
1. סקירה כללית
תארו לעצמכם אפליקציית אופנה שעוזרת לכם למצוא את הלבוש המושלם, וגם מספקת לכם עצות סטיילינג בזמן אמת – והכול בזכות השילוב של AI גנרטיבי מתקדם! בהרצאה הזו נסביר איך בנינו אפליקציה כזו באמצעות יכולות החיפוש הווקטורי של AlloyDB, בשילוב עם אינדקס ScaNN של Google, כדי לאפשר חיפושים מהירים במיוחד של פריטי לבוש תואמים ולספק המלצות אופנה מיידיות.
בנוסף, נסביר איך אינדקס ScaNN של AlloyDB מבצע אופטימיזציה של שאילתות מורכבות כדי ליצור הצעות לסגנונות בהתאמה אישית. נשתמש גם ב-Gemini וב-Imagen, מודלים חזקים של AI גנרטיבי, כדי לספק לכם השראה לעיצובים יצירתיים ואפילו להמחיש את המראה המותאם אישית שלכם. האפליקציה כולה מבוססת על ארכיטקטורה ללא שרתים, כדי להבטיח חוויה חלקה וניתנת להרחבה למשתמשים.
האתגר: האפליקציה מציעה הצעות מותאמות אישית לבגדים, במטרה לעזור לאנשים שמתקשים להחליט מה ללבוש. זה גם עוזר להימנע מעייפות בקבלת החלטות שנובעת מתכנון הלבוש.
הפתרון: אפליקציית ההמלצות לבגדים פותרת את הבעיה של מתן חוויית אופנה חכמה, מותאמת אישית ומושכת למשתמשים, תוך הצגת היכולות של AlloyDB, AI גנרטיבי וטכנולוגיות ללא שרת.
מה תפַתחו
במסגרת ה-Lab הזה:
- יצירה של מכונת AlloyDB וטעינה של מערך נתונים של מסחר אלקטרוני
- הפעלת התוספים pgvector ומודל AI גנרטיבי ב-AlloyDB
- יצירת הטמעות מתיאור המוצר
- פריסת הפתרון בפונקציות של Cloud Run ללא שרת
- מעלים תמונה ל-Gemini ומקבלים הנחיה לתיאור התמונה.
- יצירת תוצאות חיפוש על סמך הנחיות בשילוב עם הטמעות של מערך נתונים של מסחר אלקטרוני.
- אפשר להוסיף עוד הנחיות כדי להתאים אישית את ההנחיה וליצור המלצות לסגנון.
- פריסת הפתרון בפונקציות של Cloud Run ללא שרת
דרישות
2. ארכיטקטורה
זו הארכיטקטורה הכללית של האפליקציה:
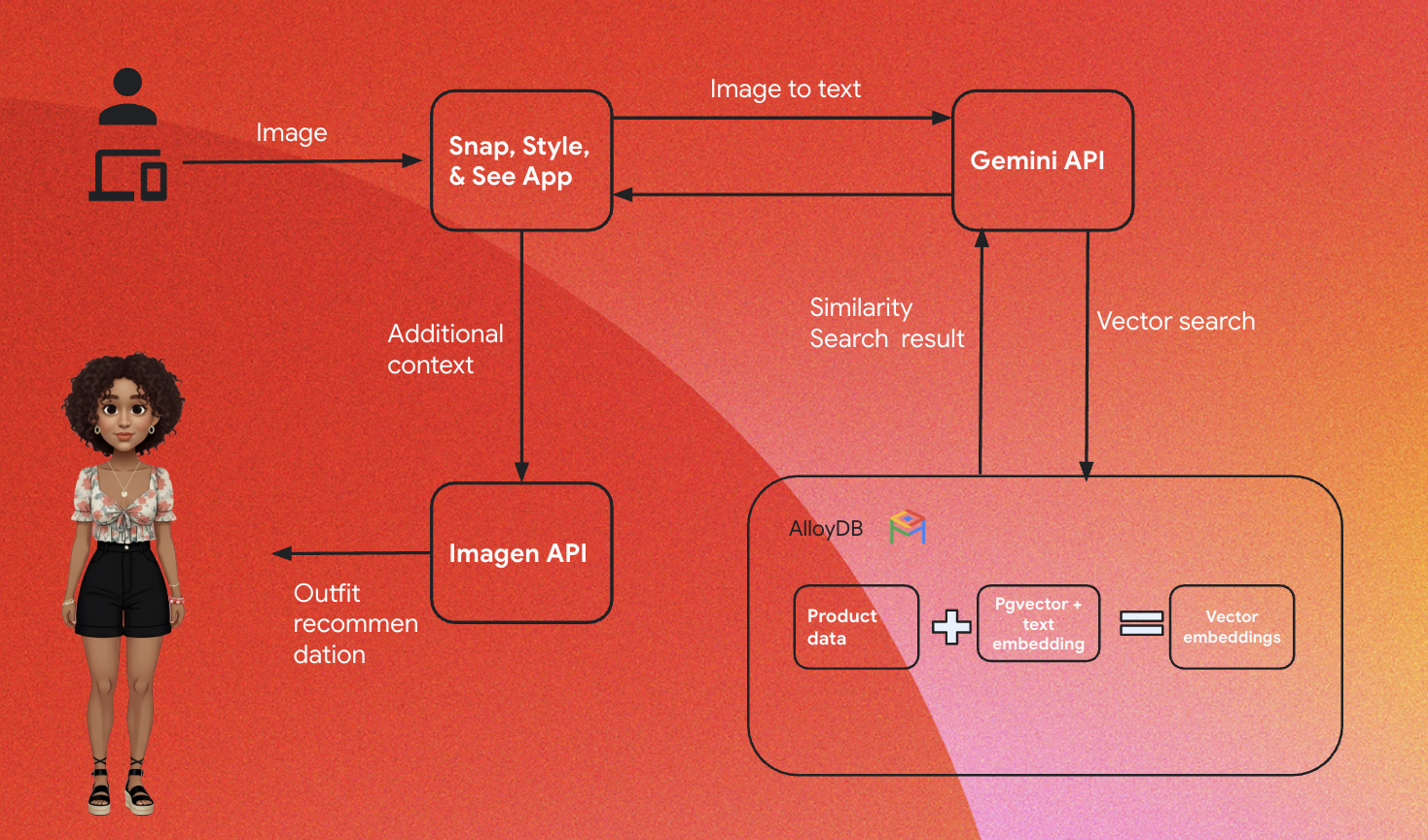
הקטעים הבאים מדגישים את רצף הפעולות ההקשרי של המדריך:
הטמעה:
השלב הראשון הוא להטמיע את הנתונים הקמעונאיים (מלאי, תיאורי מוצרים, אינטראקציות עם לקוחות) ב-AlloyDB.
מנוע Analytics:
נשתמש ב-AlloyDB כמנוע לניתוח נתונים כדי לבצע את הפעולות הבאות:
- חילוץ הקשר: המנוע מנתח את הנתונים שמאוחסנים ב-AlloyDB כדי להבין את הקשרים בין מוצרים, קטגוריות, התנהגות לקוחות וכו', לפי הצורך.
- יצירת הטמעה: נוצרות הטמעות (ייצוגים מתמטיים של טקסט) גם לשאילתה של המשתמש וגם למידע שמאוחסן ב-AlloyDB.
- חיפוש וקטורי: המנוע מבצע חיפוש דמיון, ומשווה בין הטמעת השאילתה לבין ההטמעות של תיאורי מוצרים, ביקורות ונתונים רלוונטיים אחרים. הפונקציה הזו מזהה את 25 השכנים הקרובים הרלוונטיים ביותר.
המלצה מ-Gemini:
מערך הבייטים של התמונה מועבר למודל Gemini דרך Vertex AI API, יחד עם ההנחיה לבקשת תיאור טקסטואלי של החלק העליון של הבגד, וגם הצעות לגבי החלק התחתון של הבגד.
AlloyDB RAG וחיפוש וקטורים:
התיאור של פריט הלבוש העליון משמש לשליחת שאילתה למסד הנתונים. השאילתה ממירה את טקסט החיפוש (המלצה ממודל Gemini להתאמת פריטי לבוש תחתון) להטמעות, ומבצעת חיפוש וקטורי בהטמעות שמאוחסנות במסד הנתונים כדי למצוא את השכנים הקרובים ביותר (תוצאות תואמות). הטמעות הווקטורים במסד הנתונים של AlloyDB עוברות אינדוקס באמצעות אינדקס ScaNN כדי לשפר את הריקול.
יצירת תמונות בתשובה:
התשובות שעברו אימות מובנות כמערך JSON, והמנוע כולו ארוז כפונקציית Cloud Run ללא שרת, שמופעלת מ-Agent Builder.
יצירת תמונות באמצעות Imagen:
ההנחיה של המשתמש לגבי הסגנון, ההמלצה שהמשתמש בחר וכל בקשה להתאמה אישית משולבים כדי ליצור הנחיה ל-Imagen 3 עם תמונה קיימת. תמונת הסגנון נוצרת על סמך ההנחיה הזו באמצעות Vertex AI API.
3. לפני שמתחילים
יצירת פרויקט
- ב-מסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
- תשתמשו ב-Cloud Shell, סביבת שורת פקודה שפועלת ב-Google Cloud ומגיעה עם bq שנטען מראש. לוחצים על Activate Cloud Shell (
 ) בחלק העליון של מסוף Google Cloud.
) בחלק העליון של מסוף Google Cloud. - אחרי שמתחברים ל-Cloud Shell, מוודאים שכבר עברתם אימות ושהפרויקט מוגדר למזהה הפרויקט שלכם באמצעות הפקודה הבאה:
gcloud auth list
- מריצים את הפקודה הבאה כדי לוודא שפקודות gcloud עתידיות יזהו את הפרויקט שלכם בצורה נכונה.
gcloud config list project
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו באופן מפורש:
gcloud config set project <YOUR_PROJECT_ID>
- מפעילים את ממשקי ה-API הנדרשים.
כדי להפעיל ממשקי API, לוחצים על הקישור.
אם שכחתם להפעיל ממשק API כלשהו, תמיד תוכלו להפעיל אותו במהלך ההטמעה.
מידע נוסף על פקודות gcloud ושימוש בהן מופיע במאמרי העזרה.
4. הגדרת מסד נתונים
בשיעור ה-Lab הזה נשתמש ב-AlloyDB כמסד הנתונים לאחסון מערך הנתונים של מסחר אלקטרוני קמעונאי. הוא משתמש באשכולות כדי לאחסן את כל המשאבים, כמו מסדי נתונים ויומנים. לכל אשכול יש מופע ראשי שמספק נקודת גישה לנתונים. טבלאות הן המשאב בפועל שבו מאוחסנים הנתונים.
ניצור אשכול, מופע וטבלה של AlloyDB שבהם ייטען מערך הנתונים של המסחר האלקטרוני.
יצירת אשכול ומופע
- במסוף Google Cloud, מחפשים את AlloyDB. דרך קלה למצוא את רוב הדפים ב-Cloud Console היא לחפש אותם באמצעות סרגל החיפוש של המסוף.
- לוחצים על CREATE CLUSTER (יצירת אשכול).

