
1. Trước khi bắt đầu
Lớp học lập trình này hướng dẫn bạn cách di chuyển một cơ sở dữ liệu MySQL phân mảnh tại chỗ sang cơ sở dữ liệu Cloud Spanner bằng phương ngữ GoogleSQL. Bạn sẽ sử dụng các dịch vụ của Google Cloud, bao gồm cả Công cụ di chuyển Spanner (SMT), Dataflow, Datastream, PubSub và Google Cloud Storage.
Kiến thức bạn sẽ học được:
- Môi trường phân mảnh là gì và cách thiết lập môi trường đó.
- Cách sử dụng giao diện người dùng trên web của Công cụ di chuyển Spanner (SMT) để chuyển đổi giản đồ MySQL thành giản đồ tương thích với Spanner và thực hiện các sửa đổi nâng cao đối với giản đồ.
- Cách thực hiện quy trình di chuyển hàng loạt dữ liệu từ phiên bản MySQL được phân đoạn sang Cloud Spanner bằng Dataflow.
- Cách thiết lập tính năng sao chép liên tục (CDC) từ phiên bản MySQL được phân đoạn sang Cloud Spanner bằng Datastream và Dataflow.
- Cách định cấu hình tính năng Sao chép ngược từ Spanner trở lại các phiên bản MySQL được phân đoạn.
- Cách sử dụng Biến đổi tuỳ chỉnh để điền các cột bổ sung trong quá trình di chuyển hàng loạt, trực tiếp và đảo ngược.
- Cách định cấu hình các phép biến đổi phân đoạn bằng Khoá chính.
Những nội dung KHÔNG có trong lớp học lập trình này:
- Mạng tuỳ chỉnh nâng cao.
- Tạo mẫu Dataflow tuỳ chỉnh từ đầu.
- Điều chỉnh hiệu suất di chuyển.
- Di chuyển ứng dụng: Lớp học lập trình này tập trung vào lớp cơ sở dữ liệu (giản đồ và dữ liệu). Tài liệu này không đề cập đến quy trình vận hành để triển khai lại hoặc di chuyển các dịch vụ ứng dụng của bạn.
Bạn cần có
- Một dự án trên Google Cloud đã bật tính năng thanh toán.
- Có đủ quyền IAM để bật API và tạo/quản lý các tài nguyên Spanner, Dataflow, Datastream và GCS. Mặc dù vai trò Dự án
Ownerlà đơn giản nhất đối với một lớp học lập trình, nhưng các vai trò cụ thể hơn sẽ được đề cập trong phần "Thiết lập môi trường". - Chúng ta sẽ cung cấp một VM Compute Engine nhỏ trong giai đoạn thiết lập để mô phỏng máy chủ tại chỗ. Đảm bảo hạn mức dự án của bạn cho phép tạo máy ảo.
- Một trình duyệt web, chẳng hạn như Google Chrome.
- Quen thuộc cơ bản với Google Cloud Console và các công cụ dòng lệnh như
gcloud. - Truy cập vào môi trường shell. Bạn nên dùng Cloud Shell vì công cụ này có
gcloud.
Thông tin chi tiết hơn về chế độ thiết lập nêu trên có trong phần Thiết lập môi trường.
2. Tìm hiểu quy trình di chuyển
Việc di chuyển cơ sở dữ liệu được phân đoạn bao gồm việc hợp nhất nhiều thực thể MySQL vật lý và logic thành một cơ sở dữ liệu Spanner có khả năng mở rộng theo chiều ngang. Phần này trình bày tổng quan về cấu trúc và các công cụ chính được dùng trong quá trình di chuyển.
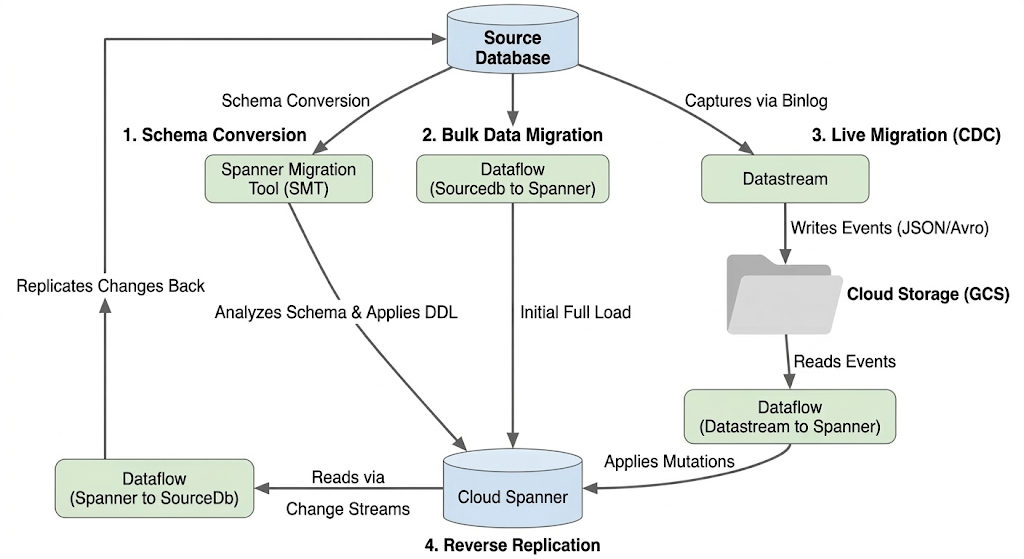
Kiến trúc luồng di chuyển
Quá trình di chuyển bao gồm các giai đoạn sau:
1. Chuyển đổi giản đồ:
- Mục đích: Chuyển đổi giản đồ cơ sở dữ liệu nguồn thành một giản đồ Cloud Spanner tương thích.
- Công cụ: Công cụ di chuyển Spanner (SMT)
- Quy trình: SMT phân tích giản đồ cơ sở dữ liệu nguồn và tạo Ngôn ngữ định nghĩa dữ liệu (DDL) tương đương của Spanner. Trong phiên bản Spanner mục tiêu, một cơ sở dữ liệu sẽ được tạo và DDL sau đó sẽ tự động được áp dụng.
2. Di chuyển dữ liệu hàng loạt:
- Mục đích: Để thực hiện thao tác tải đầy đủ dữ liệu hiện có ban đầu từ cơ sở dữ liệu nguồn vào các bảng Spanner được cung cấp.
- Công cụ: Dataflow, sử dụng mẫu
Sourcedb to Spannerdo Google cung cấp. - Quy trình: Tác vụ Dataflow này đọc tất cả dữ liệu từ các bảng nguồn được chỉ định và ghi dữ liệu đó vào các bảng Spanner tương ứng. Việc này được thực hiện sau khi bạn tạo giản đồ Spanner.
3. Di chuyển trực tiếp (CDC):
- Mục đích: Để ghi lại và áp dụng các thay đổi liên tục từ cơ sở dữ liệu nguồn vào Cloud Spanner gần như theo thời gian thực, giảm thiểu thời gian ngừng hoạt động trong quá trình di chuyển.
- Công cụ:
- Datastream: Ghi lại các thay đổi (Chèn, Cập nhật, Xoá) từ cơ sở dữ liệu nguồn và ghi các thay đổi đó vào Cloud Storage (GCS).
- Dataflow: Sử dụng mẫu
Datastream to Spannerđể đọc các sự kiện thay đổi từ GCS và áp dụng các sự kiện đó cho Cloud Spanner.
4. Sao chép ngược:
- Mục đích: Sao chép các thay đổi về dữ liệu từ Cloud Spanner trở lại cơ sở dữ liệu nguồn. Điều này có thể hữu ích cho các chiến lược dự phòng, quá trình di chuyển theo giai đoạn hoặc duy trì bản sao trong nguồn cho các trường hợp sử dụng cụ thể.
- Công cụ: Dataflow, sử dụng mẫu
Spanner to SourceDb. - Quy trình: Tác vụ này sử dụng luồng thay đổi của Spanner để ghi lại các nội dung sửa đổi trong Spanner và ghi lại các nội dung đó vào phiên bản cơ sở dữ liệu nguồn.
Sơ đồ sau đây minh hoạ các thành phần và luồng dữ liệu:
Thuật ngữ chính:
- Phân đoạn thực: Máy chủ hoặc phiên bản điện toán cơ bản thực tế lưu trữ cơ sở dữ liệu (trong trường hợp của chúng tôi, đó là VM GCE mô phỏng tại chỗ).
- Phân đoạn logic: Lược đồ cơ sở dữ liệu riêng lẻ trong một máy chủ vật lý.
- Máy ảo Compute Engine (GCE): Một máy ảo được lưu trữ trên cơ sở hạ tầng của Google Cloud. Trong lớp học lập trình này, chúng ta sẽ sử dụng một VM GCE để mô phỏng một máy chủ độc lập, "tại chỗ" không có hệ điều hành lưu trữ cơ sở dữ liệu nguồn MySQL.
- Công cụ di chuyển Spanner (SMT): Một công cụ dùng để đánh giá giản đồ MySQL, đề xuất các giản đồ tương đương của Spanner và tạo Ngôn ngữ định nghĩa dữ liệu (DDL) của Spanner.
- Ngôn ngữ định nghĩa dữ liệu (DDL): Các câu lệnh dùng để xác định và sửa đổi cấu trúc cơ sở dữ liệu, chẳng hạn như câu lệnh
CREATE TABLE. SMT tạo DDL Spanner dựa trên giản đồ Cloud SQL. - Dataflow: Một dịch vụ xử lý dữ liệu không máy chủ, được quản lý toàn diện. Trong lớp học lập trình này, bạn sẽ dùng công cụ này để chạy các mẫu do Google cung cấp cho hoạt động chuyển dữ liệu hàng loạt, áp dụng các thay đổi của Datastream và sao chép ngược.
- Datastream: Một dịch vụ sao chép và Thu thập dữ liệu thay đổi (CDC) không cần máy chủ. Trong lớp học lập trình này, công cụ này được dùng để truyền trực tuyến các thay đổi từ phiên bản MySQL được lưu trữ cục bộ vào Cloud Storage.
- Luồng thay đổi của Spanner: Một tính năng của Spanner cho phép truyền trực tuyến các thay đổi đối với dữ liệu (thao tác chèn, cập nhật, xoá) theo thời gian thực, được dùng làm nguồn để sao chép ngược.
- Pub/Sub: Một dịch vụ nhắn tin được dùng để tách các dịch vụ tạo sự kiện khỏi các dịch vụ xử lý sự kiện. Trong lớp học lập trình này, bạn sẽ kích hoạt Dataflow để xử lý các bản cập nhật bất cứ khi nào Datastream tải tệp thay đổi mới lên Cloud Storage.
3. Thiết lập môi trường
Trước khi có thể bắt đầu di chuyển, bạn cần thiết lập dự án trên đám mây trên Google Cloud và bật các dịch vụ cần thiết.
1. Chọn hoặc tạo một dự án trên Google Cloud
Bạn cần có một dự án Google Cloud đã bật tính năng thanh toán để sử dụng các dịch vụ trong lớp học lập trình này.
- Trong Google Cloud Console, hãy chuyển đến trang chọn dự án: Chuyển đến trang chọn dự án
- Chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo bạn đã bật tính năng thanh toán cho dự án của mình. Tìm hiểu cách xác nhận rằng tính năng thanh toán đã được bật cho dự án của bạn.
2. Mở Cloud Shell
Cloud Shell là một môi trường dòng lệnh chạy trong Google Cloud, được tải sẵn gcloud CLI và các công cụ khác mà bạn cần.
- Nhấp vào nút Kích hoạt Cloud Shell ở trên cùng bên phải của Bảng điều khiển Google Cloud.
- Một phiên Cloud Shell sẽ mở ra trong một khung hình mới ở cuối bảng điều khiển và hiển thị một dấu nhắc dòng lệnh.

3. Đặt các biến dự án và môi trường
Trong Cloud Shell, hãy thiết lập một số biến môi trường cho mã dự án và khu vực mà bạn sẽ sử dụng.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Bật các API bắt buộc của Google Cloud
Bật các API cần thiết cho Cloud Spanner, Dataflow, Datastream và các dịch vụ liên quan khác.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Lệnh này có thể mất vài phút để hoàn tất.
4. Thiết lập cơ sở dữ liệu MySQL nguồn
Trong phần này, chúng ta sẽ mô phỏng một cấu trúc MySQL phân mảnh tại chỗ bằng cách cung cấp 2 máy ảo Compute Engine (2 "phân mảnh vật lý"). Sau đó, chúng ta sẽ cài đặt MySQL trên cả hai và tạo 2 cơ sở dữ liệu ("phân đoạn logic") trên mỗi VM.
1. Tạo các VM Compute Engine (Phân đoạn vật lý)
Chạy các lệnh sau trong Cloud Shell để tạo 2 VM bằng Ubuntu. Chúng ta sẽ chỉ định cho chúng các thẻ mạng để cho phép lưu lượng truy cập MySQL đến sau này.
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. Định cấu hình quy tắc tường lửa
Để cho phép truy cập SSH an toàn mà không bị lộ thông tin công khai và để bật khả năng kết nối Datastream:
Tạo quy tắc tường lửa cho SSH thông qua IAP:
Quy tắc này cho phép Identity-Aware Proxy truy cập vào các VM của bạn trên cổng SSH (22).
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
Tạo quy tắc tường lửa cho luồng dữ liệu (cổng MySQL):
Datastream cần có thể truy cập vào các VM này trên cổng MySQL tiêu chuẩn (3306).
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3. Cài đặt và định cấu hình MySQL trên Phân đoạn vật lý 1
SSH vào máy ảo đầu tiên để cài đặt MySQL và định cấu hình tính năng ghi nhật ký nhị phân (Datastream bắt buộc phải có tính năng này để nhân bản trực tiếp).
- Tạo kết nối SSH vào máy ảo đầu tiên:
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- Cài đặt MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- Định cấu hình tệp
mysqld.cnfđể bật tính năng ghi nhật ký nhị phân và cho phép các kết nối bên ngoài:
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Khởi động lại MySQL để áp dụng các thay đổi:
sudo systemctl restart mysql
4. Tạo phân đoạn logic, chèn dữ liệu và tạo người dùng luồng dữ liệu (Phân đoạn 1)
Trong khi vẫn SSH vào mysql-physical-1, hãy đăng nhập vào dấu nhắc MySQL:
sudo mysql
Chạy các lệnh SQL sau. Tập lệnh này tạo ra 2 phân đoạn logic riêng biệt (shard0_db và shard1_db), thiết lập lược đồ giống hệt nhau ở cả hai phân đoạn, chèn dữ liệu có thể nhận dạng chính xác vào từng phân đoạn (để minh hoạ việc phân đoạn) và tạo người dùng sao chép cho Datastream.
Chạy các lệnh SQL sau để tạo 2 phân đoạn logic đầu tiên, một bảng và người dùng sao chép cho Datastream:
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
Bạn có thể tìm thấy tệp kết xuất cho giản đồ ở trên tại đây. Bạn cần tạo người dùng sao chép luồng dữ liệu riêng biệt vì người dùng này không có trong tệp kết xuất.
5. Xác minh dữ liệu
Nhanh chóng kiểm tra để đảm bảo dữ liệu có xuất hiện:
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
Kết quả đầu ra dự kiến:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
Nhập exit để thoát khỏi kết nối với máy ảo phân đoạn thực 1.
6. Lặp lại cho Phân đoạn vật lý 2
Giờ đây, bạn sẽ lặp lại quy trình tương tự cho VM thứ hai, nhưng bạn sẽ tạo shard2_db và shard3_db, đồng thời thay đổi server-id.
- SSH vào máy ảo thứ hai:
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- Cài đặt MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- Định cấu hình tệp
mysqld.cnfđể bật tính năng ghi nhật ký nhị phân và cho phép các kết nối bên ngoài [Lưu ý rằng server-id phải khác (ví dụ: 2)]
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Khởi động lại MySQL để áp dụng các thay đổi:
sudo systemctl restart mysql
- Nhập MySQL (
sudo mysql) và chạy một phiên bản SQL đã được sửa đổi một chút từ Bước 4:
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
Kết quả đầu ra dự kiến:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
Bạn có thể tìm thấy tệp kết xuất cho giản đồ ở trên tại đây. Bạn cần tạo người dùng sao chép luồng dữ liệu riêng biệt vì người dùng này không có trong tệp kết xuất.
Nhập exit để thoát khỏi kết nối với máy ảo.
5. Thiết lập Cloud Spanner
Bây giờ, bạn sẽ thiết lập phiên bản Cloud Spanner đích mà dữ liệu sẽ được di chuyển đến.
1. Tạo một phiên bản Cloud Spanner
Tạo một phiên bản Cloud Spanner ở cùng khu vực với VM Compute Engine để giảm thiểu độ trễ. Lệnh này sẽ tạo một phiên bản nhỏ phù hợp với lớp học lập trình này, sử dụng 100 đơn vị xử lý.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
Quá trình tạo phiên bản có thể mất một hoặc hai phút.
6. Chuyển đổi giản đồ bằng Công cụ di chuyển Spanner (SMT)
Sử dụng giao diện người dùng trên web của Công cụ di chuyển Spanner (SMT) để kết nối với một trong các phân đoạn logic của chúng tôi (shard0_db), phân tích giản đồ của phân đoạn đó và áp dụng một số điểm sửa đổi nâng cao trước khi chuyển đổi phân đoạn đó sang Cloud Spanner.
1. Cài đặt SMT
Chúng ta sẽ chạy giao diện người dùng web SMT ngay từ Cloud Shell. Trong thiết bị đầu cuối Cloud Shell, hãy tải xuống và trích xuất bản phát hành SMT mới nhất:
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
2. Kết nối với Cơ sở dữ liệu nguồn
- Xác thực phiên của bạn
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(Lưu ý: Khi được nhắc, hãy truy cập vào URL được cung cấp để uỷ quyền cho tài khoản của bạn và dán mã xác minh vào thiết bị đầu cuối.)
- Trước tiên, hãy tìm IP ngoài của phân đoạn vật lý đầu tiên bằng cách chạy lệnh này trong thẻ Cloud Shell mới:
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- In thông tin chi tiết về phiên bản Target Spanner sẽ được dùng trong khi định cấu hình SMT.
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- Khởi chạy giao diện người dùng web:
gcloud alpha spanner migrate web --port=8080
- Ở trên cùng bên phải cửa sổ Cloud Shell, hãy nhấp vào biểu tượng Xem trước trên web (có dạng hình con mắt) rồi chọn Xem trước trên cổng 8080. Thao tác này sẽ mở giao diện người dùng SMT trong một thẻ trình duyệt mới.
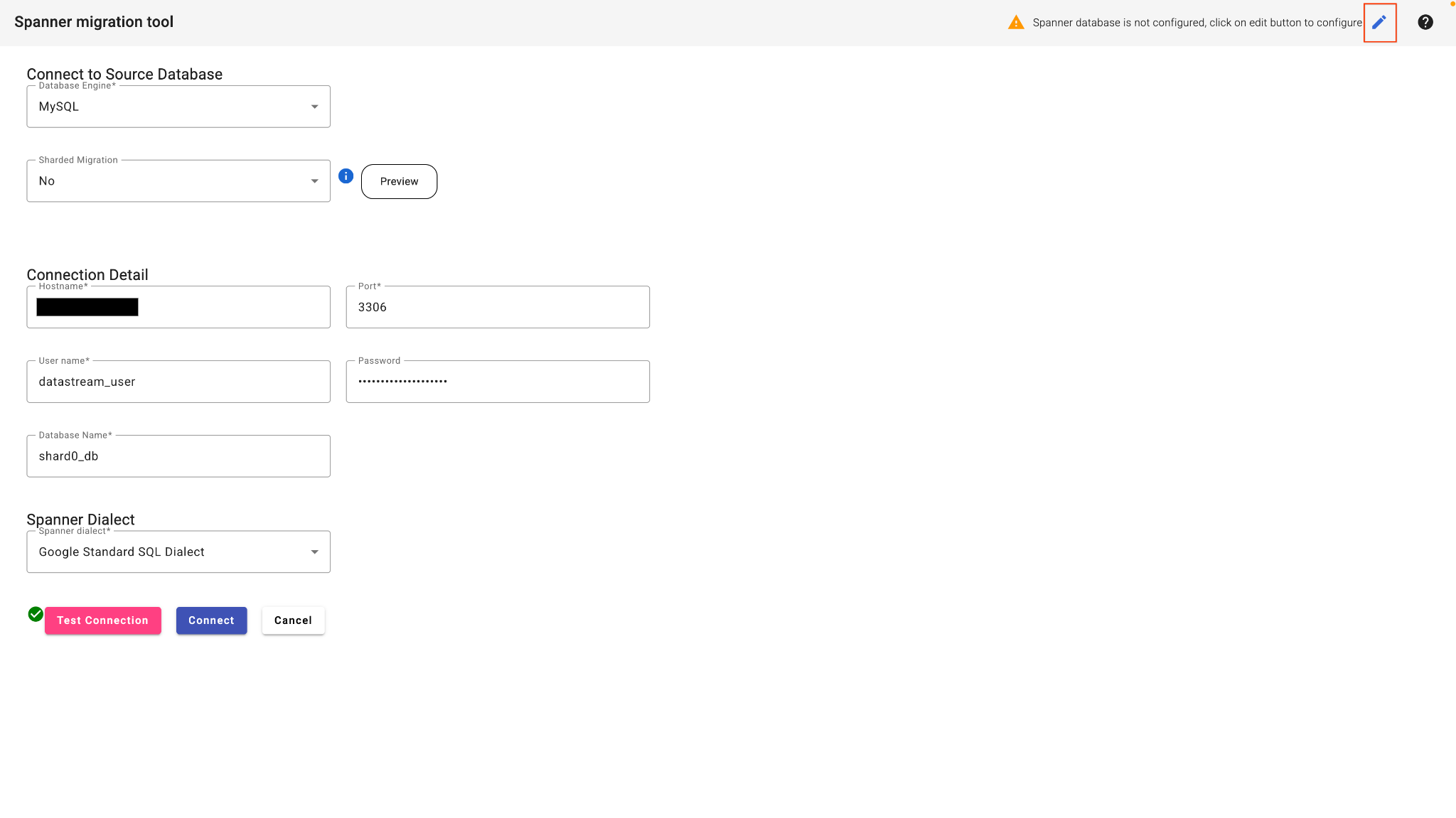
- Trong giao diện người dùng web SMT, hãy chọn Kết nối với cơ sở dữ liệu.
- Điền thông tin chi tiết về mối kết nối:
- Loại cơ sở dữ liệu: MySQL
- Máy chủ lưu trữ: (Dán địa chỉ IP từ bước 2)
- Cổng: 3306
- Người dùng:
datastream_user - Mật khẩu:
complex_password_123 - Tên cơ sở dữ liệu:
shard0_db
- Nhấp vào nút chỉnh sửa ở góc trên cùng bên phải để định cấu hình Cơ sở dữ liệu Spanner.
- Nhập thông tin chi tiết về Spanner đích:
- Mã dự án: (Dán mã dự án từ bước 3)
- Phiên bản Spanner: (Dán mã nhận dạng phiên bản từ bước 3)
- Nhấp vào Kiểm tra kết nối.
- Sau khi quá trình này hoàn tất, hãy nhấp vào Kết nối. SMT sẽ phân tích cơ sở dữ liệu nguồn và trình bày một giản đồ Spanner cơ sở.
3. Áp dụng các sửa đổi về giản đồ
Giờ đây, chúng ta sẽ định hình lại giản đồ để bao gồm các trường hợp di chuyển phức tạp.
Trong trình chỉnh sửa giản đồ của giao diện người dùng SMT, hãy thực hiện các thao tác sau:
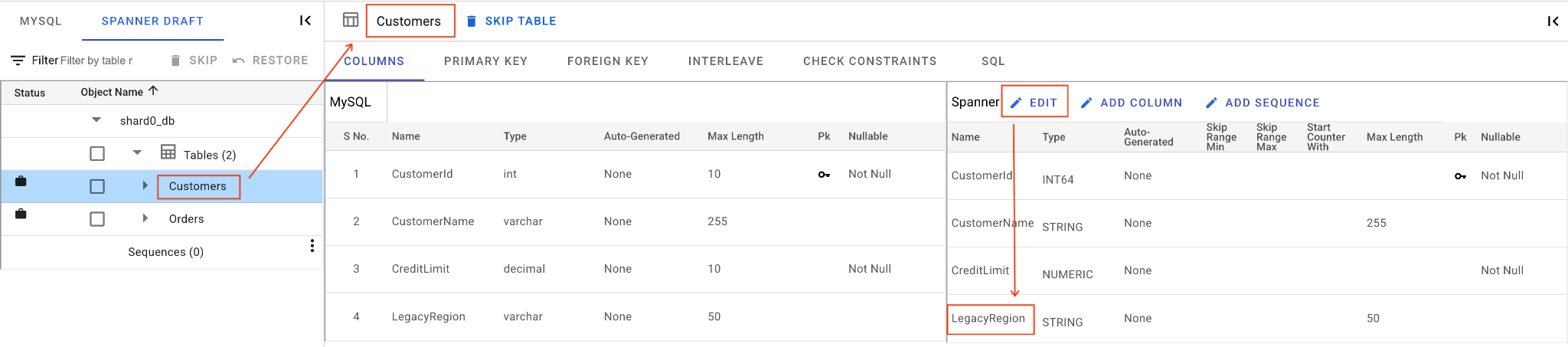
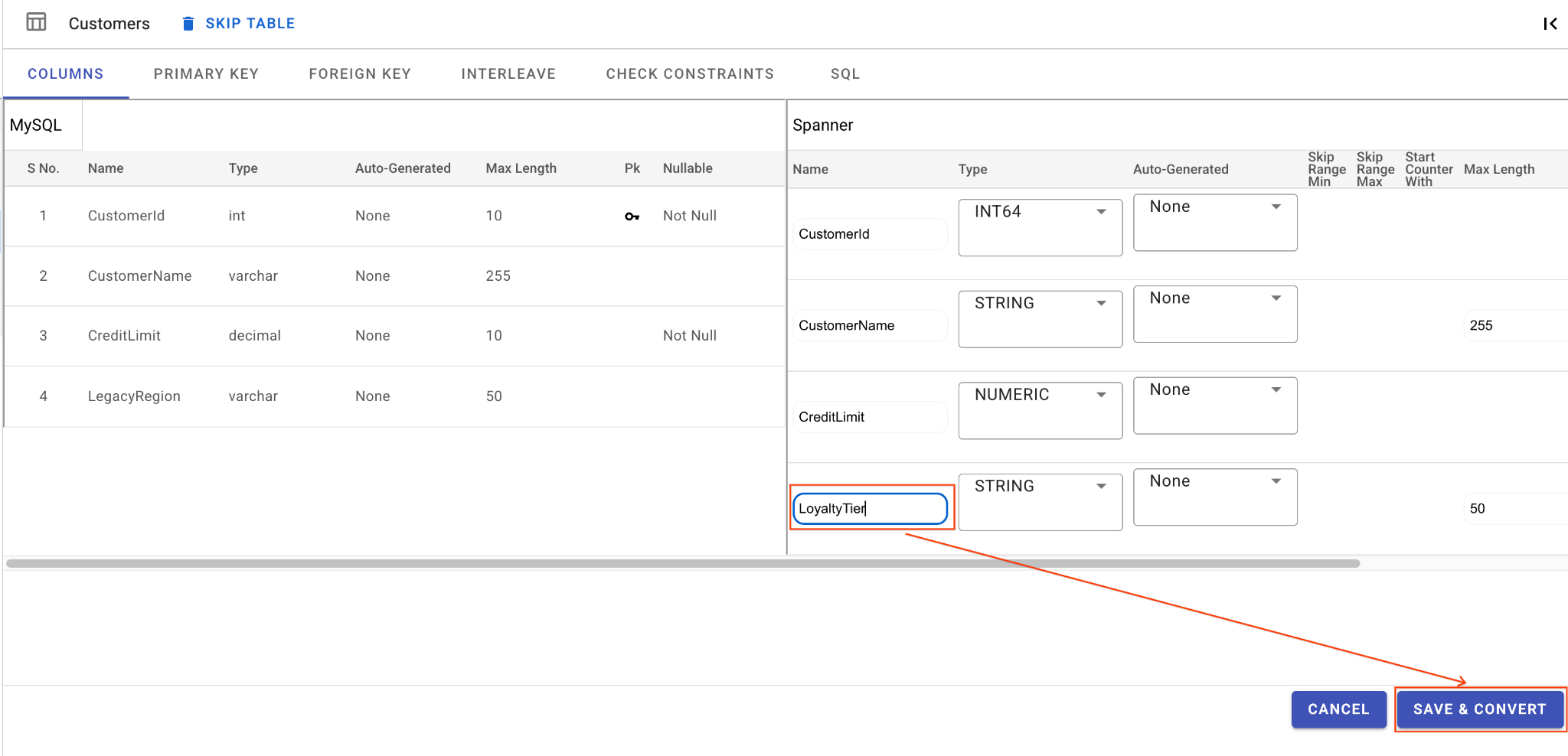
A. Đổi tên cột LegacyRegion:
- Nhấp vào bảng
Customerstrong ngăn điều hướng bên trái. Theo mặc định, thẻ Cột sẽ mở ra. - Nhấp vào nút Chỉnh sửa trong phần Spanner.
- Tìm cột
LegacyRegiontrong chế độ xem giản đồ Spanner. - Thay đổi tên cột Spanner thành
LoyaltyTierbằng cách nhập vào hộp thoại tên cột. - Nhấp vào Lưu và chuyển đổi.
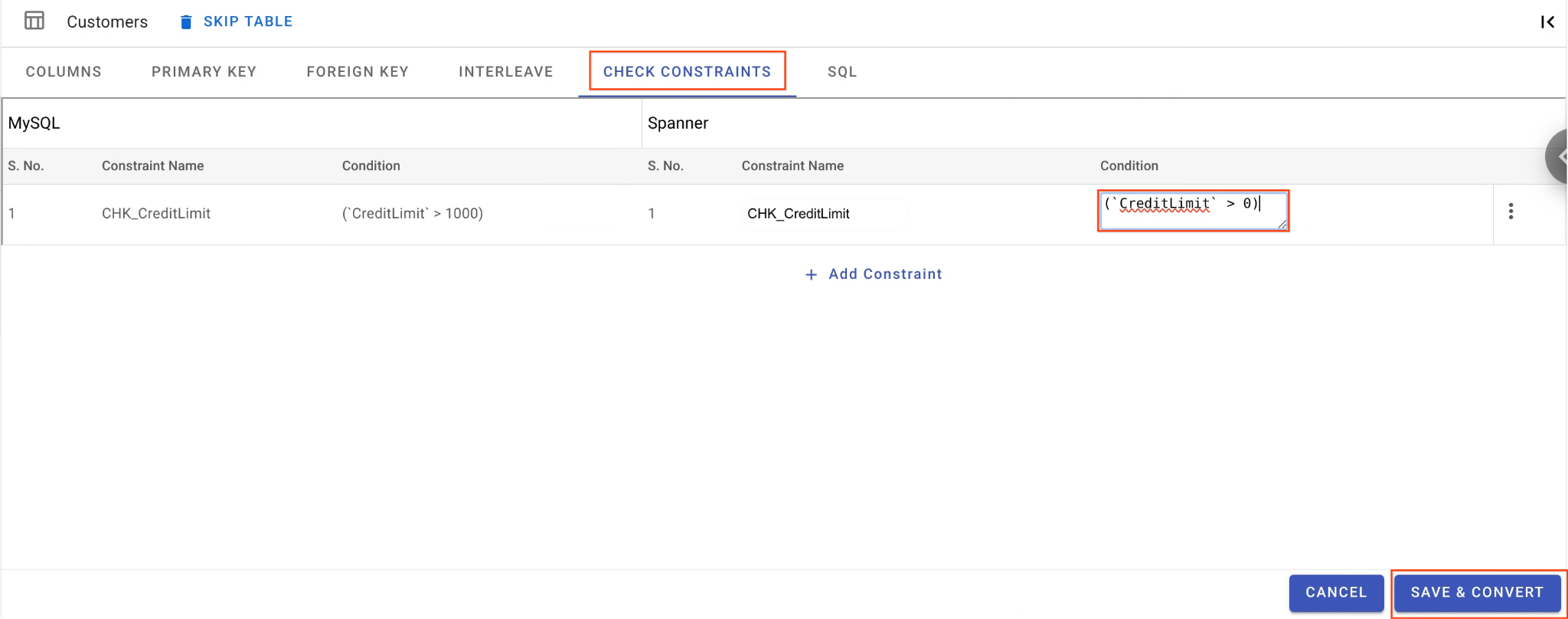
B. Nới lỏng Check Constraint:
- Vẫn ở bảng
Customers, hãy chuyển đến thẻ Check Constraints (Ràng buộc kiểm tra). - Tìm ràng buộc
CHK_CreditLimit. Nhấp vào biểu tượng Chỉnh sửa (bút chì). - Thay đổi điều kiện từ
CreditLimit > 1000thànhCreditLimit > 0. (Việc này sẽ cố ý khiến các hàng có hạn mức tín dụng thấp hơn không thể di chuyển ngược và chuyển vào DLQ).
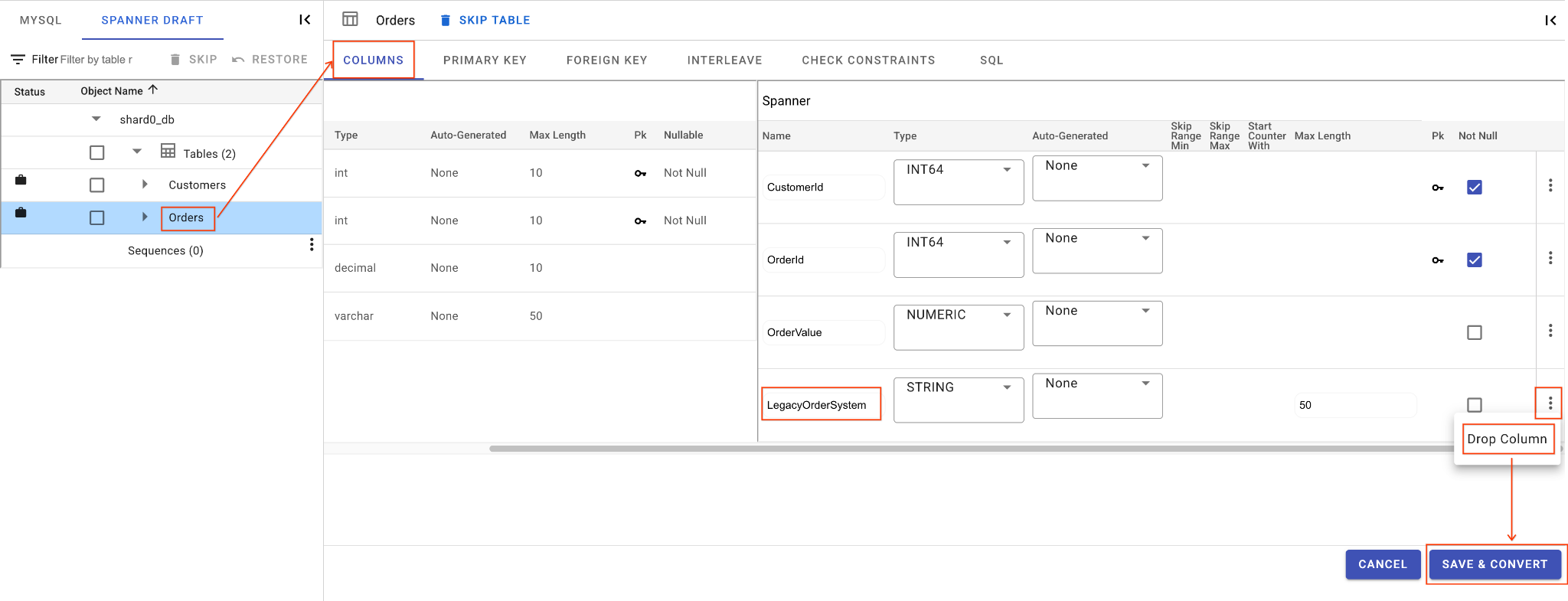
C. Thả cột LegacyOrderSystem:
- Nhấp vào bảng
Orders, thẻ Cột sẽ mở theo mặc định. - Nhấp vào nút Chỉnh sửa trong phần Spanner.
- Tìm cột
LegacyOrderSystemtrong chế độ xem giản đồ Spanner. - Nhấp vào biểu tượng trình đơn có biểu tượng 3 dấu chấm bên cạnh cột đó rồi chọn Thả cột.
- Nhấp vào Lưu và chuyển đổi.
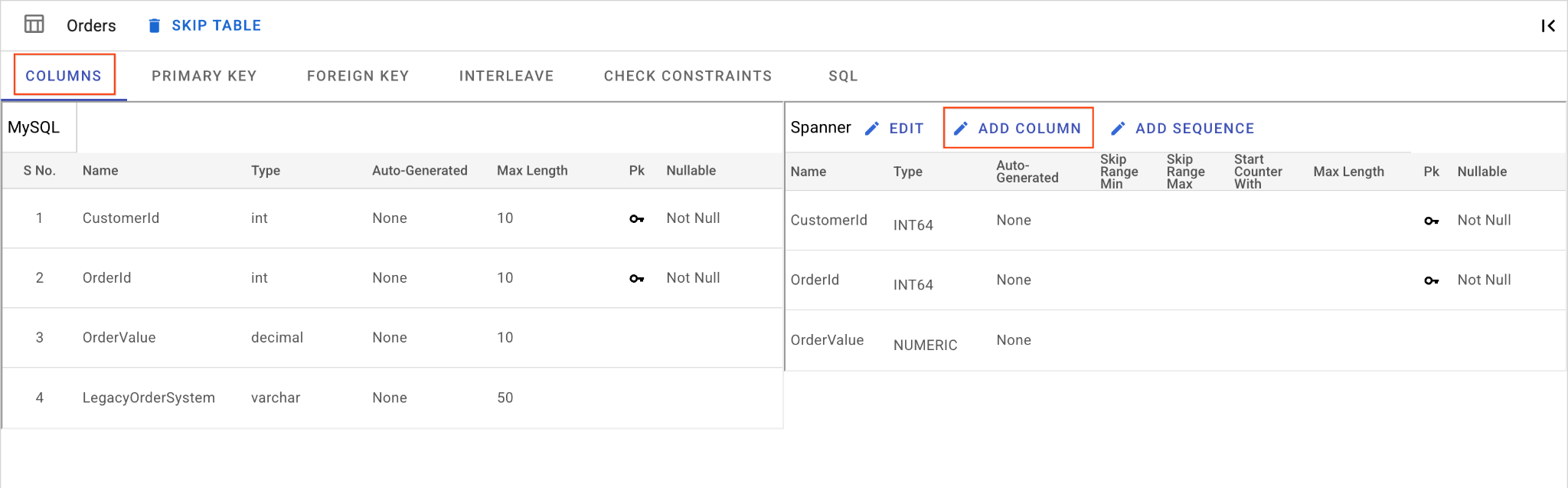
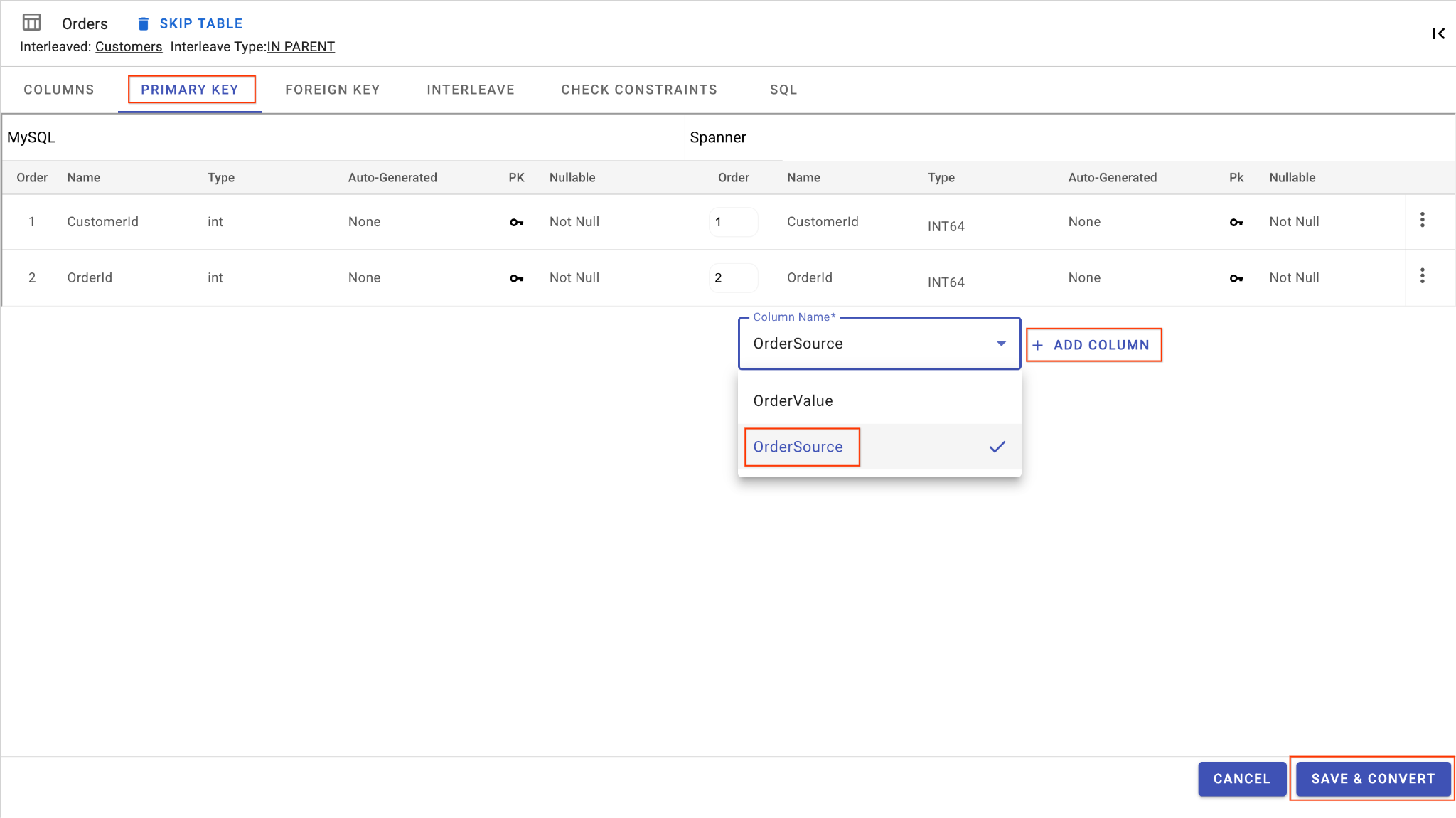
D. Thêm cột OrderSource và đặt cột này làm khoá chính:
- Vẫn ở trên bảng
Orders, hãy nhấp vào Thêm cột. Đặt tên làOrderSourcevà đặt loại thànhSTRINGvới độ dài50, không tự động tạo và đặtIsNullablethànhNo. - Chuyển đến thẻ Khoá chính.
- Nhấp vào Chỉnh sửa rồi chọn
OrderSourcetrong trình đơn thả xuống Tên cột. - Nhấp vào Thêm cột rồi nhấp vào Lưu và chuyển đổi.
