
1. مقدمة
سيرشدك هذا الدرس التطبيقي حول الترميز إلى كيفية استخدام إمكانات الذكاء الاصطناعي والرسومات البيانية في Spanner لتحسين قاعدة بيانات حالية خاصة بالبيع بالتجزئة. ستتعرّف على تقنيات عملية للاستفادة من تعلُّم الآلة في Spanner من أجل تقديم خدمة أفضل لعملائك. على وجه التحديد، سننفّذ خوارزمية الجار الأقرب (kNN) وخوارزمية الجار الأقرب التقريبية (ANN) لاكتشاف منتجات جديدة تتوافق مع احتياجات كل عميل. ستدمج أيضًا نموذجًا لغويًا كبيرًا لتقديم تفسيرات واضحة بلغة طبيعية لسبب تقديم اقتراح منتج معيّن.
بالإضافة إلى الاقتراحات، سنتناول وظيفة الرسم البياني في Spanner. ستستخدم طلبات بحث بيانية لنمذجة العلاقات بين المنتجات استنادًا إلى سجلّ الشراء للعملاء وأوصاف المنتجات. يتيح هذا الأسلوب اكتشاف سلع ذات صلة وثيقة، ما يؤدي إلى تحسين مدى ملاءمة وفعالية ميزتَي "العملاء اشتروا أيضًا" أو "سلع ذات صلة" بشكلٍ كبير. في نهاية هذا الدرس التطبيقي حول الترميز، ستكتسب المهارات اللازمة لإنشاء تطبيق بيع بالتجزئة ذكي وقابل للتوسّع ومتجاوب يستند بالكامل إلى Google Cloud Spanner.
السيناريو
أنت تعمل لدى بائع تجزئة لمعدات إلكترونية. يحتوي موقعك الإلكتروني للتجارة الإلكترونية على قاعدة بيانات Spanner عادية تتضمّن Products وOrders وOrderItems.
يصل أحد العملاء إلى موقعك الإلكتروني ولديه حاجة محدّدة: "أريد شراء لوحة مفاتيح عالية الأداء". أحيانًا أكتب الرموز البرمجية وأنا على الشاطئ، لذا قد يتعرّض للبلل".
هدفك هو استخدام ميزات Spanner المتقدّمة للردّ على هذا الطلب بذكاء:
- البحث: يمكنك تجاوز البحث البسيط عن الكلمات الرئيسية للعثور على منتجات تتطابق أوصافها دلاليًا مع طلب المستخدم باستخدام البحث المتّجه.
- الشرح: استخدِم نموذجًا لغويًا كبيرًا لتحليل أهم النتائج المطابقة وشرح سبب ملاءمة الاقتراح، ما يعزّز ثقة العملاء.
- المنتجات ذات الصلة: استخدِم طلبات البحث في الرسم البياني للعثور على منتجات أخرى اشتراها العملاء بشكل متكرّر مع المنتج المقترَح.
2. قبل البدء
- إنشاء مشروع في Google Cloud Console، في صفحة اختيار المشروع، اختَر مشروعًا على Google Cloud أو أنشِئ مشروعًا.
- تفعيل الفوترة تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع
- تفعيل Cloud Shell فعِّل Cloud Shell من خلال النقر على الزر "تفعيل Cloud Shell" في وحدة التحكّم. يمكنك التبديل بين "وحدة طرفية Cloud Shell" و"محرّر Cloud Shell".

- تفويض المشروع وضبطه بعد الاتصال بـ Cloud Shell، تأكَّد من مصادقتك ومن ضبط المشروع على رقم تعريف مشروعك.
gcloud auth list
gcloud config list project
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه، مع استبدال
<PROJECT_ID>برقم تعريف مشروعك الفعلي:
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- تفعيل واجهات برمجة التطبيقات المطلوبة فعِّل واجهات برمجة التطبيقات Spanner وVertex AI وCompute Engine. قد يستغرق ذلك بضع دقائق.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- اضبط بعض متغيرات البيئة التي ستعيد استخدامها.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- أنشئ مثيلاً تجريبيًا مجانيًا من Spanner إذا لم يكن لديك مثيل من Spanner . ستحتاج إلى مثيل Spanner لاستضافة قاعدة البيانات. سنستخدم
regional-us-central1كإعداد. يمكنك تعديل هذا الخيار إذا أردت.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3- نظرة عامة على البنية
تتضمّن Spanner جميع الوظائف الضرورية باستثناء النماذج المستضافة على Vertex AI.
4. الخطوة 1: إعداد قاعدة البيانات وإرسال طلب البحث الأول
أولاً، علينا إنشاء قاعدة البيانات وتحميل بيانات البيع بالتجزئة النموذجية وإخبار Spanner بكيفية التواصل مع Vertex AI.
في هذا القسم، ستستخدم نصوص SQL البرمجية أدناه.
- انتقِل إلى صفحة منتج Spanner.
- اختَر موضع التكرار الصحيح.
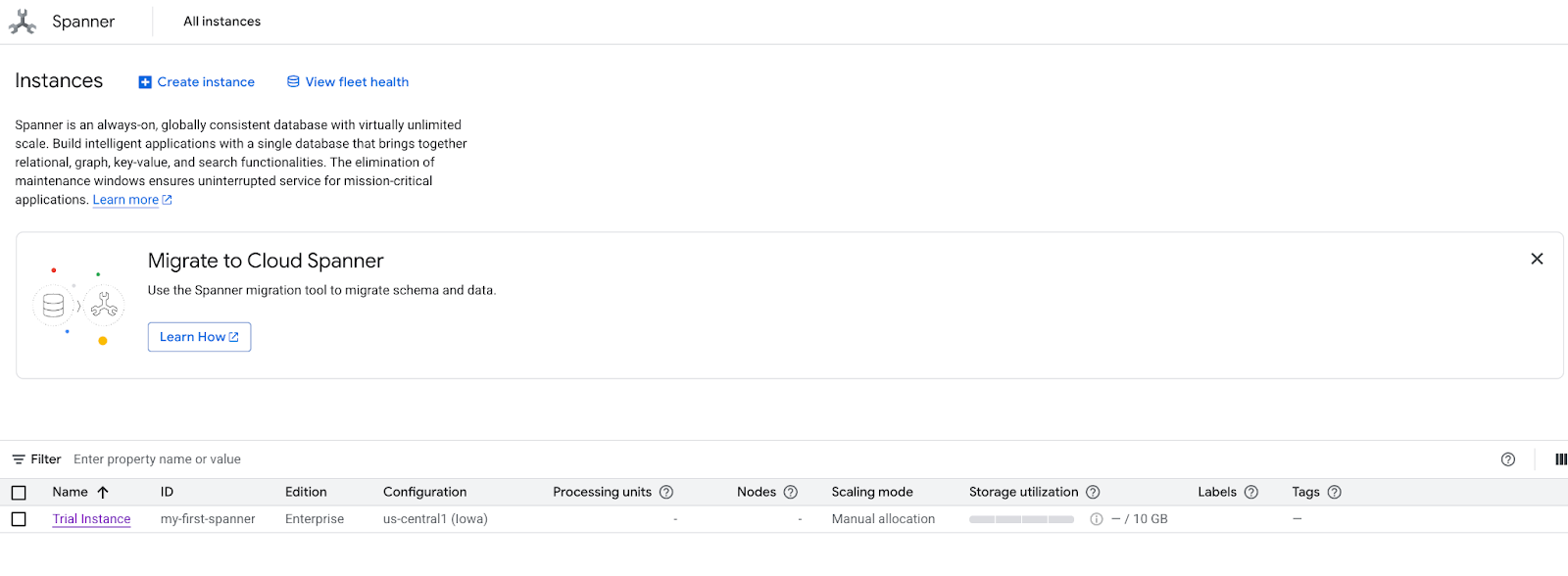
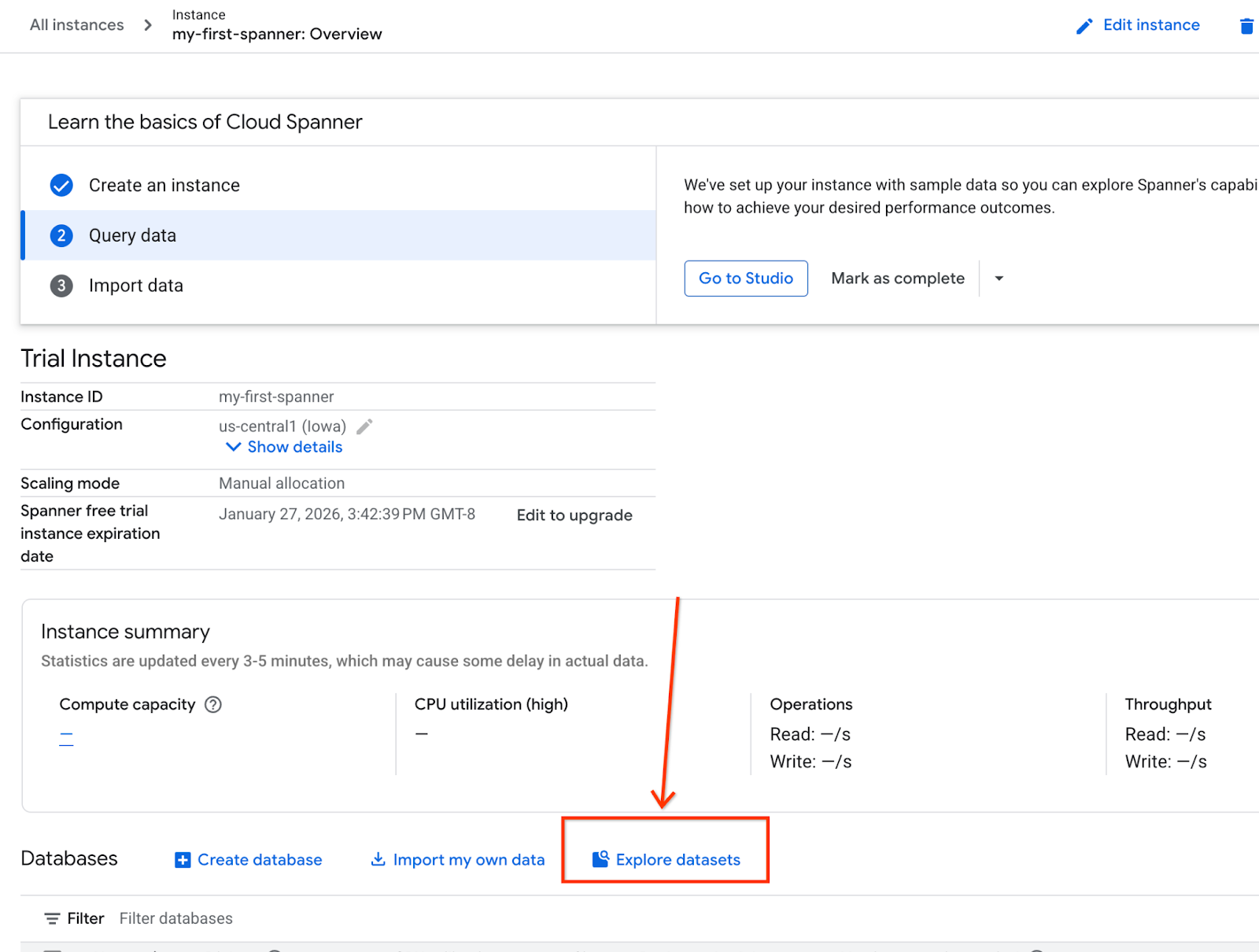
- في الشاشة، اختَر "استكشاف مجموعات البيانات". بعد ذلك، اختَر الخيار "بيع بالتجزئة" في النافذة المنبثقة.
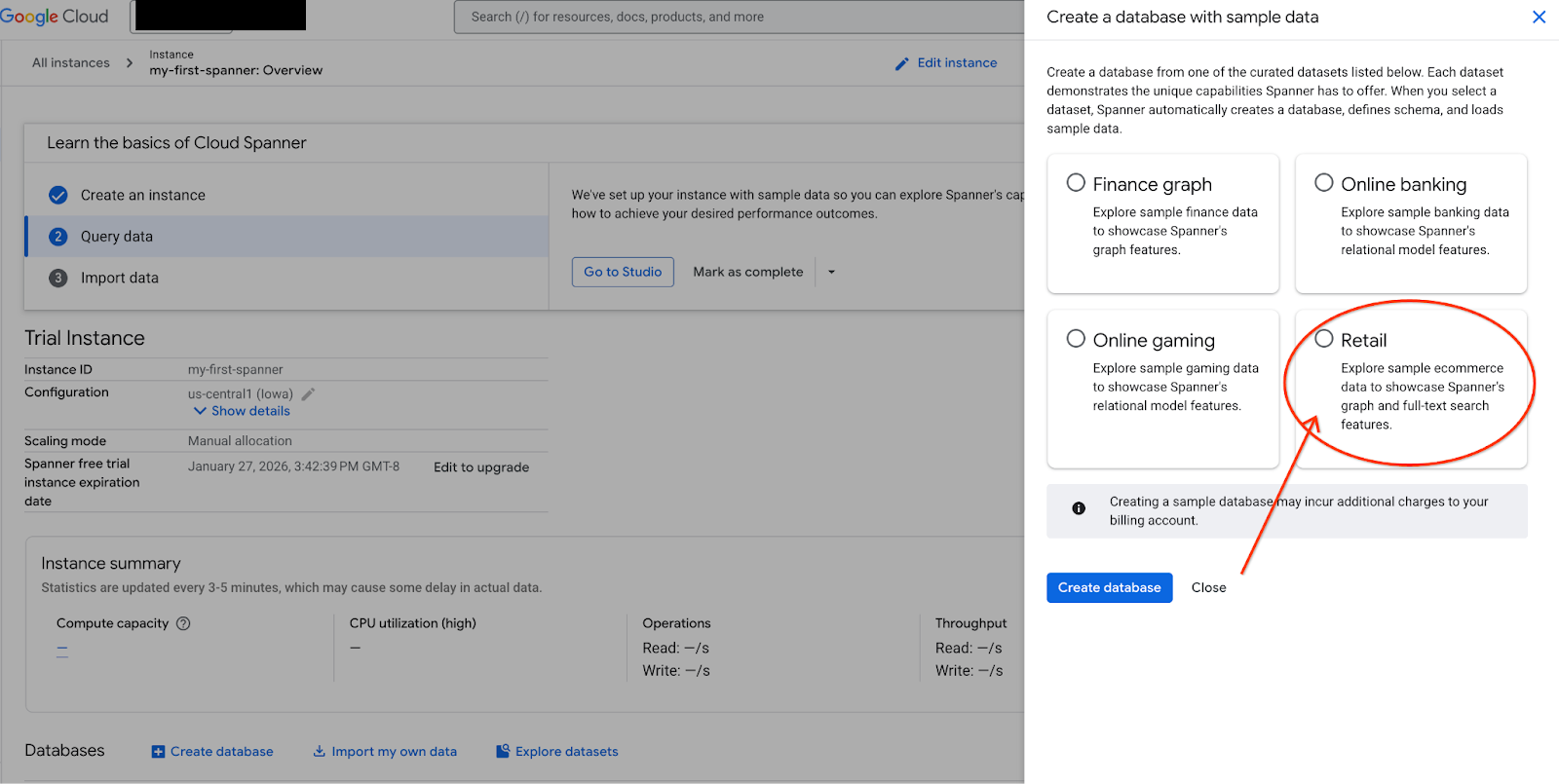
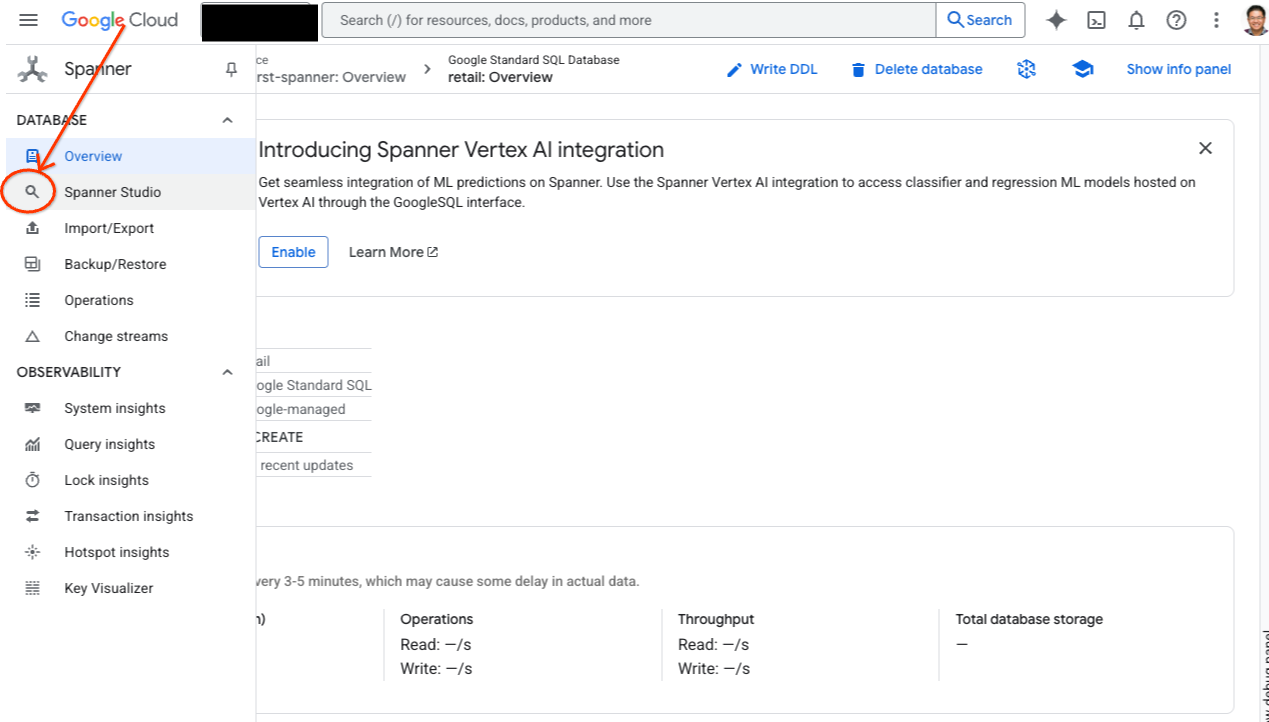
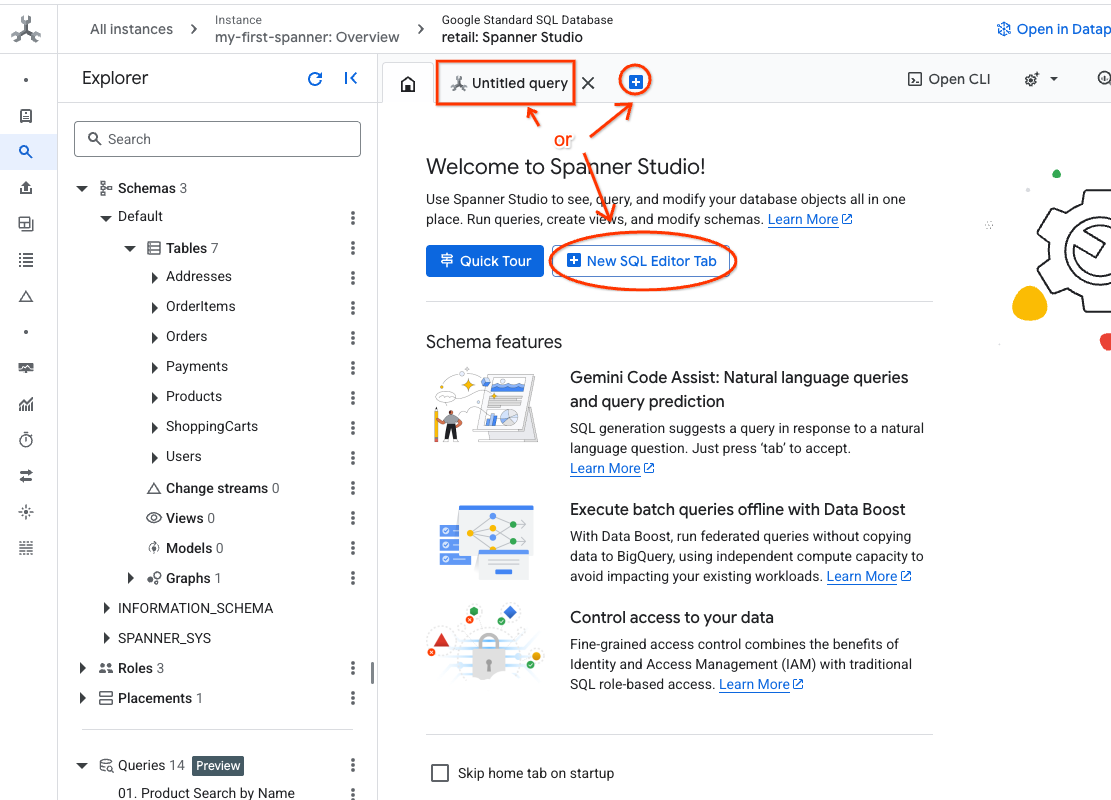
- انتقِل إلى Spanner Studio. يتضمّن Spanner Studio جزء "المستكشف" الذي يتكامل مع محرّر الاستعلامات وجدول نتائج استعلامات SQL. يمكنك تشغيل عبارات DDL وDML وSQL من هذه الواجهة. عليك توسيع القائمة على الجانب، والبحث عن العدسة المكبرة.
- قراءة جدول المنتجات أنشئ علامة تبويب جديدة أو استخدِم علامة التبويب "استعلام بدون عنوان" التي تم إنشاؤها من قبل.
SELECT *
FROM Products;
5- الخطوة 2: إنشاء نماذج الذكاء الاصطناعي
لننشئ الآن النماذج البعيدة باستخدام عناصر Spanner. تنشئ عبارات SQL هذه عناصر Spanner ترتبط بنقاط نهاية Vertex AI.
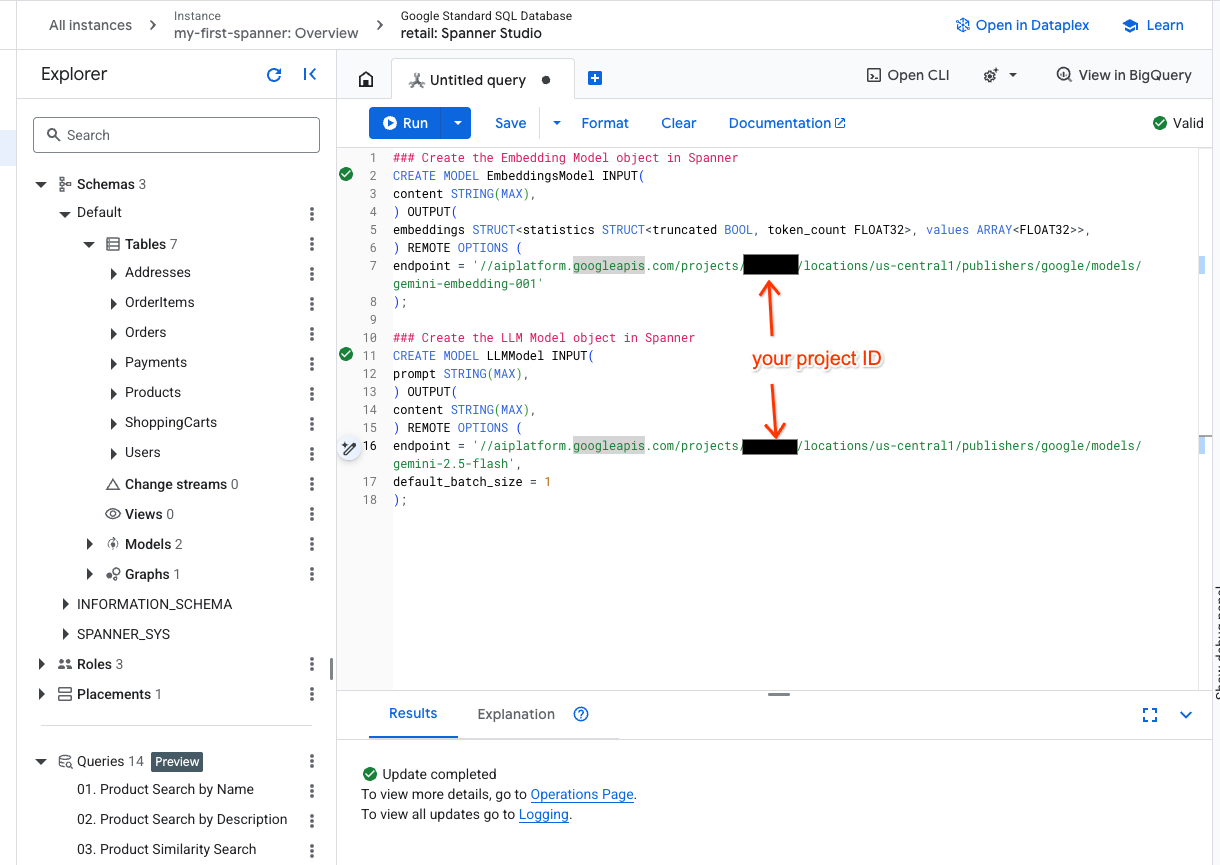
- افتح علامة تبويب جديدة في Spanner Studio وأنشئ النموذجين. الأول هو EmbeddingsModel الذي سيسمح لك بإنشاء تضمينات. الثاني هو LLMModel الذي سيسمح لك بالتفاعل مع نموذج لغوي كبير (في مثالنا، هو gemini-2.5-flash). تأكَّد من تعديل <PROJECT_ID> باستخدام رقم تعريف مشروعك.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- ملاحظة: احرص على استبدال
PROJECT_IDبـ$PROJECT_IDالفعلي.
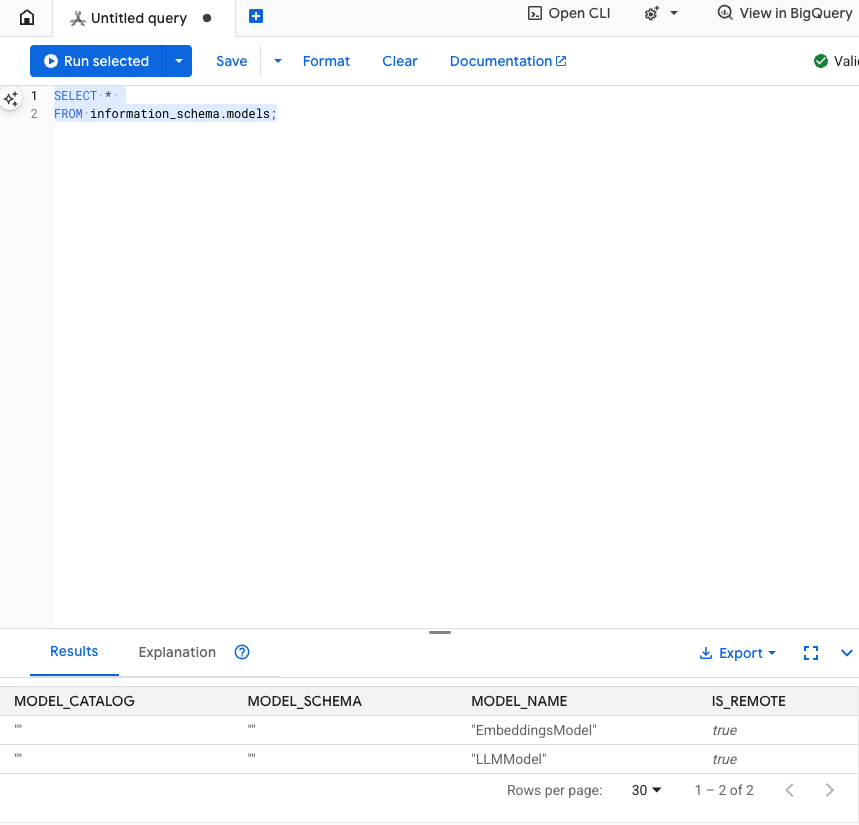
اختبار هذه الخطوة: يمكنك التحقّق من إنشاء النماذج من خلال تنفيذ ما يلي في محرّر SQL.
SELECT *
FROM information_schema.models;
6. الخطوة 3: إنشاء وتخزين التضمينات المتجهة
يحتوي جدول المنتجات على أوصاف نصية، ولكنّ نموذج الذكاء الاصطناعي يفهم المتّجهات (مصفوفات الأرقام). علينا إضافة عمود جديد لتخزين هذه المتجهات ثم ملؤه من خلال تشغيل جميع أوصاف المنتجات باستخدام EmbeddingsModel.
- أنشئ جدولاً جديدًا لتوفير عمليات التضمين. أنشئ أولاً جدولاً يمكنه التعامل مع التضمينات. نستخدم نموذج تضمين مختلفًا عن نماذج التضمين في عيّنة جدول المنتجات. عليك التأكّد من أنّ عمليات التضمين تم إنشاؤها من النموذج نفسه لكي يعمل البحث المتّجه بشكلٍ سليم.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- املأ الجدول الجديد بالتضمينات التي تم إنشاؤها من النموذج. نستخدم هنا عبارة insert into لتبسيط العملية. سيؤدي ذلك إلى نقل نتائج طلب البحث إلى الجدول الذي أنشأته للتوّ.
يجلب بيان SQL أولاً جميع أعمدة النصوص ذات الصلة التي نريد إنشاء تضمينات لها، ثم يدمجها. بعد ذلك، نعرض المعلومات ذات الصلة، بما في ذلك النص الذي استخدمناه. لا يكون ذلك ضروريًا عادةً، ولكنّنا ندرجه حتى تتمكّن من تصوّر النتائج.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
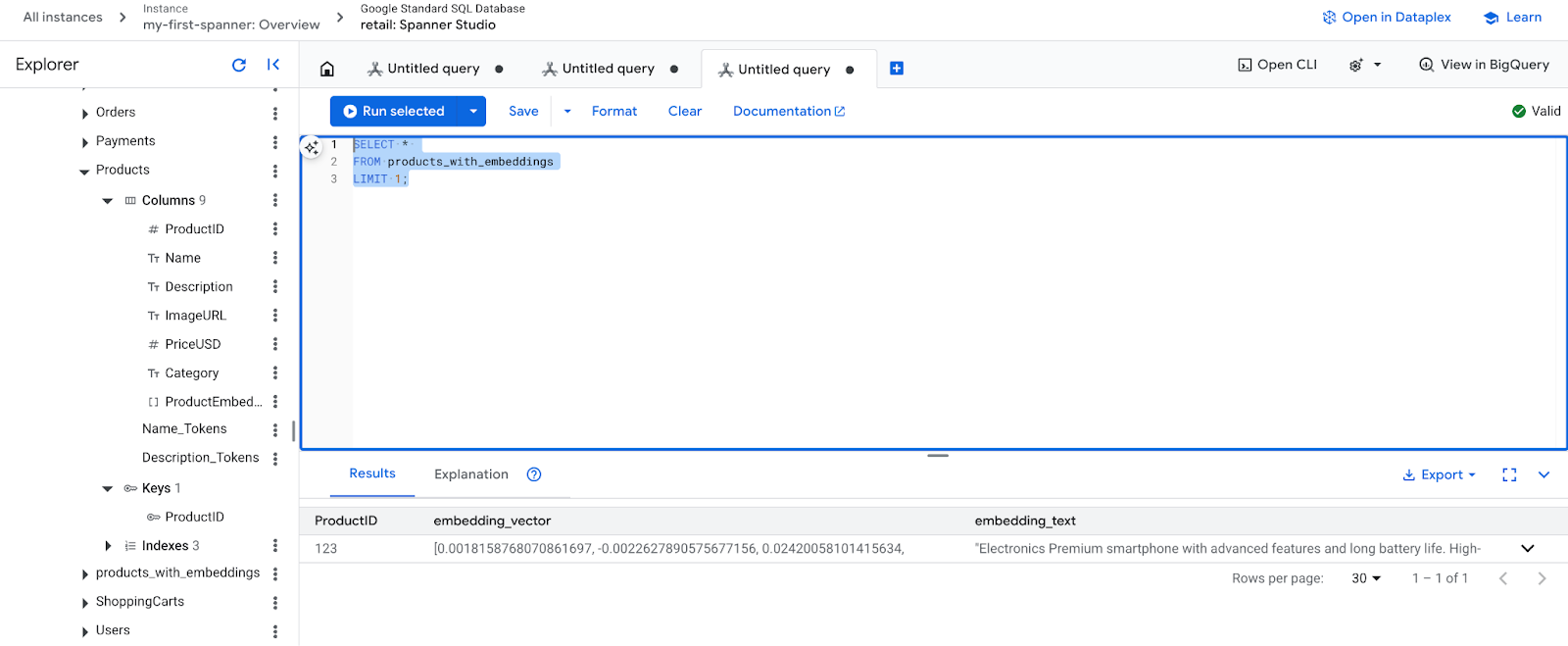
- التحقّق من عمليات التضمين الجديدة: من المفترض أن تظهر لك الآن التضمينات التي تم إنشاؤها.
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. الخطوة 4: إنشاء فهرس متّجه للبحث التقريبي عن أقرب جيران
للبحث عن ملايين المتجهات على الفور، نحتاج إلى فهرس. يتيح هذا الفهرس البحث عن أقرب جيران أقرب (ANN)، وهو سريع للغاية ويمكن توسيعه أفقيًا.
- نفِّذ طلب DDL التالي لإنشاء الفهرس. نحدّد
COSINEكمقياس للمسافة، وهو ممتاز للبحث الدلالي عن النصوص. يُرجى العِلم أنّ عبارة WHERE ضرورية في الواقع لأنّ Spanner سيجعلها شرطًا للطلب.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- يمكنك الاطّلاع على حالة إنشاء الفهرس في علامة التبويب "العمليات".
8. الخطوة 5: العثور على اقتراحات باستخدام البحث عن الجار الأقرب (KNN)
الآن نصل إلى الجانب الشيق! لنبحث عن المنتجات التي تتطابق مع طلب العميل: "أريد شراء لوحة مفاتيح عالية الأداء. أكتب أحيانًا رموزًا برمجية وأنا على الشاطئ، لذا قد يتعرّض هاتفي للبلل".
سنبدأ بالبحث عن K-Nearest Neighbor (KNN). هذا بحث مطابق يقارن بين متّجه طلب البحث ومتّجه كل منتج. وهي دقيقة ولكنّها قد تكون بطيئة عند استخدام مجموعات بيانات كبيرة جدًا (ولهذا السبب أنشأنا فهرس شبكة عصبية تقريبية للخطوة 5).
ينفّذ هذا الاستعلام الإجراءَين التاليَين:
- يستخدم الاستعلام الفرعي ML.PREDICT للحصول على متّجه التضمين الخاص باستعلام العميل.
- يستخدم طلب البحث الخارجي COSINE_DISTANCE لحساب "المسافة" بين متّجه طلب البحث ومتّجه التضمين لكل منتج. كلما كانت المسافة أقصر، كانت المطابقة أفضل.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
من المفترض أن تظهر لك قائمة بالمنتجات، مع لوحات المفاتيح المقاومة للماء في أعلى القائمة.
9- الخطوة 6: العثور على اقتراحات باستخدام البحث التقريبي (ANN)
إنّ البحث عن أقرب جيران (KNN) هو خيار رائع، ولكن بالنسبة إلى نظام إنتاج يتضمّن ملايين المنتجات وآلاف طلبات البحث في الثانية، نحتاج إلى سرعة فهرس البحث التقريبي عن أقرب جيران (ANN).
يتطلّب استخدام الفهرس تحديد الدالة APPROX_COSINE_DISTANCE.
- احصل على التضمين المتّجه للنص كما فعلت أعلاه. ننفّذ عملية ربط متقاطع لنتائج ذلك مع السجلات في جدول products_with_embeddings حتى تتمكّن من استخدامها في الدالة APPROX_COSINE_DISTANCE.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
الناتج المتوقّع: يجب أن تكون النتائج مماثلة أو مشابهة جدًا لاستعلام KNN، ولكن تم تنفيذه بكفاءة أكبر بكثير باستخدام الفهرس. قد لا تلاحظ ذلك في المثال.
10. الخطوة 7: استخدام نموذج لغوي كبير لشرح الاقتراحات
إنّ عرض قائمة بالمنتجات فقط هو أمر جيد، ولكنّ شرح سبب ملاءمتها أو عدم ملاءمتها هو أمر رائع. يمكننا استخدام LLMModel (Gemini) لإجراء ذلك.
يضمّ طلب البحث هذا طلب بحث KNN من الخطوة 4 داخل طلب ML.PREDICT. نستخدم CONCAT لإنشاء طلب للنموذج اللغوي الكبير، ونزوّده بما يلي:
- تعليمات واضحة ("أجِب بـ "نعم" أو "لا" واشرح السبب...").
- استعلام العميل الأصلي
- اسم ووصف كل منتج من المنتجات التي تطابق البحث بشكل كبير
بعد ذلك، يقيّم النموذج اللغوي الكبير كل منتج مقارنةً بطلب البحث ويقدّم ردًا باللغة الطبيعية.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
الناتج المتوقّع: ستحصل على جدول يتضمّن عمودًا جديدًا باسم LLMResponse. يجب أن تكون الاستجابة على النحو التالي: "لا، وإليك السبب: * "مقاوم للماء" ليس "مضادًا للماء". يمكن للوحة المفاتيح "المقاومة للماء" تحمُّل الرذاذ أو الأمطار الخفيفة أو الانسكابات"
11. الخطوة 8: إنشاء "رسم بياني للخصائص"
والآن، لننتقل إلى نوع مختلف من الاقتراحات: "العملاء الذين اشتروا هذا المنتج اشتروا أيضًا..."
هذا طلب بحث يستند إلى علاقة. الأداة المثالية لذلك هي مخطط بياني للعلاقات. تتيح لك خدمة Spanner إنشاء رسم بياني فوق جداولك الحالية بدون تكرار البيانات.
يحدّد بيان DDL هذا الرسم البياني:
- العُقد: جدولا
ProductوUserالعُقد هي الكيانات التي تريد استخلاص علاقة منها، أي تريد معرفة العملاء الذين اشتروا منتجك واشتروا أيضًا منتجات "س ص ع". - الحواف: جدول
Ordersالذي يربطUser(المصدر) بـProduct(الوجهة) باستخدام التصنيف "تم الشراء" توفّر الحواف العلاقة بين المستخدم وما اشتراه.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. الخطوة 9: الجمع بين Vector Search وGraph Queries
هذه هي الخطوة الأكثر فعالية. سنقوم بدمج البحث المستند إلى الذكاء الاصطناعي مع طلبات البحث المستندة إلى الرسوم البيانية في عبارة واحدة للعثور على المنتجات ذات الصلة.
يتم قراءة طلب البحث هذا على ثلاثة أجزاء مفصولة بعلامة NEXT statement، لنقسّمه إلى أقسام.
- أولاً، نعثر على أفضل تطابق باستخدام البحث المتّجه.
- تنشئ الدالة ML.PREDICT عملية تضمين متّجهة من طلب المستخدم النصي باستخدام EmbeddingsModel.
- يحسب الاستعلام COSINE_DISTANCE بين هذا التضمين الجديد وp.embedding_vector المخزّن لكل المنتجات.
- يختار هذا الإجراء منتج bestMatch واحدًا ويعرضه مع الحد الأدنى للمسافة (أعلى تشابه دلالي).
- بعد ذلك، نتنقّل في الرسم البياني بحثًا عن العلاقات.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- يتتبّع طلب البحث هذا المسار من bestMatch إلى عقد Orders الشائعة (المستخدم)، ثم إلى منتجات أخرى تم شراؤها معًا.
- تستبعد هذه الطريقة المنتج الأصلي وتستخدم GROUP BY وCOUNT(1) لتجميع عدد المرات التي يتم فيها شراء السلع معًا.
- تعرض هذه السمة أهم 3 منتجات تم شراؤها معًا (purchasedWith)، ويتم ترتيبها حسب عدد مرات الشراء معًا.
بالإضافة إلى ذلك، نعثر على علاقة طلب المستخدم.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- تنفّذ هذه الخطوة الوسيطة نمط الاجتياز لربط الكيانات الرئيسية: bestMatch وعقدة user:Orders الرابطة والسلعة purchasedWith.
- وهي تربط العلاقة نفسها على وجه التحديد على أنّها تم شراؤها لاستخراج البيانات في الخطوة التالية.
- يضمن هذا النمط تحديد السياق لاسترداد تفاصيل خاصة بالطلب والمنتج.
- أخيرًا، نعرض النتائج التي سيتم إرجاعها، إذ يجب تنسيق عُقد الرسم البياني قبل إرجاعها كنتائج SQL.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
الناتج المتوقّع: ستظهر لك عناصر JSON تمثّل أهم 3 منتجات تم شراؤها معًا، ما يقدّم اقتراحات بشأن بيع منتجات إضافية.
13. تنظيف
لتجنُّب تحمّل رسوم، يمكنك حذف الموارد التي أنشأتها.
- حذف مثيل Spanner: سيؤدي حذف المثيل إلى حذف قاعدة البيانات أيضًا.
gcloud spanner instances delete my-first-spanner --quiet
- حذف مشروع Google Cloud: إذا أنشأت هذا المشروع فقط من أجل جلسة التدريب العملي، فإنّ حذفه هو أسهل طريقة لتنظيفه.
- انتقِل إلى صفحة إدارة الموارد في Google Cloud Console.
- اختَر مشروعك وانقر على حذف.
🎉 تهانينا!
لقد أنشأت بنجاح نظام اقتراحات متطوّرًا في الوقت الفعلي باستخدام Spanner AI وGraph.
لقد تعلّمت كيفية دمج Spanner مع Vertex AI لإنشاء التضمينات والنماذج اللغوية الكبيرة، وكيفية إجراء بحث عالي السرعة عن المتّجهات (KNN وANN) للعثور على المنتجات ذات الصلة دلاليًا، وكيفية استخدام طلبات البحث في الرسومات البيانية لاكتشاف العلاقات بين المنتجات. لقد أنشأت نظامًا لا يمكنه العثور على المنتجات فحسب، بل يمكنه أيضًا شرح الاقتراحات واقتراح سلع ذات صلة، وكل ذلك من قاعدة بيانات واحدة قابلة للتوسيع.