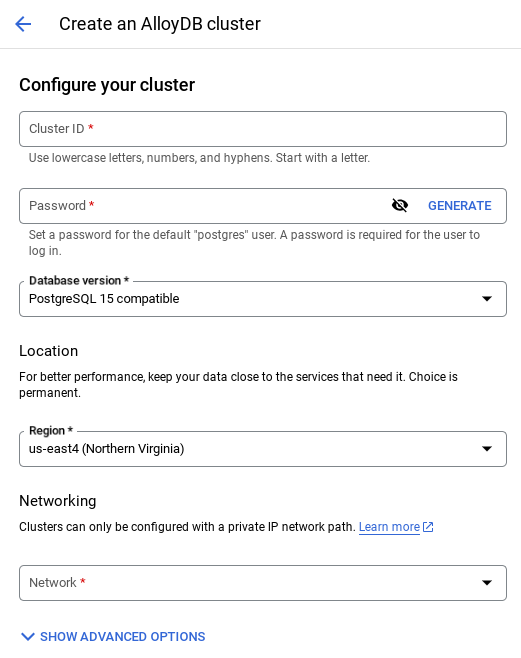
- יוצרים אשכול ומכונה עם הערכים הבאים:
- מזהה האשכול: '
shopping-cluster' - password: "
alloydb" - תואם ל-PostgreSQL 15
- אזור: '
us-central1' - רשת: "
default"
- ברשת, כשבוחרים את רשת ברירת המחדל, מופיעה האפשרות הבאה. לוחצים על הגדרת חיבור כדי להגדיר רשת כברירת מחדל.
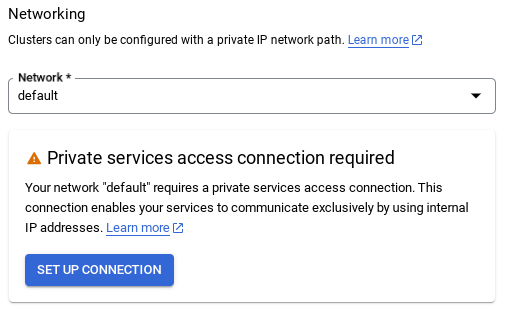
- בוחרים באפשרות שימוש בטווח כתובות IP שהוקצה באופן אוטומטי ולוחצים על המשך. אחרי שבודקים את המידע, לוחצים על יצירת קישור.
ממתינים עד שברירת המחדל ליצירת רשתות תושלם.
- בקטע Configure your primary instance (הגדרת המופע הראשי), מגדירים את Instance ID (מזהה המופע) כ-
shopping-instance".
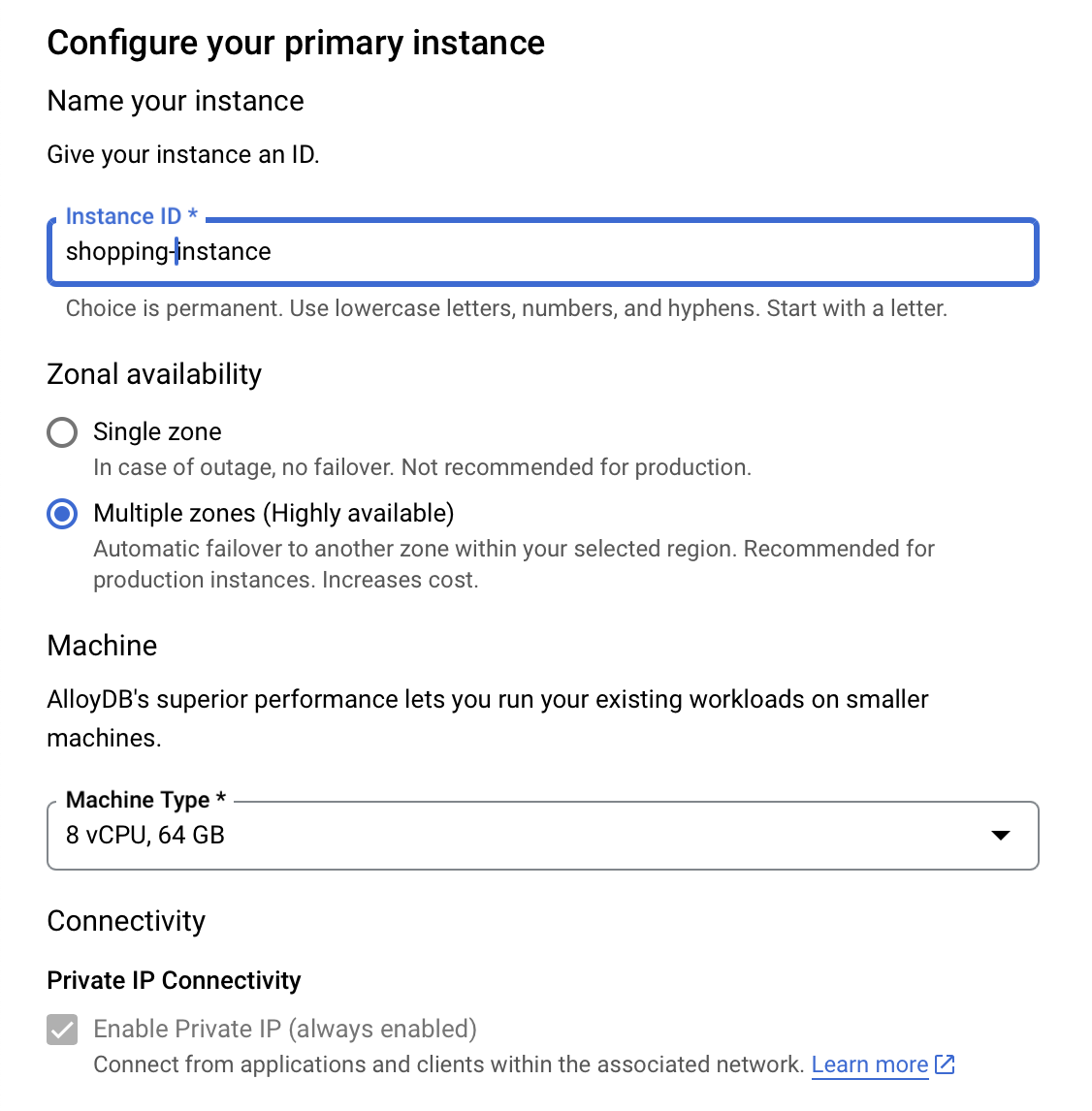
- לוחצים על יצירת אשכול כדי להשלים את הגדרת האשכול באופן הבא:
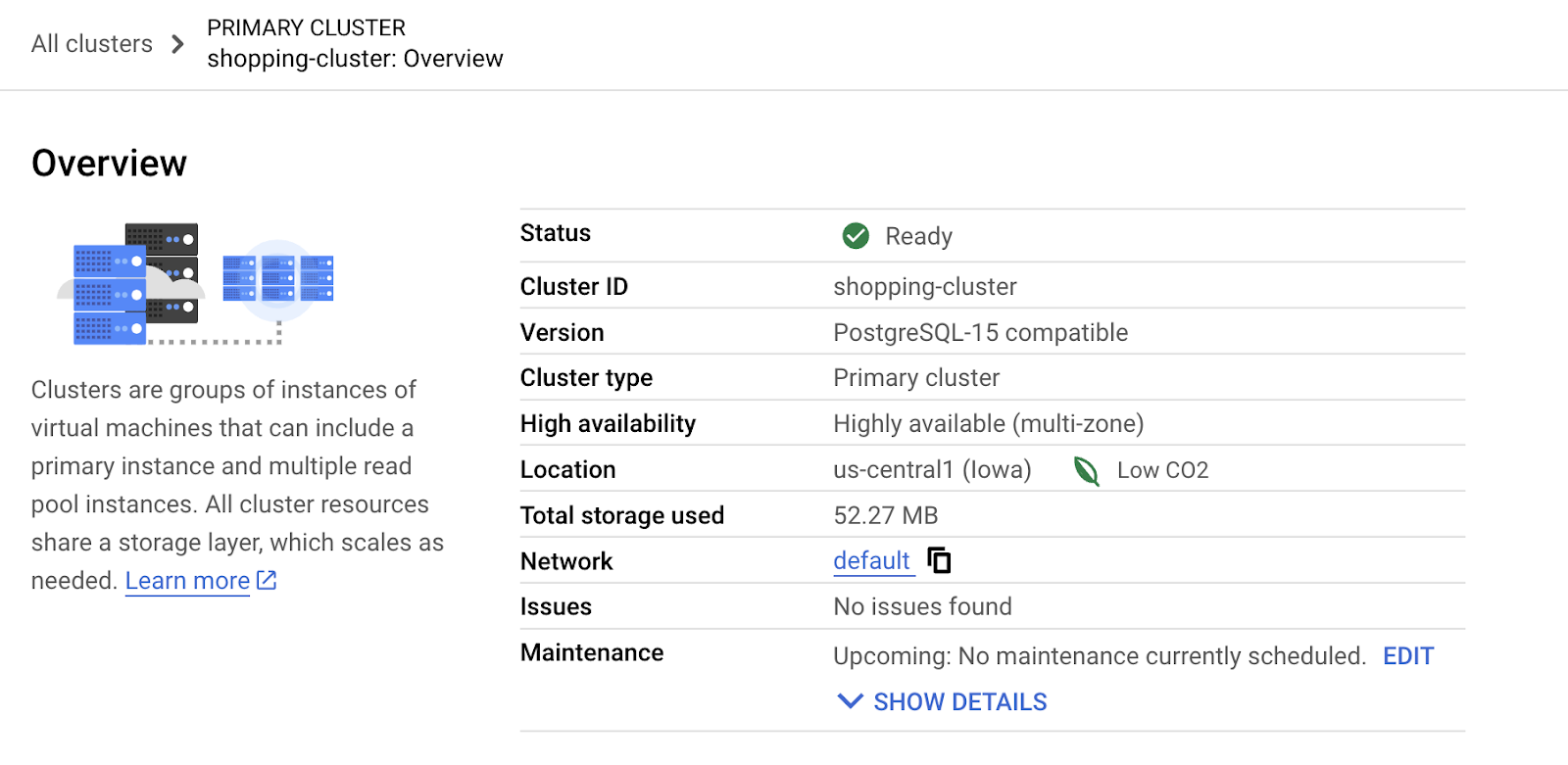
5. הטמעת נתונים
עכשיו צריך להוסיף טבלה עם הנתונים על החנות. מחכים עד שהמופע ייווצר. אחרי שיוצרים את האשכול, אפשר להיכנס ל-AlloyDB באמצעות פרטי הכניסה שהגדרתם כשיצרתם את האשכול.
אימות במסד נתונים של AlloyDB
- במסוף Google Cloud, עוברים אל AlloyDB. בוחרים את האשכול הראשי ולוחצים על AlloyDB Studio בתפריט הניווט הימני:
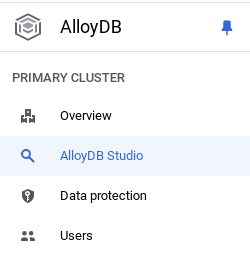
- כדי לבצע אימות למסד נתונים של AlloyDB, צריך להזין את הפרטים הבאים:
- שם משתמש : "
postgres" - מסד נתונים : "
postgres" - סיסמה : "
alloydb"
אחרי שתהליך האימות ב-AlloyDB Studio יסתיים בהצלחה, תוכלו להזין פקודות SQL בכרטיסיות העורך. אפשר להוסיף כמה חלונות של Editor באמצעות סימן הפלוס שמשמאל לכרטיסייה הראשונה של Editor.
מזינים פקודות ל-AlloyDB בחלונות של הכלי לעריכה, ומשתמשים באפשרויות 'הפעלה', 'עיצוב' ו'ניקוי' לפי הצורך.
