
1. Wprowadzenie
To ćwiczenie przeprowadzi Cię przez proces korzystania z funkcji AI i grafów Spanner'a w celu ulepszenia istniejącej bazy danych detalicznych. Poznasz praktyczne techniki wykorzystywania uczenia maszynowego w Spannerze, aby lepiej obsługiwać klientów. W tym celu wdrożymy algorytmy k-Nearest Neighbors (kNN) i Approximate Nearest Neighbors (ANN), aby odkrywać nowe produkty, które odpowiadają indywidualnym potrzebom klientów. Zintegrujesz też duży model językowy, aby podawać jasne wyjaśnienia w języku naturalnym, dlaczego przedstawiliśmy daną rekomendację produktu.
Oprócz rekomendacji przyjrzymy się funkcjom grafu Spannera. Do modelowania relacji między produktami na podstawie historii zakupów klientów i opisów produktów będziesz używać zapytań do grafu. Takie podejście pozwala odkrywać głęboko powiązane produkty, co znacznie zwiększa trafność i skuteczność funkcji „Klienci kupili też” lub „Powiązane produkty”. Po ukończeniu tego ćwiczenia będziesz mieć umiejętności potrzebne do tworzenia inteligentnych, skalowalnych i szybko reagujących aplikacji handlowych opartych w całości na Google Cloud Spanner.
Scenariusz
Pracujesz w sklepie z elektroniką. Twoja witryna e-commerce ma standardową bazę danych Spanner z Products, Orders i OrderItems.
Klient wchodzi na Twoją stronę z konkretną potrzebą: „Chcę kupić klawiaturę o wysokiej wydajności. Czasami programuję na plaży, więc może się zamoczyć”.
Twoim celem jest inteligentne wykorzystanie funkcji zaawansowanych Spannera do udzielenia odpowiedzi na to żądanie:
- Znajdowanie: wykraczaj poza proste wyszukiwanie słów kluczowych, aby znajdować produkty, których opisy są semantycznie zgodne z zapytaniem użytkownika, za pomocą wyszukiwania wektorowego.
- Wyjaśnienie: użyj LLM do analizy najlepszych wyników i wyjaśnij dlaczego rekomendacja jest odpowiednia, aby budować zaufanie klientów.
- Powiązane: użyj zapytań do wykresu, aby znaleźć inne produkty, które klienci często kupowali wraz z tą rekomendacją.
2. Zanim zaczniesz
- Utwórz projekt w chmurze: w konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt w chmurze Google.
- Włącz płatności: sprawdź, czy w projekcie w chmurze włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
- Aktywuj Cloud Shell: aktywuj Cloud Shell, klikając przycisk „Aktywuj Cloud Shell” w konsoli. Możesz przełączać się między terminalem Cloud Shell a edytorem.

- Autoryzacja i ustawianie projektu: po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu.
gcloud auth list
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić. Zastąp symbol
<PROJECT_ID>identyfikatorem projektu:
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- Włącz wymagane interfejsy API: włącz interfejsy Spanner API, Vertex AI API i Compute Engine API. To może potrwać kilka minut.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Ustaw kilka zmiennych środowiskowych, których będziesz używać ponownie.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- Utwórz instancję usługi Spanner w bezpłatnej wersji próbnej, jeśli nie masz jeszcze instancji usługi Spanner . Do hostowania bazy danych potrzebna jest instancja Spannera. Użyjemy konfiguracji
regional-us-central1. W razie potrzeby możesz to zmienić.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. Omówienie architektury
Spanner zawiera wszystkie niezbędne funkcje z wyjątkiem modeli, które są hostowane w Vertex AI.
4. Krok 1. Skonfiguruj bazę danych i prześlij pierwsze zapytanie.
Najpierw musimy utworzyć bazę danych, wczytać przykładowe dane dotyczące sprzedaży detalicznej i poinformować Spannera, jak komunikować się z Vertex AI.
W tej sekcji użyjesz poniższych skryptów SQL.
- Otwórz stronę produktu Spanner.
- Wybierz właściwą instancję.
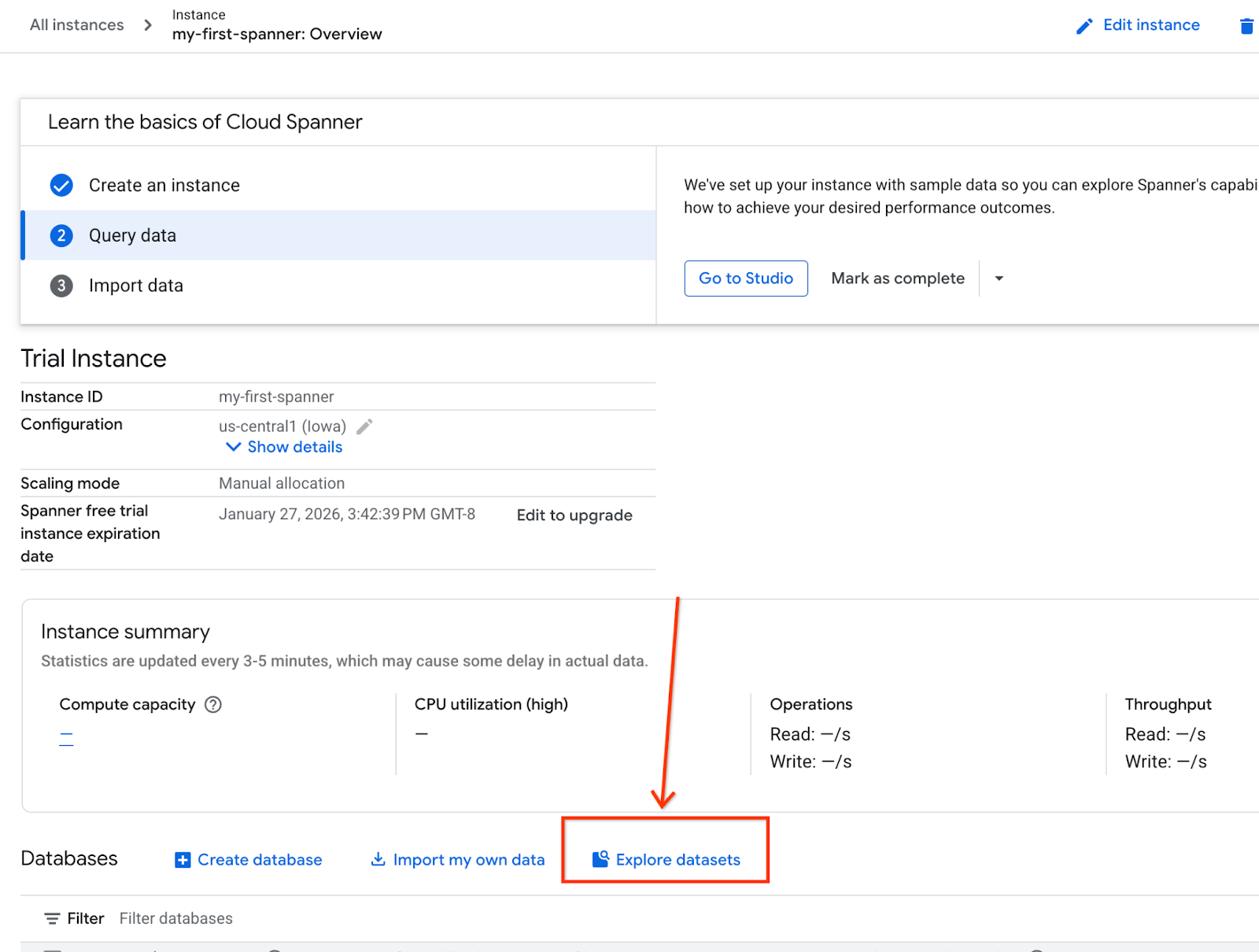
- Na ekranie wybierz Eksploruj zbiory danych. Następnie w wyskakującym okienku wybierz opcję „Sprzedaż detaliczna”.
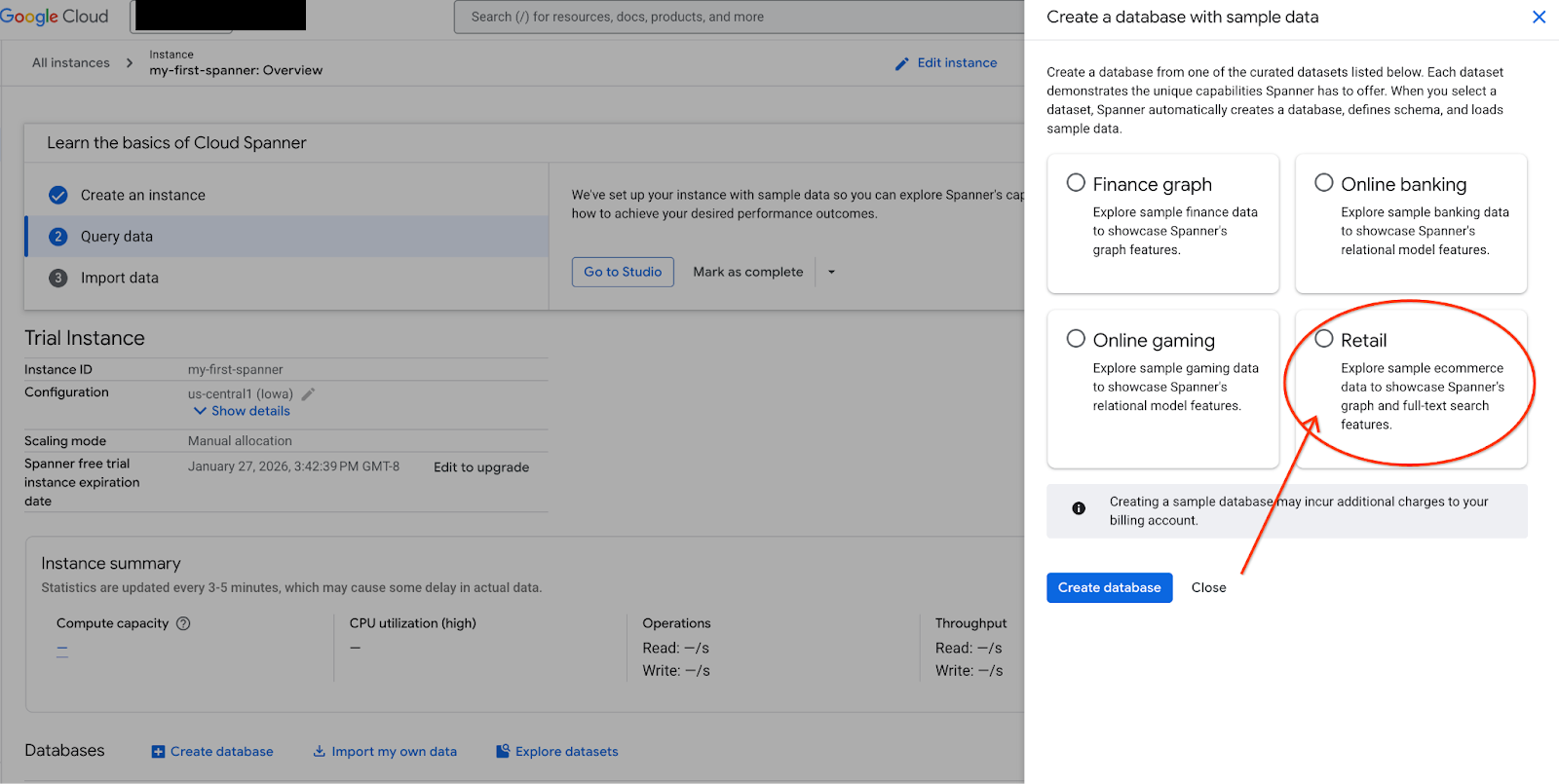
- Otwórz Spanner Studio. Spanner Studio zawiera panel Eksploratora, który jest zintegrowany z edytorem zapytań i tabelą wyników zapytań SQL. W tym interfejsie możesz uruchamiać instrukcje DDL, DML i SQL. Musisz rozwinąć menu z boku i poszukać lupy.
