
1. Objectifs de l'atelier
Full Stack Vibe pour les agents IA
Bienvenue ! Vous allez apprendre une nouvelle compétence essentielle dans le développement de logiciels : comment guider efficacement l'intelligence artificielle pour créer, tester et déployer des logiciels de qualité professionnelle. L'IA générative n'est pas un "pilote automatique", mais un copilote puissant qui a besoin d'un réalisateur compétent.
Cet atelier fournit une méthodologie structurée et reproductible pour collaborer avec l'IA à chaque étape du cycle de vie du développement logiciel (SDLC) professionnel. Vous passerez du statut de rédacteur de code ligne par ligne à celui de directeur technique, c'est-à-dire un architecte avec une vision et un entrepreneur général qui utilise l'IA pour exécuter cette vision avec précision. 🚀
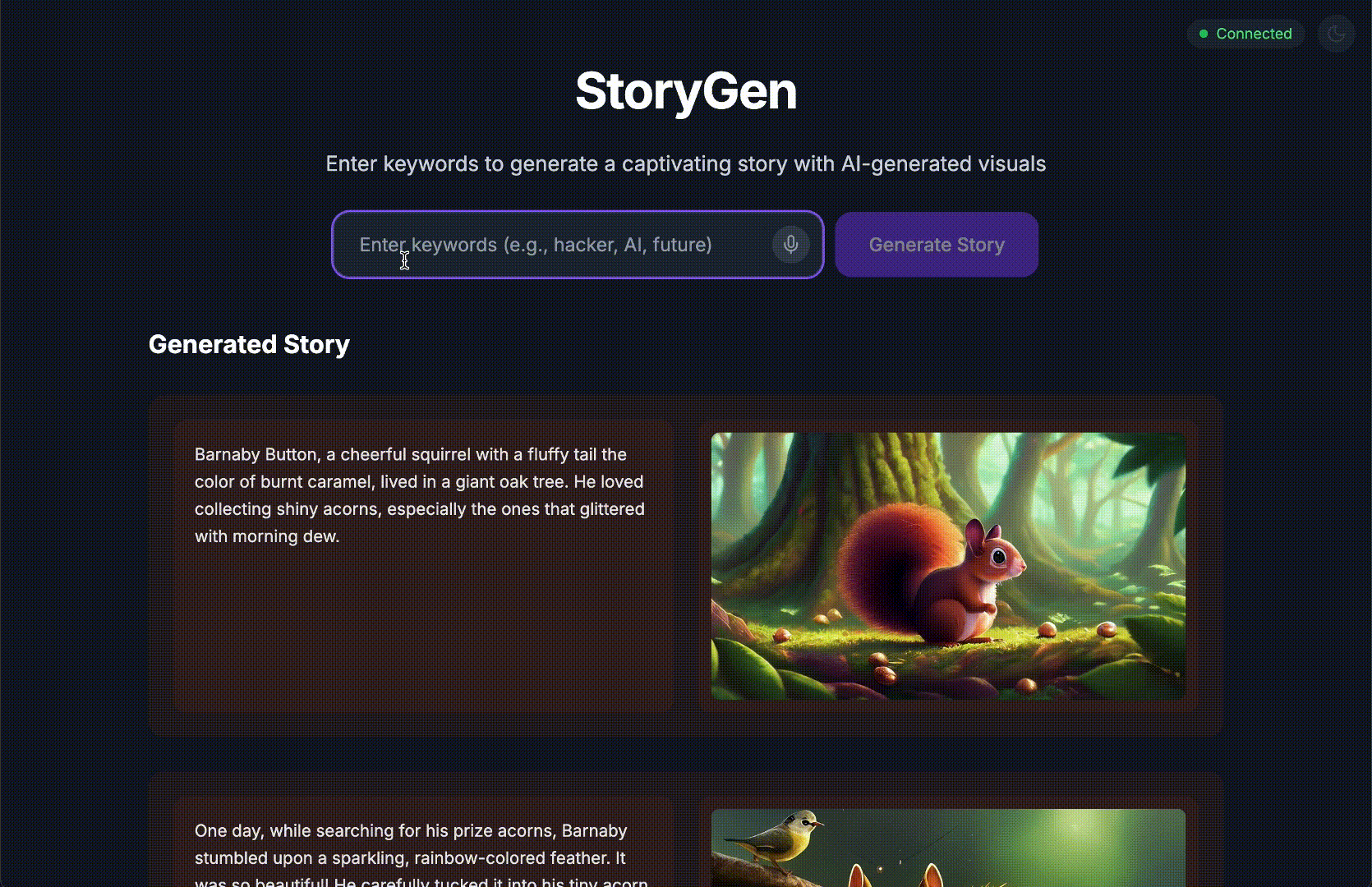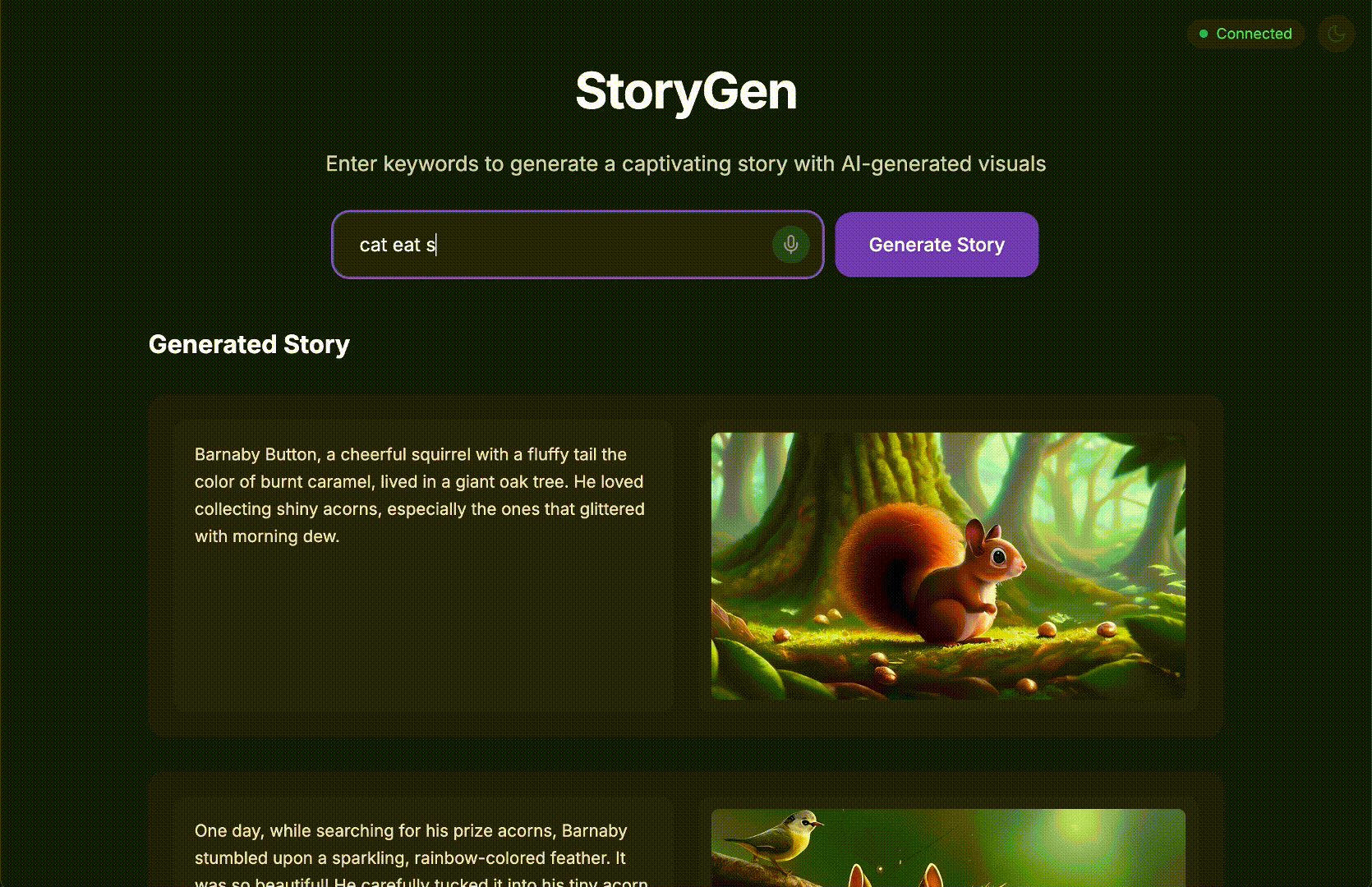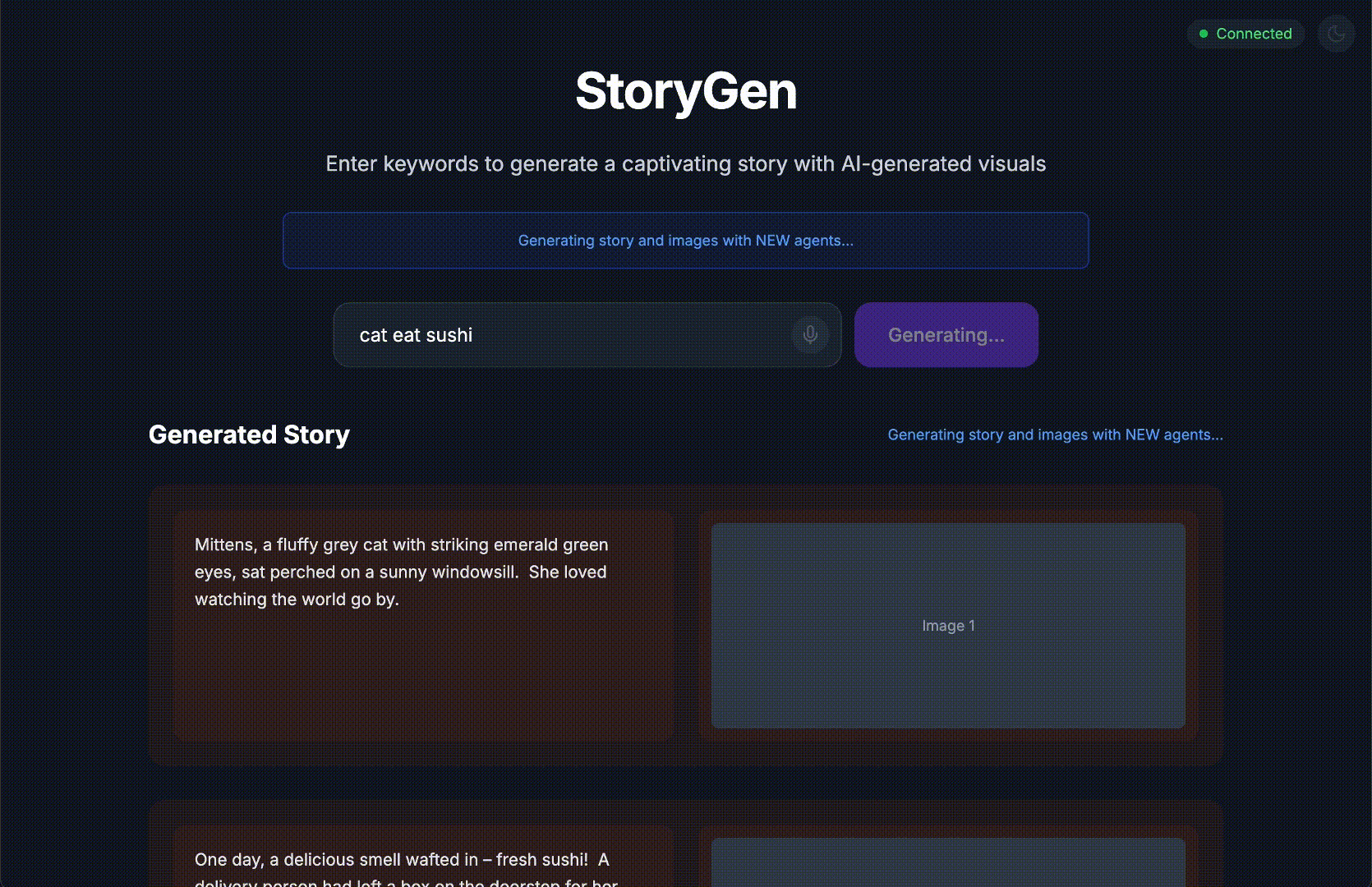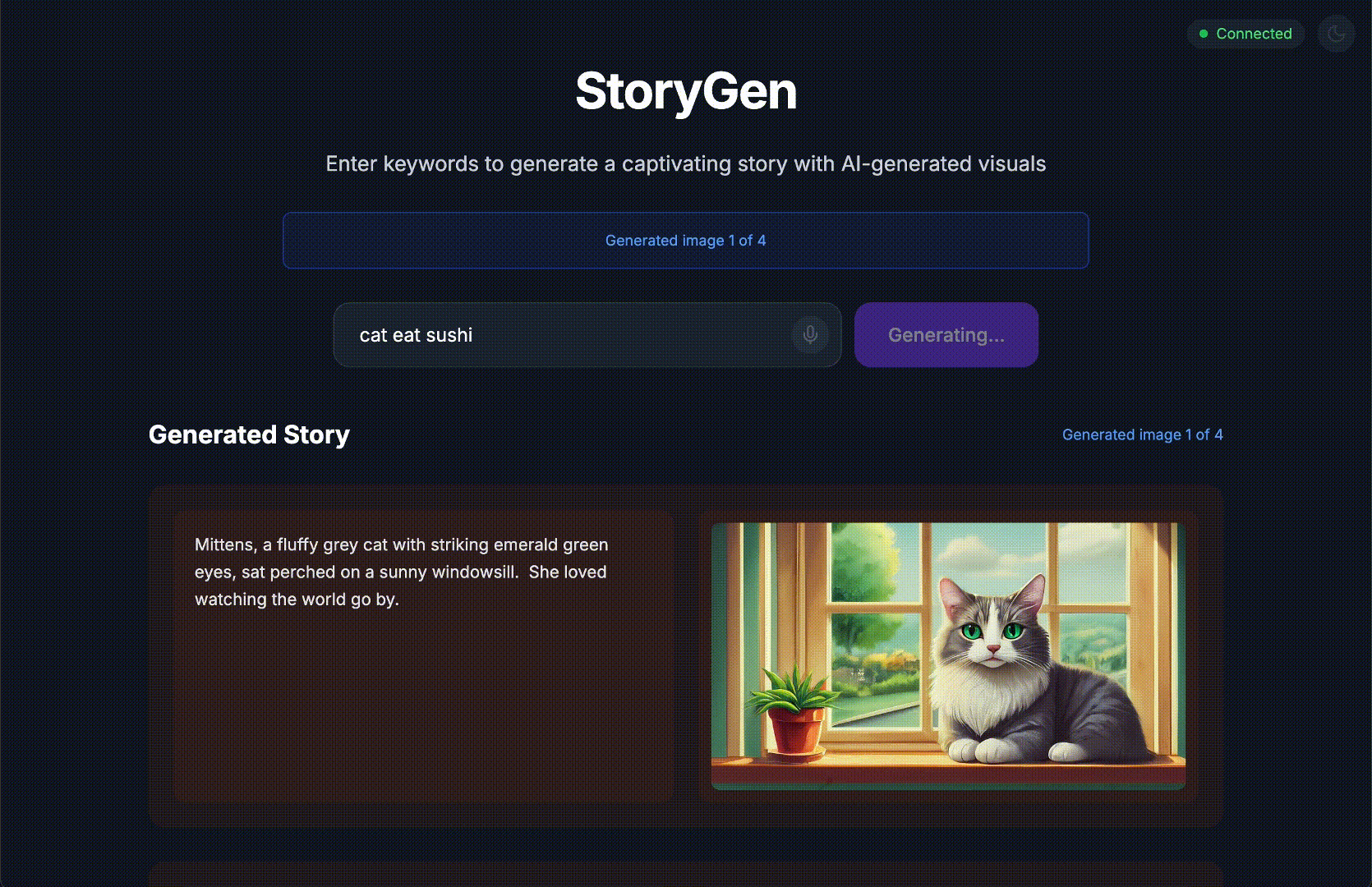
À la fin de ce tutoriel, vous aurez :
- Traduction d'une idée générale en architecture cloud à l'aide de l'IA.
