
1. परिचय
इस कोडलैब में, आपको मौजूदा खुदरा डेटाबेस को बेहतर बनाने के लिए, Spanner के एआई और ग्राफ़ की सुविधाओं का इस्तेमाल करने के बारे में बताया जाएगा. आपको Spanner में मशीन लर्निंग का इस्तेमाल करने की व्यावहारिक तकनीकों के बारे में पता चलेगा. इससे आपको अपने ग्राहकों को बेहतर सेवाएं देने में मदद मिलेगी. खास तौर पर, हम k-Nearest Neighbors (kNN) और Approximate Nearest Neighbors (ANN) को लागू करेंगे, ताकि हम ऐसे नए प्रॉडक्ट खोज सकें जो हर ग्राहक की ज़रूरतों के मुताबिक हों. इसके अलावा, आपको एलएलएम को इंटिग्रेट करना होगा, ताकि यह बताया जा सके कि किसी प्रॉडक्ट का सुझाव क्यों दिया गया है. इसके लिए, साफ़ तौर पर और सामान्य भाषा में जानकारी देनी होगी.
सुझाव के अलावा, हम Spanner की ग्राफ़ फ़ंक्शनैलिटी के बारे में भी जानेंगे. खरीदार के खरीदारी के इतिहास और प्रॉडक्ट के ब्यौरे के आधार पर, प्रॉडक्ट के बीच संबंध बनाने के लिए ग्राफ़ क्वेरी का इस्तेमाल किया जाएगा. इस तरीके से, मिलते-जुलते प्रॉडक्ट का पता लगाया जा सकता है. इससे "खरीदारों ने यह प्रॉडक्ट भी खरीदा" या "मिलते-जुलते प्रॉडक्ट" सुविधाओं को ज़्यादा काम का और असरदार बनाया जा सकता है. इस कोडलैब को पूरा करने के बाद, आपके पास Google Cloud Spanner की मदद से, एक ऐडवांस, ज़्यादा उपयोगकर्ताओं को हैंडल करने वाला, और रिस्पॉन्सिव रीटेल ऐप्लिकेशन बनाने का कौशल होगा.
उदाहरण
मान लें कि आप इलेक्ट्रॉनिक सामान बेचने वाले किसी खुदरा दुकानदार के लिए काम करते हैं. आपकी ई-कॉमर्स साइट में Products, Orders, और OrderItems के साथ एक स्टैंडर्ड Spanner डेटाबेस है.
कोई ग्राहक आपकी साइट पर किसी खास ज़रूरत के साथ आता है: "मुझे अच्छी परफ़ॉर्मेंस वाला कीबोर्ड खरीदना है. कभी-कभी मैं बीच पर कोडिंग करता हूं, इसलिए यह गीला हो सकता है."
आपका मकसद, इस अनुरोध का जवाब देने के लिए Spanner की ऐडवांस सुविधाओं का इस्तेमाल करना है:
- ढूंढना: वेक्टर सर्च का इस्तेमाल करके, कीवर्ड के आधार पर की जाने वाली सामान्य खोज से आगे बढ़ें. ऐसे प्रॉडक्ट ढूंढें जिनके ब्यौरे, उपयोगकर्ता की क्वेरी से मिलते-जुलते हों.
- जानकारी दें: एलएलएम का इस्तेमाल करके, सबसे मिलते-जुलते नतीजों का विश्लेषण करें. साथ ही, यह बताएं कि क्यों सुझाव सही है. इससे खरीदार का भरोसा बढ़ेगा.
- मिलते-जुलते प्रॉडक्ट ढूंढना: ग्राफ़ क्वेरी का इस्तेमाल करके, अन्य ऐसे प्रॉडक्ट ढूंढें जिन्हें खरीदारों ने अक्सर सुझाव के साथ खरीदा है.
2. शुरू करने से पहले
- प्रोजेक्ट बनाएं Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर जाकर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- बिलिंग की सुविधा चालू करें पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग की सुविधा चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें.
- Cloud Shell चालू करें कंसोल में "Cloud Shell चालू करें" बटन पर क्लिक करके, Cloud Shell चालू करें. Cloud Shell टर्मिनल और एडिटर के बीच टॉगल किया जा सकता है.

- प्रोजेक्ट को अनुमति देना और सेट करना Cloud Shell से कनेक्ट होने के बाद, पुष्टि करें कि आपने पुष्टि कर ली है और प्रोजेक्ट को अपने प्रोजेक्ट आईडी पर सेट किया गया है.
gcloud auth list
gcloud config list project
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए यहां दिया गया निर्देश इस्तेमाल करें. साथ ही,
<PROJECT_ID>की जगह अपना प्रोजेक्ट आईडी डालें:
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- ज़रूरी एपीआई चालू करें Spanner, Vertex AI, और Compute Engine API चालू करें. इसमें कुछ मिनट लग सकते हैं.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- कुछ ऐसे एनवायरमेंट वैरिएबल सेट करें जिनका इस्तेमाल आपको फिर से करना है.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- अगर आपके पास पहले से Spanner इंस्टेंस नहीं है, तो Spanner इंस्टेंस को बिना किसी शुल्क के आज़माएं . अपने डेटाबेस को होस्ट करने के लिए, आपको Spanner इंस्टेंस की ज़रूरत होगी. हम कॉन्फ़िगरेशन के तौर पर
regional-us-central1का इस्तेमाल करेंगे. अगर आपको यह जानकारी अपडेट करनी है, तो ऐसा किया जा सकता है.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. आर्किटेक्चर की खास जानकारी
Spanner में, Vertex AI पर होस्ट किए गए मॉडल को छोड़कर, सभी ज़रूरी सुविधाएं शामिल होती हैं.
4. पहला चरण: डेटाबेस सेट अप करें और अपनी पहली क्वेरी सबमिट करें.
सबसे पहले, हमें अपना डेटाबेस बनाना होगा. इसके बाद, हमें खुदरा कारोबार से जुड़ा सैंपल डेटा लोड करना होगा. साथ ही, Spanner को यह बताना होगा कि Vertex AI के साथ कैसे कम्यूनिकेट करना है.
इस सेक्शन के लिए, यहां दी गई एसक्यूएल स्क्रिप्ट का इस्तेमाल करें.
- Spanner के प्रॉडक्ट पेज पर जाएं.
- सही इंस्टेंस चुनें.
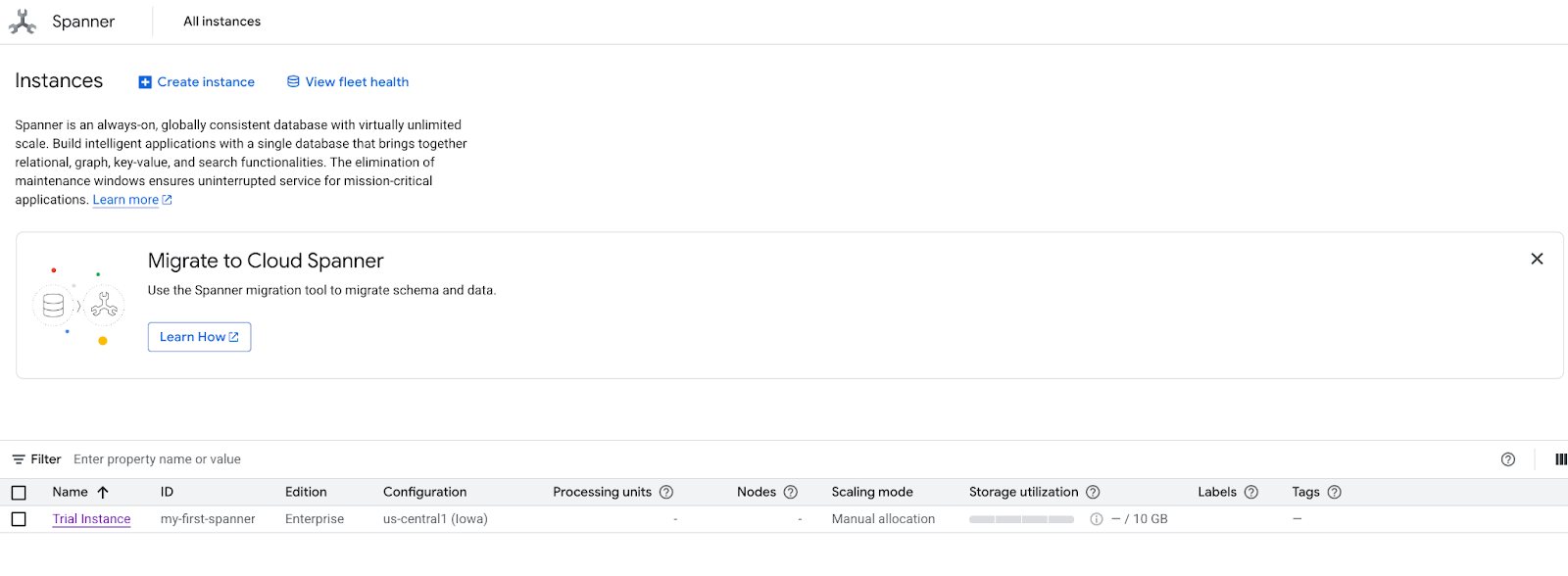
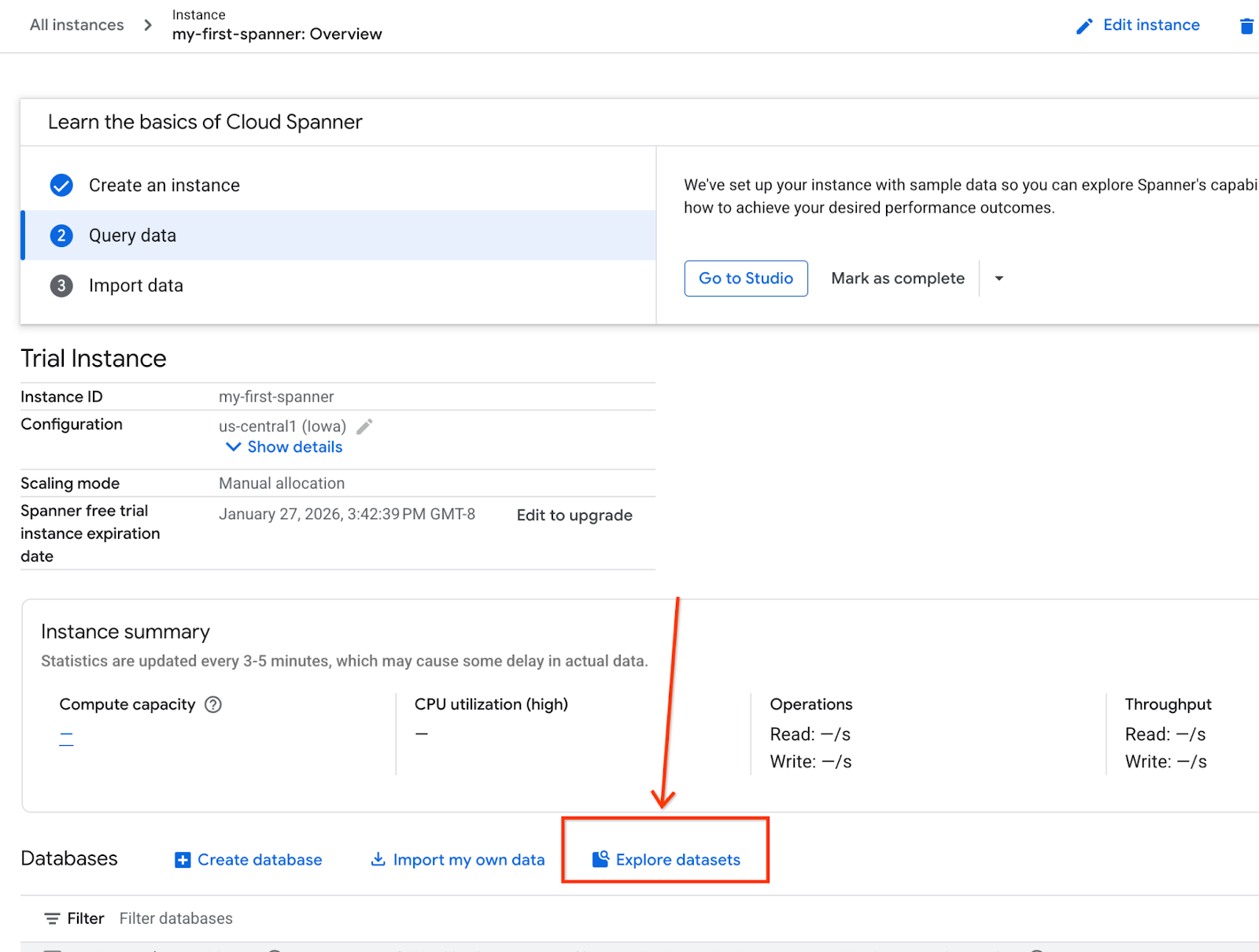
- स्क्रीन पर, डेटासेट एक्सप्लोर करें को चुनें. इसके बाद, पॉप-अप में "खुदरा स्टोर" विकल्प चुनें.
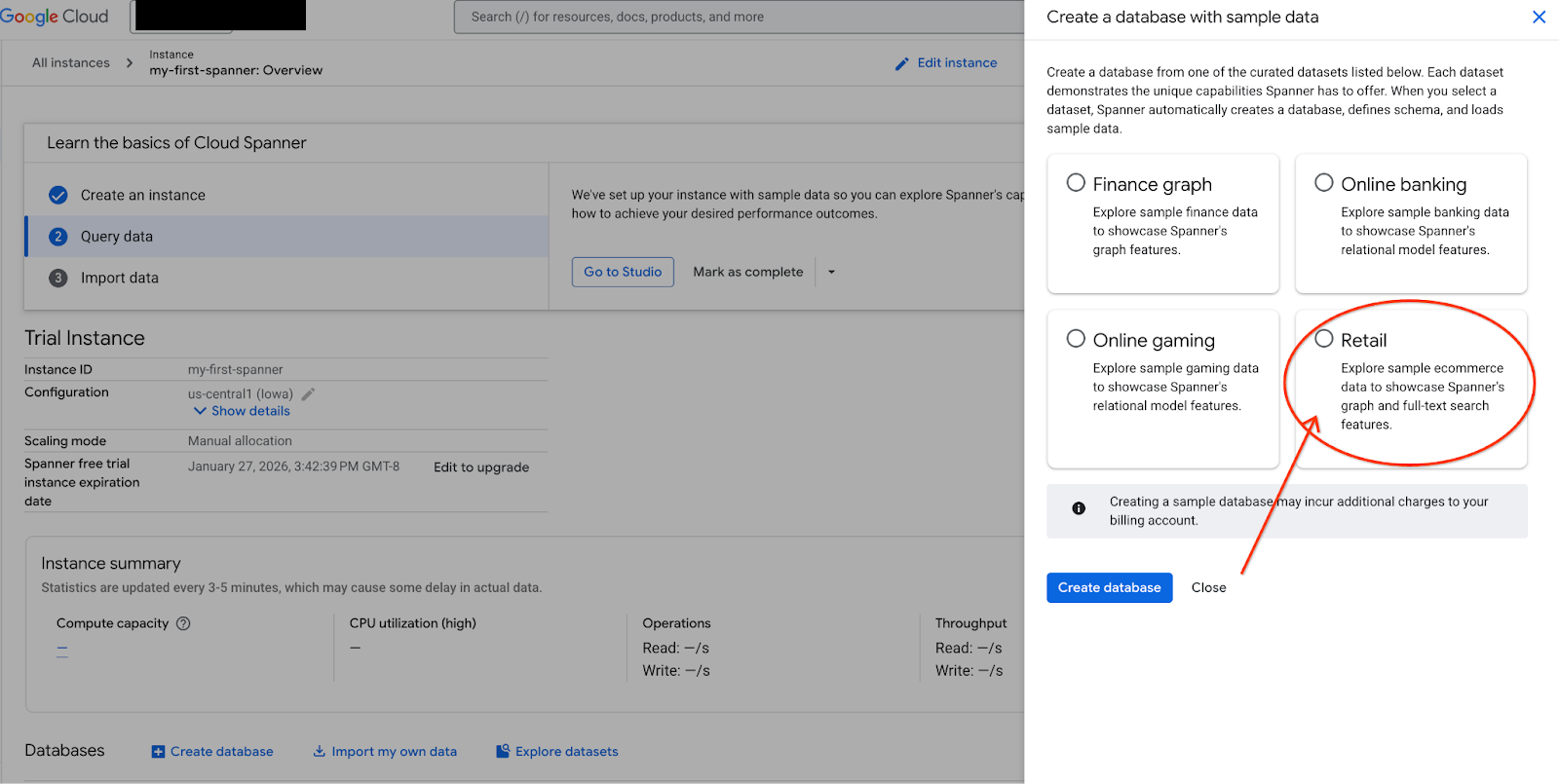
- Spanner Studio पर जाएं. Spanner Studio में एक्सप्लोरर पैनल शामिल होता है. यह क्वेरी एडिटर और SQL क्वेरी के नतीजों की टेबल के साथ इंटिग्रेट होता है. इस एक इंटरफ़ेस से, DDL, DML, और SQL स्टेटमेंट चलाए जा सकते हैं. आपको साइड में मौजूद मेन्यू को बड़ा करना होगा. इसके बाद, मैग्नीफ़ाइंग ग्लास ढूंढें.
- प्रॉडक्ट टेबल को पढ़ता है. नया टैब बनाएं या पहले से बने "Untitled query" टैब का इस्तेमाल करें.
SELECT *
FROM Products;
5. दूसरा चरण: एआई मॉडल बनाएं.
अब, Spanner ऑब्जेक्ट की मदद से रिमोट मॉडल बनाते हैं. ये SQL स्टेटमेंट, Spanner ऑब्जेक्ट बनाते हैं. ये ऑब्जेक्ट, Vertex AI एंडपॉइंट से लिंक होते हैं.
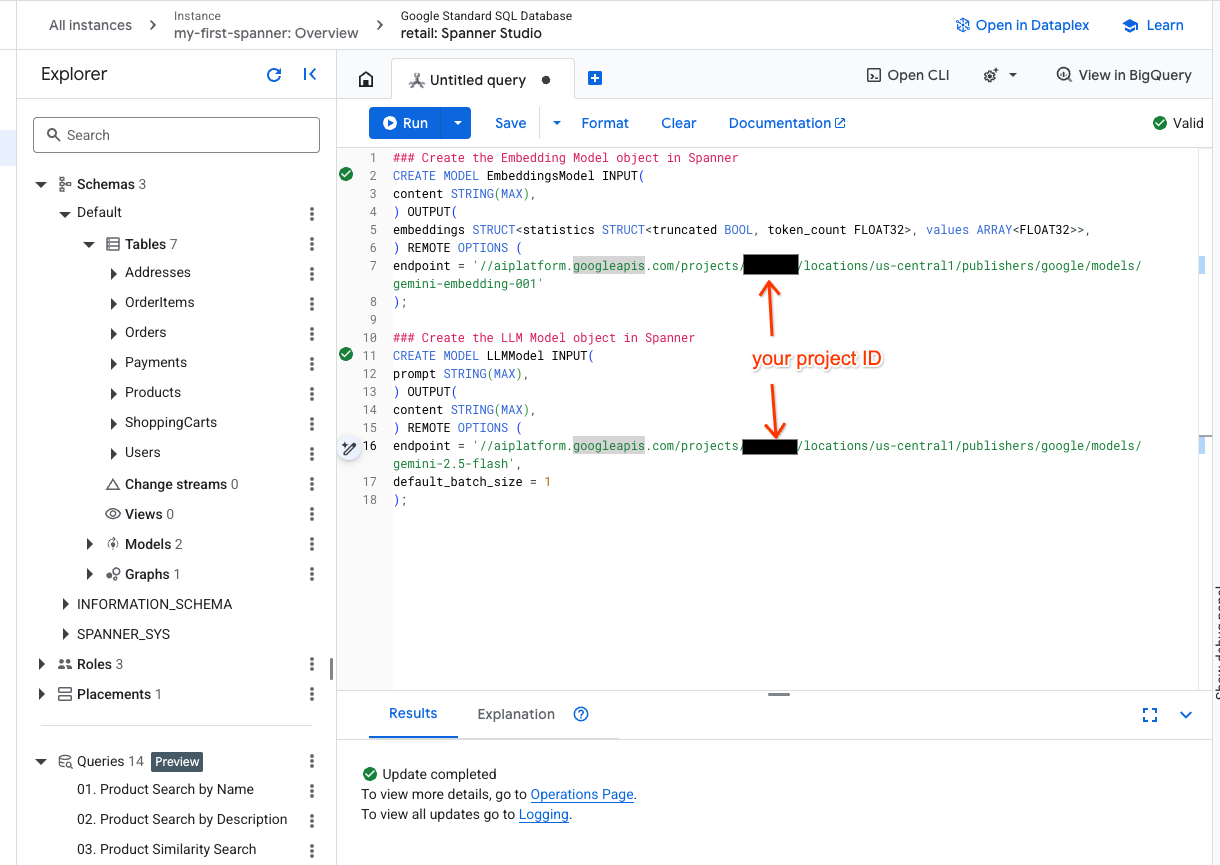
- Spanner Studio में एक नया टैब खोलें और अपने दो मॉडल बनाएं. पहला, EmbeddingsModel है. इसकी मदद से, एम्बेडिंग जनरेट की जा सकती हैं. दूसरा LLMModel है. इसकी मदद से, एलएलएम (हमारे उदाहरण में, यह gemini-2.5-flash है) के साथ इंटरैक्ट किया जा सकता है. पक्का करें कि आपने <PROJECT_ID> को अपने प्रोजेक्ट आईडी से अपडेट किया हो.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- ध्यान दें:
PROJECT_IDको अपने असल$PROJECT_IDसे बदलना न भूलें.
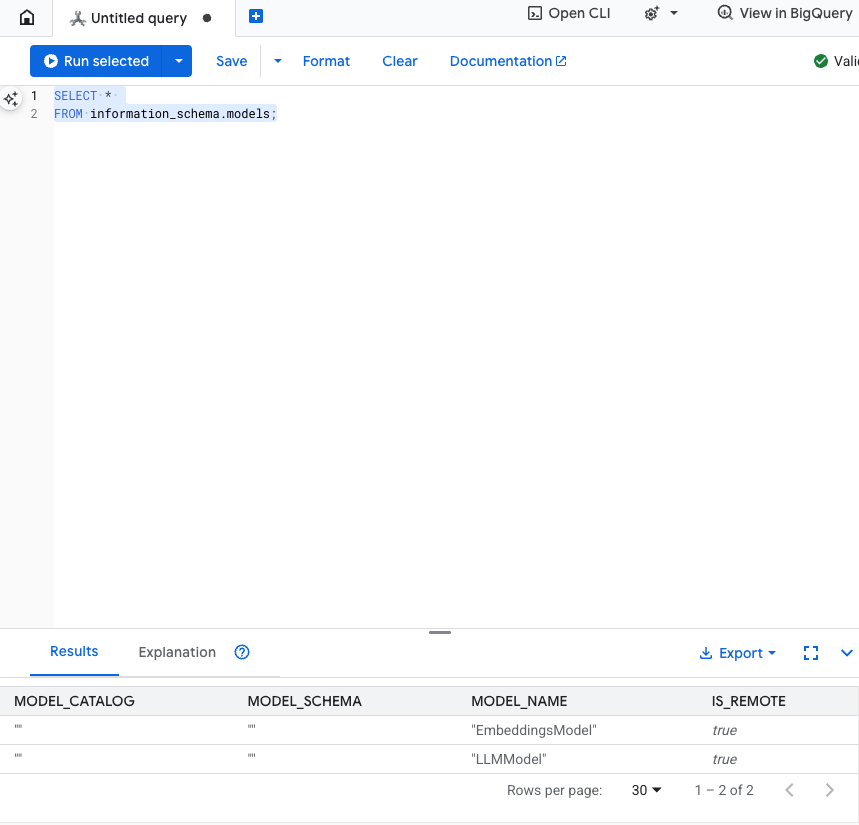
इस चरण को टेस्ट करें: एसक्यूएल एडिटर में यह कमांड चलाकर, पुष्टि की जा सकती है कि मॉडल बनाए गए हैं.
SELECT *
FROM information_schema.models;
6. तीसरा चरण: वेक्टर एम्बेडिंग जनरेट करना और उन्हें सेव करना
हमारी प्रॉडक्ट टेबल में टेक्स्ट के ब्यौरे मौजूद हैं, लेकिन एआई मॉडल वेक्टर (संख्याओं की ऐरे) को समझता है. हमें इन वेक्टर को सेव करने के लिए एक नया कॉलम जोड़ना होगा. इसके बाद, हमें अपने सभी प्रॉडक्ट के ब्यौरे को EmbeddingsModel के ज़रिए प्रोसेस करके, इस कॉलम में डेटा डालना होगा.
- एम्बेडिंग के लिए नई टेबल बनाएं. सबसे पहले, एक ऐसी टेबल बनाएं जिसमें एम्बेड करने की सुविधा काम करती हो. हम प्रॉडक्ट टेबल के सैंपल एम्बेडिंग के बजाय, किसी दूसरे एम्बेडिंग मॉडल का इस्तेमाल कर रहे हैं. वेक्टर सर्च की सुविधा ठीक से काम करे, इसके लिए आपको यह पक्का करना होगा कि एम्बेडिंग एक ही मॉडल से जनरेट की गई हों.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- मॉडल से जनरेट किए गए एम्बेडिंग की मदद से, नई टेबल में डेटा भरें. यहां हमने आसानी से समझने के लिए, insert into statement का इस्तेमाल किया है. इससे क्वेरी के नतीजे, आपकी बनाई गई टेबल में शामिल हो जाएंगे.
SQL स्टेटमेंट, सबसे पहले उन सभी टेक्स्ट कॉलम को इकट्ठा करता है और उन्हें एक साथ जोड़ता है जिनके लिए हमें एम्बेडिंग जनरेट करनी हैं. इसके बाद, हम काम की जानकारी देते हैं. इसमें वह टेक्स्ट भी शामिल होता है जिसका हमने इस्तेमाल किया है. आम तौर पर, इसकी ज़रूरत नहीं होती. हालांकि, हम इसे इसलिए शामिल करते हैं, ताकि आपको नतीजे दिख सकें.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
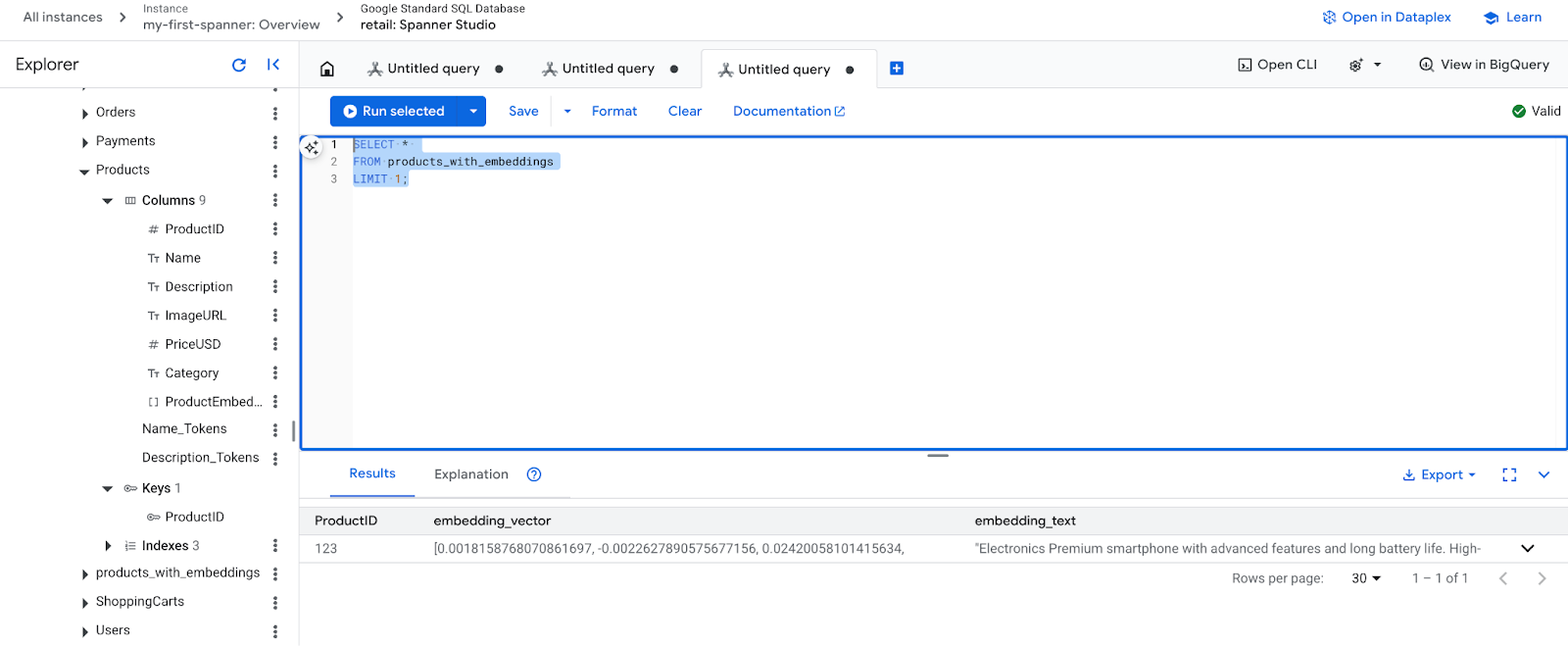
- अपने नए एम्बेड किए गए कॉन्टेंट की जांच करें. अब आपको जनरेट की गई एम्बेड की गई चीज़ें दिखेंगी.
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. चौथा चरण: एएनएन खोज के लिए वेक्टर इंडेक्स बनाना
लाखों वेक्टर को तुरंत खोजने के लिए, हमें एक इंडेक्स की ज़रूरत होती है. इस इंडेक्स की मदद से, Aप्रोक्सिमेट Nियरस्ट Nेबर (एएनएन) सर्च की जा सकती है. यह बहुत तेज़ होती है और इसे हॉरिज़ॉन्टल तरीके से बढ़ाया जा सकता है.
- इंडेक्स बनाने के लिए, यहां दी गई DDL क्वेरी चलाएं. हम दूरी के हिसाब से तय होने वाले मेट्रिक
COSINEका इस्तेमाल करते हैं. यह सिमैंटिक टेक्स्ट सर्च के लिए सबसे अच्छा है. ध्यान दें कि WHERE क्लॉज़ का इस्तेमाल करना ज़रूरी है, क्योंकि Spanner इसे क्वेरी के लिए ज़रूरी बना देगा.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- 'कार्रवाइयां' टैब में जाकर, इंडेक्स बनाने की प्रोसेस का स्टेटस देखें.
8. पांचवां चरण: K-Nearest Neighbor (KNN) Search की मदद से सुझाव ढूंढना
अब मज़ेदार हिस्सा! आइए, ऐसे प्रॉडक्ट ढूंढते हैं जो हमारे ग्राहक की क्वेरी से मेल खाते हों: "मुझे एक बेहतरीन परफ़ॉर्मेंस वाला कीबोर्ड खरीदना है. मैं कभी-कभी बीच पर कोडिंग करता हूं. इसलिए, यह भीग सकता है.".
हम K-Nearest Neighbor (KNN) सर्च से शुरुआत करेंगे. यह एक सटीक खोज है. इसमें हमारी क्वेरी वेक्टर की तुलना, हर प्रॉडक्ट वेक्टर से की जाती है. यह सटीक है, लेकिन बहुत बड़े डेटासेट पर यह धीमा हो सकता है. इसलिए, हमने पांचवें चरण के लिए एएनएन इंडेक्स बनाया है.
इस क्वेरी से दो काम होते हैं:
- सबक्वेरी, ML.PREDICT का इस्तेमाल करके ग्राहक की क्वेरी के लिए एम्बेडिंग वेक्टर हासिल करती है.
- आउटर क्वेरी, COSINE_DISTANCE का इस्तेमाल करके क्वेरी वेक्टर और हर प्रॉडक्ट के embedding_vector के बीच की "दूरी" का हिसाब लगाती है. कम दूरी का मतलब है कि खोज के नतीजे, क्वेरी से ज़्यादा मेल खाते हैं.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
आपको प्रॉडक्ट की एक सूची दिखेगी. इसमें सबसे ऊपर, पानी और धूल से सुरक्षित कीबोर्ड दिखेंगे.
9. छठा चरण: अनुमानित (एएनएन) खोज की मदद से सुझाव पाना
केएनएन एक बेहतरीन एल्गोरिदम है. हालांकि, लाखों प्रॉडक्ट और हर सेकंड में हज़ारों क्वेरी वाले प्रोडक्शन सिस्टम के लिए, हमें अपने एएनएन इंडेक्स की स्पीड की ज़रूरत होती है.
इंडेक्स का इस्तेमाल करने के लिए, आपको APPROX_COSINE_DISTANCE फ़ंक्शन तय करना होगा.
- ऊपर बताए गए तरीके से, अपने टेक्स्ट की वेक्टर एम्बेडिंग पाएं. हम उस क्वेरी के नतीजों को products_with_embeddings टेबल के रिकॉर्ड के साथ क्रॉस जॉइन करते हैं, ताकि आप इसका इस्तेमाल APPROX_COSINE_DISTANCE फ़ंक्शन में कर सकें.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
अनुमानित आउटपुट: नतीजे, KNN क्वेरी के नतीजों से मिलते-जुलते होने चाहिए. हालांकि, इंडेक्स का इस्तेमाल करके इसे ज़्यादा बेहतर तरीके से लागू किया जाता है. आपको शायद उदाहरण में यह न दिखे.
10. सातवां चरण: सुझावों के बारे में बताने के लिए एलएलएम का इस्तेमाल करना
सिर्फ़ प्रॉडक्ट की सूची दिखाना अच्छा है, लेकिन यह बताना कि यह प्रॉडक्ट क्यों सही है या क्यों सही नहीं है, बहुत अच्छा है. इसके लिए, हम अपने LLMModel (Gemini) का इस्तेमाल कर सकते हैं.
इस क्वेरी में, हमने चौथे चरण में की गई KNN क्वेरी को ML.PREDICT कॉल के अंदर नेस्ट किया है. हम एलएलएम के लिए प्रॉम्प्ट बनाने के लिए CONCAT का इस्तेमाल करते हैं. इससे एलएलएम को ये जानकारी मिलती है:
- साफ़ तौर पर निर्देश ("जवाब ‘हाँ' या ‘नहीं' में दो और बताओ कि ऐसा क्यों है...").
- ग्राहक की ओर से की गई ओरिजनल क्वेरी.
- सबसे मिलते-जुलते हर प्रॉडक्ट का नाम और जानकारी.
इसके बाद, एलएलएम क्वेरी के हिसाब से हर प्रॉडक्ट का आकलन करता है और सामान्य भाषा में जवाब देता है.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
अनुमानित आउटपुट: आपको एक टेबल मिलेगी, जिसमें LLMResponse नाम का नया कॉलम होगा. जवाब कुछ इस तरह का होना चाहिए: "नहीं. इसकी वजह यह है: * "पानी से सुरक्षित" का मतलब "वॉटरप्रूफ़" नहीं होता है. "पानी और धूल से सुरक्षित" कीबोर्ड पर पानी के छींटे पड़ने, हल्की बारिश होने या पानी गिरने से कोई असर नहीं पड़ता"
11. आठवां चरण: प्रॉपर्टी ग्राफ़ बनाना
अब एक अलग तरह के सुझाव के बारे में जानते हैं: "इसे खरीदने वाले लोगों ने यह भी खरीदा..."
यह संबंध पर आधारित क्वेरी है. इसके लिए, प्रॉपर्टी ग्राफ़ सबसे सही टूल है. Spanner की मदद से, डेटा को डुप्लीकेट किए बिना अपनी मौजूदा टेबल के ऊपर एक ग्राफ़ बनाया जा सकता है.
यह डीडीएल स्टेटमेंट हमारे ग्राफ़ को तय करता है:
- नोड:
ProductऔरUserटेबल. नोड वे इकाइयां होती हैं जिनसे आपको संबंध निकालना होता है. जैसे, आपको यह जानना है कि आपके प्रॉडक्ट खरीदने वाले खरीदारों ने ‘XYZ' प्रॉडक्ट भी खरीदे हैं. - किनारे:
Ordersटेबल, जोUser(सोर्स) कोProduct(डेस्टिनेशन) से "खरीदा गया" लेबल के साथ कनेक्ट करती है. किनारों से पता चलता है कि उपयोगकर्ता ने क्या खरीदा है.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. नौवां चरण: वेक्टर सर्च और ग्राफ़ क्वेरी को एक साथ इस्तेमाल करना
यह सबसे अहम चरण है. हम मिलते-जुलते प्रॉडक्ट ढूंढने के लिए, एक ही स्टेटमेंट में एआई वेक्टर सर्च और ग्राफ़ क्वेरी को शामिल करेंगे.
इस क्वेरी को तीन हिस्सों में पढ़ा जाता है. इन्हें NEXT statement से अलग किया गया है. आइए, इसे सेक्शन में बांटते हैं.
- सबसे पहले, हम वेक्टर सर्च का इस्तेमाल करके सबसे मिलते-जुलते नतीजे ढूंढते हैं.
- ML.PREDICT, EmbeddingsModel का इस्तेमाल करके, उपयोगकर्ता की टेक्स्ट क्वेरी से वेक्टर एम्बेडिंग जनरेट करता है.
- यह क्वेरी, सभी प्रॉडक्ट के लिए इस नई एम्बेडिंग और सेव किए गए p.embedding_vector के बीच COSINE_DISTANCE का हिसाब लगाती है.
- यह सबसे कम दूरी (सबसे ज़्यादा सिमैंटिक समानता) वाले सबसे अच्छे मैच वाले प्रॉडक्ट को चुनता है और उसे दिखाता है.
- इसके बाद, हम संबंधों का पता लगाने के लिए ग्राफ़ को ट्रैवर्स करते हैं.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- क्वेरी, सबसे अच्छे मैच से लेकर सामान्य Orders नोड (उपयोगकर्ता) तक जाती है. इसके बाद, इसे 'साथ में खरीदे गए' अन्य प्रॉडक्ट पर फ़ॉरवर्ड किया जाता है.
- यह क्वेरी, ओरिजनल प्रॉडक्ट को फ़िल्टर करती है. साथ ही, GROUP BY और COUNT(1) का इस्तेमाल करके यह पता लगाती है कि प्रॉडक्ट को कितनी बार एक साथ खरीदा गया है.
- यह फ़ंक्शन, साथ में खरीदे गए (purchasedWith) तीन सबसे ज़्यादा प्रॉडक्ट दिखाता है. इन्हें साथ में खरीदे जाने की फ़्रीक्वेंसी के हिसाब से क्रम में लगाया जाता है.
इसके अलावा, हम उपयोगकर्ता और ऑर्डर के बीच के संबंध का पता लगाते हैं.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- यह इंटरमीडिएट चरण, ट्रैवर्सल पैटर्न को लागू करता है, ताकि मुख्य इकाइयों को बाइंड किया जा सके: bestMatch, connecting user:Orders नोड, और purchasedWith आइटम.
- यह खास तौर पर, संबंध को अगले चरण में डेटा निकालने के लिए खरीदा गया संबंध के तौर पर दिखाता है.
- इस पैटर्न से यह पक्का होता है कि ऑर्डर और प्रॉडक्ट के बारे में जानकारी पाने के लिए, कॉन्टेक्स्ट सेट किया गया है.
- आखिर में, हम नतीजे दिखाते हैं. ग्राफ़ नोड को SQL के नतीजों के तौर पर दिखाने से पहले, उन्हें फ़ॉर्मैट करना ज़रूरी है.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
अनुमानित आउटपुट: आपको JSON ऑब्जेक्ट दिखेंगे. इनमें साथ में खरीदे गए टॉप 3 आइटम दिखाए जाएंगे. साथ ही, क्रॉस-सेल के सुझाव दिए जाएंगे.
13. स्टोरेज खाली करना
शुल्क से बचने के लिए, बनाए गए संसाधनों को मिटाया जा सकता है.
- Spanner इंस्टेंस मिटाना: इंस्टेंस मिटाने पर, डेटाबेस भी मिट जाएगा.
gcloud spanner instances delete my-first-spanner --quiet
- Google Cloud प्रोजेक्ट मिटाएं: अगर आपने यह प्रोजेक्ट सिर्फ़ कोडलैब के लिए बनाया है, तो इसे मिटाना सबसे आसान तरीका है.
- Google Cloud Console में, संसाधन मैनेज करें पेज पर जाएं.
- अपना प्रोजेक्ट चुनें और मिटाएं पर क्लिक करें.
🎉 बधाई हो!
आपने Spanner AI और Graph का इस्तेमाल करके, रीयल-टाइम में सुझाव देने वाला एक बेहतर सिस्टम बना लिया है!
आपने सीखा कि एम्बेडिंग और एलएलएम जनरेशन के लिए, Spanner को Vertex AI के साथ कैसे इंटिग्रेट किया जाता है. साथ ही, आपने यह भी सीखा कि अर्थ के हिसाब से मिलते-जुलते प्रॉडक्ट ढूंढने के लिए, हाई-स्पीड वेक्टर सर्च (केएनएन और एएनएन) कैसे की जाती है. इसके अलावा, आपने यह भी सीखा कि प्रॉडक्ट के बीच संबंध का पता लगाने के लिए, ग्राफ़ क्वेरी का इस्तेमाल कैसे किया जाता है. आपने एक ऐसा सिस्टम बनाया है जो न सिर्फ़ प्रॉडक्ट ढूंढ सकता है, बल्कि सुझावों के बारे में बता सकता है और मिलते-जुलते आइटम के सुझाव दे सकता है. यह सब एक ही, बड़े डेटाबेस से किया जा सकता है.