
1. ก่อนเริ่มต้น
Codelab นี้จะแนะนำวิธีย้ายข้อมูลฐานข้อมูล MySQL ภายในองค์กรที่แยกส่วนไปยังฐานข้อมูล Cloud Spanner ด้วยภาษา GoogleSQL คุณจะใช้บริการของ Google Cloud ซึ่งรวมถึงเครื่องมือย้ายข้อมูล Spanner (SMT), Dataflow, Datastream, PubSub และ Google Cloud Storage
สิ่งที่คุณจะได้เรียนรู้
- สภาพแวดล้อมแบบ Shard คืออะไรและวิธีตั้งค่า
- วิธีใช้เว็บ UI ของเครื่องมือย้ายข้อมูล Spanner (SMT) เพื่อแปลงสคีมา MySQL เป็นสคีมาที่เข้ากันได้กับ Spanner และทำการแก้ไขสคีมาขั้นสูง
- วิธีย้ายข้อมูลจำนวนมากจากอินสแตนซ์ MySQL ที่มีการแชร์ไปยัง Cloud Spanner โดยใช้ Dataflow
- วิธีตั้งค่าการจำลองอย่างต่อเนื่อง (CDC) จากอินสแตนซ์ MySQL ที่มีการแบ่งกลุ่มไปยัง Cloud Spanner โดยใช้ Datastream และ Dataflow
- วิธีกำหนดค่าการจำลองแบบย้อนกลับจาก Spanner กลับไปยังอินสแตนซ์ MySQL ที่มีการแบ่งกลุ่ม
- วิธีใช้การเปลี่ยนรูปแบบที่กำหนดเองเพื่อป้อนข้อมูลในคอลัมน์เพิ่มเติมระหว่างการย้ายข้อมูลแบบกลุ่ม แบบเรียลไทม์ และแบบย้อนกลับ
- วิธีกําหนดค่าการแปลงการแยกส่วนโดยใช้คีย์หลัก
สิ่งที่ Codelab นี้ไม่ครอบคลุม
- เครือข่ายที่กำหนดเองขั้นสูง
- การสร้างเทมเพลต Dataflow ที่กำหนดเองตั้งแต่ต้น
- การปรับแต่งประสิทธิภาพการย้ายข้อมูล
- การย้ายข้อมูลแอปพลิเคชัน: Codelab นี้มุ่งเน้นที่ชั้นฐานข้อมูล (สคีมาและข้อมูล) แต่ไม่ได้ครอบคลุมกระบวนการปฏิบัติงานในการติดตั้งใช้งานใหม่หรือการย้ายข้อมูลบริการแอปพลิเคชัน
สิ่งที่คุณต้องมี
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- สิทธิ์ IAM ที่เพียงพอในการเปิดใช้ API และสร้าง/จัดการทรัพยากร Spanner, Dataflow, Datastream และ GCS แม้ว่าบทบาท
Ownerของโปรเจ็กต์จะง่ายที่สุดสำหรับ Codelab แต่เราจะกล่าวถึงบทบาทที่เฉพาะเจาะจงมากขึ้นใน "การตั้งค่าสภาพแวดล้อม" - เราจะจัดสรร VM ของ Compute Engine ขนาดเล็กในระหว่างขั้นตอนการตั้งค่าเพื่อจำลองเซิร์ฟเวอร์ในองค์กร ตรวจสอบว่าโควต้าโปรเจ็กต์อนุญาตให้สร้าง VM
- เว็บเบราว์เซอร์ เช่น Google Chrome
- มีความคุ้นเคยเบื้องต้นกับคอนโซล Google Cloud และเครื่องมือบรรทัดคำสั่ง เช่น
gcloud - สิทธิ์เข้าถึงสภาพแวดล้อมของ Shell เราขอแนะนำให้ใช้ Cloud Shell เนื่องจากมี
gcloud
ดูรายละเอียดเพิ่มเติมเกี่ยวกับการตั้งค่าข้างต้นได้ในส่วนการตั้งค่าสภาพแวดล้อม
2. ทำความเข้าใจกระบวนการย้ายข้อมูล
การย้ายข้อมูลฐานข้อมูลที่แยกส่วนเกี่ยวข้องกับการรวมอินสแตนซ์ MySQL หลายอินสแตนซ์ทั้งทางกายภาพและเชิงตรรกะไว้ในฐานข้อมูล Spanner เดียวที่ปรับขนาดในแนวนอนได้ ส่วนนี้จะอธิบายสถาปัตยกรรมและเครื่องมือหลักที่ใช้ในการย้ายข้อมูล
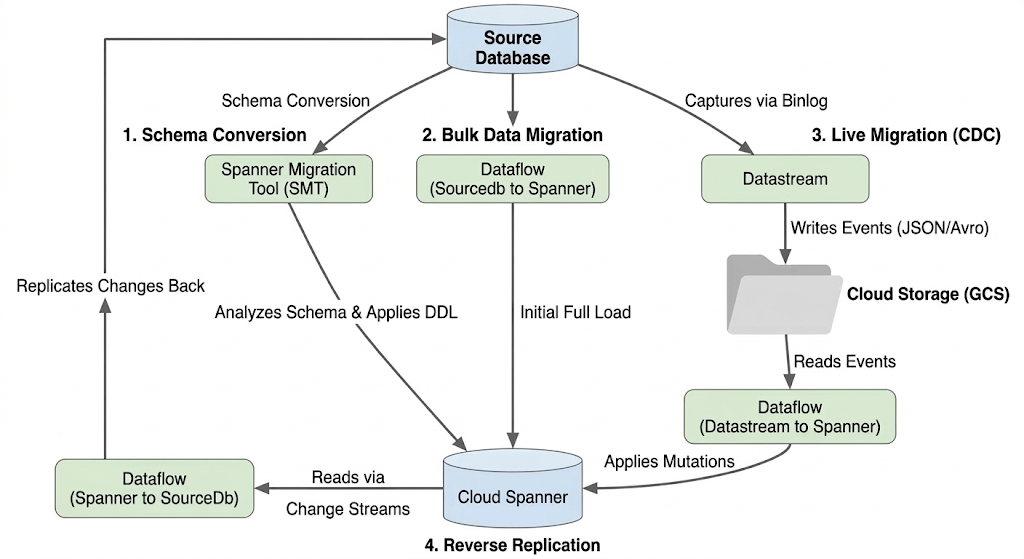
สถาปัตยกรรมโฟลว์การย้ายข้อมูล
กระบวนการย้ายข้อมูลมีขั้นตอนต่อไปนี้
1. การแปลงสคีมา
- วัตถุประสงค์: เพื่อแปลงสคีมาฐานข้อมูลต้นทางเป็นสคีมา Cloud Spanner ที่เข้ากันได้
- เครื่องมือ: เครื่องมือย้ายข้อมูล Spanner (SMT)
- กระบวนการ: SMT จะวิเคราะห์สคีมาของฐานข้อมูลต้นทางและสร้างภาษานิยามข้อมูล (DDL) ของ Spanner ที่เทียบเท่า ในอินสแตนซ์ Spanner เป้าหมาย ระบบจะสร้างฐานข้อมูลและใช้ DDL โดยอัตโนมัติ
2. การย้ายข้อมูลจำนวนมาก
- วัตถุประสงค์: เพื่อทำการโหลดข้อมูลที่มีอยู่ทั้งหมดในเบื้องต้นจากฐานข้อมูลต้นทางไปยังตาราง Spanner ที่จัดสรร
- เครื่องมือ: Dataflow โดยใช้
Sourcedb to Spannerเทมเพลตที่ Google จัดเตรียมให้ - กระบวนการ: งาน Dataflow นี้จะอ่านข้อมูลทั้งหมดจากตารางแหล่งที่มาระบุและเขียนลงในตาราง Spanner ที่เกี่ยวข้อง โดยจะดำเนินการหลังจากสร้างสคีมา Spanner แล้ว
3. การย้ายข้อมูลแบบสด (CDC):
- วัตถุประสงค์: เพื่อบันทึกและใช้การเปลี่ยนแปลงที่เกิดขึ้นอย่างต่อเนื่องจากฐานข้อมูลต้นทางไปยัง Cloud Spanner แบบเกือบเรียลไทม์ เพื่อลดช่วงหยุดทำงานระหว่างการย้ายข้อมูล
- เครื่องมือ:
- Datastream: บันทึกการเปลี่ยนแปลง (แทรก อัปเดต ลบ) จากฐานข้อมูลแหล่งที่มาและเขียนลงใน Cloud Storage (GCS)
- Dataflow: ใช้เทมเพลต
Datastream to Spannerเพื่ออ่านเหตุการณ์การเปลี่ยนแปลงจาก GCS และนำไปใช้กับ Cloud Spanner
4. การจำลองแบบย้อนกลับ
- วัตถุประสงค์: เพื่อจำลองการเปลี่ยนแปลงข้อมูลจาก Cloud Spanner กลับไปยังฐานข้อมูลแหล่งที่มา ซึ่งอาจมีประโยชน์สำหรับกลยุทธ์สำรอง การย้ายข้อมูลแบบค่อยเป็นค่อยไป หรือการรักษาสำเนาในแหล่งที่มาสำหรับกรณีการใช้งานที่เฉพาะเจาะจง
- เครื่องมือ: Dataflow โดยใช้
Spanner to SourceDbเทมเพลต - กระบวนการ: งานนี้ใช้สตรีมการเปลี่ยนแปลงของ Spanner เพื่อบันทึกการแก้ไขใน Spanner และเขียนกลับไปยังอินสแตนซ์ฐานข้อมูลต้นทาง
แผนภาพต่อไปนี้แสดงคอมโพเนนต์และโฟลว์ข้อมูล
คำศัพท์สำคัญ
- ชาร์ดจริง: เซิร์ฟเวอร์หรืออินสแตนซ์การประมวลผลพื้นฐานจริงที่โฮสต์ฐานข้อมูล (ในกรณีของเราคือ VM ของ GCE ในองค์กรที่จำลอง)
- ชาร์ดเชิงตรรกะ: สคีมาฐานข้อมูลแต่ละรายการภายในเซิร์ฟเวอร์จริง
- VM ของ Compute Engine (GCE): เครื่องเสมือนที่โฮสต์บนโครงสร้างพื้นฐานของ Google Cloud ใน Codelab นี้ เราจะใช้ VM ของ GCE เพื่อจำลองเซิร์ฟเวอร์ Bare Metal แบบสแตนด์อโลน "ในองค์กร" ที่โฮสต์ฐานข้อมูล MySQL ต้นทาง
- เครื่องมือย้ายข้อมูล Spanner (SMT): เครื่องมือที่ใช้ประเมินสคีมา MySQL, แนะนำสคีมาที่เทียบเท่ากับ Spanner และสร้างภาษานิยามข้อมูล (DDL) ของ Spanner
- ภาษานิยามข้อมูล (DDL): คำสั่งที่ใช้เพื่อกำหนดและแก้ไขโครงสร้างฐานข้อมูล เช่น คำสั่ง
CREATE TABLESMT จะสร้าง DDL ของ Spanner ตามสคีมา Cloud SQL - Dataflow: บริการประมวลผลข้อมูลแบบ Serverless ที่มีการจัดการครบวงจร ใน Codelab นี้ จะใช้เพื่อเรียกใช้เทมเพลตที่ Google จัดเตรียมไว้สำหรับการโอนข้อมูลแบบกลุ่ม การใช้การเปลี่ยนแปลง Datastream และการจำลองแบบย้อนกลับ
- Datastream: บริการ Change Data Capture (CDC) และการจำลองแบบแบบไร้เซิร์ฟเวอร์ ซึ่งใช้เพื่อสตรีมการเปลี่ยนแปลงจากอินสแตนซ์ MySQL ที่โฮสต์ไว้ในเครื่องไปยัง Cloud Storage ในโค้ดแล็บนี้
- สตรีมการเปลี่ยนแปลงของ Spanner: ฟีเจอร์ของ Spanner ที่ช่วยให้สตรีมการเปลี่ยนแปลงข้อมูล (การแทรก การอัปเดต การลบ) แบบเรียลไทม์ ซึ่งใช้เป็นแหล่งที่มาสำหรับการจำลองแบบย้อนกลับ
- Pub/Sub: บริการรับส่งข้อความที่ใช้เพื่อแยกบริการที่สร้างเหตุการณ์ออกจากบริการที่ประมวลผลเหตุการณ์เหล่านั้น ใน Codelab นี้ จะทริกเกอร์ Dataflow เพื่อประมวลผลการอัปเดตทุกครั้งที่ Datastream อัปโหลดไฟล์การเปลี่ยนแปลงใหม่ไปยัง Cloud Storage
3. การตั้งค่าสภาพแวดล้อม
ก่อนที่จะเริ่มการย้ายข้อมูลได้ คุณต้องตั้งค่าโปรเจ็กต์ที่อยู่ในระบบคลาวด์ของ Google และเปิดใช้บริการที่จำเป็น
1. เลือกหรือสร้างโปรเจ็กต์ Google Cloud
คุณต้องมีโปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงินเพื่อใช้บริการใน Codelab นี้
- ในคอนโซล Google Cloud ให้ไปที่หน้าตัวเลือกโปรเจ็กต์: ไปที่ตัวเลือกโปรเจ็กต์
- เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าโปรเจ็กต์เปิดใช้การเรียกเก็บเงินแล้ว ดูวิธียืนยันว่าโปรเจ็กต์เปิดใช้การเรียกเก็บเงินแล้ว
2. เปิด Cloud Shell
Cloud Shell เป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud ซึ่งมาพร้อมกับ gcloud CLI และเครื่องมืออื่นๆ ที่คุณต้องการ
- คลิกปุ่มเปิดใช้งาน Cloud Shell ที่ด้านขวาบนของ คอนโซล Google Cloud
- เซสชัน Cloud Shell จะเปิดในเฟรมใหม่ที่ด้านล่างของคอนโซลและแสดงข้อความแจ้งบรรทัดคำสั่ง

3. ตั้งค่าตัวแปรโปรเจ็กต์และตัวแปรสภาพแวดล้อม
ใน Cloud Shell ให้ตั้งค่าตัวแปรสภาพแวดล้อมบางอย่างสำหรับรหัสโปรเจ็กต์และภูมิภาคที่คุณจะใช้
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. เปิดใช้ Google Cloud APIs ที่จำเป็น
เปิดใช้ API ที่จำเป็นสำหรับ Cloud Spanner, Dataflow, Datastream และบริการอื่นๆ ที่เกี่ยวข้อง
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
คำสั่งนี้อาจใช้เวลาสักครู่จึงจะเสร็จสมบูรณ์
4. ตั้งค่าฐานข้อมูล MySQL ต้นทาง
ในส่วนนี้ เราจะจำลองสถาปัตยกรรม MySQL ที่มีการแบ่งข้อมูลในองค์กรโดยการจัดสรรเครื่องเสมือน Compute Engine 2 เครื่อง (ซึ่งเป็น "ชาร์ดจริง" 2 รายการ) จากนั้นเราจะติดตั้ง MySQL ในทั้ง 2 เครื่องและสร้างฐานข้อมูล 2 ฐานข้อมูล ("ชาร์ดเชิงตรรกะ") ในแต่ละ VM
1. สร้าง VM ของ Compute Engine (Shards จริง)
เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อสร้าง VM 2 รายการด้วย Ubuntu เราจะกำหนดแท็กเครือข่ายให้กับอินสแตนซ์เหล่านี้เพื่ออนุญาตการรับส่งข้อมูล MySQL ขาเข้าในภายหลัง
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. กำหนดค่ากฎไฟร์วอลล์
หากต้องการอนุญาตการเข้าถึง SSH ที่ปลอดภัยโดยไม่ต้องเปิดเผยต่อสาธารณะและเปิดใช้การเชื่อมต่อ Datastream ให้ทำดังนี้
สร้างกฎไฟร์วอลล์สำหรับ SSH ผ่าน IAP
กฎนี้อนุญาตให้ Identity-Aware Proxy เข้าถึง VM ในพอร์ต SSH (22)
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
สร้างกฎไฟร์วอลล์สำหรับ Datastream (พอร์ต MySQL)
Datastream ต้องเข้าถึง VM เหล่านี้ได้ในพอร์ต MySQL มาตรฐาน (3306)
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3. ติดตั้งและกำหนดค่า MySQL ใน Shard จริง 1
SSH เข้าสู่ VM แรกเพื่อติดตั้ง MySQL และกำหนดค่าการบันทึกแบบไบนารี (ซึ่ง Datastream ต้องใช้สำหรับการจำลองแบบเรียลไทม์)
- SSH เข้าสู่ VM เครื่องแรก
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- ติดตั้ง MySQL
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- กำหนดค่าไฟล์
mysqld.cnfเพื่อเปิดใช้การบันทึกไบนารีและอนุญาตการเชื่อมต่อภายนอก
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- รีสตาร์ท MySQL เพื่อใช้การเปลี่ยนแปลง
sudo systemctl restart mysql
4. สร้าง Shard เชิงตรรกะ แทรกข้อมูล และสร้างผู้ใช้ Datastream (Shard 1)
ขณะที่ยังคง SSH เข้าสู่ mysql-physical-1 ให้เข้าสู่ระบบพรอมต์ MySQL โดยทำดังนี้
sudo mysql
เรียกใช้คำสั่ง SQL ต่อไปนี้ สคริปต์นี้จะสร้าง Shard เชิงตรรกะที่แตกต่างกัน 2 รายการ (shard0_db และ shard1_db) ตั้งค่าสคีมาที่เหมือนกันในทั้ง 2 รายการ แทรกข้อมูลที่ระบุตัวตนได้อย่างแน่ชัดลงในแต่ละรายการ (เพื่อสาธิตการ Shard) และสร้างผู้ใช้การจำลองสำหรับ Datastream
เรียกใช้คำสั่ง SQL ต่อไปนี้เพื่อสร้าง Shard เชิงตรรกะ 2 รายการแรก ตาราง และผู้ใช้การจำลองสำหรับ Datastream
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
คุณดูไฟล์ Dump สำหรับสคีมาข้างต้นได้ที่นี่ คุณต้องสร้างผู้ใช้การจำลองแบบสตรีมข้อมูลแยกต่างหาก เนื่องจากไม่ได้รวมอยู่ในไฟล์ Dump
5. ยืนยันข้อมูล
ตรวจสอบอย่างรวดเร็วว่ามีข้อมูลอยู่หรือไม่
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
ผลลัพธ์ที่คาดหวัง
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
ป้อน exit เพื่อออกจากการเชื่อมต่อกับ VM ของ Shard จริง 1
6. ทำซ้ำสำหรับ Physical Shard 2
ตอนนี้คุณจะทำกระบวนการเดียวกันกับ VM เครื่องที่ 2 แต่จะสร้าง shard2_db และ shard3_db รวมถึงเปลี่ยน server-id
- SSH เข้าสู่ VM ที่ 2 โดยใช้คำสั่งต่อไปนี้
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- ติดตั้ง MySQL
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- กำหนดค่าไฟล์
mysqld.cnfเพื่อเปิดใช้การบันทึกแบบไบนารีและอนุญาตการเชื่อมต่อภายนอก [โปรดทราบว่า server-id ต้องแตกต่างกัน (เช่น 2)]
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- รีสตาร์ท MySQL เพื่อใช้การเปลี่ยนแปลง
sudo systemctl restart mysql
- ป้อน MySQL (
sudo mysql) แล้วเรียกใช้ SQL เวอร์ชันที่แก้ไขเล็กน้อยจากขั้นตอนที่ 4 ดังนี้
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
ผลลัพธ์ที่คาดหวัง
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
คุณดูไฟล์ Dump สำหรับสคีมาข้างต้นได้ที่นี่ คุณต้องสร้างผู้ใช้การจำลองแบบสตรีมข้อมูลแยกต่างหาก เนื่องจากไม่ได้รวมอยู่ในไฟล์ Dump
ป้อน exit เพื่อออกจากการเชื่อมต่อกับ VM
5. ตั้งค่า Cloud Spanner
ตอนนี้คุณจะตั้งค่าอินสแตนซ์ Cloud Spanner เป้าหมายที่จะย้ายข้อมูล
1. สร้างอินสแตนซ์ Cloud Spanner
สร้างอินสแตนซ์ Cloud Spanner ในภูมิภาคเดียวกับ VM ของ Compute Engine เพื่อลดเวลาในการตอบสนอง คำสั่งนี้จะสร้างอินสแตนซ์ขนาดเล็กที่เหมาะกับ Codelab นี้โดยใช้หน่วยประมวลผล 100 หน่วย
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
การสร้างอินสแตนซ์อาจใช้เวลา 1-2 นาที
6. แปลงสคีมาโดยใช้เครื่องมือย้ายข้อมูล Spanner (SMT)
ใช้เว็บ UI ของเครื่องมือย้ายข้อมูล Spanner (SMT) เพื่อเชื่อมต่อกับหนึ่งใน Shard เชิงตรรกะ (shard0_db) วิเคราะห์สคีมา และใช้การแก้ไขขั้นสูงหลายอย่างก่อนที่จะแปลงเป็น Cloud Spanner
1. ติดตั้ง SMT
เราจะเรียกใช้ SMT Web UI โดยตรงจาก Cloud Shell ในเทอร์มินัล Cloud Shell ให้ดาวน์โหลดและแตกไฟล์ SMT รุ่นล่าสุดโดยใช้คำสั่งต่อไปนี้
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
2. เชื่อมต่อกับฐานข้อมูลต้นทาง
- ตรวจสอบสิทธิ์เซสชัน
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(หมายเหตุ: เมื่อได้รับข้อความแจ้ง ให้ไปที่ URL ที่ระบุเพื่อให้สิทธิ์บัญชี แล้ววางรหัสยืนยันกลับลงในเทอร์มินัล)
- ก่อนอื่น ให้ค้นหา IP ภายนอกของ Shard จริงเครื่องแรกโดยเรียกใช้คำสั่งนี้ในแท็บ Cloud Shell ใหม่
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- พิมพ์รายละเอียดอินสแตนซ์ Spanner เป้าหมายเพื่อใช้ขณะกำหนดค่า SMT
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- เปิด UI บนเว็บ
gcloud alpha spanner migrate web --port=8080
- ที่ด้านขวาบนของหน้าต่าง Cloud Shell ให้คลิกไอคอนตัวอย่างเว็บ (มีลักษณะคล้ายดวงตา) แล้วเลือกดูตัวอย่างบนพอร์ต 8080 ซึ่งจะเป็นการเปิด UI ของ SMT ในแท็บเบราว์เซอร์ใหม่
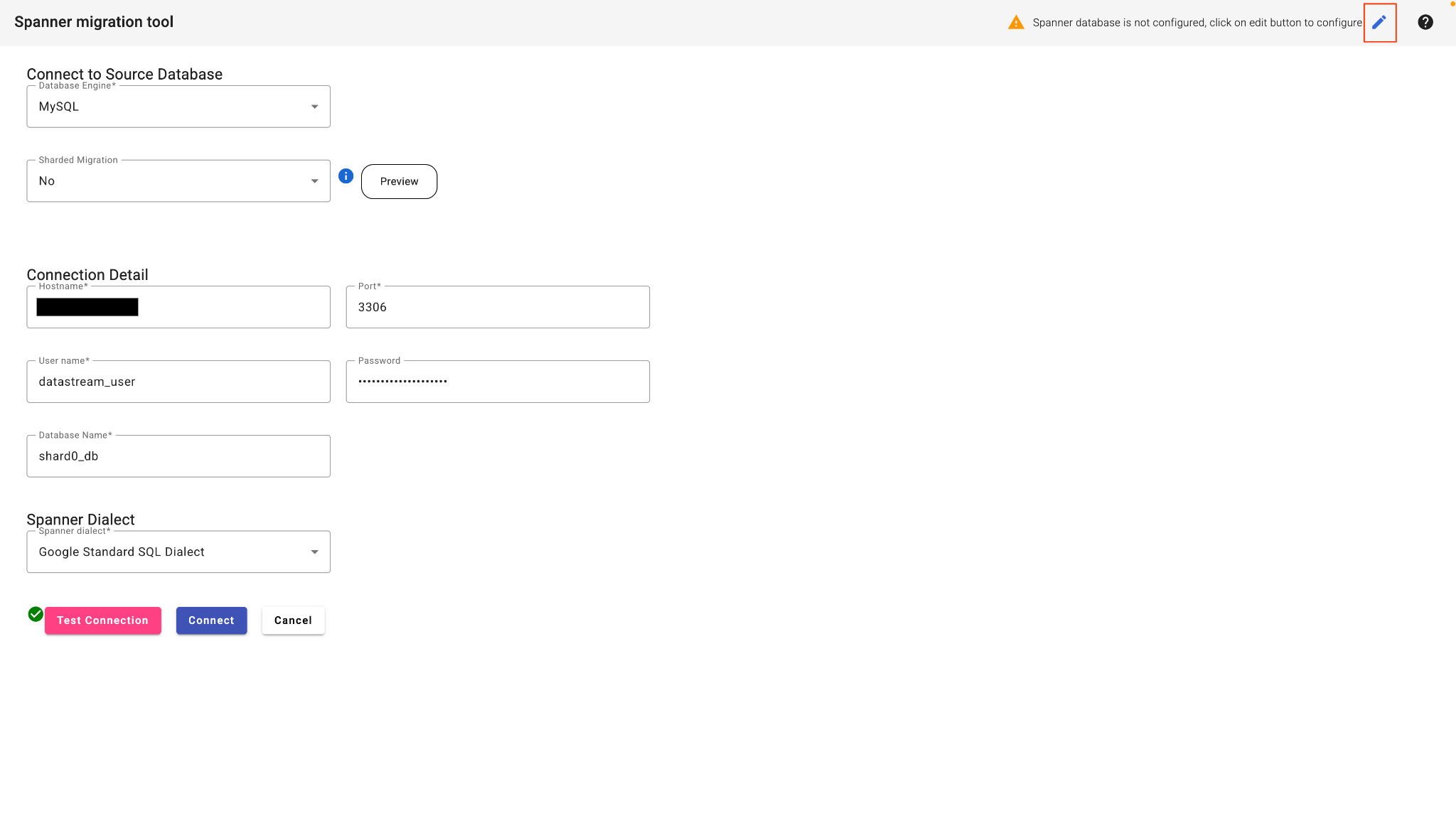
- ใน SMT Web UI ให้เลือกเชื่อมต่อกับฐานข้อมูล
- กรอกรายละเอียดการเชื่อมต่อ
- ประเภทฐานข้อมูล: MySQL
- โฮสต์: (วางที่อยู่ IP จากขั้นตอนที่ 2)
- พอร์ต: 3306
- ผู้ใช้:
datastream_user - รหัสผ่าน:
complex_password_123 - ชื่อฐานข้อมูล:
shard0_db
- คลิกปุ่มแก้ไขที่มุมขวาบนเพื่อกำหนดค่าฐานข้อมูล Spanner
- ป้อนรายละเอียด Spanner เป้าหมาย
- รหัสโปรเจ็กต์: (วางรหัสโปรเจ็กต์จากขั้นตอนที่ 3)
- อินสแตนซ์ Spanner: (วางรหัสอินสแตนซ์จากขั้นตอนที่ 3)
- คลิกทดสอบการเชื่อมต่อ
- เมื่อผ่านแล้ว ให้คลิกเชื่อมต่อ SMT จะวิเคราะห์ฐานข้อมูลต้นทางและแสดงสคีมา Spanner พื้นฐาน
3. ใช้การแก้ไขสคีมา
ตอนนี้เราจะปรับรูปร่างสคีมาเพื่อให้ครอบคลุมสถานการณ์การย้ายข้อมูลที่ซับซ้อน
ในเครื่องมือแก้ไขสคีมาของ UI ของ SMT ให้ดำเนินการต่อไปนี้
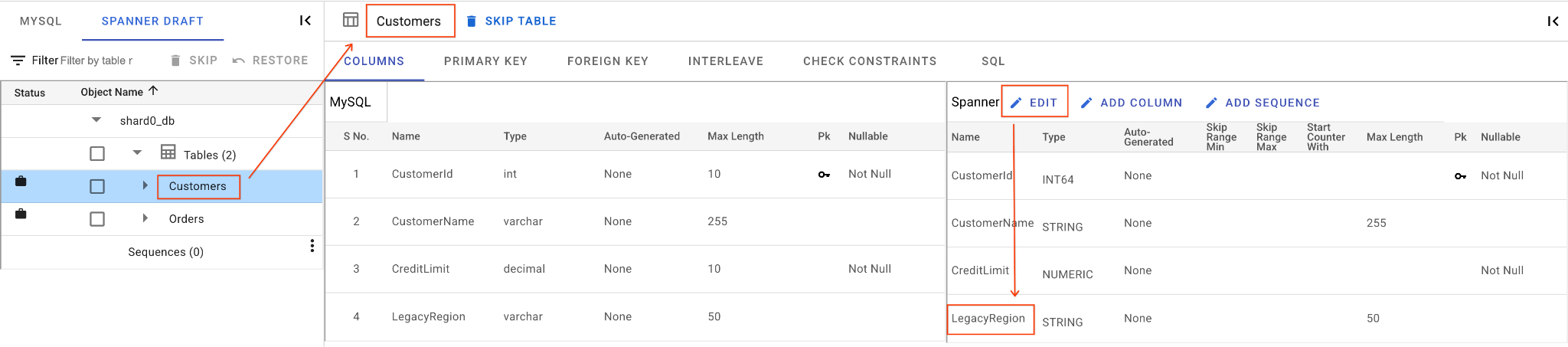
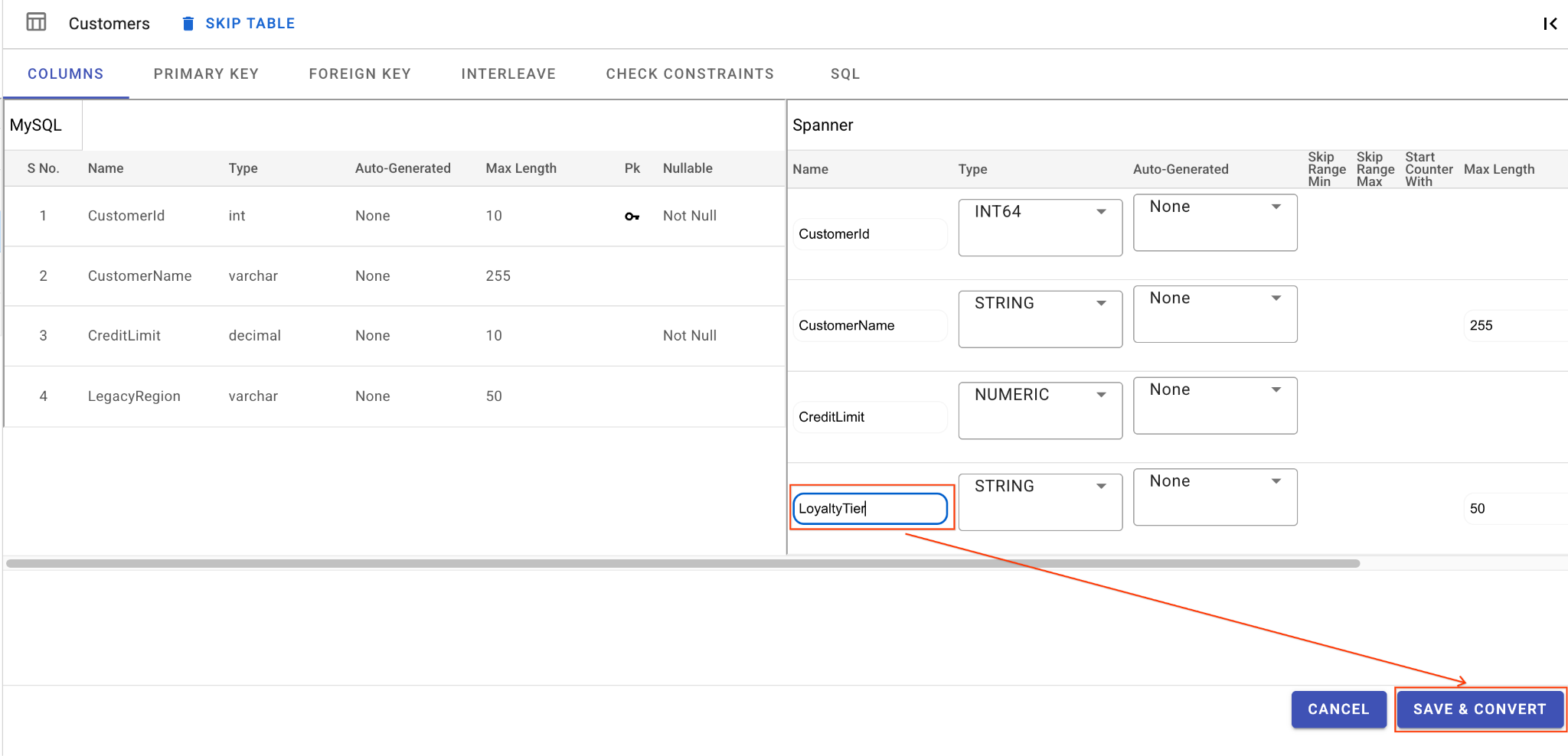
ก. เปลี่ยนชื่อคอลัมน์ LegacyRegion โดยทำดังนี้
- คลิกตาราง
Customersในแผงการนำทางด้านซ้าย ระบบจะเปิดแท็บคอลัมน์โดยค่าเริ่มต้น - คลิกปุ่มแก้ไขในส่วน Spanner
- ค้นหาคอลัมน์
LegacyRegionในมุมมองสคีมา Spanner - เปลี่ยนชื่อคอลัมน์ Spanner เป็น
LoyaltyTierโดยพิมพ์ในกล่องโต้ตอบชื่อคอลัมน์ - คลิกบันทึกและแปลง
ข. ลดความเข้มงวดของข้อจำกัด CHECK
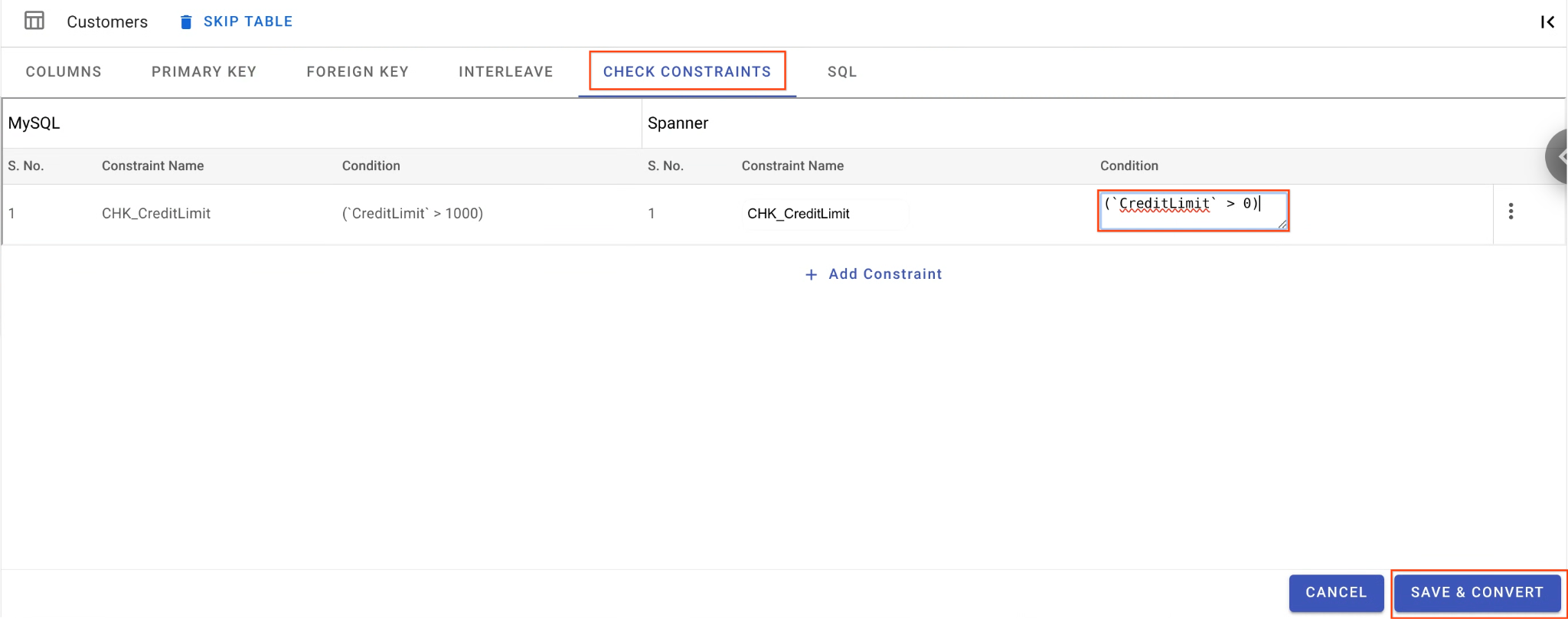
- ยังอยู่ในตาราง
Customersให้นำทางไปยังแท็บข้อจำกัดในการตรวจสอบ - ค้นหา
CHK_CreditLimitข้อจำกัด คลิกไอคอนแก้ไข (ดินสอ) - เปลี่ยนเงื่อนไขจาก
CreditLimit > 1000เป็นCreditLimit > 0(การดำเนินการนี้จะทำให้แถวที่มีวงเงินเครดิตต่ำกว่าย้ายข้อมูลย้อนกลับไม่สำเร็จและเข้าสู่ DLQ)
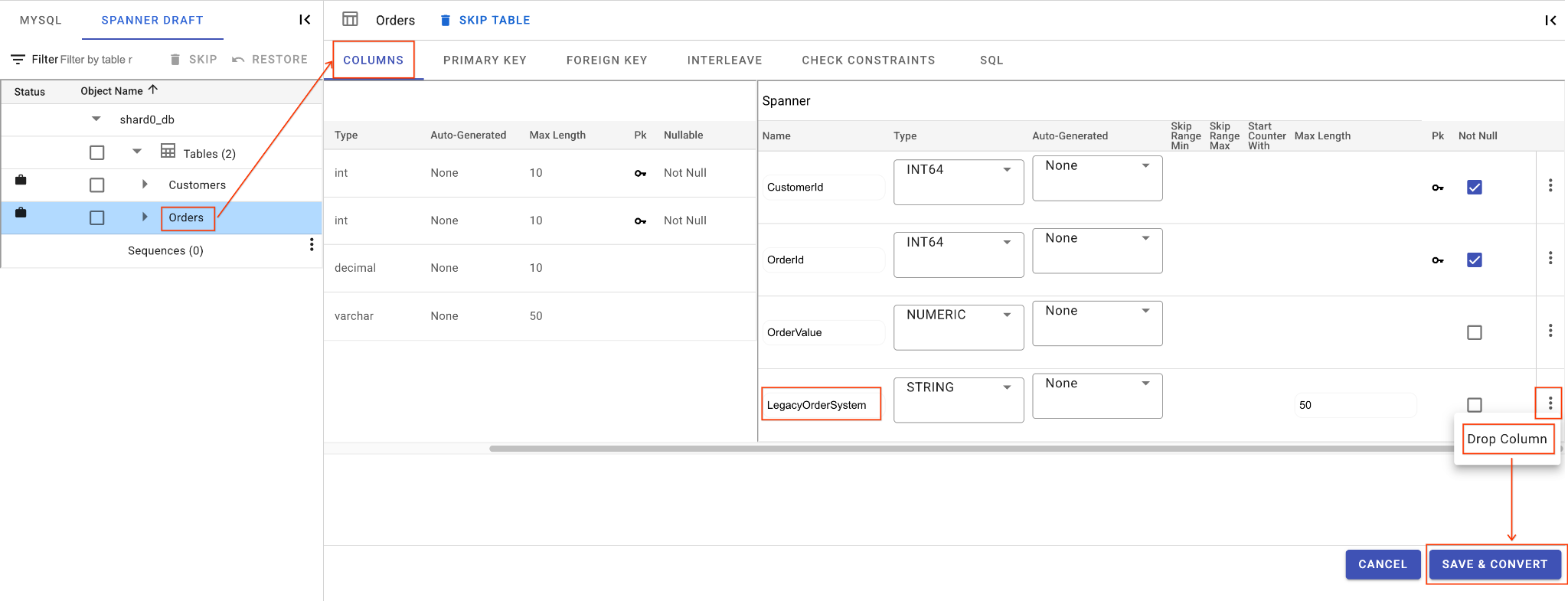
ค. ทิ้งคอลัมน์ LegacyOrderSystem
- คลิก
Ordersตาราง แล้วระบบจะเปิดแท็บคอลัมน์โดยค่าเริ่มต้น - คลิกปุ่มแก้ไขในส่วน Spanner
- ค้นหาคอลัมน์
LegacyOrderSystemในมุมมองสคีมา Spanner - คลิกไอคอนเมนู 3 จุดข้างชื่อ แล้วเลือกวางคอลัมน์
- คลิกบันทึกและแปลง
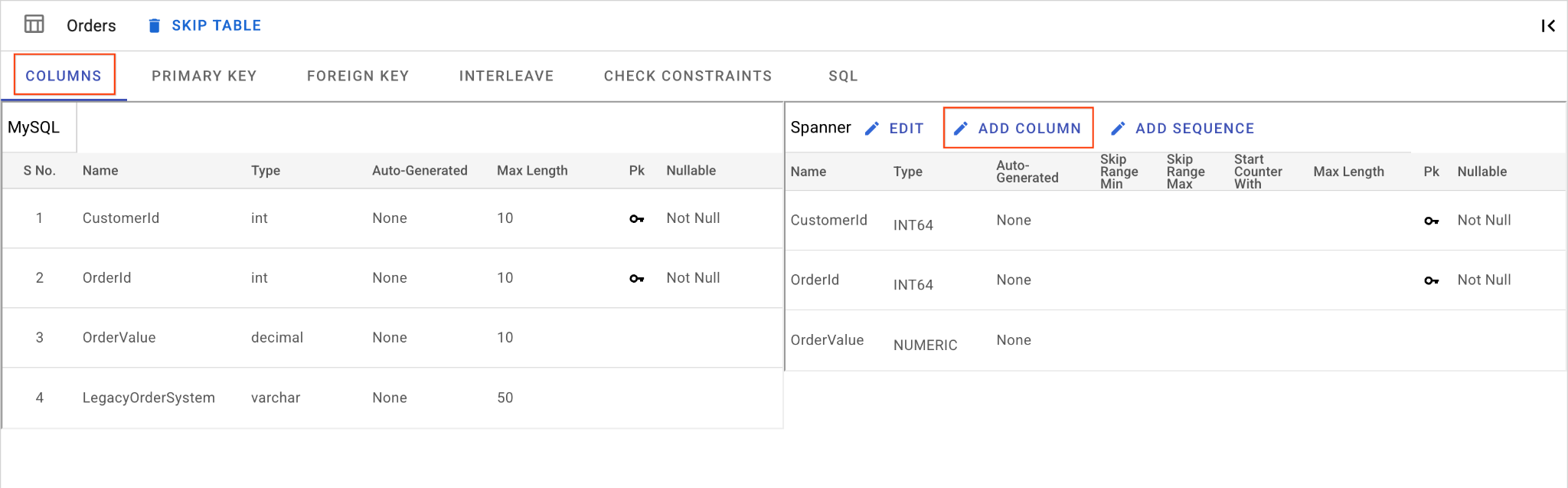
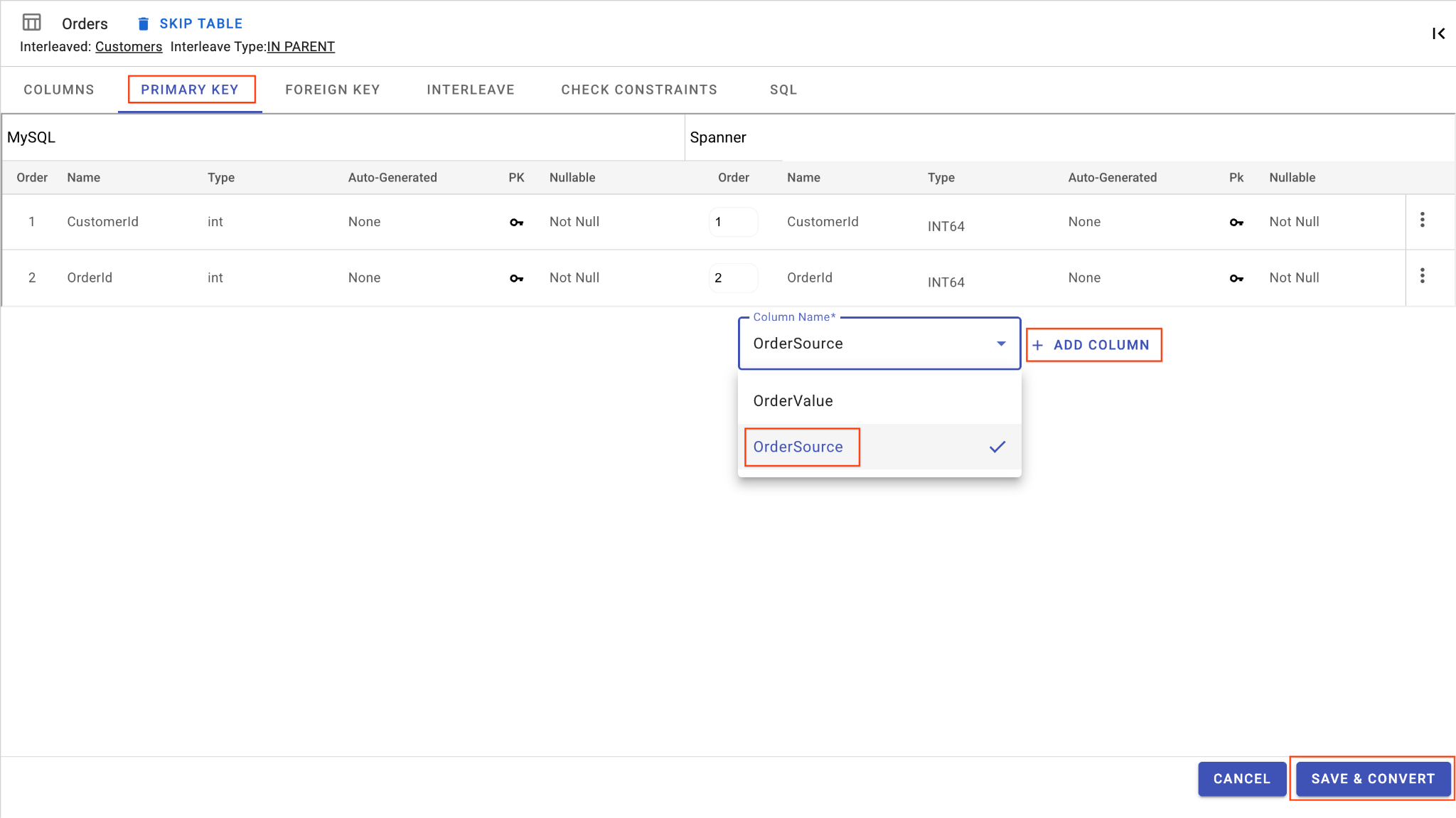
ง. เพิ่มคอลัมน์ OrderSource และกำหนดให้เป็นคีย์หลัก
- ขณะที่ยังอยู่ใน
Ordersตาราง ให้คลิกเพิ่มคอลัมน์ ตั้งชื่อเป็นOrderSourceและตั้งค่าประเภทเป็นSTRINGที่มีความยาว50โดยไม่ต้องสร้างอัตโนมัติ และตั้งค่าIsNullableเป็นNo - ไปที่แท็บคีย์หลัก
- คลิกแก้ไข แล้วเลือก
OrderSourceจากเมนูแบบเลื่อนลงของชื่อคอลัมน์ - คลิกเพิ่มคอลัมน์ แล้วคลิกบันทึกและแปลง
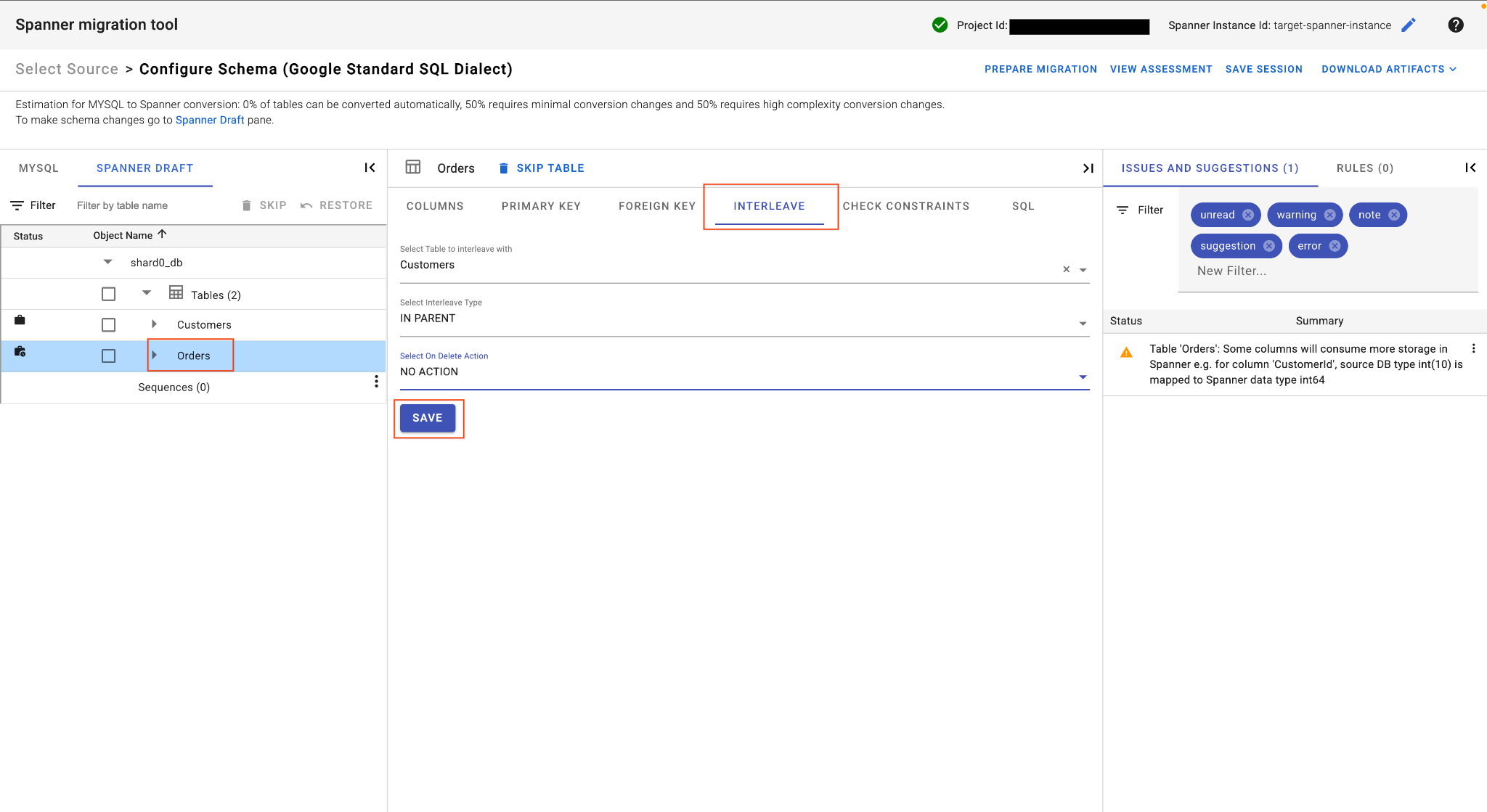
จ. สลับตารางคำสั่งซื้อ
- ในตาราง
Ordersให้ไปที่แท็บ Interleave ในมุมมองตารางหลัก - ตั้งค่าตารางหลักเป็น
Customers - เลือก
IN PARENTประเภทการสลับและNO ACTIONการดำเนินการเมื่อลบ - คลิกบันทึก
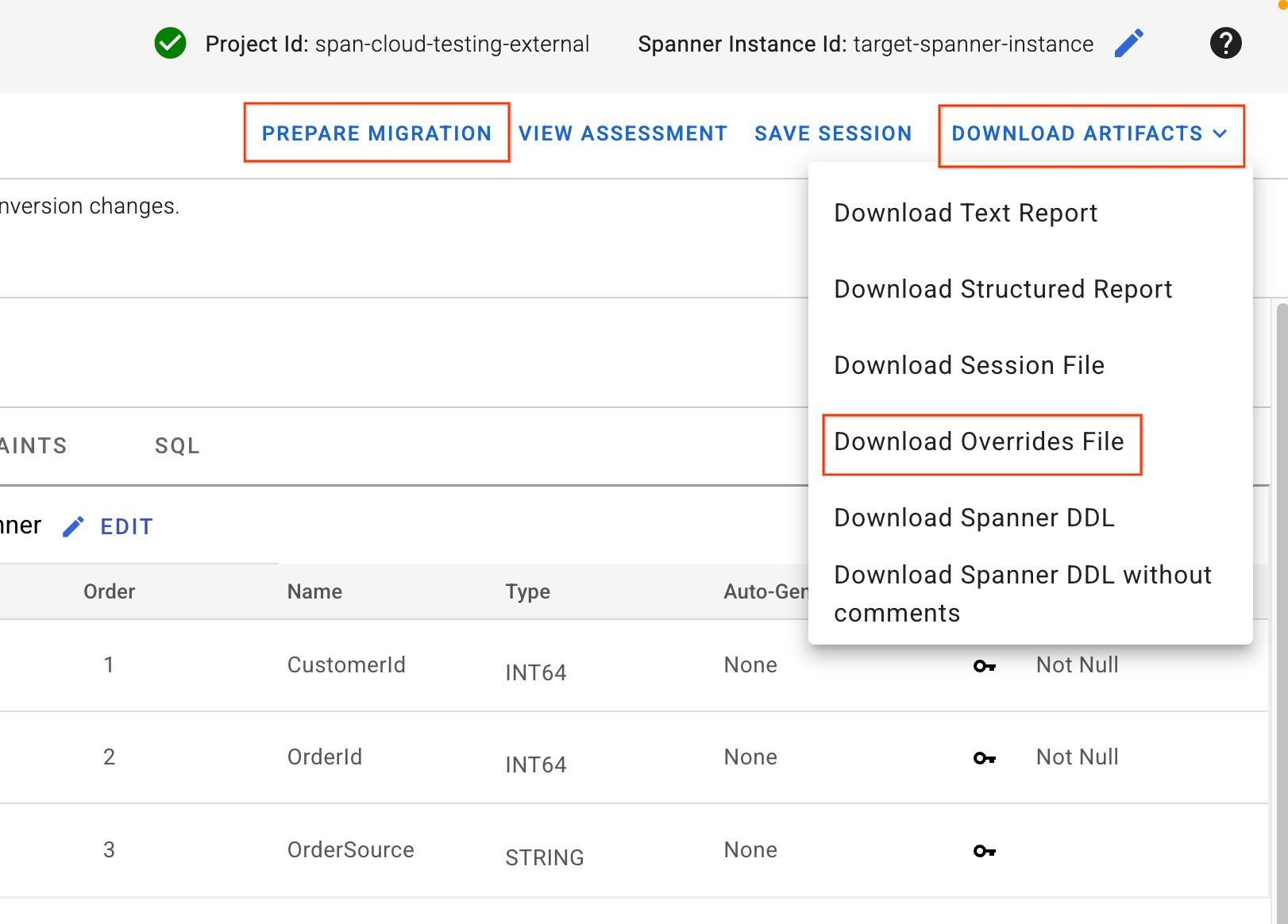
4. ดาวน์โหลดไฟล์การลบล้างและใช้สคีมา
- ที่มุมขวาบนของ UI ของ SMT ให้หาปุ่มดาวน์โหลดอาร์ติแฟกต์ เลือกตัวเลือกดาวน์โหลดไฟล์การลบล้าง บันทึกไฟล์นี้ลงในเครื่องของคุณ ไฟล์นี้มีการเปลี่ยนแปลงการแมปสคีมาทั้งหมดที่เราเพิ่งทำ และจะใช้โดยไปป์ไลน์ Dataflow
- คลิกเตรียมการย้ายข้อมูล
- เลือกโหมดการย้ายข้อมูลเป็น
Schemaจากเมนูแบบเลื่อนลง - ป้อนฐานข้อมูล Spanner เป้าหมาย:
sharded-target-db
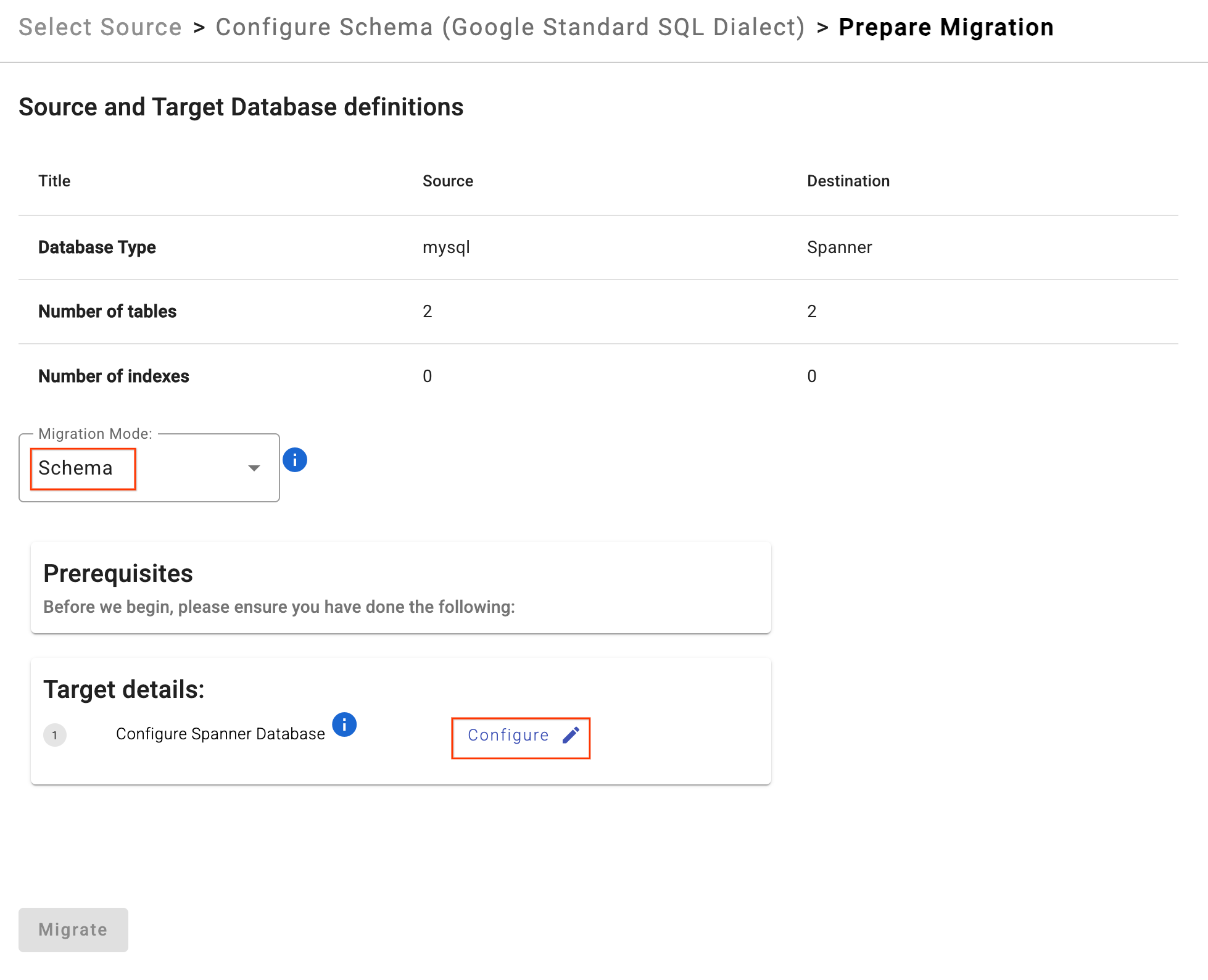
- คลิกย้ายข้อมูล
- SMT จะใช้ DDL และสร้างฐานข้อมูล Spanner คุณหยุดกระบวนการ SMT ใน Cloud Shell (
Ctrl+C) ได้อย่างปลอดภัยเมื่อกระบวนการเสร็จสมบูรณ์
5. ยืนยันสคีมาใน Cloud Spanner
ตรวจสอบว่าได้สร้างตารางในฐานข้อมูล Spanner แล้ว
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
คุณควรเห็นเอาต์พุตต่อไปนี้
table_name: Customers table_name: Orders
ไม่บังคับ: หากต้องการตรวจสอบ DDL ของ Spanner จริงเพื่อยืนยันว่าข้อจํากัดในการตรวจสอบ การแทรก และคอลัมน์เพิ่มเติมได้รับการใช้แล้ว ให้เรียกใช้คําสั่งต่อไปนี้
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
ผลลัพธ์ที่คาดหวัง
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. เริ่มต้น Change Data Capture (CDC)
ในส่วนนี้ คุณจะตั้งค่า "เครื่องบันทึก" สำหรับการย้ายข้อมูล การกำหนดค่า Datastream และ Pub/Sub ก่อนที่การโหลดข้อมูลแบบกลุ่มจะเริ่มขึ้นจะช่วยให้มั่นใจได้ว่าการเปลี่ยนแปลงทุกอย่างที่เกิดขึ้นกับฐานข้อมูลต้นทางจะได้รับการบันทึกและจัดคิว ซึ่งจะป้องกันไม่ให้ข้อมูลรั่วไหลในระหว่างการเปลี่ยน การตั้งค่านี้จำเป็นสำหรับการย้ายข้อมูลแบบสด
เนื่องจากสถาปัตยกรรมของเราเกี่ยวข้องกับเซิร์ฟเวอร์จริง 2 เครื่อง เราจึงต้องสร้างโปรไฟล์แหล่งที่มาของ Datastream และสตรีม Datastream 2 รายการแยกกัน ทั้ง 2 สตรีมจะเขียนลงใน Bucket ของ Google Cloud Storage (GCS) เดียวกัน ซึ่งจะทำหน้าที่เป็นแหล่งที่มารวมสำหรับไปป์ไลน์ Dataflow
1. สร้าง Bucket ของ Cloud Storage
Datastream ต้องมีปลายทางเพื่อจัดเก็บเหตุการณ์การเปลี่ยนแปลงที่บันทึกไว้ มาสร้างที่เก็บข้อมูล GCS กัน
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. สร้างโปรไฟล์การเชื่อมต่อ Datastream
เราต้องมีโปรไฟล์การเชื่อมต่อแหล่งข้อมูล MySQL ที่แตกต่างกัน 2 รายการ (รายการละ 1 รายการสำหรับแต่ละ Shard จริง) และโปรไฟล์การเชื่อมต่อปลายทาง 1 รายการสำหรับ Cloud Storage
รับที่อยู่ IP ต้นทาง
ก่อนอื่น ให้ดึงข้อมูลที่อยู่ IP ภายนอกของ VM ของ Compute Engine ทั้ง 2 รายการ แล้วจัดเก็บเป็นตัวแปรสภาพแวดล้อม
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
สร้างโปรไฟล์การเชื่อมต่อแหล่งที่มา (MySQL บน Compute Engine)
สร้างโปรไฟล์การเชื่อมต่อ Datastream โดยใช้ datastream_user ที่สร้างไว้ก่อนหน้านี้
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
หมายเหตุ: DataStream จะเชื่อมต่อกับ VM เหล่านี้ผ่าน IP สาธารณะ ซึ่งทำได้เนื่องจากเราได้เพิ่ม 0.0.0.0/0 ลงในกฎไฟร์วอลล์ก่อนหน้านี้แล้ว ในสภาพแวดล้อมการใช้งานจริง คุณจะอนุญาตช่วง IP สาธารณะที่เฉพาะเจาะจงของ Datastream อย่างเคร่งครัด
สร้างโปรไฟล์การเชื่อมต่อปลายทาง (Cloud Storage):
ซึ่งจะชี้ไปยังรูทของ Bucket ที่สร้างขึ้นใหม่
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3. สร้างสตรีม Datastream
ตอนนี้เราจะสร้างสตรีม CDC 2 รายการ สตรีม 1 จะบันทึก shard0_db และ shard1_db สตรีม 2 จะบันทึก shard2_db และ shard3_db ทั้ง 2 สตรีมจะเขียนไปยังที่เก็บข้อมูล GCS เดียวกันในรูปแบบ Avro
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
การใช้การตั้งค่าการหมุนเวียนไฟล์ที่เล็กลง (5 MB หรือ 15 วินาที) จะช่วยให้เราเห็นการเปลี่ยนแปลงที่จำลองได้เร็วขึ้นในระหว่างการทำโค้ดแล็บ
คำสั่งนี้อาจใช้เวลาสักครู่จึงจะเสร็จสมบูรณ์ ตรวจสอบสถานะ: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION
4. เริ่มสตรีม Datastream
เปิดใช้งานทั้ง 2 สตรีมเพื่อให้เริ่มบันทึกการเปลี่ยนแปลง
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
ตรวจสอบสถานะ: คุณเรียกใช้ gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION ได้ โดยตอนแรกสถานะจะเป็น STARTING และจะเปลี่ยนเป็น RUNNING หลังจากผ่านไปสักครู่ รอจนกว่าทั้ง 2 เครื่องจะทำงานเต็มรูปแบบก่อนเริ่มการย้ายข้อมูลแบบสด
5. ตั้งค่า Pub/Sub สำหรับการแจ้งเตือน GCS
Dataflow ต้องได้รับการแจ้งเตือนทันทีเมื่อสตรีม Datastream เขียนไฟล์ใหม่ไปยัง Bucket ของ GCS เราจะกำหนดค่า GCS ให้ส่งการแจ้งเตือนไปยังหัวข้อ Pub/Sub เดียว
สร้างหัวข้อ Pub/Sub
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
สร้างการแจ้งเตือนของ GCS
แจ้งหัวข้อเมื่อมีการสร้างออบเจ็กต์ภายใต้คำนำหน้า data/ (ซึ่งครอบคลุมทั้ง 2 สตรีมของเรา)
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
สร้างการสมัครใช้บริการ Pub/Sub
สร้างการสมัครใช้บริการโดยมีกำหนดเวลาการรับทราบที่แนะนำสำหรับ Dataflow
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. การเปลี่ยนรูปแบบที่กำหนดเอง
เนื่องจากสคีมา Spanner ของเราแตกต่างจากสคีมา MySQL (เนื่องจากคอลัมน์ที่เราเพิ่มและทิ้งผ่าน SMT Web UI) การย้ายข้อมูล Dataflow ที่พร้อมใช้งานทันทีจะล้มเหลว Dataflow ต้องมีวิธีการจับคู่ความแตกต่างเหล่านี้ในระหว่างไปป์ไลน์แบบส่งต่อ (MySQL ไปยัง Spanner) และแบบย้อนกลับ (Spanner ไปยัง MySQL)
นอกจากนี้ เนื่องจากเรากำลังทำการย้ายข้อมูลย้อนกลับแบบ Shard Dataflow จึงต้องมีกลไกการกำหนดเส้นทางเพื่อทราบว่าแถว Spanner ที่อัปเดตเป็นของ Shard เชิงตรรกะใด (shard0_db, shard1_db ฯลฯ) ในระหว่างการจำลองแบบย้อนกลับ
เราจะทําเช่นนี้ได้โดยการเขียน JAR การเปลี่ยนรูปแบบที่กําหนดเองโดยใช้เทมเพลต Shard ที่กําหนดเองของ Spanner ที่ Google จัดเตรียมให้
1. ดาวน์โหลดเทมเพลต Shard ที่กำหนดเอง
ใน Cloud Shell ให้ดาวน์โหลดที่เก็บเทมเพลต Google Cloud Dataflow แล้วไปที่โฟลเดอร์ Shard ที่กำหนดเอง
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. กำหนดค่าตรรกะการเปลี่ยนรูปแบบข้อมูล
เราต้องแก้ไขไฟล์ CustomTransformationFetcher.java
- การย้ายข้อมูลไปข้างหน้า (
toSpannerRow): ป้อนข้อมูลในคอลัมน์OrderSourceที่เพิ่มใหม่โดยใช้คอลัมน์LegacyOrderSystemจาก MySQL - การย้ายข้อมูลย้อนกลับ (
toSourceRow): สร้างคอลัมน์LegacyOrderSystemที่ถูกทิ้งซึ่ง MySQL ต้องการขึ้นมาใหม่ โดยดึงข้อมูลจากOrderSourceของ Spanner
แก้ไขไฟล์ CustomTransformationFetcher.java แทนที่จะเปิดโปรแกรมแก้ไขข้อความด้วยตนเอง ให้เรียกใช้คำสั่งต่อไปนี้เพื่อเขียนทับไฟล์เทมเพลตด้วยตรรกะที่กำหนดเองโดยอัตโนมัติ
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3. กำหนดค่าตรรกะการแยกส่วนย้อนกลับ
Dataflow ใช้ CustomShardIdFetcher.java ระหว่างการจำลองแบบย้อนกลับเพื่อกำหนดเส้นทางการเปลี่ยนแปลง Spanner เราจะใช้CustomerIdคีย์หลักและตรรกะโมดูโล (%4) เพื่อกำหนดเส้นทางระเบียนกลับไปยังชาร์ดเชิงตรรกะที่ถูกต้องแบบไดนามิก
แก้ไขไฟล์ CustomShardIdFetcher.java โดยใช้ cat และแทนที่เนื้อหาทั้งหมดด้วยโค้ดต่อไปนี้
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. สร้างและอัปโหลด JAR
ตอนนี้เราเขียนตรรกะ Java ที่กำหนดเองแล้ว เราจึงต้องคอมไพล์เป็นไฟล์ JAR และอัปโหลดไปยัง Bucket ของ Google Cloud Storage ที่เราสร้างไว้ก่อนหน้านี้เพื่อให้ Dataflow เข้าถึงได้
เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9. ย้ายข้อมูลจาก MySQL ไปยัง Spanner เป็นกลุ่ม
เมื่อมีสคีมา Spanner และสร้าง JAR การเปลี่ยนรูปแบบที่กำหนดเองแล้ว ตอนนี้เราสามารถคัดลอกข้อมูลที่มีอยู่จากฐานข้อมูล MySQL ไปยัง Cloud Spanner ได้แล้ว คุณจะใช้Sourcedb to Spannerเทมเพลต Flex ของ Dataflow ซึ่งออกแบบมาเพื่อคัดลอกข้อมูลจำนวนมากจากฐานข้อมูลที่เข้าถึงได้ผ่าน JDBC ไปยัง Spanner
1. อัปโหลดไฟล์การลบล้างสคีมา
ในส่วนที่ 6 คุณได้ดาวน์โหลดไฟล์ JSON ของการลบล้าง Spanner โดยใช้ SMT Web UI เราต้องอัปโหลดไฟล์นี้ไปยัง Bucket ของ GCS เพื่อให้ Dataflow ใช้ในการแมปความแตกต่างของสคีมา (เช่น คอลัมน์ที่เปลี่ยนชื่อ) ได้
- ใน Cloud Shell ให้คลิกเมนู 3 จุด (เพิ่มเติม) แล้วเลือกอัปโหลด
- เลือกไฟล์ JSON ของการลบล้างที่คุณดาวน์โหลดไว้ก่อนหน้านี้ (เช่น
spanner_overrides.json) - ย้ายไปยัง Bucket ของ GCS โดยทำดังนี้
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. สร้างและอัปโหลดไฟล์การกำหนดค่าการแยกส่วน
Dataflow ต้องทราบวิธีเชื่อมต่อกับ Shard เชิงตรรกะทั้ง 4 รายการใน VM จริง 2 รายการ เราจะสร้างไฟล์ sharding.json สำหรับการดำเนินการนี้
เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อสร้างและอัปโหลดการกำหนดค่า
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3. เรียกใช้งาน Dataflow Job สำหรับการย้ายข้อมูลแบบเป็นกลุ่ม
เราจะใช้เทมเพลต Flex Sourcedb ไปยัง Spanner เนื่องจากเป็นการย้ายข้อมูลแบบ Sharded ที่มีการเปลี่ยนรูปแบบที่กำหนดเอง เราจึงส่งไฟล์การลบล้าง, การกำหนดค่า Sharding และ JAR ของ Java ที่กำหนดเอง
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
คำอธิบายพารามิเตอร์หลัก
sourceConfigURL: เส้นทางไปยังไฟล์sharding.jsonที่เราสร้างขึ้น ซึ่งจะบอก Dataflow วิธีเชื่อมต่อกับ Shard MySQL เชิงตรรกะทั้ง 4 รายการใน VM จริง 2 รายการschemaOverridesFilePath: เส้นทางไปยังไฟล์ JSON ที่เราดาวน์โหลดจาก SMT Web UI ซึ่งจะสั่งให้ Dataflow จัดการการแก้ไขสคีมาที่เราทำ (เช่น คอลัมน์LegacyRegionที่ถูกทิ้งและข้อจํากัดการตรวจสอบที่เข้มงวดขึ้น)transformationJarPath: เส้นทาง GCS ไปยังไฟล์ JAR ของ Java ที่คอมไพล์แล้วซึ่งเราสร้างขึ้นในส่วนก่อนหน้า ซึ่งมีโค้ดจริงที่จะเรียกใช้การเปลี่ยนรูปแบบที่กำหนดเองtransformationClassName: ชื่อที่สมบูรณ์ในตัวเองของคลาส Java ภายใน JAR ที่ใช้ตรรกะการย้ายข้อมูลไปข้างหน้า (com.custom.CustomTransformationFetcher)outputDirectory: ตำแหน่ง GCS ที่ Dataflow จะเขียนไฟล์ชั่วคราว และที่สำคัญที่สุดคือไฟล์ Dead Letter Queue (DLQ)maxWorkers,numWorkers: ควบคุมการปรับขนาดของงาน Dataflow เก็บไว้ในระดับต่ำสำหรับชุดข้อมูลขนาดเล็กนี้instanceId,databaseId,projectId: ระบุอินสแตนซ์และฐานข้อมูล Cloud Spanner เป้าหมาย
หมายเหตุเกี่ยวกับเครือข่าย: งานนี้จะเชื่อมต่อกับอินสแตนซ์ Cloud SQL ผ่าน IP สาธารณะ ซึ่งทำได้เนื่องจากก่อนหน้านี้คุณได้เพิ่ม 0.0.0.0/0 ลงในเครือข่ายที่ได้รับอนุญาตของอินสแตนซ์ ซึ่งจะช่วยให้ VM ของผู้ปฏิบัติงาน Dataflow ที่มี IP ภายนอกเข้าถึงฐานข้อมูลได้
4. ตรวจสอบงาน Dataflow
คุณสามารถติดตามความคืบหน้าของงานได้ในคอนโซล Google Cloud โดยทำดังนี้
- ไปที่หน้า Dataflow Jobs: ไปที่ Dataflow Jobs
- ค้นหางานชื่อ
mysql-sharded-bulk-to-spanner-...แล้วคลิก - สังเกตกราฟงานและเมตริก รอให้สถานะของงานเปลี่ยนเป็นสำเร็จ การดำเนินการนี้จะใช้เวลาประมาณ 5-15 นาที
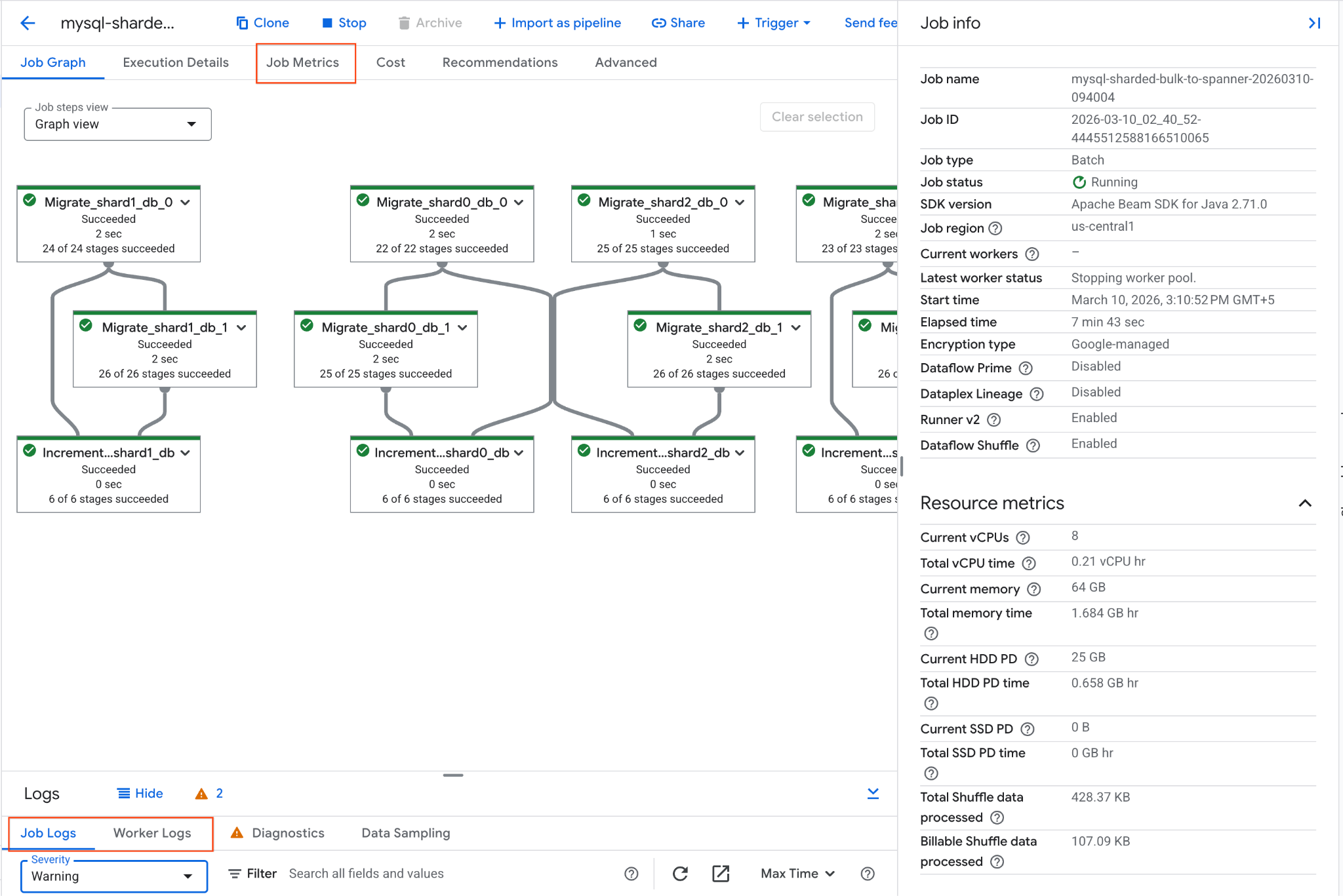
- หากงานพบปัญหา ให้ตรวจสอบแท็บบันทึกในหน้ารายละเอียดของงาน Dataflow เพื่อดูข้อความแสดงข้อผิดพลาด
- เมตริกของงานจะให้ข้อมูลเพิ่มเติมเกี่ยวกับความคืบหน้าของงานและการใช้ทรัพยากร เช่น ปริมาณงานและอัตราการใช้ CPU
5. ยืนยันข้อมูลใน Cloud Spanner และตรวจสอบคิวจดหมายที่ส่งไม่ได้ (DLQ)
เมื่องาน Dataflow เสร็จสมบูรณ์แล้ว เราต้องยืนยันว่าข้อมูลมาถึงอย่างปลอดภัยและตรวจสอบบันทึกที่เราตั้งใจให้ล้มเหลว
ก. ยืนยันสถานะโดยรวมของข้อมูลที่ย้ายข้อมูล
ใช้ gcloudCLI เพื่อเรียกใช้การตรวจสอบสถานะอย่างรวดเร็ว 2-3 รายการในฐานข้อมูล Spanner ที่ผสานรวมเพื่อให้แน่ใจว่าบันทึกที่ถูกต้องจะได้รับการย้ายข้อมูลอย่างถูกต้อง และ JAR ที่กำหนดเองของเราจะสร้างคอลัมน์พิเศษ
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
ผลลัพธ์ที่คาดหวัง
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- ย้ายข้อมูลแถวทั้งหมดในตารางลูกค้าเรียบร้อยแล้ว
- เราเห็นแถวที่ล้มเหลว 1 แถวในตาราง
Ordersเนื่องจากINTERLEAVE IN PARENTใน Spanner -CustomerId 99เป็นรายการย่อยที่ไม่มีรายการหลักเนื่องจากไม่มีแถวที่สอดคล้องกันในตารางCustomers
ข. ตรวจสอบการทำงานที่ล้มเหลวโดยเจตนาใน DLQ โดยทำดังนี้
ความล้มเหลวดังกล่าวข้างต้นจะบันทึกไว้ในโฟลเดอร์คิวจดหมายที่ส่งไม่ได้ (DLQ) ซึ่งสร้างขึ้นโดยไปป์ไลน์การย้ายข้อมูลแบบกลุ่ม
- ไปที่ Cloud Storage ในคอนโซล Google Cloud
- ไปที่ที่เก็บข้อมูลแล้วเปิดโฟลเดอร์
bulk-migration/dlq/severe - ตรวจสอบไฟล์ JSON ภายใน คุณจะเห็นแถว
Ordersที่มีCustomerIdที่ไม่มีรายการหลัก - คุณลองอีกครั้งกับข้อผิดพลาด DLQ ของการย้ายข้อมูลแบบเป็นกลุ่มได้โดยทำตามขั้นตอนที่ระบุไว้ที่นี่
การโหลดข้อมูลจำนวนมากครั้งแรกจาก Cloud SQL ไปยัง Cloud Spanner เสร็จสมบูรณ์แล้ว ขั้นตอนถัดไปคือการตั้งค่าการจำลองแบบสดเพื่อบันทึกการเปลี่ยนแปลงที่เกิดขึ้นอย่างต่อเนื่อง
10. เริ่มการย้ายข้อมูลแบบสด (CDC)
เมื่อการโหลดข้อมูลจำนวนมากเสร็จสมบูรณ์แล้ว คุณจะเปิดใช้งานงานสตรีมมิง Dataflow อย่างต่อเนื่อง งานนี้จะอ่านเหตุการณ์ Change Data Capture (CDC) ที่ Datastream เขียนลงใน Bucket ของ GCS และใช้การเปลี่ยนแปลงเหล่านั้นกับ Cloud Spanner แบบเกือบเรียลไทม์
นอกจากนี้ เราจะทดสอบไปป์ไลน์นี้โดยการแทรกข้อมูลที่ถูกต้องและข้อมูลที่ตั้งใจให้ไม่ถูกต้องเพื่อดูว่า Dataflow จัดการการจำลองแบบเรียลไทม์และกำหนดเส้นทางข้อผิดพลาดไปยังคิวจดหมายที่ส่งไม่ได้ (DLQ) อย่างไร
1. สร้างไฟล์การกำหนดค่าการแบ่งข้อมูลการย้ายข้อมูลแบบสด
ไปป์ไลน์การย้าย VM แบบสดจะอ่านเหตุการณ์ Datastream จาก GCS ซึ่งแตกต่างจากการย้ายข้อมูลจำนวนมาก (ที่ใช้สตริงการเชื่อมต่อ JDBC) โดยต้องมีการกำหนดค่า JSON ที่แตกต่างกันโดยสิ้นเชิง ซึ่งจะแมปชื่อสตรีมและฐานข้อมูล Datastream กับ Shard Spanner เชิงตรรกะ
เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อสร้างและอัปโหลดการกำหนดค่าการแบ่งกลุ่มแบบสด
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. เรียกใช้งาน Dataflow Job ของการย้ายข้อมูลแบบสด
เปิดใช้งานงาน Dataflow แบบสตรีมมิงเพื่ออ่านจาก GCS และเขียนไปยัง Spanner เทมเพลตนี้จะใช้การแจ้งเตือน Pub/Sub ของ GCS เพื่อประมวลผลไฟล์ใหม่ทันที
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
พารามิเตอร์หลัก
gcsPubSubSubscription: การสมัครใช้บริการ Pub/Sub ที่รอรับการแจ้งเตือนไฟล์ใหม่จาก GCS ซึ่งจะช่วยให้งานประมวลผลการเปลี่ยนแปลงได้ทันทีที่ Datastream เขียนการเปลี่ยนแปลงinputFileFormat="avro": บอกให้ Dataflow คาดหวังไฟล์ Avro จาก Datastream ซึ่งต้องตรงกับการกำหนดค่า "ปลายทาง" ของ Datastream (เช่นavroFileFormatกับjsonFileFormat)shardingContextFilePath: ไฟล์ JSON ที่แมปสตรีม Datastream กับ Shard เชิงตรรกะdlqRetryMinutes: จำนวนนาทีระหว่างการลองใหม่ในคิวจดหมายที่ส่งไม่ได้ ค่าเริ่มต้นคือ10dlqMaxRetryCount: จำนวนครั้งสูงสุดที่สามารถลองใหม่สำหรับข้อผิดพลาดชั่วคราวผ่าน DLQ ค่าเริ่มต้นคือ500
ตรวจสอบการเริ่มต้นงานใน Dataflow Jobs Console
3. แทรกข้อมูลสดและทริกเกอร์ความล้มเหลวโดยเจตนา
ในขณะที่งานการสตรีม Dataflow กำลังเริ่มต้น (อาจใช้เวลา 3-5 นาที) ให้ SSH ไปยัง VM ของ MySQL จริงเครื่องแรกและแทรกระเบียนใหม่ เราจะแทรกระเบียนที่ถูกต้อง 1 รายการและระเบียนที่ไม่ถูกต้อง 1 รายการ
SSH ไปยัง Shard จริงเครื่องแรก
gcloud compute ssh mysql-physical-1 --zone=$ZONE
เข้าสู่ระบบ MySQL
sudo mysql
เรียกใช้การแทรกต่อไปนี้ใน shard1_db
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
พิมพ์ exit อีกครั้งเพื่อกลับไปที่พรอมต์ของ Cloud Shell
4. ยืนยันข้อมูลการย้ายข้อมูลแบบสดและตรวจสอบ DLQ ของ CDC
ตอนนี้เราได้แทรกข้อมูลแล้ว Datastream จะบันทึกเหตุการณ์ CDC และ Dataflow จะพยายามนำไปใช้กับ Spanner
ก. ยืนยันการเปลี่ยนแปลง DML ที่ถูกต้องใน Spanner
เรียกใช้การค้นหาต่อไปนี้เพื่อยืนยันว่าเหตุการณ์ INSERT, UPDATE และ DELETE ไปถึง Spanner เรียบร้อยแล้ว และการเปลี่ยนรูปแบบที่กำหนดเองทริกเกอร์ทั้งในการแทรกและการอัปเดต
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
ผลลัพธ์ที่คาดหวัง
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
หมายเหตุ: หากคำค้นหาใดไม่แสดงผลลัพธ์ที่คาดไว้ โปรดรอสักครู่แล้วลองอีกครั้ง เนื่องจากอาจมีคนสตรีมจำนวนมากที่ยังประมวลผลคิวอยู่
ข. ตรวจสอบการล้มเหลวโดยเจตนาใน DLQ
เนื่องจาก CustomerId = 99999 ไม่มีรายการหลักในตาราง Customers Spanner จึงควรปฏิเสธและ Dataflow ควรนำไปที่ DLQ อย่างปลอดภัย
- ไปที่ Cloud Storage ในคอนโซล Google Cloud
- ไปที่ที่เก็บข้อมูลแล้วเปิดโฟลเดอร์
live-migration/dlq/severe/ - คุณควรเห็นไฟล์ JSON ที่สร้างขึ้นใหม่ คลิกเพื่อตรวจสอบเนื้อหา คุณจะเห็นรายละเอียดของ
CustomerId = 99999และข้อความแสดงข้อผิดพลาดของ Spanner ที่เฉพาะเจาะจง:NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written." - คุณลองอีกครั้งกับข้อผิดพลาด DLQ ของการย้ายข้อมูลแบบสดได้โดยเรียกใช้เทมเพลต Dataflow ที่ตั้งค่า
runMode=retryDLQไว้
5. การจัดการข้อผิดพลาดของ DLQ
ข้อผิดพลาดในไดเรกทอรี severe/ ต้องมีการแทรกแซงด้วยตนเอง มาแก้ไขปัญหาข้อมูลและประมวลผลกิจกรรมที่ไม่สำเร็จอีกครั้งกัน
ก. แก้ไขข้อมูลในแหล่งที่มา
เกิดข้อผิดพลาดเนื่องจากไม่มีระเบียนลูกค้าหลัก CustomerId = 99999 มาแทรกข้อมูลลงในฐานข้อมูล MySQL ต้นทางกัน
SSH ไปยังอินสแตนซ์ MySQL อีกครั้ง
gcloud compute ssh mysql-physical-1 --zone=$ZONE
เข้าสู่ระบบ MySQL โดยใช้ sudo mysql แล้วแทรกแถวหลักที่ขาดหายไปลงใน shard1_db
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
พิมพ์ exit เพื่อกลับไปที่ Cloud Shell
ข. เรียกใช้งาน Dataflow Job ของ retryDLQ
หากต้องการประมวลผลเหตุการณ์จาก severe/ DLQ อีกครั้ง ให้เปิดใช้เทมเพลต Dataflow เดียวกันแต่ในโหมด retryDLQ โหมดนี้จะอ่านจากdeadLetterQueueDirectory/severeเส้นทางโดยเฉพาะ เรียกใช้การเปลี่ยนรูปแบบที่กำหนดเองอีกครั้ง และนำไปใช้กับ Spanner
เปิดใช้การดำเนินการในโหมด retryDLQ โดยทำดังนี้
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
การเปลี่ยนแปลงพารามิเตอร์ที่สำคัญสำหรับการลองใหม่
runMode="retryDLQ": บอกให้เทมเพลตอ่านจากsevereไดเรกทอรี DLQ- นำออก
gcsPubSubSubscription: ไม่จำเป็นเนื่องจากเราไม่ได้อ่านจาก Bucket ของ GCS ของ Datastream ที่ใช้งานจริง
ตรวจสอบกระบวนการลองอีกครั้ง
เช่นเดียวกับไปป์ไลน์หลักของ CDC retryDLQ เป็นไปป์ไลน์การสตรีมที่จะยังคงRUNNINGจนกว่าจะมีการยกเลิกด้วยตนเอง
- ไปที่หน้างาน Dataflow สำหรับ
$JOB_NAME_RETRY - ในแผงเมตริก ให้มองหาตัวนับ 2 รายการต่อไปนี้
elementsReconsumedFromDeadLetterQueue: ประเมินเมื่อมีการดึงข้อมูลไฟล์ข้อผิดพลาดSuccessful events: เพิ่มขึ้นเมื่อเขียนบันทึกลงใน Spanner- ตรวจสอบไดเรกทอรี
severe/เพื่อดูว่ามีข้อผิดพลาดที่เกิดขึ้นซ้ำๆ หรือไม่ - เมื่อเหตุการณ์ที่สําเร็จเพิ่มขึ้นตามจํานวนสินค้าที่คุณต้องการลองอีกครั้ง (1 ในกรณีทดสอบของเรา) ให้ไปที่ขั้นตอนการยืนยันถัดไป
ค. ยืนยันข้อมูลที่ลองอีกครั้ง
หลังจากลองบันทึกที่ไม่สำเร็จอีกครั้ง (อาจใช้เวลาสักครู่จึงจะสำเร็จ) ให้ตรวจสอบ Spanner เพื่อดูว่าย้ายข้อมูลแถวลูกสำเร็จหรือไม่ โดยทำดังนี้
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
ตอนนี้คุณควรเห็นแถวต่อไปนี้
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
นอกจากนี้ ให้ตรวจสอบโฟลเดอร์ $DLQ_DIR_CDC/severe/ ใน GCS ด้วย ระบบควรย้ายหรือลบไฟล์ที่ประมวลผลแล้ว ซึ่งแสดงว่าการประมวลผลซ้ำสำเร็จ
11. ตั้งค่าการจำลองแบบย้อนกลับ (Spanner ไปยัง MySQL)
หากต้องการจัดการสถานการณ์ที่คุณอาจต้องย้อนกลับหรือซิงค์ฐานข้อมูล MySQL เดิมกับ Spanner ในช่วงเปลี่ยนผ่าน คุณสามารถตั้งค่าการจำลองแบบย้อนกลับได้
ไปป์ไลน์นี้ใช้สตรีมการเปลี่ยนแปลงของ Spanner เพื่อบันทึกการแก้ไขแบบเรียลไทม์ใน Spanner จากนั้นจะใช้ JAR การเปลี่ยนรูปแบบที่กำหนดเองเพื่อย้อนกลับการแมปความแตกต่างของสคีมา และใช้ JAR การแบ่งข้อมูลที่กำหนดเองเพื่อคำนวณว่าควรเขียนการอัปเดตกลับไปยัง VM ของ MySQL จริงและ Shard เชิงตรรกะใด
1. สร้าง Change Stream ของ Spanner
ก่อนอื่น คุณต้องสร้างสตรีมการเปลี่ยนแปลงในฐานข้อมูล Spanner เพื่อติดตามการเปลี่ยนแปลงในตาราง Customers และ Orders
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
ตอนนี้สตรีมการเปลี่ยนแปลงนี้จะบันทึกการแก้ไขข้อมูลทั้งหมดในตารางที่ระบุ
2. สร้างฐานข้อมูล Spanner สำหรับข้อมูลเมตาของ Dataflow
Spanner to SourceDB เทมเพลต Dataflow ต้องใช้ฐานข้อมูล Spanner แยกต่างหากเพื่อจัดเก็บข้อมูลเมตาสำหรับการจัดการการใช้สตรีมการเปลี่ยนแปลง
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. เตรียมการกำหนดค่าการเชื่อมต่อ Cloud SQL สำหรับ Dataflow
เทมเพลต Dataflow ต้องมีไฟล์ JSON ใน Cloud Storage ซึ่งมีรายละเอียดการเชื่อมต่อสำหรับฐานข้อมูล Cloud SQL เป้าหมาย
สร้างไฟล์ในเครื่องชื่อ shard_config.json ดังนี้
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
อัปโหลดไฟล์นี้ไปยังที่เก็บข้อมูล GCS
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. เรียกใช้งาน Dataflow Job ของการจำลองแบบย้อนกลับ
เปิดใช้งานงาน Dataflow โดยใช้ Spanner_to_SourceDbFlex Template
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
พารามิเตอร์หลัก
changeStreamName: ชื่อของสตรีมการเปลี่ยนแปลง Spanner ที่จะอ่านmetadataInstance, metadataDatabase: อินสแตนซ์/ฐานข้อมูล Spanner เพื่อจัดเก็บข้อมูลเมตาที่ตัวเชื่อมต่อใช้เพื่อควบคุมการใช้ข้อมูล Change Stream APIsourceShardsFilePath: เส้นทาง GCS ไปยังshard_config.jsonfiltrationMode: ระบุวิธีทิ้งบางระเบียนตามเกณฑ์ ค่าเริ่มต้นคือforward_migration(กรองระเบียนที่เขียนโดยใช้ไปป์ไลน์การย้ายข้อมูลไปข้างหน้า)shardingCustomJarPath: เส้นทาง GCS ไปยังไฟล์ JAR ของ Java ที่คอมไพล์แล้วซึ่งเราสร้างไว้ก่อนหน้านี้shardingCustomClassName: ชื่อคลาสที่สมบูรณ์ในตัวเอง (com.custom.CustomShardIdFetcher) ซึ่งเรียกใช้คณิตศาสตร์มอดุโล%4ที่กำหนดเองเพื่อกำหนดแบบไดนามิกว่า Shard เชิงตรรกะใดควรได้รับระเบียน
หมายเหตุเกี่ยวกับเครือข่าย: ผู้ปฏิบัติงาน Dataflow จะเชื่อมต่อกับอินสแตนซ์ Cloud SQL โดยใช้ IP สาธารณะที่ระบุใน shard_config.json การเชื่อมต่อนี้ได้รับอนุญาตเนื่องจากมีรายการ 0.0.0.0/0 ในเครือข่ายที่ได้รับอนุญาตของอินสแตนซ์ Cloud SQL
ตรวจสอบการเริ่มต้นงานใน Dataflow Jobs Console
5. แทรกข้อมูล Spanner และทริกเกอร์ความล้มเหลวโดยเจตนา
รอให้งาน Dataflow เข้าสู่สถานะ Running (อาจใช้เวลาประมาณ 5 นาที) จากนั้น เราจะเรียกใช้ชุดการค้นหาทั้งหมด (INSERT, UPDATE, DELETE) ใน Spanner โดยตรง พร้อมกับการตั้งใจให้เกิดข้อผิดพลาดเพื่อทดสอบ DLQ แบบย้อนกลับ
เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. ตรวจสอบข้อมูลการจำลองแบบย้อนกลับและตรวจสอบ DLQ
มาตรวจสอบกันว่า JAR การแบ่งข้อมูลที่กำหนดเองของเราได้กำหนดเส้นทาง CustomerId 88 ไปยัง shard0_db ใน VM จริงเครื่องแรกเรียบร้อยแล้ว และ JAR การเปลี่ยนรูปแบบที่กำหนดเองได้นำ "_TIER" ออกจากภูมิภาคเรียบร้อยแล้ว
ก. ตรวจสอบระเบียนที่ถูกต้องใน MySQL
SSH ไปยัง Shard จริงเครื่องแรก
gcloud compute ssh mysql-physical-1 --zone=$ZONE
เข้าสู่ระบบ MySQL และค้นหา shard0_db
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
เอาต์พุตที่คาดไว้ใน Cloud SQL ควรแสดงการเปลี่ยนแปลงที่ทำใน Spanner
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
ประเภท
exit
เพื่อกลับไปที่ Cloud Shell
ซึ่งเป็นการยืนยันว่าไปป์ไลน์การจำลองแบบย้อนกลับทำงานอยู่ โดยจะซิงค์การเปลี่ยนแปลงจาก Spanner กลับไปยัง Cloud SQL
ข. ตรวจสอบการล้มเหลวโดยเจตนาใน DLQ
เนื่องจากระเบียน Customers ใหม่มี CreditLimit เป็น 500 (ซึ่งละเมิดข้อจํากัดการตรวจสอบ > 1000 ที่เข้มงวดซึ่งเรากําหนดไว้ในฐานข้อมูล MySQL ต้นทาง) Dataflow จึงตรวจพบข้อผิดพลาดได้อย่างปลอดภัย
- ไปที่ Cloud Storage ในคอนโซล Google Cloud
- ไปที่ที่เก็บข้อมูลแล้วเปิดโฟลเดอร์
dlq/severe/ - เปิดไฟล์ JSON เพื่อดูระเบียน
Customersที่ถูกปฏิเสธและข้อผิดพลาดที่ละเมิดข้อจํากัดในการตรวจสอบที่แน่นอน - คุณลองอีกครั้งกับข้อผิดพลาด DLQ ของการจำลองแบบย้อนกลับได้โดยเรียกใช้เทมเพลต Dataflow ด้วยการตั้งค่า
runMode=retryDLQ
12. ล้างข้อมูลทรัพยากร
โปรดลบทรัพยากรที่สร้างขึ้นระหว่างการทำ Codelab นี้เพื่อหลีกเลี่ยงการเรียกเก็บเงินเพิ่มเติมในบัญชี Google Cloud
ตั้งค่าตัวแปรสภาพแวดล้อม (หากจำเป็น)
หากเซสชัน Cloud Shell หมดเวลาหรือคุณเปิดเทอร์มินัลใหม่ คุณจะต้องส่งออกตัวแปรสภาพแวดล้อมอีกครั้งก่อนที่จะเรียกใช้คำสั่งล้างข้อมูล
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
หยุดงานสตรีมมิง Dataflow
แสดงรายการงานเพื่อค้นหารหัสงานของงาน Dataflow ที่กําลังทํางาน ส่งออก JOB_ID_CDC และ JOB_ID_REVERSE ตามนั้น
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
ยกเลิกงาน Datastream to Spanner (การย้ายข้อมูลแบบสด) และงานลองใหม่
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
ยกเลิกงาน Spanner to Cloud SQL (การจำลองแบบย้อนกลับ)
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
ลบทรัพยากร Datastream
หยุดและลบสตรีม
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
ลบ VM ของ MySQL ต้นทาง (Compute Engine)
ลบอินสแตนซ์ Compute Engine 2 รายการที่จำลอง Shard จริงของ MySQL ในองค์กร
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
ลบกฎไฟร์วอลล์
นำกฎไฟร์วอลล์เครือข่ายที่สร้างขึ้นเพื่ออนุญาตการเข้าถึง SSH และการเชื่อมต่อ Datastream ไปยัง VM ออก (หมายเหตุ: หากคุณใช้ชื่ออื่นสำหรับกฎไฟร์วอลล์ก่อนหน้านี้ใน Codelab ให้ปรับชื่อที่นี่)
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
ลบทรัพยากร Pub/Sub
ลบการสมัครใช้บริการ
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
ลบหัวข้อ
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
ลบอินสแตนซ์ Cloud Spanner
ลบอินสแตนซ์ Cloud Spanner (ซึ่งจะลบทั้งฐานข้อมูล sharded-target-db และ migration-metadata-db ภายในโดยอัตโนมัติ)
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
ลบ Bucket และเนื้อหาของ GCS
สุดท้าย ให้ลบ Bucket ของ Cloud Storage ที่มีไฟล์ Datastream, การกำหนดค่า Dataflow และคิวจดหมายที่ส่งไม่ได้ คำสั่ง rm -r จะลบที่เก็บข้อมูลและเนื้อหาทั้งหมดแบบเรียกซ้ำ
gcloud storage rm --recursive gs://${BUCKET_NAME}
ลบไฟล์ Cloud Shell ในเครื่อง
หากต้องการล้างไฟล์และไดเรกทอรีในเครื่องที่สร้างขึ้นใน Cloud Shell ระหว่าง Codelab นี้ ให้เรียกใช้คำสั่งต่อไปนี้
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates