
۱. مقدمه
این آزمایشگاه کد شما را در استفاده از قابلیتهای هوش مصنوعی و نمودار Spanner برای بهبود پایگاه داده خردهفروشی موجود راهنمایی میکند. شما تکنیکهای عملی برای استفاده از یادگیری ماشین در Spanner را برای خدمترسانی بهتر به مشتریان خود خواهید آموخت. به طور خاص، ما k-نزدیکترین همسایه (kNN) و نزدیکترین همسایه تقریبی (ANN) را برای کشف محصولات جدیدی که با نیازهای فردی مشتری همسو هستند، پیادهسازی خواهیم کرد. همچنین شما یک LLM را برای ارائه توضیحات واضح و به زبان طبیعی در مورد دلیل توصیه یک محصول خاص ادغام خواهید کرد.
فراتر از توصیهها، به بررسی قابلیتهای نموداری Spanner خواهیم پرداخت. شما از پرسوجوهای نموداری برای مدلسازی روابط بین محصولات بر اساس سابقه خرید مشتری و توضیحات محصول استفاده خواهید کرد. این رویکرد امکان کشف اقلام عمیقاً مرتبط را فراهم میکند و ارتباط و اثربخشی ویژگیهای «مشتریان نیز خریدهاند» یا «اقلام مرتبط» شما را به طور قابل توجهی بهبود میبخشد. در پایان این آزمایشگاه کد، شما مهارتهای لازم برای ساخت یک برنامه خردهفروشی هوشمند، مقیاسپذیر و واکنشگرا را که کاملاً توسط Google Cloud Spanner پشتیبانی میشود، خواهید داشت.
سناریو
شما برای یک خردهفروش تجهیزات الکترونیکی کار میکنید. سایت تجارت الکترونیک شما دارای یک پایگاه داده استاندارد Spanner با Products ، Orders و OrderItems است.
یک مشتری با یک نیاز خاص وارد سایت شما میشود: «من میخواهم یک کیبورد با کارایی بالا بخرم. من گاهی اوقات در ساحل کد مینویسم، بنابراین ممکن است خیس شوم.»
هدف شما این است که از ویژگیهای پیشرفتهی Spanner برای پاسخ هوشمندانه به این درخواست استفاده کنید:
- یافتن: فراتر از جستجوی ساده کلمات کلیدی، با استفاده از جستجوی برداری، محصولاتی را پیدا کنید که توضیحات آنها از نظر معنایی با درخواست کاربر مطابقت دارد.
- توضیح: از یک متخصص حقوق (LLM) برای تجزیه و تحلیل بهترین موارد منطبق استفاده کنید و توضیح دهید که چرا این توصیه مناسب است و اعتماد مشتری را جلب کنید.
- ارتباط دادن: از نمودارهای جستجو برای یافتن سایر محصولاتی که مشتریان مرتباً خریداری میکنند، همراه با آن توصیه استفاده کنید.
۲. قبل از شروع
- ایجاد یک پروژه در کنسول گوگل کلود، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- فعال کردن صورتحساب مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
- فعال کردن پوسته ابری با کلیک بر روی دکمه "فعال کردن پوسته ابری" در کنسول، پوسته ابری را فعال کنید. میتوانید بین ترمینال و ویرایشگر پوسته ابری جابجا شوید.

- تأیید و تنظیم پروژه پس از اتصال به Cloud Shell، بررسی کنید که احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است.
gcloud auth list
gcloud config list project
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید و
<PROJECT_ID>را با شناسه پروژه واقعی خود جایگزین کنید:
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- فعال کردن APIهای مورد نیاز: APIهای Spanner، Vertex AI و Compute Engine را فعال کنید. این کار ممکن است چند دقیقه طول بکشد.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- چند متغیر محیطی که قرار است دوباره استفاده کنید را تنظیم کنید.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- اگر از قبل یک نمونه Spanner ندارید ، یک نمونه آزمایشی رایگان از Spanner ایجاد کنید . برای میزبانی پایگاه داده خود به یک نمونه Spanner نیاز دارید. ما
regional-us-central1به عنوان پیکربندی استفاده خواهیم کرد. در صورت تمایل میتوانید آن را بهروزرسانی کنید.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
۳. بررسی اجمالی معماری
Spanner تمام عملکردهای لازم به جز مدلهایی که در Vertex AI میزبانی میشوند را کپسولهسازی میکند.
۴. مرحله ۱: پایگاه داده را تنظیم کنید و اولین پرس و جو خود را ارسال کنید.
ابتدا باید پایگاه داده خود را ایجاد کنیم، دادههای خردهفروشی نمونه خود را بارگذاری کنیم و به Spanner بگوییم که چگونه با Vertex AI ارتباط برقرار کند.
برای این بخش، از اسکریپتهای SQL زیر استفاده خواهید کرد.
- به صفحه محصولات Spanner بروید.
- مصداق صحیح را انتخاب کنید.
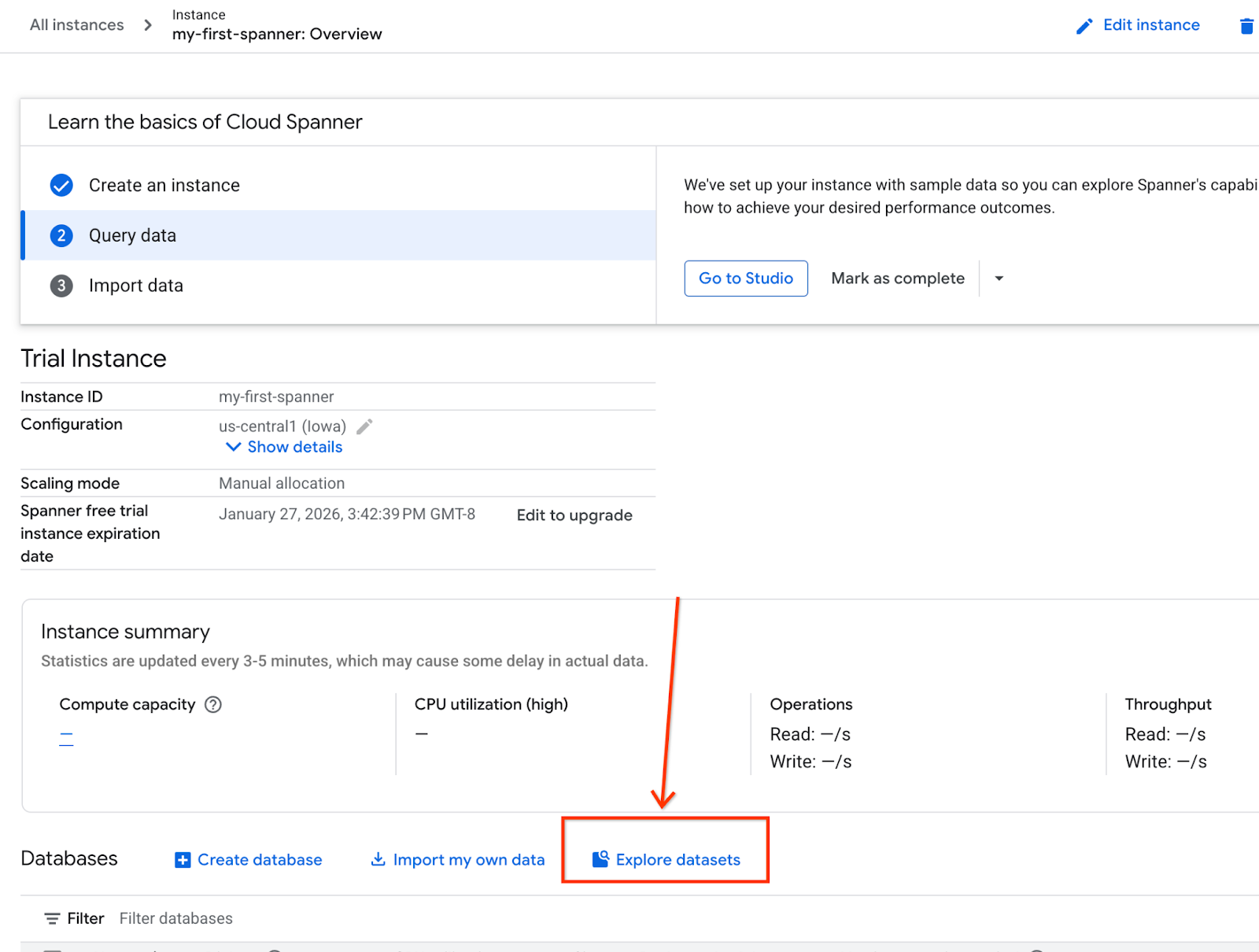
- در صفحه، گزینه Explore Datasets را انتخاب کنید. سپس در پنجره بازشو، گزینه "Retail" را انتخاب کنید.
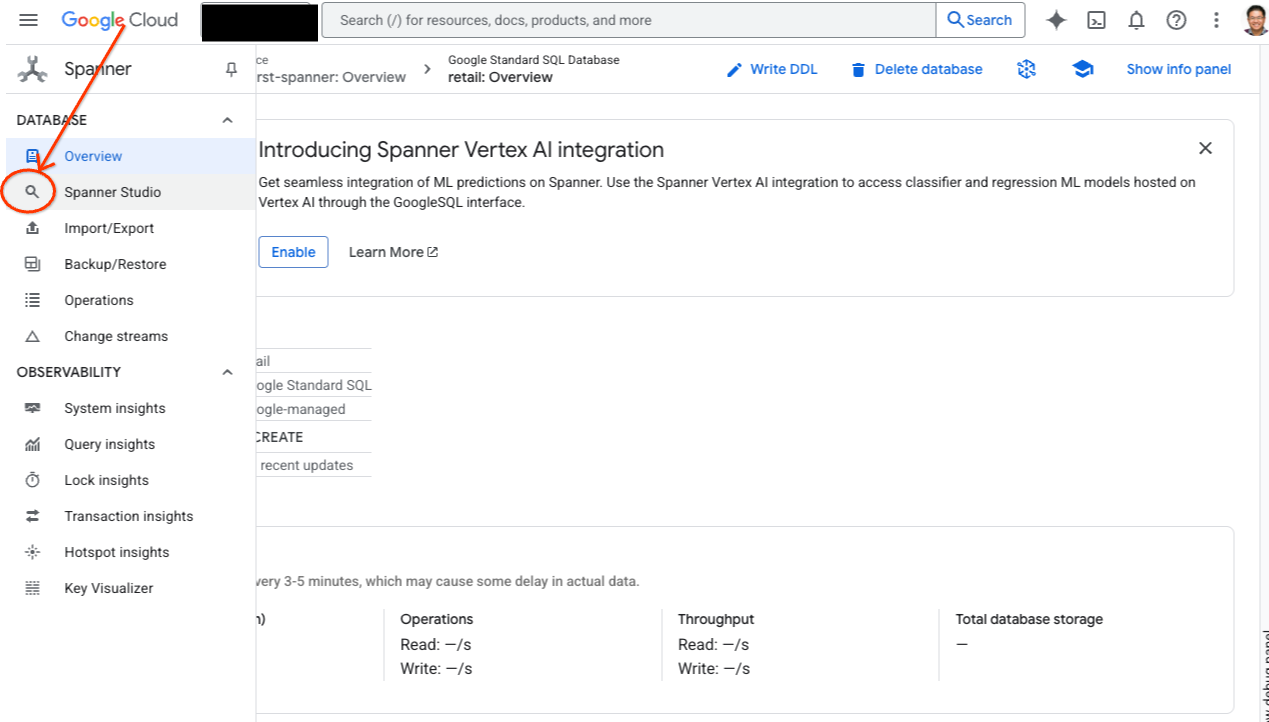
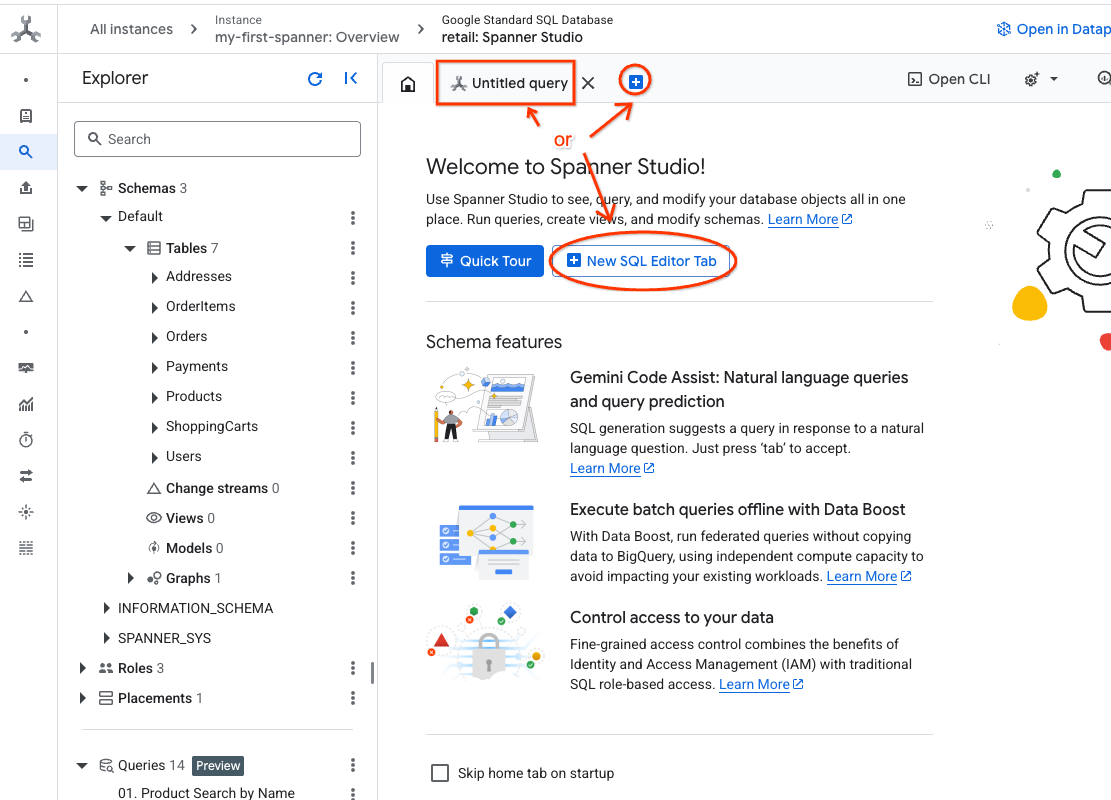
- به Spanner Studio بروید. Spanner Studio شامل یک پنجره Explorer است که با یک ویرایشگر پرس و جو و یک جدول نتایج پرس و جوی SQL ادغام شده است. میتوانید دستورات DDL، DML و SQL را از این رابط واحد اجرا کنید. باید منوی کناری را گسترش دهید، به دنبال ذرهبین بگردید.
- جدول محصولات را بخوانید. یک برگه جدید ایجاد کنید یا از برگه "پرس و جوی بدون عنوان" که قبلاً ایجاد شده است استفاده کنید.
SELECT *
FROM Products;
۵. مرحله ۲: مدلهای هوش مصنوعی را ایجاد کنید.
حالا، بیایید مدلهای راه دور را با اشیاء Spanner ایجاد کنیم. این دستورات SQL اشیاء Spanner را ایجاد میکنند که به نقاط انتهایی Vertex AI پیوند دارند.
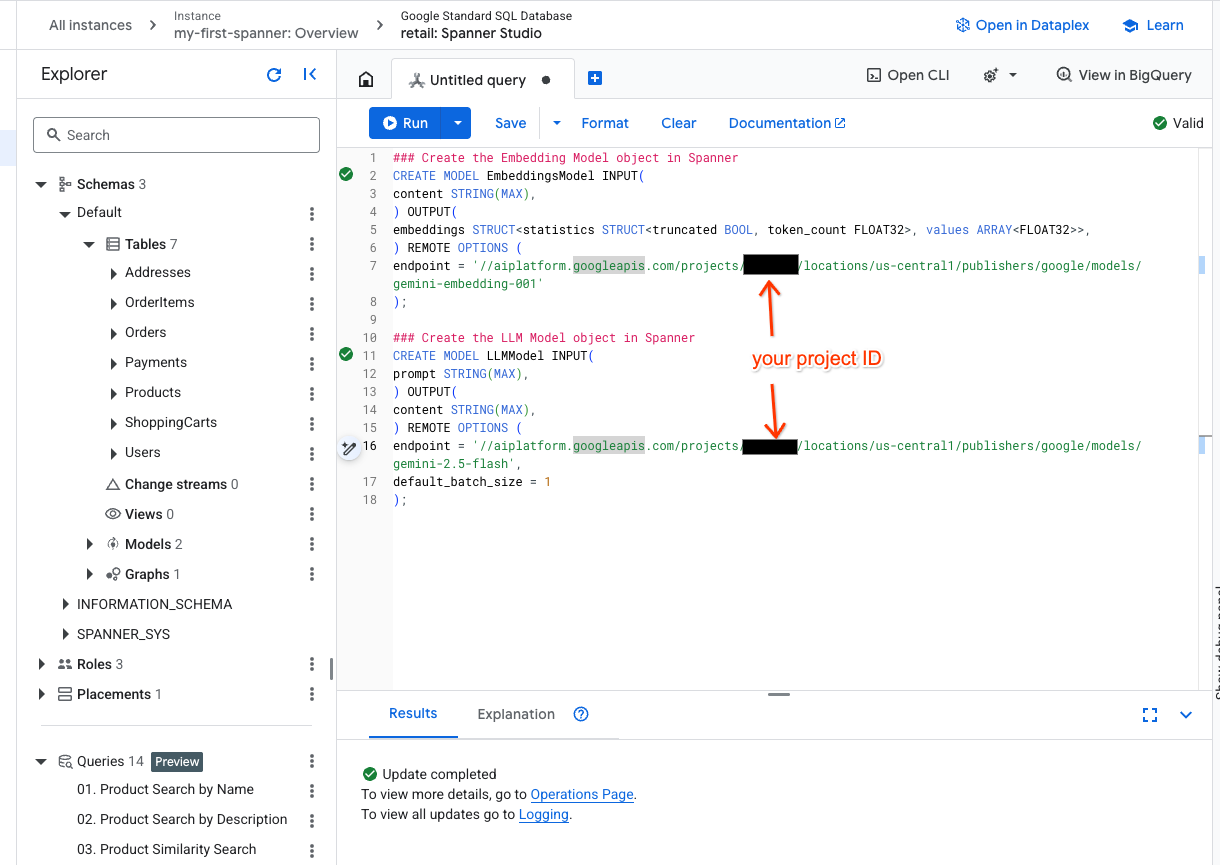
- یک تب جدید در Spanner studio باز کنید و دو مدل خود را ایجاد کنید. مدل اول EmbeddingsModel است که به شما امکان میدهد جاسازیها را ایجاد کنید. مدل دوم LLMModel است که به شما امکان میدهد با یک LLM (در مثال ما، gemini-2.5-flash) تعامل داشته باشید. مطمئن شوید که <PROJECT_ID> را با شناسه پروژه خود بهروزرسانی کردهاید.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- نکته: به یاد داشته باشید که
PROJECT_IDبا$PROJECT_IDواقعی خود جایگزین کنید.
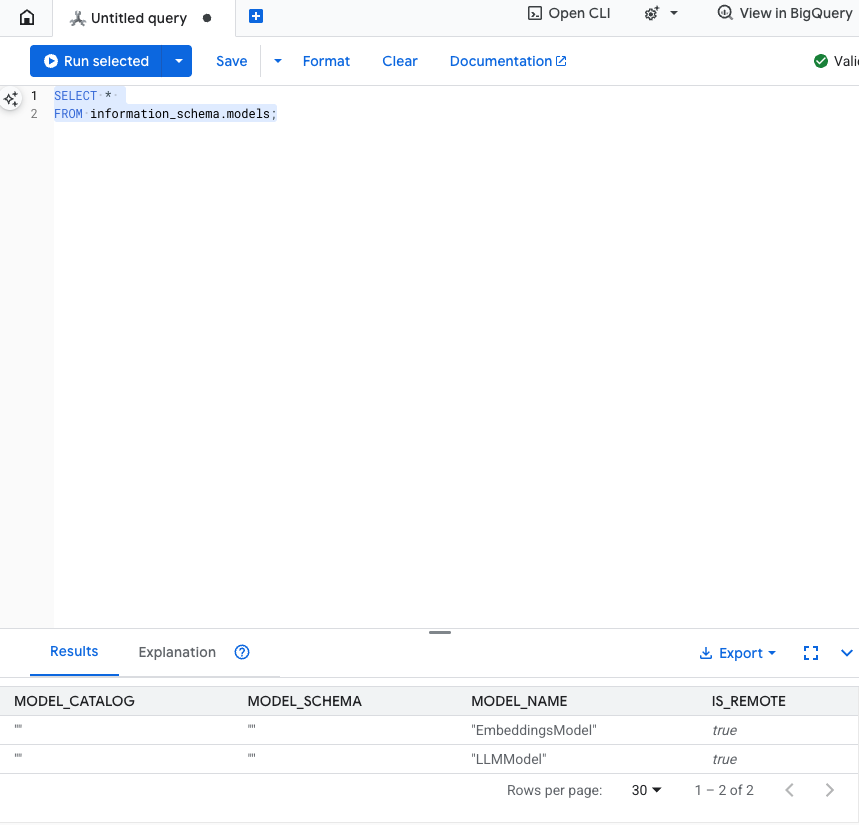
این مرحله را آزمایش کنید: میتوانید با اجرای دستور زیر در ویرایشگر SQL، تأیید کنید که مدلها ایجاد شدهاند.
SELECT *
FROM information_schema.models;
۶. مرحله ۳: تولید و ذخیره جاسازیهای برداری
جدول محصولات ما دارای توضیحات متنی است، اما مدل هوش مصنوعی بردارها (آرایههایی از اعداد) را درک میکند. ما باید یک ستون جدید برای ذخیره این بردارها اضافه کنیم و سپس با اجرای تمام توضیحات محصولات خود از طریق EmbeddingsModel، آن را پر کنیم.
- یک جدول جدید برای پشتیبانی از جاسازیها ایجاد کنید. ابتدا جدولی ایجاد کنید که بتواند از جاسازیها پشتیبانی کند. ما از یک مدل جاسازی متفاوت از جاسازیهای نمونه جدول محصول استفاده میکنیم. برای اینکه جستجوی برداری به درستی کار کند، باید مطمئن شوید که جاسازیها از همان مدل تولید شدهاند.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- جدول جدید را با جاسازیهای تولید شده از مدل پر کنید. ما در اینجا برای سادگی از دستور insert into استفاده میکنیم. این کار نتایج پرسوجو را به جدولی که اخیراً ایجاد کردهاید، وارد میکند.
دستور SQL ابتدا تمام ستونهای متنی مرتبطی را که میخواهیم جاسازیها را روی آنها ایجاد کنیم، میگیرد و به هم متصل میکند. سپس اطلاعات مرتبط، از جمله متنی که استفاده کردهایم را برمیگردانیم. این کار معمولاً ضروری نیست، اما ما آن را اضافه میکنیم تا بتوانید نتایج را تجسم کنید.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
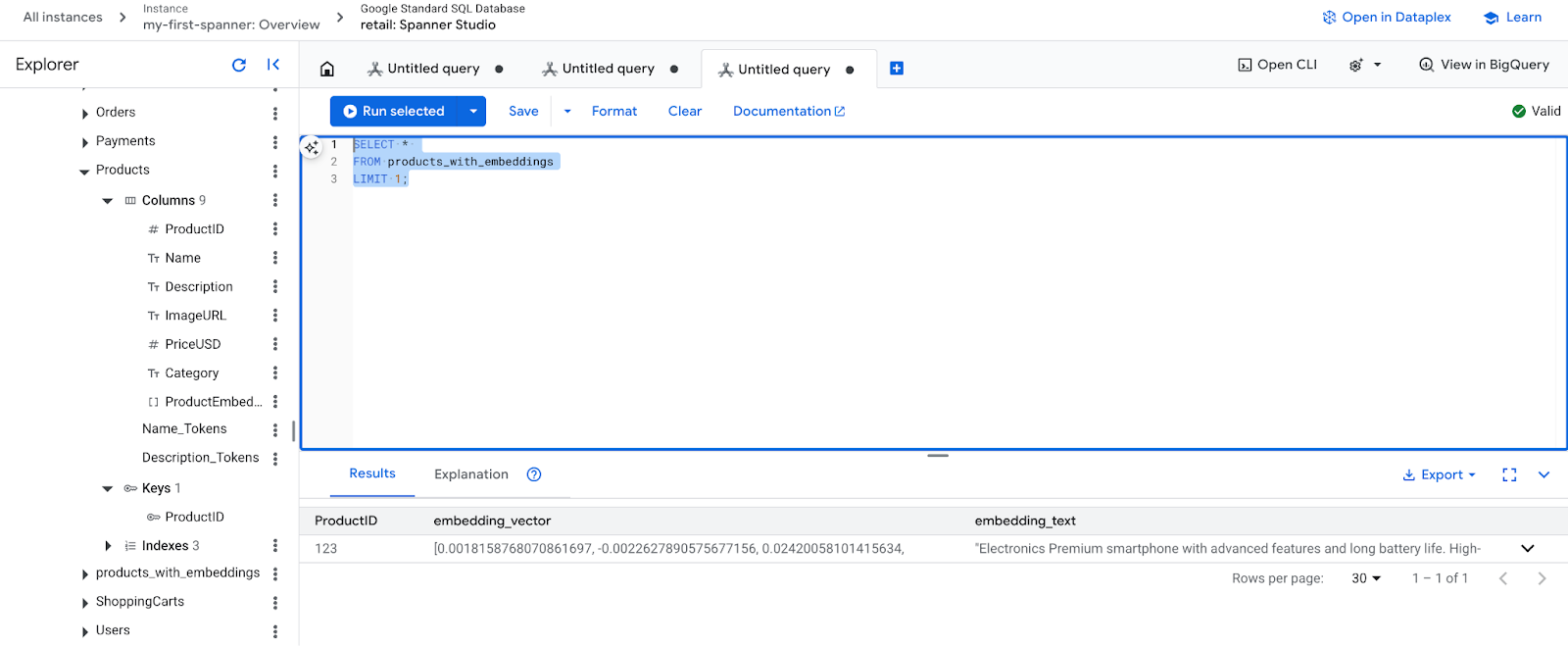
- جاسازیهای جدید خود را بررسی کنید. اکنون باید جاسازیهای ایجاد شده را ببینید.
SELECT *
FROM products_with_embeddings
LIMIT 1;
۷. مرحله ۴: ایجاد یک شاخص برداری برای جستجوی ANN
برای جستجوی فوری میلیونها بردار، به یک شاخص نیاز داریم. این شاخص امکان جستجوی تقریبی N نزدیکترین N همسایه (ANN) را فراهم میکند که فوقالعاده سریع است و به صورت افقی مقیاسپذیر است.
- کوئری DDL زیر را برای ایجاد اندیس اجرا کنید. ما
COSINEبه عنوان معیار فاصله خود تعیین میکنیم که برای جستجوی معنایی متن عالی است. توجه داشته باشید که عبارت WHERE در واقع ضروری است زیرا Spanner آن را به یک الزام برای کوئری تبدیل میکند.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- وضعیت ایجاد فهرست خود را در برگه عملیات بررسی کنید.
۸. مرحله ۵: یافتن توصیهها با جستجوی K-نزدیکترین همسایه (KNN)
حالا قسمت جالب ماجرا! بیایید محصولاتی را پیدا کنیم که با درخواست مشتری ما مطابقت داشته باشند: «من میخواهم یک کیبورد با کارایی بالا بخرم. من گاهی اوقات در ساحل کد مینویسم، بنابراین ممکن است خیس شوم.»
ما با جستجوی K - N نزدیکترین N همسایه (KNN) شروع خواهیم کرد. این یک جستجوی دقیق است که بردار جستجوی ما را با هر بردار محصول واحد مقایسه میکند. این روش دقیق است اما میتواند در مجموعه دادههای بسیار بزرگ کند باشد (به همین دلیل است که ما یک شاخص ANN برای مرحله 5 ساختیم).
این کوئری دو کار انجام میدهد:
- یک زیرپرسوجو (subquery) از ML.PREDICT برای دریافت بردار جاسازی (embedding vector) برای پرسوجوی مشتری ما استفاده میکند.
- کوئری بیرونی از COSINE_DISTANCE برای محاسبه "فاصله" بین بردار کوئری و بردار embedding_vector هر محصول استفاده میکند. فاصله کمتر به معنای تطابق بهتر است.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
شما باید لیستی از محصولات را ببینید که کیبوردهای مقاوم در برابر آب در بالای آن قرار دارند.
۹. مرحله ۶: یافتن توصیهها با جستجوی تقریبی (ANN)
KNN عالی است، اما برای یک سیستم تولیدی با میلیونها محصول و هزاران پرسوجو در ثانیه، به سرعت شاخص ANN خود نیاز داریم.
استفاده از این اندیس مستلزم مشخص کردن تابع APPROX_COSINE_DISTANCE است.
- همانطور که در بالا انجام دادید، متن خود را با بردار جاسازی کنید. ما نتایج آن را با رکوردهای جدول products_with_embeddings به صورت متقاطع پیوند میدهیم تا بتوانید از آن در تابع APPROX_COSINE_DISTANCE خود استفاده کنید.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
خروجی مورد انتظار: نتایج باید یکسان یا بسیار شبیه به کوئری KNN باشند، اما با استفاده از اندیس، بسیار کارآمدتر اجرا میشود. ممکن است در مثال متوجه این موضوع نشوید.
۱۰. مرحله ۷: از یک LLM برای توضیح توصیهها استفاده کنید
نمایش فهرستی از محصولات خوب است، اما توضیح اینکه چرا این محصول مناسب یا نامناسب است، عالی است. میتوانیم از LLMModel (Gemini) خود برای انجام این کار استفاده کنیم.
این کوئری، کوئری KNN ما از مرحله ۴ را درون یک فراخوانی ML.PREDICT قرار میدهد. ما از CONCAT برای ساخت یک اعلان برای LLM استفاده میکنیم و موارد زیر را به آن میدهیم:
- یک دستورالعمل واضح («با «بله» یا «خیر» پاسخ دهید و دلیل آن را توضیح دهید...»).
- درخواست اولیه مشتری.
- نام و توضیحات هر محصول منطبق با بالاترین رتبه.
سپس LLM هر محصول را در برابر پرس و جو ارزیابی میکند و یک پاسخ به زبان طبیعی ارائه میدهد.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
خروجی مورد انتظار: جدولی با ستون جدید LLMResponse دریافت خواهید کرد. پاسخ باید چیزی شبیه به این باشد: " خیر. دلیلش این است: * "مقاوم در برابر آب" به معنای "ضد آب" نیست. یک کیبورد "مقاوم در برابر آب" میتواند در برابر پاشش آب، باران سبک یا ریختن مایعات مقاومت کند.
۱۱. مرحله ۸: ایجاد نمودار ویژگی
حالا برای یک نوع توصیه متفاوت: «مشتریانی که این را خریدهاند، ... را هم خریدهاند.»
این یک پرسوجوی مبتنی بر رابطه است. ابزار ایدهآل برای این کار، نمودار ویژگی است. Spanner به شما امکان میدهد بدون کپی کردن دادهها، یک نمودار روی جداول موجود خود ایجاد کنید.
این دستور DDL گراف ما را تعریف میکند:
- گرهها: جداول
ProductوUser. گرهها موجودیتهایی هستند که میخواهید از آنها رابطهای استخراج کنید، میخواهید بدانید مشتریانی که محصول شما را خریداری کردهاند، محصولات «XYZ» را نیز خریداری کردهاند. - لبهها: جدول
Orders، که یکUser(منبع) را به یکProduct(مقصد) با برچسب "خریداری شده" متصل میکند. لبهها ارتباط بین کاربر و آنچه خریداری کرده را فراهم میکنند.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
۱۲. مرحله ۹: ترکیب جستجوی برداری و پرسوجوهای گراف
این قدرتمندترین مرحله است. ما جستجوی برداری هوش مصنوعی و پرسوجوهای نموداری را در یک عبارت واحد ترکیب خواهیم کرد تا محصولات مرتبط را پیدا کنیم.
این کوئری در سه بخش خوانده میشود که با NEXT statement از هم جدا شدهاند، بیایید آن را به بخشهای کوچکتر تقسیم کنیم.
- ابتدا با استفاده از جستجوی برداری، بهترین تطابق را پیدا میکنیم.
- ML.PREDICT با استفاده از EmbeddingsModel، یک بردار جاسازیشده از پرسوجوی متنی کاربر تولید میکند.
- این کوئری COSINE_DISTANCE بین این جاسازی جدید و p.embedding_vector ذخیره شده برای همه محصولات را محاسبه میکند.
- این تابع، بهترین محصول منطبق با حداقل فاصله (بالاترین شباهت معنایی) را انتخاب کرده و برمیگرداند.
- در مرحله بعد، نمودار را برای یافتن روابط پیمایش میکنیم.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- این کوئری از bestMatch به گرههای سفارشات مشترک (کاربر) برمیگردد و سپس به سایر محصولات خریداری شده با آن ارسال میشود.
- این تابع محصول اصلی را فیلتر میکند و از GROUP BY و COUNT(1) برای جمعبندی تعداد دفعات خرید مشترک اقلام استفاده میکند.
- این تابع، ۳ محصول برتر خریداریشدهی مشترک (purchasedWith) را که بر اساس فراوانی وقوع همزمان مرتب شدهاند، برمیگرداند.
علاوه بر این، رابطه سفارش کاربر را پیدا میکنیم.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- این مرحله میانی، الگوی پیمایش را برای اتصال موجودیتهای کلیدی اجرا میکند: bestMatch، گره اتصالدهنده user:Orders و آیتم purchasedWith.
- این به طور خاص خود رابطه را به عنوان خریداری شده برای استخراج دادهها در مرحله بعدی متصل میکند.
- این الگو تضمین میکند که زمینه برای دریافت جزئیات خاص سفارش و محصول ایجاد شده است.
- در نهایت، نتایجی که قرار است به عنوان گرههای گراف برگردانده شوند را خروجی میدهیم که باید قبل از برگرداندن به عنوان نتایج SQL قالببندی شوند.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
خروجی مورد انتظار: اشیاء JSON را مشاهده خواهید کرد که 3 قلم کالای برتر خریداری شده مشترک را نشان میدهند و توصیههای فروش متقابل را ارائه میدهند.
۱۳. تمیز کردن
برای جلوگیری از متحمل شدن هزینه، میتوانید منابعی را که ایجاد کردهاید حذف کنید.
- حذف نمونه Spanner: حذف نمونه، پایگاه داده را نیز حذف خواهد کرد.
gcloud spanner instances delete my-first-spanner --quiet
- حذف پروژه گوگل کلود: اگر این پروژه را فقط برای آزمایشگاه کد ایجاد کردهاید، حذف آن سادهترین راه برای پاکسازی است.
- به صفحه مدیریت منابع در کنسول گوگل کلود بروید.
- پروژه خود را انتخاب کنید و روی حذف کلیک کنید.
🎉 تبریک میگویم!
شما با موفقیت یک سیستم توصیهگر پیچیده و بلادرنگ با استفاده از هوش مصنوعی Spanner و Graph ساختید!
شما یاد گرفتهاید که چگونه Spanner را با Vertex AI برای جاسازیها و تولید LLM ادغام کنید، چگونه جستجوی برداری پرسرعت (KNN و ANN) را برای یافتن محصولات مرتبط از نظر معنایی انجام دهید، و چگونه از پرسوجوهای گراف برای کشف روابط بین محصولات استفاده کنید. شما سیستمی ساختهاید که نه تنها میتواند محصولات را پیدا کند ، بلکه توصیهها را توضیح داده و موارد مرتبط را پیشنهاد میدهد ، همه از یک پایگاه داده واحد و مقیاسپذیر.