- Zapoznaj się z tabelą produktów. Utwórz nową kartę lub użyj już utworzonej karty „Zapytanie bez nazwy”.
SELECT *
FROM Products;
5. Krok 2. Utwórz modele AI.
Teraz utwórzmy modele zdalne z obiektami Spanner. Te instrukcje SQL tworzą obiekty Spanner, które są połączone z punktami końcowymi Vertex AI.
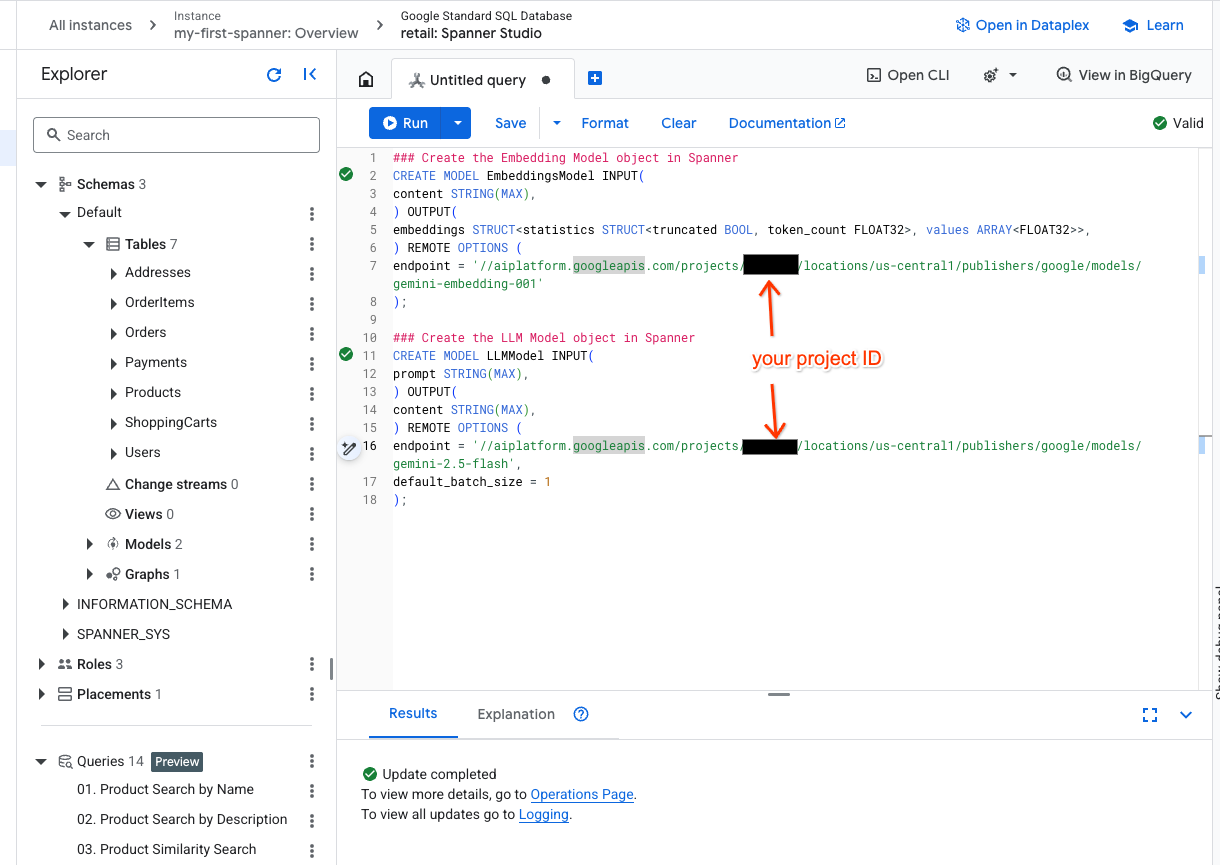
- Otwórz nową kartę w Spanner Studio i utwórz 2 modele. Pierwszy to EmbeddingsModel, który umożliwia generowanie wektorów dystrybucyjnych. Drugi to LLMModel, który umożliwia interakcję z LLM (w naszym przykładzie jest to gemini-2.5-flash). Upewnij się, że w miejscu <PROJECT_ID> podano identyfikator projektu.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- Uwaga: pamiętaj, aby zastąpić
PROJECT_IDrzeczywistym$PROJECT_ID.
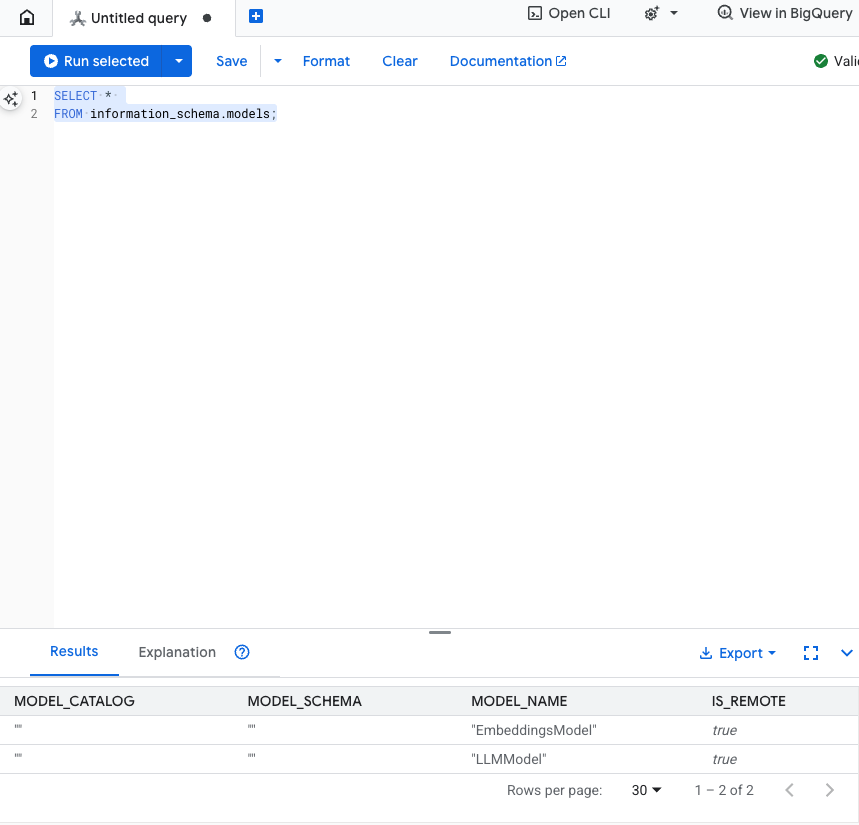
Sprawdź ten krok: możesz sprawdzić, czy modele zostały utworzone, uruchamiając w edytorze SQL to polecenie:
SELECT *
FROM information_schema.models;
6. Krok 3. Wygeneruj i zapisz wektory dystrybucyjne
Nasza tabela produktów zawiera opisy tekstowe, ale model AI rozumie wektory (tablice liczb). Musimy dodać nową kolumnę do przechowywania tych wektorów, a następnie wypełnić ją, przetwarzając wszystkie opisy produktów za pomocą modelu EmbeddingsModel.
- Utwórz nową tabelę, która będzie obsługiwać wektory dystrybucyjne. Najpierw utwórz tabelę, która może obsługiwać osadzanie. Używamy innego modelu wektorów dystrybucyjnych niż w przykładowych wektorach dystrybucyjnych tabeli produktów. Aby wyszukiwanie wektorowe działało prawidłowo, musisz mieć pewność, że wektory dystrybucyjne zostały wygenerowane na podstawie tego samego modelu.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- Wypełnij nową tabelę wektorami dystrybucyjnymi wygenerowanymi przez model. Dla uproszczenia używamy tutaj instrukcji wstawiania. Spowoduje to przesłanie wyników zapytania do utworzonej tabeli.
Instrukcja SQL najpierw pobiera i łączy wszystkie odpowiednie kolumny tekstowe, na podstawie których chcemy wygenerować wektory. Następnie zwracamy odpowiednie informacje, w tym użyty tekst. Zwykle nie jest to konieczne, ale dodajemy to, aby umożliwić Ci wizualizację wyników.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
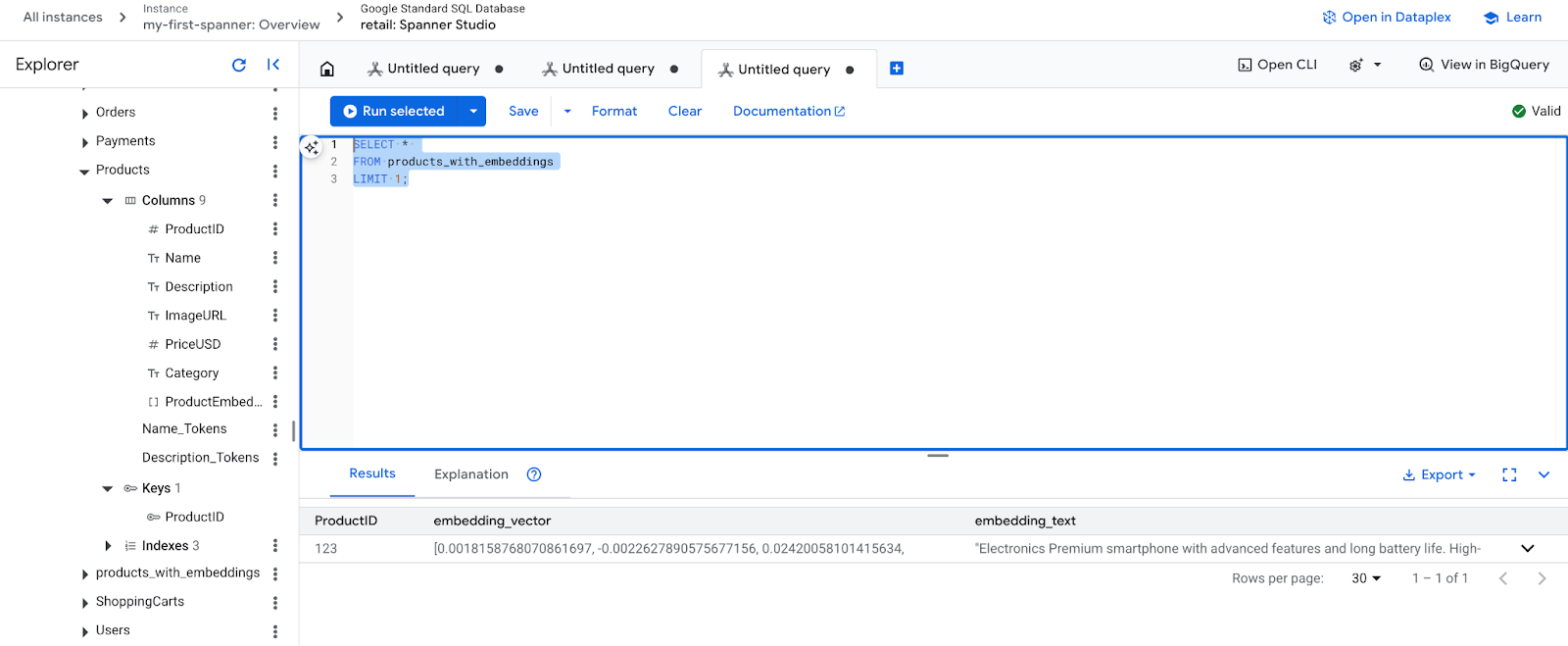
- Sprawdź nowe osadzenia. Powinny być teraz widoczne wygenerowane wektory.
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. Krok 4. Utwórz indeks wektorowy na potrzeby wyszukiwania ANN
Aby natychmiast przeszukiwać miliony wektorów, potrzebujemy indeksu. Ten indeks umożliwia wyszukiwanie Aproksymatywnych Najbliższych Sąsiadów (ANN), które jest niezwykle szybkie i skalowalne w poziomie.
- Uruchom to zapytanie DDL, aby utworzyć indeks. Jako miarę odległości podajemy
COSINE, która doskonale sprawdza się w przypadku semantycznego wyszukiwania tekstu. Klauzula WHERE jest niezbędna, ponieważ Spanner wymaga jej w zapytaniu.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- Sprawdź stan tworzenia indeksu na karcie operacji.
8. Krok 5. Znajdź rekomendacje za pomocą wyszukiwania K-Nearest Neighbor (KNN)
A teraz czas na zabawę! Znajdźmy produkty pasujące do zapytania klienta: „Chcę kupić klawiaturę o wysokiej wydajności. Czasami programuję na plaży, więc może się zamoczyć”.
Zaczniemy od wyszukiwania K-Najbliższych Najbliższych sąsiadów (KNN). Jest to wyszukiwanie dokładne, które porównuje wektor zapytania z każdym wektorem produktu. Jest precyzyjna, ale może działać wolno w przypadku bardzo dużych zbiorów danych (dlatego w kroku 5 utworzyliśmy indeks ANN).
To zapytanie wykonuje 2 czynności:
- Podzapytanie używa funkcji ML.PREDICT, aby uzyskać wektor dystrybucyjny zapytania klienta.
- Zapytanie zewnętrzne używa funkcji COSINE_DISTANCE do obliczania „odległości” między wektorem zapytania a wektorem embedding_vector każdego produktu. Mniejsza odległość oznacza lepsze dopasowanie.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Powinna się wyświetlić lista produktów, a na jej szczycie klawiatury odporne na zalanie.
9. Krok 6. Znajdź rekomendacje za pomocą przybliżonego wyszukiwania (ANN)
KNN jest świetnym rozwiązaniem, ale w przypadku systemu produkcyjnego z milionami produktów i tysiącami zapytań na sekundę potrzebujemy szybkości naszego indeksu ANN.
Aby użyć indeksu, musisz określić funkcję APPROX_COSINE_DISTANCE.
- Uzyskaj wektor dystrybucyjny tekstu w sposób opisany powyżej. Łączymy iloczynowo wyniki z rekordami w tabeli products_with_embeddings, aby można było ich używać w funkcji APPROX_COSINE_DISTANCE.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Oczekiwane dane wyjściowe: wyniki powinny być identyczne lub bardzo podobne do wyników zapytania KNN, ale zapytanie zostało wykonane znacznie wydajniej dzięki użyciu indeksu. W tym przykładzie możesz tego nie zauważyć.
10. Krok 7. Użyj LLM do wyjaśnienia rekomendacji
Sama lista produktów jest przydatna, ale wyjaśnienie, dlaczego dany produkt jest lub nie jest odpowiedni, jest jeszcze lepsze. Możemy to zrobić za pomocą modelu LLMModel (Gemini).
To zapytanie zagnieżdża zapytanie KNN z kroku 4 w wywołaniu ML.PREDICT. Używamy funkcji CONCAT, aby utworzyć prompta dla LLM, podając mu:
- jasne instrukcje („Odpowiedz „Tak” lub „Nie” i wyjaśnij dlaczego…”);
- Pierwotne zapytanie klienta.
- Nazwa i opis każdego najlepiej dopasowanego produktu.
Następnie LLM ocenia każdy produkt pod kątem zapytania i generuje odpowiedź w języku naturalnym.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
Oczekiwane dane wyjściowe: otrzymasz tabelę z nową kolumną LLMResponse. Odpowiedź powinna brzmieć mniej więcej tak: „Nie. Oto dlaczego: * „Wodoodporny” to nie to samo co „wodoszczelny”. Klawiatura „wodoodporna” jest odporna na zachlapania, lekki deszcz i rozlany płyn.
11. Krok 8. Utwórz wykres właściwości
A teraz inny rodzaj rekomendacji: „klienci, którzy kupili ten produkt, kupili też…”
Jest to zapytanie oparte na relacjach. Idealnym narzędziem do tego celu jest wykres właściwości. Spanner umożliwia tworzenie wykresu na podstawie istniejących tabel bez duplikowania danych.
Ta instrukcja DDL definiuje nasz wykres:
- Węzły: tabele
ProductiUser. Węzły to jednostki, z których chcesz wyodrębnić relację. Chcesz wiedzieć, czy klienci, którzy kupili Twój produkt, kupili też produkty „XYZ”. - Krawędzie: tabela
Orders, która łączyUser(źródło) zProduct(miejsce docelowe) za pomocą etykiety „Kupiono”. Krawędzie pokazują relację między użytkownikiem a tym, co kupił.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. Krok 9. Łączenie wyszukiwania wektorowego i zapytań grafowych
To najważniejszy krok. Aby znaleźć produkty powiązane, połączymy w jednym stwierdzeniu wyszukiwanie wektorowe oparte na AI i zapytania do wykresu.
To zapytanie jest odczytywane w 3 częściach rozdzielonych znakiem NEXT statement. Przyjrzyjmy się poszczególnym sekcjom.
- Najpierw wyszukujemy najlepsze dopasowanie za pomocą wyszukiwania wektorowego.
- Funkcja ML.PREDICT generuje wektor dystrybucyjny z zapytania tekstowego użytkownika za pomocą funkcji EmbeddingsModel.
- Zapytanie oblicza COSINE_DISTANCE między tym nowym osadzeniem a przechowywanym p.embedding_vector dla wszystkich produktów.
- Wybiera i zwraca jeden produkt bestMatch o minimalnej odległości (największym podobieństwie semantycznym).
- Następnie przeszukujemy graf w poszukiwaniu relacji.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- Zapytanie śledzi ścieżkę od węzła bestMatch do wspólnych węzłów Orders (użytkownik), a następnie do innych produktów purchasedWith.
- Filtruje oryginalny produkt i używa funkcji GROUP BY oraz COUNT(1), aby zliczać, jak często produkty są kupowane razem.
- Zwraca 3 najczęściej kupowane razem produkty (purchasedWith) uporządkowane według częstotliwości współwystępowania.
Dodatkowo znajdujemy relację między użytkownikiem a zamówieniem.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- Ten krok pośredni wykonuje wzorzec przechodzenia, aby powiązać kluczowe jednostki: bestMatch, węzeł łączący user:Orders i element purchasedWith.
- W szczególności wiąże samą relację jako zakupioną na potrzeby wyodrębniania danych w następnym kroku.
- Ten wzorzec zapewnia kontekst umożliwiający pobieranie szczegółów dotyczących zamówienia i produktu.
- Na koniec przekształcamy wyniki w węzły grafu, które muszą zostać sformatowane, zanim zostaną zwrócone jako wyniki SQL.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
Oczekiwane dane wyjściowe: zobaczysz obiekty JSON reprezentujące 3 najczęściej kupowane razem produkty, które zawierają rekomendacje dotyczące sprzedaży krzyżowej.
13. Czyszczę dane
Aby uniknąć opłat, możesz usunąć utworzone zasoby.
- Usuń instancję Spannera: usunięcie instancji spowoduje też usunięcie bazy danych.
gcloud spanner instances delete my-first-spanner --quiet
- Usuń projekt Google Cloud: jeśli projekt został utworzony tylko na potrzeby tego ćwiczenia, najłatwiej będzie go usunąć.
- Otwórz stronę Zarządzanie zasobami w konsoli Google Cloud.
- Wybierz projekt i kliknij Usuń.
🎉 Gratulacje!
Udało Ci się utworzyć zaawansowany system rekomendacji w czasie rzeczywistym przy użyciu Spanner AI i Spanner Graph.
Dowiedziałeś się, jak zintegrować Spanner z Vertex AI na potrzeby generowania wektorów dystrybucyjnych i modeli LLM, jak przeprowadzać szybkie wyszukiwanie wektorowe (KNN i ANN), aby znajdować produkty o podobnym znaczeniu, oraz jak używać zapytań grafowych do odkrywania relacji między produktami. Stworzyliśmy system, który nie tylko wyszukuje produkty, ale też wyjaśnia rekomendacje i sugeruje powiązane produkty. Wszystko to w ramach jednej, skalowalnej bazy danych.