
1. Introduzione
Questo codelab ti guiderà nell'utilizzo delle funzionalità di AI e grafici di Spanner per migliorare un database di vendita al dettaglio esistente. Imparerai tecniche pratiche per utilizzare il machine learning in Spanner per servire meglio i tuoi clienti. Nello specifico, implementeremo k-Nearest Neighbors (kNN) e Approximate Nearest Neighbors (ANN) per scoprire nuovi prodotti in linea con le esigenze dei singoli clienti. Integrerai anche un LLM per fornire spiegazioni chiare e in linguaggio naturale sul motivo per cui è stato dato un suggerimento specifico per un prodotto.
Oltre al suggerimento, approfondiremo la funzionalità del grafico di Spanner. Utilizzerai le query grafiche per modellare le relazioni tra i prodotti in base alla cronologia acquisti dei clienti e alle descrizioni dei prodotti. Questo approccio consente di scoprire articoli correlati in modo approfondito, migliorando significativamente la pertinenza e l'efficacia delle funzionalità "I clienti hanno acquistato anche" o "Articoli correlati". Al termine di questo codelab, avrai le competenze per creare un'applicazione di vendita al dettaglio intelligente, scalabile e reattiva basata interamente su Google Cloud Spanner.
Scenario
Lavori per un rivenditore di apparecchiature elettroniche. Il tuo sito di e-commerce ha un database Spanner standard con Products, Orders e OrderItems.
Un cliente arriva sul tuo sito con un'esigenza specifica: "Vorrei acquistare una tastiera ad alte prestazioni. A volte programmo mentre sono in spiaggia, quindi potrebbe bagnarsi."
Il tuo obiettivo è utilizzare le funzionalità avanzate di Spanner per rispondere in modo intelligente a questa richiesta:
- Trova:vai oltre la semplice ricerca per parole chiave per trovare prodotti le cui descrizioni corrispondono semanticamente alla richiesta dell'utente utilizzando la ricerca vettoriale.
- Spiega:utilizza un LLM per analizzare le corrispondenze principali e spiegare perché il suggerimento è una buona soluzione, in modo da rafforzare la fiducia dei clienti.
- Correlati:utilizza le query del grafico per trovare altri prodotti che i clienti hanno acquistato di frequente insieme al prodotto consigliato.
2. Prima di iniziare
- Crea un progetto: nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Attiva la fatturazione. Assicurati che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
- Attiva Cloud Shell. Attiva Cloud Shell facendo clic sul pulsante "Attiva Cloud Shell" nella console. Puoi passare alternativamente dal terminale di Cloud Shell all'editor.

- Autorizza e imposta il progetto: una volta connesso a Cloud Shell, verifica di essere autenticato e che il progetto sia impostato sul tuo ID progetto.
gcloud auth list
gcloud config list project
- Se il progetto non è impostato, utilizza il comando seguente per impostarlo, sostituendo
<PROJECT_ID>con l'ID progetto effettivo:
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- Abilita le API richieste: abilita le API Spanner, Vertex AI e Compute Engine. L'operazione potrebbe richiedere alcuni minuti.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Imposta alcune variabili di ambiente che riutilizzerai.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- Crea un'istanza di prova senza costi di Spanner se non ne hai già una . Per ospitare il database, devi disporre di un'istanza Spanner. Utilizzeremo
regional-us-central1come configurazione. Se vuoi, puoi aggiornare questa informazione.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. Panoramica dell'architettura
Spanner include tutte le funzionalità necessarie, tranne i modelli ospitati su Vertex AI.
4. Passaggio 1: configura il database e invia la prima query.
Innanzitutto, dobbiamo creare il nostro database, caricare i dati di vendita al dettaglio di esempio e indicare a Spanner come comunicare con Vertex AI.
Per questa sezione, utilizzerai gli script SQL riportati di seguito.
- Vai alla pagina del prodotto Spanner.
- Seleziona l'istanza corretta.
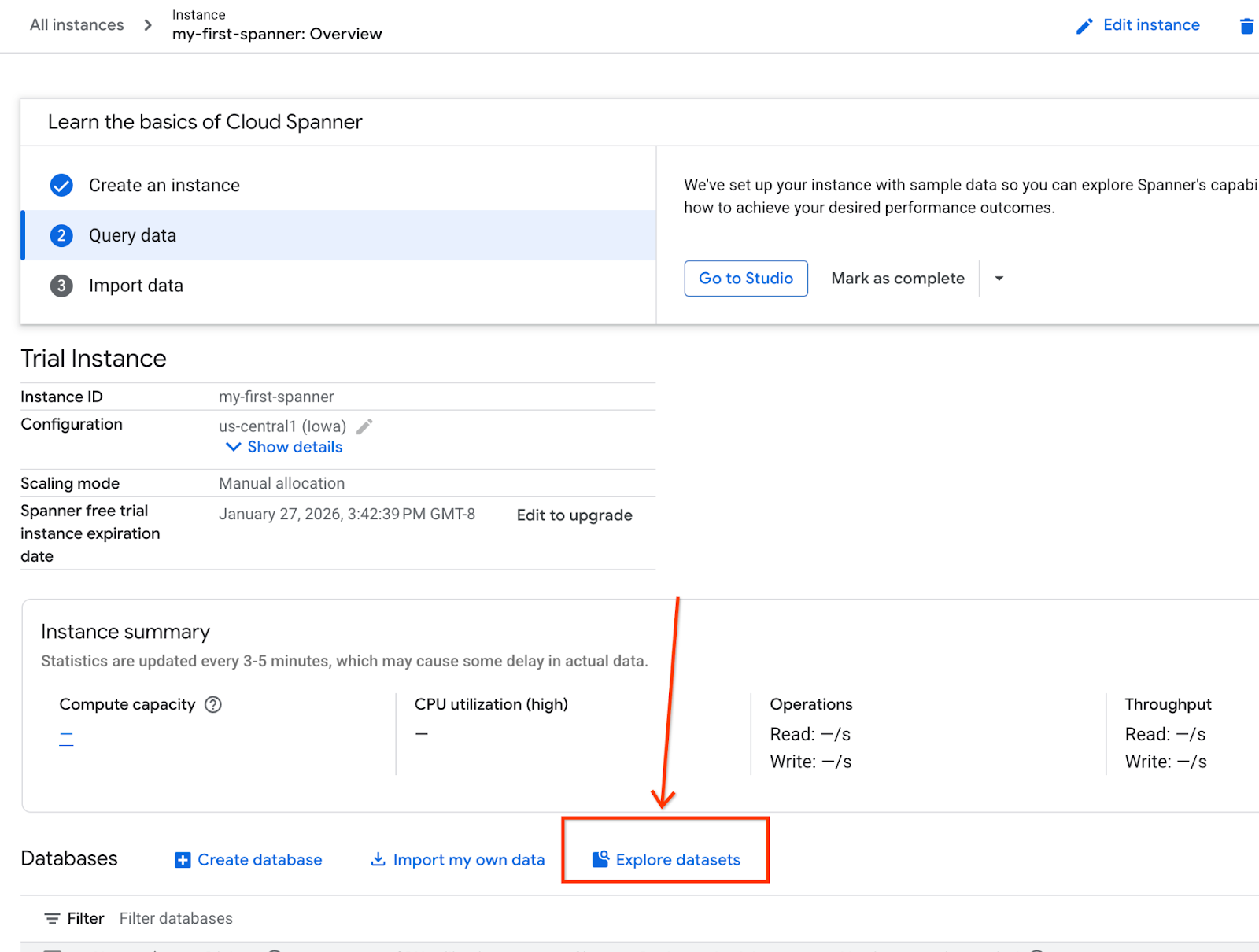
- Nella schermata, seleziona Esplora set di dati. Quindi, nel popup seleziona l'opzione "Vendita al dettaglio".
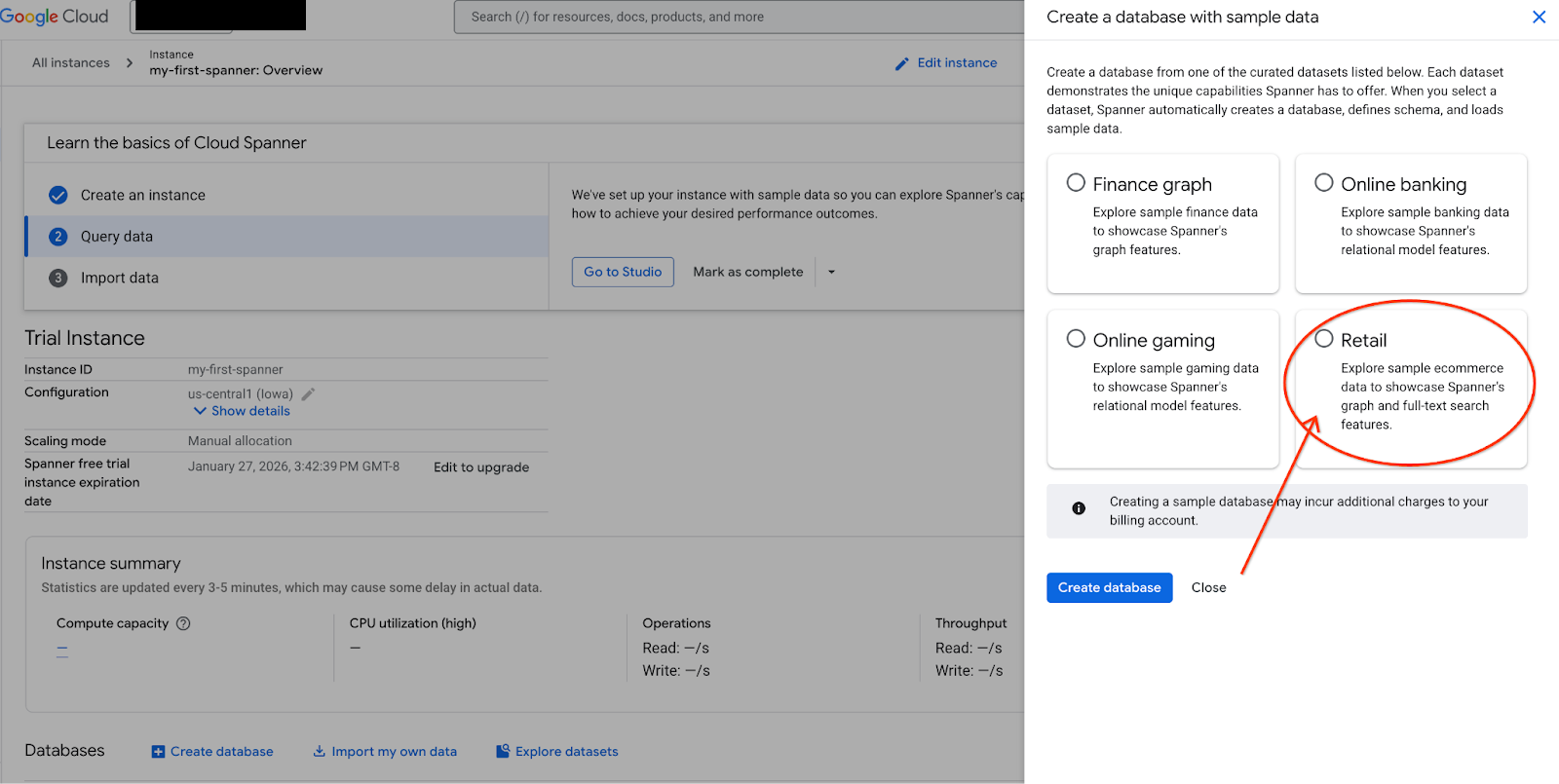
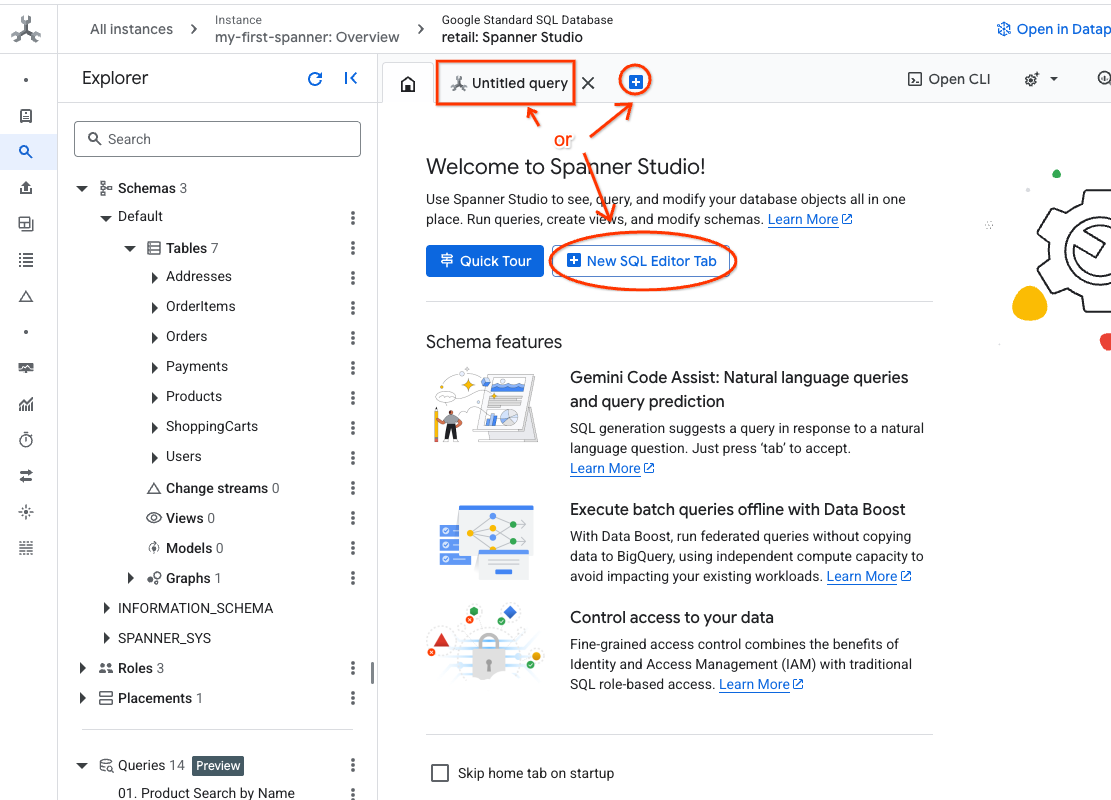
- Vai a Spanner Studio. Spanner Studio include un riquadro Explorer che si integra con un editor di query e una tabella dei risultati delle query SQL. Puoi eseguire istruzioni DDL, DML e SQL da questa unica interfaccia. Dovrai espandere il menu laterale e cercare la lente d'ingrandimento.
- Leggi la tabella Prodotti. Crea una nuova scheda o utilizza la scheda "Query senza titolo" già creata.
SELECT *
FROM Products;
5. Passaggio 2: crea i modelli di AI.
Ora creiamo i modelli remoti con gli oggetti Spanner. Queste istruzioni SQL creano oggetti Spanner che si collegano agli endpoint Vertex AI.
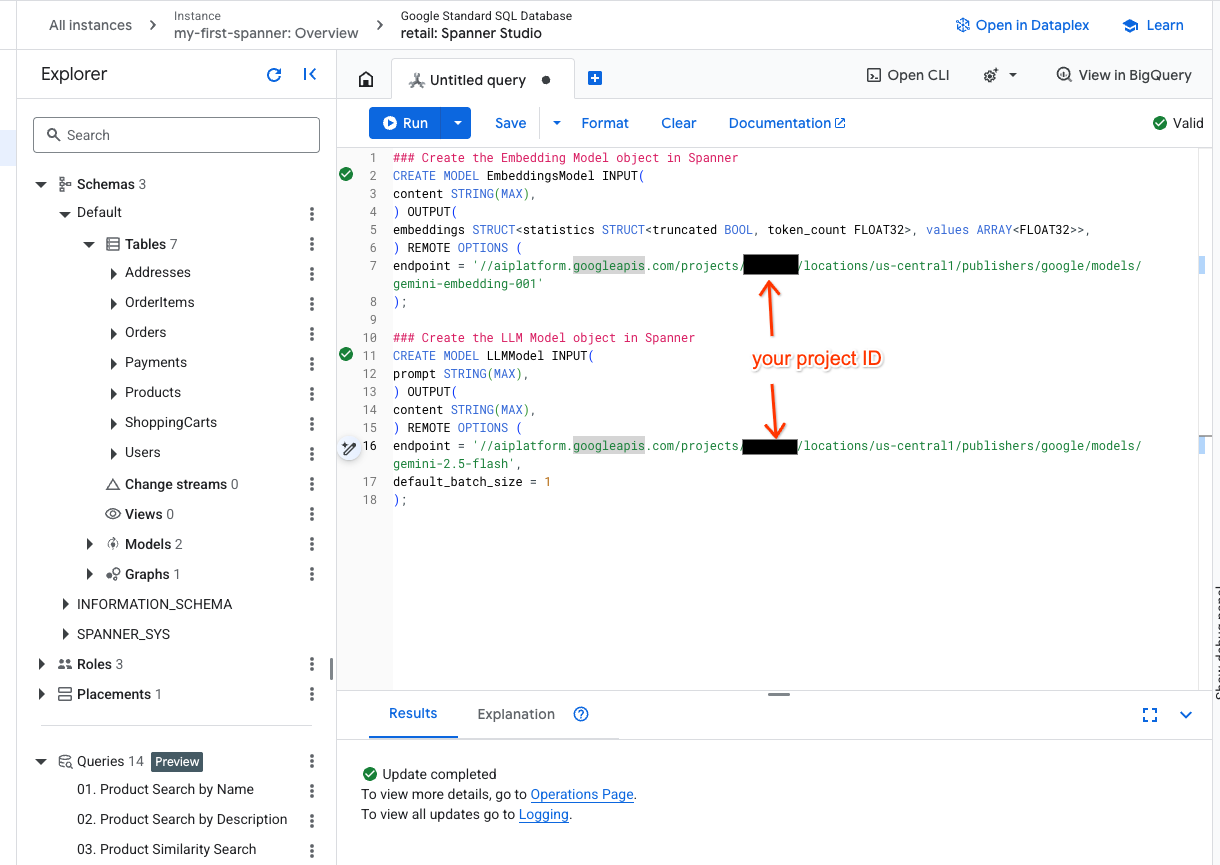
- Apri una nuova scheda in Spanner Studio e crea i due modelli. Il primo è EmbeddingsModel, che ti consente di generare embedding. Il secondo è LLMModel, che ti consente di interagire con un LLM (nel nostro esempio, gemini-2.5-flash). Assicurati di aver aggiornato <PROJECT_ID> con il tuo ID progetto.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- Nota:ricordati di sostituire
PROJECT_IDcon il tuo$PROJECT_IDeffettivo.
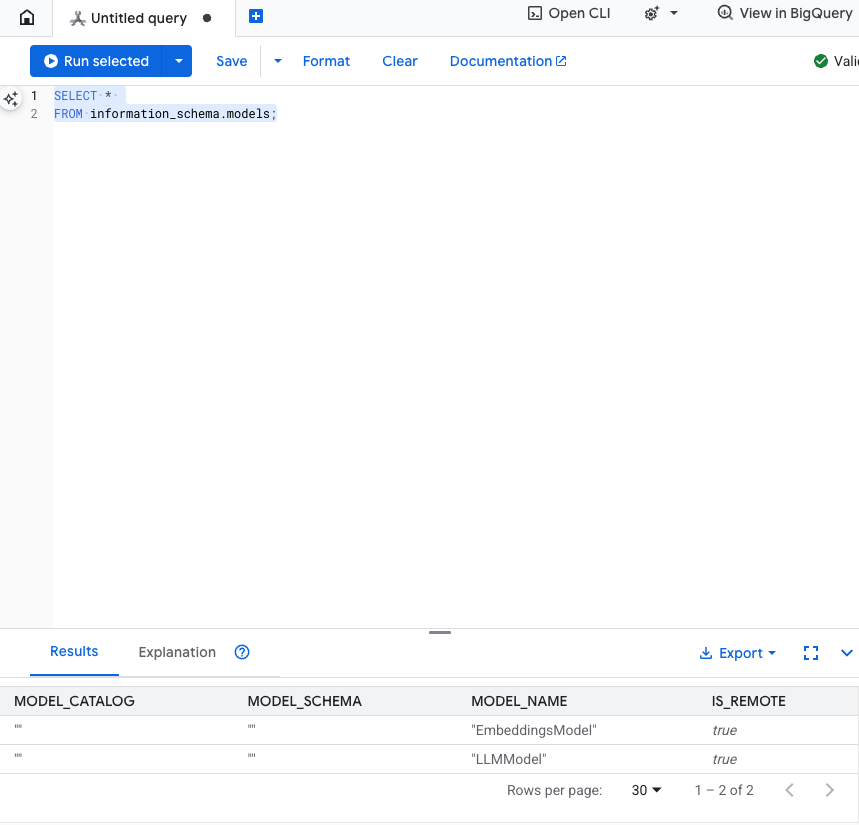
Testa questo passaggio: puoi verificare che i modelli siano stati creati eseguendo il seguente comando nell'editor SQL.
SELECT *
FROM information_schema.models;
6. Passaggio 3: genera e memorizza i vector embedding
La nostra tabella Prodotto contiene descrizioni di testo, ma il modello di AI comprende i vettori (array di numeri). Dobbiamo aggiungere una nuova colonna per archiviare questi vettori e poi compilarla eseguendo tutte le descrizioni dei prodotti tramite EmbeddingsModel.
- Crea una nuova tabella per supportare gli incorporamenti. Per prima cosa, crea una tabella che possa supportare gli incorporamenti. Stiamo utilizzando un modello di embedding diverso da quelli di esempio della tabella dei prodotti. Perché la ricerca vettoriale funzioni correttamente, devi assicurarti che gli embedding siano stati generati dallo stesso modello.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- Compila la nuova tabella con gli embedding generati dal modello. Per semplicità, qui utilizziamo un'istruzione insert into. In questo modo, i risultati della query verranno inseriti nella tabella appena creata.
L'istruzione SQL recupera e concatena innanzitutto tutte le colonne di testo pertinenti su cui vogliamo generare incorporamenti. Poi restituiamo le informazioni pertinenti, incluso il testo che abbiamo utilizzato. Normalmente non è necessario, ma lo includiamo per consentirti di visualizzare i risultati.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
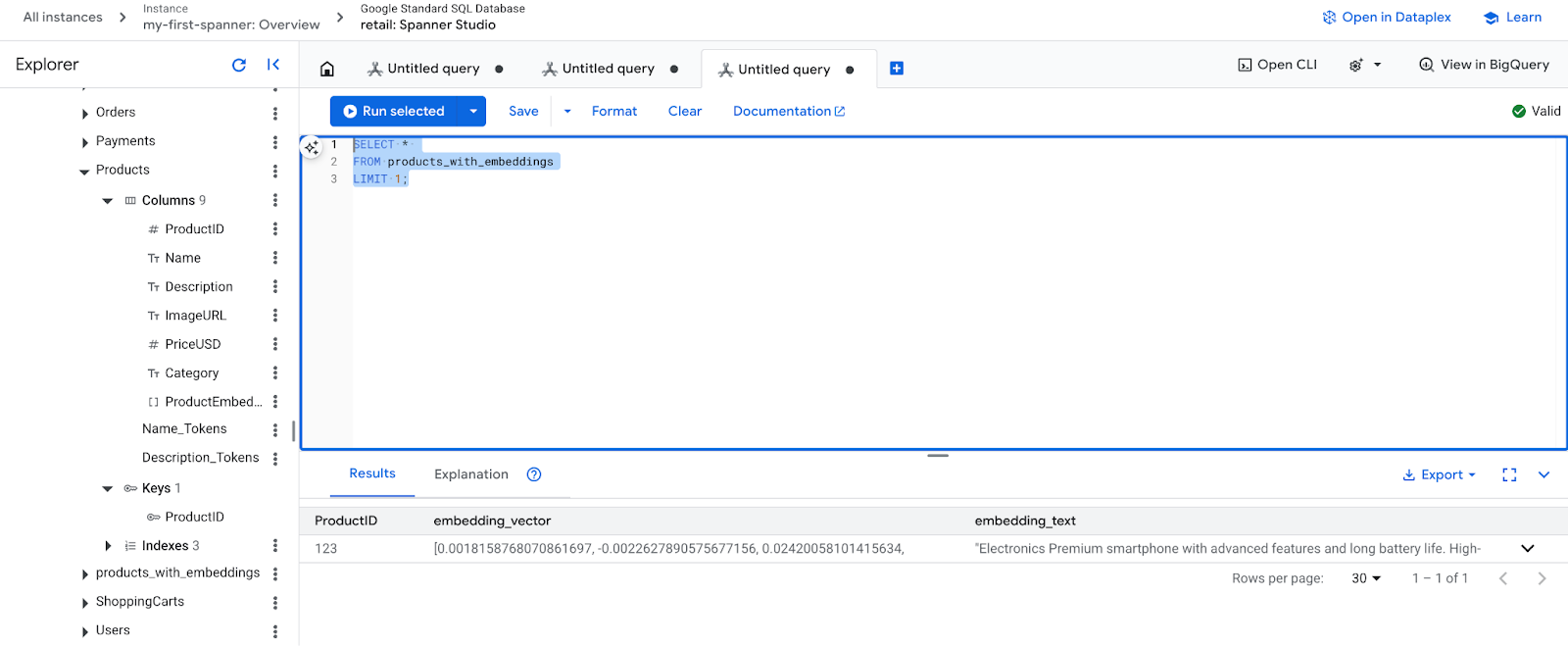
- Controlla i nuovi incorporamenti. A questo punto dovresti vedere gli incorporamenti generati.
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. Passaggio 4: crea un indice vettoriale per la ricerca ANN
Per cercare milioni di vettori all'istante, abbiamo bisogno di un indice. Questo indice consente la ricerca Approximate Nearest Neighbor (ANN), che è incredibilmente veloce e si adatta orizzontalmente.
- Esegui la seguente query DDL per creare l'indice. Specifichiamo
COSINEcome metrica di distanza, che è eccellente per la ricerca semantica di testo. Tieni presente che la clausola WHERE è effettivamente necessaria, in quanto Spanner la renderà un requisito per la query.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- Controlla lo stato della creazione dell'indice nella scheda Operazioni.
8. Passaggio 5: trova i consigli con la ricerca K-Nearest Neighbor (KNN)
E ora la parte divertente. Troviamo i prodotti che corrispondono alla query del nostro cliente: "Vorrei acquistare una tastiera ad alte prestazioni. A volte programmo mentre sono in spiaggia, quindi potrebbe bagnarsi.".
Inizieremo con la ricerca K-Nearest Neighbor (KNN). Si tratta di una ricerca esatta che confronta il nostro vettore di query con ogni singolo vettore di prodotto. È preciso, ma può essere lento su set di dati molto grandi (motivo per cui abbiamo creato un indice ANN per il passaggio 5).
Questa query esegue due operazioni:
- Una sottoquery utilizza ML.PREDICT per ottenere il vettore di embedding per la query del cliente.
- La query esterna utilizza COSINE_DISTANCE per calcolare la "distanza" tra il vettore della query e l'embedding_vector di ogni prodotto. Una distanza più breve indica una corrispondenza migliore.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Dovresti visualizzare un elenco di prodotti, con le tastiere resistenti all'acqua in cima.
9. Passaggio 6: trova i consigli con la ricerca approssimativa (ANN)
KNN è ottimo, ma per un sistema di produzione con milioni di prodotti e migliaia di query al secondo, abbiamo bisogno della velocità del nostro indice ANN.
L'utilizzo dell'indice richiede di specificare la funzione APPROX_COSINE_DISTANCE.
- Ottieni l'embedding vettoriale del testo come hai fatto sopra. Eseguiamo il cross join dei risultati con i record della tabella products_with_embeddings in modo che tu possa utilizzarli nella funzione APPROX_COSINE_DISTANCE.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Output previsto:i risultati devono essere identici o molto simili alla query KNN, ma l'esecuzione è molto più efficiente grazie all'utilizzo dell'indice. Potresti non notarlo nell'esempio.
10. Passaggio 7: utilizza un LLM per spiegare i consigli
Mostrare un elenco di prodotti è utile, ma spiegare perché sono adatti o meno è ancora meglio. Per farlo, possiamo utilizzare il nostro LLMModel (Gemini).
Questa query annida la query KNN del passaggio 4 all'interno di una chiamata ML.PREDICT. Utilizziamo CONCAT per creare un prompt per l'LLM, fornendogli:
- Un'istruzione chiara ("Rispondi con "Sì" o "No" e spiega perché…").
- La query originale del cliente.
- Il nome e la descrizione di ogni prodotto con corrispondenza migliore.
L'LLM valuta quindi ogni prodotto in base alla query e fornisce una risposta in linguaggio naturale.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
Output previsto:otterrai una tabella con una nuova colonna LLMResponse. La risposta dovrebbe essere qualcosa del tipo: "No. Ecco perché: * "Resistente all'acqua" non significa "impermeabile". Una tastiera "resistente all'acqua" può gestire schizzi, pioggia leggera o liquidi versati"
11. Passaggio 8: crea un grafico delle proprietà
Ora passiamo a un altro tipo di consiglio: "I clienti che hanno acquistato questo prodotto hanno acquistato anche…"
Questa è una query basata sulle relazioni. Lo strumento perfetto per questo scopo è un grafico delle proprietà. Spanner ti consente di creare un grafico sopra le tabelle esistenti senza duplicare i dati.
Questa istruzione DDL definisce il nostro grafico:
- Nodi : tabelle
ProducteUser. I nodi sono le entità da cui vuoi derivare una relazione. Vuoi sapere se i clienti che hanno acquistato il tuo prodotto hanno acquistato anche i prodotti "XYZ". - Archi:la tabella
Orders, che collega unUser(origine) a unaProduct(destinazione) con l'etichetta "Acquistato". Gli archi forniscono la relazione tra un utente e ciò che ha acquistato.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. Passaggio 9: combina la ricerca vettoriale e le query grafiche
Questo è il passaggio più efficace. Combineremo la ricerca vettoriale AI e le query sui grafi in un'unica istruzione per trovare i prodotti correlati.
Questa query viene letta in tre parti, separate da NEXT statement. Analizziamola in sezioni.
- Innanzitutto, troviamo la corrispondenza migliore utilizzando la ricerca vettoriale.
- ML.PREDICT genera un vector embedding dalla query di testo dell'utente utilizzando EmbeddingsModel.
- La query calcola la COSINE_DISTANCE tra questo nuovo embedding e p.embedding_vector memorizzato per tutti i prodotti.
- Seleziona e restituisce il singolo prodotto bestMatch con la distanza minima (massima somiglianza semantica).
- Successivamente, attraversiamo il grafico alla ricerca delle relazioni.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- La query risale da bestMatch ai nodi Orders comuni (utente) e poi va avanti verso altri prodotti acquistati con.
- Filtra il prodotto originale e utilizza GROUP BY e COUNT(1) per aggregare la frequenza con cui gli articoli vengono acquistati insieme.
- Restituisce i primi tre prodotti acquistati insieme (purchasedWith) ordinati in base alla frequenza di co-occorrenza.
Inoltre, troviamo la relazione tra utente e ordine.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- Questo passaggio intermedio esegue il pattern di attraversamento per associare le entità chiave: bestMatch, il nodo utente di collegamento:Orders e l'elemento purchasedWith.
- Vincola specificamente la relazione stessa come acquistata per l'estrazione dei dati nel passaggio successivo.
- Questo pattern garantisce che il contesto sia stabilito per recuperare i dettagli specifici dell'ordine e del prodotto.
- Infine, restituiamo i risultati da restituire in quanto i nodi del grafico devono essere formattati prima di essere restituiti come risultati SQL.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
Output previsto:vedrai oggetti JSON che rappresentano i primi tre articoli acquistati insieme, fornendo consigli per il cross-sell.
13. Pulizia
Per evitare addebiti, puoi eliminare le risorse che hai creato.
- Elimina l'istanza Spanner:l'eliminazione dell'istanza comporta anche l'eliminazione del database.
gcloud spanner instances delete my-first-spanner --quiet
- Elimina il progetto Google Cloud:se hai creato questo progetto solo per il codelab, eliminarlo è il modo più semplice per liberare spazio.
- Vai alla pagina Gestisci risorse nella console Google Cloud.
- Seleziona il progetto e fai clic su Elimina.
🎉 Congratulazioni!
Hai creato correttamente un sistema di suggerimenti sofisticato e in tempo reale utilizzando Spanner AI e Graph.
Hai imparato a integrare Spanner con Vertex AI per la generazione di incorporamenti e LLM, a eseguire ricerche vettoriali ad alta velocità (KNN e ANN) per trovare prodotti semanticamente pertinenti e a utilizzare query grafiche per scoprire le relazioni tra i prodotti. Hai creato un sistema in grado non solo di trovare i prodotti, ma anche di spiegare i consigli e di suggerire articoli correlati, il tutto da un unico database scalabile.