
1. 始める前に
この Codelab では、シャード化されたオンプレミス MySQL データベースを GoogleSQL 言語の Cloud Spanner データベースに移行する手順について説明します。Spanner Migration Tool(SMT)、Dataflow、Datastream、Pub/Sub、Google Cloud Storage などの Google Cloud サービスを使用します。
演習内容
- シャード環境とは何か、その設定方法。
- Spanner 移行ツール(SMT)ウェブ UI を使用して MySQL スキーマを Spanner 互換スキーマに変換し、高度なスキーマ変更を行う方法。
- Dataflow を使用して、シャーディングされた MySQL インスタンスから Cloud Spanner に一括データ移行を行う方法について説明します。
- Datastream と Dataflow を使用して、シャーディングされた MySQL インスタンスから Cloud Spanner への継続的レプリケーション(CDC)を設定する方法について説明します。
- Spanner からシャード化された MySQL インスタンスへのリバース レプリケーションを構成する方法。
- カスタム変換を使用して、一括移行、ライブ移行、逆移行中に追加の列を入力する方法。
- 主キーを使用してシャーディング変換を構成する方法。
この Codelab で取り上げない内容:
- 高度なカスタム ネットワーキング。
- カスタム Dataflow テンプレートをゼロから構築する。
- 移行のパフォーマンス チューニング。
- アプリケーションの移行: この Codelab では、データベース レイヤ(スキーマとデータ)に焦点を当てています。アプリケーション サービスの再デプロイまたは移行の運用プロセスについては説明していません。
必要なもの
- 課金を有効にした Google Cloud プロジェクト
- API を有効にして、Spanner、Dataflow、Datastream、GCS リソースを作成/管理するための十分な IAM 権限。この Codelab ではプロジェクトの
Ownerロールが最も簡単ですが、より具体的なロールについては「環境設定」で説明します。 - 設定フェーズでは、オンプレミス サーバーをシミュレートするために、サイズの小さい Compute Engine VM をプロビジョニングします。プロジェクトの割り当てで VM の作成が許可されていることを確認します。
- ウェブブラウザ(Google Chrome など)。
- Google Cloud コンソールと
gcloudなどのコマンドライン ツールに関する基本的な知識。 - シェル環境へのアクセス。
gcloudが含まれているため、Cloud Shell をおすすめします。
上記のセットアップの詳細については、環境のセットアップのセクションをご覧ください。
2. 移行プロセスについて
シャーディングされたデータベースの移行では、複数の物理インスタンスと論理インスタンスの MySQL を 1 つの水平方向にスケーラブルな Spanner データベースに統合します。このセクションでは、移行で使用されるアーキテクチャと主要なツールについて説明します。
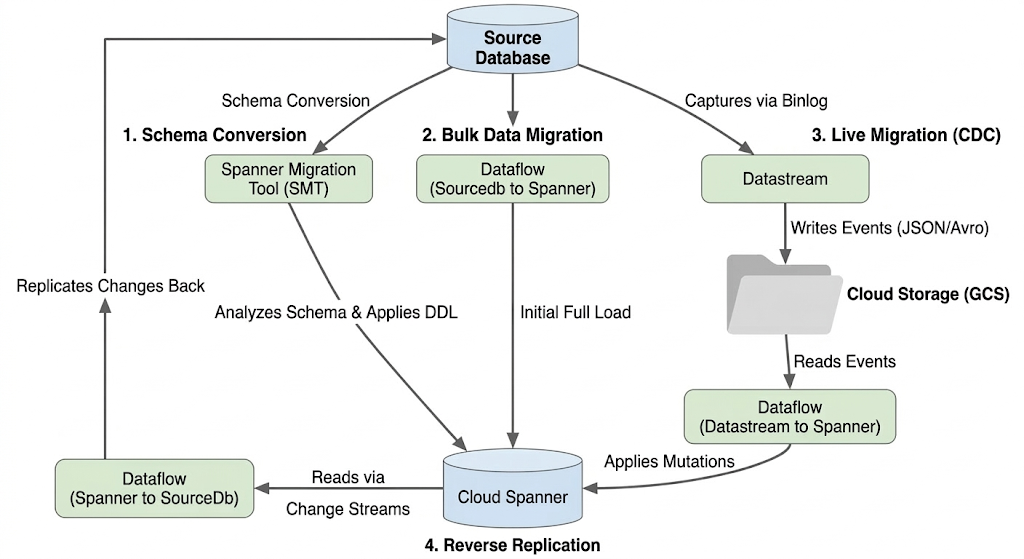
移行フローのアーキテクチャ
移行プロセスには次のステージがあります。
1. スキーマの変換:
- 目的: 移行元データベース スキーマを互換性のある Cloud Spanner スキーマに変換します。
- ツール: Spanner 移行ツール(SMT)
- プロセス: SMT は、ソース データベース スキーマを分析し、同等の Spanner データ定義言語(DDL)を生成します。移行先の Spanner インスタンスにデータベースが作成され、DDL が自動的に適用されます。
2. 一括データ移行:
- 目的: 移行元データベースからプロビジョニングされた Spanner テーブルに既存のデータの初期完全読み込みを実行します。
- ツール: Google 提供の
Sourcedb to Spannerテンプレートを使用する Dataflow。 - プロセス: この Dataflow ジョブは、指定されたソーステーブルからすべてのデータを読み取り、対応する Spanner テーブルに書き込みます。これは、Spanner スキーマの作成後に行われます。
3. ライブ マイグレーション(CDC):
- 目的: ソース データベースからの進行中の変更を準リアルタイムで Cloud Spanner にキャプチャして適用し、移行中のダウンタイムを最小限に抑えます。
- ツール:
- Datastream: ソース データベースから変更(挿入、更新、削除)をキャプチャし、Cloud Storage(GCS)に書き込みます。
- Dataflow:
Datastream to Spannerテンプレートを使用して、GCS から変更イベントを読み取り、Cloud Spanner に適用します。
4. リバース レプリケーション:
- 目的: Cloud Spanner から移行元データベースにデータ変更を複製します。これは、フォールバック戦略、段階的な移行、特定のユースケースのソースでレプリカを維持する場合に役立ちます。
- ツール:
Spanner to SourceDbテンプレートを使用する Dataflow。 - プロセス: このジョブは、Spanner 変更ストリームを使用して Spanner の変更をキャプチャし、ソース データベース インスタンスに書き戻します。
次の図は、コンポーネントとデータフローを示しています。
主な用語:
- 物理シャード: データベースをホストする実際の基盤となるサーバーまたはコンピューティング インスタンス(この場合は、シミュレートされたオンプレミス GCE VM)。
- 論理シャード: 物理サーバー内の個々のデータベース スキーマ。
- Compute Engine(GCE)VM: Google Cloud クラウド インフラストラクチャでホストされる仮想マシン。この Codelab では、GCE VM を使用して、ソース MySQL データベースをホストするスタンドアロンの「オンプレミス」ベアメタル サーバーをシミュレートします。
- Spanner 移行ツール(SMT): MySQL スキーマの評価、Spanner スキーマの同等物の提案、Spanner データ定義言語(DDL)の生成に使用されるツール。
- データ定義言語(DDL):
CREATE TABLEステートメントなど、データベース構造の定義と変更に使用されるステートメント。SMT は、Cloud SQL スキーマに基づいて Spanner DDL を生成します。 - Dataflow: フルマネージドのサーバーレス データ処理サービス。この Codelab では、一括データ転送、Datastream の変更の適用、逆レプリケーションのために Google 提供のテンプレートを実行するために使用されます。
- Datastream: サーバーレスの変更データ キャプチャ(CDC)とレプリケーション サービス。この Codelab では、ローカルでホストされている MySQL インスタンスから Cloud Storage に変更をストリーミングするために使用します。
- Spanner 変更ストリーム: データの変更(挿入、更新、削除)をリアルタイムでストリーミングできる Spanner の機能。逆レプリケーションのソースとして使用されます。
- Pub/Sub: イベントを生成するサービスとイベントを処理するサービスを切り離すために使用されるメッセージング サービス。この Codelab では、Datastream が新しい変更ファイルを Cloud Storage にアップロードするたびに、Dataflow がトリガーされて更新が処理されます。
3. 環境設定
移行を開始する前に、Google Cloud プロジェクトを設定し、必要なサービスを有効にする必要があります。
1. Google Cloud プロジェクトを選択または作成する
この Codelab のサービスを使用するには、課金が有効になっている Google Cloud プロジェクトが必要です。
- Google Cloud コンソールで、プロジェクト セレクタ ページに移動します。プロジェクト セレクタに移動
- Google Cloud プロジェクトを選択または作成します。
- プロジェクトに対して課金が有効になっていることを確認します。プロジェクトに対して課金が有効になっていることを確認する方法をご覧ください。
2. Cloud Shell を開く
Cloud Shell は、Google Cloud で実行されるコマンドライン環境です。gcloud CLI やその他の必要なツールがプリロードされています。
- Google Cloud コンソールの右上にある [Cloud Shell をアクティブにする] ボタンをクリックします。
- コンソールの下部の新しいフレーム内で Cloud Shell セッションが開き、コマンドライン プロンプトが表示されます。

3. プロジェクトと環境変数を設定する
Cloud Shell で、プロジェクト ID と使用するリージョンの環境変数を設定します。
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. 必要な Google Cloud APIs を有効にする
Cloud Spanner、Dataflow、Datastream、その他の関連サービスに必要な API を有効にします。
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
このコマンドが完了するまで数分かかる場合があります。
4. ソース MySQL データベースを設定する
このセクションでは、2 つの Compute Engine 仮想マシン(2 つの「物理シャード」)をプロビジョニングして、オンプレミスのシャード化された MySQL アーキテクチャをシミュレートします。次に、両方に MySQL をインストールし、各 VM に 2 つのデータベース(「論理シャード」)を作成します。
1. Compute Engine VM(物理シャード)を作成する
Cloud Shell で次のコマンドを実行して、Ubuntu を使用する 2 つの VM を作成します。後でインバウンド MySQL トラフィックを許可するために、ネットワーク タグを割り当てます。
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. ファイアウォール ルールを構成する
公開せずに安全な SSH アクセスを許可し、Datastream 接続を有効にするには:
IAP 経由の SSH 用のファイアウォール ルールを作成します。
このルールにより、Identity-Aware Proxy は SSH ポート(22)で VM に到達できます。
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
Datastream(MySQL ポート)のファイアウォール ルールを作成します。
Datastream は、標準の MySQL ポート(3306)でこれらの VM に到達できる必要があります。
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3. 物理シャード 1 に MySQL をインストールして構成する
最初の VM に SSH 接続して MySQL をインストールし、バイナリ ロギングを構成します(これは Datastream でライブ レプリケーションを行うために必要です)。
- 最初の VM に SSH 接続します。
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- MySQL をインストールします。
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- バイナリ ロギングを有効にして外部接続を許可するように
mysqld.cnfファイルを構成します。
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- MySQL を再起動して変更を適用します。
sudo systemctl restart mysql
4. 論理シャードの作成、データの挿入、Datastream ユーザーの作成(シャード 1)
mysql-physical-1 に SSH 接続したまま、MySQL プロンプトにログインします。
sudo mysql
次の SQL コマンドを実行します。このスクリプトは、2 つの個別の論理シャード(shard0_db と shard1_db)を作成し、両方に同一のスキーマを設定し、それぞれに一意に特定可能なデータを挿入し(シャーディングをデモンストレートするため)、Datastream のレプリケーション ユーザーを作成します。
次の SQL コマンドを実行して、最初の 2 つの論理シャード、テーブル、Datastream のレプリケーション ユーザーを作成します。
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
上記のスキーマのダンプファイルはこちらで確認できます。ダンプファイルには含まれていないため、データストリーム レプリケーション ユーザーを別途作成することが重要です。
5. データを確認する
データが存在することをすばやく確認します。
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
予想される出力:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
「exit」と入力して、物理シャード 1 VM への接続を終了します。
6. 物理シャード 2 について繰り返す
2 つ目の VM に対して同じプロセスを繰り返しますが、shard2_db と shard3_db を作成し、server-id を変更します。
- 2 番目の VM に SSH 接続します。
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- MySQL をインストールします。
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- バイナリ ロギングを有効にして外部接続を許可するように
mysqld.cnfファイルを構成します(server-id は異なる値にする必要があります(例: 2))。
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- MySQL を再起動して変更を適用します。
sudo systemctl restart mysql
- MySQL(
sudo mysql)を入力し、ステップ 4 の SQL のわずかに変更されたバージョンを実行します。
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
予想される出力:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
上記のスキーマのダンプファイルはこちらで確認できます。ダンプファイルには含まれていないため、データストリーム レプリケーション ユーザーを別途作成することが重要です。
「exit」と入力して、VM への接続を終了します。
5. Cloud Spanner を設定する
次に、データの移行先となるターゲット Cloud Spanner インスタンスを設定します。
1. Cloud Spanner インスタンスを作成する
レイテンシを最小限に抑えるため、Compute Engine VM と同じリージョンに Cloud Spanner インスタンスを作成します。このコマンドは、100 処理単位を使用して、この Codelab に適した小規模なインスタンスを作成します。
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
インスタンスの作成には 1 ~ 2 分かかることがあります。
6. Spanner 移行ツール(SMT)を使用してスキーマを変換する
Spanner Migration Tool(SMT)ウェブ UI を使用して、論理シャード(shard0_db)のいずれかに接続し、そのスキーマを分析して、Cloud Spanner に変換する前にいくつかの高度な変更を適用します。
1. SMT をインストールする
SMT Web UI は Cloud Shell から直接実行します。Cloud Shell ターミナルで、最新の SMT リリースをダウンロードして抽出します。
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
2. ソース データベースに接続する
- セッションを認証する
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(注: プロンプトが表示されたら、指定された URL にアクセスしてアカウントを承認し、確認コードをターミナルに貼り付けます)。
- まず、新しい Cloud Shell タブで次のコマンドを実行して、最初の物理シャードの外部 IP を見つけます。
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- SMT の構成時に使用するターゲット Spanner インスタンスの詳細を出力します。
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- ウェブ UI を起動します。
gcloud alpha spanner migrate web --port=8080
- Cloud Shell ウィンドウの右上にある [ウェブでプレビュー] アイコン(目のアイコン)をクリックし、[ポート 8080 でプレビュー] を選択します。新しいブラウザタブで SMT UI が開きます。
- SMT ウェブ UI で、[Connect to database] を選択します。
- 接続の詳細を入力します。
- Database Type: MySQL
- ホスト: (ステップ 2 の IP アドレスを貼り付けます)
- ポート: 3306
- ユーザー:
datastream_user - パスワード:
complex_password_123 - データベース名:
shard0_db
- 右上の編集ボタンをクリックして、Spanner データベースを構成します。
- ターゲット Spanner の詳細を入力します。
- プロジェクト ID: (ステップ 3 でコピーしたプロジェクト ID を貼り付けます)
- Spanner インスタンス: (ステップ 3 のインスタンス ID を貼り付けます)
- [Test Connection] をクリックします。
- このテストに合格したら、[接続] をクリックします。SMT はソース データベースを分析し、ベースラインの Spanner スキーマを表示します。
3. スキーマの変更を適用する
ここでは、複雑な移行シナリオに対応するようにスキーマを再構築します。
SMT UI のスキーマ エディタで、次の操作を行います。
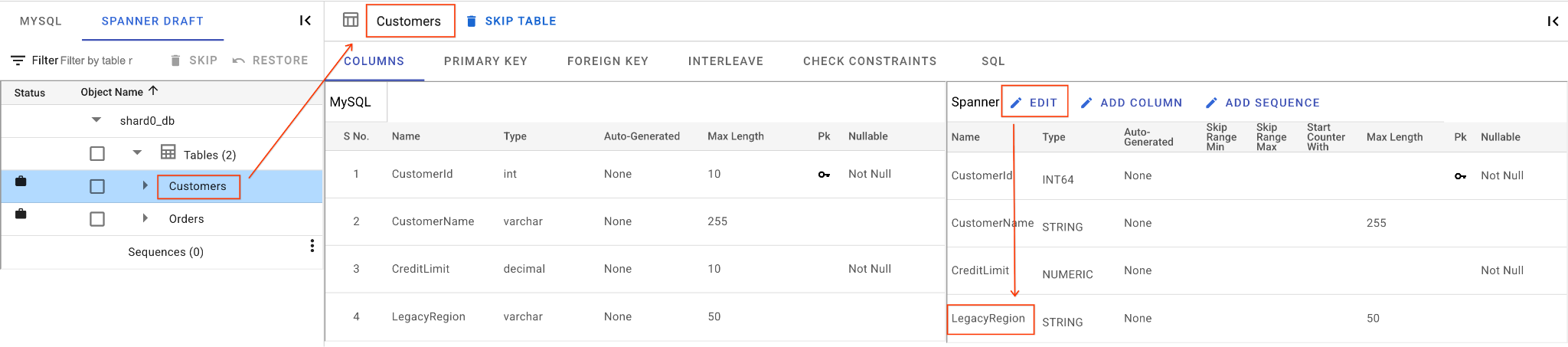
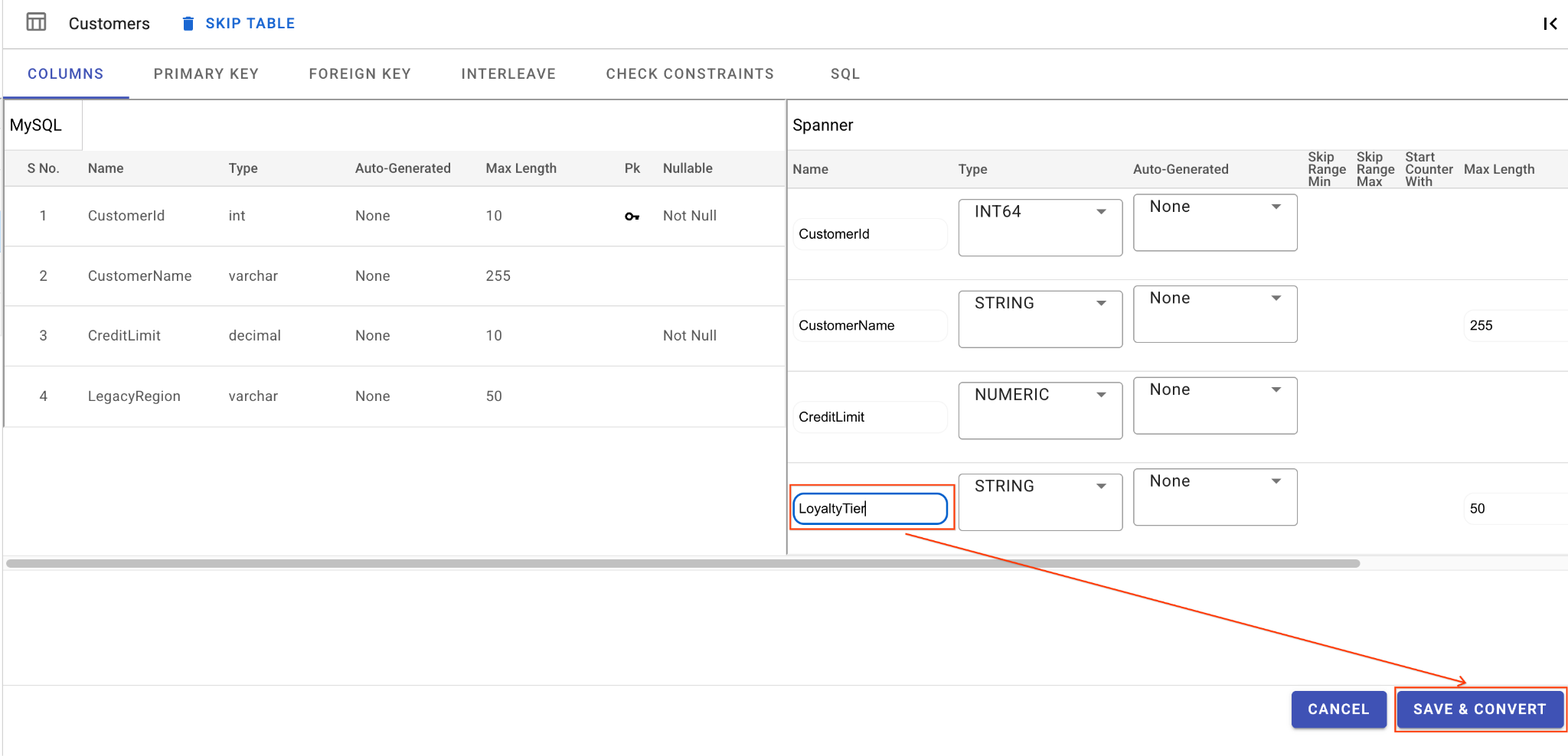
A. LegacyRegion 列の名前を変更します。
- 左側のナビゲーション パネルで
Customersテーブルをクリックします。デフォルトで [列] タブが開きます。 - [Spanner] セクションの [編集] ボタンをクリックします。
- Spanner スキーマ ビューで
LegacyRegion列を見つけます。 - 列名のダイアログに入力して、Spanner 列名を
LoyaltyTierに変更します。 - [保存して変換] をクリックします。
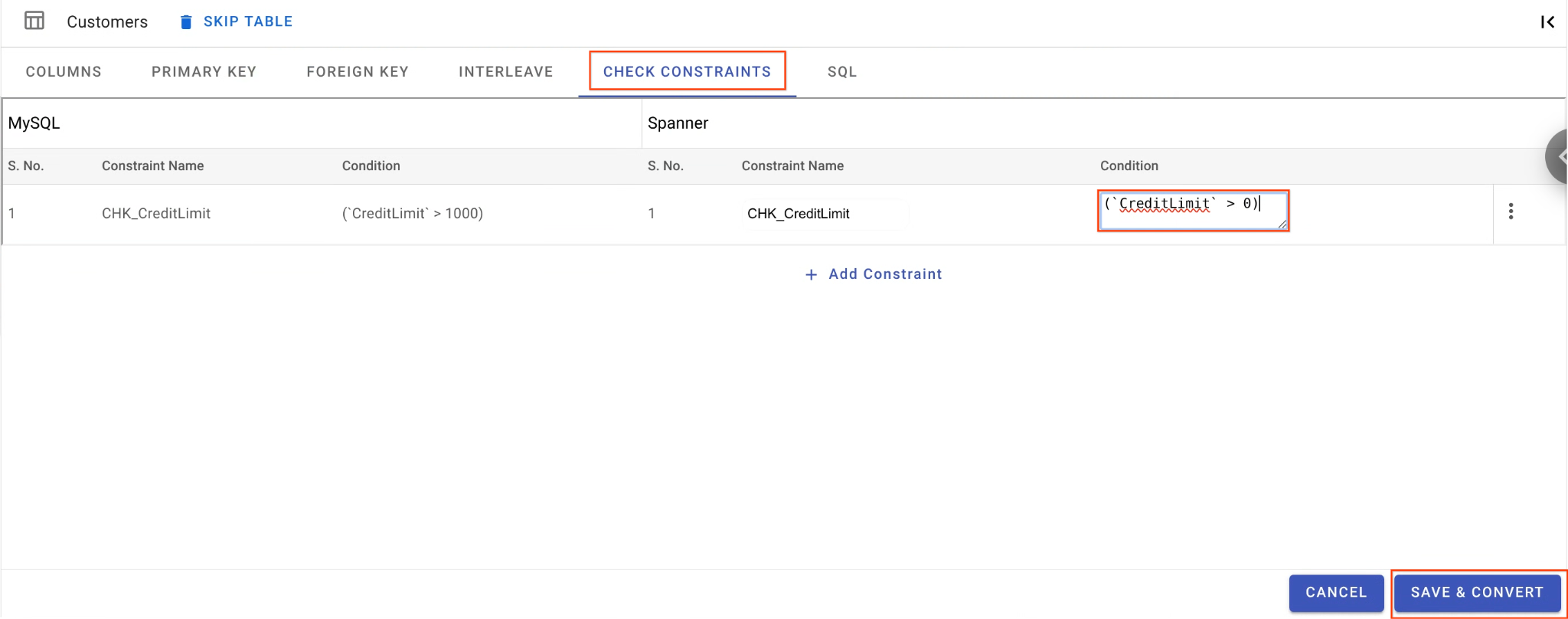
B. チェック制約を緩和します。
Customersテーブルで、[チェック制約] タブに移動します。CHK_CreditLimit制約を見つけます。編集アイコン(鉛筆のアイコン)をクリックします。- 条件を
CreditLimit > 1000からCreditLimit > 0に変更します。(これにより、クレジット上限が低い行は意図的にリバース移行に失敗し、DLQ にドロップされます)。
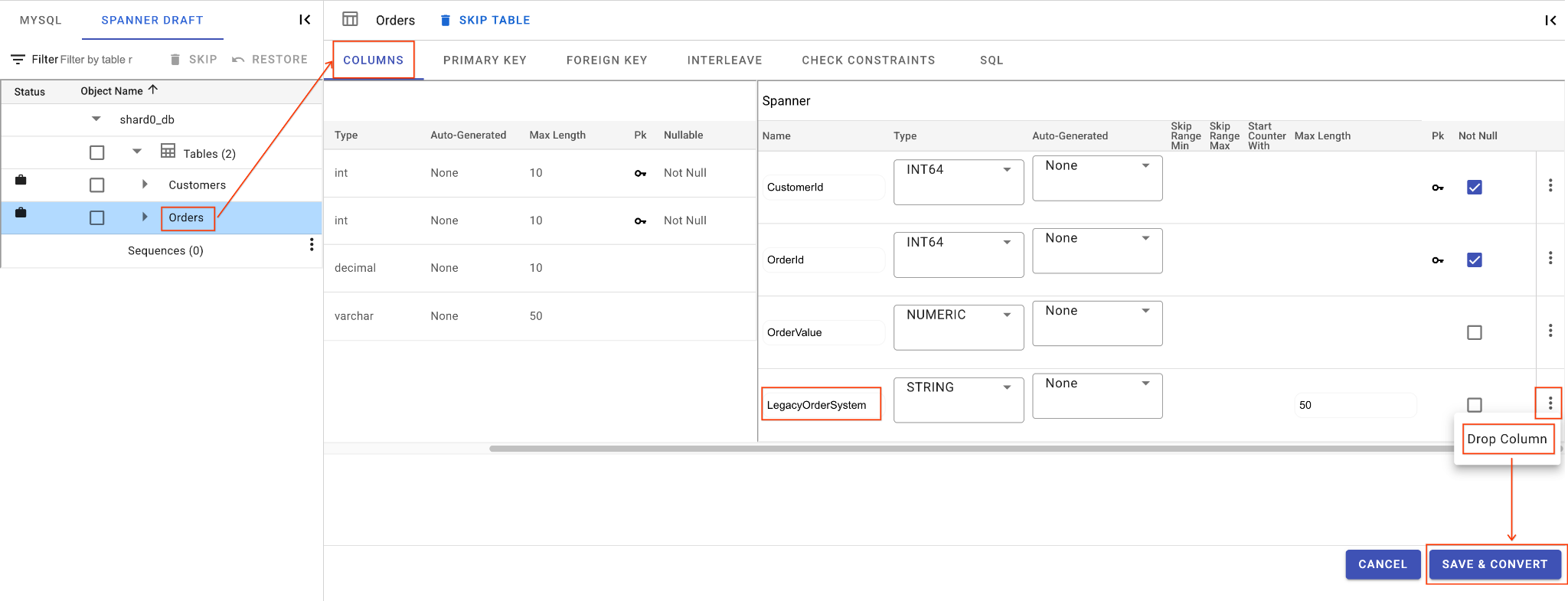
C. LegacyOrderSystem 列を削除します。
Ordersテーブルをクリックすると、デフォルトで [表示項目] タブが開きます。- [Spanner] セクションの [編集] ボタンをクリックします。
- Spanner スキーマ ビューで
LegacyOrderSystem列を見つけます。 - その横にあるその他メニュー アイコンをクリックし、[列を削除] を選択します。
- [保存して変換] をクリックします。
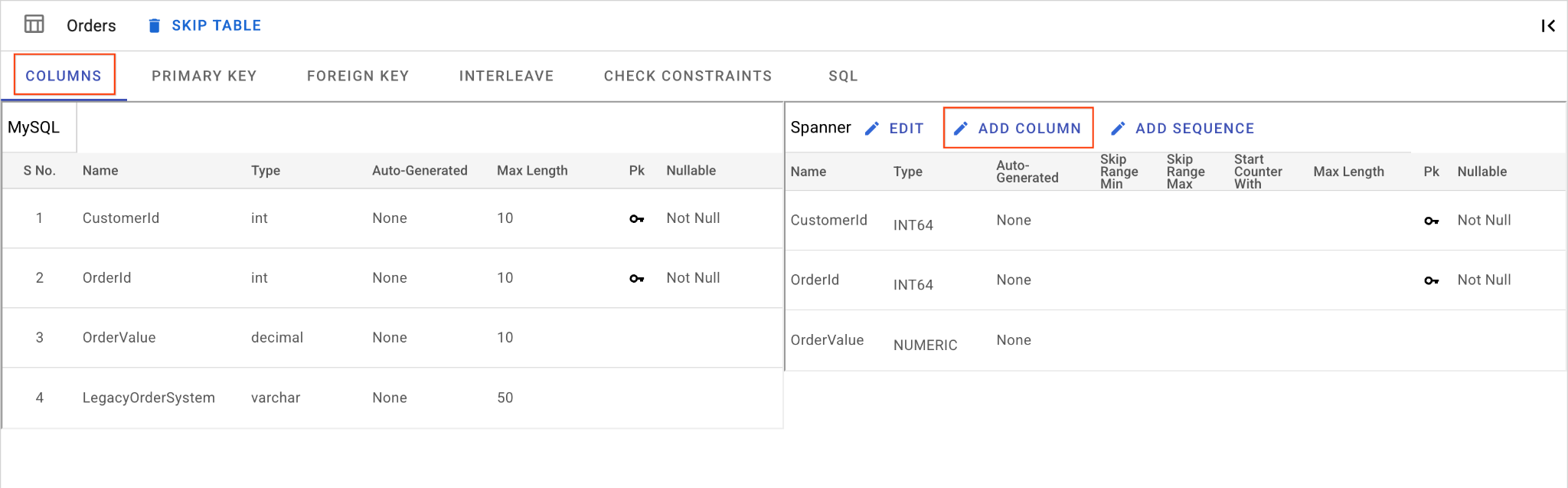
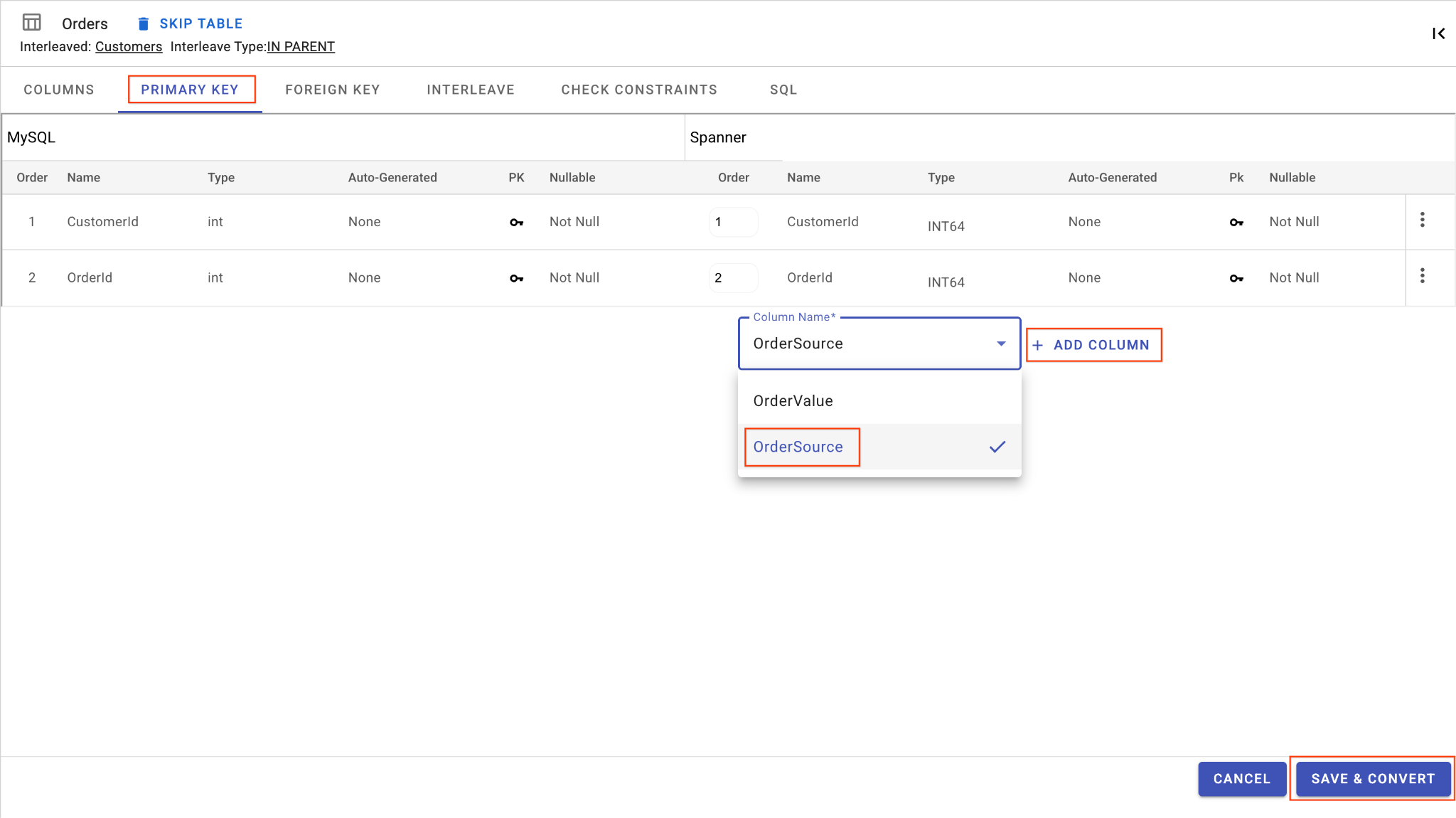
D. OrderSource 列を追加して主キーにする:
Ordersテーブルで、[列を追加] をクリックします。名前をOrderSourceに設定し、型をSTRINGに設定して、長さ50、自動生成なし、IsNullableをNoに設定します。- [主キー] タブに移動します。
- [編集] をクリックし、[列名] プルダウンから
OrderSourceを選択します。 - [列を追加]、[保存して変換] の順にクリックします。
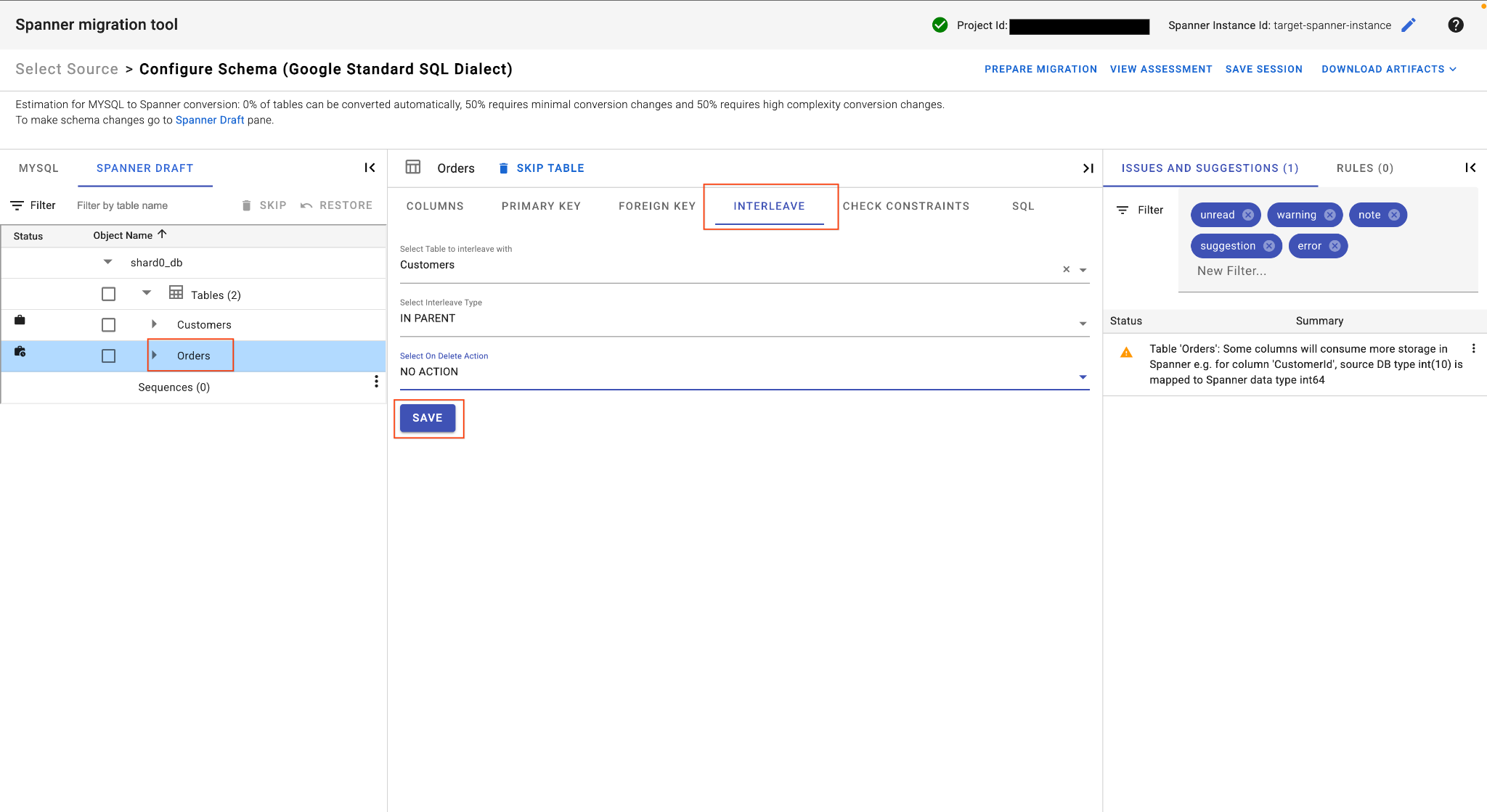
E. Orders テーブルをインターリーブします。
Ordersテーブルのメイン テーブルビューで、[インターリーブ] タブを見つけます。- 親テーブルを
Customersに設定します。 IN PARENTインターリーブ タイプとNO ACTION削除時のアクションを選択します。- [保存] をクリックします。
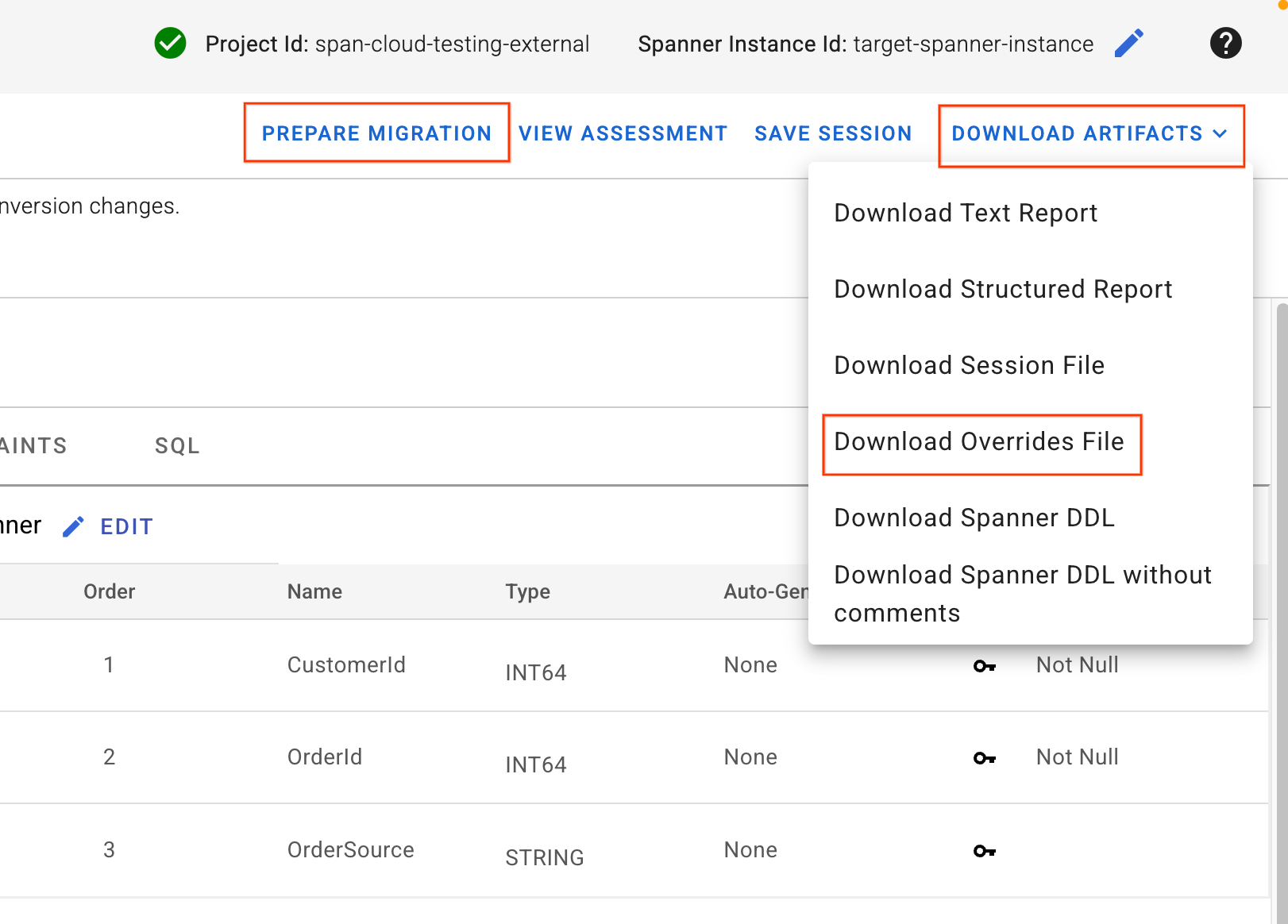
4. オーバーライド ファイルをダウンロードしてスキーマを適用する
- SMT UI の右上にある [Download Artifacts](アーティファクトをダウンロード)ボタンを見つけます。[Download Overrides File] オプションを選択します。このファイルをローカルマシンに保存します。このファイルには、先ほど行ったスキーマ マッピングの変更がすべて含まれており、Dataflow パイプラインで使用されます。
- [移行を準備] をクリックします。
- プルダウンから [移行モード] を
Schemaとして選択します。 - [Target Spanner Database] に
sharded-target-dbを入力します。
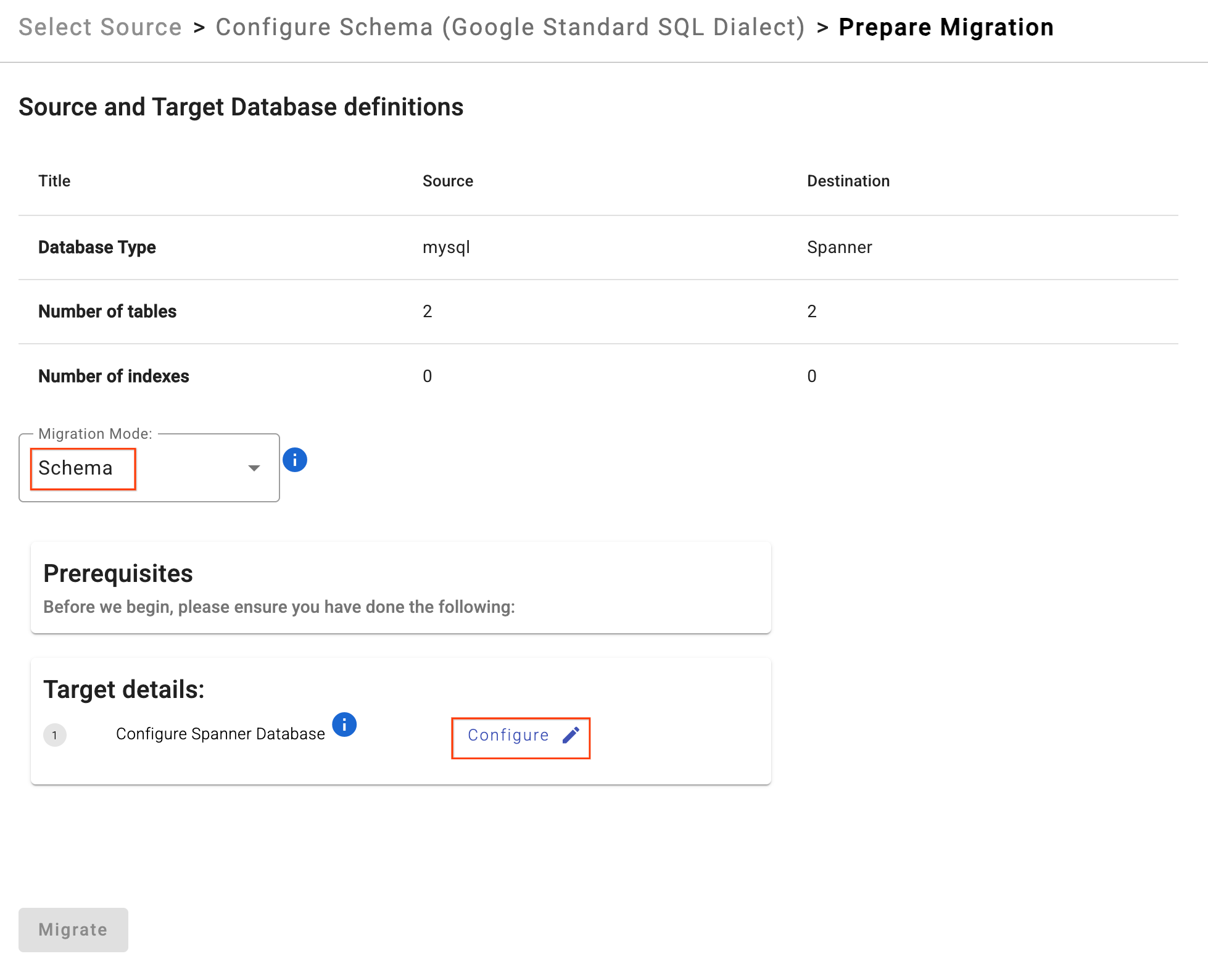
- [移行] をクリックします。
- SMT は DDL を適用し、Spanner データベースを作成します。SMT プロセスが完了したら、Cloud Shell(
Ctrl+C)で安全に停止できます。
5. Cloud Spanner でスキーマを確認する
テーブルが Spanner データベースに作成されていることを確認します。
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
次の出力が表示されます。
table_name: Customers table_name: Orders
省略可: 実際の Spanner DDL を確認して、チェック制約、インターリーブ、追加の列が適用されたことを確認する場合は、次のコマンドを実行します。
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
予想される出力:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. 変更データ キャプチャ(CDC)を初期化します。
このセクションでは、移行の「レコーダー」を設定します。一括データ読み込みを開始する前に Datastream と Pub/Sub を構成すると、ソース データベースに加えられたすべての変更がキャプチャされてキューに登録され、移行中のデータ損失を防ぐことができます。この設定はライブ マイグレーションに必要です。
このアーキテクチャには 2 つの物理サーバーが含まれているため、2 つの別々の Datastream ソース プロファイルと 2 つの Datastream ストリームを作成する必要があります。両方のストリームは単一の Google Cloud Storage(GCS)バケットに書き込みます。このバケットは、Dataflow パイプラインの統合ソースとして機能します。
1. Cloud Storage バケットを作成する
Datastream では、キャプチャされた変更イベントを保存する宛先が必要です。GCS バケットを作成しましょう。
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. Datastream 接続プロファイルを作成する
2 つの異なる MySQL ソース接続プロファイル(物理シャードごとに 1 つ)と、Cloud Storage の移行先接続プロファイルが 1 つ必要です。
送信元 IP アドレスを取得する
まず、2 つの Compute Engine VM の外部 IP アドレスを取得し、環境変数として保存します。
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
ソース接続プロファイルを作成する(Compute Engine 上の MySQL)
先ほど作成した datastream_user を使用して、Datastream 接続プロファイルを作成します。
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
注: Datastream は、これらの VM にパブリック IP 経由で接続します。これは、先ほどファイアウォール ルールに 0.0.0.0/0 を追加したため許可されています。本番環境では、Datastream の特定のパブリック IP 範囲を厳密に許可リストに登録します。
移行先接続プロファイル(Cloud Storage)を作成します。
これは、新しく作成したバケットのルートをポイントします。
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3. Datastream ストリームを作成する
ここで、2 つの CDC ストリームを作成します。ストリーム 1 は shard0_db と shard1_db をキャプチャします。ストリーム 2 は shard2_db と shard3_db をキャプチャします。両方のストリームが同じ GCS バケットに Avro 形式で書き込みます。
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
ファイル ローテーションの設定を小さく(5 MB または 15 秒)すると、Codelab で複製された変更をより早く確認できます。
このコマンドが完了するまでに時間がかかることがあります。ステータスを確認します: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION。
4. Datastream ストリームを開始する
両方のストリームを有効にして、変更の記録を開始します。
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
ステータスの確認: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION を実行できます。状態は最初は STARTING になり、数分後に RUNNING に変わります。両方が完全に実行されるまで待ってから、ライブ マイグレーションを開始します。
5. GCS 通知用に Pub/Sub を設定する
Dataflow は、Datastream ストリームのいずれかが新しいファイルを GCS バケットに書き込んだときに、直ちに通知を受ける必要があります。GCS が単一の Pub/Sub トピックに通知を送信するように構成します。
Pub/Sub トピックを作成します。
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
GCS 通知を作成する
data/ 接頭辞(両方のストリームをカバー)でオブジェクトが作成されたときにトピックに通知します。
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Pub/Sub サブスクリプションを作成する
Dataflow の推奨される確認応答期限でサブスクリプションを作成します。
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. カスタム変換
Spanner スキーマは MySQL スキーマと異なるため(SMT ウェブ UI を介して追加および削除した列が原因)、デフォルトの Dataflow 移行は失敗します。Dataflow には、転送(MySQL から Spanner)パイプラインと逆転送(Spanner から MySQL)パイプラインでこれらの違いをマッピングする方法に関する手順が必要です。
また、シャード化された逆移行を行うため、Dataflow には、逆レプリケーション中に更新された Spanner 行がどの論理シャード(shard0_db、shard1_db など)に属するかを認識するためのルーティング メカニズムが必要です。
これを行うには、Google 提供の Spanner カスタム シャード テンプレートを使用してカスタム変換 JAR を作成します。
1. カスタム シャード テンプレートをダウンロードする
Cloud Shell で、Google Cloud Dataflow テンプレート リポジトリをダウンロードし、カスタム シャード フォルダに移動します。
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. データ変換ロジックを構成する
CustomTransformationFetcher.java ファイルを編集する必要があります。
- 前方移行(
toSpannerRow): MySQL のLegacyOrderSystem列を使用して、新しく追加されたOrderSource列にデータを入力します。 - 逆移行(
toSourceRow): MySQL で必要な削除されたLegacyOrderSystem列を、Spanner のOrderSourceから導出して再入力します。
CustomTransformationFetcher.java ファイルを編集します。テキスト エディタを手動で開く代わりに、次のコマンドを実行して、テンプレート ファイルをカスタム ロジックで自動的に上書きします。
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3. リバース シャーディング ロジックを構成する
Dataflow は、逆レプリケーション中に CustomShardIdFetcher.java を使用して、Spanner ミューテーションの転送先を決定します。CustomerId 主キーとモジュロ(%4)ロジックを使用して、レコードを正しい論理シャードに動的にルーティングします。
cat を使用して CustomShardIdFetcher.java ファイルを編集し、その内容を次のコードに置き換えます。
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. JAR をビルドしてアップロードする
カスタム Java ロジックが記述されたので、これを JAR ファイルにコンパイルし、Dataflow がアクセスできるように、先ほど作成した Google Cloud Storage バケットにアップロードする必要があります。
Cloud Shell で次のコマンドを実行します。
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9. MySQL から Spanner にデータを一括移行する
Spanner スキーマが設定され、カスタム変換 JAR がビルドされたので、MySQL データベースから Cloud Spanner に既存のデータをコピーできます。ここでは、JDBC アクセス可能なデータベースから Spanner にデータを一括コピーするように設計された Sourcedb to Spanner Dataflow Flex テンプレートを使用します。
1. スキーマ オーバーライド ファイルをアップロードする
セクション 6 では、SMT ウェブ UI を使用して Spanner Overrides JSON ファイルをダウンロードしました。Dataflow がこれを使用してスキーマの差異(列名の変更など)をマッピングできるように、これを GCS バケットにアップロードする必要があります。
- Cloud Shell で、その他メニュー(3 つのドット)をクリックし、[アップロード] を選択します。
- 先ほどダウンロードしたオーバーライド JSON ファイル(例:
spanner_overrides.json)を選択します。 - GCS バケットに移動します。
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. シャーディング構成ファイルを作成してアップロードする
Dataflow は、2 つの物理 VM にまたがる 4 つの論理シャードすべてに接続する方法を認識する必要があります。このために sharding.json ファイルを作成します。
Cloud Shell で次のコマンドを実行して、構成を生成してアップロードします。
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3. 一括移行 Dataflow ジョブを実行する
Sourcedb to Spanner Flex テンプレートを使用します。これはカスタム変換を使用したシャーディングされた移行であるため、オーバーライド ファイル、シャーディング構成、カスタム Java JAR を渡します。
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
主なパラメータの説明:
sourceConfigURL: 作成したsharding.jsonファイルのパス。これにより、2 つの物理 VM にある 4 つの論理 MySQL シャードすべてに接続する方法が Dataflow に指示されます。schemaOverridesFilePath: SMT ウェブ UI からダウンロードした JSON ファイルのパス。これにより、削除されたLegacyRegion列や厳格化されたチェック制約など、行ったスキーマ変更の処理方法が Dataflow に指示されます。transformationJarPath: 前のセクションでビルドしたコンパイル済み Java JAR ファイルの GCS パス。これには、カスタム変換を実行する実際のコードが含まれています。transformationClassName: 転送移行ロジック(com.custom.CustomTransformationFetcher)を実装する JAR 内の Java クラスの完全修飾名。outputDirectory: Dataflow が一時ファイルと、最も重要なデッドレター キュー(DLQ)ファイルを書き込む GCS の場所。maxWorkers、numWorkers: Dataflow ジョブのスケーリングを制御します。この小さなデータセットでは低く保たれています。instanceId、databaseId、projectId: ターゲットの Cloud Spanner インスタンスとデータベースを指定します。
ネットワークに関する注: このジョブは、パブリック IP 経由で Cloud SQL インスタンスに接続します。これは、以前に 0.0.0.0/0 をインスタンスの承認済みネットワークに追加したためです。これにより、外部 IP を持つ Dataflow ワーカー VM がデータベースにアクセスできるようになります。
4. Dataflow ジョブをモニタリングする
ジョブの進行状況は Google Cloud コンソールで確認できます。
- Dataflow の [ジョブ] ページに移動します。[Dataflow ジョブ] に移動
mysql-sharded-bulk-to-spanner-...という名前のジョブを見つけてクリックします。- ジョブグラフと指標を確認します。ジョブ ステータスが [完了] に変わるまで待ちます。これには約 5 ~ 15 分かかります。
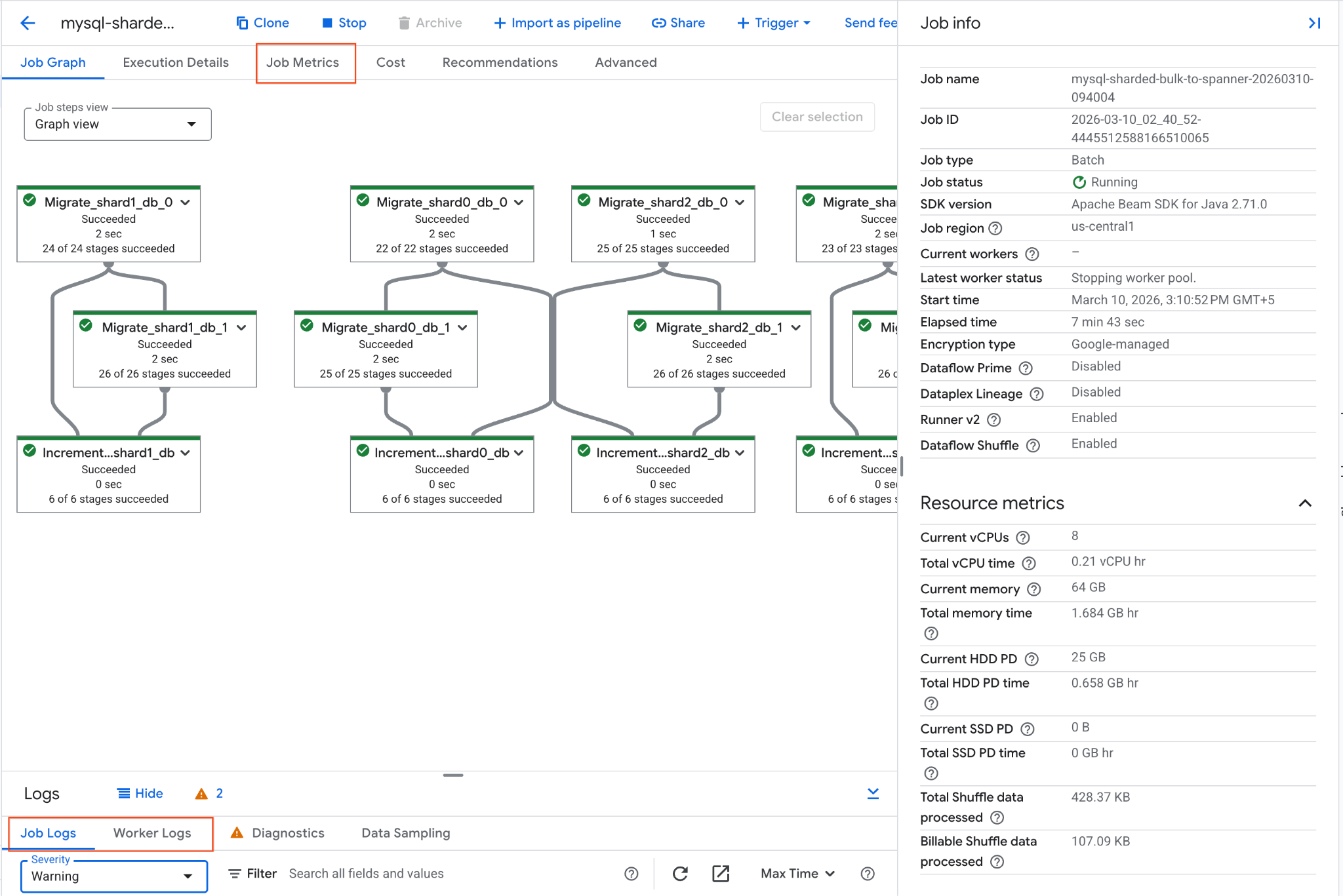
- ジョブで問題が発生した場合は、Dataflow ジョブの詳細ページの [ログ] タブでエラー メッセージを確認します。
- ジョブ指標には、ジョブの進行状況と、スループットや CPU 使用率などのリソース消費量に関する詳細情報が表示されます。
5. Cloud Spanner でデータを確認し、デッドレター キュー(DLQ)を検査する
Dataflow ジョブが正常に完了したら、データが安全に到着したことを確認し、意図的に失敗するように設計したレコードを検査する必要があります。
A. 移行したデータの全体的な健全性を確認します。
gcloud CLI を使用して、統合された Spanner データベースでいくつかの簡単なヘルスチェックを実行し、有効なレコードが正しく移行され、カスタム JAR が追加の列にデータを取り込んでいることを確認します。
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
予想される出力:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- Customers テーブルのすべての行が正常に移行されました。
- Spanner の
INTERLEAVE IN PARENTが原因で、Ordersテーブルに 1 行の失敗が見られます。CustomerId 99はCustomersテーブルに対応する行がないため、孤立した子です。
B. DLQ の意図的な失敗を確認します。
上記の障害は、一括移行パイプラインによって作成されたデッドレター キュー(DLQ)フォルダに記録されます。
- Google Cloud コンソールで [Cloud Storage] に移動します。
- バケットに移動して、
bulk-migration/dlq/severeフォルダを開きます。 - 内部の JSON ファイルを調べます。孤立した
CustomerIdを含むOrders行が表示されます。 - 一括移行 DLQ エラーは、こちらの手順に沿って再試行できます。
Cloud SQL から Cloud Spanner へのデータの初期一括読み込みが完了しました。次のステップでは、進行中の変更をキャプチャするようにライブ レプリケーションを設定します。
10. ライブ マイグレーション(CDC)を開始する
一括データ読み込みが完了したので、継続的な Dataflow ストリーミング ジョブを起動します。このジョブは、Datastream が GCS バケットに書き込んでいる変更データ キャプチャ(CDC)イベントを読み取り、これらの変更を Cloud Spanner に準リアルタイムで適用します。
また、有効なデータと意図的に無効なデータを挿入してこのパイプラインをテストし、Dataflow がライブ レプリケーションを処理し、障害をデッドレター キュー(DLQ)にルーティングする方法を確認します。
1. ライブ マイグレーション シャーディング構成ファイルを作成する
一括移行(JDBC 接続文字列を使用)とは異なり、ライブ移行パイプラインは GCS から Datastream イベントを読み取ります。Datastream ストリーム名とデータベースを論理 Spanner シャードにマッピングする、まったく異なる JSON 構成が必要です。
Cloud Shell で次のコマンドを実行して、ライブ シャーディング構成を作成してアップロードします。
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. ライブ マイグレーション Dataflow ジョブを実行する
ストリーミング Dataflow ジョブを起動して、GCS から読み取り、Spanner に書き込みます。このテンプレートは、GCS Pub/Sub 通知を使用して新しいファイルを即座に処理します。
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
主なパラメータ
gcsPubSubSubscription: GCS からの新しいファイル通知をリッスンする Pub/Sub サブスクリプション。これにより、Datastream が変更を書き込むと、ジョブは変更を即座に処理できます。inputFileFormat="avro": Datastream から Avro ファイルが送信されることを Dataflow に伝えます。これは、Datastream の [宛先] 構成(avroFileFormatとjsonFileFormatなど)と一致している必要があります。shardingContextFilePath: Datastream ストリームを論理シャードにマッピングする JSON ファイル。dlqRetryMinutes: デッドレター キューの再試行間隔(分)。デフォルトは10です。dlqMaxRetryCount: DLQ で一時的なエラーが発生した場合に再試行できる最大回数。デフォルトは500です。
Dataflow ジョブ コンソールでジョブの起動をモニタリングします。
3. ライブデータを挿入して意図的な障害をトリガーする
Dataflow ストリーミング ジョブの起動中(3 ~ 5 分かかることがあります)に、最初の物理 MySQL VM に SSH 接続して、新しいレコードを挿入します。有効なレコードと無効なレコードを 1 つずつ挿入します。
最初の物理シャードに SSH 接続します。
gcloud compute ssh mysql-physical-1 --zone=$ZONE
MySQL にログインします。
sudo mysql
shard1_db で次の挿入を実行します。
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
もう一度 exit と入力して Cloud Shell プロンプトに戻ります。
4. ライブ マイグレーションのデータを確認し、CDC DLQ を検査する
データを挿入すると、Datastream が CDC イベントをキャプチャし、Dataflow が Spanner に適用しようとします。
A. Spanner で有効な DML 変更を確認する
次のクエリを実行して、INSERT、UPDATE、DELETE のイベントが Spanner に正常に到達し、挿入と更新の両方でカスタム変換がトリガーされたことを確認します。
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
予想される出力:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
注: クエリで想定される結果が表示されない場合は、ストリーミング ワーカーがキューを処理している可能性があるため、1 分待ってからもう一度試してください。
B. DLQ で意図的な失敗を確認します。
CustomerId = 99999 には Customers テーブルに親がないため、Spanner によって拒否され、Dataflow によって DLQ に安全に転送されるはずです。
- Google Cloud コンソールで [Cloud Storage] に移動します。
- バケットに移動して、
live-migration/dlq/severe/フォルダを開きます。 - 新しく生成された JSON ファイルが表示されます。クリックして内容を確認します。
CustomerId = 99999の詳細と、Spanner の特定のエラー メッセージNOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written."が表示されます。 - ライブ マイグレーション DLQ エラーは、
runMode=retryDLQを設定して Dataflow テンプレートを実行することで再試行できます。
5. DLQ エラーの処理
severe/ ディレクトリのエラーには手動での介入が必要です。データの問題を修正し、失敗したイベントを再処理しましょう。
A. ソースのデータを修正する
親顧客レコード CustomerId = 99999 がないため、エラーが発生しました。ソース MySQL データベースに挿入してみましょう。
MySQL インスタンスに再度 SSH 接続します。
gcloud compute ssh mysql-physical-1 --zone=$ZONE
sudo mysql を使用して MySQL にログインし、欠落している親行を shard1_db に挿入します。
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
exit と入力して Cloud Shell に戻ります。
B. retryDLQ Dataflow ジョブを実行する
severe/ DLQ からイベントを再処理するには、同じ Dataflow テンプレートを retryDLQ モードで起動します。このモードでは、deadLetterQueueDirectory/severe パスから読み取り、カスタム変換を再度実行して、Spanner に適用します。
retryDLQ モードでジョブを起動します。
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
再試行の主なパラメータの変更
runMode="retryDLQ": テンプレートにsevereDLQ ディレクトリから読み取るよう指示します。gcsPubSubSubscriptionを削除しました。ライブ Datastream GCS バケットから読み取っていないため、不要です。
再試行プロセスをモニタリングします。
メインの CDC パイプラインと同様に、retryDLQ はストリーミング パイプラインであり、手動でキャンセルされるまで RUNNING のままになります。
$JOB_NAME_RETRYの Dataflow ジョブページに移動します。- [指標] ペインで、次の 2 つのカウンタを探します。
elementsReconsumedFromDeadLetterQueue: エラー ファイルの取得時に評価されます。Successful events: レコードが Spanner に書き込まれるたびに増加します。severe/ディレクトリで繰り返し発生する障害を確認します。- [Successful] イベントが再試行するアイテム数(テストケースでは 1)だけ増えたら、次の検証ステップに進みます。
C. 再試行されたデータを確認する
失敗したレコードが再試行されたら(成功するまでに時間がかかることがあります)、Spanner を確認して、子行が正常に移行されたかどうかを確認します。
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
次のように行が表示されます。
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
また、GCS の $DLQ_DIR_CDC/severe/ フォルダも確認します。処理済みのファイルは移動または削除され、再処理が成功したことを示します。
11. リバース レプリケーションを設定する(Spanner から MySQL)
ロールバックが必要になる可能性のあるシナリオや、移行期間中に元の MySQL データベースと Spanner の同期を維持する必要があるシナリオに対応するには、リバース レプリケーションを設定します。
このパイプラインは、Spanner 変更ストリームを使用して Spanner のライブ変更をキャプチャします。次に、カスタム変換 JAR を使用してスキーマの差異を逆マッピングし、カスタム シャーディング JAR を使用して、更新を書き戻す必要がある物理 MySQL VM と論理シャードを正確に計算します。
1. Spanner 変更ストリームを作成する
まず、Spanner データベースに Customers テーブルと Orders テーブルの変更を追跡する変更ストリームを作成する必要があります。
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
この変更ストリームは、指定されたテーブルに対するすべてのデータ変更を記録するようになります。
2. Dataflow メタデータ用の Spanner データベースを作成する
Spanner to SourceDB Dataflow テンプレートでは、変更ストリームの使用量を管理するためのメタデータを保存するために、別の Spanner データベースが必要です。
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Dataflow 用の Cloud SQL 接続構成を準備する
Dataflow テンプレートには、ターゲット Cloud SQL データベースの接続詳細を含む Cloud Storage 内の JSON ファイルが必要です。
shard_config.json という名前のローカル ファイルを作成します。
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
このファイルを GCS バケットにアップロードします。
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. リバース レプリケーションの Dataflow ジョブを実行する
Spanner_to_SourceDb Flex テンプレートを使用して Dataflow ジョブを起動します。
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
主なパラメータ
changeStreamName: 読み取る Spanner 変更ストリームの名前。metadataInstance, metadataDatabase: コネクタが変更ストリーム API データの使用量を制御するために使用するメタデータを保存する Spanner インスタンス/データベース。sourceShardsFilePath:shard_config.jsonの GCS パス。filtrationMode: 条件に基づいて特定のレコードを削除する方法を指定します。デフォルトはforward_migration(前方移行パイプラインを使用して書き込まれたレコードをフィルタする)です。shardingCustomJarPath: 先ほどビルドしたコンパイル済み Java JAR ファイルの GCS パス。shardingCustomClassName: カスタム%4モジュロ演算を実行して、どの論理シャードがレコードを受け取るかを動的に決定する完全修飾クラス名(com.custom.CustomShardIdFetcher)。
ネットワークに関する注: Dataflow ワーカーは、shard_config.json で指定されたパブリック IP を使用して Cloud SQL インスタンスに接続します。この接続は、Cloud SQL インスタンスの承認済みネットワークの 0.0.0.0/0 エントリによって許可されています。
Dataflow ジョブ コンソールでジョブの起動をモニタリングします。
5. Spanner データを挿入して意図的な障害をトリガーする
Dataflow ジョブが Running 状態になるまで待ちます(約 5 分かかることがあります)。次に、逆 DLQ をテストするために、意図的に失敗を発生させながら、一連のクエリ(INSERT、UPDATE、DELETE)を Spanner に直接実行します。
Cloud Shell で次のコマンドを実行します。
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. 逆レプリケーション データを確認し、DLQ を検査する
カスタム シャーディング JAR が最初の物理 VM で CustomerId 88 を shard0_db に正常にルーティングし、カスタム変換 JAR がリージョンから "_TIER" を正常に削除したことを確認しましょう。
A. MySQL で有効なレコードを確認します。
最初の物理シャードに SSH 接続します。
gcloud compute ssh mysql-physical-1 --zone=$ZONE
MySQL にログインして shard0_db をクエリします。
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
Cloud SQL の出力は、Spanner で行われた変更を反映している必要があります。
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
タイプ
exit
Cloud Shell に戻ります。
これにより、リバース レプリケーション パイプラインが機能し、Spanner から Cloud SQL に変更が同期されていることを確認できます。
B. DLQ で意図的な失敗を確認する
新しい Customers レコードの CreditLimit が 500(ソース MySQL データベースで定義した厳密な > 1000 チェック制約に違反)であるため、Dataflow はエラーを安全にキャッチしました。
- Google Cloud コンソールで [Cloud Storage] に移動します。
- バケットに移動して、
dlq/severe/フォルダを開きます。 - JSON ファイルを開いて、拒否された
Customersレコードと、チェック制約違反のエラーを確認します。 - リバース レプリケーション DLQ エラーは、
runMode=retryDLQを設定して Dataflow テンプレートを実行することで再試行できます。
12. リソースをクリーンアップする
Google Cloud アカウントに課金されないようにするには、この Codelab で作成したリソースを削除します。
環境変数を設定する(必要な場合)
Cloud Shell セッションがタイムアウトした場合や、新しいターミナルを開いた場合は、クリーンアップ コマンドを実行する前に環境変数を再エクスポートする必要があります。
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
Dataflow ストリーミング ジョブを停止する
ジョブを一覧表示して、実行中の Dataflow ジョブのジョブ ID を確認します。必要に応じて JOB_ID_CDC と JOB_ID_REVERSE をエクスポートします。
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Datastream to Spanner(ライブ マイグレーション)ジョブとその再試行ジョブをキャンセルします。
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
Spanner to Cloud SQL(逆レプリケーション)ジョブをキャンセルします。
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Datastream リソースを削除する
ストリームを停止して削除します。
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
ソース MySQL VM(Compute Engine)を削除する
オンプレミス MySQL 物理シャードをシミュレートした 2 つの Compute Engine インスタンスを削除します。
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
ファイアウォール ルールを削除する
VM への SSH アクセスと Datastream 接続を許可するために作成したネットワーク ファイアウォール ルールを削除します。(注: Codelab の前半でファイアウォール ルールに別の名前を使用した場合は、ここで調整してください)。
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
Pub/Sub リソースを削除する
サブスクリプションの削除:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
トピックを削除:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Cloud Spanner インスタンスを削除する
Cloud Spanner インスタンスを削除します(これにより、インスタンス内の sharded-target-db データベースと migration-metadata-db データベースの両方が自動的に削除されます)。
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
GCS バケットとコンテンツを削除する
最後に、Datastream ファイル、Dataflow 構成、デッドレター キューを保持する Cloud Storage バケットを削除します。rm -r コマンドは、バケットとそのすべてのコンテンツを再帰的に削除します。
gcloud storage rm --recursive gs://${BUCKET_NAME}
ローカル Cloud Shell ファイルを削除する
この Codelab で Cloud Shell に生成されたローカル ファイルとディレクトリをクリーンアップするには、次のコマンドを実行します。
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates