
1. Einführung
In diesem Codelab erfahren Sie, wie Sie die KI- und Grafikfunktionen von Spanner verwenden, um eine bestehende Einzelhandelsdatenbank zu optimieren. Sie lernen praktische Techniken kennen, mit denen Sie Machine Learning in Spanner nutzen können, um Ihren Kunden einen besseren Service zu bieten. Konkret werden wir k-Nearest Neighbors (kNN) und Approximate Nearest Neighbors (ANN) implementieren, um neue Produkte zu finden, die den individuellen Kundenanforderungen entsprechen. Außerdem binden Sie ein LLM ein, um klare Erklärungen in natürlicher Sprache dafür zu liefern, warum eine bestimmte Produktempfehlung ausgesprochen wurde.
Neben Empfehlungen werden wir uns auch die Graphfunktionen von Spanner ansehen. Sie verwenden Grafabfragen, um Beziehungen zwischen Produkten auf Grundlage des bisherigen Kaufverhaltens von Kunden und Produktbeschreibungen zu modellieren. So lassen sich eng verwandte Artikel ermitteln, was die Relevanz und Effektivität der Funktionen „Kunden kauften auch“ oder „Ähnliche Artikel“ deutlich verbessert. Am Ende dieses Codelabs haben Sie die erforderlichen Kenntnisse, um eine intelligente, skalierbare und reaktionsfähige Einzelhandelsanwendung zu erstellen, die vollständig auf Google Cloud Spanner basiert.
Szenario
Sie arbeiten für einen Einzelhändler für elektronische Geräte. Ihre E-Commerce-Website hat eine Standard-Spanner-Datenbank mit Products, Orders und OrderItems.
Ein Kunde kommt mit einem bestimmten Bedarf auf Ihre Website: „Ich möchte eine leistungsstarke Tastatur kaufen. Ich programmiere manchmal am Strand, daher kann es nass werden.“
Ihr Ziel ist es, die erweiterten Funktionen von Spanner zu nutzen, um diese Anfrage intelligent zu beantworten:
- Finden:Mit der Vektorsuche können Sie über die einfache Keyword-Suche hinaus Produkte finden, deren Beschreibungen semantisch mit der Anfrage des Nutzers übereinstimmen.
- Erklären:Verwenden Sie ein LLM, um die besten Übereinstimmungen zu analysieren und zu erklären, warum die Empfehlung gut passt. So können Sie das Vertrauen der Kunden stärken.
- In Beziehung setzen:Verwenden Sie Grafabfragen, um andere Produkte zu finden, die Kunden häufig zusammen mit dieser Empfehlung gekauft haben.
2. Hinweis
- Projekt erstellen: Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Abrechnung aktivieren: Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
- Cloud Shell aktivieren: Klicken Sie in der Console auf den Button „Cloud Shell aktivieren“, um Cloud Shell zu aktivieren. Sie können zwischen dem Cloud Shell-Terminal und dem Editor wechseln.

- Projekt autorisieren und festlegen: Prüfen Sie nach der Verbindung mit Cloud Shell, ob Sie authentifiziert sind und das Projekt auf Ihre Projekt-ID eingestellt ist.
gcloud auth list
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen. Ersetzen Sie dabei
<PROJECT_ID>durch Ihre tatsächliche Projekt-ID:
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- Erforderliche APIs aktivieren: Aktivieren Sie die APIs für Spanner, Vertex AI und Compute Engine. Dies kann einige Minuten dauern.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Legen Sie einige Umgebungsvariablen fest, die Sie wiederverwenden werden.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- Erstellen Sie eine kostenlose Spanner-Testinstanz, falls Sie noch keine Spanner-Instanz haben . Sie benötigen eine Spanner-Instanz, um Ihre Datenbank zu hosten. Wir verwenden
regional-us-central1als Konfiguration. Sie können diese Einstellung bei Bedarf ändern.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. Architekturübersicht
Spanner umfasst alle erforderlichen Funktionen mit Ausnahme der Modelle, die in Vertex AI gehostet werden.
4. Schritt 1: Datenbank einrichten und erste Anfrage senden
Zuerst müssen wir unsere Datenbank erstellen, unsere Beispiel-Einzelhandelsdaten laden und Spanner mitteilen, wie die Kommunikation mit Vertex AI erfolgen soll.
In diesem Abschnitt verwenden Sie die folgenden SQL-Scripts.
- Rufen Sie die Produktseite von Spanner auf.
- Wählen Sie die richtige Instanz aus.
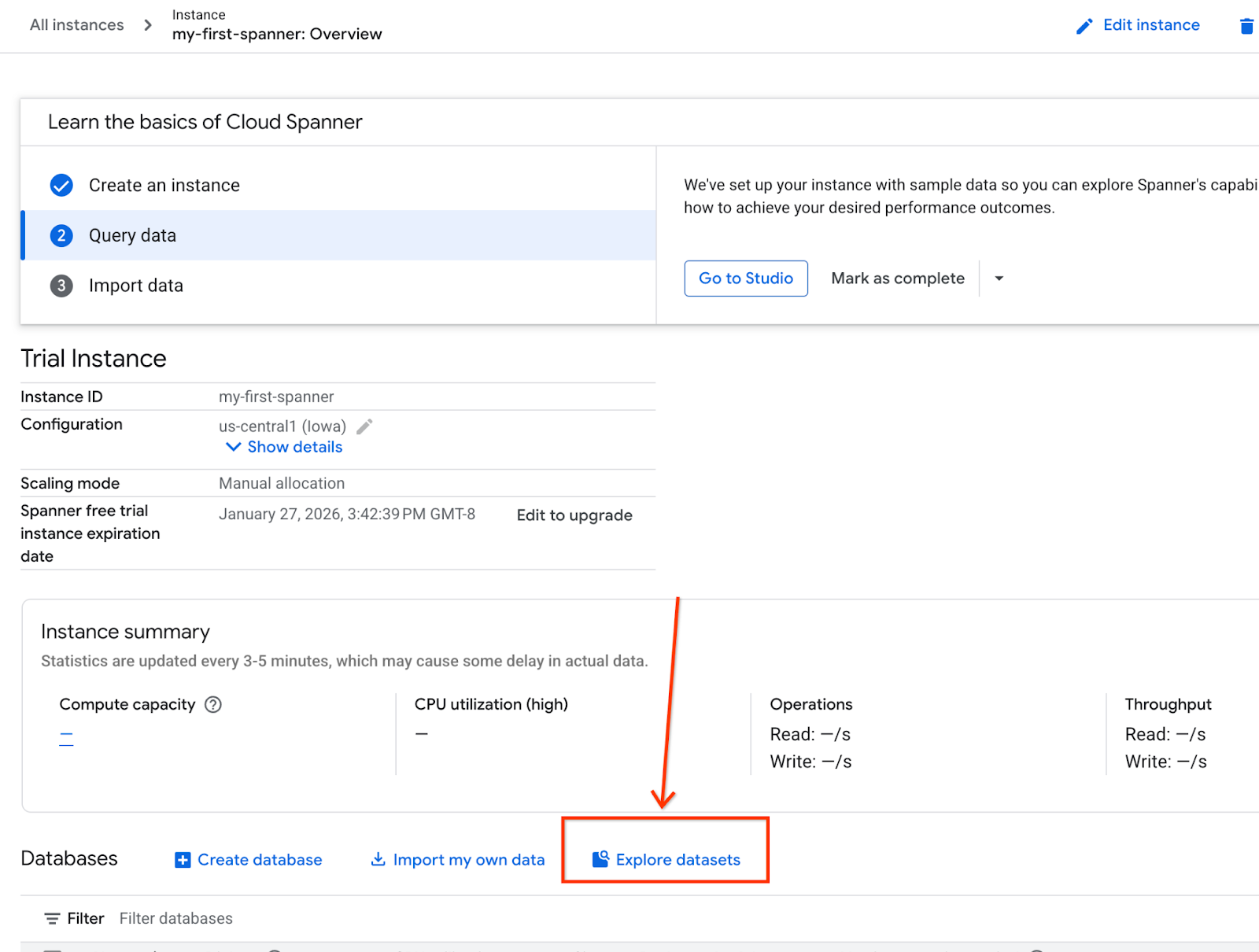
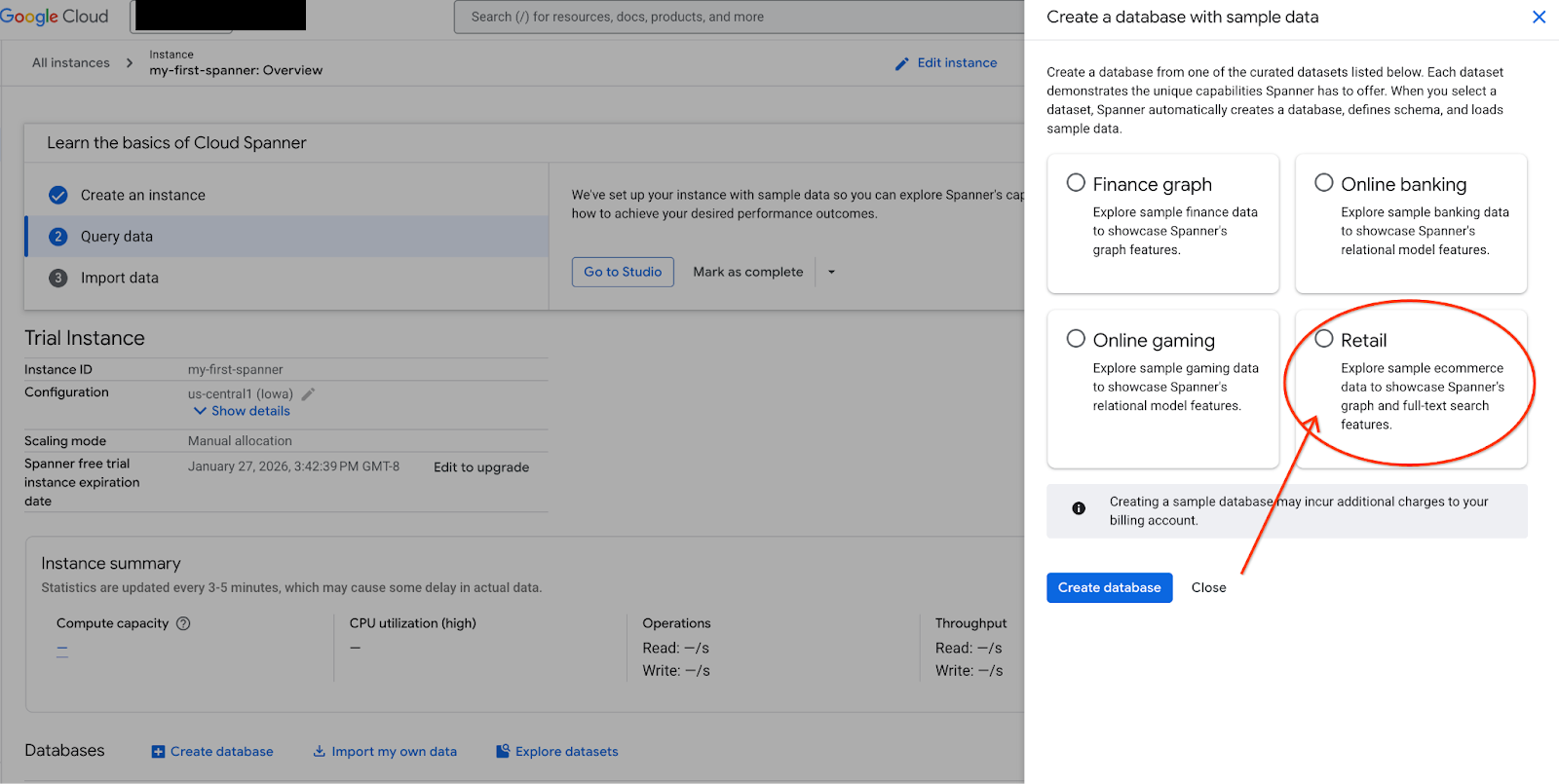
- Wählen Sie auf dem Bildschirm „Datasets untersuchen“ aus. Wählen Sie dann im Pop-up die Option „Einzelhandel“ aus.
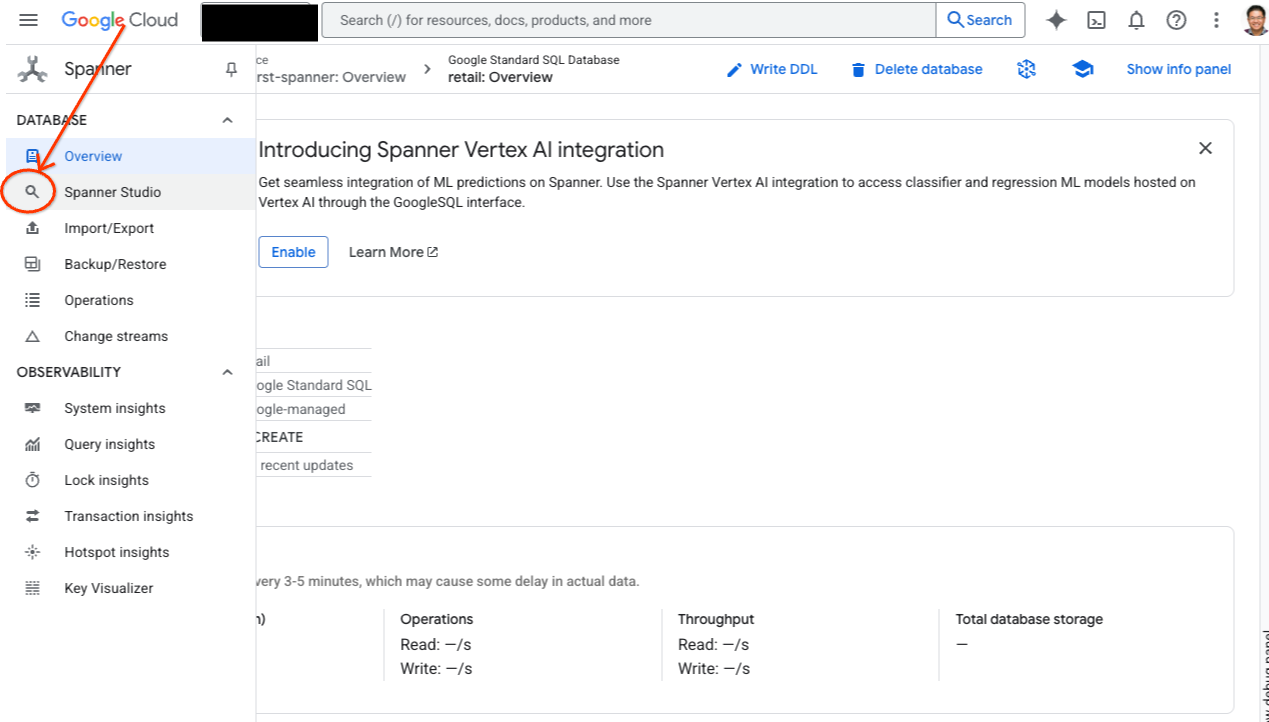
- Spanner Studio aufrufen Spanner Studio enthält den Bereich „Explorer“, der in Abfrageeditoren und Tabellen mit SQL-Abfrageergebnissen eingebunden werden kann. Über diese Schnittstelle können Sie DDL-, DML- und SQL-Anweisungen ausführen. Sie müssen das Menü auf der Seite maximieren und nach der Lupe suchen.
- Produkttabelle lesen Erstellen Sie einen neuen Tab oder verwenden Sie den Tab „Unbenannte Abfrage“.
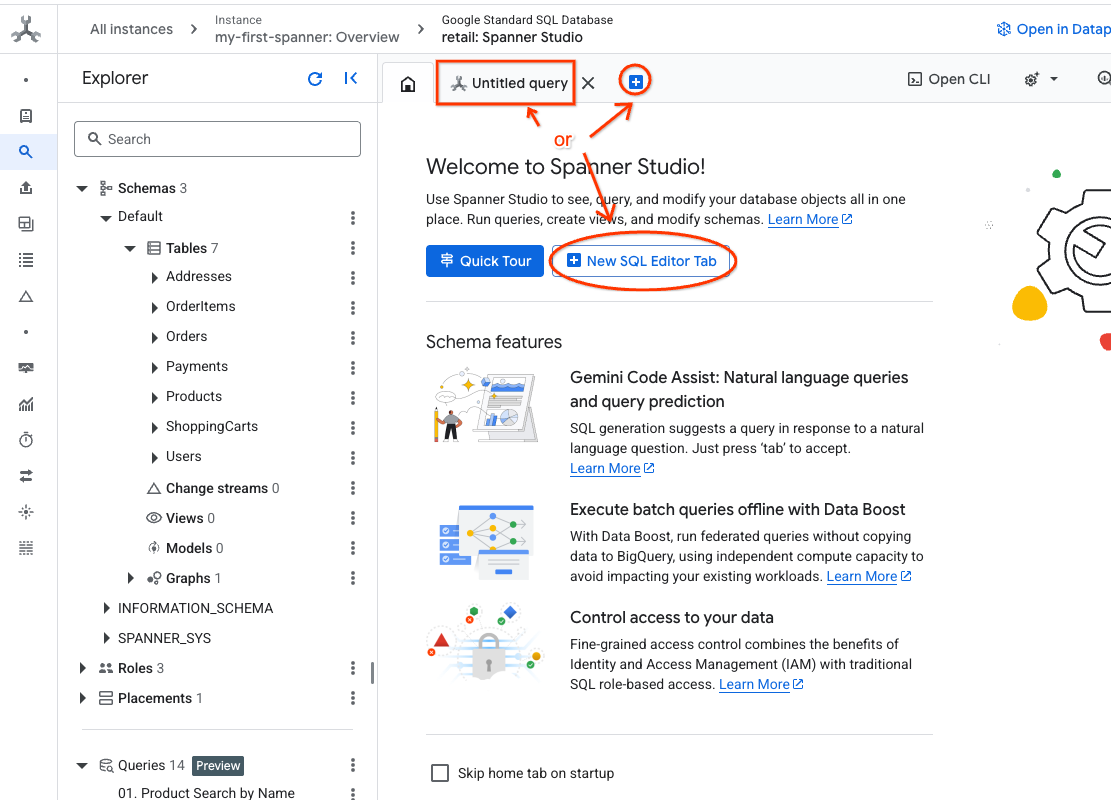
SELECT *
FROM Products;
5. Schritt 2: KI-Modelle erstellen
Erstellen wir nun die Remote-Modelle mit Spanner-Objekten. Mit diesen SQL-Anweisungen werden Spanner-Objekte erstellt, die mit Vertex AI-Endpunkten verknüpft sind.
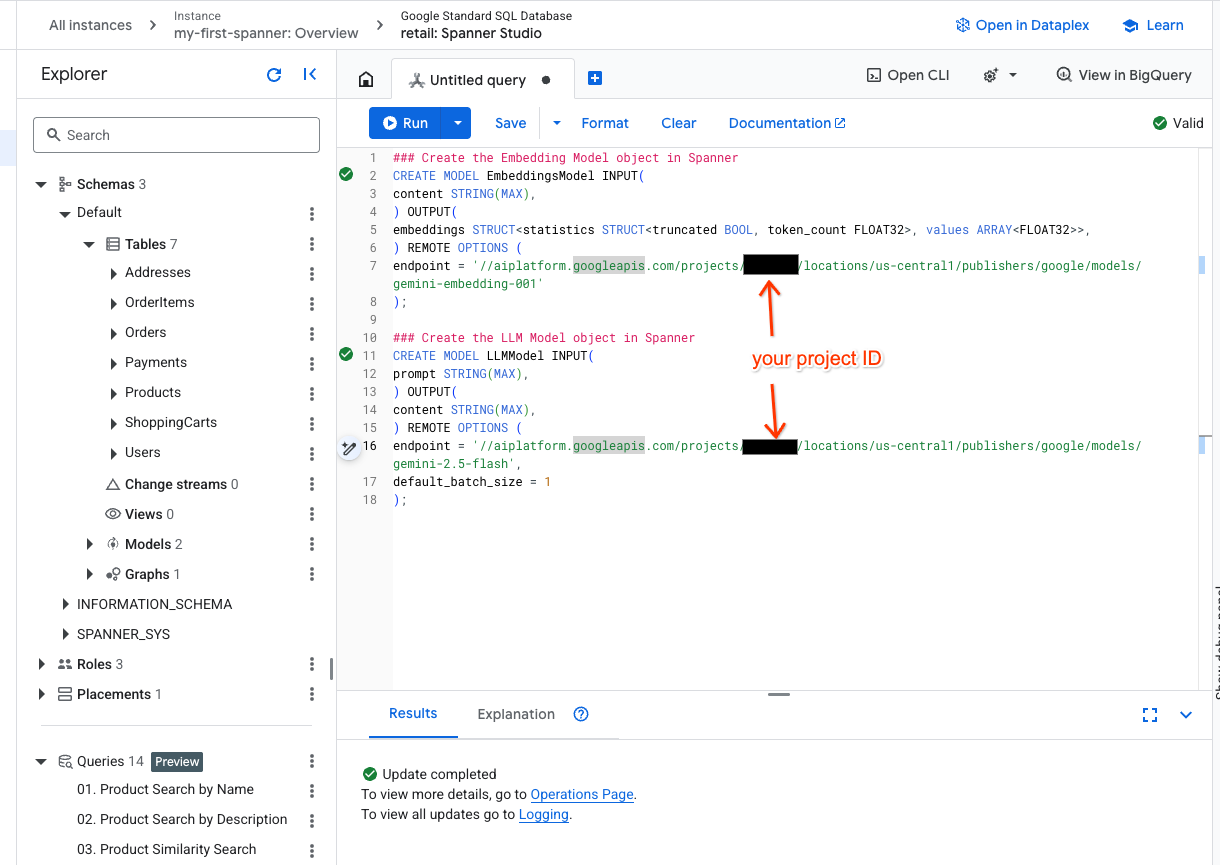
- Öffnen Sie einen neuen Tab in Spanner Studio und erstellen Sie die beiden Modelle. Das erste ist das EmbeddingsModel, mit dem Sie Einbettungen generieren können. Das zweite ist das LLMModel, mit dem Sie mit einem LLM interagieren können (in unserem Beispiel ist es gemini-2.5-flash). Achten Sie darauf, dass Sie <PROJECT_ID> durch Ihre Projekt-ID ersetzt haben.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- Hinweis:Ersetzen Sie
PROJECT_IDdurch Ihre tatsächliche$PROJECT_ID.
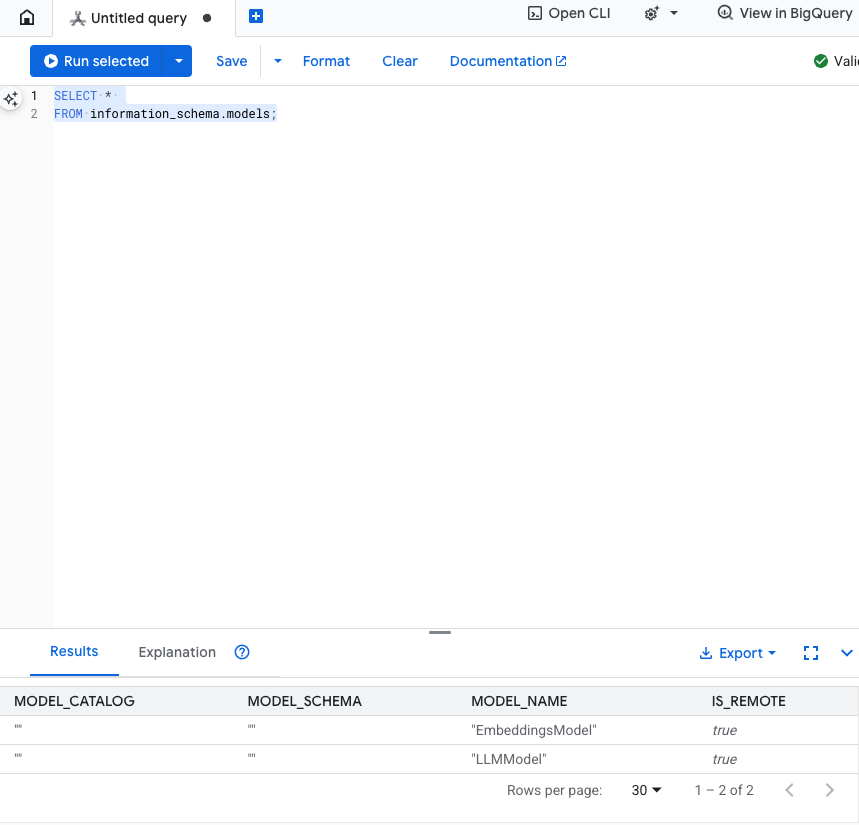
Diesen Schritt testen:Sie können überprüfen, ob die Modelle erstellt wurden, indem Sie Folgendes im SQL-Editor ausführen.
SELECT *
FROM information_schema.models;
6. Schritt 3: Vektoreinbettungen generieren und speichern
Unsere Produkttabelle enthält Textbeschreibungen, das KI-Modell versteht jedoch Vektoren (Arrays von Zahlen). Wir müssen eine neue Spalte hinzufügen, um diese Vektoren zu speichern, und sie dann füllen, indem wir alle unsere Produktbeschreibungen durch das EmbeddingsModel laufen lassen.
- Neue Tabelle zur Unterstützung der Einbettungen erstellen Erstellen Sie zuerst eine Tabelle, die Einbettungen unterstützt. Wir verwenden ein anderes Einbettungsmodell als die Beispiel-Einbettungen in der Produkttabelle. Damit die Vektorsuche richtig funktioniert, müssen die Einbettungen mit demselben Modell generiert worden sein.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- Füllen Sie die neue Tabelle mit den aus dem Modell generierten Einbettungen. Der Einfachheit halber verwenden wir hier eine insert into-Anweisung. Dadurch werden die Abfrageergebnisse in die gerade erstellte Tabelle übertragen.
Mit der SQL-Anweisung werden zuerst alle relevanten Textspalten abgerufen und verkettet, für die wir Einbettungen generieren möchten. Anschließend geben wir die relevanten Informationen zurück, einschließlich des verwendeten Texts. Das ist normalerweise nicht erforderlich, aber wir haben es eingefügt, damit Sie die Ergebnisse visualisieren können.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
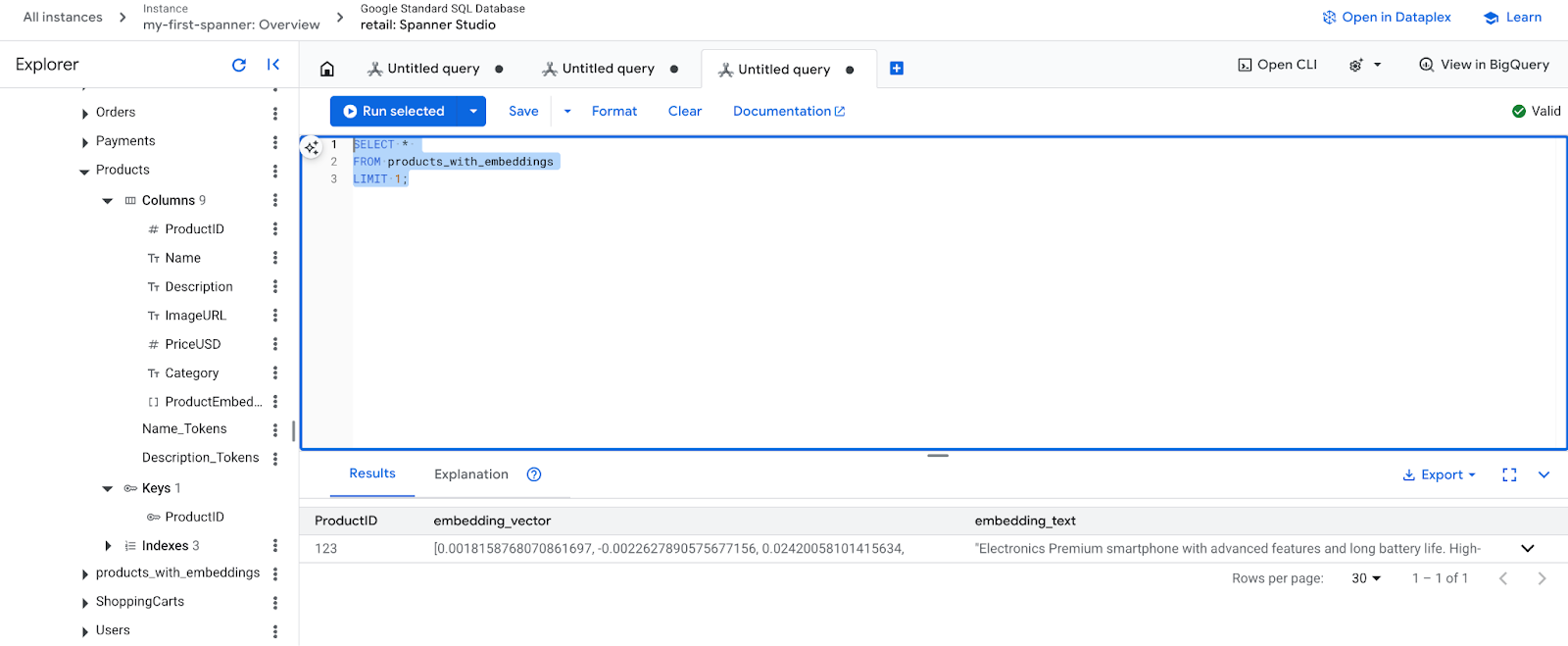
- Neue Einbettungen prüfen: Sie sollten jetzt die generierten Einbettungen sehen.
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. Schritt 4: Vektorindex für die ANN-Suche erstellen
Um Millionen von Vektoren sofort durchsuchen zu können, benötigen wir einen Index. Dieser Index ermöglicht die Approximate Nearest Neighbor (ANN) Search, die unglaublich schnell ist und horizontal skaliert wird.
- Führen Sie die folgende DDL-Abfrage aus, um den Index zu erstellen. Wir geben
COSINEals Distanzmesswert an, der sich hervorragend für die semantische Textsuche eignet. Die WHERE-Klausel ist erforderlich, da Spanner sie für die Abfrage voraussetzt.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- Den Status der Indexerstellung können Sie auf dem Tab „Vorgänge“ prüfen.
8. Schritt 5: Empfehlungen mit der Suche nach dem nächsten Nachbarn (K-Nearest Neighbor, KNN) finden
Jetzt kommen wir zur Darstellung der Ergebnisse in einer Präsentation. Suchen wir nach Produkten, die zur Anfrage unseres Kunden passen: „Ich möchte eine leistungsstarke Tastatur kaufen. Ich programmiere manchmal am Strand, daher kann es nass werden.“
Wir beginnen mit der K-Nearest Neighbor-Suche (KNN). Dies ist eine genaue Suche, bei der unser Abfragevektor mit jedem einzelnen Produktvektor verglichen wird. Sie ist präzise, kann aber bei sehr großen Datasets langsam sein. Deshalb haben wir für Schritt 5 einen ANN-Index erstellt.
Diese Abfrage führt zwei Aufgaben aus:
- In einer Unterabfrage wird ML.PREDICT verwendet, um den Einbettungsvektor für die Anfrage des Kunden abzurufen.
- In der äußeren Abfrage wird mit COSINE_DISTANCE die „Entfernung“ zwischen dem Abfragevektor und dem embedding_vector jedes Produkts berechnet. Eine kleinere Distanz bedeutet eine bessere Übereinstimmung.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Es sollte eine Liste mit Produkten angezeigt werden, wobei wasserabweisende Tastaturen ganz oben stehen.
9. Schritt 6: Empfehlungen mit der ungefähren Suche (Approximate Nearest Neighbor, ANN) finden
KNN ist zwar gut, aber für ein Produktionssystem mit Millionen von Produkten und Tausenden von Anfragen pro Sekunde benötigen wir die Geschwindigkeit unseres ANN-Index.
Wenn Sie den Index verwenden möchten, müssen Sie die Funktion APPROX_COSINE_DISTANCE angeben.
- Rufen Sie die Vektoreinbettung Ihres Texts wie oben beschrieben ab. Die Ergebnisse werden mit den Datensätzen in der Tabelle „products_with_embeddings“ zusammengeführt, damit Sie sie in der Funktion „APPROX_COSINE_DISTANCE“ verwenden können.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Erwartete Ausgabe:Die Ergebnisse sollten mit denen der KNN-Abfrage identisch oder sehr ähnlich sein, die Ausführung erfolgt jedoch durch Verwendung des Index viel effizienter. Im Beispiel ist das möglicherweise nicht zu sehen.
10. Schritt 7: LLM zum Erläutern von Empfehlungen verwenden
Eine Liste von Produkten zu präsentieren, ist gut. Noch besser ist es jedoch, zu erklären, warum ein Produkt gut oder schlecht geeignet ist. Dazu können wir unser LLMModel (Gemini) verwenden.
In dieser Abfrage wird die KNN-Abfrage aus Schritt 4 in einen ML.PREDICT-Aufruf eingebettet. Wir verwenden CONCAT, um einen Prompt für das LLM zu erstellen, der Folgendes enthält:
- Eine klare Anleitung („Antworte mit ‚Ja‘ oder ‚Nein‘ und erkläre, warum…“).
- Die ursprüngliche Anfrage des Kunden.
- Der Name und die Beschreibung jedes Produkts, das am besten passt.
Das LLM vergleicht dann jedes Produkt mit der Anfrage und gibt eine Antwort in natürlicher Sprache aus.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
Erwartete Ausgabe:Sie erhalten eine Tabelle mit einer neuen Spalte „LLMResponse“. Die Antwort sollte in etwa so lauten: Nein. Hier sind die Gründe: * „Wasserabweisend“ ist nicht „wasserdicht“. Eine „wasserabweisende“ Tastatur kann Spritzer, leichten Regen oder verschüttete Flüssigkeiten aushalten.
11. Schritt 8: Property Graph erstellen
Nun zu einer anderen Art von Empfehlung: „Kunden, die dieses Produkt gekauft haben, haben auch Folgendes gekauft…“
Dies ist eine beziehungsbasierte Anfrage. Dafür ist eine Attributgrafik das perfekte Tool. Mit Spanner können Sie ein Diagramm auf Grundlage Ihrer vorhandenen Tabellen erstellen, ohne Daten zu duplizieren.
Mit dieser DDL-Anweisung wird unser Diagramm definiert:
- Knoten :
Product- undUser-Tabellen. Die Knoten sind die Einheiten, aus denen Sie eine Beziehung ableiten möchten. Sie möchten wissen, ob Kunden, die Ihr Produkt gekauft haben, auch Produkte von „XYZ“ gekauft haben. - Kanten:Die Tabelle
Orders, in der eineUser(Quelle) mit einerProduct(Ziel) mit dem Label „Gekauft“ verbunden wird. Die Kanten stellen die Beziehung zwischen einem Nutzer und dem dar, was er gekauft hat.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. Schritt 9: Vektorsuche und Graphabfragen kombinieren
Das ist der wichtigste Schritt. Wir kombinieren KI-Vektorsuche und Graphabfragen in einer einzigen Anweisung, um ähnliche Produkte zu finden.
Diese Abfrage wird in drei durch NEXT statement getrennten Teilen gelesen. Wir unterteilen sie in Abschnitte.
- Zuerst wird mit der Vektorsuche die beste Übereinstimmung gefunden.
- Mit ML.PREDICT wird mithilfe von EmbeddingsModel eine Vektoreinbettung aus der Textanfrage des Nutzers generiert.
- Mit der Abfrage wird die COSINE_DISTANCE zwischen dieser neuen Einbettung und dem gespeicherten p.embedding_vector für alle Produkte berechnet.
- Es wird das einzelne bestMatch-Produkt mit der minimalen Distanz (höchste semantische Ähnlichkeit) ausgewählt und zurückgegeben.
- Als Nächstes durchlaufen wir den Graphen auf der Suche nach den Beziehungen.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- Die Abfrage verfolgt den Pfad von „bestMatch“ zurück zu gemeinsamen „Orders“-Knoten (Nutzer) und dann vorwärts zu anderen „purchasedWith“-Produkten.
- Das ursprüngliche Produkt wird herausgefiltert und mit GROUP BY und COUNT(1) wird aggregiert, wie oft Artikel gemeinsam gekauft werden.
- Es werden die drei am häufigsten gemeinsam gekauften Produkte (purchasedWith) zurückgegeben, sortiert nach der Häufigkeit des gemeinsamen Auftretens.
Außerdem wird die Beziehung zwischen Nutzer und Bestellung ermittelt.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- In diesem Zwischenschritt wird das Traversierungsmuster ausgeführt, um die wichtigsten Einheiten zu binden: „bestMatch“, den verbindenden Knoten „user:Orders“ und das gekaufte Element.
- Damit wird die Beziehung selbst als gekauft für die Datenextraktion im nächsten Schritt gebunden.
- Dieses Muster sorgt dafür, dass der Kontext für das Abrufen von bestell- und produktspezifischen Details festgelegt wird.
- Schließlich geben wir die Ergebnisse aus, die als Grafknoten zurückgegeben werden sollen. Diese müssen formatiert werden, bevor sie als SQL-Ergebnisse zurückgegeben werden.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
Erwartete Ausgabe:Sie sehen JSON-Objekte, die die drei am häufigsten zusammen gekauften Artikel darstellen und Cross-Selling-Empfehlungen enthalten.
13. Bereinigen
Sie können die erstellten Ressourcen löschen, um Gebühren zu vermeiden.
- Spanner-Instanz löschen:Wenn Sie die Instanz löschen, wird auch die Datenbank gelöscht.
gcloud spanner instances delete my-first-spanner --quiet
- Google Cloud-Projekt löschen:Wenn Sie dieses Projekt nur für das Codelab erstellt haben, ist das Löschen die einfachste Möglichkeit, es zu bereinigen.
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie Ihr Projekt aus und klicken Sie auf Löschen.
🎉 Glückwunsch!
Sie haben mit Spanner AI und Graph erfolgreich ein anspruchsvolles Echtzeit-Empfehlungssystem erstellt.
Sie haben gelernt, wie Sie Spanner in Vertex AI für Einbettungen und LLM-Generierung einbinden, wie Sie eine schnelle Vektorsuche (KNN und ANN) durchführen, um semantisch relevante Produkte zu finden, und wie Sie mit Grafabfragen Produktbeziehungen ermitteln. Sie haben ein System entwickelt, das nicht nur Produkte finden, sondern auch Empfehlungen erläutern und ähnliche Artikel vorschlagen kann – alles über eine einzige, skalierbare Datenbank.