
1. Descripción general
Imagina una app de moda que no solo te ayude a encontrar el atuendo perfecto, sino que también te brinde asesoramiento de estilo en tiempo real, todo gracias al poder de la integración de IA generativa de vanguardia. En esta charla, exploraremos cómo creamos una app de este tipo con las capacidades de búsqueda de vectores de AlloyDB, junto con el índice de ScaNN de Google, lo que permite realizar búsquedas ultrarrápidas de conjuntos coincidentes y ofrecer recomendaciones de moda instantáneas.
También profundizaremos en cómo el índice ScaNN de AlloyDB optimiza las consultas complejas para generar sugerencias de estilo personalizadas. También usaremos Gemini e Imagen, modelos de IA generativa potentes, para brindarte inspiración creativa sobre cómo combinar tu ropa y, hasta, visualizar tus looks personalizados. Toda esta aplicación se basa en una arquitectura sin servidores, lo que garantiza una experiencia fluida y escalable para los usuarios.
El desafío: La app ofrece sugerencias de atuendos personalizados para ayudar a las personas que tienen problemas para decidir qué ponerse. También ayuda a evitar la fatiga de decisión que genera planificar qué usar.
La solución: La app de recomendación de atuendos resuelve el problema de brindar a los usuarios una experiencia de moda inteligente, personalizada y atractiva, al mismo tiempo que muestra las capacidades de AlloyDB, la IA generativa y las tecnologías sin servidores.
Qué compilarás
Como parte de este lab, harás lo siguiente:
- Crea una instancia de AlloyDB y carga el conjunto de datos de comercio electrónico
- Habilita las extensiones de pgvector y del modelo de IA generativa en AlloyDB
- Genera incorporaciones a partir de la descripción del producto
- Implementa la solución en Cloud Run Functions sin servidores
- Sube una imagen a Gemini y genera una instrucción de descripción de la imagen.
- Genera resultados de la búsqueda basados en instrucciones combinadas con embeddings de conjuntos de datos de comercio electrónico.
- Agrega instrucciones adicionales para personalizar la instrucción y generar recomendaciones de estilo.
- Implementa la solución en Cloud Run Functions sin servidores
Requisitos
2. Arquitectura
La arquitectura de alto nivel de la app es la siguiente:

En las siguientes secciones, se destaca el flujo contextual del instructivo:
Transferencia:
El primer paso es transferir los datos de Retail (inventario, descripciones de productos, interacciones con los clientes) a AlloyDB.
Motor de Analytics:
Usaremos AlloyDB como motor de análisis para realizar las siguientes acciones:
- Extracción de contexto: El motor analiza los datos almacenados en AlloyDB para comprender las relaciones entre los productos, las categorías, el comportamiento del cliente, etc., según corresponda.
- Creación de embeddings: Se generan embeddings (representaciones matemáticas del texto) tanto para la búsqueda del usuario como para la información almacenada en AlloyDB.
- Vector Search: El motor realiza una búsqueda de similitud, comparando la incorporación de la búsqueda con las incorporaciones de las descripciones de los productos, las opiniones y otros datos relevantes. Esto identifica los 25 "vecinos más cercanos" más relevantes.
Recomendación de Gemini:
El array de bytes de la imagen se pasa al modelo de Gemini a través de la API de Vertex AI, junto con la instrucción que solicita una descripción textual de la prenda superior y sugerencias de prendas inferiores.
RAG y búsqueda de vectores de AlloyDB:
La descripción de la prenda superior se usa para consultar la base de datos. La búsqueda convierte el texto de búsqueda (recomendación del modelo de Gemini para prendas inferiores a juego) en embeddings y realiza una búsqueda de vectores en los embeddings almacenados en la base de datos para encontrar los vecinos más cercanos (resultados coincidentes). Los embeddings de vectores en la base de datos de AlloyDB se indexan con el índice ScaNN para mejorar la recuperación.
Generación de imágenes de respuesta:
Las respuestas validadas se estructuran en un array JSON, y todo el motor se empaqueta en una función de Cloud Run sin servidores que se invoca desde Agent Builder.
Generación de imágenes con Imagen:
La instrucción de diseño del usuario, una recomendación seleccionada por el usuario y cualquier solicitud de personalización se combinan para indicarle a Imagen 3 que use una imagen existente. La imagen de diseño se genera en función de esta instrucción, con la API de Vertex AI.
3. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto .
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud y que viene precargado con bq. Haz clic en Activar Cloud Shell (
 ) en la parte superior de la consola de Google Cloud.
) en la parte superior de la consola de Google Cloud. - Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto usando el siguiente comando:
gcloud auth list
- Ejecuta el siguiente comando para confirmar que los futuros comandos de gcloud identificarán tu proyecto correctamente.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para establecerlo de forma explícita:
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las APIs necesarias.
Sigue el vínculo para habilitar las APIs.
Si olvidas habilitar alguna API, puedes hacerlo durante el proceso de implementación.
Para obtener más información sobre los comandos y el uso de gcloud, consulta la documentación.
4. Configuración de la base de datos
En este lab, usaremos AlloyDB como la base de datos para almacenar el conjunto de datos de comercio electrónico minorista. Utiliza clústeres para almacenar todos los recursos, como bases de datos y registros. Cada clúster tiene una instancia principal que proporciona un punto de acceso a los datos. Las tablas son el recurso real que almacena datos.
Crearemos un clúster, una instancia y una tabla de AlloyDB en los que se cargará el conjunto de datos de comercio electrónico.
Crea un clúster y una instancia
- En la consola de Google Cloud, busca AlloyDB. Una forma sencilla de encontrar la mayoría de las páginas en la consola de Cloud es buscarlas con la barra de búsqueda de la consola.
- Haz clic en CREAR CLÚSTER.

