
1. Pengantar
Codelab ini akan memandu Anda menggunakan kemampuan AI dan grafik Spanner untuk meningkatkan kualitas database retail yang ada. Anda akan mempelajari teknik praktis untuk memanfaatkan machine learning dalam Spanner guna melayani pelanggan dengan lebih baik. Secara khusus, kami akan menerapkan k-Nearest Neighbors (kNN) dan Approximate Nearest Neighbors (ANN) untuk menemukan produk baru yang sesuai dengan kebutuhan masing-masing pelanggan. Anda juga akan mengintegrasikan LLM untuk memberikan penjelasan bahasa alami yang jelas tentang alasan rekomendasi produk tertentu dibuat.
Selain rekomendasi, kita akan mempelajari fungsi grafik Spanner. Anda akan menggunakan kueri grafik untuk memodelkan hubungan antar-produk berdasarkan histori pembelian pelanggan dan deskripsi produk. Pendekatan ini memungkinkan penemuan item yang sangat terkait, sehingga meningkatkan relevansi dan efektivitas fitur "Pelanggan juga membeli" atau "Item terkait" Anda secara signifikan. Di akhir codelab ini, Anda akan memiliki keterampilan untuk membangun aplikasi retail yang cerdas, skalabel, dan responsif yang sepenuhnya didukung oleh Google Cloud Spanner.
Skenario
Anda bekerja untuk retailer peralatan elektronik. Situs e-commerce Anda memiliki database Spanner standar dengan Products, Orders, dan OrderItems.
Pelanggan membuka situs Anda dengan kebutuhan tertentu: "Saya ingin membeli keyboard berperforma tinggi. Saya terkadang membuat kode saat berada di pantai sehingga perangkat saya bisa basah."
Tujuan Anda adalah menggunakan fitur lanjutan Spanner untuk menjawab permintaan ini secara cerdas:
- Temukan: Melampaui penelusuran kata kunci sederhana untuk menemukan produk yang deskripsinya cocok secara semantik dengan permintaan pengguna menggunakan penelusuran vektor.
- Jelaskan: Gunakan LLM untuk menganalisis kecocokan teratas dan menjelaskan mengapa rekomendasi tersebut cocok, sehingga membangun kepercayaan pelanggan.
- Menghubungkan: Gunakan kueri grafik untuk menemukan produk lainnya yang sering dibeli pelanggan bersama dengan rekomendasi tersebut.
2. Sebelum memulai
- Buat Project Di Konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Google Cloud.
- Aktifkan Penagihan Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project.
- Aktifkan Cloud Shell Aktifkan Cloud Shell dengan mengklik tombol "Activate Cloud Shell" di konsol. Anda dapat beralih antara Terminal dan Editor Cloud Shell.

- Otorisasi dan Tetapkan Project Setelah terhubung ke Cloud Shell, periksa apakah Anda telah diautentikasi dan project telah ditetapkan ke project ID Anda.
gcloud auth list
gcloud config list project
- Jika project Anda belum ditetapkan, gunakan perintah berikut untuk menetapkannya, dengan mengganti
<PROJECT_ID>dengan project ID Anda yang sebenarnya:
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- Aktifkan API yang Diperlukan Aktifkan Spanner, Vertex AI, dan Compute Engine API. Tindakan ini mungkin memerlukan waktu beberapa menit.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Tetapkan beberapa variabel lingkungan yang akan Anda gunakan kembali.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- Buat instance Spanner uji coba gratis jika Anda belum memiliki instance Spanner . Anda memerlukan instance Spanner untuk menghosting database. Kita akan menggunakan
regional-us-central1sebagai konfigurasi. Anda dapat memperbaruinya jika ingin.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. Ringkasan Arsitektur
Spanner merangkum semua fungsi yang diperlukan, kecuali model yang dihosting di Vertex AI.
4. Langkah 1: Siapkan Database dan kirimkan kueri pertama Anda.
Pertama, kita perlu membuat database, memuat data retail contoh, dan memberi tahu Spanner cara berkomunikasi dengan Vertex AI.
Untuk bagian ini, Anda akan menggunakan skrip SQL di bawah.
- Buka halaman produk Spanner.
- Pilih instance yang benar.
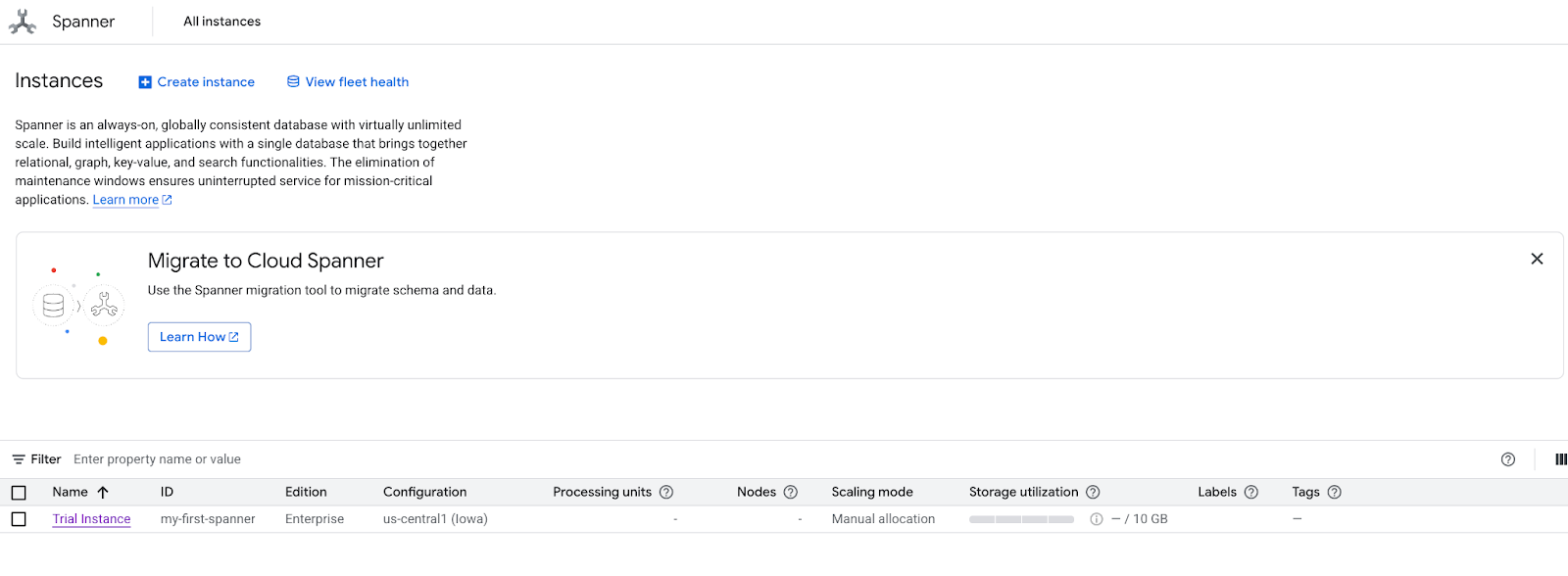
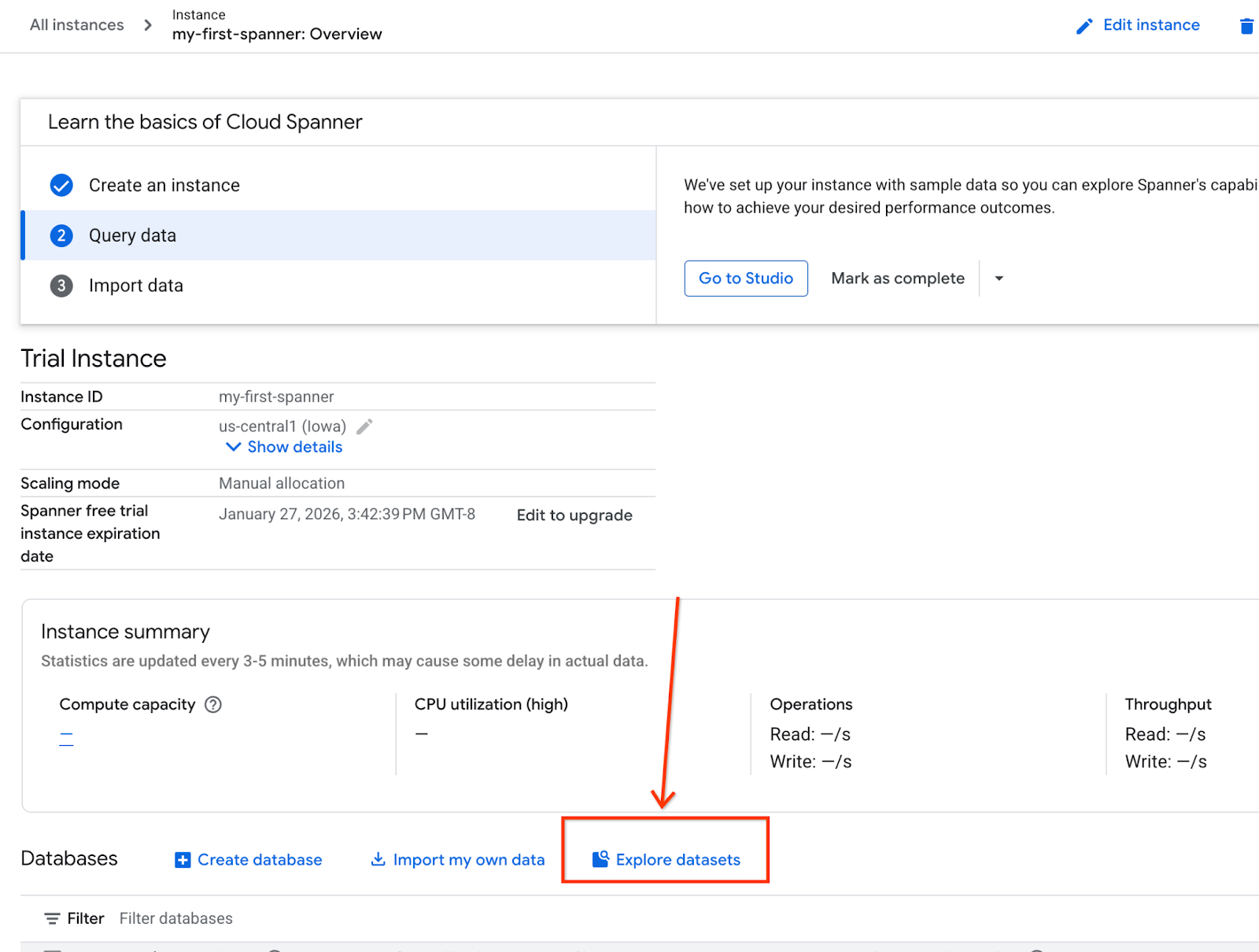
- Di layar, pilih Jelajahi Set Data. Kemudian, pilih opsi "Retail" di pop-up.
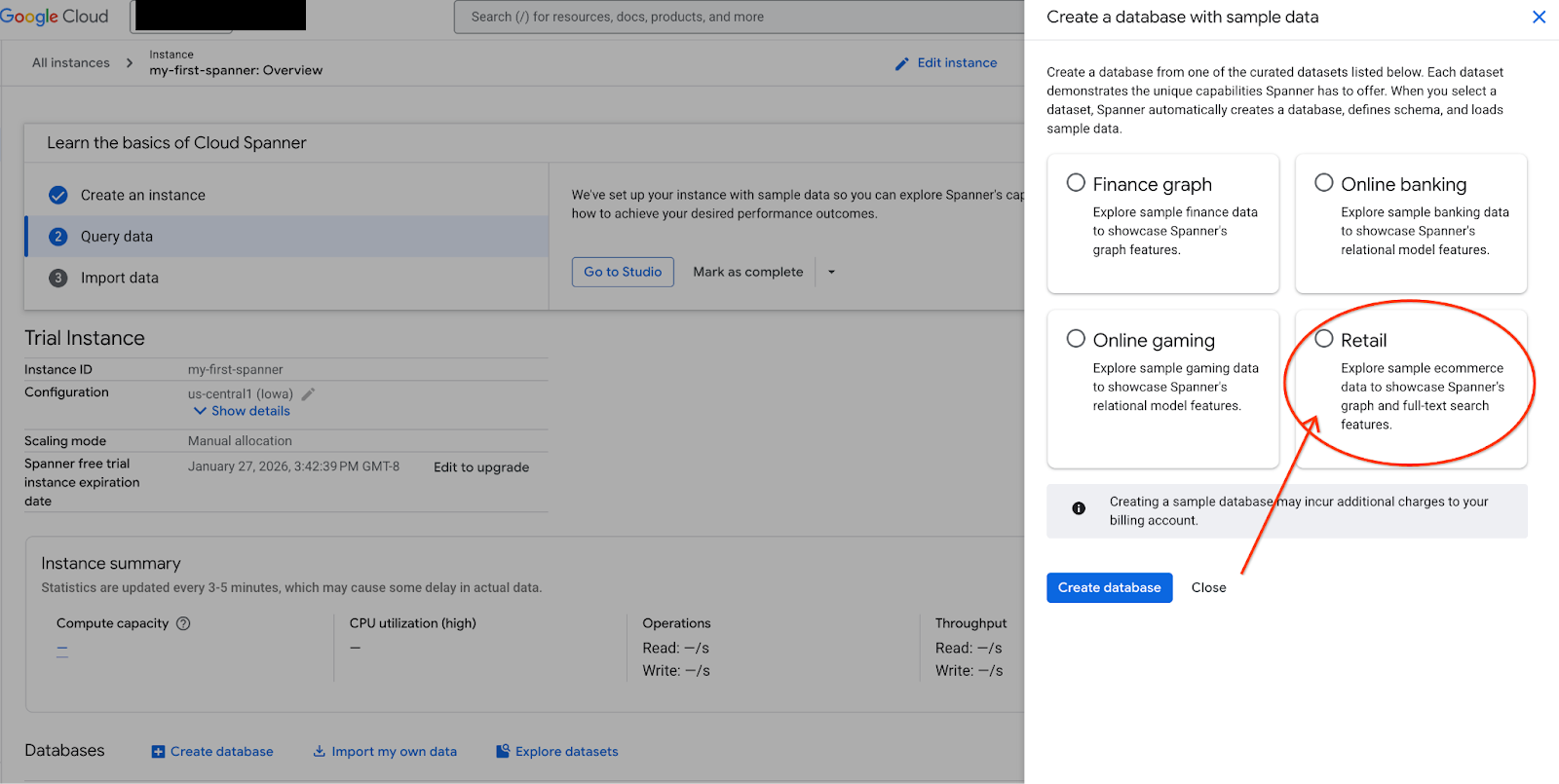
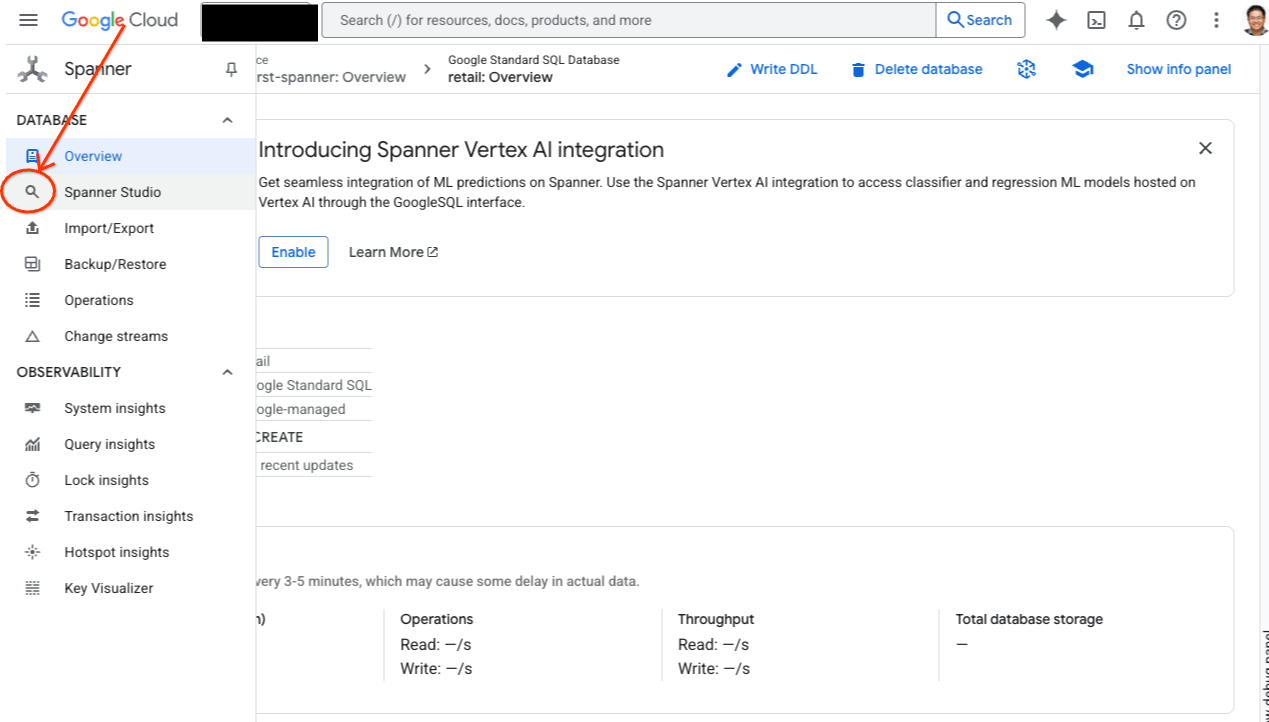
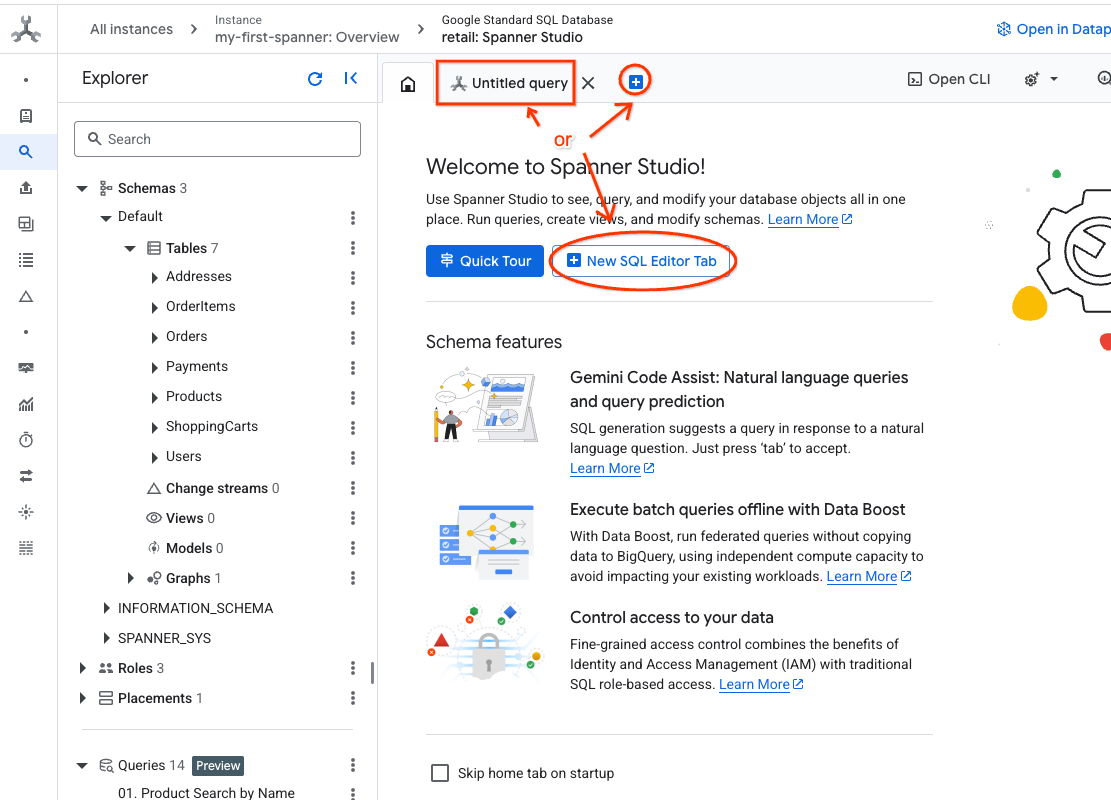
- Buka Spanner Studio. Spanner Studio menyertakan panel Explorer yang terintegrasi dengan editor kueri dan tabel hasil kueri SQL. Anda dapat menjalankan pernyataan DDL, DML, dan SQL dari satu antarmuka ini. Anda harus meluaskan menu di samping, lalu cari ikon kaca pembesar.
- Baca tabel Produk. Buat tab baru atau gunakan tab "Untitled query" yang sudah dibuat.
SELECT *
FROM Products;
5. Langkah 2: Buat Model AI.
Sekarang, mari kita buat model jarak jauh dengan objek Spanner. Pernyataan SQL ini membuat objek Spanner yang ditautkan ke endpoint Vertex AI.
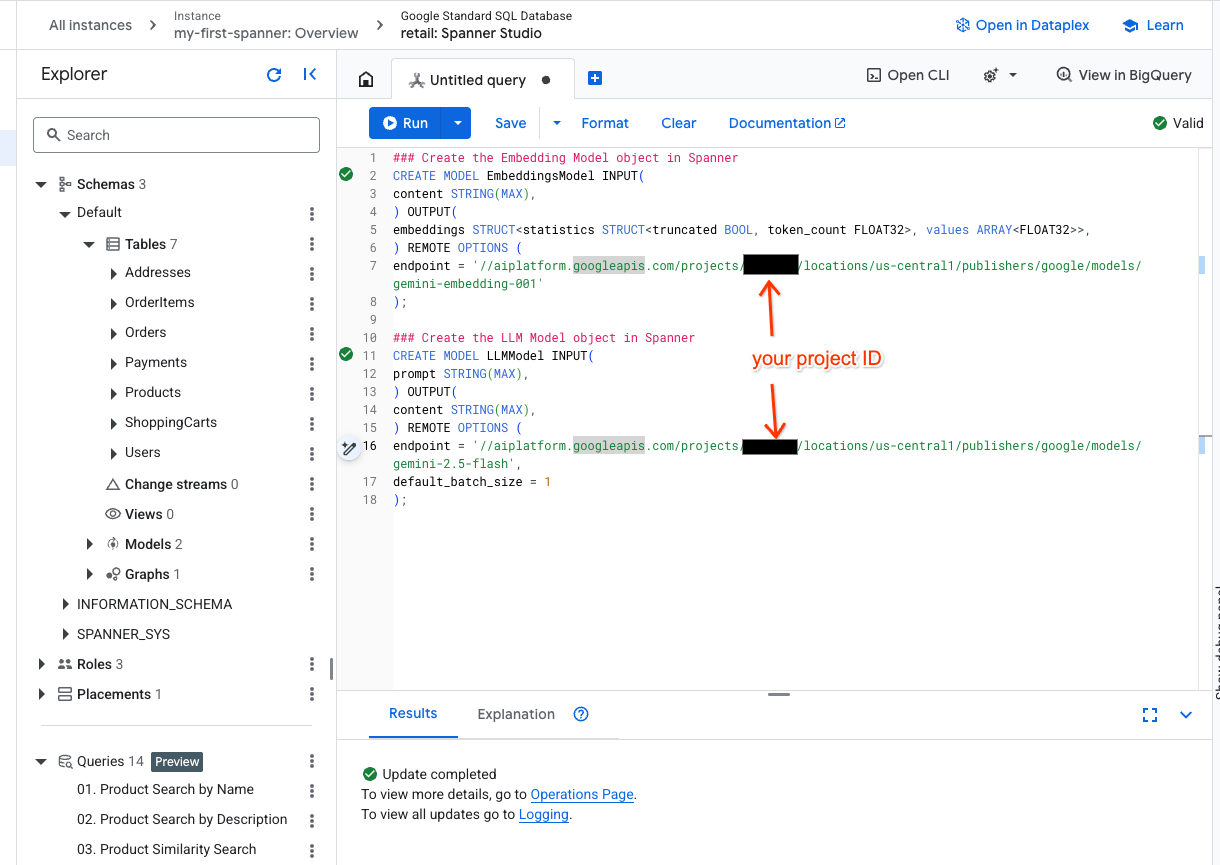
- Buka tab baru di Spanner Studio dan buat dua model Anda. Yang pertama adalah EmbeddingsModel yang akan memungkinkan Anda membuat embedding. Yang kedua adalah LLMModel yang akan memungkinkan Anda berinteraksi dengan LLM (dalam contoh kami, ini adalah gemini-2.5-flash). Pastikan Anda telah memperbarui <PROJECT_ID> dengan project ID Anda.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- Catatan: Jangan lupa untuk mengganti
PROJECT_IDdengan$PROJECT_IDAnda yang sebenarnya.
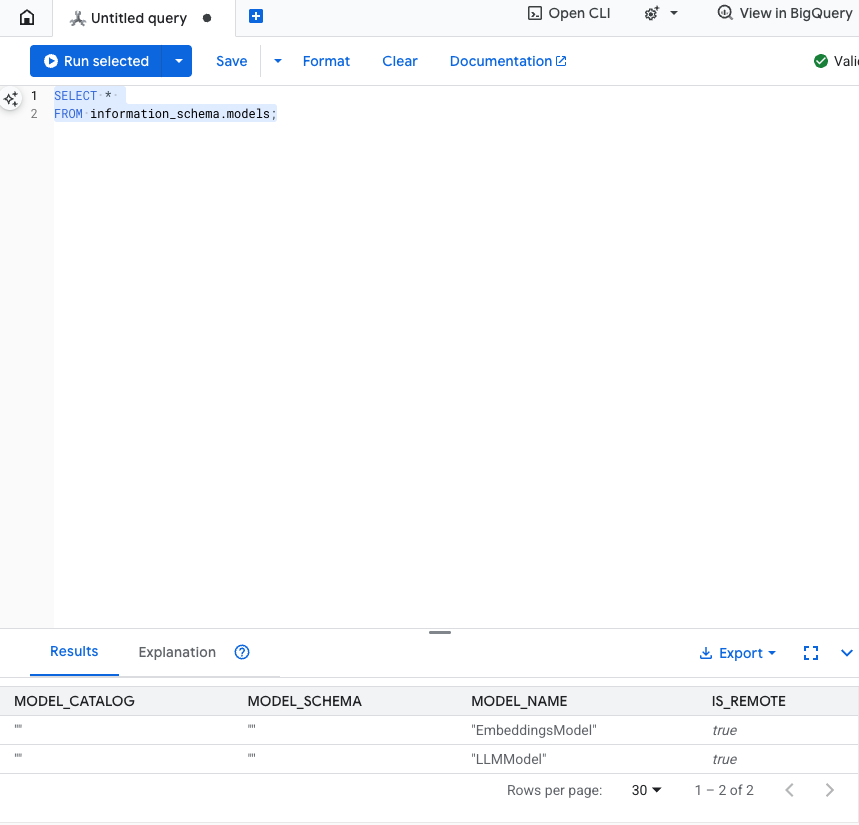
Uji langkah ini: Anda dapat memverifikasi bahwa model telah dibuat dengan menjalankan perintah berikut di editor SQL.
SELECT *
FROM information_schema.models;
6. Langkah 3: Buat dan Simpan Embedding Vektor
Tabel Produk kami memiliki deskripsi teks, tetapi model AI memahami vektor (array angka). Kita perlu menambahkan kolom baru untuk menyimpan vektor ini, lalu mengisinya dengan menjalankan semua deskripsi produk melalui EmbeddingsModel.
- Buat tabel baru untuk mendukung embedding. Pertama, buat tabel yang dapat mendukung penyematan. Kami menggunakan model embedding yang berbeda dengan embedding sampel tabel produk. Anda harus memastikan embedding dibuat dari model yang sama agar penelusuran vektor berfungsi dengan benar.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- Isi tabel baru dengan embedding yang dihasilkan dari model. Kita menggunakan pernyataan insert into untuk mempermudah di sini. Tindakan ini akan mendorong hasil kueri ke dalam tabel yang baru saja Anda buat.
Pernyataan SQL pertama-tama mengambil dan menggabungkan semua kolom teks yang relevan yang ingin kita buatkan embedding-nya. Kemudian, kami akan menampilkan informasi yang relevan, termasuk teks yang kami gunakan. Biasanya hal ini tidak diperlukan, tetapi kami menyertakannya agar Anda dapat memvisualisasikan hasilnya.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
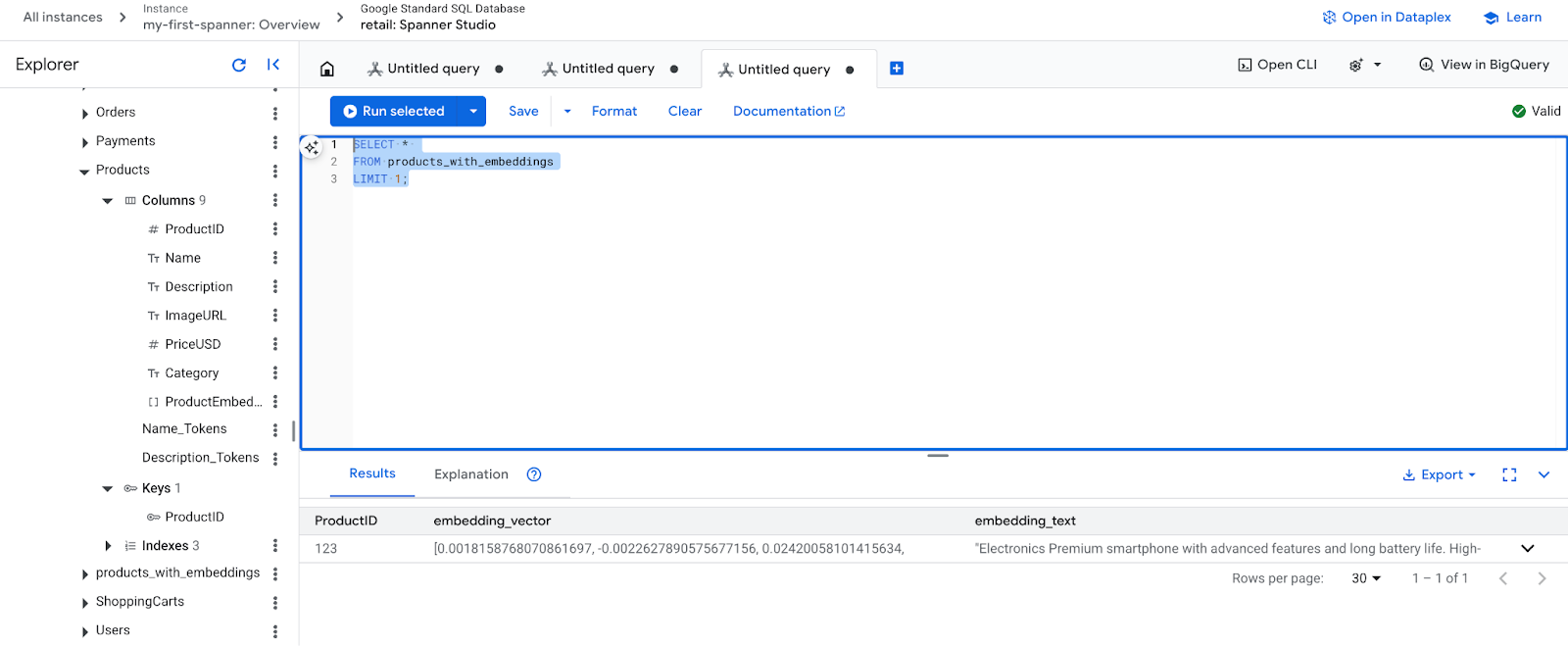
- Periksa sematan baru Anda. Sekarang Anda akan melihat sematan yang dihasilkan.
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. Langkah 4: Buat Indeks Vektor untuk Penelusuran ANN
Untuk menelusuri jutaan vektor secara instan, kita memerlukan indeks. Indeks ini memungkinkan penelusuran Approximate Nearest Neighbor (ANN), yang sangat cepat dan dapat diskalakan secara horizontal.
- Jalankan kueri DDL berikut untuk membuat indeks. Kita menentukan
COSINEsebagai metrik jarak, yang sangat baik untuk penelusuran teks semantik. Perhatikan bahwa klausa WHERE sebenarnya diperlukan karena Spanner akan menjadikannya sebagai persyaratan untuk kueri.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- Periksa status pembuatan indeks Anda di tab operasi.
8. Langkah 5: Menemukan Rekomendasi dengan Penelusuran K-Nearest Neighbor (KNN)
Sekarang saatnya bersenang-senang! Mari temukan produk yang cocok dengan kueri pelanggan: "Saya ingin membeli keyboard berperforma tinggi. Saya terkadang membuat kode saat berada di pantai sehingga ponsel saya bisa basah.".
Kita akan mulai dengan penelusuran K-Nearest Neighbor (KNN). Ini adalah penelusuran persis yang membandingkan vektor kueri kita dengan setiap vektor produk. Metode ini akurat, tetapi bisa lambat pada set data yang sangat besar (itulah sebabnya kami membuat indeks ANN untuk Langkah 5).
Kueri ini melakukan dua hal:
- Subkueri menggunakan ML.PREDICT untuk mendapatkan vektor embedding untuk kueri pelanggan kami.
- Kueri luar menggunakan COSINE_DISTANCE untuk menghitung "jarak" antara vektor kueri dan embedding_vector setiap produk. Jarak yang lebih kecil berarti kecocokan yang lebih baik.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Anda akan melihat daftar produk, dengan keyboard yang tahan air di bagian paling atas.
9. Langkah 6: Menemukan Rekomendasi dengan Penelusuran Perkiraan (ANN)
KNN sangat bagus, tetapi untuk sistem produksi dengan jutaan produk dan ribuan kueri per detik, kita memerlukan kecepatan indeks ANN.
Penggunaan indeks mengharuskan Anda menentukan fungsi APPROX_COSINE_DISTANCE.
- Dapatkan embedding vektor teks Anda seperti yang Anda lakukan di atas. Kita melakukan cross join hasil tersebut dengan data dalam tabel products_with_embeddings sehingga Anda dapat menggunakannya dalam fungsi APPROX_COSINE_DISTANCE.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Output yang Diharapkan: Hasilnya harus identik atau sangat mirip dengan kueri KNN, tetapi dieksekusi dengan lebih efisien menggunakan indeks. Anda mungkin tidak melihatnya dalam contoh.
10. Langkah 7: Menggunakan LLM untuk Menjelaskan Rekomendasi
Hanya menampilkan daftar produk sudah bagus, tetapi menjelaskan mengapa produk tersebut cocok atau tidak cocok sangatlah bagus. Kita dapat menggunakan LLMModel (Gemini) untuk melakukannya.
Kueri ini menyusun kueri KNN dari Langkah 4 di dalam panggilan ML.PREDICT. Kita menggunakan CONCAT untuk membuat perintah bagi LLM, dengan memberikan:
- Petunjuk yang jelas ("Jawab dengan ‘Ya' atau ‘Tidak' dan jelaskan alasannya...").
- Kueri asli pelanggan.
- Nama dan deskripsi setiap produk yang paling cocok.
Kemudian, LLM mengevaluasi setiap produk berdasarkan kueri dan memberikan respons dalam bahasa alami.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
Output yang Diharapkan: Anda akan mendapatkan tabel dengan kolom LLMResponse baru. Responsnya kurang lebih akan seperti ini: "Tidak. Berikut alasannya: * "Tahan air" tidak sama dengan "kedap air". Keyboard "tahan air" dapat menahan percikan air, hujan ringan, atau tumpahan"
11. Langkah 8: Buat Grafik Properti
Sekarang untuk jenis rekomendasi yang berbeda: "pelanggan yang membeli ini juga membeli..."
Ini adalah kueri berbasis hubungan. Alat yang tepat untuk hal ini adalah grafik properti. Spanner memungkinkan Anda membuat grafik di atas tabel yang ada tanpa menduplikasi data.
Pernyataan DDL ini menentukan grafik kita:
- Node: Tabel
ProductdanUser. Node adalah entitas yang ingin Anda dapatkan hubungannya, Anda ingin mengetahui pelanggan yang membeli produk Anda juga membeli produk 'XYZ'. - Tepi: Tabel
Orders, yang menghubungkanUser(Sumber) keProduct(Tujuan) dengan label "Dibeli". Edge memberikan hubungan antara pengguna dan apa yang mereka beli.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. Langkah 9: Gabungkan Kueri Grafis dan Penelusuran Vektor
Ini adalah langkah yang paling efektif. Kami akan menggabungkan penelusuran vektor AI dan kueri grafik dalam satu pernyataan untuk menemukan produk terkait.
Kueri ini dibaca dalam tiga bagian, yang dipisahkan oleh NEXT statement, mari kita bagi menjadi beberapa bagian.
- Pertama, kami menemukan kecocokan terbaik menggunakan penelusuran vektor.
- ML.PREDICT menghasilkan embedding vektor dari kueri teks pengguna menggunakan EmbeddingsModel.
- Kueri menghitung COSINE_DISTANCE antara sematan baru ini dan p.embedding_vector yang disimpan untuk semua produk.
- Fungsi ini memilih dan menampilkan satu produk bestMatch dengan jarak minimum (kemiripan semantik tertinggi).
- Selanjutnya, kita menjelajahi grafik untuk mencari hubungan.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- Kueri melacak kembali dari bestMatch ke node Pesanan umum (pengguna), lalu meneruskan ke produk purchasedWith lainnya.
- Kueri ini memfilter produk asli dan menggunakan GROUP BY dan COUNT(1) untuk menggabungkan seberapa sering item dibeli bersama.
- Fungsi ini menampilkan 3 produk yang paling sering dibeli bersama (purchasedWith) yang diurutkan berdasarkan frekuensi kemunculannya.
Selain itu, kita menemukan Hubungan Pesanan Pengguna.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- Langkah perantara ini menjalankan pola traversal untuk mengikat entitas utama: bestMatch, node user:Orders yang menghubungkan, dan item purchasedWith.
- Hal ini secara khusus mengikat hubungan itu sendiri sebagai dibeli untuk ekstraksi data pada langkah berikutnya.
- Pola ini memastikan konteks ditetapkan untuk mengambil detail khusus pesanan dan khusus produk.
- Terakhir, kita akan menampilkan hasil yang akan ditampilkan sebagai node grafik yang harus diformat sebelum ditampilkan sebagai hasil SQL.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
Output yang Diharapkan: Anda akan melihat objek JSON yang merepresentasikan 3 item teratas yang dibeli bersama, yang memberikan rekomendasi cross-sell.
13. Pembersihan
Untuk menghindari timbulnya biaya, Anda dapat menghapus resource yang Anda buat.
- Hapus Instance Spanner: Menghapus instance juga akan menghapus database.
gcloud spanner instances delete my-first-spanner --quiet
- Hapus Project Google Cloud: Jika Anda membuat project ini hanya untuk codelab, menghapusnya adalah cara termudah untuk membersihkan.
- Buka halaman Manage Resources di Konsol Google Cloud.
- Pilih project Anda, lalu klik Hapus.
🎉 Selamat!
Anda telah berhasil membangun sistem rekomendasi real-time yang canggih menggunakan Spanner AI dan Graph.
Anda telah mempelajari cara mengintegrasikan Spanner dengan Vertex AI untuk pembuatan embedding dan LLM, cara melakukan penelusuran vektor berkecepatan tinggi (KNN dan ANN) untuk menemukan produk yang relevan secara semantik, dan cara menggunakan kueri grafik untuk menemukan hubungan produk. Anda telah membangun sistem yang tidak hanya dapat menemukan produk, tetapi juga menjelaskan rekomendasi dan menyarankan item terkait, semuanya dari satu database yang dapat diskalakan.