
1. מבוא
ב-Codelab הזה נסביר איך להשתמש ביכולות ה-AI והגרפים של Spanner כדי לשפר מסד נתונים קיים של קמעונאות. תלמדו טכניקות מעשיות לשימוש בלמידת מכונה ב-Spanner כדי לספק שירות טוב יותר ללקוחות. בפרט, נטמיע את האלגוריתמים k-Nearest Neighbors (שכנים קרובים) ו-Approximate Nearest Neighbors (שכנים קרובים משוערים) כדי לגלות מוצרים חדשים שתואמים לצרכים של כל לקוח. בנוסף, נשלב LLM כדי לספק הסברים ברורים בשפה טבעית לגבי הסיבה להמלצה על מוצר מסוים.
בנוסף להמלצות, נסביר על פונקציית הגרף של Spanner. תשתמשו בשאילתות גרף כדי ליצור מודל של קשרים בין מוצרים על סמך היסטוריית הרכישות של הלקוחות ותיאורי המוצרים. הגישה הזו מאפשרת לגלות פריטים שקשורים זה לזה באופן הדוק, וכך לשפר משמעותית את הרלוונטיות והיעילות של התכונות 'לקוחות שרכשו את הפריט הזה רכשו גם את הפריטים הבאים' או 'פריטים קשורים'. בסיום ה-Codelab הזה, תהיה לכם היכולת לבנות אפליקציה חכמה, רספונסיבית וניתנת להרחבה למכירות קמעונאיות, שמבוססת כולה על Google Cloud Spanner.
תרחיש
אתם עובדים בחנות קמעונאית לציוד אלקטרוני. באתר המסחר האלקטרוני שלכם יש מסד נתונים רגיל של Spanner עם Products, Orders ו-OrderItems.
לקוח נכנס לאתר שלכם עם צורך ספציפי: "אני רוצה לקנות מקלדת עם ביצועים גבוהים. לפעמים אני מתכנת בחוף, אז יכול להיות שהוא יירטב".
המטרה שלך היא להשתמש בתכונות המתקדמות של Spanner כדי לענות לבקשה הזו בצורה חכמה:
- חיפוש: חיפוש וקטורי מאפשר למצוא מוצרים שהתיאורים שלהם תואמים סמנטית לבקשת המשתמש, ולא רק באמצעות חיפוש פשוט של מילות מפתח.
- הסבר: שימוש ב-LLM כדי לנתח את ההתאמות המובילות ולהסביר למה ההמלצה מתאימה, כדי לבנות את אמון הלקוחות.
- הקשר: אפשר להשתמש בשאילתות גרף כדי למצוא מוצרים אחרים שהלקוחות רכשו לעיתים קרובות יחד עם ההמלצה הזו.
2. לפני שמתחילים
- יצירת פרויקט בענן במסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים פרויקט בענן או יוצרים פרויקט בענן חדש ב-Google Cloud.
- הפעלת החיוב מוודאים שהחיוב מופעל בפרויקט בענן שלכם. כך בודקים אם החיוב מופעל בפרויקט
- הפעלת Cloud Shell לוחצים על הלחצן 'הפעלת Cloud Shell' במסוף כדי להפעיל את Cloud Shell. אפשר לעבור בין Cloud Shell Terminal לבין Editor.

- אישור והגדרת הפרויקט אחרי שמתחברים ל-Cloud Shell, מוודאים שהאימות בוצע והפרויקט מוגדר לפי מזהה הפרויקט.
gcloud auth list
gcloud config list project
- אם הפרויקט לא מוגדר, מריצים את הפקודה הבאה כדי להגדיר אותו. מחליפים את
<PROJECT_ID>במזהה הפרויקט בפועל:
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- הפעלה של ממשקי ה-API הנדרשים מפעילים את ממשקי ה-API של Spanner, Vertex AI ו-Compute Engine. הפעולה הזו עשויה להימשך כמה דקות.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- מגדירים כמה משתני סביבה שבהם תשתמשו שוב.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- אם עדיין אין לכם מכונה של Spanner, אתם יכולים ליצור מכונה של Spanner לתקופת ניסיון בחינם . כדי לארח את מסד הנתונים, צריך מופע של Spanner. נשתמש ב-
regional-us-central1בתור ההגדרה. אם רוצים, אפשר לעדכן את המידע הזה.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. Architectural Overview
Spanner כולל את כל הפונקציות הנדרשות, למעט המודלים שמארח Vertex AI.
4. שלב 1: מגדירים את מסד הנתונים ושולחים את השאילתה הראשונה.
קודם כל, צריך ליצור את מסד הנתונים, לטעון את נתוני הקמעונאות לדוגמה ולציין ל-Spanner איך לתקשר עם Vertex AI.
בקטע הזה תשתמשו בסקריפטים הבאים של SQL.
- עוברים לדף המוצר של Spanner.
- בוחרים את המופע הנכון.
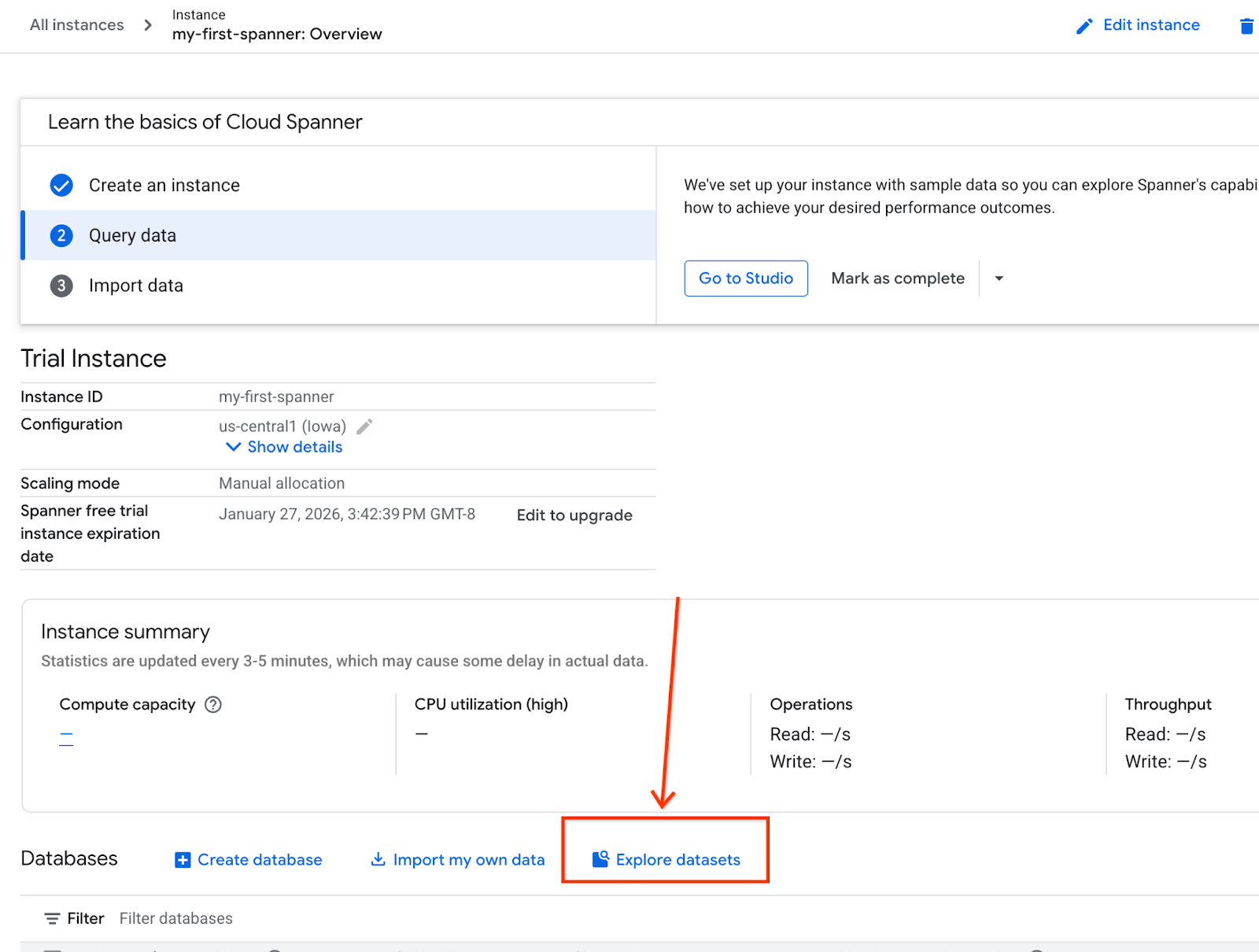
- במסך, בוחרים באפשרות 'ניתוח מערכי נתונים'. ואז בוחרים באפשרות 'קמעונאות' בחלון הקופץ.
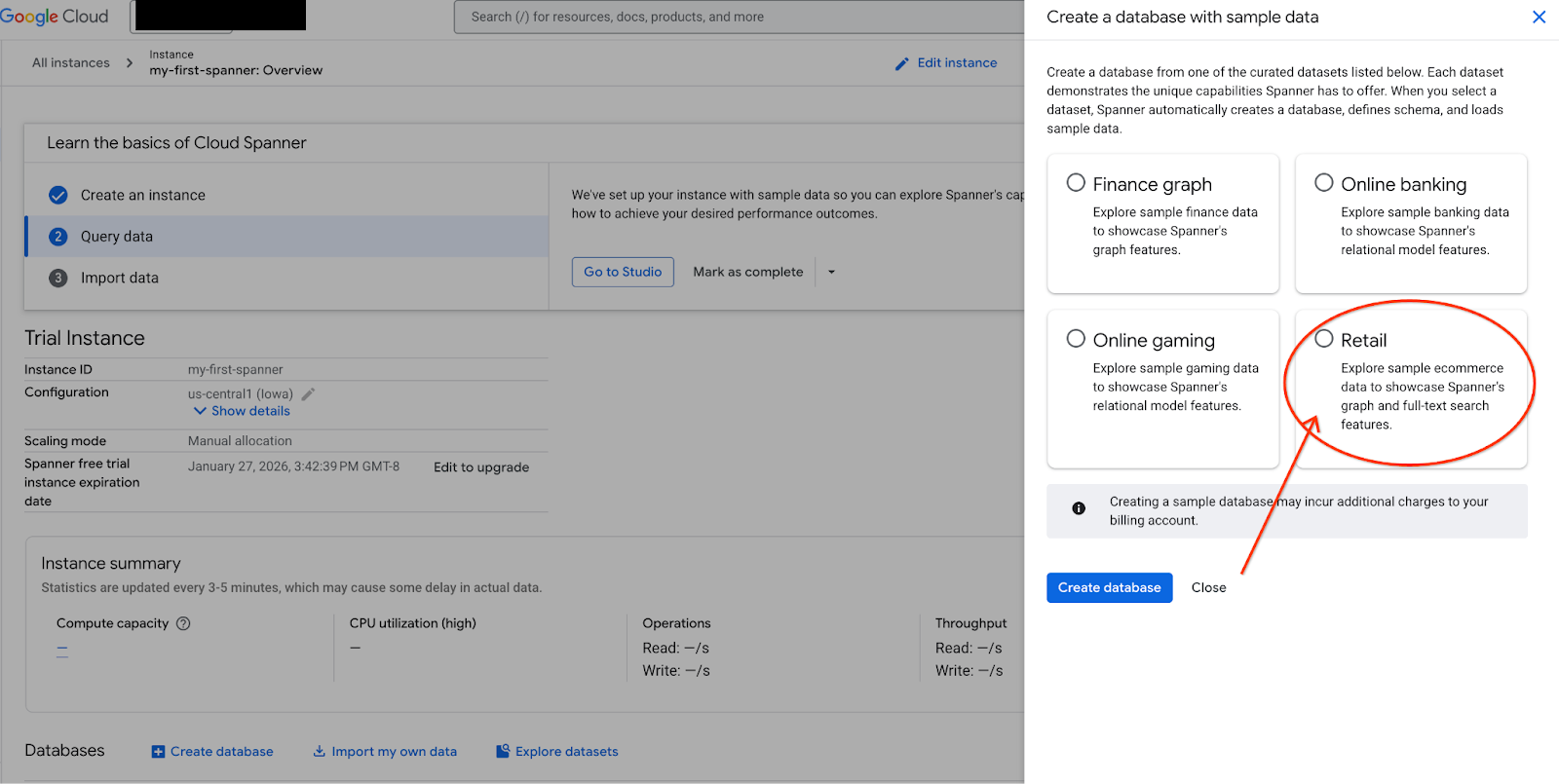
- עוברים אל Spanner Studio. ב-Spanner Studio יש חלונית Explorer שמשולבת עם כלי לעריכת שאילתות וטבלה של תוצאות שאילתות SQL. אפשר להריץ הצהרות DDL, DML ו-SQL מממשק אחד. צריך להרחיב את התפריט בצד ולחפש את סמל הזכוכית המגדלת.
- קריאת טבלת המוצרים יוצרים כרטיסייה חדשה או משתמשים בכרטיסייה 'שאילתה ללא שם' שכבר נוצרה.
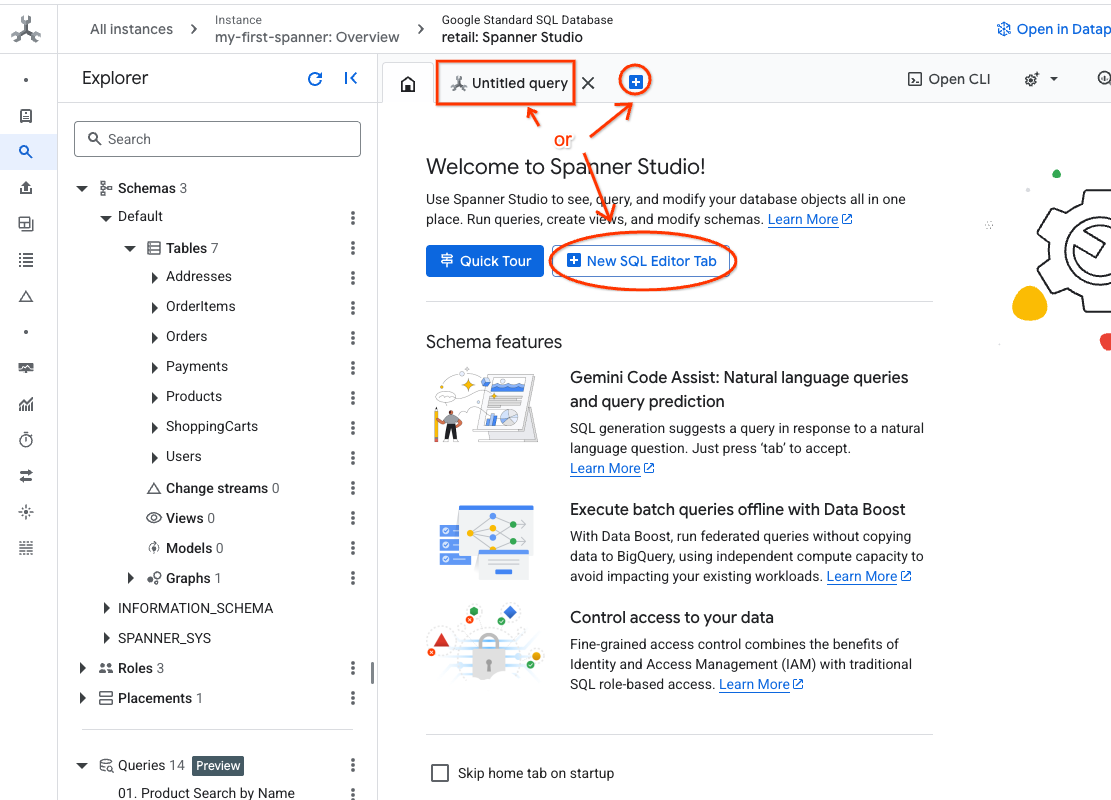
SELECT *
FROM Products;
5. שלב 2: יוצרים את מודלי ה-AI.
עכשיו ניצור את המודלים המרוחקים באמצעות אובייקטים של Spanner. הצהרות ה-SQL האלה יוצרות אובייקטים של Spanner שמקושרים לנקודות קצה (endpoints) של Vertex AI.
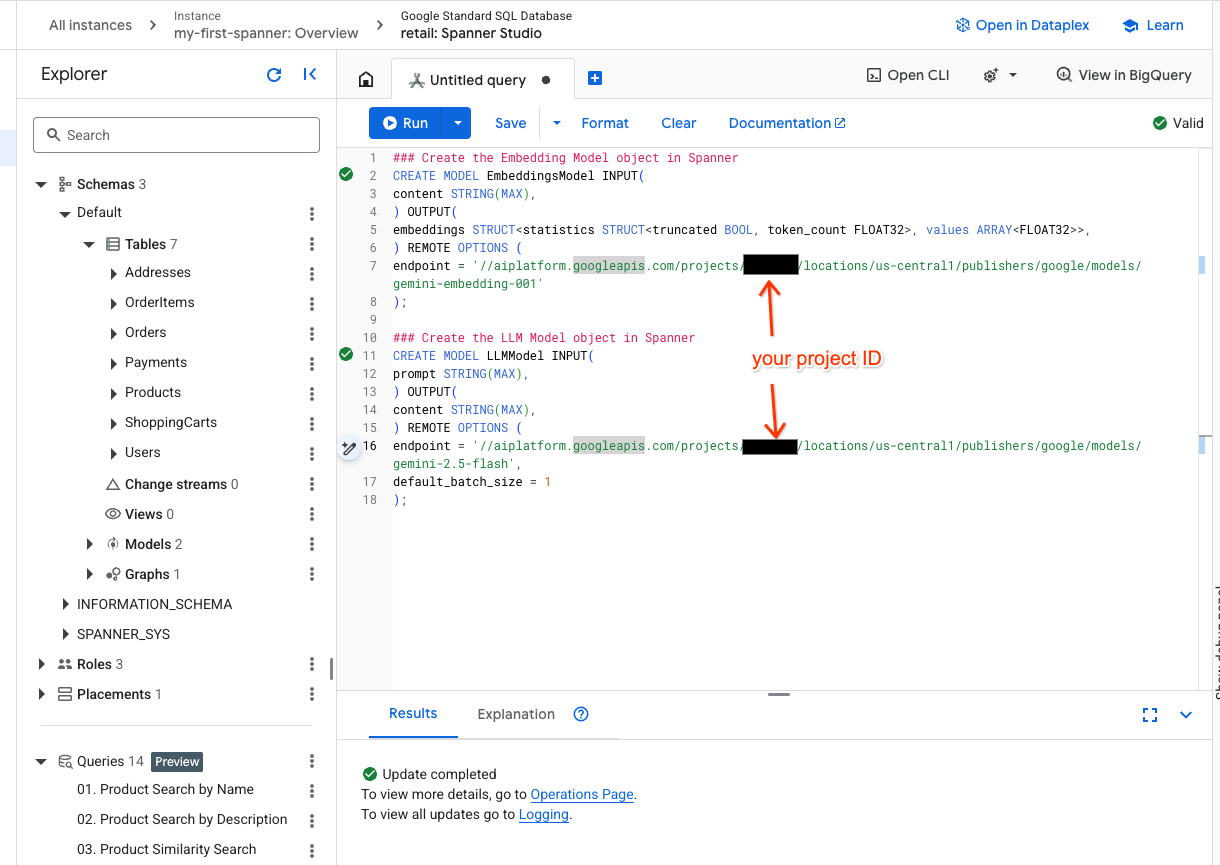
- פותחים כרטיסייה חדשה ב-Spanner Studio ויוצרים את שני המודלים. הראשון הוא EmbeddingsModel, שיאפשר לכם ליצור הטמעות. השני הוא LLMModel, שיאפשר לכם לקיים אינטראקציה עם LLM (בדוגמה שלנו, זהו gemini-2.5-flash). חשוב לוודא שעדכנתם את <PROJECT_ID> במזהה הפרויקט שלכם.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- הערה: חשוב להחליף את
PROJECT_IDב$PROJECT_IDהאמיתי שלכם.
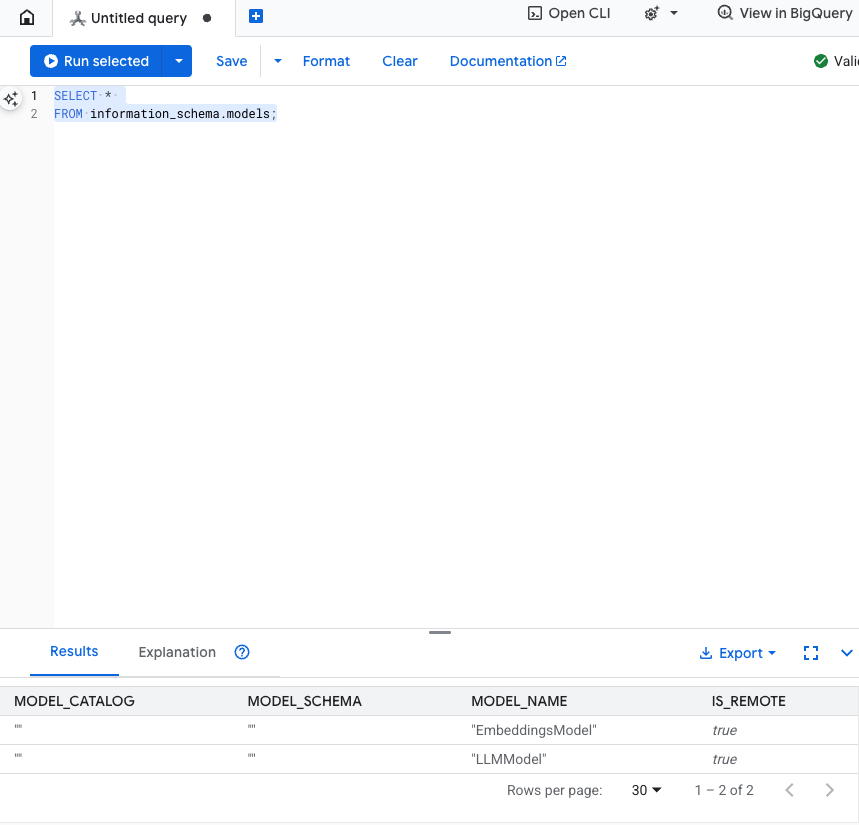
בדיקת השלב הזה: כדי לוודא שהמודלים נוצרו, מריצים את הפקודה הבאה בכלי לעריכת SQL.
SELECT *
FROM information_schema.models;
6. שלב 3: יצירה ואחסון של הטמעות וקטוריות
בטבלת המוצרים שלנו יש תיאורי טקסט, אבל מודל ה-AI מבין וקטורים (מערכים של מספרים). אנחנו צריכים להוסיף עמודה חדשה כדי לאחסן את הווקטורים האלה, ואז לאכלס אותה על ידי הפעלת כל תיאורי המוצרים דרך EmbeddingsModel.
- יוצרים טבלה חדשה לתמיכה בהטמעות. קודם יוצרים טבלה שיכולה לתמוך בהטמעות. אנחנו משתמשים במודל הטמעה שונה מזה שמופיע בדוגמאות של הטמעות בטבלת המוצרים. כדי שהחיפוש הווקטורי יפעל בצורה תקינה, צריך לוודא שההטמעות נוצרו מאותו מודל.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- מאכלסים את הטבלה החדשה עם ההטמעות שנוצרו מהמודל. כדי לפשט את הדברים, אנחנו משתמשים כאן בהצהרת insert into. תוצאות השאילתה יועברו לטבלה שיצרתם.
הוראת ה-SQL קודם אוספת ומשרשרת את כל עמודות הטקסט הרלוונטיות שרוצים ליצור להן הטמעות. לאחר מכן אנחנו מחזירים את המידע הרלוונטי, כולל הטקסט שבו השתמשנו. בדרך כלל אין צורך בכך, אבל אנחנו כוללים את השלב הזה כדי שתוכלו לראות את התוצאות.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
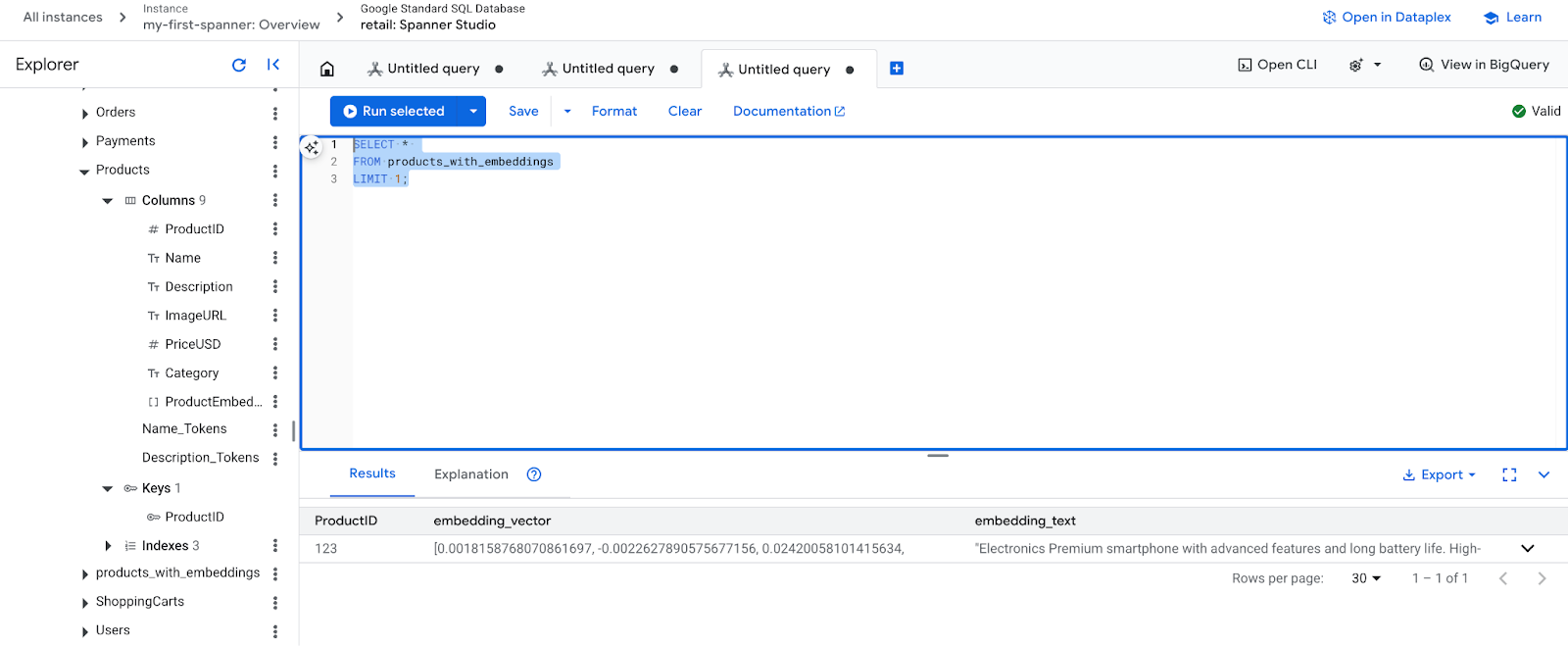
- בודקים את ההטמעות החדשות. עכשיו אמורים להופיע ההטמעות שנוצרו.