- Crea un clúster y una instancia con los siguientes valores:
- ID del clúster: "
shopping-cluster" - contraseña: "
alloydb" - Compatible con PostgreSQL 15
- Región: "
us-central1" - Conexiones: "
default"

- En Red, cuando seleccionas la red predeterminada, aparece la siguiente opción. Haz clic en CONFIGURAR CONEXIÓN para configurar una red predeterminada.

- Selecciona Usar un rango de IP asignado automáticamente y haz clic en Continuar. Después de revisar la información, haz clic en CREAR CONEXIÓN.

Espera a que se complete la creación de la red predeterminada.
- En Configura tu instancia principal, establece el ID de la instancia como "
shopping-instance"".

- Haz clic en CREATE CLUSTER para completar la configuración del clúster de la siguiente manera:

5. Transferencia de datos
Ahora es momento de agregar una tabla con los datos de la tienda. Espera a que termine de crearse la instancia. Una vez que se cree, podrás acceder a AlloyDB con las credenciales que configuraste cuando creaste el clúster.
Autenticación en la base de datos de AlloyDB
- En la consola de Google Cloud, ve a AlloyDB. Selecciona el clúster principal y, luego, haz clic en AlloyDB Studio en el panel de navegación de la izquierda:

- Ingresa los siguientes detalles para autenticarte en la base de datos de AlloyDB:
- Nombre de usuario : "
postgres" - Base de datos : "
postgres" - Contraseña : "
alloydb"
Una vez que te hayas autenticado correctamente en AlloyDB Studio, ingresa los comandos SQL en las pestañas del Editor. Puedes agregar varias ventanas del editor con el signo más que se encuentra a la derecha de la primera pestaña del editor.

