
1. Обзор
Представьте себе модное приложение, которое не только помогает найти идеальный наряд, но и предоставляет советы по стилю в режиме реального времени, и все это благодаря интеграции передового искусственного интеллекта! В этом докладе мы расскажем, как мы создали такое приложение, используя возможности векторного поиска AlloyDB в сочетании с индексом ScaNN от Google, что позволило нам осуществлять молниеносный поиск подходящих нарядов и мгновенно предоставлять рекомендации по моде.
Мы также подробно рассмотрим, как индекс ScaNN в AlloyDB оптимизирует сложные запросы для генерации персонализированных предложений по стилю. Кроме того, мы будем использовать Gemini и Imagen, мощные модели генеративного ИИ, для предоставления креативных идей по стилю и даже визуализации ваших индивидуальных образов. Всё это приложение построено на бессерверной архитектуре, что обеспечивает бесперебойную и масштабируемую работу для пользователей.
Задача: Предлагая персонализированные варианты нарядов, приложение призвано помочь людям, испытывающим трудности с выбором одежды. Оно также помогает избежать усталости от принятия решений при планировании образов.
Решение: Приложение для рекомендаций по выбору одежды решает проблему предоставления пользователям интеллектуального, персонализированного и увлекательного опыта в сфере моды, одновременно демонстрируя возможности AlloyDB, генеративного ИИ и бессерверных технологий.
Что вы построите
В рамках этой лабораторной работы вы:
- Создайте экземпляр AlloyDB и загрузите набор данных по электронной коммерции.
- Включите расширения pgvector и генеративного ИИ в AlloyDB.
- Сгенерируйте векторные представления на основе описания товара.
- Разверните решение в бессерверной среде Cloud Run Functions.
- Загрузите изображение в Gemini и сгенерируйте запрос на описание изображения.
- Формирование результатов поиска на основе подсказок в сочетании с векторными представлениями данных из наборов данных по электронной коммерции.
- Добавьте дополнительные подсказки, чтобы настроить подсказку и сгенерировать рекомендации по стилю.
- Разверните решение в бессерверной среде Cloud Run Functions.
Требования
2. Архитектура
Архитектура приложения на высоком уровне выглядит следующим образом:

В следующих разделах представлена контекстная структура учебного пособия:
Приём внутрь :
Наш первый шаг — это загрузка данных о розничной торговле (инвентарь, описания товаров, взаимодействие с клиентами) в AlloyDB.
Аналитический механизм:
Для выполнения следующих действий мы будем использовать AlloyDB в качестве аналитического механизма:
- Извлечение контекста: Механизм анализирует данные, хранящиеся в AlloyDB, чтобы понять взаимосвязи между продуктами, категориями, поведением клиентов и т. д., в зависимости от ситуации.
- Создание векторных представлений: Векторные представления (математические представления текста) генерируются как для запроса пользователя, так и для информации, хранящейся в AlloyDB.
- Векторный поиск: поисковая система выполняет поиск сходства, сравнивая векторное представление запроса с векторными представлениями описаний товаров, отзывов и других релевантных данных. Это позволяет определить 25 наиболее релевантных «ближайших соседей».
Рекомендация от Близнецов:
Массив байтов изображения передается модели Gemini через API Vertex AI вместе с запросом на текстовое описание износа верхней части тела и рекомендациями по износу нижней части тела.
Поиск по алгоритмам RAG и векторный поиск в AlloyDB:
Описание износа верхней части используется для запроса к базе данных. Запрос преобразует поисковый текст (рекомендации модели Gemini для сопоставления износа нижней части) в векторные представления и выполняет векторный поиск по векторным представлениям, хранящимся в базе данных, для нахождения ближайших соседей (совпадающих результатов). Векторные представления в базе данных AlloyDB индексируются с использованием индекса ScaNN для повышения полноты поиска.
Генерация изображений-ответов:
Проверенные ответы структурируются в массив JSON, а весь механизм упаковывается в бессерверную облачную функцию запуска, которая вызывается из Agent Builder.
Генерация изображений:
Запрос пользователя на изменение стиля, выбранная пользователем рекомендация и любые запросы на персонализацию объединяются для того, чтобы предоставить Imagen 3 существующее изображение. Изображение для изменения стиля генерируется на основе этого запроса с использованием API Vertex AI.
3. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud и поставляемую с предустановленным bq. Нажмите «Активировать Cloud Shell» (
 ) в верхней части консоли Google Cloud.
) в верхней части консоли Google Cloud. - После подключения к Cloud Shell убедитесь, что вы прошли аутентификацию и что проект настроен на ваш идентификатор проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду, чтобы убедиться, что будущие команды gcloud будут правильно идентифицировать ваш проект.
gcloud config list project
- Если ваш проект не задан, используйте следующую команду, чтобы задать его явно:
gcloud config set project <YOUR_PROJECT_ID>
- Включите необходимые API.
Перейдите по ссылке , чтобы включить API.
Если вы забыли включить какой-либо API, вы всегда можете сделать это в процессе внедрения.
Для получения более подробной информации о командах gcloud и их использовании обратитесь к документации .
4. Настройка базы данных
В этой лабораторной работе мы будем использовать AlloyDB в качестве базы данных для хранения набора данных по розничной электронной коммерции. Она использует кластеры для хранения всех ресурсов, таких как базы данных и журналы. Каждый кластер имеет основной экземпляр , который обеспечивает точку доступа к данным. Таблицы — это фактический ресурс, в котором хранятся данные.
Давайте создадим кластер AlloyDB, экземпляр и таблицу, куда будут загружены данные об электронной коммерции.
Создайте кластер и экземпляр.
- В консоли Google Cloud найдите AlloyDB . Большинство страниц в консоли Cloud легко найти, используя строку поиска.
- Нажмите «СОЗДАТЬ КЛАСТЕР» .

- Создайте кластер и экземпляр со следующими значениями:
- Идентификатор кластера: "
shopping-cluster" - пароль: "
alloydb" - Совместимость с PostgreSQL 15
- Регион: "
us-central1" - Сетевые настройки: "
default"

- В разделе «Сеть» при выборе сети по умолчанию появляется следующая опция. Нажмите «НАСТРОИТЬ ПОДКЛЮЧЕНИЕ» , чтобы настроить сеть по умолчанию.

- Выберите « Использовать автоматически выделенный диапазон IP-адресов» и нажмите «Продолжить» . После проверки информации нажмите «СОЗДАТЬ СОЕДИНЕНИЕ» .

Дождитесь завершения создания сети по умолчанию.
- В разделе «Настройка основного экземпляра» укажите идентификатор экземпляра как «
shopping-instance".

- Нажмите кнопку «СОЗДАТЬ КЛАСТЕР» , чтобы завершить настройку кластера следующим образом:

5. Ввод данных
Теперь пришло время добавить таблицу с данными о магазине. Дождитесь завершения создания экземпляра. После его создания вы сможете войти в AlloyDB, используя учетные данные, которые вы указали при создании кластера.
Аутентификация в базе данных AlloyDB
- В консоли Google Cloud перейдите в раздел AlloyDB . Выберите основной кластер, а затем в левой панели навигации нажмите AlloyDB Studio :

- Для аутентификации в базе данных AlloyDB введите следующие данные:
- Имя пользователя: "
postgres" - База данных: "
postgres" - Пароль: "
alloydb"
После успешной аутентификации в AlloyDB Studio команды SQL вводятся во вкладках редактора . Вы можете добавить несколько окон редактора, используя значок плюса справа от первой вкладки редактора.

Команды для AlloyDB будут вводиться в окнах редактора, используя при необходимости параметры «Выполнить», «Форматировать» и «Очистить».
Включить расширения
Для создания этого приложения мы будем использовать расширения " pgvector" и " google_ml_integration" .
- Расширение pgvector позволяет хранить и искать векторные представления.
- Расширение google_ml_integration предоставляет функции, которые вы можете использовать для доступа к конечным точкам прогнозирования Vertex AI, чтобы получать прогнозы в формате SQL.
- Для активации этих расширений выполните следующие DDL-скрипты:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
- Проверьте, установлены ли расширения, выполнив следующую SQL-команду:
select extname, extversion from pg_extension;
Создайте таблицу
- Создайте таблицу, используя следующее оператор DDL:
CREATE TABLE
apparels ( id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
embedding vector(768) );
После успешного выполнения указанной выше команды вы сможете просмотреть таблицу.
база данных. На следующем изображении показан пример:

Ввод данных
Для этой лабораторной работы у нас есть тестовые данные, содержащие около 200 записей в этом SQL-файле . Он включает в себя поля id, category, sub_category, uri, image и content . Остальные поля будут заполнены позже в ходе лабораторной работы.
- Скопируйте 20 строк/операторов вставки из SQL-файла в новую вкладку редактора в AlloyDB Studio и нажмите кнопку ВЫПОЛНИТЬ .
- Разверните раздел «Проводник», пока не увидите таблицу с названием
apparels. - Щелкните значок меню [ ⋮ ] и выберите «Запрос» . В новой вкладке редактора откроется оператор SELECT.

- Нажмите кнопку «Выполнить» , чтобы убедиться, что строки вставлены.
Предоставить пользователю разрешение
Мы предоставим пользователю postgres разрешение на генерацию эмбеддингов из AlloyDB . В AlloyDB Studio выполните следующую команду, чтобы предоставить пользователю postgres права на выполнение функции генерации embedding :
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Предоставьте учетной записи службы AlloyDB роль пользователя Vertex AI.
Мы будем использовать модели встраивания текста от Vertex AI для генерации векторных представлений, для которых роль пользователя Vertex AI привязана к учетной записи службы AlloyDB.
В консоли Google Cloud нажмите на терминал Cloud Shell [ ] значок и выполните следующую команду:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
6. Создание контекста
Для создания встраивания нам потребуется context , то есть вся информация, которую мы хотим включить в одно поле. Мы сделаем это, создав описание продукта, которое сохраним в столбце pdt_desc в таблице apparels .
В нашем случае мы будем использовать всю информацию о каждом продукте, но если вы будете делать то же самое со своими данными, вы можете свободно обрабатывать данные любым способом, который сочтете целесообразным для вашего бизнеса.
На вкладке «Редактор AlloyDB Studio» выполните следующую команду, которая обновит поле pdt_desc данными контекста:
UPDATE
apparels
SET
pdt_desc = CONCAT('This product category is: ', category, ' and sub_category is: ', sub_category, '. The description of the product is as follows: ', content, '. The product image is stored at: ', uri)
WHERE
id IS NOT NULL;
Этот DML-оператор создает простую контекстную сводку, используя информацию из всех доступных полей таблицы и других зависимостей (если таковые имеются в вашем случае). Для более точного набора информации и создания контекста вы можете настроить данные любым способом, который сочтете целесообразным для вашего бизнеса.
7. Создайте векторные представления для контекста.
Компьютерам гораздо проще обрабатывать числа, чем текст. Система встраивания преобразует текст в последовательность чисел с плавающей запятой, которые должны представлять текст независимо от его формулировки, используемого языка и т. д.
Рассмотрим описание приморского места. Его можно назвать "on the water », « beachfront », « walk from your room to the ocean », « sur la mer », « на берегу океана » и т. д. Все эти термины выглядят по-разному, но их семантическое значение или, в терминологии машинного обучения, их векторные представления должны быть очень близки друг к другу.
Теперь, когда данные и контекст готовы, мы выполним SQL-запрос для добавления векторных представлений столбца описания продукта (pdt_desc ) в таблицу в поле embedding . Существует множество моделей векторных представлений, которые можно использовать. Мы используем text-embedding-005 от Vertex AI.
- В AlloyDB Studio выполните следующую команду для генерации эмбеддингов и обновите столбец
pdt_desc, указав в нем эмбеддинги для хранящихся в нем данных:
UPDATE
apparels
SET
embedding = embedding( 'text-embedding-005',
pdt_desc)
WHERE
TRUE;
- Убедитесь, что эмбеддинги сгенерированы, выполнив следующую команду:
SELECT
id,
category,
sub_category,
content,
embedding
FROM
Apparels
LIMIT 5;
Ниже приведён пример вектора эмбеддингов, который выглядит как массив чисел с плавающей запятой, для приведенного ниже примера текста в запросе:

8. Выполните векторный поиск.
Теперь, когда таблица, данные и векторные представления готовы, давайте выполним векторный поиск в реальном времени для поискового запроса пользователя.
Предположим, что поисковый запрос пользователя звучит так: « pink color, casual, pure cotton tops for women ».
Для поиска совпадений по этому запросу выполните следующий SQL-запрос:
SELECT
id,
category,
sub_category,
content,
pdt_desc AS description
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-005',
'pink color, casual, pure cotton tops for women')::vector
LIMIT
5;
Давайте рассмотрим этот запрос подробнее:
В этом запросе,
- Поисковый запрос пользователя: "
I want womens tops, pink casual only pure cotton." - Мы преобразуем этот поисковый текст в векторные представления, используя метод
embedding()вместе с моделью:text-embedding-005. Этот шаг должен показаться вам знакомым после предыдущего шага, где мы применили функцию embedding ко всем элементам таблицы. - "
<=>" обозначает использование метода расстояния COSINE SIMILARITY . Все доступные меры сходства можно найти в документации pgvector . - Мы преобразуем результат метода встраивания в векторный тип данных, чтобы обеспечить его совместимость с векторами, хранящимися в базе данных.
- Параметр LIMIT 5 означает, что мы хотим извлечь 5 ближайших соседей для искомого текста.
Ниже приведён пример ответа на этот SQL-запрос:

Как вы можете видеть в результатах, совпадения довольно близки к поисковому запросу. Попробуйте изменить цвет, чтобы увидеть, как изменятся результаты.
Индекс AlloyDB ScaNN для повышения производительности запросов
Теперь предположим, что мы хотим повысить производительность (время выполнения запроса), эффективность и полноту результатов векторного поиска, используя индекс ScaNN .
Если вы хотите использовать индекс ScaNN, выполните следующие шаги:
- Поскольку кластер, экземпляр, контекст и эмбеддинги уже созданы, нам остается только установить расширение ScaNN, используя следующую команду:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- Создайте индекс ScaNN:
CREATE INDEX apparel_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=54);
В приведенном выше DDL:
-
apparel_index— это название индекса. -
apparels— это название таблицы. -
scann— это метод индексации. -
embedding— это столбец в таблице, который вы хотите проиндексировать. -
cosine— это метод измерения расстояния, который следует использовать с индексом. -
54— это количество разделов, применяемых к этому индексу. Установите любое значение от 1 до 1048576. Для получения дополнительной информации о том, как определить это значение, см. раздел «Настройка индекса ScaNN» .
В соответствии с рекомендациями репозитория ScaNN , мы использовали квадратный корень из количества точек данных. При разбиении на разделы num_leaves должно быть приблизительно равно квадратному корню из количества точек данных.
- Проверьте, создан ли индекс, используя следующий запрос:
SELECT * FROM pg_stat_ann_indexes;
- Выполните векторный поиск, используя тот же запрос, что и раньше, но без индекса:
select * from apparels
ORDER BY embedding <=> CAST(embedding('textembedding-gecko', 'white tops for girls without any print') as vector(768))
LIMIT 20
Приведенный выше запрос — тот же самый, который мы использовали в лабораторной работе на шаге 8. Однако теперь поле проиндексировано с помощью индекса ScaNN.
- Проведите тестирование с помощью простого поискового запроса с индексом и без него. Для тестирования без индекса необходимо удалить индекс:
white tops for girls without any print
Приведенный выше поисковый запрос в векторном поиске по индексированным данным эмбеддингов обеспечивает качественные результаты поиска и высокую эффективность. Эффективность значительно повышается (по времени выполнения: 10,37 мс без ScaNN и 0,87 мс с ScaNN) при использовании индекса. Для получения дополнительной информации по этой теме, пожалуйста, обратитесь к этому блогу .
9. Проверка соответствия с помощью LLM
Прежде чем переходить к созданию сервиса для подбора наиболее подходящих вариантов для приложения, давайте воспользуемся моделью генеративного ИИ, чтобы проверить, действительно ли эти потенциальные ответы релевантны и безопасны для предоставления пользователю.
Убедитесь, что экземпляр настроен для работы с Gemini.
- Убедитесь, что интеграция
google_ml_integrationуже включена для вашего кластера и экземпляра. В AlloyDB Studio выполните следующую команду:
show google_ml_integration.enable_model_support;
Если значение отображается как «включено» , вы можете пропустить следующие 2 шага и сразу перейти к настройке.
Интеграция AlloyDB и модели искусственного интеллекта Vertex.
- Перейдите к основному экземпляру вашего кластера AlloyDB и нажмите «РЕДАКТИРОВАТЬ ОСНОВНОЙ ЭКЗЕМПЛЯР» .

- В разделе «Расширенные параметры конфигурации » разверните раздел «Новый флаг базы данных» и убедитесь, что
google_ml_integration.enable_model_support flagустановлен в значение «on» следующим образом:
 3. Если параметр не установлен в положение «вкл.», установите его в положение «вкл.», а затем нажмите **ОБНОВИТЬ ЭКЗЕМПЛЯР**.
3. Если параметр не установлен в положение «вкл.», установите его в положение «вкл.», а затем нажмите **ОБНОВИТЬ ЭКЗЕМПЛЯР**.
Этот шаг займет несколько минут.
Интеграция AlloyDB и модели искусственного интеллекта Vertex
Теперь вы можете подключиться к AlloyDB Studio и выполнить следующую инструкцию DML для настройки доступа к моделям Gemini из AlloyDB, используя идентификатор вашего проекта там, где это указано. Перед выполнением команды может появиться предупреждение о синтаксической ошибке, но в целом она должна выполниться без проблем.
- В консоли Google Cloud перейдите в раздел AlloyDB . Выберите основной кластер, а затем в левой панели навигации нажмите AlloyDB Studio .
- Мы будем использовать
gemini-1.5-pro:generateContent, который доступен по умолчанию в расширенииgoogle_ml_integration.
- Проверить модели, настроенные для доступа, можно с помощью следующей команды в AlloyDB Studio:
select model_id,model_type from google_ml.model_info_view;
- Предоставьте пользователям базы данных разрешение на выполнение функции ml_predict_row для запуска прогнозов с использованием моделей искусственного интеллекта Google Vertex, выполнив следующую команду:
GRANT EXECUTE ON FUNCTION ml_predict_row to postgres;
Оценка ответов
Хотя в следующем разделе, где мы фактически запустим приложение в Cloud Run, мы будем использовать один большой запрос, чтобы убедиться в его адекватности, сам запрос может быть сложным для понимания.
Мы рассмотрим отдельные разделы, которые в дальнейшем формируют более крупный запрос, который мы в итоге используем.
- Сначала мы отправим запрос к базе данных, чтобы получить 5 наиболее близких совпадений с запросом пользователя. Для простоты мы зададим запрос жестко, но не волнуйтесь, мы добавим его в запрос позже.
Мы добавляем описание товара из таблицы apparels и два новых поля — одно объединяет описание с индексом, а другое — с исходным запросом. Эти данные сохраняются в таблице с именем xyz , которое является временным именем таблицы.
CREATE TABLE
xyz AS
SELECT
id || ' - ' || pdt_desc AS literature,
pdt_desc AS content,
'I want womens tops, pink casual only pure cotton.' AS user_text
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-005',
'I want womens tops, pink casual only pure cotton.')::vector
LIMIT
5;
Результатом этого запроса станут 5 строк, наиболее похожих на запрос пользователя.
Новая таблица xyz будет содержать 5 строк, каждая из которых будет иметь следующие столбцы:
-
literature -
content -
user_text
- Чтобы определить, насколько корректны ответы, мы воспользуемся сложным запросом, в котором объясним, как оценивать ответы. В качестве части запроса используются
user_textиcontentиз таблицыxyz.
"Read this user search text: ', user_text,
' Compare it against the product inventory data set: ', content,
' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
- Используя этот запрос, мы затем проверим «качество» ответов в таблице
xyz. Под качеством мы подразумеваем, насколько точно сгенерированные ответы соответствуют нашим ожиданиям.
CREATE TABLE
x AS
SELECT
json_array_elements( google_ml.predict_row( model_id => 'gemini-1.5',
request_body => CONCAT('{
"contents": [
{ "role": "user",
"parts":
[ { "text": "Read this user search text: ', user_text, ' Compare it against the product inventory data set: ', content, ' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
} ]
}
] }'
)::json))-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'
AS LLM_RESPONSE
FROM
xyz;
- Функция
predict_rowвозвращает результат в формате JSON. Код "-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'"используется для извлечения фактического текста из этого JSON. Чтобы увидеть фактический возвращаемый JSON, вы можете удалить этот код. - Наконец, чтобы получить поле LLM, вам просто нужно извлечь его из таблицы x:
SELECT
LLM_RESPONSE
FROM
x;
- Это можно объединить в один запрос следующим образом:
Предупреждение : Если вы выполнили указанные выше запросы для проверки промежуточных результатов,
Перед выполнением этого запроса убедитесь, что вы удалили таблицы xyz и x из базы данных AlloyDB.
SELECT
LLM_RESPONSE
FROM (
SELECT
json_array_elements( google_ml.predict_row( model_id => 'gemini-1.5',
request_body => CONCAT('{
"contents": [
{ "role": "user",
"parts":
[ { "text": "Read this user search text: ', user_text, ' Compare it against the product inventory data set: ', content, ' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
} ]
}
] }'
)::json))-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'
AS LLM_RESPONSE
FROM (
SELECT
id || ' - ' || pdt_desc AS literature,
pdt_desc AS content,
'I want womens tops, pink casual only pure cotton.' user_text
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-005',
'I want womens tops, pink casual only pure cotton.')::vector
LIMIT
5 ) AS xyz ) AS X;
Более полный запрос представляет собой комбинацию всех запросов, выполненных на предыдущих этапах. Результаты показывают, есть ли совпадение, каков процент совпадения и некоторое объяснение рейтинга.
Обратите внимание, что в модели Gemini потоковая передача включена по умолчанию, поэтому фактический ответ распределяется по нескольким строкам: 
10. Разместите приложение в интернете.
Теперь мы разместим это приложение на нашем сервере, чтобы к нему можно было получить доступ через интернет.
Создайте функцию запуска в облаке.
- В консоли Google Cloud перейдите в раздел Cloud Run Functions по следующей ссылке:
https://console.cloud.google.com/run/create?deploymentType=function
- В разделе «Настройка» укажите имя функции как « retail-engine » и выберите регион как « us-central1 ».
- В поле "URL конечной точки" выберите среду выполнения Java 17 .
- В разделе «Аутентификация» выберите «Разрешить неаутентифицированные вызовы» .
- Разверните разделы «Контейнеры», «Тома», «Сеть», «Безопасность» и перейдите на вкладку «Сеть» .
- Выберите «Подключиться к VPC для исходящего трафика» , а затем нажмите « Использовать коннекторы доступа к VPC без сервера» .
- В разделе «Сеть» нажмите «Добавить новый коннектор VPC» . Включите API доступа к VPC без сервера , если он еще не включен.
- В поле «Создать коннектор» укажите имя
alloydb-test-conn. - Установите регион на
us-central. - Оставьте значение параметра «Сеть» по умолчанию и установите параметр «Подсеть» как «Пользовательский диапазон IP-адресов» с диапазоном IP-адресов 10.8.0.0 или аналогичным доступным значением.
- Разверните раздел «Показать параметры масштабирования» и установите минимальное количество экземпляров равным 2, а максимальное — 3.
- Выберите тип экземпляра f1-micro . Ниже показаны параметры создания коннектора:

- Нажмите «Создать», чтобы создать коннектор.
- В разделе «Маршрутизация трафика» выберите «Направлять весь трафик в VPC» .
- Нажмите «Создать» , чтобы создать функцию.
Разверните приложение
После создания функции обновите исходный код и повторно разверните приложение.
- В Cloud Run перейдите на вкладку «Сервисы» и выберите функцию retail-engine .
- Перейдите на вкладку «Источник». Оставьте значение по умолчанию для точки входа функции равным "
gcfv2.HelloHttpFunction". - Замените содержимое файла HelloHttpFunction.java содержимым этого Java-файла .
- Обновите данные AlloyDbJdbcConnector в файле в соответствии с данными вашего экземпляра и кластера AlloyDB. Замените
$PROJECT_IDна идентификатор проекта вашего кластера и экземпляра AlloyDB.
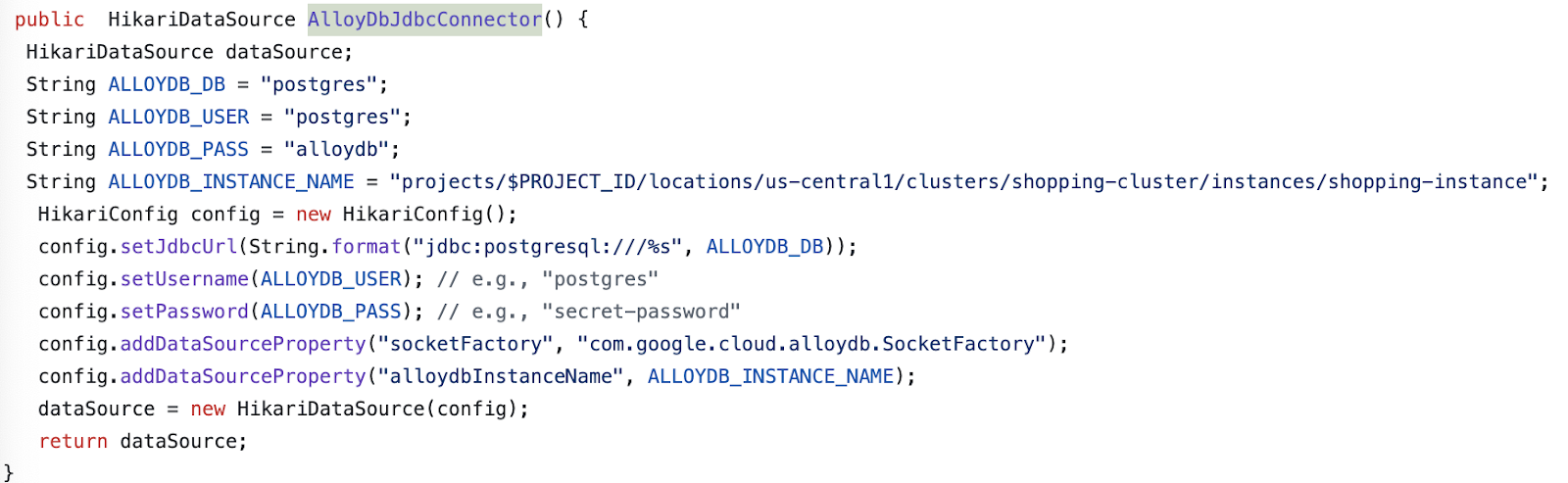
- Замените содержимое файла pom.xml содержимым этого XML- файла.
- Нажмите «Сохранить и повторно развернуть» , чтобы развернуть функцию.
11. Протестируйте приложение для розничной торговли.
После развертывания обновленной облачной функции вы должны увидеть конечную точку в следующем формате:
https://retail-engine-PROJECT_NUMBER.us-central1.run.app
Вы можете проверить это в терминале Cloud Shell, выполнив следующую команду:
gcloud functions call retail-engine --region=us-central1 --gen2 --data '{"search": "I want some kids clothes themed on Disney"}'
В качестве альтернативы, вы можете протестировать функцию Cloud Run следующим образом:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST https://retail-engine-$PROJECT_NUMBER.us-central1.run.app \
-H 'Content-Type: application/json' \
-d '{"search":"I want some kids clothes themed on Disney"}' \
| jq .
И вот результат:

Теперь, когда мы выполнили поиск векторов сходства с использованием модели эмбеддингов на данных AlloyDB, мы можем перейти к созданию приложения, которое будет использовать эти эмбеддинги вместе с вашим изображением и предлагать варианты стилизации.
12. Понимание процесса подбора одежды.
Приложение для рекомендаций по выбору одежды — это приложение, разработанное в рамках спринта, которое настроено для работы с созданными нами в приложении AlloyDB retail-engine, а также с Gemini и Imagen для генерации визуальных вариантов оформления одежды. Оно также позволяет добавлять пользовательские подсказки и импровизировать рекомендации.
Представьте себе: вы загружаете в это приложение изображение ярко-розового топа из своего гардероба. Когда вы нажимаете «Показать», на основе подсказки, заданной в коде приложения, и данных из базы данных AlloyDB, приложение генерирует несколько вариантов, соответствующих исходному изображению. Теперь вы задаетесь вопросом, как предложенные варианты будут выглядеть с синим ожерельем, поэтому вы добавляете подсказку в этом ключе и нажимаете «Стиль». В итоге генерируется изображение, которое сочетает в себе удачное сочетание исходного изображения и рекомендаций для создания подходящего комплекта одежды.
Чтобы начать создание приложения для подбора одежды, выполните следующие шаги:
- В Cloud Run откройте приложение retail-engine и запишите URL-адрес вашего приложения. Это репозиторий встраиваний, который мы будем использовать для генерации похожих предложений.
- В вашей IDE клонируйте репозиторий https://github.com/AbiramiSukumaran/outfit-recommender/ . Для этого упражнения описанные шаги выполняются в среде разработки Visual Studio Code.
git clone https://github.com/AbiramiSukumaran/outfit-recommender/
Ниже перечислены некоторые важные файлы в каталоге приложения:
-
src/main: Каталог исходных файлов, где находятся файлы приложения и HTML-код: -
HelloWorldApplication.java: Основная точка входа для приложения Spring Boot. -
HelloWorldController.java: REST-контроллер Spring Boot, обрабатывающий HTTP-запросы, связанные с приложением для рекомендаций одежды. Этот файл обрабатывает GET и POST запросы, обрабатывает запросы пользователя, анализирует изображения, взаимодействует с эмбеддингами AlloyDB и возвращает окончательный ответ в пользовательский интерфейс. Этот контроллер вызывает класс GenerateImageSample. -
GenerateImageSample.java: Содержит класс генерации изображений, который подключается к Vertex AI, форматирует запрос пользователя, выполняет вызовы API к модели Imagen и возвращает предсказанное изображение в класс контроллера. -
Resources: В этом каталоге содержатся изображения и HTML-файлы, необходимые для генерации пользовательского интерфейса приложения. -
Pom.xml: Определяет зависимости и конфигурации проекта.
- В Visual Studio Code откройте файл
HelloWorldController.javaи обновите идентификатор проекта и местоположение в соответствии с тем, где создан ваш экземпляр AlloyDB.

- Обновите
endpoint, указав URL-адрес приложения retail-engine, которое вы разместили ранее.

- Откройте файл
GenerateImageSample.javaи обновите идентификатор проекта и местоположение в соответствии с тем, где создан ваш экземпляр AlloyDB.

- Сохраните все файлы.
Теперь мы развернем это приложение в бессерверной среде выполнения Cloud Run.
13. Разместите приложение в интернете.
Теперь, когда мы добавили соответствующий проект, местоположение и сведения о приложении retail-engine в приложение рекомендаций одежды на Spring Boot, мы можем развернуть приложение в Cloud Run.
Для развертывания приложения мы будем использовать команду gcloud run deploy в терминале Visual Code Studio. Для Visual Studio Code можно установить расширение Google Cloud Code, чтобы начать использовать интерфейс командной строки gcloud.
Для развертывания приложения выполните следующие действия:
- В вашей IDE откройте клонированную директорию и запустите терминал. В Visual Code Studio нажмите Терминал > Новый терминал .
- Для установки интерфейса командной строки gcloud следуйте инструкциям в этом документе .
- Если вы используете Visual Code Studio, нажмите «Расширения» , найдите Google Cloud Code и установите расширение.
- В терминале IDE выполните аутентификацию своей учетной записи Google, выполнив следующую команду:
gcloud auth application-default login
- Установите идентификатор проекта равным идентификатору проекта, в котором расположен ваш экземпляр AlloyDB.
gcloud config set project PROJECT_ID
- Запустите процесс развертывания.
gcloud run deploy
- В
Source code locationнажмите Enter, чтобы выбрать клонированную директорию GitHub. - В
Service nameвведите название службы, например, outfit-recommender, и нажмите Enter. - В
Please specify a regionвведите местоположение, где размещен ваш экземпляр AlloyDB и приложение retail-engine, например, 32 для us-central1, и нажмите Enter.

- В поле
Allow unauthenticated invocations to [..]введите Y и нажмите Enter.
На следующем изображении показан ход развертывания вашего приложения:
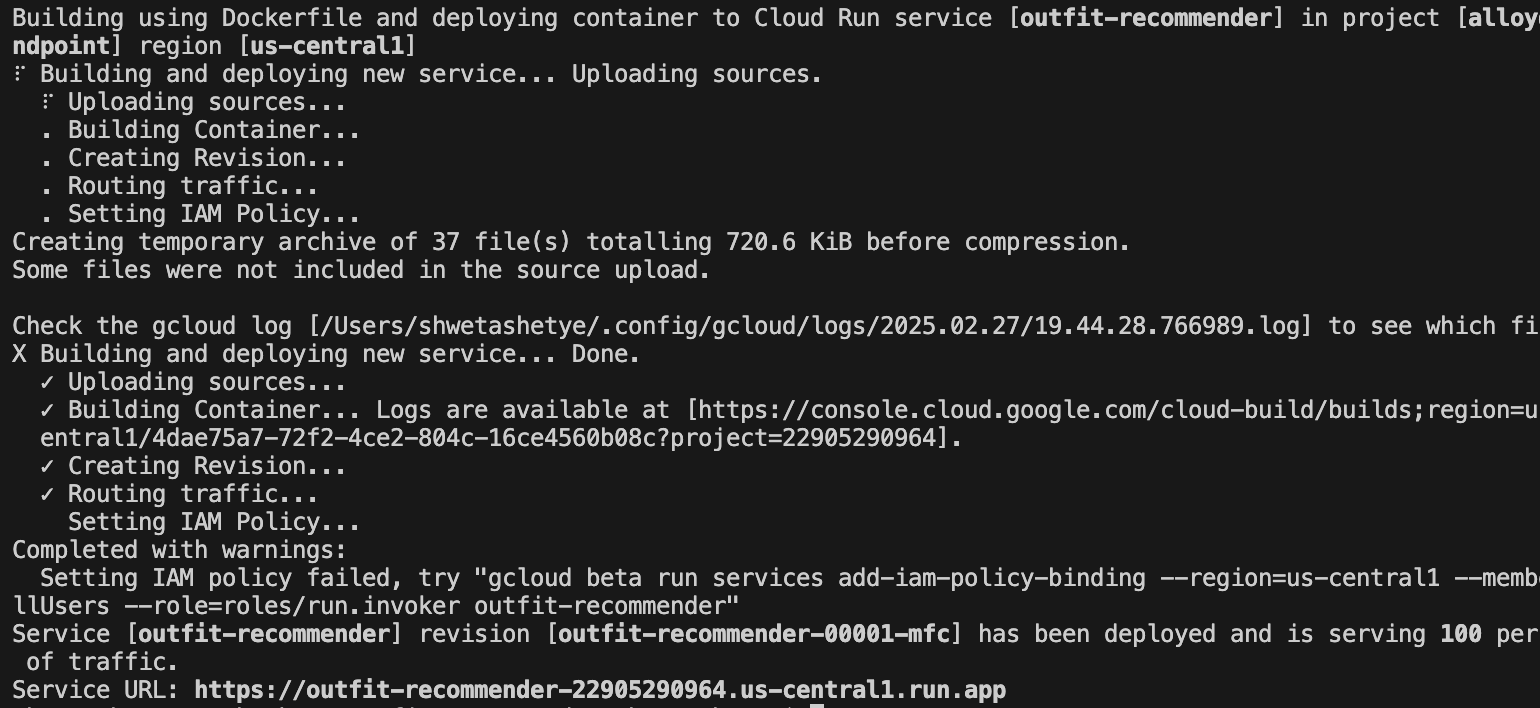
14. Протестируйте приложение для подбора одежды.
После успешного развертывания приложения в Cloud Run вы сможете увидеть сервис в консоли Google Cloud следующим образом:
- В консоли Google Cloud перейдите в раздел Cloud Run .
- В разделе «Службы» щелкните службу рекомендаций комплектов одежды, которую вы развернули. Вы должны увидеть как службу retail-engine , так и службу outfit-recommender, как показано ниже:

- Нажмите на URL-адрес приложения, чтобы открыть пользовательский интерфейс приложения-рекомендателя.

The following is a sample URL that you will use:
https://outfit-recommender-22905290964.us-central1.run.app/style
Развернутое приложение выглядит следующим образом:

Используя приложение
Чтобы начать использовать приложение, выполните следующие шаги:
- Нажмите «Загрузить» и загрузите фотографию предмета одежды.
- После загрузки изображения нажмите «Стиль» . Приложение использует изображение в качестве подсказки и генерирует варианты нижнего белья на основе подсказки из приложения для розничной торговли, которое включает в себя встраивание данных для набора данных о розничной торговле.
Приложение генерирует варианты изображений, а также подсказывает, как их лучше стилизовать. Например: A white semi-sheer button up blouse with pink floral patterns on it, with balloon sleeves.
- Вы можете добавить дополнительные подсказки к этой автоматически сгенерированной рекомендации по стилю. Например,
STYLE RECOMMENDATION: Cute brown skirt on a curly updo. Make it photo realistic. Accessorize with cherry earrings and burgundy plastic case sling bag. - Нажмите «Показать» , чтобы увидеть окончательный вариант оформления.

15. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этой статье, выполните следующие действия:
- В консоли Google Cloud перейдите на страницу «Управление ресурсами» .
- В списке проектов выберите проект, который хотите удалить, и нажмите кнопку «Удалить» .
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить» , чтобы удалить проект.
16. Поздравляем!
Поздравляем! Вы успешно выполнили поиск сходства с использованием AlloyDB, pgvector и Vector search, а также применили результаты поиска к мощной модели Imagen для генерации рекомендаций по стилю.