
1. Antes de começar
Neste codelab, você vai migrar um banco de dados MySQL no local fragmentado para um banco de dados do Cloud Spanner com o dialeto GoogleSQL. Você vai usar os serviços do Google Cloud, incluindo a ferramenta de migração do Spanner (SMT), o Dataflow, o Datastream, o Pub/Sub e o Google Cloud Storage.
Você vai saber:
- O que é um ambiente fragmentado e como configurá-lo.
- Como usar a interface da Web da ferramenta de migração do Spanner (SMT, na sigla em inglês) para converter um esquema do MySQL em um esquema compatível com o Spanner e fazer modificações avançadas no esquema.
- Como realizar a migração de dados em massa de uma instância fragmentada do MySQL para o Cloud Spanner usando o Dataflow.
- Como configurar a replicação contínua (CDC) de uma instância fragmentada do MySQL para o Cloud Spanner usando o Datastream e o Dataflow.
- Como configurar a replicação inversa do Spanner de volta para as instâncias fragmentadas do MySQL.
- Como usar transformações personalizadas para preencher colunas extras durante migrações em massa, em tempo real e inversas.
- Como configurar transformações de fragmentação usando chaves primárias.
O que este codelab NÃO aborda:
- Rede personalizada avançada.
- Criar modelos personalizados do Dataflow do zero.
- Ajuste de desempenho da migração.
- Migração de aplicativos:este codelab se concentra na camada de banco de dados (esquema e dados). Ele não aborda o processo operacional de reimplantação ou migração dos serviços de aplicativos.
O que é necessário
- Ter um projeto do Google Cloud com o faturamento ativado.
- Permissões do IAM suficientes para ativar APIs e criar/gerenciar recursos do Spanner, Dataflow, Datastream e GCS. Embora a função
Ownerdo projeto seja mais simples para um codelab, funções mais específicas serão abordadas na "Configuração do ambiente". - Vamos provisionar uma pequena VM do Compute Engine durante a fase de configuração para simular nosso servidor local. Verifique se a cota do projeto permite a criação de VMs.
- Um navegador da Web, como o Google Chrome.
- Familiaridade básica com o console do Google Cloud e ferramentas de linha de comando, como
gcloud. - Acesso a um ambiente shell. Recomendamos o Cloud Shell, porque ele inclui o
gcloud.
Mais detalhes sobre a configuração acima são abordados na seção Configuração do ambiente.
2. Entender o processo de migração
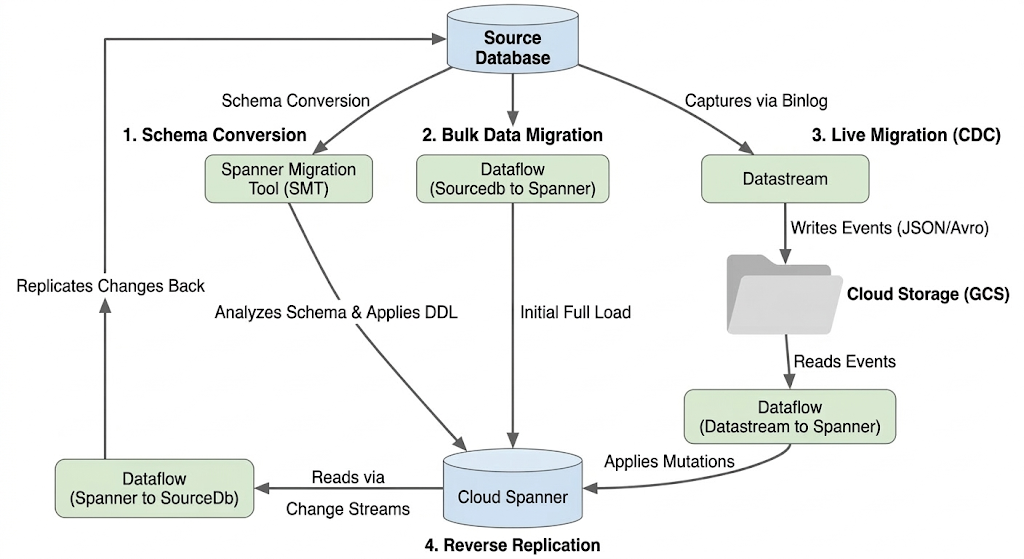
A migração de um banco de dados fragmentado envolve a consolidação de várias instâncias físicas e lógicas do MySQL em um único banco de dados do Spanner escalonável horizontalmente. Esta seção descreve a arquitetura e as principais ferramentas usadas na migração.
Arquitetura do fluxo de migração
O processo de migração envolve estas etapas:
1. Conversão de esquema:
- Finalidade:converter o esquema do banco de dados de origem em um esquema compatível do Cloud Spanner.
- Ferramenta:ferramenta de migração do Spanner (SMT, na sigla em inglês)
- Processo:o SMT analisa o esquema do banco de dados de origem e gera a Linguagem de definição de dados (DDL) equivalente do Spanner. Na instância de destino do Spanner, um banco de dados é criado e a DDL é aplicada automaticamente.
2. Migração de dados em massa:
- Finalidade:realizar uma carga inicial e completa dos dados atuais do banco de dados de origem para as tabelas provisionadas do Spanner.
- Ferramenta:Dataflow, usando o modelo
Sourcedb to Spannerfornecido pelo Google. - Processo:esse job do Dataflow lê todos os dados das tabelas de origem especificadas e os grava nas tabelas correspondentes do Spanner. Isso é feito depois que o esquema do Spanner é criado.
3. Migração em tempo real (CDC):
- Objetivo:capturar e aplicar mudanças contínuas do banco de dados de origem ao Cloud Spanner quase em tempo real, minimizando o tempo de inatividade durante a migração.
- Ferramentas:
- Datastream:captura mudanças (inserções, atualizações, exclusões) do banco de dados de origem e as grava no Cloud Storage (GCS).
- Dataflow:usa o modelo
Datastream to Spannerpara ler os eventos de mudança do GCS e aplicá-los ao Cloud Spanner.
4. Replicação reversa:
- Finalidade:replicar as mudanças de dados do Cloud Spanner de volta para o banco de dados de origem. Isso pode ser útil para estratégias de substituição, migrações graduais ou manutenção de uma réplica na origem para casos de uso específicos.
- Ferramenta:Dataflow, usando o modelo
Spanner to SourceDb. - Processo:esse job usa fluxos de alterações do Spanner para capturar modificações no Spanner e gravá-las de volta na instância do banco de dados de origem.
O diagrama a seguir ilustra os componentes e o fluxo de dados:
Terminologia importante:
- Fragmento físico:o servidor ou a instância de computação real que hospeda o banco de dados (no nosso caso, a VM do GCE local simulada).
- Fragmento lógico:o esquema de banco de dados individual em um servidor físico.
- VM do Compute Engine (GCE):uma máquina virtual hospedada na infraestrutura em nuvem do Google. Neste codelab, usamos uma VM do GCE para simular um servidor bare metal independente "local" que hospeda nosso banco de dados MySQL de origem.
- Ferramenta de migração do Spanner (SMT):uma ferramenta usada para avaliar esquemas do MySQL, sugerir equivalentes de esquema do Spanner e gerar a linguagem de definição de dados (DDL) do Spanner.
- Linguagem de definição de dados (DDL): instruções usadas para definir e modificar a estrutura do banco de dados, como instruções
CREATE TABLE. O SMT gera DDL do Spanner com base no esquema do Cloud SQL. - Dataflow:um serviço de processamento de dados sem servidor totalmente gerenciado. Neste codelab, ele é usado para executar modelos fornecidos pelo Google para transferência de dados em massa, aplicar mudanças do Datastream e fazer replicação inversa.
- Datastream:um serviço de replicação e captura de dados alterados (CDC) sem servidor. Ele é usado para transmitir mudanças da instância do MySQL hospedada localmente para o Cloud Storage neste codelab.
- Fluxos de alterações do Spanner:um recurso do Spanner que permite transmitir alterações nos dados (inserções, atualizações, exclusões) em tempo real, usado como a origem da replicação inversa.
- Pub/Sub:um serviço de mensagens usado para separar serviços que produzem eventos daqueles que os processam. Neste codelab, ele aciona o Dataflow para processar atualizações sempre que o Datastream faz upload de novos arquivos de mudança para o Cloud Storage.
3. Configuração do ambiente
Antes de iniciar a migração, configure seu projeto na nuvem do Google Cloud e ative os serviços necessários.
1. Selecionar ou criar um projeto do Google Cloud
Você precisa de um projeto do Google Cloud com o faturamento ativado para usar os serviços neste codelab.
- No console do Google Cloud, acesse a página do seletor de projetos: Acessar o seletor de projetos
- Selecione ou crie um projeto do Google Cloud.
- Verifique se o faturamento foi ativado para o projeto. Saiba como confirmar se o faturamento está ativado para o projeto.
2. Abrir o Cloud Shell
O Cloud Shell é um ambiente de linha de comando em execução no Google Cloud que vem pré-carregado com a CLI gcloud e outras ferramentas necessárias.
- Clique no botão Ativar Cloud Shell no canto superior direito do console do Google Cloud.
- Uma sessão do Cloud Shell é aberta em um novo frame na parte inferior do console e um prompt de linha de comando é exibido.

3. Definir variáveis de ambiente e do projeto
No Cloud Shell, configure algumas variáveis de ambiente para o ID do projeto e a região que você vai usar.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Ativar as APIs obrigatórias do Cloud
Ative as APIs necessárias para o Cloud Spanner, o Dataflow, o Datastream e outros serviços relacionados.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Isso pode demorar alguns minutos.
4. Configurar o banco de dados MySQL de origem
Nesta seção, vamos simular uma arquitetura do MySQL fragmentada no local provisionando duas máquinas virtuais do Compute Engine (nossos dois "fragmentos físicos"). Em seguida, vamos instalar o MySQL nas duas e criar dois bancos de dados (nossos "fragmentos lógicos") em cada VM.
1. Criar as VMs do Compute Engine (fragmentos físicos)
Execute os comandos a seguir no Cloud Shell para criar duas VMs com Ubuntu. Vamos atribuir tags de rede a elas para permitir o tráfego de entrada do MySQL mais tarde.
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. Configurar regras de firewall
Para permitir o acesso SSH seguro sem exposição pública e ativar a conectividade do Datastream:
Crie uma regra de firewall para SSH via IAP:
Essa regra permite que o Identity-Aware Proxy alcance suas VMs na porta SSH (22).
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
Criar regra de firewall para o Datastream (porta do MySQL):
O Datastream precisa conseguir acessar essas VMs na porta padrão do MySQL (3306).
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3. Instalar e configurar o MySQL no fragmento físico 1
Faça login SSH na primeira VM para instalar o MySQL e configurar a geração de registros binários, que é necessária para a replicação ativa do Datastream.
- Conecte-se por SSH à primeira VM:
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- Instale o MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- Configure o arquivo
mysqld.cnfpara ativar a geração de registros binários e permitir conexões externas:
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Reinicie o MySQL para aplicar as mudanças:
sudo systemctl restart mysql
4. Criar fragmentos lógicos, inserir dados e criar usuário do Datastream (fragmento 1)
Ainda com SSH em mysql-physical-1, faça login no prompt do MySQL:
sudo mysql
Execute os comandos SQL a seguir. Esse script cria dois shards lógicos distintos (shard0_db e shard1_db), configura o esquema idêntico em ambos, insere dados claramente identificados em cada um (para demonstrar o sharding) e cria o usuário de replicação para o Datastream.
Execute os seguintes comandos SQL para criar os dois primeiros fragmentos lógicos, uma tabela e o usuário de replicação do Datastream:
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
O arquivo dump do esquema acima pode ser encontrado aqui. É importante criar o usuário de replicação do Datastream separadamente, já que ele não está incluído no arquivo dump.
5. Verificar dados
Verifique rapidamente se os dados estão presentes:
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
Saída esperada:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
Digite exit para sair da conexão com a VM do fragmento físico 1.
6. Repita para o fragmento físico 2.
Agora, repita o mesmo processo para a segunda VM, mas crie shard2_db e shard3_db e mude o server-id.
- Conecte-se por SSH à segunda VM:
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- Instale o MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- Configure o arquivo
mysqld.cnfpara ativar o registro binário e permitir conexões externas.O server-id precisa ser diferente (por exemplo, 2).
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Reinicie o MySQL para aplicar as mudanças:
sudo systemctl restart mysql
- Insira MySQL (
sudo mysql) e execute uma versão ligeiramente modificada do SQL da etapa 4:
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
Saída esperada:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
O arquivo dump do esquema acima pode ser encontrado aqui. É importante criar o usuário de replicação do Datastream separadamente, já que ele não está incluído no arquivo dump.
Digite exit para sair da conexão com a VM.
5. Configurar o Cloud Spanner
Agora, configure a instância de destino do Cloud Spanner em que os dados serão migrados.
1. Criar uma instância do Cloud Spanner
Crie uma instância do Cloud Spanner na mesma região das VMs do Compute Engine para minimizar a latência. Esse comando cria uma pequena instância adequada para este codelab, usando 100 unidades de processamento.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
A criação da instância pode levar alguns minutos.
6. Converter o esquema usando a ferramenta de migração do Spanner (SMT)
Use a interface da Web da Ferramenta de migração do Spanner (SMT) para se conectar a um dos nossos fragmentos lógicos (shard0_db), analisar o esquema e aplicar várias modificações avançadas antes de convertê-lo para o Cloud Spanner.
1. Instalar SMT
Vamos executar a interface da Web do SMT diretamente no Cloud Shell. No terminal do Cloud Shell, faça o download e extraia a versão mais recente do SMT:
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
2. Conectar-se ao banco de dados de origem
- Autenticar sua sessão
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
Observação: quando solicitado, siga o URL fornecido para autorizar sua conta e cole o código de verificação de volta no terminal.
- Primeiro, encontre o IP externo do primeiro fragmento físico executando este comando em uma nova guia do Cloud Shell:
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- Imprime os detalhes da instância de destino do Spanner a serem usados ao configurar a SMT.
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- Inicie a interface da Web:
gcloud alpha spanner migrate web --port=8080
- No canto superior direito da janela do Cloud Shell, clique no ícone Visualização da Web (parece um olho) e selecione Visualizar na porta 8080. Isso vai abrir a interface do SMT em uma nova guia do navegador.
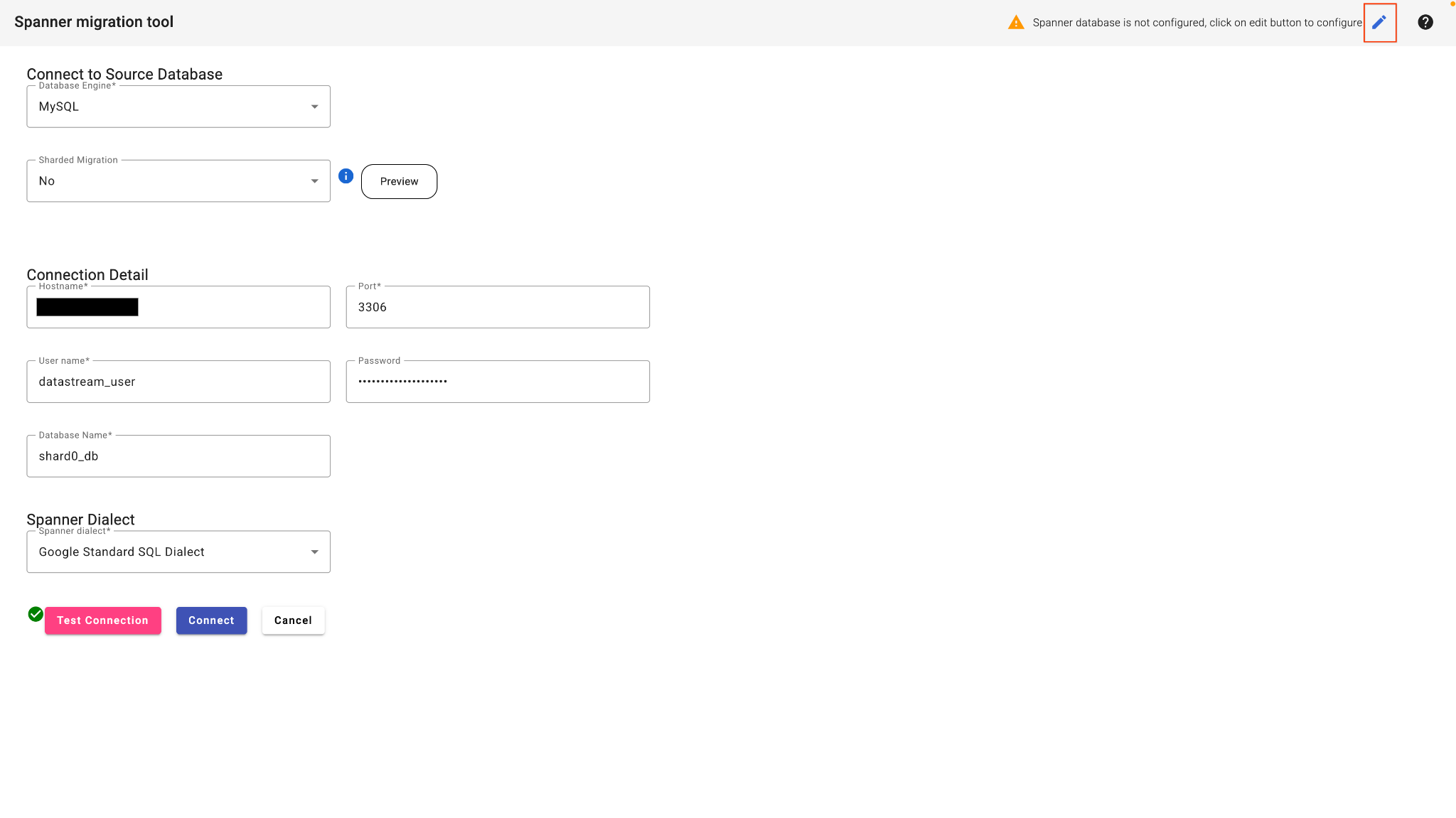
- Na interface da Web do SMT, selecione Conectar ao banco de dados.
- Preencha os detalhes da conexão:
- Tipo de banco de dados:MySQL
- Host : (cole o endereço IP da etapa 2)
- Porta:3306
- Usuário:
datastream_user - Senha:
complex_password_123 - Nome do banco de dados :
shard0_db
- Clique no botão de edição no canto superior direito para configurar o banco de dados do Spanner.
- Insira os detalhes do Spanner de destino:
- ID do projeto : (cole o ID do projeto da etapa 3)
- Instância do Spanner : (cole o ID da instância da etapa 3)
- Clique em Testar conexão.
- Quando isso acontecer, clique em Conectar. O SMT vai analisar o banco de dados de origem e apresentar um esquema básico do Spanner.
3. Aplicar modificações de esquema
Agora vamos remodelar o esquema para abranger nossos cenários de migração complexos.
No editor de esquema da interface do SMT, faça o seguinte:
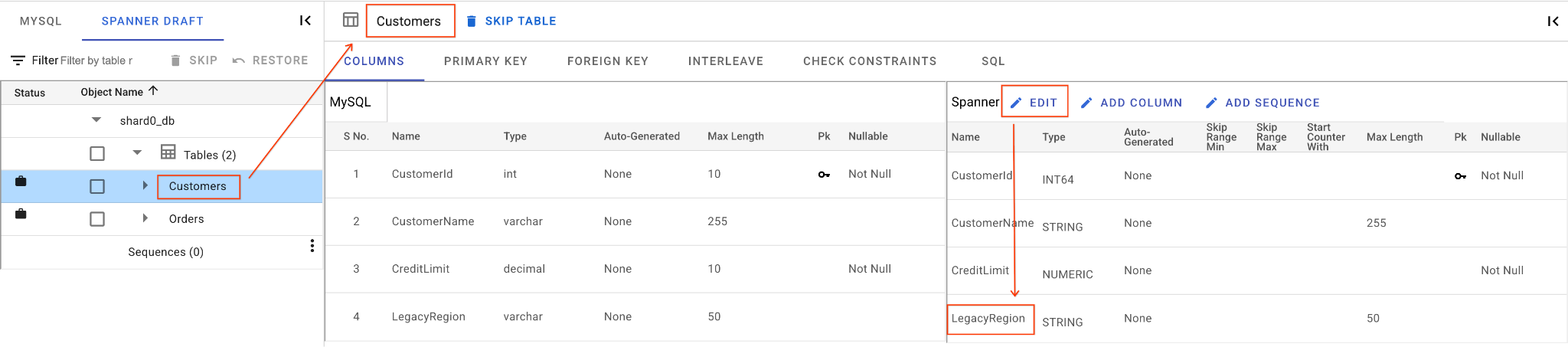
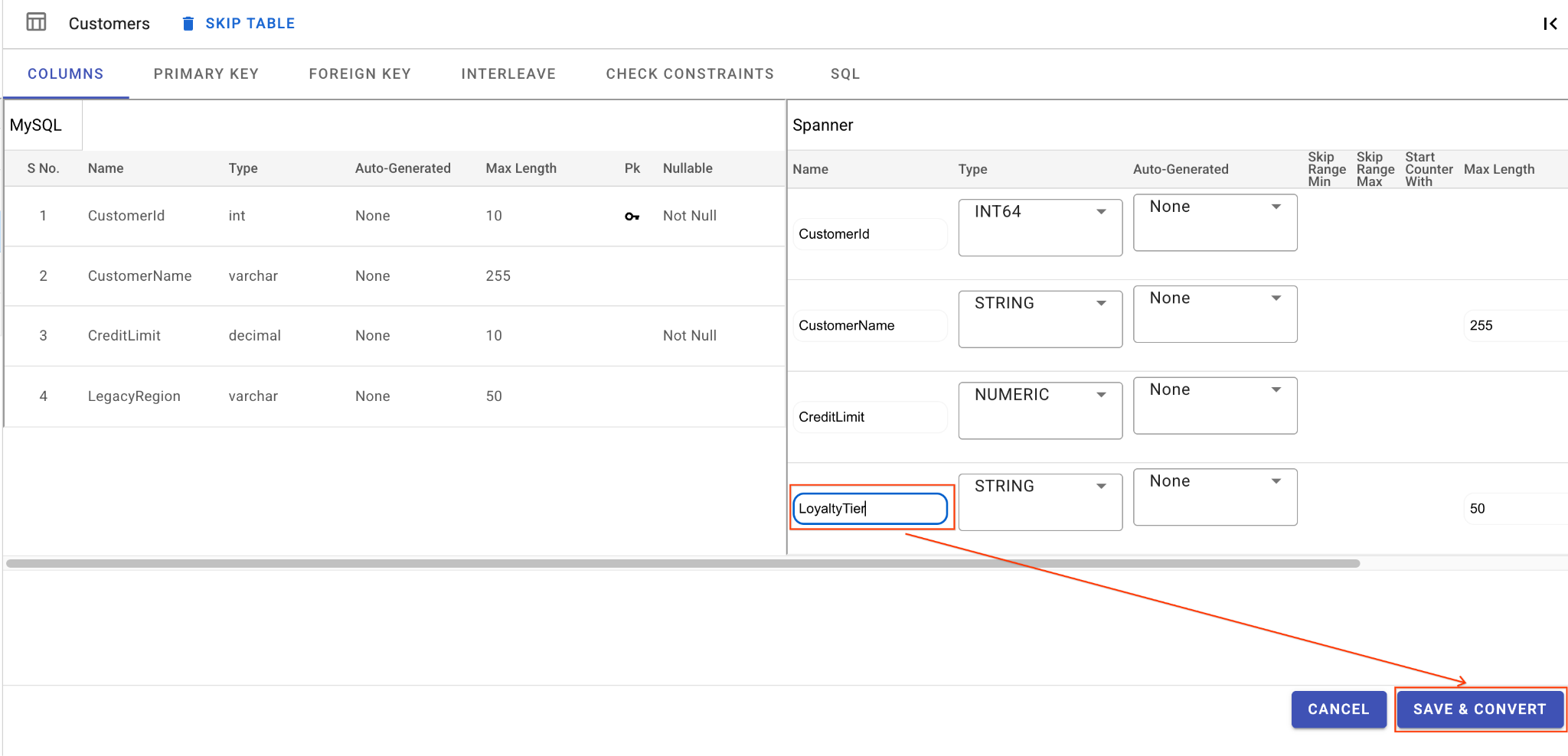
A. Renomeie a coluna "LegacyRegion":
- Clique na tabela
Customersno painel de navegação à esquerda. A guia Colunas será aberta por padrão. - Clique no botão "Editar" na seção "Spanner".
- Localize a coluna
LegacyRegionna visualização do esquema do Spanner. - Mude o nome da coluna do Spanner para
LoyaltyTierdigitando na caixa de diálogo de nome da coluna. - Clique em Salvar e converter.
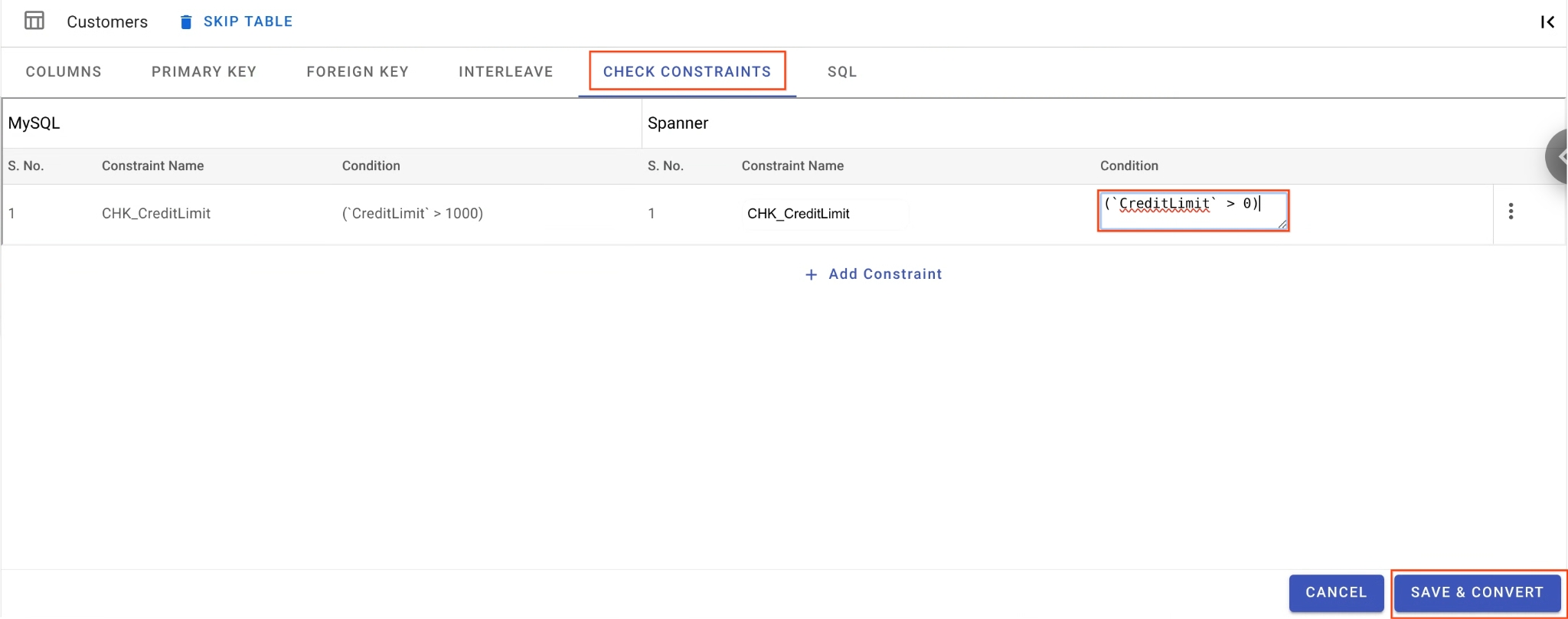
B. Reduza a restrição de verificação:
- Ainda na tabela
Customers, acesse a guia Verificar restrições. - Encontre a restrição
CHK_CreditLimit. Clique no ícone Editar (lápis). - Mude a condição de
CreditLimit > 1000paraCreditLimit > 0. Isso vai fazer com que as linhas com limites de crédito mais baixos falhem na migração reversa e sejam descartadas na DLQ.
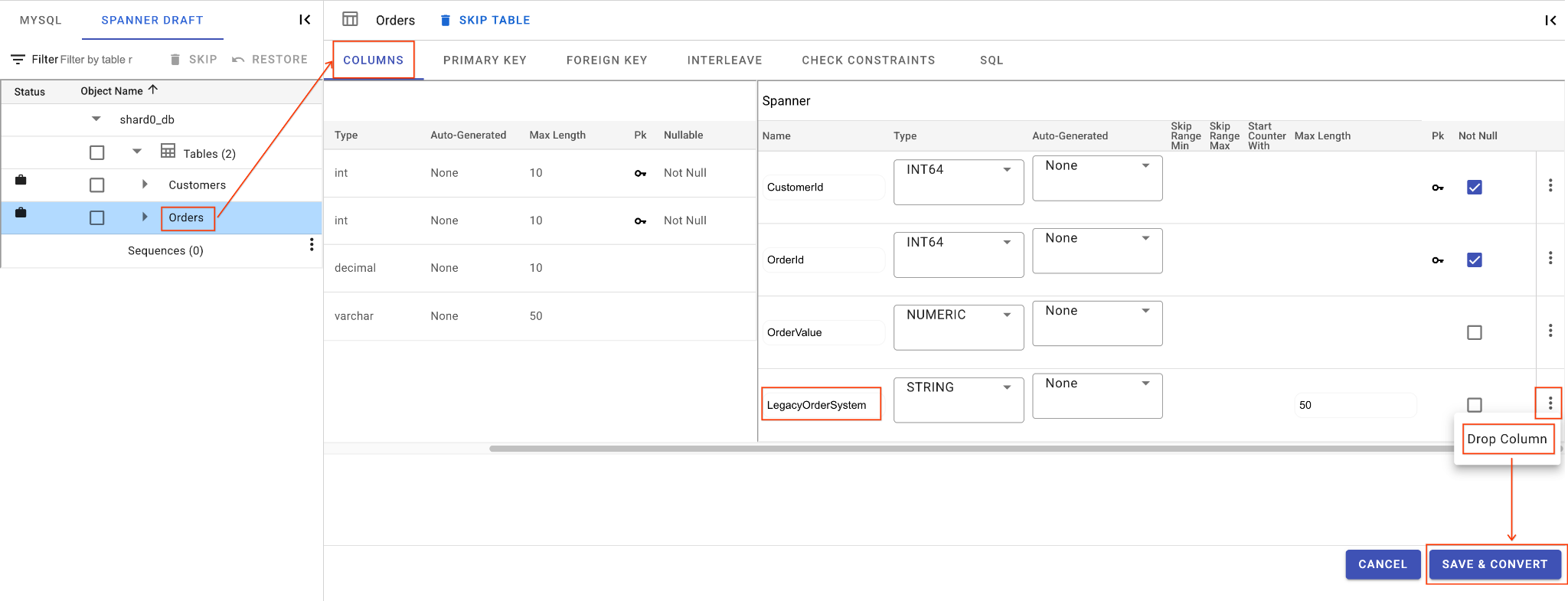
C. Remova a coluna "LegacyOrderSystem":
- Clique na tabela
Orders. A guia Colunas será aberta por padrão. - Clique no botão "Editar" na seção "Spanner".
- Localize a coluna
LegacyOrderSystemna visualização do esquema do Spanner. - Clique no ícone do menu de três pontos ao lado dele e selecione Remover coluna.
- Clique em Salvar e converter.
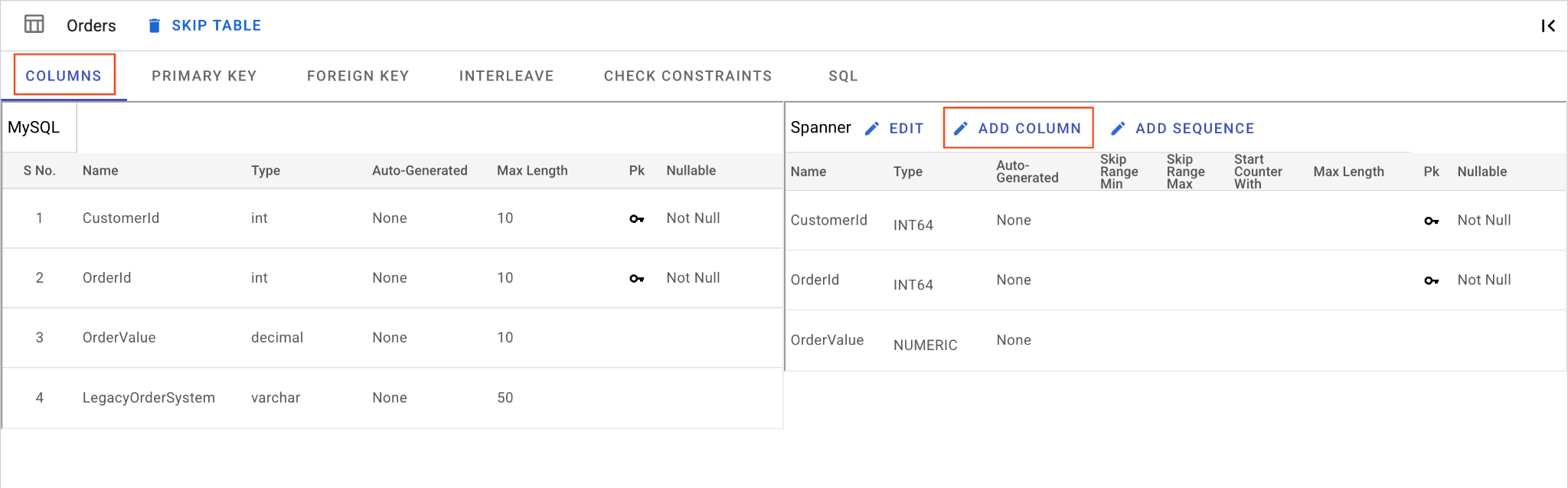
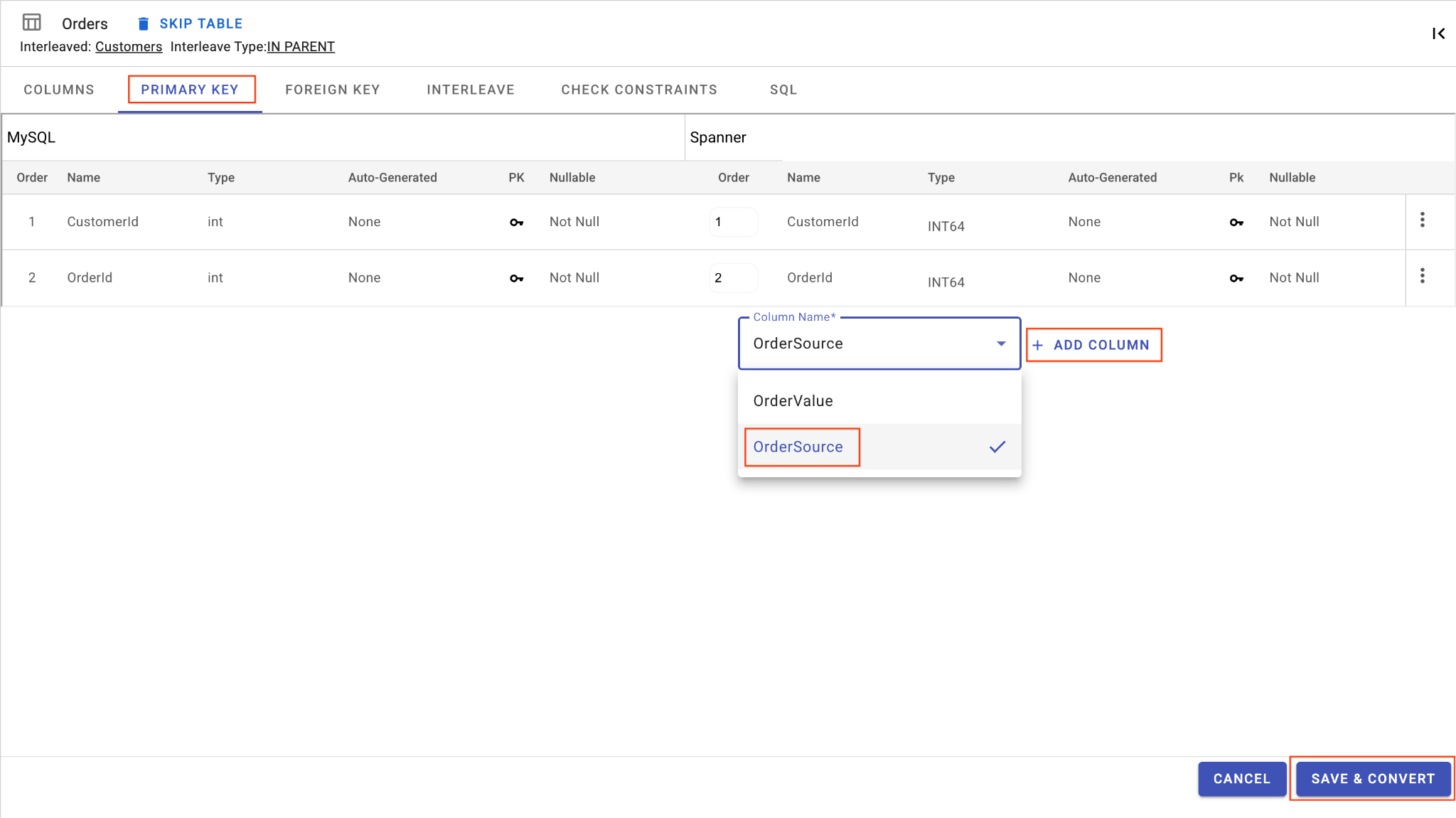
D. Adicionar a coluna "OrderSource" e torná-la uma chave primária:
- Ainda na tabela
Orders, clique em Adicionar coluna. Nomeie comoOrderSourcee defina o tipo comoSTRINGcom comprimento50, sem geração automática e definaIsNullablecomoNo. - Acesse a guia Chave primária.
- Clique em Editar e escolha
OrderSourceno menu suspenso "Nome da coluna". - Clique em Adicionar coluna e em Salvar e converter.
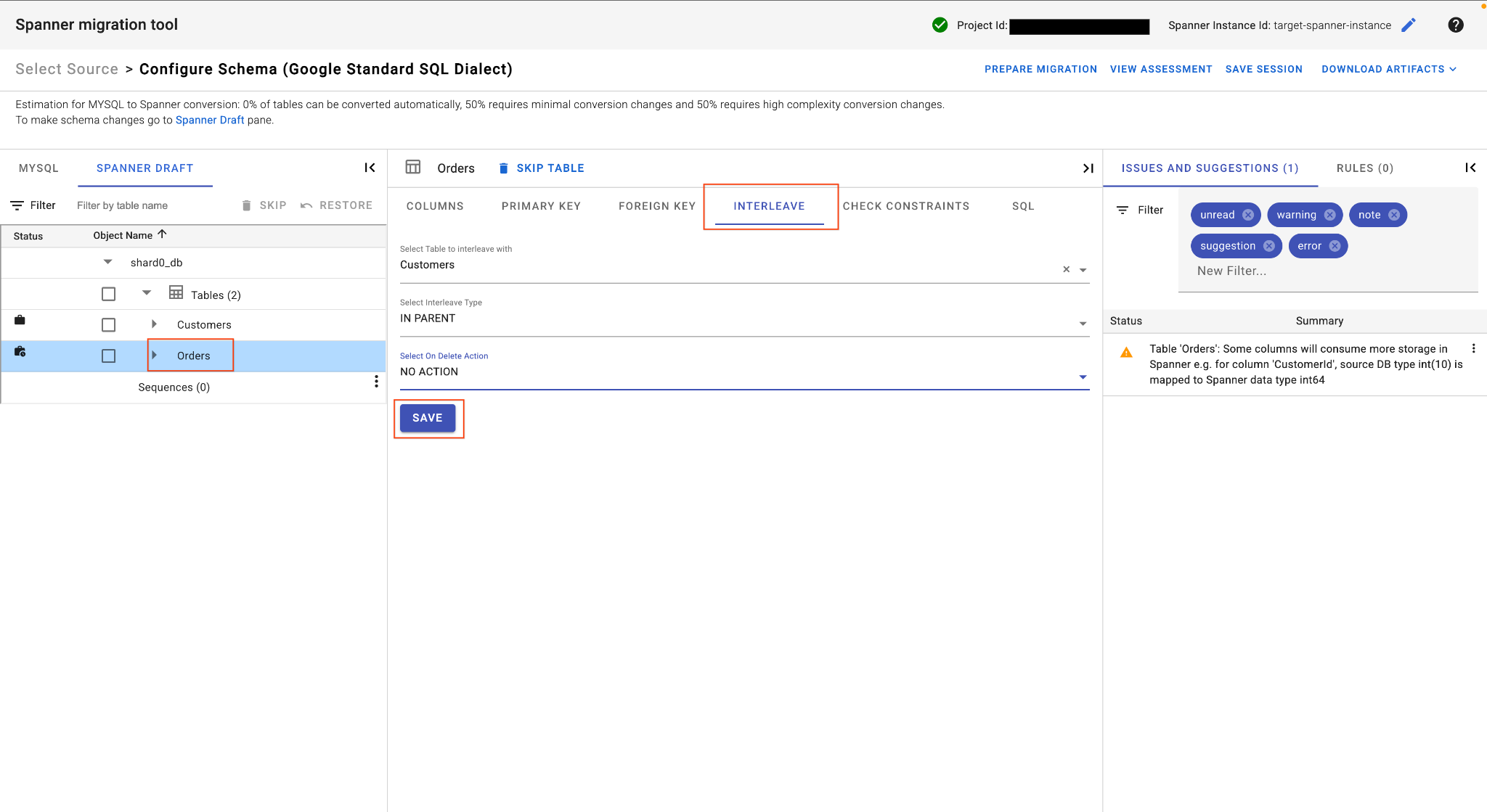
E. Intercale a tabela de pedidos:
- Ainda na tabela
Orders, na visualização principal, localize a guia Intercalação. - Defina a tabela principal como
Customers. - Escolha
IN PARENTTipo de intercalação eNO ACTIONAção de exclusão. - Clique em Salvar.
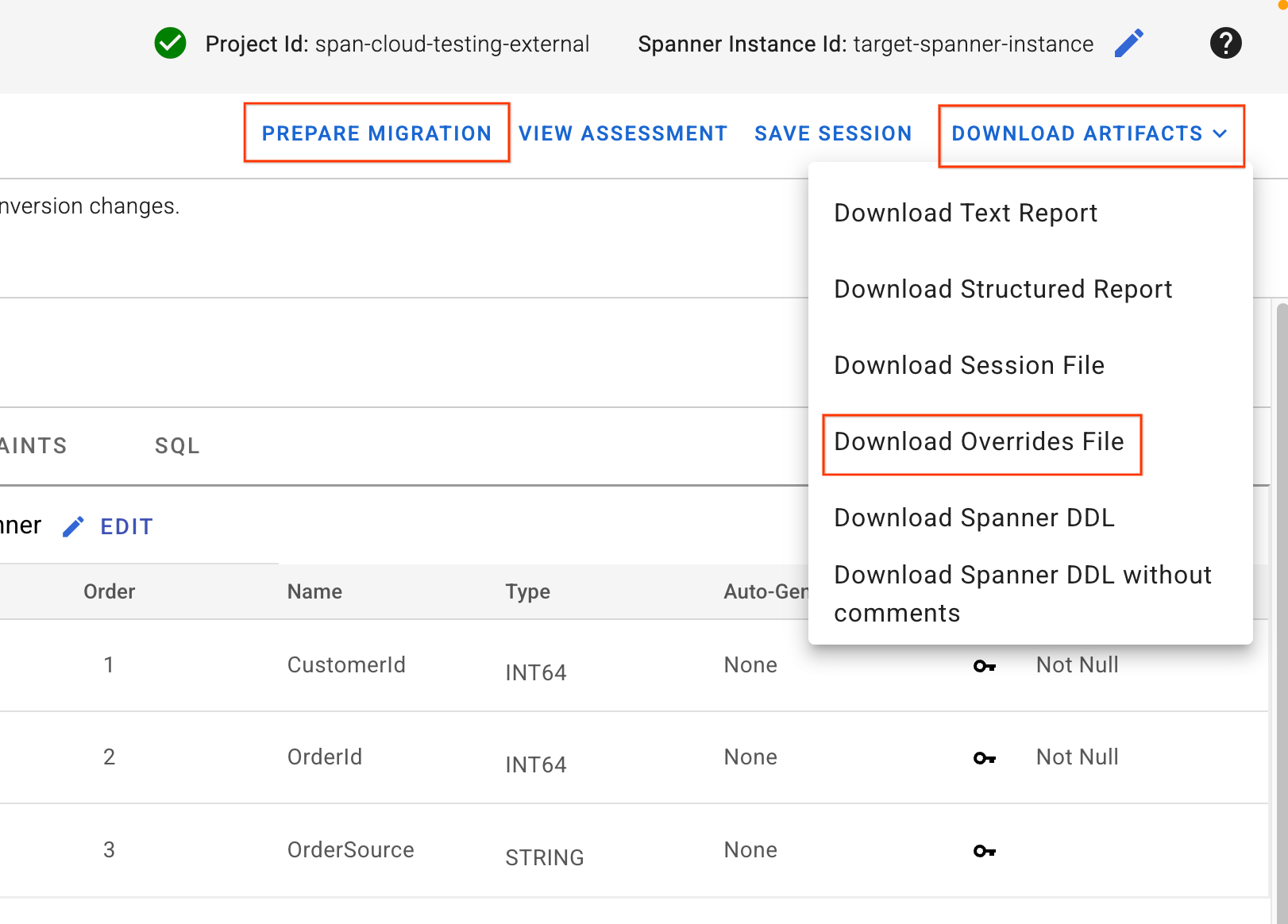
4. Fazer o download do arquivo de substituições e aplicar o esquema
- No canto superior direito da interface do SMT, localize o botão Fazer o download de artefatos. Selecione a opção Fazer o download do arquivo de substituições. Salve esse arquivo na sua máquina local. Esse arquivo contém todas as mudanças de mapeamento de esquema que acabamos de fazer e será usado pelos nossos pipelines do Dataflow.
- Clique em Preparar migração.
- Escolha Modo de migração como
Schemano menu suspenso. - Insira o banco de dados de destino do Spanner:
sharded-target-db
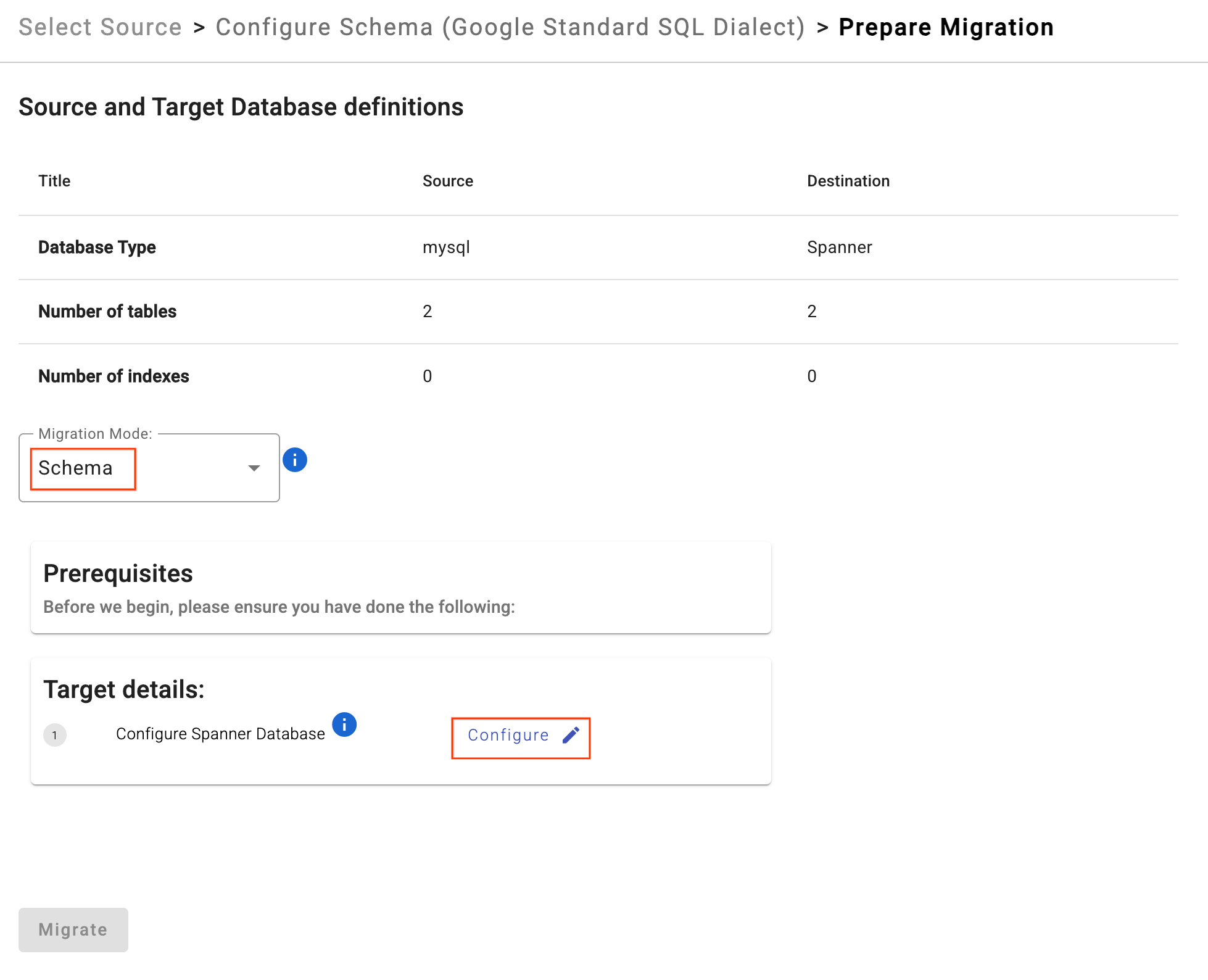
- Clique em Migrar.
- O SMT vai aplicar a DDL e criar o banco de dados do Spanner. Você pode interromper o processo do SMT no Cloud Shell (
Ctrl+C) com segurança quando ele for concluído.
5. Verificar o esquema no Cloud Spanner
Verifique se as tabelas foram criadas no banco de dados do Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Você verá esta resposta:
table_name: Customers table_name: Orders
Opcional:se você quiser verificar a DDL do Spanner real para confirmar se as restrições de verificação, o intercalamento e as colunas extras foram aplicados, execute o seguinte comando:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
Saída esperada:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. Inicializar a captura de dados alterados (CDC)
Nesta seção, você vai configurar o "gravador" para sua migração. Ao configurar o Datastream e o Pub/Sub antes do início do carregamento de dados em massa, você garante que todas as mudanças feitas nos bancos de dados de origem sejam capturadas e enfileiradas, evitando a perda de dados durante a transição. Essa configuração é obrigatória para a migração dinâmica.
Como nossa arquitetura envolve dois servidores físicos, precisamos criar dois perfis de origem e dois fluxos do Datastream separados. Os dois fluxos vão gravar em um único bucket do Google Cloud Storage (GCS), que vai atuar como a origem unificada do nosso pipeline do Dataflow.
1. Crie um bucket do Cloud Storage
O Datastream exige um destino para armazenar os eventos de mudança capturados. Vamos criar um bucket do GCS.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. Criar perfis de conexão do Datastream
Precisamos de dois perfis de conexão de origem do MySQL distintos (um para cada fragmento físico) e um perfil de conexão de destino para o Cloud Storage.
Receber endereços IP de origem
Primeiro, busque os endereços IP externos das duas VMs do Compute Engine e armazene-os como variáveis de ambiente:
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
Criar perfis de conexão de origem (MySQL no Compute Engine)
Crie os perfis de conexão do Datastream usando o datastream_user criado anteriormente.
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
Observação:o Datastream se conecta a essas VMs usando os IPs públicos delas, o que é permitido porque adicionamos 0.0.0.0/0 às nossas regras de firewall anteriormente. Em um ambiente de produção, você permitiria estritamente os intervalos de IP públicos específicos do Datastream.
Criar perfil de conexão de destino (Cloud Storage):
Ela aponta para a raiz do bucket recém-criado.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3. Criar streams do Datastream
Agora vamos criar dois fluxos de CDC. O stream 1 vai capturar shard0_db e shard1_db. O stream 2 vai capturar shard2_db e shard3_db. Os dois fluxos gravam no mesmo bucket do GCS no formato Avro.
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
Usar configurações menores de rotação de arquivos (5 MB ou 15 segundos) ajuda a ver as mudanças replicadas mais rápido durante o codelab.
Esse comando pode levar algum tempo para ser concluído. Verifique o status: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION.
4. Iniciar os fluxos do Datastream
Ative os dois streams para que eles comecem a gravar as mudanças.
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
Verificar o status: execute gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION. O estado vai ser STARTING inicialmente e vai mudar para RUNNING depois de alguns instantes. Aguarde até que ambos estejam em execução completa antes de iniciar a migração dinâmica.
5. Configurar o Pub/Sub para notificações do GCS
O Dataflow precisa ser notificado imediatamente quando o stream do Datastream grava um novo arquivo no bucket do GCS. Vamos configurar o GCS para enviar notificações a um único tópico do Pub/Sub.
Crie um tópico do Pub/Sub:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
Criar notificação do GCS
Notifique o tópico sempre que um objeto for criado com o prefixo data/, que abrange os dois fluxos.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Crie uma assinatura do Pub/Sub
Crie a assinatura com um prazo de confirmação recomendado para o Dataflow.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Transformação personalizada
Como nosso esquema do Spanner é diferente do esquema do MySQL (devido às colunas que adicionamos e descartamos pela interface da Web do SMT), a migração do Dataflow pronta para uso vai falhar. O Dataflow precisa de instruções sobre como mapear essas diferenças durante os pipelines de encaminhamento (MySQL para Spanner) e de inversão (Spanner para MySQL).
Além disso, como estamos fazendo uma migração reversa fragmentada, o Dataflow precisa de um mecanismo de roteamento para saber a qual fragmento lógico (shard0_db, shard1_db etc.) uma linha atualizada do Spanner pertence durante a replicação reversa.
Para isso, vamos gravar um JAR de transformação personalizada usando o modelo de fragmentação personalizada do Spanner fornecido pelo Google.
1. Baixar o modelo de fragmentação personalizada
No Cloud Shell, faça o download do repositório de modelos do Google Cloud Dataflow e navegue até a pasta de fragmentação personalizada:
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. Configurar a lógica de transformação de dados
Precisamos editar o arquivo CustomTransformationFetcher.java.
- Migração direta (
toSpannerRow): preenche a colunaOrderSourcerecém-adicionada usando a colunaLegacyOrderSystemdo MySQL. - Migração reversa (
toSourceRow): repovoa a colunaLegacyOrderSystemdescartada que o MySQL exige, derivando-a doOrderSourcedo Spanner.
Edite o arquivo CustomTransformationFetcher.java. Em vez de abrir um editor de texto manualmente, execute o comando a seguir para substituir automaticamente o arquivo de modelo pela nossa lógica personalizada:
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3. Configurar a lógica de fragmentação inversa
O Dataflow usa CustomShardIdFetcher.java durante a replicação inversa para determinar onde uma mutação do Spanner deve ser roteada. Vamos usar a chave primária CustomerId e a lógica de módulo (%4) para rotear dinamicamente os registros de volta ao fragmento lógico correto.
Edite o arquivo CustomShardIdFetcher.java usando cat e substitua todo o conteúdo pelo seguinte código:
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. Criar e fazer upload do JAR
Agora que a lógica Java personalizada foi escrita, precisamos compilá-la em um arquivo JAR e fazer upload para o bucket do Cloud Storage criado anteriormente para que o Dataflow possa acessá-lo.
Execute os comandos a seguir no Cloud Shell:
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9. Migrar dados em massa do MySQL para o Spanner
Com o esquema do Spanner no lugar e o JAR de transformação personalizada criado, agora podemos copiar os dados atuais do banco de dados MySQL para o Cloud Spanner. Você vai usar o modelo flex do Dataflow Sourcedb to Spanner, que foi projetado para copiar dados em massa de bancos de dados acessíveis por JDBC para o Spanner.
1. Fazer upload do arquivo de modificações de esquema
Na seção 6, você baixou o arquivo JSON de substituições do Spanner usando a interface da Web do SMT. Precisamos fazer upload disso para nosso bucket do GCS para que o Dataflow possa usar para mapear as diferenças de esquema (como colunas renomeadas).
- No Cloud Shell, clique no menu de três pontos (Mais) e selecione Fazer upload.
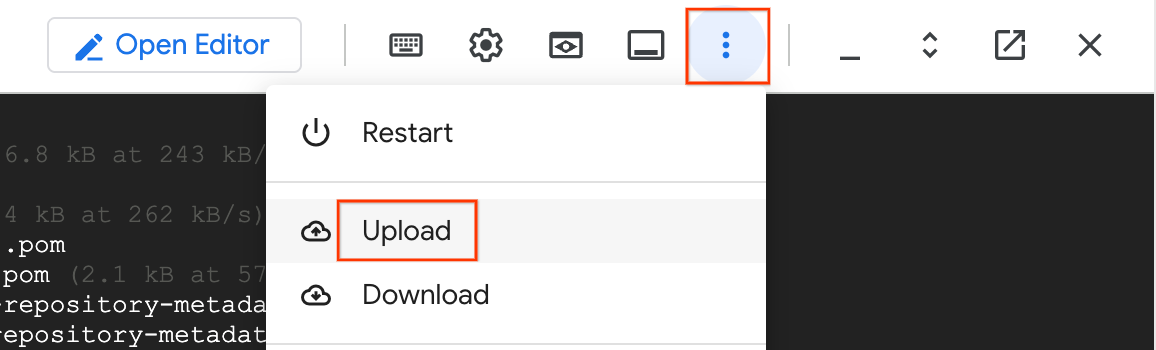
- Selecione o arquivo JSON de substituições que você baixou antes (por exemplo,
spanner_overrides.json). - Mova para o bucket do GCS:
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. Criar e fazer upload do arquivo de configuração de fragmentação
O Dataflow precisa saber como se conectar a todos os quatro fragmentos lógicos nas duas VMs físicas. Vamos criar um arquivo sharding.json para isso.
Execute o seguinte no Cloud Shell para gerar e fazer upload da configuração:
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3. Executar o job do Dataflow de migração em massa
Vamos usar o modelo Flex Sourcedb para Spanner. Como essa é uma migração fragmentada com transformações personalizadas, transmitimos o arquivo de substituições, a configuração de fragmentação e nosso JAR Java personalizado.
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
Explicação dos principais parâmetros:
sourceConfigURL: o caminho para o arquivosharding.jsonque criamos. Isso informa ao Dataflow como se conectar a todos os quatro fragmentos lógicos do MySQL nas duas VMs físicas.schemaOverridesFilePath: o caminho para o arquivo JSON baixado da interface da Web do SMT. Isso instrui o Dataflow sobre como processar as modificações de esquema que fizemos (como a colunaLegacyRegiondescartada e a restrição de verificação mais rígida).transformationJarPath: o caminho do GCS para o arquivo JAR Java compilado que criamos na seção anterior. Ele contém o código real para executar nossas transformações personalizadas.transformationClassName: o nome totalmente qualificado da classe Java no nosso JAR que implementa a lógica de migração direta (com.custom.CustomTransformationFetcher).outputDirectory: o local do GCS em que o Dataflow vai gravar os arquivos temporários e, principalmente, os arquivos da fila de mensagens mortas (DLQ, na sigla em inglês).maxWorkers,numWorkers: controla o escalonamento do job do Dataflow. Mantido baixo para esse conjunto de dados pequeno.instanceId,databaseId,projectId: especifica a instância e o banco de dados de destino do Cloud Spanner.
Observação sobre a rede:esse job se conecta à instância do Cloud SQL pelo IP público dela. Isso é possível porque você adicionou 0.0.0.0/0 às redes autorizadas da instância. Isso permite que as VMs de worker do Dataflow, que têm IPs externos, alcancem o banco de dados.
4. Monitorar o job do Dataflow
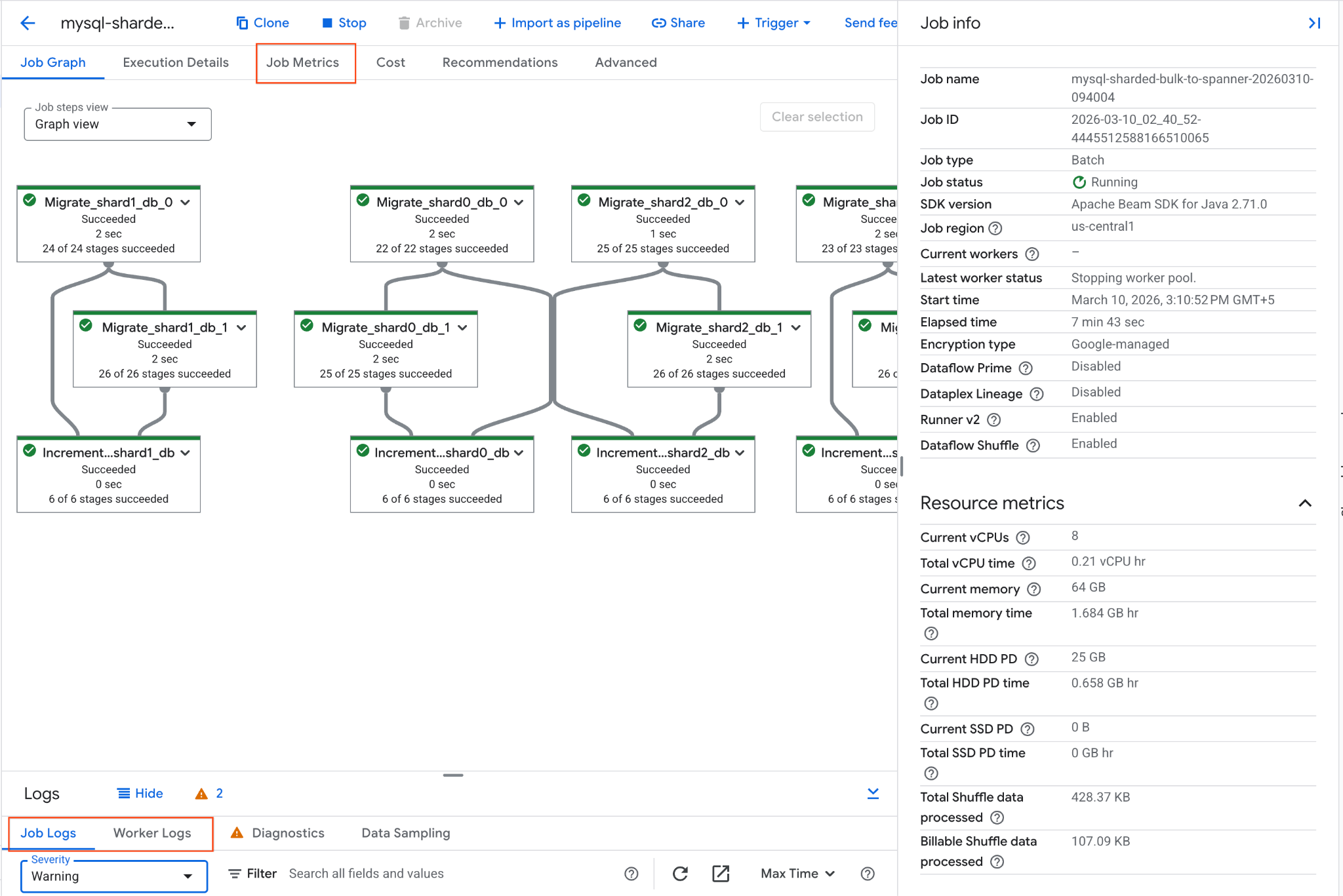
É possível acompanhar o progresso do job no console do Google Cloud:
- Acesse a página "Jobs do Dataflow": Acessar Jobs do Dataflow
- Localize o job chamado
mysql-sharded-bulk-to-spanner-...e clique nele. - Observe o gráfico e as métricas do job. Aguarde o status do job mudar para Concluído. Esse processo leva de 5 a 15 minutos.
- Se o job encontrar problemas, revise a guia Registros na página de detalhes do job do Dataflow para ver mensagens de erro.
- As métricas de job oferecem mais informações sobre o progresso do job e o consumo de recursos, como taxa de transferência e uso da CPU.
5. Verificar dados no Cloud Spanner e inspecionar a fila de mensagens mortas (DLQ)
Depois que o job do Dataflow for concluído, precisamos verificar se os dados chegaram com segurança e inspecionar os registros que criamos intencionalmente para falhar.
A. Verifique a integridade geral dos dados migrados:
Use a CLI gcloud para executar algumas verificações rápidas de integridade no banco de dados consolidado do Spanner e garantir que os registros válidos foram migrados corretamente e que nosso JAR personalizado preencheu a coluna extra.
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
Saída esperada:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- Todas as linhas da tabela "Clientes" foram migradas.
- Vemos 1 falha de linha na tabela
Ordersdevido aINTERLEAVE IN PARENTno Spanner.CustomerId 99é um filho órfão porque não há uma linha correspondente na tabelaCustomers.
B. Verifique as falhas intencionais na DLQ:
A falha acima está documentada na pasta da fila de mensagens inativas (DLQ) criada pelo pipeline de migração em massa.
- Acesse Cloud Storage no console do Google Cloud.
- Acesse seu bucket e abra a pasta
bulk-migration/dlq/severe. - Inspecione os arquivos JSON dentro dele. Você vai encontrar a linha
Orderscom oCustomerIdórfão. - Para tentar novamente os erros da DLQ de migração em massa, siga as etapas mencionadas aqui.
O carregamento em massa inicial de dados do Cloud SQL para o Cloud Spanner foi concluído. A próxima etapa é configurar a replicação ativa para capturar as mudanças em andamento.
10. Iniciar migração em tempo real (CDC)
Agora que a carga de dados em massa foi concluída, você vai iniciar um job de streaming contínuo do Dataflow. Esse job vai ler os eventos de captura de dados alterados (CDC) que o Datastream está gravando no seu bucket do GCS e aplicar essas mudanças ao Cloud Spanner quase em tempo real.
Também vamos testar esse pipeline injetando dados válidos e intencionalmente inválidos para observar como o Dataflow lida com a replicação ativa e roteia falhas para a fila de mensagens mortas (DLQ).
1. Criar o arquivo de configuração de fragmentação da migração dinâmica
Ao contrário da migração em massa (que usa strings de conexão JDBC), o pipeline de migração em tempo real lê eventos do Datastream no GCS. Ele precisa de uma configuração JSON completamente diferente que mapeia nomes de fluxos e bancos de dados do Datastream para seus fragmentos lógicos do Spanner.
Execute o seguinte no Cloud Shell para criar e fazer upload da configuração de fragmentação dinâmica:
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. Executar o job do Dataflow de migração em tempo real
Inicie o job de streaming do Dataflow para ler do GCS e gravar no Spanner. Esse modelo usa notificações do Pub/Sub do GCS para processar novos arquivos instantaneamente.
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
Parâmetros principais
gcsPubSubSubscription: a assinatura do Pub/Sub que detecta novas notificações de arquivos do GCS. Isso permite que o job processe as mudanças instantaneamente à medida que o Datastream as grava.inputFileFormat="avro": informa ao Dataflow que ele deve esperar arquivos Avro do Datastream. Isso precisa corresponder à configuração de "Destino" do Datastream (por exemplo,avroFileFormatxjsonFileFormat).shardingContextFilePath: um arquivo JSON que mapeia streams do Datastream para fragmentos lógicos.dlqRetryMinutes: o número de minutos entre novas tentativas de fila de mensagens inativas (DLQ). O padrão é10.dlqMaxRetryCount: o número máximo de vezes que os erros temporários podem ser repetidos pela DLQ. O padrão é500.
Monitore a inicialização do job no console de jobs do Dataflow.
3. Injetar dados ativos e acionar falhas intencionais
Enquanto o job de streaming do Dataflow é iniciado (isso pode levar de 3 a 5 minutos), vamos usar o SSH na nossa primeira VM física do MySQL e inserir alguns novos registros. Vamos inserir um registro válido e um inválido.
Conecte-se por SSH ao primeiro fragmento físico:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Faça login no MySQL:
sudo mysql
Execute as inserções a seguir em shard1_db:
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
Digite exit novamente para voltar ao prompt do Cloud Shell.
4. Verificar os dados da migração em tempo real e inspecionar a DLQ de CDC
Agora que injetamos os dados, o Datastream vai capturar os eventos de CDC, e o Dataflow vai tentar aplicá-los ao Spanner.
A. Verificar as mudanças válidas de DML no Spanner
Execute as consultas a seguir para verificar se os eventos INSERT, UPDATE e DELETE chegaram ao Spanner e se a transformação personalizada foi acionada na inserção e na atualização.
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Saída esperada:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
Observação: se uma consulta não mostrar o resultado esperado, aguarde um minuto e tente de novo, já que os trabalhadores de streaming ainda podem estar processando a fila.
B. Verifique a falha intencional na DLQ:
Como CustomerId = 99999 não tem um pai na tabela Customers, ele deveria ter sido rejeitado pelo Spanner e encaminhado com segurança para a DLQ pelo Dataflow.
- Acesse Cloud Storage no console do Google Cloud.
- Acesse seu bucket e abra a pasta
live-migration/dlq/severe/. - Os arquivos JSON recém-gerados vão aparecer. Clique neles para inspecionar o conteúdo. Você vai ver os detalhes de
CustomerId = 99999e a mensagem de erro específica do Spanner:NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written." - É possível repetir os erros da DLQ da migração ativa executando o modelo do Dataflow com
runMode=retryDLQdefinido.
5. Como lidar com erros de DLQ
Erros no diretório severe/ exigem intervenção manual. Vamos corrigir o problema de dados e reprocessar o evento com falha.
A. Corrigir os dados na origem
O erro ocorreu porque o registro do cliente principal CustomerId = 99999 está faltando. Vamos inserir no banco de dados MySQL de origem.
Acesse a instância do MySQL novamente:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Faça login no MySQL usando sudo mysql e insira a linha principal ausente em shard1_db:
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
Digite exit para voltar ao Cloud Shell.
B. Executar o job do Dataflow retryDLQ
Para reprocessar eventos da DLQ severe/, inicie o mesmo modelo do Dataflow, mas no modo retryDLQ. Esse modo lê especificamente o caminho deadLetterQueueDirectory/severe, executa novamente as transformações personalizadas e as aplica ao Spanner.
Inicie o job no modo retryDLQ:
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
Principais mudanças de parâmetros para novas tentativas
runMode="retryDLQ": informa ao modelo para ler do diretório de DLQsevere.- Removemos
gcsPubSubSubscription: não é necessário porque não estamos lendo do bucket do GCS do Datastream ativo.
Monitore o processo de nova tentativa:
Assim como o pipeline principal de CDC, retryDLQ é um pipeline de streaming que vai permanecer RUNNING até ser cancelado manualmente.
- Acesse a página do job do Dataflow para
$JOB_NAME_RETRY. - No painel Métricas, procure estes dois contadores:
elementsReconsumedFromDeadLetterQueue: avalia quando os arquivos de erro estão sendo buscados.Successful events: incrementa quando o registro é gravado no Spanner.- Verifique se há falhas recorrentes no diretório
severe/. - Quando os eventos bem-sucedidos aumentarem pelo número de itens que você quer tentar de novo (1 no nosso caso de teste), vá para a próxima etapa de verificação.
C. Verificar os dados repetidos
Depois que o registro com falha for repetido (pode levar algum tempo para ser concluído), verifique o Spanner para saber se a linha filha foi migrada:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Agora você vai ver a linha:
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
Verifique também a pasta $DLQ_DIR_CDC/severe/ no GCS. Os arquivos processados deveriam ter sido movidos ou excluídos, indicando um reprocessamento bem-sucedido.
11. Configurar a replicação inversa (Spanner para MySQL)
Para lidar com cenários em que talvez seja necessário fazer um rollback ou manter o banco de dados MySQL original sincronizado com o Spanner por um período de transição, configure a replicação reversa.
Esse pipeline usa fluxos de alterações do Spanner para capturar modificações em tempo real no Spanner. Em seguida, ele usa nosso JAR de transformação personalizada para fazer o mapeamento inverso das diferenças de esquema e nosso JAR de fragmentação personalizada para calcular exatamente em qual VM física do MySQL e fragmento lógico a atualização deve ser gravada novamente.
1. Criar um fluxo de alterações do Spanner
Primeiro, crie um fluxo de mudanças no banco de dados do Spanner para rastrear as mudanças nas tabelas Customers e Orders.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
Esse fluxo de alterações agora vai registrar todas as modificações de dados nas tabelas especificadas.
2. Criar um banco de dados do Spanner para metadados do Dataflow
O modelo do Dataflow Spanner to SourceDB exige um banco de dados do Spanner separado para armazenar metadados e gerenciar o consumo do fluxo de alterações.
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Preparar a configuração de conexão do Cloud SQL para o Dataflow
O modelo do Dataflow precisa de um arquivo JSON no Cloud Storage com os detalhes da conexão do banco de dados de destino do Cloud SQL.
Crie um arquivo local chamado shard_config.json:
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
Faça upload deste arquivo para o bucket do GCS:
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. Executar o job do Dataflow de replicação inversa
Inicie o job do Dataflow usando o modelo Flex Spanner_to_SourceDb.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
Parâmetros principais
changeStreamName: o nome do fluxo de alterações a ser lido pelo Spanner.metadataInstance, metadataDatabase: a instância/o banco de dados do Spanner para armazenar os metadados usados pelo conector para controlar o consumo dos dados da API Change Stream.sourceShardsFilePath: o caminho do GCS para seushard_config.json.filtrationMode: especifica como descartar determinados registros com base em um critério. O padrão éforward_migration(filtra registros gravados usando o pipeline de migração direta).shardingCustomJarPath: o caminho do GCS para o arquivo JAR Java compilado que criamos anteriormente.shardingCustomClassName: o nome de classe totalmente qualificado (com.custom.CustomShardIdFetcher) que executa a matemática de módulo%4personalizada para determinar dinamicamente qual fragmento lógico vai receber o registro.
Observação sobre a rede:os workers do Dataflow se conectarão à instância do Cloud SQL usando o IP público especificado em shard_config.json. Essa conexão é permitida devido à entrada 0.0.0.0/0 nas redes autorizadas da instância do Cloud SQL.
Monitore a inicialização do job no console de jobs do Dataflow.
5. Injetar dados do Spanner e acionar falhas intencionais
Aguarde até que o job do Dataflow entre no estado Running. Isso pode levar cerca de cinco minutos. Em seguida, vamos executar um conjunto completo de consultas (INSERT, UPDATE, DELETE) diretamente no Spanner, além de uma falha intencional para testar a DLQ reversa.
Execute o seguinte no Cloud Shell:
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. Verificar os dados de replicação inversa e inspecionar a DLQ
Vamos confirmar se o JAR de fragmentação personalizada roteou CustomerId 88 para shard0_db na nossa primeira VM física e se o JAR de transformação personalizada removeu "_TIER" da região.
A. Verifique o registro válido no MySQL:
Conecte-se por SSH ao primeiro fragmento físico:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Faça login no MySQL e consulte shard0_db:
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
A saída esperada no Cloud SQL deve refletir as mudanças feitas no Spanner.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
Tipo
exit
para voltar ao Cloud Shell.
Isso confirma que o pipeline de replicação inversa está funcionando, sincronizando as mudanças do Spanner de volta para o Cloud SQL.
B. Verificar a falha intencional na DLQ
Como nosso novo registro Customers tem um CreditLimit de 500 (que viola a restrição de verificação > 1000 estrita definida no banco de dados MySQL de origem), o Dataflow detectou o erro com segurança.
- Acesse Cloud Storage no console do Google Cloud.
- Acesse seu bucket e abra a pasta
dlq/severe/. - Abra o arquivo JSON para ver o registro
Customersrejeitado e o erro exato de violação da restrição de verificação. - É possível repetir os erros da DLQ de replicação inversa executando o modelo do Dataflow com
runMode=retryDLQdefinido.
12. Limpar recursos
Para evitar mais cobranças na sua conta do Google Cloud, exclua os recursos criados durante este codelab.
Definir variáveis de ambiente (se necessário)
Se a sessão do Cloud Shell expirou ou você abriu um novo terminal, será necessário exportar novamente as variáveis de ambiente antes de executar os comandos de limpeza.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
Interromper jobs de streaming do Dataflow
Liste seus jobs para encontrar os IDs dos jobs do Dataflow em execução. Exporte JOB_ID_CDC e JOB_ID_REVERSE de acordo com a necessidade.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Cancele o job de Datastream to Spanner (migração em tempo real) e a nova tentativa:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
Cancele o job de Spanner to Cloud SQL (replicação inversa):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Excluir recursos do Datastream
Parar e excluir o stream:
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Excluir as VMs do MySQL de origem (Compute Engine)
Exclua as duas instâncias do Compute Engine que simularam os fragmentos físicos do MySQL no local.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
Excluir regras de firewall
Remova as regras de firewall de rede criadas para permitir o acesso SSH e a conectividade do Datastream às suas VMs. Observação: se você usou nomes diferentes para as regras de firewall no início do codelab, ajuste-os aqui.
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
Excluir recursos do Pub/Sub
Excluir assinatura:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Excluir tema:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Excluir instância do Cloud Spanner
Exclua a instância do Cloud Spanner. Isso exclui automaticamente os bancos de dados sharded-target-db e migration-metadata-db nela.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Excluir bucket e conteúdo do GCS
Por fim, exclua o bucket do Cloud Storage que contém os arquivos do Datastream, as configurações do Dataflow e as filas de mensagens não entregues. O comando rm -r exclui recursivamente o bucket e todo o conteúdo dele.
gcloud storage rm --recursive gs://${BUCKET_NAME}
Excluir arquivos locais do Cloud Shell
Para limpar os arquivos e diretórios locais gerados no Cloud Shell durante este codelab, execute os seguintes comandos:
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates