
1. Sebelum memulai
Codelab ini memandu Anda memigrasikan database MySQL lokal yang di-shard ke database Cloud Spanner dengan dialek GoogleSQL. Anda akan menggunakan layanan Google Cloud, termasuk Spanner Migration Tool (SMT), Dataflow, Datastream, PubSub, dan Google Cloud Storage.
Hal-hal yang akan Anda pelajari:
- Apa itu lingkungan yang di-shard dan cara menyiapkannya.
- Cara menggunakan UI Web Spanner Migration Tool (SMT) untuk mengonversi skema MySQL menjadi skema yang kompatibel dengan Spanner dan melakukan modifikasi skema lanjutan.
- Cara melakukan migrasi data massal dari instance MySQL yang di-shard ke Cloud Spanner menggunakan Dataflow.
- Cara menyiapkan replikasi berkelanjutan (CDC) dari instance MySQL yang di-shard ke Cloud Spanner menggunakan Datastream dan Dataflow.
- Cara mengonfigurasi Replikasi Terbalik dari Spanner kembali ke instance MySQL yang di-shard.
- Cara menggunakan Transformasi Kustom untuk mengisi kolom tambahan selama migrasi massal, langsung, dan terbalik.
- Cara mengonfigurasi transformasi sharding menggunakan Kunci Primer.
Hal yang TIDAK dibahas dalam codelab ini:
- Jaringan kustom lanjutan.
- Membangun template Dataflow kustom dari awal.
- Penyesuaian performa migrasi.
- Migrasi Aplikasi: Codelab ini berfokus pada lapisan database (skema dan data). Panduan ini tidak mencakup proses operasional untuk men-deploy ulang atau memigrasikan layanan aplikasi Anda.
Yang Anda butuhkan
- Project Google Cloud yang mengaktifkan penagihan.
- Izin IAM yang memadai untuk mengaktifkan API dan membuat/mengelola resource Spanner, Dataflow, Datastream, dan GCS. Meskipun peran Project
Ownerpaling sederhana untuk codelab, peran yang lebih spesifik akan dibahas di "Penyiapan Lingkungan". - Kita akan menyediakan VM Compute Engine kecil selama fase penyiapan untuk menyimulasikan server lokal. Pastikan kuota project Anda mengizinkan pembuatan VM.
- Browser web, seperti Google Chrome.
- Pemahaman dasar tentang Konsol Google Cloud dan alat command line seperti
gcloud. - Akses ke lingkungan shell. Cloud Shell direkomendasikan karena mencakup
gcloud.
Detail selengkapnya tentang penyiapan di atas dibahas di bagian Penyiapan Lingkungan.
2. Memahami Proses Migrasi
Memigrasikan database yang di-shard melibatkan penggabungan beberapa instance MySQL fisik dan logis menjadi satu database Spanner yang dapat diskalakan secara horizontal. Bagian ini menguraikan arsitektur dan alat utama yang digunakan dalam migrasi.
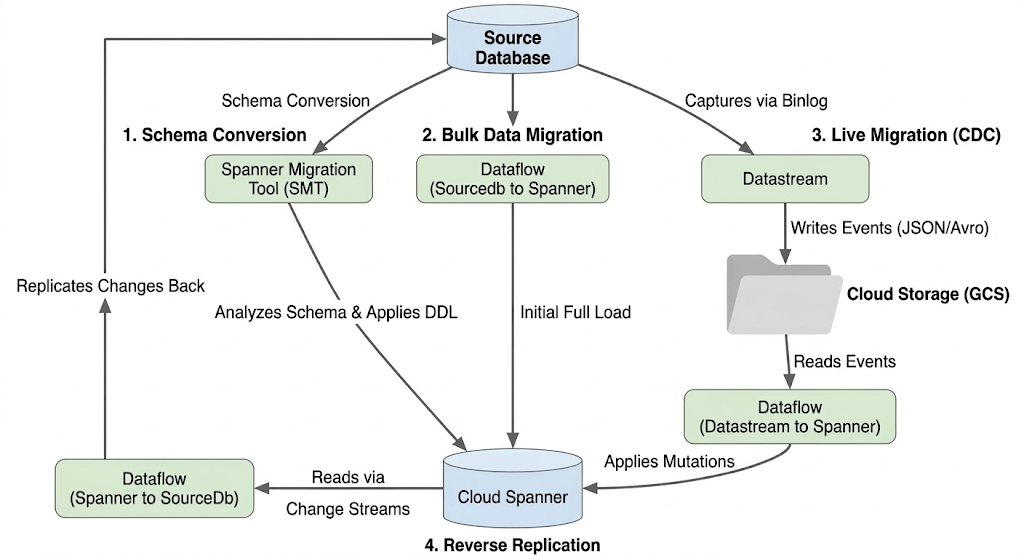
Arsitektur Alur Migrasi
Proses migrasi mencakup tahap-tahap berikut:
1. Konversi Skema:
- Tujuan: Mengonversi skema database sumber ke skema Cloud Spanner yang kompatibel.
- Alat: Alat Migrasi Spanner (SMT)
- Proses: SMT menganalisis skema database sumber dan menghasilkan Bahasa Definisi Data (DDL) Spanner yang setara. Di instance Spanner target, database dibuat dan DDL kemudian diterapkan secara otomatis.
2. Migrasi Data Massal:
- Tujuan: Untuk melakukan pemuatan penuh awal data yang ada dari database sumber ke tabel Spanner yang disediakan.
- Alat: Dataflow, menggunakan template
Sourcedb to Spanneryang disediakan Google. - Proses: Tugas Dataflow ini membaca semua data dari tabel sumber yang ditentukan dan menuliskannya ke tabel Spanner yang sesuai. Tindakan ini dilakukan setelah skema Spanner dibuat.
3. Migrasi Langsung (CDC):
- Tujuan: Untuk merekam dan menerapkan perubahan yang sedang berlangsung dari database sumber ke Cloud Spanner mendekati real time, sehingga meminimalkan periode nonaktif selama migrasi.
- Alat:
- Datastream: Merekam perubahan (Penyisipan, Pembaruan, Penghapusan) dari database sumber dan menuliskannya ke Cloud Storage (GCS).
- Dataflow: Menggunakan template
Datastream to Spanneruntuk membaca peristiwa perubahan dari GCS dan menerapkannya ke Cloud Spanner.
4. Replikasi Terbalik:
- Tujuan: Untuk mereplikasi perubahan data dari Cloud Spanner kembali ke database sumber. Hal ini dapat berguna untuk strategi penggantian, migrasi bertahap, atau mempertahankan replika di sumber untuk kasus penggunaan tertentu.
- Alat: Dataflow, menggunakan template
Spanner to SourceDb. - Proses: Tugas ini menggunakan aliran data perubahan Spanner untuk merekam modifikasi di Spanner dan menuliskannya kembali ke instance database sumber.
Diagram berikut menggambarkan komponen dan alur data:
Terminologi Utama:
- Shard Fisik: Server atau instance komputasi pokok yang sebenarnya menghosting database (dalam kasus ini, VM GCE on-prem yang disimulasikan).
- Shard Logis: Skema database individual dalam server fisik.
- VM Compute Engine (GCE): Virtual machine yang dihosting di infrastruktur Google Cloud. Dalam codelab ini, kita menggunakan VM GCE untuk menyimulasikan server bare metal "on-premise" mandiri yang menghosting database MySQL sumber kita.
- Alat Migrasi Spanner (SMT): Alat yang digunakan untuk menilai skema MySQL, menyarankan skema Spanner yang setara, dan membuat Bahasa Definisi Data (DDL) Spanner.
- Bahasa Definisi Data (DDL): Pernyataan yang digunakan untuk menentukan dan mengubah struktur database, seperti pernyataan
CREATE TABLE. SMT menghasilkan DDL Spanner berdasarkan skema Cloud SQL. - Dataflow: Layanan pemrosesan data serverless yang terkelola sepenuhnya. Dalam codelab ini, alat ini digunakan untuk menjalankan template yang disediakan Google untuk transfer data massal, menerapkan perubahan Datastream, dan replikasi terbalik.
- Datastream: Layanan replikasi dan Pengambilan Data Perubahan (CDC) serverless. Bucket ini digunakan untuk melakukan streaming perubahan dari instance MySQL yang dihosting secara lokal ke Cloud Storage dalam codelab ini.
- Aliran Data Perubahan Spanner: Fitur Spanner yang memungkinkan streaming perubahan pada data (penyisipan, pembaruan, penghapusan) secara real-time, yang digunakan sebagai sumber untuk replikasi terbalik.
- Pub/Sub: Layanan pesan yang digunakan untuk memisahkan layanan yang menghasilkan peristiwa dari layanan yang memprosesnya. Dalam codelab ini, Dataflow dipicu untuk memproses update setiap kali Datastream mengupload file perubahan baru ke Cloud Storage.
3. Penyiapan Lingkungan
Sebelum dapat memulai migrasi, Anda perlu menyiapkan project Google Cloud dan mengaktifkan layanan yang diperlukan.
1. Memilih atau Membuat Project Google Cloud
Anda memerlukan project Google Cloud dengan penagihan yang diaktifkan untuk menggunakan layanan dalam codelab ini.
- Di Konsol Google Cloud, buka halaman pemilih project: Buka Pemilih Project
- Pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Anda. Pelajari cara mengonfirmasi bahwa penagihan diaktifkan untuk project Anda.
2. Buka Cloud Shell
Cloud Shell adalah lingkungan command line yang berjalan di Google Cloud yang telah dilengkapi dengan gcloud CLI dan alat lain yang Anda perlukan.
- Klik tombol Activate Cloud Shell di kanan atas Konsol Google Cloud.
- Sesi Cloud Shell akan terbuka di dalam frame baru di bagian bawah konsol dan menampilkan perintah command-line.

3. Menetapkan Variabel Project dan Lingkungan
Di Cloud Shell, siapkan beberapa variabel lingkungan untuk project ID dan region yang akan Anda gunakan.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Mengaktifkan Google Cloud API yang Diperlukan
Aktifkan API yang diperlukan untuk Cloud Spanner, Dataflow, Datastream, dan layanan terkait lainnya.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Pemrosesan perintah ini mungkin membutuhkan waktu beberapa menit.
4. Menyiapkan Database MySQL Sumber
Di bagian ini, kita akan menyimulasikan arsitektur MySQL yang di-shard di lokal dengan menyediakan dua virtual machine Compute Engine (2 "shard fisik" kita). Kemudian, kita akan menginstal MySQL di kedua VM dan membuat dua database ("shard logis") di setiap VM.
1. Buat VM Compute Engine (Shard Fisik)
Jalankan perintah berikut di Cloud Shell untuk membuat dua VM dengan Ubuntu. Kita akan menetapkan tag jaringan untuk mengizinkan traffic MySQL masuk nanti.
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. Mengonfigurasi Aturan Firewall
Untuk mengizinkan akses SSH yang aman tanpa eksposur publik dan untuk mengaktifkan konektivitas Datastream:
Buat Aturan Firewall untuk SSH melalui IAP:
Aturan ini memungkinkan Identity-Aware Proxy menjangkau VM Anda di port SSH (22).
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
Buat Aturan Firewall untuk Datastream (Port MySQL):
Datastream harus dapat menjangkau VM ini di port MySQL standar (3306).
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3. Menginstal dan Mengonfigurasi MySQL di Shard Fisik 1
Hubungkan SSH ke VM pertama Anda untuk menginstal MySQL dan mengonfigurasi logging biner (yang diperlukan oleh Datastream untuk replikasi langsung).
- Gunakan SSH untuk terhubung ke VM pertama:
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- Instal MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- Konfigurasi file
mysqld.cnfuntuk mengaktifkan logging biner dan mengizinkan koneksi eksternal:
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Mulai ulang MySQL untuk menerapkan perubahan:
sudo systemctl restart mysql
4. Buat Shard Logis, Sisipkan Data, dan Buat Pengguna Datastream (Shard 1)
Saat masih terhubung ke mysql-physical-1 melalui SSH, login ke prompt MySQL:
sudo mysql
Jalankan perintah SQL berikut. Skrip ini membuat dua shard logis yang berbeda (shard0_db dan shard1_db), menyiapkan skema yang identik di keduanya, memasukkan data yang dapat diidentifikasi secara unik ke masing-masing shard (untuk mendemonstrasikan sharding), dan membuat pengguna replikasi untuk Datastream.
Jalankan perintah SQL berikut untuk membuat dua shard logis pertama, tabel, dan pengguna replikasi untuk Datastream:
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
File dump untuk skema di atas dapat ditemukan di sini. Penting untuk membuat pengguna replikasi aliran data secara terpisah karena tidak disertakan dalam file dump.
5. Memverifikasi Data
Periksa dengan cepat apakah data ada:
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
Output yang Diharapkan:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
Masukkan exit untuk keluar dari koneksi ke VM shard fisik 1.
6. Ulangi untuk Physical Shard 2
Sekarang Anda akan mengulangi proses yang sama persis untuk VM kedua, tetapi Anda akan membuat shard2_db dan shard3_db, serta mengubah server-id.
- Gunakan SSH untuk terhubung ke VM kedua:
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- Instal MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- Konfigurasi file
mysqld.cnfuntuk mengaktifkan logging biner dan mengizinkan koneksi eksternal [Perhatikan bahwa server-id harus berbeda (misalnya, 2)]
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Mulai ulang MySQL untuk menerapkan perubahan:
sudo systemctl restart mysql
- Masukkan MySQL (
sudo mysql) dan jalankan versi SQL yang sedikit dimodifikasi dari Langkah 4:
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
Output yang Diharapkan:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
File dump untuk skema di atas dapat ditemukan di sini. Penting untuk membuat pengguna replikasi aliran data secara terpisah karena tidak disertakan dalam file dump.
Masukkan exit untuk keluar dari koneksi ke VM.
5. Menyiapkan Cloud Spanner
Sekarang, Anda akan menyiapkan instance Cloud Spanner target tempat data akan dimigrasikan.
1. Membuat Instance Cloud Spanner
Buat instance Cloud Spanner di region yang sama dengan VM Compute Engine Anda untuk meminimalkan latensi. Perintah ini membuat instance kecil yang cocok untuk codelab ini, menggunakan 100 unit pemrosesan.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
Pembuatan instance mungkin memerlukan waktu satu atau dua menit.
6. Mengonversi Skema menggunakan Alat Migrasi Spanner (SMT)
Gunakan UI Web Spanner Migration Tool (SMT) untuk terhubung ke salah satu shard logis kami (shard0_db), menganalisis skemanya, dan menerapkan beberapa modifikasi lanjutan sebelum mengonversinya ke Cloud Spanner.
1. Menginstal SMT
Kita akan menjalankan UI Web SMT langsung dari Cloud Shell. Di terminal Cloud Shell, download dan ekstrak rilis SMT terbaru:
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
2. Menghubungkan ke Database Sumber
- Mengautentikasi sesi Anda
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(Catatan: Saat diminta, ikuti URL yang diberikan untuk mengizinkan akun Anda dan tempelkan kembali kode verifikasi ke terminal.)
- Pertama, temukan IP eksternal shard fisik pertama Anda dengan menjalankan perintah ini di tab Cloud Shell baru:
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- Mencetak detail Instance Spanner Target yang akan digunakan saat mengonfigurasi SMT.
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- Luncurkan UI Web:
gcloud alpha spanner migrate web --port=8080
- Di kanan atas jendela Cloud Shell, klik ikon Web Preview (terlihat seperti mata), lalu pilih Preview on port 8080. Tindakan ini akan membuka UI SMT di tab browser baru.
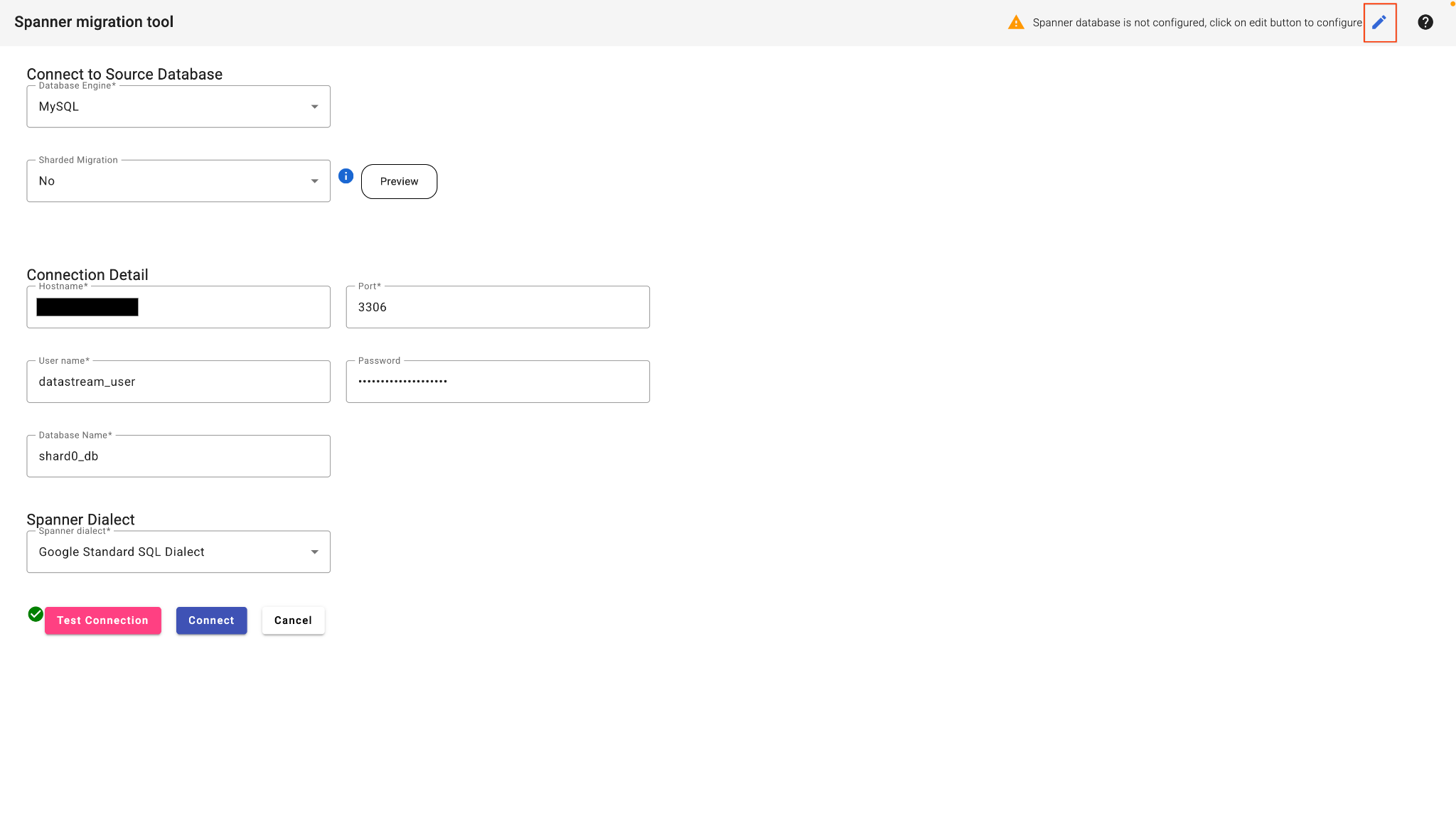
- Di UI Web SMT, pilih Connect to database.
- Isi detail koneksi:
- Jenis Database: MySQL
- Host: (Tempelkan alamat IP dari langkah 2)
- Port: 3306
- Pengguna:
datastream_user - Sandi:
complex_password_123 - Nama Database:
shard0_db
- Klik tombol edit di sudut kanan atas untuk mengonfigurasi Database Spanner.
- Masukkan detail Target Spanner Anda:
- Project ID: (Tempelkan Project ID dari langkah 3)
- Instance Spanner: (Tempelkan ID Instance dari langkah 3)
- KlikUji Koneksi.
- Setelah lulus, klik Hubungkan. SMT akan menganalisis database sumber dan menampilkan skema Spanner dasar.
3. Menerapkan Modifikasi Skema
Sekarang kita akan mengubah bentuk skema untuk mencakup skenario migrasi yang kompleks.
Di editor skema UI SMT, lakukan tindakan berikut:
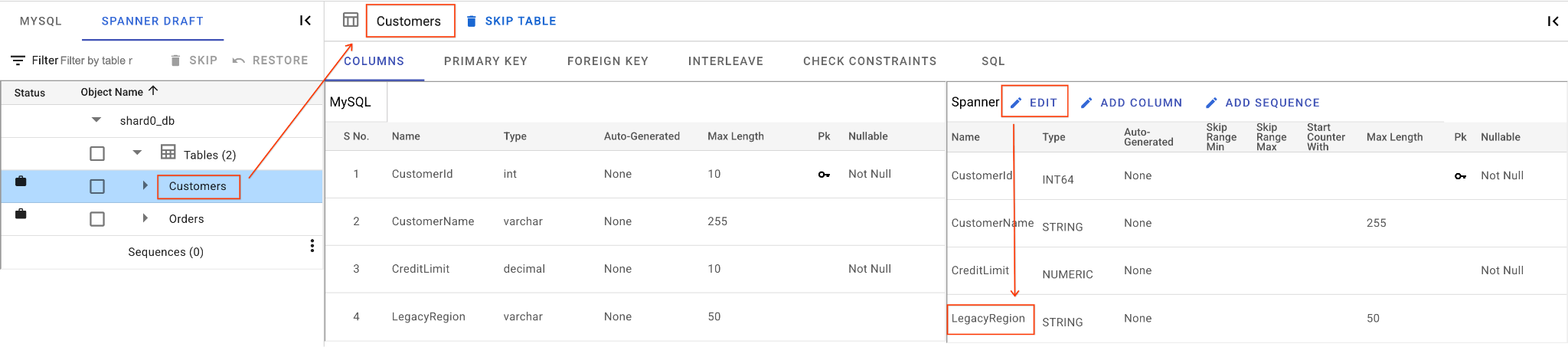
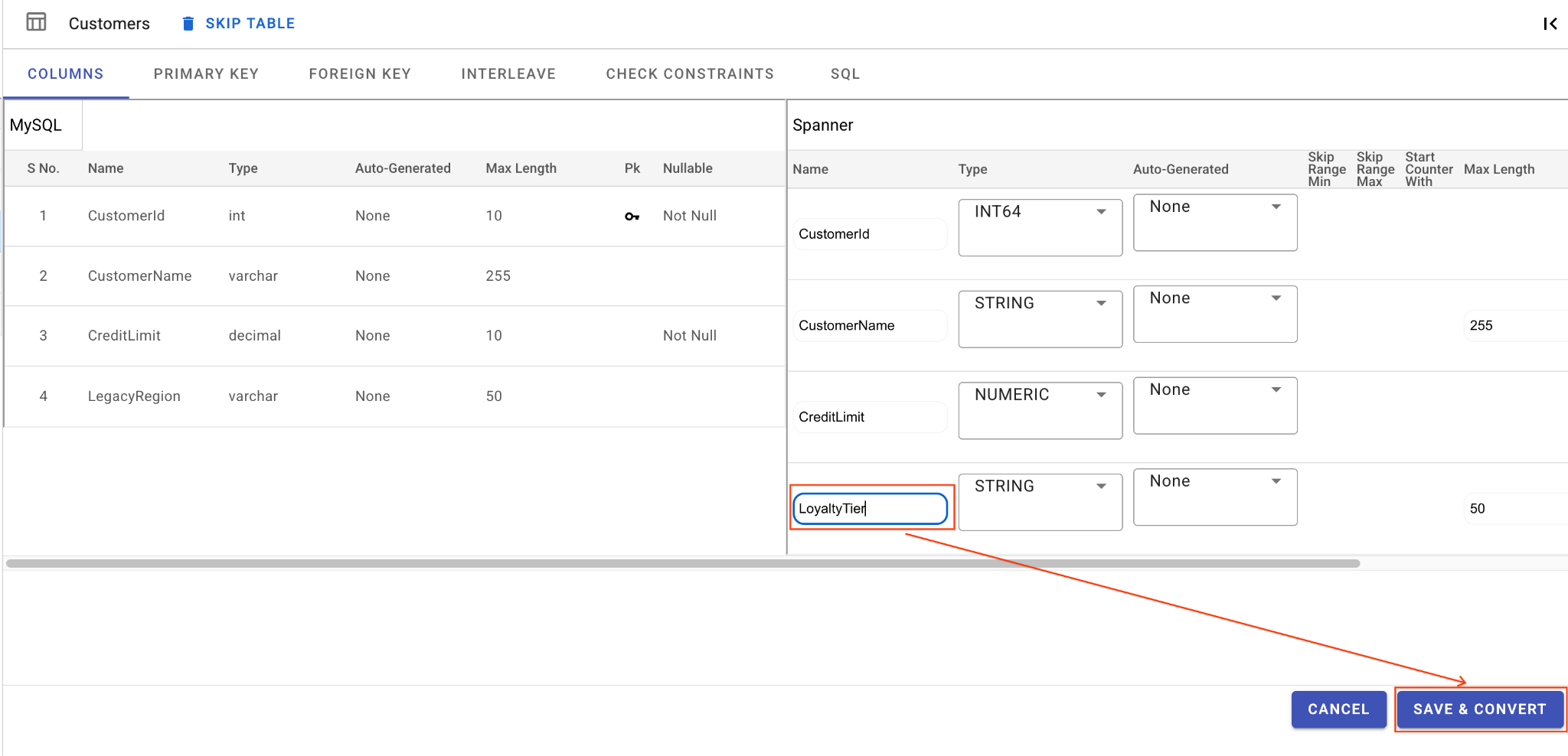
A. Ganti Nama Kolom LegacyRegion:
- Klik tabel
Customersdi panel navigasi sebelah kiri. Tab Kolom akan terbuka secara default. - Klik tombol Edit di bagian Spanner.
- Temukan kolom
LegacyRegiondi tampilan skema Spanner. - Ubah nama kolom Spanner menjadi
LoyaltyTierdengan mengetik nama kolom dalam dialog nama kolom. - Klik Simpan & Konversi.
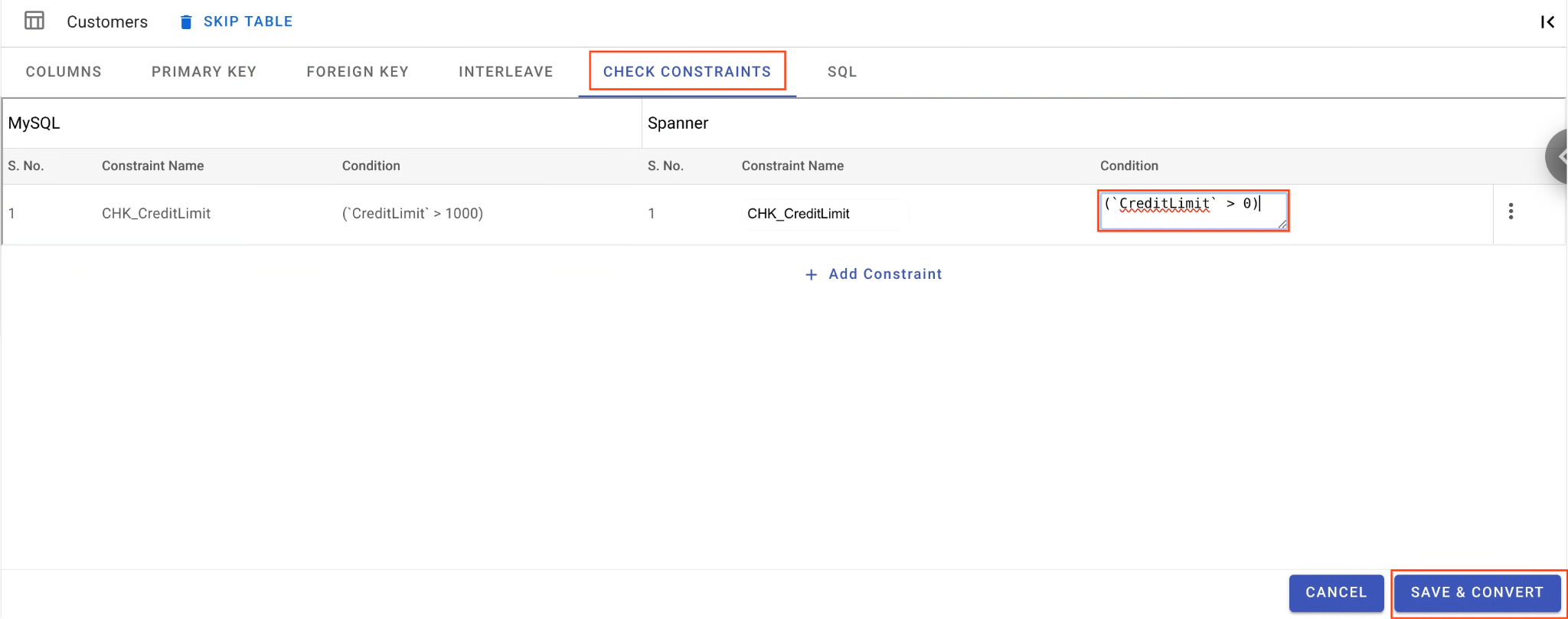
B. Melonggarkan Batasan Pemeriksaan:
- Masih di tabel
Customers, buka tab Check Constraints. - Temukan batasan
CHK_CreditLimit. Klik ikon Edit (pensil). - Ubah kondisi dari
CreditLimit > 1000menjadiCreditLimit > 0. (Tindakan ini akan menyebabkan baris dengan batas kredit yang lebih rendah sengaja gagal dalam migrasi terbalik dan masuk ke DLQ).
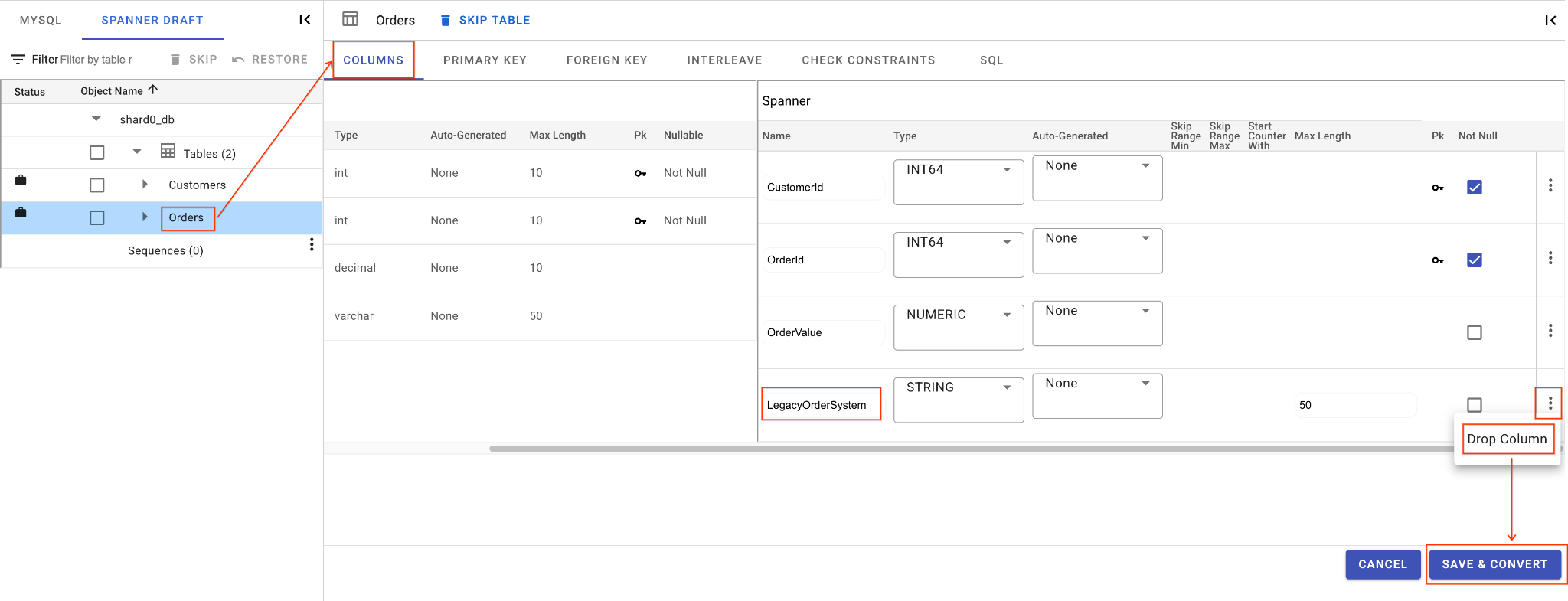
C. Hapus Kolom LegacyOrderSystem:
- Klik tabel
Orders, tab Kolom akan terbuka secara default. - Klik tombol Edit di bagian Spanner.
- Temukan kolom
LegacyOrderSystemdi tampilan skema Spanner. - Klik ikon menu 3 titik di sampingnya, lalu pilih Lepaskan Kolom.
- Klik Simpan dan Konversi.
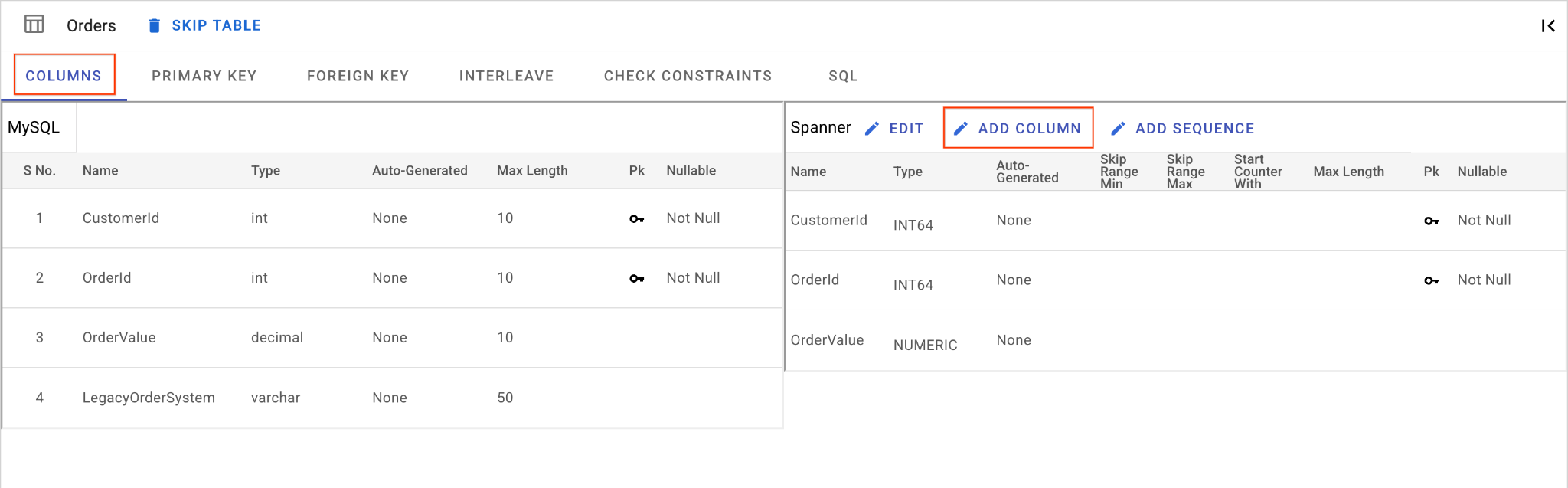
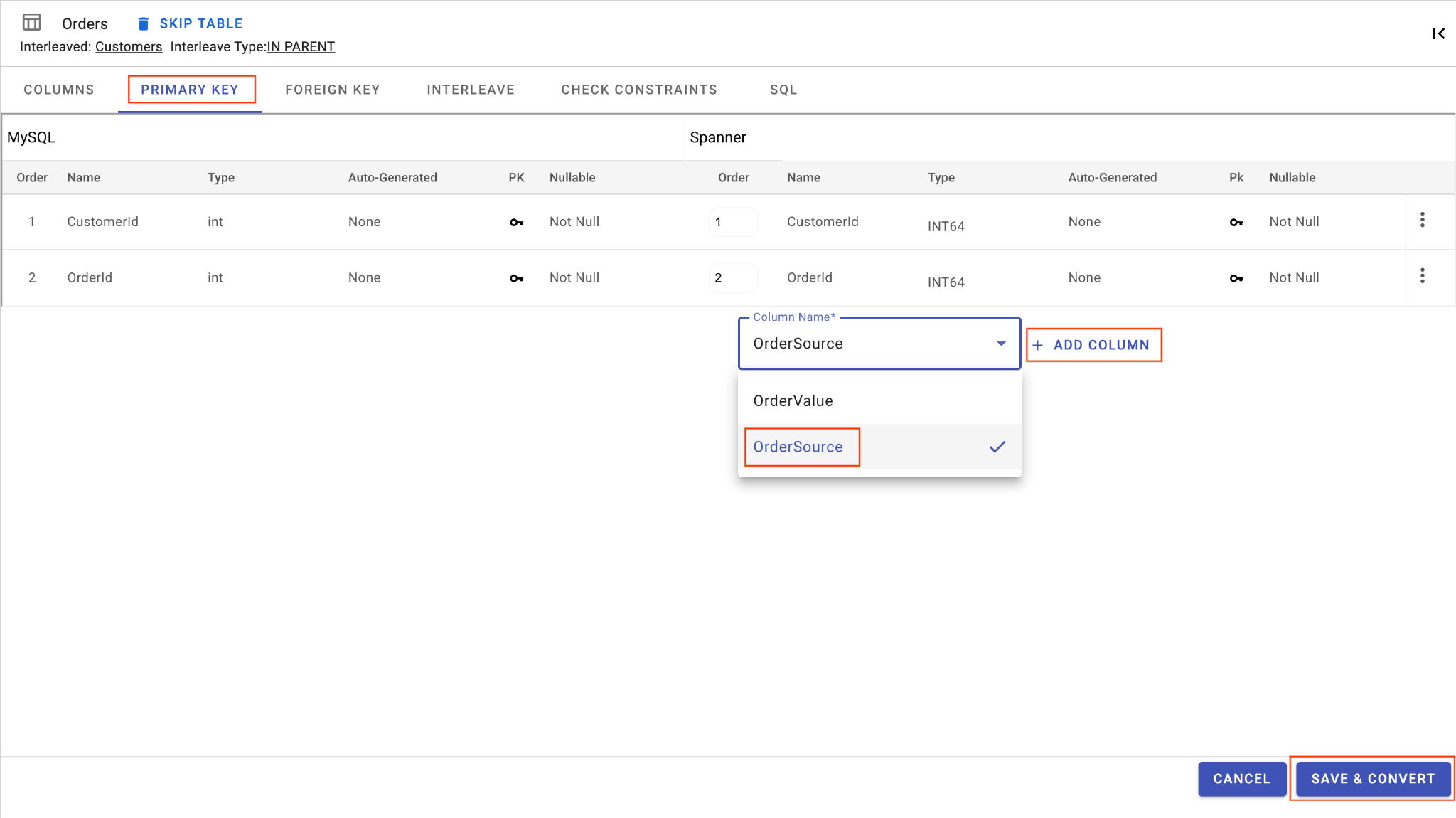
D. Tambahkan Kolom OrderSource dan Jadikan sebagai Kunci Utama:
- Masih di tabel
Orders, klik Tambahkan Kolom. Beri namaOrderSourcedan tetapkan jenis keSTRINGdengan panjang50, tanpa pembuatan otomatis, dan tetapkanIsNullablekeNo. - Buka tab Primary Key.
- Klik Edit dan pilih
OrderSourcedari dropdown Nama Kolom. - Klik Tambahkan Kolom, lalu Simpan & Konversi.
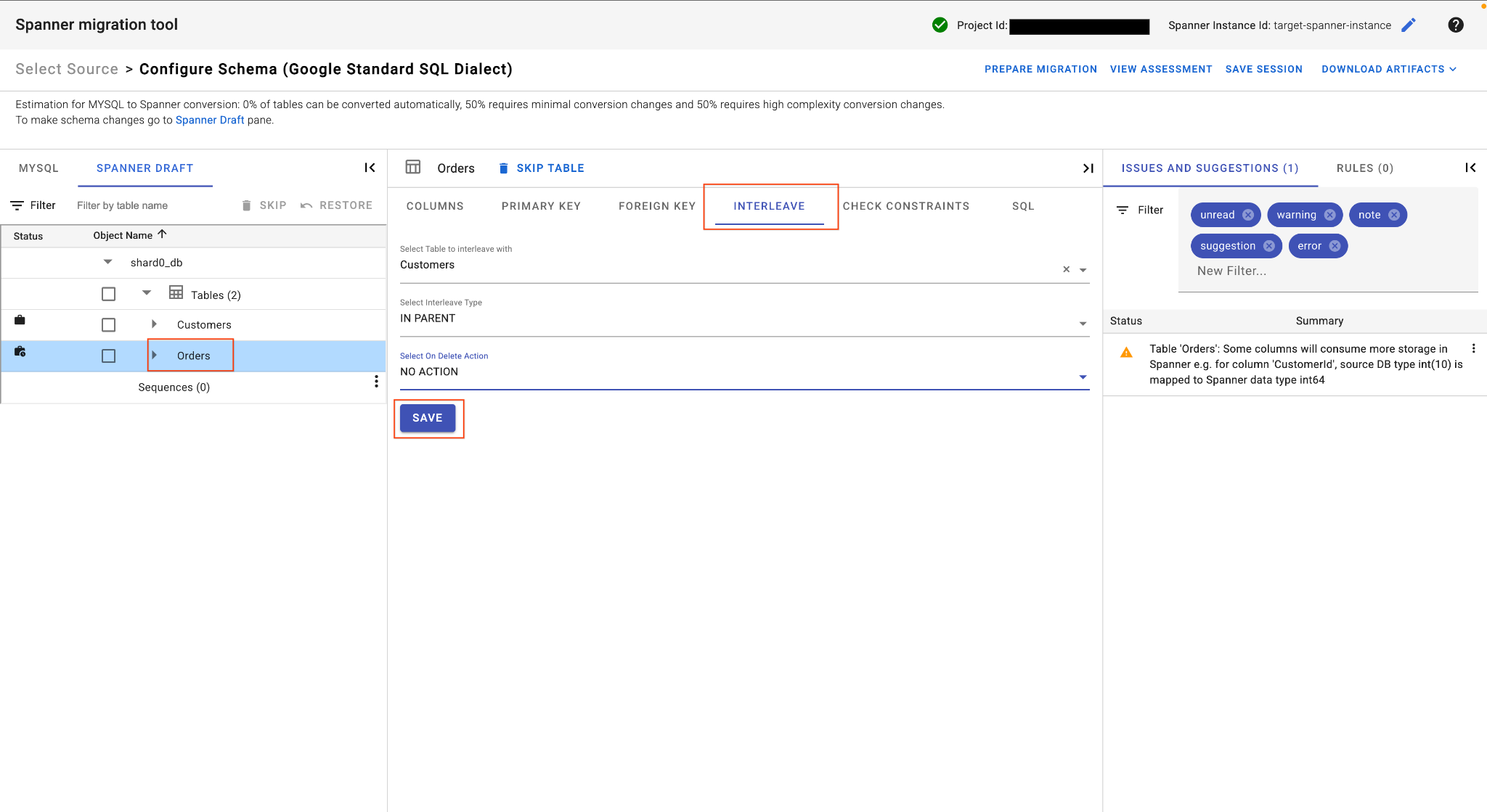
E. Menyisipkan Tabel Pesanan:
- Masih di tabel
Orders, di tampilan tabel utama, temukan tab Interleave. - Tetapkan tabel induk ke
Customers. - Pilih
IN PARENTInterleave type danNO ACTIONOn Delete Action. - Klik Simpan.
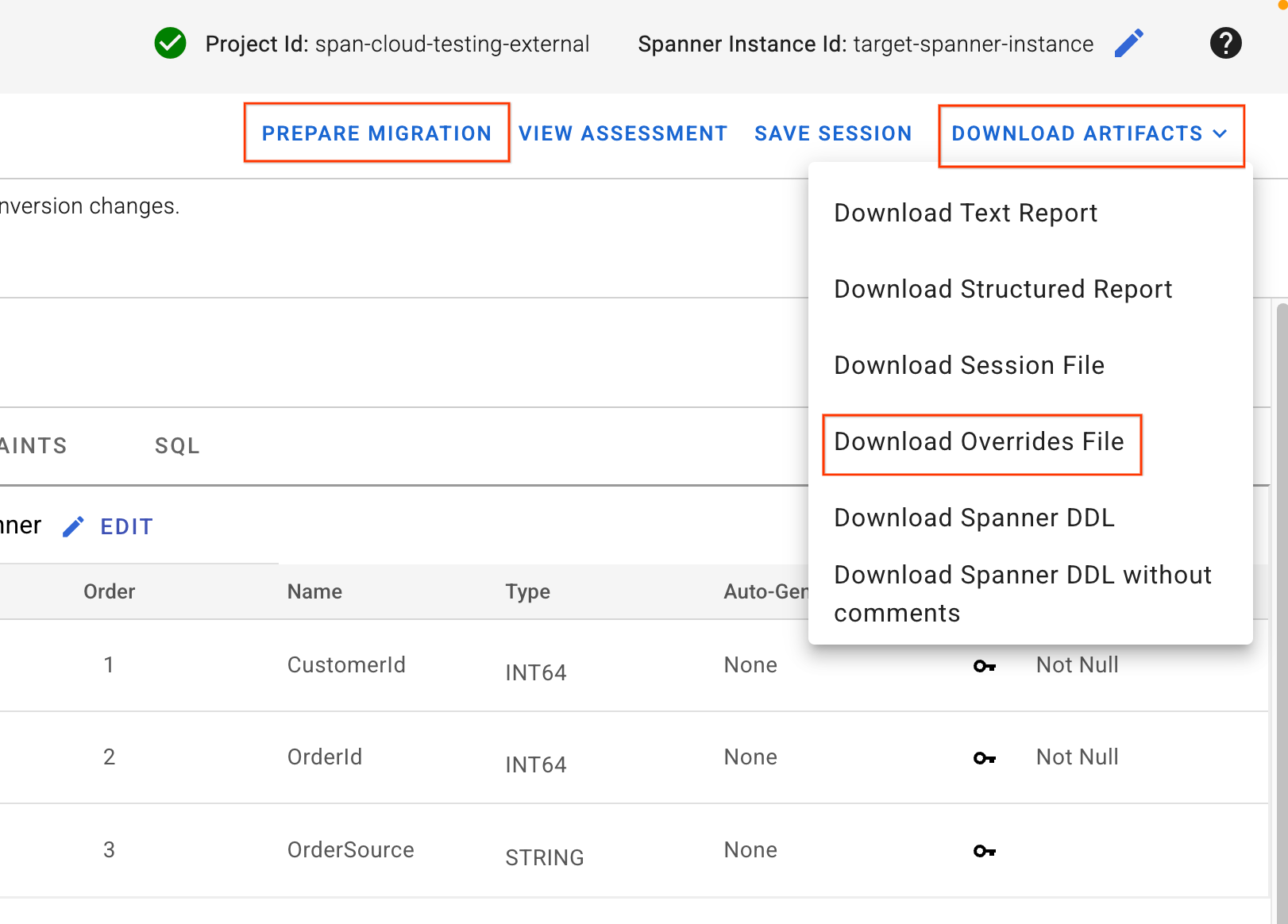
4. Mendownload File Penggantian & Menerapkan Skema
- Di pojok kanan atas UI SMT, cari tombol Download Artifacts. Pilih opsi Download File Penggantian. Simpan file ini ke komputer lokal Anda. File ini berisi semua perubahan pemetaan skema yang baru saja kita buat dan akan digunakan oleh pipeline Dataflow kita.
- Klik Siapkan Migrasi.
- Pilih Mode Migrasi sebagai
Schemadari dropdown. - Masukkan Target Spanner Database Anda:
sharded-target-db
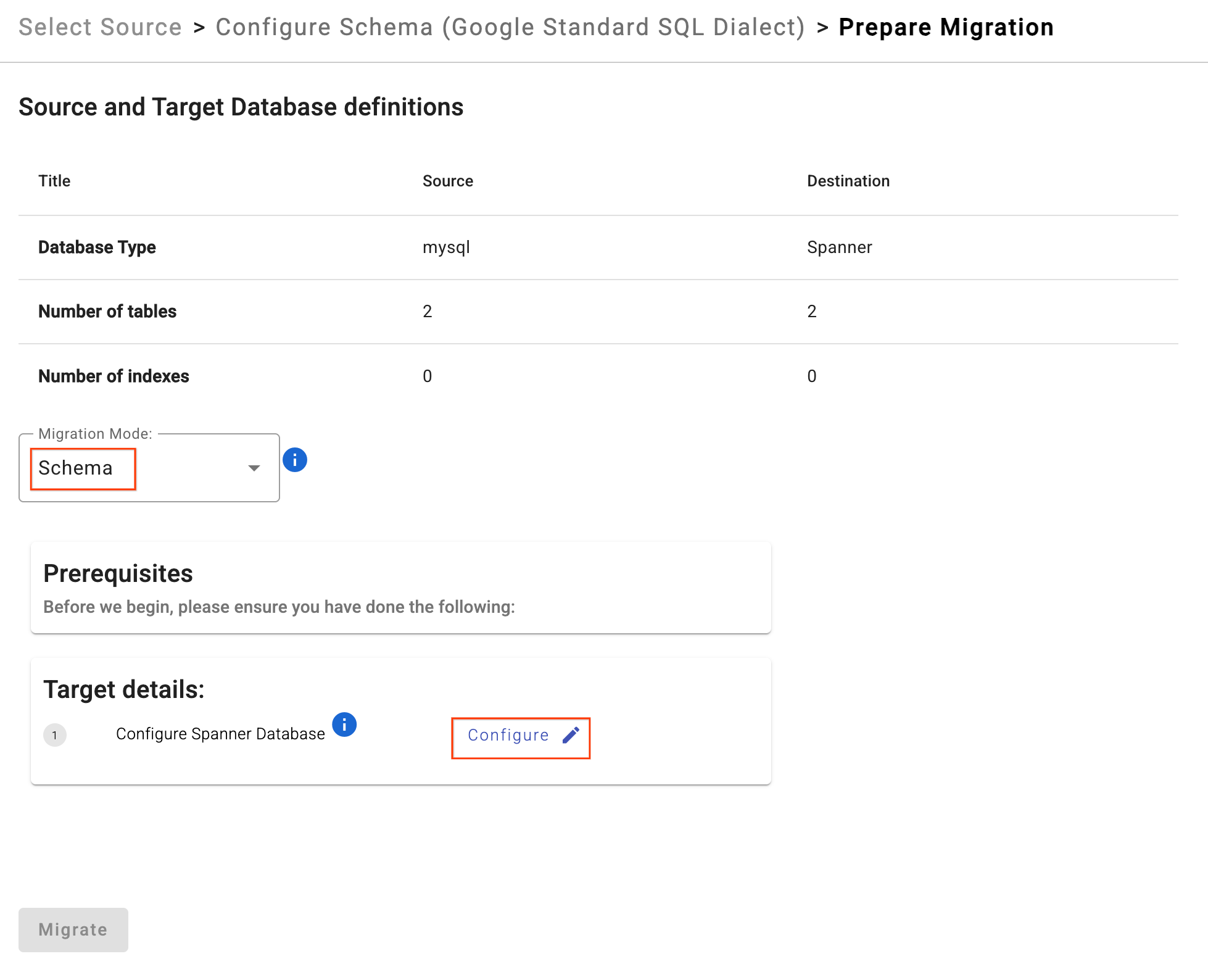
- Klik Migrasikan.
- SMT akan menerapkan DDL dan membuat database Spanner. Anda dapat menghentikan proses SMT dengan aman di Cloud Shell (
Ctrl+C) setelah selesai.
5. Memverifikasi Skema di Cloud Spanner
Pastikan bahwa tabel telah dibuat di database Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Anda akan melihat output berikut:
table_name: Customers table_name: Orders
Opsional: Jika Anda ingin memeriksa DDL Spanner yang sebenarnya untuk memverifikasi bahwa batasan pemeriksaan, penyisipan, dan kolom tambahan telah diterapkan, jalankan perintah berikut:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
Output yang Diharapkan:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. Menginisialisasi Pengambilan Data Perubahan (CDC)
Di bagian ini, Anda akan menyiapkan "perekam" untuk migrasi. Dengan mengonfigurasi Datastream dan Pub/Sub sebelum pemuatan data massal dimulai, Anda memastikan bahwa setiap perubahan yang dilakukan pada database sumber dicatat dan dimasukkan dalam antrean, sehingga mencegah kehilangan data selama transisi. Penyiapan ini diperlukan untuk Migrasi Langsung.
Karena arsitektur kami melibatkan dua server fisik, kami harus membuat dua profil sumber Datastream dan dua aliran Datastream yang terpisah. Kedua aliran akan menulis ke satu bucket Google Cloud Storage (GCS), yang akan bertindak sebagai sumber terpadu untuk pipeline Dataflow kita.
1. Membuat Bucket Cloud Storage
Datastream memerlukan tujuan untuk menyimpan peristiwa perubahan yang diambil. Mari buat bucket GCS.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. Membuat Profil Koneksi Datastream
Kita memerlukan dua profil koneksi sumber MySQL yang berbeda (satu untuk setiap shard fisik) dan satu profil koneksi target untuk Cloud Storage.
Mendapatkan Alamat IP Sumber
Pertama, ambil alamat IP eksternal dari dua VM Compute Engine kita dan simpan sebagai variabel lingkungan:
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
Membuat Profil Koneksi Sumber (MySQL di Compute Engine)
Buat profil koneksi Datastream menggunakan datastream_user yang dibuat sebelumnya.
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
Catatan: Datastream terhubung ke VM ini melalui IP publiknya, yang diizinkan karena kita telah menambahkan 0.0.0.0/0 ke aturan firewall sebelumnya. Dalam lingkungan produksi, Anda akan secara ketat memasukkan rentang IP publik tertentu Datastream ke dalam daftar yang diizinkan.
Buat Profil Koneksi Tujuan (Cloud Storage):
Ini menunjuk ke root bucket yang baru dibuat.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3. Membuat Aliran Datastream
Sekarang kita akan membuat dua aliran CDC. Aliran 1 akan merekam shard0_db dan shard1_db. Stream 2 akan merekam shard2_db dan shard3_db. Kedua aliran menulis ke bucket GCS yang sama dalam format Avro.
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
Menggunakan setelan rotasi file yang lebih kecil (5 MB atau 15 detik) membantu kita melihat perubahan yang direplikasi lebih cepat selama codelab.
Pemrosesan perintah ini mungkin memerlukan waktu beberapa saat. Periksa status: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION.
4. Mulai Aliran Datastream
Aktifkan kedua aliran data agar mulai merekam perubahan.
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
Periksa status: Anda dapat menjalankan gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION. Awalnya statusnya adalah STARTING dan akan berubah menjadi RUNNING setelah beberapa saat. Tunggu hingga keduanya berjalan sepenuhnya sebelum memulai Migrasi Langsung.
5. Menyiapkan Pub/Sub untuk Notifikasi GCS
Dataflow harus segera diberi tahu saat salah satu aliran Datastream menulis file baru ke bucket GCS. Kita akan mengonfigurasi GCS untuk mengirim notifikasi ke satu topik Pub/Sub.
Buat Topik Pub/Sub:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
Membuat Notifikasi GCS
Memberi tahu topik saat ada pembuatan objek dengan awalan data/ (yang mencakup kedua aliran kami).
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Buat Langganan Pub/Sub
Buat langganan dengan batas waktu konfirmasi yang direkomendasikan untuk Dataflow.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Transformasi Kustom
Karena skema Spanner kita berbeda dengan skema MySQL (karena kolom yang kita tambahkan dan hapus melalui UI Web SMT), migrasi Dataflow langsung akan gagal. Dataflow memerlukan petunjuk tentang cara memetakan perbedaan ini selama pipeline maju (MySQL ke Spanner) dan mundur (Spanner ke MySQL).
Selain itu, karena kita melakukan migrasi terbalik yang di-shard, Dataflow memerlukan mekanisme perutean untuk mengetahui shard logis (shard0_db, shard1_db, dll.) yang menjadi tujuan baris Spanner yang diupdate selama replikasi terbalik.
Kita akan melakukannya dengan menulis JAR Transformasi Kustom menggunakan template Shard Kustom Spanner yang disediakan Google.
1. Download Template Shard Kustom
Di Cloud Shell, download repositori Google Cloud Dataflow Templates dan buka folder shard kustom:
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. Mengonfigurasi Logika Transformasi Data
Kita perlu mengedit file CustomTransformationFetcher.java.
- Migrasi Maju (
toSpannerRow): Mengisi kolomOrderSourceyang baru ditambahkan menggunakan kolomLegacyOrderSystemdari MySQL. - Migrasi Terbalik (
toSourceRow): Mengisi kembali kolomLegacyOrderSystemyang dihapus yang diperlukan MySQL, yang berasal dariOrderSourceSpanner.
Edit file CustomTransformationFetcher.java. Daripada membuka editor teks secara manual, jalankan perintah berikut untuk otomatis mengganti file template dengan logika kustom kita:
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3. Mengonfigurasi Logika Sharding Terbalik
Dataflow menggunakan CustomShardIdFetcher.java selama replikasi terbalik untuk menentukan ke mana mutasi Spanner harus dirutekan. Kami akan menggunakan logika modulo (%4) dan kunci utama CustomerId untuk merutekan kembali data secara dinamis ke shard logis yang benar.
Edit file CustomShardIdFetcher.java menggunakan cat dan ganti seluruh isinya dengan kode berikut:
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. Membangun dan Mengupload JAR
Setelah logika Java kustom ditulis, kita perlu mengompilasinya ke dalam file JAR dan menguploadnya ke bucket Google Cloud Storage yang kita buat sebelumnya agar dapat diakses oleh Dataflow.
Jalankan perintah berikut di Cloud Shell:
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9. Memigrasikan Data dalam Jumlah Besar dari MySQL ke Spanner
Setelah skema Spanner tersedia dan JAR Transformasi Kustom dibuat, kita dapat menyalin data yang ada dari database MySQL Anda ke Cloud Spanner. Anda akan menggunakan Sourcedb to Spanner Template Fleksibel Dataflow, yang dirancang untuk menyalin data dalam jumlah besar dari database yang dapat diakses JDBC ke Spanner.
1. Upload File Penggantian Skema
Di Bagian 6, Anda mendownload file JSON Penggantian Spanner menggunakan UI Web SMT. Kita perlu menguploadnya ke bucket GCS agar Dataflow dapat menggunakannya untuk memetakan perbedaan skema (seperti kolom yang diganti namanya).
- Di Cloud Shell, klik menu tiga titik (Lainnya), lalu pilih Upload.
- Pilih file JSON Penggantian yang Anda download sebelumnya (misalnya,
spanner_overrides.json). - Pindahkan ke bucket GCS Anda:
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. Membuat dan Mengupload File Konfigurasi Sharding
Dataflow perlu mengetahui cara terhubung ke keempat shard logis di kedua VM fisik Anda. Kita akan membuat file sharding.json untuk ini.
Jalankan perintah berikut di Cloud Shell untuk membuat dan mengupload konfigurasi:
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3. Menjalankan Tugas Dataflow Migrasi Massal
Kita akan menggunakan Template Flex Sourcedb to Spanner. Karena ini adalah migrasi yang di-shard dengan transformasi kustom, kita meneruskan file Penggantian, konfigurasi Sharding, dan JAR Java kustom.
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
Penjelasan Parameter Utama:
sourceConfigURL: Jalur ke filesharding.jsonyang kita buat. Hal ini memberi tahu Dataflow cara terhubung ke keempat shard MySQL logis kita di dua VM fisik.schemaOverridesFilePath: Jalur ke file JSON yang kita download dari UI Web SMT. Hal ini menginstruksikan Dataflow tentang cara menangani modifikasi skema yang kami lakukan (seperti kolomLegacyRegionyang dihapus dan batasan pemeriksaan yang diperketat).transformationJarPath: Jalur GCS ke file JAR Java yang dikompilasi yang kita buat di bagian sebelumnya. File ini berisi kode sebenarnya untuk menjalankan transformasi kustom kita.transformationClassName: Nama class Java yang sepenuhnya memenuhi syarat di dalam JAR yang menerapkan logika migrasi penerusan (com.custom.CustomTransformationFetcher).outputDirectory: Lokasi GCS tempat Dataflow akan menulis file sementara dan, yang paling penting, file Dead Letter Queue (DLQ).maxWorkers,numWorkers: Mengontrol penskalaan tugas Dataflow. Tetap rendah untuk set data kecil ini.instanceId,databaseId,projectId: Menentukan instance dan database Cloud Spanner target.
Catatan Jaringan: Tugas ini terhubung ke instance Cloud SQL melalui IP Publiknya. Hal ini memungkinkan karena sebelumnya Anda menambahkan 0.0.0.0/0 ke Jaringan yang Diizinkan instance. Hal ini memungkinkan VM worker Dataflow, yang memiliki IP eksternal, untuk menjangkau database.
4. Memantau Tugas Dataflow
Anda dapat melacak progres tugas di Konsol Google Cloud:
- Buka halaman Dataflow Jobs: Buka Dataflow Jobs
- Temukan tugas bernama
mysql-sharded-bulk-to-spanner-..., lalu klik. - Amati grafik dan metrik tugas. Tunggu hingga status tugas berubah menjadi Succeeded. Proses ini akan memakan waktu sekitar 5-15 menit.
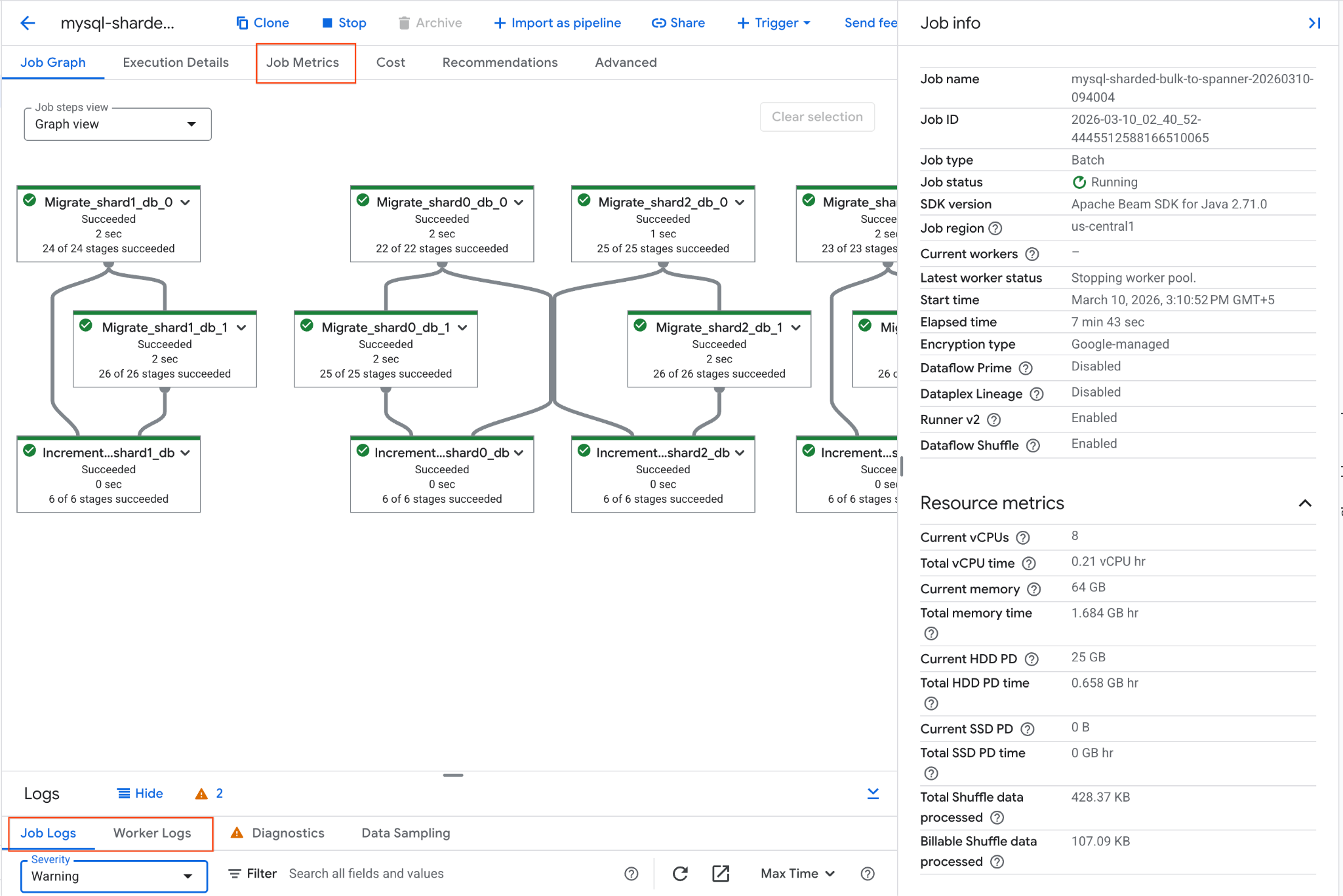
- Jika tugas mengalami masalah, tinjau tab Log di halaman detail tugas Dataflow untuk melihat pesan error.
- Metrik Tugas memberikan informasi selengkapnya mengenai progres tugas dan penggunaan resource seperti throughput dan pemakaian CPU.
5. Memverifikasi Data di Cloud Spanner dan Memeriksa Dead Letter Queue (DLQ)
Setelah tugas Dataflow berhasil diselesaikan, kita perlu memverifikasi bahwa data kita telah tiba dengan aman dan memeriksa catatan yang sengaja kita buat agar gagal.
A. Verifikasi Kesehatan Keseluruhan Data yang Dimigrasikan:
Gunakan CLI gcloud untuk menjalankan beberapa pemeriksaan kondisi cepat pada database Spanner gabungan Anda untuk memastikan bahwa catatan yang valid dimigrasikan dengan benar dan JAR kustom kami mengisi kolom tambahan.
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
Output yang Diharapkan:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- Semua baris di tabel Pelanggan berhasil dimigrasikan.
- Kita melihat 1 kegagalan baris dalam tabel
OrderskarenaINTERLEAVE IN PARENTdi Spanner -CustomerId 99adalah turunan yatim piatu karena tidak ada baris yang sesuai dalam tabelCustomers.
B. Periksa Kegagalan yang Disengaja di DLQ:
Kegagalan di atas didokumentasikan di folder Dead Letter Queue (DLQ) yang dibuat oleh pipeline Migrasi Massal.
- Buka Cloud Storage di Konsol Google Cloud.
- Buka bucket Anda, lalu buka folder
bulk-migration/dlq/severe. - Periksa file JSON di dalamnya. Anda akan menemukan baris
OrdersdenganCustomerIdyatim piatu. - Error DLQ Migrasi Massal dapat dicoba lagi dengan mengikuti langkah-langkah yang disebutkan di sini.
Pemuatan data massal awal dari Cloud SQL ke Cloud Spanner kini telah selesai. Langkah selanjutnya adalah menyiapkan replikasi langsung untuk merekam perubahan yang sedang berlangsung.
10. Mulai Migrasi Langsung (CDC)
Setelah pemuatan data massal selesai, Anda akan meluncurkan tugas streaming Dataflow berkelanjutan. Tugas ini akan membaca peristiwa Pengambilan Data Perubahan (CDC) yang ditulis Datastream ke bucket GCS Anda dan menerapkan perubahan tersebut ke Cloud Spanner mendekati real-time.
Kita juga akan menguji pipeline ini dengan menyuntikkan data yang valid dan data yang sengaja tidak valid untuk mengamati cara Dataflow menangani replikasi langsung dan mengalihkan kegagalan ke Dead Letter Queue (DLQ).
1. Membuat File Konfigurasi Sharding Migrasi Langsung
Tidak seperti migrasi massal (yang menggunakan string koneksi JDBC), pipeline migrasi langsung membaca peristiwa Datastream dari GCS. Konfigurasi ini memerlukan konfigurasi JSON yang sama sekali berbeda yang memetakan nama dan database aliran Datastream ke shard Spanner logis Anda.
Jalankan perintah berikut di Cloud Shell untuk membuat dan mengupload konfigurasi sharding aktif:
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. Menjalankan Tugas Dataflow Migrasi Langsung
Luncurkan tugas Dataflow streaming untuk membaca dari GCS dan menulis ke Spanner. Template ini akan menggunakan notifikasi Pub/Sub GCS untuk memproses file baru secara instan.
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
Parameter Utama
gcsPubSubSubscription: Langganan Pub/Sub yang memproses notifikasi file baru dari GCS. Hal ini memungkinkan tugas memproses perubahan secara instan saat Datastream menuliskannya.inputFileFormat="avro": Memberi tahu Dataflow untuk mengharapkan file Avro dari Datastream. Ini harus cocok dengan konfigurasi "Tujuan" Aliran Data Anda (misalnya,avroFileFormatvs.jsonFileFormat).shardingContextFilePath: File JSON yang memetakan aliran Datastream ke shard logis.dlqRetryMinutes: Jumlah menit antara percobaan ulang antrean pesan yang tidak diproses. Nilai defaultnya adalah10.dlqMaxRetryCount: Jumlah maksimum percobaan ulang error sementara melalui DLQ. Nilai defaultnya adalah500.
Pantau mulai tugas di Konsol Tugas Dataflow.
3. Menyuntikkan Data Langsung dan Memicu Kegagalan yang Disengaja
Saat tugas streaming Dataflow dimulai (dapat memerlukan waktu 3-5 menit), mari kita SSH ke VM MySQL fisik pertama dan menyisipkan beberapa rekaman baru. Kita akan memasukkan satu data yang valid dan satu data yang tidak valid.
SSH ke shard fisik pertama:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Login ke MySQL:
sudo mysql
Jalankan penyisipan berikut di shard1_db:
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
Ketik exit lagi untuk kembali ke perintah Cloud Shell.
4. Memverifikasi Data Migrasi Langsung dan Memeriksa DLQ CDC
Setelah data disisipkan, Datastream akan merekam peristiwa CDC, dan Dataflow akan mencoba menerapkannya ke Spanner.
A. Memverifikasi Perubahan DML yang Valid di Spanner
Jalankan kueri berikut untuk memverifikasi bahwa peristiwa INSERT, UPDATE, dan DELETE berhasil mencapai Spanner, dan bahwa Transformasi Kustom diaktifkan pada penyisipan dan pembaruan.
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Output yang Diharapkan:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
Catatan: Jika ada kueri yang tidak menampilkan hasil yang diharapkan, tunggu sebentar dan coba lagi, karena pekerja streaming mungkin masih memproses antrean.
B. Periksa Kegagalan yang Disengaja di DLQ:
Karena CustomerId = 99999 tidak memiliki induk dalam tabel Customers, CustomerId = 99999 seharusnya ditolak oleh Spanner dan dialihkan dengan aman ke DLQ oleh Dataflow.
- Buka Cloud Storage di Konsol Google Cloud.
- Buka bucket Anda, lalu buka folder
live-migration/dlq/severe/. - Anda akan melihat file JSON yang baru dibuat. Klik untuk memeriksa isinya. Anda akan melihat detail
CustomerId = 99999dan pesan error Spanner tertentu:NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written." - Error DLQ Migrasi Langsung dapat dicoba lagi dengan menjalankan template dataflow dengan setelan
runMode=retryDLQ.
5. Menangani Error DLQ
Error di direktori severe/ memerlukan intervensi manual. Mari kita perbaiki masalah data dan memproses ulang acara yang gagal.
A. Memperbaiki Data di Sumber
Error terjadi karena data pelanggan induk CustomerId = 99999 tidak ada. Mari kita masukkan ke database MySQL sumber.
SSH ke instance MySQL lagi:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Login ke MySQL menggunakan sudo mysql dan masukkan baris induk yang hilang ke shard1_db:
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
Ketik exit untuk kembali ke Cloud Shell.
B. Menjalankan Tugas Dataflow retryDLQ
Untuk memproses ulang peristiwa dari DLQ severe/, Anda meluncurkan template Dataflow yang sama, tetapi dalam mode retryDLQ. Mode ini secara khusus membaca dari jalur deadLetterQueueDirectory/severe, menjalankan ulang melalui transformasi kustom Anda, dan menerapkannya ke Spanner.
Luncurkan tugas dalam mode retryDLQ:
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
Perubahan Parameter Utama untuk Coba Ulang
runMode="retryDLQ": Memberi tahu template untuk membaca dari direktori DLQsevere.- Menghapus
gcsPubSubSubscription: Tidak diperlukan karena kita tidak membaca dari bucket GCS Datastream aktif.
Memantau Proses Coba Lagi:
Seperti pipeline CDC utama, retryDLQ adalah pipeline streaming yang akan tetap RUNNING hingga dibatalkan secara manual.
- Buka halaman Tugas Dataflow untuk
$JOB_NAME_RETRY. - Di panel Metrik, cari dua penghitung berikut:
elementsReconsumedFromDeadLetterQueue: Mengevaluasi saat file error diambil.Successful events: Bertambah saat data ditulis ke Spanner.- Periksa direktori
severe/untuk mengetahui kegagalan berulang. - Setelah peristiwa Berhasil bertambah sesuai jumlah item yang ingin Anda coba lagi (1 dalam kasus pengujian kami), lanjutkan ke langkah verifikasi berikutnya.
C. Memverifikasi Data yang Dicoba Lagi
Setelah percobaan ulang data yang gagal (mungkin perlu waktu beberapa saat hingga berhasil), periksa Spanner untuk melihat apakah baris anak berhasil dimigrasikan:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Sekarang Anda akan melihat baris:
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
Selain itu, periksa folder $DLQ_DIR_CDC/severe/ di GCS. File yang diproses seharusnya sudah dipindahkan atau dihapus, yang menunjukkan pemrosesan ulang berhasil.
11. Menyiapkan Replikasi Terbalik (Spanner ke MySQL)
Untuk menangani skenario saat Anda mungkin perlu me-roll back atau menyinkronkan database MySQL asli dengan Spanner selama periode transisi, Anda dapat menyiapkan replikasi terbalik.
Pipeline ini menggunakan Aliran Data Perubahan Spanner untuk merekam modifikasi live di Spanner. Kemudian, JAR Transformasi Kustom kami digunakan untuk memetakan kembali perbedaan skema, dan JAR Sharding Kustom kami digunakan untuk menghitung secara tepat VM MySQL fisik dan shard logis mana yang harus ditulisi kembali oleh update.
1. Membuat Aliran Data Perubahan Spanner
Pertama, Anda perlu membuat aliran perubahan di database Spanner untuk melacak perubahan pada tabel Customers dan Orders.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
Aliran perubahan ini kini akan mencatat semua modifikasi data ke tabel yang ditentukan.
2. Membuat Database Spanner untuk Metadata Dataflow
Template Dataflow Spanner to SourceDB memerlukan database Spanner terpisah untuk menyimpan metadata guna mengelola penggunaan aliran perubahan.
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Menyiapkan Konfigurasi Koneksi Cloud SQL untuk Dataflow
Template Dataflow memerlukan file JSON di Cloud Storage yang berisi detail koneksi untuk database Cloud SQL target.
Buat file lokal bernama shard_config.json:
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
Upload file ini ke bucket GCS Anda:
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. Menjalankan Tugas Dataflow Replikasi Terbalik
Luncurkan tugas Dataflow menggunakan Spanner_to_SourceDb Template Flex.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
Parameter Utama
changeStreamName: Nama aliran data perubahan Spanner yang akan dibaca.metadataInstance, metadataDatabase: Instance/database Spanner untuk menyimpan metadata yang digunakan oleh konektor untuk mengontrol penggunaan data Change Stream API.sourceShardsFilePath: Jalur GCS keshard_config.jsonAnda.filtrationMode: Menentukan cara menghilangkan rekaman tertentu berdasarkan kriteria. Defaultnya adalahforward_migration(memfilter data yang ditulis menggunakan pipeline migrasi penerusan)shardingCustomJarPath: Jalur GCS ke file JAR Java yang dikompilasi yang kita buat sebelumnya.shardingCustomClassName: Nama class yang sepenuhnya memenuhi syarat (com.custom.CustomShardIdFetcher) yang menjalankan matematika modulo%4kustom untuk menentukan secara dinamis shard logis mana yang harus menerima data.
Catatan Jaringan: Pekerja Dataflow akan terhubung ke instance Cloud SQL menggunakan IP Publik yang ditentukan di shard_config.json. Koneksi ini diizinkan karena adanya entri 0.0.0.0/0 di Jaringan yang Diizinkan pada instance Cloud SQL.
Pantau mulai tugas di Konsol Tugas Dataflow.
5. Menyuntikkan Data Spanner dan Memicu Kegagalan yang Disengaja
Tunggu hingga tugas Dataflow memasuki status Running (mungkin perlu waktu sekitar 5 menit). Kemudian, mari kita jalankan rangkaian lengkap kueri (INSERT, UPDATE, DELETE) langsung ke Spanner, beserta kegagalan yang disengaja untuk menguji DLQ terbalik.
Jalankan perintah berikut di Cloud Shell:
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. Memverifikasi Data Replikasi Terbalik dan Memeriksa DLQ
Mari kita konfirmasi bahwa JAR Sharding Kustom berhasil merutekan CustomerId 88 ke shard0_db di VM fisik pertama kita, dan JAR Transformasi Kustom berhasil menghapus "_TIER" dari region.
A. Verifikasi Valid Record di MySQL:
SSH ke shard fisik pertama:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Login ke MySQL dan kueri shard0_db:
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
Output yang diharapkan di Cloud SQL harus mencerminkan perubahan yang dilakukan di Spanner.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
Jenis
exit
untuk kembali ke Cloud Shell.
Hal ini mengonfirmasi bahwa pipeline replikasi terbalik berfungsi, menyinkronkan perubahan dari Spanner kembali ke Cloud SQL.
B. Memeriksa Kegagalan yang Disengaja di DLQ
Karena rekaman Customers baru kita memiliki CreditLimit sebesar 500 (yang melanggar batasan pemeriksaan > 1000 ketat yang kita tetapkan dalam database MySQL sumber), Dataflow menangkap error dengan aman.
- Buka Cloud Storage di Konsol Google Cloud.
- Buka bucket Anda, lalu buka folder
dlq/severe/. - Buka file JSON untuk melihat data
Customersyang ditolak dan error pelanggaran batasan pemeriksaan yang tepat. - Error DLQ Replikasi Terbalik dapat dicoba lagi dengan menjalankan template dataflow dengan setelan
runMode=retryDLQ.
12. Membersihkan Resource
Agar tidak menimbulkan biaya lebih lanjut pada akun Google Cloud Anda, hapus resource yang dibuat selama codelab ini.
Menetapkan Variabel Lingkungan (jika diperlukan)
Jika sesi Cloud Shell Anda berakhir karena waktu habis atau Anda membuka terminal baru, Anda harus mengekspor ulang variabel lingkungan sebelum menjalankan perintah pembersihan.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
Menghentikan Tugas Streaming Dataflow
Buat daftar tugas Anda untuk menemukan ID Tugas dari tugas Dataflow yang sedang berjalan. Ekspor JOB_ID_CDC dan JOB_ID_REVERSE dengan tepat.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Membatalkan tugas Datastream to Spanner (Migrasi Langsung) dan tugas percobaan ulangnya:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
Membatalkan tugas Spanner to Cloud SQL (Replikasi Terbalik):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Menghapus Resource Datastream
Hentikan dan Hapus Aliran Data:
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Hapus VM MySQL Sumber (Compute Engine)
Hapus dua instance Compute Engine yang menyimulasikan shard fisik MySQL lokal.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
Menghapus Aturan Firewall
Hapus aturan firewall jaringan yang dibuat untuk mengizinkan akses SSH dan konektivitas Datastream ke VM Anda. (Catatan: Jika Anda menggunakan nama yang berbeda untuk aturan firewall sebelumnya dalam codelab, sesuaikan di sini).
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
Menghapus Resource Pub/Sub
Menghapus Langganan:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Menghapus Topik:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Menghapus Instance Cloud Spanner
Hapus instance Cloud Spanner (tindakan ini akan otomatis menghapus database sharded-target-db dan migration-metadata-db di dalamnya).
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Menghapus Bucket dan Konten GCS
Terakhir, hapus bucket Cloud Storage yang menyimpan file Datastream, konfigurasi Dataflow, dan Dead Letter Queue. Perintah rm -r akan menghapus bucket dan semua isinya secara rekursif.
gcloud storage rm --recursive gs://${BUCKET_NAME}
Menghapus File Cloud Shell Lokal
Untuk membersihkan file dan direktori lokal yang dihasilkan di Cloud Shell selama codelab ini, jalankan perintah berikut:
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates