
1. 소개
이 Codelab에서는 Spanner의 AI 및 그래프 기능을 사용하여 기존 소매 데이터베이스를 개선하는 방법을 안내합니다. Spanner 내에서 머신러닝을 활용하여 고객에게 더 나은 서비스를 제공하는 실용적인 기법을 배우게 됩니다. 구체적으로는 k-Nearest Neighbors (kNN) 및 Approximate Nearest Neighbors (ANN)를 구현하여 개별 고객의 요구사항에 부합하는 신제품을 발견할 예정입니다. 또한 LLM을 통합하여 특정 제품 추천이 이루어진 이유를 명확한 자연어로 설명합니다.
추천 외에도 Spanner의 그래프 기능을 자세히 살펴보겠습니다. 그래프 쿼리를 사용하여 고객 구매 내역과 제품 설명을 기반으로 제품 간의 관계를 모델링합니다. 이 접근 방식을 사용하면 깊이 관련성이 있는 상품을 발견할 수 있어 '다른 고객이 구매한 상품' 또는 '관련 상품' 기능의 관련성과 효과가 크게 개선됩니다. 이 Codelab을 마치면 Google Cloud Spanner로 완전히 구동되는 지능적이고 확장 가능하며 반응형 소매 애플리케이션을 빌드할 수 있습니다.
시나리오
전자 장비 소매업체에서 일한다고 가정해 보겠습니다. 전자상거래 사이트에는 Products, Orders, OrderItems이 포함된 표준 Spanner 데이터베이스가 있습니다.
고객이 '고성능 키보드를 구매하고 싶어'라는 구체적인 요구사항을 가지고 사이트에 방문합니다. 해변에 있을 때 코딩을 하기도 해서 물에 젖을 수도 있습니다.'
목표는 Spanner의 고급 기능을 사용하여 이 요청에 지능적으로 답변하는 것입니다.
- 찾기: 벡터 검색을 사용하여 간단한 키워드 검색을 넘어 사용자의 요청과 의미상 일치하는 설명이 있는 제품을 찾습니다.
- 설명: LLM을 사용하여 상위 일치 항목을 분석하고 추천이 적합한 이유를 설명하여 고객의 신뢰를 구축합니다.
- 연관성: 그래프 쿼리를 사용하여 고객이 해당 추천과 함께 자주 구매한 다른 제품을 찾습니다.
2. 시작하기 전에
- 프로젝트 만들기 Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- 결제 사용 설정 Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
- Cloud Shell 활성화 콘솔에서 'Cloud Shell 활성화' 버튼을 클릭하여 Cloud Shell을 활성화합니다. Cloud Shell 터미널과 편집기 간에 전환할 수 있습니다.

- 인증 및 프로젝트 설정 Cloud Shell에 연결되면 인증이 완료되었고 프로젝트가 해당 프로젝트 ID로 설정된 것을 확인할 수 있습니다.
gcloud auth list
gcloud config list project
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정하고
<PROJECT_ID>를 실제 프로젝트 ID로 바꿉니다.
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- 필수 API 사용 설정 Spanner, Vertex AI, Compute Engine API를 사용 설정합니다. 이 작업은 몇 분 정도 소요될 수 있습니다.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- 재사용할 환경 변수를 몇 개 설정합니다.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- Spanner 인스턴스가 아직 없다면 무료 체험판 Spanner 인스턴스를 만드세요 . 데이터베이스를 호스팅하려면 Spanner 인스턴스가 필요합니다.
regional-us-central1을 구성으로 사용합니다. 원하는 경우 업데이트할 수 있습니다.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. 아키텍처 개요
Spanner는 Vertex AI에서 호스팅되는 모델을 제외한 모든 필수 기능을 캡슐화합니다.
4. 1단계: 데이터베이스를 설정하고 첫 번째 쿼리를 제출합니다.
먼저 데이터베이스를 만들고 샘플 소매 데이터를 로드하고 Spanner가 Vertex AI와 통신하는 방법을 알려야 합니다.
이 섹션에서는 아래의 SQL 스크립트를 사용합니다.
- Spanner 제품 페이지로 이동합니다.
- 올바른 인스턴스를 선택합니다.
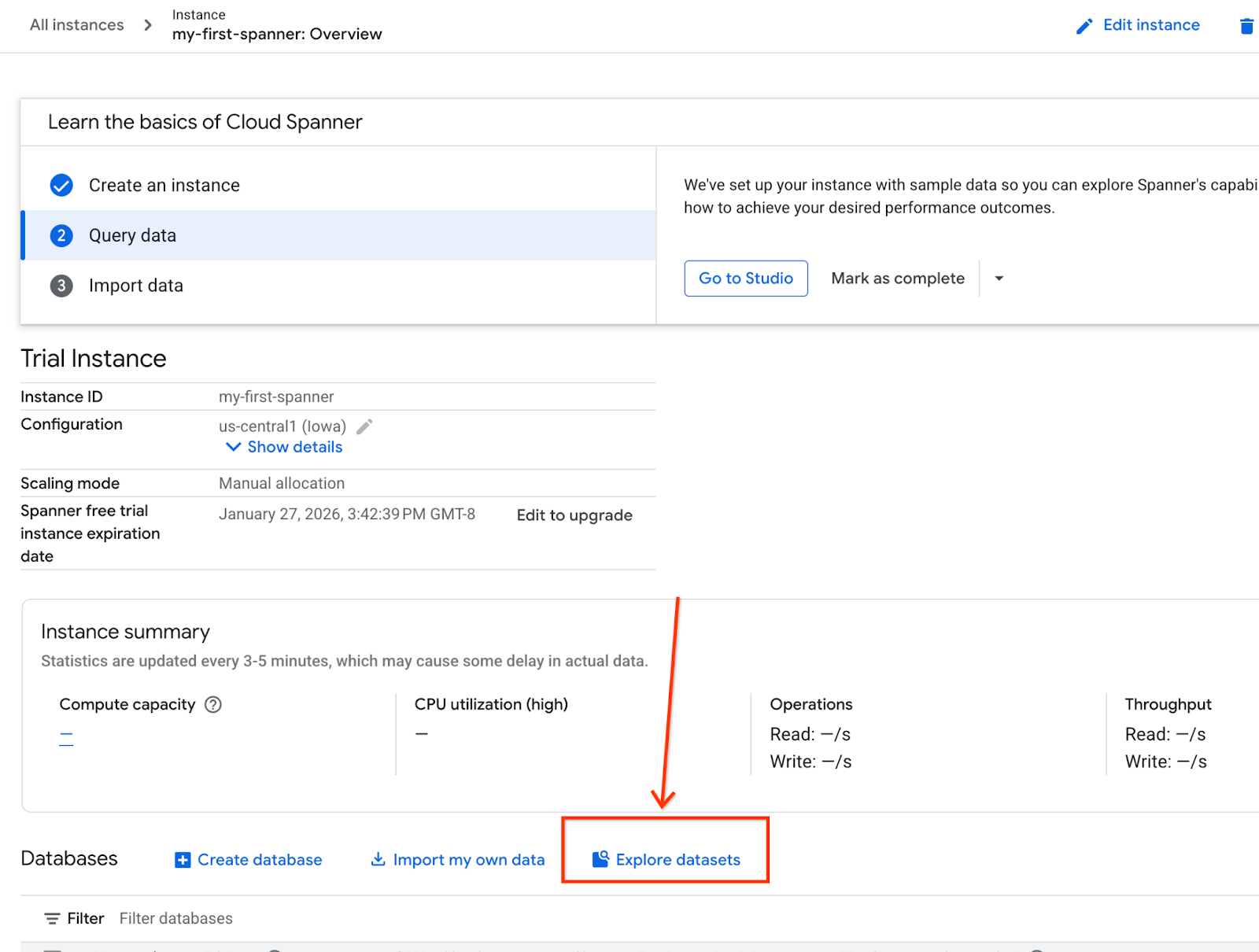
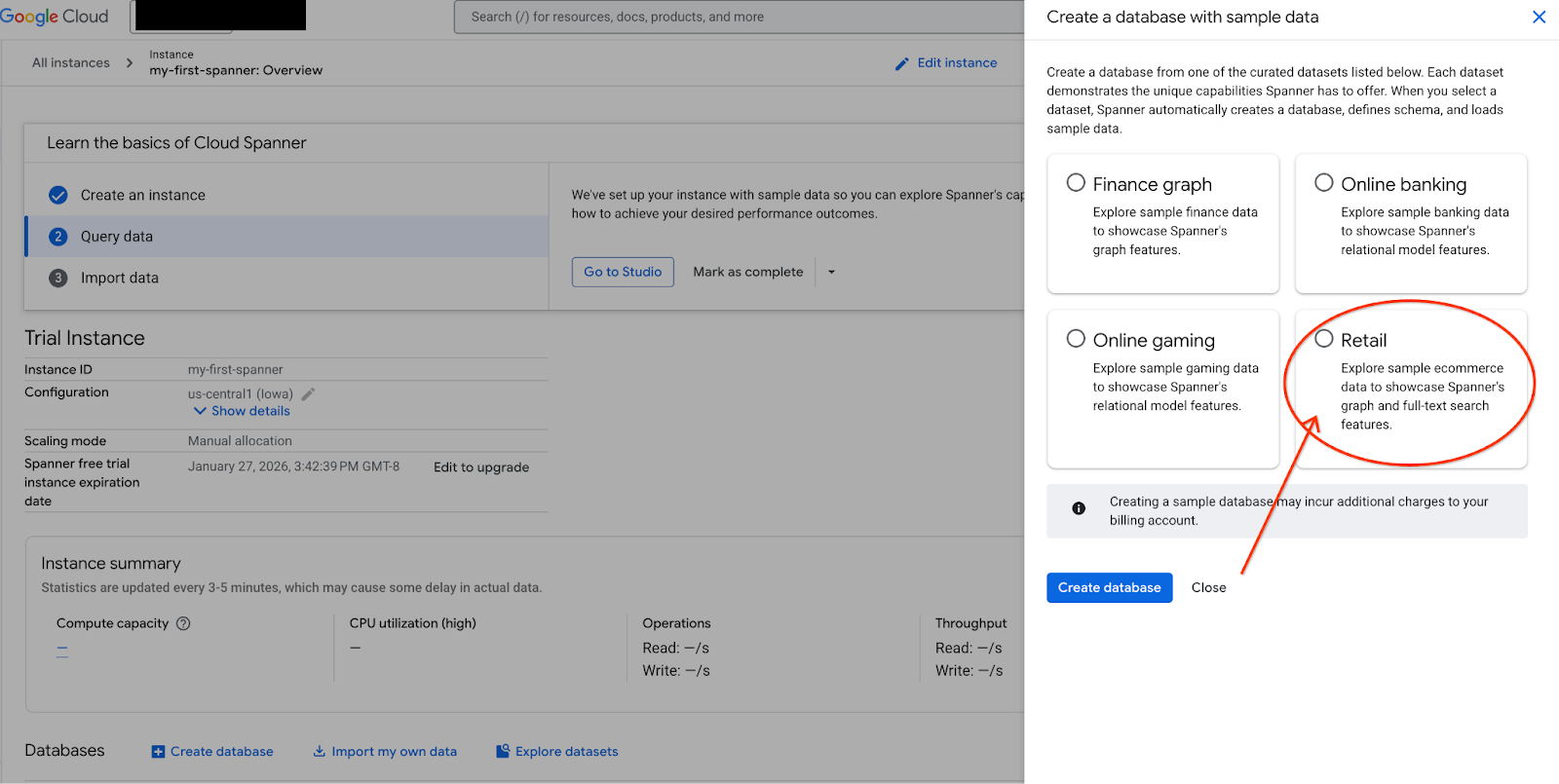
- 화면에서 데이터 세트 탐색을 선택합니다. 그런 다음 팝업에서 '소매' 옵션을 선택합니다.
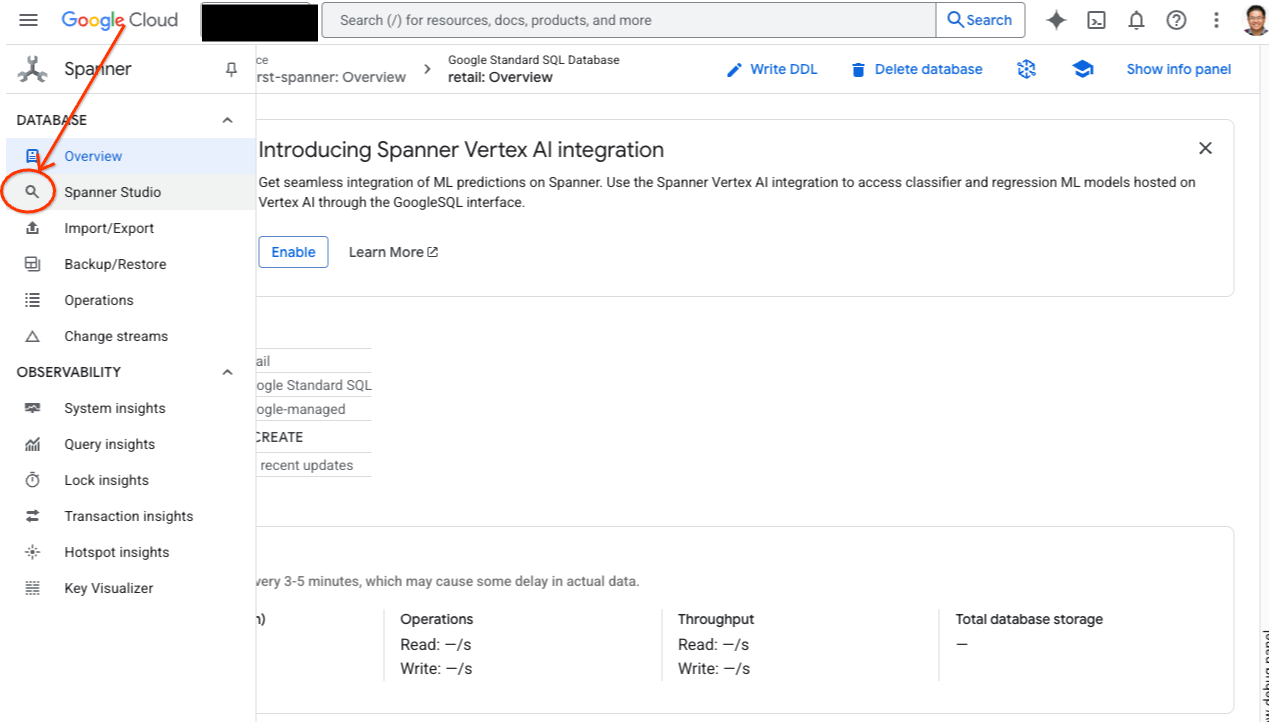
- Spanner 스튜디오로 이동합니다. Spanner 스튜디오에는 쿼리 편집기 및 SQL 쿼리 결과 테이블과 통합되는 탐색기 창이 포함되어 있습니다. 이 인터페이스 하나에서 DDL, DML, SQL 문을 실행할 수 있습니다. 측면의 메뉴를 펼치고 돋보기를 찾습니다.
- 제품 표를 읽습니다. 새 탭을 만들거나 이미 만들어진 '제목 없는 쿼리' 탭을 사용합니다.
SELECT *
FROM Products;
5. 2단계: AI 모델을 만듭니다.
이제 Spanner 객체를 사용하여 원격 모델을 만들어 보겠습니다. 이러한 SQL 문은 Vertex AI 엔드포인트에 연결되는 Spanner 객체를 만듭니다.
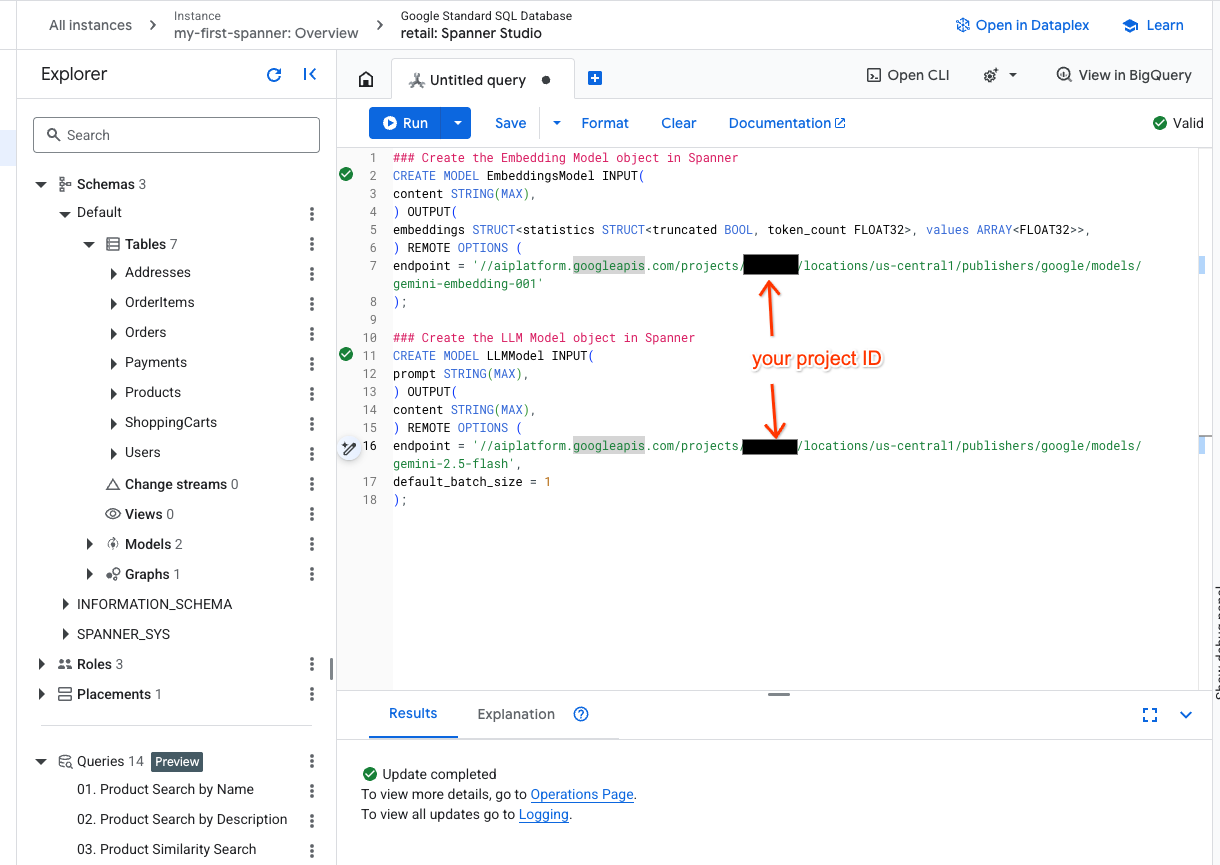
- Spanner 스튜디오에서 새 탭을 열고 두 모델을 만듭니다. 첫 번째는 임베딩을 생성할 수 있는 EmbeddingsModel입니다. 두 번째는 LLM과 상호작용할 수 있는 LLMModel입니다 (이 예에서는 gemini-2.5-flash). <PROJECT_ID>를 프로젝트 ID로 업데이트했는지 확인합니다.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- 참고:
PROJECT_ID를 실제$PROJECT_ID로 바꿔야 합니다.
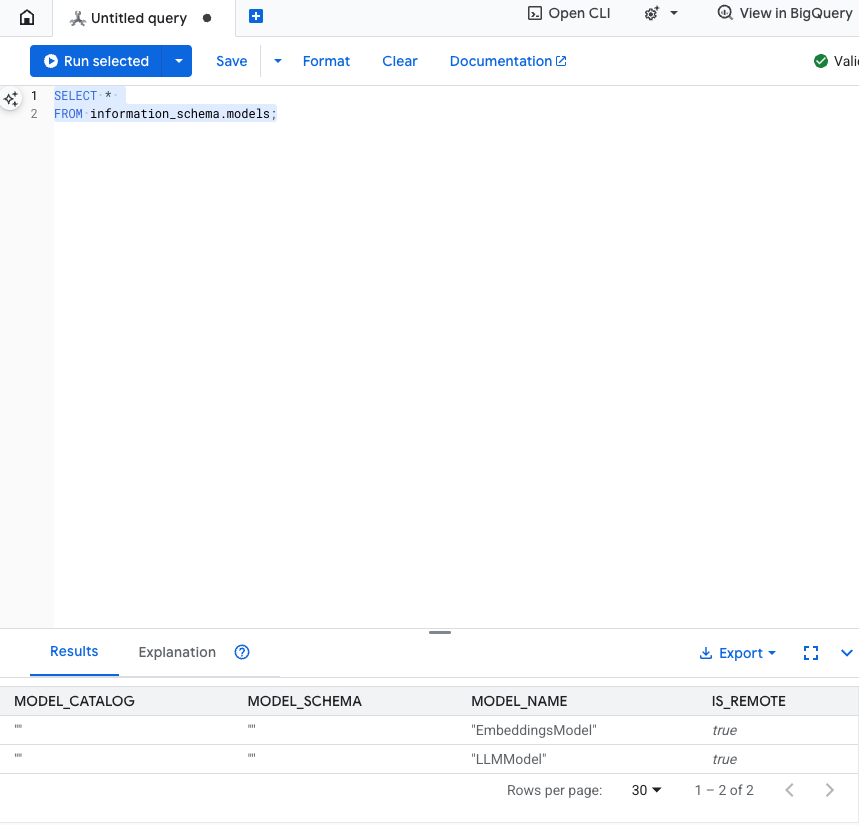
이 단계 테스트: SQL 편집기에서 다음을 실행하여 모델이 생성되었는지 확인할 수 있습니다.
SELECT *
FROM information_schema.models;
6. 3단계: 벡터 임베딩 생성 및 저장
제품 테이블에는 텍스트 설명이 있지만 AI 모델은 벡터 (숫자 배열)를 이해합니다. 이러한 벡터를 저장할 새 열을 추가한 다음 EmbeddingsModel을 통해 모든 제품 설명을 실행하여 열을 채워야 합니다.
- 임베딩을 지원하는 새 테이블을 만듭니다. 먼저 임베딩을 지원할 수 있는 테이블을 만듭니다. 제품 표 샘플 임베딩과 다른 임베딩 모델을 사용하고 있습니다. 벡터 검색이 제대로 작동하려면 임베딩이 동일한 모델에서 생성되었는지 확인해야 합니다.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- 모델에서 생성된 임베딩으로 새 테이블을 채웁니다. 여기서는 간단하게 insert into 문을 사용합니다. 이렇게 하면 쿼리 결과가 방금 만든 테이블로 푸시됩니다.
SQL 문은 먼저 임베딩을 생성하려는 모든 관련 텍스트 열을 가져와 연결합니다. 그런 다음 사용된 텍스트를 포함한 관련 정보를 반환합니다. 일반적으로 필요하지 않지만 결과를 시각화할 수 있도록 포함했습니다.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
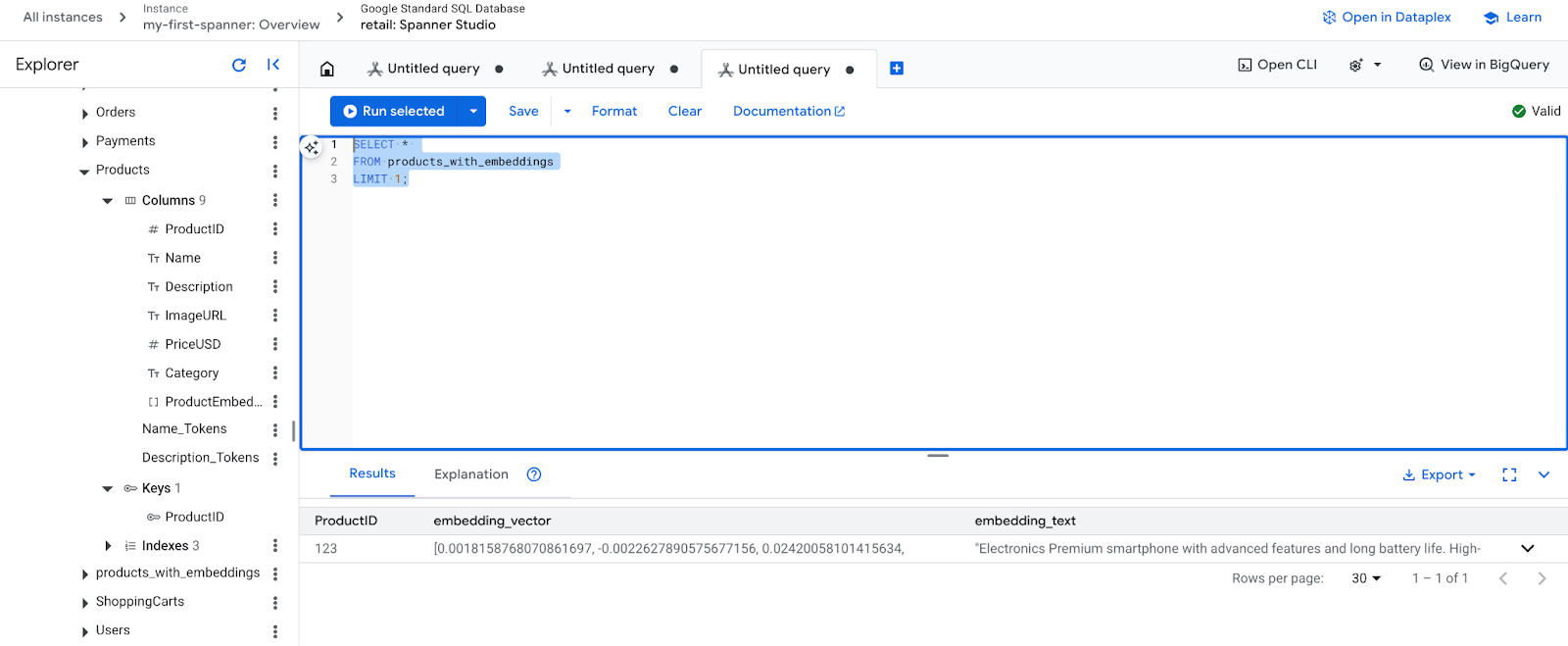
- 새로운 삽입을 확인합니다. 이제 생성된 삽입이 표시됩니다.
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. 4단계: ANN 검색을 위한 벡터 색인 만들기
수백만 개의 벡터를 즉시 검색하려면 색인이 필요합니다. 이 색인을 사용하면 매우 빠르고 수평으로 확장되는 Approximate Nearest Neighbor (ANN) 검색이 가능합니다.
- 다음 DDL 쿼리를 실행하여 색인을 만듭니다.
COSINE를 거리 측정항목으로 지정합니다. 이는 시맨틱 텍스트 검색에 적합합니다. Spanner에서 쿼리에 WHERE 절이 필요하므로 실제로 WHERE 절이 필요합니다.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- 작업 탭에서 색인 생성 상태를 확인합니다.
8. 5단계: K-최근접 이웃 (KNN) 검색으로 추천 찾기
이제 재미있는 부분을 살펴볼까요? 고객의 질문과 일치하는 제품을 찾아보세요. "고성능 키보드를 사고 싶어. 해변에 있을 때 코딩을 하기도 해서 물에 젖을 수도 있습니다.'
K-Nearest Neighbor (KNN) 검색부터 시작하겠습니다. 이는 쿼리 벡터를 모든 제품 벡터와 비교하는 정확한 검색입니다. 정확하지만 매우 큰 데이터 세트에서는 속도가 느릴 수 있습니다 (그래서 5단계에서 ANN 색인을 빌드했습니다).
이 쿼리는 다음 두 가지 작업을 수행합니다.
- 하위 쿼리는 ML.PREDICT를 사용하여 고객 쿼리의 임베딩 벡터를 가져옵니다.
- 외부 쿼리는 COSINE_DISTANCE를 사용하여 쿼리 벡터와 모든 제품의 embedding_vector 간의 '거리'를 계산합니다. 거리가 짧을수록 더 일치합니다.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
제품 목록이 표시되며, 맨 위에 생활 방수 키보드가 표시됩니다.
9. 6단계: 근사 (ANN) 검색으로 추천 찾기
KNN도 좋지만 수백만 개의 제품과 초당 수천 개의 쿼리가 있는 프로덕션 시스템에는 ANN 색인의 속도가 필요합니다.
색인을 사용하려면 APPROX_COSINE_DISTANCE 함수를 지정해야 합니다.
- 위에서와 같이 텍스트의 벡터 임베딩을 가져옵니다. 이 결과를 products_with_embeddings 테이블의 레코드와 교차 결합하여 APPROX_COSINE_DISTANCE 함수에서 사용할 수 있습니다.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
예상 출력: 결과는 KNN 쿼리와 동일하거나 매우 유사하지만 색인을 사용하여 훨씬 효율적으로 실행됩니다. 예시에서는 이를 확인하지 못할 수도 있습니다.
10. 7단계: LLM을 사용하여 추천 설명
제품 목록을 보여주는 것도 좋지만, 적합한지 아닌지 이유를 설명하는 것이 좋습니다. LLMModel (Gemini)을 사용하여 이 작업을 수행할 수 있습니다.
이 쿼리는 4단계의 KNN 쿼리를 ML.PREDICT 호출 내부에 중첩합니다. Google에서는 CONCAT을 사용하여 LLM의 프롬프트를 빌드하고 다음을 제공합니다.
- 명확한 지침 ('예' 또는 '아니요'로 답하고 이유를 설명해 줘')
- 고객의 원래 질문입니다.
- 일치도가 가장 높은 각 제품의 이름과 설명입니다.
그런 다음 LLM은 쿼리에 대해 각 제품을 평가하고 자연어 응답을 제공합니다.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
예상 출력: 새로운 LLMResponse 열이 있는 표가 표시됩니다. 대답은 다음과 같이 표시되어야 합니다. '아니요. 이유는 다음과 같습니다. * '방수'는 '완전 방수'가 아닙니다. '내수성' 키보드는 물이 튀거나 가벼운 비를 맞거나 물을 쏟는 정도는 견딜 수 있습니다.
11. 8단계: 속성 그래프 만들기
이제 다른 유형의 추천인 '이 제품을 구매한 다른 사용자가 함께 구매한 제품'을 살펴보겠습니다.
이는 관계 기반 쿼리입니다. 이러한 작업에 적합한 도구는 속성 그래프입니다. Spanner를 사용하면 데이터를 복제하지 않고 기존 테이블 위에 그래프를 만들 수 있습니다.
이 DDL 문은 그래프를 정의합니다.
- 노드:
Product및User테이블 노드는 관계를 도출하려는 항목입니다. 예를 들어 제품을 구매한 고객이 'XYZ' 제품도 구매했는지 알고 싶을 수 있습니다. - 에지:
User(소스)을Product(대상)에 '구매됨' 라벨로 연결하는Orders테이블 에지는 사용자와 사용자가 구매한 항목 간의 관계를 제공합니다.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. 9단계: 벡터 검색과 그래프 쿼리 결합
가장 강력한 단계입니다. 관련 제품을 찾기 위해 단일 문장에서 AI 벡터 검색과 그래프 쿼리를 결합합니다.
이 질문은 NEXT statement로 구분된 세 부분으로 읽습니다. 섹션으로 나누어 보겠습니다.
- 먼저 벡터 검색을 사용하여 가장 적합한 항목을 찾습니다.
- ML.PREDICT는 EmbeddingsModel을 사용하여 사용자의 텍스트 쿼리에서 벡터 임베딩을 생성합니다.
- 이 쿼리는 이 새로운 임베딩과 모든 제품에 대해 저장된 p.embedding_vector 간의 COSINE_DISTANCE를 계산합니다.
- 거리가 가장 짧은 (시맨틱 유사성이 가장 높은) 단일 bestMatch 제품을 선택하여 반환합니다.
- 다음으로 관계를 찾기 위해 그래프를 순회합니다.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- 이 쿼리는 bestMatch에서 공통 Orders 노드 (사용자)로 거슬러 올라간 다음 purchasedWith 제품으로 전달됩니다.
- 원래 제품을 필터링하고 GROUP BY 및 COUNT(1)을 사용하여 항목이 공동 구매되는 빈도를 집계합니다.
- 동시 구매 빈도순으로 정렬된 상위 3개 동시 구매 제품 (purchasedWith)을 반환합니다.
또한 사용자 주문 관계를 찾습니다.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- 이 중간 단계에서는 순회 패턴을 실행하여 주요 항목(bestMatch, 연결 사용자:Orders 노드, purchasedWith 항목)을 바인딩합니다.
- 특히 다음 단계에서 데이터 추출을 위해 관계 자체를 구매한 것으로 바인딩합니다.
- 이 패턴은 주문별 및 제품별 세부정보를 가져오기 위해 컨텍스트가 설정되도록 합니다.
- 마지막으로 그래프 노드로 반환될 결과를 출력합니다. SQL 결과로 반환되기 전에 형식을 지정해야 합니다.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
예상 출력: 공동 구매된 상위 3개 상품을 나타내는 JSON 객체가 표시되어 크로스셀 추천을 제공합니다.
13. 삭제
요금이 발생하지 않도록 하려면 생성한 리소스를 삭제하면 됩니다.
- Spanner 인스턴스 삭제: 인스턴스를 삭제하면 데이터베이스도 삭제됩니다.
gcloud spanner instances delete my-first-spanner --quiet
- Google Cloud 프로젝트 삭제: 코드랩을 위해서만 이 프로젝트를 만든 경우 삭제하는 것이 가장 쉬운 정리 방법입니다.
- Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
- 프로젝트를 선택하고 삭제를 클릭합니다.
🎉 수고하셨습니다.
Spanner AI 및 그래프를 사용하여 정교한 실시간 추천 시스템을 성공적으로 빌드했습니다.
임베딩 및 LLM 생성을 위해 Spanner를 Vertex AI와 통합하는 방법, 고속 벡터 검색 (KNN 및 ANN)을 실행하여 의미적으로 관련된 제품을 찾는 방법, 그래프 쿼리를 사용하여 제품 관계를 파악하는 방법을 알아보았습니다. 제품을 찾을 뿐만 아니라 추천을 설명하고 관련 상품을 추천할 수 있는 시스템을 단일 확장 가능한 데이터베이스에서 구축했습니다.