
1. 시작하기 전에
이 Codelab에서는 샤딩된 온프레미스 MySQL 데이터베이스를 GoogleSQL 언어를 사용하는 Cloud Spanner 데이터베이스로 마이그레이션하는 방법을 안내합니다. Spanner Migration Tool (SMT), Dataflow, Datastream, PubSub, Google Cloud Storage 등의 Google Cloud 서비스를 사용합니다.
다루는 내용:
- 샤드 환경이란 무엇이며 어떻게 설정하는지 알아봅니다.
- Spanner 마이그레이션 도구 (SMT) 웹 UI를 사용하여 MySQL 스키마를 Spanner 호환 스키마로 변환하고 고급 스키마 수정을 실행하는 방법
- Dataflow를 사용하여 샤딩된 MySQL 인스턴스에서 Cloud Spanner로 대량 데이터 마이그레이션을 실행하는 방법
- Datastream 및 Dataflow를 사용하여 샤딩된 MySQL 인스턴스에서 Cloud Spanner로 지속적인 복제 (CDC)를 설정하는 방법
- Spanner에서 샤딩된 MySQL 인스턴스로 다시 역방향 복제를 구성하는 방법
- 맞춤 변환을 사용하여 일괄, 라이브, 역방향 마이그레이션 중에 추가 열을 채우는 방법
- 기본 키를 사용하여 샤딩 변환을 구성하는 방법
이 Codelab에서 다루지 않는 내용은 다음과 같습니다.
- 고급 맞춤 네트워킹
- 처음부터 커스텀 Dataflow 템플릿을 빌드합니다.
- 마이그레이션 성능 조정
- 애플리케이션 마이그레이션: 이 Codelab에서는 데이터베이스 레이어 (스키마 및 데이터)에 중점을 둡니다. 애플리케이션 서비스를 재배포하거나 이전하는 운영 프로세스는 다루지 않습니다.
필요한 항목
- 결제가 사용 설정된 Google Cloud 프로젝트.
- API를 사용 설정하고 Spanner, Dataflow, Datastream, GCS 리소스를 만들고 관리할 수 있는 충분한 IAM 권한 프로젝트
Owner역할이 Codelab에서는 가장 간단하지만, 더 구체적인 역할은 '환경 설정'에서 다룹니다. - 설정 단계에서 온프레미스 서버를 시뮬레이션하기 위해 소규모 Compute Engine VM이 프로비저닝됩니다. 프로젝트 할당량이 VM 생성을 허용하는지 확인합니다.
- 웹브라우저(예: Chrome)
- Google Cloud 콘솔 및
gcloud와 같은 명령줄 도구에 대한 기본적인 이해 - 셸 환경에 대한 액세스
gcloud이 포함된 Cloud Shell을 사용하는 것이 좋습니다.
위 설정에 대한 자세한 내용은 환경 설정 섹션을 참고하세요.
2. 마이그레이션 프로세스 이해
샤딩된 데이터베이스를 마이그레이션하려면 여러 물리적 및 논리적 MySQL 인스턴스를 수평으로 확장 가능한 단일 Spanner 데이터베이스로 통합해야 합니다. 이 섹션에서는 마이그레이션에 사용되는 아키텍처와 주요 도구를 간략하게 설명합니다.
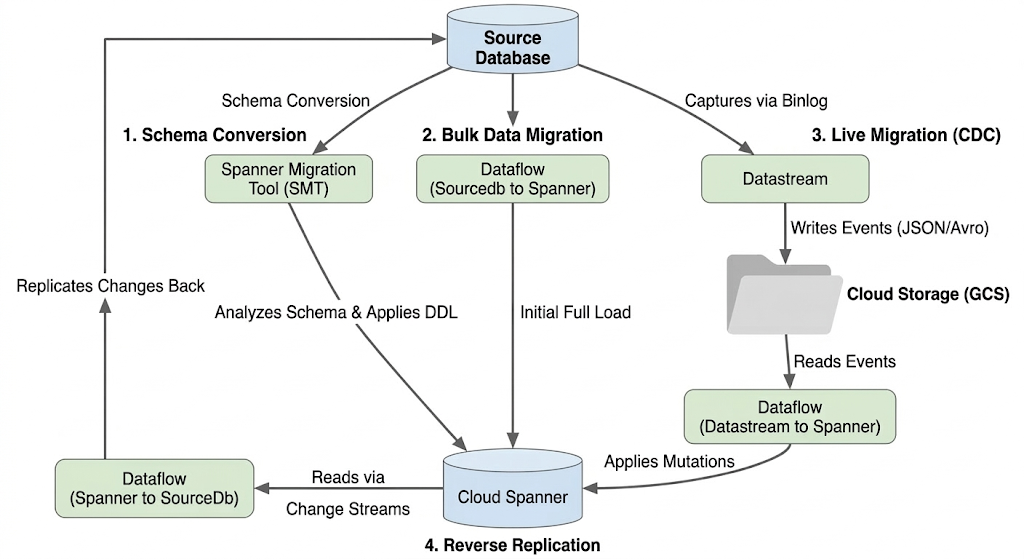
마이그레이션 흐름 아키텍처
마이그레이션 프로세스에는 다음 단계가 포함됩니다.
1. 스키마 변환:
- 목적: 소스 데이터베이스 스키마를 호환되는 Cloud Spanner 스키마로 변환합니다.
- 도구: Spanner 마이그레이션 도구 (SMT)
- 프로세스: SMT는 소스 데이터베이스 스키마를 분석하고 이에 상응하는 Spanner 데이터 정의 언어 (DDL)를 생성합니다. 타겟 Spanner 인스턴스에서 데이터베이스가 생성되고 DDL이 자동으로 적용됩니다.
2. 대량 데이터 이전:
- 목적: 소스 데이터베이스에서 프로비저닝된 Spanner 테이블로 기존 데이터를 초기 전체 로드합니다.
- 도구: Google에서 제공하는
Sourcedb to Spanner템플릿을 사용하는 Dataflow - 프로세스: 이 Dataflow 작업은 지정된 소스 테이블에서 모든 데이터를 읽어 해당 Spanner 테이블에 씁니다. 이는 Spanner 스키마가 생성된 후에 실행됩니다.
3. 라이브 마이그레이션 (CDC):
- 목적: 소스 데이터베이스의 진행 중인 변경사항을 거의 실시간으로 Cloud Spanner에 캡처하고 적용하여 마이그레이션 중 다운타임을 최소화합니다.
- 도구:
- Datastream: 소스 데이터베이스의 변경사항 (삽입, 업데이트, 삭제)을 캡처하여 Cloud Storage (GCS)에 씁니다.
- Dataflow:
Datastream to Spanner템플릿을 사용하여 GCS에서 변경 이벤트를 읽고 Cloud Spanner에 적용합니다.
4. 역방향 복제:
- 목적: Cloud Spanner에서 소스 데이터베이스로 데이터 변경사항을 복제합니다. 이는 대체 전략, 단계적 마이그레이션 또는 특정 사용 사례를 위해 소스에 복제본을 유지하는 데 유용할 수 있습니다.
- 도구:
Spanner to SourceDb템플릿을 사용하는 Dataflow - 처리: 이 작업은 Spanner 변경 내역을 활용하여 Spanner의 수정사항을 캡처하고 소스 데이터베이스 인스턴스에 다시 씁니다.
다음 다이어그램은 구성요소와 데이터 흐름을 보여줍니다.
주요 용어:
- 물리적 샤드: 데이터베이스를 호스팅하는 실제 기본 서버 또는 컴퓨팅 인스턴스입니다 (이 경우 시뮬레이션된 온프레미스 GCE VM).
- 논리적 샤드: 물리적 서버 내의 개별 데이터베이스 스키마입니다.
- Compute Engine (GCE) VM: Google Cloud 인프라에서 호스팅되는 가상 머신입니다. 이 Codelab에서는 GCE VM을 사용하여 소스 MySQL 데이터베이스를 호스팅하는 독립형 '온프레미스' 베어메탈 서버를 시뮬레이션합니다.
- Spanner 마이그레이션 도구 (SMT): MySQL 스키마를 평가하고, Spanner 스키마에 상응하는 항목을 제안하고, Spanner 데이터 정의 언어 (DDL)를 생성하는 데 사용되는 도구입니다.
- 데이터 정의 언어 (DDL):
CREATE TABLE문과 같이 데이터베이스 구조를 정의하고 수정하는 데 사용되는 문입니다. SMT는 Cloud SQL 스키마를 기반으로 Spanner DDL을 생성합니다. - Dataflow: 완전 관리형 서버리스 데이터 처리 서비스입니다. 이 Codelab에서는 일괄 데이터 전송, Datastream 변경사항 적용, 역방향 복제를 위해 Google에서 제공하는 템플릿을 실행하는 데 사용됩니다.
- Datastream: 서버리스 변경 데이터 캡처 (CDC) 및 복제 서비스입니다. 이 Codelab에서는 로컬로 호스팅된 MySQL 인스턴스의 변경사항을 Cloud Storage로 스트림하는 데 사용됩니다.
- Spanner 변경 스트림: 데이터 변경사항 (삽입, 업데이트, 삭제)을 실시간으로 스트리밍할 수 있는 Spanner 기능으로, 역방향 복제의 소스로 사용됩니다.
- Pub/Sub: 이벤트를 생성하는 서비스와 이벤트를 처리하는 서비스를 분리하는 데 사용되는 메시징 서비스입니다. 이 Codelab에서는 Datastream이 Cloud Storage에 새 변경사항 파일을 업로드할 때마다 Dataflow가 업데이트를 처리하도록 트리거합니다.
3. 환경 설정
마이그레이션을 시작하기 전에 Google Cloud 프로젝트를 설정하고 필요한 서비스를 사용 설정해야 합니다.
1. Google Cloud 프로젝트 선택 또는 만들기
이 Codelab의 서비스를 사용하려면 결제가 사용 설정된 Google Cloud 프로젝트가 필요합니다.
- Google Cloud 콘솔에서 프로젝트 선택기 페이지로 이동합니다. 프로젝트 선택기로 이동
- Google Cloud 프로젝트를 선택하거나 만듭니다.
- 프로젝트에 결제가 사용 설정되어 있는지 확인하세요. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
2. Cloud Shell 열기
Cloud Shell은 Google Cloud에서 실행되는 명령줄 환경으로, gcloud CLI 및 기타 필요한 도구가 미리 로드되어 있습니다.
- Google Cloud 콘솔의 오른쪽 상단에 있는 Cloud Shell 활성화 버튼을 클릭합니다.
- 콘솔 하단에 있는 새 프레임 내에 Cloud Shell 세션이 열리면서 명령줄 프롬프트가 표시됩니다.

3. 프로젝트 및 환경 변수 설정
Cloud Shell에서 프로젝트 ID와 사용할 리전의 환경 변수를 설정합니다.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. 필수 Google Cloud API 사용 설정
Cloud Spanner, Dataflow, Datastream 및 기타 관련 서비스에 필요한 API를 사용 설정합니다.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
이 명령어를 완료하는 데 몇 분이 걸릴 수 있습니다.
4. 소스 MySQL 데이터베이스 설정
이 섹션에서는 Compute Engine 가상 머신 두 개('물리적 샤드' 2개)를 프로비저닝하여 온프레미스 샤딩된 MySQL 아키텍처를 시뮬레이션합니다. 그런 다음 두 VM에 모두 MySQL을 설치하고 각 VM에 두 개의 데이터베이스('논리적 샤드')를 만듭니다.
1. Compute Engine VM (물리적 샤드) 만들기
Cloud Shell에서 다음 명령어를 실행하여 Ubuntu가 설치된 VM 두 개를 만듭니다. 나중에 인바운드 MySQL 트래픽을 허용하도록 네트워크 태그를 할당할 예정입니다.
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. 방화벽 규칙 구성
공개 노출 없이 보안 SSH 액세스를 허용하고 Datastream 연결을 사용 설정하려면 다음 단계를 따르세요.
IAP를 통한 SSH용 방화벽 규칙을 만듭니다.
이 규칙을 사용하면 Identity-Aware Proxy가 SSH 포트 (22)에서 VM에 도달할 수 있습니다.
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
Datastream (MySQL 포트)의 방화벽 규칙을 만듭니다.
Datastream은 표준 MySQL 포트 (3306)에서 이러한 VM에 연결할 수 있어야 합니다.
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3. 물리적 샤드 1에 MySQL 설치 및 구성
첫 번째 VM에 SSH로 연결하여 MySQL을 설치하고 바이너리 로깅을 구성합니다 (바이너리 로깅은 Datastream에서 라이브 복제에 필요함).
- 첫 번째 VM에 SSH를 통해 연결합니다.
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- MySQL을 설치합니다.
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- 바이너리 로깅을 사용 설정하고 외부 연결을 허용하도록
mysqld.cnf파일을 구성합니다.
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- MySQL을 다시 시작하여 변경사항을 적용합니다.
sudo systemctl restart mysql
4. 논리적 샤드 생성, 데이터 삽입, Datastream 사용자 생성 (샤드 1)
mysql-physical-1에 SSH로 연결된 상태에서 MySQL 프롬프트에 로그인합니다.
sudo mysql
다음 SQL 명령어를 실행합니다. 이 스크립트는 두 개의 고유한 논리적 샤드(shard0_db 및 shard1_db)를 만들고, 두 샤드 모두에 동일한 스키마를 설정하고, 각 샤드에 고유하게 식별 가능한 데이터를 삽입하여 샤딩을 보여주고, Datastream의 복제 사용자를 만듭니다.
다음 SQL 명령어를 실행하여 처음 두 개의 논리적 샤드, 테이블, Datastream의 복제 사용자를 만듭니다.
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
위 스키마의 덤프 파일은 여기에서 확인할 수 있습니다. 덤프 파일에 포함되지 않으므로 데이터 스트림 복제 사용자를 별도로 만들어야 합니다.
5. 데이터 확인
데이터가 있는지 빠르게 확인합니다.
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
예상 출력:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
exit를 입력하여 물리적 샤드 1 VM과의 연결을 종료합니다.
6. 물리적 샤드 2에 대해 반복
이제 두 번째 VM에 대해 동일한 프로세스를 반복하지만 shard2_db 및 shard3_db를 만들고 server-id를 변경합니다.
- 두 번째 VM에 SSH를 통해 연결합니다.
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- MySQL을 설치합니다.
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- 바이너리 로깅을 사용 설정하고 외부 연결을 허용하도록
mysqld.cnf파일을 구성합니다. [server-id는 달라야 합니다 (예: 2)]
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- MySQL을 다시 시작하여 변경사항을 적용합니다.
sudo systemctl restart mysql
- MySQL (
sudo mysql)을 입력하고 4단계의 SQL을 약간 수정한 버전을 실행합니다.
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
예상 출력:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
위 스키마의 덤프 파일은 여기에서 확인할 수 있습니다. 덤프 파일에 포함되지 않으므로 데이터 스트림 복제 사용자를 별도로 만들어야 합니다.
exit를 입력하여 VM과의 연결을 종료합니다.
5. Cloud Spanner 설정
이제 데이터를 이전할 대상 Cloud Spanner 인스턴스를 설정합니다.
1. Cloud Spanner 인스턴스 만들기
지연 시간을 최소화하려면 Compute Engine VM과 동일한 리전에 Cloud Spanner 인스턴스를 만드세요. 이 명령어는 처리 단위 100개를 사용하여 이 Codelab에 적합한 작은 인스턴스를 만듭니다.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
인스턴스를 만드는 데 1~2분 정도 걸릴 수 있습니다.
6. Spanner 마이그레이션 도구 (SMT)를 사용하여 스키마 변환
Spanner Migration Tool (SMT) 웹 UI를 사용하여 논리적 샤드 (shard0_db) 중 하나에 연결하고, 스키마를 분석하고, Cloud Spanner로 변환하기 전에 몇 가지 고급 수정사항을 적용합니다.
1. SMT 설치
Cloud Shell에서 직접 SMT 웹 UI를 실행합니다. Cloud Shell 터미널에서 최신 SMT 버전을 다운로드하고 추출합니다.
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
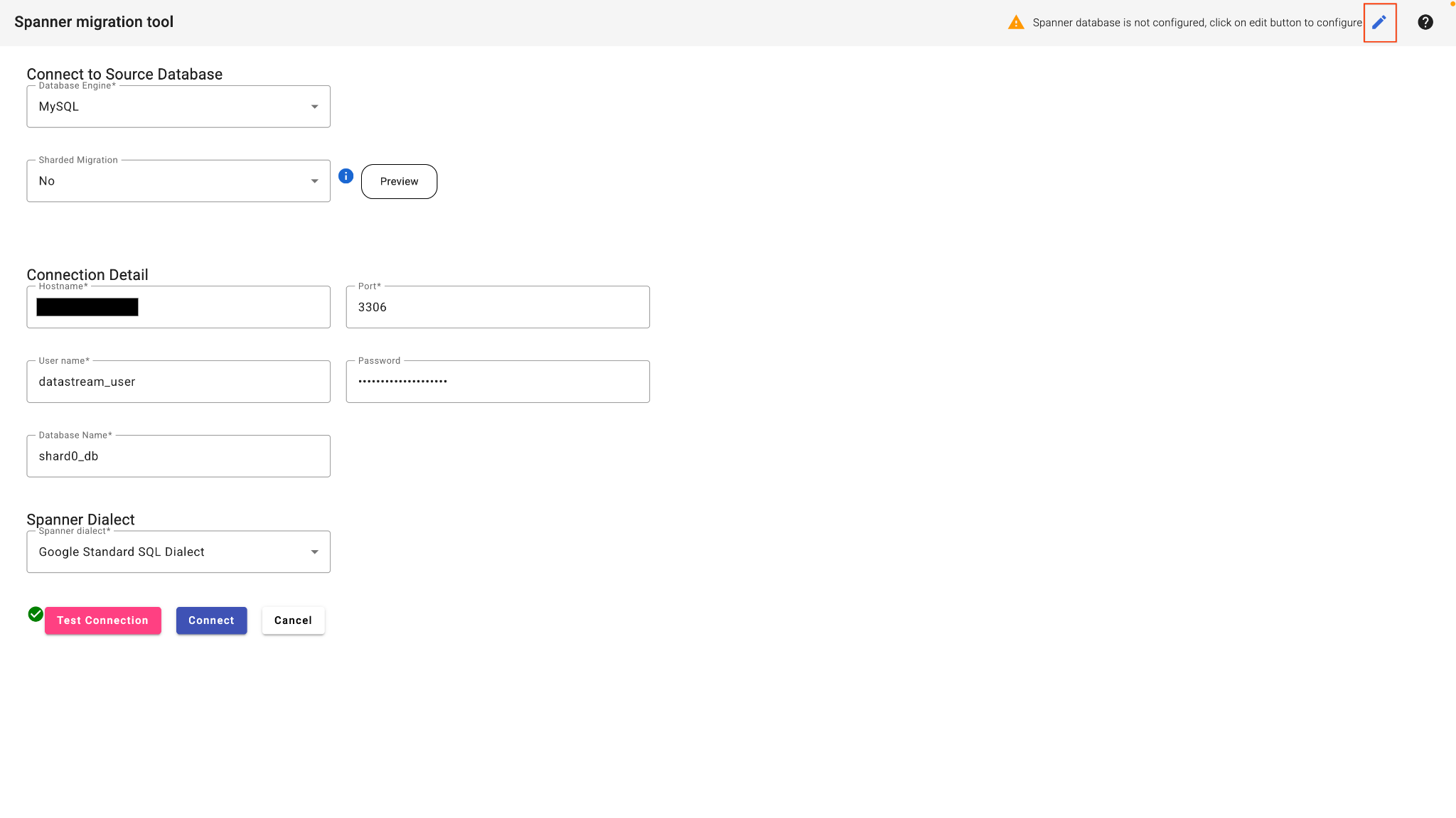
2. 소스 데이터베이스에 연결
- 세션 인증
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(참고: 메시지가 표시되면 제공된 URL을 따라 계정을 승인하고 인증 코드를 터미널에 다시 붙여넣으세요.)
- 먼저 새 Cloud Shell 탭에서 다음을 실행하여 첫 번째 실제 샤드의 외부 IP를 찾습니다.
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- SMT를 구성하는 동안 사용할 타겟 Spanner 인스턴스 세부정보를 출력합니다.
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- 웹 UI를 실행합니다.
gcloud alpha spanner migrate web --port=8080
- Cloud Shell 창 오른쪽 상단에서 웹 미리보기 아이콘 (눈 모양)을 클릭하고 포트 8080에서 미리보기를 선택합니다. 그러면 새 브라우저 탭에서 SMT UI가 열립니다.
- SMT 웹 UI에서 데이터베이스에 연결을 선택합니다.
- 연결 세부정보를 입력합니다.
- 데이터베이스 유형: MySQL
- 호스트: (2단계의 IP 주소 붙여넣기)
- 포트: 3306
- 사용자:
datastream_user - 비밀번호:
complex_password_123 - 데이터베이스 이름:
shard0_db
- 오른쪽 상단에 있는 수정 버튼을 클릭하여 Spanner 데이터베이스를 구성합니다.
- 타겟 Spanner 세부정보를 입력합니다.
- 프로젝트 ID: (3단계에서 프로젝트 ID 붙여넣기)
- Spanner 인스턴스: (3단계의 인스턴스 ID 붙여넣기)
- Test Connection(연결 테스트)을 클릭합니다.
- 이 단계를 통과하면 연결을 클릭합니다. SMT가 소스 데이터베이스를 분석하고 기준 Spanner 스키마를 표시합니다.
3. 스키마 수정사항 적용
이제 복잡한 이전 시나리오를 처리할 수 있도록 스키마를 재구성합니다.
SMT UI의 스키마 편집기에서 다음 작업을 실행합니다.
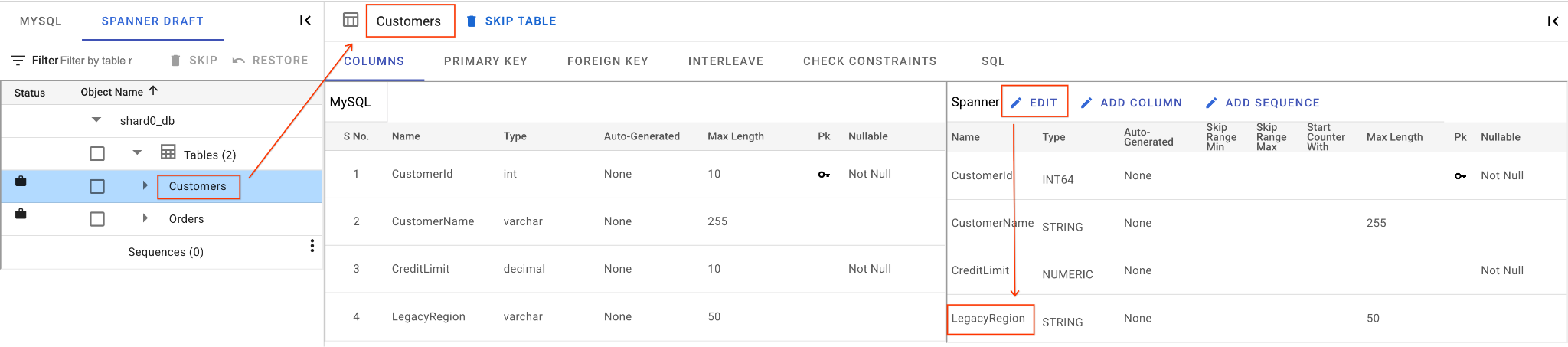
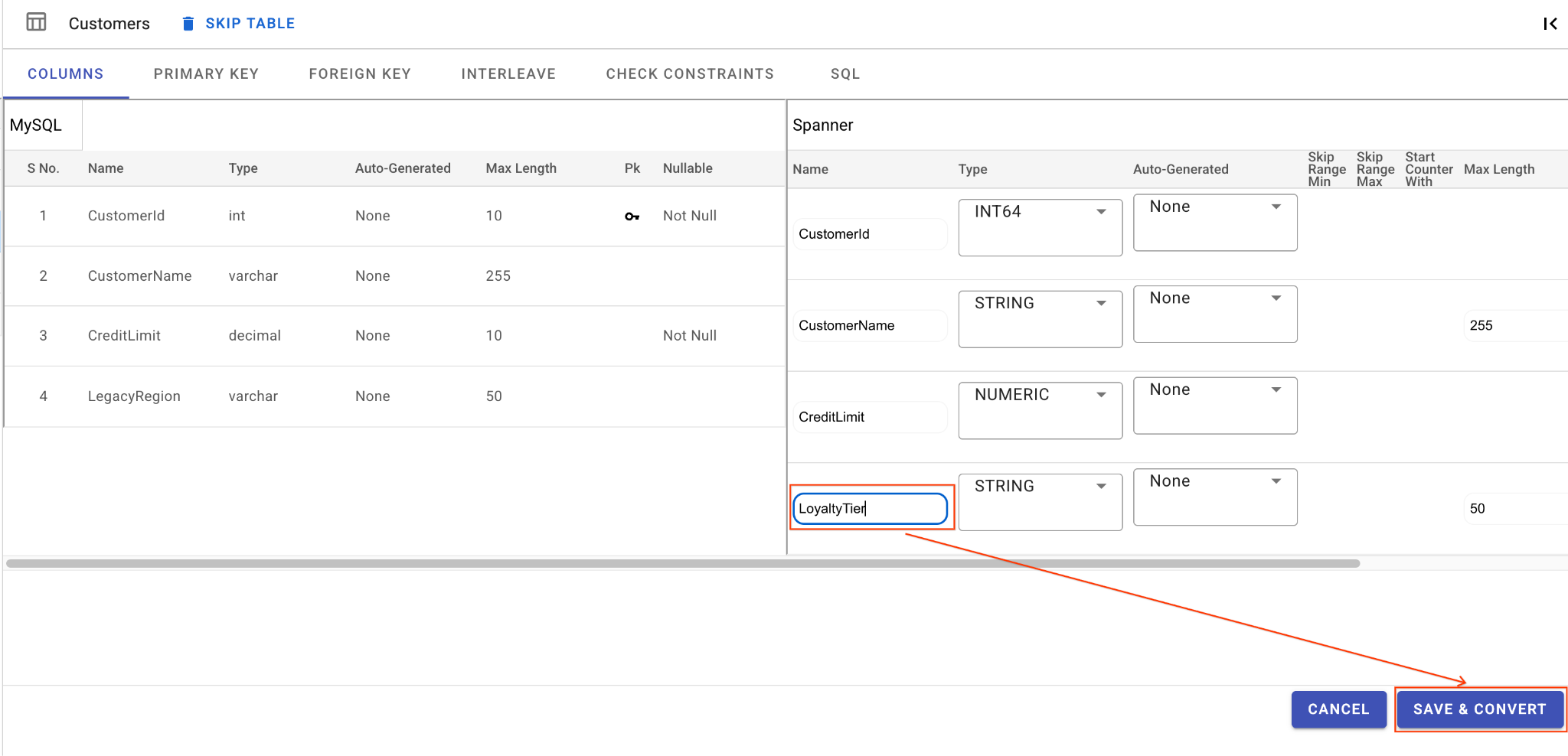
A. LegacyRegion 열의 이름을 바꿉니다.
- 왼쪽 탐색창에서
Customers표를 클릭합니다. 기본적으로 열 탭이 열립니다. - 스패너 섹션에서 수정 버튼을 클릭합니다.
- Spanner 스키마 뷰에서
LegacyRegion열을 찾습니다. - 열 이름 대화상자에 입력하여 Spanner 열 이름을
LoyaltyTier로 변경합니다. - 저장 및 변환을 클릭합니다.
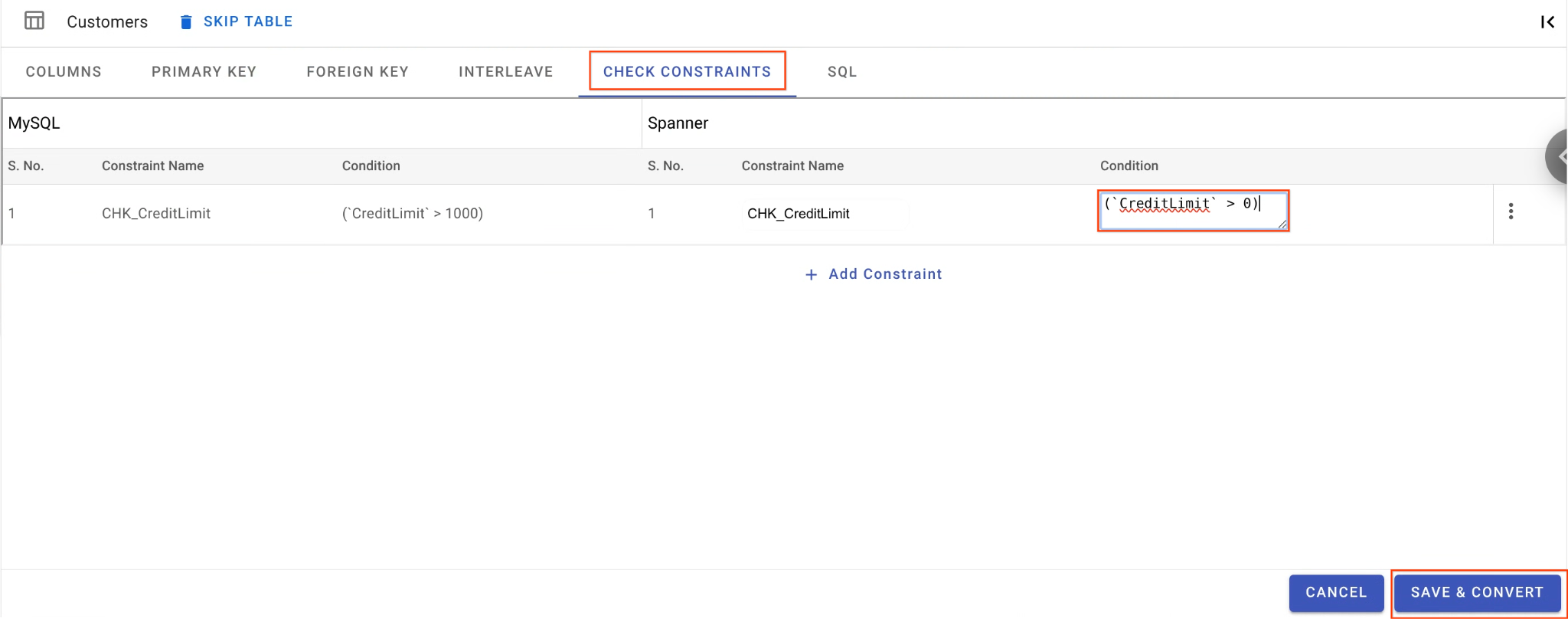
B. 확인 제약조건을 완화합니다.
Customers표에서 확인 제약 조건 탭으로 이동합니다.CHK_CreditLimit제약 조건을 찾습니다. 수정 (연필) 아이콘을 클릭합니다.- 조건을
CreditLimit > 1000에서CreditLimit > 0으로 변경합니다. (이렇게 하면 크레딧 한도가 낮은 행이 의도적으로 역방향 마이그레이션에 실패하고 DLQ로 이동합니다.)
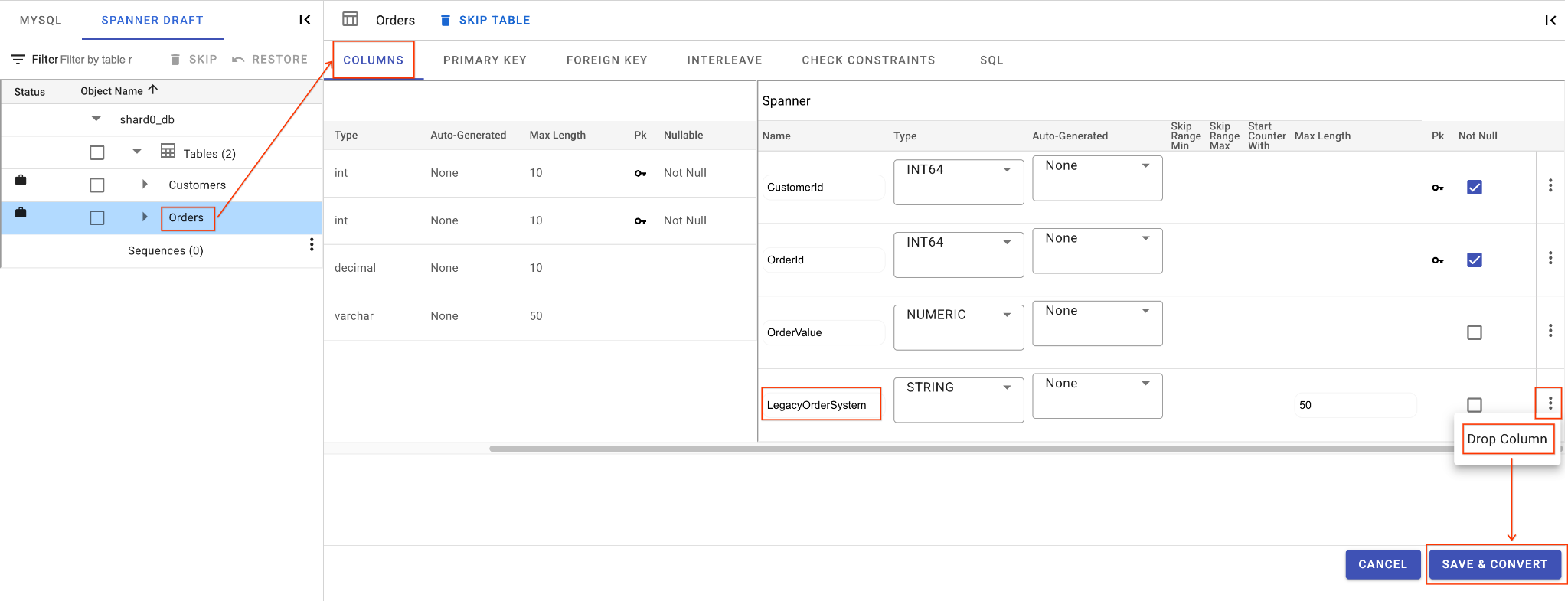
C. LegacyOrderSystem 열을 삭제합니다.
Orders표를 클릭하면 기본적으로 열 탭이 열립니다.- 스패너 섹션에서 수정 버튼을 클릭합니다.
- Spanner 스키마 뷰에서
LegacyOrderSystem열을 찾습니다. - 옆에 있는 점 3개 메뉴 아이콘을 클릭하고 열 삭제를 선택합니다.
- 저장 및 변환을 클릭합니다.
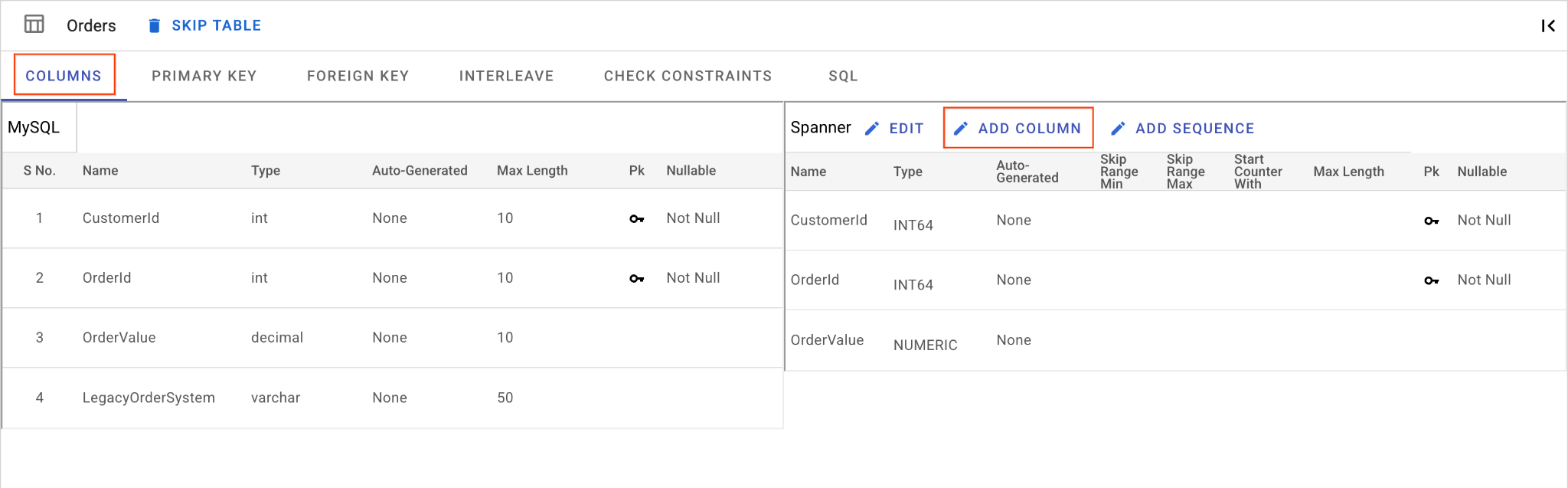
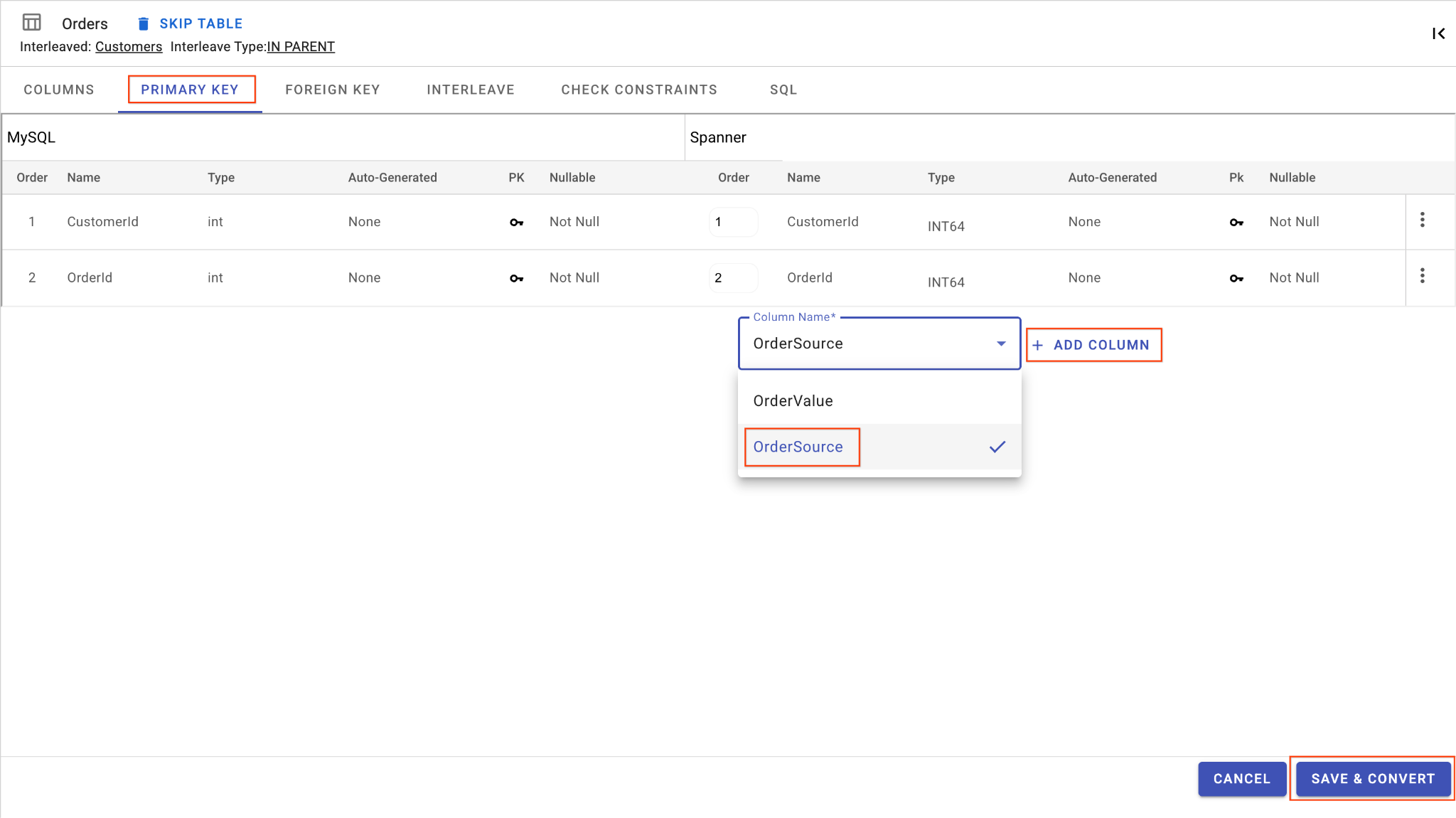
D. OrderSource 열을 추가하고 기본 키로 지정합니다.
Orders표에서 열 추가를 클릭합니다. 이름을OrderSource로 지정하고 길이는50, 자동 생성 없음, 유형은STRING로 설정하고IsNullable을No로 설정합니다.- 기본 키 탭으로 이동합니다.
- 수정을 클릭하고 열 이름 드롭다운에서
OrderSource를 선택합니다. - 열 추가를 클릭한 다음 저장 및 변환을 클릭합니다.
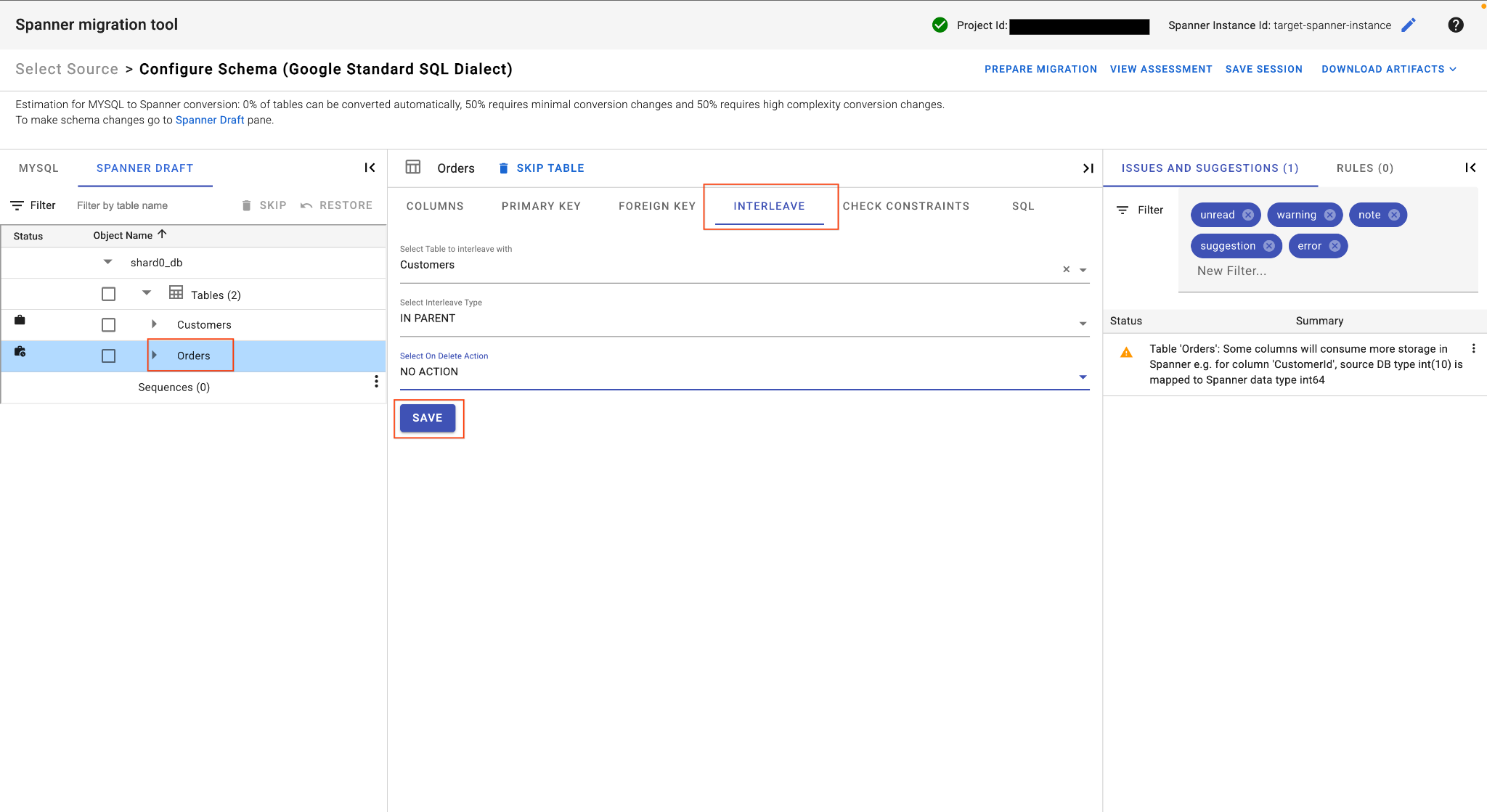
E. 주문 테이블을 인터리브 처리합니다.
Orders테이블에서 기본 테이블 뷰의 인터리브 탭을 찾습니다.- 상위 테이블을
Customers로 설정합니다. IN PARENT인터리브 유형과NO ACTION삭제 시 작업을 선택합니다.- 저장을 클릭합니다.
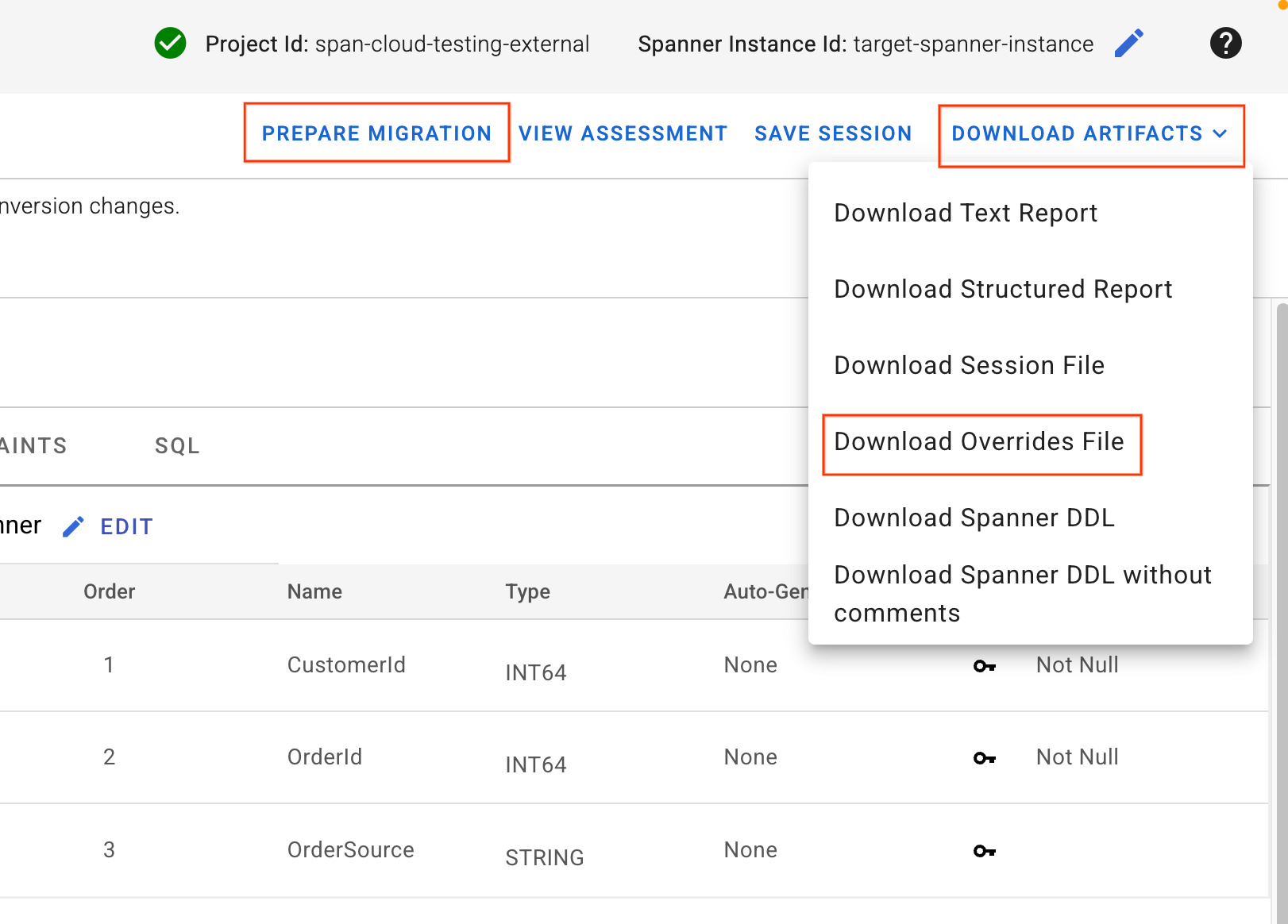
4. 재정의 파일 다운로드 및 스키마 적용
- SMT UI의 오른쪽 상단에서 Download Artifacts 버튼을 찾습니다. 재정의 파일 다운로드 옵션을 선택합니다. 이 파일을 로컬 머신에 저장합니다. 이 파일에는 방금 적용한 모든 스키마 매핑 변경사항이 포함되어 있으며 Dataflow 파이프라인에서 사용됩니다.
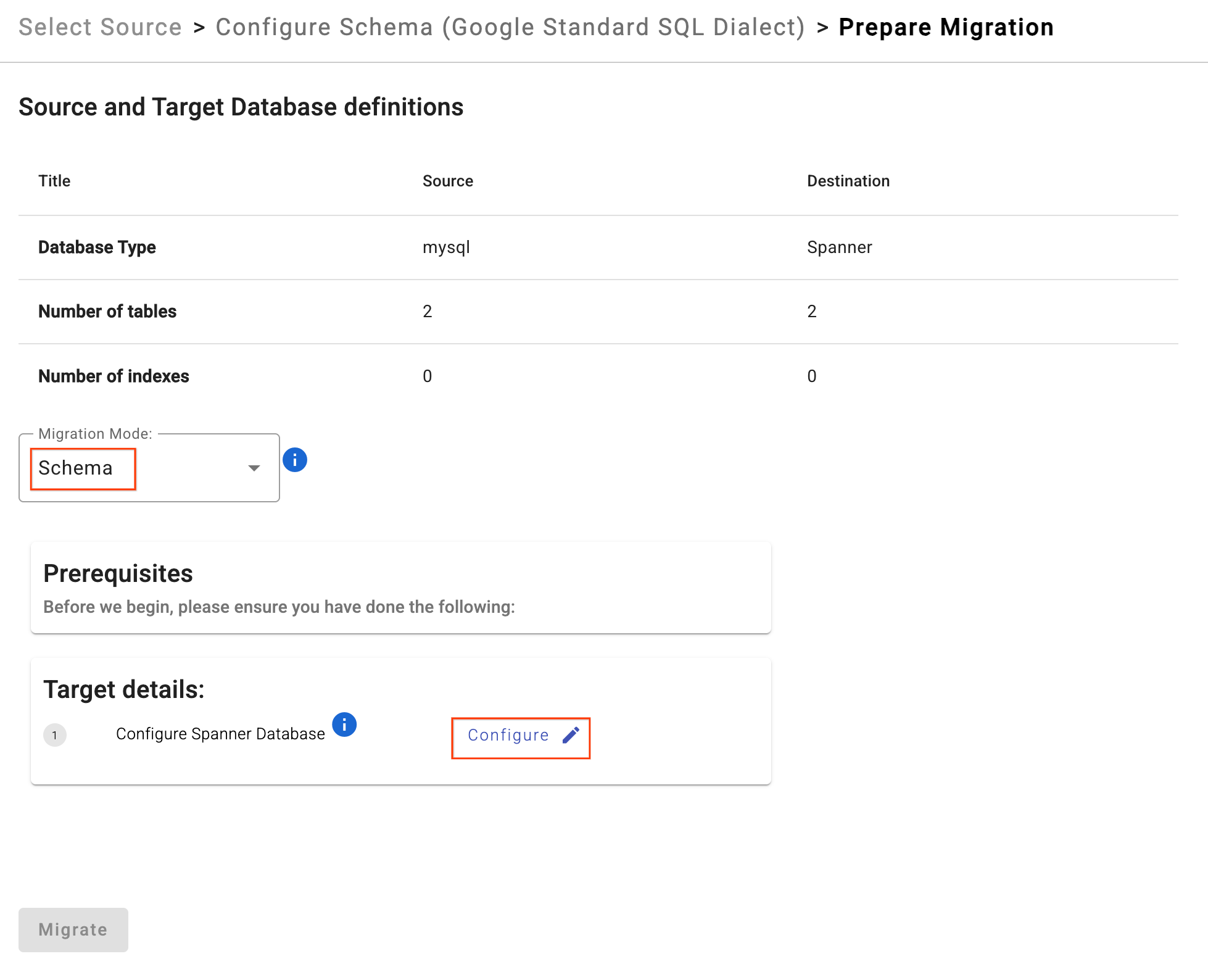
- 마이그레이션 준비를 클릭합니다.
- 드롭다운에서 마이그레이션 모드를
Schema로 선택합니다. - 대상 Spanner 데이터베이스를 입력하세요.
sharded-target-db
- 이전을 클릭합니다.
- SMT가 DDL을 적용하고 Spanner 데이터베이스를 만듭니다. SMT 프로세스가 완료되면 Cloud Shell (
Ctrl+C)에서 안전하게 중지할 수 있습니다.
5. Cloud Spanner에서 스키마 확인
Spanner 데이터베이스에 테이블이 생성되었는지 확인합니다.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
다음과 같은 출력이 표시됩니다.
table_name: Customers table_name: Orders
선택사항: 실제 Spanner DDL을 확인하여 검사 제약 조건, 인터리빙, 추가 열이 적용되었는지 확인하려면 다음 명령어를 실행합니다.
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
예상 출력:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. 변경 데이터 캡처 (CDC) 초기화
이 섹션에서는 이전의 '레코더'를 설정합니다. 일괄 데이터 로드가 시작되기 전에 Datastream과 Pub/Sub을 구성하면 소스 데이터베이스에 적용된 모든 변경사항이 캡처되고 대기열에 추가되어 전환 중에 데이터가 손실되지 않습니다. 이 설정은 라이브 마이그레이션에 필요합니다.
아키텍처에 두 개의 실제 서버가 포함되므로 Datastream 소스 프로필과 Datastream 스트림을 각각 두 개씩 만들어야 합니다. 두 스트림 모두 단일 Google Cloud Storage (GCS) 버킷에 쓰며, 이 버킷은 Dataflow 파이프라인의 통합 소스 역할을 합니다.
1. Cloud Storage 버킷 만들기
Datastream에는 캡처된 변경 이벤트를 저장할 대상이 필요합니다. GCS 버킷을 만들어 보겠습니다.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. Datastream 연결 프로필 만들기
MySQL 소스 연결 프로필 (물리적 샤드별 하나) 2개와 Cloud Storage용 대상 연결 프로필 1개가 필요합니다.
소스 IP 주소 가져오기
먼저 두 Compute Engine VM의 외부 IP 주소를 가져와 환경 변수로 저장합니다.
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
소스 연결 프로필 만들기 (Compute Engine의 MySQL)
앞서 만든 datastream_user를 사용하여 Datastream 연결 프로필을 만듭니다.
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
참고: Datastream은 공개 IP를 통해 이러한 VM에 연결되며, 이는 앞서 방화벽 규칙에 0.0.0.0/0를 추가했기 때문에 허용됩니다. 프로덕션 환경에서는 DataStream의 특정 공개 IP 범위를 엄격하게 허용 목록에 추가합니다.
대상 연결 프로필 만들기 (Cloud Storage):
새로 만든 버킷의 루트를 가리킵니다.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3. Datastream 스트림 만들기
이제 두 개의 CDC 스트림을 만듭니다. 스트림 1은 shard0_db 및 shard1_db를 캡처합니다. 스트림 2는 shard2_db 및 shard3_db을 캡처합니다. 두 스트림 모두 Avro 형식으로 동일한 GCS 버킷에 기록됩니다.
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
더 작은 파일 순환 설정 (5MB 또는 15초)을 사용하면 Codelab 중에 복제된 변경사항을 더 빠르게 확인할 수 있습니다.
이 명령은 완료하는 데 다소 시간이 걸릴 수 있습니다. 상태 확인: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION
4. Datastream 스트림 시작
두 스트림을 모두 활성화하여 변경사항 녹화를 시작합니다.
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
상태 확인: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION를 실행할 수 있습니다. 상태는 처음에 STARTING이며 잠시 후 RUNNING로 변경됩니다. 둘 다 완전히 실행될 때까지 기다린 후 라이브 마이그레이션을 시작합니다.
5. GCS 알림을 위한 Pub/Sub 설정
Datastream 스트림이 GCS 버킷에 새 파일을 기록하면 Dataflow에 즉시 알림이 전송되어야 합니다. 단일 Pub/Sub 주제로 알림을 전송하도록 GCS를 구성합니다.
Pub/Sub 주제를 만듭니다.
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
GCS 알림 만들기
data/ 접두사 (두 스트림 모두 포함) 아래에서 객체가 생성되면 주제에 알립니다.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Pub/Sub 구독 만들기
Dataflow에 권장되는 승인 기한으로 구독을 만듭니다.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. 맞춤 변환
Spanner 스키마가 MySQL 스키마와 다르므로 (SMT 웹 UI를 통해 추가 및 삭제한 열로 인해) 기본 Dataflow 마이그레이션이 실패합니다. Dataflow에는 순방향 (MySQL에서 Spanner로) 및 역방향 (Spanner에서 MySQL로) 파이프라인 중에 이러한 차이점을 매핑하는 방법에 관한 안내가 필요합니다.
또한 샤드 역방향 마이그레이션을 실행하므로 Dataflow는 역방향 복제 중에 업데이트된 Spanner 행이 속한 논리적 샤드 (shard0_db, shard1_db 등)를 알기 위한 라우팅 메커니즘이 필요합니다.
Google에서 제공하는 Spanner 맞춤 샤드 템플릿을 사용하여 맞춤 변환 JAR을 작성하여 이를 달성합니다.
1. 맞춤 샤드 템플릿 다운로드
Cloud Shell에서 Google Cloud Dataflow 템플릿 저장소를 다운로드하고 커스텀 샤드 폴더로 이동합니다.
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. 데이터 변환 로직 구성
CustomTransformationFetcher.java 파일을 수정해야 합니다.
- 정방향 마이그레이션 (
toSpannerRow): MySQL의LegacyOrderSystem열을 사용하여 새로 추가된OrderSource열을 채웁니다. - 역방향 마이그레이션 (
toSourceRow): MySQL에 필요한 삭제된LegacyOrderSystem열을 Spanner의OrderSource에서 파생하여 다시 채웁니다.
CustomTransformationFetcher.java 파일을 수정합니다. 텍스트 편집기를 수동으로 여는 대신 다음 명령어를 실행하여 템플릿 파일을 맞춤 로직으로 자동 덮어씁니다.
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3. 역 샤딩 로직 구성
Dataflow는 역방향 복제 중에 CustomShardIdFetcher.java를 사용하여 Spanner 변형을 라우팅해야 하는 위치를 결정합니다. CustomerId 기본 키와 모듈로 (%4) 로직을 사용하여 레코드를 올바른 논리적 샤드로 동적으로 라우팅합니다.
cat을 사용하여 CustomShardIdFetcher.java 파일을 수정하고 콘텐츠를 다음 코드로 완전히 바꿉니다.
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. JAR 빌드 및 업로드
이제 맞춤 Java 로직을 작성했으므로 Dataflow가 액세스할 수 있도록 JAR 파일로 컴파일하고 이전에 만든 Google Cloud Storage 버킷에 업로드해야 합니다.
Cloud Shell에서 다음 명령어를 실행합니다.
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9. MySQL에서 Spanner로 데이터 일괄 마이그레이션
Spanner 스키마가 준비되고 맞춤 변환 JAR이 빌드되었으므로 이제 MySQL 데이터베이스의 기존 데이터를 Cloud Spanner로 복사할 수 있습니다. JDBC 액세스 가능 데이터베이스에서 Spanner로 데이터를 일괄 복사하도록 설계된 Sourcedb to Spanner Dataflow Flex 템플릿을 사용합니다.
1. 스키마 재정의 파일 업로드
섹션 6에서는 SMT 웹 UI를 사용하여 Spanner 재정의 JSON 파일을 다운로드했습니다. Dataflow가 이를 사용하여 스키마 차이 (예: 이름이 바뀐 열)를 매핑할 수 있도록 이 파일을 GCS 버킷에 업로드해야 합니다.
- Cloud Shell에서 점 3개 메뉴 (더보기)를 클릭하고 업로드를 선택합니다.
- 이전에 다운로드한 재정의 JSON 파일 (예:
spanner_overrides.json)을 선택합니다. - GCS 버킷으로 이동합니다.
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. 샤딩 구성 파일 만들기 및 업로드
Dataflow는 두 개의 물리적 VM에 있는 네 개의 논리적 샤드에 모두 연결하는 방법을 알아야 합니다. 이를 위한 sharding.json 파일을 만들어 보겠습니다.
Cloud Shell에서 다음을 실행하여 구성을 생성하고 업로드합니다.
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3. 일괄 마이그레이션 Dataflow 작업 실행
Sourcedb to Spanner Flex 템플릿을 사용합니다. 맞춤 변환이 있는 샤딩된 마이그레이션이므로 재정의 파일, 샤딩 구성, 맞춤 Java JAR를 전달합니다.
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
주요 매개변수 설명:
sourceConfigURL: 생성한sharding.json파일의 경로입니다. 이렇게 하면 두 개의 실제 VM에 있는 네 개의 논리적 MySQL 샤드에 연결하는 방법을 Dataflow에 알려줍니다.schemaOverridesFilePath: SMT 웹 UI에서 다운로드한 JSON 파일의 경로입니다. 이는 삭제된LegacyRegion열과 강화된 검사 제약 조건과 같은 스키마 수정사항을 처리하는 방법을 Dataflow에 알려줍니다.transformationJarPath: 이전 섹션에서 빌드한 컴파일된 Java JAR 파일의 GCS 경로입니다. 여기에는 맞춤 변환을 실행하는 실제 코드가 포함됩니다.transformationClassName: 순방향 마이그레이션 로직 (com.custom.CustomTransformationFetcher)을 구현하는 JAR 내부 Java 클래스의 정규화된 이름입니다.outputDirectory: Dataflow가 임시 파일과 가장 중요한 데드 레터 큐 (DLQ) 파일을 쓰는 GCS 위치입니다.maxWorkers,numWorkers: Dataflow 작업의 확장/축소를 제어합니다. 이 작은 데이터 세트에서는 낮게 유지됩니다.instanceId,databaseId,projectId: 타겟 Cloud Spanner 인스턴스 및 데이터베이스를 지정합니다.
네트워크 참고: 이 작업은 공개 IP를 통해 Cloud SQL 인스턴스에 연결됩니다. 이는 이전에 인스턴스의 승인된 네트워크에 0.0.0.0/0를 추가했기 때문에 가능합니다. 이렇게 하면 외부 IP가 있는 Dataflow 작업자 VM이 데이터베이스에 도달할 수 있습니다.
4. Dataflow 작업 모니터링
Google Cloud 콘솔에서 작업 진행 상황을 추적할 수 있습니다.
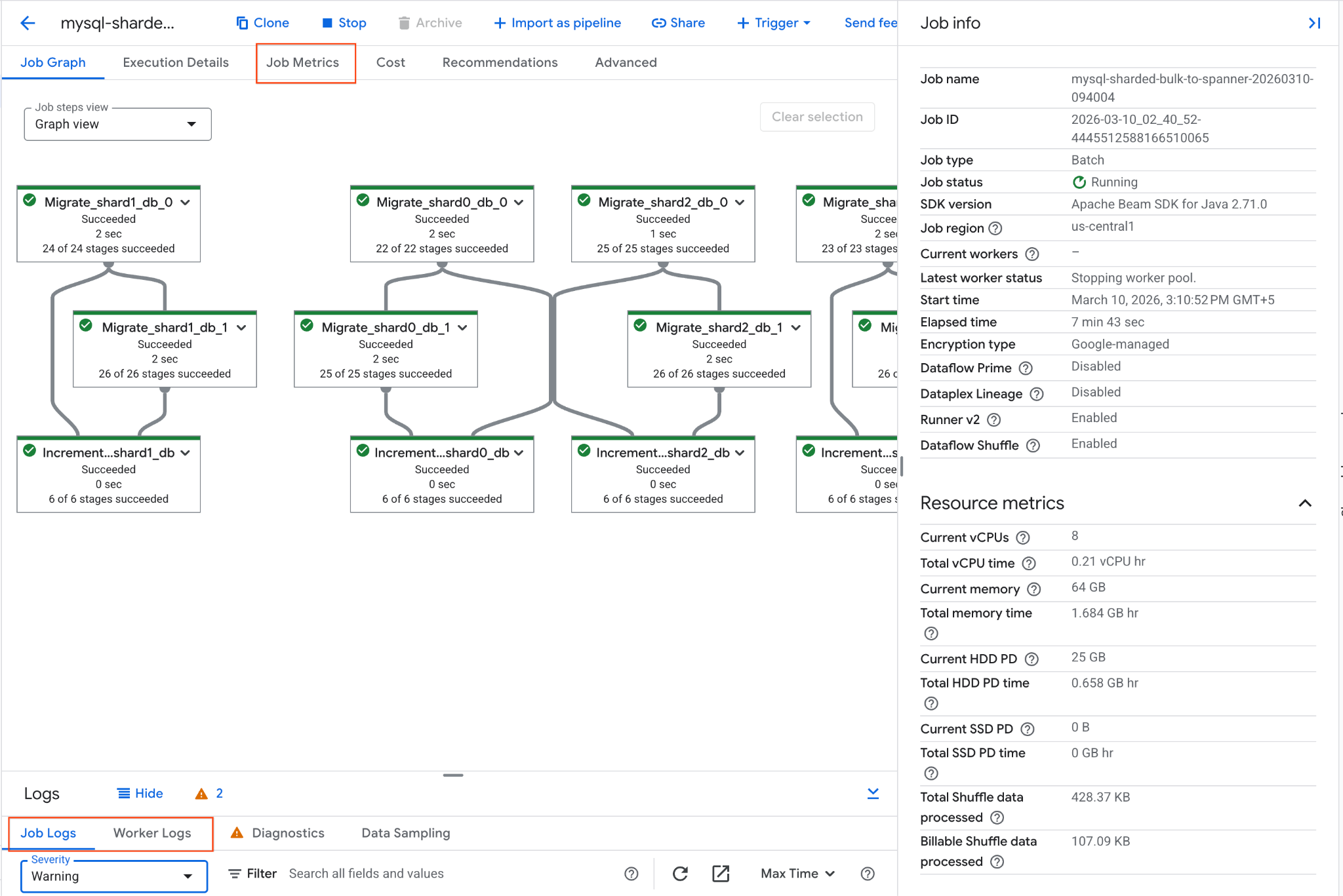
- Dataflow 작업 페이지로 이동합니다. Dataflow 작업으로 이동
mysql-sharded-bulk-to-spanner-...라는 작업을 찾아 클릭합니다.- 작업 그래프와 측정항목을 확인합니다. 작업 상태가 성공으로 바뀔 때까지 기다립니다. 약 5~15분 정도 걸립니다.
- 작업에 문제가 발생하면 Dataflow 작업 세부정보 페이지의 로그 탭에서 오류 메시지를 검토하세요.
- 작업 측정항목은 작업 진행 상황과 처리량, CPU 사용률과 같은 리소스 소비에 관한 자세한 정보를 제공합니다.
5. Cloud Spanner에서 데이터 확인 및 데드 레터 큐 (DLQ) 검사
Dataflow 작업이 성공적으로 완료되면 데이터가 안전하게 도착했는지 확인하고 의도적으로 실패하도록 설계한 레코드를 검사해야 합니다.
A. 마이그레이션된 데이터의 전반적인 상태 확인:
gcloud CLI를 사용하여 통합된 Spanner 데이터베이스에서 몇 가지 빠른 상태 점검을 실행하여 유효한 레코드가 올바르게 이전되었고 맞춤 JAR이 추가 열을 채웠는지 확인합니다.
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
예상 출력:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- Customers 테이블의 모든 행이 성공적으로 이전되었습니다.
- Spanner의
INTERLEAVE IN PARENT로 인해Orders테이블에 1개 행 실패가 표시됩니다.Customers테이블에 해당하는 행이 없으므로CustomerId 99이 고아 하위 항목입니다.
B. DLQ에서 의도적인 실패를 확인합니다.
위의 실패는 일괄 마이그레이션 파이프라인에서 생성된 데드 레터 큐 (DLQ) 폴더에 문서화되어 있습니다.
- Google Cloud 콘솔에서 Cloud Storage로 이동합니다.
- 버킷으로 이동하여
bulk-migration/dlq/severe폴더를 엽니다. - 내부의 JSON 파일을 검사합니다. 고아
CustomerId이 있는Orders행을 찾을 수 있습니다. - 여기에 설명된 단계에 따라 일괄 마이그레이션 DLQ 오류를 다시 시도할 수 있습니다.
이제 Cloud SQL에서 Cloud Spanner로의 초기 데이터 일괄 로드가 완료되었습니다. 다음 단계는 지속적인 변경사항을 포착하기 위해 실시간 복제를 설정하는 것입니다.
10. 라이브 마이그레이션 (CDC) 시작
이제 대량 데이터 로드가 완료되었으므로 연속 Dataflow 스트리밍 작업을 실행합니다. 이 작업은 Datastream이 GCS 버킷에 쓰는 변경 데이터 캡처 (CDC) 이벤트를 읽고 이러한 변경사항을 거의 실시간으로 Cloud Spanner에 적용합니다.
또한 유효한 데이터와 의도적으로 유효하지 않은 데이터를 모두 삽입하여 Dataflow가 실시간 복제를 처리하고 실패를 데드 레터 큐 (DLQ)로 라우팅하는 방식을 관찰하여 이 파이프라인을 테스트합니다.
1. 실시간 이전 샤딩 구성 파일 만들기
JDBC 연결 문자열을 사용하는 일괄 마이그레이션과 달리 라이브 마이그레이션 파이프라인은 GCS에서 Datastream 이벤트를 읽습니다. Datastream 스트림 이름과 데이터베이스를 논리적 Spanner 샤드에 매핑하는 완전히 다른 JSON 구성이 필요합니다.
Cloud Shell에서 다음을 실행하여 라이브 샤딩 구성을 만들고 업로드합니다.
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. 라이브 마이그레이션 Dataflow 작업 실행
스트리밍 Dataflow 작업을 실행하여 GCS에서 읽고 Spanner에 씁니다. 이 템플릿은 GCS Pub/Sub 알림을 사용하여 새 파일을 즉시 처리합니다.
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
주요 매개변수
gcsPubSubSubscription: GCS에서 새 파일 알림을 수신하는 Pub/Sub 구독입니다. 이렇게 하면 Datastream이 변경사항을 쓰는 즉시 작업에서 변경사항을 처리할 수 있습니다.inputFileFormat="avro": Dataflow가 Datastream에서 Avro 파일을 예상하도록 지시합니다. 이는 Datastream '대상' 구성과 일치해야 합니다 (예:avroFileFormat대jsonFileFormat).shardingContextFilePath: Datastream 스트림을 논리적 샤드에 매핑하는 JSON 파일입니다.dlqRetryMinutes: 데드 레터 큐 재시도 간격(분)입니다. 기본값은10입니다.dlqMaxRetryCount: DLQ를 통해 임시 오류를 재시도할 수 있는 최대 횟수입니다. 기본값은500입니다.
Dataflow 작업 콘솔에서 작업 시작을 모니터링합니다.
3. 실시간 데이터 삽입 및 의도적인 실패 트리거
Dataflow 스트리밍 작업이 시작되는 동안 (3~5분 소요) 첫 번째 실제 MySQL VM에 SSH로 연결하여 새 레코드를 삽입해 보겠습니다. 유효한 레코드 하나와 유효하지 않은 레코드 하나를 삽입합니다.
첫 번째 실제 샤드에 SSH로 연결합니다.
gcloud compute ssh mysql-physical-1 --zone=$ZONE
MySQL에 로그인합니다.
sudo mysql
shard1_db에서 다음 삽입을 실행합니다.
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
exit를 다시 입력하여 Cloud Shell 프롬프트로 돌아갑니다.
4. 실시간 마이그레이션 데이터 확인 및 CDC DLQ 검사
이제 데이터를 삽입했으므로 Datastream이 CDC 이벤트를 캡처하고 Dataflow가 이를 Spanner에 적용하려고 시도합니다.
A. Spanner에서 유효한 DML 변경사항 확인
다음 쿼리를 실행하여 INSERT, UPDATE, DELETE 이벤트가 Spanner에 도달했고 삽입과 업데이트 모두에서 맞춤 변환이 실행되었는지 확인합니다.
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
예상 출력:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
참고: 스트리밍 작업자가 아직 대기열을 처리 중일 수 있으므로 쿼리에서 예상한 결과가 표시되지 않으면 잠시 기다린 후 다시 시도하세요.
B. DLQ에서 의도적 실패를 확인합니다.
CustomerId = 99999에는 Customers 테이블에 상위 요소가 없으므로 Spanner에서 거부되고 Dataflow에 의해 DLQ로 안전하게 라우팅되어야 합니다.
- Google Cloud 콘솔에서 Cloud Storage로 이동합니다.
- 버킷으로 이동하여
live-migration/dlq/severe/폴더를 엽니다. - 새로 생성된 JSON 파일이 표시됩니다. 클릭하여 콘텐츠를 검사합니다.
CustomerId = 99999의 세부정보와 구체적인 Spanner 오류 메시지NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written."이 표시됩니다. runMode=retryDLQ가 설정된 Dataflow 템플릿을 실행하여 실시간 이전 DLQ 오류를 재시도할 수 있습니다.
5. DLQ 오류 처리
severe/ 디렉터리의 오류에는 수동 개입이 필요합니다. 데이터 문제를 해결하고 실패한 이벤트를 다시 처리해 보겠습니다.
A. 소스의 데이터 수정
상위 고객 기록 CustomerId = 99999이 누락되어 오류가 발생했습니다. 소스 MySQL 데이터베이스에 삽입해 보겠습니다.
MySQL 인스턴스에 다시 SSH로 연결합니다.
gcloud compute ssh mysql-physical-1 --zone=$ZONE
sudo mysql를 사용하여 MySQL에 로그인하고 누락된 상위 행을 shard1_db에 삽입합니다.
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
exit를 입력하여 Cloud Shell로 돌아갑니다.
B. retryDLQ Dataflow 작업 실행
severe/ DLQ의 이벤트를 다시 처리하려면 동일한 Dataflow 템플릿을 retryDLQ 모드로 실행합니다. 이 모드는 특히 deadLetterQueueDirectory/severe 경로에서 읽고, 맞춤 변환을 통해 다시 실행하고, Spanner에 적용합니다.
retryDLQ 모드에서 작업을 실행합니다.
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
재시도를 위한 주요 매개변수 변경사항
runMode="retryDLQ": 템플릿이severeDLQ 디렉터리에서 읽도록 지시합니다.gcsPubSubSubscription삭제: 라이브 Datastream GCS 버킷에서 읽지 않으므로 필요하지 않습니다.
재시도 프로세스 모니터링:
기본 CDC 파이프라인과 마찬가지로 retryDLQ는 수동으로 취소될 때까지 RUNNING로 유지되는 스트리밍 파이프라인입니다.
$JOB_NAME_RETRY의 Dataflow 작업 페이지로 이동합니다.- 측정항목 창에서 다음 두 카운터를 찾습니다.
elementsReconsumedFromDeadLetterQueue: 오류 파일을 가져올 때 평가됩니다.Successful events: 레코드가 Spanner에 기록될 때 증가합니다.severe/디렉터리에서 반복되는 실패를 확인합니다.- 성공한 이벤트가 재시도하려는 항목 수 (테스트 사례에서는 1)만큼 증가하면 다음 확인 단계로 이동합니다.
C. 재시도된 데이터 확인
실패한 레코드가 다시 시도된 후 (성공하는 데 시간이 걸릴 수 있음) Spanner에서 하위 행이 성공적으로 이전되었는지 확인합니다.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
이제 다음과 같은 행이 표시됩니다.
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
GCS의 $DLQ_DIR_CDC/severe/ 폴더도 확인합니다. 처리된 파일이 이동되거나 삭제되어 재처리가 완료되었음을 나타냅니다.
11. 역방향 복제 설정 (Spanner에서 MySQL로)
전환 기간 동안 롤백하거나 원본 MySQL 데이터베이스를 Spanner와 동기화해야 하는 시나리오를 처리하려면 역방향 복제를 설정하면 됩니다.
이 파이프라인은 Spanner 변경 내역을 사용하여 Spanner의 실시간 수정사항을 캡처합니다. 그런 다음 Google의 맞춤 변환 JAR을 사용하여 스키마 차이를 역매핑하고 Google의 맞춤 샤딩 JAR을 사용하여 업데이트를 다시 작성해야 하는 정확한 물리적 MySQL VM과 논리적 샤드를 계산합니다.
1. Spanner 변경 스트림 만들기
먼저 Spanner 데이터베이스에서 변경 내역을 만들어 Customers 및 Orders 테이블의 변경사항을 추적해야 합니다.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
이제 이 변경 내역은 지정된 테이블에 대한 모든 데이터 수정사항을 기록합니다.
2. Dataflow 메타데이터용 Spanner 데이터베이스 만들기
Spanner to SourceDB Dataflow 템플릿에는 변경 내역 소비를 관리하기 위한 메타데이터를 저장할 별도의 Spanner 데이터베이스가 필요합니다.
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Dataflow용 Cloud SQL 연결 구성 준비
Dataflow 템플릿에는 대상 Cloud SQL 데이터베이스의 연결 세부정보가 포함된 Cloud Storage의 JSON 파일이 필요합니다.
shard_config.json이라는 로컬 파일을 만듭니다.
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
이 파일을 GCS 버킷에 업로드합니다.
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. 역방향 복제 Dataflow 작업 실행
Spanner_to_SourceDb Flex 템플릿을 사용하여 Dataflow 작업을 실행합니다.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
주요 매개변수
changeStreamName: 읽어올 Spanner 변경 내역의 이름입니다.metadataInstance, metadataDatabase: 변경 내역 API 데이터 소비를 제어하기 위해 커넥터에서 사용되는 메타데이터를 저장하기 위한 Spanner 인스턴스/데이터베이스입니다.sourceShardsFilePath:shard_config.json의 GCS 경로입니다.filtrationMode: 기준에 따라 특정 레코드를 삭제하는 방법을 지정합니다. 기본값은forward_migration(전방 마이그레이션 파이프라인을 사용하여 작성된 레코드 필터링)입니다.shardingCustomJarPath: 이전에 빌드한 컴파일된 Java JAR 파일의 GCS 경로입니다.shardingCustomClassName: 커스텀%4모듈로 수학을 실행하여 레코드를 수신해야 하는 논리적 샤드를 동적으로 결정하는 정규화된 클래스 이름 (com.custom.CustomShardIdFetcher)입니다.
네트워크 참고: Dataflow 작업자는 shard_config.json에 지정된 공개 IP를 사용하여 Cloud SQL 인스턴스에 연결합니다. 이 연결은 Cloud SQL 인스턴스의 승인된 네트워크에 있는 0.0.0.0/0 항목으로 인해 허용됩니다.
Dataflow 작업 콘솔에서 작업 시작을 모니터링합니다.
5. Spanner 데이터 삽입 및 의도적인 실패 트리거
Dataflow 작업이 Running 상태가 될 때까지 기다립니다 (약 5분 소요). 그런 다음 의도적으로 실패를 유발하여 역방향 DLQ를 테스트하는 것과 함께 Spanner에 직접 전체 쿼리 모음 (INSERT, UPDATE, DELETE)을 실행합니다.
Cloud Shell에서 다음 명령어를 실행해 보세요.
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. 역방향 복제 데이터 확인 및 DLQ 검사
맞춤 샤딩 JAR이 첫 번째 실제 VM에서 CustomerId 88를 shard0_db로 성공적으로 라우팅하고 맞춤 변환 JAR이 리전에서 "_TIER"를 성공적으로 삭제했는지 확인해 보겠습니다.
A. MySQL에서 유효한 레코드를 확인합니다.
첫 번째 실제 샤드에 SSH로 연결합니다.
gcloud compute ssh mysql-physical-1 --zone=$ZONE
MySQL에 로그인하고 shard0_db를 쿼리합니다.
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
Cloud SQL의 예상 출력은 Spanner에서 변경된 사항을 반영해야 합니다.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
유형
exit
Cloud Shell로 돌아갑니다.
이를 통해 역방향 복제 파이프라인이 작동하여 Spanner의 변경사항을 Cloud SQL로 다시 동기화하는지 확인할 수 있습니다.
B. DLQ에서 의도적 실패 확인
새 Customers 레코드의 CreditLimit이 500 (소스 MySQL 데이터베이스에 정의된 엄격한 > 1000 검사 제약 조건을 위반)이므로 Dataflow에서 오류를 안전하게 포착했습니다.
- Google Cloud 콘솔에서 Cloud Storage로 이동합니다.
- 버킷으로 이동하여
dlq/severe/폴더를 엽니다. - JSON 파일을 열어 거부된
Customers레코드와 정확한 검사 제약 조건 위반 오류를 확인합니다. runMode=retryDLQ가 설정된 데이터 흐름 템플릿을 실행하여 역방향 복제 DLQ 오류를 재시도할 수 있습니다.
12. 리소스 정리
Google Cloud 계정에 추가 비용이 청구되지 않도록 하려면 이 Codelab 중에 생성된 리소스를 삭제합니다.
환경 변수 설정 (필요한 경우)
Cloud Shell 세션이 타임아웃되었거나 새 터미널을 연 경우 정리 명령어를 실행하기 전에 환경 변수를 다시 내보내야 합니다.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
Dataflow 스트리밍 작업 중지
작업을 나열하여 실행 중인 Dataflow 작업의 작업 ID를 찾습니다. JOB_ID_CDC 및 JOB_ID_REVERSE을 적절하게 내보냅니다.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Datastream to Spanner (라이브 마이그레이션) 작업과 재시도 작업을 취소합니다.
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
Spanner to Cloud SQL (역방향 복제) 작업을 취소합니다.
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
데이터 스트림 리소스 삭제
스트림 중지 및 삭제:
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
소스 MySQL VM (Compute Engine) 삭제
온프레미스 MySQL 물리적 샤드를 시뮬레이션한 두 개의 Compute Engine 인스턴스를 삭제합니다.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
방화벽 규칙 삭제
VM에 대한 SSH 액세스 및 Datastream 연결을 허용하기 위해 생성된 네트워크 방화벽 규칙을 삭제합니다. (참고: Codelab 앞부분에서 방화벽 규칙에 다른 이름을 사용한 경우 여기에서 조정하세요).
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
Pub/Sub 리소스 삭제
구독 삭제:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
주제 삭제:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Cloud Spanner 인스턴스 삭제
Cloud Spanner 인스턴스를 삭제합니다. 그러면 인스턴스 내의 sharded-target-db 및 migration-metadata-db 데이터베이스가 모두 자동으로 삭제됩니다.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
GCS 버킷 및 콘텐츠 삭제
마지막으로 Datastream 파일, Dataflow 구성, 데드 레터 대기열을 보유한 Cloud Storage 버킷을 삭제합니다. rm -r 명령어는 버킷과 모든 콘텐츠를 재귀적으로 삭제합니다.
gcloud storage rm --recursive gs://${BUCKET_NAME}
로컬 Cloud Shell 파일 삭제
이 Codelab 중에 Cloud Shell에서 생성된 로컬 파일과 디렉터리를 정리하려면 다음 명령어를 실행하세요.
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates