổi tài khoản thanh toán, rồi sao chép kho lưu trữ github và chuyển đến dự án bằng các lệnh bên dưới:
git clone https://github.com/AbiramiSukumaran/easy-alloydb-setup
cd easy-alloydb-setup
- Sau khi hoàn tất bước này, kho lưu trữ sẽ được sao chép vào trình chỉnh sửa Cloud Shell cục bộ và bạn có thể chạy lệnh bên dưới từ thư mục dự án (bạn cần đảm bảo rằng bạn đang ở trong thư mục dự án):
sh run.sh
- Bây giờ, hãy sử dụng giao diện người dùng (nhấp vào đường liên kết trong thiết bị đầu cuối hoặc nhấp vào đường liên kết "xem trước trên web" trong thiết bị đầu cuối.
- Nhập thông tin chi tiết về mã dự án, tên cụm và tên phiên bản để bắt đầu.
- Hãy đi lấy một tách cà phê trong khi nhật ký cuộn và bạn có thể đọc về cách nhật ký thực hiện việc này ở chế độ nền tại đây.
Các lỗi thường gặp và cách khắc phục sự cố
Vấn đề về "Tính kiên nhẫn" | Cụm cơ sở dữ liệu là cơ sở hạ tầng lớn. Nếu làm mới trang hoặc kết thúc phiên Cloud Shell vì phiên này "có vẻ bị treo", bạn có thể gặp phải một phiên bản "ảo" được cung cấp một phần và không thể xoá nếu không có sự can thiệp thủ công. |
Khu vực không khớp | Nếu đã bật API trong |
Nhóm zombie | Nếu trước đây bạn đã dùng cùng một tên cho một cụm và chưa xoá cụm đó, thì tập lệnh có thể cho biết tên cụm đã tồn tại. Tên cụm phải là duy nhất trong một dự án. |
Thời gian chờ của Cloud Shell | Nếu bạn giải lao uống cà phê trong 30 phút, Cloud Shell có thể chuyển sang chế độ ngủ và ngắt kết nối quy trình |
4. Cung cấp giản đồ
Sau khi bạn chạy cụm và thực thể AlloyDB, hãy chuyển đến trình chỉnh sửa SQL của AlloyDB Studio để bật các tiện ích AI và cung cấp giản đồ.
Bạn có thể phải đợi phiên bản của mình được tạo xong. Sau khi tạo, hãy đăng nhập vào AlloyDB bằng thông tin đăng nhập mà bạn đã tạo khi tạo cụm. Sử dụng dữ liệu sau để xác thực với PostgreSQL:
- Tên người dùng : "
postgres" - Cơ sở dữ liệu : "
postgres" - Mật khẩu : "
alloydb" (hoặc mật khẩu bạn đặt tại thời điểm tạo)
Sau khi bạn xác thực thành công vào AlloyDB Studio, các lệnh SQL sẽ được nhập vào Trình chỉnh sửa. Bạn có thể thêm nhiều cửa sổ Trình chỉnh sửa bằng cách nhấp vào dấu cộng ở bên phải cửa sổ cuối cùng.
Bạn sẽ nhập các lệnh cho AlloyDB trong cửa sổ trình chỉnh sửa, sử dụng các lựa chọn Chạy, Định dạng và Xoá khi cần.
Bật tiện ích
Để tạo ứng dụng này, chúng ta sẽ sử dụng các tiện ích pgvector và google_ml_integration. Tiện ích pgvector cho phép bạn lưu trữ và tìm kiếm các vectơ nhúng. Tiện ích google_ml_integration cung cấp các hàm mà bạn dùng để truy cập vào các điểm cuối dự đoán của Vertex AI nhằm nhận thông tin dự đoán bằng SQL. Bật các tiện ích này bằng cách chạy các DDL sau:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Tạo bảng
Bạn có thể tạo một bảng bằng câu lệnh DDL bên dưới trong AlloyDB Studio:
DROP TABLE IF EXISTS shipments;
DROP TABLE IF EXISTS products;
-- 1. Product Inventory Table
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
category VARCHAR(100),
stock_level INTEGER,
distribution_center VARCHAR(100),
region VARCHAR(50),
embedding vector(768),
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. Logistics & Shipments
CREATE TABLE shipments (
shipment_id SERIAL PRIMARY KEY,
product_id INTEGER REFERENCES products(id),
status VARCHAR(50), -- 'In Transit', 'Delayed', 'Delivered', 'Pending'
estimated_arrival TIMESTAMP,
route_efficiency_score DECIMAL(3, 2)
);
Cột embedding sẽ cho phép lưu trữ các giá trị vectơ của một số trường văn bản.
