
1. 学習内容
AI エージェントのバイブ フルスタック
ようこそ。このコースでは、ソフトウェア開発における次の重要なスキル、つまり、AI を効果的に活用して本番環境グレードのソフトウェアを構築、テスト、デプロイする方法について学びます。生成 AI は「自動操縦」ではなく、熟練したディレクターが必要な強力な副操縦士です。
このワークショップでは、プロフェッショナル ソフトウェア開発ライフサイクル(SDLC)のあらゆる段階で AI と連携するための構造化された再現可能な方法論を提供します。コードを 1 行ずつ書く人から、ビジョンを持つアーキテクトであり、AI を使用してそのビジョンを正確に実行するゼネコンであるテクニカル ディレクターへと成長できます。🚀
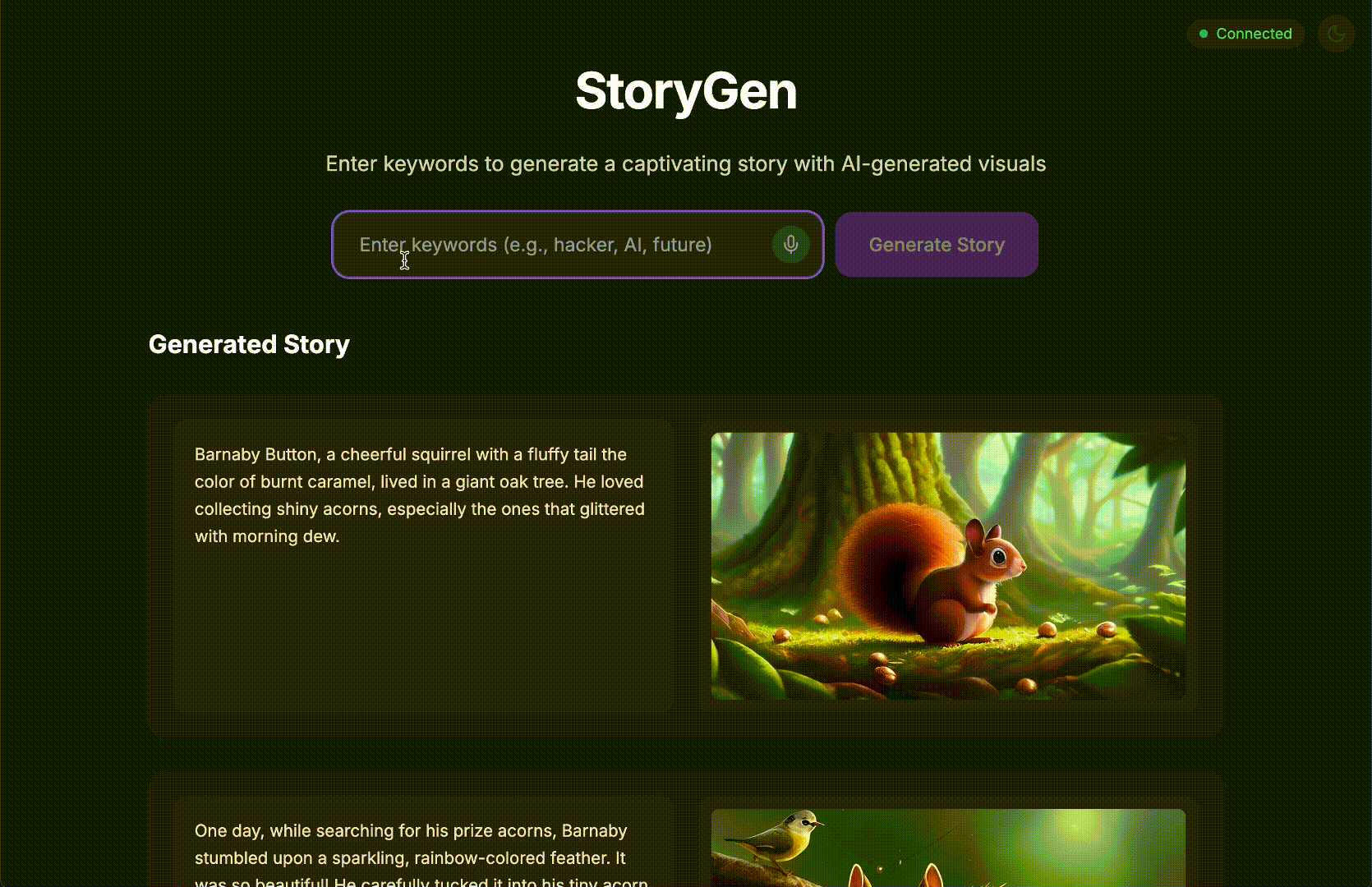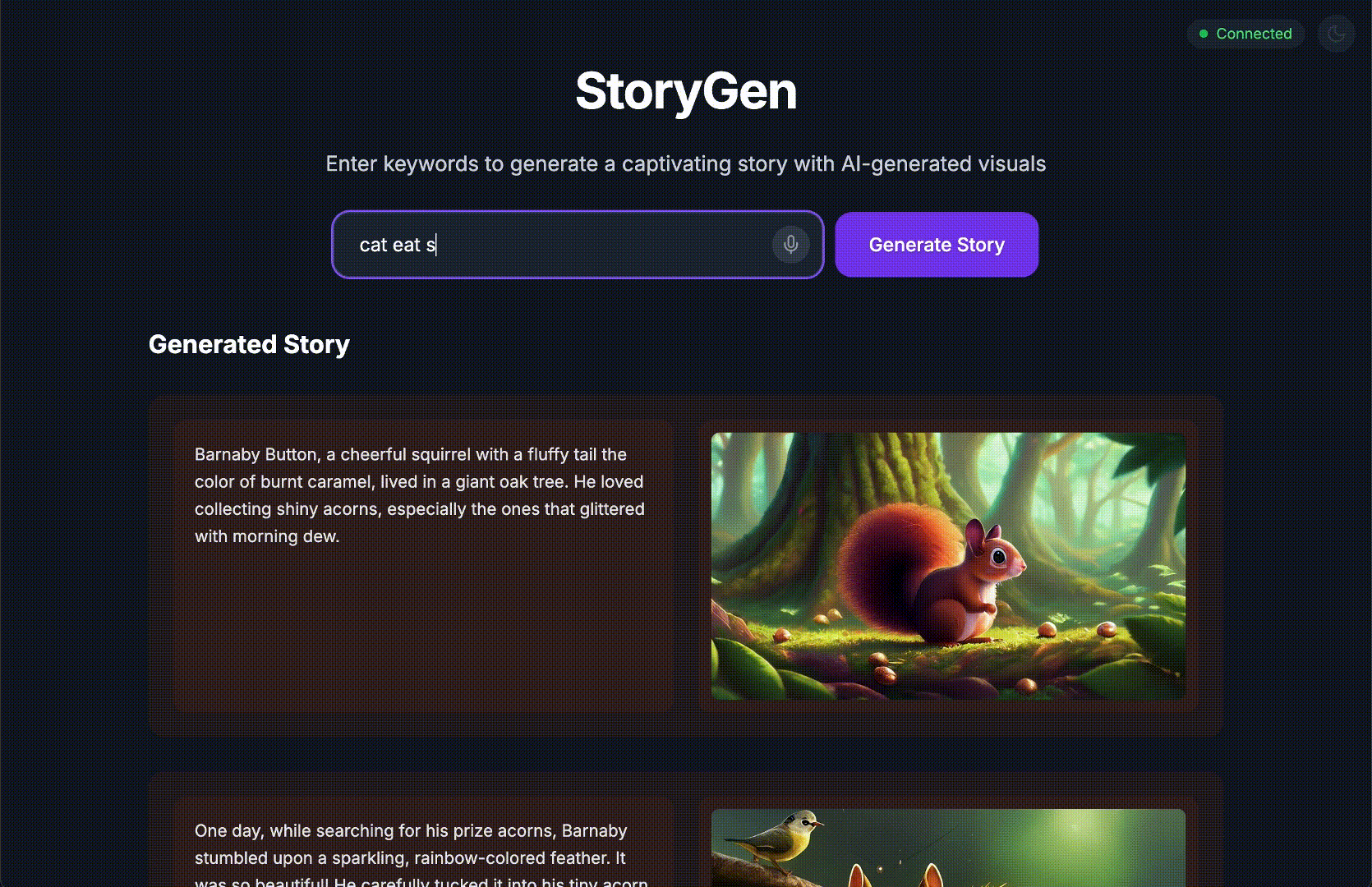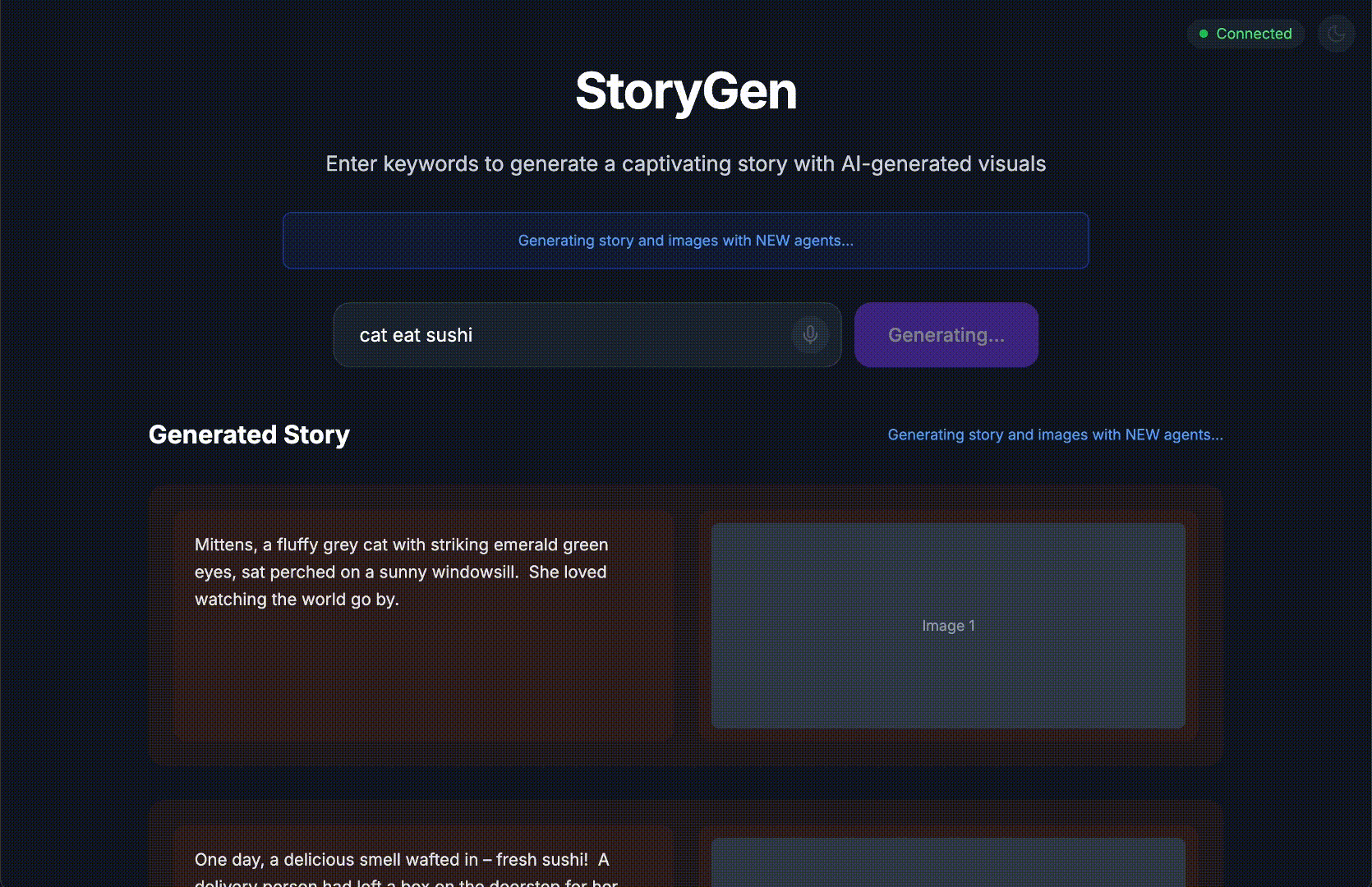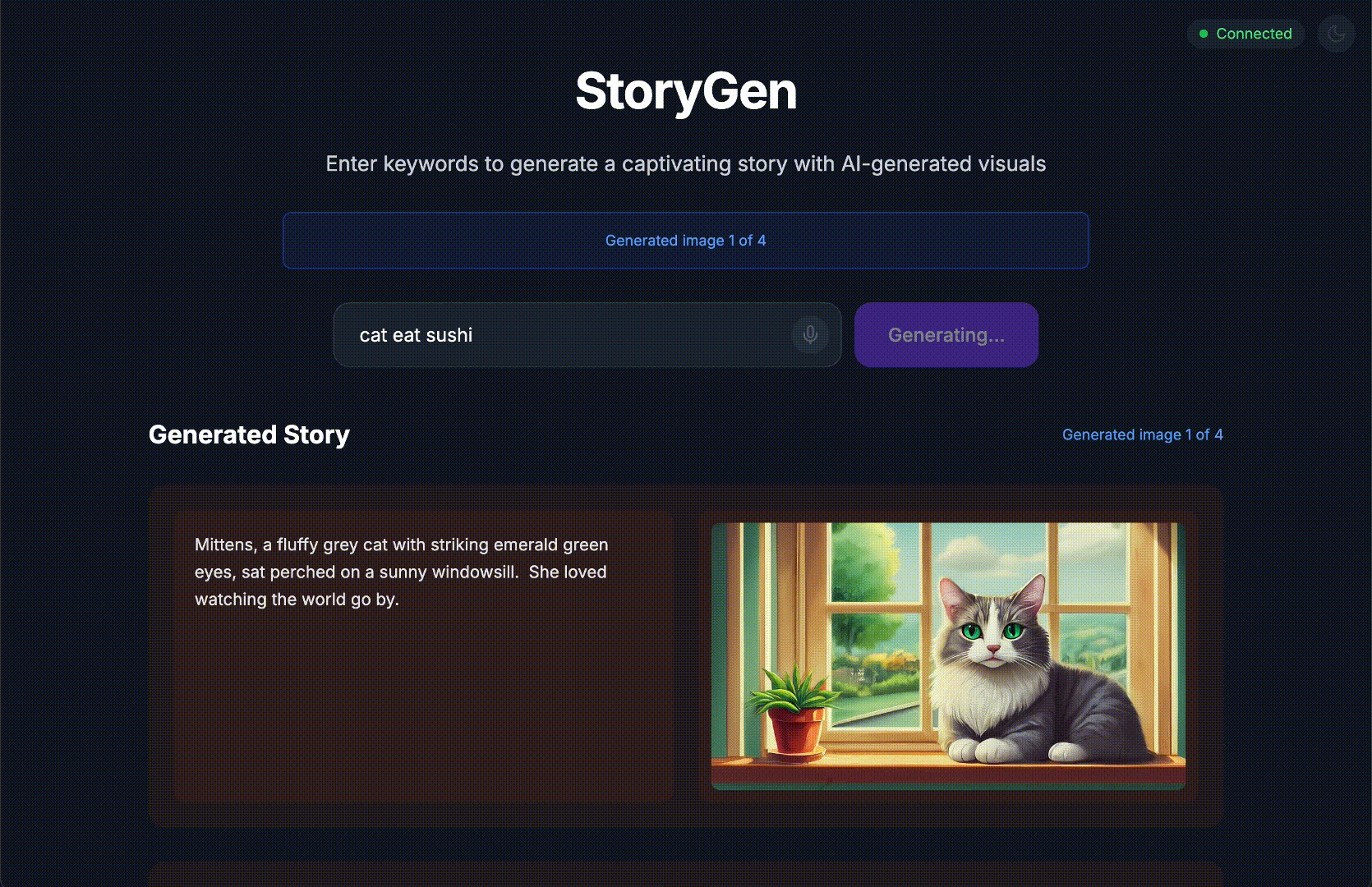
このチュートリアルを修了すると、次のことができるようになります。
- AI を使用して、大まかなアイデアをクラウド アーキテクチャに変換しました。
- 対象を絞った具体的なプロンプトを使用して、完全な Python バックエンドを生成しました。
- AI をペア プログラマーとして使用して、コードのデバッグと修正を行いました。
- モックを含む単体テストの作成を AI に委任しました。
- Terraform を使用して、プロダクション レディな Infrastructure as Code(IaC)を生成しました。
- 1 つのプロンプトで GitHub Actions に完全な CI/CD パイプラインを作成しました。
- AI を活用した運用ツールを使用して、ライブ アプリケーションをモニタリングして管理しました。
この Codelab を終えると、実際に動作するアプリだけでなく、AI 拡張開発のブループリントも手に入ります。では、始めましょう。
2. 前提条件と設定
始める前に、環境を準備しましょう。これは、ワークショップをスムーズに進めるために重要なステップです。
新しい GCP アカウントを作成して請求先をリンクする
AI エージェントを強化するには、基盤となる Google Cloud プロジェクトと、Google の強力なモデルにアクセスするための Gemini API キーの 2 つが必要です。
ステップ 1: 請求先アカウントを有効にする
この Codelab を実行するには、クレジットが残っている請求先アカウントが必要です。この Codelab の上部にあるバナーのクレジットを使用して、開始します。請求先アカウントにすでに接続している場合は、この手順をスキップできます。
ステップ 2: 新しい GCP プロジェクトを作成する
- Google Cloud コンソールに移動し、新しいプロジェクトを作成します。
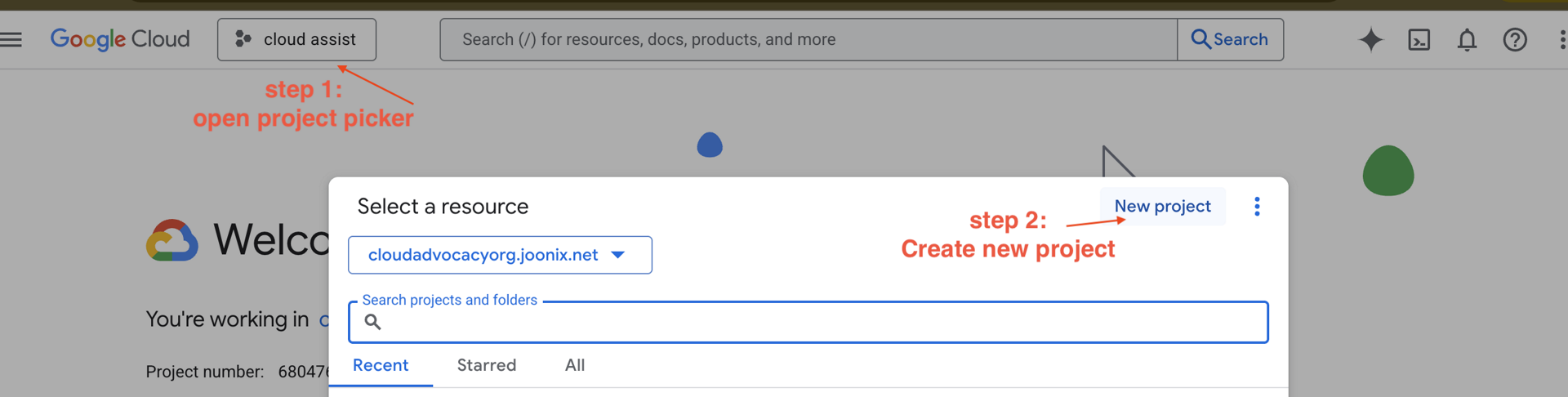
- 左側のパネルを開き、
Billingをクリックして、請求先アカウントがこの GCP アカウントにリンクされているかどうかを確認します。
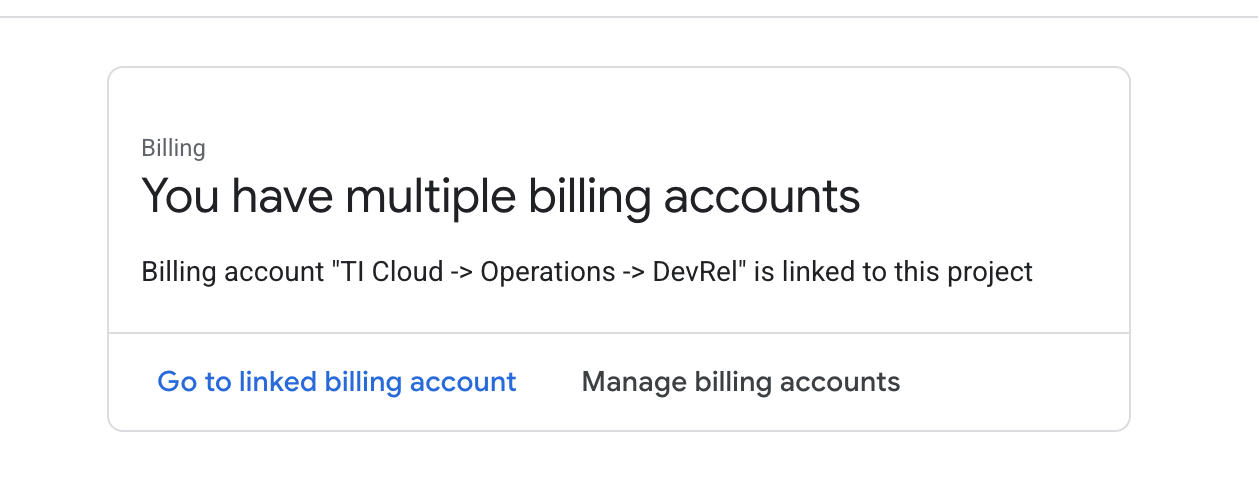
このページが表示されたら、manage billing account をオンにして、Google Cloud Trial One を選択してリンクします。
ステップ 3: Gemini API キーを生成する
鍵を保護するには、鍵が必要です。
- Google AI Studio(https://aistudio.google.com/)に移動します。
- Gmail アカウントでログインします。
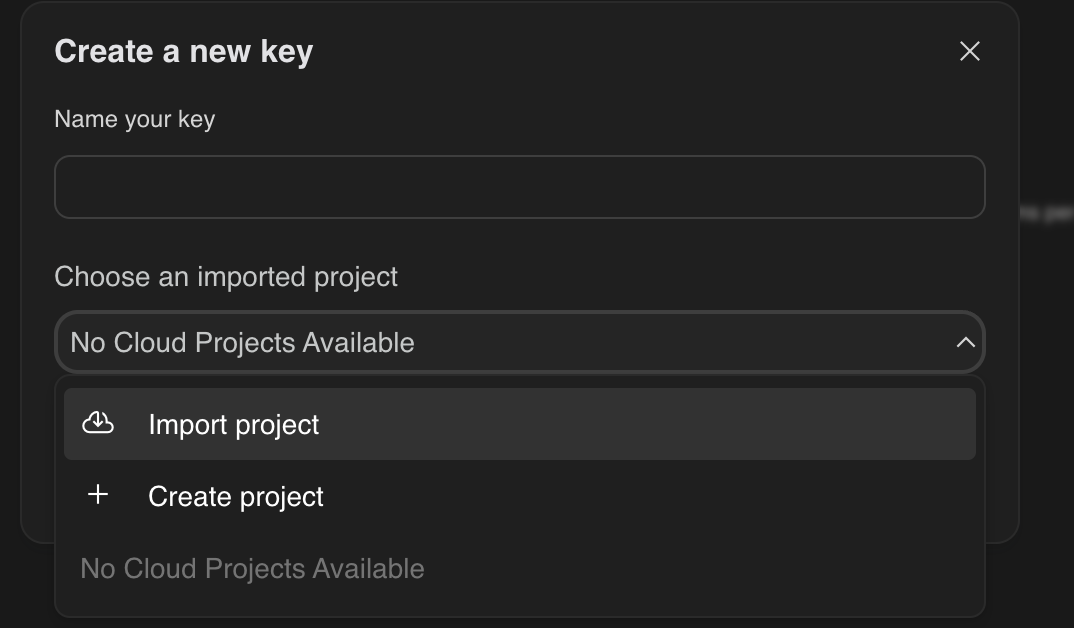
- 通常は左側のナビゲーション ペインまたは右上の隅にある [API キーを取得] ボタンをクリックします。
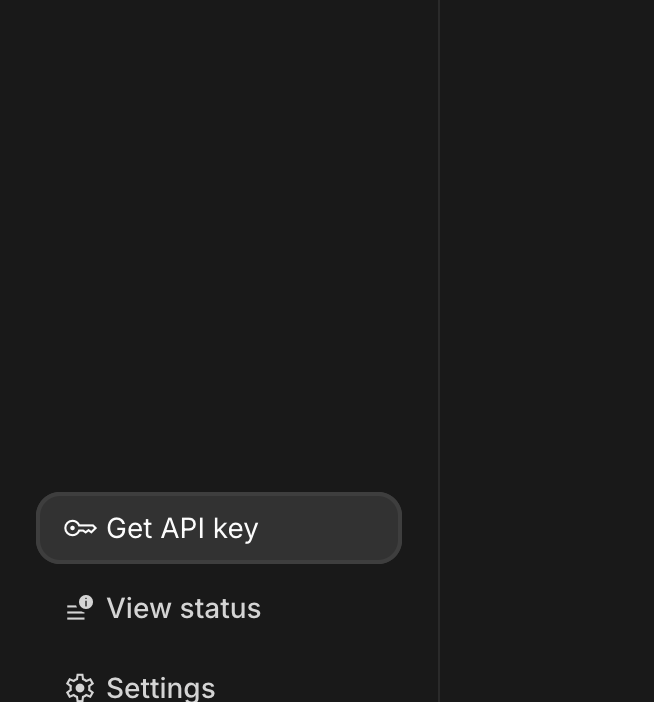
- [API キー] ダイアログで、[新しいプロジェクトで API キーを作成] をクリックします。
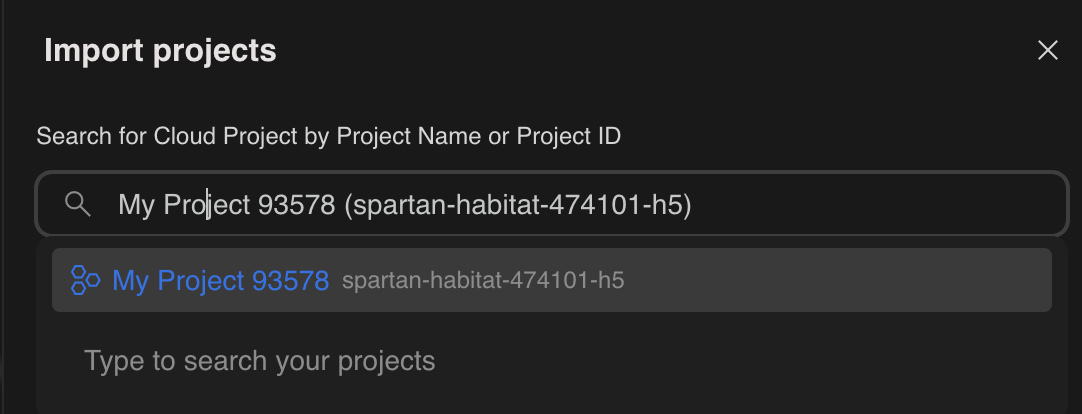
- 請求先アカウントが設定されている、作成した新しいプロジェクトを選択します。
- 新しい API キーが生成されます。
このキーをすぐにコピーして、安全な場所に一時的に保存します(パスワード マネージャーや安全なメモなど)。これは次のステップで使用する値です。
GitHub 認証
Google Cloud コンソールに移動し、右上の [Cloud Shell をアクティブにする] ボタンをクリックして、Cloud Shell を開きます。
ステップ 1: Cloud Shell を開く
👉Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします(Cloud Shell ペインの上部にあるターミナル型のアイコンです)。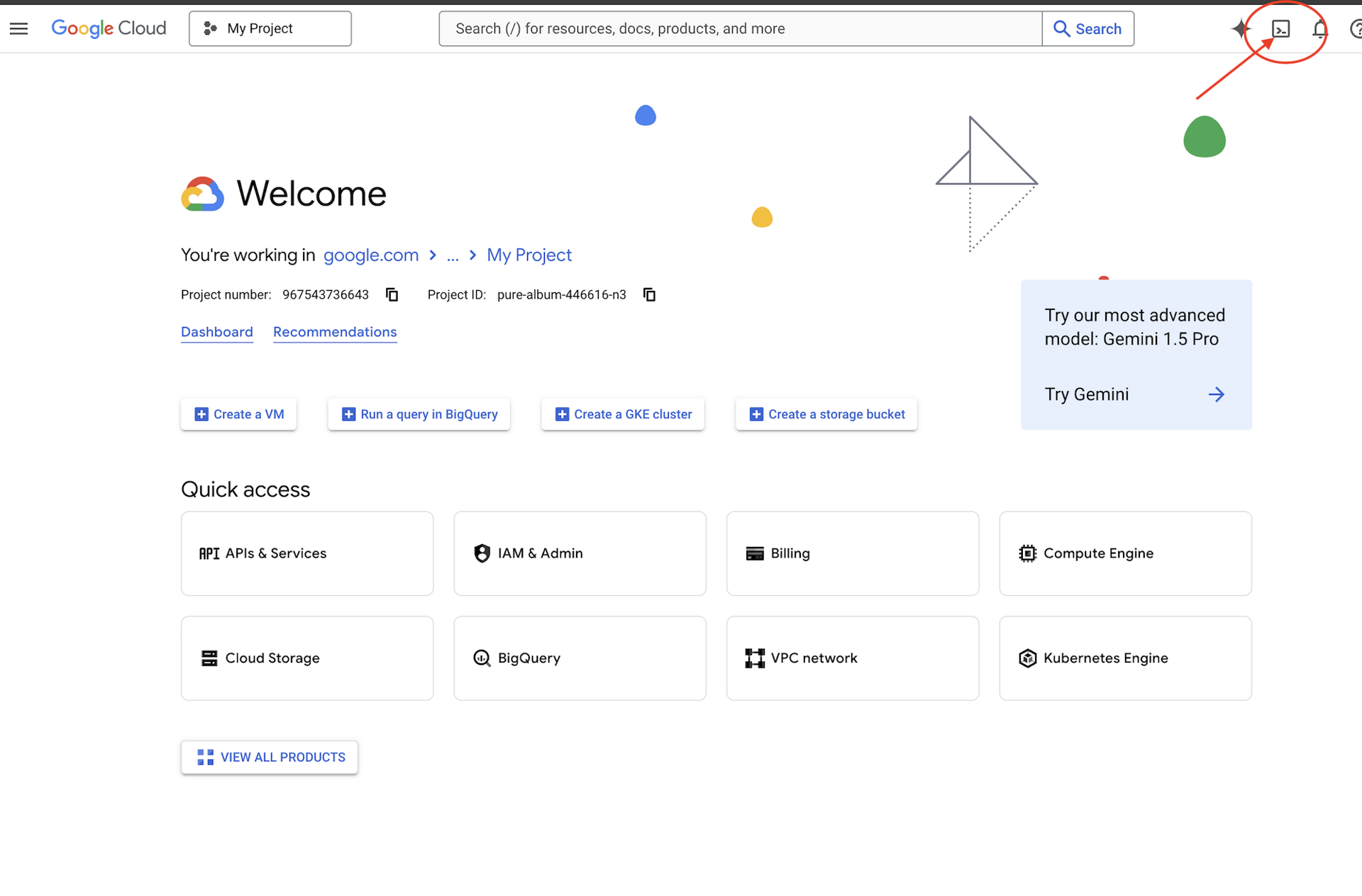
👉[エディタを開く] ボタン(開いたフォルダと鉛筆のアイコン)をクリックします。ウィンドウに Cloud Shell コードエディタが開きます。左側にファイル エクスプローラが表示されます。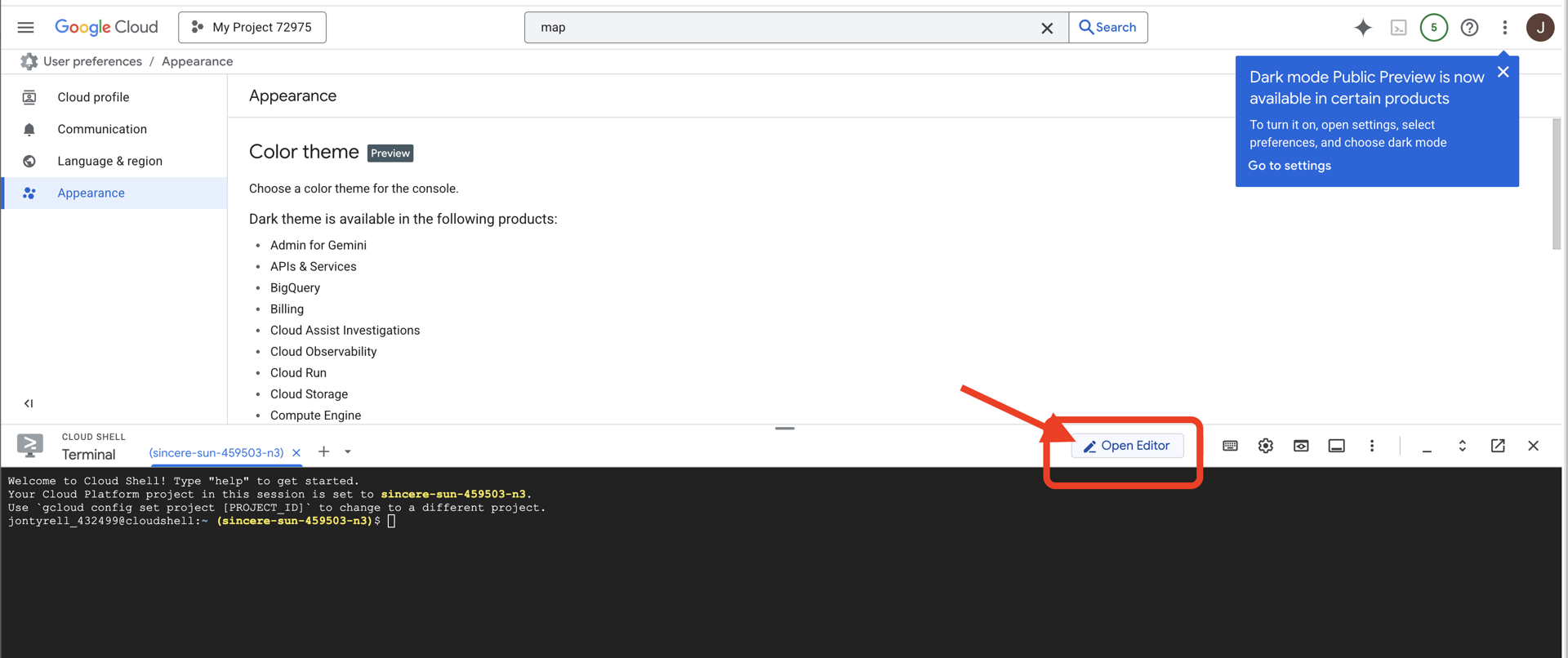
👉エディタを開いたら、クラウド IDE でターミナルを開きます。
👉💻 ターミナルで、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
ステップ 2: GitHub で認証してフォークする
GitHub で認証します。
👉💻 コマンドをコピーしてクラウド ターミナルに貼り付けます。
gh auth login
- [Where do you use GitHub] で [GitHub.com] を選択します。
- 「What is you preferred protocol for Git operations on this host?」で「HTTPS」を選択します。
- [Authenticate Git with your GitHub credentials?](GitHub 認証情報で Git を認証しますか?)で [Yes](はい)を選択します。
- 「How would you like to authenticate GitHub CLI?」と表示されたら、「Login with a web browser」を選択します。
重要!! まだ「Enter」キーを押さないでください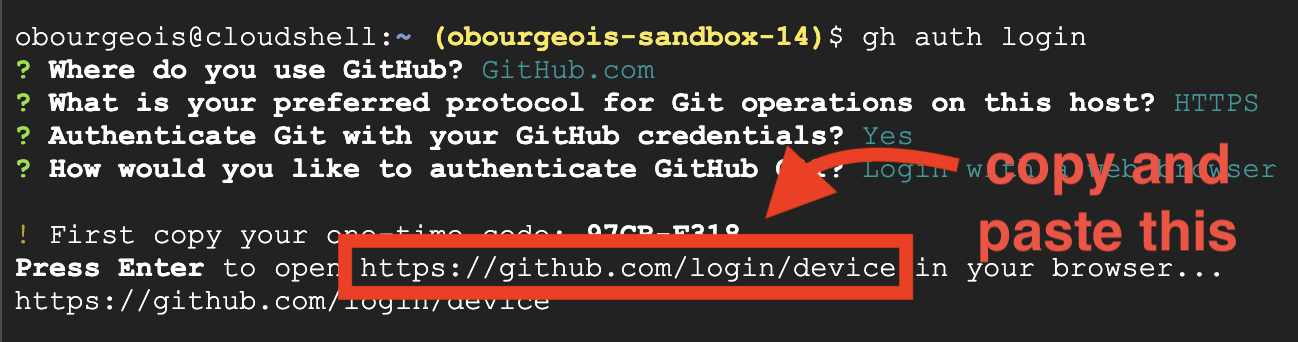
ターミナルからログイン確認ページにコードをコピーします。
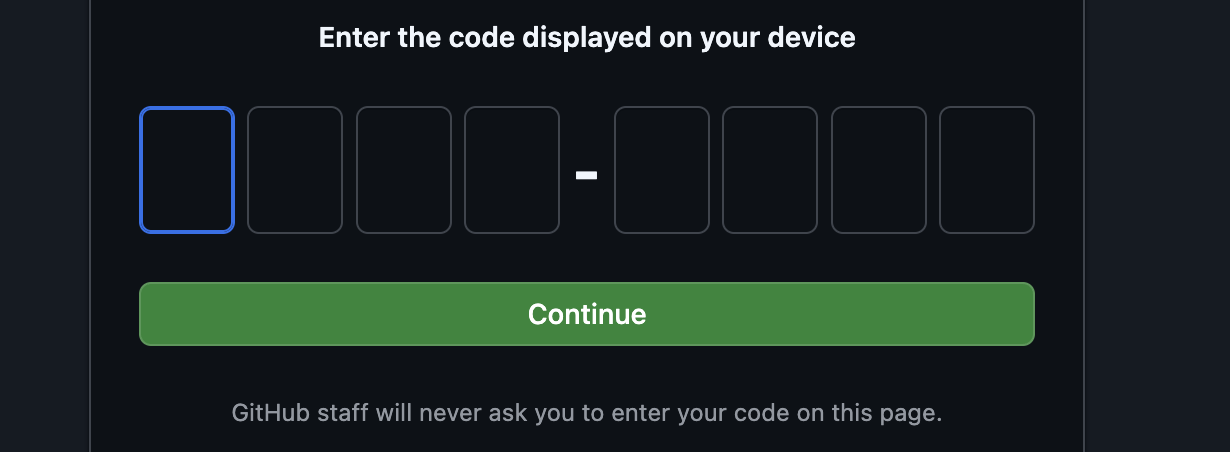
コードの入力が完了したら、Cloud Shell ターミナルに戻り、Enter キーを押して続行します。

ステップ 4: リポジトリをフォークしてクローンを作成します。
👉💻 コマンドをコピーしてクラウド ターミナルに貼り付けます。
gh repo fork cuppibla/storygen-learning --clone=true
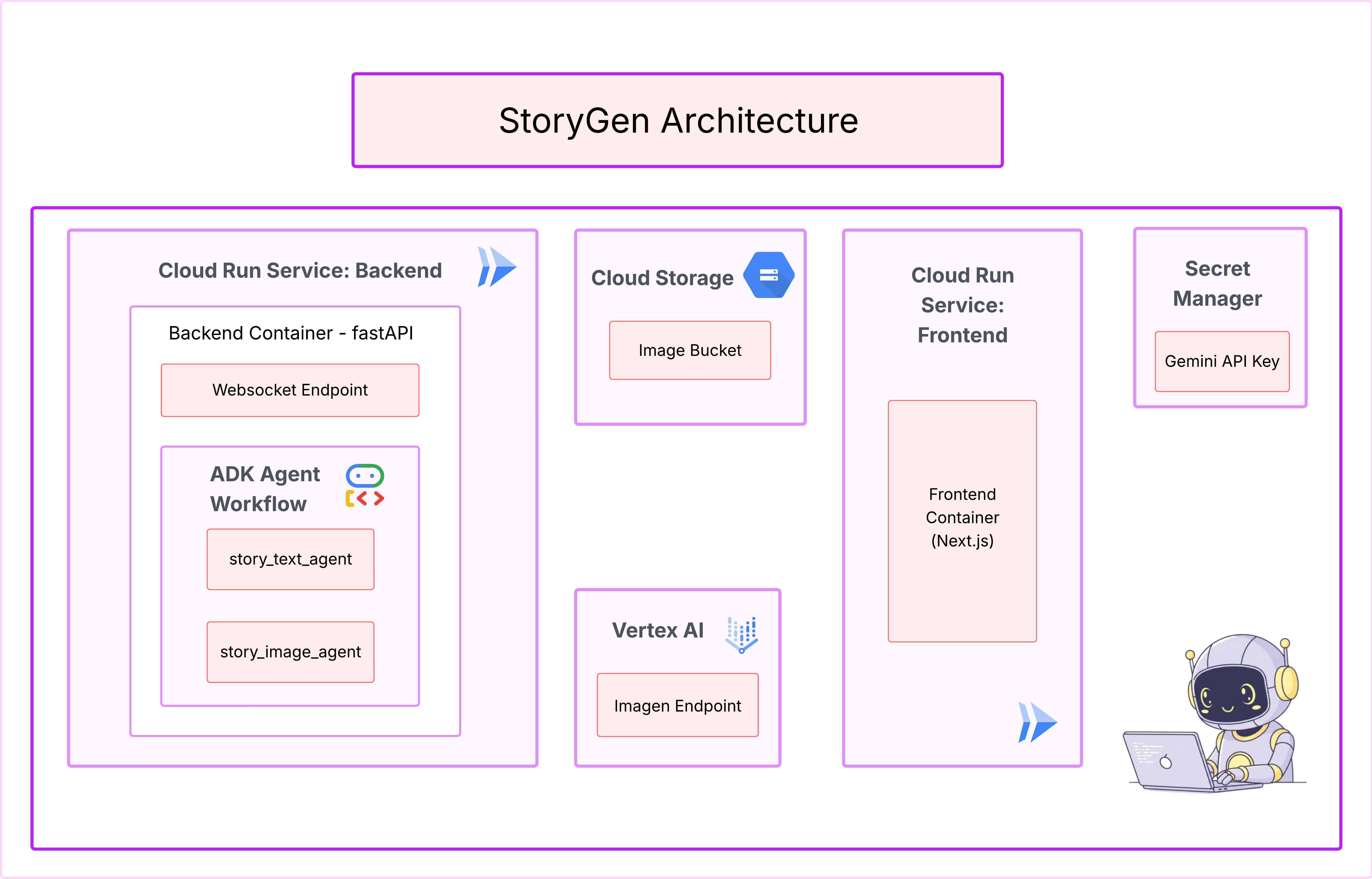
3. アーキテクチャ: Cloud Assist を使用したアイデアからブループリントへの変換
優れたプロジェクトは、明確なビジョンから始まります。AI コパイロットである Cloud Assist を使用して、アプリのアーキテクチャを設計します。
操作
- Google Cloud コンソール(https://console.cloud.google.com)を開きます。
- 右上にある [Cloud Assist Chat を開く] をクリックします。
Cloud Assist を有効にする
Get Gemini Assist、Enable Cloud Assist at no costの順にクリックします。- チャットを開始しましょう。
 Cloud Assist に次の詳細なプロンプトを入力します。
Cloud Assist に次の詳細なプロンプトを入力します。
アイデアを入力する
Generate a Python web application that uses AI to generate children's stories and illustrations. It has Python backend and React frontend host separately on Cloudrun. They communicate through Websocket. It needs to use a generative model for text and another for images. The generated images must be used by Imagen from Vertex AI and stored in a Google Cloud Storage bucket so that frontend can fetch from the bucket to render images. I do not want any load balancer or a database for the story text. We need a solution to store the API key.
アプリのブループリントを入手する
- [アプリのデザインを編集] をクリックすると、図が表示されます。右上のパネル [<> Get Code] をクリックして、Terraform コードをダウンロードします。
- Cloud Assist がアーキテクチャ図を生成します。これがビジュアル ブループリントです。
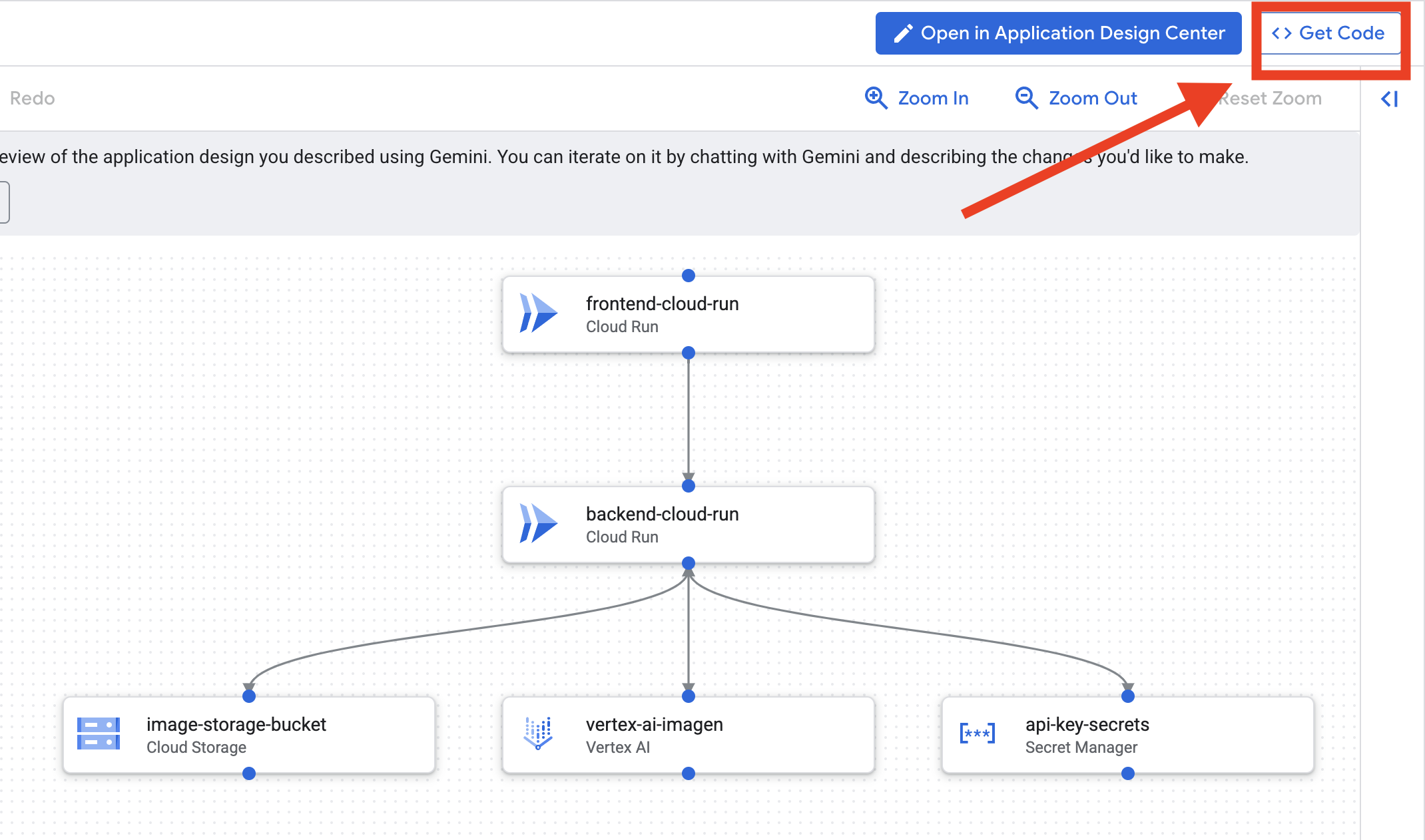
このコードでは対応は不要です。詳しくは、以下をご覧ください。
生成された Terraform コードについて。Cloud Assist から Terraform ファイルの完全なセットが届きました。このコードについては、今のところ何もする必要はありませんが、このコードが何であり、なぜ強力なのかを簡単に説明します。
Terraform とは何かTerraform は Infrastructure as Code(IaC)ツールです。これは、コードで記述されたクラウド環境のブループリントと考えることができます。Google Cloud コンソールで手動でクリックしてサービス、ストレージ、権限を作成する代わりに、これらの構成ファイルでこれらのリソースをすべて定義します。Terraform はブループリントを読み取り、その環境を自動的に構築します。
ビジュアル プランから実行可能コードへ。Cloud Assist が提供するアーキテクチャ図は、視覚的なプランです。Terraform コードは、同じプランの機械可読バージョンです。これは、設計コンセプトを再現可能な自動化された現実にするための重要なリンクです。インフラストラクチャをコードで定義すると、次のことができます。
- 作成の自動化: 同じ環境を繰り返し確実に構築します。
- バージョン管理を使用する: アプリケーション コードと同様に、Git でインフラストラクチャの変更を追跡します。
- エラーの防止: ウェブ インターフェースをクリックする際に発生する可能性のある手動ミスを回避します。
このワークショップでは、この Terraform コードを自分で実行する必要はありません。これは、今後の手順で構築してデプロイするインフラストラクチャの専門的なブループリント(「解答」)と考えることができます。
4. 開発: Gemini CLI の概要
👉💻 Cloud Shell ターミナルで、個人用ディレクトリに移動します。
cd ~/storygen-learning
👉💻 Gemini を初めて試す。
clear
gemini --model=gemini-2.5-flash
Do you want to connect Cloud Shell editor to Gemini CLI? と表示されたら、[NO] を選択します。
👉✨ すべての Gemini ツールに説明があります。今すぐお読みください。Gemini プロンプトに次のように入力します。
Gemini CLI の場合
/help
👉✨ Gemini CLI には、独自の組み込み機能セットがあります。検査するには:
Gemini CLI の場合
/tools
ReadFile、WriteFile、GoogleSearch などのリストが表示されます。これらは、外部の武器庫から調達する必要なく呼び出すことができるデフォルトのテクニックです。
👉✨ Gemini Blade は、アクションをガイドする「戦術的認識」(コンテキスト)を保持できます。
Gemini CLI の場合
/memory show
現在は空で、白紙の状態です。
👉✨ まず、エージェントのメモリにペルソナを追加します。これにより、専門分野が定義されます。
Gemini CLI の場合
/memory add "I am master at python development"
/memory show をもう一度実行して、ブレードがこの知識を吸収したことを確認します。
👉✨ @ 記号を使用してファイルを参照する方法を示すために、まず「ミッション ブリーフ」ファイルを作成しましょう。
新しいターミナルを開き、次のコマンドを実行してミッション ファイルを作成します。
!echo "## Mission Objective: Create Imagen ADK Agent for Story Book" > mission.md
👉✨Gemini CLI にブリーフィングを分析して結果を報告するよう指示します。
Gemini CLI の場合
Explain the contents of the file @mission.md
メイン武器が目標を認識するようになりました。
👉💻 Ctrl+C キーを 2 回押して Gemini CLI を終了します
学習:
Gemini CLI のスーパーパワーの仕組み: gemini.md 手続きを進める前に、Gemini CLI を特定のプロジェクトに合わせて調整する方法を理解しておくことが重要です。汎用チャットツールとして使用できますが、その真価は特別な構成ファイルである gemini.md にあります。
gemini コマンドを実行すると、現在のディレクトリで gemini.md ファイルが自動的に検索されます。このファイルは、AI のプロジェクト固有の取扱説明書として機能します。次の 3 つの重要なことを定義できます。
- ペルソナ: AI に誰であるべきかを伝えることができます。たとえば、「あなたは Google Cloud を専門とする Python のエキスパート デベロッパーです。」これにより、回答とスタイルが絞り込まれます。
- ツール: 特定のファイル(@file.py)や Google 検索(@google)へのアクセス権を付与できます。これにより、AI はプロジェクトのコードに関する質問に答えるために必要なコンテキストを取得します。
- メモリ: このプロジェクトで AI が常に記憶しておくべき事実やルールを指定できます。これにより、一貫性を維持できます。
gemini.md ファイルを使用すると、汎用的な Gemini モデルが、プロジェクトの目標についてすでに説明を受けており、適切な情報にアクセスできる専門家のアシスタントに変わります。
5. 開発: Gemini CLI を使用して ADK を構築する
環境の設定
Cloud Shell に移動し、[ターミナルを開く] ボタンをクリックします。
- 環境テンプレートをコピーします。
cd ~/storygen-learning cp ~/storygen-learning/env.template ~/storygen-learning/.env
.env が見つからない場合はエディタで非表示ファイルを表示する
- 上部のメニューバーで [表示] をクリックします。
- [Toggle Hidden Files] を選択します。
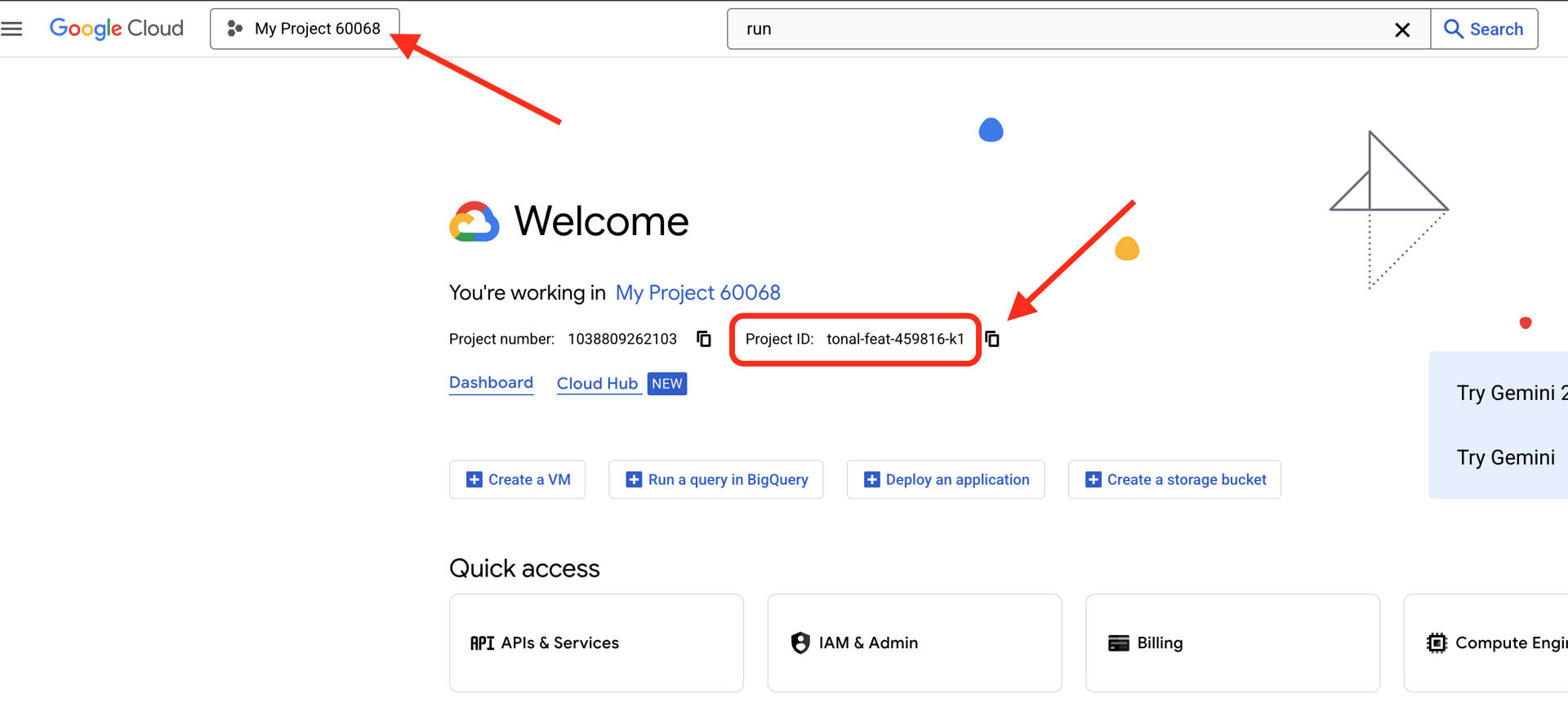
👉Google Cloud プロジェクト ID を確認します。
- Google Cloud コンソールを開きます: リンク
- ページの上部にあるプロジェクト プルダウンから、このワークショップで使用するプロジェクトを選択します。
- プロジェクト ID は、ダッシュボードの [プロジェクト情報] カードに表示されます。
👉GitHub のユーザー名を確認する:
- GitHub にアクセスして GitHub ユーザー名を確認する
.env ファイルの編集 2. .env の次の値を置き換えます。
GOOGLE_API_KEY=[REPLACE YOUR API KEY HERE]
GOOGLE_CLOUD_PROJECT_ID=[REPLACE YOUR PROJECT ID]
GITHUB_USERNAME=[REPLACE YOUR USERNAME]
GENMEDIA_BUCKET=[REPLACE YOUR PROJECT ID]-bucket
例: プロジェクト ID が testproject の場合は、GOOGLE_CLOUD_PROJECT_ID=testproject と GENMEDIA_BUCKET=testproject-bucket を入力します。
セットアップ スクリプト
00_Starting_Here に移動 新しいターミナルを開きます(Gemini CLI ではありません)。
cd ~/storygen-learning/00_Starting_Here
完全なセットアップを実行します。
./setup-complete.sh
ターミナルに設定結果が表示されます
最初のエージェントを構築する
01a_First_Agent_Ready に移動します。Gemini CLI を使用して ADK エージェントを作成しましょう。
cd ~/storygen-learning/01a_First_Agent_Ready
Gemini CLI を開く
gemini
Gemini CLI ウィンドウで、次のプロンプトを試します。
I need you to help me create a Google ADK (Agent Development Kit) agent for story generation. I'm working on a children's storybook app that generates creative stories with visual scenes.
Please create a complete `agent.py` file that implements an LlmAgent using Google's ADK framework. The agent should:
**Requirements:**
1. Use the `google.adk.agents.LlmAgent` class
2. Use the "gemini-2.5-flash" model (supports streaming)
3. Be named "story_agent"
4. Generate structured stories with exactly 4 scenes each
5. Output valid JSON with story text, main characters, and scene data
6. No tools needed (images are handled separately)
**Agent Specifications:**
- **Model:** gemini-2.5-flash
- **Name:** story_agent
- **Description:** "Generates creative short stories and accompanying visual keyframes based on user-provided keywords and themes."
**Story Structure Required:**
- Exactly 4 scenes: Setup → Inciting Incident → Climax → Resolution
- 100-200 words total
- Simple, charming language for all audiences
- Natural keyword integration
**JSON Output Format:**
{
"story": "Complete story text...",
"main_characters": [
{
"name": "Character Name",
"description": "VERY detailed visual description with specific colors, features, size, etc."
}
],
"scenes": [
{
"index": 1,
"title": "The Setup",
"description": "Scene action and setting WITHOUT character descriptions",
"text": "Story text for this scene"
}
// ... 3 more scenes
]
}
**Key Instructions for the Agent:**
- Extract 1-2 main characters maximum
- Character descriptions should be extremely detailed and visual
- Scene descriptions focus on ACTION and SETTING only
- Do NOT repeat character appearance in scene descriptions
- Always respond with valid JSON
Please include a complete example in the instructions showing the exact format using keywords like "tiny robot", "lost kitten", "rainy city".
The file should start with necessary imports, define an empty tools list, include a print statement for initialization, and then create the LlmAgent with all the detailed instructions.
Can you create this agent in backend/story_agent/agent.py
完了したら、Control+C を使用して Gemini CLI ターミナルをオフにします。
—————————————— 省略可。ソリューションの部分にスキップできます。——————————————–
ADK Web で変更を確認する
cd ~/storygen-learning/01a_First_Agent_Ready/backend
source ../../.venv/bin/activate
adk web --port 8080
続行するには、コマンド プロンプトが必要です。
ウェブサイトを起動する
cd ~/storygen-learning/01a_First_Agent_Ready
./start.sh
変更が機能しない場合は、ADK ウェブ UI とウェブサイトにエラーが表示されます。
—————————————— 解決策はここから始まります ———————————————
ソリューション
Control+C で前のプロセスを終了するか、別のターミナルを開きます。
cd ~/storygen-learning/01b_First_Agent_Done
ウェブサイトを起動する:
./start.sh
ウェブサイトが表示されます。
ADK UI を試す: 別のターミナルを開きます。
cd ~/storygen-learning/01b_First_Agent_Done/backend
source ../../.venv/bin/activate
adk web --port 8080
ADK UI が表示され、エージェントに質問できます。
次のセクションに進む前に、Ctrl+C キーを押してプロセスを終了します。
6. 開発: Gemini CLI を使用した ADK の構築 - (コンテキスト エンジニアリングの方法)
初期設定
01a_First_Agent_Ready/backend/story_agent/agent.py で、前に生成したエージェント ファイルを削除します。
01a_First_Agent_Ready に移動します。Gemini CLI を使用して ADK エージェントを作成しましょう。
cd ~/storygen-learning/01a_First_Agent_Ready/backend
Gemini CLI を開く
gemini
Gemini CLI ウィンドウで、次のプロンプトを試します。
Summarize the design doc @design.md for me, do not attempt to create file just yet.
👉💻 Ctrl+C を 2 回押して、Gemini を一時的に終了します。
👉💻 ターミナルで次のコマンドを実行して、ガイドライン ファイルを書き込みます。
cat << 'EOF' > GEMINI.md
### **Coding Guidelines**
**1. Python Best Practices:**
* **Type Hinting:** All function and method signatures should include type hints for arguments and return values.
* **Docstrings:** Every module, class, and function should have a docstring explaining its purpose, arguments, and return value, following a consistent format like reStructuredText or
Google Style.
* **Linter & Formatter:** Use a linter like `ruff` or `pylint` and a code formatter like `black` to enforce a consistent style and catch potential errors.
* **Imports:** Organize imports into three groups: standard library, third-party libraries, and local application imports. Sort them alphabetically within each group.
* **Naming Conventions:**
* `snake_case` for variables, functions, and methods.
* `PascalCase` for classes.
* `UPPER_SNAKE_CASE` for constants.
* **Dependency Management:** All Python dependencies must be listed in a `requirements.txt` file.
**2. Web APIs (FastAPI):**
* **Data Validation:** Use `pydantic` models for request and response data validation.
* **Dependency Injection:** Utilize FastAPI's dependency injection system for managing resources like database connections.
* **Error Handling:** Implement centralized error handling using middleware or exception handlers.
* **Asynchronous Code:** Use `async` and `await` for I/O-bound operations to improve performance.
EOF
cat GEMINI.md
法律が刻まれたので、AI パートナーを再度召喚して、アーティファクトの魔法を目撃しましょう。
👉💻 shadowblade ディレクトリから Gemini CLI を再起動します。
cd ~/storygen-learning/01a_First_Agent_Ready/backend
clear
gemini
👉✨ Gemini に、考えていることを表示するようリクエストしてみましょう。ルーンが読まれました。
/memory show
👉✨ これは、エージェントを構築する単一の強力なコマンドです。今すぐ発行します。
You are an expert Python developer specializing in the Google Agent Development Kit (ADK). Your task is to write the complete, production-quality code for `agent.py` by following the technical specifications outlined in the provided design document verbatim.
Analyze the design document at `@design.md` and generate the corresponding Python code for `agent.py`.
I need you to generate a Python script based on the provided design document and reference examples. Follow these requirements:
Read the design document carefully - it contains the complete technical specification for the code you need to write
Follow the structure and patterns shown in the reference context files
Adhere to all Python best practices specified in the coding standards document
Implement every requirement mentioned in the design document exactly as specified
Use the exact variable names, function names, and string values mentioned in the specifications
The design document describes the complete architecture, dependencies, configuration, and logic flow. Your generated code must match these specifications precisely while following professional Python coding standards.
Generate clean, production-ready Python code that can be used immediately without modifications.
完了したら、Control+C を使用して Gemini CLI ターミナルをオフにします。
—————————————— 省略可。ソリューションの部分にスキップできます。——————————————–
ADK Web で変更を確認する
cd ~/storygen-learning/01a_First_Agent_Ready/backend
source ../../.venv/bin/activate
adk web --port 8080
続行するには、コマンド プロンプトが必要です。
ウェブサイトを起動する
cd ~/storygen-learning/01a_First_Agent_Ready
./start.sh
変更が機能しない場合は、ADK ウェブ UI とウェブサイトにエラーが表示されます。
—————————————— 解決策はここから始まります ———————————————
ソリューション
Control+C で前のプロセスを終了するか、別のターミナルを開きます。
cd ~/storygen-learning/01b_First_Agent_Done
ウェブサイトを起動する:
./start.sh
ウェブサイトが表示されます。
ADK UI を試す: 別のターミナルを開きます。
cd ~/storygen-learning/01b_First_Agent_Done/backend
source ../../.venv/bin/activate
adk web --port 8080
ADK UI が表示され、エージェントに質問できます。
次のセクションに進む前に、Ctrl+C キーを押してプロセスを終了します。
7. 開発: Imagen を使用してカスタム エージェントを構築する
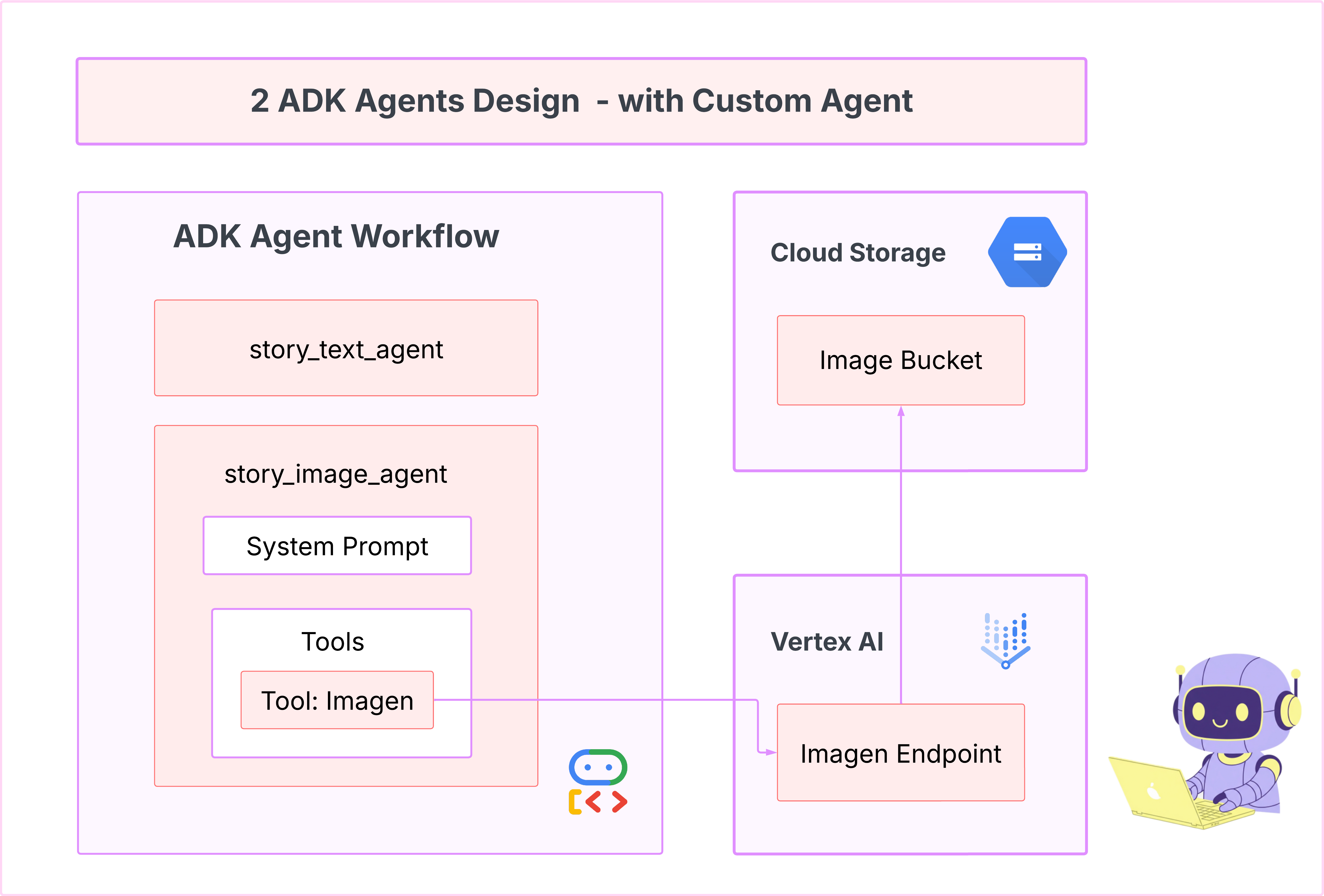
Imagen ツール(2 番目のエージェント)を生成する
cd ~/storygen-learning/02a_Image_Agent_Ready
Gemini CLI を使用して画像生成エージェントを作成します。
gemini generate "I need you to help me create a custom Google ADK (Agent Development Kit) agent for image generation. This is different from the story agent - this one handles image generation directly using the BaseAgent pattern for full control over tool execution.
Please create a complete `agent.py` file that implements a custom image generation agent. The agent should:
**Requirements:**
1. Use the `google.adk.agents.BaseAgent` class (NOT LlmAgent)
2. Be named "custom_image_agent"
3. Directly execute the ImagenTool without LLM intermediation
4. Handle JSON input with scene descriptions and character descriptions
5. Store results in session state for retrieval by main.py
6. Use async generators and yield Events
**Key Specifications:**
- **Class Name:** CustomImageAgent (inherits from BaseAgent)
- **Agent Name:** "custom_image_agent"
- **Tool:** Uses ImagenTool for direct image generation
- **Purpose:** Bypass LLM agent limitations and directly call ImagenTool
**Input Format:**
The agent should handle JSON input like:
{
"scene_description": "Scene action and setting",
"character_descriptions": {
"CharacterName": "detailed visual description"
}
}
**Core Method:** `async def _run_async_impl(self, ctx: InvocationContext) -> AsyncGenerator[Event, None]:`
- Extract user message from `ctx.user_content.parts`
- Parse JSON input or fallback to plain text
- Extract scene_description and character_descriptions
- Build image prompt with style prefix: "Children's book cartoon illustration with bright vibrant colors, simple shapes, friendly characters."
- Include character descriptions for consistency
- Call `await self.imagen_tool.run()` directly
- Store results in `ctx.session.state["image_result"]`
- Yield Event with results
**Session State:**
- Store JSON results in `ctx.session.state["image_result"]`
- Include success/error status
- Store actual image URLs or error messages
Expected Output Structure:
- Successful results stored as JSON with image URLs
- Error results stored as JSON with error messages
- Results accessible via session state in main.py
Can you create this agent in backend/story_image_agent/agent.py
"
—————————————— 省略可。ソリューションの部分にスキップできます。——————————————–
ADK Web で変更を確認する
cd ~/storygen-learning/02a_Image_Agent_Ready/backend
source ../../.venv/bin/activate
adk web --port 8080
ウェブサイトを起動する
cd ~/storygen-learning/02a_Second_Agent_Ready
./start.sh
変更が機能しない場合は、ADK ウェブ UI とウェブサイトにエラーが表示されます。
—————————————- ソリューションはここから始まります ——————————————–
ソリューション
Control+C で前のプロセスを終了するか、別のターミナルを開きます。
# Open new terminal
cd ~/storygen-learning/02b_Image_Agent_Done
ウェブサイトを起動する:
./start.sh
ウェブサイトが表示されます。
ADK UI を試す: 別のターミナルを開きます。
# Open new terminal
cd ~/storygen-learning/02b_Image_Agent_Done/backend
source ../../.venv/bin/activate
adk web --port 8080
ADK UI が表示され、エージェントに質問できるようになります。
次のセクションに進む前に、Ctrl+C キーを押してプロセスを終了します。
学習
最初のエージェントはテキストの生成に優れていましたが、今度は画像を生成する必要があります。このタスクでは、より直接的な制御が必要です。LLM に画像の作成を判断させるのではなく、直接指示したい。これは BaseAgent に最適なジョブです。
宣言型の LlmAgent とは異なり、BaseAgent は命令型です。つまり、デベロッパーは _run_async_impl メソッド内に正確なステップバイステップの Python ロジックを記述します。実行フローを完全に制御できます。
BaseAgent は、次のような場合に選択します。
決定論的ロジック: エージェントは、特定の変更不可能な手順のシーケンスに従う必要があります。
Direct Tool Execution: LLM の介入なしでツールを直接呼び出す場合。
複雑なワークフロー: プロセスには、カスタム データ操作、API 呼び出し、プロンプトだけでは LLM が確実に推論できないほど複雑なロジックが含まれます。
このアプリでは、BaseAgent を使用して最初のエージェントからシーンの説明を受け取り、Imagen ツールを直接呼び出して、各シーンの画像が生成されるようにします。
8. テスト: エージェントの評価
アプリは動作しますが、テストの自動化された安全ネットが必要です。これは、AI 副操縦士に委任するのに最適なタスクです。
操作
cd ~/storygen-learning/03a_Agent_Evaluation_Ready/backend
Gemini CLI を使用して包括的なテストを作成する:
Gemini CLI を開く
gemini
Gemini CLI ウィンドウで、次のプロンプトを試します。
I need you to create comprehensive test files for my backend/story_agent in Google ADK. I need three specific JSON files that match the testing structure used in ADK evaluation.
**Context:**
- The story agent generates structured JSON stories with exactly 4 scenes
- It uses LlmAgent with no tools, just direct LLM responses
- Input: Keywords
- Output: JSON with story, main_characters, and scenes arrays
**Files to Create:**
### 1. `story_agent_eval.evalset.json` (Comprehensive Integration Tests)
Create a comprehensive evaluation set with:
- **eval_set_id**: "story_agent_comprehensive_evalset"
- **name**: "Story Agent Comprehensive Evaluation Set"
- **description**: "Comprehensive evaluation scenarios for story_agent covering various keyword combinations, edge cases, and story quality metrics"
Each eval_case should include:
- Full conversation arrays with invocation_id, user_content, final_response
- Complete expected JSON responses with detailed stories, characters, and 4 scenes
- session_input with app_name "story_agent"
- All fields: story (narrative text), main_characters (with detailed visual descriptions), scenes (with index, title, description, text)
### 2. `story_generation.test.json` (Unit Tests)
Create basic generation tests with:
- **eval_set_id**: "story_agent_basic_generation_tests"
- **name**: "Story Agent Basic Generation Tests"
- **description**: "Unit tests for story_agent focusing on JSON structure compliance, scene generation, and keyword integration"
### 3. `test_config.json` (Evaluation Configuration)
Create test configuration with:
- **criteria**: response_match_score: 0.7, tool_trajectory_avg_score: 1.0
- **custom_evaluators**:
- json_structure_validator (validates required fields, scene count, character fields)
- story_quality_metrics (word count 80-250, keyword integration threshold 0.8)
- **evaluation_notes**: Story agent specifics and trajectory expectations
**Important Requirements:**
1. All responses must be valid, parseable JSON
2. Stories must have exactly 4 scenes with indices 1-4
3. Each scene must have: index, title, description, text
4. Main characters must have detailed visual descriptions
5. No tool_uses expected (empty arrays) since story agent uses direct LLM
6. Word count should be 100-200 words total
7. Keywords must be naturally integrated into the narrative
Please generate all three files with realistic example stories and comprehensive test coverage matching the ADK evaluation format.
—————————————— 省略可。ソリューションの部分にスキップできます。——————————————–
評価を確認するには:
./run_adk_web_persistent.sh
ADK UI の [eval] タブに移動します。
永続的なテスト機能が備わった ADK ウェブ UI が表示されます
重要な学習ポイント: AI は、品質保証の自動化において強力なパートナーとなります。テスト作成のボイラープレートを処理できるため、機能の構築に集中できます。
—————————————— 解決策はここから始まります ———————————————
ソリューション
- ソリューション フォルダに移動します。
cd ~/storygen-learning/03b_Agent_Evaluation_Done/backend
- ADK ウェブ UI を開く
./run_adk_web_persistent.sh
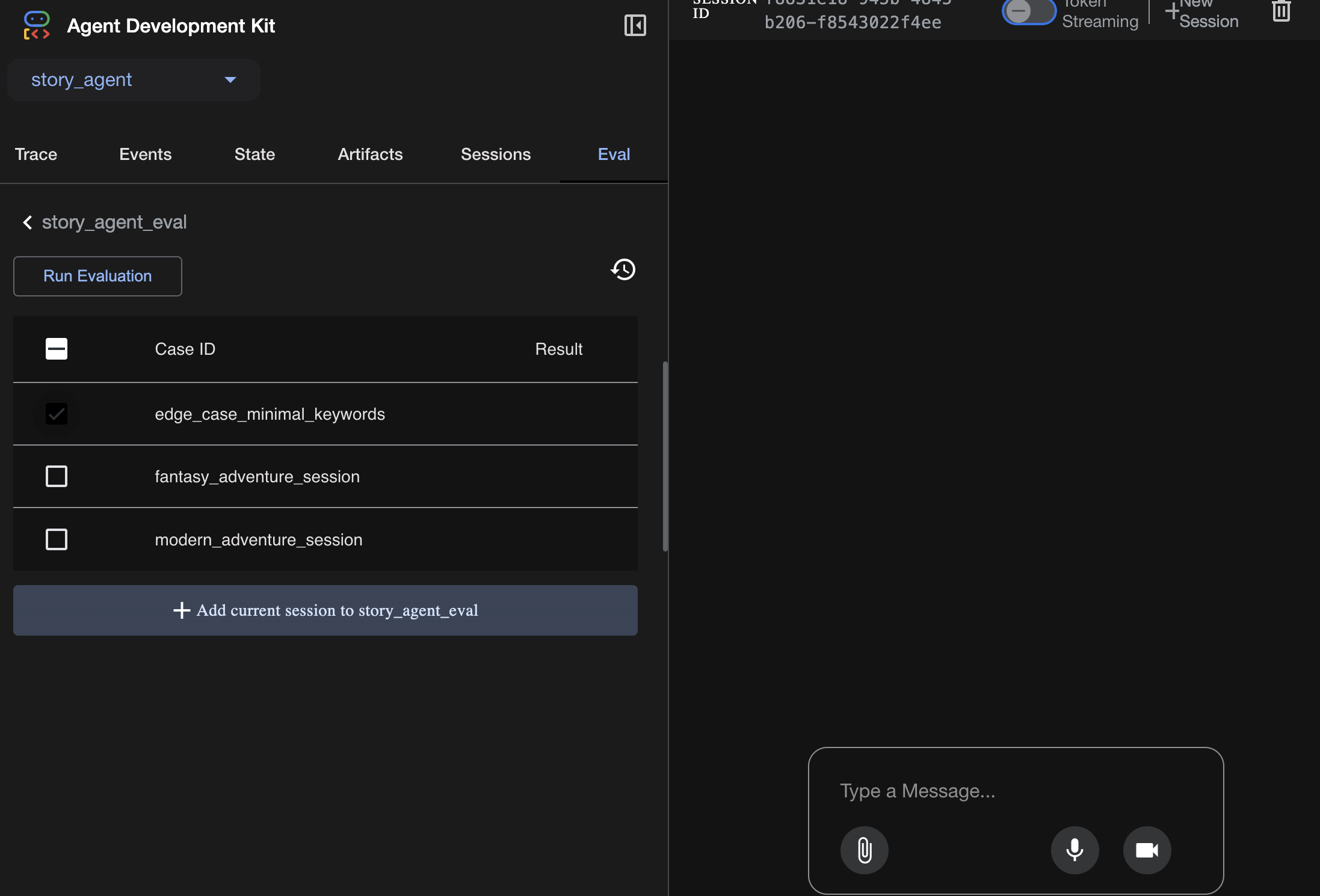
テストケースは Eval タブで確認できます。
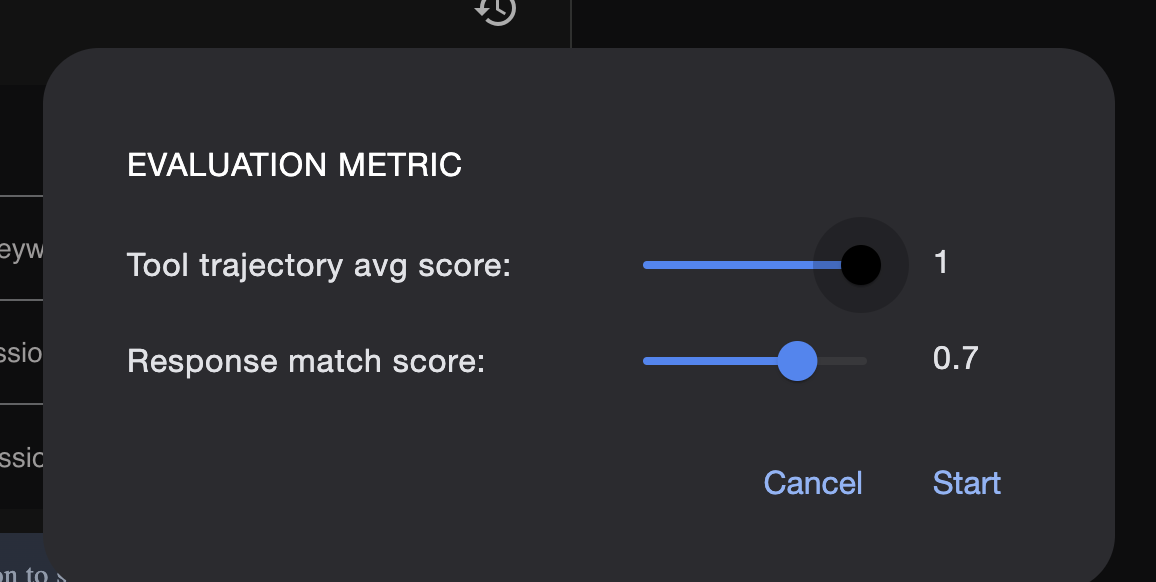
ここで指標を調整します。
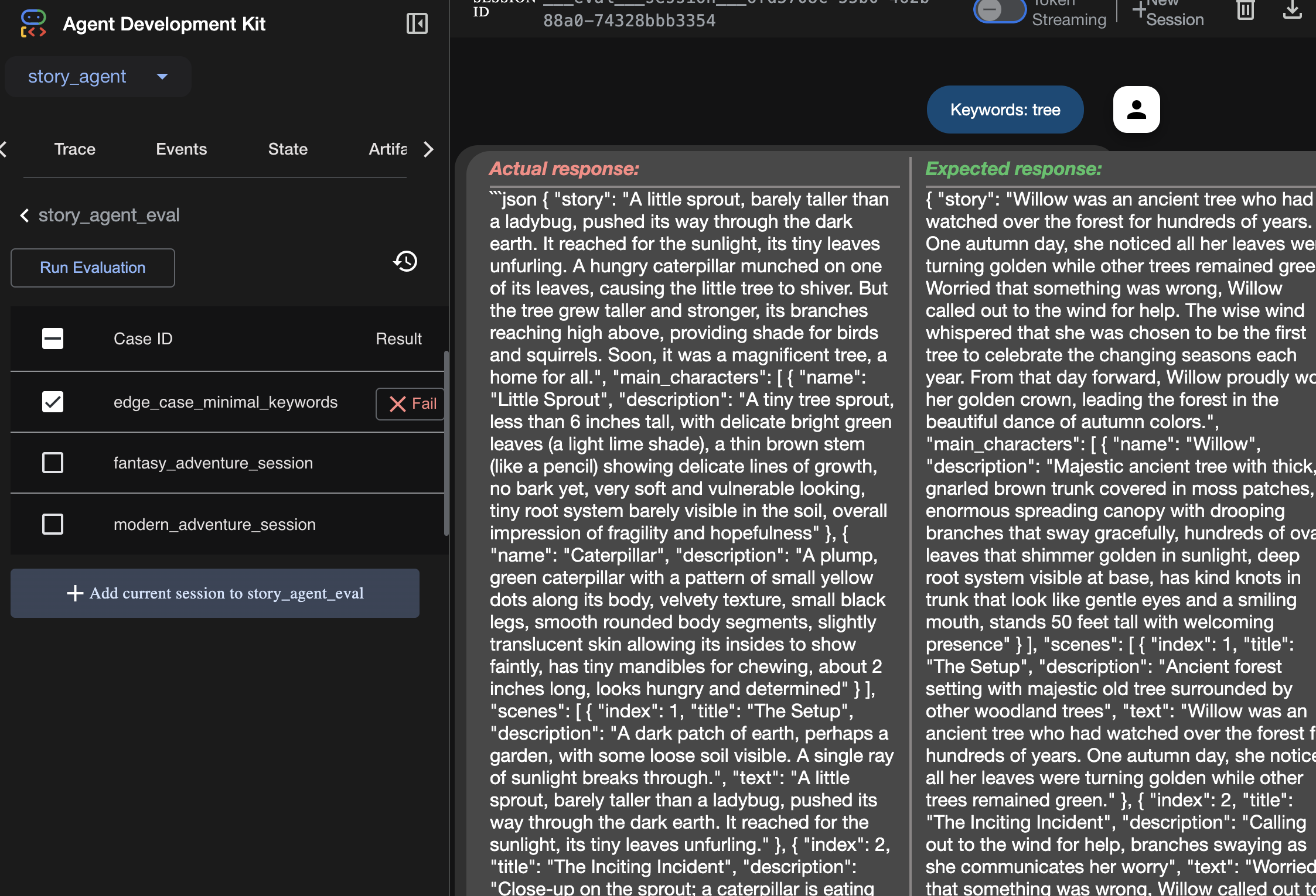
評価の実行結果は、こちらで確認できます。
学習
エージェントはエラーなしで実行されるため「動作」しますが、正しい出力を生成しているかどうかをどのように確認すればよいでしょうか?ストーリーは面白いですか?JSON 形式は正しいですか?ここで ADK の評価フレームワークが役立ちます。
エージェント評価は、エージェントの回答の品質と正確性を測定するように設計された自動テストシステムです。コードエラーをチェックするだけでなく、エージェントの動作が期待どおりであるかどうかもチェックします。フレームワークでは、主に次のキーファイルが使用されます。
evalset.json: マスター テストスイート。このファイル内の各「評価ケース」には、会話のサンプル(ユーザー プロンプトなど)と、エージェントが生成することを期待する理想的な「ゴールデン」レスポンスが含まれています。
test_config.json: このファイルは成功のルールを定義します。ここでは、次のような条件を設定します。
response_match_score: エージェントの回答は「正解」の回答とどの程度一致している必要がありますか?(スコアが 1.0 の場合は、同一である必要があります)。
custom_evaluators: 「レスポンスは有効な JSON でなければならない」や「ストーリーは 100 語以上でなければならない」などの独自のルールを作成できます。
評価を実行すると、エージェントを数十のシナリオに対して自動的にテストし、プロンプトやツールへの変更によってコア機能が誤って破損しないようにすることができます。これは、本番環境対応の AI エージェントを構築するための強力なセーフティ ネットです。
9. Infrastructure as Code(IaC): クラウドに家を建てる
コードはテスト済みですが、プロダクション レディ(な)ホームが必要です。「Infrastructure as Code」を使用して環境を定義します。
Docker とは
Docker は、コンテナでアプリケーションを作成して実行するためのプラットフォームです。コンテナは、ソフトウェアの標準化された輸送コンテナのようなものと考えてください。アプリケーションの実行に必要なものがすべて単一の隔離されたパッケージにバンドルされます。
- アプリケーション コード自体
- 必要なランタイム(特定のバージョンの Python など)
- すべてのシステム ツールとライブラリ
このコンテナ化されたアプリケーションは、Docker がインストールされている任意のマシンで実行できるため、従来の「私のマシンでは動いたのに」という問題を解決できます。
このセクションでは、Gemini に Dockerfile の生成を依頼します。これは、アプリケーションのコンテナ イメージをビルドするためのレシピまたはブループリントです。
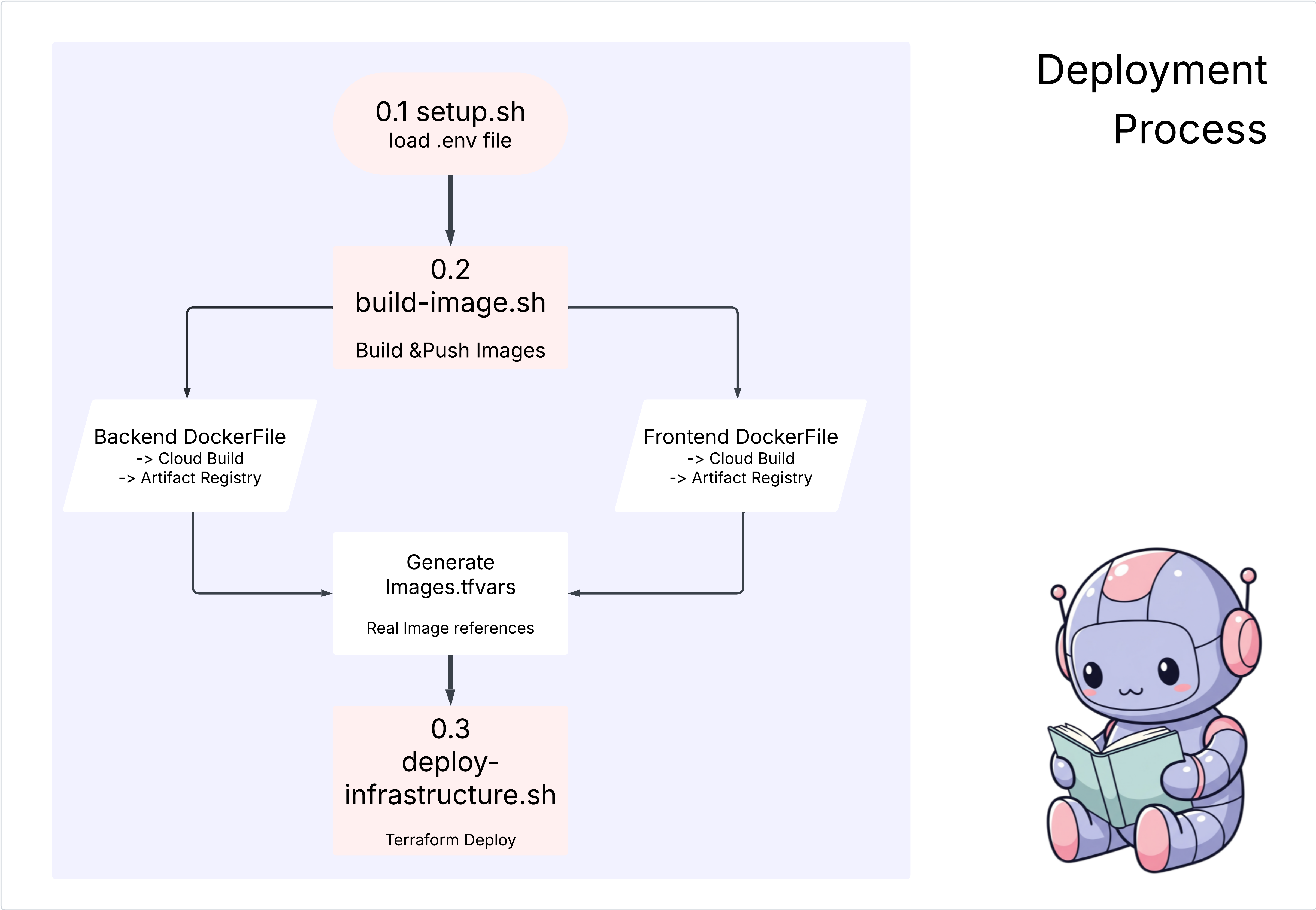
操作
cd ~/storygen-learning/04a_Manual_Deployment_Ready
Gemini CLI を使用してバックエンドの Dockerfile を作成します。Gemini CLI を開きます。
Gemini
Gemini CLI で、次のプロンプトを試します。
Create a manual deployment plan for my StoryGen app with Google Cloud Platform. I have a Next.js frontend, Python backend, and Terraform infrastructure.
Generate these deployment files:
1. **01-setup.sh** - Environment setup and authentication
2. **02-build-images.sh** - Build and push Docker images to Google Container Registry
3. **03-deploy-infrastructure.sh** - Deploy with Terraform and configure services
4. **load-env.sh** - Load environment variables for deployment
**Requirements:**
- Use Google Cloud Run for both frontend and backend
- Configure Imagen API and storage buckets
- Set up proper IAM permissions
- Use environment variables from .env file
- Include error handling and status checks
Keep scripts simple, well-commented, and production-ready for manual execution.
解決策:
cd ~/storygen-learning/04b_Manual_Deployment_Done
次のコマンドを実行します。
source ../.venv/bin/activate
./01-setup.sh
./02-build-images.sh
./03-deploy-infrastructure.sh
デプロイ結果とインフラストラクチャの作成が表示されます
10. 自動化(CI/CD): デジタル アセンブリ ライン
アプリケーションを手動でデプロイすると、可動部分を理解するのに役立ちますが、時間がかかり、手作業が必要で、人的ミスが発生する可能性があります。プロフェッショナルなソフトウェア開発では、このプロセス全体が CI/CD と呼ばれる手法を使用して自動化されます。
CI/CD は、継続的インテグレーションと継続的デプロイの略です。これは、変更を行うたびにコードを自動的にビルド、テスト、デプロイする方法です。
- 継続的インテグレーション(CI): これは「ビルドとテスト」のフェーズです。デベロッパーがコード変更を共有リポジトリ(GitHub など)に push するとすぐに、自動システムが起動します。アプリケーションをビルドし、作成したエージェント評価などのすべてのテストを実行して、新しいコードが正しく統合され、バグが発生しないことを確認します。
- 継続的デプロイ(CD): これは「リリース」フェーズです。CI フェーズが正常に完了すると、システムはテスト済みの新しいバージョンのアプリケーションを本番環境に自動的にデプロイし、ユーザーが利用できるようにします。
この自動化されたパイプラインは、「デジタル アセンブリ ライン」を作成し、デベロッパーのパソコンから本番環境にコードを迅速、安全、確実に移行します。このセクションでは、GitHub Actions と Google Cloud Build を使用して、このアセンブリ ラインを構築するように AI アシスタントに依頼します。
操作
cd ~/storygen-learning/05a_CICD_Pipeline_Ready
Gemini CLI を使用して GitHub で CI/CD パイプラインを構築する:
Gemini CLI を開く
Gemini
Gemini CLI で、次のプロンプトを試します。
Create a CI/CD pipeline for my StoryGen app using Google Cloud Build and GitHub integration.
Generate these automation files:
1. **cloudbuild.yaml** (for backend) - Automated build, test, and deploy pipeline
2. **GitHub Actions workflow** - Trigger builds on push/PR
3. **Deployment automation scripts** - Streamlined deployment process
**Requirements:**
- Auto-trigger on GitHub push to main branch
- Build and push Docker images
- Run automated tests if available
- Deploy to Google Cloud Run
- Environment-specific deployments (staging/prod)
- Notification on success/failure
Focus on fully automated deployment with minimal manual intervention. Include proper secret management and rollback capabilities.
—————————————— 解決策はここから始まります ———————————————
解決策:
cd ~/storygen-learning/06_Final_Solution/
# Copy the GitHub workflow to parent folder
cp -r 06_Final_Solution/.GitHub ../../../.GitHub
06_Final_Solution フォルダに戻り、スクリプトを実行します。
cd ~/storygen-learning/06_Final_Solution/
./setup-cicd-complete.sh
CI/CD パイプラインのセットアップが完了したことを確認する
ワークフローをトリガーする: コードを main に commit して push します。権限を許可するには、GitHub のメールアドレスと名前を設定する必要があります。
git add .
git commit -m "feat: Add backend, IaC, and CI/CD workflow"
git push origin main
GitHub リポジトリの [Actions] タブに移動して、自動デプロイの実行を確認します。
11. 運用: AI コントロール タワー
ライブ配信中!しかし、道のりはまだ終わっていません。これは「2 日目」の運用です。Cloud Assist に戻って、実行中のアプリケーションを管理しましょう。
操作
- Google Cloud コンソールで Cloud Run サービスに移動します。ライブアプリを操作して、多少の交通量とログを生成します。
- Cloud Assist ペインを開き、次のようなプロンプトを使用して運用上の副操縦士として使用します。
ログの分析:
Summarize the errors in my Cloud Run logs for the service 'genai-backend' from the last 15 minutes.
パフォーマンス チューニング:
My Cloud Run service 'genai-backend' has high startup latency. What are common causes for a Python app and how can I investigate with Cloud Trace?
費用の最適化:
Analyze the costs for my 'genai-backend' service and its GCS bucket. Are there any opportunities to save money?
重要な学習ポイント: AI SDLC は継続的なループです。アプリケーションの構築を支援した同じ AI コパイロットは、本番環境でのモニタリング、トラブルシューティング、最適化に不可欠なパートナーです。