
1. はじめに
この Codelab では、 Spanner の AI 機能とグラフ機能を使用して、既存の小売データベースを強化する方法について説明します。Spanner 内で機械学習を活用して顧客により良いサービスを提供するための実践的な手法を学びます。具体的には、k 近傍法(kNN)と近似最近傍法(ANN)を実装して、個々の顧客のニーズに合った新しい商品を見つけます。また、LLM を統合して、特定の商品のおすすめが表示された理由をわかりやすい自然言語で説明します。
おすすめだけでなく、Spanner のグラフ機能についても詳しく説明します。グラフクエリを使用して、顧客の購入履歴と商品説明に基づいて商品間の関係をモデル化します。このアプローチにより、深く関連するアイテムを見つけることができ、「お客様はこんな商品も購入しています」や「関連商品」機能の関連性と効果を大幅に向上させることができます。この Codelab を完了すると、Google Cloud Spanner だけで動作するインテリジェントでスケーラブルなレスポンシブ小売アプリケーションを構築できるようになります。
シナリオ
あなたは電子機器小売店に勤めています。e コマースサイトには、Products、Orders、OrderItems を含む標準の Spanner データベースがあります。
お客様が特定のニーズを持ってサイトにアクセスしました。「高性能なキーボードを購入したいのですが、ビーチでコーディングすることもあるので、濡れてしまうかもしれません。」
Spanner の高度な機能を使用して、このリクエストにインテリジェントに対応することが目標です。
- 検索: 単純なキーワード検索だけでなく、ベクトル検索を使用して、ユーザーのリクエストと意味的に一致する 商品説明 の商品を見つけます。
- 説明: LLM を使用して上位一致を分析し、おすすめが適切な理由を説明して、顧客の信頼を築きます。
- 関連付け: グラフクエリを使用して、おすすめの商品と一緒に顧客がよく購入する 他の 商品を見つけます。
2. 始める前に
- プロジェクトを作成する Google Cloud コンソール のプロジェクト セレクタ ページで、Google Cloud プロジェクトを選択または作成します。
- 課金を有効にする Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- Cloud Shell をアクティブにする コンソールで [Cloud Shell をアクティブにする] ボタンをクリックして、Cloud Shell をアクティブにします。Cloud Shell ターミナルとエディタを切り替えることができます。

- プロジェクトを承認して設定する Cloud Shell に接続したら、認証されていることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
<PROJECT_ID>は実際のプロジェクト ID に置き換えてください。
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- 必要な API を有効にする Spanner、Vertex AI、Compute Engine の各 API を有効にします。これには数分かかることがあります。
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- 再利用する環境変数をいくつか設定します。
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- Spanner インスタンスがない場合は、無料トライアルの Spanner インスタンスを作成します 。データベースをホストするには、Spanner インスタンスが必要です。構成には
regional-us-central1を使用します。必要に応じて更新できます。
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. アーキテクチャの概要
Spanner は、Vertex AI でホストされているモデルを除く、必要なすべての機能をカプセル化します。
4. ステップ 1: データベースを設定して最初のクエリを送信する。
まず、データベースを作成し、サンプル小売データを読み込み、Spanner に Vertex AI との通信方法を指示する必要があります。
このセクションでは、次の SQL スクリプトを使用します。
- [Spanner] のプロダクト ページに移動します。
- 正しいインスタンスを選択します。
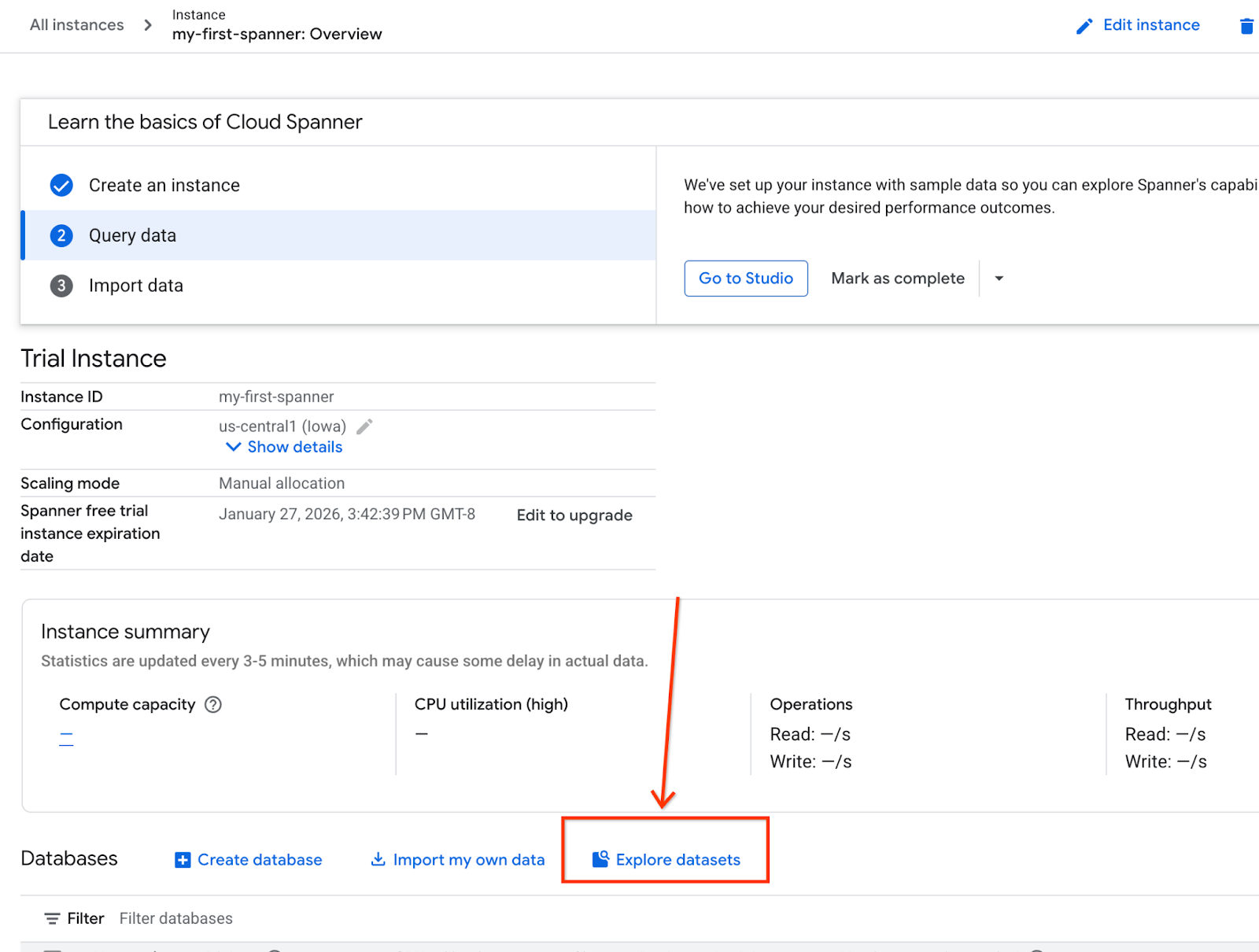
- 画面で [データセットを探索] を選択します。ポップアップで [小売] オプションを選択します。
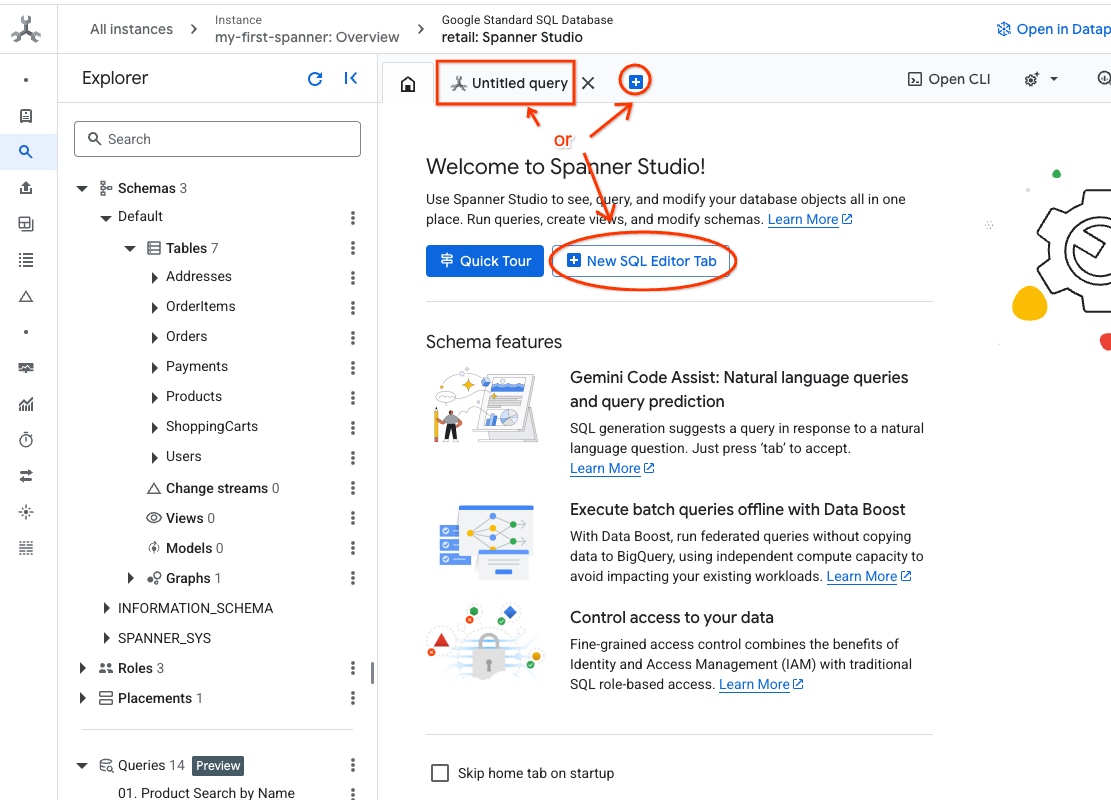
- Spanner Studio に移動します。 Spanner Studio には [エクスプローラ] ペインがあり、クエリエディタと SQL クエリ結果テーブルが統合されています。 この 1 つのインターフェースから DDL、DML、SQL ステートメントを実行できます。横のメニューを開き、虫眼鏡を探す必要があります。
- Products テーブルを読み取ります。新しいタブを作成するか、すでに作成されている [Untitled query] タブを使用します。
SELECT *
FROM Products;
5. ステップ 2: AI モデルを作成する。
次に、Spanner オブジェクトを使用してリモートモデルを作成しましょう。これらの SQL ステートメントは、Vertex AI エンドポイントにリンクする Spanner オブジェクトを作成します。
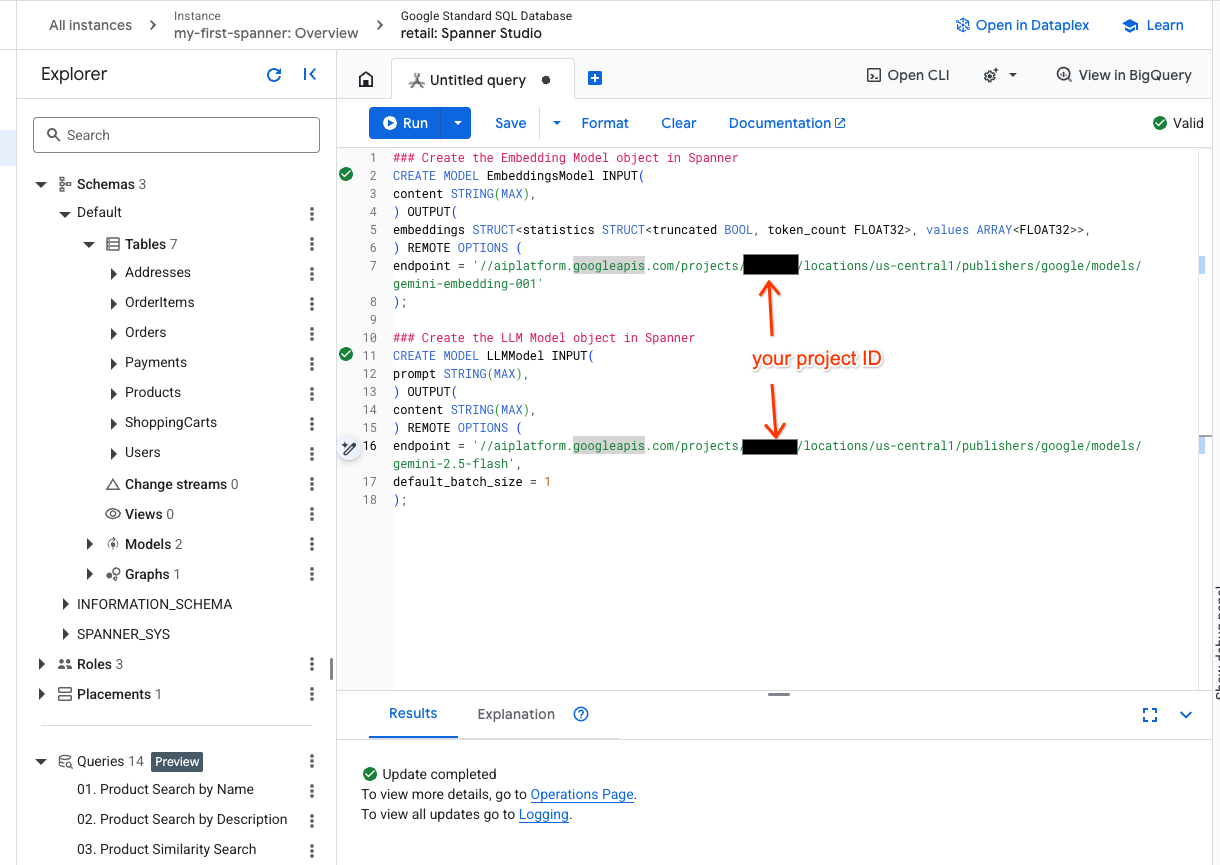
- Spanner Studio で新しいタブを開き、2 つのモデルを作成します。1 つ目は EmbeddingsModel で、エンベディングを生成できます。2 つ目は LLMModel で、LLM(この例では gemini-2.5-flash)を操作できます。<PROJECT_ID> がプロジェクト ID で更新されていることを確認してください。
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- 注:
PROJECT_IDは実際の$PROJECT_IDに置き換えてください。
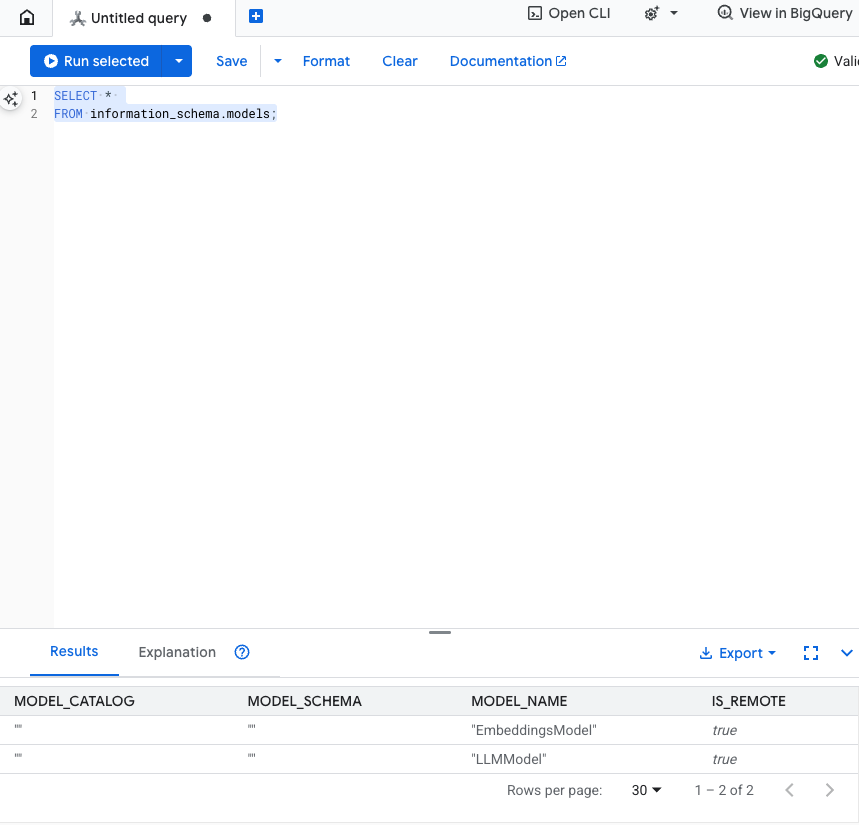
このステップをテストする: モデルが作成されたことを確認するには、SQL エディタで次のコマンドを実行します。
SELECT *
FROM information_schema.models;
6. ステップ 3: ベクトル エンベディングを生成して保存する
Product テーブルにはテキストの説明がありますが、AI モデルはベクトル(数値の配列)を理解します。 これらのベクトルを保存するための新しい列を追加し、EmbeddingsModel を使用してすべての商品説明を実行してデータを入力する必要があります。
- エンベディングをサポートする新しいテーブルを作成します。まず、エンベディングをサポートできるテーブルを作成します。ここでは、商品テーブルのサンプル エンベディングとは異なるエンベディング モデルを使用しています。ベクトル検索が正しく機能するには、エンベディングが同じモデルから生成されていることを確認する必要があります。
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- モデルから生成されたエンベディングを使用して新しいテーブルを入力します。ここでは、わかりやすくするために insert into ステートメント を使用します。これにより、クエリ結果が作成したテーブルに push されます。
SQL ステートメントは、まずエンベディングを生成する関連するテキスト列をすべて取得して連結します。次に、使用したテキストなどの関連情報を返します。通常は必要ありませんが、結果を可視化できるように含めています。
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
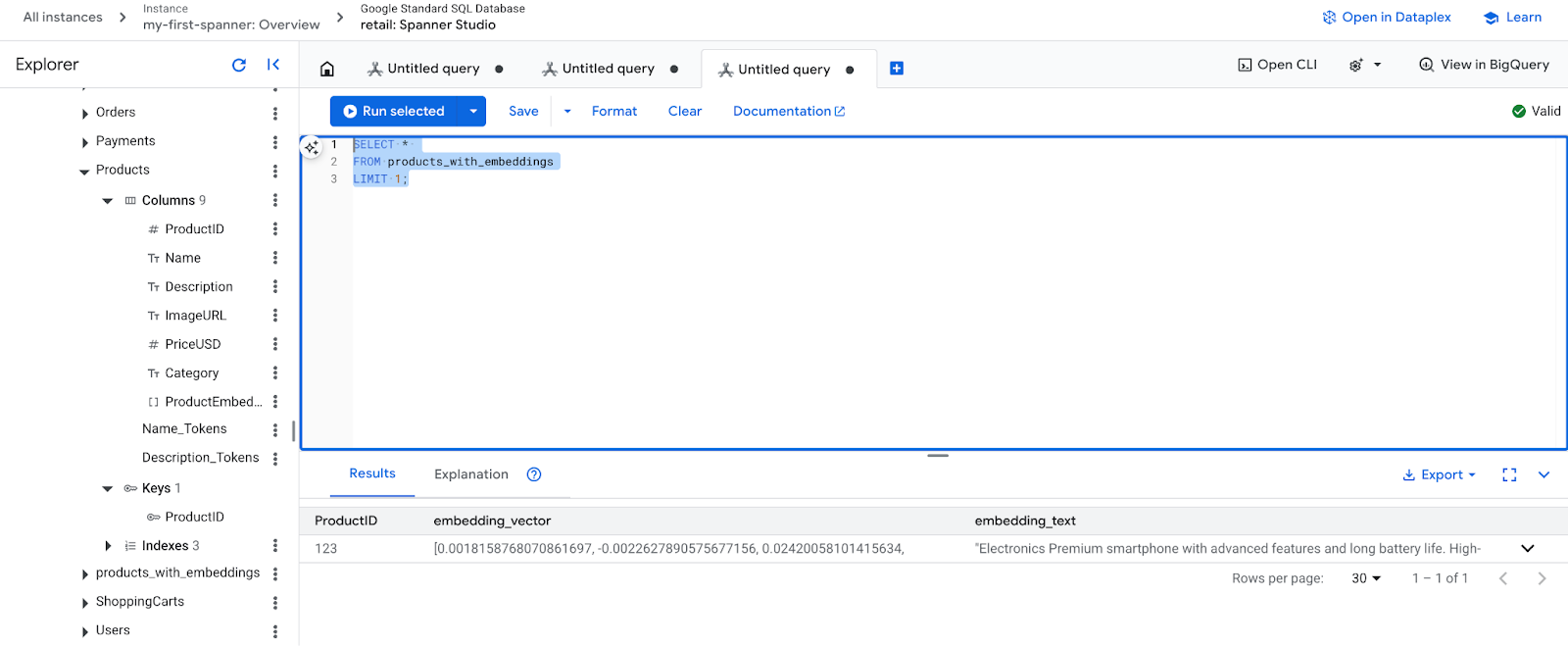
- 新しいエンベディングを確認します。生成されたエンベディングが表示されます。
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. ステップ 4: ANN 検索用のベクトル インデックスを作成する
数百万のベクトルを瞬時に検索するには、インデックスが必要です。このインデックスにより、Approximate Nearest Neighbor(ANN)検索が可能になります。これは非常に高速で、水平方向にスケーリングできます。
- 次の DDL クエリを実行してインデックスを作成します。距離指標として
COSINEを指定します。これは、セマンティック テキスト検索に最適です。WHERE 句は、Spanner がクエリの要件とするため、実際には必要です。
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- [オペレーション] タブでインデックス作成のステータスを確認します。
8. ステップ 5: K 近傍(KNN)検索でおすすめを見つける
ここからが面白いところです。お客様のクエリ「高性能なキーボードを購入したいのですが、ビーチでコーディングすることもあるので、濡れてしまうかもしれません。」。
まず、K-Nearest Neighbor(KNN)検索から始めます。これは、クエリベクトルをすべての商品ベクトルと比較する正確な検索です。正確ですが、非常に大規模なデータセットでは処理が遅くなる可能性があります(ステップ 5 で ANN インデックスを作成した理由です)。
このクエリでは 2 つのタスクを実行します。
- サブクエリは ML.PREDICT を使用して、お客様のクエリのエンベディング ベクトルを取得します。
- 外部クエリは COSINE_DISTANCE を使用して、クエリベクトルとすべての商品の embedding_vector の間の「距離」を計算します。距離が短いほど、一致度が高くなります。
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
商品のリストが表示され、一番上に防水キーボードが表示されます。
9. ステップ 6: 近似(ANN)検索でおすすめを見つける
KNN は優れていますが、数百万の商品と 1 秒間クエリ数千件を処理する本番環境システムでは、ANN インデックスの速度が必要です。
インデックスを使用するには、APPROX_COSINE_DISTANCE 関数を指定する必要があります。
- 上記と同様に、テキストのベクトル エンベディングを取得します。その結果を products_with_embeddings テーブルのレコードとクロス結合して、APPROX_COSINE_DISTANCE 関数で使用できるようにします。
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
予想される出力: 結果は KNN クエリと同一または非常に類似していますが、インデックスを使用することでより効率的に実行されます。この例では、これに気づかない場合があります。
10. ステップ 7: LLM を使用しておすすめを説明する
商品のリストを表示するだけでも十分ですが、おすすめが適切かどうかを説明するとさらに効果的です。これには LLMModel(Gemini)を使用できます。
このクエリは、ステップ 4 の KNN クエリを ML.PREDICT 呼び出し内にネストします。CONCAT を使用して LLM のプロンプトを作成し、次の情報を指定します。
- 明確な指示(「「はい」または「いいえ」で答え、理由を説明してください...」)。
- お客様の元のクエリ。
- 上位一致する各商品の名前と説明。
次に、LLM はクエリに対して各商品を評価し、自然言語のレスポンスを提供します。
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
予想される出力: 新しい LLMResponse 列を含むテーブルが表示されます。レスポンスは次のようになります。"いいえ。 理由は次のとおりです。* "防水"は"防水"ではありません。「防水」キーボードは、水しぶき、小雨、こぼれた液体に対応できます。
11. ステップ 8: プロパティ グラフを作成する
次に、別のタイプのおすすめ「この商品を購入したお客様はこんな商品も購入しています」について説明します。
これは関係ベースのクエリです。これに最適なのは、プロパティ グラフ です。Spanner では、データを複製せずに既存のテーブルの上にグラフを作成できます。
この DDL ステートメントはグラフを定義します。
- ノード:
ProductとUserテーブル。ノードは、関係を導出するエンティティです。たとえば、商品を購入した顧客が「XYZ」商品も購入したかどうかを知りたいとします。 - エッジ:
Ordersテーブル。User(ソース)をProduct(宛先)に「Purchased」というラベルで接続します。エッジは、ユーザーと購入した商品の関係を示します。
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. ステップ 9: ベクトル検索とグラフクエリを組み合わせる
これは最も強力なステップです。1 つのステートメントでAI ベクトル検索とグラフクエリを組み合わせて 、関連商品を見つけます。
このクエリは NEXT statement で区切られた 3 つの部分で読み取られます。セクションに分割してみましょう。
- まず、ベクトル検索を使用して最適な一致を見つけます。
- ML.PREDICT は、EmbeddingsModel を使用して、ユーザーのテキスト クエリからベクトル エンベディングを生成します。
- このクエリは、この新しいエンベディングと、すべての商品の保存済み p.embedding_vector の間の COSINE_DISTANCE を計算します。
- 距離が最小(意味的類似性が最も高い)の単一の bestMatch 商品を選択して返します。
- 次に、グラフを走査して関係を検索します。
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- このクエリは、bestMatch から共通の Orders ノード(ユーザー)に遡り、他の purchasedWith 商品に転送します。
- 元の商品をフィルタで除外し、GROUP BY と COUNT(1) を使用して、商品を同時購入する頻度を集計します。
- 同時購入の頻度で並べ替えられた、同時購入された上位 3 つの商品(purchasedWith)を返します。
また、ユーザーの注文の関係も見つけます。
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- この中間ステップでは、走査パターンを実行して、主要なエンティティ(bestMatch、接続ユーザー:Orders ノード、purchasedWith アイテム)をバインドします。
- 次のステップでデータを抽出するために、関係自体を purchased として明示的にバインドします。
- このパターンにより、注文固有の詳細と商品固有の詳細を取得するためのコンテキストが確立されます。
- 最後に、結果を出力します。グラフノードは SQL 結果として返される前にフォーマットする必要があります。
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
予想される出力: 同時購入された上位 3 つのアイテムを表す JSON オブジェクトが表示され、クロスセルのおすすめが表示されます。
13. クリーンアップ
料金が発生しないようにするには、作成したリソースを削除します。
- Spanner インスタンスを削除する: インスタンスを削除すると、データベースも削除されます。
gcloud spanner instances delete my-first-spanner --quiet
- Google Cloud プロジェクトを削除する: このプロジェクトを Codelab のために作成した場合は、削除するのが最も簡単なクリーンアップ方法です。
- Google Cloud コンソール の [リソースの管理] ページに移動します。
- プロジェクトを選択して [削除] をクリックします。
🎉 これで完了です。
Spanner AI と Graph を使用して、高度なリアルタイム レコメンデーション システムを構築できました。
エンベディングと LLM 生成のために Spanner を Vertex AI と統合する方法、高速ベクトル検索(KNN と ANN)を実行して意味的に関連する商品を見つける方法、グラフクエリを使用して商品の関係を見つける方法を学習しました。商品の検索だけでなく、おすすめの説明や関連商品の提案も、すべて 1 つのスケーラブルなデータベースから行うことができるシステムを構築しました。