
১. ভূমিকা
এই কোডল্যাবটি আপনাকে স্প্যানারের এআই (AI) এবং গ্রাফ সক্ষমতা ব্যবহার করে একটি বিদ্যমান রিটেইল ডেটাবেসকে উন্নত করার পদ্ধতি শেখাবে। আপনি স্প্যানারের মধ্যে মেশিন লার্নিং ব্যবহার করে আপনার গ্রাহকদের আরও ভালোভাবে পরিষেবা দেওয়ার জন্য বাস্তবসম্মত কৌশল শিখবেন। বিশেষত, আমরা গ্রাহকের ব্যক্তিগত চাহিদার সাথে সামঞ্জস্যপূর্ণ নতুন পণ্য খুঁজে বের করার জন্য কে-নিয়ারেস্ট নেইবারস (k-Nearest Neighbors - kNN) এবং অ্যাপ্রক্সিমেট নিয়ারেস্ট নেইবারস (Approximate Nearest Neighbors - ANN) প্রয়োগ করব। এছাড়াও, একটি নির্দিষ্ট পণ্যের সুপারিশ কেন করা হয়েছে তার স্পষ্ট, স্বাভাবিক ভাষার ব্যাখ্যা দেওয়ার জন্য আপনি একটি এলএলএম (LLM) ইন্টিগ্রেট করবেন।
সুপারিশের বাইরে, আমরা স্প্যানারের গ্রাফ কার্যকারিতা নিয়ে বিস্তারিত আলোচনা করব। আপনি গ্রাহকের ক্রয়ের ইতিহাস এবং পণ্যের বিবরণের উপর ভিত্তি করে পণ্যগুলির মধ্যে সম্পর্ক মডেল করতে গ্রাফ কোয়েরি ব্যবহার করবেন। এই পদ্ধতিটি গভীরভাবে সম্পর্কিত আইটেমগুলি খুঁজে বের করতে সাহায্য করে, যা আপনার "গ্রাহকরা আরও কিনেছেন" বা "সম্পর্কিত আইটেম" বৈশিষ্ট্যগুলির প্রাসঙ্গিকতা এবং কার্যকারিতা উল্লেখযোগ্যভাবে উন্নত করে। এই কোডল্যাবের শেষে, আপনি সম্পূর্ণরূপে গুগল ক্লাউড স্প্যানার দ্বারা চালিত একটি ইন্টেলিজেন্ট, স্কেলেবল এবং রেসপন্সিভ রিটেইল অ্যাপ্লিকেশন তৈরি করার দক্ষতা অর্জন করবেন।
দৃশ্যকল্প
আপনি একটি ইলেকট্রনিক্স সরঞ্জাম বিক্রেতা প্রতিষ্ঠানে কাজ করেন। আপনার ই-কমার্স সাইটে Products , Orders এবং OrderItems সহ একটি স্ট্যান্ডার্ড স্প্যানার ডেটাবেস রয়েছে।
একজন গ্রাহক একটি নির্দিষ্ট প্রয়োজন নিয়ে আপনার সাইটে আসেন: "আমি একটি উচ্চ কর্মক্ষমতা সম্পন্ন কিবোর্ড কিনতে চাই। আমি মাঝে মাঝে সমুদ্র সৈকতে কোড করি, তাই এটি ভিজে যেতে পারে।"
আপনার লক্ষ্য হলো স্প্যানারের উন্নত বৈশিষ্ট্যগুলো ব্যবহার করে বুদ্ধিমত্তার সাথে এই অনুরোধটির উত্তর দেওয়া:
- খুঁজুন: ভেক্টর সার্চ ব্যবহার করে সাধারণ কীওয়ার্ড সার্চের বাইরে গিয়ে এমন পণ্য খুঁজুন, যার বিবরণ ব্যবহারকারীর অনুরোধের সাথে অর্থগতভাবে মেলে।
- ব্যাখ্যা করুন: সেরা ম্যাচগুলো বিশ্লেষণ করতে একটি এলএলএম (LLM) ব্যবহার করুন এবং গ্রাহকের আস্থা তৈরির জন্য সুপারিশটি কেন উপযুক্ত, তা ব্যাখ্যা করুন।
- সম্পর্ক স্থাপন করুন: গ্রাফ কোয়েরি ব্যবহার করে এমন অন্যান্য পণ্য খুঁজুন যা গ্রাহকরা সেই সুপারিশটির সাথে প্রায়শই কিনেছেন।
২. শুরু করার আগে
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- বিলিং সক্ষম করুন। আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং সক্ষম করা আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং সক্ষম আছে কিনা তা কীভাবে পরীক্ষা করবেন তা জানুন।
- কনসোলে থাকা 'Activate Cloud Shell' বোতামে ক্লিক করে ক্লাউড শেল সক্রিয় করুন। আপনি ক্লাউড শেল টার্মিনাল এবং এডিটরের মধ্যে টগল করতে পারবেন।

- অনুমোদন করুন এবং প্রজেক্ট সেট করুন। ক্লাউড শেলে সংযুক্ত হওয়ার পর, যাচাই করুন যে আপনি প্রমাণীকৃত এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে।
gcloud auth list
gcloud config list project
- আপনার প্রজেক্ট সেট করা না থাকলে, এটি সেট করতে নিম্নলিখিত কমান্ডটি ব্যবহার করুন, যেখানে
<PROJECT_ID>এর জায়গায় আপনার আসল প্রজেক্ট আইডি বসান:
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- প্রয়োজনীয় এপিআইগুলো সক্রিয় করুন। স্প্যানার, ভার্টেক্স এআই, এবং কম্পিউট ইঞ্জিন এপিআইগুলো সক্রিয় করুন। এতে কয়েক মিনিট সময় লাগতে পারে।
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- কয়েকটি এনভায়রনমেন্ট ভেরিয়েবল সেট করুন যেগুলো আপনি পুনরায় ব্যবহার করবেন।
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- আপনার যদি আগে থেকে কোনো স্প্যানার ইনস্ট্যান্স না থাকে, তবে একটি ফ্রি ট্রায়াল স্প্যানার ইনস্ট্যান্স তৈরি করুন । আপনার ডাটাবেস হোস্ট করার জন্য একটি স্প্যানার ইনস্ট্যান্সের প্রয়োজন হবে। আমরা কনফিগারেশন হিসেবে
regional-us-central1ব্যবহার করব। আপনি চাইলে এটি আপডেট করতে পারেন।
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
৩. স্থাপত্যের সংক্ষিপ্ত বিবরণ
ভার্টেক্স এআই-তে হোস্ট করা মডেলগুলো ছাড়া স্প্যানার সমস্ত প্রয়োজনীয় কার্যকারিতা অন্তর্ভুক্ত করে।
৪. ধাপ ১: ডাটাবেস সেট আপ করুন এবং আপনার প্রথম কোয়েরি জমা দিন।
প্রথমে, আমাদের ডেটাবেস তৈরি করতে হবে, আমাদের নমুনা খুচরা ডেটা লোড করতে হবে এবং ভার্টেক্স এআই-এর সাথে কীভাবে যোগাযোগ করতে হবে তা স্প্যানারকে জানাতে হবে।
এই অংশের জন্য, আপনি নিচের SQL স্ক্রিপ্টগুলো ব্যবহার করবেন।
- স্প্যানারের প্রোডাক্ট পেজে যান।
- সঠিক দৃষ্টান্তটি নির্বাচন করুন।
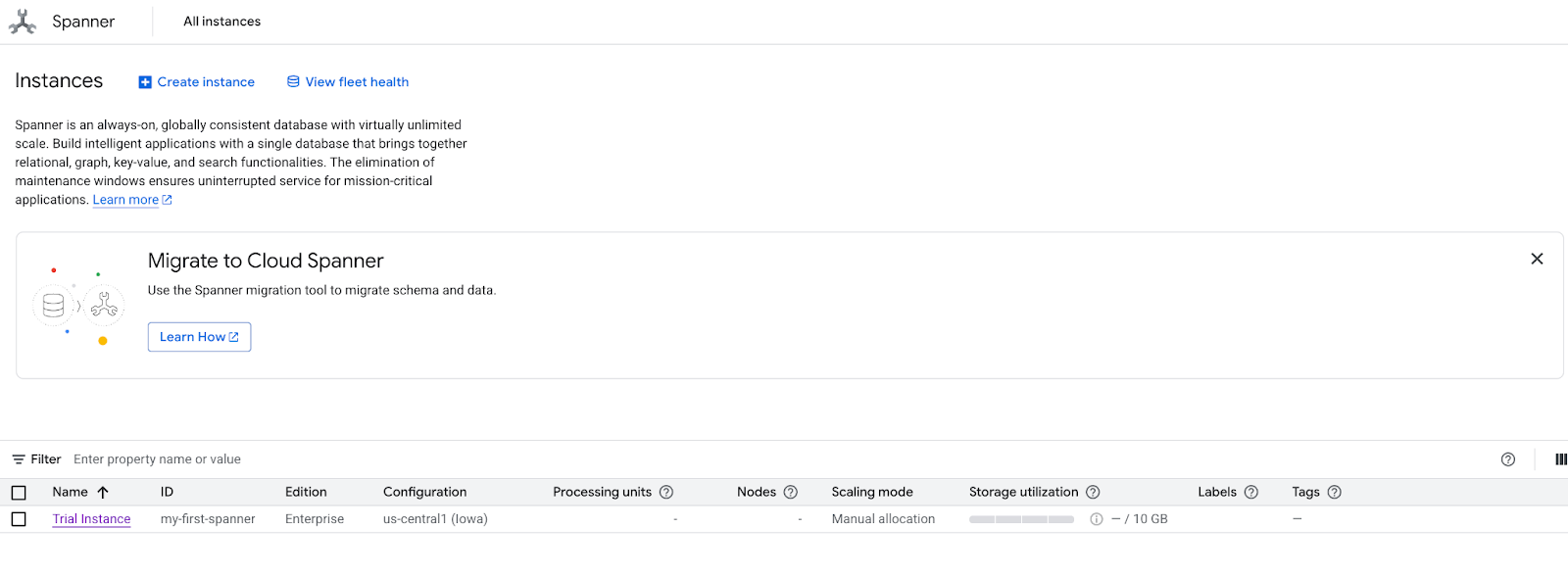
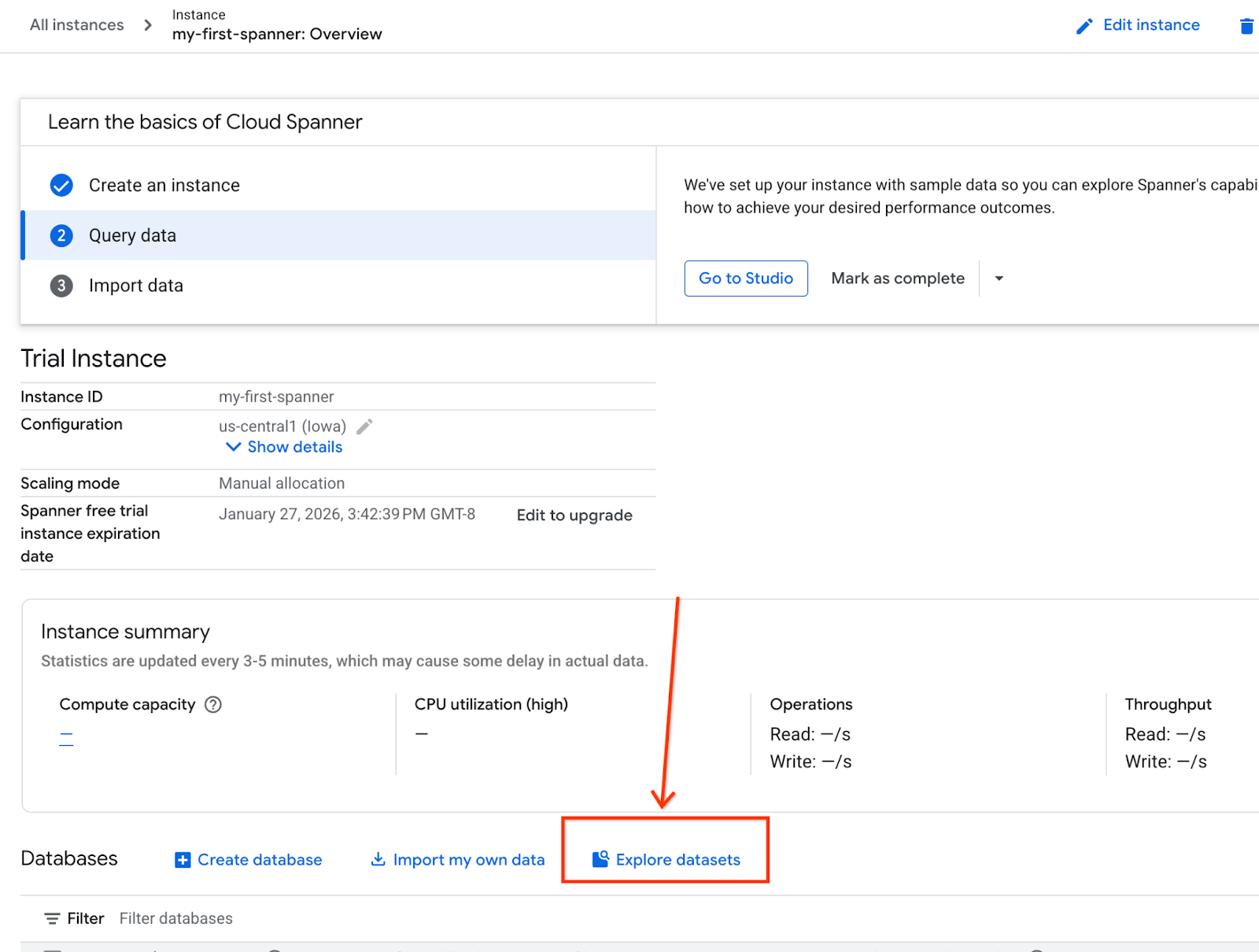
- স্ক্রিনে, ‘Explore Datasets’ নির্বাচন করুন। তারপর পপ-আপে ‘Retail’ বিকল্পটি নির্বাচন করুন।
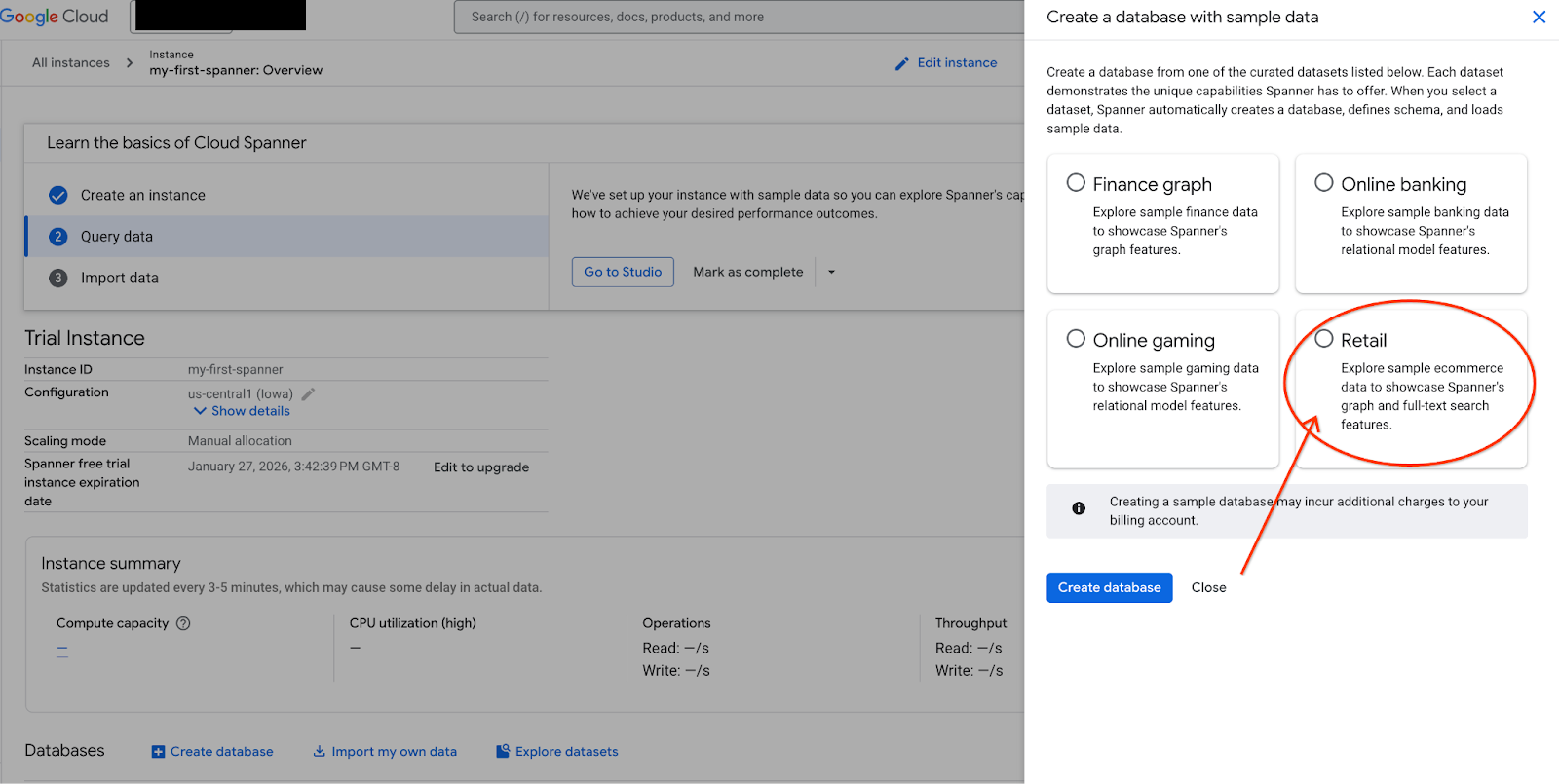
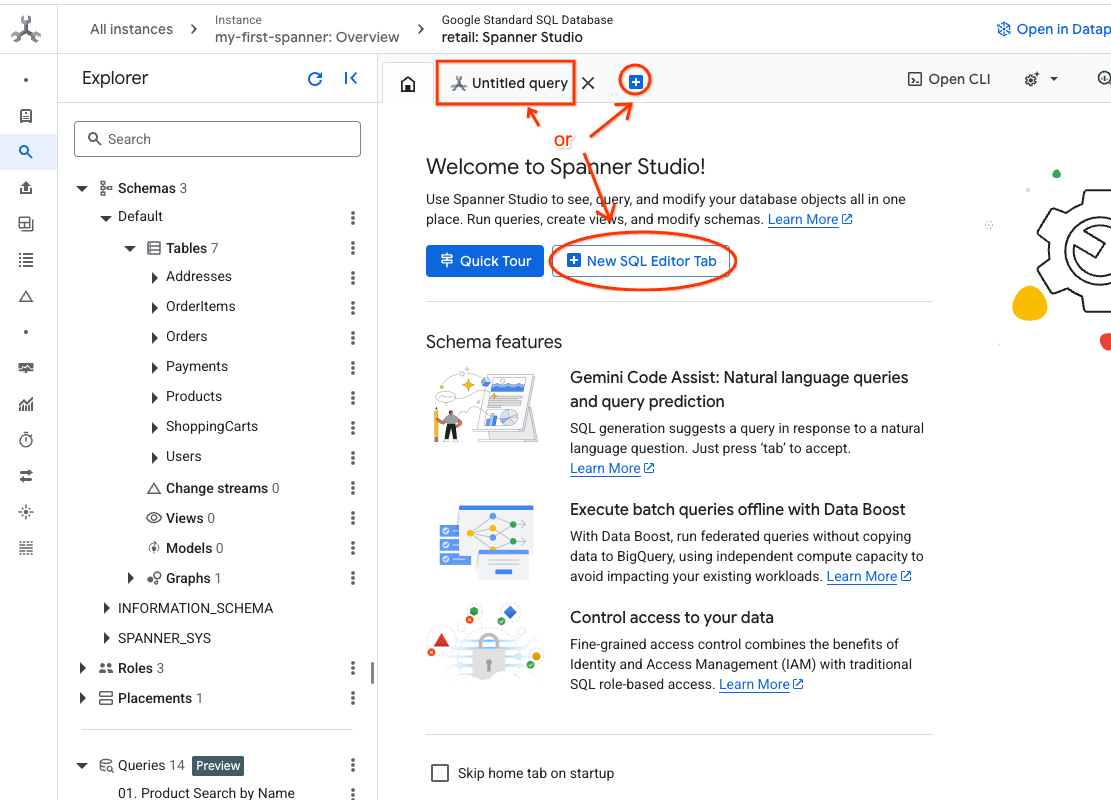
- স্প্যানার স্টুডিওতে যান। স্প্যানার স্টুডিওতে একটি এক্সপ্লোরার পেইন রয়েছে যা একটি কোয়েরি এডিটর এবং একটি SQL কোয়েরি রেজাল্ট টেবিলের সাথে সংযুক্ত। আপনি এই একটি ইন্টারফেস থেকেই DDL, DML, এবং SQL স্টেটমেন্ট চালাতে পারবেন। আপনাকে পাশের মেনুটি এক্সপ্যান্ড করতে হবে এবং ম্যাগনিফাইং গ্লাসটি খুঁজতে হবে।
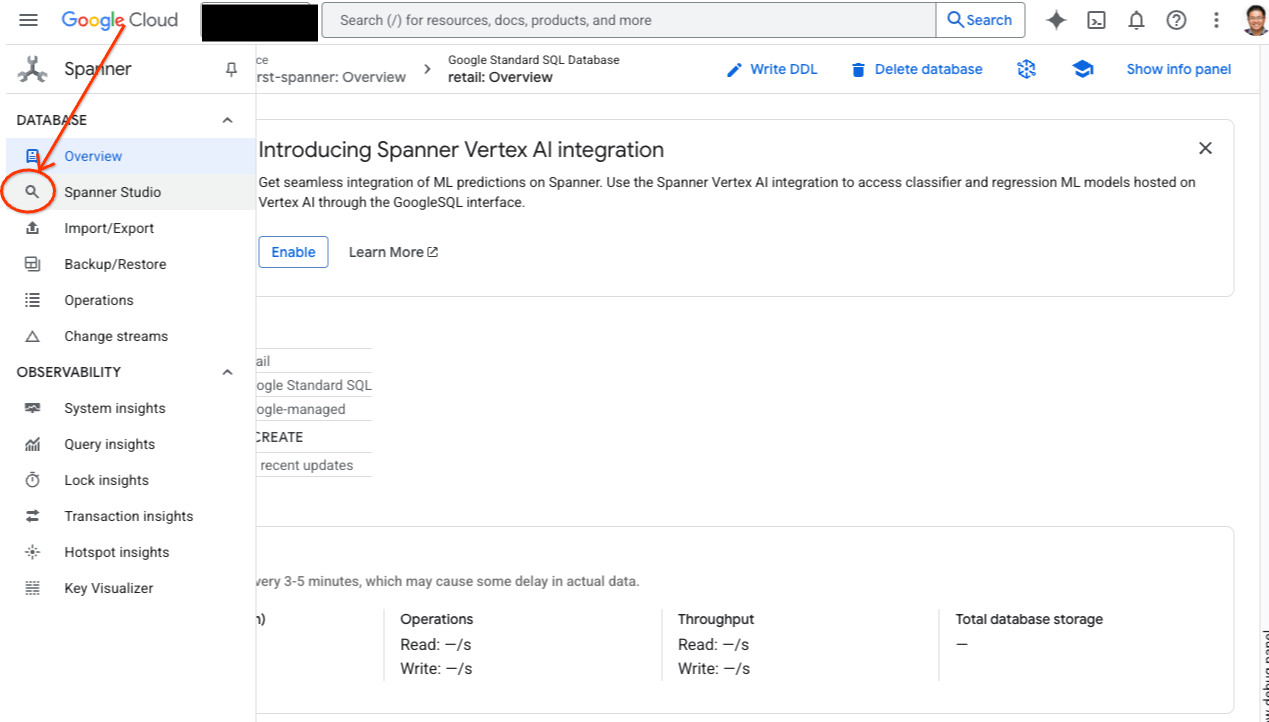
- Products টেবিলটি পড়ুন। একটি নতুন ট্যাব তৈরি করুন অথবা আগে থেকে তৈরি থাকা 'Untitled query' ট্যাবটি ব্যবহার করুন।
SELECT *
FROM Products;
৫. ধাপ ২: এআই মডেলগুলো তৈরি করুন।
এখন, স্প্যানার অবজেক্ট ব্যবহার করে রিমোট মডেলগুলো তৈরি করা যাক। এই SQL স্টেটমেন্টগুলো স্প্যানার অবজেক্ট তৈরি করে, যা ভার্টেক্স এআই এন্ডপয়েন্টগুলোর সাথে লিঙ্ক করা থাকে।
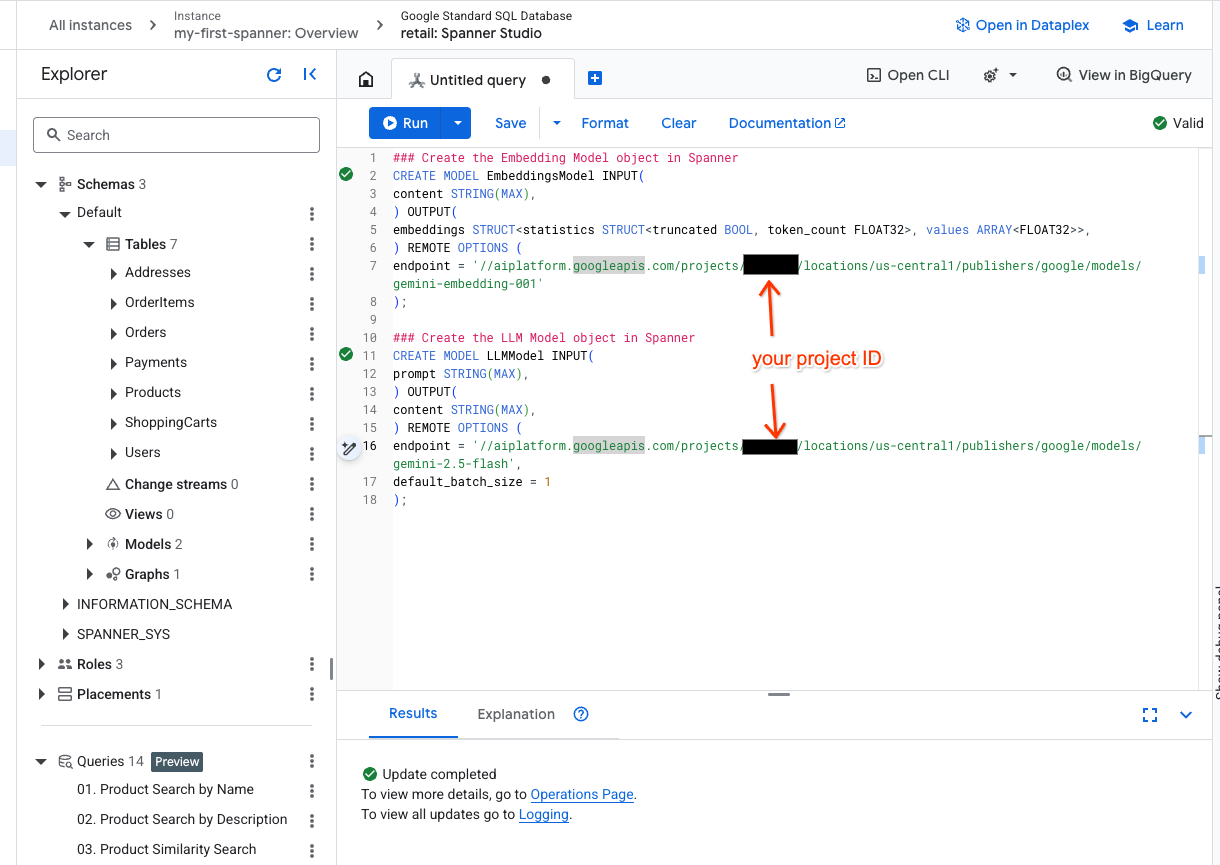
- স্প্যানার স্টুডিওতে একটি নতুন ট্যাব খুলুন এবং আপনার দুটি মডেল তৈরি করুন। প্রথমটি হলো EmbeddingsModel, যা আপনাকে এমবেডিং তৈরি করতে দেবে। দ্বিতীয়টি হলো LLMModel, যা আপনাকে একটি LLM-এর সাথে ইন্টারঅ্যাক্ট করতে দেবে (আমাদের উদাহরণে, এটি হলো gemini-2.5-flash)। নিশ্চিত করুন যে আপনি আপনার প্রজেক্ট আইডি দিয়ে <PROJECT_ID> আপডেট করেছেন।
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- দ্রষ্টব্য:
PROJECT_IDজায়গায় আপনার আসল$PROJECT_IDবসাতে মনে রাখবেন।
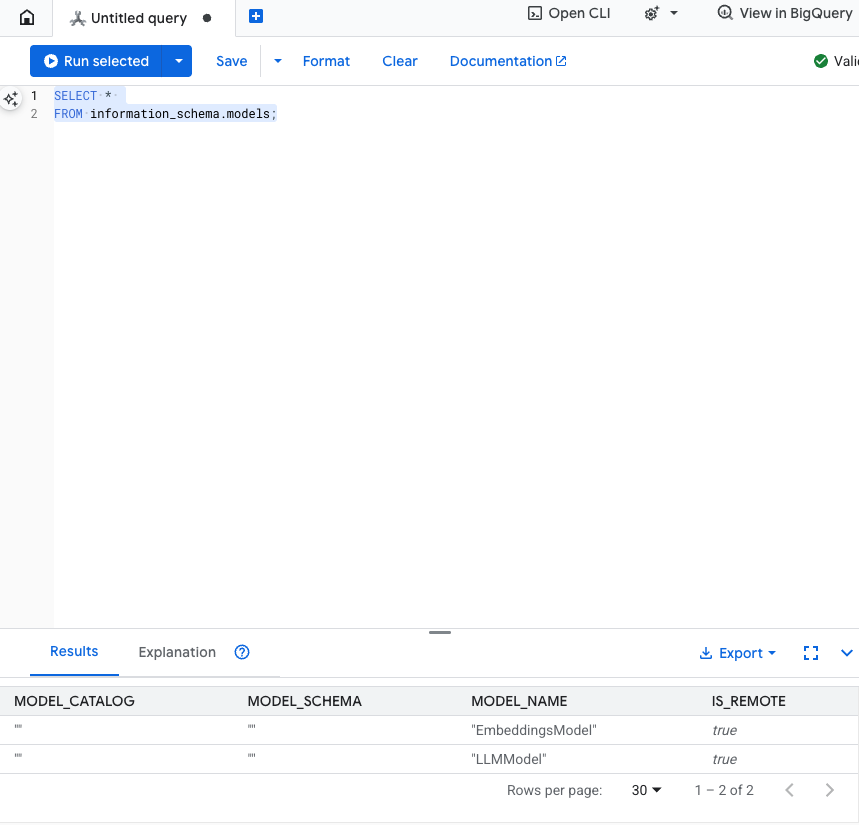
এই ধাপটি পরীক্ষা করুন: SQL এডিটরে নিম্নলিখিতটি চালিয়ে আপনি মডেলগুলো তৈরি হয়েছে কিনা তা যাচাই করতে পারেন।
SELECT *
FROM information_schema.models;
৬. ধাপ ৩: ভেক্টর এমবেডিং তৈরি এবং সংরক্ষণ করুন
আমাদের প্রোডাক্ট টেবিলে টেক্সট ডেসক্রিপশন আছে, কিন্তু এআই মডেল ভেক্টর (সংখ্যার অ্যারে) বোঝে। এই ভেক্টরগুলো সংরক্ষণের জন্য আমাদের একটি নতুন কলাম যোগ করতে হবে এবং তারপর আমাদের সমস্ত প্রোডাক্ট ডেসক্রিপশন EmbeddingsModel-এর মাধ্যমে চালিয়ে কলামটি পূরণ করতে হবে।
- এমবেডিং সমর্থন করার জন্য একটি নতুন টেবিল তৈরি করুন। প্রথমে এমন একটি টেবিল তৈরি করুন যা এমবেডিং সমর্থন করতে পারে। আমরা প্রোডাক্ট টেবিলের স্যাম্পল এমবেডিং থেকে ভিন্ন একটি এমবেডিং মডেল ব্যবহার করছি। ভেক্টর সার্চ সঠিকভাবে কাজ করার জন্য আপনাকে নিশ্চিত করতে হবে যে এমবেডিংগুলো একই মডেল থেকে তৈরি করা হয়েছে।
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- মডেল থেকে তৈরি এমবেডিংগুলো দিয়ে নতুন টেবিলটি পূরণ করুন। এখানে সরলতার জন্য আমরা একটি insert into স্টেটমেন্ট ব্যবহার করছি। এটি আপনার সদ্য তৈরি করা টেবিলটিতে কোয়েরির ফলাফলগুলো পাঠিয়ে দেবে।
SQL স্টেটমেন্টটি প্রথমে সেই সমস্ত প্রাসঙ্গিক টেক্সট কলামগুলো সংগ্রহ করে এবং একত্রিত করে, যেগুলোর ওপর ভিত্তি করে আমরা এমবেডিং তৈরি করতে চাই। তারপর আমরা ব্যবহৃত টেক্সটসহ প্রাসঙ্গিক তথ্যগুলো ফেরত দিই। সাধারণত এর প্রয়োজন হয় না, কিন্তু আমরা এটি অন্তর্ভুক্ত করি যাতে আপনি ফলাফলগুলো দেখতে পারেন।
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
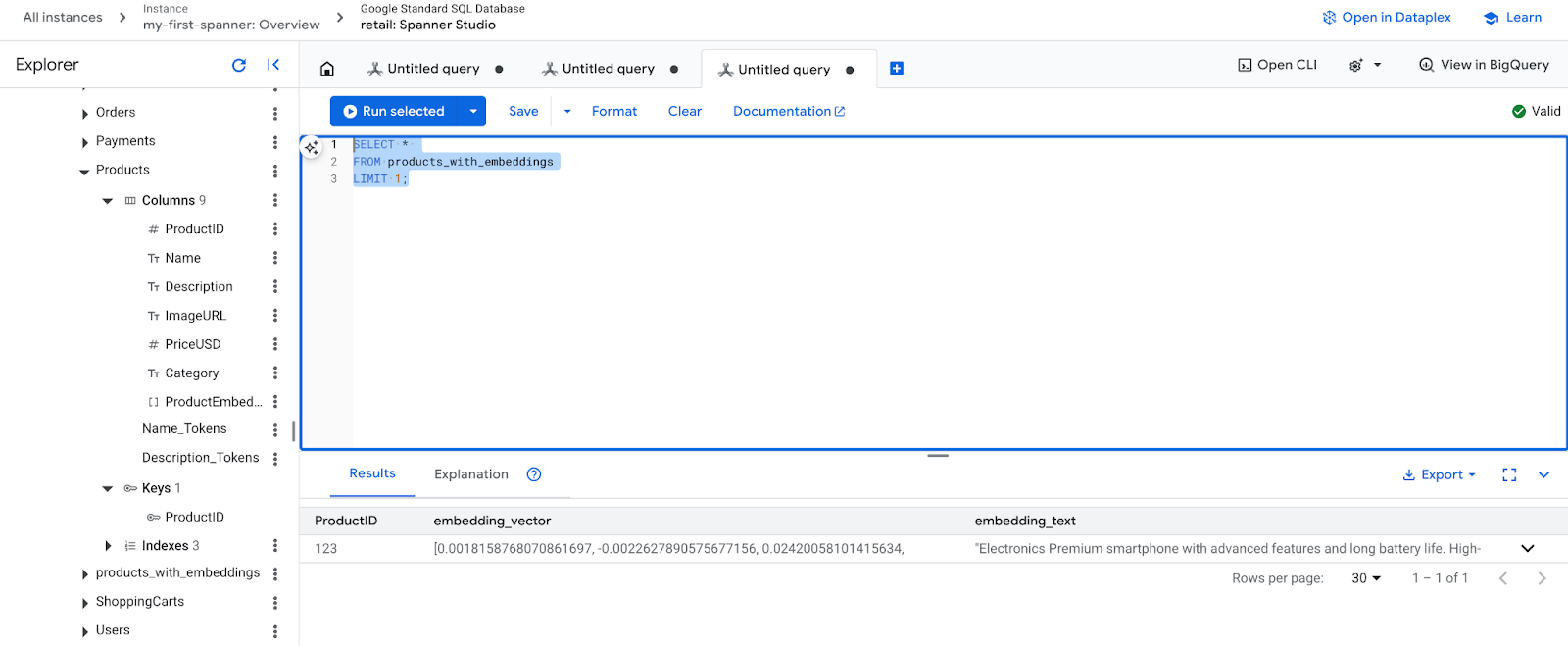
- আপনার নতুন এমবেডিংগুলো পরীক্ষা করুন। এখন আপনি তৈরি হওয়া এমবেডিংগুলো দেখতে পাবেন।
SELECT *
FROM products_with_embeddings
LIMIT 1;
৭. ধাপ ৪: এএনএন অনুসন্ধানের জন্য একটি ভেক্টর সূচক তৈরি করুন
লক্ষ লক্ষ ভেক্টর তাৎক্ষণিকভাবে অনুসন্ধান করার জন্য আমাদের একটি ইনডেক্স প্রয়োজন। এই ইনডেক্স অ্যাপ্রক্সিমেট নিয়ারেস্ট নেইবার (ANN) সার্চকে সক্ষম করে, যা অত্যন্ত দ্রুত এবং আনুভূমিকভাবে সম্প্রসারণযোগ্য।
- ইনডেক্স তৈরি করতে নিম্নলিখিত DDL কোয়েরিটি চালান। আমরা আমাদের ডিসট্যান্স মেট্রিক হিসেবে
COSINEনির্দিষ্ট করেছি, যা সিমান্টিক টেক্সট সার্চের জন্য চমৎকার। উল্লেখ্য যে, WHERE ক্লজটি আসলে প্রয়োজনীয়, কারণ স্প্যানার কোয়েরিটির জন্য এটিকে একটি আবশ্যিক শর্ত করে দেবে।
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- অপারেশনস ট্যাবে আপনার ইনডেক্স তৈরির অবস্থা যাচাই করুন।
৮. ধাপ ৫: কে-নিয়ারেস্ট নেইবার (কেএনএন) সার্চের মাধ্যমে সুপারিশ খুঁজুন।
এবার আসল মজার পালা! চলুন আমাদের গ্রাহকের জিজ্ঞাসার সাথে মেলে এমন পণ্য খুঁজে বের করি: "আমি একটি উচ্চ কর্মক্ষমতা সম্পন্ন কিবোর্ড কিনতে চাই। আমি মাঝে মাঝে সমুদ্র সৈকতে কোড করি, তাই এটি ভিজে যেতে পারে।"
আমরা কে - নিয়ারেস্ট নেইবার ( KNN) সার্চ দিয়ে শুরু করব। এটি একটি নির্ভুল সার্চ যা আমাদের কোয়েরি ভেক্টরকে প্রতিটি প্রোডাক্ট ভেক্টরের সাথে তুলনা করে। এটি সুনির্দিষ্ট, কিন্তু খুব বড় ডেটাসেটের ক্ষেত্রে ধীরগতির হতে পারে (এ কারণেই আমরা ধাপ ৫-এর জন্য একটি এএনএন ইনডেক্স তৈরি করেছিলাম)।
এই কোয়েরিটি দুটি কাজ করে:
- একটি সাবকোয়েরি আমাদের গ্রাহকের কোয়েরির জন্য এমবেডিং ভেক্টর পেতে ML.PREDICT ব্যবহার করে।
- বাইরের কোয়েরিটি কোয়েরি ভেক্টর এবং প্রতিটি পণ্যের এমবেডিং ভেক্টরের মধ্যে 'দূরত্ব' গণনা করতে COSINE_DISTANCE ব্যবহার করে। দূরত্ব যত কম হয়, মিল তত ভালো হয়।
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
আপনি পণ্যগুলির একটি তালিকা দেখতে পাবেন, যার একেবারে শীর্ষে জলরোধী কিবোর্ডগুলি থাকবে।
৯. ধাপ ৬: আনুমানিক (ANN) অনুসন্ধানের মাধ্যমে সুপারিশ খুঁজুন
KNN চমৎকার, কিন্তু লক্ষ লক্ষ পণ্য এবং প্রতি সেকেন্ডে হাজার হাজার কোয়েরি সম্পন্নকারী একটি প্রোডাকশন সিস্টেমের জন্য আমাদের ANN ইনডেক্সের গতি প্রয়োজন।
ইনডেক্সটি ব্যবহার করার জন্য আপনাকে APPROX_COSINE_DISTANCE ফাংশনটি নির্দিষ্ট করতে হবে।
- উপরে যেমন করেছেন, সেভাবেই আপনার টেক্সটের ভেক্টর এমবেডিং বের করুন। আমরা এর ফলাফলকে products_with_embeddings টেবিলের রেকর্ডগুলোর সাথে ক্রস জয়েন করি, যাতে আপনি এটি আপনার APPROX_COSINE_DISTANCE ফাংশনে ব্যবহার করতে পারেন।
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
প্রত্যাশিত আউটপুট: ফলাফলগুলো KNN কোয়েরির অনুরূপ বা হুবহু একই হওয়া উচিত, কিন্তু ইনডেক্স ব্যবহারের ফলে এটি আরও অনেক বেশি দক্ষতার সাথে সম্পাদিত হয়েছে। উদাহরণটিতে আপনি হয়তো এটি লক্ষ্য করবেন না।
১০. ধাপ ৭: সুপারিশসমূহ ব্যাখ্যা করতে এলএলএম ব্যবহার করুন
শুধু পণ্যের তালিকা দেখানো ভালো, কিন্তু কেন এটি উপযুক্ত বা অনুপযুক্ত, তা ব্যাখ্যা করা আরও ভালো। আমরা আমাদের LLMModel (Gemini) ব্যবহার করে এটি করতে পারি।
এই কোয়েরিটি আমাদের ধাপ ৪-এর KNN কোয়েরিটিকে একটি ML.PREDICT কলের ভিতরে স্থাপন করে। আমরা LLM-এর জন্য একটি প্রম্পট তৈরি করতে CONCAT ব্যবহার করি, এবং এটিকে দিই:
- একটি স্পষ্ট নির্দেশনা ("'হ্যাঁ' বা 'না'-তে উত্তর দাও এবং কারণ ব্যাখ্যা করো...")।
- গ্রাহকের মূল জিজ্ঞাসা।
- সর্বাধিক মিলে যাওয়া প্রতিটি পণ্যের নাম ও বিবরণ।
এরপর এলএলএম কোয়েরির সাপেক্ষে প্রতিটি পণ্য মূল্যায়ন করে এবং স্বাভাবিক ভাষায় একটি প্রতিক্রিয়া প্রদান করে।
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
প্রত্যাশিত আউটপুট: আপনি একটি নতুন LLMResponse কলাম সহ একটি টেবিল পাবেন। প্রতিক্রিয়াটি এইরকম হওয়া উচিত: " না। কারণটা হলো: * "Water-resistant" (জল-প্রতিরোধী) মানে "waterproof" (জলরোধী) নয়। একটি "water-resistant" (জল-প্রতিরোধী) কীবোর্ড ছিটে আসা জল, হালকা বৃষ্টি বা পড়ে যাওয়া তরল সামলাতে পারে।"
১১. ধাপ ৮: একটি প্রপার্টি গ্রাফ তৈরি করুন
এবার অন্য ধরনের একটি সুপারিশ: "যেসব গ্রাহক এটি কিনেছেন, তাঁরা আরও কিনেছেন..."
এটি একটি সম্পর্ক-ভিত্তিক কোয়েরি। এর জন্য সবচেয়ে উপযুক্ত টুল হলো একটি প্রপার্টি গ্রাফ । স্প্যানার আপনাকে ডেটার পুনরাবৃত্তি না করেই আপনার বিদ্যমান টেবিলগুলোর উপরে একটি গ্রাফ তৈরি করতে দেয়।
এই DDL স্টেটমেন্টটি আমাদের গ্রাফকে সংজ্ঞায়িত করে:
- নোড:
ProductএবংUserটেবিল। নোডগুলো হলো সেইসব সত্তা যাদের সাথে আপনি একটি সম্পর্ক স্থাপন করতে চান; আপনি জানতে চান যে, যেসব গ্রাহক আপনার পণ্য কিনেছেন, তারা 'XYZ' পণ্যগুলোও কিনেছেন কি না। - এজ:
Ordersটেবিল, যা একজনUser(উৎস) "ক্রয়কৃত" লেবেলযুক্ত একটিProduct(গন্তব্য) সাথে সংযুক্ত করে। এই এজগুলো একজন ব্যবহারকারী এবং তার ক্রয়কৃত পণ্যের মধ্যে সম্পর্ক স্থাপন করে।
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
১২. ধাপ ৯: ভেক্টর সার্চ এবং গ্রাফ কোয়েরি একত্রিত করুন
এটি সবচেয়ে শক্তিশালী পদক্ষেপ। আমরা সম্পর্কিত পণ্য খুঁজে বের করার জন্য একটিমাত্র স্টেটমেন্টে এআই ভেক্টর সার্চ এবং গ্রাফ কোয়েরি একত্রিত করব।
এই কোয়েরিটি NEXT statement দ্বারা বিভক্ত তিনটি অংশে পড়া হয়, চলুন এটিকে বিভিন্ন অংশে বিশ্লেষণ করা যাক।
- প্রথমে আমরা ভেক্টর সার্চ ব্যবহার করে সেরা মিলটি খুঁজে বের করি।
- ML.PREDICT, EmbeddingsModel ব্যবহার করে ব্যবহারকারীর টেক্সট কোয়েরি থেকে একটি ভেক্টর এমবেডিং তৈরি করে।
- এই কোয়েরিটি সমস্ত পণ্যের জন্য এই নতুন এমবেডিং এবং সংরক্ষিত p.embedding_vector-এর মধ্যে COSINE_DISTANCE গণনা করে।
- এটি সর্বনিম্ন দূরত্ব (সর্বোচ্চ শব্দার্থিক সাদৃশ্য) সহ একক সেরা ম্যাচ পণ্যটি নির্বাচন করে ফেরত দেয়।
- এরপর আমরা সম্পর্কগুলো খোঁজার জন্য গ্রাফটি পরিভ্রমণ করি।
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- কোয়েরিটি bestMatch থেকে সাধারণ Orders নোড (user) পর্যন্ত ট্র্যাক করে এবং তারপর অন্যান্য purchasedWith প্রোডাক্টগুলোর দিকে ফরোয়ার্ড করে।
- এটি মূল পণ্যটিকে ফিল্টার করে এবং আইটেমগুলি কতবার একসাথে কেনা হয় তা একত্রিত করতে GROUP BY এবং COUNT(1) ব্যবহার করে।
- এটি একত্রে ক্রয়ের পুনরাবৃত্তির হার অনুসারে সাজানো শীর্ষ ৩টি একত্রে ক্রয়কৃত পণ্য (purchasedWith) ফেরত দেয়।
এছাড়াও, আমরা ব্যবহারকারী-অর্ডার সম্পর্কটি খুঁজে পাই।
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- এই মধ্যবর্তী ধাপে মূল সত্তাগুলোকে—bestMatch, সংযোগকারী user:Orders নোড এবং purchasedWith আইটেমকে—বাইন্ড করার জন্য ট্র্যাভার্সাল প্যাটার্নটি কার্যকর করা হয়।
- এটি পরবর্তী ধাপে ডেটা নিষ্কাশনের জন্য ক্রয়কৃত সম্পর্কটিকে সুনির্দিষ্টভাবে আবদ্ধ করে।
- এই প্যাটার্নটি অর্ডার-ভিত্তিক এবং পণ্য-ভিত্তিক বিবরণ আনার জন্য প্রেক্ষাপট প্রতিষ্ঠা করা নিশ্চিত করে।
- অবশেষে, আমরা ফলাফলগুলো আউটপুট করি যা গ্রাফ নোড হিসাবে ফেরত দেওয়া হবে; SQL ফলাফল হিসাবে ফেরত দেওয়ার আগে সেগুলোকে অবশ্যই ফরম্যাট করতে হবে।
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
প্রত্যাশিত আউটপুট: আপনি যৌথভাবে কেনা শীর্ষ ৩টি পণ্যের তালিকা সম্বলিত JSON অবজেক্ট দেখতে পাবেন, যা ক্রস-সেলিংয়ের সুপারিশ প্রদান করবে।
১৩. পরিষ্কার করা
চার্জ এড়ানোর জন্য, আপনি আপনার তৈরি করা রিসোর্সগুলো মুছে ফেলতে পারেন।
- স্প্যানার ইনস্ট্যান্সটি মুছে ফেলুন: ইনস্ট্যান্সটি মুছে ফেললে ডাটাবেসটিও মুছে যাবে।
gcloud spanner instances delete my-first-spanner --quiet
- গুগল ক্লাউড প্রজেক্টটি মুছে ফেলুন: আপনি যদি এই প্রজেক্টটি শুধু কোডল্যাবের জন্য তৈরি করে থাকেন, তবে এটি মুছে ফেলাই সবকিছু পরিষ্কার করার সবচেয়ে সহজ উপায়।
- গুগল ক্লাউড কনসোলের ম্যানেজ রিসোর্সেস পৃষ্ঠায় যান।
- আপনার প্রজেক্টটি নির্বাচন করুন এবং ডিলিট-এ ক্লিক করুন।
🎉 অভিনন্দন!
আপনি স্প্যানার এআই এবং গ্রাফ ব্যবহার করে সফলভাবে একটি অত্যাধুনিক, রিয়েল-টাইম সুপারিশ ব্যবস্থা তৈরি করেছেন!
আপনি শিখেছেন কীভাবে এমবেডিং এবং এলএলএম জেনারেশনের জন্য স্প্যানারকে ভার্টেক্স এআই-এর সাথে ইন্টিগ্রেট করতে হয়, কীভাবে অর্থগতভাবে প্রাসঙ্গিক পণ্য খুঁজে বের করার জন্য দ্রুতগতির ভেক্টর সার্চ (কেএনএন এবং এএনএন) করতে হয়, এবং কীভাবে পণ্যের সম্পর্ক আবিষ্কার করতে গ্রাফ কোয়েরি ব্যবহার করতে হয়। আপনি এমন একটি সিস্টেম তৈরি করেছেন যা কেবল পণ্যই খুঁজে বের করে না, বরং একটিমাত্র, স্কেলেবল ডেটাবেস থেকে সুপারিশ ব্যাখ্যা করতে এবং সম্পর্কিত আইটেমও সাজেস্ট করতে পারে ।