
1. Czego się nauczysz
AI Agent Vibe Full Stack
Witamy! Za chwilę poznasz kolejną kluczową umiejętność w zakresie tworzenia oprogramowania: jak skutecznie kierować sztuczną inteligencją, aby tworzyć, testować i wdrażać oprogramowanie klasy produkcyjnej. Generatywna AI nie jest „autopilotem”, ale potężnym kopilotem, który potrzebuje doświadczonego dyrektora.
Te warsztaty zapewniają ustrukturyzowaną, powtarzalną metodologię współpracy z AI na każdym etapie profesjonalnego cyklu życia oprogramowania (SDLC). Z osoby piszącej kod wiersz po wierszu staniesz się dyrektorem technicznym – architektem z wizją i generalnym wykonawcą, który wykorzystuje AI do precyzyjnego realizowania tej wizji. 🚀
Po ukończeniu tego samouczka:
- Przekształcanie ogólnego pomysłu w architekturę chmury za pomocą AI.
- Wygenerowano kompletny backend w Pythonie z ukierunkowanymi, konkretnymi promptami.
- Używanie AI jako programisty do debugowania i poprawiania kodu.
- Przekazanie AI tworzenia testów jednostkowych, w tym atrap.
- Wygenerowano gotową do użytku produkcyjnego infrastrukturę jako kod (IaC) za pomocą Terraform.
- Utworzono pełny potok CI/CD w GitHub Actions za pomocą jednego prompta.
- monitorować i zarządzać aplikacją w wersji produkcyjnej za pomocą narzędzi operacyjnych opartych na AI;
Po zakończeniu szkolenia będziesz mieć nie tylko działającą aplikację, ale też plan rozwoju z wykorzystaniem AI. Zaczynajmy!
2. Wymagania wstępne i konfiguracja
Zanim zaczniemy, przygotujmy środowisko. To kluczowy krok, który zapewni płynny przebieg warsztatów.
Tworzenie nowego konta GCP i łączenie go z płatnościami
Aby uruchomić naszych agentów AI, potrzebujemy dwóch rzeczy: projektu Google Cloud, który będzie stanowić podstawę, oraz klucza interfejsu Gemini API, który umożliwi dostęp do zaawansowanych modeli Google.
Krok 1. Włącz konto rozliczeniowe
Aby wykonać to ćwiczenie, musisz mieć konto rozliczeniowe z pewną ilością środków. Aby rozpocząć, użyj środków z banera u góry tego modułu. Jeśli masz już połączenie z kontem rozliczeniowym, możesz pominąć ten krok.
Krok 2. Utwórz nowy projekt GCP
- Otwórz konsolę Google Cloud i utwórz nowy projekt.
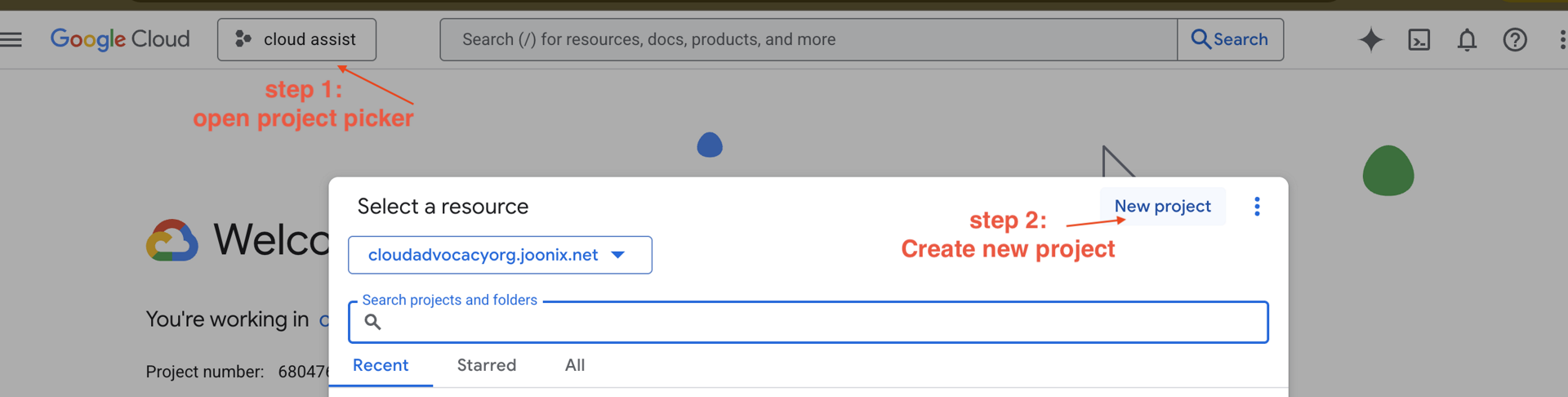
- Otwórz panel po lewej stronie, kliknij
Billingi sprawdź, czy konto rozliczeniowe jest połączone z tym kontem GCP.
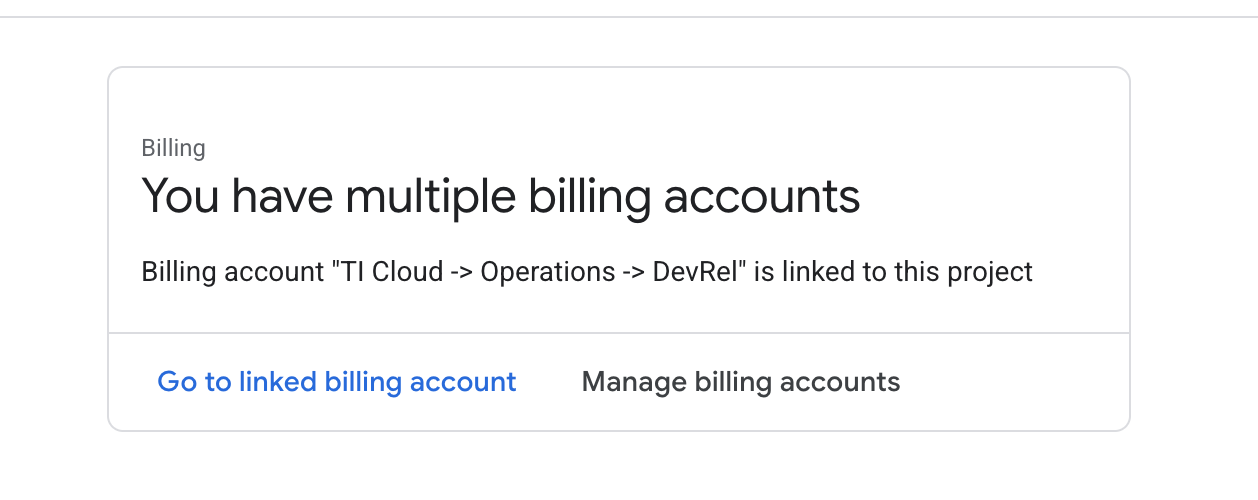
Jeśli widzisz tę stronę, zaznacz manage billing account, wybierz Google Cloud Trial One i połącz się z nim.
Krok 3. Wygeneruj klucz interfejsu Gemini API
Zanim zabezpieczysz klucz, musisz go mieć.
- Otwórz Google AI Studio : https://aistudio.google.com/
- Zaloguj się na konto Gmail.
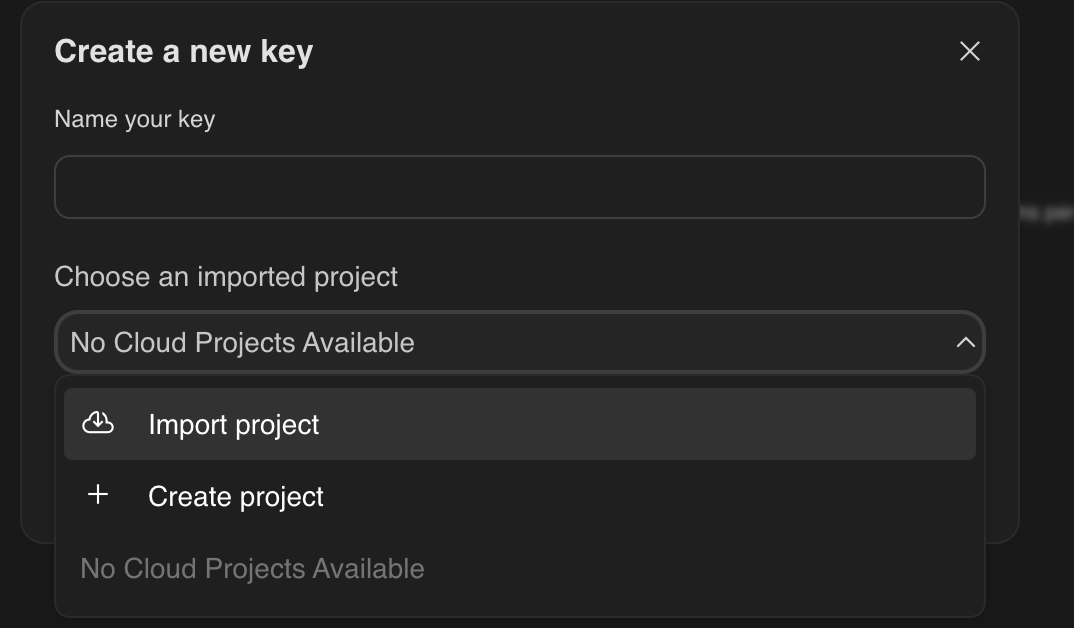
- Kliknij przycisk „Uzyskaj klucz API”, który zwykle znajduje się w panelu nawigacji po lewej stronie lub w prawym górnym rogu.
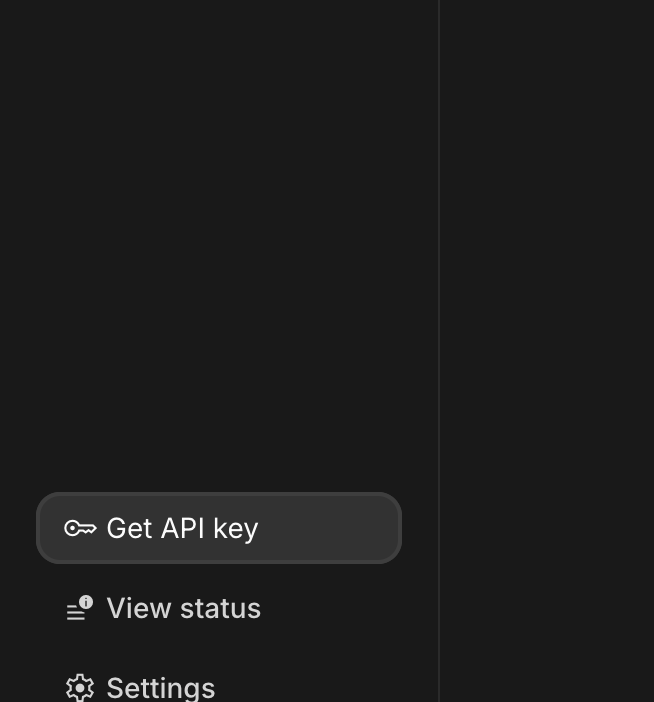
- W oknie „Klucze interfejsu API” kliknij „Utwórz klucz interfejsu API w nowym projekcie”.
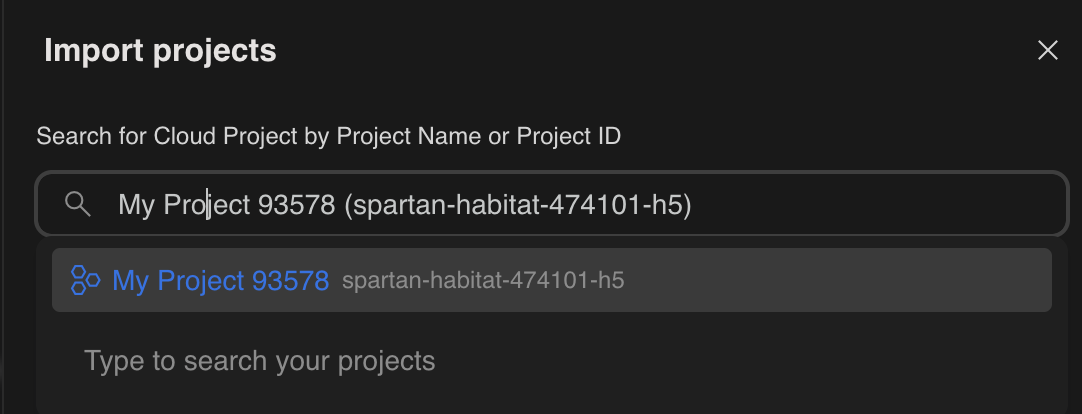
- Wybierz utworzony przez siebie nowy projekt, w którym skonfigurowano konto rozliczeniowe.
- Wygenerujemy dla Ciebie nowy klucz interfejsu API.
Natychmiast skopiuj ten klucz i tymczasowo zapisz go w bezpiecznym miejscu (np. w menedżerze haseł lub bezpiecznej notatce). Tej wartości użyjesz w kolejnych krokach.
Uwierzytelnianie w GitHub
Otwórz Cloud Shell, przechodząc do konsoli Google Cloud i klikając przycisk „Aktywuj Cloud Shell” w prawym górnym rogu.
Krok 1. Otwórz Cloud Shell
👉 U góry konsoli Google Cloud kliknij „Aktywuj Cloud Shell” (jest to ikona terminala u góry panelu Cloud Shell). 
👉 Kliknij przycisk „Otwórz edytor” (wygląda jak otwarty folder z ołówkiem). W oknie otworzy się edytor kodu Cloud Shell. Po lewej stronie zobaczysz eksplorator plików. 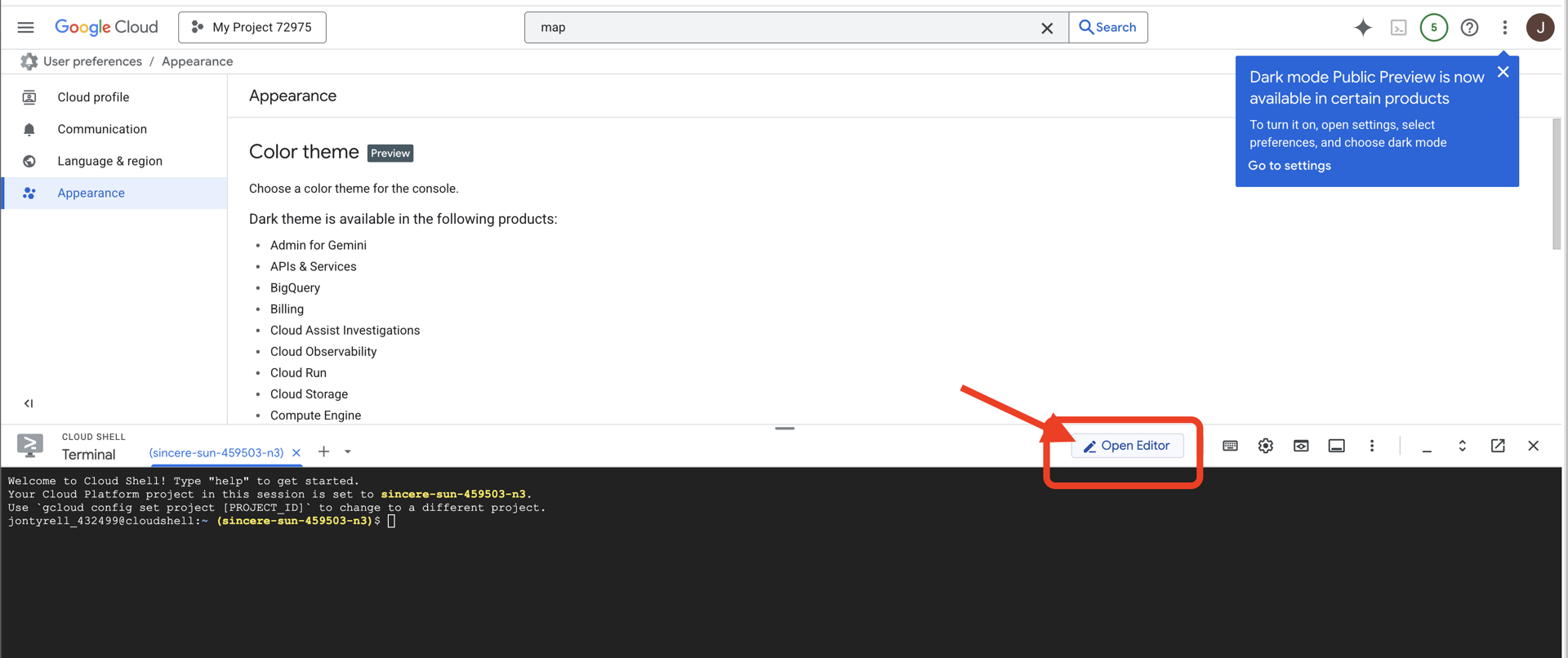
👉Po otwarciu edytora otwórz terminal w chmurze IDE.
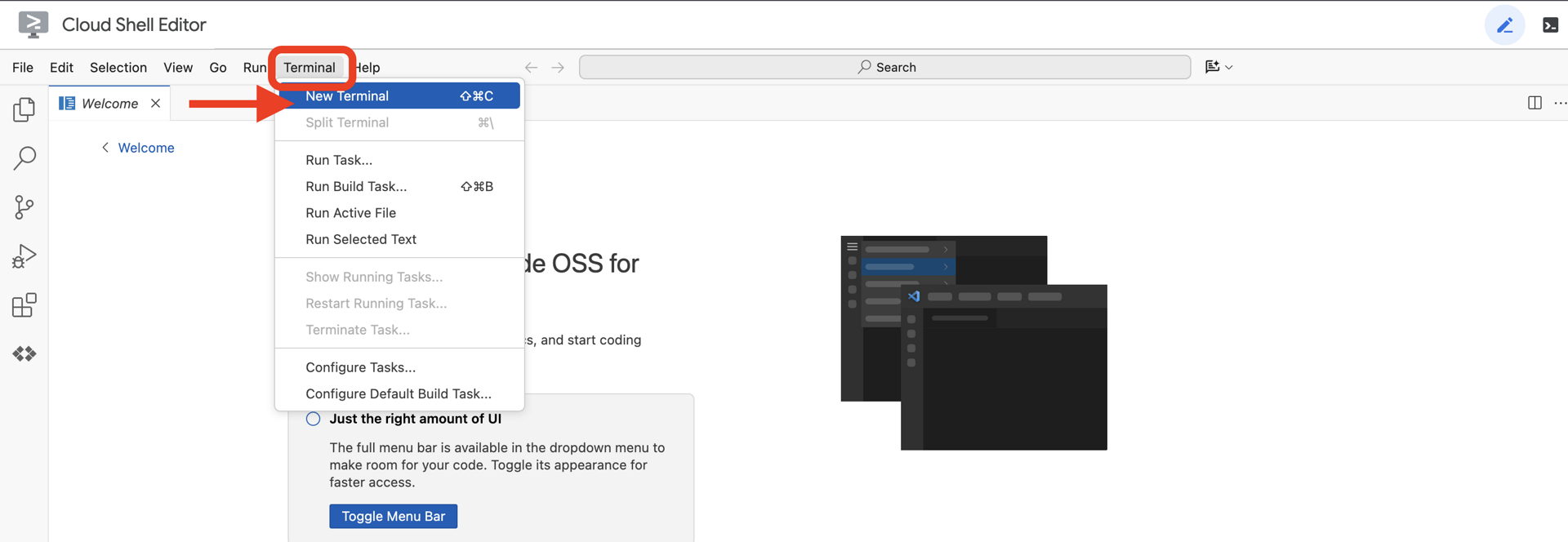
👉💻 W terminalu sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
Krok 2. Uwierzytelnij w usłudze GitHub i utwórz fork
Uwierzytelnianie w GitHub:
👉💻 Skopiuj i wklej polecenie do terminala w chmurze:
gh auth login
- W sekcji „Where do you use GitHub” (Gdzie korzystasz z GitHub) wybierz „GitHub.com”.
- „What is you preferred protocol for Git operations on this host?” (Jaki protokół wolisz do operacji Git na tym hoście?) wybierz „HTTPS”.
- „Uwierzytelnić Git za pomocą danych logowania do GitHub?”, wybierz „Tak”.
- „How would you like to authenticate GitHub CLI?” (Jak chcesz uwierzytelnić interfejs wiersza poleceń GitHub?), wybierz „Login with a web browser” (Zaloguj się w przeglądarce).
ważne!! nie naciskaj jeszcze klawisza „Enter”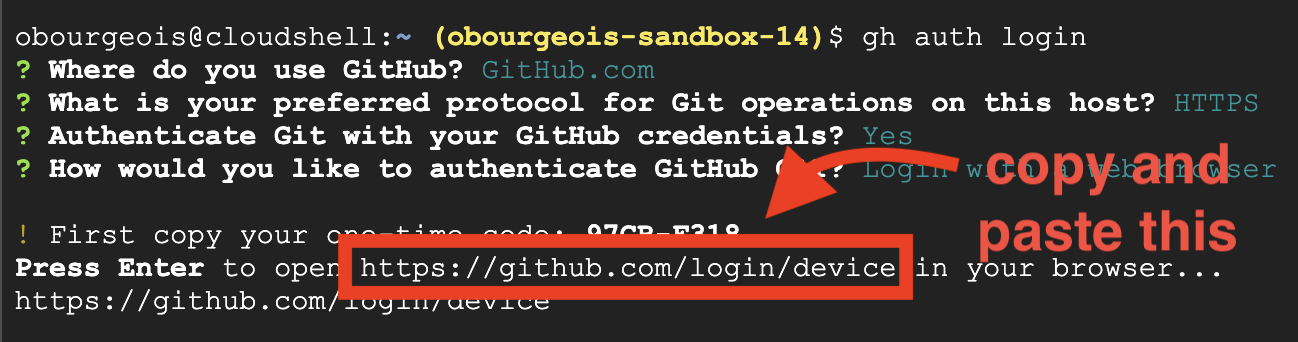
skopiuj kod z terminala na stronę weryfikacji logowania,
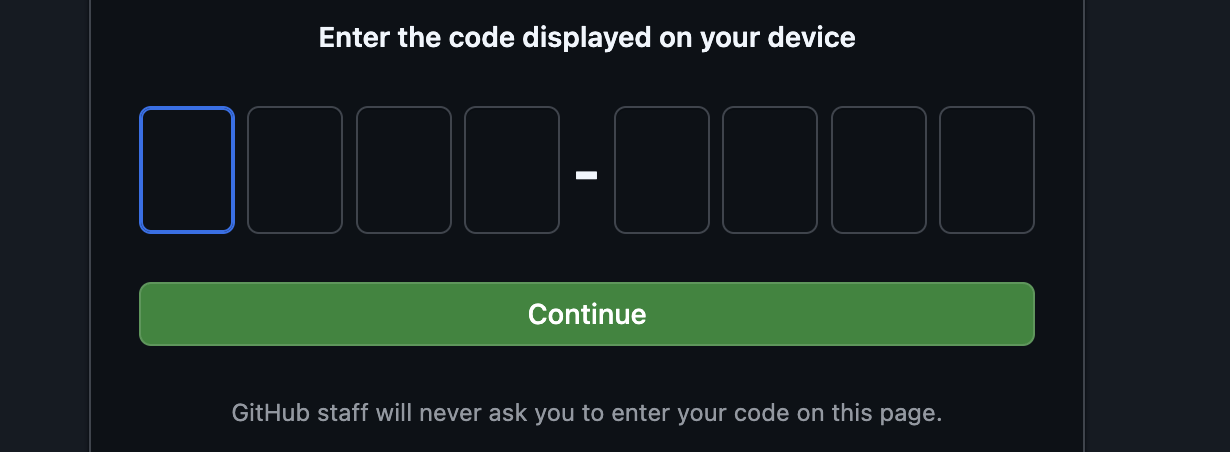
Po wpisaniu kodu wróć do terminala Cloud Shell i naciśnij „Enter”, aby kontynuować.

Krok 4. Utwórz fork i sklonuj repozytorium:
👉💻 Skopiuj i wklej polecenie do terminala w chmurze:
gh repo fork cuppibla/storygen-learning --clone=true
3. Architektura: od pomysłu do projektu z pomocą Cloud Assist
Każdy wspaniały projekt zaczyna się od jasnej wizji. Do zaprojektowania architektury aplikacji użyjemy naszego asystenta AI, Cloud Assist.
Działania
- Otwórz konsolę Google Cloud: [https://console.cloud.google.com](Google Cloud Console)
- W prawym górnym rogu kliknij „Otwórz czat Cloud Assist”.
Włączanie Cloud Assist
- Kliknij
Get Gemini Assist, a potemEnable Cloud Assist at no cost. - i rozpocznij czat.
 Podaj Cloud Assist ten szczegółowy prompt:
Podaj Cloud Assist ten szczegółowy prompt:
Wpisz swój pomysł
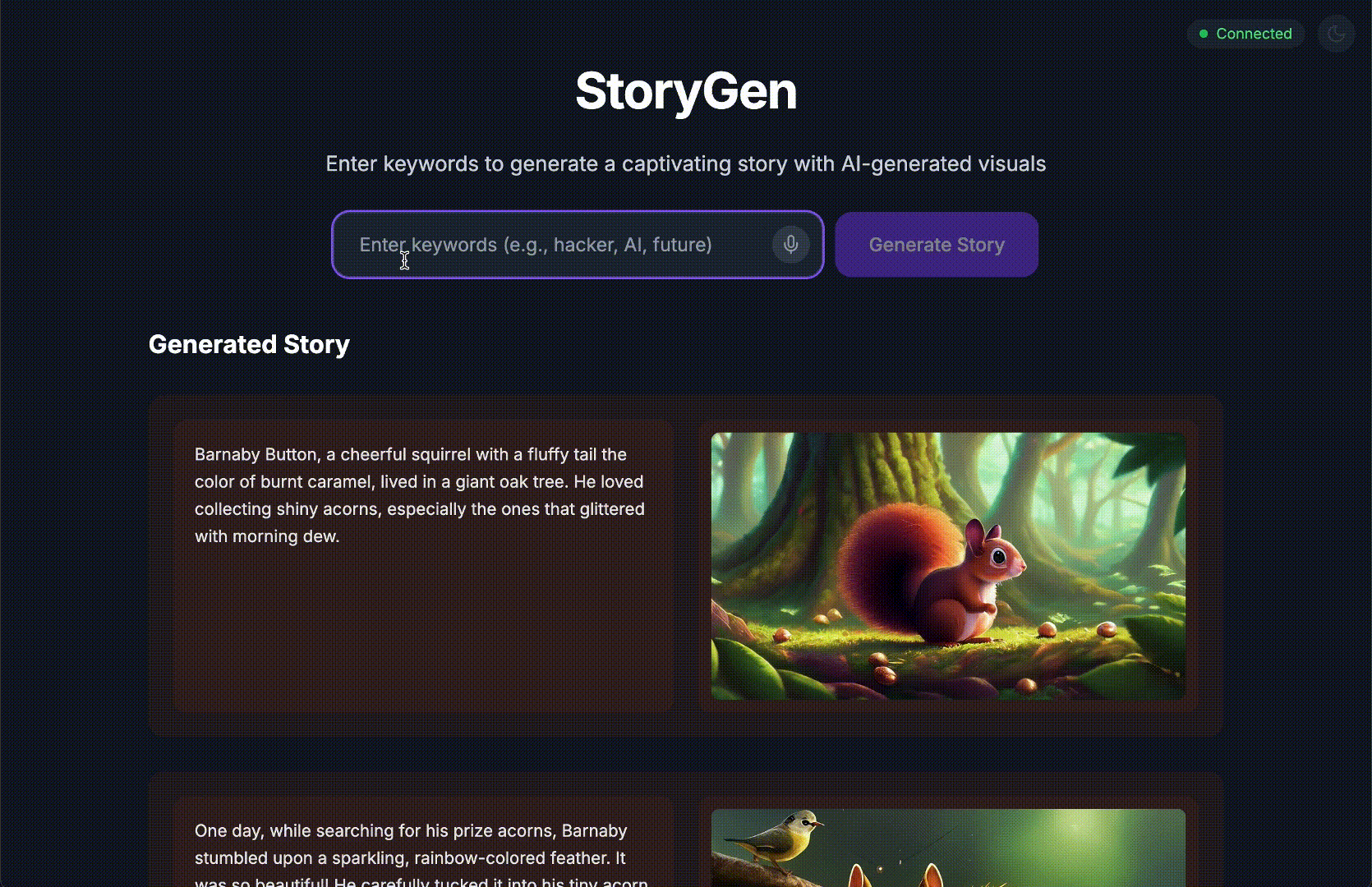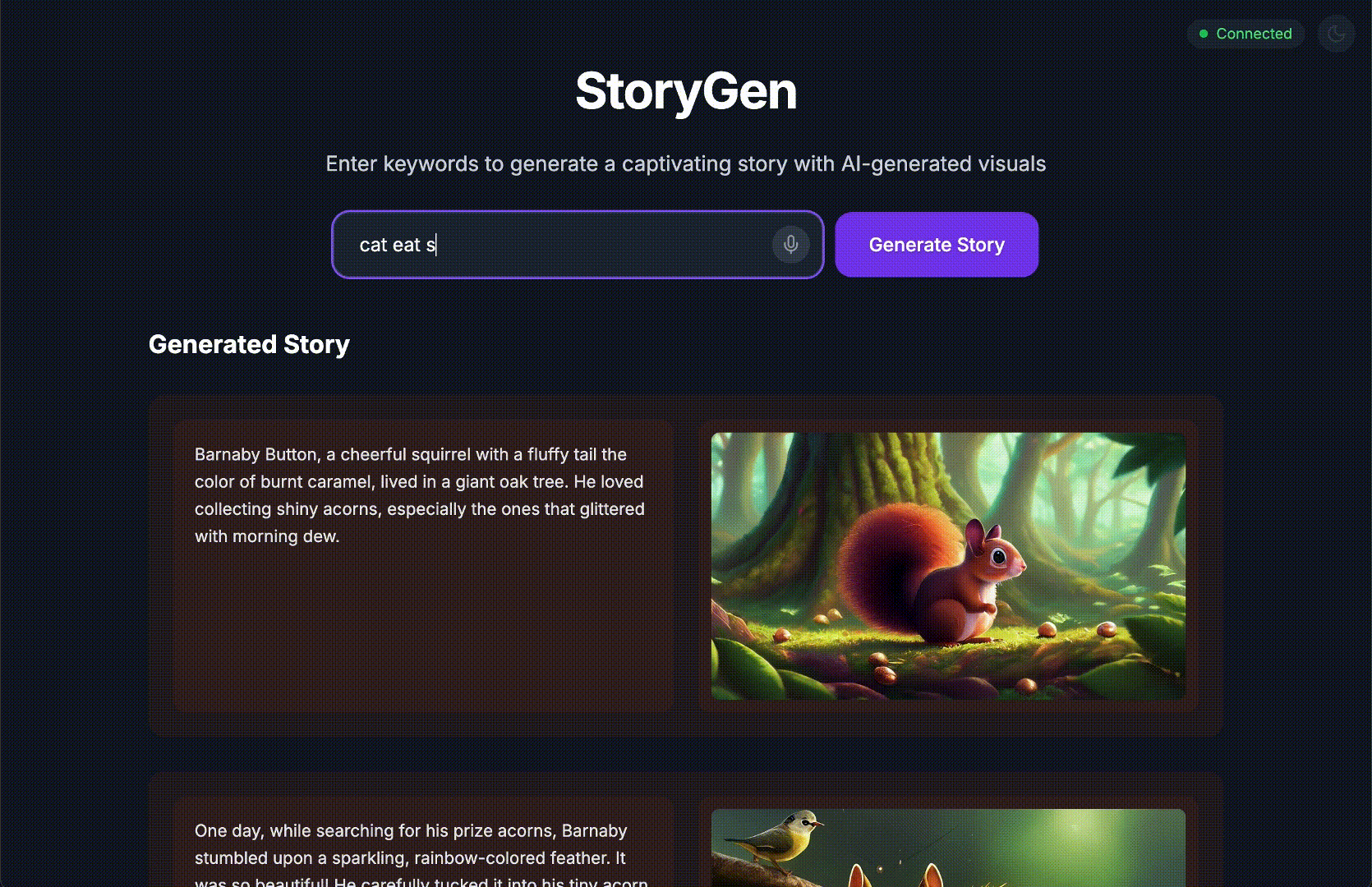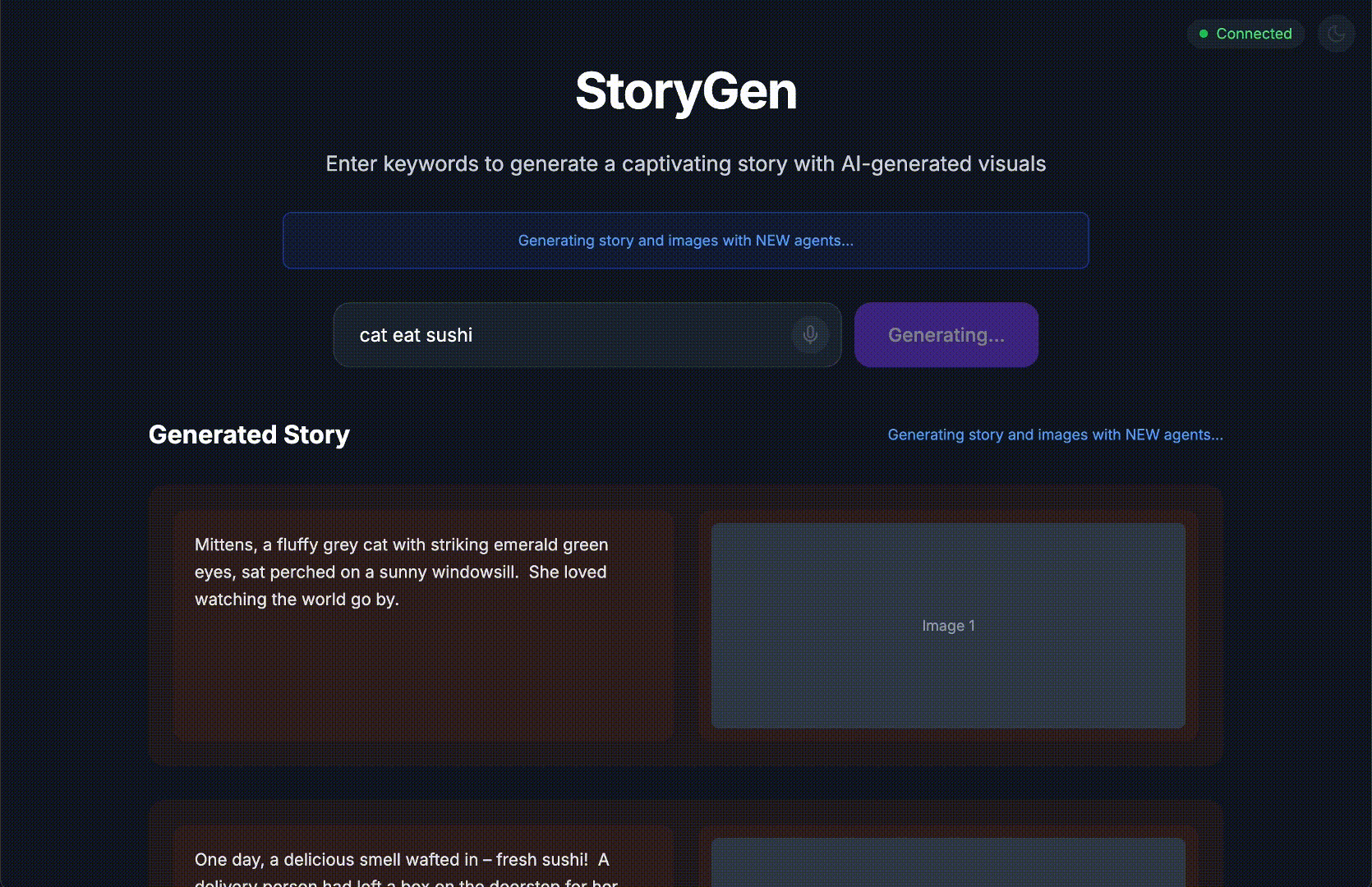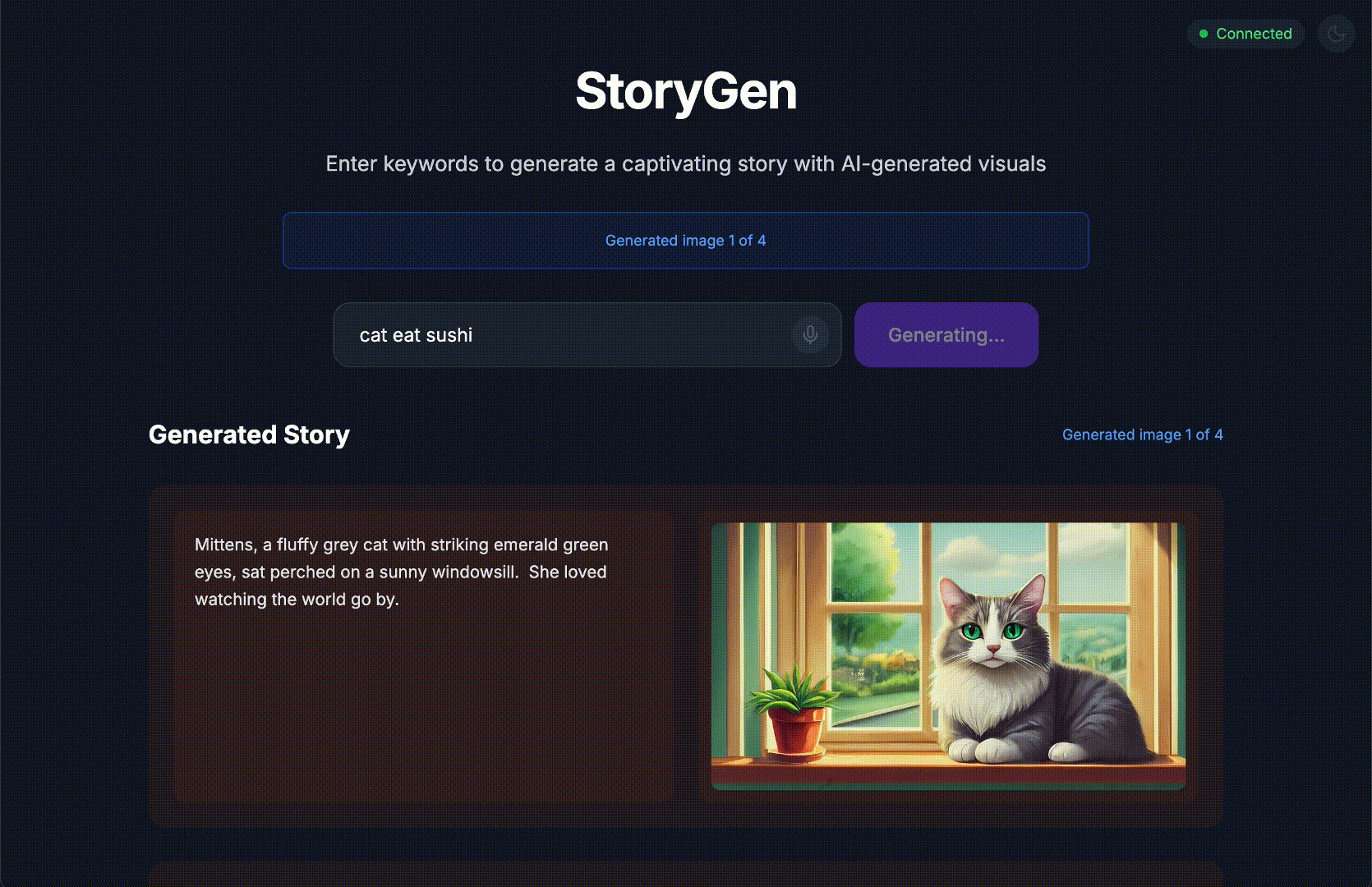
Generate a Python web application that uses AI to generate children's stories and illustrations. It has Python backend and React frontend host separately on Cloudrun. They communicate through Websocket. It needs to use a generative model for text and another for images. The generated images must be used by Imagen from Vertex AI and stored in a Google Cloud Storage bucket so that frontend can fetch from the bucket to render images. I do not want any load balancer or a database for the story text. We need a solution to store the API key.
Uzyskaj plan aplikacji
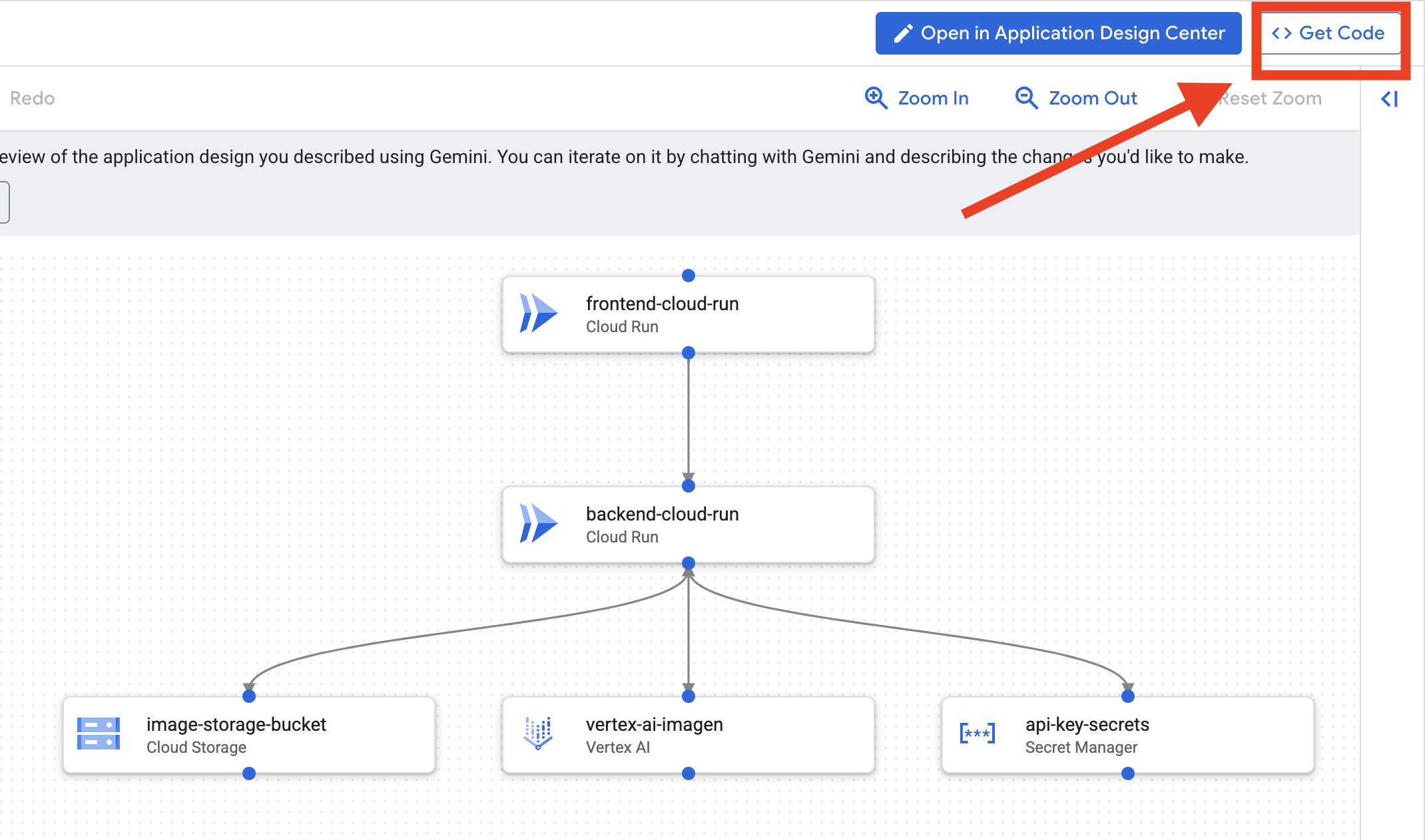
- Kliknij „Edytuj projekt aplikacji”, aby wyświetlić diagram. Aby pobrać kod Terraform, kliknij panel w prawym górnym rogu „<> Get Code” (Pobierz kod).
- Cloud Assist wygeneruje diagram architektury. To nasz wizualny plan.
Ten kod nie wymaga żadnych działań. Więcej informacji znajdziesz poniżej
Informacje o wygenerowanym kodzie Terraform Właśnie otrzymujesz od Cloud Assist pełny zestaw plików Terraform. Na razie nie musisz nic robić z tym kodem, ale szybko wyjaśnimy, czym on jest i dlaczego jest tak przydatny.
Czym jest Terraform? Terraform to narzędzie infrastruktury jako kodu (IaC). Możesz ją traktować jako plan środowiska chmurowego zapisany w kodzie. Zamiast ręcznie klikać w konsoli Google Cloud, aby utworzyć usługi, miejsce na dane i uprawnienia, możesz zdefiniować wszystkie te zasoby w plikach konfiguracyjnych. Terraform odczytuje następnie Twój projekt i automatycznie tworzy dokładnie takie środowisko.
Od planu wizualnego do kodu wykonywalnego Diagram architektury udostępniony przez Cloud Assist to Twój plan wizualny. Kod Terraform to czytelna dla komputera wersja tego samego planu. To kluczowe ogniwo, które przekształca koncepcję projektu w powtarzalną, zautomatyzowaną rzeczywistość. Definiując infrastrukturę w kodzie, możesz:
- Automatyzacja tworzenia: niezawodne tworzenie tego samego środowiska wielokrotnie.
- Korzystaj z kontroli wersji: śledź zmiany w infrastrukturze w Git, tak jak w przypadku kodu aplikacji.
- Zapobieganie błędom: unikaj błędów ręcznych, które mogą wystąpić podczas klikania interfejsu internetowego.
W przypadku tych warsztatów nie musisz samodzielnie uruchamiać tego kodu Terraform. Możesz go traktować jako profesjonalny plan – „klucz odpowiedzi” – infrastruktury, którą utworzysz i wdrożysz w kolejnych krokach.
4. Programowanie: wprowadzenie do interfejsu wiersza poleceń Gemini
👉💻 W terminalu Cloud Shell otwórz katalog osobisty.
cd ~/storygen-learning
👉💻 Wypróbuj Gemini po raz pierwszy
clear
gemini --model=gemini-2.5-flash
Jeśli pojawi się pytanie Do you want to connect Cloud Shell editor to Gemini CLI?, wybierz NIE.
👉✨ Każde narzędzie Gemini ma opis. Przeczytaj je. W prompcie dla Gemini wpisz:
W interfejsie wiersza poleceń Gemini
/help
👉✨ Interfejs wiersza poleceń Gemini ma własny zestaw wbudowanych funkcji. Aby je sprawdzić:
W interfejsie wiersza poleceń Gemini
/tools
Zobaczysz listę, na której znajdą się m.in. ReadFile, WriteFile i GoogleSearch. Są to domyślne techniki, których możesz używać bez korzystania z zewnętrznego arsenału.
👉✨ Gemini Blade może przechowywać „świadomość taktyczną” (kontekst), aby kierować swoimi działaniami.
W interfejsie wiersza poleceń Gemini
/memory show
Jest ona obecnie pusta, to czysta karta.
👉✨ Najpierw dodaj do pamięci agenta personę. Określi to obszar specjalizacji:
W interfejsie wiersza poleceń Gemini
/memory add "I am master at python development"
Uruchom ponownie /memory show, aby potwierdzić, że ostrze przyswoiło tę wiedzę.
👉✨ Aby pokazać, jak odwoływać się do plików za pomocą symbolu @, najpierw utwórzmy plik „mission brief”.
Otwórz nowy terminal i uruchom to polecenie, aby utworzyć plik misji:
!echo "## Mission Objective: Create Imagen ADK Agent for Story Book" > mission.md
👉✨Teraz poproś interfejs wiersza poleceń Gemini o analizę briefu i przedstawienie wyników:
W interfejsie wiersza poleceń Gemini
Explain the contents of the file @mission.md
Twoja broń główna zna już swój cel.
👉💻 Naciśnij dwukrotnie Ctrl+C, aby zamknąć interfejs wiersza poleceń Gemini.
Nauka:
Jak interfejs wiersza poleceń Gemini zyskuje swoje supermoce: gemini.md Zanim przejdziesz dalej, dowiedz się, jak dostosować interfejs wiersza poleceń Gemini do konkretnego projektu. Możesz używać go jako ogólnego narzędzia do czatu, ale jego prawdziwa moc tkwi w specjalnym pliku konfiguracyjnym: gemini.md.
Gdy uruchomisz polecenie gemini, automatycznie wyszuka ono plik gemini.md w bieżącym katalogu. Ten plik działa jak instrukcja obsługi AI dla konkretnego projektu. Może określać 3 kluczowe elementy:
- Persona: możesz określić, kim ma być AI. Na przykład: „Jesteś doświadczonym programistą Pythona specjalizującym się w Google Cloud”. Dzięki temu odpowiedzi i styl będą bardziej dopasowane.
- Narzędzia: możesz przyznać mu dostęp do konkretnych plików (@file.py) lub nawet do wyszukiwania w Google (@google). Dzięki temu AI będzie mieć kontekst potrzebny do odpowiadania na pytania dotyczące kodu projektu.
- Pamięć: możesz podać fakty lub reguły, które AI powinna zawsze pamiętać w przypadku tego projektu, co pomaga zachować spójność.
Korzystając z gemini.md, możesz przekształcić ogólny model Gemini w specjalistycznego asystenta, który zna już cele Twojego projektu i ma dostęp do odpowiednich informacji.
5. Tworzenie pakietu ADK za pomocą interfejsu wiersza poleceń Gemini
Konfiguracja środowiska
Otwórz Cloud Shell i kliknij przycisk „Otwórz terminal”.
- Skopiuj szablon środowiska:
cd ~/storygen-learning cp ~/storygen-learning/env.template ~/storygen-learning/.env
Wyświetlanie ukrytego pliku w edytorze, jeśli nie możesz znaleźć pliku .env
- Na pasku menu u góry kliknij Wyświetl.
- Kliknij Przełącz ukryte pliki.
👉Znajdź identyfikator projektu Google Cloud:
- Otwórz konsolę Google Cloud: link
- Z menu projektów u góry strony wybierz projekt, którego chcesz użyć w tych warsztatach.
- Identyfikator projektu jest wyświetlany na karcie Informacje o projekcie w panelu.
👉Znajdź nazwę użytkownika GitHuba:
- Otwórz GitHub i znajdź swoją nazwę użytkownika GitHub.
Edytowanie pliku .env 2. Zastąp te wartości w pliku .env:
GOOGLE_API_KEY=[REPLACE YOUR API KEY HERE]
GOOGLE_CLOUD_PROJECT_ID=[REPLACE YOUR PROJECT ID]
GITHUB_USERNAME=[REPLACE YOUR USERNAME]
GENMEDIA_BUCKET=[REPLACE YOUR PROJECT ID]-bucket
Jeśli np.identyfikator projektu to testproject, wpisz GOOGLE_CLOUD_PROJECT_ID=testproject i GENMEDIA_BUCKET=testproject-bucket.
Skrypty konfiguracyjne
Przejdź do 00_Starting_Here Otwórz nowy terminal (nie w interfejsie wiersza poleceń Gemini)
cd ~/storygen-learning/00_Starting_Here
Przeprowadź pełną konfigurację:
./setup-complete.sh
Wyniki konfiguracji powinny być widoczne w terminalu.
Tworzenie pierwszego agenta
Otwórz plik 01a_First_Agent_Ready. Użyjmy interfejsu wiersza poleceń Gemini, aby utworzyć agenta ADK:
cd ~/storygen-learning/01a_First_Agent_Ready
Otwieranie interfejsu wiersza poleceń Gemini
gemini
W oknie interfejsu wiersza poleceń Gemini wypróbuj prompta:
I need you to help me create a Google ADK (Agent Development Kit) agent for story generation. I'm working on a children's storybook app that generates creative stories with visual scenes.
Please create a complete `agent.py` file that implements an LlmAgent using Google's ADK framework. The agent should:
**Requirements:**
1. Use the `google.adk.agents.LlmAgent` class
2. Use the "gemini-2.5-flash" model (supports streaming)
3. Be named "story_agent"
4. Generate structured stories with exactly 4 scenes each
5. Output valid JSON with story text, main characters, and scene data
6. No tools needed (images are handled separately)
**Agent Specifications:**
- **Model:** gemini-2.5-flash
- **Name:** story_agent
- **Description:** "Generates creative short stories and accompanying visual keyframes based on user-provided keywords and themes."
**Story Structure Required:**
- Exactly 4 scenes: Setup → Inciting Incident → Climax → Resolution
- 100-200 words total
- Simple, charming language for all audiences
- Natural keyword integration
**JSON Output Format:**
{
"story": "Complete story text...",
"main_characters": [
{
"name": "Character Name",
"description": "VERY detailed visual description with specific colors, features, size, etc."
}
],
"scenes": [
{
"index": 1,
"title": "The Setup",
"description": "Scene action and setting WITHOUT character descriptions",
"text": "Story text for this scene"
}
// ... 3 more scenes
]
}
**Key Instructions for the Agent:**
- Extract 1-2 main characters maximum
- Character descriptions should be extremely detailed and visual
- Scene descriptions focus on ACTION and SETTING only
- Do NOT repeat character appearance in scene descriptions
- Always respond with valid JSON
Please include a complete example in the instructions showing the exact format using keywords like "tiny robot", "lost kitten", "rainy city".
The file should start with necessary imports, define an empty tools list, include a print statement for initialization, and then create the LlmAgent with all the detailed instructions.
Can you create this agent in backend/story_agent/agent.py
Po zakończeniu wyłącz terminal interfejsu wiersza poleceń Gemini za pomocą ikony Control+C.
—————————————— Opcjonalnie, możesz przejść do części Rozwiązanie——————————————–
Teraz zweryfikuj zmianę w interfejsie internetowym ADK
cd ~/storygen-learning/01a_First_Agent_Ready/backend
source ../../.venv/bin/activate
adk web --port 8080
Aby kontynuować, musisz mieć wiersz poleceń.
Uruchomienie witryny
cd ~/storygen-learning/01a_First_Agent_Ready
./start.sh
Jeśli zmiana nie zadziała, w interfejsie ADK i witrynie powinny pojawić się błędy.
——————————————– Rozwiązanie zaczyna się tutaj ——————————————–
Rozwiązanie
Zakończ poprzedni proces, klikając Control+C, lub otwórz inny terminal:
cd ~/storygen-learning/01b_First_Agent_Done
Uruchom witrynę:
./start.sh
Zobaczysz witrynę:
Wypróbuj interfejs ADK: otwórz kolejny terminal:
cd ~/storygen-learning/01b_First_Agent_Done/backend
source ../../.venv/bin/activate
adk web --port 8080
Zobaczysz interfejs ADK, w którym możesz zadawać agentowi pytania.
Zanim przejdziesz do następnej sekcji, naciśnij Ctrl+C, aby zakończyć proces.
6. Tworzenie pakietu ADK za pomocą interfejsu wiersza poleceń Gemini (inżynieria kontekstu)
Konfiguracja początkowa
Upewnij się, że usuniesz wygenerowany wcześniej plik agenta w folderze 01a_First_Agent_Ready/backend/story_agent/agent.py:
Otwórz plik 01a_First_Agent_Ready. Użyjmy interfejsu wiersza poleceń Gemini, aby utworzyć agenta ADK:
cd ~/storygen-learning/01a_First_Agent_Ready/backend
Otwieranie interfejsu wiersza poleceń Gemini
gemini
W oknie interfejsu wiersza poleceń Gemini wypróbuj prompta:
Summarize the design doc @design.md for me, do not attempt to create file just yet.
👉💻 Aby na chwilę zamknąć Gemini, naciśnij dwukrotnie Ctrl+C.
👉💻 W terminalu uruchom to polecenie, aby zapisać plik wytycznych.
cat << 'EOF' > GEMINI.md
### **Coding Guidelines**
**1. Python Best Practices:**
* **Type Hinting:** All function and method signatures should include type hints for arguments and return values.
* **Docstrings:** Every module, class, and function should have a docstring explaining its purpose, arguments, and return value, following a consistent format like reStructuredText or
Google Style.
* **Linter & Formatter:** Use a linter like `ruff` or `pylint` and a code formatter like `black` to enforce a consistent style and catch potential errors.
* **Imports:** Organize imports into three groups: standard library, third-party libraries, and local application imports. Sort them alphabetically within each group.
* **Naming Conventions:**
* `snake_case` for variables, functions, and methods.
* `PascalCase` for classes.
* `UPPER_SNAKE_CASE` for constants.
* **Dependency Management:** All Python dependencies must be listed in a `requirements.txt` file.
**2. Web APIs (FastAPI):**
* **Data Validation:** Use `pydantic` models for request and response data validation.
* **Dependency Injection:** Utilize FastAPI's dependency injection system for managing resources like database connections.
* **Error Handling:** Implement centralized error handling using middleware or exception handlers.
* **Asynchronous Code:** Use `async` and `await` for I/O-bound operations to improve performance.
EOF
cat GEMINI.md
Po zapisaniu zasad przywołajmy ponownie naszego partnera AI i zobaczmy magię artefaktu.
👉💻 Ponownie uruchom interfejs wiersza poleceń Gemini z katalogu shadowblade:
cd ~/storygen-learning/01a_First_Agent_Ready/backend
clear
gemini
👉✨ Teraz poproś Gemini, aby pokazała Ci, o czym myśli. Runy zostały odczytane.
/memory show
👉✨ To jedno, zaawansowane polecenie, które utworzy Twojego agenta. Wystaw teraz:
You are an expert Python developer specializing in the Google Agent Development Kit (ADK). Your task is to write the complete, production-quality code for `agent.py` by following the technical specifications outlined in the provided design document verbatim.
Analyze the design document at `@design.md` and generate the corresponding Python code for `agent.py`.
I need you to generate a Python script based on the provided design document and reference examples. Follow these requirements:
Read the design document carefully - it contains the complete technical specification for the code you need to write
Follow the structure and patterns shown in the reference context files
Adhere to all Python best practices specified in the coding standards document
Implement every requirement mentioned in the design document exactly as specified
Use the exact variable names, function names, and string values mentioned in the specifications
The design document describes the complete architecture, dependencies, configuration, and logic flow. Your generated code must match these specifications precisely while following professional Python coding standards.
Generate clean, production-ready Python code that can be used immediately without modifications.
Po zakończeniu wyłącz terminal interfejsu wiersza poleceń Gemini za pomocą ikony Control+C.
—————————————— Opcjonalnie, możesz przejść do części Rozwiązanie——————————————–
Teraz zweryfikuj zmianę w interfejsie internetowym ADK
cd ~/storygen-learning/01a_First_Agent_Ready/backend
source ../../.venv/bin/activate
adk web --port 8080
Aby kontynuować, musisz mieć wiersz poleceń.
Uruchomienie witryny
cd ~/storygen-learning/01a_First_Agent_Ready
./start.sh
Jeśli zmiana nie zadziała, w interfejsie ADK i witrynie powinny pojawić się błędy.
——————————————– Rozwiązanie zaczyna się tutaj ——————————————–
Rozwiązanie
Zakończ poprzedni proces, klikając Control+C, lub otwórz inny terminal:
cd ~/storygen-learning/01b_First_Agent_Done
Uruchom witrynę:
./start.sh
Zobaczysz witrynę:
Wypróbuj interfejs ADK: otwórz kolejny terminal:
cd ~/storygen-learning/01b_First_Agent_Done/backend
source ../../.venv/bin/activate
adk web --port 8080
Zobaczysz interfejs ADK, w którym możesz zadawać agentowi pytania.
Zanim przejdziesz do następnej sekcji, naciśnij Ctrl+C, aby zakończyć proces.
7. Tworzenie własnego agenta za pomocą Imagen
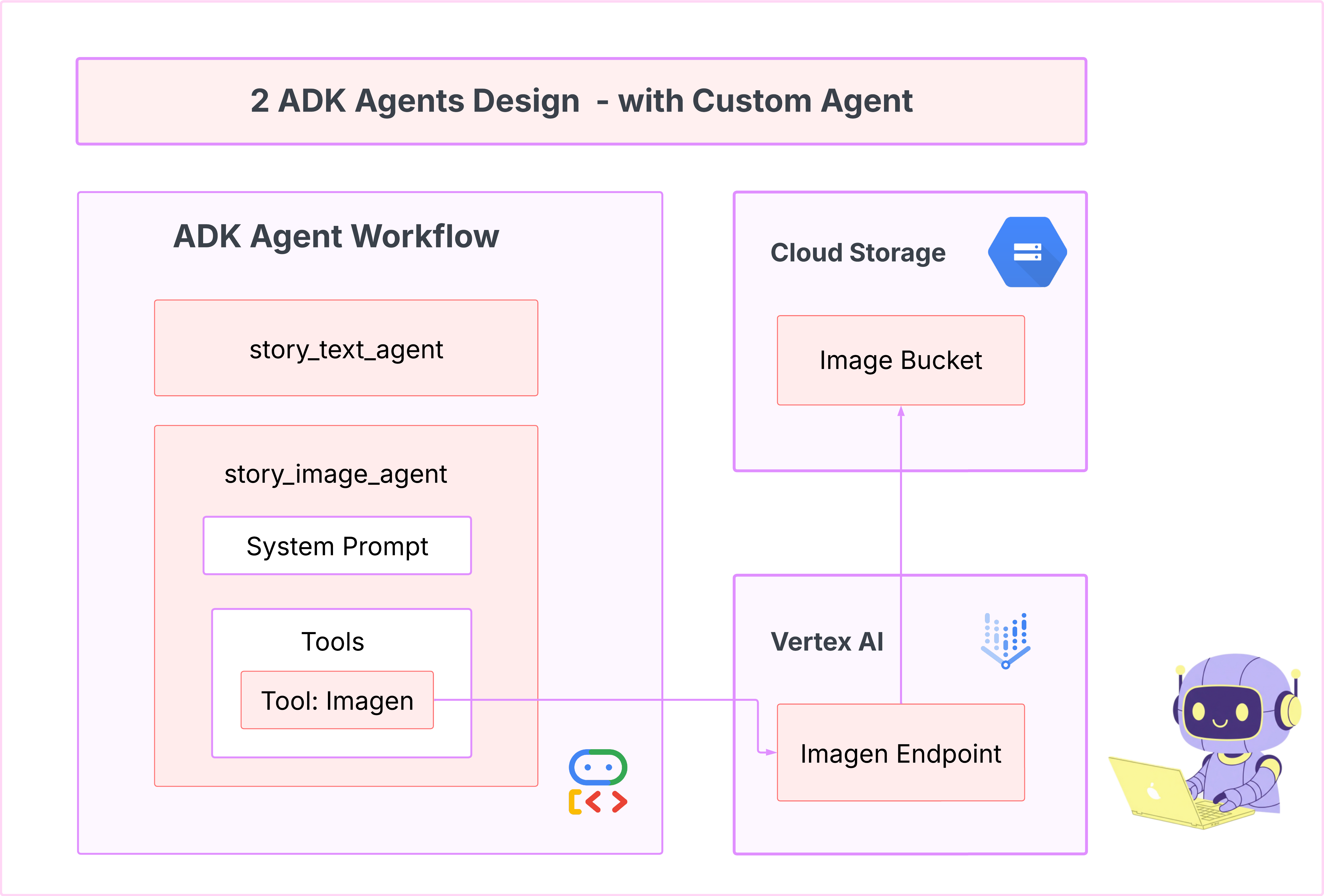
Generowanie narzędzia Imagen (drugi agent)
cd ~/storygen-learning/02a_Image_Agent_Ready
Użyj interfejsu wiersza poleceń Gemini, aby utworzyć agenta do generowania obrazów:
gemini generate "I need you to help me create a custom Google ADK (Agent Development Kit) agent for image generation. This is different from the story agent - this one handles image generation directly using the BaseAgent pattern for full control over tool execution.
Please create a complete `agent.py` file that implements a custom image generation agent. The agent should:
**Requirements:**
1. Use the `google.adk.agents.BaseAgent` class (NOT LlmAgent)
2. Be named "custom_image_agent"
3. Directly execute the ImagenTool without LLM intermediation
4. Handle JSON input with scene descriptions and character descriptions
5. Store results in session state for retrieval by main.py
6. Use async generators and yield Events
**Key Specifications:**
- **Class Name:** CustomImageAgent (inherits from BaseAgent)
- **Agent Name:** "custom_image_agent"
- **Tool:** Uses ImagenTool for direct image generation
- **Purpose:** Bypass LLM agent limitations and directly call ImagenTool
**Input Format:**
The agent should handle JSON input like:
{
"scene_description": "Scene action and setting",
"character_descriptions": {
"CharacterName": "detailed visual description"
}
}
**Core Method:** `async def _run_async_impl(self, ctx: InvocationContext) -> AsyncGenerator[Event, None]:`
- Extract user message from `ctx.user_content.parts`
- Parse JSON input or fallback to plain text
- Extract scene_description and character_descriptions
- Build image prompt with style prefix: "Children's book cartoon illustration with bright vibrant colors, simple shapes, friendly characters."
- Include character descriptions for consistency
- Call `await self.imagen_tool.run()` directly
- Store results in `ctx.session.state["image_result"]`
- Yield Event with results
**Session State:**
- Store JSON results in `ctx.session.state["image_result"]`
- Include success/error status
- Store actual image URLs or error messages
Expected Output Structure:
- Successful results stored as JSON with image URLs
- Error results stored as JSON with error messages
- Results accessible via session state in main.py
Can you create this agent in backend/story_image_agent/agent.py
"
—————————————— Opcjonalnie, możesz przejść do części Rozwiązanie——————————————–
Teraz zweryfikuj zmianę w interfejsie internetowym ADK
cd ~/storygen-learning/02a_Image_Agent_Ready/backend
source ../../.venv/bin/activate
adk web --port 8080
Uruchomienie witryny
cd ~/storygen-learning/02a_Second_Agent_Ready
./start.sh
Jeśli zmiana nie zadziała, w interfejsie ADK i witrynie powinny pojawić się błędy.
—————————————- Rozwiązanie zaczyna się tutaj ——————————————–
Rozwiązanie
Zakończ poprzedni proces, klikając Control+C, lub otwórz inny terminal:
# Open new terminal
cd ~/storygen-learning/02b_Image_Agent_Done
Uruchom witrynę:
./start.sh
Zobaczysz witrynę:
Wypróbuj interfejs ADK: otwórz kolejny terminal:
# Open new terminal
cd ~/storygen-learning/02b_Image_Agent_Done/backend
source ../../.venv/bin/activate
adk web --port 8080
Zobaczysz interfejs ADK, w którym możesz zadawać pytania agentowi:
Zanim przejdziesz do następnej sekcji, naciśnij Ctrl+C, aby zakończyć proces.
Nauka
Nasz pierwszy agent świetnie generował tekst, ale teraz musimy generować obrazy. W tym przypadku potrzebujemy większej kontroli. Nie chcemy, aby LLM decydował, czy utworzyć obraz. Chcemy bezpośrednio wydać mu polecenie, aby to zrobił. To idealne zadanie dla BaseAgent.
W przeciwieństwie do deklaratywnego agenta LlmAgent, agent BaseAgent jest imperatywny. Oznacza to, że deweloper pisze dokładną logikę Pythona krok po kroku w metodzie _run_async_impl. Masz pełną kontrolę nad przepływem wykonywania.
Wybierz BaseAgent, jeśli potrzebujesz:
Logika deterministyczna: agent musi wykonywać określoną, niezmienną sekwencję działań.
Bezpośrednie wykonywanie narzędzi: chcesz wywoływać narzędzie bezpośrednio, bez interwencji LLM.
Złożone przepływy pracy: proces obejmuje niestandardową manipulację danymi, wywołania interfejsu API i logikę, która jest zbyt złożona, aby LLM mógł ją wiarygodnie wywnioskować na podstawie samego promptu.
W przypadku naszej aplikacji użyjemy klasy BaseAgent, aby otrzymywać opisy scen od pierwszego agenta i bezpośrednio wywoływać narzędzie Imagen, co zagwarantuje wygenerowanie obrazu dla każdej sceny.
8. Testowanie: ocena agenta
Nasza aplikacja działa, ale potrzebujemy automatycznej siatki bezpieczeństwa w postaci testów. To idealne zadanie do przekazania naszemu asystentowi AI.
Działania
cd ~/storygen-learning/03a_Agent_Evaluation_Ready/backend
Użyj interfejsu wiersza poleceń Gemini do pisania kompleksowych testów:
Otwieranie interfejsu wiersza poleceń Gemini
gemini
W oknie interfejsu wiersza poleceń Gemini wypróbuj prompta:
I need you to create comprehensive test files for my backend/story_agent in Google ADK. I need three specific JSON files that match the testing structure used in ADK evaluation.
**Context:**
- The story agent generates structured JSON stories with exactly 4 scenes
- It uses LlmAgent with no tools, just direct LLM responses
- Input: Keywords
- Output: JSON with story, main_characters, and scenes arrays
**Files to Create:**
### 1. `story_agent_eval.evalset.json` (Comprehensive Integration Tests)
Create a comprehensive evaluation set with:
- **eval_set_id**: "story_agent_comprehensive_evalset"
- **name**: "Story Agent Comprehensive Evaluation Set"
- **description**: "Comprehensive evaluation scenarios for story_agent covering various keyword combinations, edge cases, and story quality metrics"
Each eval_case should include:
- Full conversation arrays with invocation_id, user_content, final_response
- Complete expected JSON responses with detailed stories, characters, and 4 scenes
- session_input with app_name "story_agent"
- All fields: story (narrative text), main_characters (with detailed visual descriptions), scenes (with index, title, description, text)
### 2. `story_generation.test.json` (Unit Tests)
Create basic generation tests with:
- **eval_set_id**: "story_agent_basic_generation_tests"
- **name**: "Story Agent Basic Generation Tests"
- **description**: "Unit tests for story_agent focusing on JSON structure compliance, scene generation, and keyword integration"
### 3. `test_config.json` (Evaluation Configuration)
Create test configuration with:
- **criteria**: response_match_score: 0.7, tool_trajectory_avg_score: 1.0
- **custom_evaluators**:
- json_structure_validator (validates required fields, scene count, character fields)
- story_quality_metrics (word count 80-250, keyword integration threshold 0.8)
- **evaluation_notes**: Story agent specifics and trajectory expectations
**Important Requirements:**
1. All responses must be valid, parseable JSON
2. Stories must have exactly 4 scenes with indices 1-4
3. Each scene must have: index, title, description, text
4. Main characters must have detailed visual descriptions
5. No tool_uses expected (empty arrays) since story agent uses direct LLM
6. Word count should be 100-200 words total
7. Keywords must be naturally integrated into the narrative
Please generate all three files with realistic example stories and comprehensive test coverage matching the ADK evaluation format.
—————————————— Opcjonalnie, możesz przejść do części Rozwiązanie——————————————–
Aby wyświetlić ocenę:
./run_adk_web_persistent.sh
Otwórz kartę eval w interfejsie ADK.
Powinien być widoczny interfejs internetowy ADK z możliwością ciągłego testowania.
Kluczowy moment nauki: AI to potężny partner w automatyzacji zapewniania jakości. Może ona obsługiwać powtarzalne elementy pisania testów, dzięki czemu możesz skupić się na tworzeniu funkcji.
——————————————– Rozwiązanie zaczyna się tutaj ——————————————–
Rozwiązanie
- Otwórz folder rozwiązania:
cd ~/storygen-learning/03b_Agent_Evaluation_Done/backend
- Otwieranie internetowego interfejsu pakietu ADK
./run_adk_web_persistent.sh
Przypadki testowe możesz zobaczyć na karcie Eval:
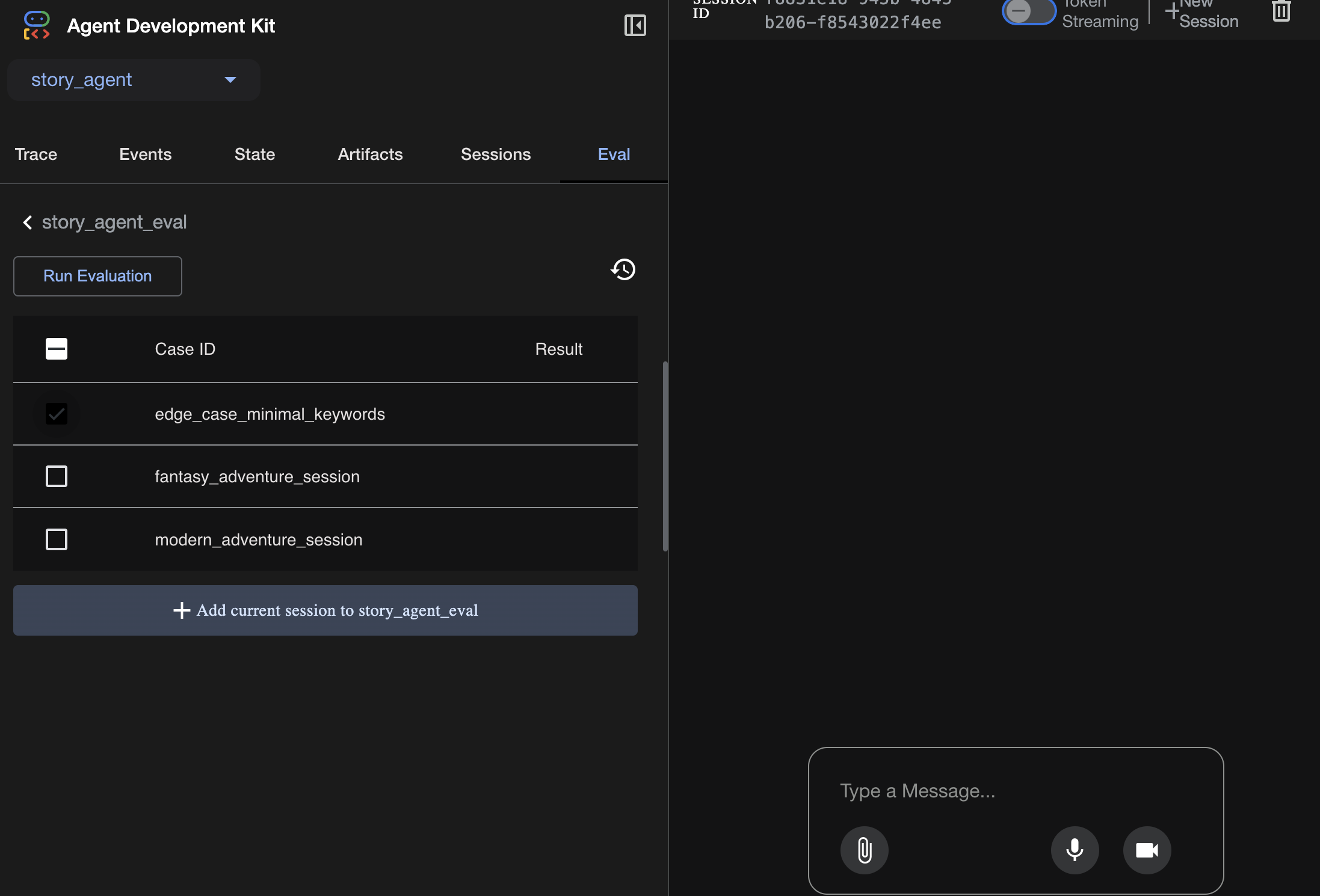
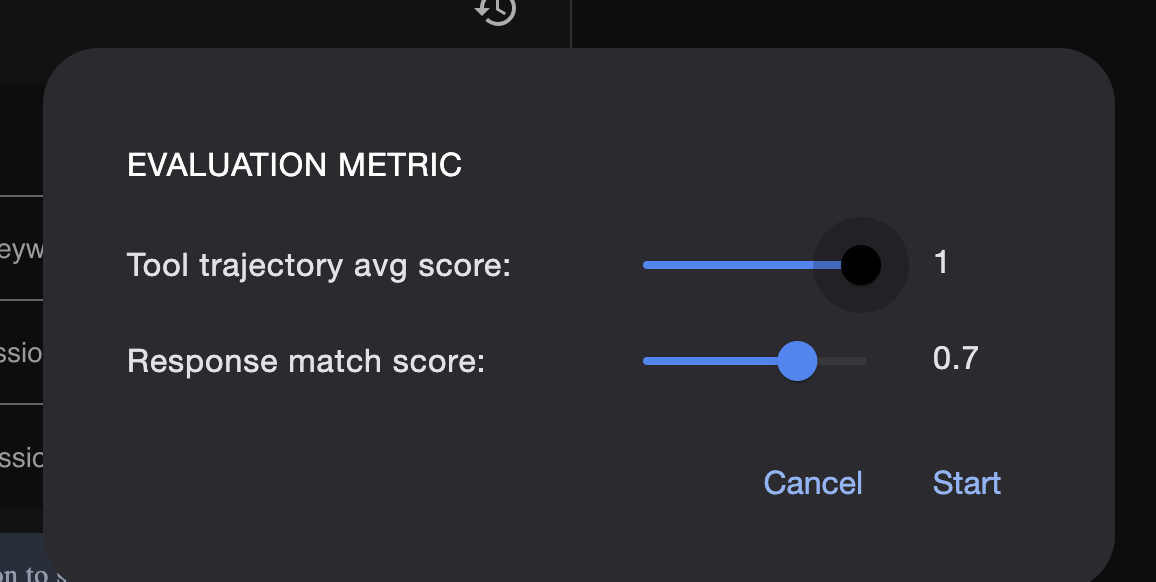
Dostosuj dane tutaj:
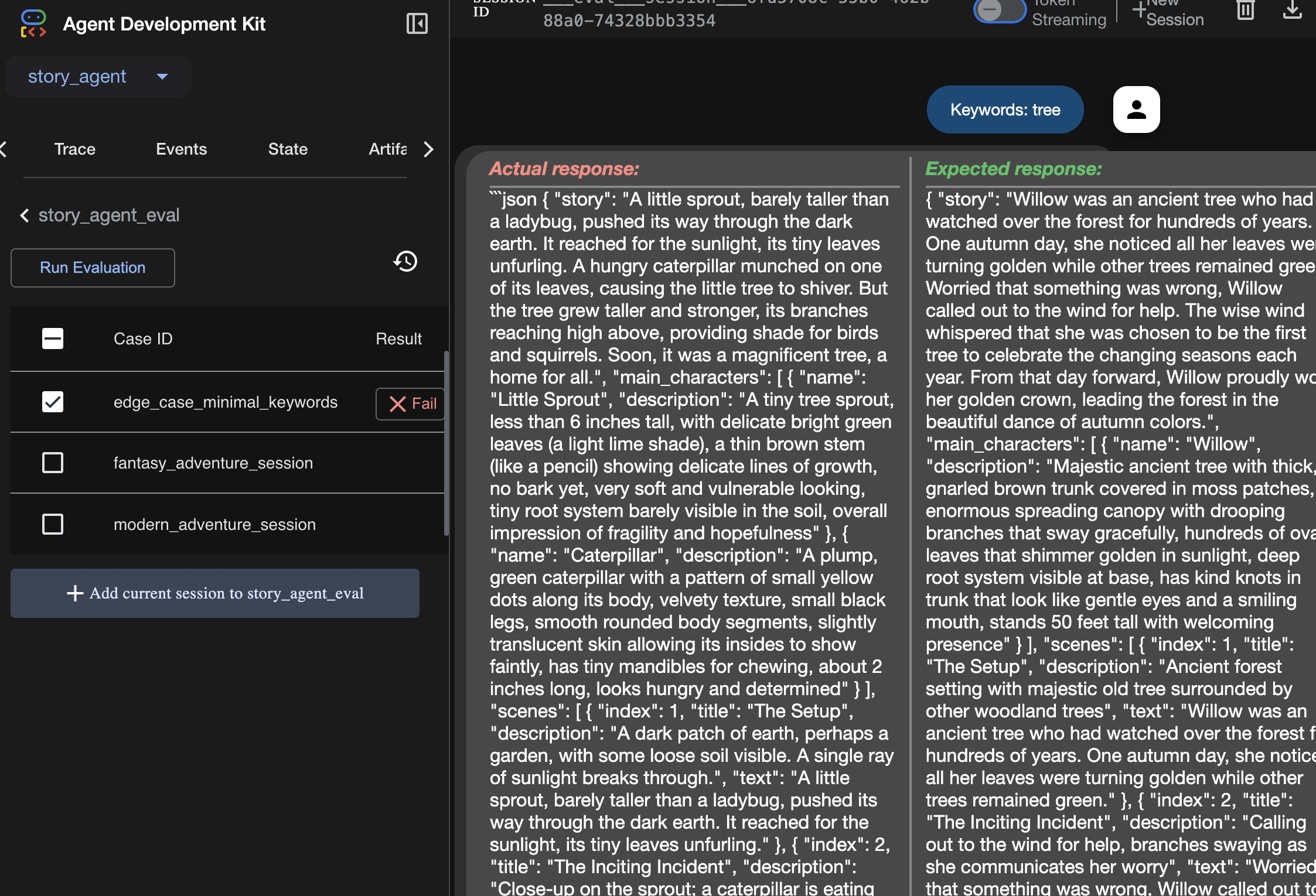
Wynik uruchomionej oceny możesz wyświetlić tutaj:
Nauka
Agent może „działać”, czyli uruchamiać się bez błędów, ale skąd mamy wiedzieć, czy generuje prawidłowe dane wyjściowe? Czy historia jest dobra? Czy format JSON jest prawidłowy? W takiej sytuacji przydatna jest platforma oceny ADK.
Ocena agenta to automatyczny system testowania, który służy do pomiaru jakości i poprawności odpowiedzi agenta. Zamiast sprawdzać tylko błędy w kodzie, sprawdza, czy działanie agenta jest zgodne z Twoimi oczekiwaniami. Framework korzysta głównie z kilku kluczowych plików:
evalset.json: to jest główny zestaw testów. Każdy „przypadek testowy” w tym pliku zawiera przykładową rozmowę (np. prompt użytkownika) i idealną, „złotą” odpowiedź, której oczekujesz od agenta.
test_config.json: ten plik określa reguły powodzenia. Możesz tu ustawić kryteria, takie jak:
response_match_score jak bardzo odpowiedź agenta musi być zbliżona do „złotej” odpowiedzi? (Wynik 1,0 oznacza, że muszą być identyczne).
custom_evaluators: możesz tworzyć własne reguły, np. „Odpowiedź musi być prawidłowym formatem JSON” lub „Opowiadanie musi zawierać więcej niż 100 słów”.
Przeprowadzając ocenę, możesz automatycznie przetestować agenta w dziesiątkach scenariuszy, aby mieć pewność, że zmiany w prompcie lub narzędziach nie spowodują przypadkowego uszkodzenia jego głównej funkcjonalności. To skuteczna siatka bezpieczeństwa do tworzenia agentów AI gotowych do wdrożenia w środowisku produkcyjnym.
9. Infrastruktura jako kod (IaC): budowanie domu w chmurze
Nasz kod jest przetestowany, ale potrzebuje środowiska produkcyjnego. Do zdefiniowania środowiska użyjemy infrastruktury jako kodu.
Czym jest Docker?
Docker to platforma do tworzenia i uruchamiania aplikacji w kontenerach. Kontener to standardowy kontener transportowy dla oprogramowania. Zawiera wszystko, czego aplikacja potrzebuje do działania, w jednym, odizolowanym pakiecie:
- sam kod aplikacji,
- wymagane środowisko wykonawcze (np. konkretna wersja Pythona);
- Wszystkie narzędzia i biblioteki systemowe
Aplikację w kontenerze można uruchomić na dowolnym komputerze z zainstalowanym Dockerem, co rozwiązuje klasyczny problem „u mnie działa”.
W tej sekcji poprosimy Gemini o wygenerowanie pliku Dockerfile, który jest po prostu przepisem lub planem tworzenia obrazu kontenera aplikacji.
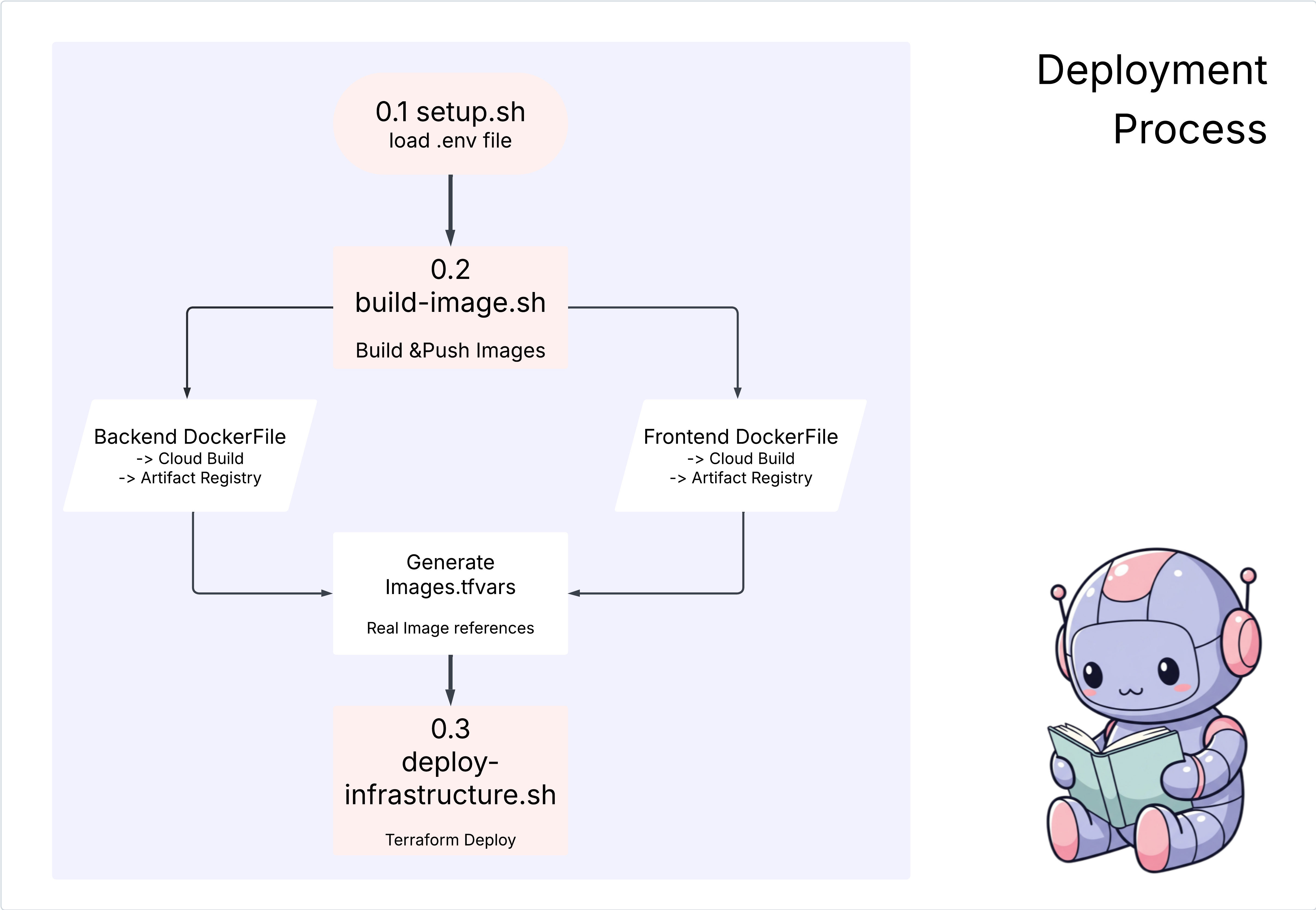
Działania
cd ~/storygen-learning/04a_Manual_Deployment_Ready
Użyj interfejsu wiersza poleceń Gemini, aby utworzyć plik Dockerfile dla backendu: otwórz interfejs wiersza poleceń Gemini.
Gemini
W interfejsie wiersza poleceń Gemini wypróbuj prompta:
Create a manual deployment plan for my StoryGen app with Google Cloud Platform. I have a Next.js frontend, Python backend, and Terraform infrastructure.
Generate these deployment files:
1. **01-setup.sh** - Environment setup and authentication
2. **02-build-images.sh** - Build and push Docker images to Google Container Registry
3. **03-deploy-infrastructure.sh** - Deploy with Terraform and configure services
4. **load-env.sh** - Load environment variables for deployment
**Requirements:**
- Use Google Cloud Run for both frontend and backend
- Configure Imagen API and storage buckets
- Set up proper IAM permissions
- Use environment variables from .env file
- Include error handling and status checks
Keep scripts simple, well-commented, and production-ready for manual execution.
Rozwiązanie:
cd ~/storygen-learning/04b_Manual_Deployment_Done
Uruchomienie:
source ../.venv/bin/activate
./01-setup.sh
./02-build-images.sh
./03-deploy-infrastructure.sh
Powinny się wyświetlić wyniki wdrożenia i tworzenie infrastruktury
10. Automatyzacja (CI/CD): cyfrowa linia montażowa
Ręczne wdrażanie aplikacji to świetny sposób na poznanie jej poszczególnych elementów, ale jest to proces powolny, wymagający ręcznej pracy i może prowadzić do błędów. W profesjonalnym tworzeniu oprogramowania cały ten proces jest zautomatyzowany za pomocą praktyki zwanej CI/CD.
CI/CD to skrót od ciągłej integracji i ciągłego wdrażania. Jest to metoda automatycznego kompilowania, testowania i wdrażania kodu za każdym razem, gdy wprowadzisz zmianę.
- Ciągła integracja (CI): to faza „kompilacji i testowania”. Gdy tylko programista prześle zmianę kodu do repozytorium współdzielonego (np. GitHub), włącza się automatyczny system. Buduje aplikację i uruchamia wszystkie testy (np. oceny agentów, które utworzyliśmy), aby upewnić się, że nowy kod jest prawidłowo zintegrowany i nie zawiera błędów.
- Ciągłe wdrażanie (CD): to faza „wdrażania”. Jeśli faza CI zakończy się pomyślnie, system automatycznie wdroży nową, przetestowaną wersję aplikacji w środowisku produkcyjnym, udostępniając ją użytkownikom.
Ten zautomatyzowany potok tworzy „cyfrową linię montażową”, która szybko, bezpiecznie i niezawodnie przenosi kod z komputera programisty do środowiska produkcyjnego. W tej sekcji poprosimy asystenta AI o utworzenie linii montażowej za pomocą GitHub Actions i Google Cloud Build.
Działania
cd ~/storygen-learning/05a_CICD_Pipeline_Ready
Użyj interfejsu wiersza poleceń Gemini, aby utworzyć potok CI/CD za pomocą GitHuba:
Otwórz interfejs wiersza poleceń Gemini
Gemini
W interfejsie wiersza poleceń Gemini wypróbuj prompta:
Create a CI/CD pipeline for my StoryGen app using Google Cloud Build and GitHub integration.
Generate these automation files:
1. **cloudbuild.yaml** (for backend) - Automated build, test, and deploy pipeline
2. **GitHub Actions workflow** - Trigger builds on push/PR
3. **Deployment automation scripts** - Streamlined deployment process
**Requirements:**
- Auto-trigger on GitHub push to main branch
- Build and push Docker images
- Run automated tests if available
- Deploy to Google Cloud Run
- Environment-specific deployments (staging/prod)
- Notification on success/failure
Focus on fully automated deployment with minimal manual intervention. Include proper secret management and rollback capabilities.
——————————————– Rozwiązanie zaczyna się tutaj ——————————————–
Rozwiązanie:
cd ~/storygen-learning/06_Final_Solution/
# Copy the GitHub workflow to parent folder
cp -r 06_Final_Solution/.GitHub ../../../.GitHub
Wróć do folderu 06_Final_Solution i uruchom skrypt:
cd ~/storygen-learning/06_Final_Solution/
./setup-cicd-complete.sh
Powinno się wyświetlić zakończenie konfiguracji potoku CI/CD
Uruchom przepływ pracy: zatwierdź i wypchnij kod do głównej gałęzi. Aby zezwolić na dostęp, musisz skonfigurować adres e-mail i nazwę w usłudze GitHub.
git add .
git commit -m "feat: Add backend, IaC, and CI/CD workflow"
git push origin main
Otwórz kartę „Actions” (Działania) w repozytorium GitHub, aby zobaczyć uruchomienie automatycznego wdrażania.
11. Operacje: wieża kontrolna AI
Jesteśmy na żywo! Ale to jeszcze nie koniec. To jest „Dzień 2” – operacje. Wróćmy do Cloud Assist, aby zarządzać uruchomioną aplikacją.
Działania
- W konsoli Google Cloud otwórz usługę Cloud Run. Korzystaj z aplikacji w wersji produkcyjnej, aby wygenerować przeciętny ruch i logi.
- Otwórz panel Cloud Assist i używaj go jako pomocnika operacyjnego, korzystając z takich promptów jak te:
Analiza logów:
Summarize the errors in my Cloud Run logs for the service 'genai-backend' from the last 15 minutes.
Dostrajanie wydajności:
My Cloud Run service 'genai-backend' has high startup latency. What are common causes for a Python app and how can I investigate with Cloud Trace?
Optymalizacja kosztów:
Analyze the costs for my 'genai-backend' service and its GCS bucket. Are there any opportunities to save money?
Kluczowy moment nauki: cykl życia oprogramowania AI to ciągła pętla. Ten sam asystent AI, który pomógł w tworzeniu aplikacji, jest niezastąpionym partnerem w monitorowaniu, rozwiązywaniu problemów i optymalizowaniu jej w środowisku produkcyjnym.