- Génération d'un backend Python complet avec des requêtes ciblées et spécifiques.
- Utilisé l'IA comme assistant en programmation pour déboguer et corriger du code.
- Délégation de la création de tests unitaires, y compris des mocks, à l'IA.
- Générez une infrastructure as code (IaC) prête pour la production avec Terraform.
- Création d'un pipeline CI/CD complet dans GitHub Actions à l'aide d'une seule requête.
- Surveillez et gérez votre application en production à l'aide d'outils opérationnels optimisés par l'IA.
Vous repartirez non seulement avec une application fonctionnelle, mais aussi avec un plan pour le développement augmenté par l'IA. C'est parti !
2. Conditions préalables et configuration
Avant de commencer, préparons votre environnement. Il s'agit d'une étape cruciale pour garantir une expérience fluide lors de l'atelier.
Créer un compte GCP et associer votre facturation
Pour alimenter nos agents d'IA, nous avons besoin de deux éléments : un projet Google Cloud pour fournir la base et une clé API Gemini pour accéder aux puissants modèles de Google.
Étape 1 : Activez le compte de facturation
Pour effectuer cet atelier de programmation, vous avez besoin d'un compte de facturation avec un certain crédit. Utilisez les crédits de la bannière en haut de cet atelier de programmation pour commencer. Si vous êtes déjà associé à un compte de facturation, vous pouvez ignorer cette étape.
Étape 2 : Créer un projet GCP
- Accédez à la console Google Cloud et créez un projet.
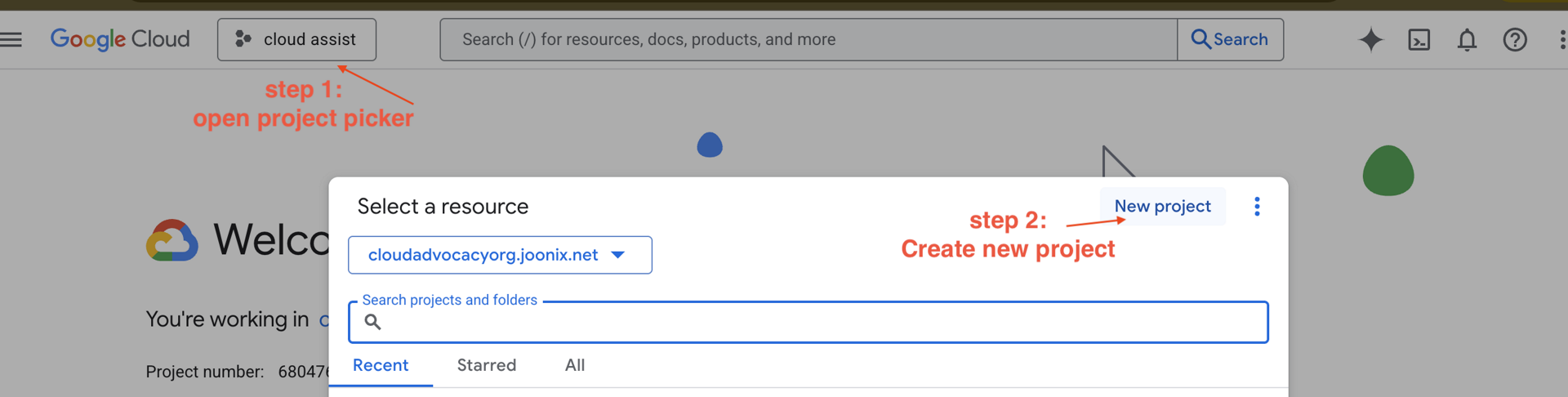
- Ouvrez le panneau de gauche, cliquez sur
Billinget vérifiez si le compte de facturation est associé à ce compte GCP.
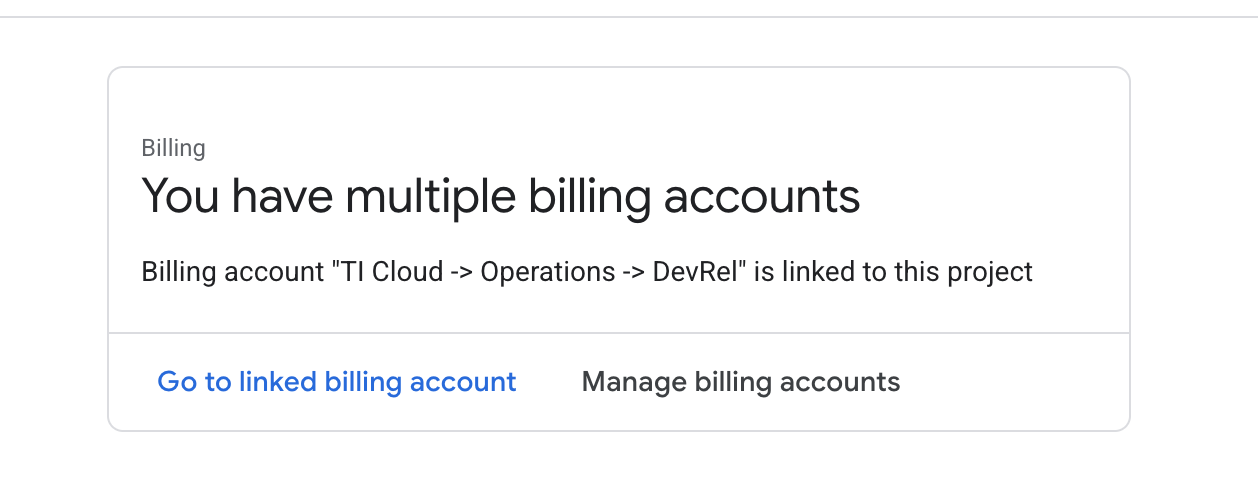
Si cette page s'affiche, cochez la case manage billing account, choisissez l'essai Google Cloud One et associez-le.
Étape 3 : Générez votre clé API Gemini
Avant de pouvoir sécuriser une clé, vous devez en avoir une.
- Accédez à Google AI Studio : https://aistudio.google.com/.
- Connectez-vous avec votre compte Gmail.
- Cliquez sur le bouton Obtenir une clé API, généralement situé dans le volet de navigation de gauche ou en haut à droite.
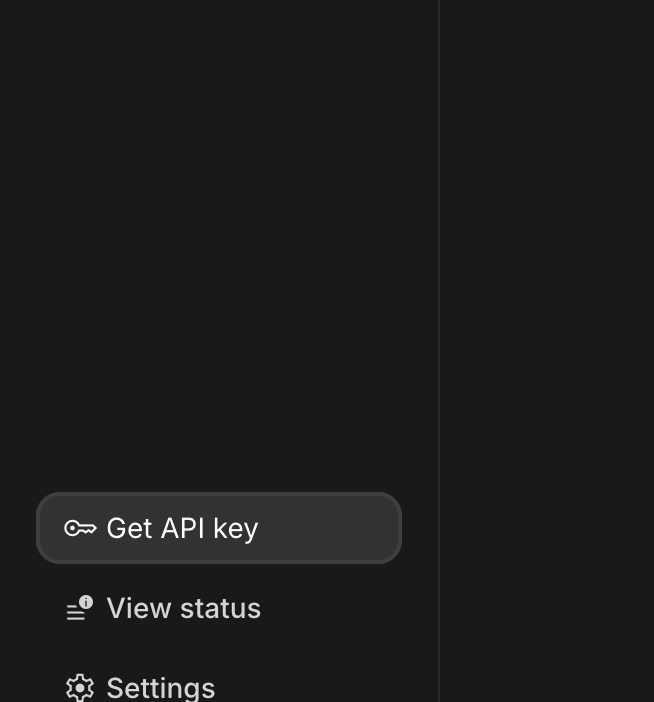
- Dans la boîte de dialogue Clés API, cliquez sur "Créer une clé API dans un nouveau projet".
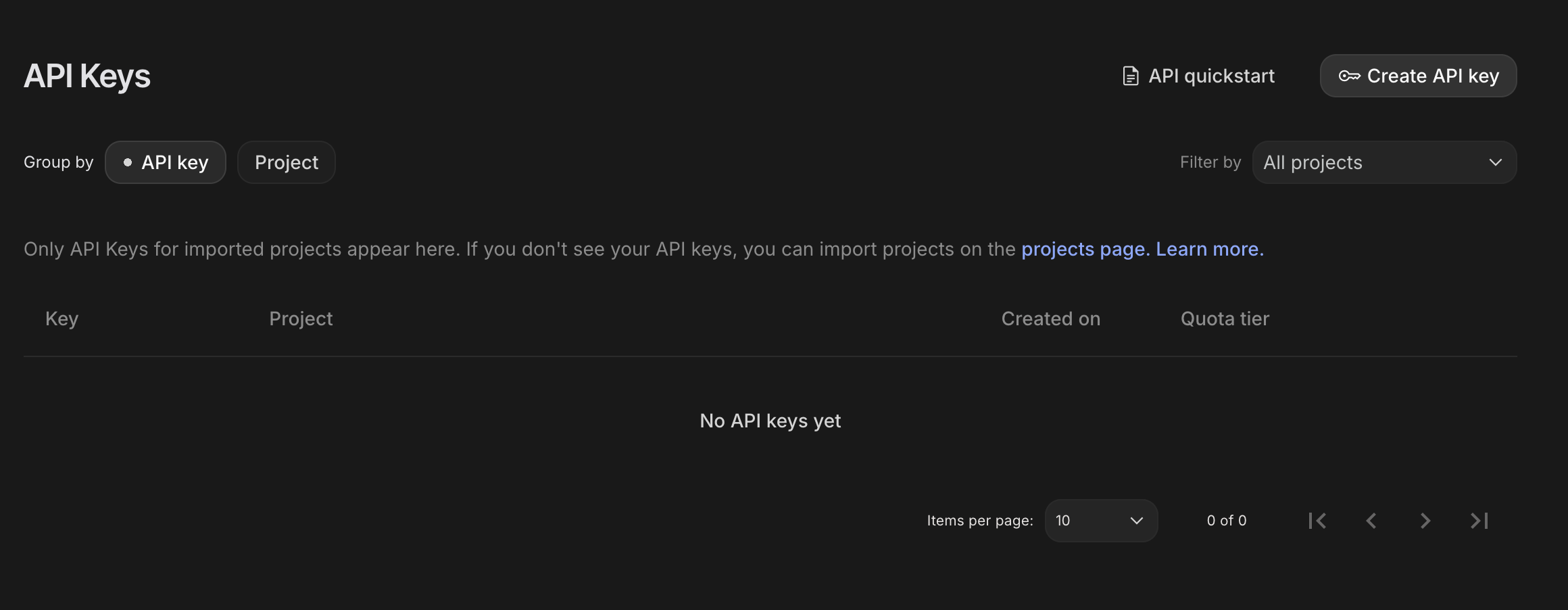
- Choisissez le nouveau projet que vous avez créé et pour lequel vous avez configuré un compte de facturation.
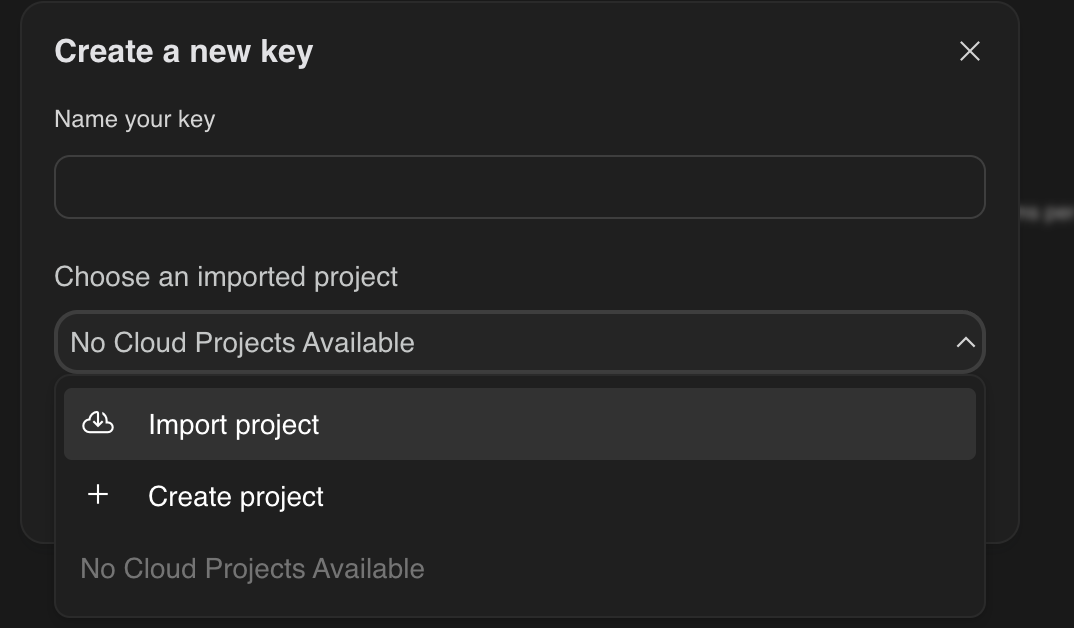
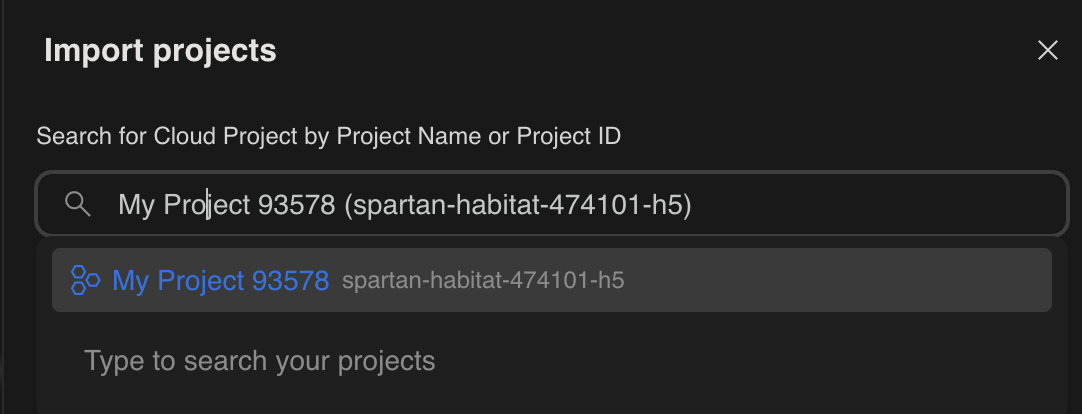
- Une nouvelle clé API sera générée pour vous.
Copiez immédiatement cette clé et stockez-la temporairement dans un endroit sûr (comme un gestionnaire de mots de passe ou une note sécurisée). Il s'agit de la valeur que vous utiliserez dans les étapes suivantes.
Authentification GitHub
Ouvrez Cloud Shell en accédant à la console Google Cloud, puis cliquez sur le bouton "Activer Cloud Shell" en haut à droite.
Étape 1 : Ouvrez Cloud Shell
👉 Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud (icône en forme de terminal en haut du volet Cloud Shell), 
👉 Cliquez sur le bouton "Ouvrir l'éditeur" (icône en forme de dossier ouvert avec un crayon). L'éditeur de code Cloud Shell s'ouvre dans la fenêtre. Un explorateur de fichiers s'affiche sur la gauche. 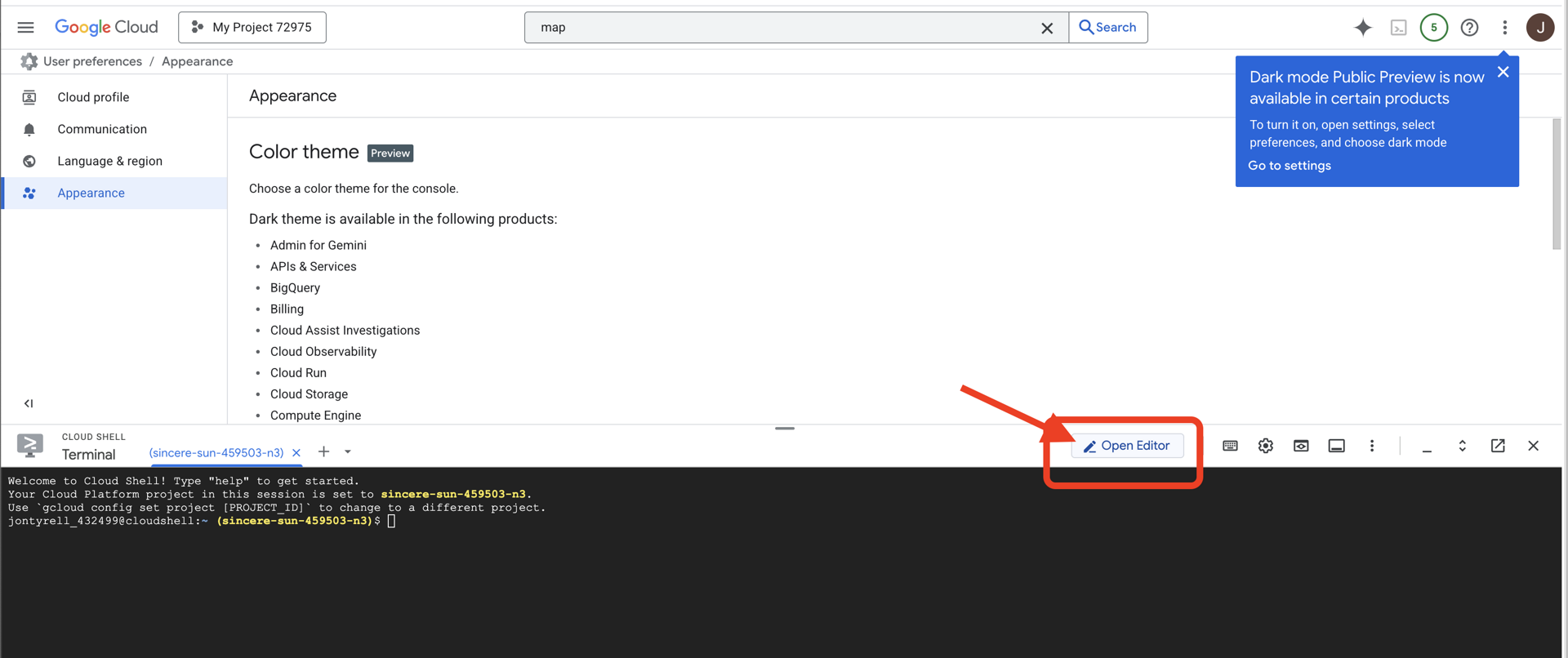
👉 Une fois l'éditeur ouvert, ouvrez le terminal dans l'IDE Cloud.
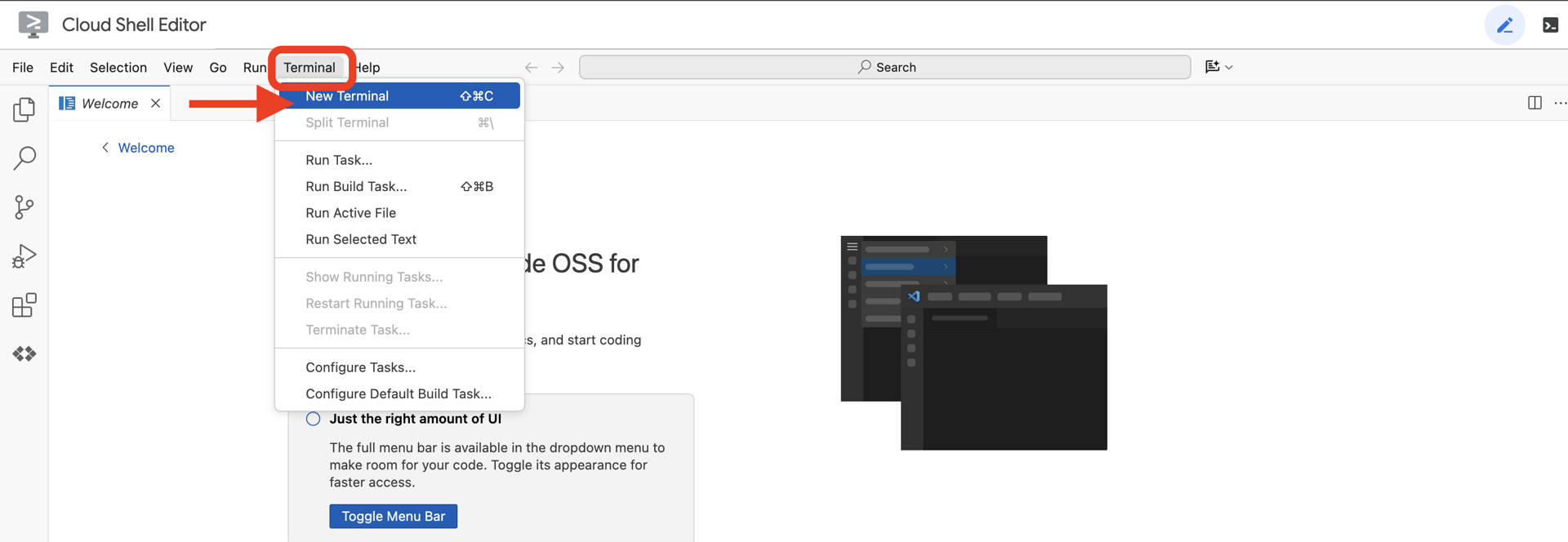
👉💻 Dans le terminal, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
Étape 2 : S'authentifier auprès de GitHub et dupliquer
S'authentifier avec GitHub :
👉💻 Copiez et collez la commande dans votre terminal cloud :
gh auth login
- Dans "Où utilisez-vous GitHub", sélectionnez "GitHub.com".
- "Quel est votre protocole préféré pour les opérations Git sur cet hôte ?", choisissez "HTTPS".
- Sélectionnez "Oui" lorsque vous êtes invité à authentifier Git avec vos identifiants GitHub.
- "Comment souhaitez-vous authentifier GitHub CLI ?", sélectionnez "Se connecter avec un navigateur Web".
Important : n'appuyez pas encore sur "Entrée"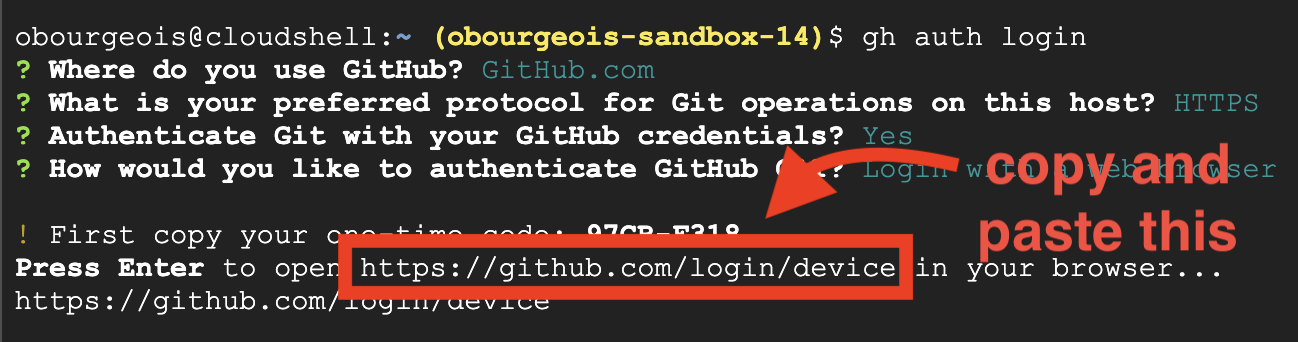
copier le code du terminal sur la page de validation de la connexion ;
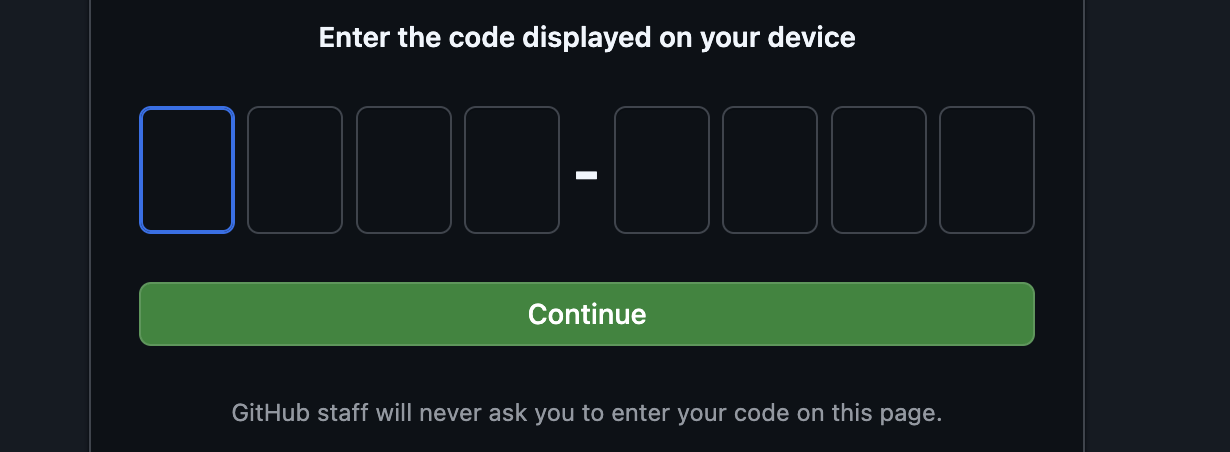
Une fois le code saisi, revenez à votre terminal Cloud Shell, puis appuyez sur "Entrée" pour continuer.

Étape 4 : Fork et clone du dépôt :
👉💻 Copiez et collez la commande dans votre terminal cloud :
gh repo fork cuppibla/storygen-learning --clone=true
3. Architecture : de l'idée au plan avec Cloud Assist
Tout grand projet commence par une vision claire. Nous allons utiliser notre copilote d'IA, Cloud Assist, pour concevoir l'architecture de notre application.
Actions
- Ouvrez la console Google Cloud : [https://console.cloud.google.com](console Google Cloud)
- En haut à droite, cliquez sur "Ouvrir le chat Cloud Assist".
Activer Cloud Assist
- Cliquez sur
Get Gemini Assist, puis surEnable Cloud Assist at no cost. - Commencez à discuter !
 Fournissez le prompt détaillé suivant à Cloud Assist :
Fournissez le prompt détaillé suivant à Cloud Assist :
Saisissez votre idée
Generate a Python web application that uses AI to generate children's stories and illustrations. It has Python backend and React frontend host separately on Cloudrun. They communicate through Websocket. It needs to use a generative model for text and another for images. The generated images must be used by Imagen from Vertex AI and stored in a Google Cloud Storage bucket so that frontend can fetch from the bucket to render images. I do not want any load balancer or a database for the story text. We need a solution to store the API key.
Obtenir le plan de votre application
- Cliquez sur "Modifier la conception de l'application" pour afficher le diagramme. Cliquez sur le panneau en haut à droite "<> Obtenir le code" pour télécharger le code Terraform.
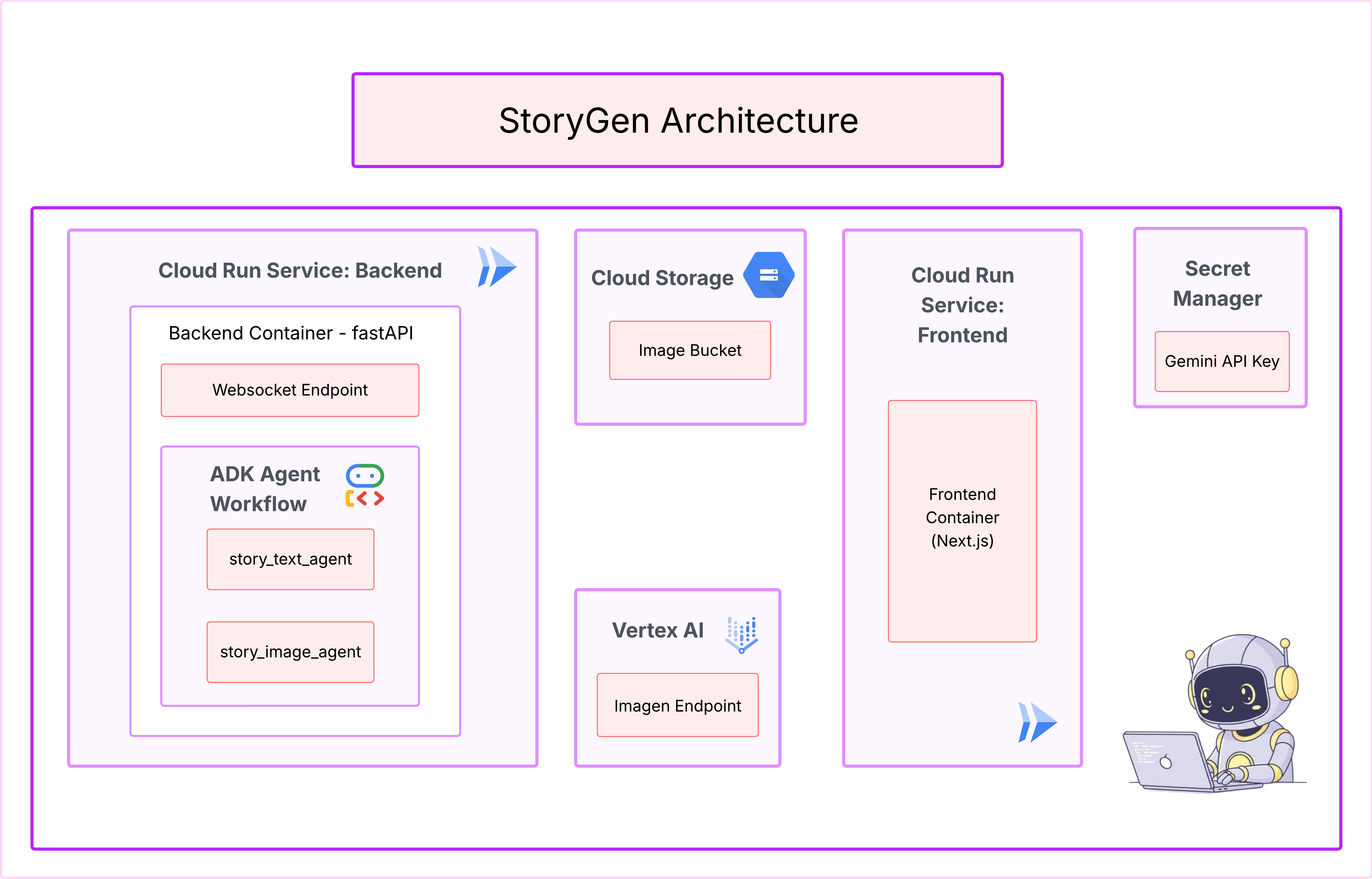
- Cloud Assist génère un schéma d'architecture. Voici notre plan visuel.
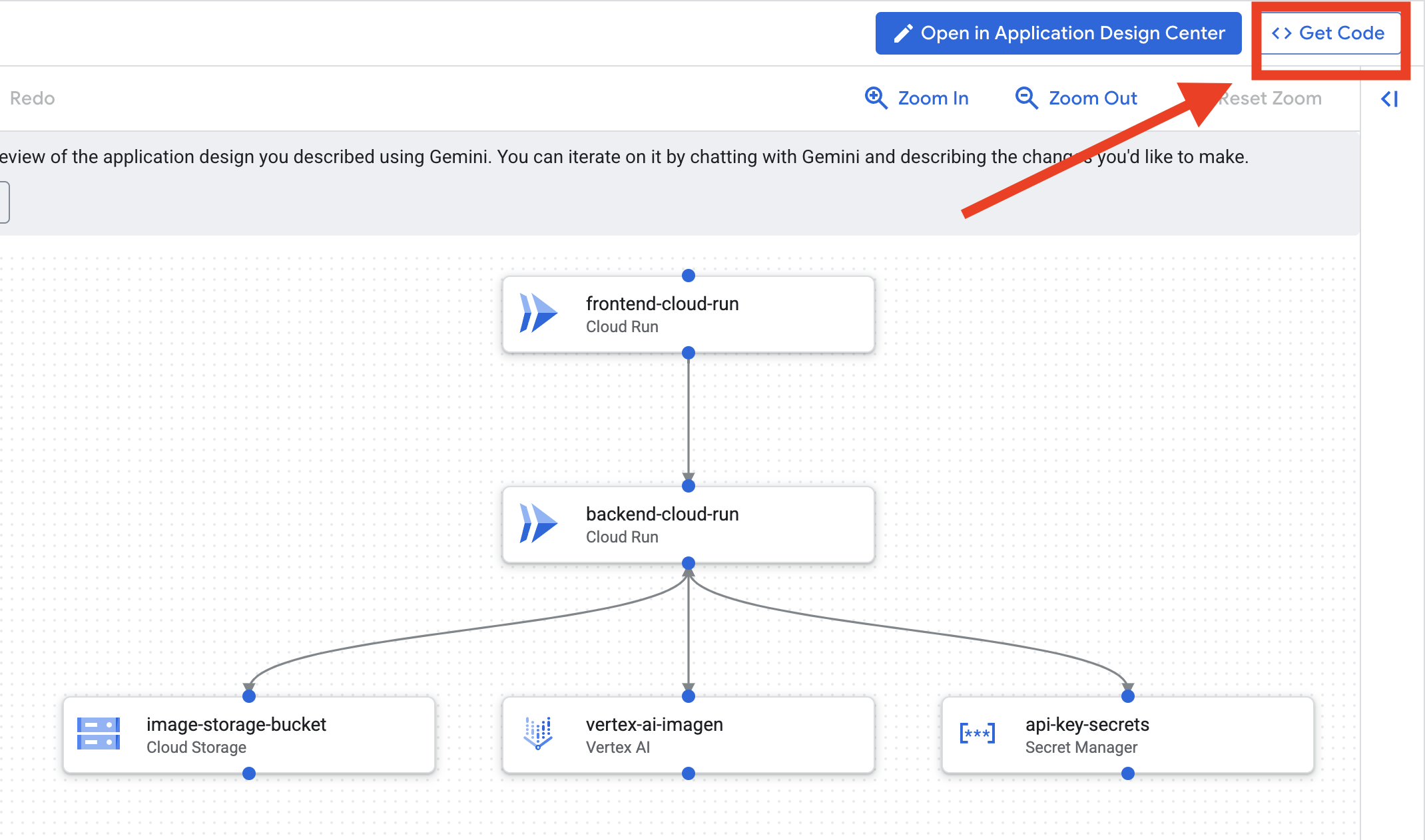
Aucune action n'est requise avec ce code. Pour en savoir plus, consultez les informations ci-dessous.
Comprendre le code Terraform généré Vous venez de recevoir un ensemble complet de fichiers Terraform de la part de Cloud Assist. Aucune action n'est requise pour le moment avec ce code, mais examinons rapidement ce qu'il est et pourquoi il est si puissant.
Qu'est-ce que Terraform ? Terraform est un outil Infrastructure as Code (IaC). Considérez-le comme un plan de votre environnement cloud, écrit en code. Au lieu de cliquer manuellement dans la console Google Cloud pour créer des services, du stockage et des autorisations, vous définissez toutes ces ressources dans ces fichiers de configuration. Terraform lit ensuite votre plan et crée automatiquement l'environnement exact.
Du plan visuel au code exécutable. Le schéma d'architecture fourni par Cloud Assist est votre plan visuel. Le code Terraform est la version lisible par machine de ce même plan. Il s'agit du lien essentiel qui transforme un concept de conception en une réalité reproductible et automatisée. En définissant votre infrastructure dans le code, vous pouvez :
- Création automatisée : créez le même environnement de manière fiable, encore et encore.
- Utilisez le contrôle des versions : suivez les modifications apportées à votre infrastructure dans Git, comme vous le faites pour le code de votre application.
- Évitez les erreurs : évitez les erreurs manuelles qui peuvent se produire lorsque vous cliquez sur une interface Web.
Pour cet atelier, vous n'aurez pas besoin d'exécuter vous-même ce code Terraform. Considérez-le comme le plan professionnel (la "clé de réponse") de l'infrastructure que vous allez créer et déployer dans les prochaines étapes.
4. Développement : présentation de Gemini CLI
👉💻 Dans votre terminal Cloud Shell, accédez à votre répertoire personnel.
cd ~/storygen-learning
👉 💻 Essayez Gemini pour la première fois.
clear
gemini --model=gemini-2.5-flash
Si vous êtes invité à Do you want to connect Cloud Shell editor to Gemini CLI?, sélectionnez NON.
👉✨ Chaque outil Gemini comporte une description. Lisez-les dès maintenant. Dans le prompt Gemini, saisissez :
Dans Gemini CLI
/help
👉✨ La CLI Gemini possède son propre ensemble de capacités intégrées. Pour les inspecter :
Dans Gemini CLI
/tools
Une liste s'affiche, incluant ReadFile, WriteFile et GoogleSearch. Il s'agit des techniques par défaut que vous pouvez utiliser sans avoir à puiser dans un arsenal externe.
👉✨ La lame Gemini peut contenir une "conscience tactique" (contexte) pour guider ses actions.
Dans Gemini CLI
/memory show
Il est actuellement vide.
👉✨ Commencez par ajouter un persona à la mémoire de l'agent. Cela définira son domaine d'expertise :
Dans Gemini CLI
/memory add "I am master at python development"
Exécutez /memory show à nouveau pour confirmer que votre lame a assimilé ces connaissances.
👉✨ Pour vous montrer comment référencer des fichiers avec le symbole @, commençons par créer un fichier "mission brief" (brief de mission).
Ouvrez un nouveau terminal et exécutez la commande suivante pour créer votre fichier de mission :
!echo "## Mission Objective: Create Imagen ADK Agent for Story Book" > mission.md
👉✨ Maintenant, demandez à Gemini CLI d'analyser le brief et de vous faire part de ses conclusions :
Dans Gemini CLI
Explain the contents of the file @mission.md
Votre arme principale connaît désormais son objectif.
👉💻 Appuyez deux fois sur Ctrl+C pour quitter Gemini CLI.
Apprentissage :
Comment Gemini CLI obtient ses superpouvoirs : gemini.md Avant de continuer, il est important de comprendre comment Gemini CLI peut être adapté à un projet spécifique. Bien que vous puissiez l'utiliser comme outil de chat à usage général, sa véritable puissance réside dans un fichier de configuration spécial : gemini.md.
Lorsque vous exécutez la commande gemini, elle recherche automatiquement un fichier gemini.md dans le répertoire actuel. Ce fichier sert de manuel d'instructions spécifique au projet pour l'IA. Il peut définir trois éléments clés :
- Persona : vous pouvez indiquer à l'IA qui elle doit être. Par exemple : "Tu es un développeur Python expert spécialisé dans Google Cloud." Cela permet de concentrer ses réponses et son style.
- Outils : vous pouvez lui donner accès à des fichiers spécifiques (@file.py) ou même à des recherches Google (@google). L'IA dispose ainsi du contexte dont elle a besoin pour répondre aux questions sur le code de votre projet.
- Mémoire : vous pouvez fournir des faits ou des règles que l'IA doit toujours mémoriser pour ce projet, ce qui permet de maintenir la cohérence.
En utilisant un fichier gemini.md, vous transformez le modèle Gemini générique en un assistant spécialisé qui est déjà informé des objectifs de votre projet et qui a accès aux bonnes informations.
5. Développement : créer l'ADK avec Gemini CLI
Configuration de l'environnement
Accédez à votre Cloud Shell, puis cliquez sur le bouton "Ouvrir le terminal".
- Copiez le modèle d'environnement :
cd ~/storygen-learning cp ~/storygen-learning/env.template ~/storygen-learning/.env
Afficher le fichier caché dans l'éditeur si vous ne trouvez pas .env
- Cliquez sur Afficher dans la barre de menu supérieure.
- Sélectionnez Toggle Hidden Files (Activer/Désactiver les fichiers cachés).
👉 Trouvez votre ID de projet Google Cloud :
- Ouvrez la console Google Cloud : lien.
- Sélectionnez le projet que vous souhaitez utiliser pour cet atelier dans le menu déroulant en haut de la page.
- L'ID de votre projet est affiché dans la fiche "Informations sur le projet" du tableau de bord.
👉 Trouvez votre nom d'utilisateur GitHub :
- Accédez à votre compte GitHub et trouvez votre nom d'utilisateur GitHub.
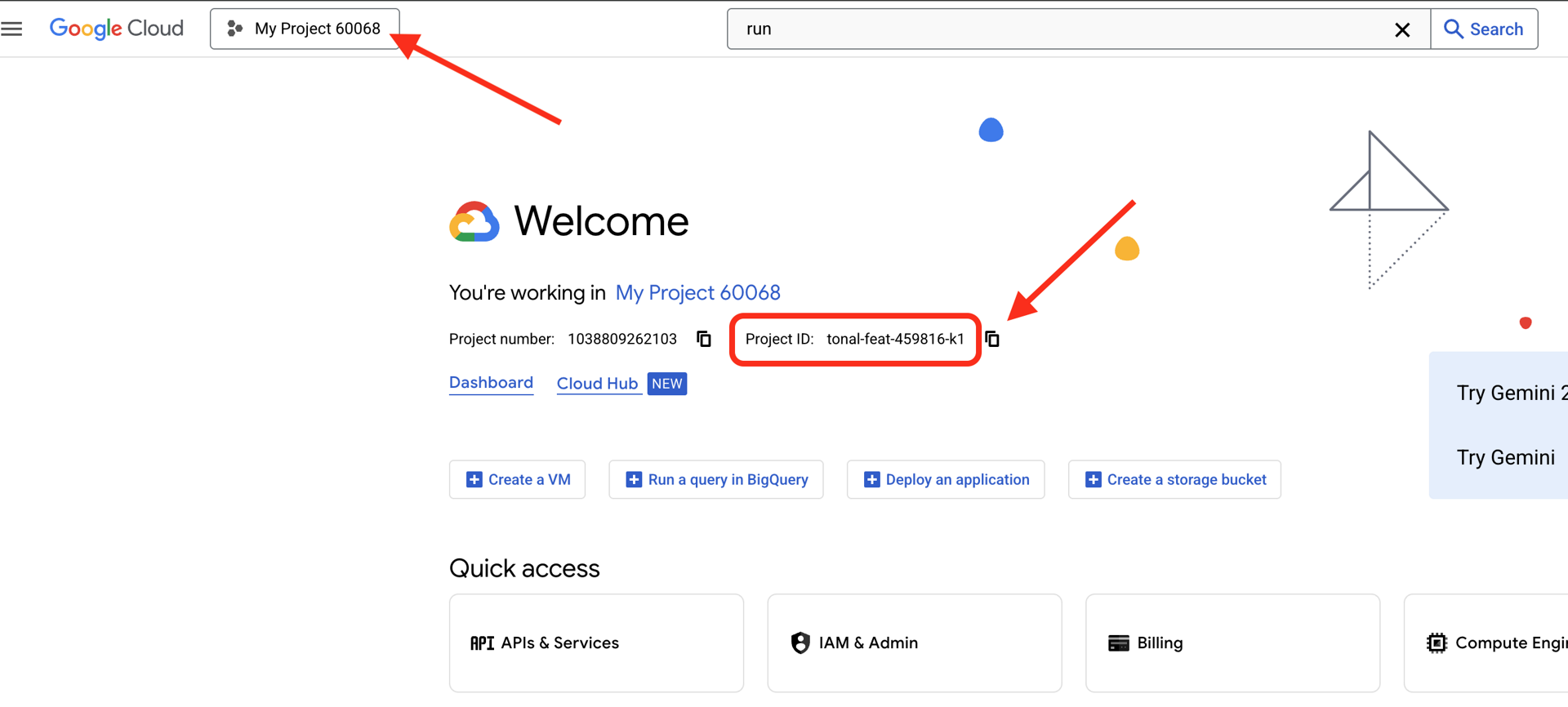
Modifier le fichier .env 2. Remplacez les valeurs suivantes dans .env :
GOOGLE_API_KEY=[REPLACE YOUR API KEY HERE]
GOOGLE_CLOUD_PROJECT_ID=[REPLACE YOUR PROJECT ID]
GITHUB_USERNAME=[REPLACE YOUR USERNAME]
GENMEDIA_BUCKET=[REPLACE YOUR PROJECT ID]-bucket
Par exemple, si votre ID de projet est testproject, vous devez saisir GOOGLE_CLOUD_PROJECT_ID=testproject et GENMEDIA_BUCKET=testproject-bucket.
Scripts de configuration
Accédez à 00_Starting_Here Ouvrez un nouveau terminal (pas dans Gemini CLI).
cd ~/storygen-learning/00_Starting_Here
Exécutez la configuration complète :
./setup-complete.sh
Les résultats de la configuration devraient s'afficher dans le terminal.
Créer votre premier agent
Accédez à 01a_First_Agent_Ready. Utilisons Gemini CLI pour créer l'agent ADK :
cd ~/storygen-learning/01a_First_Agent_Ready
Ouvrir Gemini CLI
gemini
Dans la fenêtre Gemini CLI, essayez le prompt suivant :
I need you to help me create a Google ADK (Agent Development Kit) agent for story generation. I'm working on a children's storybook app that generates creative stories with visual scenes.
Please create a complete `agent.py` file that implements an LlmAgent using Google's ADK framework. The agent should:
**Requirements:**
1. Use the `google.adk.agents.LlmAgent` class
2. Use the "gemini-2.5-flash" model (supports streaming)
3. Be named "story_agent"
4. Generate structured stories with exactly 4 scenes each
5. Output valid JSON with story text, main characters, and scene data
6. No tools needed (images are handled separately)
**Agent Specifications:**
- **Model:** gemini-2.5-flash
- **Name:** story_agent
- **Description:** "Generates creative short stories and accompanying visual keyframes based on user-provided keywords and themes."
**Story Structure Required:**
- Exactly 4 scenes: Setup → Inciting Incident → Climax → Resolution
- 100-200 words total
- Simple, charming language for all audiences
- Natural keyword integration
**JSON Output Format:**
{
"story": "Complete story text...",
"main_characters": [
{
"name": "Character Name",
"description": "VERY detailed visual description with specific colors, features, size, etc."
}
],
"scenes": [
{
"index": 1,
"title": "The Setup",
"description": "Scene action and setting WITHOUT character descriptions",
"text": "Story text for this scene"
}
// ... 3 more scenes
]
}
**Key Instructions for the Agent:**
- Extract 1-2 main characters maximum
- Character descriptions should be extremely detailed and visual
- Scene descriptions focus on ACTION and SETTING only
- Do NOT repeat character appearance in scene descriptions
- Always respond with valid JSON
Please include a complete example in the instructions showing the exact format using keywords like "tiny robot", "lost kitten", "rainy city".
The file should start with necessary imports, define an empty tools list, include a print statement for initialization, and then create the LlmAgent with all the detailed instructions.
Can you create this agent in backend/story_agent/agent.py
Une fois terminé, désactivez le terminal Gemini CLI avec Control+C.
—————————————— Facultatif, vous pouvez passer à la section Solution——————————————–
Vérifiez maintenant votre modification dans ADK Web.
cd ~/storygen-learning/01a_First_Agent_Ready/backend
source ../../.venv/bin/activate
adk web --port 8080
Pour continuer, vous aurez besoin d'une invite de commande.
Lancer le site Web
cd ~/storygen-learning/01a_First_Agent_Ready
./start.sh
Si votre modification ne fonctionne pas, vous devriez voir des erreurs dans l'interface utilisateur Web de l'ADK et sur le site Web.
—————————————— Solution à partir d'ici ——————————————–
Solution
Mettez fin au processus précédent avec Control+C ou ouvrez un autre terminal :
cd ~/storygen-learning/01b_First_Agent_Done
Lancer le site Web :
./start.sh
Le site Web s'affiche :
Essayez l'UI ADK : ouvrez un autre terminal :
cd ~/storygen-learning/01b_First_Agent_Done/backend
source ../../.venv/bin/activate
adk web --port 8080
L'UI ADK s'affiche, et vous pouvez y poser des questions à l'agent.
Avant de passer à la section suivante, appuyez sur Ctrl+C pour mettre fin au processus.
6. Développement : créer ADK avec Gemini CLI (approche d'ingénierie contextuelle)
Configuration initiale
Assurez-vous de supprimer le fichier d'agent que nous avons généré précédemment dans 01a_First_Agent_Ready/backend/story_agent/agent.py :
Accédez à 01a_First_Agent_Ready. Utilisons Gemini CLI pour créer l'agent ADK :
cd ~/storygen-learning/01a_First_Agent_Ready/backend
Ouvrir Gemini CLI
gemini
Dans la fenêtre Gemini CLI, essayez le prompt suivant :
Summarize the design doc @design.md for me, do not attempt to create file just yet.
👉💻 Quittez Gemini pendant un instant en appuyant deux fois sur Ctrl+C.
👉💻 Dans votre terminal, exécutez la commande suivante pour écrire le fichier de consignes.
cat << 'EOF' > GEMINI.md
### **Coding Guidelines**
**1. Python Best Practices:**
* **Type Hinting:** All function and method signatures should include type hints for arguments and return values.
* **Docstrings:** Every module, class, and function should have a docstring explaining its purpose, arguments, and return value, following a consistent format like reStructuredText or
Google Style.
* **Linter & Formatter:** Use a linter like `ruff` or `pylint` and a code formatter like `black` to enforce a consistent style and catch potential errors.
* **Imports:** Organize imports into three groups: standard library, third-party libraries, and local application imports. Sort them alphabetically within each group.
* **Naming Conventions:**
* `snake_case` for variables, functions, and methods.
* `PascalCase` for classes.
* `UPPER_SNAKE_CASE` for constants.
* **Dependency Management:** All Python dependencies must be listed in a `requirements.txt` file.
**2. Web APIs (FastAPI):**
* **Data Validation:** Use `pydantic` models for request and response data validation.
* **Dependency Injection:** Utilize FastAPI's dependency injection system for managing resources like database connections.
* **Error Handling:** Implement centralized error handling using middleware or exception handlers.
* **Asynchronous Code:** Use `async` and `await` for I/O-bound operations to improve performance.
EOF
cat GEMINI.md
Maintenant que les lois sont inscrites, invoquons à nouveau notre partenaire IA et observons la magie de l'artefact.
👉💻 Relancez la CLI Gemini depuis le répertoire shadowblade :
cd ~/storygen-learning/01a_First_Agent_Ready/backend
clear
gemini
👉✨ Demandez maintenant à Gemini de vous montrer ce à quoi il pense. Les runes ont été lues.
/memory show
👉✨ Il s'agit de la seule et unique commande puissante qui construira votre agent. Émettez-le maintenant :
You are an expert Python developer specializing in the Google Agent Development Kit (ADK). Your task is to write the complete, production-quality code for `agent.py` by following the technical specifications outlined in the provided design document verbatim.
Analyze the design document at `@design.md` and generate the corresponding Python code for `agent.py`.
I need you to generate a Python script based on the provided design document and reference examples. Follow these requirements:
Read the design document carefully - it contains the complete technical specification for the code you need to write
Follow the structure and patterns shown in the reference context files
Adhere to all Python best practices specified in the coding standards document
Implement every requirement mentioned in the design document exactly as specified
Use the exact variable names, function names, and string values mentioned in the specifications
The design document describes the complete architecture, dependencies, configuration, and logic flow. Your generated code must match these specifications precisely while following professional Python coding standards.
Generate clean, production-ready Python code that can be used immediately without modifications.
Une fois terminé, désactivez le terminal Gemini CLI avec Control+C.
—————————————— Facultatif, vous pouvez passer à la section Solution——————————————–
Vérifiez maintenant votre modification dans ADK Web.
cd ~/storygen-learning/01a_First_Agent_Ready/backend
source ../../.venv/bin/activate
adk web --port 8080
Pour continuer, vous aurez besoin d'une invite de commande.
Lancer le site Web
cd ~/storygen-learning/01a_First_Agent_Ready
./start.sh
Si votre modification ne fonctionne pas, vous devriez voir des erreurs dans l'interface utilisateur Web de l'ADK et sur le site Web.
—————————————— Solution à partir d'ici ——————————————–
Solution
Mettez fin au processus précédent avec Control+C ou ouvrez un autre terminal :
cd ~/storygen-learning/01b_First_Agent_Done
Lancer le site Web :
./start.sh
Le site Web s'affiche :
Essayez l'UI ADK : ouvrez un autre terminal :
cd ~/storygen-learning/01b_First_Agent_Done/backend
source ../../.venv/bin/activate
adk web --port 8080
L'UI ADK s'affiche, et vous pouvez y poser des questions à l'agent.
Avant de passer à la section suivante, appuyez sur Ctrl+C pour mettre fin au processus.
7. Développement : créez votre agent personnalisé avec Imagen
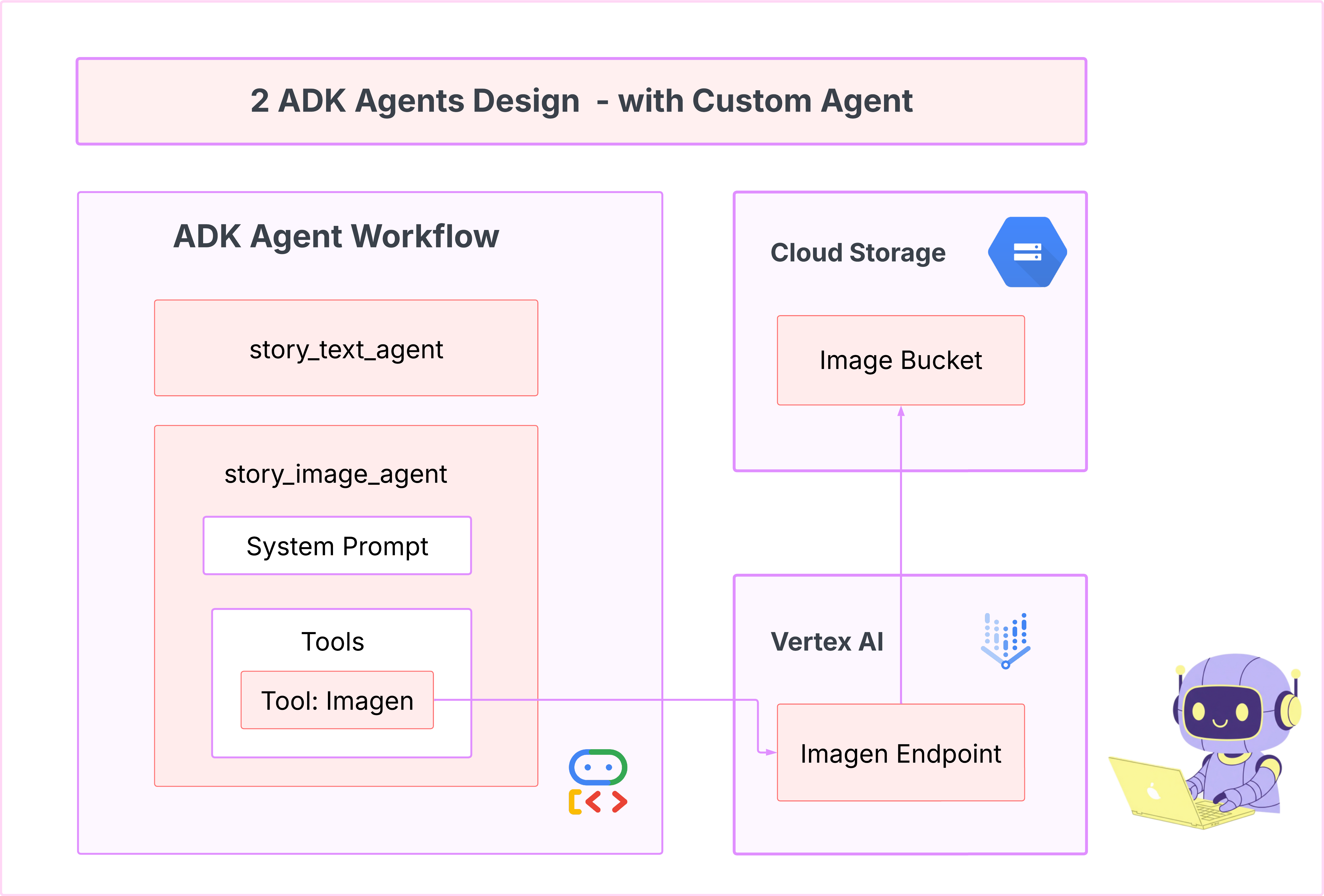
Générer l'outil Imagen (deuxième agent)
cd ~/storygen-learning/02a_Image_Agent_Ready
Utilisez Gemini CLI pour créer l'agent de génération d'images :
gemini generate "I need you to help me create a custom Google ADK (Agent Development Kit) agent for image generation. This is different from the story agent - this one handles image generation directly using the BaseAgent pattern for full control over tool execution.
Please create a complete `agent.py` file that implements a custom image generation agent. The agent should:
**Requirements:**
1. Use the `google.adk.agents.BaseAgent` class (NOT LlmAgent)
2. Be named "custom_image_agent"
3. Directly execute the ImagenTool without LLM intermediation
4. Handle JSON input with scene descriptions and character descriptions
5. Store results in session state for retrieval by main.py
6. Use async generators and yield Events
**Key Specifications:**
- **Class Name:** CustomImageAgent (inherits from BaseAgent)
- **Agent Name:** "custom_image_agent"
- **Tool:** Uses ImagenTool for direct image generation
- **Purpose:** Bypass LLM agent limitations and directly call ImagenTool
**Input Format:**
The agent should handle JSON input like:
{
"scene_description": "Scene action and setting",
"character_descriptions": {
"CharacterName": "detailed visual description"
}
}
**Core Method:** `async def _run_async_impl(self, ctx: InvocationContext) -> AsyncGenerator[Event, None]:`
- Extract user message from `ctx.user_content.parts`
- Parse JSON input or fallback to plain text
- Extract scene_description and character_descriptions
- Build image prompt with style prefix: "Children's book cartoon illustration with bright vibrant colors, simple shapes, friendly characters."
- Include character descriptions for consistency
- Call `await self.imagen_tool.run()` directly
- Store results in `ctx.session.state["image_result"]`
- Yield Event with results
**Session State:**
- Store JSON results in `ctx.session.state["image_result"]`
- Include success/error status
- Store actual image URLs or error messages
Expected Output Structure:
- Successful results stored as JSON with image URLs
- Error results stored as JSON with error messages
- Results accessible via session state in main.py
Can you create this agent in backend/story_image_agent/agent.py
"
—————————————— Facultatif, vous pouvez passer à la section Solution——————————————–
Vérifiez maintenant votre modification dans ADK Web.
cd ~/storygen-learning/02a_Image_Agent_Ready/backend
source ../../.venv/bin/activate
adk web --port 8080
Lancer le site Web
cd ~/storygen-learning/02a_Second_Agent_Ready
./start.sh
Si votre modification ne fonctionne pas, vous devriez voir des erreurs dans l'interface utilisateur Web de l'ADK et sur le site Web.
—————————————- Solution Starting Here ——————————————–
Solution
Mettez fin au processus précédent avec Control+C ou ouvrez un autre terminal :
# Open new terminal
cd ~/storygen-learning/02b_Image_Agent_Done
Lancer le site Web :
./start.sh
Le site Web s'affiche :
Essayez l'UI ADK : ouvrez un autre terminal :
# Open new terminal
cd ~/storygen-learning/02b_Image_Agent_Done/backend
source ../../.venv/bin/activate
adk web --port 8080
L'UI ADK s'affiche. Vous pouvez y poser des questions à l'agent :
Avant de passer à la section suivante, appuyez sur Ctrl+C pour mettre fin au processus.
Apprentissage
Notre premier agent était excellent pour générer du texte, mais nous devons maintenant générer des images. Pour cette tâche, nous avons besoin d'un contrôle plus direct. Nous ne voulons pas que le LLM décide s'il doit créer une image. Nous voulons lui demander directement de le faire. C'est le travail idéal pour un BaseAgent.
Contrairement à l'agent LlmAgent déclaratif, un agent BaseAgent est impératif. Cela signifie que vous, le développeur, écrivez la logique Python exacte, étape par étape, dans la méthode _run_async_impl. Vous contrôlez entièrement le flux d'exécution.
Choisissez un BaseAgent lorsque vous avez besoin :
Logique déterministe : l'agent doit suivre une séquence d'étapes spécifique et immuable.
Exécution directe d'outils : vous souhaitez appeler un outil directement sans intervention du LLM.
Workflows complexes : le processus implique une manipulation personnalisée des données, des appels d'API et une logique trop complexe pour qu'un LLM puisse l'inférer de manière fiable à partir d'une requête seule.
Pour notre application, nous utiliserons un BaseAgent pour recevoir les descriptions de scène du premier agent et appeler directement l'outil Imagen afin de garantir la génération d'une image pour chaque scène.
8. Test : évaluation des agents
Notre application fonctionne, mais nous avons besoin d'un filet de sécurité automatisé de tests. C'est une tâche idéale à déléguer à notre copilote IA.
Actions
cd ~/storygen-learning/03a_Agent_Evaluation_Ready/backend
Utiliser Gemini CLI pour rédiger des tests complets :
Ouvrir Gemini CLI
gemini
Dans la fenêtre Gemini CLI, essayez le prompt suivant :
I need you to create comprehensive test files for my backend/story_agent in Google ADK. I need three specific JSON files that match the testing structure used in ADK evaluation.
**Context:**
- The story agent generates structured JSON stories with exactly 4 scenes
- It uses LlmAgent with no tools, just direct LLM responses
- Input: Keywords
- Output: JSON with story, main_characters, and scenes arrays
**Files to Create:**
### 1. `story_agent_eval.evalset.json` (Comprehensive Integration Tests)
Create a comprehensive evaluation set with:
- **eval_set_id**: "story_agent_comprehensive_evalset"
- **name**: "Story Agent Comprehensive Evaluation Set"
- **description**: "Comprehensive evaluation scenarios for story_agent covering various keyword combinations, edge cases, and story quality metrics"
Each eval_case should include:
- Full conversation arrays with invocation_id, user_content, final_response
- Complete expected JSON responses with detailed stories, characters, and 4 scenes
- session_input with app_name "story_agent"
- All fields: story (narrative text), main_characters (with detailed visual descriptions), scenes (with index, title, description, text)
### 2. `story_generation.test.json` (Unit Tests)
Create basic generation tests with:
- **eval_set_id**: "story_agent_basic_generation_tests"
- **name**: "Story Agent Basic Generation Tests"
- **description**: "Unit tests for story_agent focusing on JSON structure compliance, scene generation, and keyword integration"
### 3. `test_config.json` (Evaluation Configuration)
Create test configuration with:
- **criteria**: response_match_score: 0.7, tool_trajectory_avg_score: 1.0
- **custom_evaluators**:
- json_structure_validator (validates required fields, scene count, character fields)
- story_quality_metrics (word count 80-250, keyword integration threshold 0.8)
- **evaluation_notes**: Story agent specifics and trajectory expectations
**Important Requirements:**
1. All responses must be valid, parseable JSON
2. Stories must have exactly 4 scenes with indices 1-4
3. Each scene must have: index, title, description, text
4. Main characters must have detailed visual descriptions
5. No tool_uses expected (empty arrays) since story agent uses direct LLM
6. Word count should be 100-200 words total
7. Keywords must be naturally integrated into the narrative
Please generate all three files with realistic example stories and comprehensive test coverage matching the ADK evaluation format.
—————————————— Facultatif, vous pouvez passer à la section Solution——————————————–
Pour afficher l'évaluation :
./run_adk_web_persistent.sh
Accédez à l'onglet eval de l'interface utilisateur ADK.
L'UI Web d'ADK devrait s'afficher avec des fonctionnalités de test persistantes.
Point clé à retenir : l'IA est un partenaire puissant pour automatiser l'assurance qualité. Il peut gérer le code récurrent de l'écriture de tests, ce qui vous permet de vous concentrer sur la création de fonctionnalités.
—————————————— Solution à partir d'ici ——————————————–
Solution
- Accédez au dossier de la solution :
cd ~/storygen-learning/03b_Agent_Evaluation_Done/backend
- Ouvrir l'interface utilisateur Web ADK
./run_adk_web_persistent.sh
Vous pouvez consulter les scénarios de test dans l'onglet Eval :
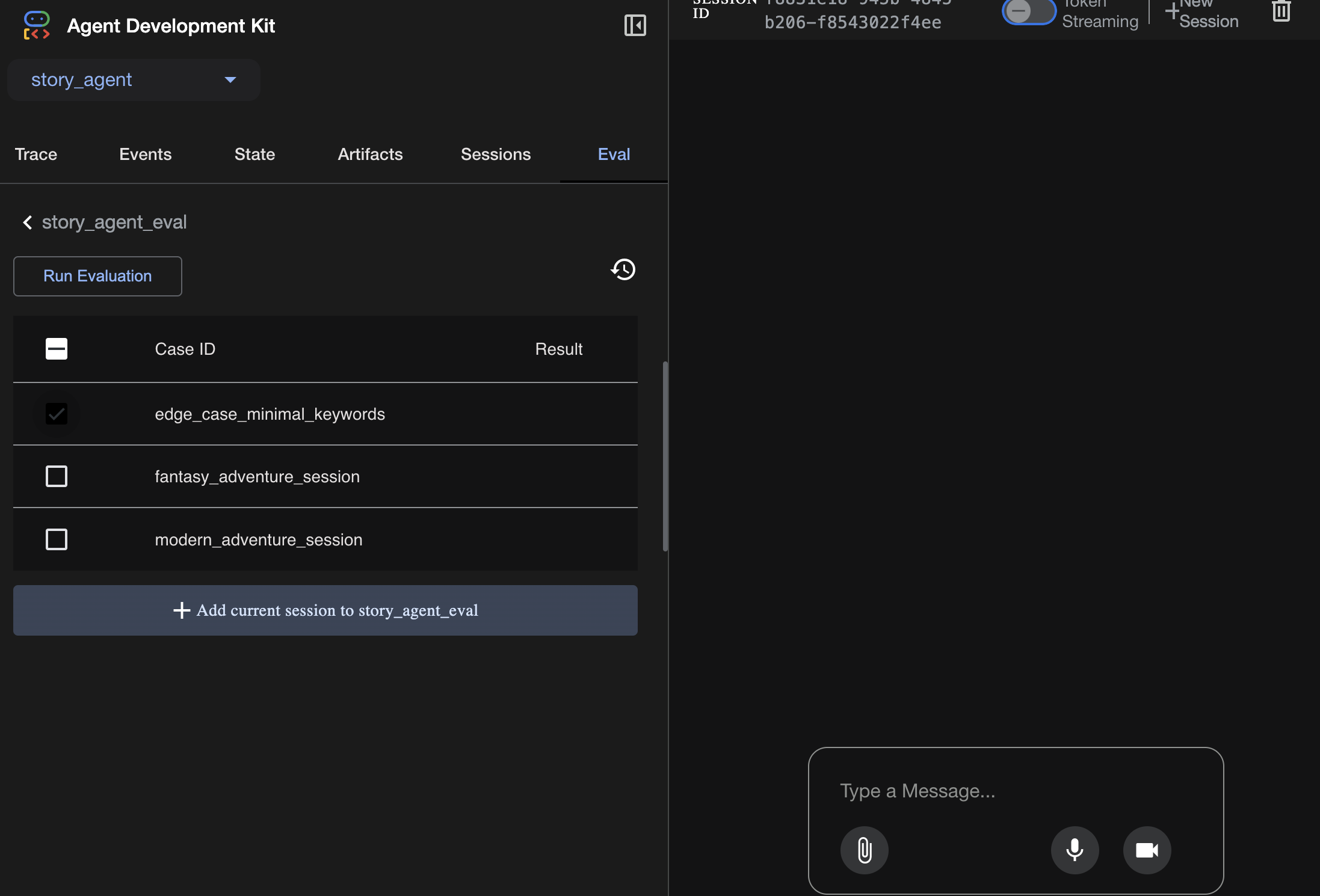
Ajustez les métriques ici :
Affichez le résultat de l'exécution de l'évaluation :
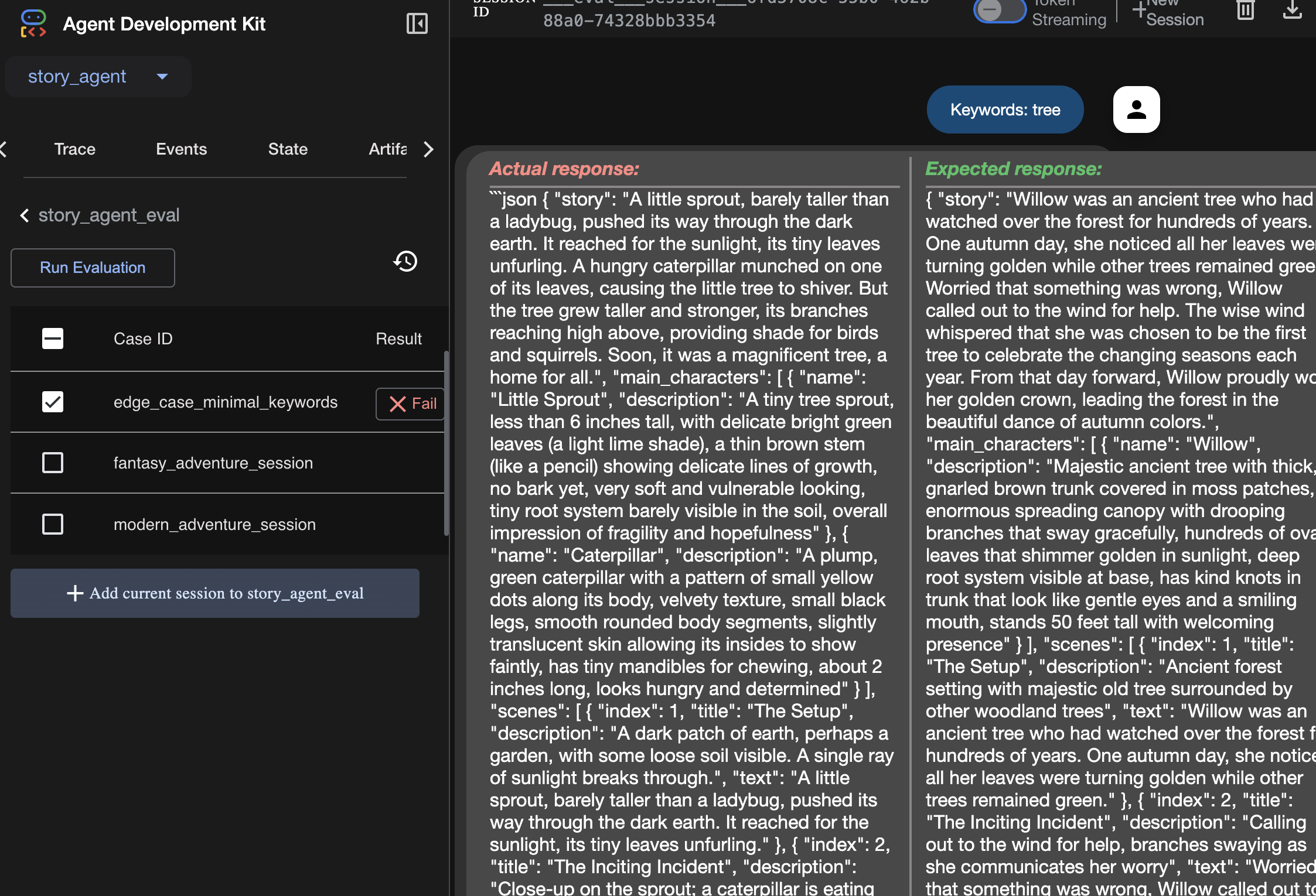
Apprentissage
Un agent peut "fonctionner" en s'exécutant sans erreur, mais comment savoir s'il produit le bon résultat ? L'histoire est-elle bonne ? Le format JSON est-il correct ? C'est là qu'intervient le framework d'évaluation de l'ADK.
L'évaluation des agents est un système de test automatisé conçu pour mesurer la qualité et la justesse des réponses de votre agent. Au lieu de simplement vérifier les erreurs de code, il vérifie si le comportement de l'agent répond à vos attentes. Le framework utilise principalement quelques fichiers clés :
evalset.json : il s'agit de votre suite de tests principale. Chaque "cas d'évaluation" de ce fichier contient un exemple de conversation (par exemple, une requête utilisateur) et la réponse idéale ("golden") que vous attendez de l'agent.
