
1. Introducción
En este codelab, se te guiará para que uses las capacidades de IA y gráficos de Spanner para mejorar una base de datos minorista existente. Aprenderás técnicas prácticas para utilizar el aprendizaje automático en Spanner y atender mejor a tus clientes. Específicamente, implementaremos k-vecinos más cercanos (kNN) y vecinos más cercanos aproximados (ANN) para descubrir productos nuevos que se alineen con las necesidades de cada cliente. También integrarás un LLM para proporcionar explicaciones claras en lenguaje natural sobre por qué se hizo una recomendación de producto específica.
Además de las recomendaciones, profundizaremos en la funcionalidad de gráficos de Spanner. Usarás consultas de grafos para modelar las relaciones entre los productos según el historial de compras de los clientes y las descripciones de los productos. Este enfoque permite descubrir artículos profundamente relacionados, lo que mejora significativamente la relevancia y la eficacia de las funciones "Los clientes también compraron" o "Artículos relacionados". Al final de este codelab, tendrás las habilidades necesarias para compilar una aplicación de venta minorista inteligente, escalable y responsiva que funcione completamente con Google Cloud Spanner.
Situación
Trabajas para un minorista de equipos electrónicos. Tu sitio de comercio electrónico tiene una base de datos estándar de Spanner con Products, Orders y OrderItems.
Un cliente llega a tu sitio con una necesidad específica: "Quiero comprar un teclado de alto rendimiento. A veces, escribo código mientras estoy en la playa, por lo que se puede mojar".
Tu objetivo es usar las funciones avanzadas de Spanner para responder esta solicitud de forma inteligente:
- Encontrar: Ve más allá de la simple búsqueda por palabras clave para encontrar productos cuyas descripciones coincidan semánticamente con la solicitud del usuario a través de la búsqueda de vectores.
- Explicar: Usa un LLM para analizar las coincidencias principales y explicar por qué la recomendación es adecuada, lo que genera confianza en el cliente.
- Relacionar: Usa consultas de grafos para encontrar otros productos que los clientes compraron con frecuencia junto con esa recomendación.
2. Antes de comenzar
- Crea un proyecto. En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Habilita la facturación. Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
- Activa Cloud Shell. Para ello, haz clic en el botón "Activar Cloud Shell" en la consola. Puedes alternar entre la terminal y el editor de Cloud Shell.

- Autoriza y configura el proyecto Una vez que te conectes a Cloud Shell, verifica que te hayas autenticado y que el proyecto esté configurado con tu ID del proyecto.
gcloud auth list
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo y reemplaza
<PROJECT_ID>por el ID de tu proyecto real:
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- Habilita las APIs requeridas: Habilita las APIs de Spanner, Vertex AI y Compute Engine. Esta acción podría demorar unos minutos.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Configura algunas variables de entorno que reutilizarás.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- Crea una instancia de Spanner de prueba gratuita si aún no tienes una . Necesitarás una instancia de Spanner para alojar tu base de datos. Usaremos
regional-us-central1como configuración. Puedes actualizar esta información si lo deseas.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. Descripción general de la arquitectura
Spanner encapsula toda la funcionalidad necesaria, excepto los modelos que se alojan en Vertex AI.
4. Paso 1: Configura la base de datos y envía tu primera consulta.
Primero, debemos crear nuestra base de datos, cargar nuestros datos de muestra de comercio minorista y decirle a Spanner cómo comunicarse con Vertex AI.
En esta sección, usarás las siguientes secuencias de comandos de SQL.
- Navega a la página del producto de Spanner.
- Selecciona la instancia correcta.
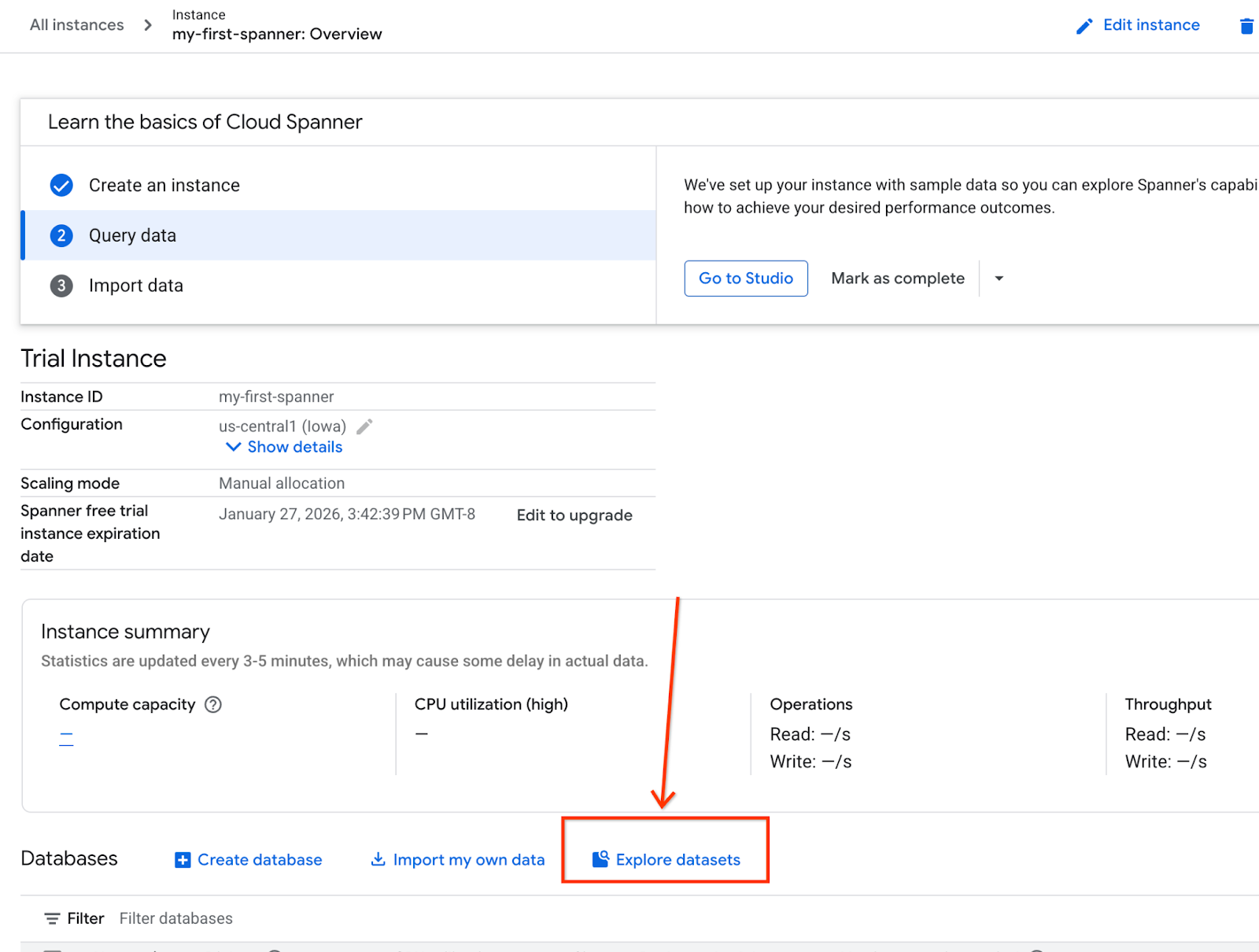
- En la pantalla, selecciona Explorar conjuntos de datos. Luego, en la ventana emergente, selecciona la opción "Minorista".
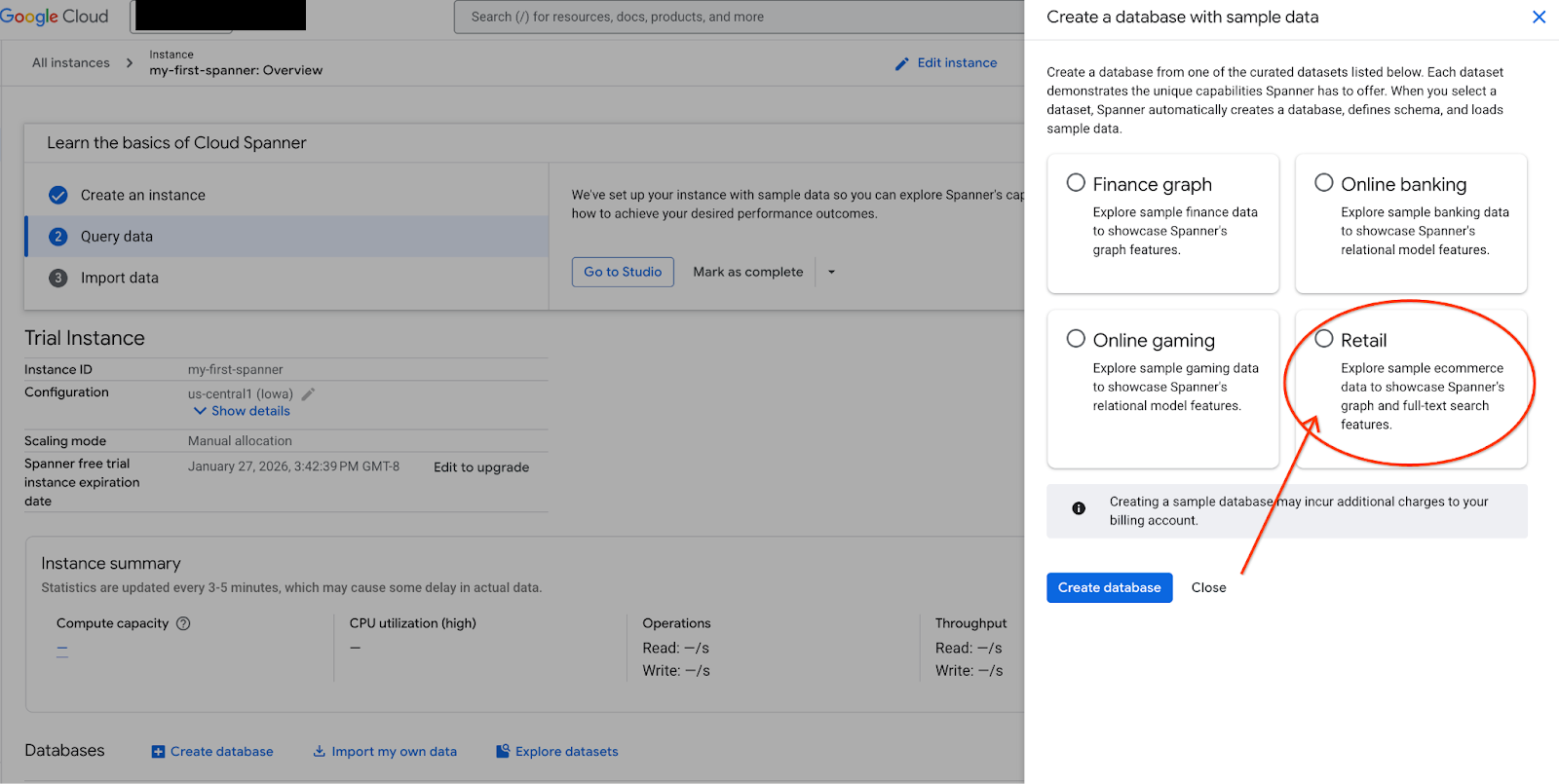
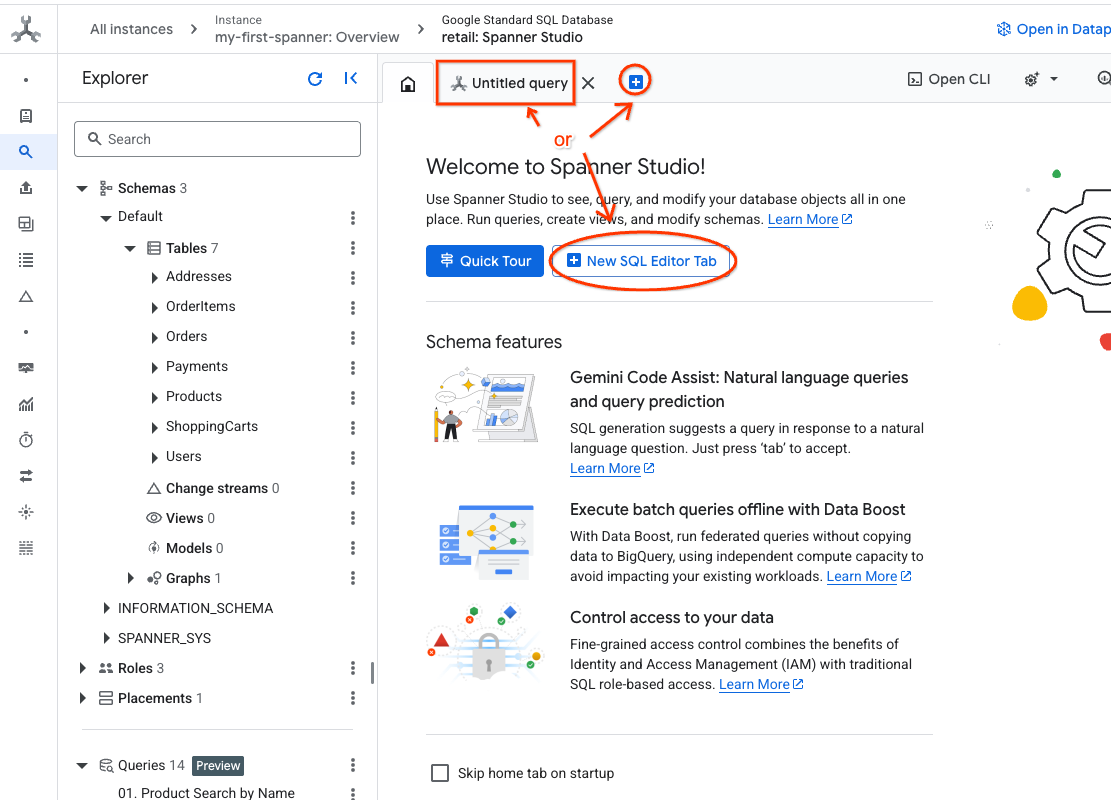
- Navega a Spanner Studio. Spanner Studio incluye un panel Explorador que se integra con un editor de consultas y una tabla de resultados de consultas en SQL. Puedes ejecutar declaraciones DDL, DML y SQL desde esta misma interfaz. Deberás expandir el menú lateral y buscar la lupa.
- Lee la tabla de productos. Crea una pestaña nueva o usa la pestaña "Consulta sin título" que ya se creó.
SELECT *
FROM Products;
5. Paso 2: Crea los modelos de IA.
Ahora, creemos los modelos remotos con objetos de Spanner. Estas instrucciones de SQL crean objetos de Spanner que se vinculan a los endpoints de Vertex AI.
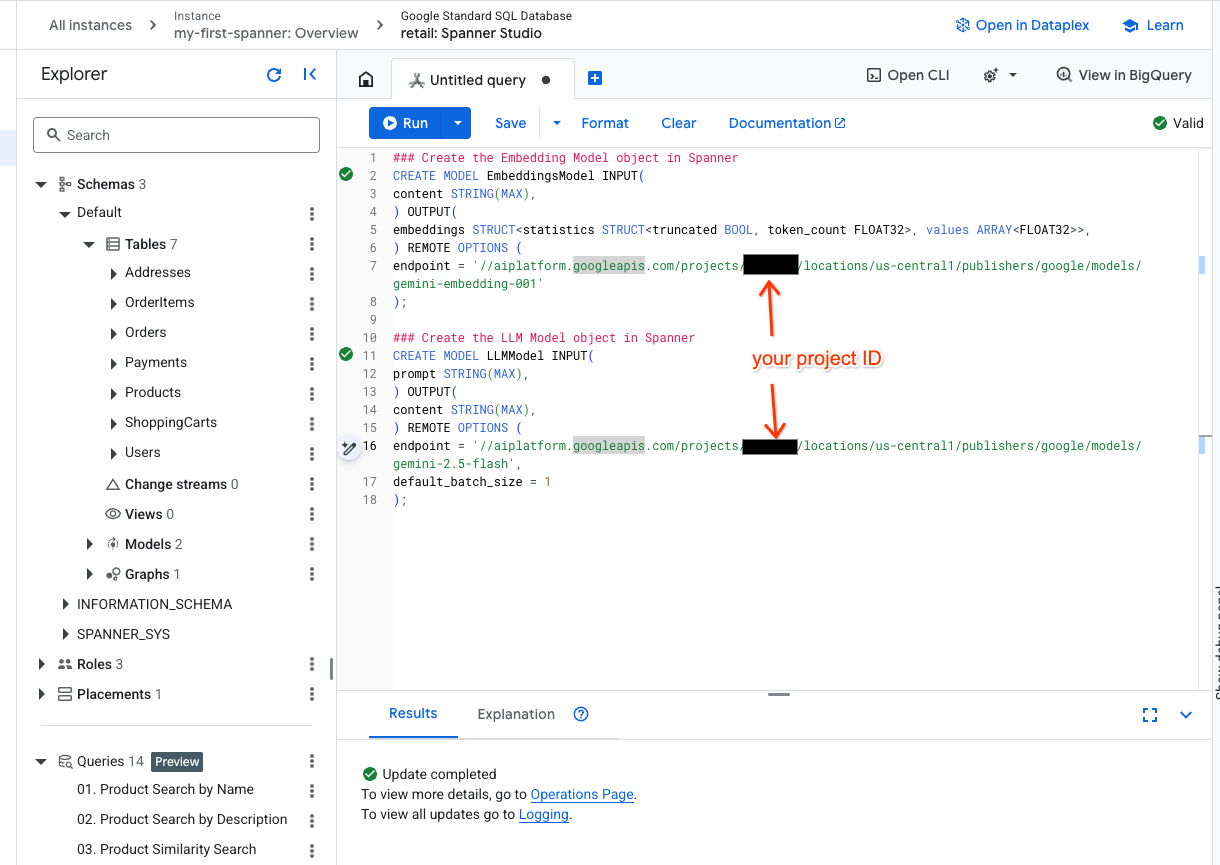
- Abre una pestaña nueva en Spanner Studio y crea tus dos modelos. El primero es EmbeddingsModel, que te permitirá generar embeddings. El segundo es LLMModel, que te permitirá interactuar con un LLM (en nuestro ejemplo, es gemini-2.5-flash). Asegúrate de haber actualizado <PROJECT_ID> con el ID de tu proyecto.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- Nota: Recuerda reemplazar
PROJECT_IDpor tu$PROJECT_IDreal.
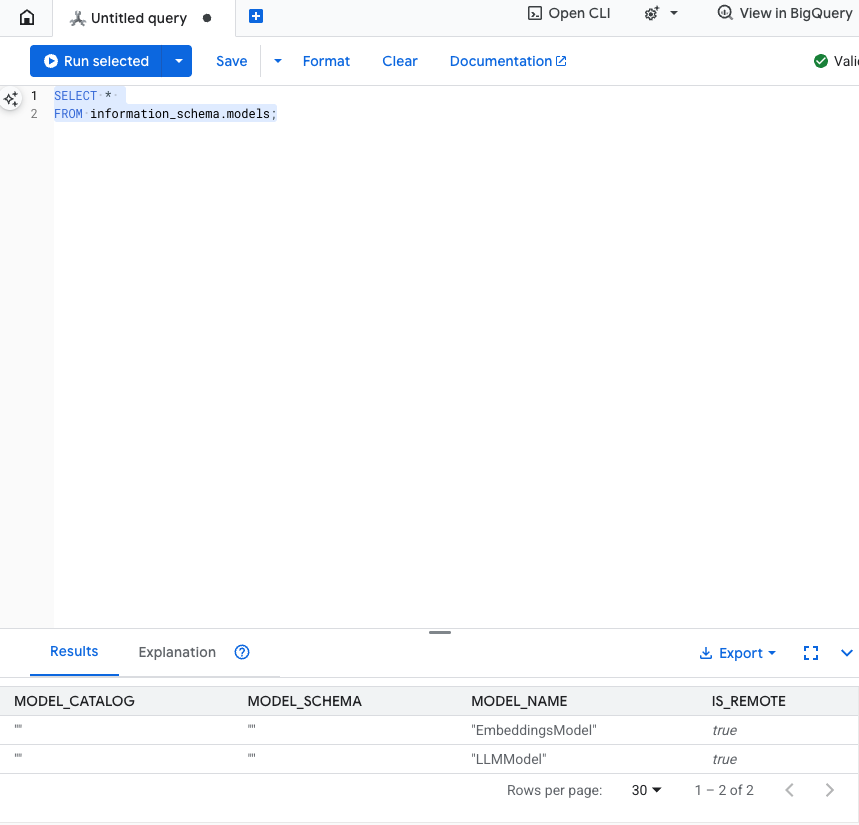
Prueba este paso: Para verificar que se crearon los modelos, ejecuta lo siguiente en el editor de SQL.
SELECT *
FROM information_schema.models;
6. Paso 3: Genera y almacena embeddings de vectores
Nuestra tabla de productos tiene descripciones de texto, pero el modelo de IA comprende vectores (arrays de números). Debemos agregar una columna nueva para almacenar estos vectores y, luego, propagarla ejecutando todas nuestras descripciones de productos a través de EmbeddingsModel.
- Crea una tabla nueva para admitir los embeddings. Primero, crea una tabla que admita embeddings. Usamos un modelo de embedding diferente al de las muestras de embeddings de la tabla de productos. Debes asegurarte de que los embeddings se hayan generado a partir del mismo modelo para que la búsqueda de vectores funcione correctamente.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- Propaga la tabla nueva con los embeddings generados a partir del modelo. Aquí, usamos una instrucción insert into para simplificar. Esta acción enviará los resultados de la consulta a la tabla que acabas de crear.
Primero, la instrucción de SQL toma y concatena todas las columnas de texto relevantes para las que queremos generar incorporaciones. Luego, devolvemos la información pertinente, incluido el texto que usamos. Por lo general, esto no es necesario, pero lo incluimos para que puedas visualizar los resultados.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
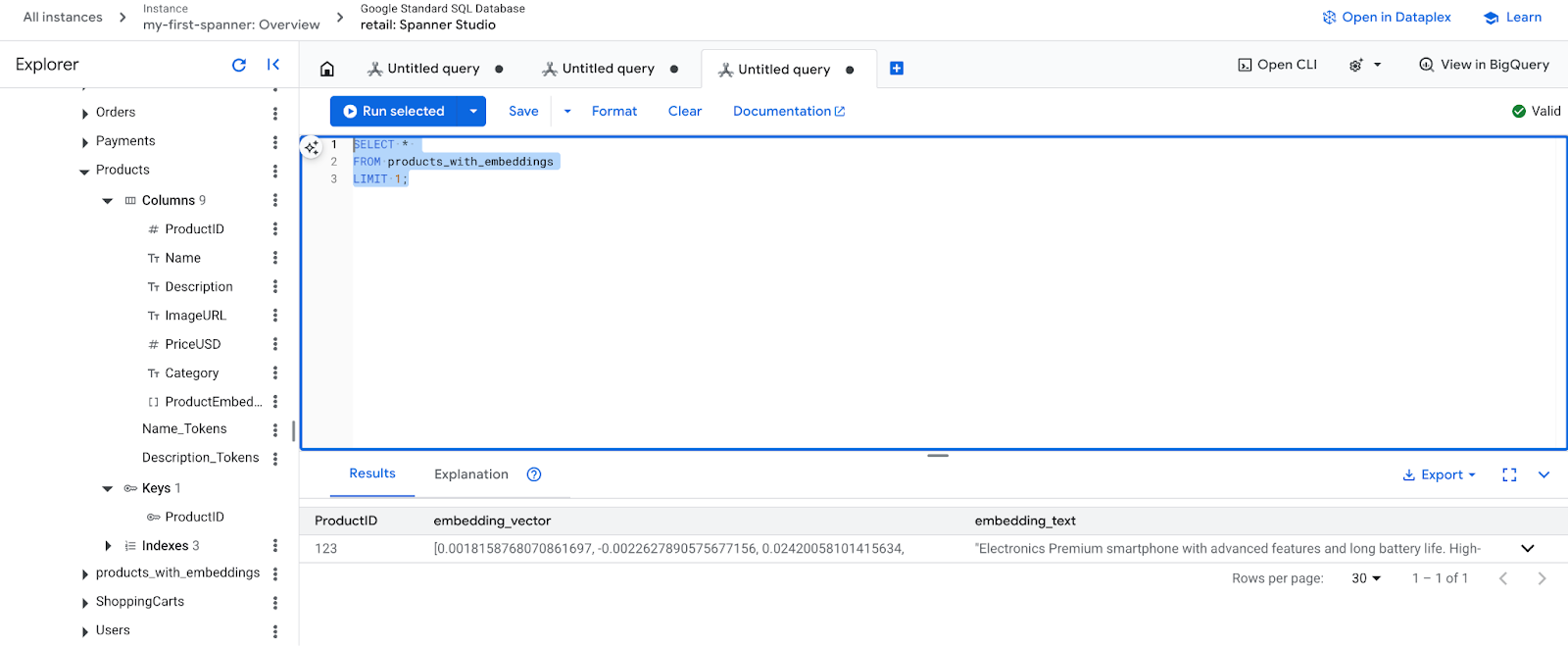
- Verifica tus nuevas incorporaciones. Ahora deberías ver las incorporaciones que se generaron.
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. Paso 4: Crea un índice de vectores para la búsqueda de ANN
Para buscar millones de vectores al instante, necesitamos un índice. Este índice permite la búsqueda de Vecinos Aproximados Más Cercanos (ANN), que es increíblemente rápida y se escala horizontalmente.
- Ejecuta la siguiente consulta DDL para crear el índice. Especificamos
COSINEcomo nuestra métrica de distancia, que es excelente para la búsqueda semántica de texto. Ten en cuenta que la cláusula WHERE es necesaria, ya que Spanner la requerirá para la consulta.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- Verifica el estado de la creación del índice en la pestaña Operaciones.
8. Paso 5: Encuentra recomendaciones con la búsqueda de k-vecino más cercano (KNN)
Aquí comienza la diversión. Busquemos productos que coincidan con la búsqueda de nuestro cliente: "Me gustaría comprar un teclado de alto rendimiento. A veces, escribo código mientras estoy en la playa, por lo que se puede mojar".
Comenzaremos con la búsqueda de K-Neighbor Nearest (KNN). Esta es una búsqueda exacta que compara nuestro vector de búsqueda con cada uno de los vectores de productos. Es preciso, pero puede ser lento en conjuntos de datos muy grandes (por eso creamos un índice de ANN para el paso 5).
Esta consulta realiza dos acciones:
- Una subconsulta usa ML.PREDICT para obtener el vector de incorporación de la búsqueda de nuestro cliente.
- La consulta externa usa COSINE_DISTANCE para calcular la "distancia" entre el vector de búsqueda y el vector de incorporación de cada producto. Una distancia más pequeña significa una mejor coincidencia.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Deberías ver una lista de productos, con los teclados resistentes al agua en la parte superior.
9. Paso 6: Encuentra recomendaciones con la búsqueda aproximada (ANN)
El KNN es excelente, pero para un sistema de producción con millones de productos y miles de búsquedas por segundo, necesitamos la velocidad de nuestro índice de ANN.
Para usar el índice, debes especificar la función APPROX_COSINE_DISTANCE.
- Obtén el embedding de vector de tu texto como lo hiciste antes. Unimos los resultados de esa consulta con los registros de la tabla products_with_embeddings para que puedas usarla en tu función APPROX_COSINE_DISTANCE.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Resultado esperado: Los resultados deben ser idénticos o muy similares a los de la búsqueda de KNN, pero se ejecutaron de manera mucho más eficiente con el índice. Es posible que no lo notes en el ejemplo.
10. Paso 7: Usa un LLM para explicar las recomendaciones
Mostrar una lista de productos es bueno, pero explicar por qué son adecuados o no es excelente. Podemos usar nuestro LLMModel (Gemini) para hacerlo.
Esta consulta anida nuestra consulta de KNN del paso 4 dentro de una llamada ML.PREDICT. Usamos CONCAT para crear una instrucción para el LLM, que le proporciona lo siguiente:
- Una instrucción clara ("Responde con "Sí" o "No" y explica por qué…").
- Es la búsqueda original del cliente.
- El nombre y la descripción de cada producto que mejor coincide
Luego, el LLM evalúa cada producto en función de la búsqueda y proporciona una respuesta en lenguaje natural.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
Resultado esperado: Obtendrás una tabla con una nueva columna LLMResponse. La respuesta debería ser algo así: "No. Estos son los motivos: * "Resistente al agua" no es lo mismo que "impermeable". Un teclado "resistente al agua" puede soportar salpicaduras, lluvia ligera o derrames.
11. Paso 8: Crea un gráfico de propiedades
Ahora, veamos otro tipo de recomendación: "Los clientes que compraron este artículo también compraron…".
Esta es una búsqueda basada en relaciones. La herramienta perfecta para esto es un grafo de propiedad. Spanner te permite crear un gráfico sobre tus tablas existentes sin duplicar datos.
Esta instrucción DDL define nuestro gráfico:
- Nodos: Tablas
ProductyUserLos nodos son las entidades a partir de las que deseas derivar una relación. Por ejemplo, quieres saber qué clientes que compraron tu producto también compraron productos de "XYZ". - Bordes: La tabla
Orders, que conecta unUser(origen) con unProduct(destino) con la etiqueta "Comprado". Los bordes proporcionan la relación entre un usuario y lo que compró.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. Paso 9: Combina la búsqueda de vectores y las consultas de gráficos
Este es el paso más importante. Combinaremos la búsqueda de vectores con IA y las consultas de gráficos en una sola instrucción para encontrar productos relacionados.
Esta consulta se lee en tres partes, separadas por el NEXT statement. Analicémosla por secciones.
- Primero, encontramos la mejor coincidencia con la búsqueda de vectores.
- ML.PREDICT genera un embedding de vector a partir de la búsqueda de texto del usuario con EmbeddingsModel.
- La consulta calcula la función COSINE_DISTANCE entre esta nueva incorporación y el p.embedding_vector almacenado para todos los productos.
- Selecciona y devuelve el único producto bestMatch con la distancia mínima (mayor similitud semántica).
- A continuación, recorremos el gráfico en busca de las relaciones.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- La consulta rastrea desde bestMatch hasta los nodos de Orders comunes (usuario) y, luego, hacia otros productos comprados con.
- Filtra el producto original y usa GROUP BY y COUNT(1) para agregar la frecuencia con la que se compran artículos en conjunto.
- Devuelve los 3 productos que se compran juntos con mayor frecuencia (purchasedWith), ordenados según la frecuencia de la correlación.
Además, encontramos la relación entre el usuario y el pedido.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- Este paso intermedio ejecuta el patrón de recorrido para vincular las entidades clave: bestMatch, el nodo de conexión user:Orders y el elemento purchasedWith.
- Vincula específicamente la relación como comprada para la extracción de datos en el siguiente paso.
- Este patrón garantiza que se establezca el contexto para recuperar detalles específicos del pedido y del producto.
- Por último, generamos los resultados que se devolverán como nodos del grafo, que deben formatearse antes de devolverse como resultados de SQL.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
Resultado esperado: Verás objetos JSON que representan los 3 artículos que más se compran juntos, lo que proporciona recomendaciones de venta cruzada.
13. Realiza una limpieza
Para evitar que se generen cargos, puedes borrar los recursos que creaste.
- Borra la instancia de Spanner: Si borras la instancia, también se borrará la base de datos.
gcloud spanner instances delete my-first-spanner --quiet
- Borra el proyecto de Google Cloud: Si creaste este proyecto solo para el codelab, borrarlo es la forma más fácil de realizar una limpieza.
- Ve a la página Administrar recursos en la consola de Google Cloud.
- Selecciona tu proyecto y haz clic en Borrar.
🎉 ¡Felicitaciones!
Creaste con éxito un sistema de recomendaciones sofisticado en tiempo real con Spanner AI y Graph.
Aprendiste a integrar Spanner con Vertex AI para la generación de LLM y embeddings, a realizar búsquedas de vectores de alta velocidad (KNN y ANN) para encontrar productos semánticamente relevantes y a usar consultas de gráficos para descubrir relaciones entre productos. Creaste un sistema que no solo puede encontrar productos, sino también explicar recomendaciones y sugerir artículos relacionados, todo desde una sola base de datos escalable.