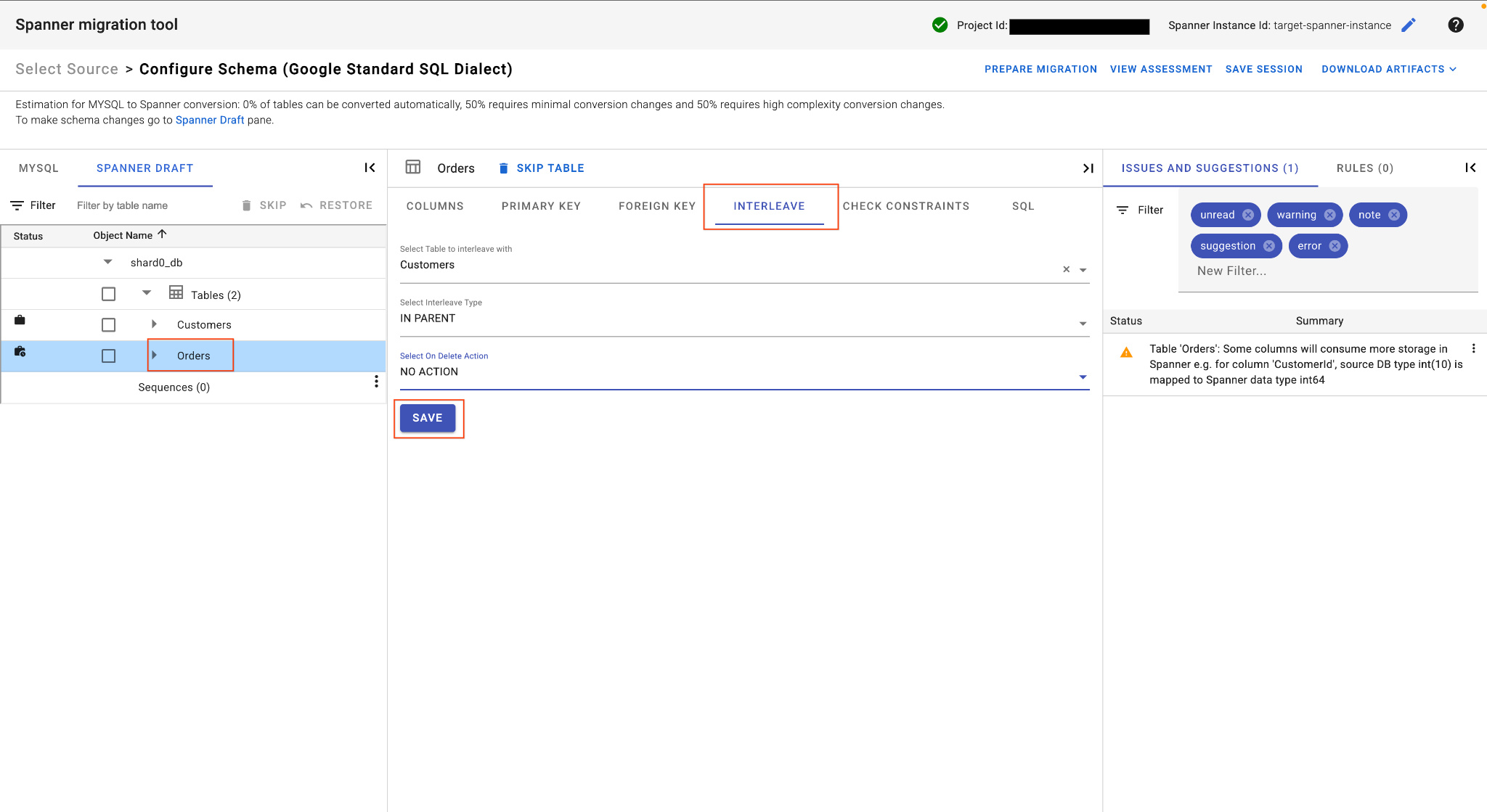
E. Xen kẽ Bảng đơn đặt hàng:
- Vẫn ở trên bảng
Orders, trong chế độ xem bảng chính, hãy tìm thẻ Interleave (Xen kẽ). - Đặt bảng mẹ thành
Customers. - Chọn
IN PARENTInterleave type (Loại xen kẽ) vàNO ACTIONOn Delete Action (Hành động khi xoá). - Nhấp vào Lưu.
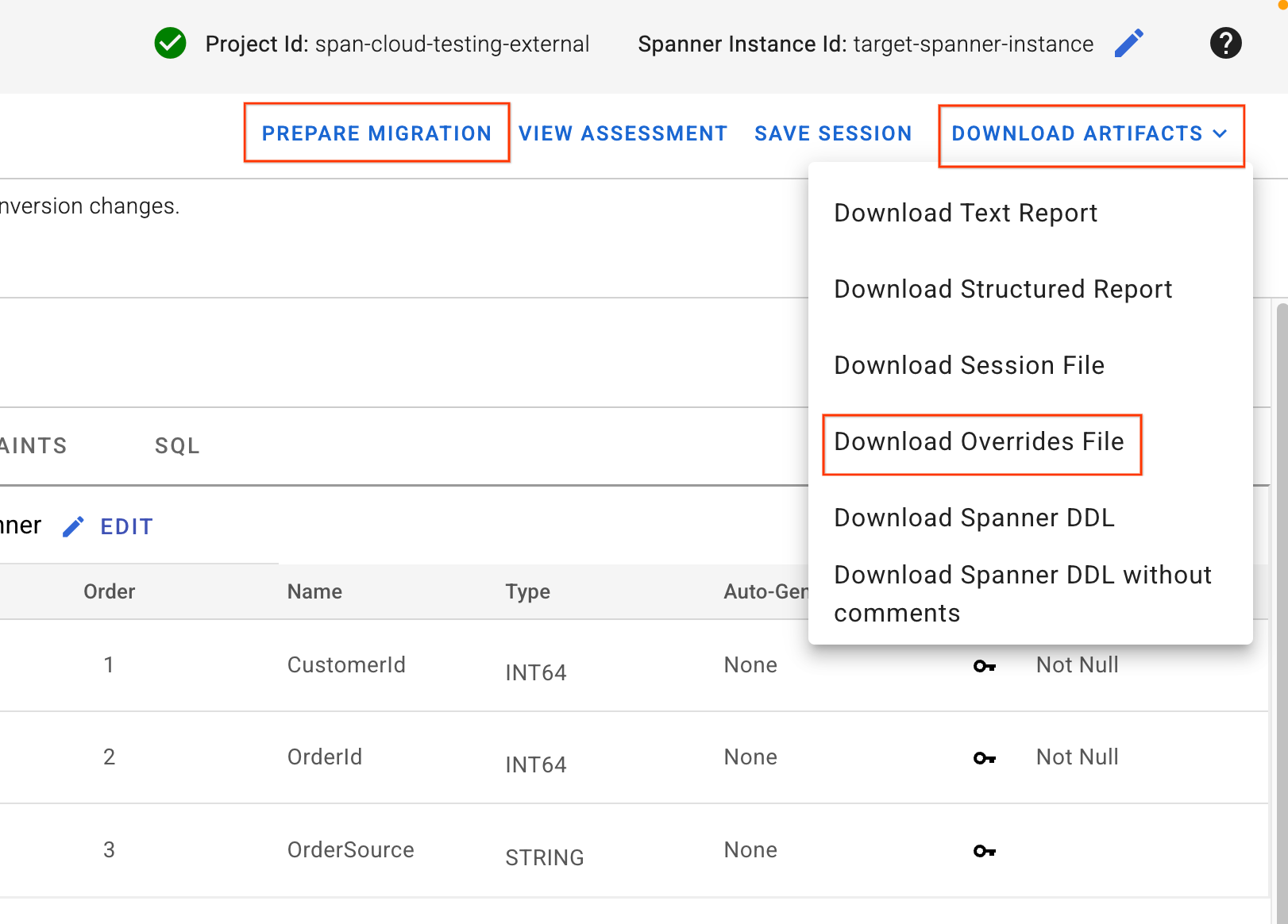
4. Tải tệp ghi đè xuống và áp dụng giản đồ
- Ở góc trên cùng bên phải của giao diện người dùng SMT, hãy tìm nút Download Artifacts (Tải cấu phần phần mềm xuống). Chọn Tải tệp ghi đè xuống. Lưu tệp này vào máy cục bộ. Tệp này chứa tất cả các thay đổi về việc liên kết giản đồ mà chúng tôi vừa thực hiện và sẽ được các quy trình Dataflow của chúng tôi sử dụng.
- Nhấp vào Chuẩn bị di chuyển.
- Chọn Chế độ di chuyển là
Schematrong trình đơn thả xuống. - Nhập Cơ sở dữ liệu Spanner đích:
sharded-target-db
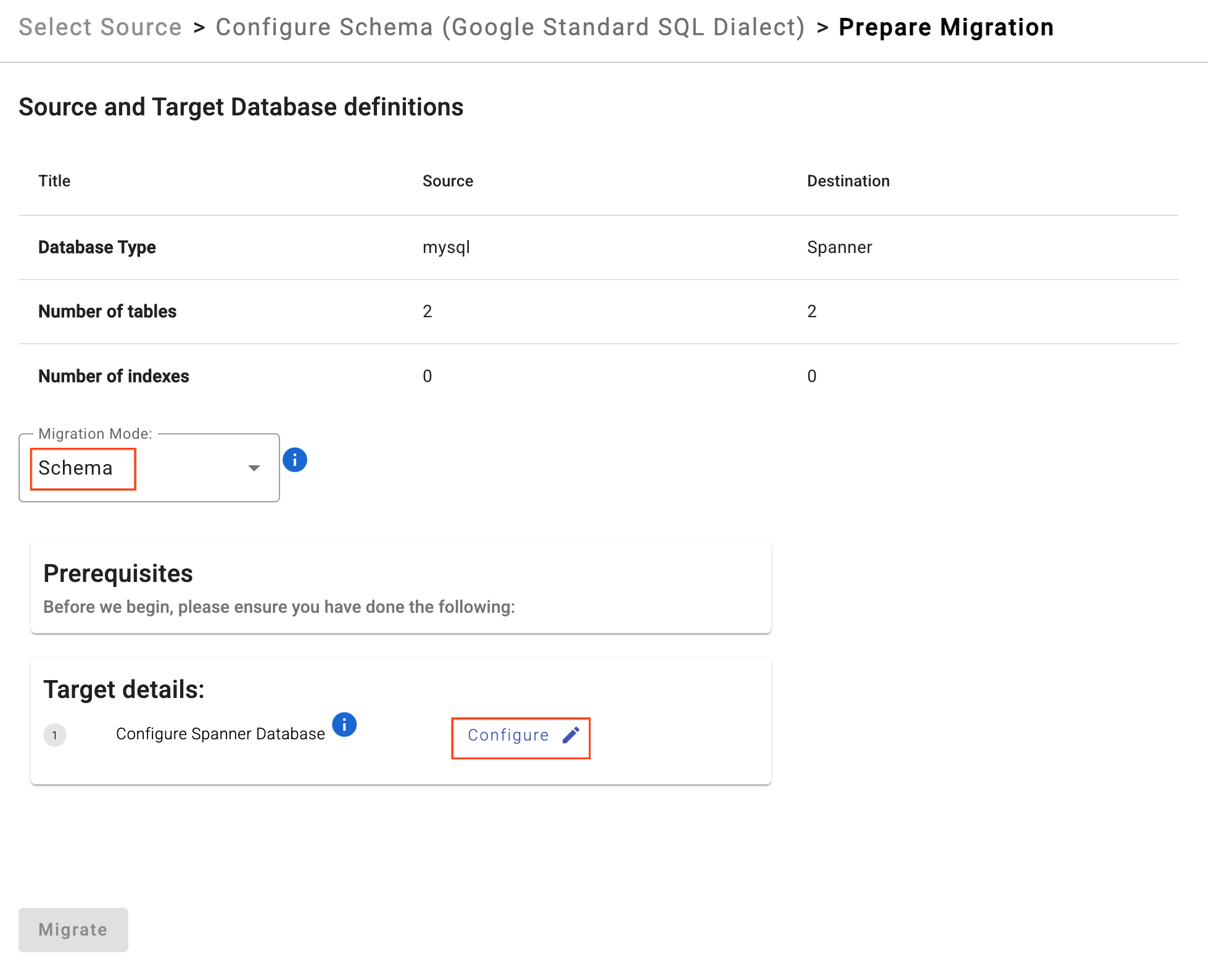
- Nhấp vào Di chuyển.
- SMT sẽ áp dụng DDL và tạo cơ sở dữ liệu Spanner. Bạn có thể dừng quy trình SMT trong Cloud Shell (
Ctrl+C) một cách an toàn sau khi quy trình này hoàn tất.
5. Xác minh giản đồ trong Cloud Spanner
Kiểm tra để đảm bảo các bảng đã được tạo trong cơ sở dữ liệu Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Bạn sẽ thấy kết quả sau đây:
table_name: Customers table_name: Orders
Không bắt buộc: Nếu bạn muốn kiểm tra DDL thực tế của Spanner để xác minh rằng các ràng buộc kiểm tra, việc xen kẽ và các cột bổ sung đã được áp dụng, hãy chạy lệnh sau:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
Kết quả đầu ra dự kiến:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. Khởi chạy tính năng Ghi nhận thay đổi dữ liệu (CDC)
Trong phần này, bạn sẽ thiết lập "trình ghi" cho quá trình di chuyển. Bằng cách định cấu hình Datastream và Pub/Sub trước khi quá trình tải dữ liệu hàng loạt bắt đầu, bạn đảm bảo rằng mọi thay đổi đối với cơ sở dữ liệu nguồn đều được ghi lại và đưa vào hàng đợi, ngăn chặn mọi trường hợp mất dữ liệu trong quá trình chuyển đổi. Bạn phải thiết lập để sử dụng tính năng Di chuyển trực tiếp.
Vì cấu trúc của chúng tôi bao gồm 2 máy chủ vật lý, nên chúng tôi phải tạo 2 hồ sơ nguồn Datastream riêng biệt và 2 luồng Datastream. Cả hai luồng sẽ ghi vào một bộ chứa Google Cloud Storage (GCS) duy nhất. Bộ chứa này sẽ đóng vai trò là nguồn hợp nhất cho quy trình Dataflow của chúng tôi.
1. Tạo một bộ chứa Cloud Storage
Datastream cần có một đích đến để lưu trữ các sự kiện thay đổi được ghi lại. Hãy tạo một vùng lưu trữ GCS.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. Tạo hồ sơ kết nối Datastream
Chúng ta cần 2 hồ sơ kết nối nguồn MySQL riêng biệt (mỗi hồ sơ cho một phân đoạn vật lý) và một hồ sơ kết nối đích cho Cloud Storage.
Nhận địa chỉ IP nguồn
Trước tiên, hãy tìm nạp địa chỉ IP ngoài của 2 VM Compute Engine và lưu trữ các địa chỉ này dưới dạng biến môi trường:
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
Tạo hồ sơ kết nối nguồn (MySQL trên Compute Engine)
Tạo hồ sơ kết nối Datastream bằng datastream_user đã tạo trước đó.
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
Lưu ý: Datastream kết nối với các VM này thông qua IP công khai của chúng. Điều này được cho phép vì trước đó, chúng tôi đã thêm 0.0.0.0/0 vào các quy tắc tường lửa. Trong môi trường phát hành, bạn sẽ chỉ cho phép các dải IP công khai cụ thể của Datastream.
Tạo hồ sơ kết nối đích (Cloud Storage):
Thao tác này sẽ trỏ đến thư mục gốc của bộ chứa bạn vừa tạo.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3. Tạo luồng dữ liệu Datastream
Giờ đây, chúng ta sẽ tạo 2 luồng CDC. Luồng 1 sẽ ghi lại shard0_db và shard1_db. Luồng 2 sẽ ghi lại shard2_db và shard3_db. Cả hai luồng đều ghi vào cùng một vùng chứa GCS ở định dạng Avro.
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
Việc sử dụng chế độ xoay tệp nhỏ hơn (5 MB hoặc 15 giây) giúp chúng ta thấy các thay đổi được sao chép nhanh hơn trong lớp học lập trình.
Lệnh này có thể mất một chút thời gian để hoàn tất. Kiểm tra trạng thái: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION.
4. Bắt đầu luồng Datastream
Kích hoạt cả hai luồng để bắt đầu ghi lại các thay đổi.
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
Kiểm tra trạng thái: Bạn có thể chạy gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION. Ban đầu, trạng thái sẽ là STARTING và sẽ thay đổi thành RUNNING sau vài giây. Hãy đợi cho đến khi cả hai đều chạy hoàn toàn rồi mới bắt đầu Di chuyển trực tiếp.
5. Thiết lập Pub/Sub cho thông báo GCS
Dataflow cần được thông báo ngay khi luồng Datastream ghi một tệp mới vào vùng lưu trữ GCS. Chúng ta sẽ định cấu hình GCS để gửi thông báo đến một chủ đề Pub/Sub duy nhất.
Tạo một chủ đề Pub/Sub:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
Tạo thông báo GCS
Thông báo cho chủ đề khi có bất kỳ đối tượng nào được tạo theo tiền tố data/ (bao gồm cả hai luồng của chúng tôi).
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Tạo gói thuê bao Pub/Sub
Tạo thuê bao có thời hạn xác nhận được đề xuất cho Dataflow.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Biến đổi tuỳ chỉnh
Vì giản đồ Spanner của chúng tôi khác với giản đồ MySQL (do các cột mà chúng tôi đã thêm và xoá thông qua giao diện người dùng web SMT), nên quá trình di chuyển Dataflow có sẵn sẽ không thành công. Dataflow cần hướng dẫn về cách liên kết những điểm khác biệt này trong các quy trình chuyển tiếp (MySQL sang Spanner) và đảo ngược (Spanner sang MySQL).
Ngoài ra, vì chúng ta đang thực hiện quá trình di chuyển ngược được phân đoạn, nên Dataflow cần một cơ chế định tuyến để biết hàng Spanner được cập nhật thuộc về phân đoạn logic nào (shard0_db, shard1_db, v.v.) trong quá trình sao chép ngược.
Chúng ta sẽ đạt được điều này bằng cách viết một JAR Chuyển đổi tuỳ chỉnh bằng cách sử dụng mẫu Phân đoạn tuỳ chỉnh Spanner do Google cung cấp.
1. Tải Mẫu phân đoạn tuỳ chỉnh xuống
Trong Cloud Shell, hãy tải kho lưu trữ Google Cloud Dataflow Templates xuống rồi chuyển đến thư mục phân đoạn tuỳ chỉnh:
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. Định cấu hình logic chuyển đổi dữ liệu
Chúng ta cần chỉnh sửa tệp CustomTransformationFetcher.java.
- Di chuyển tiến (
toSpannerRow): Điền sẵn cộtOrderSourcemới thêm bằng cách sử dụng cộtLegacyOrderSystemtrong MySQL. - Di chuyển ngược (
toSourceRow): Điền lại cộtLegacyOrderSystemđã bị xoá mà MySQL yêu cầu, lấy cột này từOrderSourcecủa Spanner.
Chỉnh sửa tệp CustomTransformationFetcher.java. Thay vì mở trình chỉnh sửa văn bản theo cách thủ công, hãy chạy lệnh sau để tự động ghi đè tệp mẫu bằng logic tuỳ chỉnh của chúng tôi:
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3. Định cấu hình logic phân đoạn đảo ngược
Dataflow sử dụng CustomShardIdFetcher.java trong quá trình sao chép ngược để xác định vị trí cần định tuyến một đột biến Spanner. Chúng ta sẽ sử dụng khoá chính CustomerId và logic modulo (%4) để định tuyến động các bản ghi trở lại phân đoạn logic chính xác của chúng.
Chỉnh sửa tệp CustomShardIdFetcher.java bằng cat và thay thế toàn bộ nội dung của tệp bằng đoạn mã sau:
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. Tạo và tải JAR lên
Bây giờ, sau khi viết logic Java tuỳ chỉnh, chúng ta cần biên dịch logic đó thành tệp JAR và tải lên bộ chứa Google Cloud Storage mà chúng ta đã tạo trước đó để Dataflow có thể truy cập vào tệp này.
Chạy các lệnh sau trong Cloud Shell:
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9. Di chuyển hàng loạt dữ liệu từ MySQL sang Spanner
Sau khi thiết lập giản đồ Spanner và tạo JAR Chuyển đổi tuỳ chỉnh, giờ đây, chúng ta có thể sao chép dữ liệu hiện có từ cơ sở dữ liệu MySQL sang Cloud Spanner. Bạn sẽ sử dụng Sourcedb to Spanner Dataflow Flex Template, được thiết kế để sao chép hàng loạt dữ liệu từ các cơ sở dữ liệu có thể truy cập bằng JDBC sang Spanner.
1. Tải tệp ghi đè giản đồ lên
Trong Phần 6, bạn đã tải tệp JSON Spanner Overrides xuống bằng giao diện người dùng web SMT. Chúng ta cần tải tệp này lên vùng chứa GCS để Dataflow có thể dùng tệp này để liên kết các điểm khác biệt về giản đồ (chẳng hạn như các cột được đổi tên).
- Trong Cloud Shell, hãy nhấp vào trình đơn có biểu tượng ba dấu chấm (Tuỳ chọn khác) rồi chọn Tải lên.
- Chọn tệp JSON ghi đè mà bạn đã tải xuống trước đó (ví dụ:
spanner_overrides.json). - Chuyển tệp đó vào bộ chứa GCS:
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. Tạo và tải tệp cấu hình phân đoạn lên
Dataflow cần biết cách kết nối với cả 4 phân đoạn logic trên 2 máy ảo thực. Chúng ta sẽ tạo một tệp sharding.json cho việc này.
Chạy lệnh sau trong Cloud Shell để tạo và tải cấu hình lên:
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3. Chạy lệnh di chuyển hàng loạt Dataflow
Chúng ta sẽ sử dụng Mẫu linh hoạt Sourcedb to Spanner. Vì đây là quá trình di chuyển phân đoạn với các biến đổi tuỳ chỉnh, nên chúng ta sẽ truyền tệp Overrides, cấu hình Phân đoạn và JAR Java tuỳ chỉnh.
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
Giải thích về các thông số chính:
sourceConfigURL: Đường dẫn đến tệpsharding.jsonmà chúng ta đã tạo. Thao tác này cho Dataflow biết cách kết nối với cả 4 phân đoạn MySQL logic của chúng tôi trên 2 VM thực.schemaOverridesFilePath: Đường dẫn đến tệp JSON mà chúng ta đã tải xuống từ giao diện người dùng web SMT. Thao tác này hướng dẫn Dataflow cách xử lý các sửa đổi về giản đồ mà chúng ta đã thực hiện (chẳng hạn như cộtLegacyRegionbị loại bỏ và ràng buộc kiểm tra chặt chẽ hơn).transformationJarPath: Đường dẫn GCS đến tệp JAR Java đã biên dịch mà chúng ta tạo ở phần trước. Tệp này chứa mã thực để thực thi các phép biến đổi tuỳ chỉnh của chúng ta.transformationClassName: Tên đủ điều kiện của lớp Java trong JAR của chúng tôi, triển khai logic di chuyển chuyển tiếp (com.custom.CustomTransformationFetcher).outputDirectory: Vị trí GCS nơi Dataflow sẽ ghi các tệp tạm thời và quan trọng nhất là các tệp Hàng đợi thư không gửi được (DLQ).maxWorkers,numWorkers: Kiểm soát việc mở rộng quy mô của công việc Dataflow. Được giữ ở mức thấp cho tập dữ liệu nhỏ này.instanceId,databaseId,projectId: Chỉ định cơ sở dữ liệu và phiên bản Cloud Spanner mục tiêu.
Lưu ý về mạng: Tác vụ này kết nối với phiên bản Cloud SQL qua IP công khai. Bạn làm được điều này vì trước đây bạn đã thêm 0.0.0.0/0 vào Mạng được uỷ quyền của phiên bản. Điều này cho phép các VM worker Dataflow (có IP bên ngoài) truy cập vào cơ sở dữ liệu.
4. Theo dõi Dataflow Job
Bạn có thể theo dõi tiến trình của công việc trong Bảng điều khiển Google Cloud:
- Chuyển đến trang Dataflow Jobs: Chuyển đến Dataflow Jobs
- Tìm việc làm có tên
mysql-sharded-bulk-to-spanner-...rồi nhấp vào việc làm đó. - Quan sát biểu đồ và chỉ số của công việc. Chờ trạng thái của lệnh chuyển thành Đã thành công. Quá trình này thường mất khoảng 5 đến 15 phút.
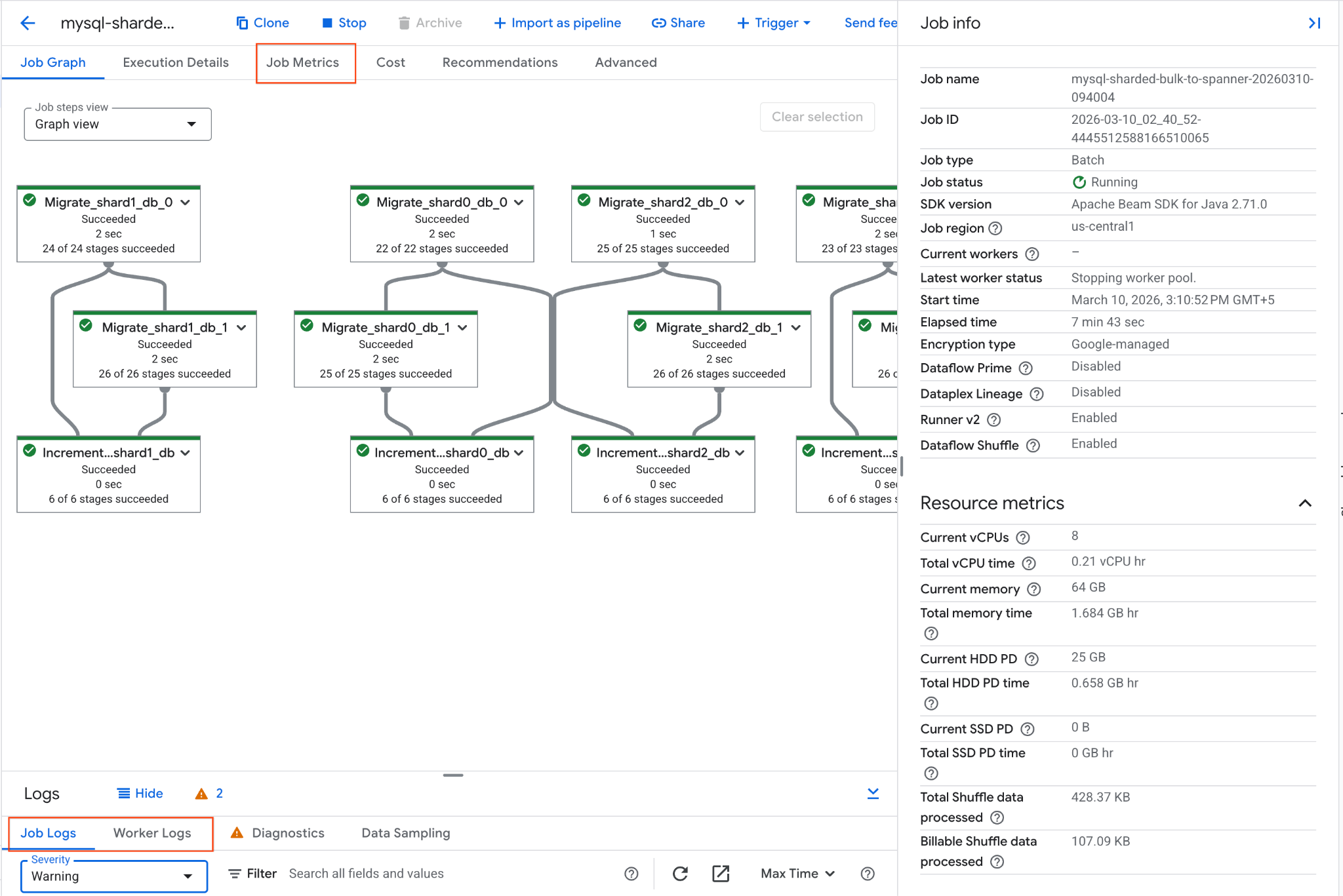
- Nếu công việc gặp vấn đề, hãy xem thẻ Nhật ký trong trang thông tin chi tiết về công việc Dataflow để biết thông báo lỗi.
- Chỉ số về công việc cung cấp thêm thông tin về tiến trình của công việc và mức tiêu thụ tài nguyên, chẳng hạn như thông lượng và mức sử dụng CPU.
5. Xác minh dữ liệu trong Cloud Spanner và kiểm tra hàng đợi thư không gửi được (DLQ)
Sau khi Dataflow hoàn tất thành công, chúng ta cần xác minh rằng dữ liệu đã đến nơi an toàn và kiểm tra các bản ghi mà chúng ta cố tình thiết kế để thất bại.
A. Xác minh tình trạng tổng thể của dữ liệu đã di chuyển:
Sử dụng CLI gcloud để chạy một số quy trình kiểm tra nhanh tình trạng của cơ sở dữ liệu Spanner hợp nhất nhằm đảm bảo các bản ghi hợp lệ được di chuyển đúng cách và JAR tuỳ chỉnh của chúng tôi đã điền vào cột bổ sung.
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
Kết quả đầu ra dự kiến:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- Đã di chuyển thành công tất cả các hàng trong bảng Khách hàng.
- Chúng tôi thấy 1 hàng bị lỗi trong bảng
OrdersdoINTERLEAVE IN PARENTtrên Spanner –CustomerId 99là một phần tử con không có phần tử mẹ do không có hàng tương ứng trong bảngCustomers.
B. Kiểm tra Lỗi có chủ ý trong DLQ:
Lỗi nêu trên được ghi lại trong thư mục Hàng đợi thư không gửi được (DLQ) do quy trình Di chuyển hàng loạt tạo ra.
- Chuyển đến Cloud Storage trong Google Cloud Console.
- Chuyển đến nhóm của bạn rồi mở thư mục
bulk-migration/dlq/severe. - Kiểm tra các tệp JSON bên trong. Bạn sẽ thấy hàng
OrderscóCustomerIdkhông có hàng gốc. - Bạn có thể thử lại các lỗi DLQ di chuyển hàng loạt bằng cách làm theo các bước được đề cập tại đây.
Quá trình tải hàng loạt dữ liệu ban đầu từ Cloud SQL lên Cloud Spanner hiện đã hoàn tất. Bước tiếp theo là thiết lập tính năng sao chép trực tiếp để ghi lại những thay đổi đang diễn ra.
10. Bắt đầu di chuyển trực tiếp (CDC)
Sau khi quá trình tải dữ liệu hàng loạt hoàn tất, bạn sẽ chạy một công việc truyền trực tuyến Dataflow liên tục. Tác vụ này sẽ đọc các sự kiện Thu thập dữ liệu thay đổi (CDC) mà Datastream đang ghi vào bộ chứa GCS của bạn và áp dụng những thay đổi đó cho Cloud Spanner gần như theo thời gian thực.
Chúng ta cũng sẽ kiểm thử quy trình này bằng cách chèn cả dữ liệu hợp lệ và dữ liệu không hợp lệ một cách có chủ ý để quan sát cách Dataflow xử lý việc sao chép trực tiếp và chuyển các lỗi đến Hàng đợi thư không gửi được (DLQ).
1. Tạo tệp cấu hình phân đoạn di chuyển trực tiếp
Không giống như quy trình di chuyển hàng loạt (sử dụng chuỗi kết nối JDBC), quy trình di chuyển trực tiếp sẽ đọc các sự kiện Datastream từ GCS. Bạn cần có một cấu hình JSON hoàn toàn khác để ánh xạ tên luồng và cơ sở dữ liệu Datastream với các phân đoạn Spanner logic.
Chạy lệnh sau trong Cloud Shell để tạo và tải cấu hình phân đoạn trực tiếp lên:
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. Chạy lệnh Live Migration Dataflow Job
Khởi chạy đối tượng công việc Dataflow truyền trực tuyến để đọc từ GCS và ghi vào Spanner. Mẫu này sẽ sử dụng thông báo Pub/Sub của GCS để xử lý ngay các tệp mới.
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
Thông số chính
gcsPubSubSubscription: Gói thuê bao Pub/Sub lắng nghe thông báo về tệp mới từ GCS. Điều này cho phép tác vụ xử lý các thay đổi ngay lập tức khi Datastream ghi các thay đổi đó.inputFileFormat="avro": Yêu cầu Dataflow dự kiến các tệp Avro từ Datastream. Giá trị này phải khớp với cấu hình "Đích đến" của Luồng dữ liệu (ví dụ:avroFileFormatso vớijsonFileFormat).shardingContextFilePath: Tệp JSON ánh xạ các luồng Datastream với các phân đoạn logic.dlqRetryMinutes: Số phút giữa các lần thử lại của hàng đợi thư không gửi được. Giá trị mặc định là10.dlqMaxRetryCount: Số lần tối đa có thể thử lại các lỗi tạm thời thông qua DLQ. Giá trị mặc định là500.
Theo dõi quá trình khởi động tác vụ trong Bảng điều khiển tác vụ Dataflow.
3. Chèn dữ liệu trực tiếp và kích hoạt lỗi có chủ ý
Trong khi công việc truyền phát trực tiếp Dataflow đang khởi động (quá trình này có thể mất từ 3 đến 5 phút), hãy SSH vào VM MySQL thực đầu tiên và chèn một số bản ghi mới. Chúng ta sẽ chèn một bản ghi hợp lệ và một bản ghi không hợp lệ.
SSH vào phân đoạn vật lý đầu tiên:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Đăng nhập vào MySQL:
sudo mysql
Chạy các lệnh chèn sau trên shard1_db:
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
Nhập lại exit để quay lại dấu nhắc Cloud Shell.
4. Xác minh dữ liệu di chuyển trực tiếp và kiểm tra CDC DLQ
Giờ đây, sau khi chúng ta đã chèn dữ liệu, Datastream sẽ nắm bắt các sự kiện CDC và Dataflow sẽ cố gắng áp dụng các sự kiện đó vào Spanner.
A. Xác minh các thay đổi hợp lệ về DML trong Spanner
Chạy các truy vấn sau để xác minh rằng các sự kiện INSERT, UPDATE và DELETE đã đến được Spanner, đồng thời Custom Transformation đã kích hoạt cả thao tác chèn và cập nhật.
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Kết quả đầu ra dự kiến:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
Lưu ý: Nếu có truy vấn không cho thấy kết quả như mong đợi, hãy đợi một phút rồi thử lại, vì các worker truyền phát trực tiếp có thể vẫn đang xử lý hàng đợi.
B. Kiểm tra Lỗi có chủ ý trong DLQ:
Vì CustomerId = 99999 không có đối tượng mẹ trong bảng Customers, nên đối tượng này sẽ bị Spanner từ chối và được Dataflow chuyển an toàn đến DLQ.
- Chuyển đến Cloud Storage trong Google Cloud Console.
