
1. Прежде чем начать
Этот практический урок покажет вам, как перенести сегментированную локальную базу данных MySQL в базу данных Cloud Spanner с диалектом GoogleSQL. Вы будете использовать сервисы Google Cloud, включая инструмент миграции Spanner (SMT), Dataflow, Datastream, PubSub и Google Cloud Storage.
Что вы узнаете:
- Что такое сегментированная среда и как её настроить?
- Как использовать веб-интерфейс Spanner Migration Tool (SMT) для преобразования схемы MySQL в схему, совместимую со Spanner, и выполнения сложных изменений схемы.
- Как выполнить массовую миграцию данных из сегментированного экземпляра MySQL в Cloud Spanner с помощью Dataflow.
- Как настроить непрерывную репликацию (CDC) с сегментированного экземпляра MySQL на Cloud Spanner с использованием Datastream и Dataflow.
- Как настроить обратную репликацию из Spanner обратно на сегментированные экземпляры MySQL.
- Как использовать пользовательские преобразования для заполнения дополнительных столбцов во время массовой, оперативной и обратной миграции.
- Как настроить преобразования для сегментирования данных с использованием первичных ключей.
В этом практическом занятии НЕ рассматриваются следующие темы:
- Расширенные возможности настройки сети.
- Создание пользовательских шаблонов Dataflow с нуля.
- Оптимизация производительности миграции.
- Миграция приложений: Данный практический урок посвящен уровню базы данных (схема и данные). Он не охватывает операционный процесс повторного развертывания или миграции сервисов вашего приложения.
Что вам понадобится
- Проект Google Cloud с включенной функцией выставления счетов.
- Для работы с API и создания/управления ресурсами Spanner, Dataflow, Datastream и GCS необходимы достаточные права доступа IAM . Хотя роль
Ownerпроекта является наиболее простой для практического занятия, более специфические роли будут рассмотрены в разделе «Настройка среды». - На этапе настройки мы создадим небольшую виртуальную машину Compute Engine, чтобы имитировать наш локальный сервер. Убедитесь, что квота вашего проекта позволяет создавать виртуальные машины.
- Веб-браузер, например, Google Chrome.
- Базовые знания консоли Google Cloud и инструментов командной строки, таких как
gcloud. - Доступ к командной оболочке. Рекомендуется использовать Cloud Shell , поскольку она включает
gcloud.
Более подробная информация о вышеописанной настройке приведена в разделе « Настройка среды» .
2. Понимание миграционного процесса
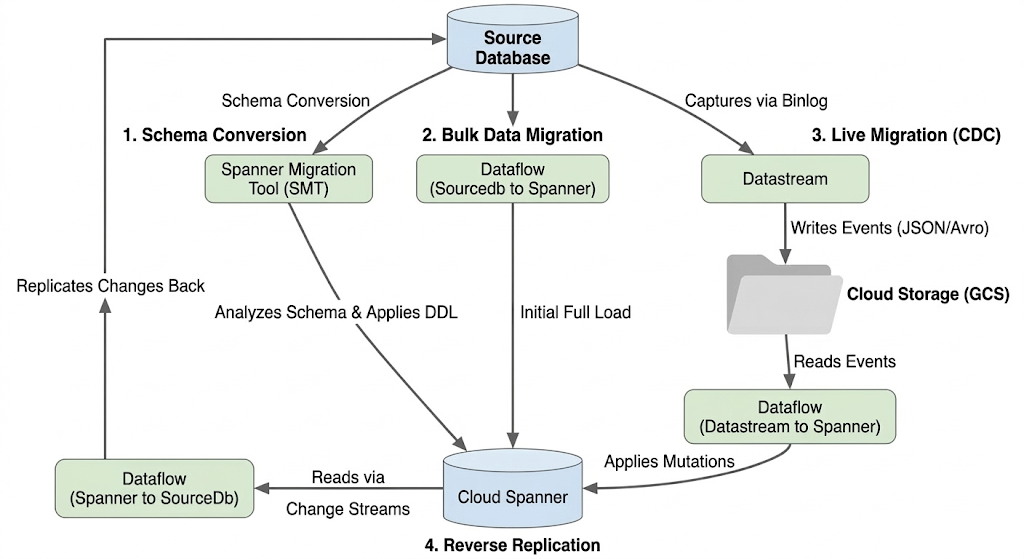
Миграция сегментированной базы данных включает в себя объединение нескольких физических и логических экземпляров MySQL в единую, горизонтально масштабируемую базу данных Spanner. В этом разделе описывается архитектура и основные инструменты, используемые при миграции.
Архитектура потока миграции
Процесс миграции включает следующие этапы:
1. Преобразование схемы:
- Цель: Преобразовать схему исходной базы данных в совместимую схему Cloud Spanner.
- Инструмент: Инструмент миграции Spanner (SMT)
- Процесс: SMT анализирует схему исходной базы данных и генерирует эквивалентный язык определения данных Spanner (DDL). В целевом экземпляре Spanner создается база данных, после чего DDL автоматически применяется.
2. Массовая миграция данных:
- Цель: Выполнить первоначальную полную загрузку существующих данных из исходной базы данных в подготовленные таблицы Spanner.
- Инструмент: Dataflow, с использованием предоставленного Google шаблона
Sourcedb to Spanner. - Процесс: Данная задача Dataflow считывает все данные из указанных исходных таблиц и записывает их в соответствующие таблицы Spanner. Это выполняется после создания схемы Spanner.
3. Живая миграция (CDC):
- Цель: Захват и применение текущих изменений из исходной базы данных к Cloud Spanner практически в режиме реального времени, минимизируя время простоя во время миграции.
- Инструменты:
- Datastream: Захватывает изменения (вставки, обновления, удаления) из исходной базы данных и записывает их в облачное хранилище (GCS).
- Dataflow: Использует шаблон
Datastream to Spannerдля чтения событий изменений из GCS и их применения к Cloud Spanner.
4. Обратная репликация:
- Назначение: Реплицировать изменения данных из Cloud Spanner обратно в исходную базу данных. Это может быть полезно для стратегий резервного копирования, поэтапной миграции или поддержания реплики в исходной базе данных для конкретных сценариев использования.
- Инструмент: Dataflow, с использованием шаблона
Spanner to SourceDb. - Процесс: В этой задаче используются потоки изменений Spanner для фиксации изменений в Spanner и их записи обратно в исходный экземпляр базы данных.
Следующая диаграмма иллюстрирует компоненты и поток данных:
Ключевые термины:
- Физический сегмент: Фактический базовый сервер или вычислительный экземпляр, на котором размещена база данных (в нашем случае, имитированная локальная виртуальная машина GCE).
- Логический сегмент: отдельная схема базы данных внутри физического сервера.
- Виртуальная машина Compute Engine (GCE) : виртуальная машина, размещенная в инфраструктуре Google Cloud. В этом практическом задании мы используем виртуальную машину GCE для имитации автономного «локального» сервера, на котором размещена наша исходная база данных MySQL.
- Инструмент миграции Spanner (SMT) : инструмент, используемый для оценки схем MySQL, предложения эквивалентов схем Spanner и генерации языка определения данных Spanner (DDL) .
- Язык определения данных (DDL): операторы, используемые для определения и изменения структуры базы данных, например, операторы
CREATE TABLE. SMT генерирует DDL Spanner на основе схемы Cloud SQL. - Dataflow : Полностью управляемый бессерверный сервис обработки данных. В этом практическом задании он используется для запуска предоставленных Google шаблонов для массовой передачи данных, применения изменений Dataflow и обратной репликации.
- Datastream : Бессерверный сервис для отслеживания изменений данных (CDC) и репликации. В этом практическом задании он используется для потоковой передачи изменений из локально размещенного экземпляра MySQL в облачное хранилище.
- Функция Spanner Change Streams : функция Spanner, позволяющая передавать изменения данных (вставки, обновления, удаления) в режиме реального времени, используемая в качестве источника для обратной репликации.
- Pub/Sub : служба обмена сообщениями, используемая для разделения служб, генерирующих события, от служб, обрабатывающих их. В этом практическом задании она запускает обработку обновлений Dataflow всякий раз, когда Datastream загружает новые файлы изменений в Cloud Storage.
3. Настройка среды
Прежде чем начать миграцию, необходимо настроить проект Google Cloud и включить необходимые сервисы.
1. Выберите или создайте проект Google Cloud.
Для использования сервисов в этом практическом задании вам потребуется проект Google Cloud с включенной функцией выставления счетов.
- В консоли Google Cloud перейдите на страницу выбора проекта: Перейти к выбору проекта
- Выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего проекта включена функция выставления счетов. Узнайте, как подтвердить включение этой функции для вашего проекта .
2. Open Cloud Shell
Cloud Shell — это среда командной строки, работающая в Google Cloud, которая поставляется с предустановленным CLI-интерфейсом gcloud и другими необходимыми инструментами.
- Нажмите кнопку «Активировать Cloud Shell» в правом верхнем углу консоли Google Cloud.
- В нижней части консоли открывается новая панель, в которой отображается приглашение командной строки.

3. Настройка переменных проекта и среды.
В Cloud Shell настройте несколько переменных среды для идентификатора вашего проекта и используемого региона.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Включите необходимые API Google Cloud.
Включите необходимые API для Cloud Spanner, Dataflow, Datastream и других связанных сервисов.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Выполнение этой команды может занять несколько минут.
4. Настройка исходной базы данных MySQL.
В этом разделе мы смоделируем локальную сегментированную архитектуру MySQL, выделив две виртуальные машины Compute Engine (наши 2 «физических сегмента»). Затем мы установим MySQL на обе машины и создадим две базы данных (наши «логические сегменты») на каждой виртуальной машине.
1. Создайте виртуальные машины Compute Engine (физические сегменты).
Выполните следующие команды в Cloud Shell, чтобы создать две виртуальные машины с Ubuntu. Позже мы присвоим им сетевые теги, чтобы разрешить входящий трафик MySQL.
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. Настройка правил брандмауэра
Для обеспечения безопасного доступа по SSH без публичного доступа и для обеспечения возможности подключения к Datastream:
Создание правила брандмауэра для SSH через IAP:
Это правило позволяет Identity-Aware Proxy подключаться к вашим виртуальным машинам через порт SSH (22).
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
Создание правила брандмауэра для Datastream (порт MySQL):
Для работы Datastream необходимо иметь возможность подключаться к этим виртуальным машинам через стандартный порт MySQL (3306).
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3. Установите и настройте MySQL на физическом сегменте 1.
Подключитесь по SSH к вашей первой виртуальной машине, чтобы установить MySQL и настроить бинарное логирование (которое необходимо Datastream для репликации в реальном времени).
- Подключитесь к первой виртуальной машине по SSH:
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- Установите MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- Настройте файл
mysqld.cnf, чтобы включить двоичное логирование и разрешить внешние подключения:
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Перезапустите MySQL, чтобы применить изменения:
sudo systemctl restart mysql
4. Создание логических сегментов, вставка данных и создание пользователя потока данных (сегмент 1)
Оставаясь подключенным по SSH к mysql-physical-1 , войдите в командную строку MySQL:
sudo mysql
Выполните следующие SQL-команды. Этот скрипт создаст два отдельных логических сегмента ( shard0_db и shard1_db ), настроит в обоих идентичную схему, вставит в каждый из них уникально идентифицируемые данные (для демонстрации сегментирования) и создаст пользователя репликации для Datastream.
Выполните следующие SQL-команды, чтобы создать первые два логических сегмента, таблицу и пользователя репликации для Datastream:
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
Файл дампа для указанной выше схемы можно найти здесь . Важно создать пользователя для репликации потока данных отдельно, поскольку он не включен в файл дампа.
5. Проверка данных
Быстро проверьте наличие данных:
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
Ожидаемый результат:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
Нажмите клавишу exit , чтобы разорвать соединение с физической виртуальной машиной сегмента 1.
6. Повторите для физического осколка 2.
Теперь повторите тот же самый процесс для второй виртуальной машины, но создайте shard2_db и shard3_db и измените server-id .
- Подключитесь ко второй виртуальной машине по SSH:
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- Установите MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- Настройте файл
mysqld.cnf, чтобы включить двоичное логирование и разрешить внешние подключения [Обратите внимание, что server-id должен быть другим (например, 2)].
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Перезапустите MySQL, чтобы применить изменения:
sudo systemctl restart mysql
- Введите команду MySQL (
sudo mysql) и выполните немного измененную версию SQL-запроса из шага 4:
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
Ожидаемый результат:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
Файл дампа для указанной выше схемы можно найти здесь . Важно создать пользователя для репликации потока данных отдельно, поскольку он не включен в файл дампа.
Нажмите клавишу exit , чтобы разорвать соединение с виртуальной машиной.
5. Настройка Cloud Spanner
Теперь вам нужно настроить целевой экземпляр Cloud Spanner, куда будут перенесены данные.
1. Создайте экземпляр Cloud Spanner.
Создайте экземпляр Cloud Spanner в том же регионе, что и ваши виртуальные машины Compute Engine, чтобы минимизировать задержку. Эта команда создаст небольшой экземпляр, подходящий для данного практического задания, с использованием 100 вычислительных блоков.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
Создание экземпляра может занять одну-две минуты.
6. Преобразуйте схему с помощью инструмента миграции Spanner (SMT).
Используйте веб-интерфейс Spanner Migration Tool (SMT), чтобы подключиться к одному из наших логических сегментов ( shard0_db ), проанализировать его схему и внести ряд расширенных изменений, прежде чем преобразовать его в Cloud Spanner.
1. Установите SMT.
Мы будем запускать веб-интерфейс SMT непосредственно из Cloud Shell. В терминале Cloud Shell загрузите и распакуйте последнюю версию SMT:
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
2. Подключитесь к исходной базе данных.
- Подтвердите свою сессию.
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(Примечание: При появлении запроса перейдите по указанной ссылке, чтобы авторизовать свою учетную запись, и вставьте код подтверждения обратно в терминал.)
- Для начала найдите внешний IP-адрес вашего первого физического сегмента, выполнив следующую команду в новой вкладке Cloud Shell:
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- Вывести подробные сведения об экземпляре целевого гаечного ключа, которые будут использоваться при настройке SMT.
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- Запустите веб-интерфейс:
gcloud alpha spanner migrate web --port=8080
- В правом верхнем углу окна Cloud Shell щелкните значок « Предварительный просмотр веб-страниц» (он выглядит как глаз) и выберите «Предварительный просмотр на порту 8080» . Это откроет пользовательский интерфейс SMT в новой вкладке браузера.
- В веб-интерфейсе SMT выберите «Подключиться к базе данных» .
- Укажите данные для подключения:
- Тип базы данных: MySQL
- Хост: (Вставьте IP-адрес из шага 2)
- Порт: 3306
- Пользователь:
datastream_user - Пароль:
complex_password_123 - Имя базы данных:
shard0_db
- Чтобы настроить базу данных Spanner, нажмите кнопку редактирования в правом верхнем углу.
- Введите данные вашего ключа Target Spanner:
- Идентификатор проекта: (Вставьте идентификатор проекта из шага 3)
- Экземпляр Spanner: (Вставьте идентификатор экземпляра из шага 3)
- Нажмите «Проверить соединение» .
- После завершения этого процесса нажмите «Подключиться» . SMT проанализирует исходную базу данных и представит базовую схему Spanner.
3. Применение изменений схемы
Теперь мы перестроим схему, чтобы она охватывала наши сложные сценарии миграции.
В редакторе схем пользовательского интерфейса SMT выполните следующие действия:
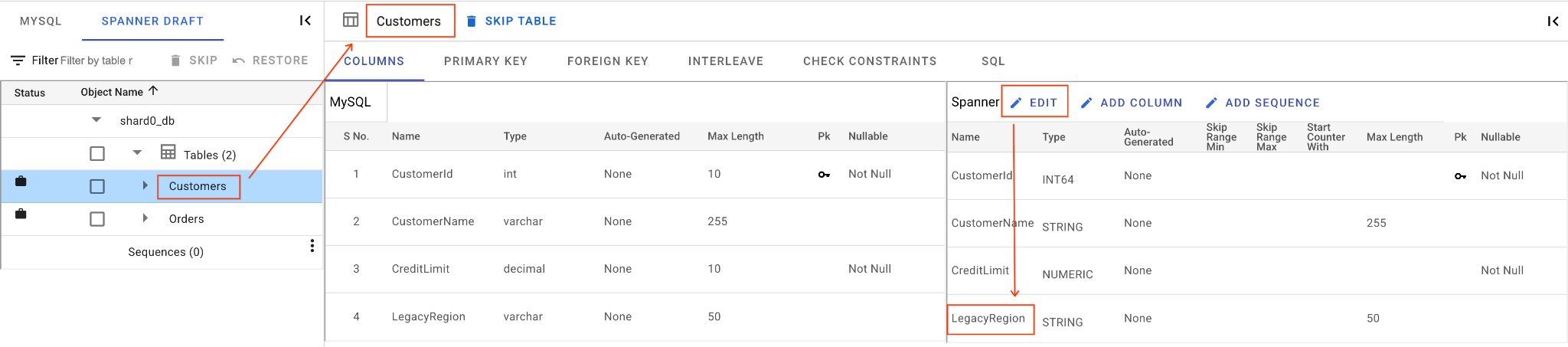
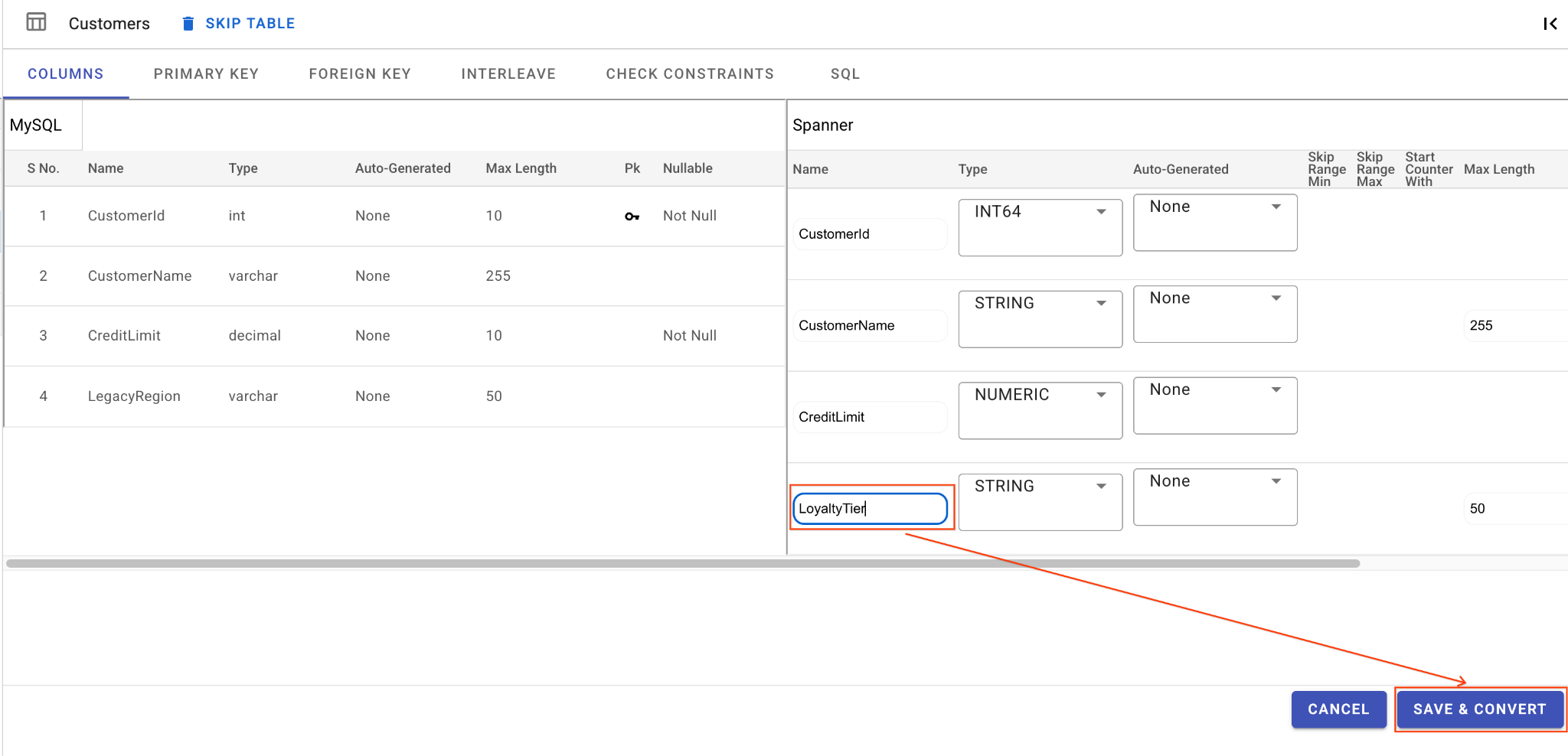
А. Переименуйте столбец LegacyRegion:
- Щелкните по таблице
Customersв левой панели навигации. По умолчанию откроется вкладка «Столбцы» . - Нажмите кнопку «Редактировать» в разделе «Гвоздь».
- Найдите столбец
LegacyRegionв представлении схемы Spanner. - Измените имя столбца Spanner на
LoyaltyTier, введя его в диалоговом окне имени столбца. - Нажмите «Сохранить и конвертировать» .
Б. Ослабить ограничение проверки:
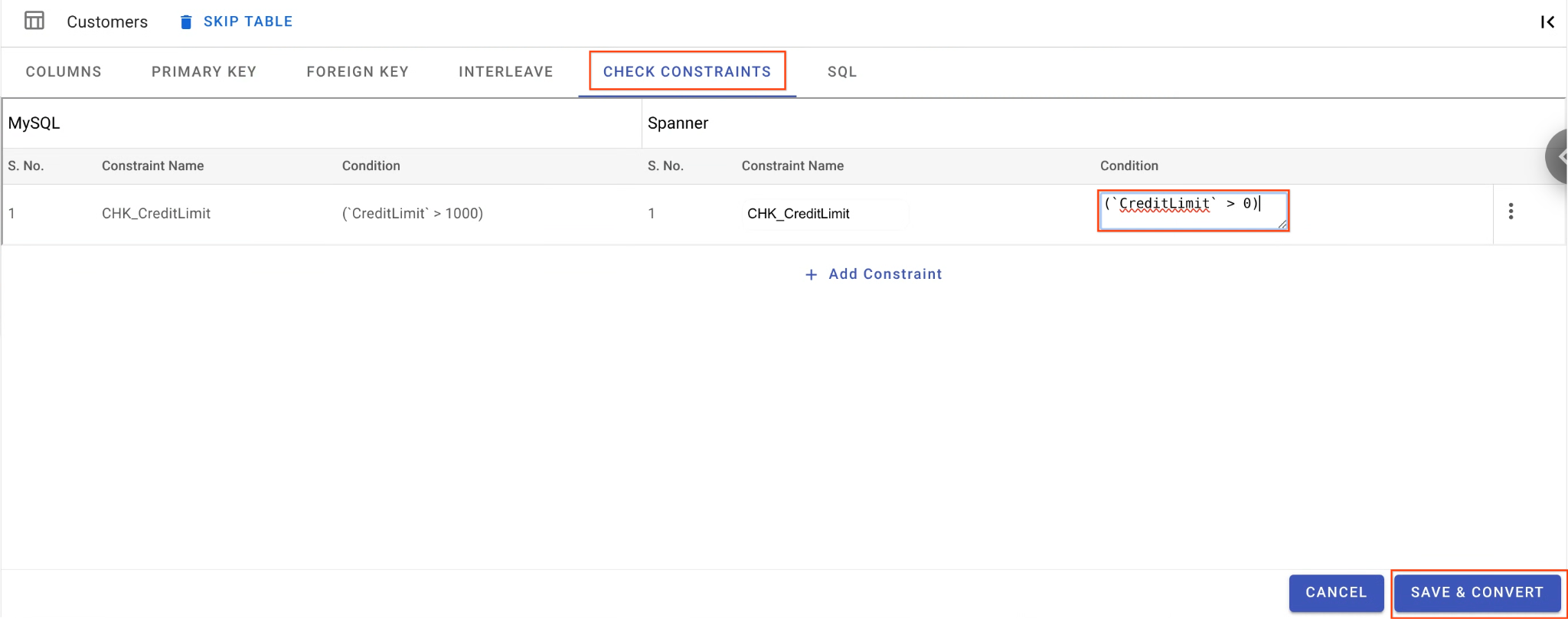
- Оставаясь в таблице
Customers, перейдите на вкладку «Проверка ограничений» . - Найдите ограничение
CHK_CreditLimit. Щелкните значок «Редактировать » (карандаш). - Измените условие с
CreditLimit > 1000наCreditLimit > 0(Это намеренно приведет к тому, что строки с более низкими кредитными лимитами не пройдут обратную миграцию и попадут в очередь недоставленных сообщений).
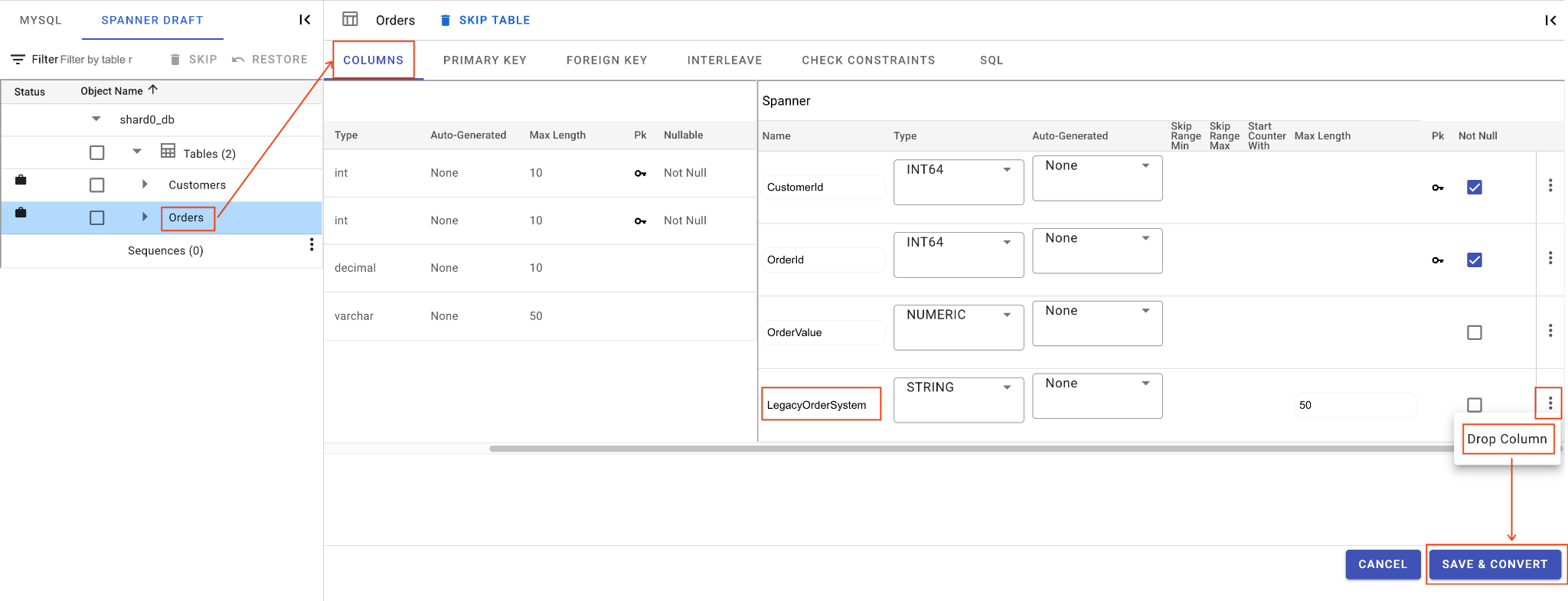
C. Удалите столбец LegacyOrderSystem:
- Щёлкните по таблице
Orders, по умолчанию откроется вкладка «Столбцы» . - Нажмите кнопку «Редактировать» в разделе «Гвоздь».
- Найдите столбец
LegacyOrderSystemв представлении схемы Spanner. - Щелкните значок меню с тремя точками рядом с ним и выберите «Переместить столбец» .
- Нажмите «Сохранить и конвертировать» .
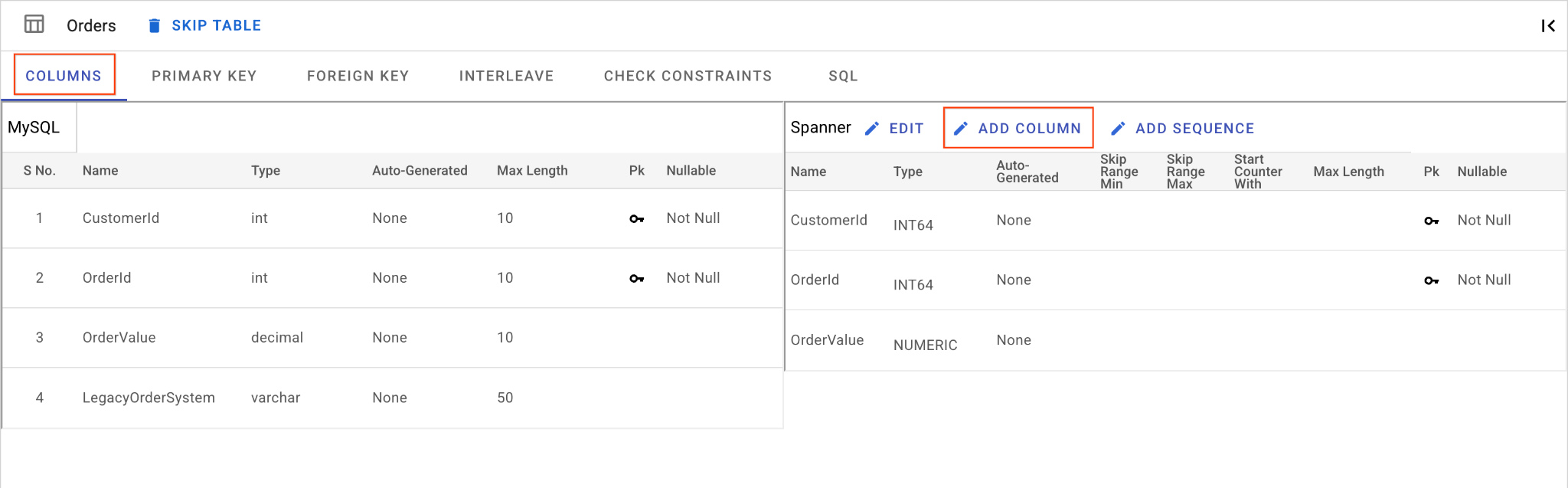
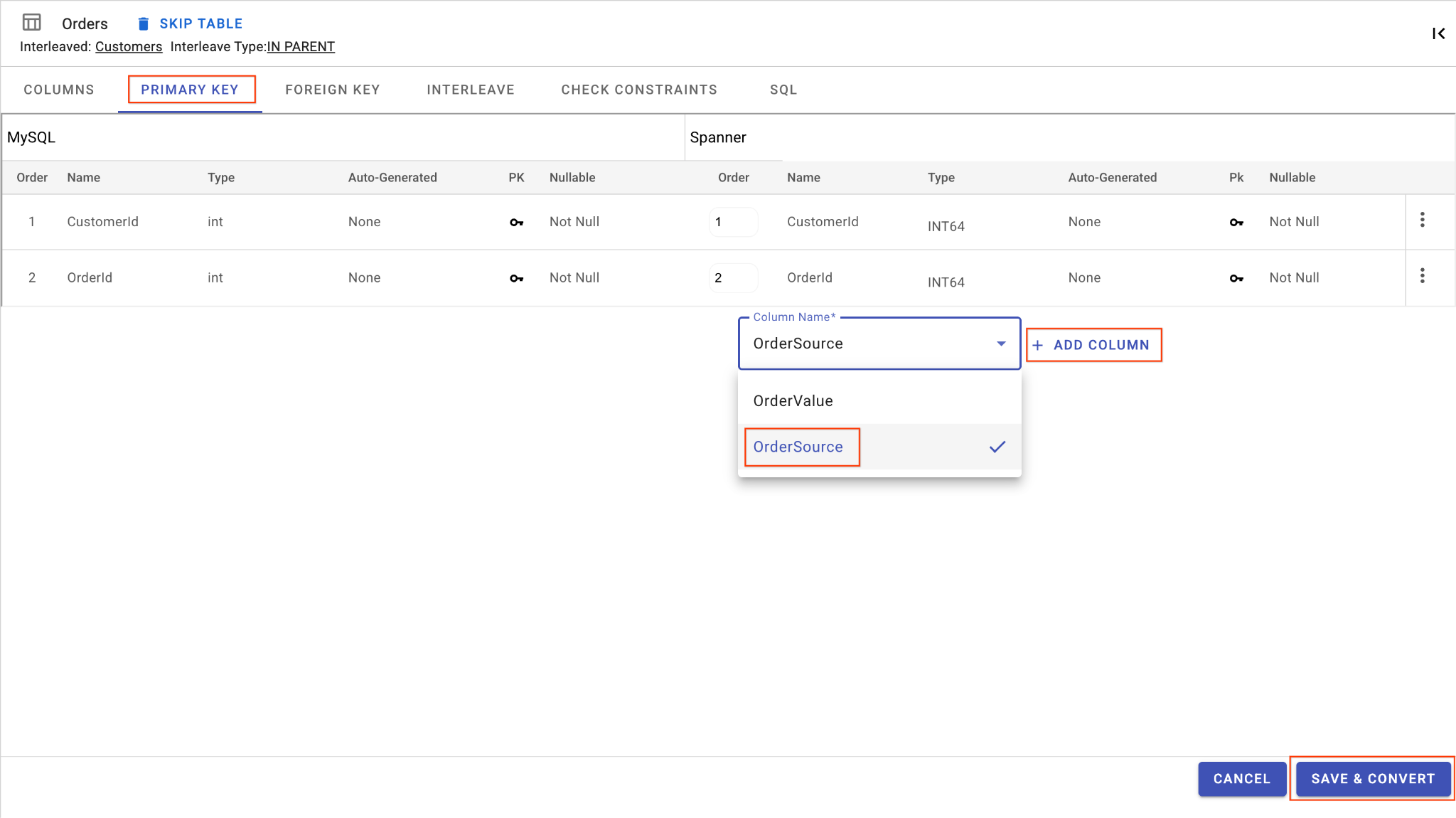
D. Добавьте столбец OrderSource и сделайте его первичным ключом:
- Оставаясь в таблице
Orders, нажмите «Добавить столбец» . Назовите егоOrderSource, установите типSTRINGс длиной50, без автоматической генерации и задайте параметрIsNullableвNo - Перейдите на вкладку «Первичный ключ» .
- Нажмите «Редактировать» и выберите
OrderSourceиз раскрывающегося списка «Название столбца». - Нажмите «Добавить столбец» , а затем «Сохранить и преобразовать» .
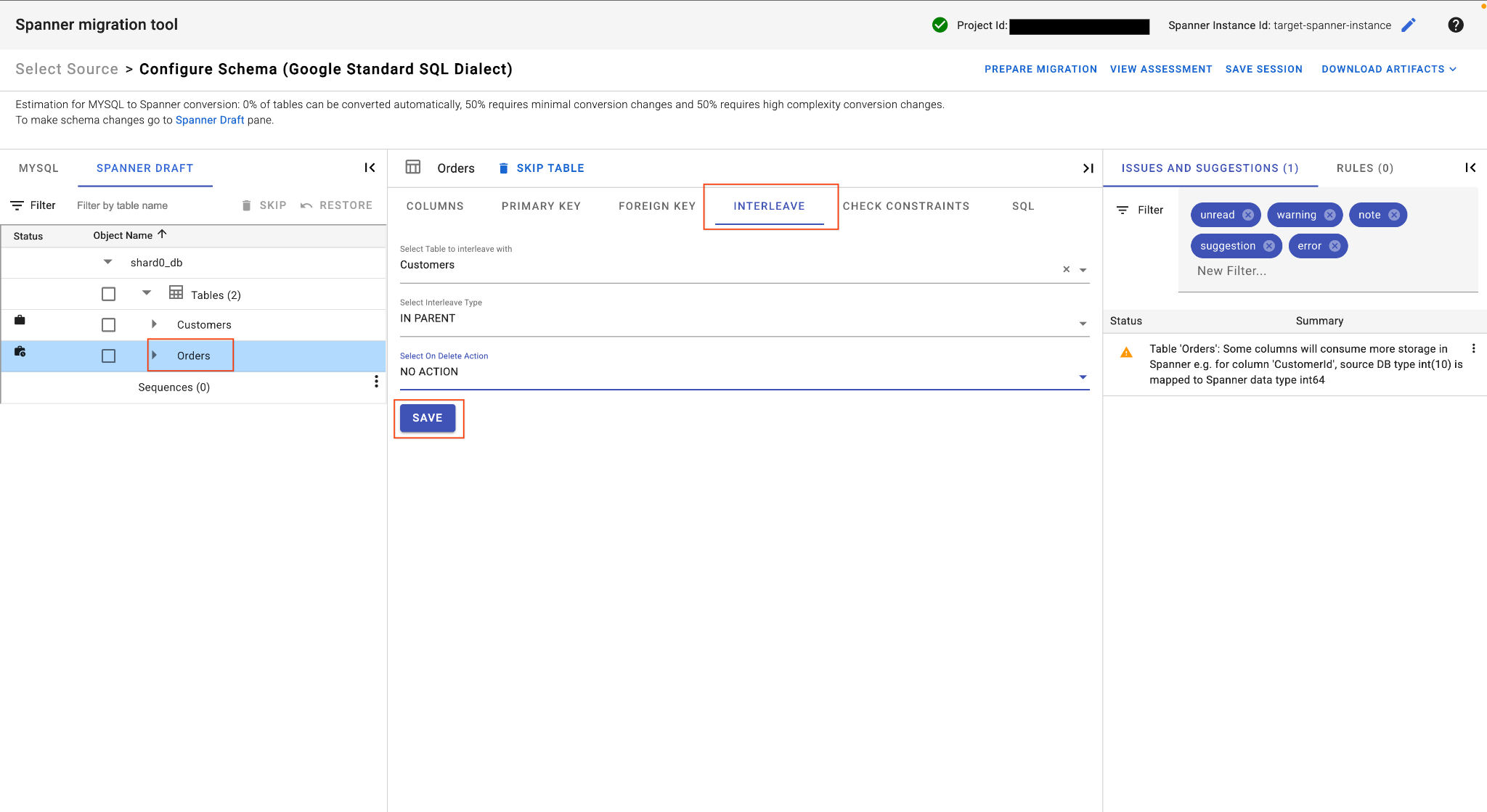
Е. Перемешайте таблицу заказов:
- Оставаясь в таблице
Orders, в главном окне таблицы найдите вкладку «Перемешивание» . - Установите родительскую таблицу на
Customers. - Выберите тип чередования «
IN PARENTи действиеNO ACTIONпри удалении». - Нажмите « Сохранить ».
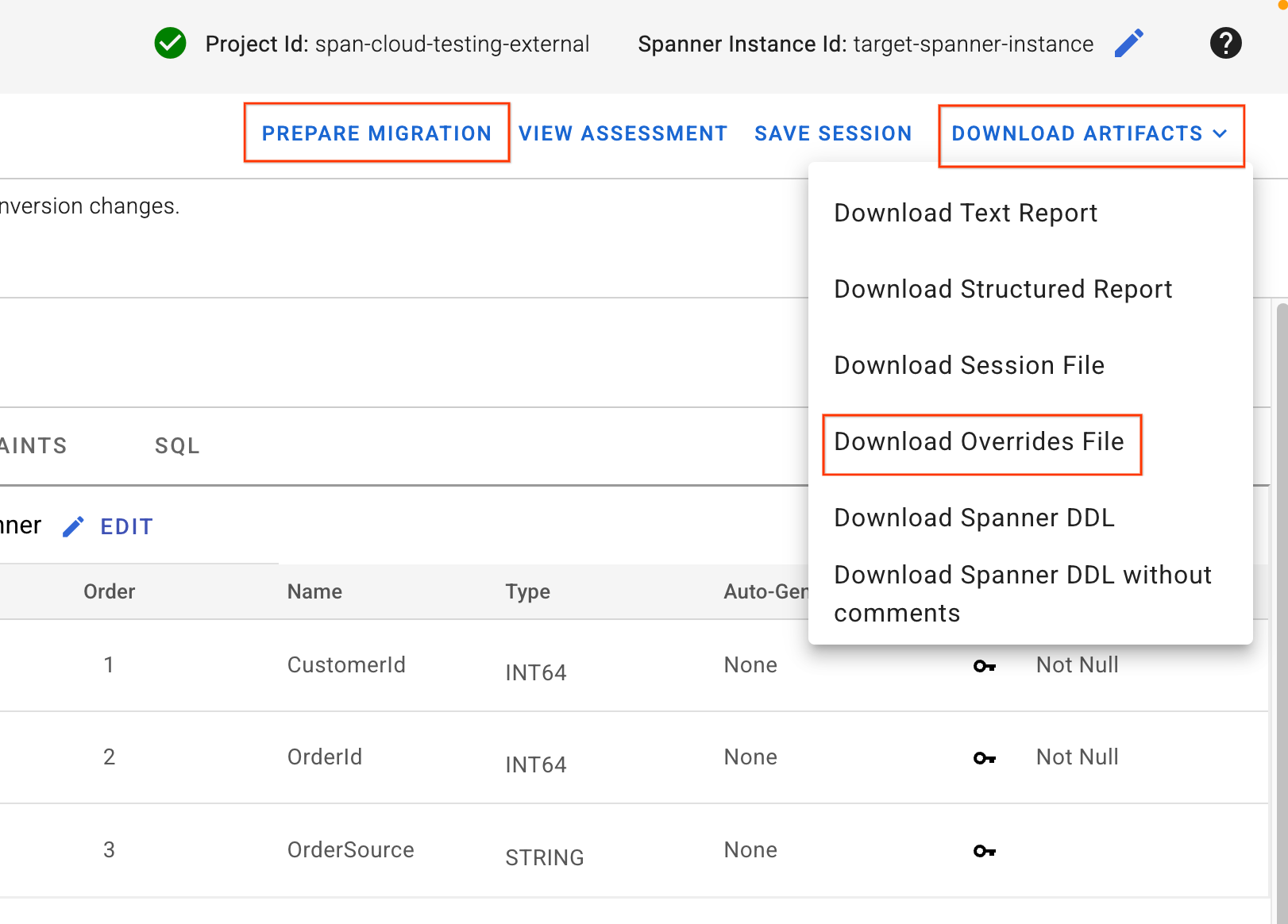
4. Загрузите файл переопределений и примените схему.
- В правом верхнем углу пользовательского интерфейса SMT найдите кнопку «Загрузить артефакты» . Выберите опцию «Загрузить файл переопределений» . Сохраните этот файл на свой локальный компьютер. Этот файл содержит все изменения в сопоставлении схем, которые мы только что внесли, и будет использоваться нашими конвейерами Dataflow.
- Нажмите «Подготовить миграцию» .
- Выберите в раскрывающемся списке режим миграции
Schema. - Введите вашу целевую базу данных Spanner:
sharded-target-db
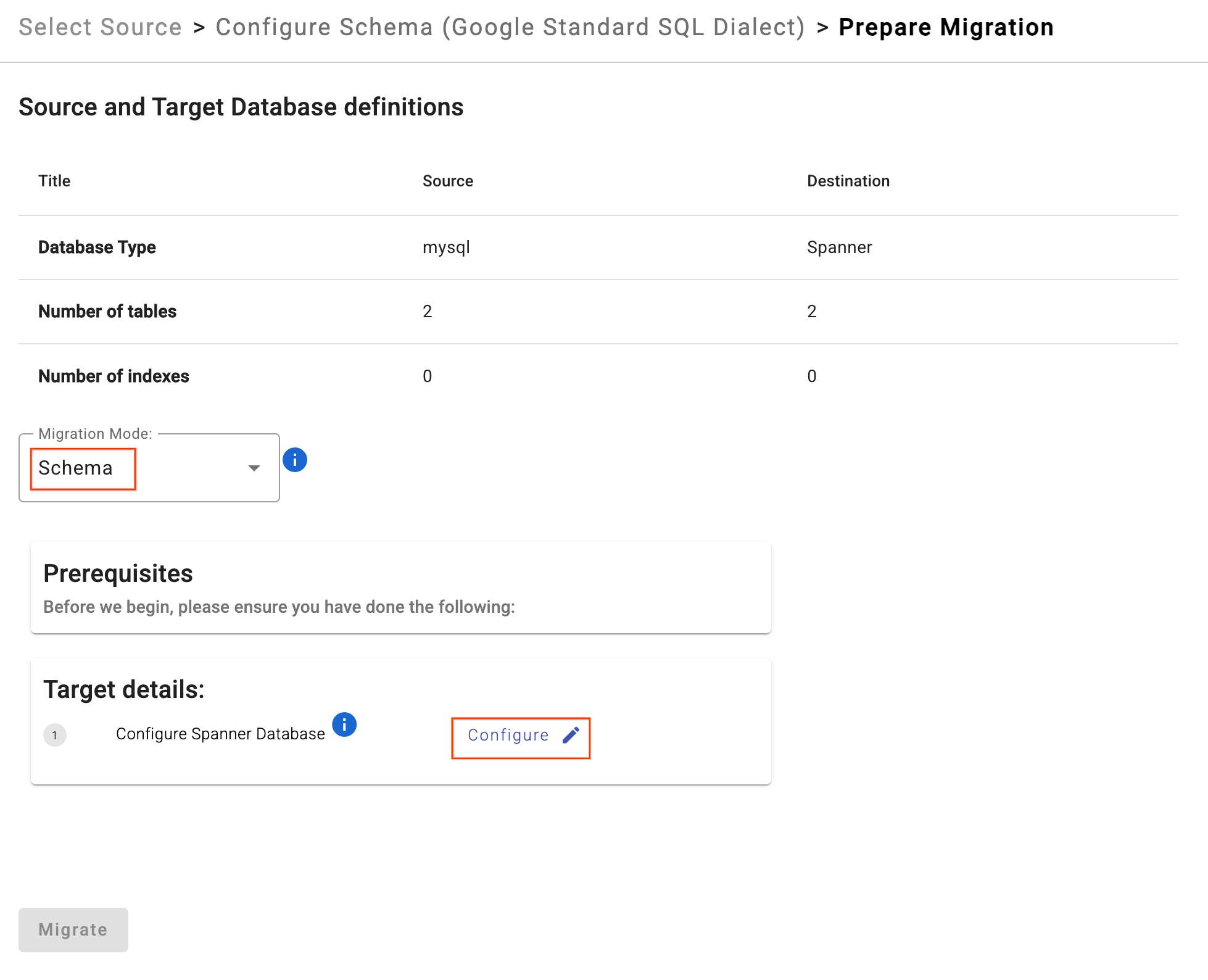
- Нажмите «Мигрировать».
- SMT выполнит DDL-скрипт и создаст базу данных Spanner. После завершения процесса SMT вы можете безопасно остановить его в Cloud Shell (
Ctrl+C).
5. Проверка схемы в Cloud Spanner.
Убедитесь, что таблицы созданы в базе данных Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Вы должны увидеть следующий результат:
table_name: Customers table_name: Orders
Необязательно: Если вы хотите проверить фактический DDL-скрипт Spanner, чтобы убедиться, что ваши ограничения проверки, чередование и дополнительные столбцы были применены, выполните следующую команду:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
Ожидаемый результат:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. Инициализация системы отслеживания изменений данных (CDC)
В этом разделе вы настроите «регистратор» для миграции. Настроив Datastream и Pub/Sub до начала массовой загрузки данных, вы гарантируете, что каждое изменение, внесенное в исходные базы данных, будет зафиксировано и поставлено в очередь, предотвращая потерю данных во время перехода. Эта настройка необходима для миграции в реальном времени.
Поскольку наша архитектура включает два физических сервера, нам необходимо создать два отдельных профиля источника Datastream и два потока Datastream. Оба потока будут записывать данные в один сегмент Google Cloud Storage (GCS), который будет выступать в качестве единого источника для нашего конвейера Dataflow.
1. Создайте сегмент облачного хранилища.
Для работы Datastream требуется место назначения для хранения зафиксированных событий изменений. Давайте создадим корзину GCS.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. Создание профилей подключения к потоку данных
Нам необходимы два отдельных профиля подключения к источнику MySQL (по одному для каждого физического сегмента) и один профиль подключения к целевому хранилищу Cloud Storage.
Получение исходных IP-адресов
Сначала получим внешние IP-адреса наших двух виртуальных машин Compute Engine и сохраним их в качестве переменных среды:
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
Создание профилей подключения к источнику (MySQL на Compute Engine)
Создайте профили подключения к Datastream, используя созданный ранее пользователь datastream_user .
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
Примечание: Datastream подключается к этим виртуальным машинам через их публичные IP-адреса, что разрешено, поскольку мы ранее добавили 0.0.0.0/0 в правила брандмауэра. В производственной среде следует строго разрешать доступ только к определенным диапазонам публичных IP-адресов Datastream.
Создание профиля подключения к целевому хранилищу (облачное хранилище):
Это указывает на корневой каталог вашего недавно созданного хранилища.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3. Создание потоков данных.
Теперь мы создадим два потока CDC. Поток 1 будет захватывать данные shard0_db и shard1_db . Поток 2 будет захватывать данные shard2_db и shard3_db . Оба потока записывают данные в один и тот же сегмент GCS в формате Avro.
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
Использование меньших значений параметра поворота файлов (5 МБ или 15 секунд) помогает нам быстрее увидеть повторяющиеся изменения во время выполнения практического задания.
Выполнение этой команды может занять некоторое время. Проверьте статус: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION .
4. Запустите потоки данных.
Активируйте оба потока, чтобы они начали записывать изменения.
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
Проверка статуса: Вы можете запустить команду gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION . Первоначально состояние будет STARTING , а через несколько мгновений изменится на ` RUNNING . Подождите, пока оба потока полностью заработают, прежде чем начинать миграцию в реальном времени.
5. Настройка механизма публикации/подписки для уведомлений GCS.
Необходимо, чтобы Dataflow немедленно получал уведомления, когда любой из потоков Datastream записывает новый файл в хранилище GCS. Мы настроим GCS для отправки уведомлений в одну тему Pub/Sub.
Создайте тему для публикации/подписки:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
Создать уведомление GCS
Уведомлять тему при создании любого объекта с префиксом data/ (который охватывает оба наших потока).
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Создать подписку Pub/Sub
Создайте подписку с рекомендуемым сроком подтверждения для Dataflow.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Пользовательское преобразование
Поскольку наша схема Spanner отличается от схемы MySQL (из-за столбцов, которые мы добавляли и удаляли через веб-интерфейс SMT), стандартная миграция Dataflow завершится неудачей. Dataflow необходимы инструкции по сопоставлению этих различий в процессе прямой (из MySQL в Spanner) и обратной (из Spanner в MySQL) миграции.
Кроме того, поскольку мы выполняем сегментированную обратную миграцию, Dataflow нуждается в механизме маршрутизации, чтобы определить, к какому логическому сегменту ( shard0_db , shard1_db и т. д.) относится обновленная строка Spanner во время обратной репликации.
Мы добьемся этого, написав JAR-файл пользовательского преобразования, используя предоставленный Google шаблон Spanner Custom Shard.
1. Скачайте шаблон пользовательского шарда.
В Cloud Shell загрузите репозиторий шаблонов Google Cloud Dataflow и перейдите в папку с пользовательскими сегментами:
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. Настройте логику преобразования данных.
Нам необходимо отредактировать файл CustomTransformationFetcher.java .
- Прямая миграция (
toSpannerRow): Заполняет недавно добавленный столбецOrderSource, используя столбецLegacyOrderSystemиз MySQL. - Обратная миграция (
toSourceRow): Восстанавливает заполненный удаленный столбецLegacyOrderSystem, необходимый MySQL, получая его изOrderSourceот Spanner.
Отредактируйте файл CustomTransformationFetcher.java . Вместо того чтобы вручную открывать текстовый редактор, выполните следующую команду, чтобы автоматически перезаписать файл шаблона нашей пользовательской логикой:
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3. Настройте логику обратного сегментирования.
Dataflow использует CustomShardIdFetcher.java во время обратной репликации для определения того, куда следует направлять изменения Spanner. Мы будем использовать первичный ключ CustomerId и логику по модулю ( %4 ) для динамической маршрутизации записей обратно в их правильный логический сегмент.
Отредактируйте файл CustomShardIdFetcher.java с помощью команды `cat` и полностью замените его содержимое следующим кодом:
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. Соберите и загрузите JAR-файл.
Теперь, когда наша собственная Java-логика написана, нам нужно скомпилировать её в JAR-файл и загрузить в созданный ранее сегмент Google Cloud Storage, чтобы Dataflow мог получить к ней доступ.
Выполните следующие команды в Cloud Shell:
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9. Массовая миграция данных из MySQL в Spanner.
После того, как схема Spanner настроена и создан наш JAR-файл пользовательского преобразования, мы можем скопировать существующие данные из вашей базы данных MySQL в Cloud Spanner. Вы будете использовать гибкий шаблон потока данных Sourcedb to Spanner , предназначенный для массового копирования данных из баз данных, доступных по JDBC, в Spanner.
1. Загрузите файл переопределений схемы.
В разделе 6 вы загрузили JSON-файл Spanner Overrides с помощью веб-интерфейса SMT. Нам необходимо загрузить его в наш бакет GCS, чтобы Dataflow мог использовать его для сопоставления различий в схеме (например, переименованных столбцов).
- В Cloud Shell нажмите на меню с тремя точками (Дополнительно) и выберите «Загрузить» .
- Выберите загруженный ранее JSON-файл с настройками переопределений (например,
spanner_overrides.json). - Переместите его в свой контейнер GCS:
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. Создайте и загрузите файл конфигурации шардинга.
Dataflow необходимо знать, как подключиться ко всем четырем логическим сегментам на ваших двух физических виртуальных машинах. Для этого мы создадим файл sharding.json .
Для генерации и загрузки конфигурации выполните следующие действия в Cloud Shell:
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3. Запустите задание массовой миграции данных.
Мы будем использовать шаблон Sourcedb to Spanner Flex Template. Поскольку это сегментированная миграция с пользовательскими преобразованиями, мы передадим файл Overrides, конфигурацию сегментирования и наш пользовательский Java JAR-файл.
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
Ключевые параметры объяснены:
-
sourceConfigURL: Путь к созданному нами файлуsharding.json. Он указывает Dataflow, как подключаться ко всем четырем логическим сегментам MySQL на двух физических виртуальных машинах. -
schemaOverridesFilePath: Путь к JSON-файлу, загруженному из веб-интерфейса SMT. Это указывает Dataflow, как обрабатывать внесенные нами изменения в схему (например, удаление столбцаLegacyRegionи ужесточение ограничения проверки). -
transformationJarPath: Путь к скомпилированному Java JAR-файлу, созданному в предыдущем разделе, в системе контроля версий (GCS). Он содержит фактический код для выполнения наших пользовательских преобразований. -
transformationClassName: Полное имя Java-класса внутри нашего JAR-файла, реализующего логику прямой миграции (com.custom.CustomTransformationFetcher). -
outputDirectory: Местоположение в GCS, куда Dataflow будет записывать свои временные файлы и, что наиболее важно, файлы очереди недоставленных сообщений (DLQ). -
maxWorkers,numWorkers: Управляет масштабированием задачи Dataflow. Для этого небольшого набора данных установите низкое значение. -
instanceId,databaseId,projectId: Указывает целевой экземпляр Cloud Spanner и базу данных.
Примечание по сети: Это задание подключается к экземпляру Cloud SQL через его публичный IP-адрес. Это возможно, потому что вы ранее добавили 0.0.0.0/0 в список авторизованных сетей экземпляра. Это позволяет виртуальным машинам Dataflow, имеющим внешние IP-адреса, подключаться к базе данных.
4. Мониторинг задания потока данных.
Вы можете отслеживать ход выполнения задания в консоли Google Cloud:
- Перейдите на страницу заданий Dataflow: Перейдите в раздел «Задания Dataflow».
- Найдите задание с именем
mysql-sharded-bulk-to-spanner-...и щелкните по нему. - Проанализируйте график выполнения задания и показатели. Дождитесь, пока статус задания изменится на «Успешно» . Это займет приблизительно 5-15 минут.
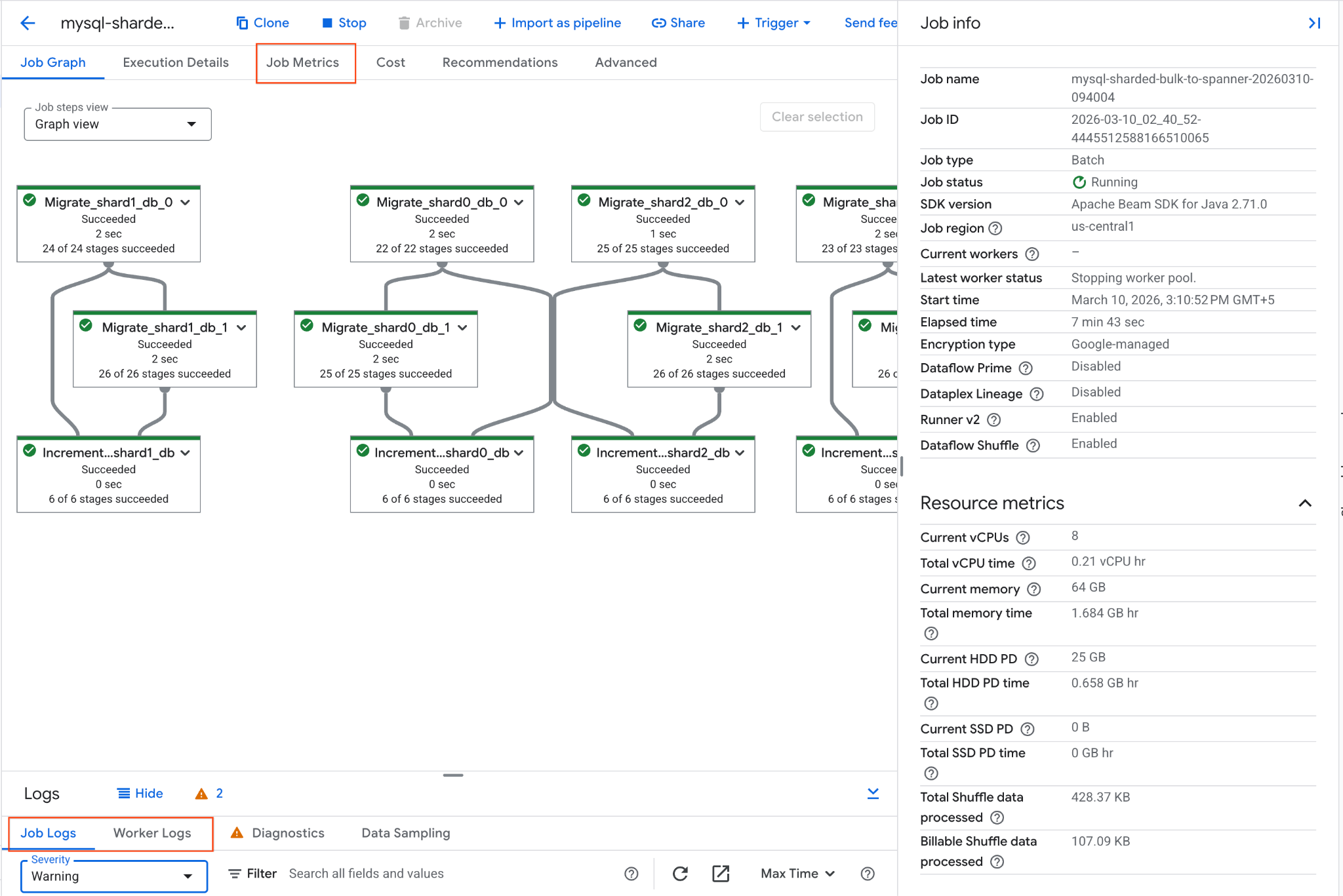
- Если в процессе выполнения задания возникнут проблемы, просмотрите вкладку «Журналы» на странице сведений о задании Dataflow, чтобы ознакомиться с сообщениями об ошибках.
- Метрики задания предоставляют более подробную информацию о ходе выполнения задания и потреблении ресурсов, таких как пропускная способность и загрузка ЦП.
5. Проверьте данные в Cloud Spanner и просмотрите очередь недоставленных писем (DLQ).
После успешного завершения задания Dataflow нам необходимо убедиться, что данные поступили в целости и сохранности, и проверить записи, которые мы специально запрограммировали на сбой.
А. Проверьте общее состояние перенесенных данных:
Используйте интерфейс командной строки gcloud , чтобы выполнить несколько быстрых проверок работоспособности вашей объединенной базы данных Spanner и убедиться, что корректные записи были перенесены правильно, а наш пользовательский JAR-файл заполнил дополнительный столбец.
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
Ожидаемый результат:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- Все строки в таблице "Клиенты" были успешно перенесены.
- Мы обнаружили одну ошибку в таблице
Ordersиз-за ошибкиINTERLEAVE IN PARENTв Spanner —CustomerId 99является дочерним элементом-сиротой, поскольку в таблицеCustomersнет соответствующей строки.
Б. Проверьте преднамеренные ошибки в анкете DLQ:
Указанная выше ошибка задокументирована в папке «Очередь недоставленных сообщений» (DLQ), созданной конвейером массовой миграции.
- Перейдите в раздел «Облачное хранилище» в консоли Google Cloud.
- Перейдите в свой бакет и откройте папку
bulk-migration/dlq/severe. - Изучите JSON-файлы. Вы найдете строку
Ordersс «оставшимся без имени»CustomerId. - Ошибки в очереди недоставленных запросов при массовой миграции можно повторить, выполнив действия, описанные здесь .
Первоначальная массовая загрузка данных из Cloud SQL в Cloud Spanner завершена. Следующий шаг — настройка репликации в реальном времени для фиксации текущих изменений.
10. Начать миграцию в реальном времени (CDC)
Теперь, когда загрузка больших объемов данных завершена, вы запустите задачу непрерывной потоковой передачи данных Dataflow. Эта задача будет считывать события Change Data Capture (CDC), которые Datastream записывает в ваш сегмент GCS, и применять эти изменения в Cloud Spanner практически в режиме реального времени.
Мы также протестируем этот конвейер, внедрив как корректные, так и намеренно некорректные данные, чтобы понаблюдать, как Dataflow обрабатывает репликацию в реальном времени и направляет ошибки в очередь недоставленных сообщений (DLQ).
1. Создайте файл конфигурации сегментирования для миграции в реальном времени.
В отличие от массовой миграции (которая использует строки подключения JDBC), конвейер миграции в реальном времени считывает события Datastream из GCS. Для этого требуется совершенно другая конфигурация JSON, которая сопоставляет имена потоков Datastream и базы данных с вашими логическими сегментами Spanner.
Для создания и загрузки конфигурации активного шардинга выполните следующие действия в Cloud Shell:
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. Запустите задание потока данных для миграции в реальном времени.
Запустите потоковое задание Dataflow для чтения из GCS и записи в Spanner. Этот шаблон будет использовать уведомления GCS Pub/Sub для мгновенной обработки новых файлов.
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
Ключевые параметры
-
gcsPubSubSubscription: Подписка Pub/Sub, которая отслеживает уведомления о новых файлах от GCS. Это позволяет заданию обрабатывать изменения мгновенно по мере их записи в Datastream. -
inputFileFormat="avro": Указывает Dataflow ожидать файлы Avro из Datastream. Это должно соответствовать конфигурации "Destination" вашего Datastream (например,avroFileFormatилиjsonFileFormat). -
shardingContextFilePath: JSON-файл, сопоставляющий потоки Datastream с логическими сегментами. -
dlqRetryMinutes: Количество минут между повторными попытками обработки недоставленных сообщений. По умолчанию —10. -
dlqMaxRetryCount: Максимальное количество попыток повторной обработки временных ошибок через DLQ. Значение по умолчанию —500.
Отслеживайте запуск задания в консоли заданий Dataflow .
3. Внедрение данных в реальном времени и инициирование сбоев.
Пока запускается задача потоковой обработки данных Dataflow (это может занять 3-5 минут), давайте подключимся по SSH к нашей первой физической виртуальной машине MySQL и вставим несколько новых записей. Мы вставим одну действительную запись и одну недействительную.
Подключитесь по SSH к первому физическому сегменту:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Войдите в MySQL:
sudo mysql
Выполните следующие операции вставки в базу данных shard1_db :
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
Чтобы вернуться к командной строке Cloud Shell, снова введите команду exit .
4. Проверьте данные о миграции в режиме реального времени и ознакомьтесь с данными CDC DLQ.
Теперь, когда мы ввели данные, Datastream будет перехватывать события CDC, а Dataflow попытается применить их к Spanner.
А. Проверьте корректность изменений DML в программе Spanner.
Выполните следующие запросы, чтобы убедиться, что события INSERT , UPDATE и DELETE успешно достигли Spanner, и что пользовательское преобразование сработало как при вставке, так и при обновлении.
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Ожидаемый результат:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
Примечание: Если какой-либо запрос не выдает ожидаемый результат, подождите минуту и попробуйте снова, так как потоковые обработчики могут все еще обрабатывать очередь.
Б. Проверьте наличие преднамеренной ошибки в анкете DLQ:
Поскольку CustomerId = 99999 нет родителя в таблице Customers , Spanner должен был отклонить запрос, а Dataflow — безопасно перенаправить его в очередь недоставленных сообщений.
- Перейдите в раздел «Облачное хранилище» в консоли Google Cloud.
- Перейдите в свой бакет и откройте папку
live-migration/dlq/severe/. - You should see newly generated JSON files. Click on them to inspect the contents. You will see the details of
CustomerId = 99999and the specific Spanner error message:NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written." - Live Migration DLQ errors can be retried by running the dataflow template with
runMode=retryDLQset.
5. Handling DLQ Errors
Errors in the severe/ directory require manual intervention. Let's fix the data issue and reprocess the failed event.
A. Fix the Data in the Source
The error occurred because the parent customer record CustomerId = 99999 is missing. Let's insert it into the source MySQL database.
SSH into the MySQL instance again:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Log into MySQL using sudo mysql and insert the missing parent row into shard1_db :
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
Type exit to return to Cloud Shell.
B. Run the retryDLQ Dataflow Job
To reprocess events from the severe/ DLQ, you launch the same Dataflow template but in retryDLQ mode. This mode specifically reads from the deadLetterQueueDirectory/severe path, re-runs them through your custom transformations, and applies them to Spanner.
Launch the job in retryDLQ mode:
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
Key Parameter Changes for Retry
-
runMode="retryDLQ": Tells the template to read from thesevereDLQ directory. - Removed
gcsPubSubSubscription: Not needed as we are not reading from the live Datastream GCS bucket.
Monitor the Retry Process:
Like the main CDC pipeline, retryDLQ is a streaming pipeline that will remain RUNNING till manually cancelled.
- Go to the Dataflow Job page for
$JOB_NAME_RETRY. - Under the Metrics pane, look for these two counters:
-
elementsReconsumedFromDeadLetterQueue: Evaluates when the error files are being fetched. -
Successful events: Increments when the record is written into Spanner. - Check the
severe/directory for recurring failures. - Once Successful events has incremented by the number of items you wanted to retry (1 in our test case), go to the next verification step.
C. Verify the Retried Data
After the failed record is retried (might take some time to succeed), check Spanner to see if the child row was migrated successfully:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
You should now see the row:
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
Also, check the $DLQ_DIR_CDC/severe/ folder in GCS. The processed files should have been moved or deleted, indicating successful reprocessing.
11. Set Up Reverse Replication (Spanner to MySQL)
To handle scenarios where you might need to rollback or keep the original MySQL database in sync with Spanner for a transitional period, you can set up reverse replication.
This pipeline uses Spanner Change Streams to capture live modifications in Spanner. It then uses our Custom Transformation JAR to reverse-map the schema differences, and our Custom Sharding JAR to calculate exactly which physical MySQL VM and logical shard the update should be written back to.
1. Create a Spanner Change Stream
First, you need to create a change stream in your Spanner database to track changes on the Customers and Orders tables.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
This change stream will now record all data modifications to the specified tables.
2. Create a Spanner Database for Dataflow Metadata
The Spanner to SourceDB Dataflow template requires a separate Spanner database to store metadata for managing the change stream consumption.
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Prepare Cloud SQL Connection Configuration for Dataflow
The Dataflow template needs a JSON file in Cloud Storage containing the connection details for the target Cloud SQL database.
Create a local file named shard_config.json :
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
Upload this file to your GCS bucket:
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. Run the Reverse Replication Dataflow Job
Launch the Dataflow job using the Spanner_to_SourceDb Flex Template.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
Key Parameters
-
changeStreamName: The name of the Spanner change stream to read from. -
metadataInstance, metadataDatabase: The Spanner instance/database to store the metadata used by the connector to control the consumption of the change stream API data. -
sourceShardsFilePath: The GCS path to yourshard_config.json. -
filtrationMode: Specifies how to drop certain records based on a criteria. Defaults toforward_migration(filter records written using the forward migration pipeline) -
shardingCustomJarPath: The GCS path to the compiled Java JAR file we built earlier. -
shardingCustomClassName: The fully qualified class name (com.custom.CustomShardIdFetcher) that executes our custom%4modulo math to dynamically determine which logical shard should receive the record.
Network Note: The Dataflow workers will connect to the Cloud SQL instance using the Public IP specified in shard_config.json . This connection is permitted due to the 0.0.0.0/0 entry in the Cloud SQL instance's Authorized Networks.
Monitor the job startup in the Dataflow Jobs Console .
5. Inject Spanner Data and Trigger Intentional Failures
Wait for the Dataflow job to enter the Running state (this can take ~5 minutes). Then, let's execute a full suite of queries ( INSERT , UPDATE , DELETE ) directly into Spanner, along with an intentional failure to test the reverse DLQ.
Run the following in Cloud Shell:
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. Verify Reverse Replication Data and Inspect the DLQ
Let's confirm that our Custom Sharding JAR successfully routed CustomerId 88 to shard0_db on our first physical VM, and that the Custom Transformation JAR successfully stripped "_TIER" from the region.
A. Verify the Valid Record in MySQL:
SSH into the first physical shard:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Log into MySQL and query shard0_db :
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
Expected output in Cloud SQL should reflect the changes made in Spanner.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
Тип
exit
to return to Cloud Shell.
This confirms that the reverse replication pipeline is functioning, synchronizing changes from Spanner back to Cloud SQL.
B. Check the Intentional Failure in the DLQ
Because our new Customers record has a CreditLimit of 500 (which violates the strict > 1000 check constraint we defined in our source MySQL database), Dataflow safely caught the error.
- Navigate to Cloud Storage in the Google Cloud Console.
- Go to your bucket and open the
dlq/severe/folder. - Open the JSON file to see the rejected
Customersrecord and the exact check constraint violation error. - Reverse Replication DLQ errors can be retried by running the dataflow template with
runMode=retryDLQset.
12. Clean Up Resources
To avoid incurring further charges to your Google Cloud account, delete the resources created during this codelab.
Set Environment Variables (if needed)
If your Cloud Shell session timed out or you opened a new terminal, you will need to re-export your environment variables before running the cleanup commands.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
Stop Dataflow Streaming Jobs
List your jobs to find the Job IDs of the running dataflow jobs. Export JOB_ID_CDC and JOB_ID_REVERSE accordingly.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Cancel the Datastream to Spanner (Live Migration) job and its retry job:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
Cancel the Spanner to Cloud SQL (Reverse Replication) job:
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Delete Datastream Resources
Stop and Delete the Stream:
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Delete the Source MySQL VMs (Compute Engine)
Delete the two Compute Engine instances that simulated the on-prem MySQL physical shards.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
Delete Firewall Rules
Remove the network firewall rules created to allow SSH access and Datastream connectivity to your VMs. (Note: If you used different names for your firewall rules earlier in the codelab, adjust them here).
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
Delete Pub/Sub Resources
Delete Subscription:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Delete Topic:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Delete Cloud Spanner Instance
Delete the Cloud Spanner instance (this automatically deletes both the sharded-target-db and the migration-metadata-db databases inside it).
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Delete GCS Bucket and Contents
Finally, delete the Cloud Storage bucket that holds the Datastream files, Dataflow configs, and Dead Letter Queues. The rm -r command recursively deletes the bucket and all its contents.
gcloud storage rm --recursive gs://${BUCKET_NAME}
Delete Local Cloud Shell Files
To clean up the local files and directories generated in your Cloud Shell during this codelab, run the following commands:
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates