
1. 概览
在当今快节奏的零售环境中,提供卓越的客户服务并打造个性化的购物体验至关重要。我们将带您踏上技术之旅,了解如何创建一款知识驱动型聊天应用,该应用旨在回答客户问题、引导客户发现产品并量身定制搜索结果。这一创新解决方案将 AlloyDB 的数据存储功能、用于上下文理解的内部分析引擎、用于相关性验证的 Gemini(大语言模型)以及用于快速引导智能对话助理的 Google Agent Builder 融为一体。
挑战:现代零售客户希望获得即时解答,并希望获得符合其独特偏好的商品推荐。传统搜索方法往往无法提供这种程度的个性化体验。
解决方案:我们基于知识的聊天应用可直接应对这一挑战。它会利用从零售数据中提取的丰富知识库来了解客户意图、智能响应并提供高度相关的结果。
构建内容
在本实验(第 1 部分)中,您将:
- 创建 AlloyDB 实例并加载电子商务数据集
- 在 AlloyDB 中启用 pgvector 和生成式 AI 模型扩展程序
- 根据商品说明生成嵌入
- 针对用户搜索文本执行实时余弦相似度搜索
- 在无服务器 Cloud Run Functions 中部署解决方案
本实验的第二部分将介绍 Agent Builder 的步骤。
要求
2. 架构
数据流:我们来仔细了解一下数据在系统中的流动方式:
提取:
第一步是将零售数据(库存、产品说明、客户互动)注入 AlloyDB。
Analytics Engine:
我们将使用 AlloyDB 作为分析引擎来执行以下操作:
- 上下文提取:引擎会分析 AlloyDB 中存储的数据,以了解产品、类别、客户行为等之间的关系(如适用)。
- 嵌入创建:系统会为用户查询和 AlloyDB 中存储的信息生成嵌入(文本的数学表示形式)。
- Vector Search:引擎会执行相似度搜索,将查询嵌入与产品说明、评价和其他相关数据的嵌入进行比较。这会标识 25 个最相关的“最近邻”。
Gemini 验证:
这些潜在回答会发送给 Gemini 进行评估。Gemini 会判断这些信息是否真正相关且可以安全地与用户分享。
回答生成:
经过验证的回答会以 JSON 数组的形式进行结构化处理,整个引擎会打包到从 Agent Builder 调用的无服务器 Cloud Run 函数中。
对话式互动:
Agent Builder 以自然语言格式向用户呈现回答,从而促成来回对话。后续实验将介绍这部分内容。
3. 准备工作
创建项目
- 在 Google Cloud Console 的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
- 您将使用 Cloud Shell,这是一个在 Google Cloud 中运行的命令行环境,它预加载了 bq。点击 Google Cloud 控制台顶部的“激活 Cloud Shell”。

- 连接到 Cloud Shell 后,您可以使用以下命令检查自己是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目。
gcloud config list project
- 如果项目未设置,请使用以下命令进行设置:
gcloud config set project <YOUR_PROJECT_ID>
- 启用所需的 API。
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
除了使用 gcloud 命令,您还可以通过控制台搜索每个产品或使用此链接。
如果遗漏了任何 API,您始终可以在实施过程中启用它。
如需了解 gcloud 命令和用法,请参阅文档。
4. 数据库设置
在本实验中,我们将使用 AlloyDB 作为存储零售数据的数据库。它使用集群来保存所有资源,例如数据库和日志。每个集群都有一个主实例,可提供对数据的接入点。表将包含实际数据。
我们来创建 AlloyDB 集群、实例和表,以便加载电子商务数据集。
创建集群和实例
- 在 Cloud 控制台中浏览 AlloyDB 页面。在 Cloud 控制台中查找大多数页面的简单方法是使用控制台的搜索栏进行搜索。
- 在该页面中选择“创建集群”:

- 您会看到如下所示的界面。使用以下值创建集群和实例:
- 集群 ID:“
shopping-cluster” - 密码:“
alloydb” - 与 PostgreSQL 15 兼容
- 地区:“
us-central1” - 联网:“
default”