Nhập dữ liệu
Chạy tập hợp câu lệnh SQL bên dưới để chèn hàng loạt 50.000 bản ghi vào bảng sản phẩm:
-- We use a CROSS JOIN pattern with realistic naming segments to create meaningful variety
DO $$
DECLARE
brand_names TEXT[] := ARRAY['Artisan', 'Nature', 'Elite', 'Pure', 'Global', 'Eco', 'Velocity', 'Heritage', 'Aura', 'Summit'];
product_types TEXT[] := ARRAY['Ice Cream', 'Body Wash', 'Laundry Detergent', 'Shampoo', 'Mayonnaise', 'Deodorant', 'Tea', 'Soup', 'Face Cream', 'Soap'];
variants TEXT[] := ARRAY['Classic', 'Gold', 'Premium', 'Eco-Friendly', 'Organic', 'Night-Repair', 'Extra-Fresh', 'Zero-Sugar', 'Sensitive', 'Maximum-Strength'];
regions TEXT[] := ARRAY['EMEA', 'APAC', 'LATAM', 'NAMER'];
dcs TEXT[] := ARRAY['London-Hub', 'Mumbai-Central', 'Sao-Paulo-Logistics', 'Singapore-Port', 'Rotterdam-Gate', 'New-York-DC'];
BEGIN
INSERT INTO products (name, category, stock_level, distribution_center, region)
SELECT
b || ' ' || v || ' ' || t as name,
CASE
WHEN t IN ('Ice Cream', 'Mayonnaise', 'Tea', 'Soup') THEN 'Food & Refreshment'
WHEN t IN ('Body Wash', 'Shampoo', 'Deodorant', 'Face Cream', 'Soap') THEN 'Personal Care'
ELSE 'Home Care'
END as category,
floor(random() * 20000 + 100)::int as stock_level,
dcs[floor(random() * 6 + 1)] as distribution_center,
regions[floor(random() * 4 + 1)] as region
FROM
unnest(brand_names) b,
unnest(variants) v,
unnest(product_types) t,
generate_series(1, 50); -- 10 * 10 * 10 * 50 = 50,000 records
END $$;
Hãy chèn các bản ghi cụ thể về bản minh hoạ để đảm bảo câu trả lời có thể dự đoán cho các câu hỏi theo phong cách điều hành
-- These ensure you have predictable answers for specific "Executive" questions
INSERT INTO products (name, category, stock_level, distribution_center, region) VALUES
('Magnum Ultra Gold Limited Edition', 'Food & Refreshment', 45, 'Rotterdam-Gate', 'EMEA'),
('Dove Pro-Health Deep Moisture', 'Personal Care', 12000, 'Mumbai-Central', 'APAC'),
('Hellmanns Real Organic Mayonnaise', 'Food & Refreshment', 8000, 'London-Hub', 'EMEA');
Chèn dữ liệu về lô hàng
-- Shipments Generation (More shipments than products)
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT
id,
CASE
WHEN random() > 0.8 THEN 'Delayed'
WHEN random() > 0.4 THEN 'In Transit'
ELSE 'Delivered'
END,
NOW() + (random() * 10 || ' days')::interval,
(random() * 0.5 + 0.5)::decimal(3,2)
FROM products
WHERE random() > 0.3; -- Create shipments for ~70% of products
-- Add duplicate shipments for some products to show complex logistics
INSERT INTO shipments (product_id, status, estimated_arrival, route_efficiency_score)
SELECT id, 'In Transit', NOW() + INTERVAL '12 days', 0.88
FROM products
LIMIT 5000;
Cấp quyền
Chạy câu lệnh bên dưới để cấp quyền thực thi cho hàm "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Cấp vai trò Người dùng Vertex AI cho tài khoản dịch vụ AlloyDB
Trên bảng điều khiển IAM của Google Cloud, hãy cấp cho tài khoản dịch vụ AlloyDB (có dạng như sau: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) quyền truy cập vào vai trò "Người dùng Vertex AI". PROJECT_NUMBER sẽ có số dự án của bạn.
Ngoài ra, bạn có thể chạy lệnh bên dưới trong Cloud Shell Terminal:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Tạo vectơ nhúng
Tiếp theo, hãy tạo các vectơ nhúng cho các trường văn bản có ý nghĩa cụ thể:
WITH
rows_to_update AS (
SELECT
id
FROM
products
WHERE
embedding IS NULL
LIMIT
5000 )
UPDATE
products
SET
embedding = ai.embedding('text-embedding-005', name || ' ' || category || ' ' || distribution_center || ' ' || region)::vector
FROM
rows_to_update
WHERE
products.id = rows_to_update.id
AND embedding IS null;
Trong câu lệnh trên, chúng ta đã đặt giới hạn là 5000, vì vậy, hãy nhớ kích hoạt câu lệnh này nhiều lần cho đến khi không còn hàng nào trong bảng có cột nhúng là NULL.
Các lỗi thường gặp và cách khắc phục sự cố
Vòng lặp "Quên mật khẩu" | Nếu bạn sử dụng chế độ thiết lập "Một lần nhấp" và không nhớ mật khẩu, hãy chuyển đến trang Thông tin cơ bản về phiên bản trong bảng điều khiển rồi nhấp vào "Chỉnh sửa" để đặt lại mật khẩu |
Lỗi "Không tìm thấy tiện ích" | Nếu |
Khoảng trống truyền tải IAM | Bạn đã chạy lệnh IAM |
Kích thước vectơ không khớp | Bảng |
Lỗi chính tả mã dự án | Trong lệnh gọi |
5. Thiết lập công cụ và hộp công cụ
Bộ công cụ MCP dành cho cơ sở dữ liệu là một máy chủ MCP nguồn mở dành cho cơ sở dữ liệu. Nhờ đó, bạn có thể phát triển các công cụ dễ dàng, nhanh chóng và an toàn hơn bằng cách xử lý các điểm phức tạp như nhóm kết nối, xác thực và nhiều điểm khác. Toolbox giúp bạn tạo các công cụ AI tạo sinh cho phép các tác nhân truy cập vào dữ liệu trong cơ sở dữ liệu của bạn.
Chúng tôi sử dụng Bộ công cụ Giao thức ngữ cảnh mô hình (MCP) cho cơ sở dữ liệu làm "nhạc trưởng". Đây là một phần mềm trung gian được chuẩn hoá giữa các tác nhân và AlloyDB. Bằng cách xác định cấu hình tools.yaml, hộp công cụ sẽ tự động hiển thị các thao tác phức tạp trên cơ sở dữ liệu dưới dạng các công cụ có thể thực thi rõ ràng như search_products_by_context hoặc check_inventory_levels. Điều này giúp bạn không cần phải gộp kết nối theo cách thủ công hoặc sử dụng SQL nguyên mẫu trong logic của tác nhân.
Cài đặt máy chủ Hộp công cụ
Trong Cloud Shell Terminal, hãy tạo một thư mục để lưu tệp yaml công cụ mới và tệp nhị phân của hộp công cụ:
mkdir scm-agent-toolbox
cd scm-agent-toolbox
Trong thư mục mới đó, hãy chạy tập hợp lệnh sau:
# see releases page for other versions
export VERSION=0.27.0
curl -L -o toolbox https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Tiếp theo, hãy tạo tệp tools.yaml bên trong thư mục mới đó bằng cách chuyển đến Cloud Shell Editor rồi sao chép nội dung của tệp repo này vào tệp tools.yaml.
sources:
supply_chain_db:
kind: "alloydb-postgres"
project: "YOUR_PROJECT_ID"
region: "us-central1"
cluster: "YOUR_CLUSTER"
instance: "YOUR_INSTANCE"
database: "postgres"
user: "postgres"
password: "YOUR_PASSWORD"
tools:
search_products_by_context:
kind: postgres-sql
source: supply_chain_db
description: Find products in the inventory using natural language search and vector embeddings.
parameters:
- name: search_text
type: string
description: Description of the product or category the user is looking for.
statement: |
SELECT name, category, stock_level, distribution_center, region
FROM products
ORDER BY embedding <=> ai.embedding('text-embedding-005', $1)::vector
LIMIT 5;
check_inventory_levels:
kind: postgres-sql
source: supply_chain_db
description: Get precise stock levels for a specific product name.
parameters:
- name: product_name
type: string
description: The exact or partial name of the product.
statement: |
SELECT name, stock_level, distribution_center, last_updated
FROM products
WHERE name ILIKE '%' || $1 || '%'
ORDER BY stock_level DESC;
track_shipment_status:
kind: postgres-sql
source: supply_chain_db
description: Retrieve real-time logistics and shipping status for a specific region or product.
parameters:
- name: region
type: string
description: The geographical region to filter shipments (e.g., EMEA, APAC).
statement: |
SELECT p.name, s.status, s.estimated_arrival, s.route_efficiency_score
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE p.region = $1
ORDER BY s.estimated_arrival ASC;
analyze_supply_chain_risk:
kind: postgres-sql
source: supply_chain_db
description: Rerank and filter shipments based on risk profiles and efficiency scores using Google ML reranker.
parameters:
- name: risk_context
type: string
description: The business context for risk analysis (e.g., 'heatwave impact' or 'port strike').
statement: |
WITH initial_ranking AS (
SELECT s.shipment_id, p.name, s.status, p.distribution_center,
ROW_NUMBER() OVER () AS ref_number
FROM shipments s
JOIN products p ON s.product_id = p.id
WHERE s.status != 'Delivered'
LIMIT 10
),
reranked_results AS (
SELECT index, score FROM
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => $1,
documents => (SELECT ARRAY_AGG(name || ' at ' || distribution_center ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT i.name, i.status, i.distribution_center, r.score
FROM initial_ranking i, reranked_results r
WHERE i.ref_number = r.index
ORDER BY r.score DESC;
toolsets:
supply_chain_toolset:
- search_products_by_context
- check_inventory_levels
- track_shipment_status
- analyze_supply_chain_risk
Bây giờ, hãy kiểm thử tệp tools.yaml trong máy chủ cục bộ:
./toolbox --tools-file "tools.yaml"
Ngoài ra, bạn có thể kiểm thử trong giao diện người dùng
./toolbox --ui
Tuyệt vời!! Sau khi bạn chắc chắn rằng mọi thứ đều hoạt động, hãy triển khai ứng dụng trong Cloud Run như sau.
Triển khai Cloud Run
- Đặt biến môi trường PROJECT_ID:
export PROJECT_ID="my-project-id"
- Khởi động gcloud CLI:
gcloud init
gcloud config set project $PROJECT_ID
- Bạn phải bật các API sau:
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Tạo một tài khoản dịch vụ phụ trợ nếu bạn chưa có:
gcloud iam service-accounts create toolbox-identity
- Cấp quyền sử dụng trình quản lý bí mật:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
- Cấp thêm các quyền cho tài khoản dịch vụ dành riêng cho nguồn AlloyDB của chúng tôi (roles/alloydb.client và roles/serviceusage.serviceUsageConsumer)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role serviceusage.serviceUsageConsumer
- Tải tools.yaml lên dưới dạng một khoá bí mật:
gcloud secrets create tools-scm-agent --data-file=tools.yaml
- Nếu bạn đã có một khoá bí mật và muốn cập nhật phiên bản khoá bí mật, hãy thực thi lệnh sau:
gcloud secrets versions add tools-scm-agent --data-file=tools.yaml
- Đặt một biến môi trường cho hình ảnh vùng chứa mà bạn muốn dùng cho Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Triển khai Toolbox lên Cloud Run bằng lệnh sau:
Nếu bạn đã bật quyền truy cập công khai trong phiên bản AlloyDB (không nên dùng), hãy làm theo lệnh bên dưới để triển khai vào Cloud Run:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
Nếu bạn đang sử dụng mạng VPC, hãy dùng lệnh bên dưới:
gcloud run deploy toolbox-scm-agent \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-scm-agent:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
# TODO(dev): update the following to match your VPC details
--network <<YOUR_NETWORK_NAME>> \
--subnet <<YOUR_SUBNET_NAME>> \
--allow-unauthenticated
6. Thiết lập tác nhân
Bằng Bộ công cụ phát triển tác nhân (ADK), chúng tôi đã chuyển từ các câu lệnh nguyên khối sang một cấu trúc chuyên biệt, nhiều tác nhân:
- InventorySpecialist: Tập trung vào các chỉ số về kho hàng và nhà kho của sản phẩm.
- LogisticsManager: Chuyên gia về các tuyến vận chuyển toàn cầu và phân tích rủi ro.
- GlobalOrchestrator: "Bộ não" sử dụng khả năng suy luận để uỷ quyền các nhiệm vụ và tổng hợp thông tin.
Nhân bản kho lưu trữ này vào dự án của bạn và hãy xem qua kho lưu trữ này.
Để sao chép dự án này, hãy chạy lệnh sau từ Cloud Shell Terminal (trong thư mục gốc hoặc từ bất cứ nơi nào bạn muốn tạo dự án này):
git clone https://github.com/AbiramiSukumaran/scm-memory-agent
- Thao tác này sẽ tạo dự án và bạn có thể xác minh dự án đó trong Cloud Shell Editor.

- Đừng quên cập nhật tệp .env bằng các giá trị cho dự án và phiên bản của bạn.
Hướng dẫn từng bước về mã
Xem nhanh Tác nhân điều phối
Go to app.py and you should be able to see the following snippet:
orchestrator = adk.Agent(
name="GlobalOrchestrator",
model="gemini-2.5-flash",
description="Global Supply Chain Orchestrator root agent.",
instruction="""
You are the Global Supply Chain Brain. You are responsible for products, inventory and logistics.
You also have access to the memory tool, remember to include all the information that the tool can provide you with about the user before you respond.
1. Understand intent and delegate to specialists. As the Global Orchestrator, you have access to the full conversation history with the user.
When you transfer a query to a specialist agent, sub agent or tool, share the important facts and information from your memory to them so they can operate with the full context.
2. Ensure the final response is professional and uses Markdown tables for data.
3. If a specialist provides a long list, ensure only the top 10 items are shown initially.
4. Conclude with a brief, high-level executive summary of what the data implies.
""",
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
sub_agents=[inventory_agent, logistics_agent],
#after_agent_callback=auto_save_session_to_memory_callback,
)
Đoạn mã này là định nghĩa cho gốc là tác nhân điều phối nhận cuộc trò chuyện hoặc yêu cầu từ người dùng và định tuyến đến tác nhân phụ tương ứng hoặc người dùng các công cụ tương ứng dựa trên tác vụ.
- Hãy xem xét tác nhân kho hàng
inventory_agent = adk.Agent(
name="InventorySpecialist",
model="gemini-2.5-flash",
description="Specialist in product stock and warehouse data.",
instruction="""
Analyze inventory levels.
1. Use 'search_products_by_context' or 'check_inventory_levels'.
2. ALWAYS format results as a clean Markdown table.
3. If there are many results, display only the TOP 10 most relevant ones.
4. At the end, state: 'There are additional records available. Would you like to see more?'
""",
tools=tools
)
Trợ lý ảo phụ này chuyên về các hoạt động liên quan đến kho hàng, chẳng hạn như tìm kiếm sản phẩm theo ngữ cảnh và kiểm tra mức tồn kho.
- Sau đó là đại lý phụ về dịch vụ hậu cần:
logistics_agent = adk.Agent(
name="LogisticsManager",
model="gemini-2.5-flash",
description="Expert in global shipping routes and logistics tracking.",
instruction="""
Check shipment statuses.
1. Use 'track_shipment_status' or 'analyze_supply_chain_risk'.
2. ALWAYS format results as a clean Markdown table.
3. Limit initial output to the top 10 shipments.
4. Ask if the user needs the full manifest if more results exist.
""",
tools=tools
)
Trợ lý ảo này chuyên về các hoạt động hậu cần như theo dõi lô hàng và phân tích rủi ro trong chuỗi cung ứng.
