
1. Introduction
Cet atelier de programmation vous guidera dans l'utilisation des fonctionnalités d'IA et de graphiques de Spanner pour améliorer une base de données de vente au détail existante. Vous apprendrez des techniques pratiques pour utiliser le machine learning dans Spanner afin de mieux servir vos clients. Plus précisément, nous allons implémenter les algorithmes k-Nearest Neighbors (kNN) et Approximate Nearest Neighbors (ANN) pour découvrir de nouveaux produits qui correspondent aux besoins de chaque client. Vous intégrerez également un LLM pour fournir des explications claires et en langage naturel sur les raisons pour lesquelles une recommandation de produit spécifique a été faite.
Au-delà des recommandations, nous allons explorer la fonctionnalité de graphique de Spanner. Vous utiliserez des requêtes de graphe pour modéliser les relations entre les produits en fonction de l'historique des achats des clients et des descriptions de produits. Cette approche permet de découvrir des articles étroitement liés, ce qui améliore considérablement la pertinence et l'efficacité de vos fonctionnalités "Les clients ont également acheté" ou "Articles associés". À la fin de cet atelier de programmation, vous aurez acquis les compétences nécessaires pour créer une application de vente au détail intelligente, évolutive et réactive, entièrement basée sur Google Cloud Spanner.
Scénario
Vous travaillez pour un marchand d'équipements électroniques. Votre site d'e-commerce dispose d'une base de données Spanner standard avec Products, Orders et OrderItems.
Un client arrive sur votre site avec un besoin spécifique : "J'aimerais acheter un clavier hautes performances. Il m'arrive de coder à la plage, donc il peut être mouillé."
Votre objectif est d'utiliser les fonctionnalités avancées de Spanner pour répondre intelligemment à cette demande :
- Trouver : allez au-delà de la simple recherche par mots clés pour trouver des produits dont les descriptions correspondent sémantiquement à la demande de l'utilisateur à l'aide de la recherche vectorielle.
- Expliquer : utilisez un LLM pour analyser les meilleurs résultats et expliquer pourquoi la recommandation est pertinente, afin de renforcer la confiance des clients.
- Associer : utilisez des requêtes de graphe pour trouver d'autres produits que les clients ont fréquemment achetés avec cette recommandation.
2. Avant de commencer
- Créer un projet : dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
- Activez la facturation : assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
- Activer Cloud Shell : cliquez sur le bouton "Activer Cloud Shell" dans la console. Vous pouvez basculer entre le terminal Cloud Shell et l'éditeur.

- Autoriser et définir le projet : une fois connecté à Cloud Shell, vérifiez que vous êtes authentifié et que le projet est défini sur votre ID de projet.
gcloud auth list
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir, en remplaçant
<PROJECT_ID>par l'ID de votre projet :
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- Activer les API requises : activez les API Spanner, Vertex AI et Compute Engine. Cela peut prendre quelques minutes.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Définissez quelques variables d'environnement que vous réutiliserez.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- Créez une instance Spanner d'essai sans frais si vous n'en avez pas déjà une . Vous aurez besoin d'une instance Spanner pour héberger votre base de données. Nous allons utiliser
regional-us-central1comme configuration. Vous pouvez le modifier si vous le souhaitez.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. Présentation de l'architecture
Spanner englobe toutes les fonctionnalités nécessaires, à l'exception des modèles hébergés sur Vertex AI.
4. Étape 1 : Configurez la base de données et envoyez votre première requête.
Tout d'abord, nous devons créer notre base de données, charger nos exemples de données de vente au détail et indiquer à Spanner comment communiquer avec Vertex AI.
Pour cette section, vous allez utiliser les scripts SQL ci-dessous.
- Accédez à la page produit de Spanner.
- Sélectionnez l'instance appropriée.
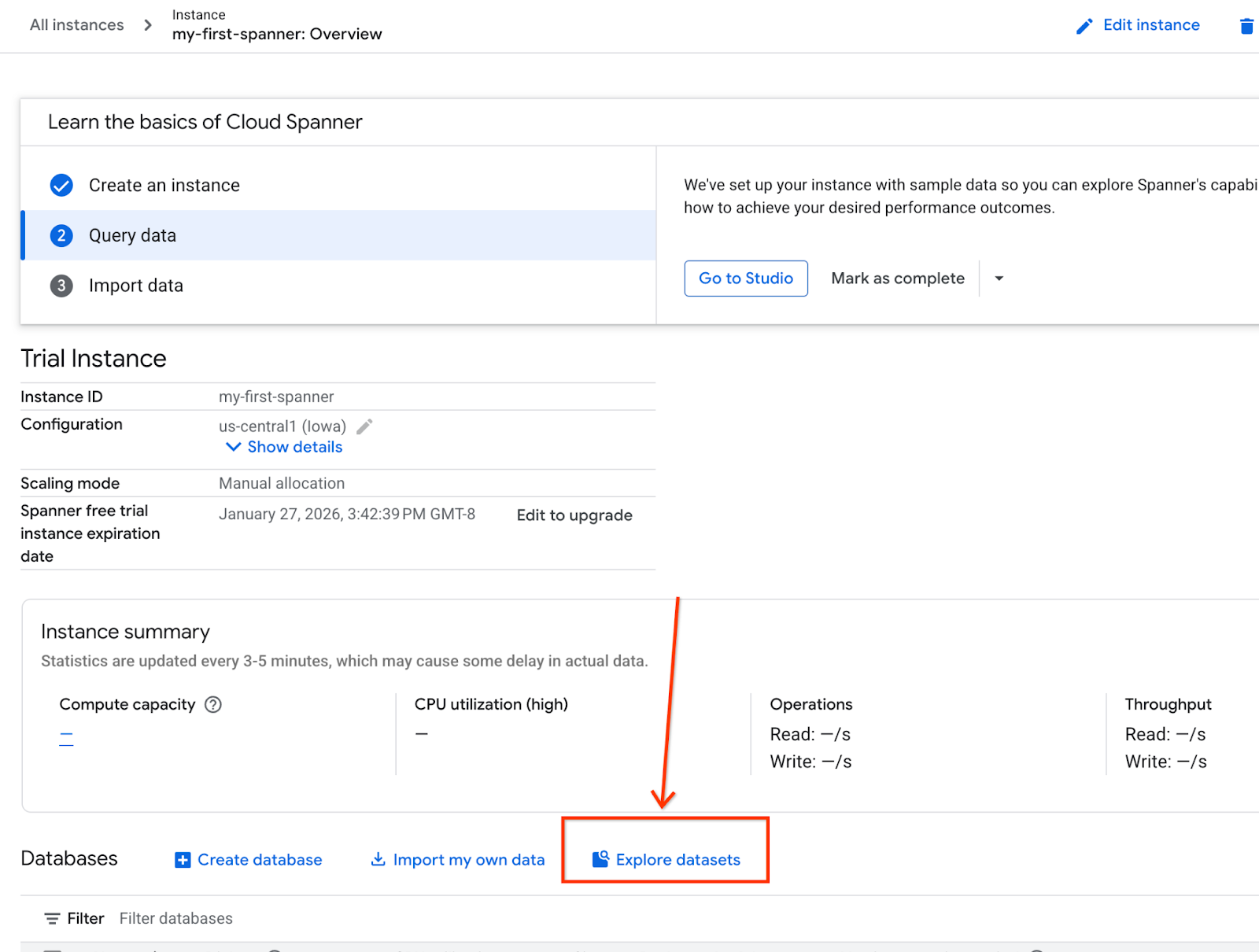
- Sur l'écran, sélectionnez "Explorer les ensembles de données". Ensuite, dans le pop-up, sélectionnez l'option "Vente au détail".
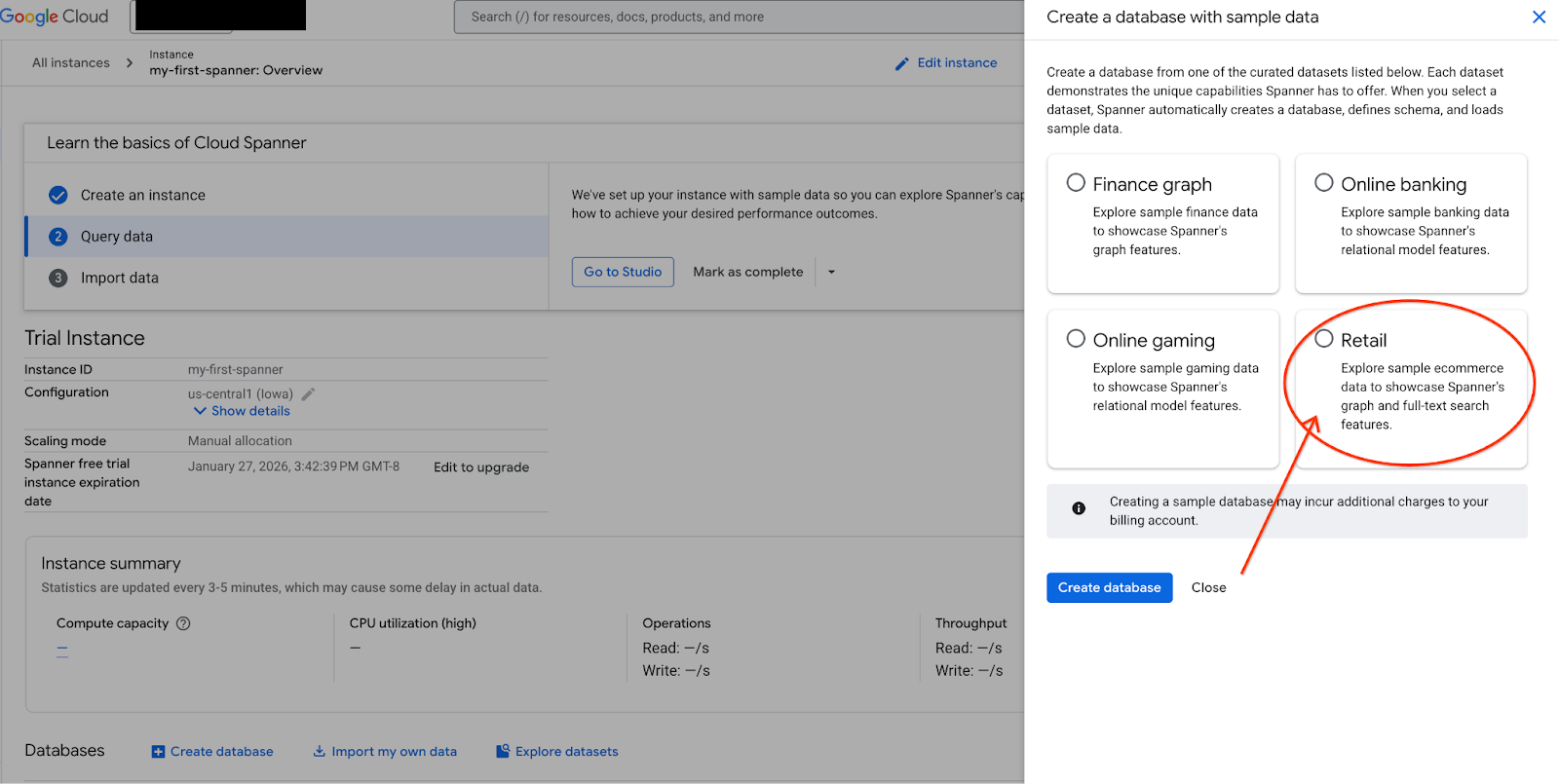
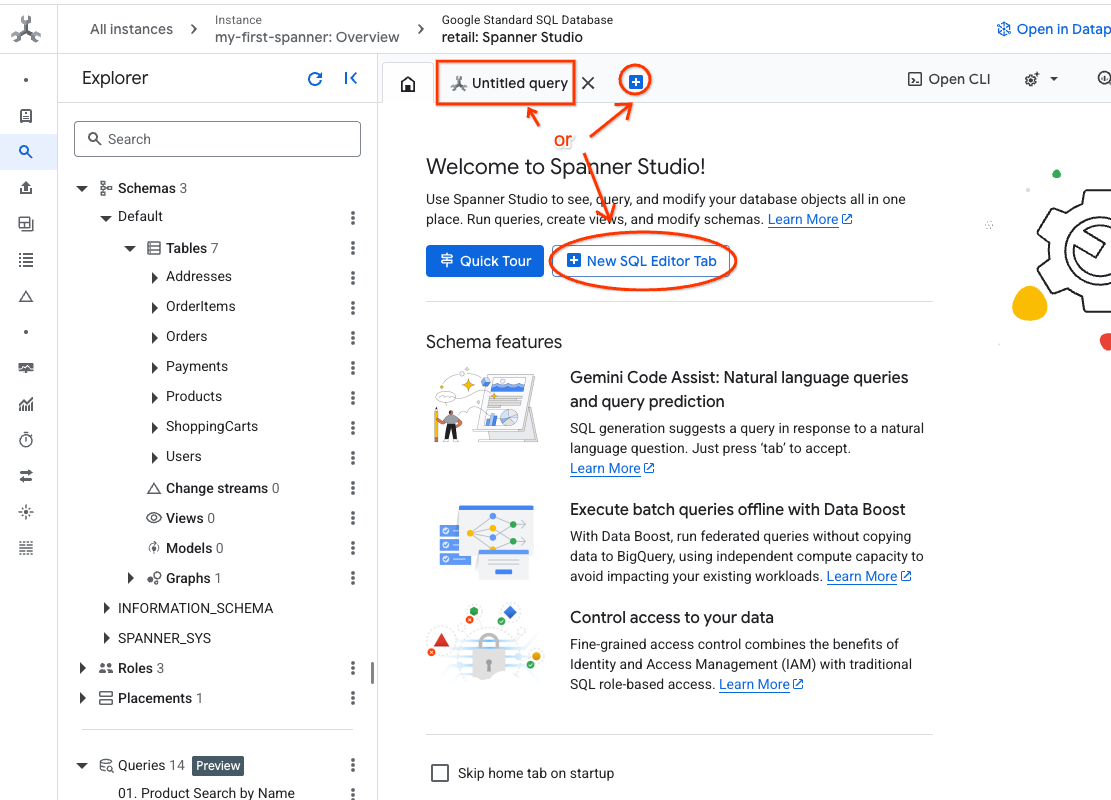
- Accédez à Spanner Studio. Spanner Studio comprend un volet "Explorateur" qui s'intègre à un éditeur de requêtes et à une table de résultats de requête SQL. Vous pouvez exécuter des instructions LDD, LMD et SQL à partir de cette interface. Vous devrez développer le menu sur le côté et rechercher la loupe.
- Lisez le tableau "Produits". Créez un onglet ou utilisez l'onglet "Requête sans titre" déjà créé.
SELECT *
FROM Products;
5. Étape 2 : Créez les modèles d'IA.
À présent, créons les modèles distants avec des objets Spanner. Ces instructions SQL créent des objets Spanner qui sont associés à des points de terminaison Vertex AI.
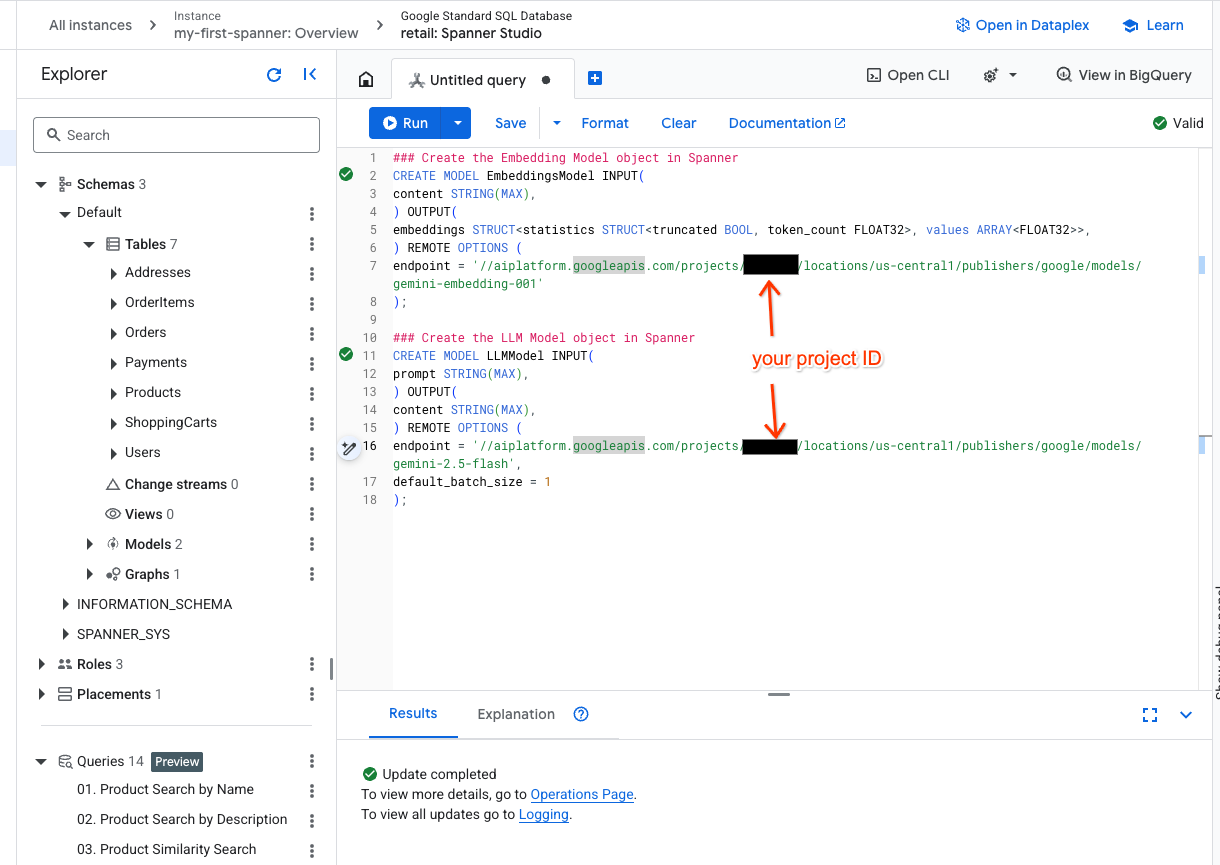
- Ouvrez un nouvel onglet dans Spanner Studio et créez vos deux modèles. Le premier est EmbeddingsModel, qui vous permettra de générer des embeddings. Le second est LLMModel, qui vous permettra d'interagir avec un LLM (dans notre exemple, il s'agit de gemini-2.5-flash). Assurez-vous d'avoir remplacé <PROJECT_ID> par l'ID de votre projet.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- Remarque : N'oubliez pas de remplacer
PROJECT_IDpar votre$PROJECT_ID.
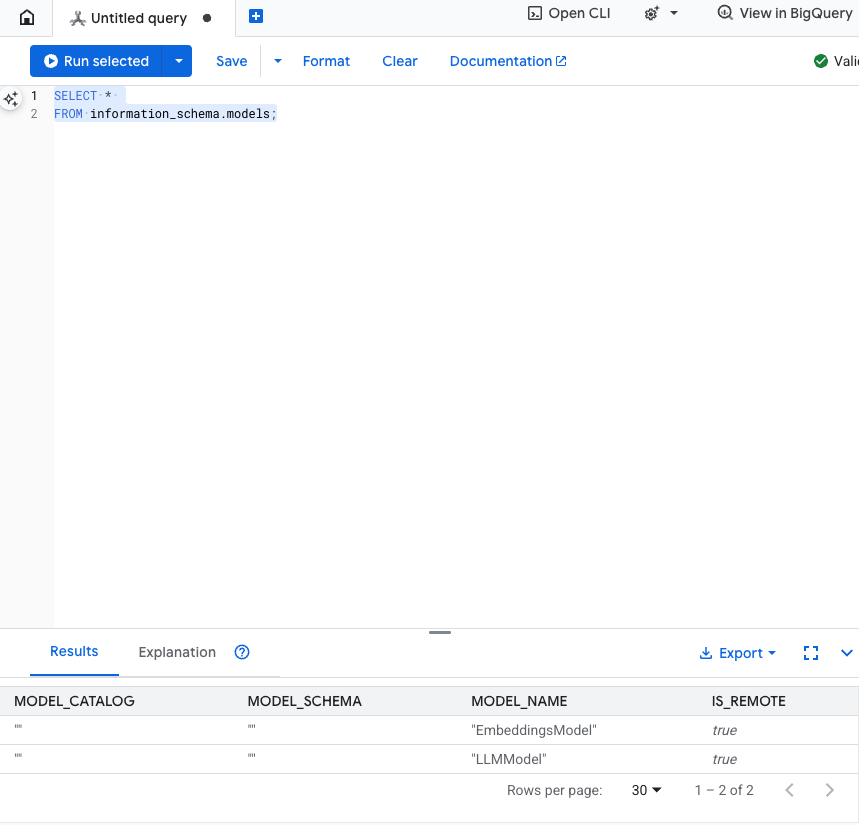
Testez cette étape : vous pouvez vérifier que les modèles ont été créés en exécutant la commande suivante dans l'éditeur SQL.
SELECT *
FROM information_schema.models;
6. Étape 3 : Générer et stocker des embeddings vectoriels
Notre tableau "Produit" contient des descriptions textuelles, mais le modèle d'IA comprend les vecteurs (tableaux de nombres). Nous devons ajouter une colonne pour stocker ces vecteurs, puis la remplir en exécutant toutes nos descriptions de produits via EmbeddingsModel.
- Créez une table pour prendre en charge les embeddings. Commencez par créer une table compatible avec les embeddings. Nous utilisons un modèle d'embedding différent de celui des exemples d'embeddings de tables de produits. Pour que la recherche vectorielle fonctionne correctement, vous devez vous assurer que les embeddings ont été générés à partir du même modèle.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- Remplissez la nouvelle table avec les embeddings générés à partir du modèle. Pour plus de simplicité, nous utilisons ici une instruction d'insertion. Les résultats de la requête seront alors insérés dans la table que vous venez de créer.
L'instruction SQL récupère et concatène d'abord toutes les colonnes de texte pertinentes pour lesquelles nous souhaitons générer des embeddings. Nous renvoyons ensuite les informations pertinentes, y compris le texte que nous avons utilisé. Cette étape n'est normalement pas nécessaire, mais nous l'incluons pour que vous puissiez visualiser les résultats.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
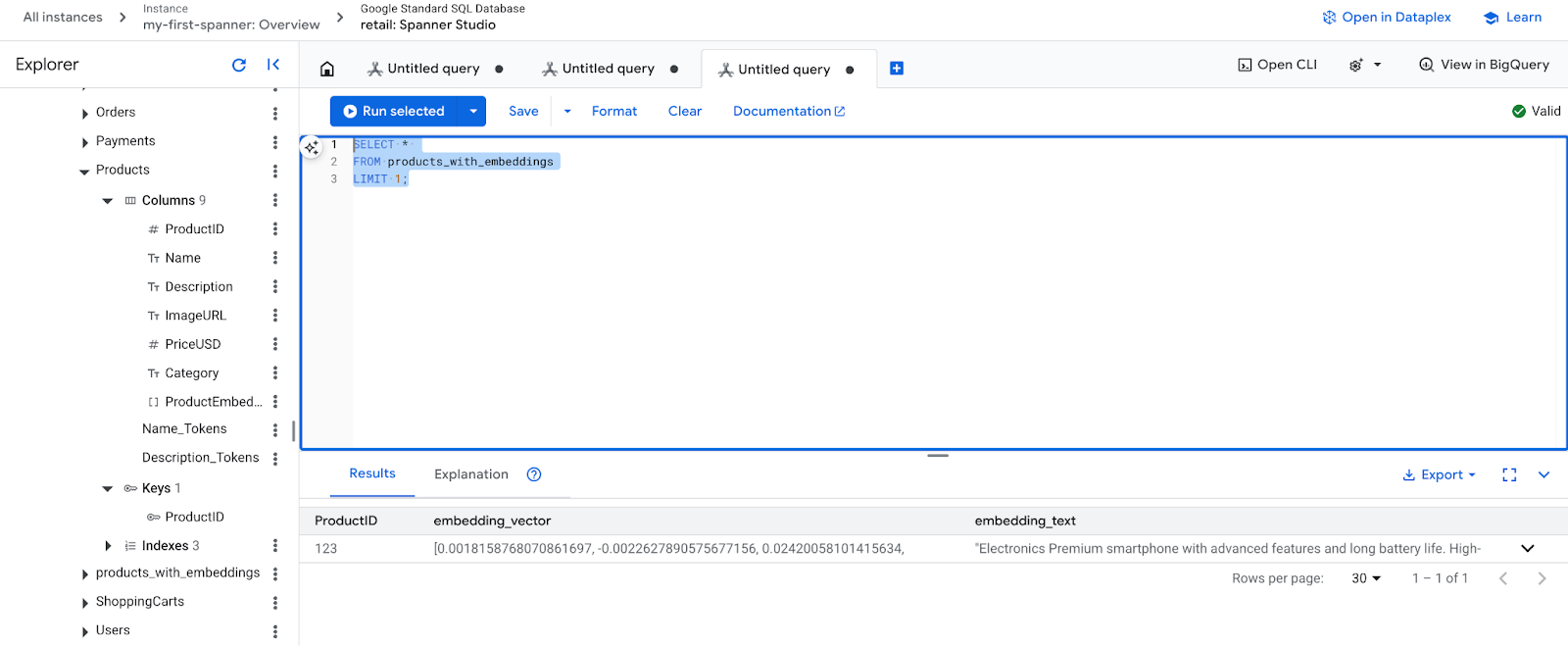
- Vérifiez vos nouveaux embeddings. Vous devriez maintenant voir les embeddings qui ont été générés.
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. Étape 4 : Créer un index vectoriel pour la recherche ANN
Pour rechercher instantanément des millions de vecteurs, nous avons besoin d'un index. Cet index permet la recherche Approximate Nearest Neighbor (ANN), qui est incroyablement rapide et évolutive.
- Exécutez la requête LDD suivante pour créer l'index. Nous spécifions
COSINEcomme métrique de distance, ce qui est excellent pour la recherche sémantique de texte. Notez que la clause WHERE est en fait nécessaire, car Spanner l'exigera pour la requête.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- Vérifiez l'état de la création de votre index dans l'onglet "Opérations".
8. Étape 5 : Trouver des recommandations avec la recherche des k plus proches voisins (KNN)
Passons maintenant à la partie la plus intéressante : Trouvons des produits qui correspondent à la requête de notre client : "J'aimerais acheter un clavier performant. Il m'arrive de coder à la plage, il peut donc être mouillé.".
Nous allons commencer par la recherche des k plus proches voisins (KNN). Il s'agit d'une recherche exacte qui compare le vecteur de notre requête à chaque vecteur de produit. Elle est précise, mais peut être lente sur de très grands ensembles de données (c'est pourquoi nous avons créé un index ANN pour l'étape 5).
Cette requête effectue deux opérations :
- Une sous-requête utilise ML.PREDICT pour obtenir le vecteur d'embedding de la requête de notre client.
- La requête externe utilise COSINE_DISTANCE pour calculer la "distance" entre le vecteur de requête et le vecteur embedding de chaque produit. Plus la distance est petite, plus la correspondance est bonne.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Vous devriez voir une liste de produits, avec les claviers résistants à l'eau tout en haut.
9. Étape 6 : Rechercher des recommandations avec la recherche approximative (ANN)
KNN est une excellente solution, mais pour un système de production avec des millions de produits et des milliers de requêtes par seconde, nous avons besoin de la vitesse de notre index ANN.
Pour utiliser l'index, vous devez spécifier la fonction APPROX_COSINE_DISTANCE.
- Obtenez l'embedding vectoriel de votre texte comme vous l'avez fait ci-dessus. Nous effectuons une jointure croisée des résultats avec les enregistrements de la table products_with_embeddings afin que vous puissiez l'utiliser dans votre fonction APPROX_COSINE_DISTANCE.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Résultat attendu : les résultats doivent être identiques ou très similaires à ceux de la requête KNN, mais l'exécution est beaucoup plus efficace grâce à l'index. Vous ne le remarquerez peut-être pas dans l'exemple.
10. Étape 7 : Utiliser un LLM pour expliquer les recommandations
Afficher une liste de produits est bien, mais expliquer pourquoi ils conviennent ou non est encore mieux. Pour ce faire, nous pouvons utiliser notre LLMModel (Gemini).
Cette requête imbrique notre requête KNN de l'étape 4 dans un appel ML.PREDICT. Nous utilisons CONCAT pour créer une requête pour le LLM, en lui fournissant :
- Une instruction claire ("Réponds par "Oui" ou "Non" et explique pourquoi…").
- Requête initiale du client.
- Nom et description de chaque produit correspondant le mieux.
Le LLM évalue ensuite chaque produit par rapport à la requête et fournit une réponse en langage naturel.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
Résultat attendu : vous obtiendrez un tableau avec une nouvelle colonne "LLMResponse". La réponse devrait ressembler à ceci : Non. Voici pourquoi : * "Résistant à l'eau" n'est pas synonyme de "étanche". Un clavier "résistant à l'eau" peut supporter les éclaboussures, la pluie légère ou les liquides renversés.
11. Étape 8 : Créez un graphique de propriétés
Passons à un autre type de recommandation : "Les clients qui ont acheté cet article ont également acheté…"
Il s'agit d'une requête basée sur une relation. L'outil idéal pour cela est un graphe de propriétés. Spanner vous permet de créer un graphique à partir de vos tables existantes sans dupliquer les données.
Cette instruction LDD définit notre graphique :
- Nœuds : tables
ProductetUser. Les nœuds sont les entités à partir desquelles vous souhaitez établir une relation. Par exemple, vous souhaitez savoir si les clients qui ont acheté votre produit ont également acheté les produits "XYZ". - Arêtes : table
Orders, qui relie uneUser(source) à uneProduct(destination) avec le libellé "Acheté". Les arêtes indiquent la relation entre un utilisateur et ce qu'il a acheté.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. Étape 9 : Combiner la recherche vectorielle et les requêtes de graphe
C'est l'étape la plus importante. Nous allons combiner la recherche vectorielle par IA et les requêtes de graphe dans une seule instruction pour trouver les produits associés.
Cette requête se lit en trois parties, séparées par le symbole NEXT statement. Décomposons-la en sections.
- Nous trouvons d'abord la meilleure correspondance à l'aide de la recherche vectorielle.
- ML.PREDICT génère un embedding vectoriel à partir de la requête textuelle de l'utilisateur à l'aide d'EmbeddingsModel.
- La requête calcule la COSINE_DISTANCE entre ce nouvel embedding et le p.embedding_vector stocké pour tous les produits.
- Elle sélectionne et renvoie le produit bestMatch unique avec la distance minimale (similitude sémantique la plus élevée).
- Nous parcourons ensuite le graphique à la recherche des relations.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- La requête remonte de bestMatch aux nœuds Orders (utilisateur) communs, puis avance vers les autres produits purchasedWith.
- Il filtre le produit d'origine et utilise GROUP BY et COUNT(1) pour agréger la fréquence à laquelle les articles sont achetés ensemble.
- Elle renvoie les trois produits les plus souvent achetés ensemble (purchasedWith), classés par fréquence de co-occurrence.
Nous trouvons également la relation entre l'utilisateur et la commande.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- Cette étape intermédiaire exécute le modèle de traversée pour lier les entités clés : bestMatch, le nœud Orders de l'utilisateur de connexion et l'élément purchasedWith.
- Il lie spécifiquement la relation elle-même comme achetée pour l'extraction des données à l'étape suivante.
- Ce modèle garantit que le contexte est établi pour récupérer les détails spécifiques à la commande et au produit.
- Enfin, nous affichons les résultats à renvoyer. Les nœuds de graphique doivent être mis en forme avant d'être renvoyés en tant que résultats SQL.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
Résultat attendu : vous verrez des objets JSON représentant les trois principaux articles achetés ensemble, qui fournissent des recommandations de vente croisée.
13. Nettoyer
Pour éviter que des frais ne vous soient facturés, vous pouvez supprimer les ressources que vous avez créées.
- Supprimez l'instance Spanner : la suppression de l'instance entraînera également la suppression de la base de données.
gcloud spanner instances delete my-first-spanner --quiet
- Supprimez le projet Google Cloud : si vous avez créé ce projet uniquement pour l'atelier de programmation, le supprimer est le moyen le plus simple de le nettoyer.
- Accédez à la page Gérer les ressources de la console Google Cloud.
- Sélectionnez votre projet, puis cliquez sur Supprimer.
🎉 Félicitations !
Vous avez créé un système de recommandation sophistiqué en temps réel à l'aide de Spanner AI et Graph.
Vous avez appris à intégrer Spanner à Vertex AI pour la génération d'embeddings et de LLM, à effectuer une recherche vectorielle à grande vitesse (KNN et ANN) pour trouver des produits sémantiquement pertinents et à utiliser des requêtes graphiques pour découvrir les relations entre les produits. Vous avez créé un système capable non seulement de trouver des produits, mais aussi d'expliquer des recommandations et de suggérer des articles associés, le tout à partir d'une seule base de données évolutive.