
1. نظرة عامة
تخيَّل تطبيقًا للموضة لا يساعدك في العثور على الملابس المثالية فحسب، بل يقدّم أيضًا نصائح بشأن تنسيق الملابس في الوقت الفعلي، وكل ذلك بفضل إمكانات دمج الذكاء الاصطناعي التوليدي المتطورة. في هذه الجلسة، سنتعرّف على كيفية إنشاء تطبيق من هذا النوع باستخدام إمكانات البحث المتّجه في AlloyDB، بالإضافة إلى فهرس ScaNN من Google، ما يتيح إجراء عمليات بحث فائقة السرعة عن الملابس المتطابقة وتقديم اقتراحات فورية بشأن الموضة.
سنتناول أيضًا كيفية تحسين فهرس ScaNN في AlloyDB لطلبات البحث المعقّدة من أجل إنشاء اقتراحات مخصّصة للأسلوب. سنستخدم أيضًا Gemini وImagen، وهما نموذجان قويان للذكاء الاصطناعي التوليدي، لتقديم أفكار إبداعية بشأن الأناقة وحتى عرض مظهرك المخصّص. تم إنشاء هذا التطبيق بالكامل على بنية أساسية بدون خادم، ما يضمن توفير تجربة سلسة وقابلة للتوسّع للمستخدمين.
التحدي: يهدف التطبيق إلى مساعدة الأشخاص الذين يواجهون صعوبة في اتخاذ قرارات بشأن الموضة من خلال تقديم اقتراحات مخصّصة بشأن الملابس. كما يساعد في تجنُّب الإجهاد الناتج عن اتّخاذ القرارات بشأن الملابس.
الحل: يحل تطبيق اقتراح الأزياء مشكلة توفير تجربة أزياء ذكية ومخصَّصة وجذابة للمستخدمين، مع عرض إمكانات AlloyDB والذكاء الاصطناعي التوليدي والتقنيات بدون خادم.
ما ستنشئه
في هذا الدرس التطبيقي، ستنفّذ ما يلي:
- إنشاء مثيل AlloyDB وتحميل مجموعة بيانات التجارة الإلكترونية
- تفعيل إضافات pgvector ونموذج الذكاء الاصطناعي التوليدي في AlloyDB
- إنشاء تضمينات من وصف المنتج
- نشر الحلّ في "دوال Cloud Run" بدون خادم
- حمِّل صورة إلى Gemini واطلب منه إنشاء طلب وصف صورة.
- إنشاء نتائج بحث استنادًا إلى الطلبات المقترنة بتضمينات مجموعة بيانات التجارة الإلكترونية
- أضِف طلبات إضافية لتخصيص الطلب والحصول على اقتراحات بشأن الأسلوب.
- نشر الحلّ في "دوال Cloud Run" بدون خادم
المتطلبات
2. الهندسة المعمارية
في ما يلي البنية العالية المستوى للتطبيق:
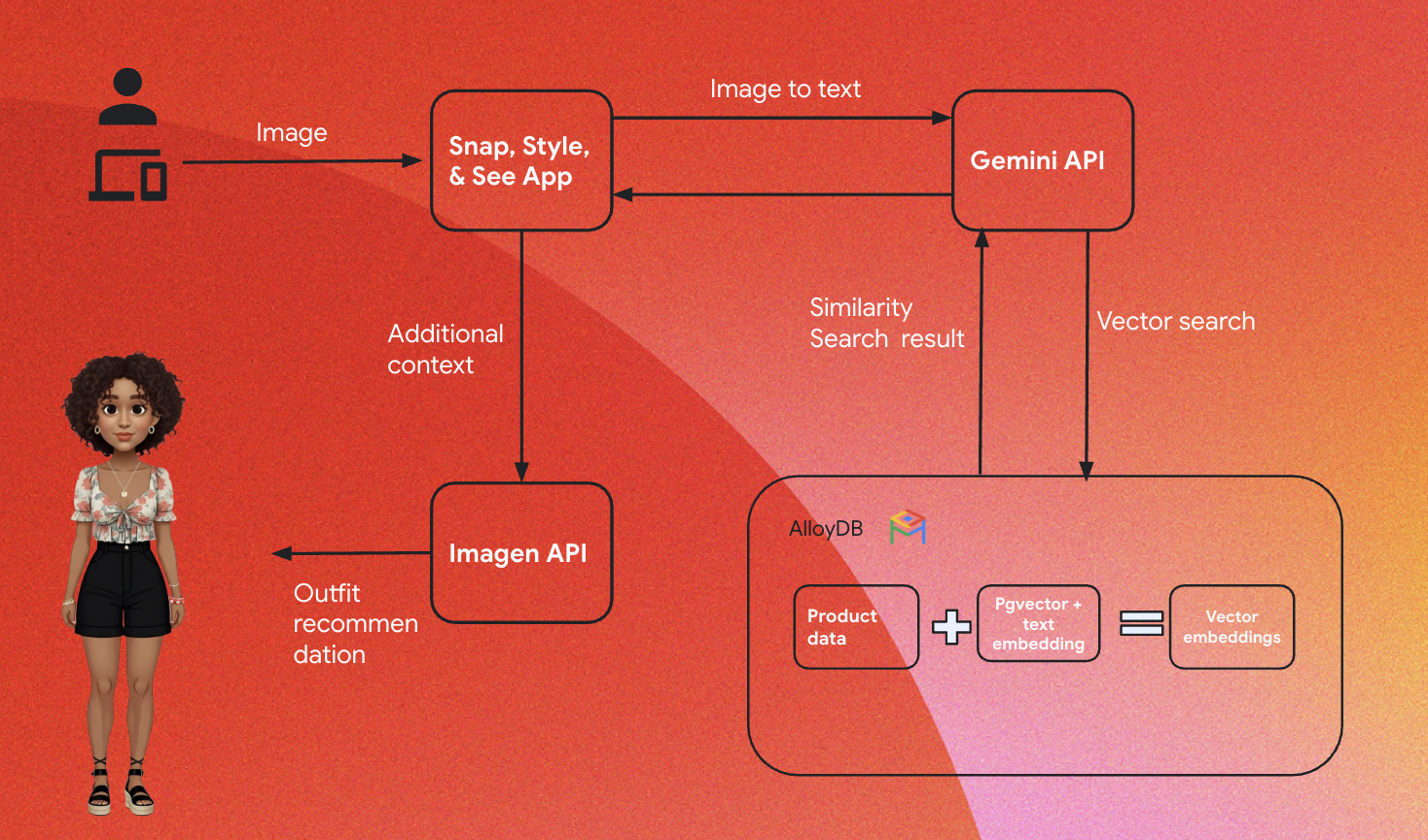
توضّح الأقسام التالية السياق الذي يتم فيه عرض البرنامج التعليمي:
الاستيعاب:
تتمثل خطوتنا الأولى في نقل بيانات البيع بالتجزئة (المستودع وأوصاف المنتجات وتفاعلات العملاء) إلى AlloyDB.
محرك الإحصاءات:
سنستخدم AlloyDB كمحرّك إحصاءات لتنفيذ ما يلي:
- استخراج السياق: يحلّل المحرّك البيانات المخزّنة في AlloyDB لفهم العلاقات بين المنتجات والفئات وسلوك العملاء وما إلى ذلك حسب الاقتضاء.
- إنشاء التضمينات: يتم إنشاء تضمينات (تمثيلات رياضية للنصوص) لكلّ من طلب المستخدم والمعلومات المخزّنة في AlloyDB.
- البحث المتّجه: ينفّذ محرّك البحث بحثًا عن التشابه، ويقارن تضمين الطلب بتضمينات أوصاف المنتجات والمراجعات والبيانات الأخرى ذات الصلة. يحدّد هذا الإجراء 25 "جارًا أقرب" الأكثر صلةً.
اقتراح Gemini:
يتم تمرير مصفوفة وحدات البايت الخاصة بالصورة إلى نموذج Gemini من خلال Vertex AI API، بالإضافة إلى الطلب الذي يطلب وصفًا نصيًا للملابس العلوية مع اقتراحات بشأن الملابس السفلية.
التوليد المعزّز بالاسترجاع (RAG) والبحث المتّجه في AlloyDB:
يُستخدم وصف الملابس العلوية للاستعلام عن قاعدة البيانات. يحوّل طلب البحث النص (اقتراح من نموذج Gemini بشأن الملابس السفلية المطابقة) إلى تضمينات، ويُجري عملية "البحث المتّجهي" على التضمينات المخزّنة في قاعدة البيانات للعثور على أقرب الجيران (النتائج المطابقة). يتم فهرسة عمليات التضمين المتّجهة في قاعدة بيانات AlloyDB باستخدام فهرس ScaNN لتحسين الاسترجاع.
إنشاء صور للردود:
يتم تنظيم الردود التي تم التحقّق من صحتها في مصفوفة JSON، ويتم تجميع المحرّك بأكمله في دالة Cloud Run غير مستنِدة إلى خادم يتم استدعاؤها من Agent Builder.
إنشاء الصور باستخدام Imagen:
يتم دمج طلب الأسلوب الذي يحدده المستخدم مع اقتراح يختاره المستخدم وأي طلبات تخصيص لإنشاء طلب جديد في Imagen 3 باستخدام صورة حالية. يتم إنشاء صورة التصميم استنادًا إلى هذا الطلب باستخدام Vertex AI API.
3- قبل البدء
إنشاء مشروع
- في Google Cloud Console، ضمن صفحة اختيار المشروع، اختَر مشروعًا على Google Cloud أو أنشِئه.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. تعرَّف على كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع .
- ستستخدم Cloud Shell، وهي بيئة سطر أوامر تعمل في Google Cloud ومحمّلة مسبقًا بأداة bq. انقر على تفعيل Cloud Shell (
 ) في أعلى "وحدة تحكّم Google Cloud".
) في أعلى "وحدة تحكّم Google Cloud". - بعد الاتصال بـ Cloud Shell، تأكَّد من أنّك قد أثبتّ هويتك وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list
- نفِّذ الأمر التالي للتأكّد من أنّ أوامر gcloud المستقبلية ستحدّد مشروعك بشكل صحيح.
gcloud config list project
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه بشكلٍ صريح:
gcloud config set project <YOUR_PROJECT_ID>
- فعِّل واجهات برمجة التطبيقات المطلوبة.
اتّبِع الرابط لتفعيل واجهات برمجة التطبيقات.
إذا فاتك تفعيل أي واجهة برمجة تطبيقات، يمكنك تفعيلها في أي وقت أثناء عملية التنفيذ.
لمزيد من المعلومات حول أوامر gcloud واستخدامها، يُرجى الرجوع إلى المستندات.
4. إعداد قاعدة البيانات
في هذا الدرس العملي، سنستخدم AlloyDB كقاعدة بيانات لتخزين مجموعة بيانات التجارة الإلكترونية الخاصة بالبيع بالتجزئة. يستخدم المجموعات لتخزين جميع الموارد، مثل قواعد البيانات والسجلات. تحتوي كل مجموعة على مثيل أساسي يوفّر نقطة وصول إلى البيانات. الجداول هي المورد الفعلي الذي يخزّن البيانات.
لننشئ الآن مجموعة ومثيل وجدول AlloyDB سيتم تحميل مجموعة بيانات التجارة الإلكترونية فيها.
إنشاء مجموعة ومثيل
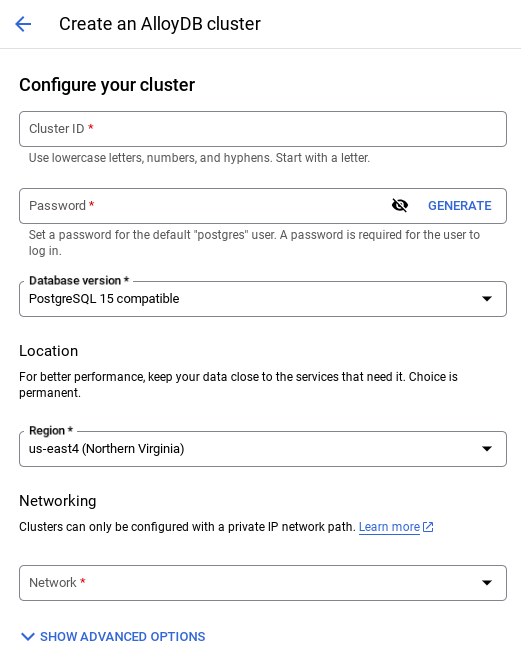
- في Google Cloud Console، ابحث عن AlloyDB. تتمثّل إحدى الطرق السهلة للعثور على معظم الصفحات في Cloud Console في البحث عنها باستخدام شريط البحث في وحدة التحكّم.
- انقر على إنشاء مجموعة.

- أنشئ مجموعة ومثيل بالقيم التالية:
- رقم تعريف المجموعة: "
shopping-cluster" - كلمة المرور: "
alloydb" - متوافق مع PostgreSQL 15
- المنطقة: "
us-central1" - الشبكات: "
default"
- في "الشبكة"، عند اختيار الشبكة التلقائية، يظهر الخيار التالي. انقر على إعداد الاتصال لإعداد شبكة تلقائية.
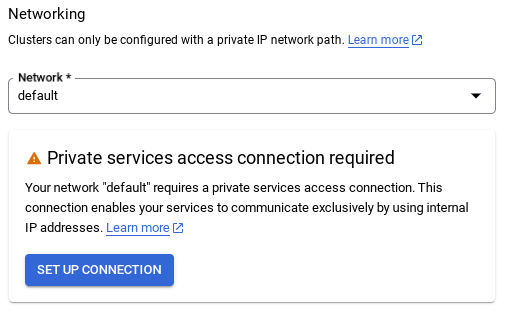
- اختَر استخدام نطاق عنوان IP المخصّص تلقائيًا وانقر على متابعة. بعد مراجعة المعلومات، انقر على إنشاء اتصال.
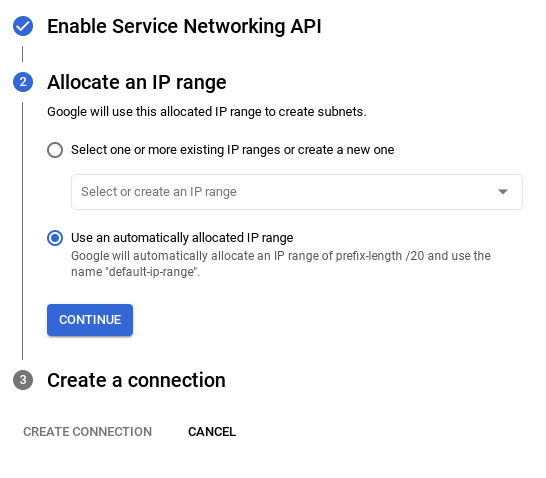
انتظِر إلى أن تكتمل عملية إنشاء الشبكة التلقائية.
- في "ضبط مثيلك الأساسي"، اضبط معرّف المثيل على
shopping-instance".
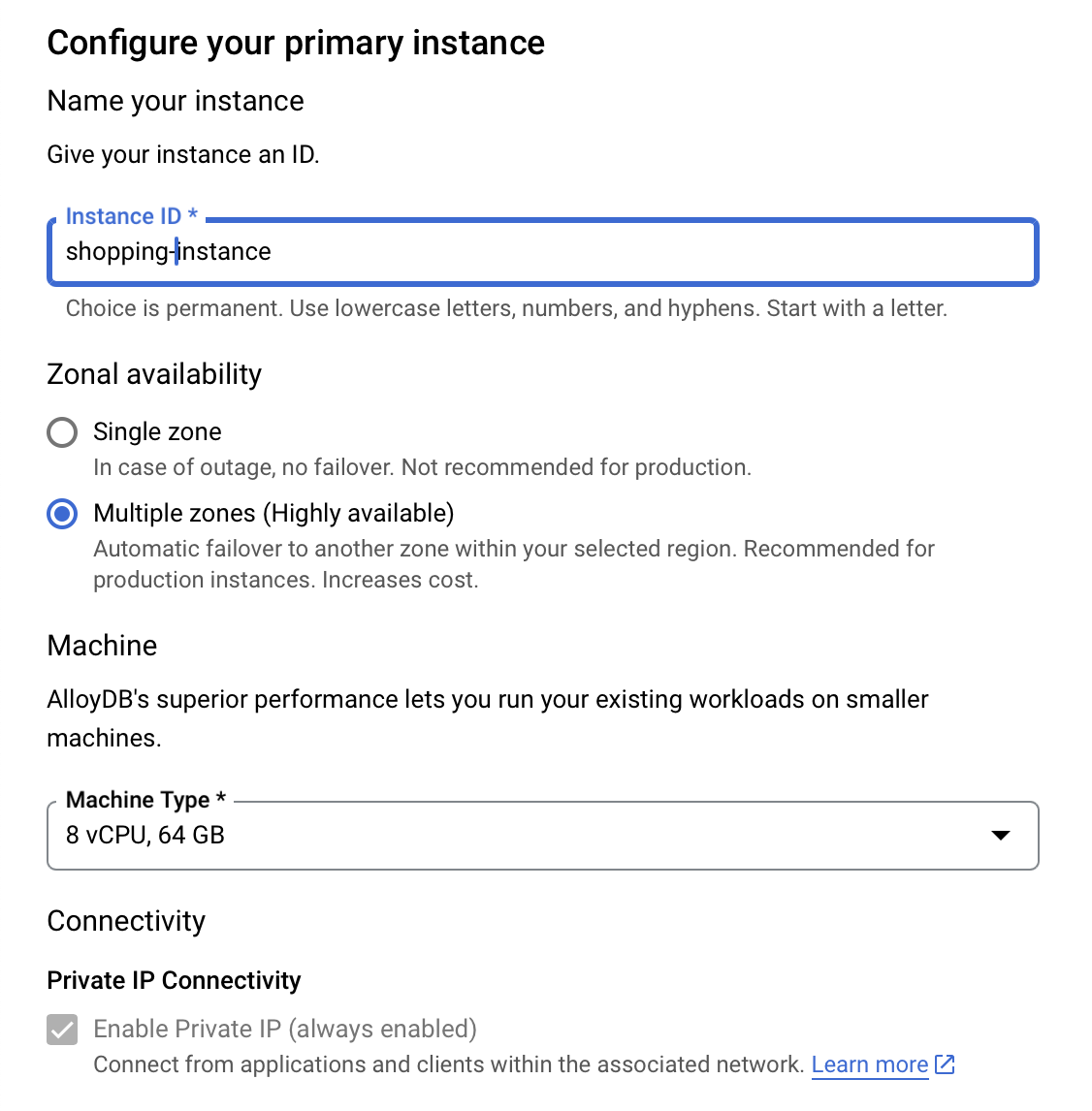
- انقر على إنشاء مجموعة لإكمال إعداد المجموعة على النحو التالي:
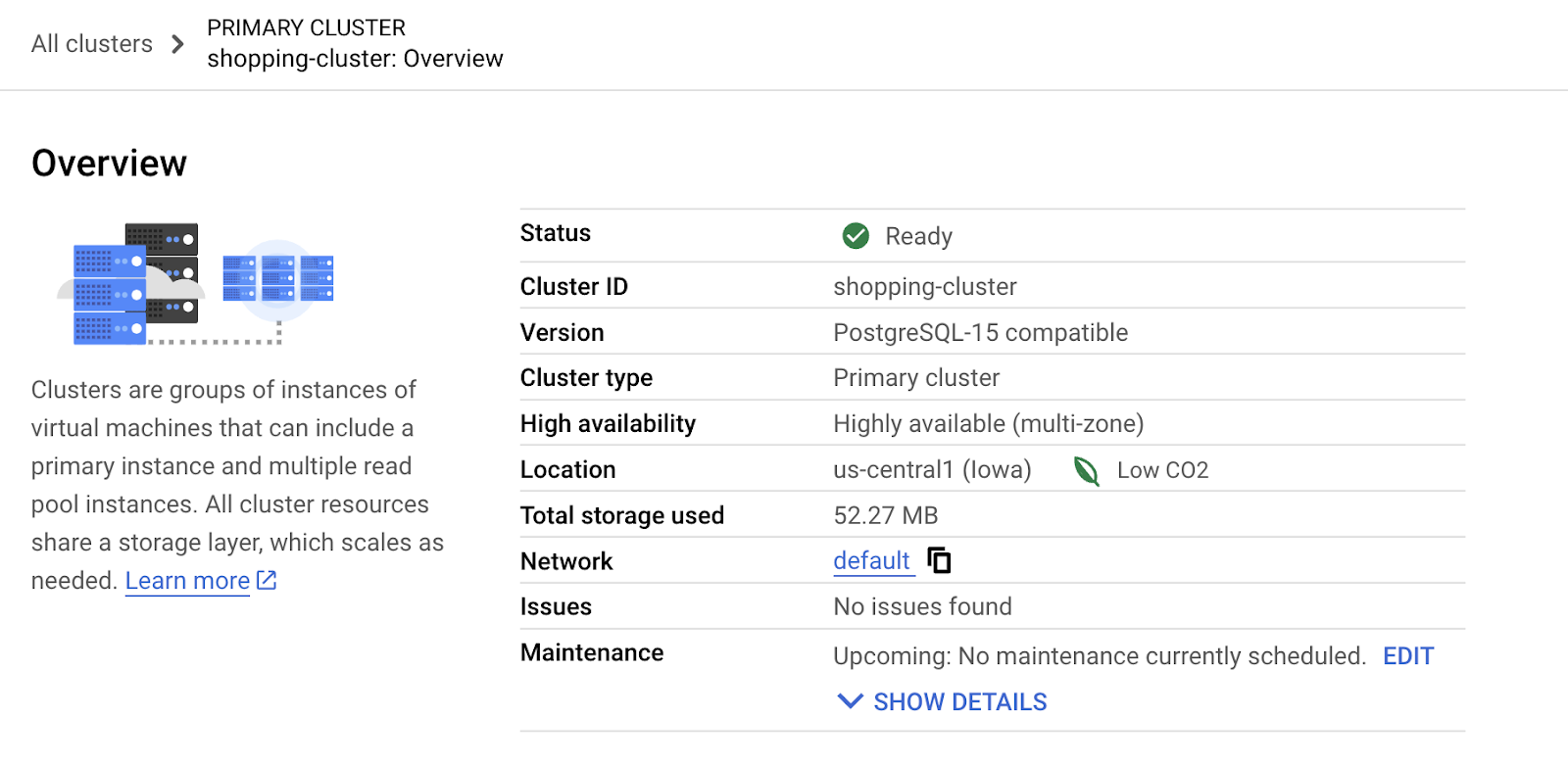
5- نقل البيانات
حان الوقت الآن لإضافة جدول يتضمّن بيانات حول المتجر. انتظِر إلى أن ينتهي إنشاء الجهاز الظاهري. بعد إنشائه، يمكنك تسجيل الدخول إلى AlloyDB باستخدام بيانات الاعتماد التي حدّدتها عند إنشاء المجموعة.
المصادقة على قاعدة بيانات AlloyDB
- في Google Cloud Console، انتقِل إلى AlloyDB. اختَر المجموعة الرئيسية، ثم انقر على AlloyDB Studio في قائمة التنقّل اليمنى:

- أدخِل التفاصيل التالية للمصادقة على قاعدة بيانات AlloyDB:
- اسم المستخدم : "
postgres" - قاعدة البيانات : "
postgres" - كلمة المرور : "
alloydb"
بعد إكمال عملية المصادقة بنجاح في AlloyDB Studio، يتم إدخال أوامر SQL في علامات التبويب المحرّر. يمكنك إضافة نوافذ "المحرّر" متعددة باستخدام علامة الجمع على يسار علامة التبويب الأولى في "المحرّر".
ستُدخل أوامر AlloyDB في نوافذ "المحرّر"، باستخدام الخيارات "تشغيل" و"تنسيق" و"محو" حسب الحاجة.
تفعيل الإضافات
لإنشاء هذا التطبيق، سنستخدم الإضافتين "pgvector"" و"google_ml_integration"".
- تتيح لك إضافة pgvector تخزين عمليات التضمين المتجهة والبحث فيها.
- توفّر الإضافة google_ml_integration وظائف يمكنك استخدامها للوصول إلى نقاط نهاية التوقّعات في Vertex AI من أجل الحصول على توقّعات في SQL.
- فعِّل هذه الإضافات من خلال تنفيذ تعريفات البيانات التالية:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
- تأكَّد من تثبيت الإضافات من خلال تنفيذ أمر SQL التالي:
select extname, extversion from pg_extension;
إنشاء جدول
- أنشئ جدولاً باستخدام عبارة DDL التالية:
CREATE TABLE
apparels ( id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
embedding vector(768) );
عند تنفيذ الأمر أعلاه بنجاح، من المفترض أن تتمكّن من عرض الجدول في
قاعدة البيانات. تعرض الصورة التالية مثالاً:

نقل البيانات
في هذا التمرين العملي، لدينا بيانات اختبار تتضمّن حوالي 200 سجلّ في ملف SQL هذا. تتضمّن id, category, sub_category, uri, image وcontent. سيتم ملء الحقول الأخرى لاحقًا في الدرس التطبيقي.
- انسخ الأسطر/عبارات الإدراج الـ 20 من ملف SQL في علامة تبويب "المحرّر" جديدة في AlloyDB Studio، ثم انقر على RUN.
- وسِّع قسم "المستكشف" إلى أن يظهر الجدول المسمّى
apparels. - انقر على رمز القائمة [⋮] ثمّ على طلب بحث. سيتم فتح عبارة SELECT في علامة تبويب "المحرّر" جديدة.
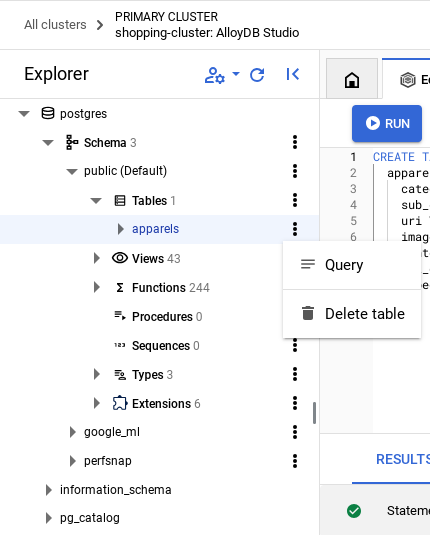
- انقر على تشغيل للتأكّد من إدراج الصفوف.
منح الإذن للمستخدم
سنمنح المستخدم postgres إذنًا بإنشاء تضمينات من داخل AlloyDB. في AlloyDB Studio، شغِّل العبارة التالية لمنح حقوق التنفيذ على الدالة embedding للمستخدم postgres:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
منح دور "مستخدم Vertex AI" لحساب خدمة AlloyDB
سنستخدم نماذج تضمين النصوص من Vertex AI لإنشاء تضمينات، والتي تتطلّب منح دور مستخدم Vertex AI لحساب خدمة AlloyDB.
في Google Cloud Console، انقر على رمز وحدة طرفية Cloud Shell [ ] ونفِّذ الأمر التالي:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
6. إنشاء سياق
لإنشاء تضمين، يجب أن يتوفّر لدينا context، أي كل المعلومات التي نريد تضمينها في حقل واحد. سننفّذ ذلك من خلال إنشاء وصف للمنتج سنخزّنه في العمود pdt_desc في الجدول apparels.
في حالتنا، سنستخدم جميع المعلومات المتعلّقة بكل منتج، ولكن عندما تفعل ذلك باستخدام بياناتك الخاصة، يمكنك تصميم البيانات بأي طريقة تراها مناسبة لنشاطك التجاري.
في علامة التبويب "محرّر AlloyDB Studio"، نفِّذ الأمر التالي الذي يعدّل الحقل pdt_desc باستخدام بيانات السياق:
UPDATE
apparels
SET
pdt_desc = CONCAT('This product category is: ', category, ' and sub_category is: ', sub_category, '. The description of the product is as follows: ', content, '. The product image is stored at: ', uri)
WHERE
id IS NOT NULL;
تنشئ لغة معالجة البيانات هذه ملخّصًا بسيطًا للسياق باستخدام المعلومات من جميع الحقول المتاحة في الجدول والتبعيات الأخرى (إذا كانت هناك أي تبعيات في حالة الاستخدام). للحصول على مجموعة أكثر دقة من المعلومات وإنشاء سياق، يمكنك تصميم البيانات بأي طريقة تراها مناسبة لنشاطك التجاري.
7. إنشاء تضمينات للسياق
فمن الأسهل على أجهزة الكمبيوتر معالجة الأرقام مقارنةً بمعالجة النصوص. يحوّل نظام التضمين النص إلى سلسلة من الأرقام النقطية العائمة التي من المفترض أن تمثّل النص، بغض النظر عن صياغته أو اللغة المستخدَمة فيه أو غير ذلك.
يمكنك وصف موقع جغرافي على شاطئ البحر. قد يُطلق عليها اسم "on the water أو beachfront أو walk from your room to the ocean أو sur la mer أو на берегу океана وما إلى ذلك. تبدو هذه المصطلحات مختلفة، ولكن يجب أن يكون معناها الدلالي أو تضميناتها في مصطلحات تعلُّم الآلة قريبًا جدًا من بعضها البعض.
بعد أن أصبحت البيانات والسياق جاهزين، سننفّذ عبارة SQL لإضافة تضمينات عمود وصف المنتج(pdt_desc) إلى الجدول في الحقل embedding. تتوفّر مجموعة متنوعة من نماذج التضمين التي يمكنك استخدامها. نحن نستخدم text-embedding-005 من Vertex AI.
- في AlloyDB Studio، نفِّذ الأمر التالي لإنشاء التضمينات، وعدِّل العمود
pdt_descباستخدام التضمينات للبيانات التي يخزّنها:
UPDATE
apparels
SET
embedding = embedding( 'text-embedding-005',
pdt_desc)
WHERE
TRUE;
- تأكَّد من إنشاء عمليات التضمين من خلال تنفيذ الأمر التالي:
SELECT
id,
category,
sub_category,
content,
embedding
FROM
Apparels
LIMIT 5;
في ما يلي مثال على متّجه تضمين، يبدو كمصفوفة من الأرقام العشرية، للنص النموذجي في طلب البحث على النحو التالي:
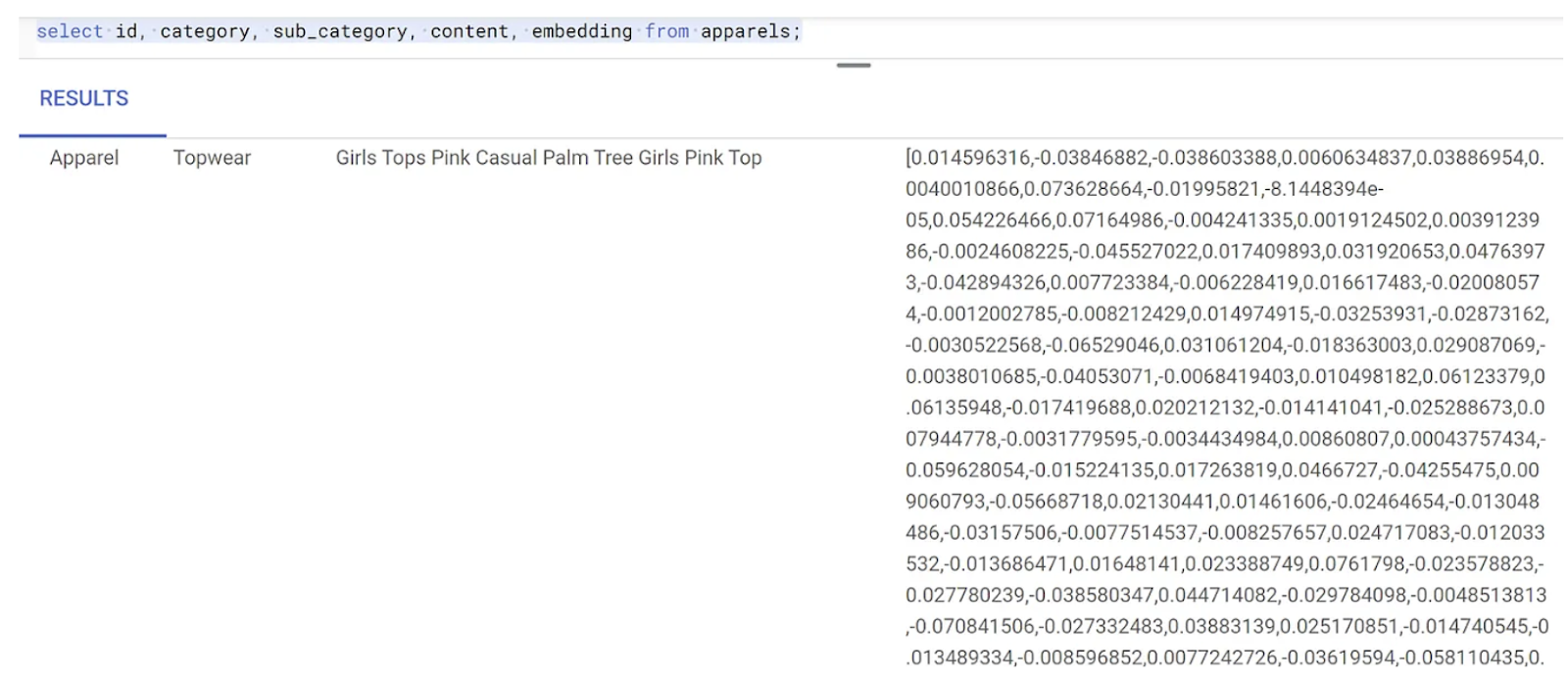
8. إجراء بحث عن المتّجهات
بعد أن أصبح الجدول والبيانات والتضمينات جاهزة، لننفّذ الآن البحث المتّجه في الوقت الفعلي عن نص بحث المستخدم.
لنفترض أنّ نص البحث الذي أدخله المستخدم هو "pink color, casual, pure cotton tops for women"
للعثور على نتائج مطابقة لطلب البحث هذا، نفِّذ طلب بحث SQL التالي:
SELECT
id,
category,
sub_category,
content,
pdt_desc AS description
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-005',
'pink color, casual, pure cotton tops for women')::vector
LIMIT
5;
لنلقِ نظرة على هذا الاستعلام بالتفصيل:
في هذا الاستعلام،
- نص البحث الذي أدخله المستخدم هو: "
I want womens tops, pink casual only pure cotton." - نحوّل نص البحث هذا إلى تضمينات باستخدام طريقة
embedding()بالإضافة إلى النموذج:text-embedding-005. من المفترض أن تكون هذه الخطوة مألوفة بعد الخطوة الأخيرة، حيث طبّقنا دالة التضمين على جميع العناصر في الجدول. - يمثّل "
<=>" استخدام طريقة قياس المسافة COSINE SIMILARITY. يمكنك العثور على جميع مقاييس التشابه المتاحة في مستندات pgvector. - نحوّل نتيجة طريقة التضمين إلى نوع بيانات متجه لكي تصبح متوافقة مع المتجهات المخزّنة في قاعدة البيانات.
- يمثّل LIMIT 5 أنّنا نريد استخراج 5 جيران أقرب للنص البحثي.
يوضّح ما يلي مثالاً على استجابة طلب بحث SQL هذا:
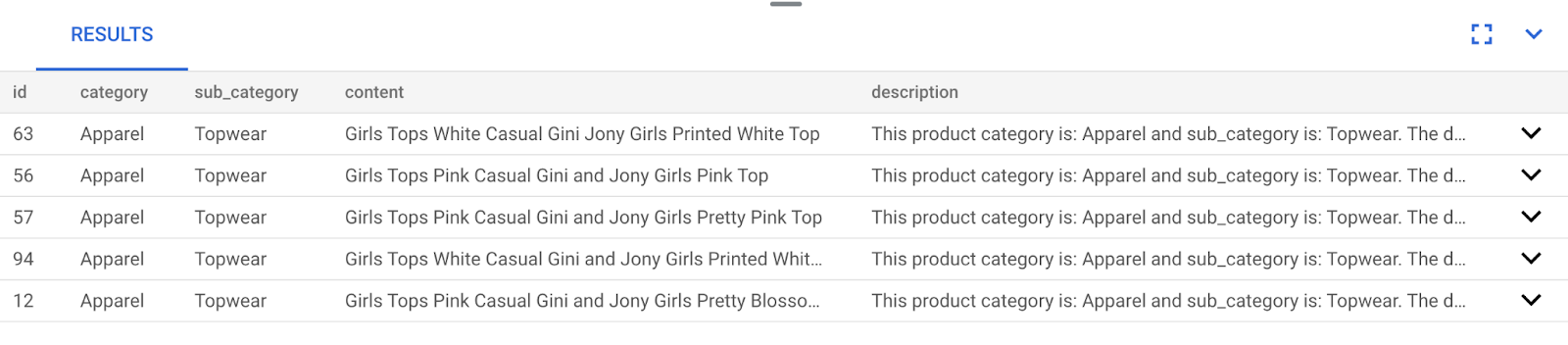
كما تلاحظ في نتائجك، تكون المطابقات قريبة جدًا من نص البحث. جرِّب تغيير اللون لمعرفة كيف تتغيّر النتائج.
فهرس ScaNN في AlloyDB لتحسين أداء طلبات البحث
لنفترض الآن أنّنا نريد تحسين أداء (وقت طلب البحث) وكفاءة واسترجاع نتيجة "البحث المتّجه" هذه باستخدام فهرس ScaNN.
إذا كنت تريد استخدام فهرس ScaNN، جرِّب الخطوات التالية:
- بما أنّ لدينا المجموعة والنموذج والسياق والتضمينات التي تم إنشاؤها، ما علينا سوى تثبيت إضافة ScaNN باستخدام العبارة التالية:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- أنشئ فهرس ScaNN:
CREATE INDEX apparel_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=54);
في تعريف البيانات أعلاه:
apparel_indexهو اسم الفهرس.apparelsهو اسم الجدول.-
scannهي طريقة الفهرسة. embeddingهو العمود في الجدول الذي تريد فهرسته.-
cosineهي طريقة قياس المسافة التي تريد استخدامها مع الفهرس. 54هو عدد الأقسام التي سيتم تطبيقها على هذا الفهرس. اضبط القيمة على أي رقم بين 1 و1048576. لمزيد من المعلومات حول كيفية تحديد هذه القيمة، اطّلِع على ضبط فهرس ScaNN.
وفقًا للاقتراح الوارد في مستودع ScaNN، استخدمنا الجذر التربيعي لعدد نقاط البيانات. عند التقسيم، يجب أن يكون num_leaves مساويًا تقريبًا للجذر التربيعي لعدد نقاط البيانات.
- تحقَّق مما إذا كان الفهرس قد تم إنشاؤه باستخدام طلب البحث التالي:
SELECT * FROM pg_stat_ann_indexes;
- نفِّذ "البحث المتّجهي" باستخدام طلب البحث نفسه الذي استخدمناه بدون الفهرس:
select * from apparels
ORDER BY embedding <=> CAST(embedding('textembedding-gecko', 'white tops for girls without any print') as vector(768))
LIMIT 20
طلب البحث أعلاه هو نفسه الذي استخدمناه في المختبر في الخطوة 8. ومع ذلك، أصبح الحقل الآن مفهرسًا باستخدام فهرس ScaNN.
- اختبِر باستخدام طلب بحث بسيط يتضمّن الفهرس وبدونه. لإجراء الاختبار بدون فهرس، يجب حذف الفهرس:
white tops for girls without any print
يؤدي نص البحث أعلاه في طلب البحث المتّجه على بيانات التضمينات المفهرسة إلى الحصول على نتائج بحث عالية الجودة وفعّالة. يتحسّن الأداء بشكل كبير (من حيث وقت التنفيذ: 10.37 ملي ثانية بدون ScaNN و0.87 ملي ثانية باستخدام ScaNN) مع الفهرس. لمزيد من المعلومات حول هذا الموضوع، يُرجى الاطّلاع على هذه المدونة.
9- مطابقة بيانات التحقّق مع النموذج اللغوي الكبير
قبل المتابعة وإنشاء خدمة لعرض أفضل النتائج المطابقة لتطبيق، لنستخدِم نموذج ذكاء اصطناعي توليدي للتحقّق مما إذا كانت هذه الردود المحتملة مناسبة حقًا وآمنة للمشاركة مع المستخدم.
التأكّد من إعداد المثيل لاستخدام Gemini
- تأكَّد من أنّ
google_ml_integrationمفعَّل حاليًا للمجموعة والمثيل. في AlloyDB Studio، نفِّذ الأمر التالي:
show google_ml_integration.enable_model_support;
إذا كانت القيمة معروضة على أنّها "مفعَّلة"، يمكنك تخطّي الخطوتَين التاليتَين والانتقال مباشرةً إلى عملية الإعداد
دمج AlloyDB وVertex AI Model
- انتقِل إلى الآلة الافتراضية الأساسية لمجموعة AlloyDB، وانقر على تعديل الآلة الافتراضية الأساسية.
- في خيارات الإعدادات المتقدّمة، وسِّع قسم علامة قاعدة البيانات الجديدة، وتأكَّد من ضبط
google_ml_integration.enable_model_support flagعلى "on" على النحو التالي:
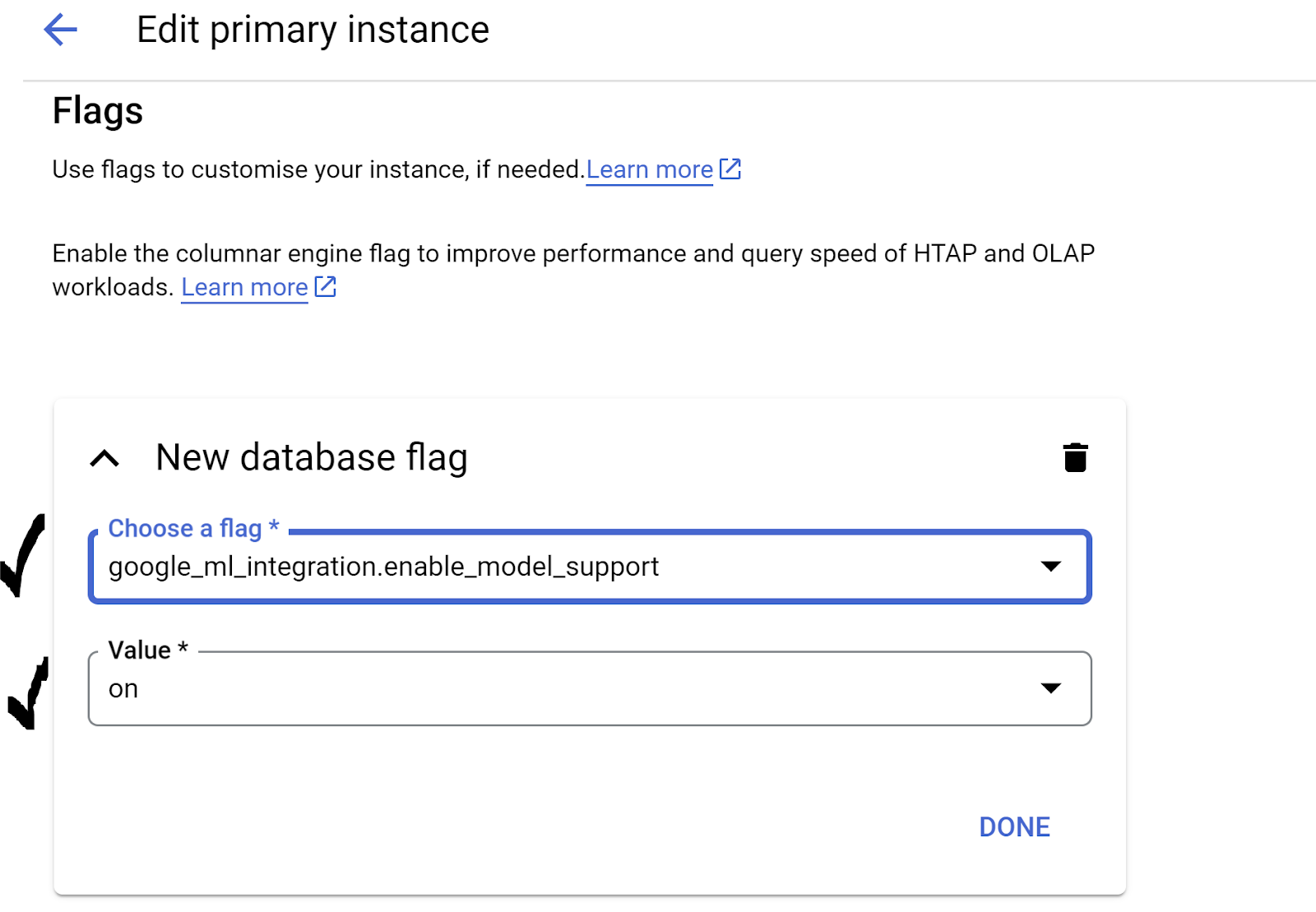 3. إذا لم يتم ضبطها على "
3. إذا لم يتم ضبطها على "on"، اضبطها على "on" ثم انقر على تعديل الجهاز الافتراضي.
ستستغرق هذه الخطوة بضع دقائق.
دمج AlloyDB مع نماذج Vertex AI
يمكنك الآن الاتصال بـ AlloyDB Studio وتنفيذ عبارة DML التالية لإعداد إمكانية الوصول إلى نموذج Gemini من AlloyDB، باستخدام رقم تعريف مشروعك حيثما يُشار إليه. قد يتم تحذيرك من خطأ في البنية قبل تنفيذ الأمر، ولكن من المفترض أن يتم تنفيذه بشكل جيد.
- في Google Cloud Console، انتقِل إلى AlloyDB. اختَر المجموعة الرئيسية، ثم انقر على AlloyDB Studio في قائمة التنقّل اليمنى.
- سنستخدم
gemini-1.5-pro:generateContentالمتاح تلقائيًا مع الإضافةgoogle_ml_integration.
- يمكنك التحقّق من النماذج التي تم ضبطها للوصول إليها باستخدام الأمر التالي في AlloyDB Studio:
select model_id,model_type from google_ml.model_info_view;
- امنح مستخدمي قاعدة البيانات الإذن بتنفيذ الدالة ml_predict_row لإجراء التوقعات باستخدام نماذج Google Vertex AI من خلال تنفيذ الأمر التالي:
GRANT EXECUTE ON FUNCTION ml_predict_row to postgres;
تقييم الردود
مع أنّنا سنستخدم طلب بحث كبيرًا واحدًا في القسم التالي حيث ننقل التطبيق إلى Cloud Run، قد يكون من الصعب فهم طلب البحث هذا لضمان أن تكون الردود من طلب البحث معقولة.
سننظر إلى الأقسام الفردية التي تؤدي إلى إنشاء طلب البحث الأكبر الذي نستخدمه في النهاية.
- أولاً، سنرسل طلبًا إلى قاعدة البيانات للحصول على أقرب 5 نتائج مطابقة لطلب بحث المستخدم. سنقوم بتضمين طلب البحث في الرمز البرمجي لإبقاء هذه العملية بسيطة، ولكن لا تقلق، سنقوم بإدخاله في طلب البحث لاحقًا.
سنضمّن وصف المنتج من الجدول apparels ونضيف حقلَين جديدَين، أحدهما يجمع الوصف مع الفهرس والآخر مع الطلب الأصلي. يتم حفظ هذه البيانات في جدول باسم xyz، وهو اسم جدول مؤقت.
CREATE TABLE
xyz AS
SELECT
id || ' - ' || pdt_desc AS literature,
pdt_desc AS content,
'I want womens tops, pink casual only pure cotton.' AS user_text
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-005',
'I want womens tops, pink casual only pure cotton.')::vector
LIMIT
5;
ستكون نتيجة طلب البحث هذا أكثر 5 صفوف تشابهًا ذات صلة بطلب بحث المستخدم.
سيتضمّن الجدول الجديد xyz 5 صفوف، وسيتضمّن كل صف الأعمدة التالية:
literaturecontentuser_text
- لتحديد مدى صحة الردود، سنستخدم طلب بحث معقّدًا نشرح فيه كيفية تقييم الردود. يستخدم هذا المثال
user_textوcontentفي جدولxyzكجزء من طلب البحث.
"Read this user search text: ', user_text,
' Compare it against the product inventory data set: ', content,
' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
- باستخدام هذا الاستعلام، سنراجع بعد ذلك "جودة" الردود في الجدول
xyz. عندما نقول "جودة"، نعني مدى دقة الردود التي يتم إنشاؤها مقارنةً بما نتوقّع أن تكون عليه.
CREATE TABLE
x AS
SELECT
json_array_elements( google_ml.predict_row( model_id => 'gemini-1.5',
request_body => CONCAT('{
"contents": [
{ "role": "user",
"parts":
[ { "text": "Read this user search text: ', user_text, ' Compare it against the product inventory data set: ', content, ' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
} ]
}
] }'
)::json))-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'
AS LLM_RESPONSE
FROM
xyz;
- تعرض الدالة
predict_rowالنتيجة بتنسيق JSON. يُستخدم الرمز "-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'"" لاستخراج النص الفعلي من ملف JSON. للاطّلاع على ملف JSON الفعلي الذي يتم عرضه، يمكنك إزالة هذا الرمز. - أخيرًا، للحصول على حقل LLM، ما عليك سوى استخراجه من الجدول x:
SELECT
LLM_RESPONSE
FROM
x;
- يمكن دمج ذلك في طلب بحث واحد على النحو التالي:
تحذير: إذا كنت قد نفّذت طلبات البحث أعلاه للتحقّق من النتائج المؤقتة،
تأكَّد من حذف/إزالة الجدولَين xyz وx من قاعدة بيانات AlloyDB قبل تنفيذ طلب البحث هذا،
SELECT
LLM_RESPONSE
FROM (
SELECT
json_array_elements( google_ml.predict_row( model_id => 'gemini-1.5',
request_body => CONCAT('{
"contents": [
{ "role": "user",
"parts":
[ { "text": "Read this user search text: ', user_text, ' Compare it against the product inventory data set: ', content, ' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
} ]
}
] }'
)::json))-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'
AS LLM_RESPONSE
FROM (
SELECT
id || ' - ' || pdt_desc AS literature,
pdt_desc AS content,
'I want womens tops, pink casual only pure cotton.' user_text
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-005',
'I want womens tops, pink casual only pure cotton.')::vector
LIMIT
5 ) AS xyz ) AS X;
الاستعلام الأكبر هو مزيج من جميع الاستعلامات التي ننفّذها في الخطوات السابقة. توضّح النتائج ما إذا كان هناك تطابق أم لا، والنسبة المئوية للتطابق، وبعض التفسيرات حول التقييم.
لاحظ أنّ نموذج Gemini يتيح البث تلقائيًا، لذا يتم توزيع الرد الفعلي على أسطر متعددة: 
10. نقل التطبيق إلى الويب
سنستضيف الآن هذا التطبيق لكي يمكن الوصول إليه من الإنترنت.
إنشاء دالة Cloud Run
- في Google Cloud Console، انتقِل إلى "دوال Cloud Run" باستخدام الرابط التالي:
https://console.cloud.google.com/run/create?deploymentType=function
- في "الإعداد" (Configure)، اضبط اسم الدالة على retail-engine واختَر المنطقة us-central1.
- في "عنوان URL لنقطة النهاية"، اختَر وقت التشغيل Java 17.
- في قسم "المصادقة"، اختَر السماح بعمليات الاستدعاء غير المصادَق عليها.
- وسِّع الحاويات ووحدات التخزين والشبكات والأمان، ثم انقر على علامة التبويب الشبكات.
- اختَر الاتصال بشبكة سحابة VPC لنقل البيانات الصادرة، ثم انقر على استخدام موصلات إمكانية الوصول إلى سحابة VPC بدون خادم.
- في "الشبكة"، انقر على إضافة موصّل VPC جديد. فعِّل واجهة برمجة التطبيقات Serverless VPC Access API، إذا لم يسبق لك تفعيلها.
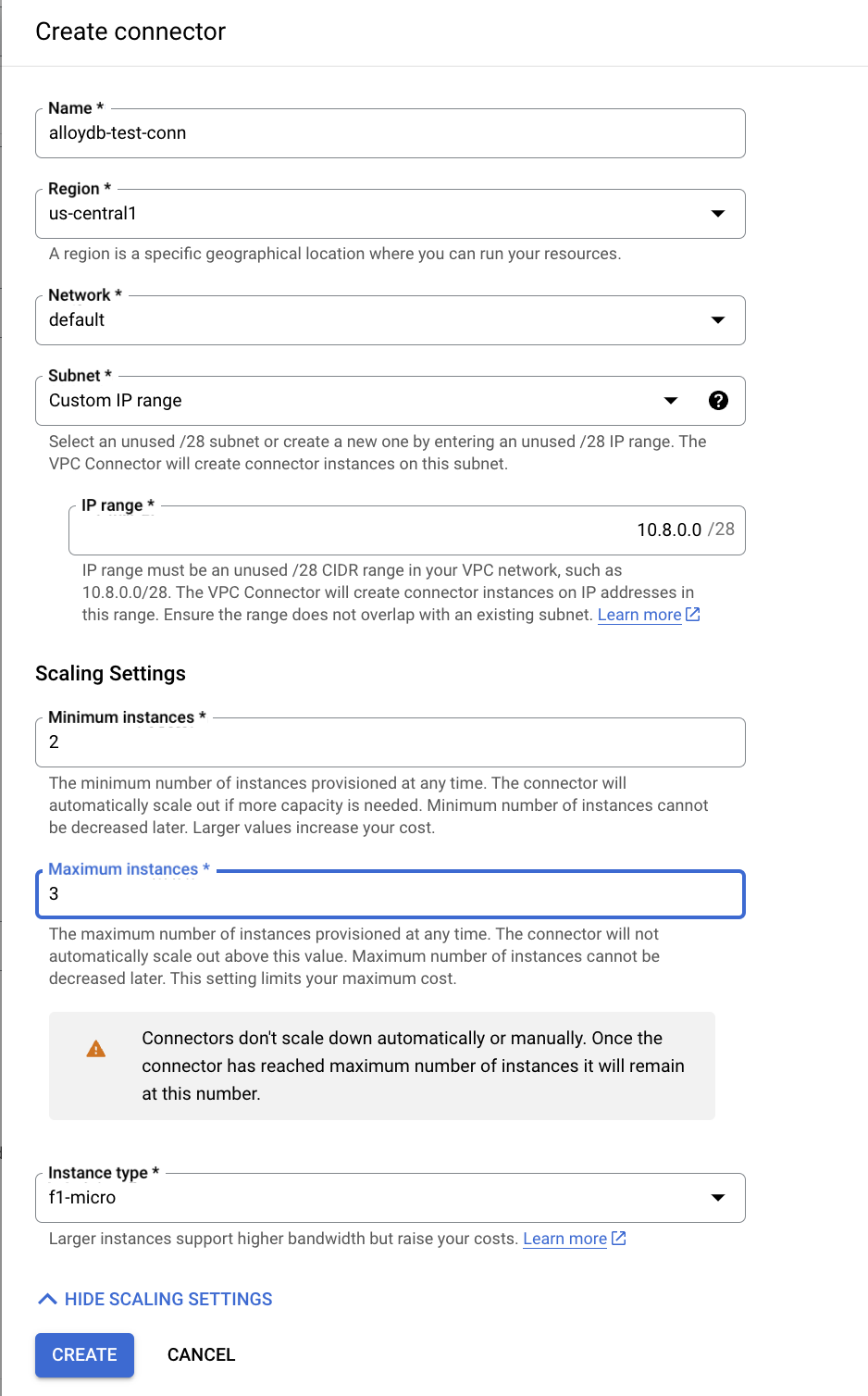
- في "إنشاء موصّل"، اضبط الاسم على
alloydb-test-conn. - اضبط المنطقة على
us-central. - اترك قيمة "الشبكة" على تلقائي واضبط الشبكة الفرعية على نطاق IP مخصّص مع نطاق IP 10.8.0.0 أو نطاق مشابه متوفّر.
- وسِّع إعدادات عرض القياس، واضبط الحد الأدنى لعدد المثيلات على 2 والحد الأقصى لعدد المثيلات على 3.
- اختَر نوع المثيل f1-micro. يوضّح ما يلي خيارات "إنشاء أداة ربط":
- انقر على "إنشاء" لإنشاء الموصل.
- في "توجيه حركة المرور"، اختَر توجيه كل حركة المرور إلى شبكة VPC.
- انقر على إنشاء لإنشاء الدالة.
نشر التطبيق
بعد إنشاء الدالة، عدِّل المصدر وأعِد نشر التطبيق.
- في Cloud Run، انقر على علامة التبويب الخدمات، ثم انقر على الدالة retail-engine.
- انقر على علامة التبويب "المصدر". اترك نقطة دخول الدالة التلقائية مضبوطة على "
gcfv2.HelloHttpFunction". - استبدِل محتوى الملف HelloHttpFunction.java بالمحتوى من ملف Java هذا.
- عدِّل تفاصيل AlloyDbJdbcConnector في الملف وفقًا لتفاصيل مثيل AlloyDB ومجموعته. استبدِل
$PROJECT_IDبرقم تعريف المشروع لمجموعة AlloyDB ونسختها.

- استبدِل محتوى ملف pom.xml بمحتوى ملف XML هذا.
- انقر على حفظ وإعادة نشر لنشر الدالة.
11. اختبار تطبيق محرك البيع بالتجزئة
بعد نشر "دالة Cloud" المعدَّلة، من المفترض أن يظهر لك نقطة النهاية بالتنسيق التالي:
https://retail-engine-PROJECT_NUMBER.us-central1.run.app
يمكنك اختباره من "وحدة طرفية Cloud Shell" عن طريق تنفيذ الأمر التالي:
gcloud functions call retail-engine --region=us-central1 --gen2 --data '{"search": "I want some kids clothes themed on Disney"}'
بدلاً من ذلك، يمكنك اختبار وظيفة Cloud Run على النحو التالي:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST https://retail-engine-$PROJECT_NUMBER.us-central1.run.app \
-H 'Content-Type: application/json' \
-d '{"search":"I want some kids clothes themed on Disney"}' \
| jq .
والنتيجة هي:

بعد أن أجرينا بحثًا عن المتّجهات المتشابهة باستخدام نموذج عمليات التضمين على بيانات AlloyDB، يمكننا الانتقال إلى إنشاء التطبيق الذي يستخدم عمليات التضمين هذه مع صورتك، ويقدّم اقتراحات بشأن الأنماط.
12. التعرّف على مسار اقتراحات الملابس
تطبيق اقتراح الأزياء هو تطبيق Spring Boot تم إعداده للعمل مع عمليات التضمين التي أنشأناها في تطبيق AlloyDB الخاص بمحرك البيع بالتجزئة، بالإضافة إلى Gemini وImagen لإنشاء خيارات مرئية لتصميم الأزياء. يتيح لك أيضًا إضافة طلبات مخصّصة وتحسين الاقتراح.
إليك طريقة عملها: يمكنك تحميل صورة لقميص وردي فاتح من خزانة ملابسك إلى هذا التطبيق. وعند النقر على "عرض" (Show)، ينشئ التطبيق خيارات متعدّدة تتطابق مع الصورة الأصلية استنادًا إلى الطلب الذي تم ضبطه في الرمز البرمجي للتطبيق وعمليات التضمين في قاعدة بيانات AlloyDB. والآن، تريد معرفة كيف ستبدو الخيارات المقترَحة مع قلادة زرقاء، لذا تضيف طلبًا على هذه السطور، وتنقر على "النمط". يتم إنشاء الصورة النهائية التي تجمع بين الصورة الأصلية والاقتراحات لإنشاء زي مطابق.
لبدء إنشاء تطبيق اقتراحات الملابس، اتّبِع الخطوات التالية:
- في Cloud Run، افتح تطبيق retail-engine، ودوِّن عنوان URL لتطبيقك. هذا هو مستودع التضمينات الذي سنستخدمه لإنشاء اقتراحات مشابهة.
- في بيئة التطوير المتكاملة (IDE)، استنسِخ المستودع https://github.com/AbiramiSukumaran/outfit-recommender/. في هذا التمرين، يتم تنفيذ الخطوات الموضّحة في بيئة التطوير المتكاملة Visual Studio Code.
git clone https://github.com/AbiramiSukumaran/outfit-recommender/
في ما يلي بعض الملفات المهمة في دليل التطبيق:
src/main: دليل ملفات المصدر الذي تتضمّن فيه ملفات التطبيق وHTML:-
HelloWorldApplication.java: نقطة الدخول الرئيسية لتطبيق Spring Boot. -
HelloWorldController.java: أداة تحكّم REST في Spring Boot تعالج طلبات HTTP ذات الصلة بتطبيق يقترح الملابس. يتعامل هذا الملف مع طلبات GET وPOST، ويعالج طلبات المستخدمين، ويحلّل الصور، ويتفاعل مع تضمينات AlloyDB، ويعرض الرد النهائي على واجهة المستخدم. يستدعي وحدة التحكّم هذه فئة GenerateImageSample. GenerateImageSample.java: يحتوي على فئة إنشاء الصور التي تتصل بـ Vertex AI، وتنسّق طلب المستخدم، وتجري طلبات البيانات من واجهة برمجة التطبيقات إلى نموذج Imagen، وتعرض الصورة المتوقّعة لفئة وحدة التحكّم.Resources: يحتوي هذا الدليل على الصور وملفات HTML المطلوبة لإنشاء واجهة مستخدم التطبيق.-
Pom.xml: تحدّد هذه السمة تبعيات المشروع وإعداداته.
- في Visual Studio Code، افتح الملف
HelloWorldController.javaوعدِّل مثيلات رقم تعريف المشروع والموقع الجغرافي وفقًا للمكان الذي تم فيه إنشاء مثيل AlloyDB.

- عدِّل
endpointإلى عنوان URL داخل تطبيق Retail Engine الذي استضفته سابقًا.
- افتح
GenerateImageSample.java، وعدِّل رقم تعريف المشروع والموقع الجغرافي وفقًا للمكان الذي تم فيه إنشاء مثيل AlloyDB.

- احفظ جميع الملفات.
سننشر هذا التطبيق الآن على بيئة التشغيل بدون خادم في Cloud Run.
13. نقل التطبيق إلى الويب
بعد أن أضفنا المشروع والموقع الجغرافي وتفاصيل تطبيق Retail Engine إلى تطبيق Spring Boot الخاص بأداة اقتراح الملابس، يمكننا نشر التطبيق على Cloud Run.
سنستخدم الأمر gcloud run deploy في نافذة Visual Code Studio الطرفية لنشر التطبيق. بالنسبة إلى Visual Studio Code، يمكنك تثبيت إضافة Google Cloud Code لبدء استخدام gcloud CLI.
لنشر التطبيق، اتّبِع الخطوات التالية:
- في بيئة التطوير المتكاملة (IDE)، افتح الدليل المستنسخ وابدأ تشغيل نافذة الأوامر. في Visual Code Studio، انقر على Terminal > New Terminal.
- اتّبِع التعليمات في هذا المستند لتثبيت gcloud CLI.
- إذا كنت تستخدم Visual Code Studio، انقر على الإضافات، وابحث عن Google Cloud Code وثبِّت الإضافة.
- في نافذة الوحدة الطرفية لبيئة التطوير المتكاملة، صادِق على حسابك على Google من خلال تنفيذ الأمر التالي:
gcloud auth application-default login
- اضبط رقم تعريف مشروعك على المشروع نفسه الذي يقع فيه مثيل AlloyDB.
gcloud config set project PROJECT_ID
- ابدأ عملية النشر.
gcloud run deploy
- في
Source code location، اضغط على Enter لاختيار دليل GitHub المستنسَخ. - في
Service name، أدخِل اسمًا للخدمة، مثل outfit-recommender، واضغط على Enter. - في
Please specify a region، أدخِل الموقع الجغرافي الذي تتم فيه استضافة آلة AlloyDB الافتراضية وتطبيق Retail Engine، مثل 32 لمنطقة us-central1، ثم اضغط على Enter.

- في
Allow unauthenticated invocations to [..]، أدخِل Y، ثم اضغط على Enter.
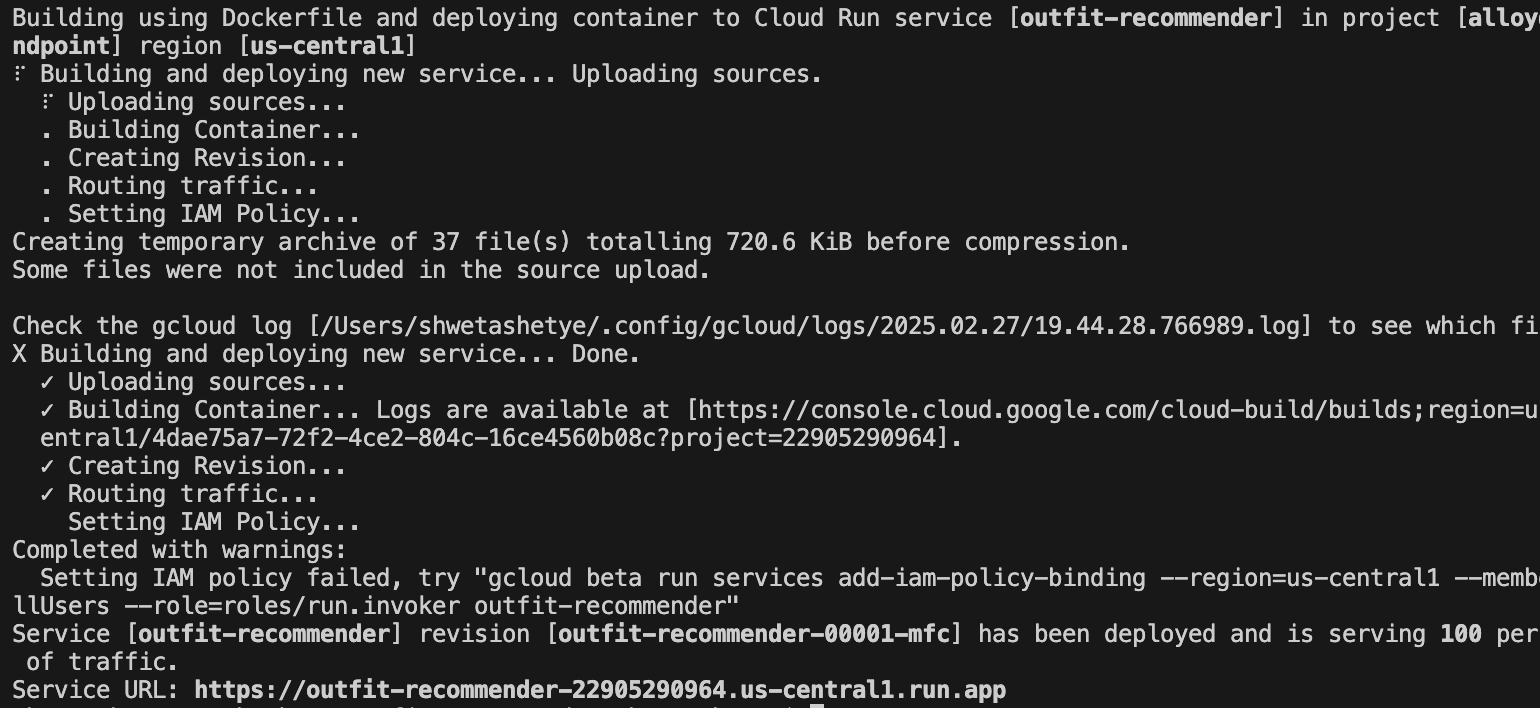
تعرض الصورة التالية تقدّم عملية نشر تطبيقك:
14. اختبار تطبيق اقتراح الملابس
بعد نشر التطبيق بنجاح على Cloud Run، يمكنك الاطّلاع على الخدمة في Google Cloud Console على النحو التالي:
- في Google Cloud Console، انتقِل إلى Cloud Run.
- في "الخدمات"، انقر على خدمة اقتراح الملابس التي نشرتها. من المفترض أن تظهر لك خدمة retail-engine وخدمة outfit-recommender على النحو التالي:

- انقر على عنوان URL الخاص بالتطبيق لفتح واجهة مستخدم تطبيق التوصية.

The following is a sample URL that you will use:
https://outfit-recommender-22905290964.us-central1.run.app/style
يمكن الاطّلاع على التطبيق الذي تم نشره على النحو التالي:
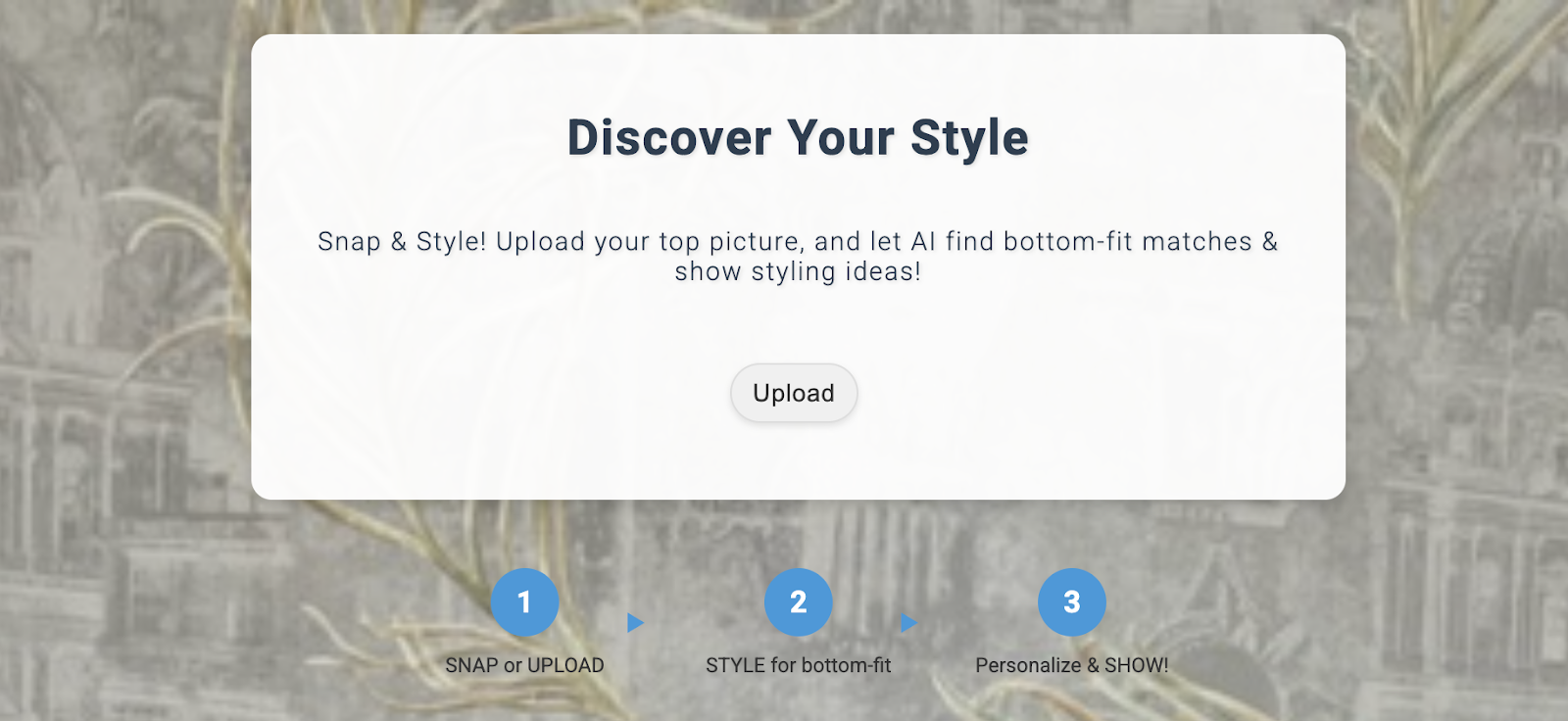
استخدام التطبيق
لبدء استخدام التطبيق، اتّبِع الخطوات التالية:
- انقر على تحميل وحمِّل صورة لقطعة ملابس.
- بعد تحميل الصورة، انقر على النمط. يستخدم التطبيق الصورة كطلب وينشئ خيارات في أسفل الشاشة استنادًا إلى الطلب من تطبيق محرك البيع بالتجزئة الذي يتضمّن عمليات تضمين لمجموعة بيانات البيع بالتجزئة.
ينشئ التطبيق اقتراحات صور مع طلب استنادًا إلى الصورة مع اقتراحات بشأن الأسلوب. على سبيل المثال، A white semi-sheer button up blouse with pink floral patterns on it, with balloon sleeves.
- يمكنك تمرير طلبات إضافية إلى اقتراح الأسلوب الذي تم إنشاؤه تلقائيًا. على سبيل المثال،
STYLE RECOMMENDATION: Cute brown skirt on a curly updo. Make it photo realistic. Accessorize with cherry earrings and burgundy plastic case sling bag. - انقر على عرض للاطّلاع على التنسيق النهائي.

15. تَنظيم
لتجنُّب تحمّل رسوم في حسابك على Google Cloud مقابل الموارد المستخدَمة في هذه المشاركة، اتّبِع الخطوات التالية:
- في Google Cloud Console، انتقِل إلى صفحة إدارة الموارد.
- في قائمة المشاريع، اختَر المشروع الذي تريد حذفه، ثم انقر على حذف.
- في مربّع الحوار، اكتب رقم تعريف المشروع، ثم انقر على إيقاف لحذف المشروع.
16. تهانينا
تهانينا! لقد أجريت بنجاح عملية بحث عن التشابه باستخدام AlloyDB وpgvector و"البحث المتّجه"، بالإضافة إلى استخدام نتيجة البحث مع نموذج Imagen الفعّال لإنشاء اقتراحات بشأن الأسلوب.