- Chuyển đến nhóm của bạn rồi mở thư mục
live-migration/dlq/severe/. - Bạn sẽ thấy các tệp JSON mới được tạo. Nhấp vào các mục đó để kiểm tra nội dung. Bạn sẽ thấy thông tin chi tiết về
CustomerId = 99999và thông báo lỗi cụ thể của Spanner:NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written." - Bạn có thể thử lại các lỗi DLQ của tính năng Di chuyển trực tiếp bằng cách chạy mẫu dataflow với
runMode=retryDLQđược đặt.
5. Xử lý lỗi DLQ
Bạn phải can thiệp theo cách thủ công đối với các lỗi trong thư mục severe/. Hãy khắc phục vấn đề về dữ liệu và xử lý lại sự kiện không thành công.
A. Khắc phục dữ liệu trong nguồn
Lỗi này xảy ra do thiếu hồ sơ khách hàng mẹ CustomerId = 99999. Hãy chèn dữ liệu đó vào cơ sở dữ liệu MySQL nguồn.
SSH vào phiên bản MySQL một lần nữa:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Đăng nhập vào MySQL bằng sudo mysql và chèn hàng chính còn thiếu vào shard1_db:
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
Nhập exit để quay lại Cloud Shell.
B. Chạy Công việc Dataflow retryDLQ
Để xử lý lại các sự kiện từ DLQ severe/, bạn sẽ chạy cùng mẫu Dataflow nhưng ở chế độ retryDLQ. Chế độ này đọc cụ thể từ đường dẫn deadLetterQueueDirectory/severe, chạy lại các đường dẫn đó thông qua các phép biến đổi tuỳ chỉnh và áp dụng chúng cho Spanner.
Khởi chạy công việc ở chế độ retryDLQ:
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
Các thay đổi chính về tham số cho hoạt động thử lại
runMode="retryDLQ": Yêu cầu mẫu đọc từ thư mục DLQsevere.- Xoá
gcsPubSubSubscription: Không cần thiết vì chúng ta không đọc từ bộ chứa GCS Datastream trực tiếp.
Theo dõi quy trình thử lại:
Giống như quy trình CDC chính, retryDLQ là một quy trình truyền phát trực tiếp sẽ vẫn ở trạng thái RUNNING cho đến khi bị huỷ theo cách thủ công.
- Chuyển đến trang Dataflow Job cho
$JOB_NAME_RETRY. - Trong ngăn Chỉ số, hãy tìm 2 bộ đếm sau:
elementsReconsumedFromDeadLetterQueue: Đánh giá khi các tệp lỗi đang được tìm nạp.Successful events: Tăng lên khi bản ghi được ghi vào Spanner.- Kiểm tra thư mục
severe/để biết các lỗi lặp lại. - Khi số lượng sự kiện Thành công tăng thêm số lượng mục mà bạn muốn thử lại (1 trong trường hợp kiểm thử của chúng tôi), hãy chuyển sang bước xác minh tiếp theo.
C. Xác minh dữ liệu được thử lại
Sau khi bản ghi không thành công được thử lại (có thể mất một khoảng thời gian để thành công), hãy kiểm tra Spanner để xem hàng con đã được di chuyển thành công hay chưa:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Lúc này, bạn sẽ thấy hàng:
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
Ngoài ra, hãy kiểm tra thư mục $DLQ_DIR_CDC/severe/ trong GCS. Các tệp đã xử lý phải được di chuyển hoặc xoá, cho biết quá trình xử lý lại đã thành công.
11. Thiết lập tính năng sao chép ngược (từ Spanner sang MySQL)
Để xử lý các trường hợp mà bạn có thể cần khôi phục hoặc giữ cho cơ sở dữ liệu MySQL ban đầu đồng bộ hoá với Spanner trong một khoảng thời gian chuyển tiếp, bạn có thể thiết lập tính năng sao chép ngược.
Quy trình này sử dụng Spanner Change Streams để ghi lại các nội dung sửa đổi trực tiếp trong Spanner. Sau đó, nó sử dụng JAR Chuyển đổi tuỳ chỉnh của chúng tôi để ánh xạ ngược các điểm khác biệt về giản đồ và JAR Phân đoạn tuỳ chỉnh của chúng tôi để tính toán chính xác VM MySQL thực và phân đoạn logic mà bản cập nhật sẽ được ghi lại.
1. Tạo một luồng thay đổi Spanner
Trước tiên, bạn cần tạo một luồng thay đổi trong cơ sở dữ liệu Spanner để theo dõi các thay đổi trên bảng Customers và Orders.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
Luồng thay đổi này sẽ ghi lại tất cả các nội dung sửa đổi dữ liệu đối với các bảng được chỉ định.
2. Tạo cơ sở dữ liệu Spanner cho siêu dữ liệu Dataflow
Mẫu Dataflow Spanner to SourceDB yêu cầu phải có một cơ sở dữ liệu Spanner riêng biệt để lưu trữ siêu dữ liệu nhằm quản lý việc sử dụng luồng thay đổi.
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Chuẩn bị cấu hình kết nối Cloud SQL cho Dataflow
Mẫu Dataflow cần một tệp JSON trong Cloud Storage chứa thông tin chi tiết về kết nối cho cơ sở dữ liệu Cloud SQL mục tiêu.
Tạo một tệp cục bộ có tên shard_config.json:
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
Tải tệp này lên bộ chứa GCS của bạn:
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. Chạy công việc Dataflow sao chép ngược
Khởi chạy công việc Dataflow bằng cách sử dụng Spanner_to_SourceDb Flex Template.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
Thông số chính
changeStreamName: Tên của luồng thay đổi Spanner cần đọc.metadataInstance, metadataDatabase: Cơ sở dữ liệu/phiên bản Spanner để lưu trữ siêu dữ liệu mà trình kết nối dùng để kiểm soát mức tiêu thụ dữ liệu API luồng thay đổi.sourceShardsFilePath: Đường dẫn GCS đếnshard_config.json.filtrationMode: Chỉ định cách loại bỏ một số bản ghi dựa trên một tiêu chí. Mặc định làforward_migration(lọc các bản ghi được ghi bằng quy trình di chuyển chuyển tiếp)shardingCustomJarPath: Đường dẫn GCS đến tệp JAR Java đã biên dịch mà chúng ta đã tạo trước đó.shardingCustomClassName: Tên lớp đủ điều kiện (com.custom.CustomShardIdFetcher) thực thi phép toán modulo%4tuỳ chỉnh của chúng ta để xác định một cách linh động phân đoạn logic nào sẽ nhận bản ghi.
Lưu ý về mạng: Các worker Dataflow sẽ kết nối với phiên bản Cloud SQL bằng IP công khai được chỉ định trong shard_config.json. Kết nối này được phép do mục 0.0.0.0/0 trong Mạng được uỷ quyền của phiên bản Cloud SQL.
Theo dõi quá trình khởi động tác vụ trong Bảng điều khiển tác vụ Dataflow.
5. Chèn dữ liệu Spanner và kích hoạt lỗi có chủ ý
Chờ cho đến khi chương trình Dataflow chuyển sang trạng thái Running (quá trình này có thể mất khoảng 5 phút). Sau đó, hãy thực thi một bộ truy vấn đầy đủ (INSERT, UPDATE, DELETE) trực tiếp vào Spanner, cùng với một lỗi có chủ ý để kiểm thử DLQ đảo ngược.
Chạy lệnh sau trong Cloud Shell:
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. Xác minh dữ liệu sao chép đảo ngược và kiểm tra DLQ
Hãy xác nhận rằng JAR Phân đoạn tuỳ chỉnh của chúng ta đã định tuyến thành công CustomerId 88 đến shard0_db trên VM thực đầu tiên và JAR Biến đổi tuỳ chỉnh đã loại bỏ thành công "_TIER" khỏi khu vực.
A. Xác minh Bản ghi hợp lệ trong MySQL:
SSH vào phân đoạn vật lý đầu tiên:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Đăng nhập vào MySQL và truy vấn shard0_db:
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
Đầu ra dự kiến trong Cloud SQL phải phản ánh những thay đổi được thực hiện trong Spanner.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
Loại
exit
để quay lại Cloud Shell.
Điều này xác nhận rằng quy trình sao chép ngược đang hoạt động, đồng bộ hoá các thay đổi từ Spanner trở lại Cloud SQL.
B. Kiểm tra Lỗi có chủ ý trong DLQ
Vì bản ghi Customers mới của chúng ta có CreditLimit là 500 (vi phạm ràng buộc kiểm tra > 1000 nghiêm ngặt mà chúng ta đã xác định trong cơ sở dữ liệu MySQL nguồn), nên Dataflow đã phát hiện lỗi một cách an toàn.
- Chuyển đến Cloud Storage trong Google Cloud Console.
- Chuyển đến nhóm của bạn rồi mở thư mục
dlq/severe/. - Mở tệp JSON để xem bản ghi
Customersbị từ chối và lỗi vi phạm ràng buộc kiểm tra chính xác. - Bạn có thể thử lại các lỗi DLQ sao chép đảo ngược bằng cách chạy mẫu luồng dữ liệu có
runMode=retryDLQđược đặt.
12. Dọn dẹp tài nguyên
Để tránh phát sinh thêm các khoản phí cho tài khoản Google Cloud của bạn, hãy xoá các tài nguyên đã tạo trong lớp học lập trình này.
Đặt các biến môi trường (nếu cần)
Nếu phiên Cloud Shell của bạn hết thời gian chờ hoặc bạn mở một thiết bị đầu cuối mới, bạn sẽ cần xuất lại các biến môi trường trước khi chạy các lệnh dọn dẹp.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
Dừng các công việc truyền trực tuyến Dataflow
Liệt kê các công việc để tìm mã công việc của các công việc luồng dữ liệu đang chạy. Xuất JOB_ID_CDC và JOB_ID_REVERSE cho phù hợp.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Huỷ lệnh Datastream to Spanner (Di chuyển trực tiếp) và lệnh thử lại:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
Huỷ lệnh Spanner to Cloud SQL (Sao chép đảo ngược):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Xoá tài nguyên Datastream
Dừng và xoá luồng dữ liệu:
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Xoá các máy ảo MySQL nguồn (Compute Engine)
Xoá 2 phiên bản Compute Engine mô phỏng các phân đoạn thực của MySQL tại chỗ.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
Xoá quy tắc tường lửa
Xoá các quy tắc tường lửa mạng đã tạo để cho phép truy cập SSH và kết nối Datastream với các VM của bạn. (Lưu ý: Nếu bạn đã sử dụng tên khác cho các quy tắc tường lửa trước đó trong lớp học lập trình, hãy điều chỉnh tên tại đây).
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
Xoá tài nguyên Pub/Sub
Xoá gói thuê bao:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Xoá chủ đề:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Xoá phiên bản Cloud Spanner
Xoá phiên bản Cloud Spanner (thao tác này sẽ tự động xoá cả cơ sở dữ liệu sharded-target-db và migration-metadata-db bên trong).
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Xoá vùng lưu trữ và nội dung trên Google Cloud Storage
Cuối cùng, hãy xoá bộ chứa Cloud Storage chứa các tệp Datastream, cấu hình Dataflow và Hàng đợi thư không gửi được. Lệnh rm -r sẽ xoá đệ quy vùng lưu trữ và mọi nội dung trong đó.
gcloud storage rm --recursive gs://${BUCKET_NAME}
Xoá tệp Cloud Shell trên máy
Để dọn dẹp các tệp và thư mục cục bộ được tạo trong Cloud Shell trong lớp học lập trình này, hãy chạy các lệnh sau:
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates