
1. Introdução
Este codelab vai orientar você no uso dos recursos de IA e gráficos do Spanner para aprimorar um banco de dados de varejo existente. Você vai aprender técnicas práticas para usar o machine learning no Spanner e atender melhor seus clientes. Especificamente, vamos implementar k-Nearest Neighbors (kNN) e Approximate Nearest Neighbors (ANN) para descobrir novos produtos que se alinham às necessidades individuais dos clientes. Você também vai integrar um LLM para fornecer explicações claras e em linguagem natural sobre por que uma recomendação de produto específica foi feita.
Além da recomendação, vamos analisar a funcionalidade de gráficos do Spanner. Você vai usar consultas de grafo para modelar relações entre produtos com base no histórico de compras dos clientes e nas descrições dos produtos. Essa abordagem permite descobrir itens profundamente relacionados, melhorando significativamente a relevância e a eficácia dos recursos "Os clientes também compraram" ou "Itens relacionados". Ao final deste codelab, você terá as habilidades necessárias para criar um aplicativo de varejo inteligente, escalonável e responsivo totalmente desenvolvido pelo Google Cloud Spanner.
Cenário
Você trabalha para um varejista de equipamentos eletrônicos. Seu site de e-commerce tem um banco de dados padrão do Spanner com Products, Orders e OrderItems.
Um cliente acessa seu site com uma necessidade específica: "Quero comprar um teclado de alto desempenho. Às vezes, programo na praia, então ele pode se molhar."
Seu objetivo é usar os recursos avançados do Spanner para responder a esta solicitação de forma inteligente:
- Encontrar:vá além da pesquisa simples por palavras-chave para encontrar produtos cujas descrições correspondam semanticamente à solicitação do usuário usando a pesquisa vetorial.
- Explicar:use um LLM para analisar as principais correspondências e explicar por que a recomendação é adequada, criando confiança do cliente.
- Relacionar:use consultas de grafo para encontrar outros produtos que os clientes costumam comprar junto com essa recomendação.
2. Antes de começar
- Criar um projeto na nuvem: no console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto na nuvem do Google Cloud.
- Ative o faturamento: verifique se o faturamento está ativado para seu projeto na nuvem. Saiba como verificar se o faturamento está ativado em um projeto.
- Ativar o Cloud Shell Ative o Cloud Shell clicando no botão "Ativar o Cloud Shell" no console do Google Cloud. É possível alternar entre o terminal e o editor do Cloud Shell.

- Autorizar e definir o projeto: depois de se conectar ao Cloud Shell, verifique se você está autenticado e se o projeto está definido com seu ID do projeto.
gcloud auth list
gcloud config list project
- Se o projeto não estiver definido, use este comando, substituindo
<PROJECT_ID>pelo ID do projeto real:
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- Ativar as APIs necessárias: ative as APIs Spanner, Vertex AI e Compute Engine. Isso pode levar alguns minutos.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Defina algumas variáveis de ambiente que você vai reutilizar.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- Crie uma instância de teste sem custo financeiro do Spanner se você ainda não tiver uma . Você vai precisar de uma instância do Spanner para hospedar seu banco de dados. Vamos usar
regional-us-central1como configuração. Você pode atualizar essa informação se quiser.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. Visão geral da arquitetura
O Spanner encapsula todas as funcionalidades necessárias, exceto os modelos hospedados na Vertex AI.
4. Etapa 1: configurar o banco de dados e enviar sua primeira consulta.
Primeiro, precisamos criar nosso banco de dados, carregar os dados de varejo de amostra e informar ao Spanner como se comunicar com a Vertex AI.
Para esta seção, use os scripts SQL abaixo.
- Acesse a página do produto Spanner.
- Selecione a instância correta.
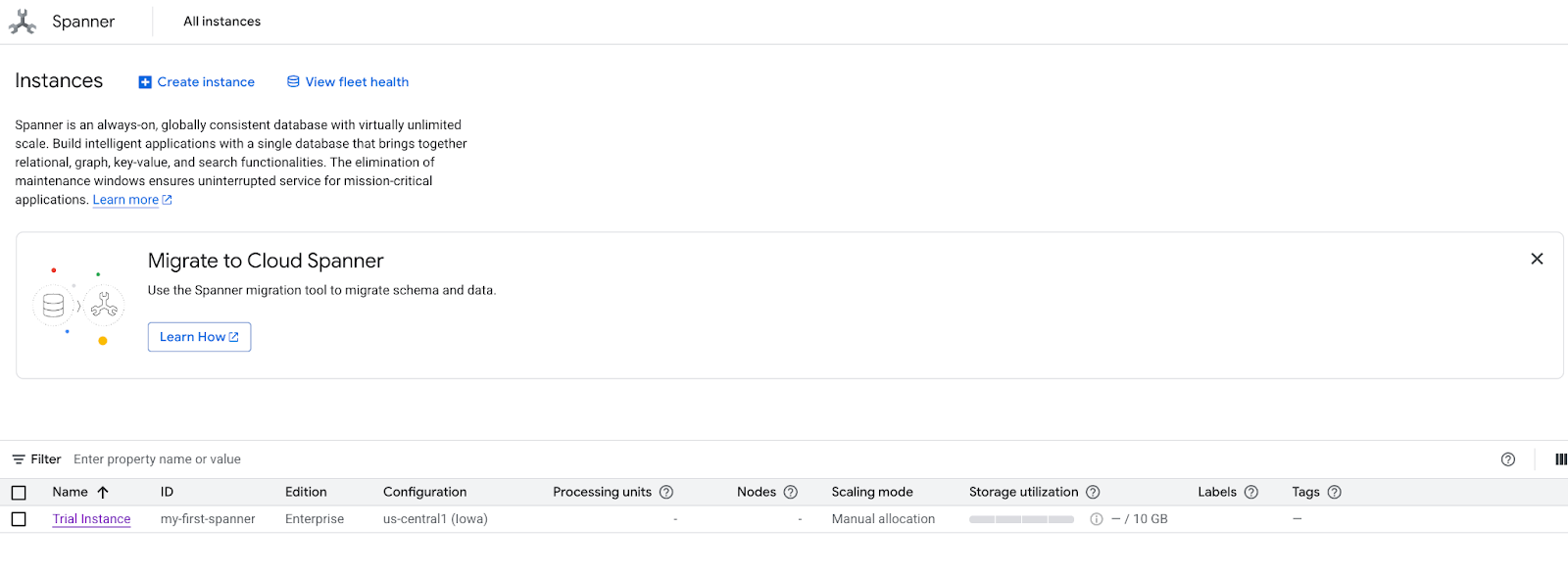
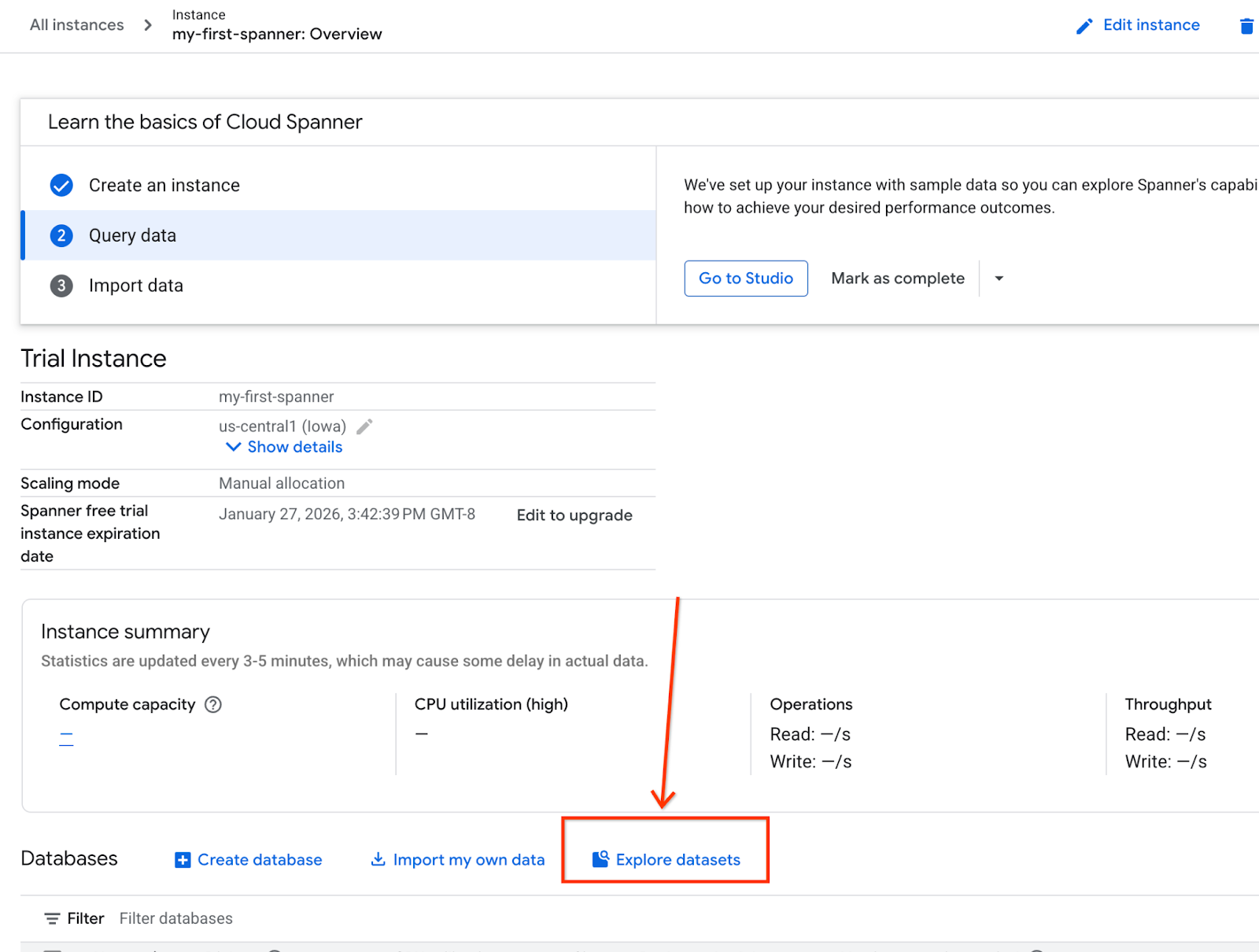
- Na tela, selecione "Explorar conjuntos de dados". Em seguida, no pop-up, selecione a opção "Varejo".
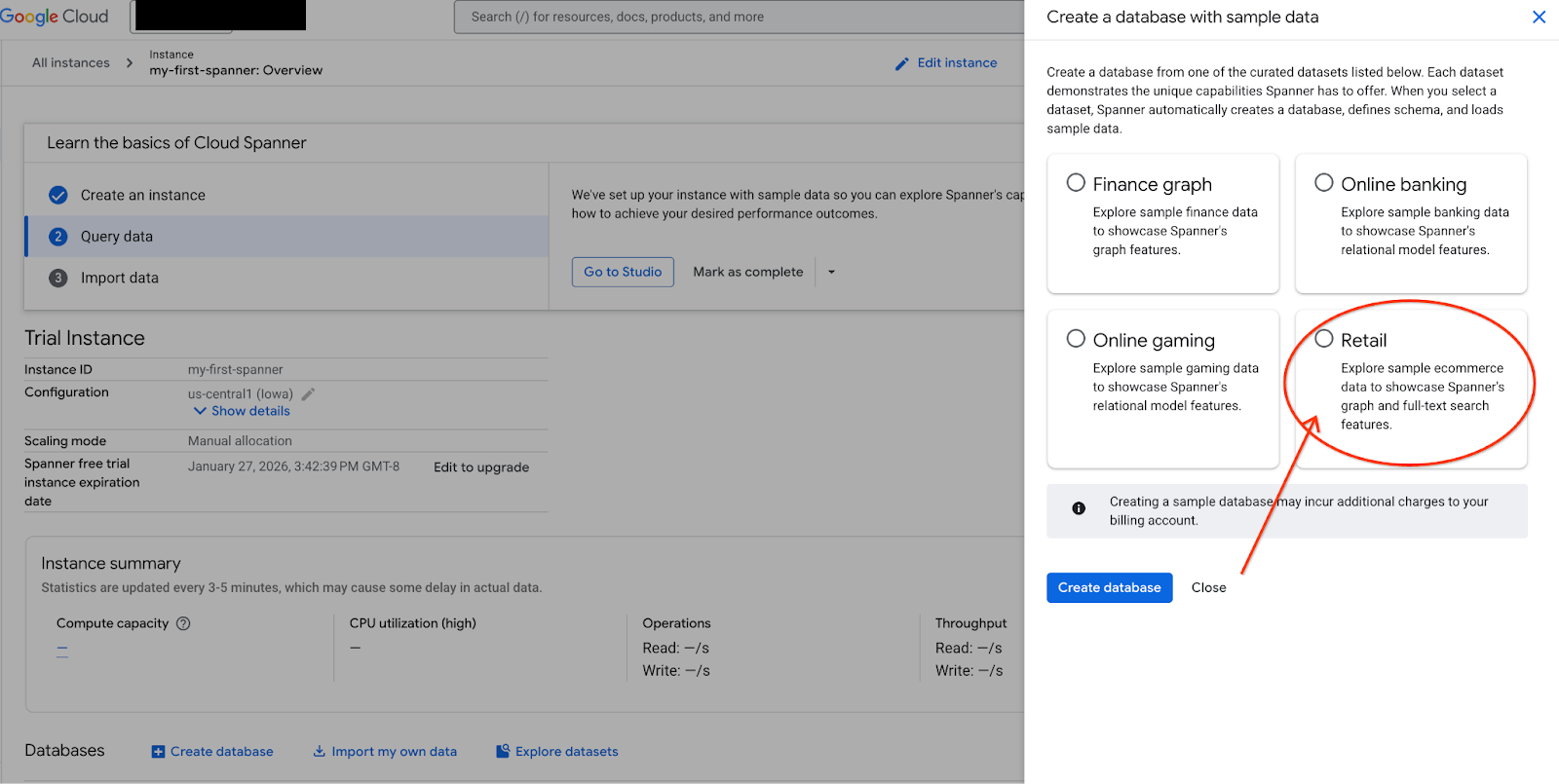
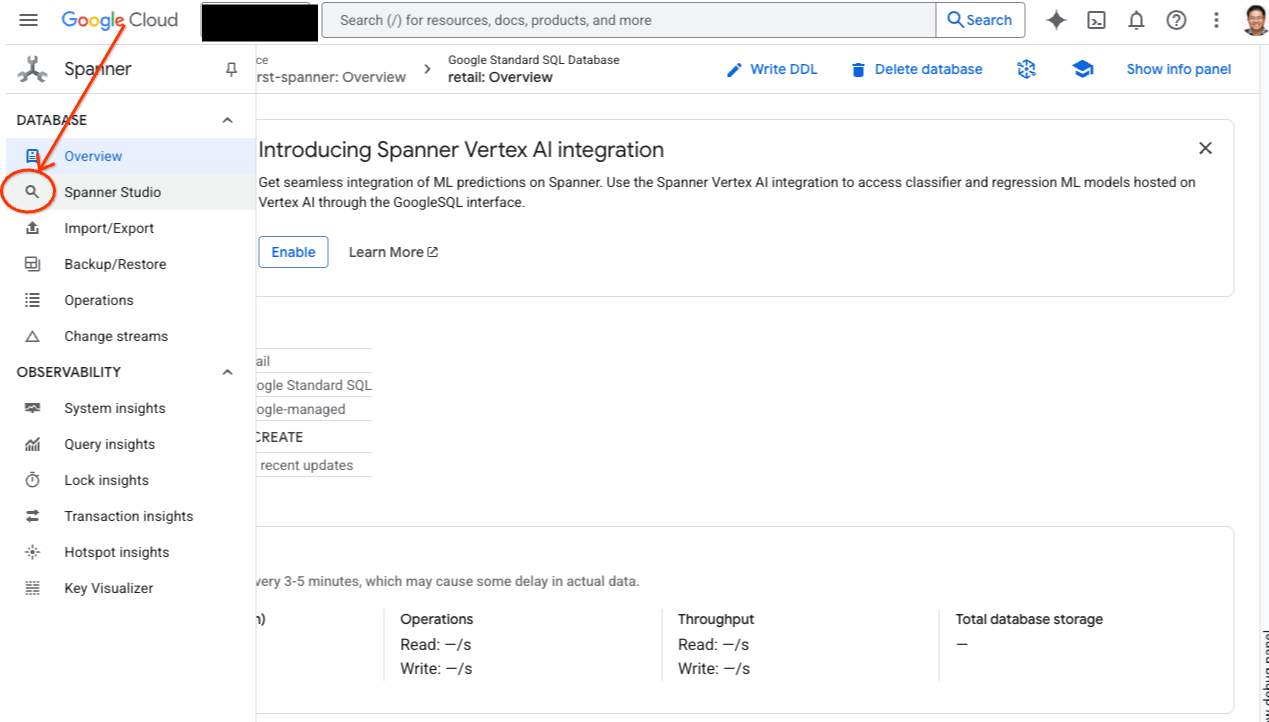
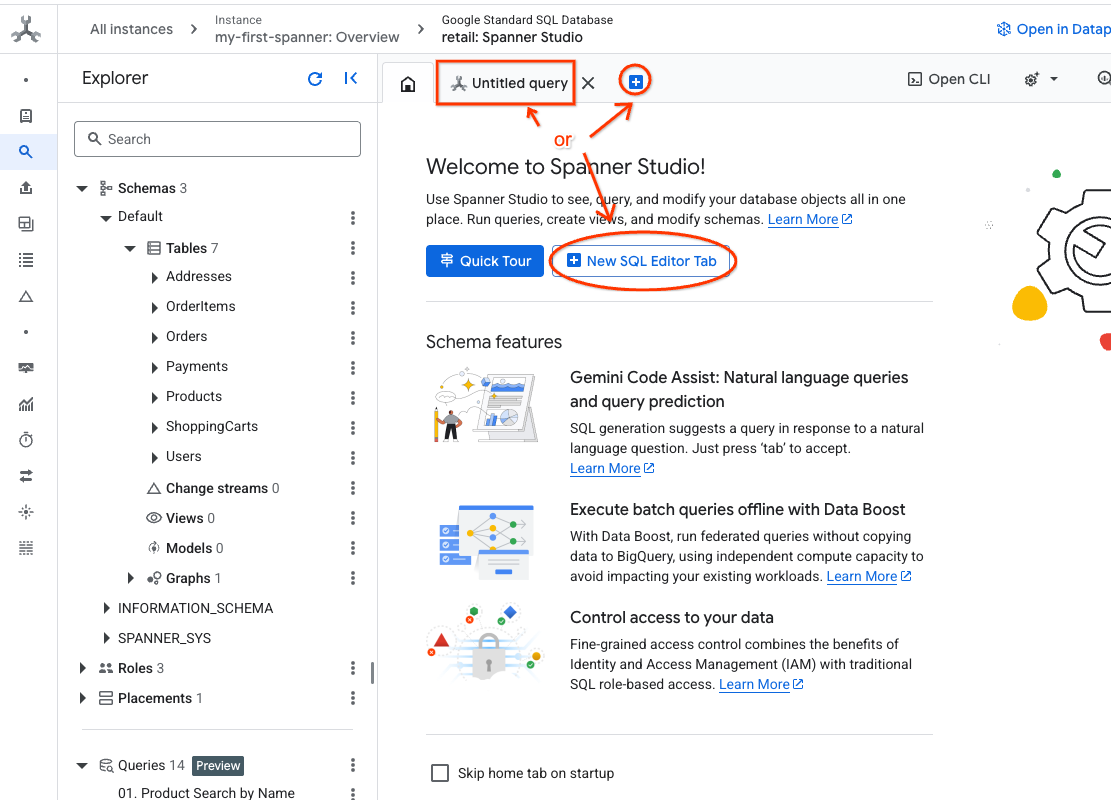
- Acesse o Spanner Studio. O Spanner Studio inclui um painel do Explorer que se integra a um editor de consultas e a uma tabela de resultados de consulta SQL. É possível executar instruções DDL, DML e SQL nessa interface. Expanda o menu na lateral e procure a lupa.
- Leia a tabela de produtos. Crie uma guia ou use a guia "Consulta sem título" já criada.
SELECT *
FROM Products;
5. Etapa 2: crie os modelos de IA.
Agora, vamos criar os modelos remotos com objetos do Spanner. Essas instruções SQL criam objetos do Spanner que se vinculam a endpoints da Vertex AI.
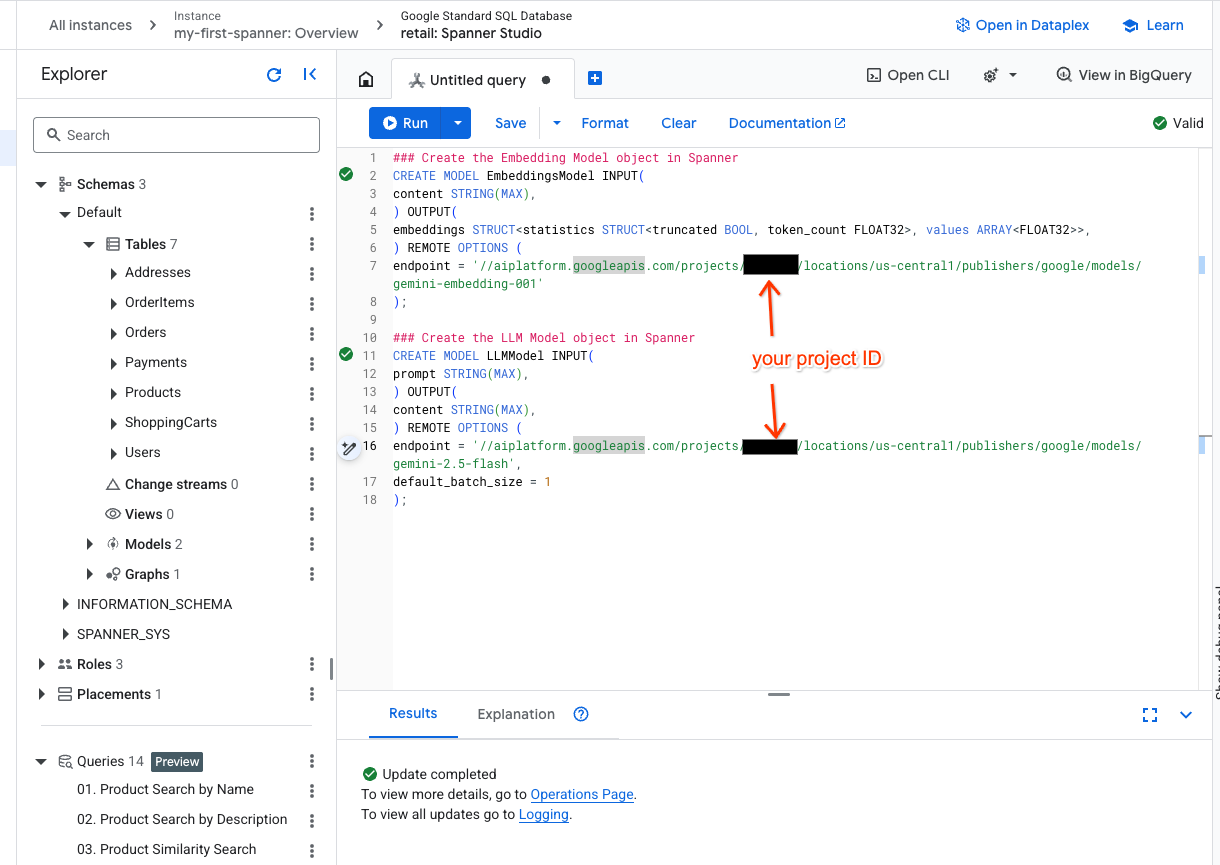
- Abra uma nova guia no Spanner Studio e crie seus dois modelos. O primeiro é o EmbeddingsModel, que permite gerar embeddings. O segundo é o LLMModel, que permite interagir com um LLM (no nosso exemplo, é o gemini-2.5-flash). Verifique se você atualizou <PROJECT_ID> com o ID do seu projeto.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- Observação:substitua
PROJECT_IDpelo seu$PROJECT_IDreal.
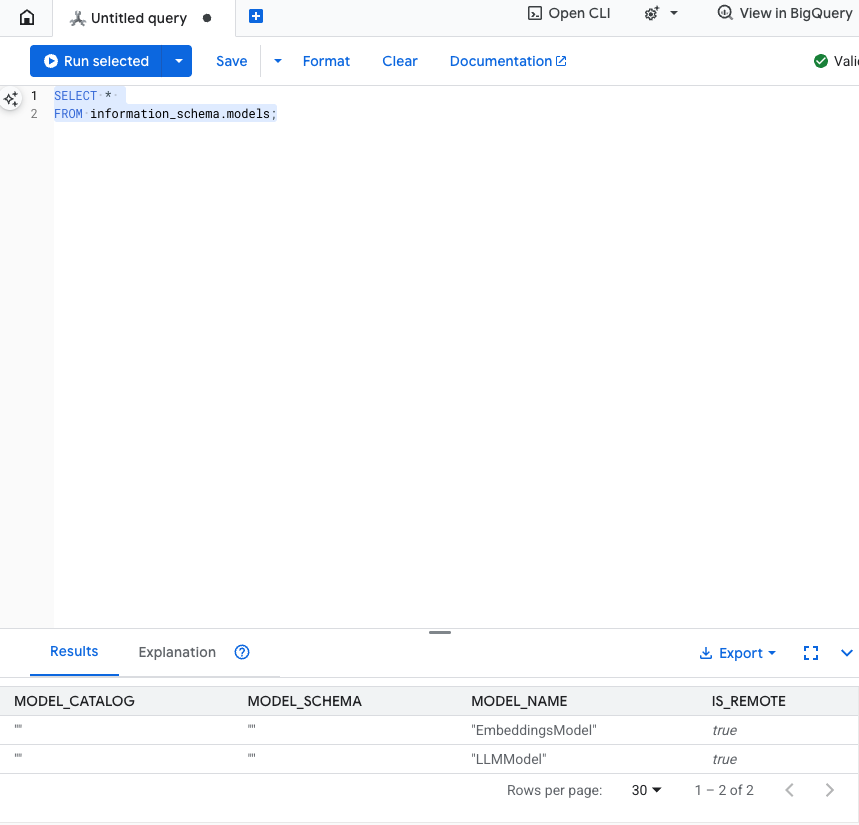
Teste esta etapa:para verificar se os modelos foram criados, execute o seguinte no editor de SQL.
SELECT *
FROM information_schema.models;
6. Etapa 3: gerar e armazenar embeddings de vetor
Nossa tabela de produtos tem descrições de texto, mas o modelo de IA entende vetores (matrizes de números). Precisamos adicionar uma nova coluna para armazenar esses vetores e preenchê-la executando todas as descrições de produtos no EmbeddingsModel.
- Crie uma tabela para oferecer suporte aos embeddings. Primeiro, crie uma tabela que possa aceitar embeddings. Estamos usando um modelo de embedding diferente dos embeddings de exemplo da tabela de produtos. É necessário garantir que os embeddings foram gerados pelo mesmo modelo para que a pesquisa vetorial funcione corretamente.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- Preencha a nova tabela com os embeddings gerados pelo modelo. Usamos uma instrução insert into para simplificar. Isso vai inserir os resultados da consulta na tabela que você acabou de criar.
A instrução SQL primeiro extrai e concatena todas as colunas de texto relevantes em que queremos gerar embeddings. Em seguida, retornamos as informações relevantes, incluindo o texto usado. Isso normalmente não é necessário, mas incluímos para que você possa visualizar os resultados.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
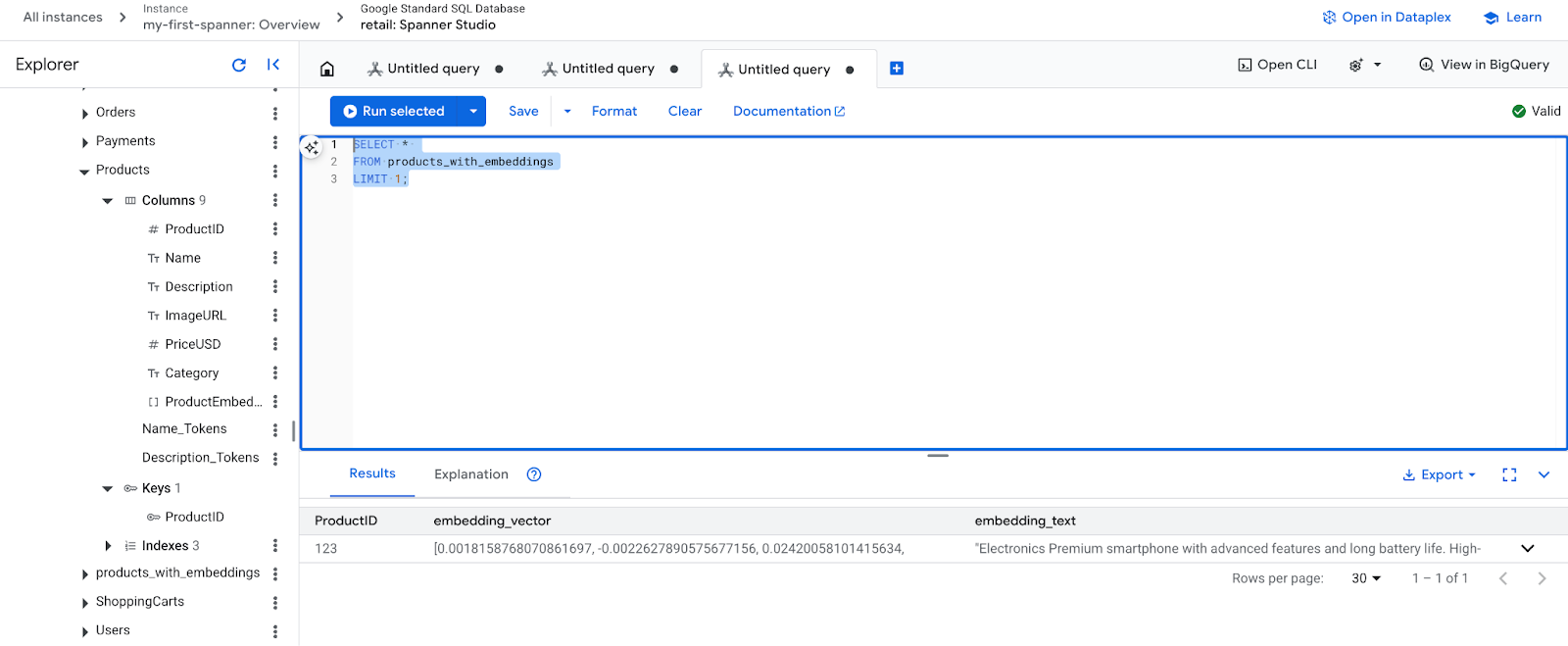
- Confira seus novos encodings. Agora você vai ver os embeddings gerados.
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. Etapa 4: criar um índice vetorial para a pesquisa de ANN
Para pesquisar milhões de vetores instantaneamente, precisamos de um índice. Esse índice permite a pesquisa de Aproximação de Neighbor Nearest (ANN), que é incrivelmente rápida e escalona horizontalmente.
- Execute a seguinte consulta DDL para criar o índice. Especificamos
COSINEcomo nossa métrica de distância, que é excelente para pesquisa semântica de texto. A cláusula WHERE é necessária porque o Spanner a exige para a consulta.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- Verifique o status da criação do índice na guia "Operações".
8. Etapa 5: encontrar recomendações com a pesquisa de vizinho k-mais perto (KNN)
A diversão começa agora! Vamos encontrar produtos que correspondam à consulta do cliente: "Quero comprar um teclado de alta performance. Às vezes, programo na praia, então ele pode se molhar.".
Vamos começar com a pesquisa de K-Nearest Neighbor (KNN). Essa é uma pesquisa exata que compara nosso vetor de consulta a todos os vetores de produtos. Ele é preciso, mas pode ser lento em conjuntos de dados muito grandes. Por isso, criamos um índice de ANN para a etapa 5.
Essa consulta faz duas coisas:
- Uma subconsulta usa ML.PREDICT para receber o vetor de embedding da consulta do cliente.
- A consulta externa usa COSINE_DISTANCE para calcular a "distância" entre o vetor de consulta e o embedding_vector de cada produto. Uma distância menor significa uma correspondência melhor.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Você vai ver uma lista de produtos, com teclados resistentes à água na parte de cima.
9. Etapa 6: encontrar recomendações com a pesquisa aproximada (ANN)
O KNN é ótimo, mas, para um sistema de produção com milhões de produtos e milhares de consultas por segundo, precisamos da velocidade do nosso índice ANN.
Para usar o índice, especifique a função APPROX_COSINE_DISTANCE.
- Receba o embedding de vetor do seu texto como fez acima. Fazemos uma correlação dos resultados com os registros na tabela "products_with_embeddings" para que você possa usar na função APPROX_COSINE_DISTANCE.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Saída esperada:os resultados devem ser idênticos ou muito semelhantes à consulta KNN, mas executados com muito mais eficiência usando o índice. Talvez você não perceba isso no exemplo.
10. Etapa 7: usar um LLM para explicar as recomendações
Mostrar uma lista de produtos é bom, mas explicar por que eles são adequados ou não é ótimo. Podemos usar nosso LLMModel (Gemini) para fazer isso.
Essa consulta aninha nossa consulta KNN da etapa 4 em uma chamada ML.PREDICT. Usamos CONCAT para criar um comando para o LLM, fornecendo:
- Uma instrução clara ("Responda com "Sim" ou "Não" e explique por quê...").
- A consulta original do cliente.
- O nome e a descrição de cada produto que mais corresponde.
Em seguida, o LLM avalia cada produto em relação à consulta e fornece uma resposta em linguagem natural.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
Saída esperada:uma tabela com uma nova coluna "LLMResponse". A resposta será algo como: "Não. Veja por quê: * "Resistente à água" não é"à prova d'água". Um teclado "resistente à água" pode lidar com respingos, chuva leve ou derramamentos.
11. Etapa 8: criar um gráfico de propriedades
Agora, um tipo diferente de recomendação: "clientes que compraram isso também compraram..."
Essa é uma consulta com base em relacionamento. A ferramenta perfeita para isso é um gráfico de propriedades. Com o Spanner, é possível criar um gráfico acima das tabelas atuais sem duplicar dados.
Esta instrução DDL define nosso gráfico:
- Nós : tabelas
ProducteUser. Os nós são as entidades de que você quer derivar uma relação. Por exemplo, você quer saber se os clientes que compraram seu produto também compraram os produtos "XYZ". - Arestas:a tabela
Orders, que conecta umUser(origem) a umProduct(destino) com o marcador "Comprado". As arestas fornecem a relação entre um usuário e o que ele comprou.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. Etapa 9: combinar a pesquisa vetorial e as consultas de gráficos
Esta é a etapa mais importante. Vamos combinar a pesquisa vetorial de IA e as consultas de gráficos em uma única instrução para encontrar produtos relacionados.
Essa consulta é lida em três partes, separadas pelo NEXT statement. Vamos dividi-la em seções.
- Primeiro, encontramos a melhor correspondência usando a pesquisa vetorial.
- O ML.PREDICT gera um embedding de vetor da consulta de texto do usuário usando EmbeddingsModel.
- A consulta calcula a COSINE_DISTANCE entre esse novo embedding e o p.embedding_vector armazenado para todos os produtos.
- Ele seleciona e retorna o único produto bestMatch com a distância mínima (maior semelhança semântica).
- Em seguida, percorremos o gráfico em busca das relações.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- A consulta rastreia de volta de bestMatch para nós de pedidos comuns (usuário) e, em seguida, para outros produtos purchasedWith.
- Ele filtra o produto original e usa GROUP BY e COUNT(1) para agregar a frequência com que os itens são comprados juntos.
- Ele retorna os três principais produtos comprados juntos (purchasedWith) ordenados pela frequência de ocorrência conjunta.
Além disso, encontramos a relação de pedidos do usuário.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- Essa etapa intermediária executa o padrão de travessia para vincular as entidades principais: bestMatch, o nó connecting user:Orders e o item purchasedWith.
- Ele vincula especificamente a própria relação como comprada para extração de dados na próxima etapa.
- Esse padrão garante que o contexto seja estabelecido para buscar detalhes específicos do pedido e do produto.
- Por fim, mostramos os resultados a serem retornados como nós de gráfico, que precisam ser formatados antes de serem retornados como resultados de SQL.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
Saída esperada:você vai ver objetos JSON representando os três principais itens comprados em conjunto, fornecendo recomendações de venda cruzada.
13. Limpar
Para evitar cobranças, exclua os recursos criados.
- Exclua a instância do Spanner:a exclusão da instância também exclui o banco de dados.
gcloud spanner instances delete my-first-spanner --quiet
- Exclua o projeto do Google Cloud:se você criou esse projeto apenas para o codelab, excluí-lo é a maneira mais fácil de limpar.
- Acesse a página Gerenciar recursos no console do Google Cloud.
- Selecione o projeto e clique em Excluir.
🎉 Parabéns!
Você criou um sistema de recomendação sofisticado e em tempo real usando o Spanner AI e o Graph.
Você aprendeu a integrar o Spanner à Vertex AI para embeddings e geração de LLM, a realizar pesquisas vetoriais de alta velocidade (KNN e ANN) para encontrar produtos semanticamente relevantes e a usar consultas de gráficos para descobrir relações entre produtos. Você criou um sistema que não apenas encontra produtos, mas também explica recomendações e sugere itens relacionados, tudo em um único banco de dados escalonável.