Ingresarás comandos para AlloyDB en las ventanas del editor, y usarás las opciones Ejecutar, Formato y Borrar según sea necesario.
Habilitar extensiones
Para compilar esta app, usaremos las extensiones "pgvector"" y "google_ml_integration"".
- La extensión pgvector te permite almacenar y buscar embeddings de vectores.
- La extensión google_ml_integration proporciona funciones que usas para acceder a los extremos de predicción de Vertex AI y obtener predicciones en SQL.
- Habilita estas extensiones ejecutando los siguientes DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
- Ejecuta este comando SQL para verificar si las extensiones están instaladas:
select extname, extversion from pg_extension;
Crea una tabla
- Crea una tabla con la siguiente declaración DDL:
CREATE TABLE
apparels ( id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
embedding vector(768) );
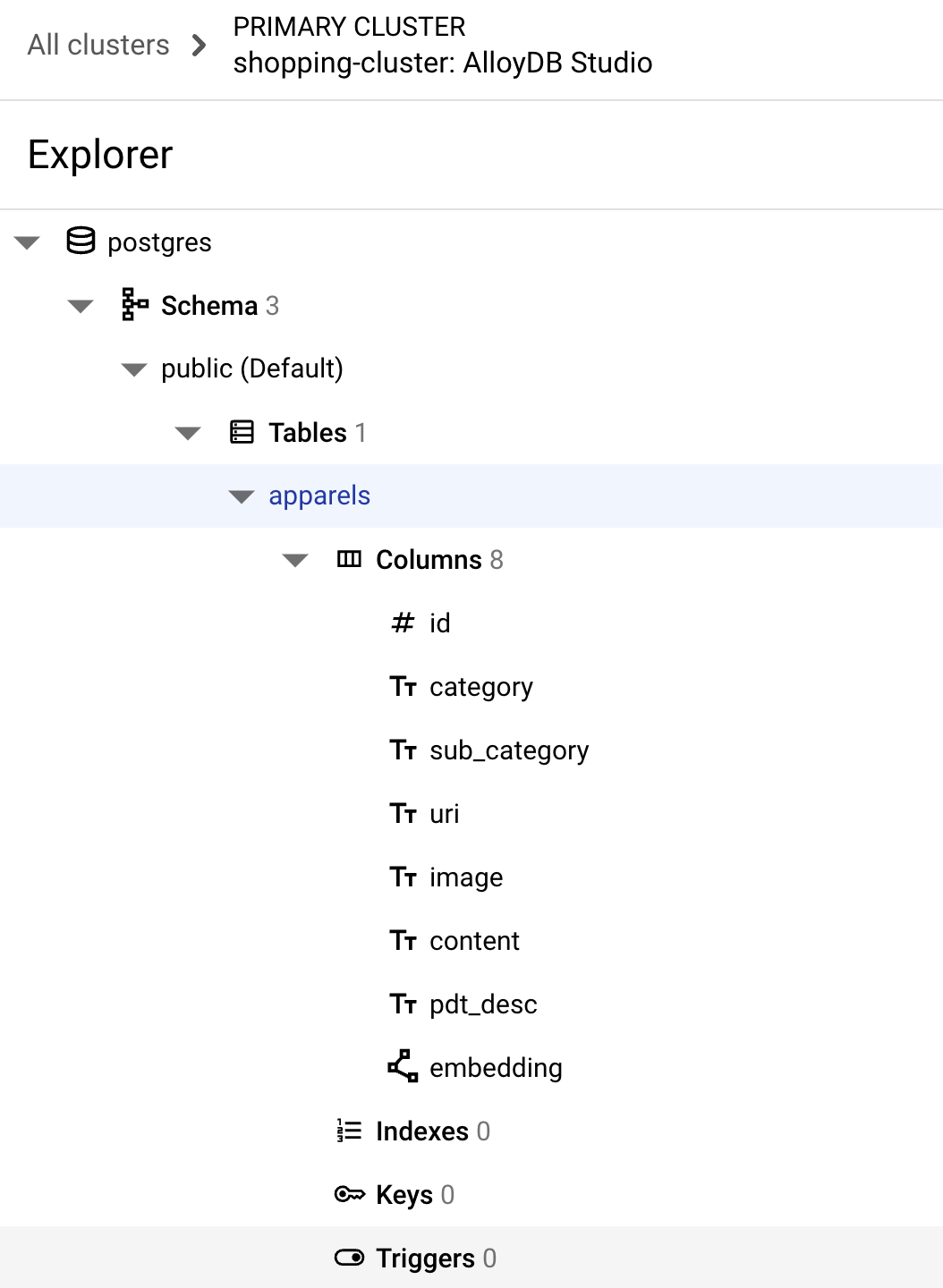
Si el comando anterior se ejecuta correctamente, podrás ver la tabla en
la base de datos. En la siguiente imagen, se muestra un ejemplo:
Transfiere datos
Para este lab, tenemos datos de prueba de alrededor de 200 registros en este archivo SQL. Contiene id, category, sub_category, uri, image y content. Los demás campos se completarán más adelante en el lab.
- Copia las 20 líneas o instrucciones de inserción del archivo SQL en una nueva pestaña del editor en AlloyDB Studio y haz clic en RUN.
- Expande la sección Explorador hasta que veas la tabla llamada
apparels. - Haz clic en el ícono de menú [⋮] y, luego, en Consulta. Se abrirá una instrucción SELECT en una nueva pestaña del editor.

- Haz clic en Ejecutar para verificar que se insertaron las filas.
Otorga permiso al usuario
Le otorgaremos permiso al usuario postgres para generar embeddings desde AlloyDB.. En AlloyDB Studio, ejecuta la siguiente instrucción para otorgar derechos de ejecución en la función embedding al usuario postgres:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Otorga el rol de usuario de Vertex AI a la cuenta de servicio de AlloyDB
Usaremos los modelos de incorporación de texto de Vertex AI para generar incorporaciones para las que se otorga el rol de usuario de Vertex AI a la cuenta de servicio de AlloyDB.
En la consola de Google Cloud, haz clic en el ícono de la terminal de Cloud Shell [] y ejecuta el siguiente comando:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
6. Contexto de compilación
Para crear una incorporación, necesitaremos un context, es decir, toda la información que queremos incluir en un solo campo. Para ello, crearemos una descripción del producto que almacenaremos en la columna pdt_desc de la tabla apparels.
En nuestro caso, usaremos toda la información sobre cada producto, pero cuando lo hagas con tus propios datos, no dudes en diseñarlos de la manera que te resulte más significativa para tu empresa.
En la pestaña Editor de AlloyDB Studio, ejecuta el siguiente comando que actualiza el campo pdt_desc con datos de contexto:
UPDATE
apparels
SET
pdt_desc = CONCAT('This product category is: ', category, ' and sub_category is: ', sub_category, '. The description of the product is as follows: ', content, '. The product image is stored at: ', uri)
WHERE
id IS NOT NULL;
Este DML crea un resumen de contexto simple con la información de todos los campos disponibles en la tabla y otras dependencias (si hay alguna en tu caso de uso). Para crear una variedad más precisa de información y contexto, no dudes en diseñar los datos de la manera que consideres más significativa para tu empresa.
7. Crea embeddings para el contexto
Es mucho más fácil para las computadoras procesar números que texto. Un sistema de embedding convierte el texto en una serie de números de punto flotante que deberían representar el texto, sin importar cómo se redacte, qué idioma use, etcétera.
Considera describir una ubicación costera. Se puede llamar "on the water", "beachfront", "walk from your room to the ocean", "sur la mer", "на берегу океана", etcétera. Todos estos términos se ven diferentes, pero su significado semántico o, en la terminología del aprendizaje automático, sus incorporaciones deben estar muy cerca entre sí.
Ahora que los datos y el contexto están listos, ejecutaremos el código SQL para agregar los embeddings de la columna de descripción del producto(pdt_desc) a la tabla en el campo embedding. Puedes usar una variedad de modelos de embedding. Usamos text-embedding-005 de Vertex AI.
- En AlloyDB Studio, ejecuta el siguiente comando para generar embeddings y actualizar la columna
pdt_desccon los embeddings de los datos que almacena:
UPDATE
apparels
SET
embedding = embedding( 'text-embedding-005',
pdt_desc)
WHERE
TRUE;
- Para verificar que se generaron las incorporaciones, ejecuta el siguiente comando:
SELECT
id,
category,
sub_category,
content,
embedding
FROM
Apparels
LIMIT 5;
A continuación, se muestra un ejemplo de vector de embeddings, que se ve como un array de números de punto flotante, para el texto de muestra en la búsqueda de la siguiente manera:

8. Realiza una búsqueda de vectores
Ahora que la tabla, los datos y los embeddings están listos, realicemos la búsqueda de vectores en tiempo real para el texto de búsqueda del usuario.
Supongamos que el texto de búsqueda del usuario es "pink color, casual, pure cotton tops for women".
Para encontrar coincidencias para esta búsqueda, ejecuta la siguiente consulta en SQL:
SELECT
id,
category,
sub_category,
content,
pdt_desc AS description
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-005',
'pink color, casual, pure cotton tops for women')::vector
LIMIT
5;
Analicemos esta consulta en detalle:
En esta consulta,
- El texto de búsqueda del usuario es: "
I want womens tops, pink casual only pure cotton.". - Convertimos este texto de búsqueda en embeddings con el método
embedding()junto con el modelo:text-embedding-005. Este paso debería resultarte familiar después del último, en el que aplicamos la función de incorporación a todos los elementos de la tabla. - "
<=>" representa el uso del método de distancia SIMILITUD DEL COSENO. Puedes encontrar todas las medidas de similitud disponibles en la documentación de pgvector. - Convertimos el resultado del método de embedding al tipo de datos vector para que sea compatible con los vectores almacenados en la base de datos.
- LIMIT 5 representa que queremos extraer 5 vecinos más cercanos para el texto de búsqueda.
A continuación, se muestra un ejemplo de la respuesta de esta consulta de SQL:

Como puedes observar en los resultados, las coincidencias son bastante cercanas al texto de búsqueda. Intenta cambiar el color para ver cómo cambian los resultados.
Índice de ScaNN de AlloyDB para el rendimiento de las consultas
Ahora supongamos que queremos aumentar el rendimiento (tiempo de consulta), la eficiencia y la recuperación de este resultado de la Búsqueda de vectores con el índice ScaNN.
Si quieres usar el índice de ScaNN, prueba los siguientes pasos:
- Como ya creamos el clúster, la instancia, el contexto y las incorporaciones, solo tenemos que instalar la extensión de ScaNN con la siguiente instrucción:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- Crea el índice de ScaNN:
CREATE INDEX apparel_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=54);
En el DDL anterior, se observa lo siguiente:
apparel_indexes el nombre del índice.apparelses el nombre de la tabla.scannes el método de indexación.embeddinges la columna de la tabla que deseas indexar.cosinees el método de distancia que deseas usar con el índice.54es la cantidad de particiones que se aplicarán a este índice. Se puede establecer en cualquier valor entre 1 y 1048576. Para obtener más información sobre cómo decidir este valor, consulta Cómo ajustar un índice de ScaNN.
Según la recomendación del repo de ScaNN, usamos la RAÍZ CUADRADA de la cantidad de puntos de datos. Cuando se realiza la partición, num_leaves debe ser aproximadamente la raíz cuadrada de la cantidad de puntos de datos.
- Verifica si se creó el índice con la siguiente consulta:
SELECT * FROM pg_stat_ann_indexes;
- Realiza una búsqueda vectorial con la misma consulta que usamos sin el índice:
select * from apparels
ORDER BY embedding <=> CAST(embedding('textembedding-gecko', 'white tops for girls without any print') as vector(768))
LIMIT 20
La consulta anterior es la misma que usamos en el lab en el paso 8. Sin embargo, ahora tenemos el campo indexado con el índice de ScaNN.
- Prueba con una consulta de búsqueda simple con y sin el índice. Para realizar pruebas sin el índice, debes descartarlo:
white tops for girls without any print
El texto de búsqueda anterior en la consulta de Vector Search sobre los datos de incorporaciones INDEXADAS genera resultados de búsqueda de calidad y eficiencia. La eficiencia mejora considerablemente (en términos de tiempo de ejecución: 10.37 ms sin ScaNN y 0.87 ms con ScaNN) con el índice. Para obtener más información sobre este tema, consulta este blog.
9. Validación de coincidencias con el LLM
Antes de continuar y crear un servicio para devolver las mejores coincidencias a una aplicación, usemos un modelo de IA generativa para validar si estas posibles respuestas son realmente relevantes y seguras para compartirlas con el usuario.
Cómo asegurarse de que la instancia esté configurada para Gemini
- Verifica que
google_ml_integrationya esté habilitado para tu clúster y tu instancia. En AlloyDB Studio, ejecuta el siguiente comando:
show google_ml_integration.enable_model_support;
Si el valor se muestra como "on", puedes omitir los próximos 2 pasos y pasar directamente a la configuración de
la integración de AlloyDB y Vertex AI Model
- Ve a la instancia principal de tu clúster de AlloyDB y haz clic en EDIT PRIMARY INSTANCE.

- En Opciones de configuración avanzadas, expande la sección Nueva marca de base de datos y asegúrate de que
google_ml_integration.enable_model_support flagesté configurado como "on" de la siguiente manera:
 3. Si no está configurado como "
3. Si no está configurado como "on", configúralo como "on" y, luego, haz clic en UPDATE INSTANCE.
Este paso tardará unos minutos.
Integración de modelos de AlloyDB y Vertex AI
Ahora puedes conectarte a AlloyDB Studio y ejecutar la siguiente instrucción DML para configurar el acceso al modelo de Gemini desde AlloyDB, usando el ID de tu proyecto donde se indique. Es posible que se te advierta sobre un error de sintaxis antes de ejecutar el comando, pero debería ejecutarse sin problemas.
- En la consola de Google Cloud, ve a AlloyDB. Selecciona el clúster principal y, luego, haz clic en AlloyDB Studio en el panel de navegación izquierdo.
- Usaremos el
gemini-1.5-pro:generateContentque está disponible de forma predeterminada con la extensióngoogle_ml_integration.
- Puedes verificar los modelos configurados para el acceso con el siguiente comando en AlloyDB Studio:
select model_id,model_type from google_ml.model_info_view;
- Otorga permiso a los usuarios de la base de datos para ejecutar la función ml_predict_row y ejecutar predicciones con los modelos de Google Vertex AI. Para ello, ejecuta el siguiente comando:
GRANT EXECUTE ON FUNCTION ml_predict_row to postgres;
Cómo evaluar las respuestas
Si bien terminaremos usando una consulta grande para la próxima sección, en la que realmente llevaremos la aplicación a Cloud Run, para garantizar que las respuestas de la consulta sean razonables, la consulta puede ser difícil de comprender.
Analizaremos las secciones individuales que componen la consulta más grande que finalmente usamos.
- Primero, enviaremos una solicitud a la base de datos para obtener las 5 coincidencias más cercanas a una búsqueda del usuario. Codificaremos la consulta de forma rígida para que sea simple, pero no te preocupes, la interpolaremos en la consulta más adelante.
Incluiremos la descripción del producto de la tabla apparels y agregaremos dos campos nuevos: uno que combine la descripción con el índice y otro con la solicitud original. Estos datos se guardan en una tabla llamada xyz, que es un nombre de tabla temporal.
CREATE TABLE
xyz AS
SELECT
id || ' - ' || pdt_desc AS literature,
pdt_desc AS content,
'I want womens tops, pink casual only pure cotton.' AS user_text
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-005',
'I want womens tops, pink casual only pure cotton.')::vector
LIMIT
5;
El resultado de esta consulta serán las 5 filas más similares relacionadas con la búsqueda del usuario. El
La nueva tabla xyz contendrá 5 filas, en las que cada una tendrá las siguientes columnas:
literaturecontentuser_text
- Para determinar la validez de las respuestas, usaremos una consulta compleja en la que explicaremos cómo evaluar las respuestas. Usa
user_textycontenten la tablaxyzcomo parte de la consulta.
"Read this user search text: ', user_text,
' Compare it against the product inventory data set: ', content,
' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
- Con esa consulta, revisaremos la "calidad" de las respuestas en la tabla
xyz. Cuando hablamos de calidad, nos referimos a qué tan precisas son las respuestas generadas en comparación con lo que esperamos que sean.
CREATE TABLE
x AS
SELECT
json_array_elements( google_ml.predict_row( model_id => 'gemini-1.5',
request_body => CONCAT('{
"contents": [
{ "role": "user",
"parts":
[ { "text": "Read this user search text: ', user_text, ' Compare it against the product inventory data set: ', content, ' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
} ]
}
] }'
)::json))-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'
AS LLM_RESPONSE
FROM
xyz;
- El
predict_rowdevuelve su resultado en formato JSON. El código "-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'"" se usa para extraer el texto real de ese JSON. Para ver el JSON real que se devuelve, puedes quitar este código. - Por último, para obtener el campo del LLM, solo debes extraerlo de la tabla x:
SELECT
LLM_RESPONSE
FROM
x;
- Esto se puede combinar en una sola consulta de la siguiente manera:
Advertencia: Si ejecutaste las consultas anteriores para verificar los resultados intermedios,
Asegúrate de borrar o quitar las tablas xyz y x de la base de datos de AlloyDB antes de ejecutar esta consulta.
SELECT
LLM_RESPONSE
FROM (
SELECT
json_array_elements( google_ml.predict_row( model_id => 'gemini-1.5',
request_body => CONCAT('{
"contents": [
{ "role": "user",
"parts":
[ { "text": "Read this user search text: ', user_text, ' Compare it against the product inventory data set: ', content, ' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
} ]
}
] }'
)::json))-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'
AS LLM_RESPONSE
FROM (
SELECT
id || ' - ' || pdt_desc AS literature,
pdt_desc AS content,
'I want womens tops, pink casual only pure cotton.' user_text
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-005',
'I want womens tops, pink casual only pure cotton.')::vector
LIMIT
5 ) AS xyz ) AS X;
La consulta más grande es una combinación de todas las consultas que ejecutamos en los pasos anteriores. Los resultados indican si hay una coincidencia, qué porcentaje representa y una explicación de la clasificación.
Ten en cuenta que el modelo de Gemini tiene la transmisión activada de forma predeterminada, por lo que la respuesta real se distribuye en varias líneas: 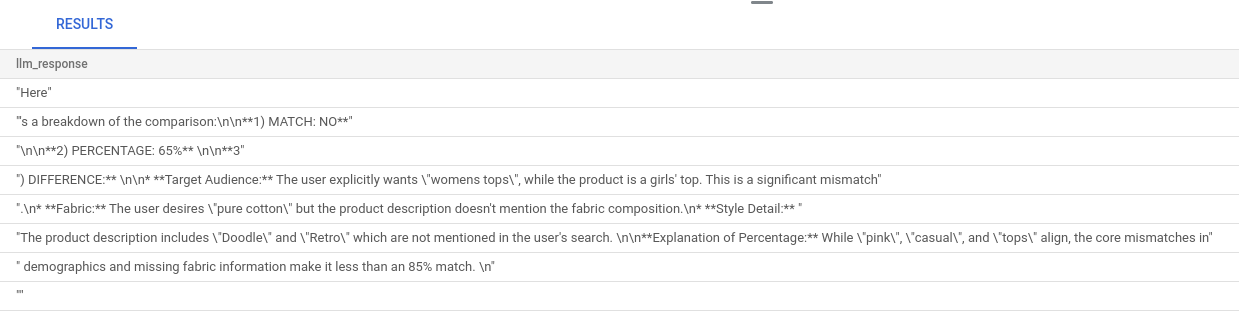
10. Lleva la aplicación a la Web
Ahora alojaremos esta aplicación para que se pueda acceder a ella desde Internet.
Crea la función de Cloud Run
- En la consola de Google Cloud, ve a Cloud Run Functions con el siguiente vínculo:
https://console.cloud.google.com/run/create?deploymentType=function
- En Configure, establece el nombre de la función como "retail-engine" y selecciona la región como "us-central1".
- En URL del extremo, selecciona el tiempo de ejecución como Java 17.
- En Autenticación, selecciona Permitir invocaciones no autenticadas.
- Expande Contenedores, volúmenes, Herramientas de redes y seguridad y haz clic en la pestaña Herramientas de redes.
- Selecciona Conéctate a una VPC para el tráfico saliente y, luego, haz clic en Usar conectores de Acceso a VPC sin servidores.
- En Red, haz clic en Agregar un nuevo conector de VPC. Habilita la API de Serverless VPC Access si aún no lo hiciste.
- En Create connector, establece el nombre en
alloydb-test-conn. - Establece la región en
us-central. - Deja el valor de la red como predeterminado y establece la subred como Rango de IP personalizado con el rango de IP 10.8.0.0 o uno similar que esté disponible.
- Expande la configuración de Mostrar escalamiento y establece Instancias mínimas en 2 y Instancias máximas en 3.
- Selecciona el tipo de instancia como f1-micro. A continuación, se muestran las opciones de Create connector:

- Haz clic en Crear para crear el conector.
- En Enrutamiento del tráfico, selecciona Enrutar todo el tráfico a la VPC.
- Haz clic en Crear para crear la función.
Implemente la aplicación
Después de crear la función, actualiza la fuente y vuelve a implementar la aplicación.
- En Cloud Run, haz clic en la pestaña Servicios y, luego, en la función retail-engine.
- Haz clic en la pestaña Fuente. Deja el punto de entrada de la función predeterminado establecido en "
gcfv2.HelloHttpFunction". - Reemplaza el contenido del archivo HelloHttpFunction.java por el contenido de este archivo Java.
- Actualiza los detalles de AlloyDbJdbcConnector en el archivo según los detalles de tu instancia y clúster de AlloyDB. Reemplaza
$PROJECT_IDpor el ID del proyecto de tu clúster y tu instancia de AlloyDB.

- Reemplaza el contenido del archivo pom.xml por el contenido de este archivo XML.
- Haz clic en Guardar y volver a implementar para implementar la función.
11. Prueba la aplicación de retail-engine
Una vez que se implemente la Cloud Function actualizada, deberías ver el extremo en el siguiente formato:
https://retail-engine-PROJECT_NUMBER.us-central1.run.app
Para probarlo desde la terminal de Cloud Shell, ejecuta el siguiente comando:
gcloud functions call retail-engine --region=us-central1 --gen2 --data '{"search": "I want some kids clothes themed on Disney"}'
También puedes probar la función de Cloud Run de la siguiente manera:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST https://retail-engine-$PROJECT_NUMBER.us-central1.run.app \
-H 'Content-Type: application/json' \
-d '{"search":"I want some kids clothes themed on Disney"}' \
| jq .
Y el resultado sería el siguiente:

Ahora que ejecutamos la búsqueda de vectores de similitud con el modelo de embeddings en los datos de AlloyDB, podemos avanzar hacia la creación de la aplicación que usa estos embeddings junto con tu imagen y mensajes para generar sugerencias de diseño.
12. Información sobre el flujo de recomendaciones de atuendos
La app de recomendación de atuendos es una aplicación de arranque de sprint configurada para funcionar con las incorporaciones que creamos en la aplicación del motor de venta minorista de AlloyDB, junto con Gemini y Imagen, para generar opciones de diseño visual de atuendos. También te permite agregar instrucciones personalizadas y mejorar la recomendación.
Piensa en esto de la siguiente manera: subes una imagen de una blusa rosa brillante de tu armario a esta app. Cuando haces clic en Mostrar, según la instrucción establecida en el código de la aplicación y los embeddings en la base de datos de AlloyDB, la aplicación genera varias opciones que coinciden con la imagen original. Ahora te preguntas cómo se verían las opciones sugeridas con un collar azul, por lo que agregas una instrucción en ese sentido y haces clic en Estilo. Se genera la imagen final que combina la potente combinación de la imagen original y las recomendaciones para crear un atuendo a juego.
Para comenzar a crear la app de recomendaciones de atuendos, sigue estos pasos:
- En Cloud Run, abre la app retail-engine y anota la URL de tu aplicación. Este es el repositorio de incorporaciones que usaremos para generar sugerencias similares.
- En tu IDE, clona el repositorio https://github.com/AbiramiSukumaran/outfit-recommender/. En este ejercicio, los pasos que se muestran se realizan en el IDE de Visual Studio Code.
git clone https://github.com/AbiramiSukumaran/outfit-recommender/
A continuación, se muestran algunos de los archivos importantes en el directorio de la app:
src/main: Directorio de origen en el que residen los archivos de la aplicación y el código HTML:HelloWorldApplication.java: Es el punto de entrada principal para la aplicación de Spring Boot.HelloWorldController.java: Es el controlador REST de Spring Boot que controla las solicitudes HTTP relacionadas con una aplicación de recomendación de atuendos. Este archivo controla las solicitudes GET y POST, procesa las instrucciones del usuario, analiza imágenes, interactúa con las incorporaciones de AlloyDB y devuelve la respuesta final a la IU. Este controlador llama a la clase GenerateImageSample.GenerateImageSample.java: Contiene la clase de generación de imágenes que se conecta a Vertex AI, da formato a la instrucción del usuario, realiza llamadas a la API del modelo de Imagen y devuelve la imagen predicha a la clase del controlador.Resources: Este directorio contiene imágenes y archivos HTML necesarios para generar la IU de la aplicación.Pom.xml: Define las dependencias y configuraciones del proyecto.
- En Visual Studio Code, abre
HelloWorldController.javay actualiza las instancias del ID y la ubicación del proyecto según dónde se creó tu instancia de AlloyDB.
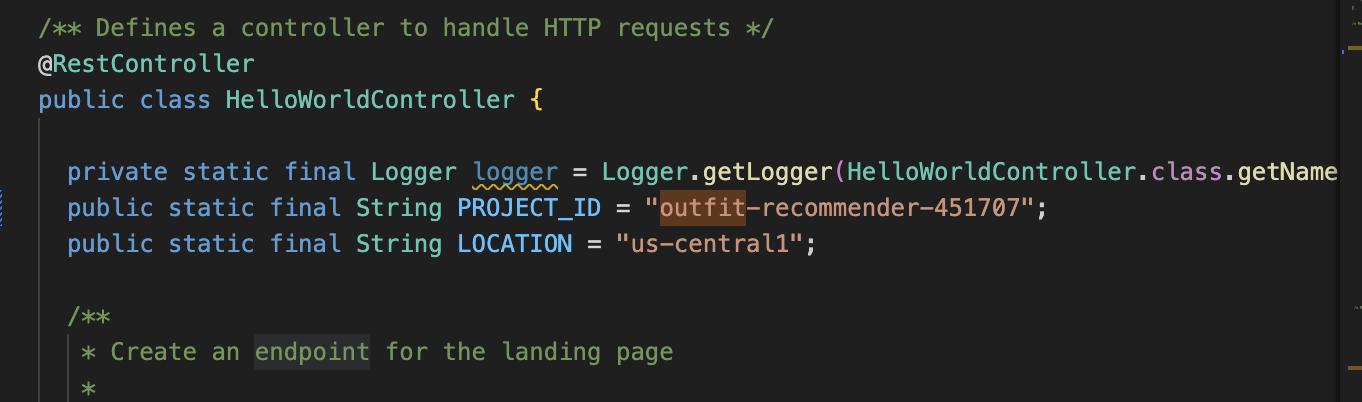
- Actualiza
endpointa la URL de la app de retail-engine que alojaste anteriormente.

- Abre
GenerateImageSample.javay actualiza el ID del proyecto y la ubicación según dónde se creó tu instancia de AlloyDB.

- Guarda todos los archivos.
Ahora implementaremos esta aplicación en el entorno de ejecución sin servidores de Cloud Run.
13. Lleva la aplicación a la Web
Ahora que agregamos el proyecto, la ubicación y los detalles de la app de retail-engine pertinentes a la aplicación de Spring Boot del recomendador de atuendos, podemos implementar la aplicación en Cloud Run.
Usaremos el comando gcloud run deploy en la terminal de Visual Studio Code para implementar la aplicación. En el caso de Visual Studio Code, puedes instalar la extensión de Google Cloud Code para comenzar a usar gcloud CLI.
Para implementar la aplicación, sigue estos pasos:
- En tu IDE, abre el directorio clonado y, luego, inicia la terminal. En Visual Studio Code, haz clic en Terminal > New Terminal.
- Sigue las instrucciones de este documento para instalar la CLI de gcloud.
- Si usas Visual Studio Code, haz clic en Extensiones, busca Google Cloud Code y, luego, instala la extensión.
- En la terminal de tu IDE, autentica tu Cuenta de Google ejecutando el siguiente comando:
gcloud auth application-default login
- Configura tu ID del proyecto en el mismo proyecto en el que se encuentra tu instancia de AlloyDB.
gcloud config set project PROJECT_ID
- Inicia el proceso de implementación.
gcloud run deploy
- En
Source code location, presiona Intro para seleccionar el directorio de GitHub clonado. - En
Service name, ingresa un nombre para el servicio, como outfit-recommender, y presiona Intro. - En
Please specify a region, ingresa la ubicación en la que se alojan tu instancia de AlloyDB y la aplicación de retail-engine, como 32 para us-central1, y presiona Intro.

- En
Allow unauthenticated invocations to [..], ingresa Y y presiona Intro.
En la siguiente imagen, se muestra el progreso de la implementación de tu aplicación:

14. Prueba la aplicación de recomendación de atuendos
Después de que la aplicación se implemente correctamente en Cloud Run, podrás ver el servicio en la consola de Google Cloud de la siguiente manera:
- En la consola de Google Cloud, ve a Cloud Run.
- En Services, haz clic en el servicio outfit recommender que implementaste. Deberías ver los servicios retail-engine y outfit-recommender de la siguiente manera:

- Haz clic en la URL de la aplicación para abrir la IU de la app de recomendaciones.

The following is a sample URL that you will use:
https://outfit-recommender-22905290964.us-central1.run.app/style
La aplicación implementada se puede ver de la siguiente manera:

Cómo usar la aplicación
Para comenzar a usar la aplicación, sigue estos pasos:
- Haz clic en Subir y sube una foto de una prenda.
- Después de subir la imagen, haz clic en Estilo. La aplicación usa la imagen como instrucción y genera opciones inferiores basadas en la instrucción de la app de Retail Engine que incluye embeddings para el conjunto de datos de venta minorista.
La app genera sugerencias de imágenes junto con una instrucción basada en la imagen con recomendaciones de diseño. Por ejemplo, A white semi-sheer button up blouse with pink floral patterns on it, with balloon sleeves.
- Puedes pasar instrucciones adicionales a esta recomendación de estilo generada automáticamente. Por ejemplo,
STYLE RECOMMENDATION: Cute brown skirt on a curly updo. Make it photo realistic. Accessorize with cherry earrings and burgundy plastic case sling bag. - Haz clic en Mostrar para ver el diseño final.

15. Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en esta publicación:
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.
16. Felicitaciones
¡Felicitaciones! Realizaste correctamente una búsqueda por similitud con AlloyDB, pgvector y la búsqueda de vectores, además de usar el resultado de la búsqueda con el potente modelo de Imagen para generar recomendaciones de diseño.