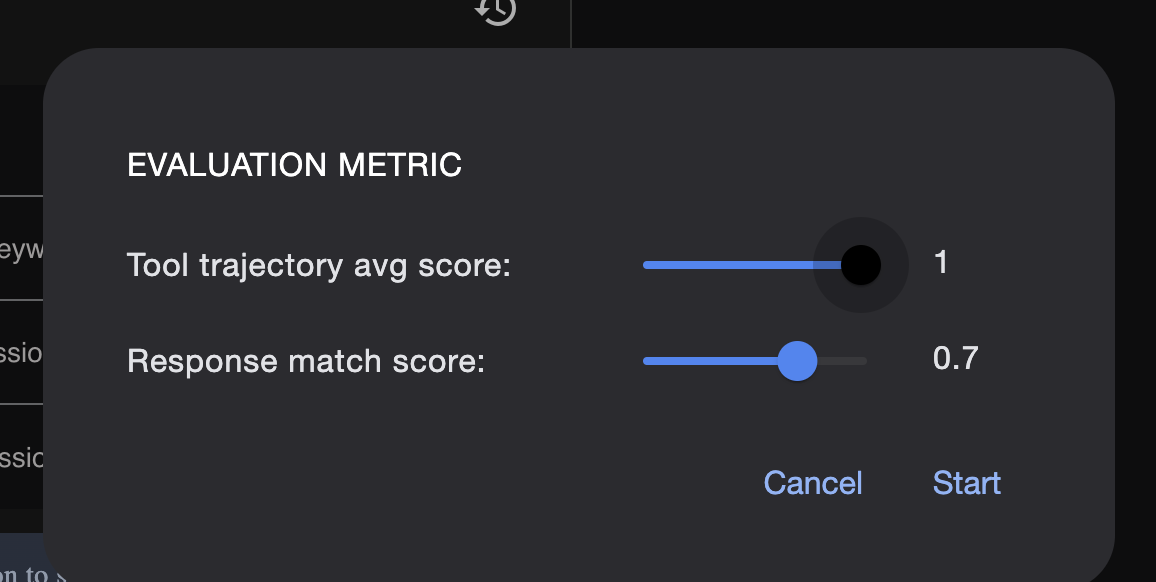
test_config.json : ce fichier définit les règles de réussite. Vous pouvez y définir des critères tels que :
response_match_score : dans quelle mesure la réponse de l'agent doit-elle correspondre à la réponse "idéale" ? (Un score de 1,0 signifie qu'il doit être identique.)
custom_evaluators : vous pouvez créer vos propres règles, comme "La réponse doit être un fichier JSON valide" ou "L'article doit contenir plus de 100 mots".
En exécutant une évaluation, vous pouvez tester automatiquement votre agent dans des dizaines de scénarios. Vous vous assurez ainsi que les modifications apportées à votre requête ou à vos outils ne nuisent pas accidentellement à ses fonctionnalités de base. Il s'agit d'un filet de sécurité puissant pour créer des agents d'IA prêts pour la production.
9. Infrastructure as Code (IaC) : construire une maison dans le cloud
Notre code est testé, mais il a besoin d'un emplacement prêt pour la production. Nous allons utiliser l'Infrastructure as Code pour définir notre environnement.
Qu'est-ce que Docker ?
Docker est une plate-forme permettant de créer et d'exécuter des applications dans des conteneurs. Considérez un conteneur comme un conteneur d'expédition standardisé pour les logiciels. Il regroupe tout ce dont votre application a besoin pour s'exécuter dans un seul package isolé :
- Le code de l'application lui-même
- L'environnement d'exécution requis (par exemple, la version spécifique de Python)
- Tous les outils et bibliothèques système
Cette application conteneurisée peut ensuite être exécutée sur n'importe quelle machine sur laquelle Docker est installé, ce qui résout le problème classique de compatibilité matérielle ou logicielle.
Dans cette section, nous allons demander à Gemini de générer un Dockerfile, qui est simplement la recette ou le plan permettant de créer l'image de conteneur de notre application.
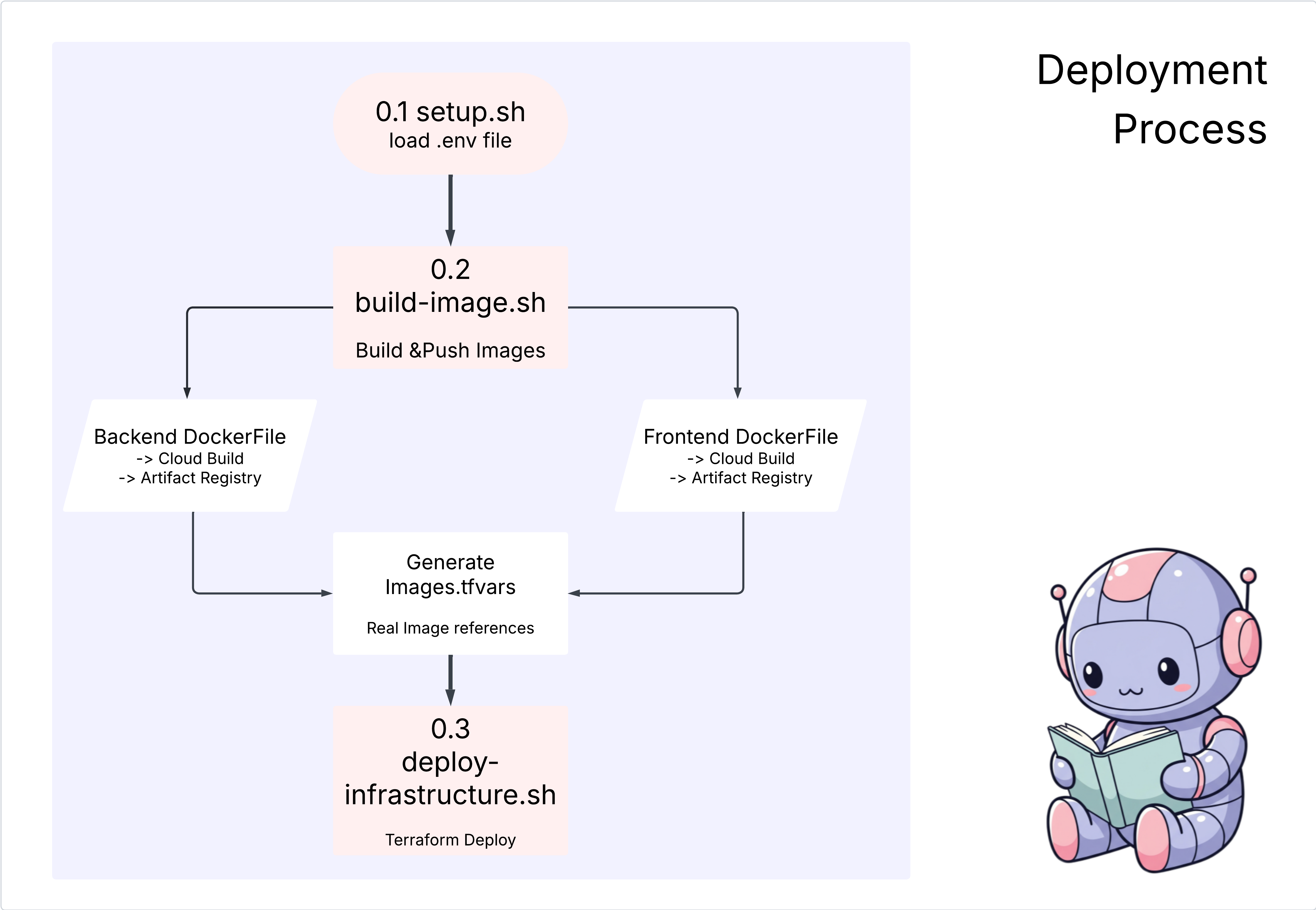
Actions
cd ~/storygen-learning/04a_Manual_Deployment_Ready
Utilisez Gemini CLI pour créer un fichier Dockerfile pour le backend : ouvrez Gemini CLI.
Gemini
Dans Gemini CLI, essayez le prompt suivant :
Create a manual deployment plan for my StoryGen app with Google Cloud Platform. I have a Next.js frontend, Python backend, and Terraform infrastructure.
Generate these deployment files:
1. **01-setup.sh** - Environment setup and authentication
2. **02-build-images.sh** - Build and push Docker images to Google Container Registry
3. **03-deploy-infrastructure.sh** - Deploy with Terraform and configure services
4. **load-env.sh** - Load environment variables for deployment
**Requirements:**
- Use Google Cloud Run for both frontend and backend
- Configure Imagen API and storage buckets
- Set up proper IAM permissions
- Use environment variables from .env file
- Include error handling and status checks
Keep scripts simple, well-commented, and production-ready for manual execution.
Solution :
cd ~/storygen-learning/04b_Manual_Deployment_Done
Exécutez la commande suivante :
source ../.venv/bin/activate
./01-setup.sh
./02-build-images.sh
./03-deploy-infrastructure.sh
Vous devriez voir les résultats du déploiement et la création de l'infrastructure.
10. Automatisation (CI/CD) : la chaîne de montage numérique
Déployer notre application manuellement est un excellent moyen de comprendre les différents éléments, mais c'est lent, cela nécessite un effort manuel et peut entraîner des erreurs humaines. Dans le développement de logiciels professionnels, l'ensemble de ce processus est automatisé à l'aide d'une pratique appelée CI/CD.
CI/CD signifie intégration continue et déploiement continu. Il s'agit d'une méthode permettant de compiler, tester et déployer automatiquement votre code chaque fois que vous le modifiez.
- Intégration continue (CI) : il s'agit de la phase de compilation et de test. Dès qu'un développeur applique une modification de code à un dépôt partagé (comme GitHub), un système automatisé se déclenche. Il compile l'application et exécute tous les tests (comme les évaluations d'agent que nous avons créées) pour s'assurer que le nouveau code s'intègre correctement et n'introduit aucun bug.
- Déploiement continu (CD) : il s'agit de la phase de "publication". Si la phase d'intégration continue se déroule correctement, le système déploie automatiquement la nouvelle version testée de l'application en production, ce qui la rend disponible pour les utilisateurs.
Ce pipeline automatisé crée une "chaîne de montage numérique" qui permet de transférer le code de la machine d'un développeur vers la production de manière rapide, sûre et fiable. Dans cette section, nous allons demander à notre assistant IA de créer cette chaîne de montage pour nous à l'aide de GitHub Actions et de Google Cloud Build.
Actions
cd ~/storygen-learning/05a_CICD_Pipeline_Ready
Utilisez Gemini CLI pour créer votre pipeline CI/CD avec GitHub :
Ouvrir Gemini CLI
Gemini
Dans Gemini CLI, essayez le prompt suivant :
Create a CI/CD pipeline for my StoryGen app using Google Cloud Build and GitHub integration.
Generate these automation files:
1. **cloudbuild.yaml** (for backend) - Automated build, test, and deploy pipeline
2. **GitHub Actions workflow** - Trigger builds on push/PR
3. **Deployment automation scripts** - Streamlined deployment process
**Requirements:**
- Auto-trigger on GitHub push to main branch
- Build and push Docker images
- Run automated tests if available
- Deploy to Google Cloud Run
- Environment-specific deployments (staging/prod)
- Notification on success/failure
Focus on fully automated deployment with minimal manual intervention. Include proper secret management and rollback capabilities.
—————————————— Solution à partir d'ici ——————————————–
Solution :
cd ~/storygen-learning/06_Final_Solution/
# Copy the GitHub workflow to parent folder
cp -r 06_Final_Solution/.GitHub ../../../.GitHub
Revenez au dossier 06_Final_Solution et exécutez le script :
cd ~/storygen-learning/06_Final_Solution/
./setup-cicd-complete.sh
Vous devriez voir que la configuration du pipeline CI/CD est terminée.
Déclenchez le workflow : validez et transférez votre code vers le dépôt principal. Notez que vous devez configurer votre adresse e-mail et votre nom GitHub pour autoriser l'accès.
git add .
git commit -m "feat: Add backend, IaC, and CI/CD workflow"
git push origin main
Accédez à l'onglet "Actions" de votre dépôt GitHub pour suivre l'exécution de votre déploiement automatisé.
11. Opérations : la tour de contrôle de l'IA
Nous sommes en direct ! Mais le chemin n'est pas terminé. C'est le "Jour 2", celui des opérations. Revenons à Cloud Assist pour gérer notre application en cours d'exécution.
Actions
- Accédez à votre service Cloud Run dans la console Google Cloud. Interagissez avec votre application en direct pour générer du trafic et des journaux.
- Ouvrez le volet Cloud Assist et utilisez-le comme copilote opérationnel avec des requêtes comme celles-ci :
Analyse des journaux :
Summarize the errors in my Cloud Run logs for the service 'genai-backend' from the last 15 minutes.
Ajustement des performances :
My Cloud Run service 'genai-backend' has high startup latency. What are common causes for a Python app and how can I investigate with Cloud Trace?
Optimisation des coûts :
Analyze the costs for my 'genai-backend' service and its GCS bucket. Are there any opportunities to save money?
Point clé à retenir : Le cycle de vie du développement logiciel de l'IA est une boucle continue. Le même copilote d'IA qui a contribué à la création de l'application est un partenaire indispensable pour la surveiller, la dépanner et l'optimiser en production.