- 选择默认网络后,您会看到如下所示的界面。选择“设置连接”。

- 然后,选择“使用自动分配的 IP 范围”,并点击“继续”。查看信息后,选择“创建连接”。

- 设置好网络后,您可以继续创建集群。点击“创建集群”,完成集群设置,如下所示:

请务必将实例 ID 更改为“shopping-instance"”。
请注意,创建集群大约需要 10 分钟。成功后,您应该会看到类似如下的界面:

5. 数据注入
现在,我们来添加一个包含商店相关数据的表格。前往 AlloyDB,选择主集群,然后选择 AlloyDB Studio:

您可能需要等待实例完成创建。完成后,使用您在创建集群时创建的凭据登录 AlloyDB。使用以下数据向 PostgreSQL 进行身份验证:
- 用户名:“
postgres” - 数据库:“
postgres” - 密码:“
alloydb”
成功通过身份验证进入 AlloyDB Studio 后,您可以在编辑器中输入 SQL 命令。您可以使用最后一个窗口右侧的加号添加多个编辑器窗口。

您将在编辑器窗口中输入 AlloyDB 命令,并根据需要使用“运行”“格式”和“清除”选项。
启用扩展程序
在构建此应用时,我们将使用扩展程序 pgvector 和 google_ml_integration。借助 pgvector 扩展程序,您可以存储和搜索向量嵌入。google_ml_integration 扩展程序提供用于访问 Vertex AI 预测端点以在 SQL 中获取预测结果的函数。运行以下 DDL 以启用这些扩展程序:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
如果您想查看数据库上已启用的扩展程序,请运行以下 SQL 命令:
select extname, extversion from pg_extension;
创建表
使用以下 DDL 语句创建表:
CREATE TABLE
apparels ( id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
embedding vector(768) );
成功执行上述命令后,您应该能够在数据库中查看该表。示例屏幕截图如下所示:

注入数据
在此实验中,我们有一个包含约 200 条记录的 SQL 文件作为测试数据。它包含 id, category, sub_category, uri, image 和 content。其他字段将在稍后的实验中填写。
从该处复制 20 行/插入语句,然后将这些行粘贴到空白编辑器标签页中,并选择“运行”。
如需查看表内容,请展开“探索器”部分,直到看到名为“apparels”的表。选择三竖点图标 (⋮),即可看到用于查询表格的选项。系统会在新的编辑器标签页中打开 SELECT 语句。

授予权限
运行以下语句,向用户 postgres 授予对 embedding 函数的执行权限:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
为 AlloyDB 服务账号授予 Vertex AI User 角色
前往 Cloud Shell 终端并输入以下命令:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
6. 背景信息
返回到“AlloyDB 实例”页面。
为了创建嵌入,我们需要一个 context,即我们想要包含在单个字段中的所有信息。为此,我们将创建一个产品说明(我们将其称为 pdt_desc)。在本例中,我们将使用每件产品的所有信息,但当您使用自己的数据执行此操作时,可以随意设计数据,只要您认为对自己的业务有意义即可。
在新建实例的 AlloyDB Studio 中运行以下语句。这将使用情境数据更新 pdt_desc 字段:
UPDATE
apparels
SET
pdt_desc = CONCAT('This product category is: ', category, ' and sub_category is: ', sub_category, '. The description of the product is as follows: ', content, '. The product image is stored at: ', uri)
WHERE
id IS NOT NULL;
此 DML 使用表中的所有可用字段和其他依赖项(如果您的使用情形中有)中的信息创建简单的上下文摘要。为了更精确地整理信息和创建上下文,您可以随意处理数据,只要您认为对自己的业务有意义即可。
7. 为上下文创建嵌入
计算机处理数字比处理文本容易得多。嵌入系统会将文本转换为一系列浮点数,这些浮点数应能表示文本,无论文本的措辞如何、使用何种语言等。
考虑描述海边位置。它可能称为“水上”“海滨”“从客房步行到海边”“sur la mer”“на берегу океана”等。这些术语看起来各不相同,但它们的语义或机器学习术语中的嵌入向量应该非常接近。
现在,数据和上下文已准备就绪,我们将运行 SQL,以将商品描述的嵌入内容添加到字段 embedding 中的表中。您可以使用各种嵌入模型。我们使用的是 Vertex AI 中的 text-embedding-004。请务必在整个项目中使用相同的嵌入模型!
注意:如果您使用的是之前创建的现有 Google Cloud 项目,可能需要继续使用旧版文本嵌入模型,例如 textembedding-gecko。
UPDATE
apparels
SET
embedding = embedding( 'text-embedding-004',
pdt_desc)
WHERE
TRUE;
再次查看 apparels 表,查看一些嵌入内容。请务必重新运行 SELECT 语句,以查看更改。
SELECT
id,
category,
sub_category,
content,
embedding
FROM
apparels;
此操作应返回嵌入向量,该向量看起来像查询中示例文本的浮点数数组,如下所示:

注意:在免费层级下新建的 Google Cloud 项目在每秒允许的嵌入请求数方面可能会遇到配额问题。我们建议您使用 ID 的过滤查询,然后在生成嵌入内容时,有选择地选择 1-5 条记录,依此类推。
8. 执行向量搜索
现在,表、数据和嵌入都已准备就绪,接下来我们来针对用户搜索文本执行实时向量搜索。
假设用户提出以下问题:
“I want womens tops, pink casual only pure cotton.”
您可以运行以下查询来查找匹配项:
SELECT
id,
category,
sub_category,
content,
pdt_desc AS description
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-004',
'I want womens tops, pink casual only pure cotton.')::vector
LIMIT
5;
我们来详细了解一下此查询:
在此查询中,
- 用户的搜索文本为:“I want womens tops, pink casual only pure cotton.”
- 我们正在使用模型
text-embedding-004在embedding()方法中将其转换为嵌入。在最后一步中,我们已将嵌入函数应用于表中的所有项,因此这一步应该很熟悉。 - “
<=>”表示使用余弦相似度距离方法。您可以在 pgvector 的文档中找到所有可用的相似度衡量指标。 - 我们将嵌入方法的结果转换为向量类型,以使其与存储在数据库中的向量兼容。
- LIMIT 5 表示我们希望提取搜索文本的 5 个最近邻项。
结果如下所示:
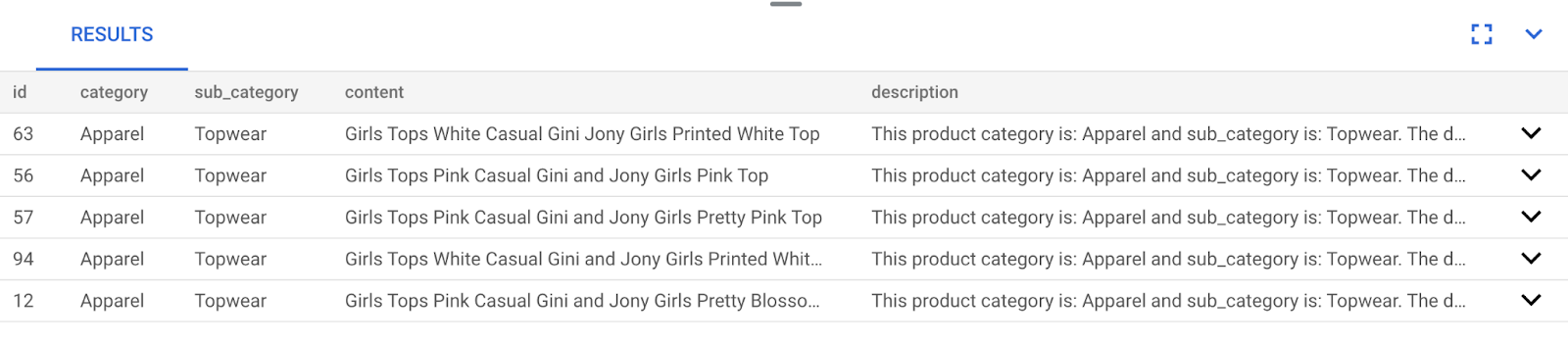
从搜索结果中可以看出,匹配项与搜索文本非常接近。尝试更改颜色,看看结果有何变化。
重要提示:
现在,假设我们想使用 ScaNN 索引来提高此向量搜索结果的性能(查询时间)、效率和召回率。请阅读这篇博客中的步骤,比较有索引和无索引时结果的差异。为方便起见,这里仅列出索引创建步骤:
- 由于我们已经创建了集群、实例、上下文和嵌入,因此只需使用以下语句安装 ScaNN 扩展程序:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- 接下来,我们将创建索引 (ScaNN):
CREATE INDEX apparel_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=54);
在上述 DDL 中,apparel_index 是索引的名称
“apparels”是我的表
“scann”是索引方法
“embedding”是表格中我想编入索引的列
“cosine”是我要用于索引的距离方法
“54”是要应用于此索引的分区数量。设置为介于 1 到 1048576 之间的任意值。如需详细了解如何确定此值,请参阅对 ScaNN 索引进行调优。
我使用了数据点数量的平方根,如 ScaNN 仓库中所建议的那样(在分区时,num_leaves 应大致为数据点数量的平方根)。
- 使用以下查询检查索引是否已创建:
SELECT * FROM pg_stat_ann_indexes;
- 使用与不含索引时相同的查询执行 Vector Search:
select * from apparels
ORDER BY embedding <=> CAST(embedding('textembedding-gecko', 'white tops for girls without any print') as vector(768))
LIMIT 20
上述查询与我们在实验的第 8 步中使用的查询相同。不过,现在我们已将该字段编入索引。
- 通过以下方式测试简单搜索查询(使用和不使用索引):
white tops for girls without any print
在已编入索引的嵌入数据上执行 Vector Search 查询时,上述搜索文本可带来优质的搜索结果和效率。使用索引后,效率大幅提高(就执行时间而言:不使用 ScaNN 时为 10.37 毫秒,使用 ScaNN 时为 0.87 毫秒)。如需详细了解此主题,请参阅这篇博文。
9. 使用 LLM 进行匹配验证
在继续操作并创建用于向应用返回最佳匹配项的服务之前,我们先使用生成式 AI 模型来验证这些潜在的回答是否确实相关且可以安全地与用户分享。
确保实例已为 Gemini 完成设置
首先,检查是否已为您的集群和实例启用 Google ML 集成。在 AlloyDB Studio 中,运行以下命令:
show google_ml_integration.enable_model_support;
如果该值显示为 "on",您可以跳过接下来的 2 个步骤,直接设置 AlloyDB 和 Vertex AI 模型集成。
- 前往 AlloyDB 集群的主实例,然后点击“修改主实例”

- 前往“高级配置选项”中的“标志”部分。并确保
google_ml_integration.enable_model_support flag设置为“on”,如下所示:

如果未设置为“on”,请将其设置为“on”,然后点击 UPDATE INSTANCE 按钮。此步骤需要几分钟时间。
AlloyDB 和 Vertex AI 模型集成
现在,您可以连接到 AlloyDB Studio 并运行以下 DML 语句,以从 AlloyDB 设置 Gemini 模型访问权限,并在指定位置使用您的项目 ID。运行该命令之前,您可能会收到语法错误警告,但该命令应该可以正常运行。
首先,我们创建 Gemini 1.5 模型连接,如下所示。请务必将以下命令中的 $PROJECT_ID 替换为您的 Google Cloud 项目 ID。
CALL
google_ml.create_model( model_id => 'gemini-1.5',
model_request_url => 'https://us-central1-aiplatform.googleapis.com/v1/projects/$PROJECT_ID/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'alloydb_service_agent_iam');
您可以在 AlloyDB Studio 中通过以下命令查看配置为可供访问的模型:
select model_id,model_type from google_ml.model_info_view;
最后,我们需要为数据库用户授予执行 ml_predict_row 函数的权限,以便通过 Google Vertex AI 模型运行预测。运行以下命令:
GRANT EXECUTE ON FUNCTION ml_predict_row to postgres;
注意:如果您使用的是现有的 Google Cloud 项目和之前创建的 AlloyDB 集群/实例,可能需要舍弃对 gemini-1.5 模型的旧引用,然后使用上述 CALL 语句重新创建,并再次运行 grant execute on function ml_predict_row,以免在即将到来的 gemini-1.5 调用中遇到问题。
评估回答
虽然我们最终会在下一部分中使用一个大型查询来确保查询的响应合理,但该查询可能难以理解。我们现在来看看这些组件,稍后会介绍它们如何协同工作。
- 首先,我们将向数据库发送请求,以获取与用户查询最接近的 5 个匹配项。为了简单起见,我们对查询进行了硬编码,但请放心,稍后我们会将其插值到查询中。我们纳入了
apparels表中的商品说明,并添加了两个新字段:一个字段将说明与索引相结合,另一个字段包含原始请求。所有这些内容都将保存在名为xyz的表中(这只是一个临时表名称)。
CREATE TABLE
xyz AS
SELECT
id || ' - ' || pdt_desc AS literature,
pdt_desc AS content,
'I want womens tops, pink casual only pure cotton.' AS user_text
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-004',
'I want womens tops, pink casual only pure cotton.')::vector
LIMIT
5;
此查询的输出将是与用户查询最相似的 5 行。新表 xyz 将包含 5 行,其中每行都将包含以下列:
literaturecontentuser_text
- 为了确定回答的有效性,我们将使用一个复杂的查询,其中会说明如何评估回答。它使用
xyz表中的user_text和content作为查询的一部分。
"Read this user search text: ', user_text,
' Compare it against the product inventory data set: ', content,
' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
- 接下来,我们将使用该查询来检查
xyz表中回答的“质量”。
CREATE TABLE
x AS
SELECT
json_array_elements( google_ml.predict_row( model_id => 'gemini-1.5',
request_body => CONCAT('{
"contents": [
{ "role": "user",
"parts":
[ { "text": "Read this user search text: ', user_text, ' Compare it against the product inventory data set: ', content, ' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
} ]
}
] }'
)::json))-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'
AS LLM_RESPONSE
FROM
xyz;
predict_row以 JSON 格式返回结果。代码“-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'"”用于从该 JSON 中提取实际文本。如需查看返回的实际 JSON,您可以移除此代码。- 最后,若要获取 LLM 字段,只需从 x 表中提取该字段即可:
SELECT
LLM_RESPONSE
FROM
x;
- 这可以合并为单个后续查询,如下所示。
如果您已运行上述查询来检查中间结果,则需要在运行此查询之前从 AlloyDB 数据库中删除/移除 xyz 和 x 表。
SELECT
LLM_RESPONSE
FROM (
SELECT
json_array_elements( google_ml.predict_row( model_id => 'gemini-1.5',
request_body => CONCAT('{
"contents": [
{ "role": "user",
"parts":
[ { "text": "Read this user search text: ', user_text, ' Compare it against the product inventory data set: ', content, ' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
} ]
}
] }'
)::json))-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'
AS LLM_RESPONSE
FROM (
SELECT
id || ' - ' || pdt_desc AS literature,
pdt_desc AS content,
'I want womens tops, pink casual only pure cotton.' user_text
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-004',
'I want womens tops, pink casual only pure cotton.')::vector
LIMIT
5 ) AS xyz ) AS X;
虽然这看起来可能仍然令人望而却步,但希望您能从中获得更多启发。结果会显示是否存在匹配项、匹配百分比以及分级说明。
请注意,Gemini 模型默认开启了流式传输功能,因此实际回答会分布在多行中:
10. 将应用迁移到 Web
准备好将此应用迁移到 Web 上了吗?请按以下步骤操作,使用 Cloud Run Functions 将此知识引擎设为无服务器:
- 前往 Google Cloud 控制台中的 Cloud Run 函数,创建新的 Cloud Run 函数,或使用以下链接:https://console.cloud.google.com/functions/add。
- 选择“Cloud Run function”作为环境。提供函数名称“retail-engine”,然后选择“us-central1”作为区域。将“身份验证”设置为“允许未经身份验证的调用”,然后点击下一步。选择 Java 17 作为运行时,并选择内嵌编辑器作为源代码。
- 默认情况下,它会将入口点设置为“
gcfv2.HelloHttpFunction”。将 Cloud Run 函数的HelloHttpFunction.java和pom.xml中的占位代码分别替换为 Java 文件和 XML 中的代码。 - 请务必在 Java 文件中将 $PROJECT_ID 占位符和 AlloyDB 连接凭据替换为您的值。AlloyDB 凭据是我们在本 Codelab 开始时使用的凭据。如果您使用了不同的值,请在 Java 文件中进行修改。
- 点击部署。
部署完成后,为了允许 Cloud Functions 访问 AlloyDB 数据库实例,我们将创建 VPC 连接器。
重要步骤:
开始部署后,您应该能够在 Google Cloud Run Functions 控制台中看到这些函数。搜索新创建的函数 (retail-engine),点击该函数,然后点击修改并更改以下内容:
- 前往“运行时、构建、连接和安全设置”
- 将超时时间增加到 180 秒
- 前往“连接”标签页:

- 在“入站流量设置”下,确保已选择“允许所有流量”。
- 在“出站流量设置”下,点击“网络”下拉菜单,然后选择“添加新的 VPC 连接器”选项,并按照随即显示的对话框中的说明操作:

- 为 VPC 连接器提供一个名称,并确保该区域与您的实例相同。将“网络”值保留为默认值,并将“子网”设置为“自定义 IP 范围”,IP 范围为 10.8.0.0 或类似的可用范围。
- 展开“显示缩放设置”,并确保您的配置完全符合以下要求:

- 点击“创建”,此连接器现在应会列在出站流量设置中。
- 选择新创建的连接器
- 选择通过此 VPC 连接器路由所有流量。
- 点击下一步,然后点击部署。
11. 测试应用
部署更新后的 Cloud Functions 函数后,您应该会看到以下格式的端点:
https://us-central1-YOUR_PROJECT_ID.cloudfunctions.net/retail-engine
您可以在 Cloud Shell 终端中运行以下命令来对其进行测试:
gcloud functions call retail-engine --region=us-central1 --gen2 --data '{"search": "I want some kids clothes themed on Disney"}'
或者,您也可以按如下方式测试 Cloud Run 函数:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST https://us-central1-$PROJECT_ID.cloudfunctions.net/retail-engine \
-H 'Content-Type: application/json' \
-d '{"search":"I want some kids clothes themed on Disney"}' \
| jq .
结果:

大功告成!使用 AlloyDB 数据上的嵌入模型执行相似度向量搜索就是这么简单。
构建对话智能体!
代理是在本实验的第 2 部分中构建的。
12. 清理
如果您计划完成本实验的第 2 部分,请跳过此步骤,因为此步骤会删除当前项目。
为避免系统因本博文中使用的资源向您的 Google Cloud 账号收取费用,请按照以下步骤操作:
- 在 Google Cloud 控制台中,前往管理资源页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关停以删除项目。
13. 恭喜
恭喜!您已成功使用 AlloyDB、pgvector 和 Vector Search 执行相似度搜索。通过结合 AlloyDB、Vertex AI 和 Vector Search 的能力,我们在实现情境搜索和向量搜索方面取得了巨大进步,让搜索变得更易于使用、更高效,并且真正以含义为导向。本实验的下一部分将介绍代理构建步骤。