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. שלב 4: יצירת אינדקס וקטורי לחיפוש ANN
כדי לחפש מיליוני וקטורים באופן מיידי, אנחנו צריכים אינדקס. האינדקס הזה מאפשר חיפוש של Approximate Nearest Neighbor (ANN), שהוא מהיר מאוד וניתן להרחבה אופקית.
- מריצים את שאילתת ה-DDL הבאה כדי ליצור את האינדקס. הגדרנו את
COSINEכמדד המרחק שלנו, והוא מצוין לחיפוש סמנטי של טקסט. שימו לב: סעיף ה-WHERE נדרש כי Spanner יגדיר אותו כדרישה לשאילתה.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- אפשר לבדוק את הסטטוס של יצירת האינדקס בכרטיסייה 'פעולות'.
8. שלב 5: איתור המלצות באמצעות חיפוש K-שכנים קרובים (KNN)
ועכשיו לחלק הכיפי! נחפש מוצרים שתואמים לשאילתה של הלקוח: "אני רוצה לקנות מקלדת עם ביצועים גבוהים. לפעמים אני כותב קוד כשאני בחוף, אז יכול להיות שהוא יירטב".
נתחיל עם חיפוש K-Nearest Neighbor (KNN). זהו חיפוש מדויק שמשווה את וקטור השאילתה שלנו לכל וקטור מוצר. הוא מדויק אבל יכול להיות איטי במערכי נתונים גדולים מאוד (לכן בנינו אינדקס ANN לשלב 5).
השאילתה הזו עושה שני דברים:
- בשילוב עם ML.PREDICT, שאילתת המשנה מקבלת את וקטור ההטמעה של השאילתה של הלקוח.
- השאילתה החיצונית משתמשת ב-COSINE_DISTANCE כדי לחשב את ה'מרחק' בין וקטור השאילתה לבין כל וקטור הטמעה של מוצר. מרחק קטן יותר מצביע על התאמה טובה יותר.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
אמורה להופיע רשימת מוצרים, עם מקלדות עמידות למים בראש הרשימה.
9. שלב 6: איתור המלצות באמצעות חיפוש משוער (ANN)
אלגוריתם KNN הוא מצוין, אבל במערכת ייצור עם מיליוני מוצרים ואלפי שאילתות לשנייה, אנחנו צריכים את המהירות של אינדקס ANN.
כדי להשתמש באינדקס, צריך לציין את הפונקציה APPROX_COSINE_DISTANCE.
- משיגים את הטמעת הווקטור של הטקסט כמו שמתואר למעלה. אנחנו מבצעים צירוף צולב של התוצאות עם הרשומות בטבלה products_with_embeddings, כדי שתוכלו להשתמש בהן בפונקציה APPROX_COSINE_DISTANCE.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
פלט צפוי: התוצאות צריכות להיות זהות או דומות מאוד לתוצאות של שאילתת KNN, אבל הביצוע שלהן יעיל הרבה יותר כי נעשה שימוש באינדקס. יכול להיות שלא תשימו לב לזה בדוגמה.
10. שלב 7: שימוש במודל שפה גדול (LLM) כדי להסביר המלצות
הצגת רשימה של מוצרים היא טובה, אבל הסבר למה המוצרים מתאימים או לא מתאימים הוא מצוין. אנחנו יכולים להשתמש במודל LLM (Gemini) כדי לעשות זאת.
השאילתה הזו משבצת את שאילתת ה-KNN משלב 4 בתוך קריאה ל-ML.PREDICT. אנחנו משתמשים בפונקציה CONCAT כדי ליצור הנחיה ל-LLM, שכוללת:
- הוראה ברורה ("תענה ב'כן' או ב'לא' ותסביר למה...").
- השאילתה המקורית של הלקוח.
- השם והתיאור של כל מוצר שתואם לחיפוש.
לאחר מכן, מודל ה-LLM מעריך כל מוצר ביחס לשאילתה ומספק תשובה בשפה טבעית.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
הפלט הצפוי: תקבלו טבלה עם עמודה חדשה בשם LLMResponse. התשובה צריכה להיות בנוסח הבא: "לא. הנה הסיבה: * 'עמיד במים' זה לא 'חסין בפני מים'. מקלדת 'עמידה במים' יכולה לעמוד בפני התזות, גשם קל או נוזלים שנשפכו
11. שלב 8: יצירת גרף נכסים
עכשיו נציג סוג אחר של המלצה: "לקוחות שקנו את המוצר הזה קנו גם..."
זו שאילתה שמבוססת על קשר. הכלי המושלם לכך הוא גרף מאפיינים. Spanner מאפשר ליצור גרף על גבי הטבלאות הקיימות בלי לשכפל נתונים.
הצהרת ה-DDL הזו מגדירה את הגרף שלנו:
- צמתים: טבלאות
Productו-User. הצמתים הם הישויות שאתם רוצים לגזור מהן קשר. אתם רוצים לדעת אילו לקוחות שקנו את המוצר שלכם קנו גם מוצרים מסוג XYZ. - קשתות: הטבלה
Ordersשמקשרת ביןUser(מקור) לביןProduct(יעד) עם התווית 'נרכש'. הקצוות מספקים את הקשר בין המשתמש לבין מה שהוא רכש.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. שלב 9: שילוב של Vector Search ושל Graph Queries
זה השלב הכי חשוב. אנחנו נשלב חיפוש וקטורי מבוסס-AI עם שאילתות גרף בהצהרה אחת כדי למצוא מוצרים קשורים.
השאילתה הזו נקראת בשלושה חלקים, שמופרדים באמצעות NEXT statement. נפרט על כל חלק:
- קודם אנחנו מוצאים את ההתאמה הכי טובה באמצעות חיפוש וקטורי.
- הפונקציה ML.PREDICT יוצרת הטמעה וקטורית מטקסט השאילתה של המשתמש באמצעות EmbeddingsModel.
- השאילתה מחשבת את COSINE_DISTANCE בין ההטמעה החדשה לבין p.embedding_vector המאוחסן של כל המוצרים.
- הפונקציה בוחרת את המוצר היחיד הכי מתאים (bestMatch) עם המרחק המינימלי (הדמיון הסמנטי הגבוה ביותר) ומחזירה אותו.
- לאחר מכן אנחנו עוברים על הגרף בחיפוש אחר הקשרים.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- השאילתה מתחילה ב-bestMatch, עוברת אחורה לצמתי Orders (משתמש) נפוצים ואז קדימה למוצרים אחרים שנרכשו עם המוצר.
- היא מסננת את המוצר המקורי ומשתמשת בפונקציות GROUP BY ו-COUNT(1) כדי לצבור את הנתונים לגבי התדירות שבה פריטים נרכשים יחד.
- הפונקציה מחזירה את 3 המוצרים המובילים שנרכשו יחד (purchasedWith) לפי סדר השכיחות של הרכישה המשותפת.
בנוסף, אנחנו מוצאים את הקשר בין המשתמש לבין ההזמנה.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- בשלב הביניים הזה מופעל דפוס המעבר כדי לקשור את ישויות המפתח: bestMatch, הצומת connecting user:Orders והפריט purchasedWith.
- היא קושרת באופן ספציפי את קשר הגומלין עצמו כקשר שנרכש לצורך חילוץ נתונים בשלב הבא.
- התבנית הזו מבטיחה שההקשר יוגדר כדי לאחזר פרטים ספציפיים להזמנה ולמוצר.
- לבסוף, אנחנו מוציאים את התוצאות שיוחזרו. צריך לעצב את צמתי הגרף לפני שהם מוחזרים כתוצאות SQL.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
פלט צפוי: יוצגו אובייקטים מסוג JSON שמייצגים את 3 הפריטים המובילים שנרכשו יחד, עם המלצות למכירת מוצרים נוספים.
13. סידור וארגון
כדי להימנע מחיובים, אפשר למחוק את המשאבים שיצרתם.
- מוחקים את מופע Spanner: אם מוחקים את המופע, מסד הנתונים נמחק גם כן.
gcloud spanner instances delete my-first-spanner --quiet
- מוחקים את הפרויקט ב-Google Cloud: אם יצרתם את הפרויקט הזה רק בשביל ה-Codelab, מחיקת הפרויקט היא הדרך הקלה ביותר לנקות את המשאבים.
- נכנסים לדף Manage Resources במסוף Google Cloud.
- בוחרים את הפרויקט ולוחצים על מחיקה.
🎉 מזל טוב!
יצרתם בהצלחה מערכת המלצות מתוחכמת בזמן אמת באמצעות Spanner AI ו-Graph!
למדתם איך לשלב את Spanner עם Vertex AI כדי ליצור הטמעות וקטורים ו-LLM, איך לבצע חיפוש וקטורי במהירות גבוהה (KNN ו-ANN) כדי למצוא מוצרים שרלוונטיים מבחינה סמנטית, ואיך להשתמש בשאילתות גרף כדי לגלות קשרים בין מוצרים. יצרתם מערכת שיכולה לא רק למצוא מוצרים, אלא גם להסביר המלצות ולהציע פריטים קשורים, והכול מתוך מסד נתונים יחיד וניתן להרחבה.