- Tất cả 3 tác nhân mà chúng ta đã thảo luận cho đến nay đều sử dụng các công cụ và các công cụ này được tham chiếu thông qua máy chủ Hộp công cụ mà chúng ta đã triển khai trong phần trước. Hãy tham khảo đoạn mã bên dưới:
from toolbox_core import ToolboxSyncClient
TOOLBOX_SERVER = os.environ["TOOLBOX_SERVER"]
TOOLBOX_TOOLSET = os.environ["TOOLBOX_TOOLSET"]
# --- ADK TOOLBOX CONFIGURATION ---
toolbox = ToolboxSyncClient(TOOLBOX_SERVER)
tools = toolbox.load_toolset(TOOLBOX_TOOLSET)
Trợ lý ảo này chuyên về các hoạt động hậu cần như theo dõi lô hàng và phân tích rủi ro trong chuỗi cung ứng.
7. Agent Engine
Trong lần chạy ban đầu, hãy tạo Agent Engine
import vertexai
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
client = vertexai.Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_LOCATION
)
agent_engine = client.agent_engines.create()
- Đối với lần chạy tiếp theo, hãy cập nhật Agent Engine bằng cấu hình Memory Bank:
agent_engine = client.agent_engines.update(
name=APP_NAME,
config={
"context_spec": {
"memory_bank_config": {
"generation_config": {
"model": f"projects/{PROJECT_ID}/locations/{GOOGLE_CLOUD_LOCATION}/publishers/google/models/gemini-2.5-flash"
}
}
}
})
8. Bối cảnh, Thời gian chạy và Bộ nhớ
Hoạt động quản lý bối cảnh được chia thành 2 lớp riêng biệt để đảm bảo rằng tác nhân có cảm giác như một đối tác liên tục thay vì một bot không trạng thái:
Bộ nhớ ngắn hạn (Phiên): Được quản lý thông qua VertexAiSessionService, bộ nhớ này theo dõi nhật ký sự kiện tức thì (tin nhắn của người dùng, câu trả lời của công cụ) trong một lượt tương tác duy nhất.
Bộ nhớ dài hạn (Ngân hàng bộ nhớ): Được hỗ trợ bởi Ngân hàng bộ nhớ Vertex AI thông qua adk.memorybankservice. Lớp này trích xuất thông tin "có ý nghĩa" (chẳng hạn như lựa chọn ưu tiên của người dùng đối với một hãng vận chuyển cụ thể hoặc tình trạng chậm trễ thường xuyên của kho hàng) và duy trì thông tin đó trong các phiên.
Khởi động phiên cho bộ nhớ phiên trong phạm vi cuộc trò chuyện
Đây là phần của đoạn mã tạo phiên cho ứng dụng hiện tại đối với người dùng hiện tại.
from google.adk.sessions import VertexAiSessionService
...
session_service = VertexAiSessionService(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
...
# Initialize the session *outside* of the route handler to avoid repeated creation
session = None
session_lock = threading.Lock()
async def initialize_session():
global session
try:
session = await session_service.create_session(app_name=APP_NAME, user_id=USER_ID)
print(f"Session {session.id} created successfully.") # Add a log
except Exception as e:
print(f"Error creating session: {e}")
session = None # Ensure session is None in case of error
# Create the session on app startup
asyncio.run(initialize_session())
Khởi động Vertex AI Memory Bank cho bộ nhớ dài hạn
Đây là phần của đoạn mã giúp tạo thực thể đối tượng Dịch vụ Vertex AI Memory Bank cho công cụ tác nhân.
from google.adk.memory import InMemoryMemoryService
from google.adk.memory import VertexAiMemoryBankService
...
try:
memory_bank_service = adk.memory.VertexAiMemoryBankService(
agent_engine_id=AGENT_ENGINE_ID,
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
)
#in_memory_service = InMemoryMemoryService()
print("Memory Bank Service initialized successfully.")
except Exception as e:
print(f"Error initializing Memory Bank Service: {e}")
memory_bank_service = None
runner = adk.Runner(
agent=orchestrator,
app_name=APP_NAME,
session_service=session_service,
memory_service=memory_bank_service,
)
...
Những gì đã được định cấu hình?
Trong phần này của đoạn mã, chúng ta đang định cấu hình Dịch vụ Ngân hàng bộ nhớ Vertex AI cho bộ nhớ dài hạn. Dịch vụ này lưu trữ theo ngữ cảnh phiên cho ứng dụng cụ thể cho người dùng cụ thể dưới dạng bộ nhớ trong ngân hàng bộ nhớ Vertex AI.
Những gì được chạy trong quá trình thực thi tác nhân?
async def run_and_collect():
final_text = ""
try:
async for event in runner.run_async(
new_message=content,
user_id=user_id,
session_id=session_id
):
if hasattr(event, 'author') and event.author:
if not any(log['agent'] == event.author for log in execution_logs):
execution_logs.append({
"agent": event.author,
"action": "Analyzing data requirements...",
"type": "orchestration_event"
})
if hasattr(event, 'text') and event.text:
final_text = event.text
elif hasattr(event, 'content') and hasattr(event.content, 'parts'):
for part in event.content.parts:
if hasattr(part, 'text') and part.text:
final_text = part.text
except Exception as e:
print(f"Error during runner.run_async: {e}")
raise # Re-raise the exception to signal failure
finally:
gc.collect()
return final_text
Thao tác này xử lý nội dung đầu vào của người dùng thành đối tượng new_message có mã người dùng và mã phiên trong phạm vi. Sau đó, tác nhân sẽ tiếp quản và phản hồi của tác nhân sẽ được xử lý và trả về.
Bộ nhớ dài hạn lưu trữ những gì?
Thông tin chi tiết về phiên trong phạm vi ứng dụng và người dùng được trích xuất trong biến phiên.
Sau đó, phiên này sẽ được thêm vào bộ nhớ cho người dùng hiện tại của ứng dụng hiện tại của đối tượng Vertex AI Memory Bank bằng phương thức "add_session_to_memory".
session = asyncio.run(session_service.get_session(app_name=APP_NAME, user_id=USER_ID, session_id=session.id))
if memory_bank_service and session: # Check memory service AND session
try:
#asyncio.run(in_memory_service.add_session_to_memory(session))
asyncio.run(memory_bank_service.add_session_to_memory(session))
'''
client.agent_engines.memories.generate(
scope={"app_name": APP_NAME, "user_id": USER_ID},
name=APP_NAME,
direct_contents_source={
"events": [
{"content": content}
]
},
config={"wait_for_completion": True},
)
'''
print("Successfully added session to memory.******")
print(session.id)
except Exception as e:
print(f"Error adding session to memory: {e}")
Truy xuất thông tin trong bộ nhớ
Chúng ta cần truy xuất bộ nhớ dài hạn đã lưu trữ bằng tên ứng dụng và tên người dùng làm phạm vi (vì đó là phạm vi mà chúng ta đã lưu trữ bộ nhớ) để có thể truyền bộ nhớ đó làm một phần của ngữ cảnh cho trình điều phối và các tác nhân khác (nếu có).
results = client.agent_engines.memories.retrieve(
name=APP_NAME,
scope={"app_name": APP_NAME, "user_id": USER_ID}
)
# RetrieveMemories returns a pager. You can use `list` to retrieve all pages' memories.
list(results)
print(list(results))
Bộ nhớ đã truy xuất được tải như thế nào trong bối cảnh?
Chúng tôi sử dụng thuộc tính sau trong định nghĩa của tác nhân Điều phối viên để cho phép tác nhân gốc tải trước ngữ cảnh từ bộ nhớ. Đây là những công cụ bổ sung mà chúng tôi truy cập từ máy chủ hộp công cụ cho các tác nhân phụ.
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()],
Ngữ cảnh gọi lại
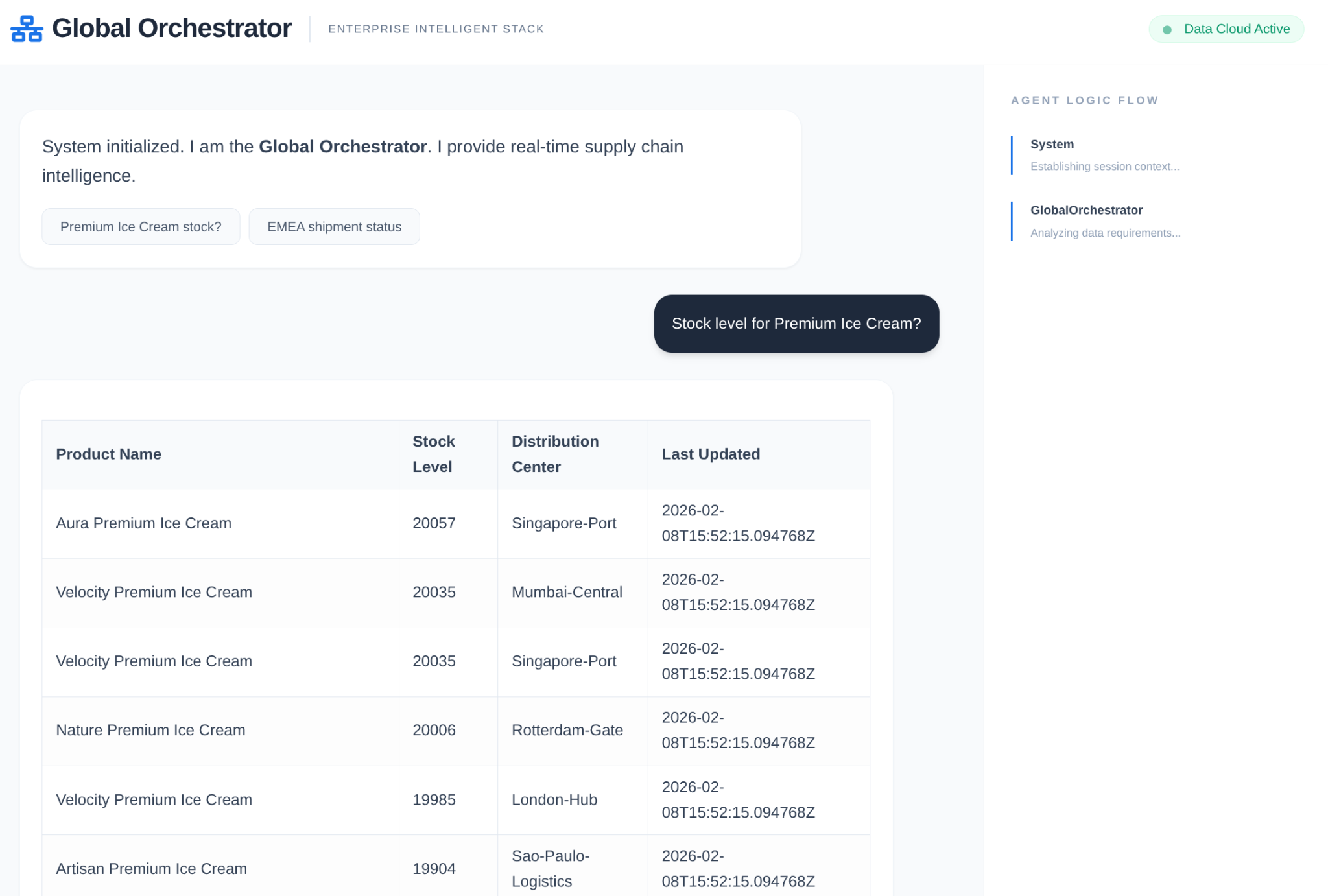
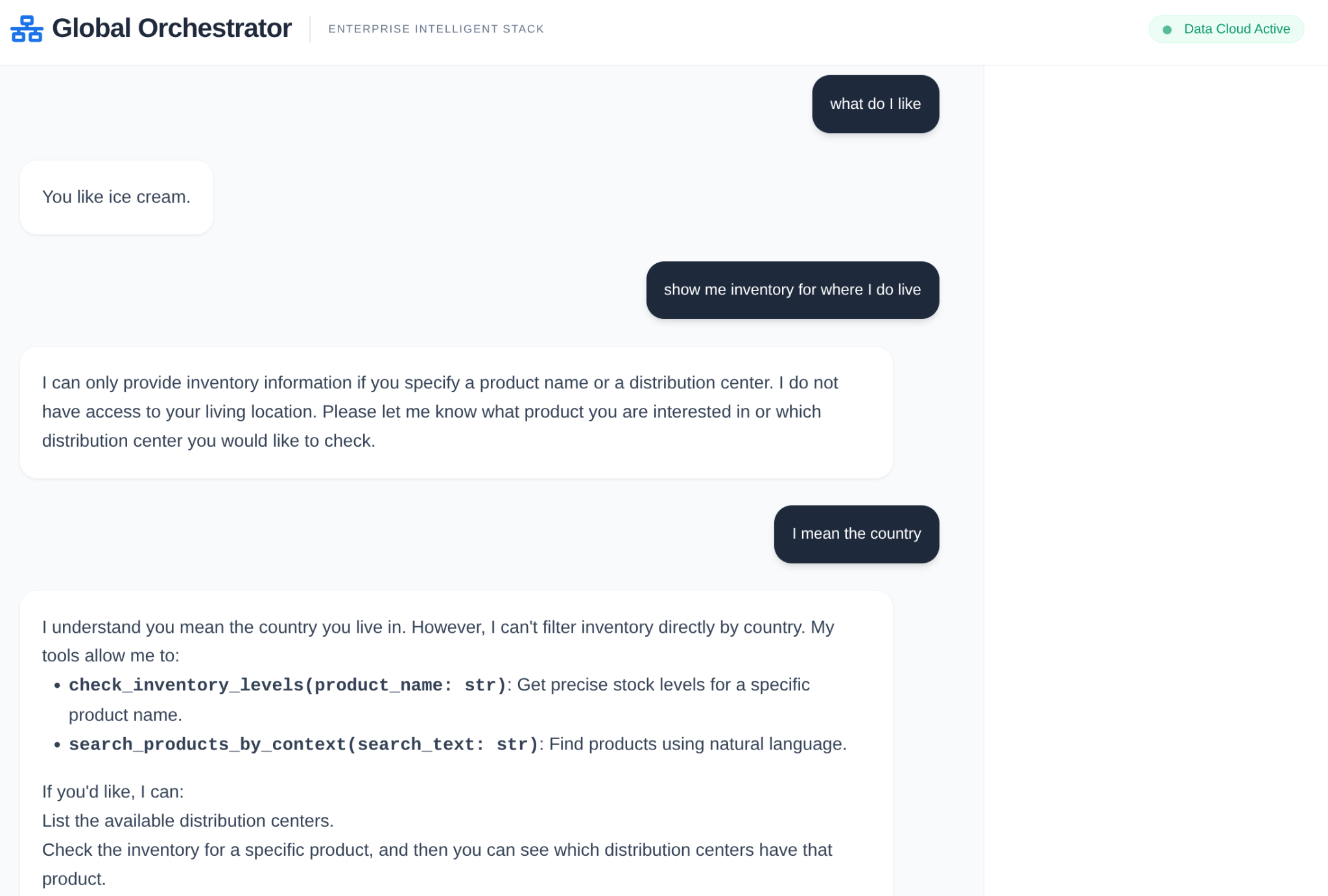
Trong chuỗi cung ứng của doanh nghiệp, bạn không thể có một "hộp đen". Chúng ta sử dụng CallbackContext của ADK để tạo Narrative Engine. Bằng cách kết nối với quá trình thực thi của tác nhân, chúng ta sẽ nắm bắt mọi quy trình suy nghĩ và lệnh gọi công cụ, truyền trực tuyến chúng đến một thanh bên trên giao diện người dùng.
- Sự kiện theo dõi: "GlobalOrchestrator is analyzing data requirements..." (GlobalOrchestrator đang phân tích các yêu cầu về dữ liệu...)
- Sự kiện theo dõi: "Uỷ quyền cho InventorySpecialist về mức tồn kho..."
- Sự kiện theo dõi: "Retrieving historical supplier delay patterns from Memory Bank..." (Đang truy xuất các mẫu độ trễ của nhà cung cấp trước đây từ Ngân hàng bộ nhớ...)
Nhật ký kiểm tra này rất hữu ích cho việc gỡ lỗi và đảm bảo rằng nhân viên vận hành có thể tin tưởng vào các quyết định tự động của trợ lý ảo.
from google.adk.agents.callback_context import CallbackContext
...
# --- ADK CALLBACKS (Narrative Engine) ---
execution_logs = []
async def trace_callback(context: CallbackContext):
"""
Captures agent and tool invocation flow for the UI narrative.
"""
agent_name = context.agent.name
event = {
"agent": agent_name,
"action": "Processing request steps...",
"type": "orchestration_event"
}
execution_logs.append(event)
return None
...
Vậy là xong!!! Chúng ta đã sao chép thành công dự án và xem xét chi tiết về nhân viên hỗ trợ, bộ nhớ và bối cảnh.
Bạn có thể kiểm thử bằng cách chuyển đến thư mục dự án của kho lưu trữ đã sao chép và thực thi các lệnh sau:
>> pip install -r requirements.txt
>> python app.py
Thao tác này sẽ khởi động nhân viên hỗ trợ của bạn trên thiết bị và bạn có thể kiểm thử nhân viên hỗ trợ đó.
9. Hãy triển khai ứng dụng này lên Cloud Run
- Triển khai ứng dụng đó trên Cloud Run bằng cách chạy lệnh sau từ Cloud Shell Terminal (nơi dự án được sao chép) và đảm bảo bạn đang ở trong thư mục gốc của dự án.
Chạy lệnh này trong thiết bị đầu cuối Cloud Shell:
gcloud run deploy supply-chain-agent --source . --platform managed --region us-central1 --allow-unauthenticated --set-env-vars GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT>>,GOOGLE_CLOUD_LOCATION=us-central1,GOOGLE_GENAI_USE_VERTEXAI=TRUE,REASONING_ENGINE_APP_NAME=<<YOUR_APP_ENGINE_URL>>,TOOLBOX_SERVER=<<YOUR_TOOLBOX_SERVER>>,TOOLBOX_TOOLSET=supply_chain_toolset,AGENT_ENGINE_ID=<<YOUR_AGENT_ENGINE_ID>>
Thay thế các giá trị cho phần giữ chỗ <<YOUR_PROJECT>>, <<YOUR_APP_ENGINE_URL>>, <<YOUR_TOOLBOX_SERVER>> và <<YOUR_AGENT_ENGINE_ID>>
Sau khi hoàn tất, lệnh này sẽ xuất ra một URL dịch vụ. Sao chép.
- Cấp vai trò AlloyDB Client cho tài khoản dịch vụ Cloud Run.Điều này cho phép ứng dụng phi máy chủ của bạn tạo đường hầm an toàn vào cơ sở dữ liệu.
Chạy lệnh này trong thiết bị đầu cuối Cloud Shell:
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
Giờ đây, hãy dùng URL dịch vụ (điểm cuối Cloud Run mà bạn đã sao chép trước đó) và kiểm thử ứng dụng.
Lưu ý: Nếu bạn gặp phải vấn đề về dịch vụ và vấn đề đó có liên quan đến bộ nhớ, hãy thử tăng giới hạn bộ nhớ được phân bổ lên 1 GiB để kiểm tra.
10. Dọn dẹp
Sau khi hoàn thành bài thực hành này, đừng quên xoá cụm và phiên bản AlloyDB.
Thao tác này sẽ dọn dẹp cụm cùng với(các) phiên bản của cụm.
11. Xin chúc mừng
Bằng cách kết hợp tốc độ của AlloyDB, hiệu quả điều phối của MCP Toolbox và "bộ nhớ tổ chức" của Vertex AI Memory Bank, chúng tôi đã xây dựng một hệ thống chuỗi cung ứng không ngừng phát triển. Gemini không chỉ trả lời câu hỏi mà còn nhớ rằng nhà kho của bạn ở Singapore luôn gặp phải tình trạng chậm trễ do gió mùa và chủ động đề xuất chuyển hướng các lô hàng trước khi bạn hỏi.