הפעלת תוספים
כדי לבנות את האפליקציה הזו, נשתמש בתוספים pgvector" ו-google_ml_integration".
- התוסף pgvector מאפשר לכם לאחסן ולחפש הטמעות וקטוריות.
- התוסף google_ml_integration מספק פונקציות שמשמשות לגישה לנקודות קצה של חיזוי ב-Vertex AI כדי לקבל חיזויים ב-SQL.
- מפעילים את התוספים האלה על ידי הפעלת פקודות ה-DDL הבאות:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
- כדי לוודא שהתוספים מותקנים, מריצים את פקודת ה-SQL הבאה:
select extname, extversion from pg_extension;
צור טבלה
- יוצרים טבלה באמצעות הצהרת ה-DDL הבאה:
CREATE TABLE
apparels ( id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
embedding vector(768) );
אם הפעלת הפקודה שלמעלה תצליח, תוכלו לראות את הטבלה ב
במסד נתונים. בתמונה הבאה אפשר לראות דוגמה:
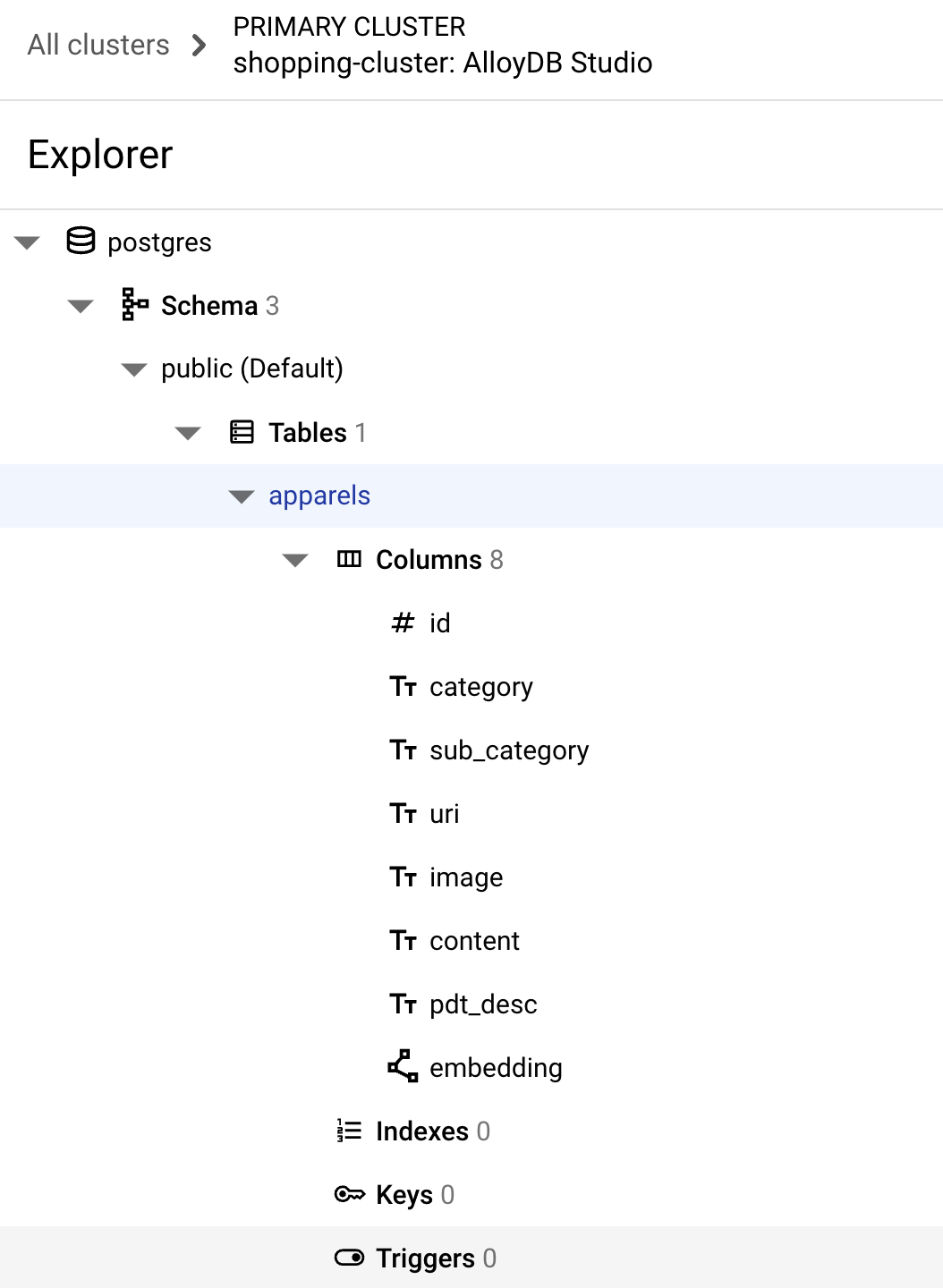
הטמעת נתונים
בשיעור ה-Lab הזה נשתמש בנתוני בדיקה של כ-200 רשומות בקובץ ה-SQL הזה. הוא מכיל את id, category, sub_category, uri, image ואת content. שאר השדות ימולאו בהמשך במעבדה.
- מעתיקים את 20 השורות או את הצהרות ההוספה מקובץ ה-SQL בכרטיסייה חדשה של העורך ב-AlloyDB Studio, ולוחצים על RUN (הפעלה).
- מרחיבים את הקטע 'Explorer' עד שרואים את הטבלה שנקראת
apparels. - לוחצים על סמל התפריט [⋮] ואז על שאילתה. הוראת SELECT תיפתח בכרטיסייה חדשה של Editor.
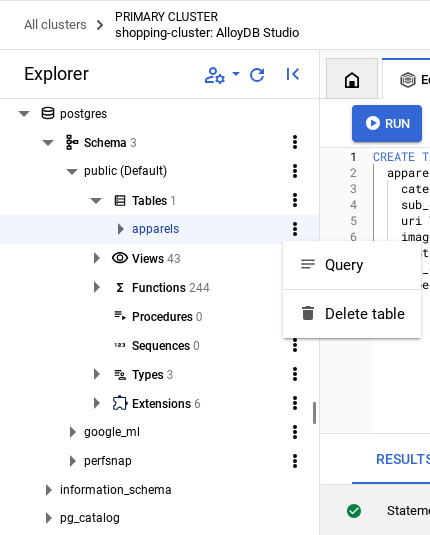
- לוחצים על Run כדי לוודא שהשורות הוכנסו.
הענקת הרשאה למשתמש
נעניק למשתמש postgres הרשאה ליצור הטמעות מתוך AlloyDB. ב-AlloyDB Studio, מריצים את ההצהרה הבאה כדי להעניק למשתמש postgres הרשאות הפעלה בפונקציה embedding:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
נותנים לחשבון השירות של AlloyDB את התפקיד Vertex AI User
נשתמש במודלים להטמעת טקסט מ-Vertex AI כדי ליצור הטמעות של תפקיד המשתמש ב-Vertex AI בחשבון השירות של AlloyDB.
ב-מסוף Google Cloud, לוחצים על הסמל של Cloud Shell terminal [ ] ומריצים את הפקודה הבאה:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
6. בניית הקשר
כדי ליצור הטמעה, אנחנו צריכים context, כלומר את כל המידע שאנחנו רוצים לכלול בשדה אחד. לשם כך, ניצור תיאור מוצר ונאחסן אותו בעמודה pdt_desc בטבלה apparels.
במקרה שלנו, נשתמש בכל המידע על כל מוצר, אבל כשאתם עושים את זה עם הנתונים שלכם, אתם יכולים לעצב את הנתונים בכל דרך שנראית לכם משמעותית לעסק שלכם.
בכרטיסייה AlloyDB Studio Editor, מריצים את הפקודה הבאה שמעדכנת את השדה pdt_desc בנתוני הקשר:
UPDATE
apparels
SET
pdt_desc = CONCAT('This product category is: ', category, ' and sub_category is: ', sub_category, '. The description of the product is as follows: ', content, '. The product image is stored at: ', uri)
WHERE
id IS NOT NULL;
ה-DML הזה יוצר סיכום פשוט של ההקשר באמצעות המידע מכל השדות שזמינים בטבלה ומהתלויות האחרות (אם יש כאלה בתרחיש לדוגמה). כדי ליצור מידע והקשר מדויקים יותר, אתם יכולים לערוך את הנתונים בכל דרך שנראית לכם משמעותית לעסק.
7. יצירת הטמעות להקשר
למחשבים קל יותר לעבד מספרים מאשר לעבד טקסט. מערכת הטמעה ממירה טקסט לסדרה של מספרים עם נקודה צפה (floating-point), שאמורים לייצג את הטקסט, לא משנה איך הוא מנוסח, באיזו שפה הוא כתוב וכו'.
אפשר לתאר מיקום ליד הים. יכול להיות שהם ייקראו "on the water, beachfront, walk from your room to the ocean, sur la mer, на берегу океана וכו'. המונחים האלה נראים שונים, אבל המשמעות הסמנטית שלהם, או במינוח של למידת מכונה, ההטבעות שלהם, צריכה להיות דומה מאוד.
עכשיו, כשהנתונים וההקשר מוכנים, נריץ את ה-SQL כדי להוסיף את ההטמעות של עמודת תיאור המוצר ((pdt_desc) לטבלה בשדה embedding. יש מגוון של מודלים להטמעה שאפשר להשתמש בהם. אנחנו משתמשים ב-text-embedding-005 מ-Vertex AI.
- ב-AlloyDB Studio, מריצים את הפקודה הבאה כדי ליצור הטמעות ולעדכן את העמודה
pdt_descעם הטמעות של הנתונים שמאוחסנים בה:
UPDATE
apparels
SET
embedding = embedding( 'text-embedding-005',
pdt_desc)
WHERE
TRUE;
- מריצים את הפקודה הבאה כדי לוודא שההטמעות נוצרות:
SELECT
id,
category,
sub_category,
content,
embedding
FROM
Apparels
LIMIT 5;
זו דוגמה לווקטור הטמעה, שנראה כמו מערך של מספרים ממשיים, עבור טקסט לדוגמה בשאילתה:
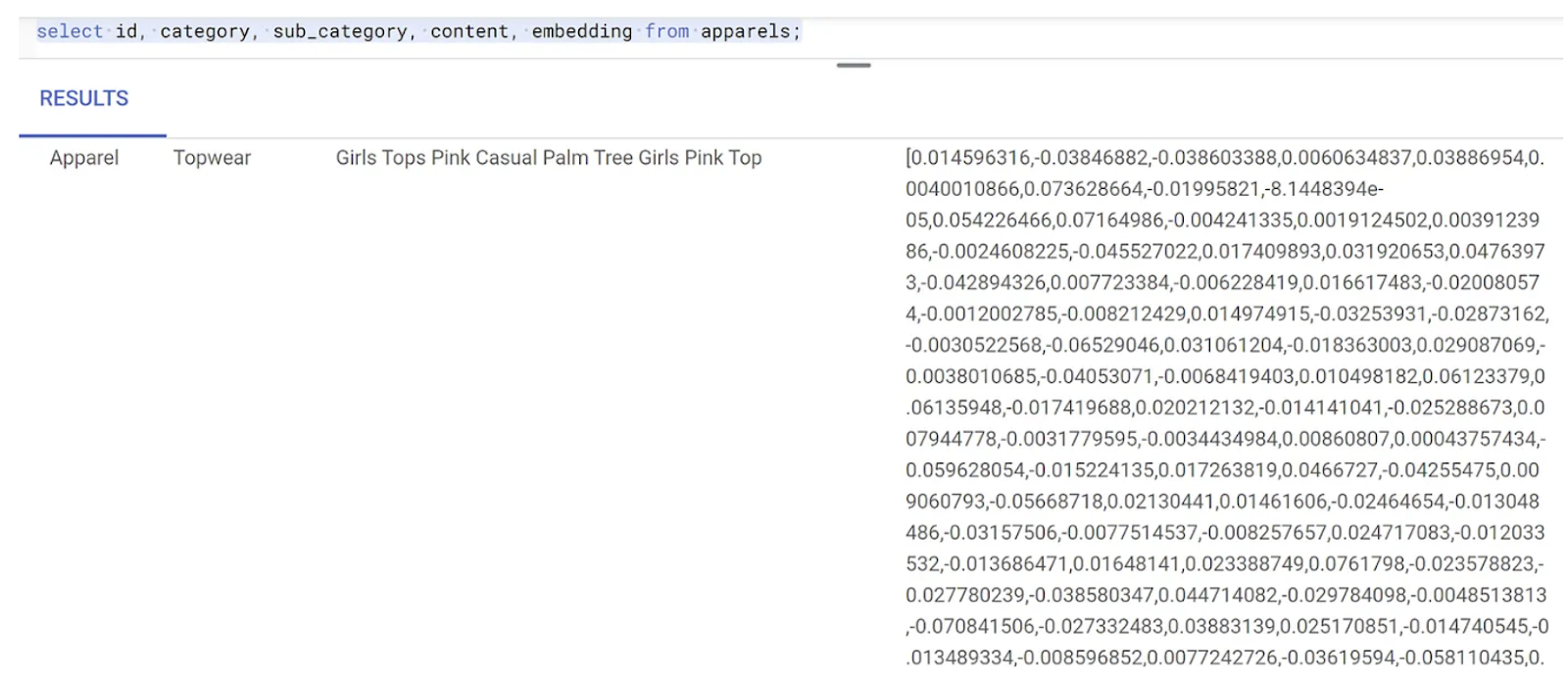
8. ביצוע חיפוש וקטור
עכשיו, אחרי שהטבלה, הנתונים וההטמעות מוכנים, אפשר לבצע חיפוש וקטורי בזמן אמת של טקסט החיפוש של המשתמש.
נניח שהטקסט שהמשתמש חיפש הוא pink color, casual, pure cotton tops for women
כדי למצוא התאמות לשאילתה הזו, מריצים את שאילתת ה-SQL הבאה:
SELECT
id,
category,
sub_category,
content,
pdt_desc AS description
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-005',
'pink color, casual, pure cotton tops for women')::vector
LIMIT
5;
בואו נבחן את השאילתה הזו בפירוט:
בשאילתה הזו,
- טקסט החיפוש של המשתמש הוא: "
I want womens tops, pink casual only pure cotton." - אנחנו ממירים את טקסט החיפוש הזה להטמעות באמצעות השיטה
embedding()יחד עם המודל:text-embedding-005. השלב הזה אמור להיראות מוכר אחרי השלב הקודם, שבו הפעלנו את פונקציית ההטמעה על כל הפריטים בטבלה. -
<=>מייצג את השימוש בשיטת המרחק COSINE SIMILARITY. אפשר למצוא את כל מדדי הדמיון שזמינים בתיעוד של pgvector. - אנחנו ממירים את התוצאה של שיטת ההטמעה לסוג הנתונים vector כדי שתהיה תאימות לווקטורים שמאוחסנים במסד הנתונים.
- LIMIT 5 מייצג את העובדה שאנחנו רוצים לחלץ 5 שכנים קרובים ביותר לטקסט החיפוש.
התגובה הבאה מציגה דוגמה לשאילתת ה-SQL הזו:
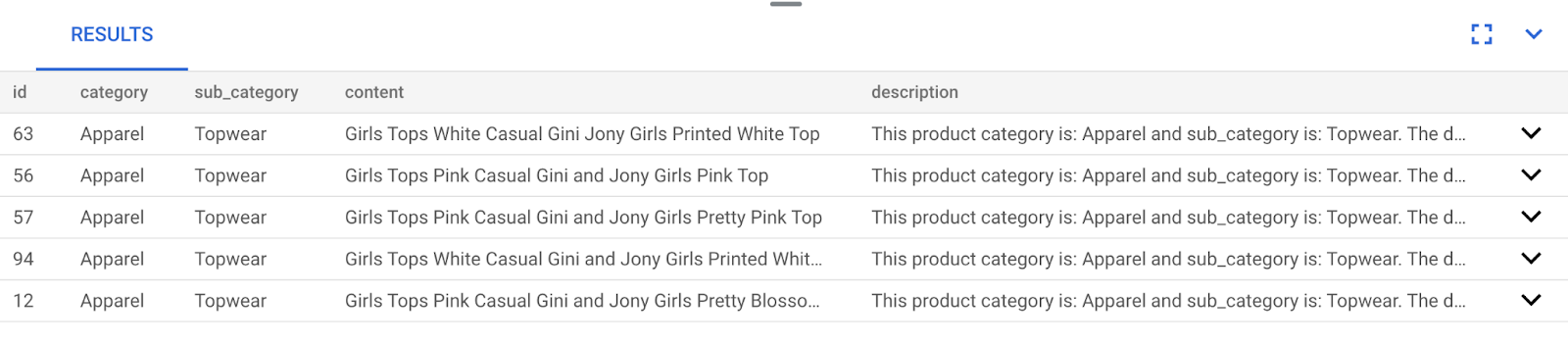
כפי שאפשר לראות בתוצאות, ההתאמות קרובות מאוד לטקסט החיפוש. כדאי לנסות לשנות את הצבע כדי לראות איך התוצאות משתנות.
אינדקס AlloyDB ScaNN לביצועי שאילתות
נניח שאנחנו רוצים לשפר את הביצועים (זמן השאילתה), היעילות וההחזרה של תוצאת החיפוש הווקטורי הזו באמצעות אינדקס ScaNN.
אם רוצים להשתמש באינדקס ScaNN, אפשר לנסות את השלבים הבאים:
- מכיוון שכבר יצרנו את האשכול, המופע, ההקשר וההטמעות, אנחנו צריכים רק להתקין את התוסף ScaNN באמצעות ההצהרה הבאה:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- יוצרים את אינדקס ScaNN:
CREATE INDEX apparel_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=54);
בדוגמת ה-DDL שלמעלה:
-
apparel_indexהוא שם האינדקס. -
apparelsהוא שם הטבלה. -
scannהיא שיטת האינדקס. -
embeddingהיא העמודה בטבלה שרוצים ליצור לה אינדקס. -
cosineהיא שיטת המרחק שרוצים להשתמש בה עם האינדקס. -
54הוא מספר המחיצות שיוחלו על האינדקס הזה. הערך יכול להיות בין 1 ל-1,048,576. מידע נוסף על קביעת הערך הזה זמין במאמר בנושא התאמה של אינדקס ScaNN.
בהתאם להמלצה במאגר ScaNN, השתמשנו בשורש ריבועי של מספר נקודות הנתונים. כשמבצעים חלוקה למחיצות, num_leaves צריך להיות בערך השורש הריבועי של מספר נקודות הנתונים.
- בודקים אם האינדקס נוצר באמצעות השאילתה:
SELECT * FROM pg_stat_ann_indexes;
- מבצעים חיפוש וקטורי באמצעות אותה שאילתה שבה השתמשנו בלי האינדקס:
select * from apparels
ORDER BY embedding <=> CAST(embedding('textembedding-gecko', 'white tops for girls without any print') as vector(768))
LIMIT 20
השאילתה שלמעלה היא אותה שאילתה שבה השתמשנו במעבדה בשלב 8. עם זאת, עכשיו השדה נוסף לאינדקס באמצעות אינדקס ScaNN.
- בודקים באמצעות שאילתת חיפוש פשוטה עם האינדקס ובלי האינדקס. כדי לבצע בדיקה בלי אינדקס, צריך להסיר את האינדקס:
white tops for girls without any print
הטקסט של החיפוש שלמעלה בשאילתת החיפוש הווקטורי בנתוני ההטבעות שעברו אינדוקס מוביל לתוצאות חיפוש איכותיות ויעילות. היעילות משתפרת באופן משמעותי (במונחים של זמן ביצוע: 10.37 אלפיות השנייה ללא ScaNN ו-0.87 אלפיות השנייה עם ScaNN) עם האינדקס. מידע נוסף על הנושא הזה זמין בבלוג.
9. אימות ההתאמה באמצעות מודל שפה גדול (LLM)
לפני שנמשיך וניצור שירות להחזרת ההתאמות הטובות ביותר לאפליקציה, נשתמש במודל AI גנרטיבי כדי לוודא שהתשובות הפוטנציאליות האלה רלוונטיות באמת ובטוחות לשיתוף עם המשתמש.
איך מוודאים שהמופע מוגדר ל-Gemini
- מוודאים ש-
google_ml_integrationכבר מופעלים באשכול ובמופע. ב-AlloyDB Studio, מריצים את הפקודה הבאה:
show google_ml_integration.enable_model_support;
אם הערך שמוצג הוא on, אפשר לדלג על שני השלבים הבאים ולעבור ישירות להגדרה
השילוב של מודלים של AlloyDB ו-Vertex AI.
- עוברים למופע הראשי של אשכול AlloyDB ולוחצים על EDIT PRIMARY INSTANCE (עריכת המופע הראשי).
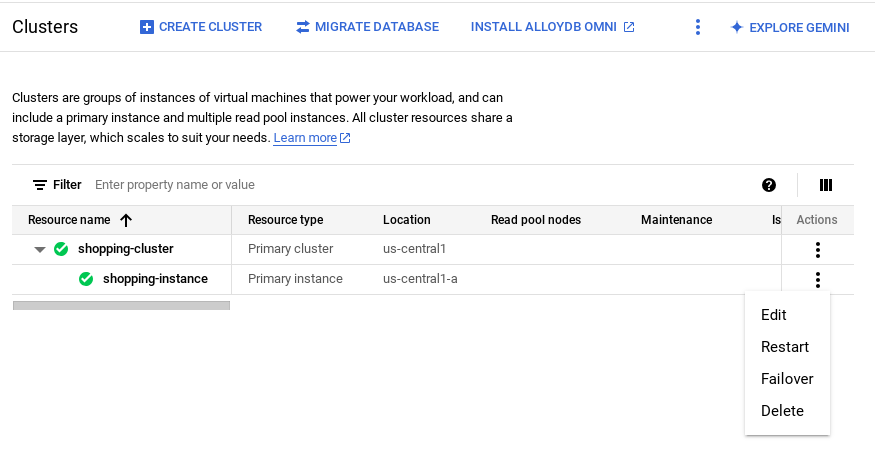
- בקטע Advanced configuration options (אפשרויות הגדרה מתקדמות), מרחיבים את הקטע New database flag (דגל חדש של מסד נתונים) ומוודאים שהערך של
google_ml_integration.enable_model_support flagמוגדר ל-onבאופן הבא:
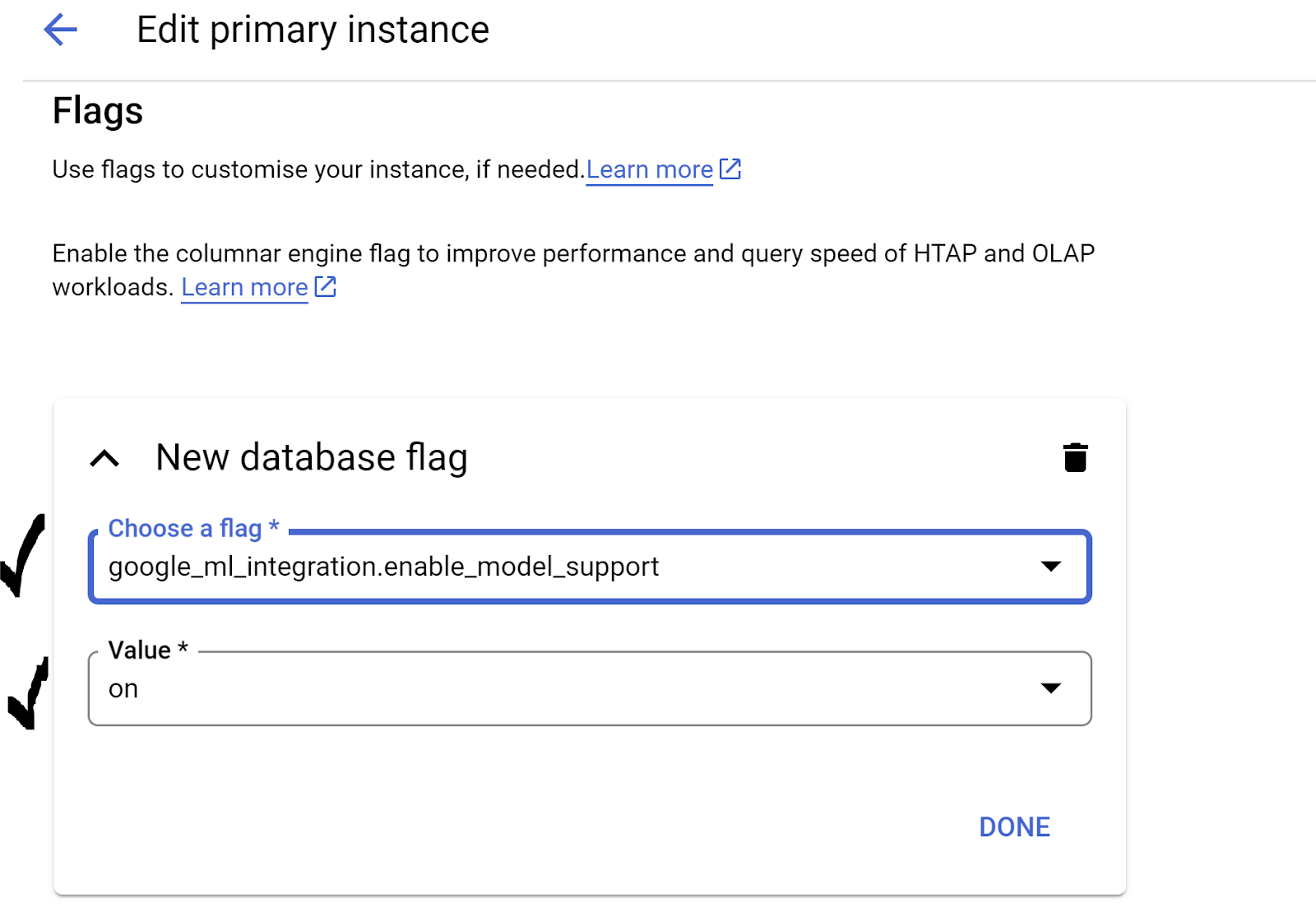 3. אם הערך לא מוגדר כ-
3. אם הערך לא מוגדר כ-on, מגדירים אותו כ-on ואז לוחצים על UPDATE INSTANCE (עדכון המופע).
השלב הזה יימשך כמה דקות.
שילוב של מודלים של AlloyDB ו-Vertex AI
עכשיו אפשר להתחבר ל-AlloyDB Studio ולהריץ את פקודת ה-DML הבאה כדי להגדיר גישה למודל Gemini מ-AlloyDB, באמצעות מזהה הפרויקט במקום שצוין. יכול להיות שתופיע אזהרה על שגיאת תחביר לפני הרצת הפקודה, אבל היא אמורה לפעול בצורה תקינה.
- במסוף Google Cloud, עוברים אל AlloyDB. בוחרים את האשכול הראשי ולוחצים על AlloyDB Studio בתפריט הניווט הימני.
- נשתמש ב-
gemini-1.5-pro:generateContentשזמין כברירת מחדל עם התוסףgoogle_ml_integration.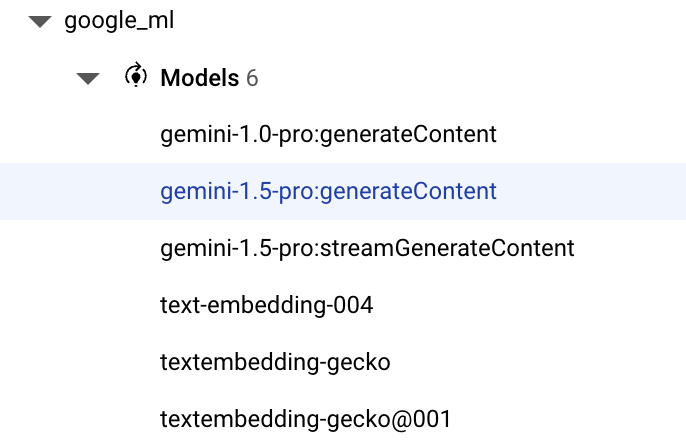
- כדי לבדוק את המודלים שהוגדרו לגישה, מריצים את הפקודה הבאה ב-AlloyDB Studio:
select model_id,model_type from google_ml.model_info_view;
- כדי להעניק למשתמשי מסד הנתונים הרשאה להריץ תחזיות באמצעות המודלים של Google Vertex AI, צריך להריץ את הפקודה הבאה כדי להפעיל את הפונקציה ml_predict_row:
GRANT EXECUTE ON FUNCTION ml_predict_row to postgres;
בדיקת התשובות
בקטע הבא נשתמש בשאילתה גדולה אחת כדי להעביר את האפליקציה ל-Cloud Run, אבל כדי לוודא שהתשובות מהשאילתה סבירות, יכול להיות שיהיה קשה להבין את השאילתה.
נבדוק את החלקים הנפרדים שמרכיבים את השאילתה הגדולה יותר שבה אנחנו משתמשים בסופו של דבר.
- קודם נשלח בקשה למסד הנתונים כדי לקבל את 5 ההתאמות הכי קרובות לשאילתת משתמש. אנחנו מקודדים את השאילתה באופן קשיח כדי לפשט את התהליך, אבל אל דאגה, נבצע אינטרפולציה של השאילתה בהמשך.
אנחנו כוללים את תיאור המוצר מהטבלה apparels ומוסיפים שני שדות חדשים – אחד שמשלב את התיאור עם האינדקס, והשני עם הבקשה המקורית. הנתונים האלה נשמרים בטבלה בשם xyz, שהוא שם זמני של טבלה.
CREATE TABLE
xyz AS
SELECT
id || ' - ' || pdt_desc AS literature,
pdt_desc AS content,
'I want womens tops, pink casual only pure cotton.' AS user_text
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-005',
'I want womens tops, pink casual only pure cotton.')::vector
LIMIT
5;
הפלט של השאילתה הזו יהיה 5 השורות הדומות ביותר שקשורות לשאילתת המשתמש. The
הטבלה החדשה xyz תכיל 5 שורות, ולכל שורה יהיו העמודות הבאות:
literaturecontentuser_text
- כדי לקבוע את התוקף של התשובות, נשתמש בשאילתה מורכבת שבה נסביר איך להעריך את התשובות. היא משתמשת ב-
user_textוב-contentבטבלהxyzכחלק מהשאילתה.
"Read this user search text: ', user_text,
' Compare it against the product inventory data set: ', content,
' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
- באמצעות השאילתה הזו, נבדוק את איכות התשובות בטבלה
xyz. כשאנחנו אומרים 'איכות', אנחנו מתכוונים לרמת הדיוק של התשובות שנוצרו בהשוואה למה שאנחנו מצפים מהן.
CREATE TABLE
x AS
SELECT
json_array_elements( google_ml.predict_row( model_id => 'gemini-1.5',
request_body => CONCAT('{
"contents": [
{ "role": "user",
"parts":
[ { "text": "Read this user search text: ', user_text, ' Compare it against the product inventory data set: ', content, ' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
} ]
}
] }'
)::json))-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'
AS LLM_RESPONSE
FROM
xyz;
- הפונקציה
predict_rowמחזירה את התוצאה שלה בפורמט JSON. הקוד-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'"משמש לחילוץ הטקסט בפועל מ-JSON. כדי לראות את ה-JSON בפועל שמוחזר, אפשר להסיר את הקוד הזה. - לבסוף, כדי לקבל את שדה ה-LLM, צריך לחלץ אותו מטבלת x:
SELECT
LLM_RESPONSE
FROM
x;
- אפשר לשלב את שתי השאילתות לשאילתה אחת באופן הבא:
אזהרה: אם הפעלתם את השאילתות שלמעלה כדי לבדוק את תוצאות הביניים,
לפני שמריצים את השאילתה הזו, מוודאים שמוחקים או מסירים את הטבלאות xyz ו-x ממסד הנתונים של AlloyDB.
SELECT
LLM_RESPONSE
FROM (
SELECT
json_array_elements( google_ml.predict_row( model_id => 'gemini-1.5',
request_body => CONCAT('{
"contents": [
{ "role": "user",
"parts":
[ { "text": "Read this user search text: ', user_text, ' Compare it against the product inventory data set: ', content, ' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
} ]
}
] }'
)::json))-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'
AS LLM_RESPONSE
FROM (
SELECT
id || ' - ' || pdt_desc AS literature,
pdt_desc AS content,
'I want womens tops, pink casual only pure cotton.' user_text
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-005',
'I want womens tops, pink casual only pure cotton.')::vector
LIMIT
5 ) AS xyz ) AS X;
השאילתה הגדולה היא שילוב של כל השאילתות שהפעלנו בשלבים הקודמים. התוצאות מציינות אם יש התאמה, מה אחוז ההתאמה וכוללות הסבר על הסיווג.
שימו לב שברירת המחדל של מודל Gemini היא סטרימינג מופעל, ולכן התשובה בפועל מופיעה בכמה שורות: 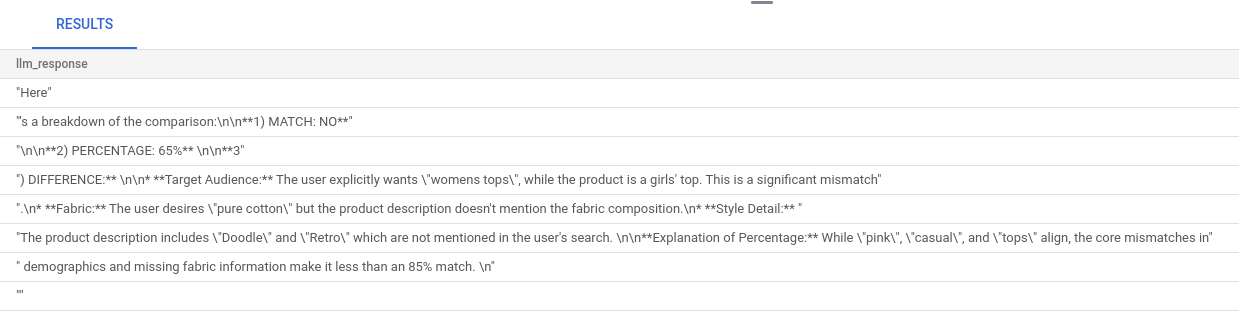
10. העברת האפליקציה לאינטרנט
עכשיו נאחסן את האפליקציה הזו כדי שאפשר יהיה לגשת אליה מהאינטרנט.
יצירת פונקציית Cloud Run
- במסוף Google Cloud, עוברים אל פונקציות Cloud Run באמצעות הקישור הבא:
https://console.cloud.google.com/run/create?deploymentType=function
- בקטע Configure (הגדרה), מגדירים את שם הפונקציה כ-retail-engine ובוחרים באזור us-central1.
- בקטע Endpoint URL (כתובת URL של נקודת הקצה), בוחרים באפשרות runtime Java 17.
- בקטע 'אימות', בוחרים באפשרות Allow unauthenticated invocations (אפשרות הפעלה ללא אימות).
- מרחיבים את Container(s), Volumes, Networking, Security ולוחצים על הכרטיסייה Networking.
- בוחרים באפשרות Connect to a VPC for outbound traffic (חיבור ל-VPC לתנועה יוצאת) ולוחצים על Use Serverless VPC Access connectors (שימוש במחברי חיבור לרשת (VPC) מאפליקציית serverless).
- בקטע Network (רשת), לוחצים על Add New VPC Connector (הוספת מחבר VPC חדש). מפעילים את Serverless VPC Access API, אם הוא עדיין לא מופעל.
- בקטע Create connector (יצירת מחבר), מגדירים את השם
alloydb-test-conn. - מגדירים את האזור ל
us-central. - משאירים את הערך של Network (רשת) כ-default (ברירת מחדל) ומגדירים את Subnet (רשת משנה) כ-Custom IP Range (טווח כתובות IP מותאם אישית) עם טווח כתובות ה-IP 10.8.0.0 או טווח דומה שזמין.
- מרחיבים את ההגדרות של הצגת שינוי קנה מידה, מגדירים את המופעים המינימליים ל-2 ואת המופעים המקסימליים ל-3.
- בוחרים את סוג האינסטנס f1-micro. אלה האפשרויות שמופיעות כשיוצרים מחבר:
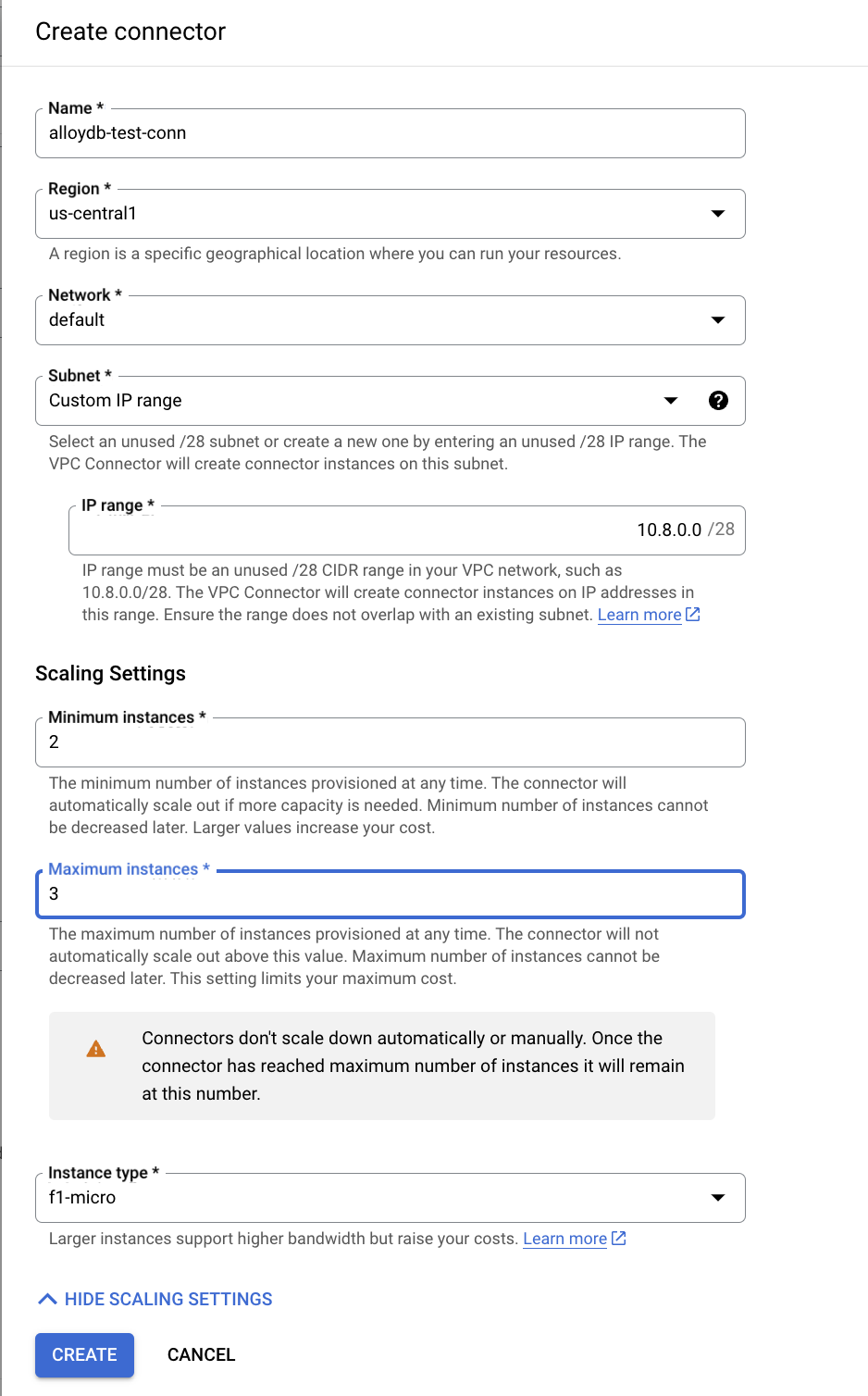
- לוחצים על Create (יצירה) כדי ליצור את המחבר.
- בניתוב תעבורה, בוחרים באפשרות ניתוב כל התעבורה אל ה-VPC.
- לוחצים על יצירה כדי ליצור את הפונקציה.
פריסת האפליקציה
אחרי שיוצרים את הפונקציה, מעדכנים את המקור ומבצעים פריסה מחדש של האפליקציה.
- ב-Cloud Run, לוחצים על הכרטיסייה Services ואז על הפונקציה retail-engine.
- לוחצים על הכרטיסייה Source (מקור). משאירים את ברירת המחדל Function entry point שמוגדרת ל-
gcfv2.HelloHttpFunction. - מחליפים את התוכן של הקובץ HelloHttpFunction.java בתוכן מקובץ ה-Java הזה.
- מעדכנים את הפרטים של AlloyDbJdbcConnector בקובץ בהתאם לפרטים של מופע וקלאסטר AlloyDB. מחליפים את
$PROJECT_IDבמזהה הפרויקט של אשכול ומופע AlloyDB.
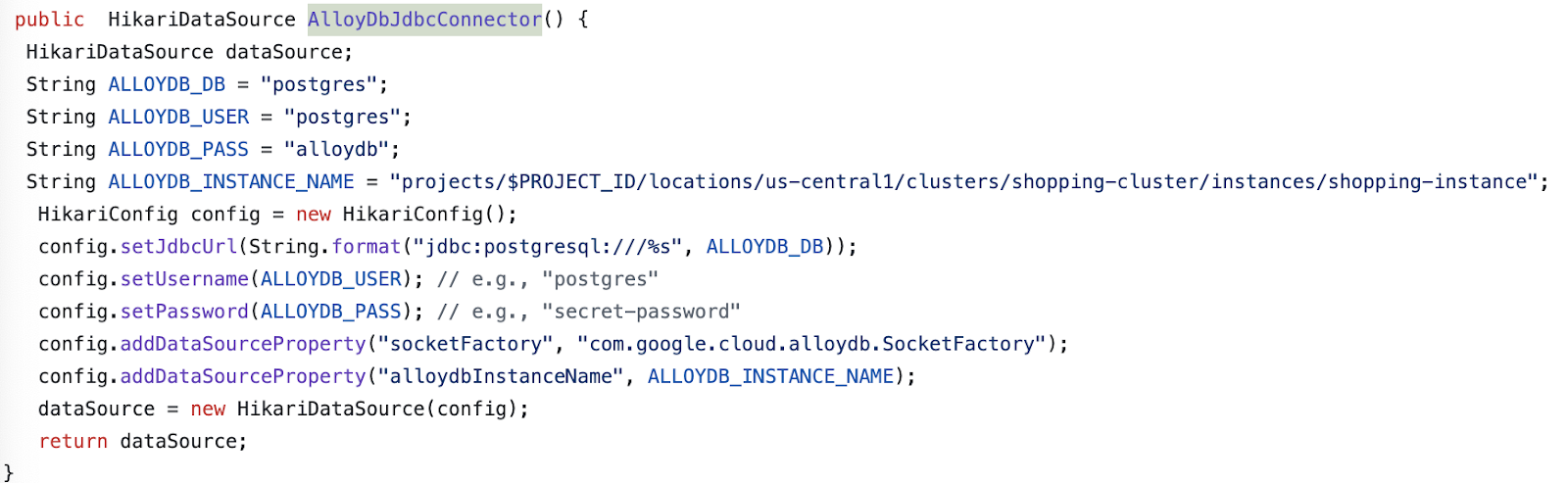
- מחליפים את התוכן של הקובץ pom.xml בתוכן של קובץ ה-XML הזה.
- לוחצים על שמירה ופריסה מחדש כדי לפרוס את הפונקציה.
11. בדיקת האפליקציה של מנוע הקמעונאות
אחרי שפורסים את פונקציית Cloud Functions המעודכנת, נקודת הקצה אמורה להופיע בפורמט הבא:
https://retail-engine-PROJECT_NUMBER.us-central1.run.app
אפשר לבדוק את זה ב-Cloud Shell Terminal על ידי הפעלת הפקודה הבאה:
gcloud functions call retail-engine --region=us-central1 --gen2 --data '{"search": "I want some kids clothes themed on Disney"}'
אפשר גם לבדוק את פונקציית Cloud Run באופן הבא:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST https://retail-engine-$PROJECT_NUMBER.us-central1.run.app \
-H 'Content-Type: application/json' \
-d '{"search":"I want some kids clothes themed on Disney"}' \
| jq .
והתוצאה:

אחרי שהפעלנו חיפוש וקטורי של דמיון באמצעות מודל ההטמעות בנתוני AlloyDB, אפשר להתקדם ליצירת האפליקציה שמשתמשת בהטמעות האלה יחד עם התמונה וההנחיות שלכם כדי ליצור הצעות לסגנון.
12. הסבר על תהליך ההמלצה על לבוש
אפליקציית ההמלצות לבגדים היא אפליקציית אתחול של ספרינט שהוגדרה לפעול עם ההטמעות שיצרנו באפליקציית AlloyDB retail-engine, יחד עם Gemini ו-Imagen, כדי ליצור אפשרויות ויזואליות של סגנונות בגדים. בנוסף, אפשר להוסיף הנחיות מותאמות אישית ולשפר את ההמלצה.
כך זה עובד: אתם מעלים לאפליקציה תמונה של חולצה בצבע ורוד פוקסיה שנמצאת בארון הבגדים שלכם. כשאתם לוחצים על 'הצגה', האפליקציה יוצרת כמה אפשרויות שמתאימות לתמונה המקורית, על סמך ההנחיה שמוגדרת בקוד האפליקציה וההטמעות במסד הנתונים של AlloyDB. עכשיו אתם רוצים לדעת איך ייראו האפשרויות המוצעות עם שרשרת כחולה, אז אתם מוסיפים הנחיה בשורות האלה ולוחצים על 'סגנון'. התמונה הסופית שנוצרת משלבת את התמונה המקורית עם ההמלצות ליצירת לבוש תואם.
כדי להתחיל ליצור את אפליקציית ההמלצות ללבוש, פועלים לפי השלבים הבאים:
- ב-Cloud Run, פותחים את האפליקציה retail-engine ורושמים את כתובת ה-URL של האפליקציה. זהו מאגר ההטמעות שבו נשתמש כדי ליצור הצעות דומות.
- בסביבת הפיתוח המשולבת, משכפלים את המאגר https://github.com/AbiramiSukumaran/outfit-recommender/. בתרגיל הזה, השלבים שמוצגים מבוצעים בסביבת הפיתוח המשולבת (IDE) של Visual Studio Code.
git clone https://github.com/AbiramiSukumaran/outfit-recommender/
אלה כמה מהקבצים החשובים בספרייה של האפליקציה:
-
src/main: ספריית קובצי המקור שבה נמצאים קובצי האפליקציה וקובצי ה-HTML: -
HelloWorldApplication.java: נקודת הכניסה הראשית לאפליקציית Spring Boot. -
HelloWorldController.java: בקר REST של Spring Boot שמטפל בבקשות HTTP שקשורות לאפליקציה להמלצה על בגדים. הקובץ הזה מטפל בבקשות GET ו-POST, מעבד הנחיות של משתמשים, מנתח תמונות, מקיים אינטראקציה עם הטמעות של AlloyDB ומחזיר את התשובה הסופית לממשק המשתמש. בקר זה קורא למחלקה GenerateImageSample. -
GenerateImageSample.java: מכיל את המחלקה ליצירת תמונות שמתחברת ל-Vertex AI, מעצב את ההנחיה של המשתמש, מבצע קריאות API למודל Imagen ומחזיר את התמונה החזויה למחלקת הבקרה. -
Resources: בספרייה הזו יש תמונות וקבצי HTML שנדרשים ליצירת ממשק המשתמש של האפליקציה. -
Pom.xml: הגדרת התלויות וההגדרות של הפרויקט.
- ב-Visual Studio Code, פותחים את הקובץ
HelloWorldController.javaומעדכנים את המופעים של מזהה הפרויקט והמיקום בהתאם למקום שבו נוצר מופע AlloyDB.
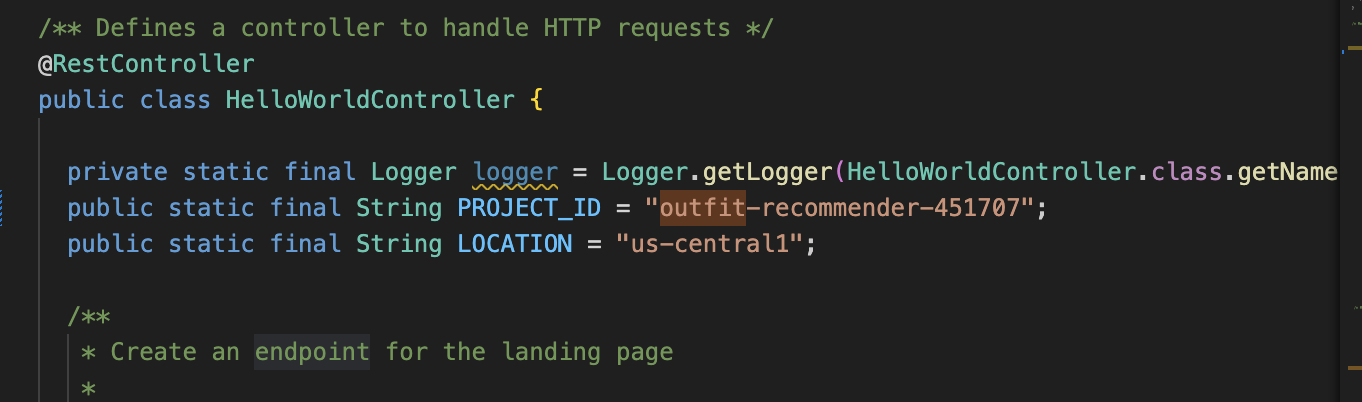
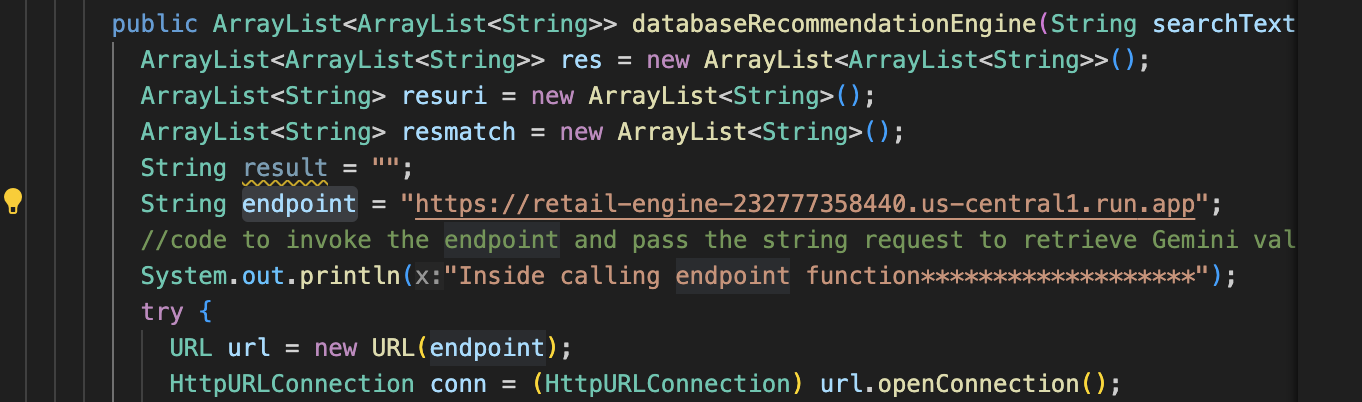
- מעדכנים את
endpointלכתובת ה-URL של אפליקציית retail-engine שאירחתם קודם.
- פותחים את
GenerateImageSample.javaומעדכנים את מזהה הפרויקט ואת המיקום בהתאם למקום שבו נוצר מופע AlloyDB.
- שומרים את כל הקבצים.
עכשיו נבצע פריסה של האפליקציה הזו בסביבת זמן ריצה ללא שרת (serverless) ב-Cloud Run.
13. העברת האפליקציה לאינטרנט
אחרי שהוספנו את הפרויקט הרלוונטי, את המיקום ואת פרטי האפליקציה של Retail Engine לאפליקציית Spring Boot של כלי ההמלצות לבגדים, אפשר לפרוס את האפליקציה ב-Cloud Run.
נשתמש בפקודה gcloud run deploy במסוף של Visual Code Studio כדי לפרוס את האפליקציה. ב-Visual Studio Code, אפשר להתקין את התוסף Google Cloud Code כדי להתחיל להשתמש ב-gcloud CLI.
כדי לפרוס את האפליקציה:
- ב-IDE, פותחים את הספרייה המשוכפלת ומפעילים את הטרמינל. ב-Visual Code Studio, לוחצים על Terminal (מסוף) > New Terminal (מסוף חדש).
- כדי להתקין את ה-CLI של gcloud, פועלים לפי ההוראות במסמך הזה.
- אם אתם משתמשים ב-Visual Code Studio, לוחצים על Extensions (תוספים), מחפשים את Google Cloud Code ומתקינים את התוסף.
- בטרמינל של סביבת הפיתוח המשולבת, מריצים את הפקודה הבאה כדי לאמת את חשבון Google:
gcloud auth application-default login
- מגדירים את מזהה הפרויקט לאותו פרויקט שבו נמצא מופע AlloyDB.
gcloud config set project PROJECT_ID
- מתחילים בתהליך הפריסה.
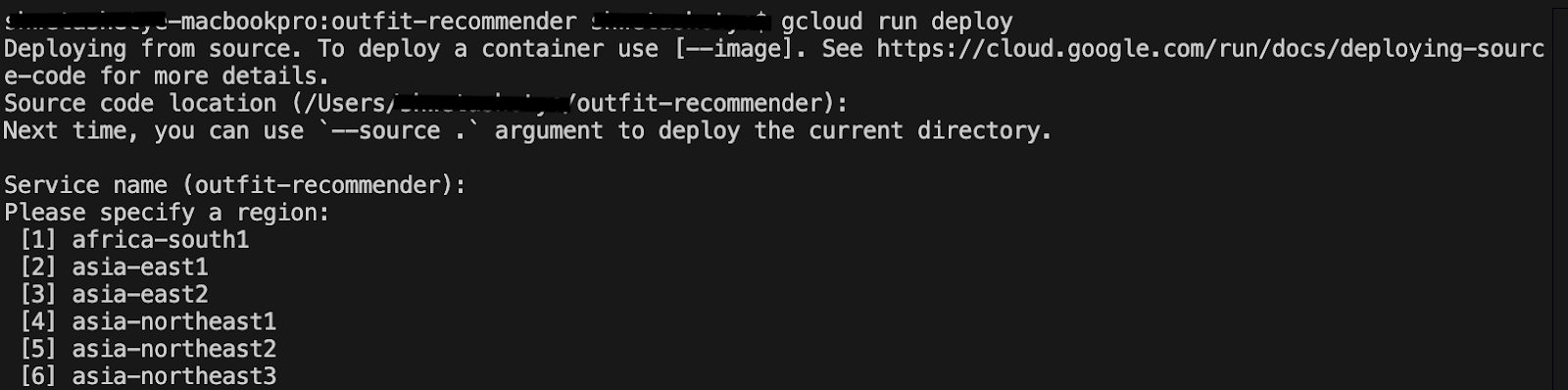
gcloud run deploy
- ב-
Source code location, מקישים על Enter כדי לבחור את ספריית GitHub המשוכפלת. - ב-
Service name, מזינים שם לשירות, כמו outfit-recommender, ולוחצים על Enter. - ב-
Please specify a region, מזינים את המיקום שבו מתארחים מופע AlloyDB ואפליקציית retail-engine, למשל 32 ל-us-central1, ומקישים על Enter.
- ב-
Allow unauthenticated invocations to [..], מזינים Y ומקישים על Enter.
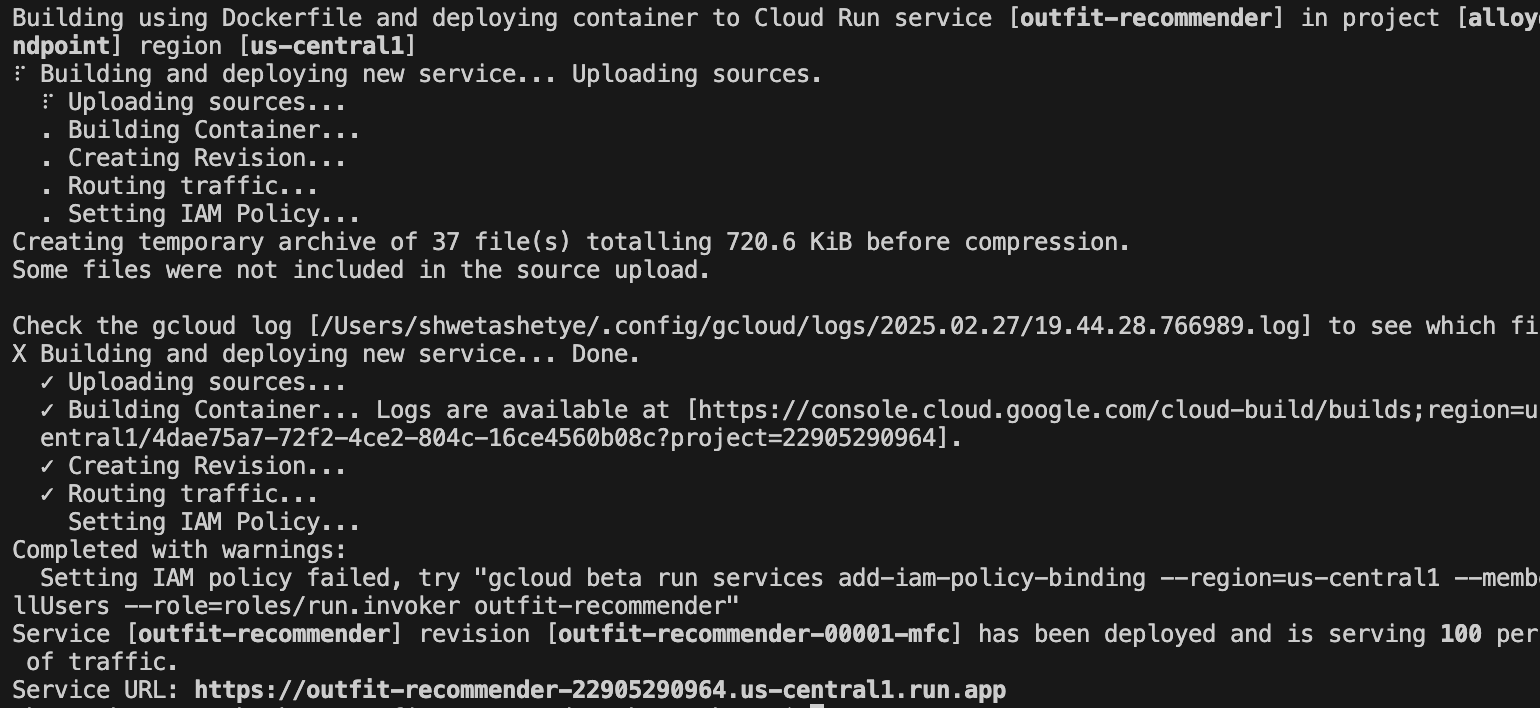
בתמונה הבאה מוצג תהליך הפריסה של האפליקציה:
14. בדיקת האפליקציה להמלצות על לבוש
אחרי שהאפליקציה נפרסת בהצלחה ב-Cloud Run, אפשר לראות את השירות במסוף Google Cloud באופן הבא:
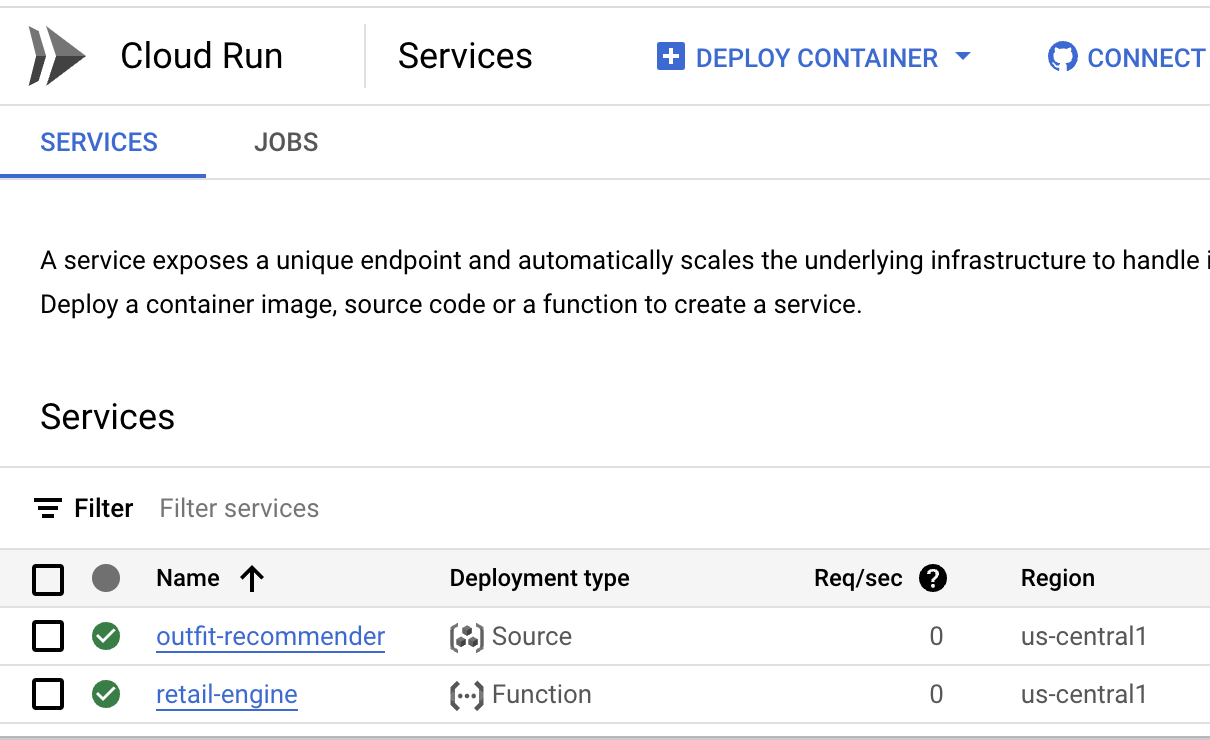
- במסוף Google Cloud, עוברים אל Cloud Run.
- בקטע Services (שירותים), לוחצים על השירות outfit recommender (המלצות לציוד) שפרסתם. שני השירותים retail-engine ו-outfit-recommender אמורים להופיע כך:
- לוחצים על כתובת ה-URL של האפליקציה כדי לפתוח את ממשק המשתמש של אפליקציית ההמלצות.
The following is a sample URL that you will use:
https://outfit-recommender-22905290964.us-central1.run.app/style
האפליקציה שנפרסה יכולה להיראות כך:
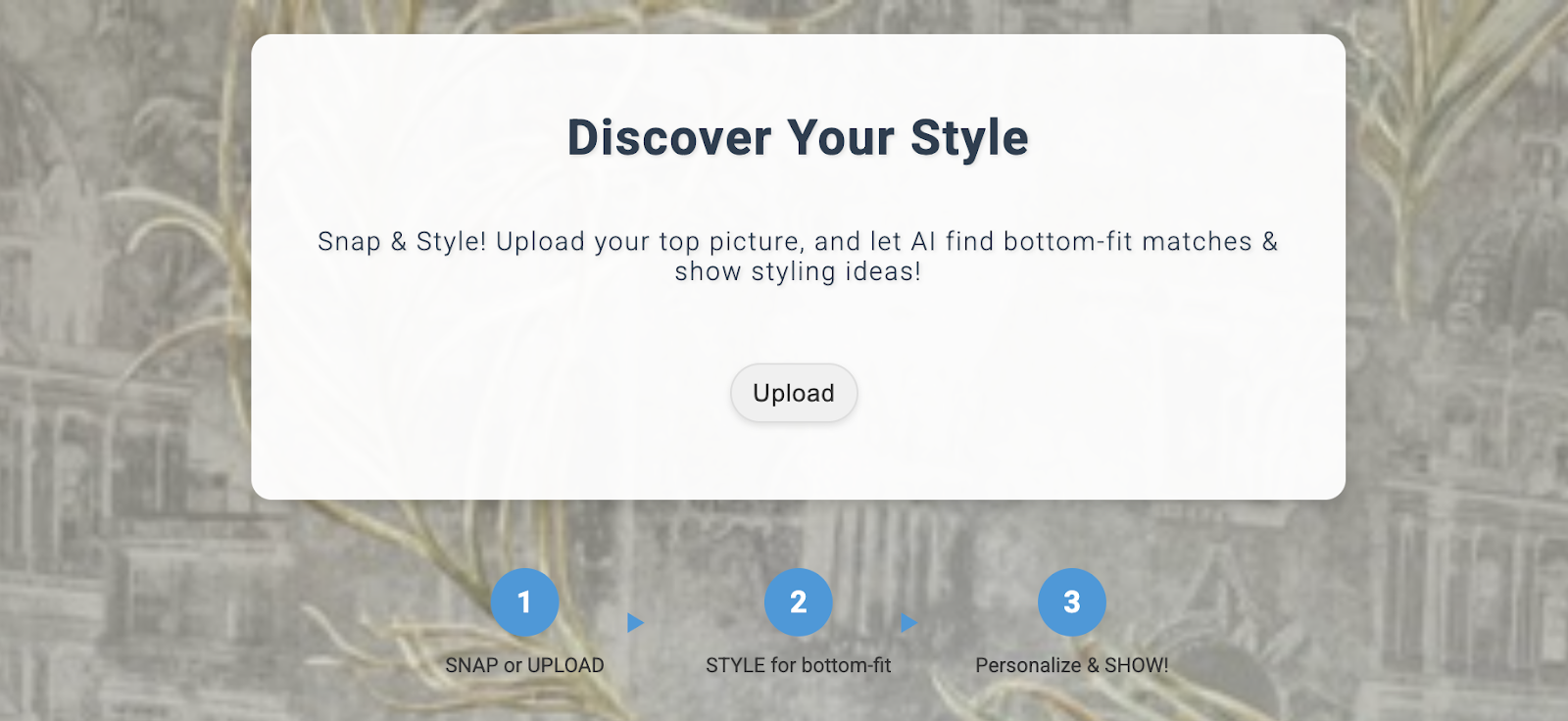
שימוש באפליקציה
כדי להתחיל להשתמש באפליקציה, פועלים לפי השלבים הבאים:
- לוחצים על העלאה ומעלים תמונה של פריט לבוש.
- אחרי שהתמונה מועלית, לוחצים על סגנון. האפליקציה משתמשת בתמונה כהנחיה ויוצרת אפשרויות של חולצות על סמך ההנחיה מאפליקציית מנוע הקמעונאות שכוללת הטמעות של מערך הנתונים הקמעונאי.
האפליקציה יוצרת הצעות לתמונות יחד עם הנחיה על סמך התמונה עם המלצות לסגנון. לדוגמה: A white semi-sheer button up blouse with pink floral patterns on it, with balloon sleeves.
- אפשר להעביר הנחיות נוספות להמלצה הזו לגבי סגנון שנוצר באופן אוטומטי. לדוגמה:
STYLE RECOMMENDATION: Cute brown skirt on a curly updo. Make it photo realistic. Accessorize with cherry earrings and burgundy plastic case sling bag. - לוחצים על הצגה כדי לראות את הסגנון הסופי.

15. הסרת המשאבים
כדי לא לצבור חיובים לחשבון Google Cloud על המשאבים שבהם השתמשתם במאמר הזה:
- במסוף Google Cloud, עוברים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
16. מזל טוב
מעולה! ביצעתם בהצלחה חיפוש דמיון באמצעות AlloyDB, pgvector וחיפוש וקטורי, בשילוב עם שימוש בתוצאת החיפוש עם מודל Imagen העוצמתי כדי ליצור המלצות לסגנון.